











 Программирование
ПрограммированиеПохожие презентации:










Язык программирования C++. Лекция 1
1.
Язык программирования C++• С++ (си плюс плюс) - высокоуровневый компилируемый язык
программирования со статической типизацией, который
подходит для создания различных приложений. На сегодняшний
день С++ один из самых распространенных языков.
• C++ - берёт основу в языке Си. В 1979-80 годах программист из
Дании Бьерн Страуструп, в своё время являвшийся
разработчиком Си, разработал расширение к языку Си - "Си с
классами". В 1983 язык был переименован в С++. В 1985 году
была выпущена первая коммерческая версия языка С++. В 1989
была выпущена новая версия языка C++ 2.0. В 1998 году была
предпринята первая попытка по стандартизации языка
организацией ISO (International Organiztion for Standartization).
1
2.
Стандарты языка• Первый стандарт получил название ISO/IEC 14882:1998 или
сокращенно С++98.
• В 2003 году вышел стандарт C++03. Стандарт включал уточнения к
C++98.
• В 2011 году вышел стандарт C++11, содержал множество
добавлений и обогащал язык С++ большим числом новых
функциональных возможностей.
• В 2017 году вышел C++17, удалены/запрещены
неиспользуемые/небезопасные зарезервированные слова,
операции, функции и т.д., добавлены новые возможности.
2
3.
Состав языка• В тексте на любом естественном языке можно выделить четыре основных
элемента: символы, слова, словосочетания и предложения.
Алгоритмический язык также содержит такие элементы, только слова
называют лексемами (элементарными конструкциями ), словосочетания –
выражениями, предложения – операторами.
Лексемы образуются из символов
Выражения из лексем и символов
Операторы из символов выражений и лексем
3
4.
Алфавит языка• Прописные и строчные буквы латинского алфавита
ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz
• Арабские цифры
0123456789
• Специальные знаки
“{},| []()+-/%*.\’:;&?<>=!#^
• Пробельные символы
пробел, символ табуляции, символ перехода на новую строку
4
5.
Лексемы языка• Идентификаторы – имена объектов СИ-программ. В идентификаторе могут быть
использованы латинские буквы, цифры и знак подчеркивания. Прописные и
строчные буквы различаются, например, NAME1, name1 и Name1 – три различных
идентификатора. Первым символом должна быть буква или знак подчеркивания
(но не цифра). Пробелы в идентификаторах не допускаются.
• Ключевые (зарезервированные) слова – это слова, которые имеют специальное
значение для компилятора. Их нельзя использовать в качестве идентификаторов.
• Знаки операций – это один или несколько символов, определяющих действие над
операндами. Операции делятся на унарные, бинарные и тернарную по количеству
участвующих в этой операции операндов.
• Константы – это неизменяемые величины. Существуют целые, вещественные,
символьные и строковые константы. Компилятор выделяет константу в качестве
лексемы (элементарной конструкции) и относит ее к одному из типов по ее
внешнему виду.
• Разделители – скобки, точка, запятая пробельные символы.
5
6.
Константы• Константа – это лексема, представляющая изображение
фиксированного числового, строкового или символьного
значения. Константы можно определить с помощью директивы
препроцессора #define и зарезервированного слова const
• Константы делятся на 5 групп:
Целые
Вещественные (с плавающей точкой)
Перечислимые
Символьные
Строковые
6
7.
Структура программы#include <iostream>
//Директива препроцессора для подключения библиотеки
using namespace std;
//Подключения пространства имен std (чтобы не писать std::cout)
void main()
//Главная функция без которой ничего не будет работать (точка входа)
{
setlocale(LC_ALL, "Russian");
//Установка локализатора для отображения русских букв
int a = 0;
//Объявление переменной целого типа с именем "a"
int b = 0;
cout << "Введите a " << endl;
//Вывод "Введите a" (endl или "\n"- переход на новую строку)
cin >> a;
//Ожидания ввода числа и запись в переменную "a"
cout << "Введите b " << endl;
cin >> b;
int c = a + b;
//Сложение переменных "a" и "b", запись результата в "c"
cout << "Результат c = " << c;
//Вывод результата пользователю
}
7
8.
Этапы обработки программы• Препроцессорное преобразование текста
Препроцессор добавляет заголовки в код (#include), убирает комментирования, заменяет
макросы (#define) их значениями, выбирает нужные куски кода в соответствии с
условиями #if, #ifdef и #ifndef.
• Компиляция
Преобразует полученный код без директив в ассемблерный код.
• Ассемблирование
Ассемблер преобразовывает ассемблерный код в машинный код, сохраняя его в объектном
файле.
• Компоновка (редактирование связей или сборка)
Компоновщик (линкер) связывает все объектные файлы и статические библиотеки в единый
исполняемый файл, который мы можем запустить.
8
9.
Препроцессорное преобразованиедо
после
#define HELLO "Hello! "
std::cout << "Hello! " << "Joe";
#define PRINT_JOE
#ifdef PRINT_JOE
std::cout << HELLO << "Joe";
#endif
#ifdef PRINT_BOB
std::cout << HELLO << "Bob";
#endif
9
10.
Типы данных• Простые типы
int – целый.
float – вещественный.
double – вещественный с двойной точностью.
char – символьный.
wchar_t – символьный расширенный.
bool – логический.
• Спецификаторы типа
short – короткий.
long – длинный.
signed – знаковый.
unsigned – беззнаковый.
10
11.
Типы данных• short int – занимает 2 байта в памяти, диапазон значений -32 768 .. +32 767.
• long int – занимает 4 байта в памяти, диапазон значений -2 147 483 648 .. +2 147 483 647.
• unsigned short int – занимает 2 байта в памяти, диапазон значений 0 .. 65 536.
• unsigned long int – занимает 4 байта, диапазон значений 0 .. +4 294 967 295.
• bool – имеет 2 состояния false и true, при этом false – это 0, а все что не 0 – это true.
• char – занимает 1 байт в памяти, представляет один символ в кодировке ASCII.
• signed char - занимает 1 байт в памяти, диапазон значений -128 .. +127.
• unsigned char - занимает 1 байт в памяти, диапазон значений 0 .. +255.
11
12.
Типы данных• wchar_t - представляет расширенный символ. На Windows занимает в памяти 2 байта, на
Linux - 4 байта, диапазон значений от 0 .. 65 535 (при 2 байтах), либо от 0 .. 4 294 967 295
(для 4 байт).
• char16_t - представляет один символ в кодировке Unicode. Занимает в памяти 2 байта (16
бит), диапазон значений 0 .. 65 535.
• char32_t - представляет один символ в кодировке Unicode. Занимает в памяти 4 байта (32
бита), диапазон значений от 0 .. 4 294 967 295.
12
13.
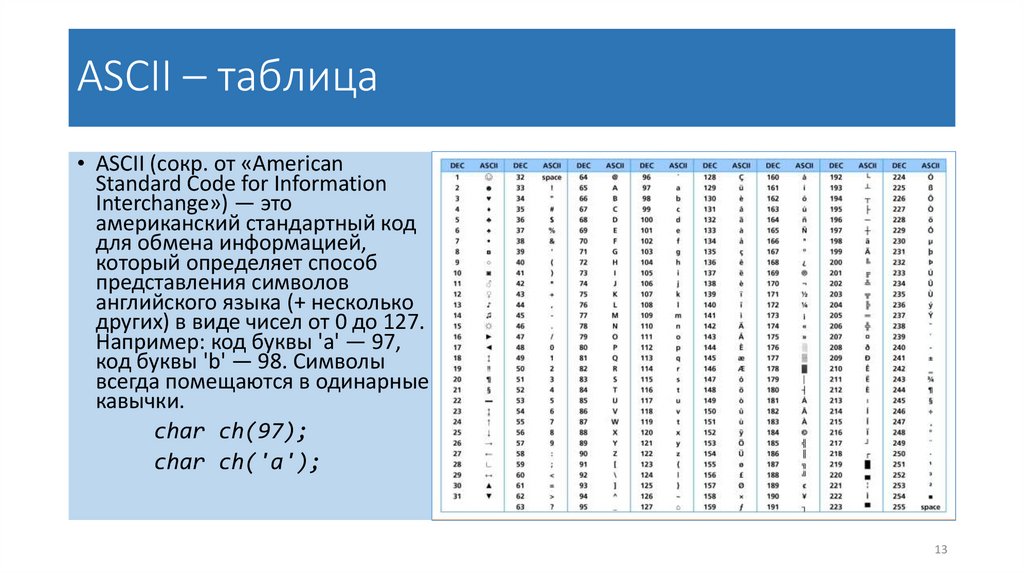
ASCII – таблица• ASCII (сокр. от «American
Standard Code for Information
Interchange») — это
американский стандартный код
для обмена информацией,
который определяет способ
представления символов
английского языка (+ несколько
других) в виде чисел от 0 до 127.
Например: код буквы 'а' — 97,
код буквы 'b' — 98. Символы
всегда помещаются в одинарные
кавычки.
char ch(97);
char ch('a');
13