





































 Программирование
ПрограммированиеПохожие презентации:










Представление информации в цифровых вычислительных системах
1.
1. Представление информации в цифровых вычислительных системахЧисловая информация:
Для представления числовой информации существует две системы счисления:
- позиционная и непозиционная (римские цифры, I, II, III, ….X…).
Позиционная система счисления — система счисления, в которой значение
каждого числового знака в записи числа зависит от его позиции.
Количество цифр, используемых в системе счисления, определяется её
основанием. В десятичной системе цифр десять, в двоичной системе — две.
То есть в Z -ричной системе счисления количество цифр равно Z, при этом
используются цифры от 0 до Z-1.
Число в Z-ричной системе счисления представляется также в виде суммы
целых степеней числа с коэффициентами:
An -1 * Zn-1 +An-2 *Zn -2 +…..+A1 *Z1 + A0 *Z0 ,
Где A – коэфициент в диапозоне от 0 до Z-1, а n – количество разрядов
Пример Z=10:
Пример Z=2:
4*102 + 2*101 + 9*100 = 429
1*22 + 0*21 + 1*20 = 5
Для знаковых чисел слева от числа добавляется дополнительный знак (разряд)
Свойства чисел с фиксированной разрядностью:
Для знака отводится старший разряд числа, поэтому диапозон чисел
уменьшается на величину старшего разряда;
При арифметических действиях над числами с фиксированной разрядностью
может возникать переполнение разрядной сетки. Старший разряд выходит за
разрядную сетку и теряется, результат операции неверный. Необходимо
программно контролировать переполнение.
Свойство числовой оси – сумма равноудоленных от 0 чисел равна 0.
Имеем 4 разрядное устройство. Для знаковых чисел старший разряд знаковый
и допустим равен 0 для положительных чисел и 9 для отрицательных
|---------|---------|---------|---------|---------|---------|---------|---------|---------9996 9997 9998 9999 0000 0001 0002 0003 0004
Проверим свойство числовой оси
9996
0004
10000
Для двоичных чисел
2.
-4-3
-2
-1
1
2
3
4
|---------|---------|---------|---------|---------|---------|---------|---------|---------1100 1101 1110 1111 0000 0001 0010 0011 0100
1111
0001
10000
Числа 996, 997, 998, 999 (100, 101, 110, 111) являются дополнением чисел 4, 3,
2, 1. Старший разряд знаковый 0 – положительное число, 9 и 1 – отрицательное.
Для двоичных чисел дополнительный код числа вычисляется
инвертированием разрядов соответствующего положительного числа и
прибавлением к нему 1.
Действие вычитание заменяется сложением А – В = А + (- В), где –В
представлено в дополнительном коде.
Пример:
Сложить два числа 5 и -3 в двоичном коде
5 - 0101
-3 - положительное 3 - 0011 инвртируем 1100 и прибавим 1 – 1101
0101
1101
10010
Сложить два числа -1 и -3 в двоичном коде
-1 1111
-3 1101
-4 11100
Умножение это сложение одного операнда со сдвигом на разряд влево
0011
0010
0000
0011
0000
0000
0000110
Деление это действие обратное умножению, используется вычитание (сложение в
дополнительном коде)
Числа с плавающей запятой представляются в экпотенциальной форме в виде
мантиссы (целое знаковое число) и порядка (целое знаковое число).
Таким образом в простешем случае арифметическое устройство вычислительной
машины представляет собой сумматор с возможностью сдвига операнда и
3.
дополненый возможностью выполнения логических операций И, ИЛИ, НЕ иисключаещее ИЛИ.
Контекстное предсавление информации.
Вся информация в микропроцессоре представляетя в виде чисел (кодов) в
двоичной системе счисления. Все остальные виды информации представляются
контекстно. То есть элемент информации кодируется двоичным числом
определенной разрядности. Величина разрядности кода определяет количество
возможных элементов данной информации.
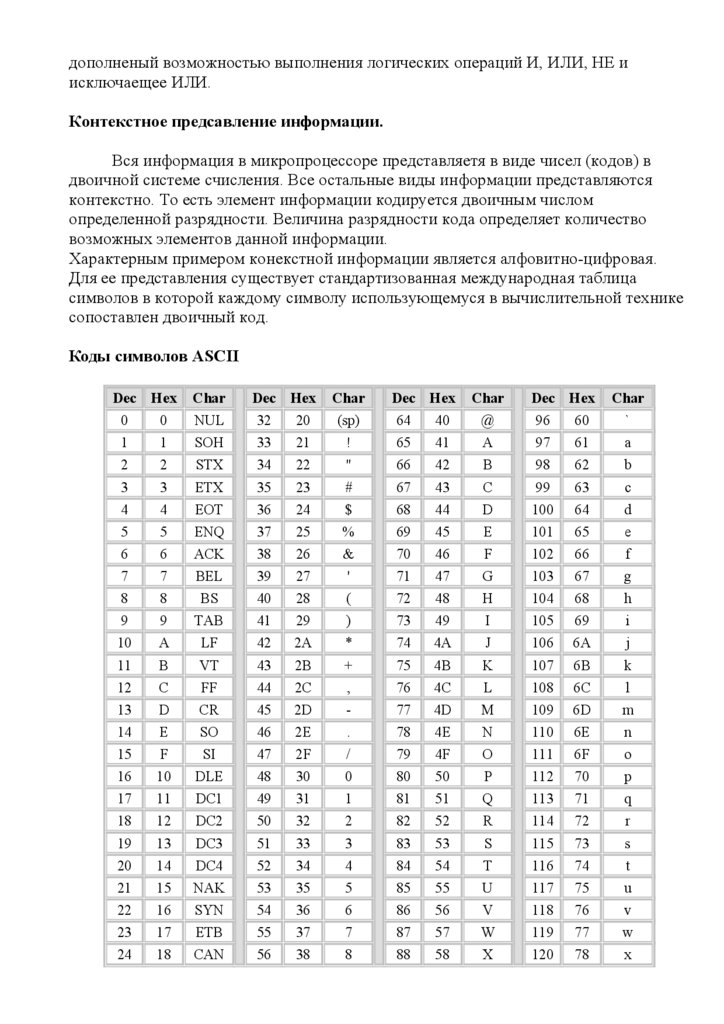
Характерным примером конекстной информации является алфовитно-цифровая.
Для ее представления существует стандартизованная международная таблица
символов в которой каждому символу использующемуся в вычислительной технике
сопоставлен двоичный код.
Коды символов ASCII
Dec
Hex
Char
Dec
Hex
Char
Dec
Hex
Char
Dec
Hex
Char
0
0
NUL
32
20
(sp)
64
40
@
96
60
`
1
1
SOH
33
21
!
65
41
A
97
61
a
2
2
STX
34
22
"
66
42
B
98
62
b
3
3
ETX
35
23
#
67
43
C
99
63
c
4
4
EOT
36
24
$
68
44
D
100
64
d
5
5
ENQ
37
25
%
69
45
E
101
65
e
6
6
ACK
38
26
&
70
46
F
102
66
f
7
7
BEL
39
27
'
71
47
G
103
67
g
8
8
BS
40
28
(
72
48
H
104
68
h
9
9
TAB
41
29
)
73
49
I
105
69
i
10
A
LF
42
2A
*
74
4A
J
106
6A
j
11
B
VT
43
2B
+
75
4B
K
107
6B
k
12
C
FF
44
2C
,
76
4C
L
108
6C
l
13
D
CR
45
2D
-
77
4D
M
109
6D
m
14
E
SO
46
2E
.
78
4E
N
110
6E
n
15
F
SI
47
2F
/
79
4F
O
111
6F
o
16
10
DLE
48
30
0
80
50
P
112
70
p
17
11
DC1
49
31
1
81
51
Q
113
71
q
18
12
DC2
50
32
2
82
52
R
114
72
r
19
13
DC3
51
33
3
83
53
S
115
73
s
20
14
DC4
52
34
4
84
54
T
116
74
t
21
15
NAK
53
35
5
85
55
U
117
75
u
22
16
SYN
54
36
6
86
56
V
118
76
v
23
17
ETB
55
37
7
87
57
W
119
77
w
24
18
CAN
56
38
8
88
58
X
120
78
x
4.
2519
EM
57
39
9
89
59
Y
121
79
y
26
1A
SUB
58
3A
:
90
5A
Z
122
7A
z
27
1B
ESC
59
3B
;
91
5B
[
123
7B
{
28
1C
FS
60
3C
<
92
5C
\
124
7C
|
29
1D
GS
61
3D
=
93
5D
]
125
7D
}
30
1E
RS
62
3E
>
94
5E
^
126
7E
~
31
1F
US
63
3F
?
95
5F
_
127
7F
DEL
2. Структура микропроцессора
С точки зрения программиста структура микропроцессора представляется как набор
регистров (внутреннея память микропроцессора с адресацией по имени регистра) и
системы команд для преобразования информации которая находится в основной и
внутренней памяти.
Рис. 1 Структура микропроцессора 8086
5.
В группу регистров данных включаются регистры АХ, ВХ, СХ и DX. Программист можетиспользовать их по своему усмотрению для временного хранения любых объектов (данных или
адресов) и выполнения над ними требуемых операций. При этом регистры допускают независимое
обращение к старшим (АН, ВН, СН и DH) и младшим (AL, BL, CL и DL) байтам регистра. Так,
команда
mov BL,AH
пересылает старший байт регистра АХ в младший байт регистра ВХ, не затрагивая при этом
вторых байтов этих регистров. Еще раз отметим, что сначала указывается операнд-приемник, а
после запятой - операнд-источник, т. е. команда выполняется как бы справа налево. В качестве
средства временного хранения данных все регистры общего назначения (да и все остальные, кроме
сегментных и указателя стека) вполне эквивалентны, однако многие команды требуют для своего
выполнения использования вполне определенных регистров. Например, команда умножения mul
требует, чтобы один из сомножителей был в регистре АХ (или AL), а команда организации цикла
loop выполняет циклический переход СХ раз.
Индексные регистры SI и DI так же, как и регистры данных, могут использоваться произвольным
образом. Однако их основное назначение - хранить индексы (смещения) относительно некоторой
базы (т. е. начала массива) при выборке операндов из памяти. Адрес базы при этом обычно
находится в одном из базовых регистров (ВХ или ВР). Примеры такого рода будут приведены
ниже.
Регистр ВР служит указателем базы при работе с данными в стековых структурах, о чем будет
речь впереди, но может использоваться и произвольным образом в большинстве арифметических
и логических операций или просто для временного хранения каких-либо данных.
Последний из регистров-указателей, указатель стека SP, стоит особняком от других в том
отношении, что используется исключительно, как указатель вершины стека и будет подробно
описан позже.
Регистры SI, DI, ВР и SP, в отличие от регистров данных, не допускают побайтовую адресацию.
Четыре сегментных регистра CS, DS, ES и SS хранят начальные адреса сегментов программы и,
тем самым, обеспечивают возможность обращения к этим сегментам.
Регистр CS обеспечивает адресацию к сегменту, в котором находятся программные коды,
регистры DS и ES - к сегментам с данными (таким образом, в любой точке программа может иметь
6.
доступ к двум сегментам данных, основному и дополнительному), а регистр SS - к сегменту стека.Сегментные регистры, естественно, не могут выступать в качестве регистров общего назначения.
Указатель команд IP (Instruction Pointer) "следит" за ходом выполнения программы, указывая в
каждый момент относительный адрес команды, следующей за исполняемой. Регистр IP
программно недоступен ; наращивание адреса в нем выполняет микропроцессор, учитывая при
этом длину текущей команды.
Регистр флагов, эквивалентный регистру состояния процессора других вычислительных систем,
содержит информацию о текущем состоянии процессора. Он включает 6 флагов состояния и 3
бита управления состоянием процессора, которые, впрочем, тоже обычно называются флагами.
Флаг переноса CF (Carry Flag) индицирует перенос или заем при выполнении арифметических
операций, а также (что для прикладного программиста гораздо важнее!) служит индикатором
ошибки при обращении к системным функциям.
Флаг паритета PF (Parity Flag) устанавливается в 1, если младшие 8 бит результата операции
содержат четное число двоичных единиц.
Флаг вспомогательного переноса AF (Auxiliary Flag) используется в операциях над упакованными
двоично-десятичными числами. Он индицирует перенос в старшую тетраду (четверку битов) или
заем из старшей тетрады.
Флаг нуля ZF (Zero Flag) устанавливается в 1, если результат операции равен нулю.
Флаг знака SF (Sign Flag) показывает знак результата операции, устанавливаясь в 1 при
отрицательном результате.
Флаг переполнения OF (Overflow Flag) фиксирует переполнение, т. е. выход результата операции
за пределы допустимого для данного процессора диапазона значений.
Флаги состояния автоматически устанавливаются процессором после выполнения каждой
команды. Так, если в регистре АХ содержится число 1, то после выполнения команды декремента
(уменьшения на единицу)
dec AX
содержимое АХ станет равно нулю и процессор сразу отметит этот факт, установив в регистре
флагов бит ZF (флаг нуля).
Если попытаться сложить два больших числа, например 58 000 и 61 000, то установится флаг
переноса CF, так как число 119 000, получающееся в результате сложения, должно занять больше
двоичных разрядов, чем помещается в регистрах или ячейках памяти, и возникает "перенос"
старшего бита этого числа в бит CF регистра флагов.
Индицирующие флаги процессора дают возможность проанализировать, если это нужно,
результат последней операции и осуществить "разветвление" программы: например, в случае
нулевого результата перейти на выполнение одного фрагмента программы, а в случае ненулевого на выполнение другого. Такие разветвления осуществляются с помощью команд условных
переходов, которые в процессе своего выполнения анализируют состояние регистра флагов. Так,
команда
jz zero
7.
осуществляет переход на метку zero, если результат выполнения предыдущей команды окажетсяравен нулю (т. е. флаг ZF установлен), а команда
jnc okey
выполнит переход на метку okey, если предыдущая команда сбросила флаг переноса CF (или
оставила его в сброшенном состоянии).
Управляющий флаг трассировки TF (Trace Flag) используется в отладчиках для осуществления
пошагового выполнения программы. Если TF=l, то после выполнения каждой команды процессор
реализует процедуру прерывания 1 (через вектор прерывания с номером 1).
Управляющий флаг разрешения прерываний IF (Interrupt Flag) разрешает (если равен единице) или
запрещает (если равен нулю) процессору реагировать на прерывания от внешних устройств.
Управляющий флаг направления DF (Direction Flag) используется особой группой команд,
предназначенных для обработки строк. Если DF=0, строка обрабатывается в прямом направлении,
от меньших адресов к большим; если DF=1, обработка строки идет в обратном направлении.
Таким образом, в отличие от битов состояния, управляющие флаги устанавливает или сбрасывает
программист, если он хочет изменить настройку системы (например, запретить на какое-то время
аппаратные прерывания или изменить направление обработки строк).
3. Организация памяти микропроцессора
Архитектурные особенности микропроцессоров корпорации Intel обусловливают сегментную
организацию программ. Важнейшей характеристикой любого процессора является разрядность его
внутренних регистров, а также внешних шин адресов и данных. МП 86 имеет 16-разрядную
внутреннюю архитектуру и такой же разрядности шину данных. Таким образом, максимальное
целое число (данное или адрес), с которым может работать микропроцессор, составляет 216-1 = 65
535 (64 К - 1). Однако адресная шина МП 86 содержит 20 линий, что соответствует адресному
пространству 220 =1 Мбайт. Для того чтобы с помощью 16-разрядных адресов можно было
обращаться в любую точку 20-разрядного адресного пространства, в процессоре предусмотрена
сегментная адресация памяти, реализуемая с помощью четырех сегментных регистров.
Суть сегментной адресации заключается в следующем. Физический 20-разрядный адрес любой
ячейки памяти вычисляется процессором путем сложения 20-разрядного начального адреса
сегмента памяти, в котором располагается эта ячейка, с 16- разрядным смещением к ней (в байтах)
от начала сегмента (см.рис.). Начальный адрес сегмента без четырех младших бит, т. е. деленный
на 16, хранится в одном из сегментных регистров. Эта величина называется сегментным адресом.
Каждый раз при загрузке в сегментный регистр сегментного адреса процессор автоматически
умножает его на 10h=16 и полученный таким образом базовый адрес сегмента сохраняет в одном
из своих внутренних регистров. При необходимости обратиться к той или иной ячейке памяти
процессор прибавляет к этому базовому адресу смещение ячейки, в результате чего образуется
физический адрес ячейки в памяти. Умножение 16-разрядного сегментного адреса - 64 Кбайт на 16
увеличивает диапазон адресуемых ячеек до величины 1 Мбайт.
8.
Программа на ассемблере представляет собой совокупность блоков памяти,называемых сегментами памяти. Программа может состоять из одного или
нескольких таких блоков-сегментов. Каждый сегмент содержит совокупность
предложений языка, каждое из которых занимает отдельную строку кода
программы.
3. Способы адресации операндов
Вопрос о том, каким образом в адресном поле команды может быть указано местоположение операндов, считается одним из центральных при разработке архитектуры ВМ. С точки
зрения сокращения аппаратурных затрат очевидно стремление разработчиков уменьшить длину
адресного поля при сохранении возможностей доступа ко всему адресному пространству. С
другой стороны, способ задания адресов должен способствовать максимальному сближению
конструктов языков программирования высокого уровня и машинных команд. Все это привело к
тому, что в архитектуре системы команд любой ВМ предусмотрены различные способы адресации
операндов.
Приступая к рассмотрению способов адресации, вначале определим понятия «исполнительный» и
«адресный код».
Исполнительным адресом операнда (Лисп) называется двоичный код номера ячейки памяти,
служащей источником или приемником операнда. Этот код подается на адресные входы
запоминающего устройства (ЗУ), и по нему происходит фактическое обращение к указанной
ячейке. Если операнд хранится не в основной памяти, а в регистре процессора, его
исполнительным адресом будет номер регистра.
Адресный код команды (Лк) — это двоичный код в адресном поле команды, из которого
необходимо сформировать исполнительный адрес операнда.
В современных ВМ исполнительный адрес и адресный код, как правило, не совпадают, и
для доступа к данным требуется соответствующее преобразование. Способ адресации — это
способ формирования исполнительного адреса операнда по адресному коду команды. Способ
адресации существенно влияет на параметры процесса обработки информации. Одни способы
позволяют увеличить емкость адресуемой памяти без удлинения команды, но снижают скорость
выполнения операции, другие — ускоряют операции над массивами данных, третьи — упрощают
работу с подпрограммами и т. д. В сегодняшних ВМ обычно имеется возможность приложения
нескольких различных способов адресации операндов к одной и той же операции.
9.
Чтобы устройство управления вычислительной машины могло определить, какой именноспособ адресации принят в данной команде, в разных ВМ используются различные приемы. Часто
разным способам адресации соответствуют и разные коды операции.
Другой подход — это добавление в состав команды специального поля способа адресации,
содержимое которого определяет, какой из способов адресации должен быть применен. Иногда в
команде имеется нескольких полей — по одному на каждый адрес. Отметим, что возможен также
вариант, когда в команде вообще отсутствует адресная информация, то есть имеет место неявная
адресация. При неявной адресации адресного поля либо просто нет, либо оно содержит не все
необходимые адреса — отсутствующий адрес подразумевается кодом операции. Так, при
исключении из команды адреса результата подразумевается, что результат помещается на место
второго операнда. Неявная адресация применяется достаточно широко, поскольку позволяет
сократить длину команды.
Выбор способов адресации является одним из важнейших вопросов разработки системы
команд и всей ВМ в целом, при этом существенное значение имеет не только удобство
программирования, но и эффективность способа. Эффективность способа адресации можно
характеризовать двумя показателями: затратами оборудования С и затратами времени Т на доступ
к адресуемым данным. Затраты оборудование определяются суммой ,
C = СВА + СЗУ
где СВА — затраты аппаратных средств, обеспечивающих вычисление исполнительных адресов;
СЗУ — затраты памяти на хранение адресных кодов команд. Обычная С ЗУ >>CВА, поэтому при
оценке затрат оборудования ограничиваются учетом величины СЗУ. Затраты времени Т
определяются суммой времени tФИА формирования исполнительного адреса и времени tЗУ выборки
или записи операнда:
Т = tФИА + tЗУ
В настоящее время используются различные виды адресации, наиболее распространенные
из которых рассматриваются ниже.
3.1. Непосредственная адресация
При непосредственной адресации (НА) в адресном поле команды вместо адреса содержится
непосредственно сам операнд. Этот способ может применяться при выполнении арифметических
операций, операций сравнения, а также для загрузки констант в регистры.
Когда операндом является число, оно обычно представляется в дополнительном коде. При
записи в регистр, имеющий разрядность, превышающую длину непосредственного операнда,
операнд размещается в младшей части регистра, а оставшиеся свободными позиции заполняются
значением знакового бита операнда
Помимо того, что в адресном поле могут быть указаны только константы, еще одним
недостатком данного способа адресации является то, что размер непосредственного операнда
ограничен длиной адресного поля команды, которое в большинстве случаев меньше длины
машинного слова.
В 50-60% команд с непосредственной адресацией длина операнда не превышает 8 бит, а в
75-80% — 16 бит. Таким образом, в подавляющем числе случаев шестнадцати разрядов вполне
достаточно, хотя для вычисления адресов могут потребоваться и более длинные константы.
Непосредственная адресация сокращает время выполнения команды, так как не требуется
обращение к памяти за операндом. Кроме того, экономится память, поскольку отпадает
необходимость в ячейке для хранения операнда. В плане эффективности этот способ можно
считать «идеальным» (СНА = 0, ТНА = 0), и его можно рекомендовать к использованию во всех
ситуациях, когда тому не препятствуют вышеупомянутые ограничения.
3.2. Прямая адресация
10.
При прямой или абсолютной адресации (ПА) адресный код прямо указывает номер ячейкипамяти, к которой производится обращение (рис. 2), то есть адресный код совпадает с исполнительным
адресом.
Команда
КОп
СА
Память
АК
Операнд
Рис. 2. Прямая адресация.
При всей простоте использования способ имеет существенный недостаток — ограниченный
размер адресного пространства, так как для адресации к памяти большой емкости нужно «длинное»
адресное поле. Однако более существенным несовершенством можно считать то, что адрес, указанный в
команде, не может быть изменен в процессе вычислений (во всяком случае, такое изменение не
рекомендуется). Это ограничивает возможности по произвольному размещению программы в памяти.
Прямую адресацию характеризуют следующие показатели эффективности: СПА = int (log2Ni),
TПА = tЗУ, где Ni — количество адресуемых операндов, int – операция взятия целой части числа.
3.3. Косвенная адресация
Одним из путей преодоления проблем, свойственных прямой адресации, может служить
прием, когда с помощью ограниченного адресного поля команды указывается адрес ячейки, в свою
очередь, содержащей полноразрядный адрес операнда (рис. 23). Этот способ известен как косвенная
адресация (КА). Запись (Лк) означает содержимое ячейки, адрес которой указан в скобках.
При косвенной адресации содержимое адресного поля команды остается неизменным, в то время
как косвенный адрес в процессе выполнения программы можно изменять. Это позволяет проводить
вычисления, когда адреса операндов заранее неизвестны и появляются лишь в процессе решения
задачи. Дополнительно такой прием упрощает обработку массивов и списков, а также передачу
параметров подпрограммам.
Команда
Память
КОп
СА
АК
Исполнительный
адрес операнда
Операнд
Рис. 3. Косвенная адресация.
Недостатком косвенной адресации является необходимость в двукратном обращении к памяти:
сначала для извлечения адреса операнда, а затем для обращения к операнду (ТКА = 2 tЗУ). Сверх того
задействуется лишняя ячейка памяти для хранения исполнительного адреса операнда. Способу
свойственны следующие затраты оборудования:
11.
СКА = Rяч + int(log2NA) = int(log2(NA + Ni),где RЯЧ— разрядность ячейки памяти, хранящей исполнительный адрес; NA — количество ячеек для
хранения исполнительных адресов; Nt — количество адресуемых операндов. Здесь выражение
int(log2NA) определяет разрядность сокращенного адресного поля команды (обычно NA << Ni).
В качестве варианта косвенной адресации, правда, достаточно редко используемого, можно
упомянуть многоуровневую или каскадную косвенную адресацию, когда к исполнительному адресу
ведет цепочка косвенных адресов. В этом случае один из битов в каждом адресе служит признаком
косвенной адресации. Состояние бита указывает, является ли содержимое ячейки очередным адресом в
цепочке адресов или это уже исполнительный адрес операнда. Особых преимуществ у такого подхода
нет, но в некоторых специфических ситуациях он оказывается весьма удобным, например, при обработке
многомерных массивов. В то же время очевиден и его недостаток — для доступа к операнду требуется
три и более обращений к памяти.
3.4. Регистровая адресация
Регистровая адресация (РА) напоминает прямую адресацию. Различие состоит в том, что
адресное поле инструкции указывает не на ячейку памяти, а на регистр процессора (рис. 4).
Идентификатор регистра в дальнейшем будем обозначать буквой R. Обычно размер адресного поля в
данном случае составляет три или четыре бита, что позволяет указать соответственно на один из 8 или
16 регистров общего назначения (РОН).
Двумя основными преимуществами регистровой адресации являются: короткое адресное поле в
команде и исключение обращений к памяти. Малое число РОН позволяет сократить длину адресного поля
команды, то есть СРА << СПА. Кроме того, ТРА = tРОН, где tРОН — время выборки операнда из регистра общего
назначения, при чем tРОН << 2tЗУ. К сожалению, возможности по использованию регистровой
адресации ограничены малым числом РОН в составе процессора.
Команда
КОп
СА
Регистры
R
Операнд
Рис. 4. Регистровая адресация.
3.5. Косвенная регистровая адресация
Косвенная регистровая адресация (КРА) представляет собой косвенную адресацию, где
исполнительный адрес операнда хранится не в ячейке основной памяти, а в регистре процессора.
Соответственно, адресное поле команды указывает не на ячейку памяти, а на регистр (рис. 5).
Команда
КОп
СА
Регистры
Память
R
Адрес
операнда
Операнд
12.
Рис. 5. Косвенная регистровая адресация.Достоинства и ограничения косвенной регистровой адресации те же, что и у обычной
косвенной адресации, но благодаря тому, что косвенный адрес хранится не в памяти, а в регистре,
для доступа к операнду требуется на одно обращение к памяти меньше. Эффективность
косвенной регистровой адресации можно оценить по формулам:
TКРА = tРОН + tЗУ; СКРА = RPOH + int(log2 NA) = int(log2(Ni + NA)), где RPOH — разрядность
регистров общего назначения.
3.6. Адресация со смещением
При адресации со смещением исполнительный адрес формируется в результате
суммирования содержимого адресного поля команды с содержимым одного или нескольких
регистров процессора (рис. 6).
Адресация со смещением предполагает, что адресная часть команды включает в себя как
минимум одно поле (Aк). В нем содержится константа, смысл которой в разных вариантах адресации
со смещением может меняться. Константа может представлять собой некий базовый адрес, к
которому добавляется хранящееся в регистре смещение. Допустим и прямо противоположный
подход: базовый адрес находится в регистре процессора, а в поле Aк указывается смещение
относительно этого адреса. В некоторых процессорах для реализации определенных вариантов
адресации со смещением предусмотрены специальные регистры, например, базовый или
индексный. Использование таких регистров предполагается по умолчанию, поэтому адресная
часть команды содержит только поле Ак.
Если же составляющая адреса может располагаться в произвольном регистре общего
назначения, то для указания конкретного регистра в команду включается дополнительное поле R
(при составлении адреса более чем из двух составляющих в команде будет несколько таких
полей). Еще одно поле R может появиться в командах, где смещение перед вычислением
исполнительного адреса умножается на масштабный коэффициент. Такой коэффициент заносится
в один из РОН, на который и указывает это дополнительное поле. В наиболее общем случае
адресация со смещением подразумевает наличие двух адресных полей: Ак и R.
Команда
КОп
СА
R1
R2
AK
Регистры
Составляющая адреса
операнда
Составляющая адреса
операнда
Память
Операнд
13.
Рис. 6. Адресация со смещением.В рамках адресации со смещением имеется еще один вариант, при котором исполнительный адрес вычисляется не суммированием, а конкатенацией (присоединением)
составляющих адреса. Здесь одна составляющая представляет собой старшую часть
исполнительного адреса, а вторая — младшую.
Ниже рассматриваются основные способы адресации со смещением, каждый из которых,
впрочем, имеет собственное название.
3.7. Относительная адресация
При относительной адресации (ОА) для получения исполнительного адреса операнда
содержимое подполя Aк команды складывается с содержимым счетчика команд (рис. 7). Таким
образом, адресный код в команде представляет собой смещение относительно адреса текущей
команды. Следует отметить, что в момент вычисления исполнительного адреса операнда в счетчике
команд может уже быть сформирован адрес следующей команды, что нужно учитывать при выборе
величины смещения. Обычно подполе Ак трактуется как двоичное число в дополнительном коде.
Команда
КОп
СА
Счетчик команд (СК)
Адрес текущей
команды
Память
AK
Текущая
команда
Операнд
Рис. 7. Относительная адресация.
Адресация относительно счетчика команд базируется на свойстве локальности,
выражающемся в том, что большая часть обращений происходит к ячейкам, расположенным в
непосредственной близости от выполняемой команды. Это позволяет сэкономить на длине адресной
части команды, поскольку разрядность подполя Ак может быть небольшой. Главное достоинство
данного способа адресации состоит в том, что он делает программу перемещаемой в памяти:
независимо от текущего расположения программы в адресном пространстве взаимное положение
команды и операнда остается неизменным, поэтому адресация операнда остается корректной.
Эффективность данного способа адресации можно описать выражениями:
TСА = tРОН + tСЛ + tЗУ; ССА = int ( log2 Ni – RСК)
где tCЛ — время сложения составляющих исполнительного адреса; RCK — разрядность
счетчика команд.
3.8. Базовая регистровая адресация
В случае базовой регистровой адресации (БРА) регистр, называемый базовым, содержит
полно разрядный адрес, а подполе Ас — смещение относительно этого адреса. Ссылка на базовый
14.
регистр может быть явной или неявной. В некоторых ВМ имеется специальный базовый регистр иего использование является неявным, то есть подполе R в команде отсутствует (рис. 8).
Команда
КОп
Память
СА
Базовый регистр (БР)
AС
Смещение
Базовый адрес
Операнд
Рис. 8. Базовая регистровая адресация с базовым регистром.
Более типичен случай, когда в роли базового регистра выступает один из регистров общего
назначения (РОН), тогда его номер явно указывается в подполе R команды (рис. 9).
Базовую регистровую адресацию обычно используют для доступа к элементам массива,
положение которого в памяти в процессе вычислений может меняться. В базовый регистр
заносится начальный адрес массива, а адрес элемента массива указывается в подполе Ас команды
в виде смещения относительно начального адреса массива. Достоинство данного способа
адресации в том, что смещение имеет меньшую длину, чем полный адрес, и это позволяет
сократить длину адресного поля команды. Короткое смещение расширяется до полной длины
исполнительного адреса путем добавления слева битов, совпадающих со значением знакового
разряда смещения.
Команда
КОп
СА
Память
R
AС
Регистры общего Смещение
назначения (РОН)
Операнд
Базовый адрес
Рис. 9. Базовая регистровая адресация с использованием одного из РОН.
Разрядность смещения RCM и, соответственно, затраты оборудования определяются из
условия RCM = СБРА = int(log2(max(Non ))), где Non, — количество операндов i-й программы.
Затраты времени составляют: ГБРА = tPOH + tСЛ + tЗУ.
3.9. Индексная адресация
При индексной адресации (ИА) подполе Ас содержит адрес ячейки памяти, а регистр
(указанный явно или неявно) — смещение относительно этого адреса. Как видно, этот способ адресации
похож на базовую регистровую адресацию. Поскольку при индексной адресации в поле Ас находится
15.
полноразрядный адрес ячейки памяти, играющий роль базы, длина этого поля больше, чем при базовойрегистровой адресации. Тем не менее вычисление исполнительного адреса операнда производится
идентично (рис. 10, рис. 11).
Команда
КОп
Память
СА
AС
Базовый адрес
Индексный регистр (ИР)
Индекс
Операнд
Рис. 10. Индексная адресация с индексным регистром.
Команда
КОп
СА
Регистры общего
назначения (РОН)
Память
R
AС
Базовый адрес
Операнд
Индекс
Рис. 11. Индексная адресация с использованием одного из РОН.
Индексная адресация предоставляет удобный механизм для организации итеративных
вычислений. Пусть, например, имеется массив чисел, расположенных в памяти последовательно,
начиная с адреса N, и мы хотим увеличить на единицу все элементы данного массива. Для этого
требуется извлечь каждое число из памяти, прибавить к нему 1 и вернуть обратно, а
последовательность исполнительных адресов будет следующей: N,N+1,N+2 и т.д., вплоть до
последней ячейки, занимаемой рассматриваемым массивом. Значение N берется из подполя Ас команды, а в выбранный регистр, называемый индексным регистром, сначала заносится 0. После
каждой операции содержимое индексного регистра увеличивается на 1.
Так как это довольно типичный случай, в большинстве ВМ увеличение или уменьшение
содержимого индексного регистра до или после обращения к нему осуществляется автоматически
как часть машинного цикла. Такой прием называется авто индексированием. Если для индексной
адресации используются специально выделенные регистры, авто индексирование может
производиться неявно и автоматически. При задействовании для хранения индексов регистров
общего назначения необходимость операции авто индексирования должна указываться в
команде специальным битом.
Авто индексирование с увеличением содержимого индексного регистра носит название
автоинкрементной адресации.
Интересным и весьма полезным является еще один вариант индексной адресации —
индексная адресация с масштабированием и смещением: содержимое индексного регистра умножается
на масштабный коэффициент и суммируется с Лс. Масштабный коэффициент может принимать
16.
значения 1,2,4 или 8, для чего в адресной части команды выделяется дополнительное поле.Описанный способ адресации реализован, например, в микропроцессорах фирмы Intel.
Следует особо отметить, что система команд многих ВМ предоставляет возможность
различным образом сочетать базовую и индексную адресации в качестве дополнительных
способов адресации.
3.10. Страничная адресация
Страничная адресация (СТА) предполагает разбиение адресного пространства на страницы.
Страница определяется своим начальным адресом, выступающим в качестве базы. Старшая часть
этого адреса хранится в специальном регистре - регистре адреса страницы (РАС). В адресном коде
команды указывается смещение внутри страницы, рассматриваемое как младшая часть
исполнительного адреса. Исполнительный адрес образуется конкатенацией (присоединением) Ас к
содержимому РАС, как показано на рис. 12.
Команда
КОп
СА
Регистр адреса
страницы (РАС)
Старшая часть
адреса страницы
Память
AС
Смещение от
начала страницы
Страница
Операнд
Регистр исполнительного адреса
Рис. 12. Страничная адресация.
Показатели эффективности страничной адресации имеют вид:
ССТА = int(log2 Ni. - log2M), TСТА = TРОН + TЗУ, где М — количество страниц в памяти.
4. Упрощенная структура программы на ассемблере
Программа на языке ассемблер состоит из предложений. Предложения ассемблера бывают
четырех типов:
команды или инструкции, представляющие собой символические аналоги машинных
команд;
макрокоманды —предложения текста программы, замещаемые во время трансляции
другими более простыми предложениями;
директивы, являющиеся указанием транслятору ассемблера на выполнение некоторых
действий. У директив нет аналогов в машинном представлении;
строки комментариев, содержащие любые символы, в том числе и буквы русского
алфавита. Комментарии игнорируются транслятором.
17.
Синтаксис команд и макрокоманд[Имя метки:]
КОП [Операнд1[ ,Операнд2]] [;Комментарий]
Имя метки — идентификатор, значением которого является адрес первого байта того
предложения исходного текста программы, которое он обозначает;
Код операции (КОП) и директива — это мнемонические обозначения соответствующей
машинной команды, макрокоманды или директивы транслятора;
Операнды — части команды, макрокоманды или директивы ассемблера, обозначающие объекты,
над которыми производятся действия. Операнды ассемблера описываются выражениями с
числовыми и текстовыми константами, метками и идентификаторами переменных с
использованием знаков операций и некоторых зарезервированных слов.
Синтаксис директив
Имя
Директива [Операнд1[ ,Операнд2]] [;Комментарий]
Имя — идентификатор, отличающий данную директиву от других одноименных директив. В
результате обработки ассемблером определенной директивы этому имени могут быть присвоены
определенные характеристики.
Допустимыми символами при написании текста программ являются:
1. все латинские буквы: A—Z, a—z. При этом заглавные и строчные буквы считаются
эквивалентными;
2. цифры от 0 до 9;
3. знаки ?, @, $, _, &;
4. разделители , . [ ] ( ) < > { } + / * % ! ' " ? \ = # ^.
Предложения ассемблера формируются из лексем, представляющих собой синтаксически
неразделимые последовательности допустимых символов языка, имеющие смысл для транслятора.
Лексемами являются:
идентификаторы — последовательности допустимых символов, использующиеся для
обозначения таких объектов программы, как коды операций, имена переменных и названия
меток. Правило записи идентификаторов заключается в следующем: идентификатор может
состоять из одного или нескольких символов. В качестве символов можно использовать
буквы латинского алфавита, цифры и некоторые специальные знаки — _, ?, $, @.
Идентификатор не может начинаться символом цифры. Длина идентификатора может быть
до 255 символов, хотя транслятор воспринимает лишь первые 32, а остальные игнорирует;
цепочки символов — последовательности символов, заключенные в одинарные или
двойные кавычки;
целые числа в одной из следующих систем счисления: двоичной, десятичной,
шестнадцатеричной. Отождествление чисел при записи их в программах на ассемблере
производится по определенным правилам:
o Десятичные числа не требуют для своего отождествления указания каких-либо
дополнительных символов, например, 25 или 139.
o Для отождествления в исходном тексте программы двоичных чисел необходимо
после записи нулей и единиц, входящих в их состав, поставить латинское “b”,
например, 10010101b.
o Шестнадцатеричные числа имеют больше условностей при своей записи:
Во-первых, они состоят из цифр 0...9, строчных и прописных букв латинского
алфавита a, b, c, d, e, f или A, B, C, D, E, F.
18.
Во-вторых, у транслятора могут возникнуть трудности с распознаваниемшестнадцатеричных чисел из-за того, что они могут состоять как из одних
цифр 0...9 (например, 190845), так и начинаться с буквы латинского алфавита
(например ef15). Для того чтобы "объяснить" транслятору, что данная
лексема не является десятичным числом или идентификатором, программист
должен специальным образом выделять шестнадцатеричное число. Для этого
на конце последовательности шестнадцатеричных цифр, составляющих
шестнадцатеричное число, записывают латинскую букву “h”. Это
обязательное условие. Если шестнадцатеричное число начинается с буквы, то
перед ним записывается ведущий ноль: 0ef15h.
5. Основные команды необходимые для выполнения лабораторных работ
5.1. Команды пересылки данных
MOV Оп1, Оп2 ;(далее Оп1, Оп2 операнды команды)
Оп1 = Оп2 - переслать Оп2 в Оп1 с учетом методов адресации операндов, разрядность Оп1 должна
быть больше или равна разрядности Оп2. Один из операндов регистр.
LEA Оп1, Оп2 – Оп2 рассматривается как адрес смещения в каком то сегменте (обычно данных)
который передается в Оп1
PUSH Оп1 - Оп1 с учетом метода адресации в стек по адресу смещения стека SP - 2
POP Оп1 – извлечение из стека по адресу смещения стека SP в Оп1 с учетом метода адресации.
После извлечения SP + 2.
PUSHF - регистр флагов в стек
POPF - стек в регистр флагов
XCHG Оп1, Оп2 - Оп1 в Оп2, а Оп2 в Оп1. Обмен значений операндов.
5.2. Арифметические команды
ADD Оп1, Оп2 – Оп1 = Оп1 + Оп2 с учетом методов адресации операндов, разрядность Оп1
должна быть больше или равна разрядности Оп2. Один из операндов регистр.
ADС Оп1, Оп2 - сложение с учетом переноса Оп1 = Оп1 + Оп2 + CF (CF флаг переноса)
SUB Оп1, Оп2 – Оп1 = Оп1 - Оп2
MUL Оп1 – Оп1 * AX или AL результат в DX:AX или AX. Умножение без знаковых чисел.
IMUL Оп1 - Умножение знаковых чисел.
В зависимости от того, какого типа операнд стоит в команде умножения (байт или слово),
умножение будет произведено над байтом (AL) или над словом (АХ). Соответственно результат
умножения будет помещен в АХ или DX:AX. После исполнения команды MUL флаги CF и OF
равны 0, если старшая половина произведения (байт или слово) равна нулю. В противном случае
оба флага равны 1. После выполнения команды IMUL флаги CF и OF равны 0, если старшая
половина произведения представляет собой лишь расширение знака младшей, В противном случае
они равны 1.
DIV Оп1 – деление без знаковых чисел.
IDIV Оп1 - деление знаковых чисел.
В зависимости от того, какого типа операнд стоит в команде деление (байт или слово), DX:AX или
AX разделить на Оп1 частное в AX илиAL, остаток в DX или AH
INC Оп1 – Оп1= Оп1 + 1. Добавление 1 к содержимому Оп1.
DEC Оп1 – Оп1= Оп1 – 1. Вычитание 1 из содержимого Оп1.
5.3. Логические команды (побитовые операции)
19.
AND Оп1, Оп2 - Оп1 = Оп1 логическое И Оп2OR Оп1, Оп2 - Оп1 = Оп1 логическое ИЛИ Оп2
XOR Оп1, Оп2 - Оп1 = Оп1 исключающее ИЛИ Оп2
Оп1
0
0
1
1
Оп2
0
1
0
1
AND
0
0
0
1
OR
0
1
1
1
XOR
0
1
1
0
NOT Оп1 – инвертирует все биты Оп1
5.4. Команды тестирования и сравнения
TEST Оп1, Оп2 - Оп1 логическое И Оп2 без записи результатов, но с установкой флагов в
регистре флагов.
CMP Оп1, Оп2 - Оп1 - Оп2 без записи результатов, но с установкой флагов в регистре флагов.
Регистр флагов индицирует состояние микропроцессора после выполнения команды в виде
побитной установки флагов в регистре.
Значение флагов (разряд регистра – флаг):
0 (CF) - флажок переноса.
1 (1) - резерв.
2 (PF) - флажок приоритета.
3 (0) - резерв.
4 (AF) - флажок дополнительного переноса.
5 (0) - резерв.
6 (ZF) - флажок нуля.
7 (SF) - флажок знака.
8 (TF) - флажок трассировки.
9 (IF) - флажок разрешения прерываний.
10 (DF) - флажок направления.
11 (OF) - флажок переполнения.
12-15 -резерв (0).
CF - флаг переноса. Равен 1, если произошел перенос при сложении или заем при
вычитании, в противном случае он равен нулю. При выполнении операции сдвига CF содержит
бит, который вышел за границу ячейки или регистра. CF также служит индикатором результата
умножения.
PF - флаг четности. Равен 1, если в результате операции получилось число с четным числом единиц, и 0 - в противном случае.
AF - вспомогательный флаг переноса. Аналогичен флагу CF, но контролирует заем
или перенос третьего бита.
ZF - флаг нуля. Равен 1, если в результате операции получен нуль, и 0 - в противоположном
случае.
SF - флаг знака. Дублирует значение старшего бита результата операции. Используется при работе
с числами со знаком.
TF - флаг трассировки. Если этот бит равен 1, то после выполнения каждой операции
микропроцессор обращается к специальной процедуре (прерыванию). Используется при отладке
программы.
IF - флаг прерывания. Если данный флаг сброшен в 0, то микропроцессор не реагирует ни на какие
внешние сигналы (сигналы прерывания). Исключение составляет немаскируемое прерывание
20.
(NMI). По линии NMI микропроцессор получает сообщения о таких критических ситуациях, какотключение питания и ошибка памяти.
DF - флаг направления. Используется строковыми (цепочечными) командами. Если
он сброшен, цепочка обрабатывается с первого элемента, имеющего наименьший адрес. В
противном случае цепочка обрабатывается от наибольшего адреса к наименьшему.
OF - флаг переполнения. Флаг равен 1, если результат сложения двух чисел с одинаковым знаком
или результат вычитания двух чисел с противоположными знаками выйдет за пределы
допустимого диапазона. Флаг обращается в 1, если старший бит операнда изменился в результате
операции арифметического сдвига. OF=0, если частное от деления двух чисел переполняет
результирующий регистр.
5.5. Команды передачи управления
JMP ИмяМетки – безусловный переход к команде с меткой ИмяМетки
КОП ИмяМетки – если условие выполняется, происходит переход к команде с меткой ИмяМетки.
В противном случае выполняется следующая по порядку команда.
Условия анализируют состояния флагов установленных командой предыдущей к команде
условного перехода.
Условные переходы:
КОП
JA
JAE
JB
JBE
JC
JCXZ
JE (то же, что и JZ)
JG
JGE
JL
JLE
JMP
JNA
JNAE
JNB
JNBE
JNC
JNE
JNG
JNGE
JNL
JNLE
JNO
JNP
JNS
JNZ
JO
Значение(переход,если...)
Jump if above (X > Y)
Jump if above or equal (X >= Y)
Jump if below (X < Y)
Jump if below or equal (X <= Y)
Jump if carry (cf=1)
Jump if CX=0
Jump if equal (X = Y)
Jump if greater (signed) (X > Y)
Jump if greater or equal (signed) (X >= Y)
Jump if less (signed) (X < Y)
Jump if less or equal (signed) (X <= Y)
Безусловный переход
Jump if not above (X <= Y)
Jump if not above or equal (X < Y)
Jump if not below (X >= Y)
Jump if not below or equal (X > Y)
Jump if not carry (cf=0)
Jump if not equal (X != Y)
Jump if not greater (signed) (X <= Y)
Jump if not greater or equal (signed) (X < Y)
Jump if not less (signed) (X >= Y)
Jump if not less or equal (signed) (X > Y)
Jump if not overflow (signed) (of=0)
Jump if no parity (pf=0)
Jump if not signed (signed) (sf=0)
Jump if not zero (X != Y)
Jump if overflow (signed) (of=1)
Условие
CF=0 & ZF=0
CF=0
CF=1
CF=1 or ZF=1
CF=1
регистр CX=0
ZF=1
ZF=0 & SF=OF
SF=OF
SF != OF
ZF=1 or SF!=OF
CF=1 or ZF=1
CF=1
CF=0
CF=1 & ZF=0
CF=0
ZF=0
ZF=1 or SF!=OF
SF!=OF
SF=OF
ZF=0 & SF=OF
OF=0
PF=0
SF=0
ZF=0
OF=1
21.
JPJPE
JPO
JS
JZ
Jump if parity (pf=1)
Jump if parity even
Jump if parity odd
Jump if signed (signed)
Jump if zero (X = Y)
PF=1
PF=1
PF=0
SF=1
ZF=1
5.6. Команда организации циклов LOOP
Циклы на ассемблере можно организовывать как с помощью команд перехода по условию, так и с
помощью специализированной команды LOOP. Данная команда использует регистр СХ как
счетчик числа циклов. Пример фрагмента программы
MOV CX, 10 ; количество итераций (повторения) тела цикла в СХ
; метка первой команды тела цикла
; команды тела цикла
LOOP M1
Команды тела цикла выполняться 10 раз.
Модификации команды LOOP дополнительно учитывающие значения флага ZF на момент
выполнения команды LOOP
LOOPE, LOOPZ – ZF =1
LOOPNE, LOOPNZ – ZF =0
При переходе к выполнению следующей итерации дополнительно проверяется флаг ZF. Это
позволяет не выполнять все итерации цикла (досрочное прерывания выполнения цикла).
M1:
5.7. Команда вызова подпрограммы
CALL Имя,
где Имя - имя подпрограммы или процедуры.
При выполнении команды адрес возврата из подпрограммы (текущее значение регистра IP,
которое указывает на адрес следующей выполняемой команды) заносится в стек по адресу, на
который указывает регистр SP - 2. В регистр IP заносится адрес начала процедуры
(подпрограммы), который находится в имени процедуры. Начинается выполнение процедуры
(подпрограммы). Последняя исполняемая команда в подпрограмме должна быть RET, по которой
из стека по адресу SP извлекается адрес возврата в регистр IP и SP увеличивается на 2.
Продолжается выполнение основной программы. Модификация команды возврата из
подпрограммы RET n, где n количество байт (кратно двум) которое прибавиться к SP после
выполнения команды для очистки параметров передаваемых в подпрограмму.
5.8. Команда вызова программных прерываний
INT n, где n номер прерывания. При выполнении команды содержимое регистра флагов,
сегментного регистра кода и адрес возврата из прерывания (регистр IP) сохраняются в стеке.
Номер прерывания (n) умножается на количество байт необходимых для хранения полного адреса
начала программы обработки прерывания (содержимого регистров CS и IP - вектор прерывания).
Для 8086 микропроцессора это 4*n. Вектора прерывания находятся в таблице векторов
прерывания, адрес которой позиционируется на нулевой адрес адресуемой памяти.
В таблице могут хранится до 256 векторов прерывания. Содержимое вектора прерывания по
вычисленному адресу в таблице прерывания (4*n) передается в регистры CS и IP. Начинается
выполнение программы обработки прерывания. Программа обработки прерывания должна
заканчиваться командой возврата из прерывания IRET. По этой команде восстанавливаются
(извлекаются) из стека регистр флагов, сегментный регистр кода и адрес возврата из прерывания
(регистр IP) и продолжается выполнение основной программы.
22.
5.9. Команды работы с портами ввода выводаIN Оп1, порт – ввести значение в порт.
OUT порт, Оп1 – вывести значение из порта, где порт либо номер порта в шестнадцатеричной
системе, либо регистр DX содержащий номер порта. Оп1 регистр или ячейка памяти.
Команды циклического сдвига
Общий формат для всех команд сдвига – КОП Оп1, Оп2
Где Оп1 регистр или ячейка памяти разрядности байт или слово
Оп2 – непосредственный операнд или регистр CL содержимое которых указывает на какое
количество бит необходимо сдвинуть Оп1. Во всех командах сдвига выдвигаемый бит помещается
в флаг CF.
КОП
RCL
RCR
ROL
ROR
SAL
SHL
SAR
SHR
Действие
Циклически сдвинуть влево через бит переноса
Циклически сдвинуть вправо через бит переноса
Циклически сдвинуть влево
Циклически сдвинуть вправо
Сдвинуть влево с учетом знака
Сдвинуть влево без учета знака (логически)
Сдвинуть вправо с учетом знака
Сдвинуть вправо без учета знака (логически)
6. Задания по лабораторной работе 1. Программирование разветвляющихся
и циклических вычислительных процессов.
Табулирование функции - это вычисление значений функции при изменении аргумента от
некоторого начального значения до некоторого конечного значения с определенным шагом.
1. Протабулировать функцию (найти значения у)
изменения x=1
у = а(х+b) а=3; b=1; 1 <= x < =10; Шаг
2. Найти max(A(I)), если А(I) состоит из целых чисел из диапазона 0 - 255, а I=1,2,...,10.
3. Для заданного массива Х(I), где I=1,2,...,10, вычислить:
у(x) = ax , если 0 < x <= 5
у(x) = ах + а , если 5 < x <= 10
у(x) = 0 , если x > 10
a=6
4. Протабулировать функцию (найти значения у), заданную в виде:
у(n) = 0 , если n < 1
у(n) = 1 , если n нечетно
у(n) = 0 , если n четно
0 <= n <= 10: Шаг изменения n=1
5. Найти min(B(I)), если B(I) состоит из целых чисел. I=1,2,...,10.
6. Отсортировать произвольно заданный массив целых чисел А(I) в порядке убывания их
значений, где I=1,2,....,10.
23.
7. Отсортировать произвольно заданный массив целых чисел А(I) в порядке возрастания ихзначений, где I=1,2,...,10.
8. Подсчитать количество нулей и единиц в произвольно заданном шестнадцатеричном числе.
9. Вычислить количество элементов массива А(I) эквивалентных заданному значению X = 4. А(I)
состоит из десяти шестнадцатеричных чисел.
10. Вычислить количество элементов массива, лежащих в следующих диапазонах: n1=(0..10);
n2=(11..20); n3=(21..255). А(I) состоит из 10 произвольно заданных целых чисел.
11. Вычислить квадраты чисел от 1 до 10.
12. Определить, попадает ли точка с координатами XO, УО в круг радиусом R. Уравнение
окружности
R2 = x2 + у2 ( R = 100 )
13. Дана квадратная матрица целых чисел А(I,J). I = J = 10. Обнулить элементы диагонали
матрицы.
14. Дана прямоугольная матрица целых чисел А(I,J). I = 6, J = 10. Обнулить каждый 4 элемент
строки матрицы.
15. Дана квадратная матрица целых чисел А(I,J). I = J = 10. Обнулить каждый четный элемент
строки матрицы.
16. Дана прямоугольная матрица целых чисел А(I,J). I = 8, J = 7. Обнулить каждую четную строку
матрицы.
17. Дана прямоугольная матрица целых чисел А(I,J). I = 8, J = 7. Обнулить каждый нечетный
столбец матрицы.
18. Даны две квадратные матрица целых чисел А(I,J) и В(I,J). I = J = 10. Вычислить С(I,J) = А(I,J) +
В(I,J).
19. Даны две квадратные матрица целых чисел А(I,J) и В(I,J). I = J = 10. Вычислить С(I,J) = А(I,J) *
В(I,J).
20. Дана квадратная матрица целых чисел А(I,J). I = J = 10. Возвести матрицу в квадрат.
21. Сформировать единичную матрицу А(I,J). I = J = 10.
22. Сформировать матрицу А(I,J). I = J = 10 с единичной побочной диагональю.
6.1. Вопросы к защите лабораторной:
Структура микропроцессора 8086 с точки зрения программиста.
Методы адресации
Организация памяти микропроцессора (включая стековую).
Вычисление физического адреса памяти.
6.2. Пример программы
Структура программы на ассемблере на примере программы вычисляющей среднее значение в
одномерном массиве из 10 чисел.
model small
;Описываем сегмент стека
.stack 100h
;Описываем сегмент данных
.data ; data –имя сегмента
24.
;описание данных в сегменте данныхmas1 db 1, 12, 43, 14, 5, 6, 5,8,19,10
; mas1 – имя массива данных
; db – размерность данных байт, dw слово
sum dw ?
; mas2 db 3 dup(1,2) пример массива 1,2,1,2,1,2
kol db 0
int_midl db 0
sing_midl db 0
; Кодовый сегмент.
.code
start: mov ax, @data ; Инициализация сегментных регистров через регистр AX.
mov ds, ax
mov cx, 10
; количество итераций цикла в регистр cx
mov sum, 0
mov ax, 0
; обнуление ячеек памяти для подсчета суммы
mov si, 0
; обнуление индексного регистра si
summa: mov al, mas1[si]
; первый элемент массива в регистр al
add sum, ax ; подсчет суммы
inc si
inc kol
loop summa ; оператор цикла
mov ax, sum
div kol ; содержимое ах разделить на kol
mov int_midl ,al ; целая часть среднего
mov sing_midl, ah ; дробная часть среднего
mov ax,4c00h
int 21h
end start ; начать программу с метки start
6.2.1 Задание для самостоятельной работы
Вычислить сумму элементов массива значения которых больше 5. Размерность массива 10
7. Лабораторная работа № 2. Применение подпрограмм в вычислительных
процессах
7.1 Немного теории
Широкое распространение подпрограммы получили при создании так называемых структурно
ориентированных языков программирования. Например, Фортран. Подпрограммы предназначены
для выполнения двух основных задач:
Первая связана с разбиением большой сложной задачи на более мелкие модули
(структурировать программу) что позволяет создавать программу коллективом разработчиков,
сделать программу более «читаемой», упростить тестирование и отладку и т.д.
Вторая, не менее важная, задача — это создание подпрограмм, решающих однотипные
задачи с разными наборами данных. Например, решение системы линейных алгебраических
уравнений различной размерности, сортировка массивов различной длины, операции с матрицами
и т.д. Сложность подпрограмм может быть различная, но основное то что, создав (написав и
25.
протестировав) программу ее можно использовать для решения этой задачи в различных частяходной большой программы, либо в других программах. Последнее позволило создавать
библиотеки подпрограмм для различных прикладных областей, что существенно упростило
создание программ.
Во второй лабораторной работе вы должны создать подпрограмму для выполнения какихто повторяющихся задач, например, есть матрица и необходимо отсортировать строки матрицы –
вы пишите подпрограмму сортировки строки матрицы и применяете ее к каждой строке.
Взаимосвязь между основной программой и подпрограммой, упрощенно можно представить
следующим образом:
1. Выполнение очередной команды основной программы
2. Команды формирования значений фактических параметров для подпрограммы. Это могут
быть регистры, переменные или указатели на массивы.
3. Вызов подпрограммы на исполнение. На ассемблере это команда Call Name, где Name –
имя подпрограммы. Перед выполнением подпрограммы команда запоминает значение
адреса следующей за командой Call команды в стеке (адрес возврата – содержание регистра
IP помещается в стековый сегмент по адресу SP-2, где SP - регистр указатель текущей
вершины стека).
4. Начинается выполнение подпрограммы. Последняя выполняемая команда подпрограммы
должна быть RET или RET n, где n – целое число которое прибавится к SP после выхода из
подпрограммы. Команда RET считывает содержимое слова в сегменте стека по адресу, на
который указывает SP и передает это содержимое в регистр IP (SP должен указывать на
слово в стековом сегменте где мы сохранили адрес возврата в основную программу) после
этого SP увеличивается на 2 (SP+2).
5. Выполняется следующая за командой CALL команда основной программы потому что мы
сохранили адрес этой команды в стеке, а перед выходом из подпрограммы поместили его в
IP. Напоминаю, регистр IP (счетчик команд) всегда содержит адрес следующей
выполняемой команды.
Таким образом для выполнения команды вызова подпрограмм используется стековый
сегмент, который имеет отличную от других сегментов организацию памяти.
По умолчанию, со стековым сегментом связаны три регистра – SS, SP и BP. Назначение
сегментного регистра SS такое же, как и других сегментных регистров – хранить адрес начала
сегмента, который используется для вычисления физического адреса памяти. Регистр SP
указывает на текущую вершину стека (адрес смещения внутри сегмента стека). Выполнение
директивы .stack 100h в начале нашей программы равносильно выполнению команды MOV SP,
100h. То есть начальная вершина стека позиционируется на 100h адрес внутри стекового сегмента.
Пространство от 0 до 100h в стековом сегменте может использоваться вашей программой.
Имеются две команды, непосредственно работающие со стековым сегментом: PUSH операнд –
содержимое операнда заносится в стек по адресу SP-2 и POP операнд – содержимое слова в
стековом сегменте по адресу SP заносится в операнд и SP увеличивается на 2 (SP+2 стек работает
только словами). Команды CALL и RET содержат в себе PUSH и POP соответственно. Такая
организация памяти позволяет организовать вложенность подпрограмм (первый пришел
последний ушел).
Передать параметры (данные) в подпрограмму можно с помощью регистров, переменных,
указателей на адреса общей памяти и через стек. В последнем случае необходимо до вызова
подпрограммы занести параметры в стек, а после вызвать подпрограмму. Для работы с
параметрами в стеке используется регистр BP и косвенная адресация. Первой командой в
подпрограмме в этом случае должна быть MOV BP, SP. Таким образом мы фиксируем положение
наших параметров относительно адреса возврата. Для считывания последнего переданного
параметра необходимо выполнить команду MOV регистр, [BP+2].
26.
7.2 Задания по лабораторной работе 2.1. Определить результативность стрельбы (n/n1) в круглую мишень радиусом R=10, где n количество попаданий; n1 - количество выстрелов. Координаты встречи пули с плоскостью
мишени заданы в виде двух массивов Х(I) и У(I); I=1,2,..,10. Определение попадания снаряда в
мишень оформить в виде подпрограммы.
2. Даны два множества заданные в виде массивов А(I) и В(I); I=1,2,..,10. Найти сумму
(объединение) множеств. C(J) - сумма двух множеств есть множество всех элементов
принадлежащих А или В. Например, {1,2,3} U {2,3,4} = {1,2,3,4}. Задачу добавления нового
элемента массива оформить в виде подпрограммы.
3. Даны два массива А(I) и В(I). Найти max(A(I)), max(B(I)), min(A(I), min(B(I)). Задачу
нахождения max и min оформить в виде подпрограмм. I=1,2,...5.
4. Даны два множества А и В. Найти произведение (пересечение) двух множеств. C(J) произведение есть множество всех элементов, принадлежащих как к А, так и к В. Например,
{1,2,3} n {2,3,4} = {2,3}. Задачу удаления элементов массива имеющих одинаковые значения
оформить в виде подпрограммы. А(I), В(I) I=1,2,...,10.
5. Протабулировать функцию у(x), заданную в виде:
y(x) = ах + b , если 1 < x <= 5
y(x) = bx + а , если 5 < x <= 10
где а - max(A(I)), а в - max(B(I)); I=1,2,...,5 Нахождение max оформить в виде подпрограммы
Шаг табуляции x=1.
6. Количество сочетаний С вычисляется выражением: Cnm = n!/((n-m)! m!)
Найти C53 , C64. Вычисление факториала оформить в виде подпрограммы.
7. Вычислить функцию у(x) = ах + в, где а и в - количество элементов массива А(I) лежащих в
диапазоне (0,...,15) и (40,...,120) соответственно. Нахождение количества элементов массива,
лежащих в заданном диапазоне оформить в виде подпрограммы I=1,2,..,10. 1<= x <= 10, шаг 1.
8. Вычислить функцию, заданную в виде:
y(x) = а , если 1 < x <= 5
y(x) = b , если 5 < x <= 10
где а и в - элементы массивов А(I), В(I), стоящие в третьей позиции после сортировки в
порядке возрастания. Сортировку массива в порядке возрастания оформить в виде подпрограммы.
I = 1,2,..,10.
9. Найти произведения сумм трех одномерных массивов А(I), В(I), C(I), где I=1,2,...,10.
Вычисление сумм оформить в виде подпрограммы.
10. Подсчитать количество четных чисел в каждой строке матрицы A(I,J), I, J = 1,2,..,5. Подсчет
количества четных чисел в строке оформить в виде подпрограммы.
11. Найти отношение следа матрицы A(I,J) к следу матрицы В(I,J), при I,J = 1,2,..,5. След матрицы
- сумму диагональных элементов матрицы А(I,I), вычислить с помощью подпрограммы.
12. Определить среднее значение элементов массива А(I) и В(I). Определение среднего значения
оформить в виде подпрограммы. I= 1,2,..,10.
27.
13. Найти сумму положительных элементов строк матрицы А(I,J). Подсчет суммы положительныхэлементов одной строки матрицы оформить в виде подпрограммы. I,J = 1,2,...5.
14. Отсортировать элементы строк матрицы A(I,J) в порядки уменьшения их значений.
Сортировку строк оформить в виде подпрограммы I,J=1,2,..,5.
15. Найти минимальное значение из максимальных значений строк матрицы А(I,J). Нахождение
максимального значения строки матрицы оформить в виде подпрограммы. I, J=1,2,...,5.
16. Даны три квадратные матрица целых чисел А(I,J), В(I,J) и D(I,J). I = J = 5. Вычислить С(I,J) =
(А(I,J) + В(I,J)) + D(I,J). Вычисление суммы матриц оформить в виде подпрограммы.
17. Даны три квадратные матрица целых чисел А(I,J), В(I,J) и D(I,J). I = J = 5. Вычислить С(I,J) =
(А(I,J) - В(I,J)) - D(I,J). Вычисление разности матриц оформить в виде подпрограммы.
18. Даны три квадратные матрица целых чисел А(I,J), В(I,J) и D(I,J). I = J = 5. Вычислить С(I,J) =
(А(I,J) * В(I,J)) * D(I,J). Вычисление произведения матриц оформить в виде подпрограммы.
19. Даны две кривые заданные массивами из десяти пар значений X и Y. Найти интеграл от
данных кривых методом трапеций. Вычисление интеграла оформить в виде подпрограммы.
20. Написать подпрограмму вычисляющую число пи методом Лейбница. Найти зависимость
точности вычисления числа пи в зависимости от числа членов ряда Лейбница по выражению:
delta_PI(I) = PI(m) – PI(I), где m = 50 и I изменяется от 2 до m -1.
21. Дана матрица А(I,J), I = J = 10. Создать массив, состоящий из средних значений элементов
строк матрицы. Вычисление средних значений оформить в виде подпрограммы.
22. Дана матрица А(I,J), I = J = 10. Создать массив, состоящий из средних значений элементов
столбцов матрицы. Вычисление средних значений оформить в виде подпрограммы.
23. Дана матрица А(I,J), I = J = 10. Создать массив, состоящий из средних значений элементов
столбцов матрицы, значение которых больше заданного числа. Вычисление средних значений
оформить в виде подпрограммы.
24. Дана матрица А(I,J), I = J = 10. Создать массив, состоящий из средних значений элементов
строк матрицы, значение которых меньше заданного числа. Вычисление средних значений
оформить в виде подпрограммы.
25. Дана трехмерная матрица А(N,M,L), где N = M = L = 5. Создать массив состоящий из сумм
диагоналей матриц А(N,M). Вычисление сумм оформить в виде подпрограммы.
7.3 Вопросы к защите лабораторной:
Выполнение команды вызова процедуры.
Способы передачи параметров в процедуру.
7.4. Пример программы на использование подпрограмм
; Задача - найти суммы нескольких массивов различной размерности
; Нахождение суммы реализовать с помощью подпрограммы
model small
.stack 256h ; задаем глубину стека в 256h байт (нач. знач. SP=256h)
28.
.datasum dw 4 dup (0) ; инициализируем 0 массив sum словами
mas1 db 22,34,135,255,30 ; mas1 - массив из 5 байт в mas1=8 адрес начала массива
long1 label byte ; long1=13 содержит адрес смещения в байтах от начала сегмента
mas2 db 1,2,3,4,5,6,7 ; mas2 - массив из 7 байт в mas2=8 адрес начала массива
long2 label byte
mas3 db 8,7,6,5,4,3,2,1
long3 label byte
mas4 db 11,22,33,44
long4 label byte
.code
sum1 proc near ;начало подпрограммы, sum1 - имя подпрограммы
mov bp, sp ; указатель стека sp (содержит указатель на адрес стека, где
; содержится адрес возврата в основную программу) в bp
push si ; регистр si используется в основной программе, сохраним его в стеке
mov si, 0
mov ax, 0
mov bx,[bp+2] ; адрес начала массива определяется в основной программе и
;передается в подпрограмму через стек перед вызовом подпрограммы. Поэтому его адрес в
стеке bp+2
cicle:
add al,ds:[bx+si]
jnc m ; если в результате сложения нет переноса (переполнения байта) тогда на m
inc ah ; если в результате сложения tcnm перенос добавим 1 в старший байт AX
m:
inc si
loop cicle ; количество итераций (регистр CX) сформировали в в основной
программе
pop si ; востанавливаем значение регистра si перед выходом из ПП, sp теперь
указывает на
; адрес возврата из подпрограммы
ret 2 ; адрес начала массива переданный из основной программы нам уже не нужен,
уберем
; мусор перед выполнением команд основной программы sp+2
sum1 endp ; конец подпрограммы
main proc ; начало основной программы
start: mov ax,@data
mov ds,ax
mov cx,offset long1 ; две команды для вычисления длины массива mas1.
; Директива offset - смещение long1 от начала сегмента данных
sub cx,offset mas1 ; длина массива в регистр CX. Передача параметров в ПП через
регистр
lea dx,mas1 ; команда lea - адрес mas1 (адрес начала массива) в регистр dx
push dx ; передача параметра (адрес начала массива) через стек
call sum1 ; вызов ПП на выполнение.
mov si,0
mov sum[si], ax ; значение суммы вычисленное в ПП хранится в регистре AX,
передаем
; в 1 элемент массива sum. Передача выходных параметров в оновную программу через
регистр
mov cx,offset long2 ; Аналогично для 2 массива
sub cx,offset long1
lea dx,mas2
push dx
call sum1
inc si
29.
inc simov sum[si], ax
mov cx,offset long3 ; Аналогично для 3 массива
sub cx,offset long2
lea dx,mas3
push dx
call sum1
inc si
inc si
mov sum[si], ax
mov cx,offset long4 ; Аналогично для 4 массива
sub cx,offset long3
lea dx,mas4
push dx
call sum1
inc si
inc si
mov sum[si], ax
mov ax, 4c00h
int 21h
main endp
end start
8. Лабораторная работа №3. Работа с монитором, прерывания BIOS
8.1 Система прерываний и исключений в архитектуре IA-32
Прерывания и исключения - это события, которые указывают на возникновение в системе
или в выполняемой в данный момент задаче определенных условий, требующих вмешательства
процессора. Возникновение таких событий вынуждает процессор прервать выполнение текущей
задачи и передать управление специальной процедуре либо задаче, называемой обработчиком
прерывания или обработчиком исключения. Различные синхронные и асинхронные события в
системе на основе ЦП IA-32 можно классифицировать следующим образом (рис. 13):
События
Программные
прерывания
Аварии
Ловушки
Исключения
Ошибки
Не маскируемые
Маскируемые
Аппаратные
прерывания
Рис. 13. Классификация событий в системе на основе архитектуры IA-32.
30.
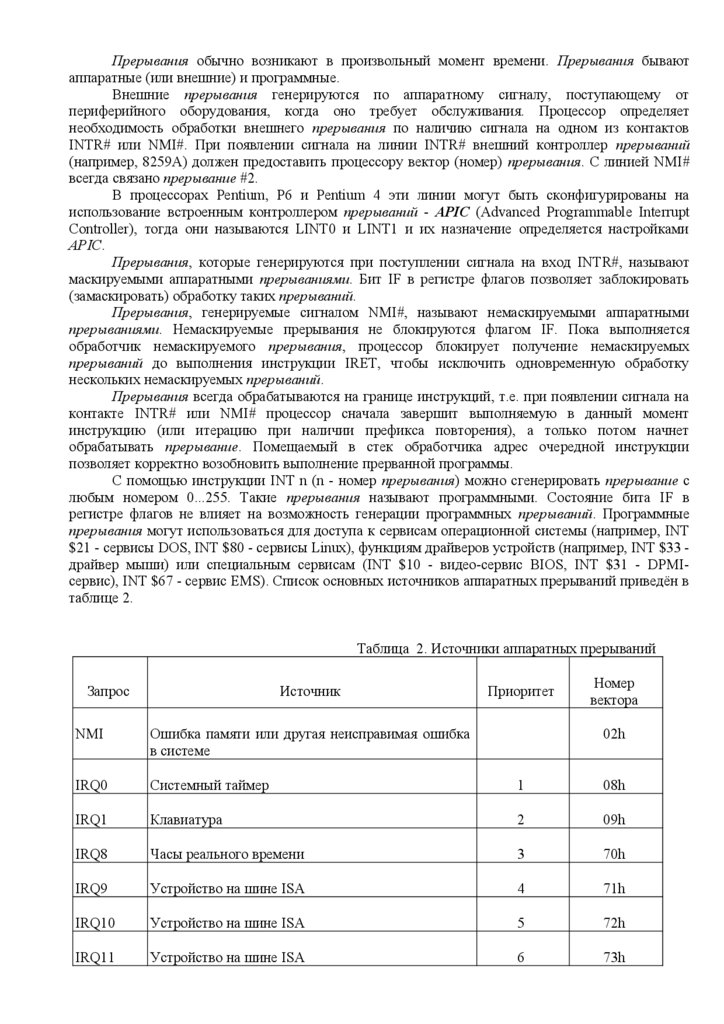
Прерывания обычно возникают в произвольный момент времени. Прерывания бываютаппаратные (или внешние) и программные.
Внешние прерывания генерируются по аппаратному сигналу, поступающему от
периферийного оборудования, когда оно требует обслуживания. Процессор определяет
необходимость обработки внешнего прерывания по наличию сигнала на одном из контактов
INTR# или NMI#. При появлении сигнала на линии INTR# внешний контроллер прерываний
(например, 8259A) должен предоставить процессору вектор (номер) прерывания. С линией NMI#
всегда связано прерывание #2.
В процессорах Pentium, P6 и Pentium 4 эти линии могут быть сконфигурированы на
использование встроенным контроллером прерываний - APIC (Advanced Programmable Interrupt
Controller), тогда они называются LINT0 и LINT1 и их назначение определяется настройками
APIC.
Прерывания, которые генерируются при поступлении сигнала на вход INTR#, называют
маскируемыми аппаратными прерываниями. Бит IF в регистре флагов позволяет заблокировать
(замаскировать) обработку таких прерываний.
Прерывания, генерируемые сигналом NMI#, называют немаскируемыми аппаратными
прерываниями. Немаскируемые прерывания не блокируются флагом IF. Пока выполняется
обработчик немаскируемого прерывания, процессор блокирует получение немаскируемых
прерываний до выполнения инструкции IRET, чтобы исключить одновременную обработку
нескольких немаскируемых прерываний.
Прерывания всегда обрабатываются на границе инструкций, т.е. при появлении сигнала на
контакте INTR# или NMI# процессор сначала завершит выполняемую в данный момент
инструкцию (или итерацию при наличии префикса повторения), а только потом начнет
обрабатывать прерывание. Помещаемый в стек обработчика адрес очередной инструкции
позволяет корректно возобновить выполнение прерванной программы.
С помощью инструкции INT n (n - номер прерывания) можно сгенерировать прерывание с
любым номером 0...255. Такие прерывания называют программными. Состояние бита IF в
регистре флагов не влияет на возможность генерации программных прерываний. Программные
прерывания могут использоваться для доступа к сервисам операционной системы (например, INT
$21 - сервисы DOS, INT $80 - сервисы Linux), функциям драйверов устройств (например, INT $33 драйвер мыши) или специальным сервисам (INT $10 - видео-сервис BIOS, INT $31 - DPMIсервис), INT $67 - сервис EMS). Список основных источников аппаратных прерываний приведён в
таблице 2.
Таблица 2. Источники аппаратных прерываний
Запрос
Источник
Приоритет
Номер
вектора
NMI
Ошибка памяти или другая неисправимая ошибка
в системе
02h
IRQ0
Системный таймер
1
08h
IRQ1
Клавиатура
2
09h
IRQ8
Часы реального времени
3
70h
IRQ9
Устройство на шине ISA
4
71h
IRQ10
Устройство на шине ISA
5
72h
IRQ11
Устройство на шине ISA
6
73h
31.
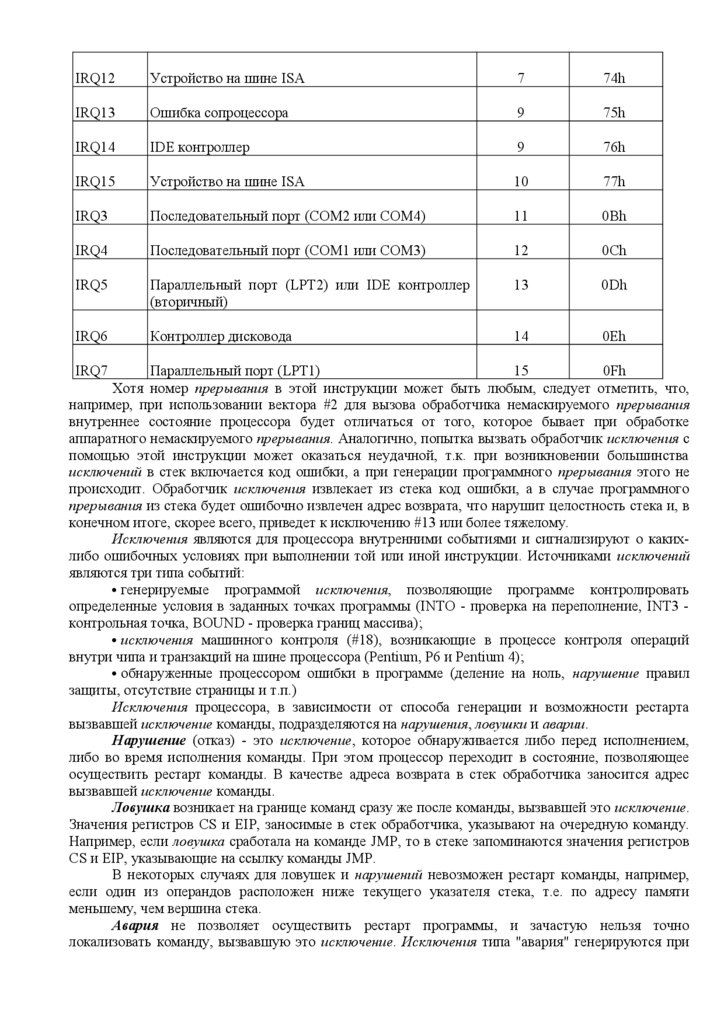
IRQ12Устройство на шине ISA
7
74h
IRQ13
Ошибка сопроцессора
9
75h
IRQ14
IDE контроллер
9
76h
IRQ15
Устройство на шине ISA
10
77h
IRQ3
Последовательный порт (COM2 или COM4)
11
0Bh
IRQ4
Последовательный порт (COM1 или COM3)
12
0Ch
IRQ5
Параллельный порт (LPT2) или IDE контроллер
(вторичный)
13
0Dh
IRQ6
Контроллер дисковода
14
0Eh
IRQ7
Параллельный порт (LPT1)
15
0Fh
Хотя номер прерывания в этой инструкции может быть любым, следует отметить, что,
например, при использовании вектора #2 для вызова обработчика немаскируемого прерывания
внутреннее состояние процессора будет отличаться от того, которое бывает при обработке
аппаратного немаскируемого прерывания. Аналогично, попытка вызвать обработчик исключения с
помощью этой инструкции может оказаться неудачной, т.к. при возникновении большинства
исключений в стек включается код ошибки, а при генерации программного прерывания этого не
происходит. Обработчик исключения извлекает из стека код ошибки, а в случае программного
прерывания из стека будет ошибочно извлечен адрес возврата, что нарушит целостность стека и, в
конечном итоге, скорее всего, приведет к исключению #13 или более тяжелому.
Исключения являются для процессора внутренними событиями и сигнализируют о какихлибо ошибочных условиях при выполнении той или иной инструкции. Источниками исключений
являются три типа событий:
генерируемые программой исключения, позволяющие программе контролировать
определенные условия в заданных точках программы (INTO - проверка на переполнение, INT3 контрольная точка, BOUND - проверка границ массива);
исключения машинного контроля (#18), возникающие в процессе контроля операций
внутри чипа и транзакций на шине процессора (Pentium, P6 и Pentium 4);
обнаруженные процессором ошибки в программе (деление на ноль, нарушение правил
защиты, отсутствие страницы и т.п.)
Исключения процессора, в зависимости от способа генерации и возможности рестарта
вызвавшей исключение команды, подразделяются на нарушения, ловушки и аварии.
Нарушение (отказ) - это исключение, которое обнаруживается либо перед исполнением,
либо во время исполнения команды. При этом процессор переходит в состояние, позволяющее
осуществить рестарт команды. В качестве адреса возврата в стек обработчика заносится адрес
вызвавшей исключение команды.
Ловушка возникает на границе команд сразу же после команды, вызвавшей это исключение.
Значения регистров CS и EIP, заносимые в стек обработчика, указывают на очередную команду.
Например, если ловушка сработала на команде JMP, то в стеке запоминаются значения регистров
CS и EIP, указывающие на ссылку команды JMP.
В некоторых случаях для ловушек и нарушений невозможен рестарт команды, например,
если один из операндов расположен ниже текущего указателя стека, т.е. по адресу памяти
меньшему, чем вершина стека.
Авария не позволяет осуществить рестарт программы, и зачастую нельзя точно
локализовать команду, вызвавшую это исключение. Исключения типа "авария" генерируются при
32.
обнаружении серьезных ошибок, таких как неразрешенные или несовместимые значения всистемных таблицах или аппаратные сбои.
Типичным случаем аварии является исключение #8 "двойная ошибка". Двойная ошибка
происходит, когда процессор пытается обработать исключение, а его обработчик генерирует еще
одно исключение. Для некоторых исключений процессор не генерирует двойную ошибку, такие
исключения называют "легкими". Только ошибки деления (исключение #0) и сегментные
исключения (#10, #11, #12, #13), называемые "тяжелыми", могут вызвать двойную ошибку. Таким
образом, получение исключения "не присутствие сегмента" во время обработки исключения
отладки не приведет к двойной ошибке, в то время как ошибка сегмента, происходящая во время
обработки ошибки деления на нуль, приведет к исключению #8.
Если при попытке вызвать обработчик исключения #8 возникает ошибка, процессор
переходит в режим отключения (shutdown mode). Вывести из этого режима процессор могут
только аппаратные сигналы: NMI#, SMI#, RESET# или INIT#. Обычно чипсет, обнаружив на шине
процессора цикл отключения, инициирует аппаратный сброс.
Если на границе инструкции обнаруживается, что требуется обработка более одного
прерывания или исключения, процессор обрабатывает прерывание или исключение с наивысшим
приоритетом. Исключения с низким приоритетом снимаются, а прерывания с низким приоритетом
откладываются. Снятые исключения могут быть потом снова сгенерированы при возврате из
обработчика.
Архитектура IA-32 предоставляет механизм обработки прерываний и исключений,
прозрачный для прикладного и системного программного обеспечения. При возникновении
прерывания или исключения текущая выполняемая задача автоматически приостанавливается на
время действий обработчика, после чего ее выполнение возобновляется без потери
непрерывности, кроме случаев, когда обработка прерывания или исключения вынуждает
завершить программу.
Все прерывания и исключения имеют номер (иногда именуемый вектором) в диапазоне от 0
до 255. Номера 0...31 зарезервированы фирмой Intel для исключений.
8.2. Задания по лабораторной работе 3.
1. Задать вывод строки символов и ее перемещение сверху - вниз.
2. Задать вывод строки символов и ее перемещение снизу вверх.
3. Задать вывод колонки символов с 0 позиции, и ее перемещение слева направо по экрану.
4. Задать вывод колонки символов в правой части экрана и ее перемещение справа налево.
5. Задать линию символов из левого верхнего угла экрана в правый нижний угол.
6. Задать линию символов из верхнего правого угла экрана в левый нижний угол.
7. Задать три строки символов и их перемещение сверху - вниз по экрану.
8. Изобразить в центре экрана квадрат со сторонами 10 на 10 символов.
9. Задать последовательное перемещение символа по строке расположенной в середине экрана.
10. Задать перемещающуюся группу символов (5 символов) по строке экрана.
11. Задать в центре экрана квадрат с изменяющимися сторонами.
12. Задать диагональную линию символов, перемещающуюся по экрану.
33.
13. Задать перемещение символа по экрану с образованием треугольника.14.Задать три колонки символов в левой части экрана и обеспечить их перемещение в правую
часть экрана.
15. Задать три колонки символов в правой части экрана и задать их перемещение в левую часть
экрана.
16. Вывести на экран эллипс вдоль экрана (экран 80 * 24)
17. Вывести на экран эллипс поперек экрана (экран 80 * 24)
18. Вывести на экран «медленно бегущую строку» с тестом «Мы изучаем ассемблер». Обеспечить
остановку вывода после 50 циклов.
19. Вывести в центре экрана «медленно мигающую строку» с тестом «Мы изучаем ассемблер».
Обеспечить остановку вывода после 50 циклов.
20. Нарисовать символом на экране кривую с координатами знакомест «строка столбец» 1,1- 1,10
– 10,1.
21. Нарисовать символом на экране кривую с координатами знакомест «строка столбец»: 1,1 – 1,10
– 10,20 – 10,1.
22. Вывести на экран эллипс, увеличивающийся из центра вдоль экрана (экран 80 * 24)
8.3. Вопросы к защите лабораторной
Виды прерываний.
Выполнение команды int
Прерывания BIOS
8.4 Пример программы
;Движение столбца символов по экрану слева направо
masm
model small
.stack 100h
; Новое для вас. Создание макроса (аналог функции) delay - имя, macro директива ;макроса, time- параметр который задается из процедуры. В time необходимо
внести ;количество итераций внешнего цикла
delay macro time
local
ext,iter ; переменные ext,iter определены как локальные
push
cx ; макрос использует регистр СХ, поэтому сохраним значение СХ на
время в стеке
mov
cx,time ; значение time в Регистр СХ, количество повторений внешнего
цикла ext:
ext:
push
cx ; внутренний цикл использует регистр СХ - сохраним его в стеке
mov
cx,5000 ; Количество повторений внутреннего цикла. Тело цикла пустое
iter:
loop
iter ; Выполнение внутреннего цикла 5000 раз (задержка)
34.
popcx ; Востановление значения СХ для внешнего цикла из стека
loop
ext ; Выполнение внешнего цикла Количество повторений задано в time
pop
cx ; Востановление значения СХ перед выходом из макроса
endm ; Конец макроса
.data ; Сегмент данных
y equ 25 ;Количество строк 25
x equ 79 ;Количество столбцов 79
.code
;Сегмент кода
main:
mov ax,@data
mov ds,ax
xor ax,ax
;Обнуление регистра ax
; Вывод на экран организуем через функции прервания BIOS int 10h
mov ah,05h
;Номер функции (5) в регистр ah
; 05H выбрать активную страницу дисплея вход:
; AL = номер страницы (большинство программ использует страницу 0)
mov al,0
; выбираем 0 страницу
int 10h ; Выполняем 5 функцию прерывания BIOS int 10h
mov cx,x; Количество столбцов в СХ внешний цикл по столбцам
mov dx,0
; Позиция курсора для функции 02h
cycl1:
push cx ; Сохраним СХ в стеке
mov cx,y; Количество строк в СХ внутренний цикл для вывода строки
cycl2:
mov ah,2h
; Номер функции (2) в ah
; 02H уст. позицию курсора. установка на строку 25 делает курсор невидимым.
; вход: BH = видео страница DH,DL = строка, колонка (считая от 0)
int 10h ; Курсор в позицию 0 0
push cx ; Сохраним СХ в стеке для цикла
mov cx,1;экземпляров символа 1
mov al,4
; 4 - адрес символа в таблице ASCII
mov ah,10 ; Функция 0ah - 10 в десятичной системе счисления
; 0aH писать символ в текущей позиции курсора вход: BH = номер видео страницы
; AL = записываемый символ CX = счетчик (сколько экземпляров символа записать)
int 10h ; вывод символа в позиции курсора
pop cx ;Восстановить СХ из стека
inc dh ; координату строки + 1
loop cycl2
; Выводим столбец
delay 500
; Обращаемся к макросу задержки. 500 количество выполнения
внешнего цикла (время задержки). Задержка необходима из за большой скорости вывода
компьютера
; Теперь необходимо стереть этот столбец. Организуем цикл анологичный предыдущему, но
выводим символ пусто
mov dh,0
mov cx,y
cycl3:
mov ah,2
int 10h
push cx
mov cx,1
mov al,0 ;
mov ah,10 ;
int 10h
pop cx
35.
inc dhloop cycl3
;
pop cx
mov dh,0
inc dl
loop cycl1
;Формируем координаты следующего столбца 0 1
;Выводим очередной столбец
exit:
mov
int
end main
ax,4c00h
21h
; Это ссылка на справочник функций BIOS и DOS
;http://www.codenet.ru/progr/dos/
; Это видио сервис BIOS
; http://www.codenet.ru/progr/dos/int_0009.php
9. Лабораторная работа №4. Работа с монитором и клавиатурой, прерывания
DOS int 21h
9.1. Задания по лабораторной работе 4.
1. Протабулировать функцию у(х(i)) = а(х(i)+b). Ввод а, b, массива х(i) и количества итераций
организовать с клавиатуры по подсказке, выведенной на монитор. Результаты вывести на экран.
2. Найти max(A(I)), если А(I) состоит из целых чисел. Ввод массива А(I) организовать с
клавиатуры по подсказке, выведенной на монитор.
3. Для заданного массива Х(I), где I=1,2,...,10, вычислить:
у(x) = ax , если 0 < x <= 5
у(x) = ах + а , если 5 < x <= 10
у(x) = 0 , если x > 10
Ввод массива Х(I) и а, организовать с клавиатуры по подсказке, выведенной на монитор.
Результаты вывести на экран.
4. Протабулировать функцию, заданную в виде:
у(n) = 0 , если n < 1
у(n) = 1 , если n нечетно
у(n) = 0 , если n четно
Ввод массива n организовать с клавиатуры по подсказке, выведенной на монитор. Результаты
вывести на экран.
5. Найти min(B(I)), если B(I) состоит из целых чисел. Ввод массива B(I)
клавиатуры по подсказке, выведенной на монитор. Результат вывести на экран.
организовать с
6. Отсортировать заданный массив целых чисел А(I) в порядке убывания их значений. I=1,2,....,10.
Ввод массива А(I) организовать с клавиатуры по подсказке, выведенной на монитор. Результат
вывести на экран.
7. Отсортировать заданный массив целых чисел А(I) в порядке возрастания их значений.
I=1,2,...,10. Ввод массива А(I) организовать с клавиатуры по подсказке, выведенной на монитор.
Результат вывести на экран.
36.
8. Подсчитать количество нулей и единиц в заданном шестнадцатеричном числе. Ввод числаорганизовать с клавиатуры по подсказке, выведенной на монитор. Результат вывести на экран.
9. Вычислить количество элементов массива А(I) эквивалентных заданному значению X. А(I)
состоит из десяти шестнадцатеричных чисел. Ввод массива А(I) и Х организовать с клавиатуры по
подсказке, выведенной на монитор. Результат вывести на экран.
10. Вычислить количество элементов массива, лежащих в следующих диапазонах: n1=(0..10);
n2=(11..20); n3=(21..255). А(I) состоит из 10 целых чисел. Ввод массива А(I) организовать с
клавиатуры по подсказке, выведенной на монитор. Результаты вывести на экран.
11. Вычислить квадраты чисел от N до M. Ввод N и М организовать с клавиатуры по подсказке,
выведенной на монитор. Результаты вывести на экран.
12. Определить, попадает ли точка с координатами XO, УО в круг радиусом R. Уравнение
окружности
R2 = x2 + у2 ( R = 100 )
Ввод х и у организовать с клавиатуры по подсказке, выведенной на монитор. Результат вывести
на экран.
13. Дана квадратная матрица целых чисел А(I,J). I = J = 10. Обнулить элементы диагонали
матрицы. Ввод матрицы организовать с клавиатуры по подсказке, выведенной на монитор.
Результаты вывести на экран.
14. Дана прямоугольная матрица целых чисел А(I,J). I = 6, J = 10. Обнулить каждый 4 элемент
строки матрицы. Ввод матрицы организовать с клавиатуры по подсказке, выведенной на монитор.
Результаты вывести на экран.
15. Дана квадратная матрица целых чисел А(I,J). I = J = 10. Обнулить каждый четный элемент
строки матрицы. Ввод матрицы организовать с клавиатуры по подсказке, выведенной на монитор.
Результаты вывести на экран.
16. Дана прямоугольная матрица целых чисел А(I,J). I = 8, J = 7. Обнулить каждую четную строку
матрицы. Ввод матрицы организовать с клавиатуры по подсказке, выведенной на монитор.
Результаты вывести на экран.
17. Дана прямоугольная матрица целых чисел А(I,J). I = 8, J = 7. Обнулить каждый нечетный
столбец матрицы. Ввод матрицы организовать с клавиатуры по подсказке, выведенной на
монитор. Результаты вывести на экран.
18. Даны две квадратные матрица целых чисел А(I,J) и В(I,J). I = J = 10. Вычислить С(I,J) = А(I,J) +
В(I,J). Ввод матриц организовать с клавиатуры по подсказке, выведенной на монитор. Результаты
вывести на экран.
19. Даны две квадратные матрица целых чисел А(I,J) и В(I,J). I = J = 10. Вычислить С(I,J) = А(I,J) *
В(I,J). Ввод матриц организовать с клавиатуры по подсказке, выведенной на монитор. Результаты
вывести на экран.
20. Дана квадратная матрица целых чисел А(I,J). I = J = 10. Возвести матрицу в квадрат. Ввод
матрицы организовать с клавиатуры по подсказке, выведенной на монитор. Результаты вывести
на экран.
21. Сформировать единичную матрицу А(I,J). Ввод I = J организовать с клавиатуры по подсказке,
выведенной на монитор. Результаты вывести на экран.
37.
22. Сформировать матрицу А(I,J). I = J = 10 с единичной побочной диагональю. Ввод I = Jорганизовать с клавиатуры по подсказке, выведенной на монитор. Результаты вывести на экран.
9.2. Вопросы к защите лабораторной
Прерывания DOS
9.3. Пример программы
Цель четвертой лабораторной работы научится вводить и выводить информацию в программу с
помощью клавиатуры и монитора. Клавиатура преобразует символьную информацию в двоичный
код. Соответствие двоичного кода символа определяется таблицей кодов ASCII. Работа с
клавиатурой и монитором организуется с помощью прерываний BIOS 10h (Видео сервис) и DOS
21h (Сервис DOS).
Для ввода цифровой информации необходимо преобразование кода символа цифры в
двоичное число. Для упрощения преобразования коды символов цифр от 1 до 9 имеют
коды от 30h до 39h, поэтому для преобразования из кода символа цифры необходимо вычесть 30h.
Это позволяет преобразовать одну цифру. Для ввода десятичного числа необходимо не только
повторить это для каждой вводимой цифры, но и умножить это число на ее десятичный вес (1, 10,
100 …). Поскольку количество вводимых цифр заранее неизвестно, необходимо определиться с
максимальной разрядностью числа для организации цикла ввода цифр и символа окончания ввода
числа. Число вводиться посимвольно, начиная со старшего разряда, но вес разряда при вводе
символа не известен до конца ввода числа, поэтому вводимые символы необходимо запомнить в
памяти для последующего преобразования. Для вывода необходимо проделать обратную
операцию, разделить на 10, 100, 1000 и т.д. и к значению прибавит 30h. Каждая цифра занимает
один байт, поэтому для байтового числа (0- 255) необходим массив байт из 3 элементов.
Пример программы, которая вводит массив из n строк и m столбцов, а затем его выводит на экран.
model small
.stack 100h
delay macro time ; макрос для задержки времени вывода
local ext,iter
push cx
mov cx,time
ext:
push cx
mov cx,5000
iter:
loop iter
pop cx
loop ext
pop cx
endm
.data
mas1 db 100 dup(0)
mas2 db 100 dup(0)
n db ?
m db ?
vv1 db 'Enter number of array rows n:$'
vv2 db 'Enter number of array columns m:$'
vv3 db 'Enter a string array after a space:$'
vv4 db ' Array mas2[$'
number db 3 dup(0)
38.
number1 db ?.code
vvod1 proc
; Ввод одного числа от 0 до 255. Результат в регистре al. Окончание ввода числа enter
push cx
;сохраним CX, bx, в стек
push bx
xor bx,bx
xor ax,ax
xor cx,cx
mov ah,01h
int 21h ; в al - первый символ
sub al,30h ; теперь первая цифра
mov ah,0 ; расширение до слова
mov bx,10
mov cx,ax ; в cx - первая цифра
L:
mov ah,01h
int 21h ; в al следующий символ
cmp al,0dh ; сравнение с enter
je E
; конец ввода
sub al,30h ; в al - следующая цифра
mov ah,0
; расширение до слова
xchg ax,cx ; теперь в ax - предыдущее число, в cx - следующая
push dx ; умножение использует регистр dx сохраним его в стеке ивосстановим после
mul bx
; ax*10
pop dx
add cx,ax
; cx=ax*10+cx
jmp L ; продолжение ввода
E : mov al,cl
pop bx
pop cx ; восстановвить CX, bx, из стека
ret
vvod1 endp
vvod2 proc
; Ввод одного числа от 0 до 255. Результат в регистре al. Окончание ввода числа space
(пробел)
; Аналогична vvod1, но разделитель чисел пробел, что позволяет вводить числа строками
; окончание ввода строки и ввода в целом обеспечивается организацией циклов в основной
программе
push cx
;сохраним CX, bx, в стек
push bx
L1:
xor bx,bx
xor ax,ax
xor cx,cx
mov ah,01h
int 21h ; в al - первый символ
sub al,30h ; теперь первая цифра
mov ah,0 ; расширение до слова
mov bx,10
mov cx,ax ; в cx - первая цифра
mov ah,01h
int 21h ; в al следующий символ
cmp al,20h ; сравнение с space (пробел)
39.
je E1; конец ввода
sub al,30h ; в al - следующая цифра
mov ah,0
; расширение до слова
xchg ax,cx ; теперь в ax - предыдущее число, в cx - следующая
push dx
mul bx
; ax*10
pop dx
add cx,ax
; cx=ax*10+cx
jmp L1 ; продолжение ввода
mov al,cl
E1 :
pop bx
pop cx ; восстановвить CX, bx, ax из стек
ret
vvod2 endp
transform proc
;преобразование числа (0-255) в 3 символа для вывода
;преобразуемое число должно быть в регистре al
; преобразованные в символы число в массиве namber[0-2]
push bx
push dx
mov number, 0
mov number+1, 0
mov number+2, 0
mov bl,10
mov ah,0
; расширение N в ax до слова (беззнаковое)
div bl
; ah=c, al=ab
add ah,30h
mov number+2,ah ; записали последнюю цифру
mov ah,0
; al =ab, расширение ab до слова (беззнаковое)
div bl
; ah=b, al=a
add ah,30h
; ah=b+’0’, al=a+’0’
add al,30h
mov number+1,ah ; записали среднюю цифру
mov number,al
; записали первую цифру
pop dx
pop bx
ret
transform endp
start:
mov ax,@data
mov ds,ax
xor ax,ax
xor dx,dx
mov ax,03h ; очистить экран функция 0
int 10h
mov ah,3h
mov al,0
int 10 ; читать позицию курсора
mov dx,0 ; координаты курсора (строка и столбец) в 0
mov ah, 2h
int 10h
; курсор в начало страницы
push dx
; функция 09h использует регистр dx сохраним его в стеке
mov ah,09h ;вывести приглашение для количества строк
lea dx,vv1
int 21h
40.
pop dx;восстановить dx из стекаcall vvod1
mov n,al
; количество строк в переменную n
;mov ah,3h
;int 10 ; читать позицию курсора
inc dh
mov dl,0
mov ah, 2h
int 10h
; курсор на следующую строку
push dx
mov ah,09h
lea dx,vv2
int 21h
;вывести приглашение для количества столбцов
pop dx;восстановить dx из стека
call vvod1
mov m,al ; количество столбцов в переменную m
inc dh
mov dl,0
mov ah, 2h
int 10h
; курсор на следующую строку
push dx
; функция 09h использует регистр dx сохраним его в стеке
mov ah,09h
lea dx,vv3
int 21h
;вывести приглашение для ввода матрицы
pop dx
inc dh
mov dl,0
mov ah, 2h
int 10h
; курсор на следующую строку
mov si,0
mov ax,0
mov cl, n
mov ch,0
;количство строк в CX
cycle1:
push cx
;сохраним CX в стеке
mov cl, m
mov ch,0
;количство столбцов в CX
cycle2:
call vvod2
mov mas1[si],al
inc si
loop cycle2
pop cx ; восстановим cx для первого цикла
inc dh
mov dl,0
mov ah, 2h
int 10h
; курсор на следующую строку
loop cycle1
; ВАША ПРОГРАММА
;Вывод организуем двумя циклами аналогично вводу
mov si,0
mov ax,0
41.
mov cl, nmov ch,0
;количство строк в CX
inc dh
mov dl,0
mov ah, 2h
int 10h
; курсор на следующую строку
cycle3:
push cx
;сохраним CX в стеке
mov cl, m
mov ch,0
;количство столбцов в CX
cycle4:
mov al,mas1[si]
call transform
mov di,0
;вывод числа посимвольно из массива number
M1:
mov al, ds: number[di]
mov ah, 0eh
int 10h
inc di
cmp di,2
jle M1
inc si
add dl,5
;позицию курсора по строке на 3+2
mov ah, 2h
int 10h
loop cycle4
pop cx ; восстановим cx для первого цикла
inc dh
mov dl,0
mov ah, 2h
int 10h
; курсор на следующую строку
loop cycle3
delay 50
; задержка для вывода
mov ax, 4c00h
int 21h
end start
10. Форма отчета по лабораторным работам
Отчет должен содержать:
1. Условие задачи;
2. Блок-схему алгоритма;
3. Текст программы на языке ассемблер с подробными комментариями.