



































































































 Базы данных
Базы данныхПохожие презентации:










Язык определения данных (DDL). Команды CREATE, ALTER, DROP. Создание таблиц БД
1.
20. Язык определения данных (DDL).Команды CREATE, ALTER, DROP.
Создание
таблиц
БД.
Создание
ограничений:
декларативные
ограничения при создании таблиц.
Ограничения на уровне поля и таблицы.
Ограничения ссылочной целостности.
Изменение таблиц (добавление и
удаление столбцов и ограничений).
Разрешение и запрет ограничений.
1
2.
Внутренний язык СУБД для работы сданными состоит из 2-х частей:
языка определения данных (DDLData Definition Language)
языка управления данными (DMLData Manipulation Language).
2
3.
Языкопределения
данных
используется
для
создания,
изменения и удаления объектов базы
данных.
Язык управления данными служит
для чтения и обновления данных,
хранимых в базе.
3
4.
Язык DDL позволяет описывать таблицыБД и связи между ними. Результатом
компиляции DDL-операторов является
набор таблиц, хранимых в особых файлах,
называемых системным каталогом.
В
системном
каталоге
содержатся
метаданные, т.е. данные, которые
описывают объекты.
4
5.
Использование языка DDL в процессеработы позволяет сделать структуру
реляционной БД динамической.
(С течением времени БД может расти, в
неё могут добавляться новые таблицы
без приостановки эксплуатации БД).
5
6.
Операторы DDL можно использовать какв интерактивном, так и в программном
SQL.
Если программе или пользователю
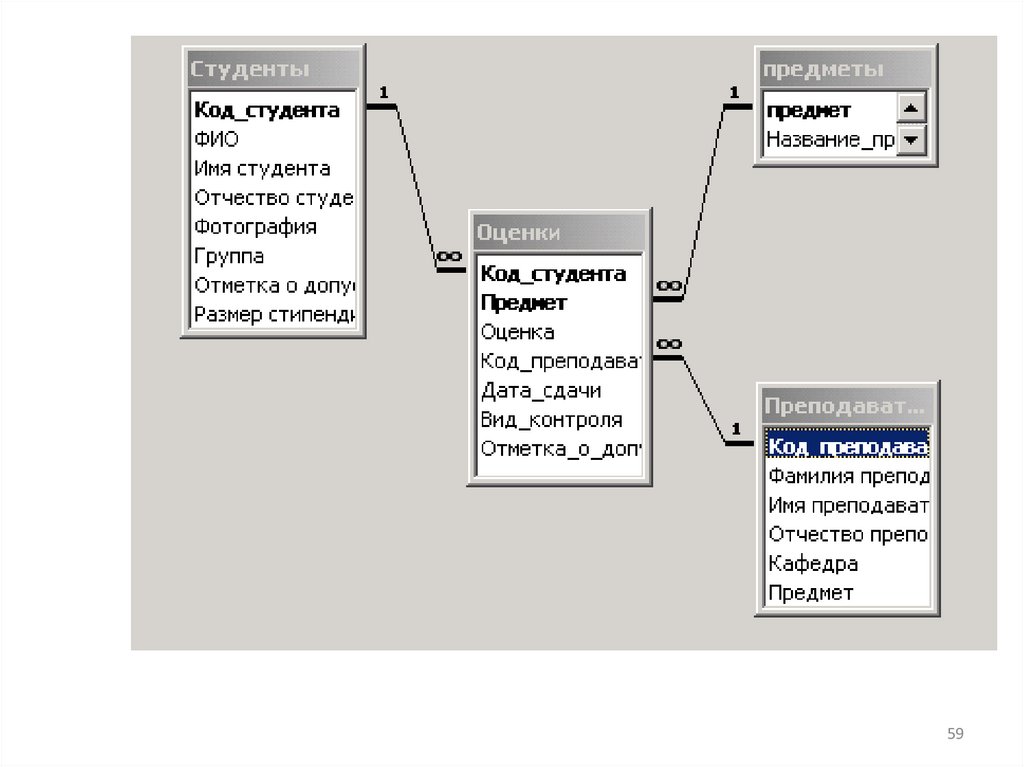
требуется таблица для временного
хранения результатов, то допускается
создать эту таблицу, заполнить ее
информацией, выполнить необходимые
манипуляции с данными и затем удалить
ее.
6
7.
Язык DML содержит набор операторов дляманипулирования данными:
вставки в БД новых сведений;
модификации сведений;
извлечение сведений, хранимых в базе;
удаления сведений из базы.
7
8.
DDL базируется на трёх командах SQL.• CREATE – позволяет определить и создать
объект БД;
• DROP - применяется для удаления
существующего объекта БД;
• ALTER - изменяет определение объекта БД.
8
9. Создание БД
С помощью операторов DDL можно:• создать новую БД,
• определить структуру новой таблицы
и создать эту таблицу,
• изменить определение существующей
таблицы,
• удалить существующую таблицу,
• обеспечить условия безопасности БД,
• создать индексы для доступа к
таблицам.
9
10.
В MS SQL SERVER существует оператор CREATEDATABASE, который является частью языка
определения данных и служит для создания
БД.
Оператор DROP DATABASE удаляет
существующую БД. Эти операторы можно
использовать как в интерактивном, так и в
программном режиме.
10
11.
Создание базы данных – это процесс указанияимени базы, определения размеров и
размещения файлов базы данных (первичного и
вторичных файлов базы данных, файла журнала
транзакций).
В primary файле базы данных (расширение mdf)
записывается информация об основных её
объектах – таблицах, индексах и т. д., а в файл
журнала транзакций (расширение ldf) информация о процессе работы с транзакциями
(состояние базы данных до и после выполнения
транзакции).
11
12.
Если в процессе использования базы данныхпланируется размещение её на нескольких
дисках, то в этом случае создаются secondary
файлы (расширение ndf).
По умолчанию базы данных имеют право
создавать только те пользователи, которым
назначены роли sysadmin и dbcreator.
12
13.
СинтаксисCREATE DATABASE имя_базы_данных
[ON
[PRIMARY] (NAME=логическое_имя_файла,
FILENAME=‘физическое_имя_файла’
[, SIZE=размер]
[, MAXSIZE=максимальный размер]
[, FILEGROWTH=шаг_приращения_размера])
[, …n]
]
[LOG ON
(NAME=логическое_имя_файла_журнала,
FILENAME=‘физическое_имя_файла_журнала’
[, SIZE=размер_журнала])
[, …n]
]
[FOR RESTORE]
13
14.
При создании базы данных можно указатьследующие параметры:
· PRIMARY указывает файлы основной группы
файлов, которая содержит все таблицы базы
данных. В любой базе данных должен быть лишь
один основной (первичный) файл данных. Он
служит отправной точкой базы данных и
указывает на все прочие её файлы.
Если ключевое слово PRIMARY опущено,
основным файлом становится первый файл в
операторе;
14
15.
• FILENAME – задаёт физическое имя ипуть к файлу.
• SIZE
–
задает
минимальный
(начальный) размер файла. Файл
может увеличиваться, однако его
нельзя сжать так, чтобы его объем стал
меньше заданного минимального
размера;
15
16.
MAXSIZE – указывает максимальный размерфайла. Если размер не указан, то файл будет
увеличиваться до полного заполнения диска;
FILEGROWTH – задает шаг приращения размера
файла. Если SQL Server необходимо увеличить
размер файла, он увеличит его на значение,
заданное
этим параметром, причем ноль
означает запрет увеличения размера. По
умолчанию (если параметр FILEGROWTH не
определен) – шаг приращения равен 10%.
16
17.
• FOR RESTORE – задаёт восстановлениесистемы по журналу транзакций в случае её
сбоя. Имеется в виду сбой системы,
нарушающий все выполняемые в данный
момент транзакции, но не нарушающий базу
данных физически. При сбое носителей,
который представляет собой физическую
угрозу
для
данных,
восстановление
осуществляется с резервной копии БД.
17
18. Создание таблиц БД
Таблицы создаются командой CREATE TABLE.Эта команда создает пустую таблицу, не
содержащую записей. Очевидно, что данные
в нее можно внести, например, с помощью
команды INSERT.
В команде CREATE TABLE определяется имя
таблицы, и набор имен полей. Кроме того,
этой же командой оговариваются типы
данных и длины полей.
18
19.
Синтаксис команды CREATE TABLE следующий:CREATE TABLE <имя таблицы>
(<имя поля1> <тип данных> [(<длина>)],
(<имя поля2> <тип данных> [(<длина>)]),
…).
19
20.
Пробелы не могут быть частью именитаблицы
или
любого
другого
создаваемого объекта, поэтому для
разделения слов, как правило,
используется символ подчёркивания.
20
21.
Значение длины поля зависит от типаданных.
Если его не указывать, то СУБД сама
назначает значение автоматически (для
числовых
данных
такой
вариант
предпочтительнее).
Для данных типа CHAR указание размера
обязательно. По умолчанию значение длины
равно 1.
21
22.
Пример:CREATE TABLE STUDENTS
(NOM_ZACH INTEGER,
SFAM CHAR (20),
SNAME CHAR (10),
STIP DECIMAL)
22
23.
Числовые типыTочные числовые типы
К категории точных числовых типов в SQL относятся те типы, значения которых точно представляют
числа. Типы данных этой категории распадаются на две части: целые типы ( INTEGER и SMALLINT ) и
типы, допускающие наличие дробной части ( NUMERIC и DECIMAL ).
целочисленные:
tinyint 0-255,
smallint (от -32 768 до 32 767),
int (от -2,147,483,648 до 2,147,483,647) и
bigint (от -2^63 до 2^63 );
десятичные: decimal и numeric (это - два названия
одного и того же типа);
денежные: money (от -2^63 до 2^63 - с точностью 4
знака после запятой) и smallmoney (от -214748.3648
до +214748.3647).;
с плавающей запятой: float (от -1.79E + 308 до 1.79E
+ 308) и real (от -3.40E + 38 до 3.40E + 38).
23
24.
с плавающей запятой:float (от -1.79E + 308 до 1.79E + 308) и
real (от -3.40E + 38 до 3.40E + 38
24
25.
DECIMAL[(точность[,масштаб])]
Параметр
точность
указывает
максимальное
количество
цифр
вводимых данных этого типа (до и после
десятичной точки в сумме), а параметр
масштаб – максимальное количество
цифр, расположенных после десятичной
точки.
25
26. Строковые типы
В SQL Server предусмотрены дведублирующих разновидности полей
для
представления
текстовых
данных:
поля Unicode и не-Unicode.
Unicode - типы данных начинаются
символом n (от слова national, то
есть с поддержкой национальных
символов).
26
27.
Всего в SQL Server предусмотреныследующие типы для текстовых данных:
char/nchar - строковые данные
фиксированной длины;
varchar/nvarchar - строковые данные
переменной длины.
27
28.
• При использовании типа Char значениядлиной короче заданной дополняются
пробелами до указанной длины.
Максимальное значение длины – 8000
символов.
• При использовании
типа VarChar
значения длиной короче заданной не
дополняются пробелами.
28
29.
Если необходимо ввести значениябольшой длины можно использовать
ключевое слово мах, что позволяет
определять столбцы до 231 байтов.
varchar(max).
29
30.
datetime (8 байт, точность до 3,33миллисекунд);
smalldatetime (4 байта, точность
до минуты).
В большинстве приложений вполне
хватает smalldatetime;
30
31.
Тип данных UNIQUEIDENTIFIER используетсядля
хранения
глобальных
уникальных
идентификационных номеров.
31
32.
SQL_VARIANT Служит для хранения значений разных типоводновременно, таких как числовые значения, строки и
даты.
Объявлять тип столбца как SQL_VARIANT следует только в
том случае, если это действительно необходимо.
Например, если столбец предназначается для хранения
значений разных типов данных или если при создании
таблицы тип данных, которые будут храниться в данном
столбце, неизвестен.
32
33.
Логический тип данных - хранитзначения вида true/false (единица/ноль).
В SQL Server он представлен типом
данных boolean.
33
34.
• GETDATE ( ) ─Возвращает значение типа datetime, которое
содержит дату и время компьютера, на
котором запущен экземпляр SQL Server.
DATEDIFF ( datepart , startdate , enddate )─ возвращает
интервал времени, прошедшего между двумя
временными отметками - startdate (начальная отметка)
и enddate (конечная отметка). Этот интервал может
быть измерен в разных единицах. Возможные
варианты определяются аргументом datepart
34
35.
36.
В ряде случаев функцию DATEPART можно заменитьболее простыми функциями.
DAY ( date ) - целочисленное представление дня
указанной даты. Эта функция эквивалентна функции
DATEPART(dd, date).
MONTH ( date ) - целочисленное представление месяца
указанной даты. Эта функция эквивалентна функции
DATEPART(mm, date).
YEAR ( date ) - целочисленное представление года
указанной даты. Эта функция эквивалентна функции
DATEPART(yy, date).
36
37.
DATEDIFF(dd, time_out, time_in)37
38.
Пользовательские типы данных.Могут использоваться при определении
какого-либо специфического или часто
употребляемого формата.
Создание пользовательского типа данных
осуществляется выполнением системной
процедуры:
sp_addtype [@typename=]type,[@phystype=]
system_data_type [,[@nulltype=]’null_type’]
38
39.
EXEC sp_addtype dt, DATETIME, 'NULL'Удаление пользовательского типа данных происходит в результате
выполнения процедуры sp_droptype type
Пример:
EXEC sp_droptype 'dt‘
http://www.intuit.ru/studies/courses/5/5/le
cture/124?page=2
39
40.
CREATE TYPE SSNFROM varchar(10) NOT NULL ;
40
41.
Получение информации о типахданных
Получить список всех типов данных,
включая пользовательские, можно из
системной таблицы systypes:
SELECT * FROM systypes
41
42. Преобразование типов
Для выполнения преобразований SQL Serverсодержит функции CONVERT и CAST, с помощью
которых
значения
одного
типа
преобразовываются в значения другого типа,
если такие изменения вообще возможны.
CONVERT
и
CAST
взаимозаменяемыми.
могут
быть
CAST(выражение AS тип_данных)
CONVERT(тип_данных[(длина)],
выражение)
42
43. Пример:
SELECT ‘сегодня ‘ +CONVERT(VARCHAR(11),GETDATE())
CAST('1977.01.07‘ AS Datetime)
43
44.
Оновные функции– поиск подстроки
CHARINDEX (expressionToFind ,expressionToSearch[ , start_location ] )
- вырезка
SUBSTRING ( expression ,start , length )
- REPLACE
заменяет указанную подстроку первого операнда строкой, заданной в
качестве второго операнда.
REPLACE( expression , string_pattern , string_replacement )
-REVERSE
- Возвращает строковое значение, где символы переставлены в обратном
порядке справа налево.
- TRIM "отсекает" последовательности указанного символа в конце или
начале заданной строки.
44
45. Временные таблицы
Временные таблицы похожи на обычные, однако они непредназначены для постоянного хранения данных. Они
создаются, удаляются и используются как обычные
таблицы.
Имена временных таблиц должны начинаться с символов #
или ##.
Временные таблицы удаляются
пользователя от базы данных.
при
отключении
Временные таблицы используются так, как будто они
входят в текущую базу данных, однако в действительности
данные хранятся в TEMPDB.
45
46.
В SQL Server существуют два типа временныхтаблиц: локальные и глобальные.
Локальные временные таблицы доступны
лишь для своего владельца. Имена локальных
временных таблиц начинаются с префикса #.
Глобальные временные таблицы доступны
для всех пользователей, их имена должны
начинаться с префикса ##.
46
47. Создание ограничений
4748. Декларативные ограничения при создании таблиц
При создании таблиц могут быть заданыдекларативные ограничения целостности
атрибутов:
значения по умолчанию (DEFAULT),
задание обязательности или необязательности
значений (NULL или NOT NULL),
условия проверки значения (CHECK),
задание уникальность столбца (UNIQUE) .
48
49.
Например, на значение стипендииможет быть наложено ограничение
(стипендия должна находиться в
пределах от 500 до 750 тысяч рублей) по
умолчанию значение стипендии равно
500 тыс. руб.
STIP MONEY DEFAULT 700 CHECK(STIP
>=700 AND <=750)
49
50.
Возраст сотрудника должен бытьне менее 18 лет:
BIRTH_DAY DATE
CHECK(DATEDIFF(YEAR,GETDATE(),BIRTH
_DAY)>=18)
50
51.
При создании ограничений необходимоучитывать следующее:
ограничение, определенное для одного
поля может ссылаться только на это поле и
называется
ограничением на уровне
поля;
Ограничение
может
ссылаться
на
несколько
полей
и
называется
ограничением на уровне таблицы.
51
52.
ограничения DEFAULT должны бытьограничениями на уровне поля;
ограничения CHECK на уровне поля могут
ссылаться только на одно поле;
ограничения CHECK на уровне таблицы
могут ссылаться на любые поля таблицы;
ограничения не могут ссылаться на поля
других таблиц.
52
53.
54.
55.
Часто для поля или группы полей требуетсяреализовать ограничение, связанное c
уникальностью значений.
В этом случае в ограничение поля (группы)
при создании таблицы помещают ключевое
слово UNIQUE. Можно определить группу
полей как уникальную, например, в
таблице USP уникальными должны быть
комбинации полей NOM_ZACH и PKOD:
UNIQUE (NOM_ZACH,PKOD)
55
56.
ОграничениеPRIMARY
KEY
действует
аналогично UNIQUE, но для таблицы должен
быть определен только один первичный ключ,
а уникальных полей может быть несколько.
Первичный ключ может быть составным (как в
таблице USP, где ключ состоит из атрибутов
NOM_ZACH и PKOD).
Для объявления составного первичного ключа
требуется объявление на уровне таблицы.
56
57.
PRIMARY KEY(NOM_ZACH, PKOD)57
58. Ссылочная целостность
5859.
5960.
6061.
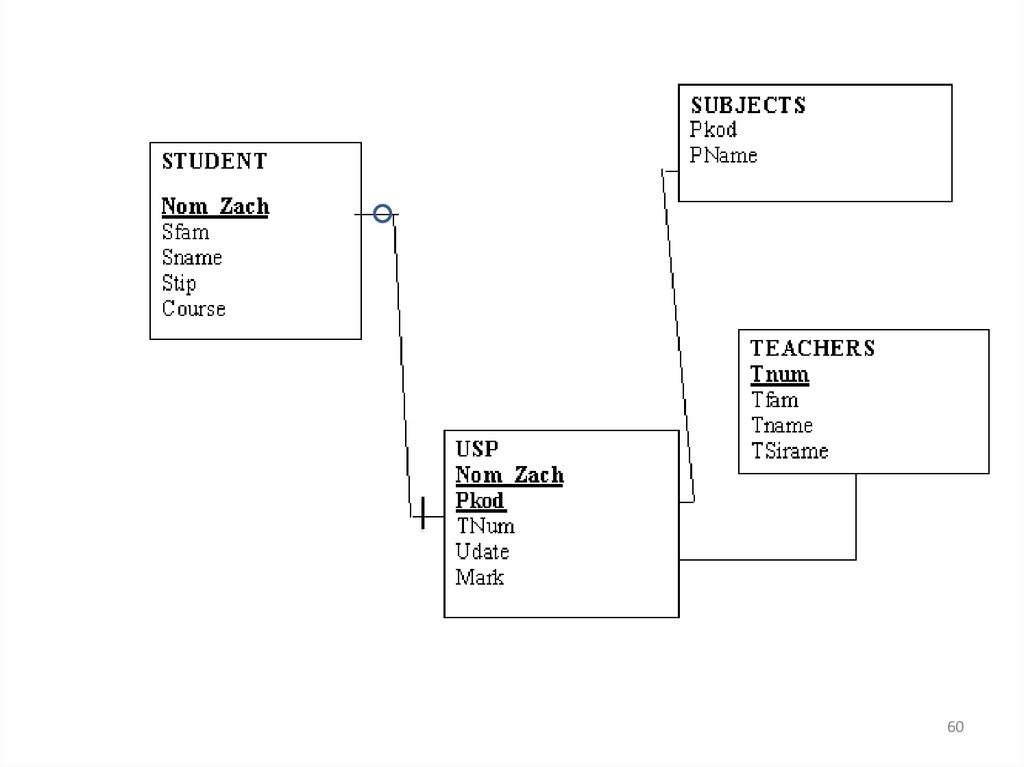
Таблица USP подчинена двум другимтаблицам: SUBJECTS и STUDENTS. При
этом таблица USP связана с таблицей
STUDENTS обязательной связью.
Каждому значению атрибута NOM_ZACH в
таблице USP обязательно должно
соответствовать ровно одно значение этого
же атрибута в таблице STUDENTS.
В таблице USP не может быть значений
атрибута NOM_ZACH, которых нет в
таблице STUDENTS. Связь с таблицей
SUBJECTS также будет обязательной.
61
62.
Для моделирования этих связейдолжны быть определены два
внешних ключа (FOREIGN KEY)
для полей NOM_ZACH и PKOD.
Для полей NOM_ZACH и PKOD
должно быть задано значение
NOT NULL, поскольку связь
обязательная.
62
63.
Ключ FOREIGN KEY ограничивает значения,которые можно ввести в БД так, чтобы
заставить внешний и родительский ключи
соответствовать
принципу
ссылочной
целостности.
Синтаксис ограничения FORIGN KEY:
FOREIGN KEY <список полей> REFERENCES
<имя таблицы, содержащей родительский
ключ>[список
полей
родительского
ключа].
63
64.
Создадим таблицу USP с полем NOM_ZACH, и PKODопределенными в качестве внешних ключей:
CREATE TABLE USP
(NOM_ZACH INTEGER NOT NULL,
PKOD INTEGER NOT NULL,
TNUM INTEGER,
UDATE DATE ,
MARK INTEGER,
PRIMARY KEY(NOM_ZACH, PKOD) ,
FOREIGN KEY (NOM_ZACH) REFERENCES STUDENTS
(NOM_ZACH),
FOREIGN KEY (PKOD) REFERENCES SUBJECTS (PKOD))
64
65.
Используя ограничения FOREIGN KEY, можно не указыватьсписок полей родительского ключа, если родительский
ключ имеет ограничение PRIMARY KEY.
CREATE TABLE USP
(NOM_ZACH INTEGER NOT NULL FOREIGN KEY
REFERENCES STUDENTS,
PKOD INTEGER NOT NULL FOREIGN KEY REFERENCES
SUBJECT,
TNUM INTEGER,
UDATE DATE ,
MARK INTEGER,
PRIMARY KEY (NOM_ZACH,PKOD));
В случае употребления ключей
со многими полями,
обязательно выполнение условия, чтобы порядок полей
во внешних и первичных ключах совпадал.
65
66.
В соответствии со стандартом, изменение илиудаление значений родительского ключа не
допускается.
Это означает, что нельзя удалить данные о
студенте из таблицы STUDENTS до тех пор, пока в
таблице USP для него имеется какая-нибудь
информация. Однако довольно часто возникают
ситуации,
когда
необходимо
удалить
информацию о студенте, например, в случае его
отчисления.
В таких случаях рассматривается возможность
каскадирования или ограничения действий.
66
67.
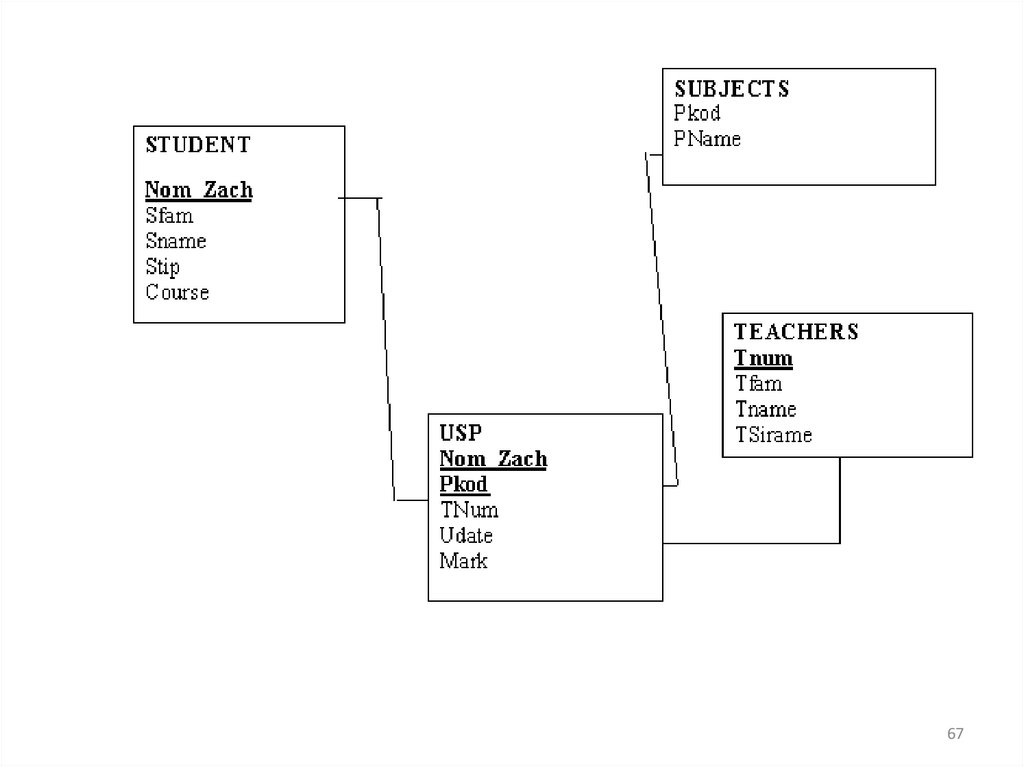
6768.
При необходимости изменить или удалить текущеессылочное значение родительского ключа
существует следующие возможности:
1. Запретить изменения (по умолчанию).
2. Сделав изменения в родительском ключе,
произвести изменения во внешнем ключе
автоматически (каскадное изменение).
3. Сделать изменение в родительском ключе и
установить внешний ключ в NULL значение либо
присвоить ему значение по умолчанию.
В пределах этих возможностей выполняются все
команды
модификации.
68
69.
Итак, изменения в родительском ключеможно разделить на
ограниченные (NO ACTION),
каскадируемые (CASCADE),
пустые (SET NULL) ,
• устанавливающие значения по умолчанию
(SET DEFAULT).
69
70.
Предположим, что есть необходимостьв изменении номера зачетной книжки,
причем оценки должны сохраниться у
этого же студента c новым номером. В
этом случае следует указать команду
UPDATE
c
каскадируемыми
изменениями.
70
71.
CREATE TABLE USP(NOM_ZACH INTEGER NOT NULL,
PKOD INTEGER,
TNUM INTEGER,
UDATE DATE ,
MARK INTEGER,
PRIMARY KEY(NOM_ZACH, PKOD)
FOREIGN KEY (PKOD) REFERENCES SUBJECTS
FOREIGN KEY (NOM_ZACH) REFERENCES
STUDENTS ON UPDATE CASCADE)
71
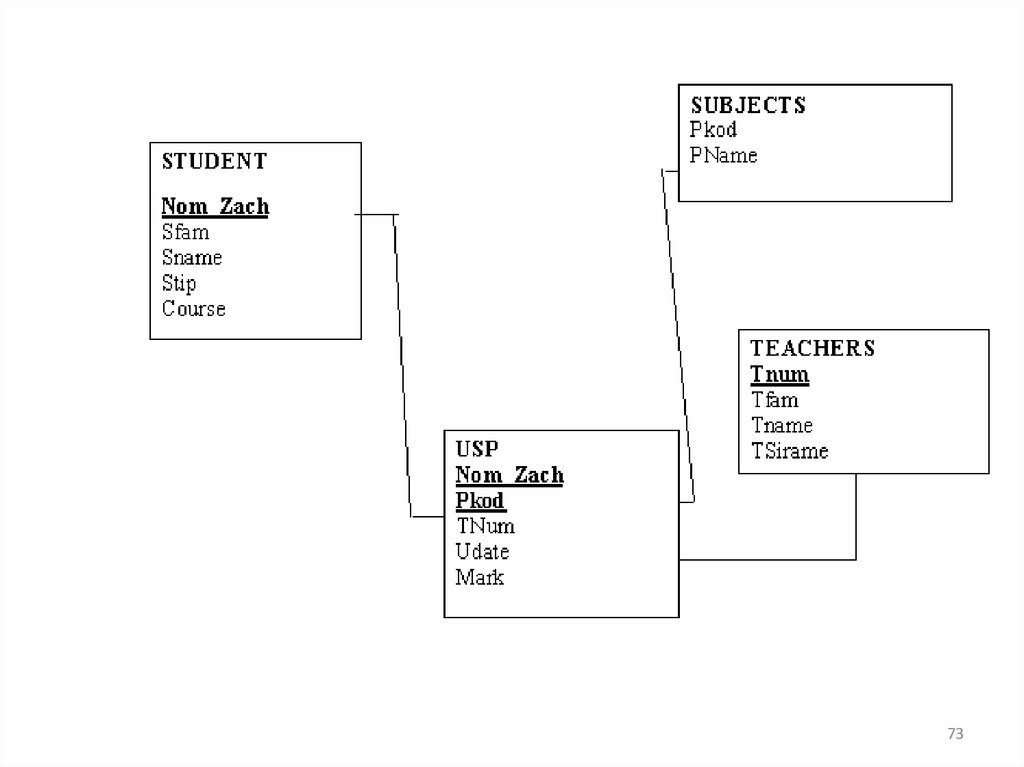
72.
Если данные о студенте удаляются, удалениеих должно быть выполнено сначала в
подчинённой (USP), а затем в главной таблице
(STUDENTS).
В этом случае используется ограничение
ON DELETE NO ACTION
После этого при удалении данных о студенте из
таблицы STUDENT команда не будет
выполнена до тех пор, пока не будут удалены
его данные из таблицы USP.
72
73.
7374. Изменение таблиц
Изменение таблицы осуществляетсякомандой ALTER TABLE.
Чаще всего с помощью этой команды
добавляют поля к таблице.
ALTER TABLE <имя таблицы>
ADD <имя поля> <тип данных> <длина
поля>
74
75.
Пример показывает добавление столбца,который допускает значения NULL В новом
столбце в каждой строке будет значение NULL.
ALTER TABLE A ADD column b VARCHAR(20) NULL
75
76.
Новое поле станет последним по порядку втаблице.
Допускается
добавление
сразу
нескольких полей. Они должны быть отделены
друг от друга запятыми.
Предполагается, что столбец может содержать
неопределенные значения, если в объявлении не
указано обратное. Если новый столбец не
допускает
неопределенных
значений,
необходимо определить для него значение по
умолчанию.
Новые столбцы могут представлять собой
вычисляемые выражения и объявляться с
ограничениями уровня столбцов.
76
77.
В таблицу могут быть добавлены и новыеограничения с помощью команды
ADD CONSTRAINT <имя ограничения>.
Имя ограничения состоит из краткого
названия типа ограничения (например, PK
для первичного ключа, ID для индекса),
символа подчёркивания, имени поля или
таблицы
и
порядкового
номера
ограничения данного типа, если к одному
объекту задаётся несколько ограничений
одного типа.
77
78.
Примеры:1. Для добавления ограничения, задающего значение по умолчанию:
ALTER TABLE USP
ADD CONSTRAINT Def_Mark DEFAULT 7 FOR MARK
2. Для добавления ограничения проверки значения:
ALTER TABLE USP
ADD CONSTRAINT Сh_Mark CHECK MARK IN (3,4,5)
3. Для добавления внешнего ключа (NOM_ZACH) в таблицу USP для
связи с таблицей STUDENTS
ALTER TABLE USP
ADD CONSTRAINT FK_USP_STUDENTS FOREIGN KEY (NOM_ZACH) REFERENCES
STUDENTS
ON UPDATE CASCADE
78
79.
Для получения информации обограничениях используется системная
процедура
sp_helpconstraint имя_таблицы
или sp_help имя ограничения.
79
80. Удаление столбцов и ограничений
Из созданной таблицы можно удалить столбцы илиограничения. При удалении ограничений следует
помнить, что выполнению команды могут помешать
некоторые зависимости.
Например, если столбец является первичным ключом,
сервер не позволит удалить его до тех пор, пока не будет
снято соответствующее ограничение. Если в другой
таблице существует ссылка на столбец, сервер также не
позволит удалить его до снятия ограничения.
Примеры:
ALTER TABLE USP
DROP CONSTRAINT Ch_Mark
ALTER TABLE USP
DROP COLUMN Udate
80
81. Разрешение и запрет ограничений
С помощью команды ALTER TABLE спредложениями ENABLE и DISABLE можно
разрешать
и
запрещать
действия
ограничений, не удаляя их.
ALTER TABLE таблица
ENABLE | DISABLE CONSTRAINT имя
ограничения
81
82. Модификация столбцов
Иногда при создании таблиц делают неверныепредположения относительно типа данных,
которые собираются хранить в таблице. Неверный
выбор приводит к неэффективному хранению
данных или же данные могут оказаться слишком
большими и не помещаться в столбцах. В таких
ситуациях следует изменить исходное определение
столбцов командой ALTER COLUMN.
Пример:
ALTER TABLE PREP
ALTER COLUMN FIO varchar(50)
82
83. Удаление таблиц
Удаление таблиц выполняется с помощью команды DROP TABLE.Для того чтобы иметь возможность удалить таблицу, пользователь
должен быть ее владельцем.
Кроме того, перед удалением SQL требует очистки таблицы от данных.
Таким образом, таблица с находящимися в ней данными не может
быть удалена. Перед удалением следует убедиться, что на таблицу не
ссылается никакая другая таблица, и что она не используется в какомлибо представлении.
Синтаксис команды удаления:
DROP TABLE <имя таблицы>
83
84. Создание индексов
Индекс - упорядоченный список полей илигрупп полей в таблице.
Таблицы могут иметь огромное количество
записей, при этом записи не находятся в
каком-либо
определённом
порядке,
поэтому на их поиск по указанному
критерию может потребоваться достаточно
продолжительное время.
84
85.
С помощью индексов осуществляетсядоступ к данным наиболее оптимальным
способом.
В индексы следует включать поля, к
которым часто выполняются запросы при
выполнении операций выборки. К ним
относятся внешние ключи, а также другие
поля, часто используемые для соединения
таблиц.
85
86.
Если создан индекс по первичномуключу, а затем необходимо найти
строку с данными, Server сначала
найдет значение индекса, а затем
использует индекс для быстрого
нахождения всей строки с данными.
Без индекса будет выполнен полный
просмотр (сканирование) всех строк
таблицы,
что
может
оказать
значительное
влияние
на
производительность.
.
86
87.
Индекс может быть создан набольшинстве столбцов таблицы или
представления.
Исключением,
являются столбцы с типами данных для
хранения больших объектов , таких как
image, text или varchar(max).
Можно создать индексы на столбцах,
предназначенных для хранения данных
в формате XML, но эти индексы
устроены
немного
иначе.
чем
стандартные
87
88.
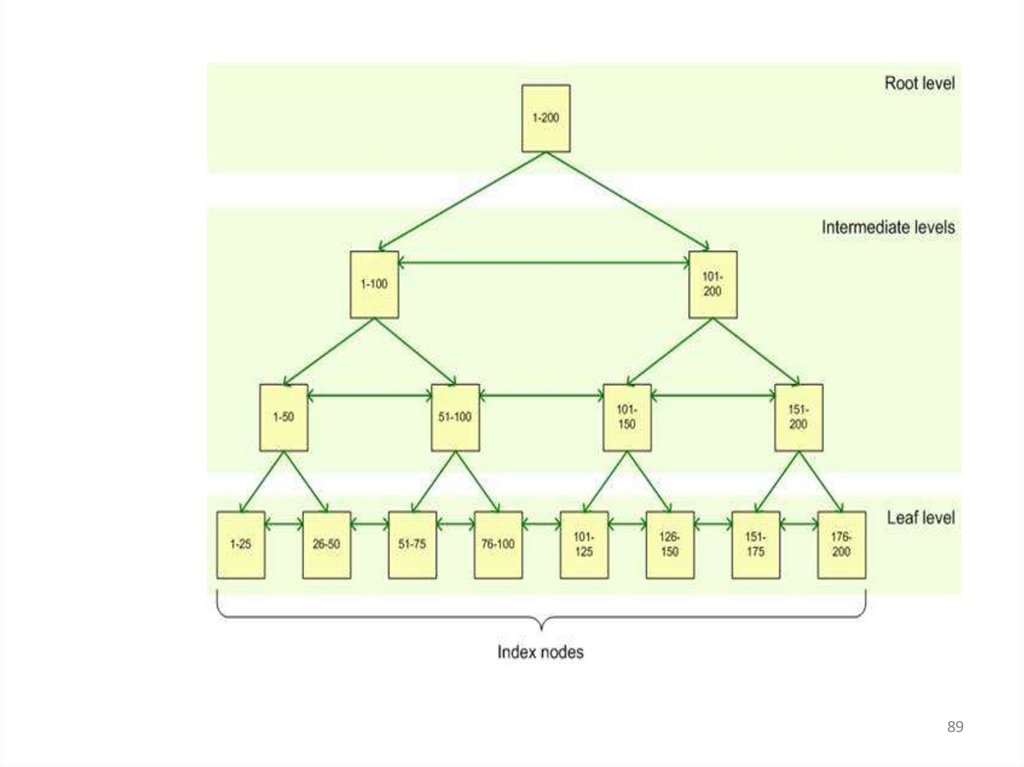
Индекс состоит из набора страниц,узлов индекса, которые организованы
в виде древовидной структуры —
сбалансированного
дерева.
Эта
структура является иерархической и
начинается с корневого узла на
вершине иерархии и конечных узлов,
листьев, в нижней части
88
89.
8990.
Когдаформируется
запрос
на
индексированный столбец, подсистема
запросов начинает идти сверху от
корневого узла и постепенно двигается
вниз через промежуточные узлы, при
этом каждый слой промежуточного
уровня содержит более детальную
информацию о данных.
Подсистема
запросов
продолжает
двигаться по узлам индекса до тех пор,
пока не достигнет нижнего уровня с
листьями индекса.
90
91.
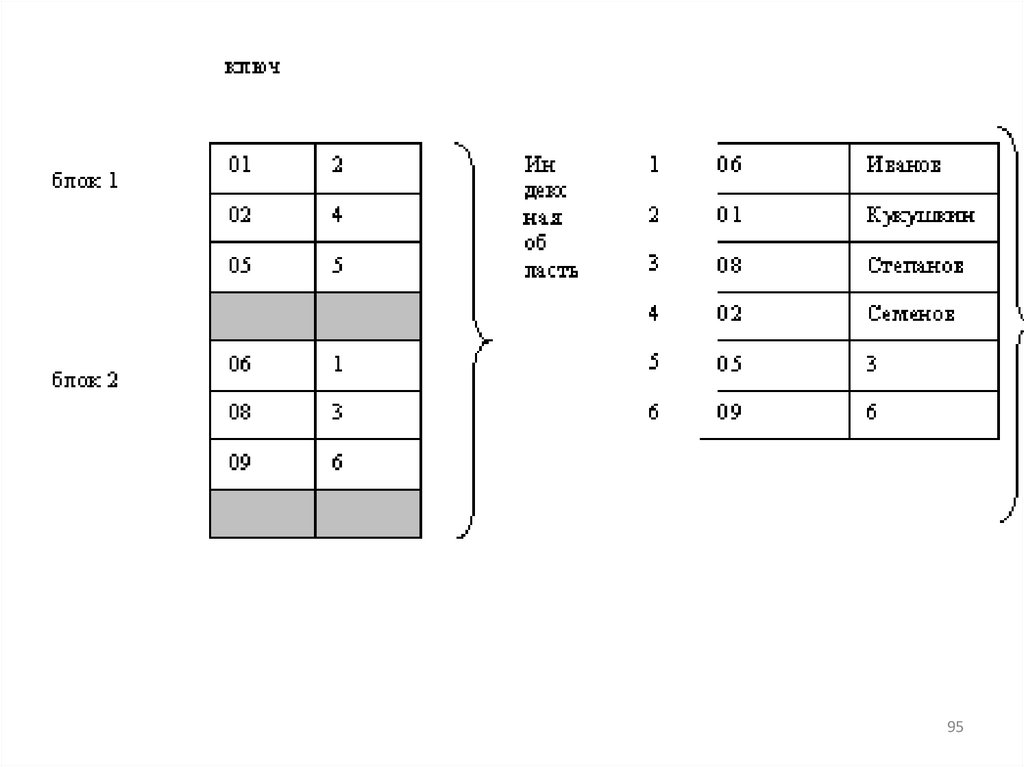
Листья индекса могут содержать каксами данные таблицы, так и просто
указатель на строки с данными в
таблице, в зависимости от типа
индекса: кластеризованный индекс
или
некластеризованный.
91
92.
• Кластеризованный индексКластеризованный
индекс
хранит
реальные строки данных в листьях
индекса. Важной характеристикой
кластеризованного индекса является
то, что все значения отсортированы в
определенном
порядке
либо
возрастания, либо убывания. Таким
образом, таблица или представление
может
иметь
только
один
кластеризованный индекс
92
93.
• Некластеризованный индексВ отличие от кластеризованного
индекса, листья некластеризованного
индекса содержат только те столбцы
(ключевые), по которым определен
данный индекс, а также содержит
указатель на строки с реальными
данными в таблице. Это означает, что
необходима
дополнительная
операция
для
обнаружения
и
получения требуемых данных.
93
94.
Содержание указателя на данныезависит от способа хранения данных:
кластеризованная таблица или куча.
Если
указатель
ссылается
на
кластеризованную таблицу, то он
ведет к кластеризованному индексу,
используя который можно найти
реальные данные.
Если указатель ссылается на кучу, то он
ведет к конкретному идентификатору
строки с данными.
94
95.
9596.
Для создания индексаоператор CREATE INDEX.
используется
Синтаксис:
CREATE INDEX имя_индекса ON таблица
(поле[, …n])
96
97.
Таблица, для которой создаётся индекс,должна уже существовать и содержать
имена индексируемых полей. При этом имя
индекса не может быть использовано для
чего-либо другого в базе данных и SQL сам
решает, когда он необходим для работы и
использует его автоматически.
97
98.
Для создания уникальных (не содержащихповторяющихся значений) индексов
используется ключевое слово UNIQUE в
операторе CREATE INDEX (CREATE UNIQUE
INDEX …).
Например, создать индекс c именем
Ind_Tnum для поля TNUM таблицы SUBJECT:
CREATE UNIQUE INDEX Ind_Tnum ON SUBJECT(TNUM)
98
99.
Для удаления индекса используется командаDROP INDEX имя индекса
Чтобы изменить индекс таблицы, необходимо удалить его
и затем создать заново в соответствии с новым
определением.
Для получения информации о текущих индексах таблицы
используется процедура sp_helpindex.
99
100.
Использование опции Clustered index позволяетпроизвести
так
называемое
кластерное
индексирование, в результате чего будут
отсортированы данные в самой таблице согласно
порядку этого индекса, и вся добавляемая
информация будет приводить к изменению
физического порядка данных. При этом нужно
учитывать, что в таблице может быть определён
только один кластерный индекс.
Синтаксис:
CREATE CLUSTERED INDEX
100
101.
Для повышения быстродействия кластерныйиндекс
следует
создавать
раньше
некластерных индексов.
По умолчанию создается некластерный
индекс.
101
102.
Проектирование индексовИндексы могут улучить производительность
системы, т.к. они обеспечивают подсистему
запросов быстрым путем для нахождения данных.
Поскольку индексы могут занимать значительное
дисковое пространство, не следует создавать
индексов больше, чем необходимо.
Индексы автоматически обновляются когда сама
строка с данными обновляется, что может привести
к дополнительным накладным расходам ресурсов
и падению производительности.
102
103.
Рекомендации при планированиистратегии индексирования
• Для
таблиц
которые
часто
обновляются следует использовать как
можно меньше индексов.
• Если таблица содержит большое
количество данных, но их изменения
незначительны,
тогда
можно
использовать
столько
индексов,
сколько необходимо для улучшение
производительности запросов.
103
104.
Создавать индексы на небольшихтаблицах не имеет смысла, т.к.
возможно использование поиска по
индексу может занять больше
времени,
нежели
простое
сканирование всех строк.
104
105. Последовательность создания таблиц
105106.
Операторы языка SQL транслируются в режимеинтерпретации
(каждый
оператор
отдельно
транслируется, то есть переводится в машинные коды, и
тут же выполняется).
Такая особенность SQL накладывает ограничение на
порядок описания создаваемых таблиц.
Если при
трансляции оператора описания подчинённой таблицы с
указанным внешним ключом и соответствующей ссылкой
на родительскую таблицу эта родительская таблица не
будет обнаружена, то мы получим сообщение об ошибке с
указанием ссылки на несуществующий объект.
Сначала должны быть описаны все
основные таблицы, а потом подчинённые
таблицы.
106