







































 Информатика
ИнформатикаПохожие презентации:
")

")
")


")



Методы и средства передачи информации. Лекция 6. Часть 1
1.
Лекция №6по курсу
«Методы и средства передачи информации ч.1»
Лектор: д.т.н., Оцоков Шамиль Алиевич,
email: [email protected]
Москва, 2022
2.
Оптимальный кодВсегда ли код Шеннона-Фано экономный?
Какими свойствами должен обладать оптимальный код?
Пусть сообщения A1, А2, ..., Аn имеют вероятности p1 , p2 ..., pN и кодируются
двоичными словами a1, a2, ..., an имеющими длины l1, l2, ..., ln
Свойство 1.
В оптимальном коде более вероятное сообщение кодируется коротким
словом. т. е. если pi > pj , то li<= lj
Доказательство:
3.
Оптимальный кодНарушается свойство оптимальности кода
Свойство 2.
Если код оптимален, то всегда можно так перенумеровать сообщения и
соответствующие им кодовые слова, что p1 ≥ p2 ≥ p3 … ≥ pn и при этом l1<= l2
…<= ln
4.
Оптимальный кодСвойство 2.
Если код оптимален, то всегда можно так перенумеровать сообщения и
соответствующие им кодовые слова, что p1 ≥ p2 ≥ p3 … ≥ pn и при этом l1<= l2
…<= ln
Доказательство:
В самом деле, если pi > pi+1 , то li<= li+1 .
Если pi = pi+1 , то li>= li+1, то переставим сообщения Аi , Аi+1 и
соответствующие им кодовые слова.
Свойство 3.
В оптимальном двоичном коде всегда найдется по крайней
мере, два слова наибольшей длины, равной Ln и таких, что они
отличаются друг от друга лишь в последнем символе.
5.
Оптимальный кодДействительно, если бы это было не так, то можно было
бы просто откинуть последний символ кодового слова aN не нарушая
свойство префиксности. При этом мы, очевидно, уменьшили бы
среднюю длину кодового слова.
Пусть слово at имеет ту же длину, что и aN и отличается от него лишь
в последнем знаке. Согласно свойству 1 и свойству 2 можно считать,
что lt= lt+1=…= lN . Если t≠N-1, то можно поменять кодовые
обозначения at и aN-1 не нарушая свойство префиксности.
Т.е. всегда существует такой оптимальный код, в котором кодовые
обозначения двух (наименее вероятных) сообщений АN-1 и АN
отличается лишь в последнем символе.
6.
Оптимальный кодРассмотрим новое множество сообщений
A (1)= {A1, A2,…,Аn-2,A} с вероятностями
p1 , p2 ..., pN-2, p = pN-1 +pN .
Оно получается из множества {A1, A2,…,Аn-2, ,Аn-1,An}
объединением двух наименее вероятных сообщений Аn-1,An
в одно сообщение А. Будем говорить, что A (1) получается
сжатием из {A1, A2,…,Аn-2, ,Аn-1,An}.
Пусть для A (1) построена некоторая система кодовых слов К(1)= {a1, a2, ..., a},
иными словами, указано некоторое кодовое дерево с концевыми вершинами
a1, a2, ..., a. Этой системе можно сопоставить код К = (a1, a2, ..., an ) для исходного
множества сообщений, в котором слова an-1 и an получаются из слова a
добавлением соответственно 0 и 1. Процедуру перехода от К(1) к К назовем
расщеплением.
7.
Оптимальный кодУтверждение
Если код К(1) для множества сообщений A (1) является оптимальным,
то оптимален также и код К для исходного множества сообщений.
Доказательство:
Для доказательства установим связь между средними длинами l(K) и l(K(1)) слов
кодов К и К(1). Она, очевидно, такова:
l(K) = l1 ∙ p1+ l2 ∙ p2 + ...+ ln ∙ pn,
l(К(1)) = l1 ∙ p1+ l2 ∙ p2 + ...+ ln-2 ∙ pn-2 + l ∙ p
l(K) = l(К(1)) – l∙p + ln-1 ∙ pn-1 + ln ∙ pn= l(К(1)) – l∙p + (l+1) ∙ pn-1 + (l+1) ∙ pn=
= l(К(1)) + p
Пусть К не является оптимальным, т.е. существует код K1 со средней длиной
l1 (K1 )< l(К) . Тогда его концевые вершины an и an-1 соответствует кодовым
словам наименее вероятных сообщений Аn и Аn-1 .
8.
Оптимальный кодТогда кодовые слова an и an-1 из K1 отличаются в последнем символе.
Рассмотрим код К1(1) в котором кодовое слово a получается из an и an-1 из K1
отбрасыванием последнего символа и средние длины связаны соотношением
l(К1(1)) = l(K1) + p
Из неравенства l(К1(1)) < l(K) следует, что l(K1)< l(К(1)) , что противоречит
оптимальности кода К(1) (по условию теоремы К(1) оптимальный код)
Проиллюстрируем процесс последовательных сжатий и расщеплений
на примере множества из пяти сообщений с вероятностями p1=0,4;
p2=p3=p4=p5 = 0,15. Процесс этот отражен в следующей таблице:
9.
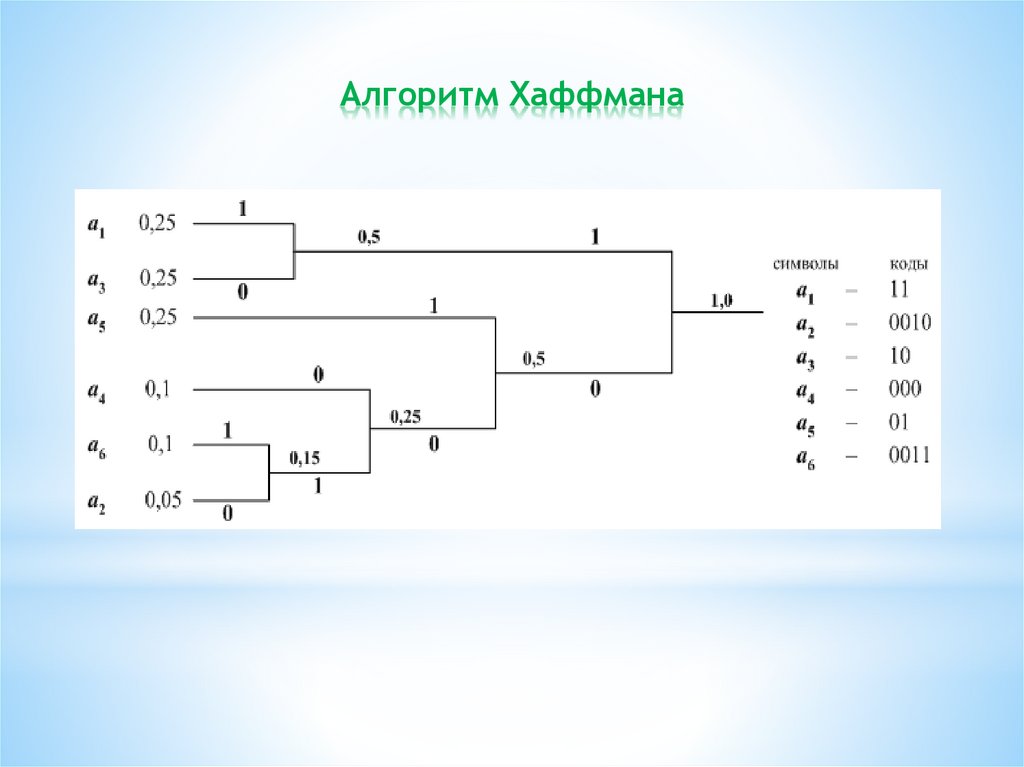
Алгоритм Хаффмана10.
Алгоритм Хаффмана11.
Линейные коды12.
Линейные коды13.
Линейные коды14.
Проверочная матрица15.
Проверочная матрица16.
Проверочная матрицаx1 + x3 + x5 + x7 = 0 (mod 2)
x2 + x3 + x6 + x7 = 0 (mod 2)
x4 + x5 + x6 + x7 = 0 (mod 2)
17.
Линейные коды18.
Порождающая матрица19.
Порождающая матрица20.
Порождающая матрица21.
Порождающая матрица22.
Порождающая матрица23.
Порождающая матрица24.
Порождающая матрица25.
Порождающая матрица26.
Порождающая матрица27.
Порождающая матрица28.
Порождающая матрица29.
УтверждениеКодовое расстояние линейного кода равно d тогда и только тогда, когда в
проверочной матрице найдётся в линейно зависимых столбцов проверочной
матрицы. Верно и обратное.
Доказательство:
30.
УтверждениеПример 1.
H = (1 1 1 1)
Код проверки на четность
Линейная комбинация 2-х столбцов будет 0.
Только 1 столбец лин независимый
Значит d = 2 т.е. обнаруживает 1 ошибку
31.
Теорема ШеннонаРазработка принципов наиболее экономичного кодирования информации.
Код - (1) правило, описывающее соответствие знаков или их сочетаний
первичного алфавита знакам или их сочетаниям вторичного алфавита
Операции кодирования и декодирования называются обратимыми, если их
последовательное применение обеспечивает возврат к исходной информации без
каких-либо ее потерь.
32.
Теорема Шеннона33.
Теорема ШеннонаОбычно N > М и I(А) > I(В), откуда К(А,В) > 1, т.е. один знак первичного алфавита
представляется несколькими знаками вторичного.
Возникает проблема выбора (или построения) наилучшего варианта – которое называется его
оптимальным кодом.
Выгодность кода при передаче и хранении информации - это экономический фактор, так как
более эффективный код позволяет затратить на передачу сообщения меньше энергии, а
также времени и, соответственно, меньше занимать линию связи; при хранении
используется меньше площади поверхности (объема) носителя
34.
Теорема ШеннонаПервая теорема Шеннона, которая называется основной теоремой о
кодировании при отсутствии помех, формулируется следующим образом:
При отсутствии помех всегда возможен такой вариант кодирования
сообщения, при котором среднее число знаков кода, приходящихся на один
знак первичного алфавита, будет сколь угодно близко к отношению средних
информации на знак первичного и вторичного алфавитов.
35.
Первая теорема Шеннона36.
Метод укрупнения алфавита37.
Произведение кодов V1 на V238.
Произведение кодов V1 на V239.
Произведение кодов V1 на V240.
Произведение кодов V1 на V241.
Произведение кодов V1 на V2Взяли два слова, отличающиеся только на 1 бит в первой строке и
первом столбце, тогда после кодирования в первой строке будут
отличия как минимум в d1 бит, в первом столбце как минимум в d2
бит, в каждом из этих d2 бит будет изменяться соответствующее
слово, поэтому d2*d1.
Пусть код V1 исправляет t1 ошибок, код V2 исправляет t2 ошибок,
тогда d1>2*t1, d2>2*t2,
d1*d2 > 4*t1*t2 = 2* (2*t1*t2)
Т.е. (2*t1*t2)