
























 Программное обеспечение
Программное обеспечениеПохожие презентации:
")


")


")



Організація та управління базами даних
1. «ОРГАНІЗАЦІЯ ТА УПРАВЛІННЯ БАЗАМИ ДАНИХ»
ДАТАЛОГІЧНИЙ РІВЕНЬПРОЕКТУВАННЯ
Презентація супроводження лекційного
курсу
проф. В.І.Кривенко
1
2. Уявлення про даталогічне проектування
На етапі даталогічного проектування здійснюється перехід від інфологічноїмоделі ПО до логічної (даталогічної) моделі. Процес переходу від
інфологічної до даталогічної моделі називається відображенням.
Даталогічна модель являє собою базу даних, структуровану на логічному рівні
й орієнтовану на конкретну СУБД.
Починається даталогічне проектування з вибору СУБД.
Основні факторами, що впливають на даталогічне проектування з боку СУБД:
1. Тип логічної моделі, що його підтримує вибрана СУБД. Найпоширенішими на
ринку програмних засобів і в практиці інформаційного забезпечення є реляційні
СУБД. Крім реляційних моделей ще існують ієрархічні й сіткові моделі баз даних.
2. Особливості фізичної організації даних у середовищі вибраної СУБД.
Наприклад, у СУБД Paradox чи dBASE-системах база даних організована у вигляді
набору взаємозв'язаних файлів, усі інші об'єкти, такі як форми та звіти, також
зберігаються в окремих файлах. У середовищі Access усі дані та інструментальні
засоби роботи з ними зберігаються в єдиному файлі бази даних.
3. Кількісні обмеження, які накладає СУБД (наприклад, кількість рівнів ієрархії
в ієрархічних моделях, можлива кількість полів, записів, файлів тощо).
2
3. Особливості СУБД
Основні функції СУБД:• управління даними у зовнішній пам'яті (на дисках);
• управління даними в оперативній пам'яті з використанням дискового кеша;
• журналізація змін, резервне копіювання і відновлення бази даних після збоїв;
• підтримка мов БД (мова визначення даних, мова маніпулювання даними).
Компоненти СУБД:
• ядро, яке відповідає за управління даними у зовнішній і оперативної пам'яті і
журналізацію;
• процесор мови бази даних, що забезпечує оптимізацію запитів на вилучення
та зміну даних і створення, як правило, машинно-незалежного виконуваного
внутрішнього коду;
• підсистему підтримки виконання, яка інтерпретує програми маніпуляції
даними, що створюють користувальницький інтерфейс із СУБД;
• сервісні програми (зовнішні утиліти), що забезпечують ряд додаткових
можливостей по обслуговуванню інформаційної системи.
3
4.
Класифікації СУБД• За моделлю даних :
- Ієрархічні СУБД
Ієрархічна модель даних - це модель даних, де використовується
представлення бази даних у вигляді деревовидної (ієрархічної) структури,
що складається з об'єктів (даних) різних рівнів.
Між об'єктами існують зв'язки, кожен об'єкт може включати в себе декілька
об'єктів більш низького рівня. Такі об'єкти перебувають у відношенні
пращура (об'єкт більш близький до кореня) до нащадка (об'єкт більш
низького рівня), при цьому можлива ситуація, коли об'єкт-пращур не має
нащадків або має їх декілька, тоді як в об'єкта-нащадка обов'язковий
тільки один пращур. Об'єкти, що мають спільного пращура, називаються
близнюками (в програмуванні стосовно до структури даних дерево
усталене назва брати).
- Мережеві (сіткові) СУБД - побудовані на основі мережевої моделі даних.
Вузол - це сукупність атрибутів даних, що описують деякий об'єкт. На
схемі ієрархічного дерева вузли представляються вершинами графа. У
мережевій структурі кожен елемент може бути пов'язаний з будь-яким
іншим елементом.
Мережеві бази даних подібні ієрархічним, за винятком того, що в них є
покажчики в обох напрямках, які з'єднують споріднену інформацію.
4
5.
- Реляційні СУБД - побудовані на основі реляційної моделі даних.Реляційна модель даних являє безліч взаємопов'язаних таблиць, кожна з
яких містить інформацію про об'єкти певного виду. Рядок таблиці містить
дані про конкретний екземпляр (наприклад, автомобіль, клієнт), а
стовпчики таблиці містять різні характеристики цих об'єктів - атрибути
(наприклад, номер двигуна, телефони фірм).
Рядки таблиці називаються записами. Усі записи таблиці мають однакову
структуру - вони складаються з полів (елементів даних), в яких
зберігаються атрибути об'єкта. Кожне поле запису містить одну
характеристику об'єкта і являє собою заданий тип даних (наприклад,
текст, число, дата). Для ідентифікації записів використовується первинний
ключ. Первинним ключем називається набір полів таблиці, комбінація
значень яких однозначно визначає кожний запис у таблиці.
- Об'єктно-орієнтовані СУБД - засновані на об'єктній моделі даних, в якій дані
моделюються у вигляді об'єктів, їх атрибутів, методів і класів.
Рекомендовані для тих випадків, коли потрібна високопродуктивна
обробка даних, які мають складну структуру.
- Об'єктно-реляційна СУБД – (різновид реляційної СУБД), що підтримує деякі
технології, які реалізують об'єктно-орієнтований підхід: об'єкти, класи та
успадкування реалізовані в структурі баз даних і мовою запитів. Об'єктнореляційними СУБД є широко відомі Oracle Database, Informix, DB2,
PostgreSQL.
5
6.
• За ступенем розподіленості- Локальні СУБД (всі частини локальної СУБД розміщуються на
одному комп'ютері);
- Розподілені СУБД (частини СУБД можуть розміщуватися на двох
і більше комп'ютерах).
• За способом доступу до БД
- Файл-серверні. У файл-серверних СУБД файли даних розташовуються
централізовано на файл-сервері. СУБД розташовується на кожному
клієнтському комп'ютері (робочій станції). Доступ СУБД до даних
здійснюється через локальну мережу. Синхронізація читань і оновлень
здійснюється за допомогою файлових блокувань. Перевагою цієї
архітектури є низьке навантаження на процесор файлового сервера.
Недоліки: потенційно високе завантаження локальної мережі;
утрудненість
або
неможливість
централізованого
управління;
утрудненість або неможливість забезпечення таких важливих
характеристик як висока надійність, висока доступність і висока безпека.
Застосовуються найчастіше в локальних додатках, які використовують
функції управління БД; в системах з низькою інтенсивністю обробки
даних і низькими піковими навантаженнями на БД. На даний момент
файл-серверна технологія вважається застарілою, а її використання у
великих інформаційних системах – недоліком.
Приклади: Microsoft Access, Paradox, dBase, FoxPro, Visual FoxPro.
6
7.
- Клієнт-серверні. Клієнт-серверна СУБД розташовується на сервері разомз БД і здійснює доступ до БД безпосередньо, в монопольному режимі. Всі
клієнтські запити на обробку даних обробляються клієнт-серверної СУБД
централізовано. Недолік клієнт-серверних СУБД полягає в підвищених
вимогах до сервера. Переваги: потенційно більш низьке завантаження
локальної мережі; зручність централізованого управління; зручність
забезпечення таких важливих характеристик як висока надійність, висока
доступність і висока безпека.
Приклади: Oracle, Firebird, Interbase, IBM DB2, Informix, MS SQL Server,
Sybase Adaptive Server Enterprise, PostgreSQL, MySQL, Caché, Лінтер.
- Що вбудовуються. Вбудована СУБД - СУБД, яка може поставлятися як
складова частина деякого програмного продукту, не вимагаючи процедури
самостійної установки. Вбудована СУБД призначена для локального
зберігання даних свого застосування і не розрахована на колективне
використання в мережі. Фізично вбудована СУБД найчастіше реалізована у
вигляді підключається бібліотеки. Доступ до даних з боку додатки може
відбуватися через SQL або через спеціальні програмні інтерфейси.
Приклади: OpenEdge, SQLite, BerkeleyDB, Firebird Embedded, Microsoft SQL
Server Compact, Лінтер.
7
8.
• За стратегією роботи з зовнішньою пам'яттю- СУБД з безпосередньою записом - це СУБД, в яких всі змінені блоки
даних негайно записуються в зовнішню пам'ять при надходженні сигналу
підтвердження будь-якої транзакції. Така стратегія використовується
тільки при високій ефективності зовнішньої пам'яті.
- СУБД з відкладеним записом - це СУБД, в яких зміни акумулюються в
буферах зовнішньої пам'яті до настання будь-якого з наступних подій:
-- контрольної точки;
-- кінець простору у зовнішній пам'яті, відведеній під журнал. СУБД
виконує контрольну точку і починає писати журнал спочатку,
затираючи попередню інформацію;
-- зупинка. СУБД чекає, коли весь вміст всіх буферів зовнішньої
пам'яті буде перенесено в зовнішню пам'ять, після чого робить
позначки, що зупинка бази даних виконана коректно;
-- при нестачі оперативної пам'яті для буферів зовнішньої пам'яті;
Така стратегія дозволяє уникнути частого обміну із зовнішньою пам'яттю
і значно збільшити ефективність роботи СУБД.
8
9.
Вибір СУБДЦе складна задача при розв'язанні якої потрібно оцінити дуже багато
факторів.
Слід вміти спрогнозувати перспективи розвитку того підприємства, для якого
робиться цей вибір з точки зору перспективи розширення функцій і задач, а
також потрібно вивчити ринок програмних засобів.
При виборі СУБД виділяють два підходи до її оцінки.
Перший підхід пов'язаний з вибором з точки зору користувача, а другий —
суто технічний-пов'язаний з продуктивністю системи.
Ураховуючи ці дві точки зору СУБД можна вибирати на підставі їх аналізу за
такими параметрами.
9
10.
1. Загальні характеристики. До цих характеристик належать тип ЕОМ,операційне середовище, тип логічної моделі бази даних, кількісні обмеження
СУБД (максимальне число записів у файлі та його максимальний обсяг,
максимальне число індексів на один файл БД тощо), наявність русифікованої
версії, фірма-виробник, обсяг оперативної пам'яті для системи, необхідність
використання постійної пам'яті, тип системи (відкрита, закрита), мова системи
(власна, СІ, Паскаль та ін.), кількість версій, що свідчить про попит на систему і
спроби виробника вдосконалити систему, наявність версії, що підтримує
розподілену базу даних.
2. Управління даними. До цих факторів належать:
• можливість підтримувати записи змінної довжини, багатозначні атрибута і
двонапрямлені зв'язки;
• наявність засобів автоматизації проектування;
• підтримка та автоматизоване ведення словника даних;
• автоматизоване протоколювання роботи системи (фіксація часу, паролів
користувачів і стану системи при вході в БД і виході з неї, статистика роботи
системи тощо);
• наявність засобів контролю з боку системи за внесенням змін з точки зору
збереження посилкової цілісності;
• наявність засобів автоматизованого відновлення й захисту інформації
(криптографування, шифрування даних тощо).
10
11.
3. Засоби підтримки прикладного програмного забезпечення. Зокрема:наявність мови запитів на базі SQL чи іншої мови;
• наявність генератора програм і генератора звітів;
• можливість захисту програмного продукту;
• наявність власного редактора;
• можливість підтримувати віконний інтерфейс.
4. Засоби підтримки роботи в мережі. Параметрами, які визначають
можливість роботи в мережі, є такі:
• можливість роботи в глобальній мережі;
• можливість роботи в локальній мережі;
• наявність автоматизованих засобів стеження за узгодженістю та цілісністю
даних мережі при колективному використанні даних. Зокрема, на початку виконання
запиту роблять копії всіх файлів, які беруть участь у його реалізації. Таким чином можна виконувати
запити будь-якої складності, тому що всі коректури, внесені іншими користувачами в файли БД
протягом виконання запиту, не впливають на його результат ;
наявність механізму встановлення замків чи виконання захватів при
паралельному внесенні змін у файли БД. Замок чи захват встановлюється на файл ВД
на період внесення змін одним користувачем. Замок захищає лише від паралельного внесення
змін; файл доступний для проведення всіх інших операцій ;
• механізм стеження за часом виконання транзакцій.
Цей механізм необхідний для
попередження зависання системи при колективному використанні даних. Якщо ліміт допустимого
часу для виконання транзакції вичерпано, то її відмінюють, і БД повертається в початковий стан .
11
12.
Відображення на реляційну модельВласне кажучи, при відображенні на реляційну модель перепроектовувати
інформаційні об'єкти, якщо не було допущено помилок на етапі інфологічного
проектування, не потрібно. Тобто інформаційні об'єкти інфологічної моделі
стають реляційними відношеннями. Необхідно лише перевірити виконання
таких умов:
1. Усі атрибути відношень мають бути атомарними, тобто неподільними.
2. Відношення не повинно мати дублюючих рядків і стовпчиків.
3. Усі атрибути у відношенні повинні мати унікальні імена.
Для СУБД, що не підтримують статичних зв'язків між реляційними
відношеннями зв'язки між відношеннями встановлюються лише для
розв'язування конкретної задачі та існують на період її розв'язування.
Тому при відображенні інфологічної моделі на реляційну всі структурні зв'язки
не описують у явному вигляді, а лише виконують перевірку на можливість
установлення цих зв'язків. Обов'язковою умовою встановлення зв'язку між
двома реляційними відношеннями є наявність у хоча б одного спільного
атрибута, що є ключем, за яким виконується зв'язок.
12
13.
Для СУБД, що підтримують зв'язки між реляційними відношеннями слідвизначити ті структурні зв'язки, які потрібно залишити в схемі реляційної бази
даних.
Для побудови схеми реляційної бази даних потрібно визначити, які з реляційних
відношень, є об'єктними, а які зв'язковими.
Об'єктними будуть ті відношення, що вміщують нормативно-довідкові дані й
первинні ключі яких не можуть дублюватися. Ці відношення можуть бути
віднесеними до умовно-постійних файлів.
З'язковими відношеннями будуть ті відношення, що вміщують оперативні дані й
ключі яких можуть дублюватися.
О'єктні відношення в схемі будуть головними. Тому при відображенні необхідно
перевірити всі об'єкти-власники інфологічної моделі і залишити лише ті зв'язки,
власниками яких є об'єктні відношення.
Зв'язкові відношення в схемі реляційної бази даних виступають як
підпорядковані. Отже, у структурних зв'язках, що залишились від попередньої
ітерації, необхідно перевірити підпорядковані об'єкти і залишити лише ті зв'язки,
підпорядкованими в яких є зв'язкові відношення. Об'єкти-зв'язки перетворюються
в самостійні рівноправні реляційні відношення.
Отриману в результаті відображення модель потрібно ще раз перевірити на
відповідність її вимогам ЗНФ (4НФ).
13
14. Уявлення про відображення на ієрархічну модель
Відображення на ієрархічну модель виконується в два етапи.1. Загальне відображення на ієрархічну модель без урахування обмежень
ієрархічної СУБД.
2. Модифікація моделі з урахуванням обмежень, які накладає вибрана
ієрархічна СУБД.
Роботи першого етапу
Ієрархічні моделі, збудовані на основі принципу підпорядкованості між
інформаційними об'єктами. Являють собою деревоподібну структуру, яка
складається з вузлів (сегментів) і дуг (гілок).
Кожний вузол — це сукупність логічно взаємозв'язаних атрибутів, що
описують певну сутність ПО, неорієнтовані дуги вказують на інформаційні
зв'язки між ними.
При відображенні ІЛМ на ієрархічну інформаційні об'єкти потрібно
трансформувати в сегменти, а структурні зв'язки — в неорієнтовані
дуги.
14
15.
Дерево в ієрархічній моделі впорядковане, тобто існують правила, за якимирозміщують його сегменти та дуги.
Правило 1. На самому верхньому рівні ієрархії знаходиться лише один
сегмент, який називається кореневим. Кожний екземпляр цього сегмента
починає один логічний запис. Тому пошук в ієрархічних моделях виконують
згори вниз, зворотного шляху пошуку в цих моделях немає.
Першим кроком відображення інфологічної моделі на ієрархічну буде вибір зпоміж інформаційних об'єктів ІЛМ кореневого сегмента. Ним може бути об'єкт,
який не має зв'язків на вході з іншими об'єктами, тобто до нього не входить
жодна дуга і він у всіх структурних зв'язках характеризується лише як власник
структурного зв'язку. Якщо з-поміж об'єктів ІЛМ немає такого об'єкта, тоді
серед них вибирають той, що має мінімальну кількість зв'язків на вході. Якщо
ж, навпаки, на роль кореня є кілька об'єктів-претендентів, то тут може бути дві
альтернативи.
Перша — об'єднати такі об'єкти-претенденти в один об'єкт і оголосити його
кореневим сегментом.
Друга — якщо сегменти неможливо об'єднати через семантичну різнорідність,
то кожний із цих об'єктів оголошують коренем різних фізичних баз даних,
тобто будують кілька деревоподібних структур.
15
16.
Правило 2. Зв'язки в ієрархічних моделях будуютьпороджений». Так, сегмент другого рівня ієрархії
першого рівня, тобто перший рівень виступає як
породжений; у свою чергу, другий є вихідним,
відносно другого рівня і т. д.
за принципом «вихідний залежатиме від сегмента
вихідний, а другий — як
а третій — породженим
Тому другим кроком відображення є аналіз інформаційних об'єктів і виявлення
з-поміж них ієрархічної підпорядкованості за принципом: «рід - вид», «ціле частина», «причина - наслідок» і т.п. Аналіз виконують між об'єктами, які
зв'язані зв'язками ВП чи ВПВ (друга частина ПВ ігнорується). В результаті
цього аналізу об'єкти розміщуються по рівнях ієрархії.
Правило 3. В ієрархічній моделі підтримуються лише такі типи співвідношень
між даними: 1:1 і 1:Б. Тому потрібно перевірити типи співвідношень
між даними і обмежитися лише названими. Далі буде розглянуто, як в
ієрархічних моделях можна реалізувати інші типи співвідношень.
Правило 4. Кожний вихідний сегмент може мати кілька породжених, але
породжений сегмент може мати щонайбільше два вихідних, один з яких є
фізично, а інший логічно вихідним. Зв'язки в одній фізичній базі даних (ФБД)
називаються фізичними, а зв'язки між двома ФБД — логічними
16
17.
На рисунку зображено дві фізичні бази даних ФБД-1 і ФБД-2, у яких сегмент X єфізично вихідним для сегмента Z, a Y — логічно вихідним для цього самого
сегмента; в цьому разі Z виступає відносно до Y як логічно породжений
сегмент, відносно X — як фізично породжений.
X
Y
Z
N
R
W
ФБД-1
ФБД-2
За описаним правилом побудови зв'язків необхідно перевірити всі породжені
сегменти на виконання зазначеного обмеження.
Надлишкові зв'язки потрібно усунути, об'єднанням кількох об'єктів в один,
якщо це можливо, чи простим абстрагуванням від деяких зв'язків.
17
18.
Роботи другого етапуДругий етап відображення полягає в модифікації отриманої моделі з
урахуванням обмежень вибраної ієрархічної СУБД.
Приклад: ієрархічна СУБД накладає такі обмеження на логічну модель БД:
1. СУБД підтримує лише співвідношення типу 1:1 і 1:Б.
2. Кількість атрибутів у сегменті не повинна перевищувати 254.
3. Кількість рівнів ієрархії — не більше 15.
4. На логічно породжені сегменти накладається ряд обмежень:
4.1. Кореневий сегмент не може бути логічно породженим, але
може бути логічно вихідним.
4.2. Логічно породжений сегмент може мати лише один логічно
вихідний сегмент.
Так,
на
рисунку
із
наведених зв'язків А і В
може існувати лише А.
Зв’язок L, при якому
кореневий сегмент X стає
логічно
породженим,
взагалі не допускається.
L
X
Y
A
Z
B
N
R
W
ФБД-1
ФБД-2
18
19.
4.3. Логічно породжений сегмент не може бути ні логічно, ніфізично вихідним для логічно породженого сегмента, тобто
два сегменти однієї ФБД, розміщені на ієрархічному шляху
безпосередньо один за одним, не можуть бути одночасно
оголошеними як логічно породжені.
4.3. Логічно вихідний сегмент може мати один чи кілька логічно
породжених в одній чи кількох ФБД.
4.5. Зв'язки між логічно вихідними і логічно породженими
сегментами можуть бути одно- або двосторонніми..
Відповідно до цих вимог і обмежень має бути модифікована ієрархічна БД,
яка працюватиме в середовищі зазначеної СУБД.
Наприклад. Як зазначалося, в ієрархічних моделях не можна підтримувати
багатозначні зв'язки в явному виді. Тому якщо потрібно реалізувати
співвідношення зазначеного типу, використовують такий штучний засіб, як
адресне посилання. Для цього необхідно, щоб сегменти, між якими необхідно
встановити зв'язок Б:Б, були розміщені в різних ФБД.
19
20.
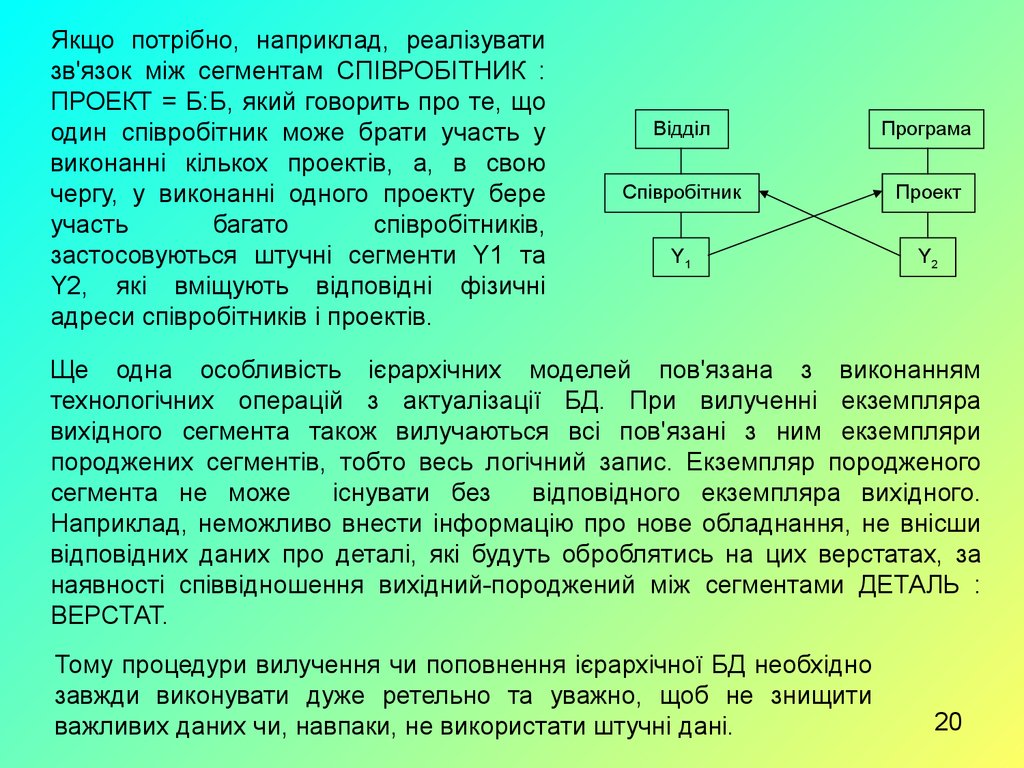
Якщо потрібно, наприклад, реалізуватизв'язок між сегментам СПІВРОБІТНИК :
ПРОЕКТ = Б:Б, який говорить про те, що
один співробітник може брати участь у
виконанні кількох проектів, а, в свою
чергу, у виконанні одного проекту бере
участь
багато
співробітників,
застосовуються штучні сегменти Y1 та
Y2, які вміщують відповідні фізичні
адреси співробітників і проектів.
Відділ
Програма
Співробітник
Проект
Y1
Y2
Ще одна особливість ієрархічних моделей пов'язана з виконанням
технологічних операцій з актуалізації БД. При вилученні екземпляра
вихідного сегмента також вилучаються всі пов'язані з ним екземпляри
породжених сегментів, тобто весь логічний запис. Екземпляр породженого
сегмента не може
існувати без
відповідного екземпляра вихідного.
Наприклад, неможливо внести інформацію про нове обладнання, не внісши
відповідних даних про деталі, які будуть оброблятись на цих верстатах, за
наявності співвідношення вихідний-породжений між сегментами ДЕТАЛЬ :
ВЕРСТАТ.
Тому процедури вилучення чи поповнення ієрархічної БД необхідно
завжди виконувати дуже ретельно та уважно, щоб не знищити
важливих даних чи, навпаки, не використати штучні дані.
20
21.
Уявлення про відображення на сіткову модельСіткова модель БД — це орієнтований граф з поіменованими дугами і
вершинами.
У сіткових моделях файли є рівноправними, тобто можуть виступати в різних
зв'язках — в одному випадку як власники, в іншому — як підпорядковані
файли.
Основними структурними елементами моделей цього типу є агрегат, запис і
набір даних.
При відображенні ІЛМ на сіткову інформаційним об’єктам ставлять у
відповідність записи. Кожний запис вміщує деяку множину атрибутів.
Розрізняють такі поняття, як «тип запису» і «екземпляр запису. Тип запису
— це абстрактні характеристики, а «екземпляр запису» – їх конкретні
значення. Наприклад, тип запису: ПОСТАЧАЛЬНИК (код постачальника,
назва постачальника, адреса постачальника, телефон), екземпляром цього
типу запису буде: 105, Вега ЛТД, Київ-147, вул. Бойченка, 75, 552-33-98.
Отже, кожному типу запису в БД може відповідати деяка сукупність
екземплярів.
Усередині запису можуть виділятись агрегати. Агрегат — це поіменована
сукупність логічно взаємозв'язаних атрибутів усередині типу запису. Ними
можуть бути вектори, групи і групи, що повторюються.
21
22.
Приклад внутрішньої структури, що може підтримуватись у сіткових моделях і вякій агрегат «іноземна мова» представлений як вектор, а агрегат «адреса» - як
група.
Табл. №
ПІБ
Посада
Адреса
Іноземна
мова
індекс
місто
вулиця
кв-ра
Тут атрибут «іноземна мова» може мати кілька значень, його можна зобразити
у вигляді вектора. Причому в одному запису може бути кілька векторів. Крім
векторів у структурі запису сіткової моделі можуть бути й групи, в тому числі
групи, що повторюються. Але при проектуванні слід пам'ятати, що групи, що
повторюються, можна включати до запису при невеликій кількості екземплярів;
якщо ця група бере участь у будь-яких інших зв'язках, то краще її виділити в
окремий файл.
Звертаючись до даних, можна звертатись як до запису в цілому, так і до
окремих його агрегатів.
Отже, запис — це агрегат, який не входить до складу інших агрегатів і є
основною одиницею обробки БД (записи запам'ятовуються, вилучаються,
поповнюються).
22
23.
Два типи записів, об'єднані між собою дугою, організують набір даних. Усіткових моделях можливе звертання до набору, тобто до двох
взаємозв'язаних типів записів.
Тип запису, з якого виходить дуга, називається власником набору, чи
основним файлом. Тип запису, в який входить дуга, називається членом
набору, чи підпорядкованим файлом. Дуга, спрямована від власника набору
до його члена, являє собою логічний взаємозв'язок «один до багатьох» між
власником і членом набору даних.
Необхідно розрізняти такі поняття, як «тип» та «екземпляр набору».
Наприклад:
1:
Постачальник
Б
ЗАМОВЛЕННЯ
Матеріал
Тип набору ЗАМОВЛЕННЯ може характеризуватись екземпляром типу
запису-власника ПОСТАЧАЛЬНИК і деякою множиною екземплярів типу
запису МАТЕРІАЛ. Отже, кожний екземпляр набору складається з одного
екземпляра типу запису-власника і кількох екземплярів типу записів-членів.
Власник типу набору має бути обов'язково унікальним.
Записи-власники можуть брати участь у кількох наборах, а записи-члени
можуть виступати як власники в інших наборах. Кожний тип набору
ідентифікується унікальним іменем.
23
24.
Існує кілька видів наборів: набори першого та другого класу і сингулярнінабори.
Набір першого класу об'єднує два типи
запису. Підпорядкований запис жорстко
пов'язаний із записом-власником і його
можна виключити з групового відношення
тільки видаливши. При видаленні записувласника всі підлеглі записи автоматично
теж видаляються.
КЛІЄНТ
Власник
набору
КЛІЄНТСЬКИЙ РАХУНОК
РАХУНОК
Ім’я
набору
Член
набору
В наборах другого класу допускається перемикання підпорядкованого
запису на іншого власника, але неможливо його існування без власника. Для
видалення запису-власника необхідно, щоб він не мав підлеглих записів з
обов'язковим членством.
Сингулярний набір (тільки один екземпляр). У такого набору немає
природного власника і в якості нього виступає система. Надалі такі набори
можуть придбати запис-власника. Можна виключити запис з групового
відношення, але зберегти її в базі даних не прикріплюючи до іншого власника.
При видаленні запису-власника її підлеглі записи - необов'язкові члени
зберігаються в базі, не беручи участь більше в груповому відношенні такого
типу.
24
25.
Відображення ІЛМ на сіткову модель виконують так само, як і відображенняна ієрархічну, в два етапи: спочатку будують загальну сіткову модель, а потім її
модифікують з урахуванням обмежень і особливостей конкретної СУБД.
Відображення інфологічної
структурних зв'язків в ІЛМ.
моделі
на
сіткову
починається
з
аналізу
Перетворення 1. У сітковій моделі можна залишати лише зв'язки типу ВП, а
зв'язки ПВ і ВПВ повинні бути перетворені. Це можливо об'єднанням об'єктів в
один. При об’єднанні власника і підпорядкованого об'єкта створюється новий
тип запису, в якому підпорядкований об’єкт виступає як агрегат типу залисувласника. Отже, зв'язок ПВ ліквідується, а зв'язок ВПВ перетворюється на ВП.
Це перетворення через злиття двох об'єктів в один можливе тоді, коли
підпорядкований об'єкт не бере участі в інших наборах.
Перетворення 2. Згідно з правилами побудови сіткових моделей кожний
набір не може мати більш як одного власника в одному й тому самому наборі.
Тому наступним кроком відображення є усунення багатозначного володіння.
Усі зв'язки типу «багато до багатьох» (Б:Б) не можуть бути реалізовані в
явному вигляді. їх моделюють так, як показано на рисунку.
25
26.
На рисунку показано, як за допомогою двохзв'язків 1:Б реалізовано взаємозв'язок Б:Б.
Реалізувати це однією дугою неможливо,
оскільки одну і ту саму операцію обробки
можуть проходити різні деталі, а це
призводить
до
порушення
правила
унікальності володіння, бо одна й та сама
деталь має стати членом одночасно двох чи
більше екземплярів одного набору. Тому
можна ввести два набори: МАРШРУТ буде
відображати зв'язок ДЕТАЛЬ — ВЕРСТАТ і
вказуватиме, на яких верстатах пройшла
обробку та чи інша деталь: ОПЕРАЦІЯ
вказуватиме, які деталі проходять обробку
на кожному верстаті.
У наборі даних ОПЕРАЦІЯ тип запису
ВЕРСТАТ виступає власником, а ДЕТАЛЬ —
членом набору, а в наборі МАРШРУТ,
навпаки, ВЕРСТАТ — член, а ДЕТАЛЬ —
власник набору.
ДЕТАЛЬ
Б:Б
ВЕРСТАТ
ДЕТАЛЬ
ОПЕРАЦІЯ
МАРШРУТ
ВЕРСТАТ
26
27.
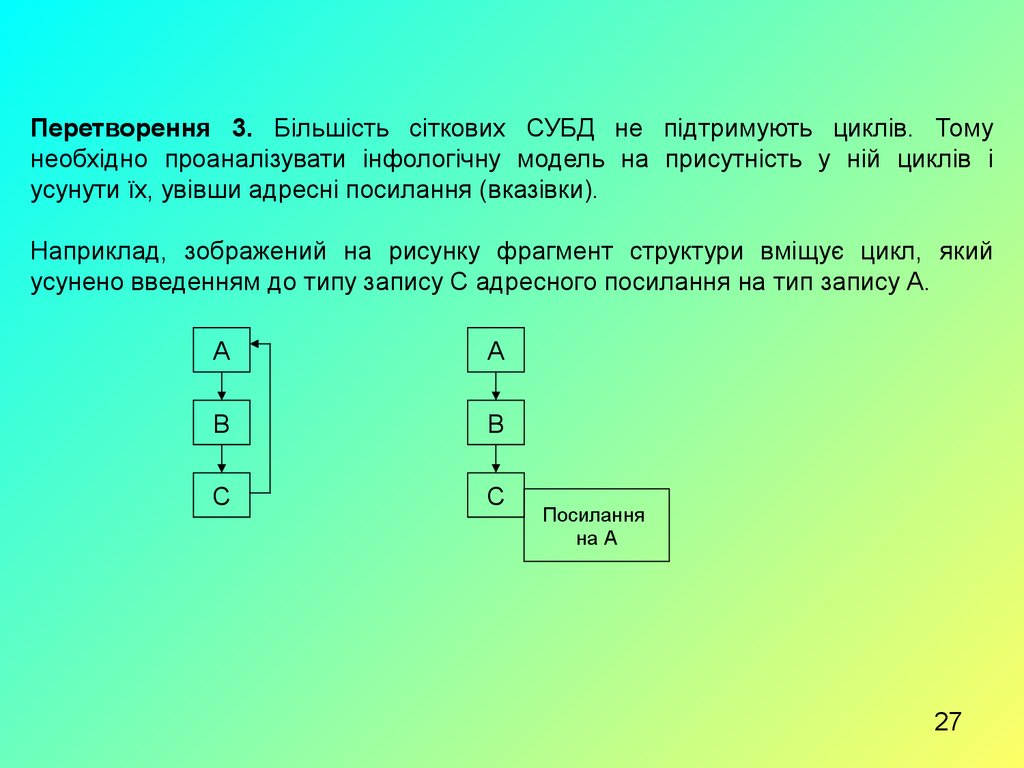
Перетворення 3. Більшість сіткових СУБД не підтримують циклів. Томунеобхідно проаналізувати інфологічну модель на присутність у ній циклів і
усунути їх, увівши адресні посилання (вказівки).
Наприклад, зображений на рисунку фрагмент структури вміщує цикл, який
усунено введенням до типу запису С адресного посилання на тип запису А.
А
А
В
В
С
С
Посилання
на А
27
28.
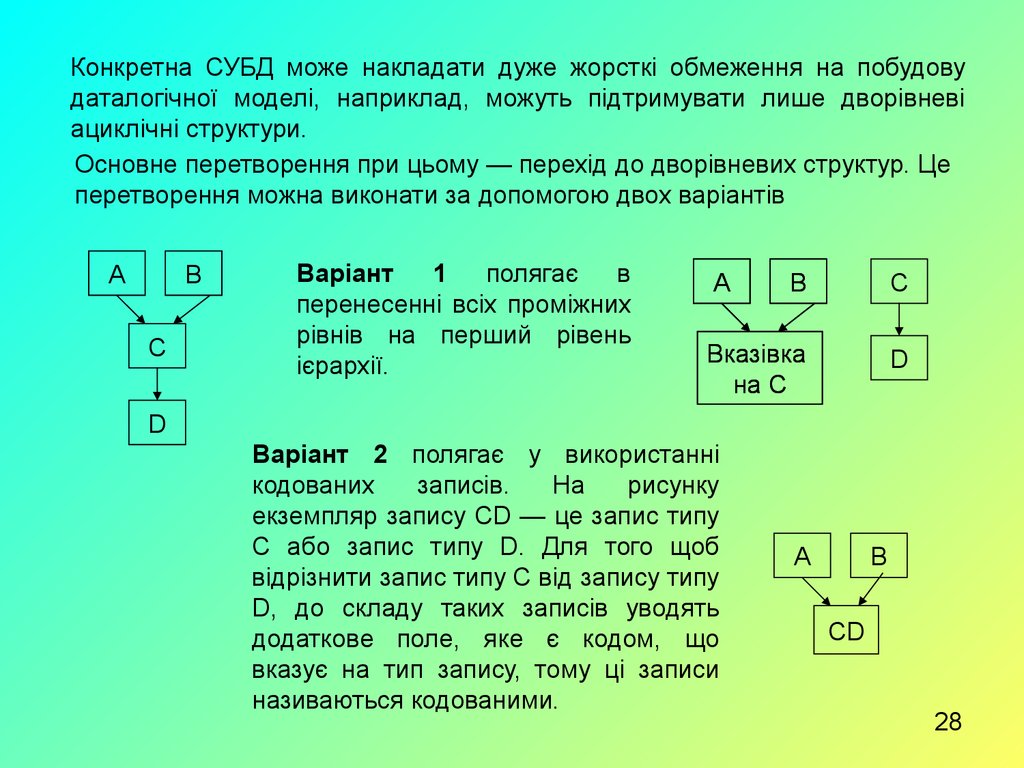
Конкретна СУБД може накладати дуже жорсткі обмеження на побудовудаталогічної моделі, наприклад, можуть підтримувати лише дворівневі
ациклічні структури.
Основне перетворення при цьому — перехід до дворівневих структур. Це
перетворення можна виконати за допомогою двох варіантів
А
В
С
Варіант
1
полягає
в
перенесенні всіх проміжних
рівнів на перший рівень
ієрархії.
А
В
С
Вказівка
на С
D
D
Варіант 2 полягає у використанні
кодованих
записів.
На
рисунку
екземпляр запису CD — це запис типу
С або запис типу D. Для того щоб
відрізнити запис типу С від запису типу
D, до складу таких записів уводять
додаткове поле, яке є кодом, що
вказує на тип запису, тому ці записи
називаються кодованими.
А
В
СD
28