













 Математика
МатематикаПохожие презентации:
")









Методы обработки и анализа информации «Оценка и проверка статистических гипотез». Практическое занятие 3
1.
Моделирование систем и процессовТема 4. Методы обработки и анализа информации
«Оценка и проверка статистических гипотез»
Практическое занятие 3
2.
Пример 1.Случайная величина X (число нестандартных изделий в партии
изделий) распределена по закону Пуассона. Количество партий – 200.
хi
ni
0
132
1
43
2
20
3
3
4
2
хi
- количество нестандартных изделий в одной партии.
ni
- количество партий содержащих нестандартных изделий
Найти числовые характеристики закона распределения случайной
величины
ak a
Pt ( k ) e
k!
n p k np
Pn k
е .
k!
M D a
3.
Пример 2.Дан статистический ряд распределения случайной величины X
отклонения от номинала 200 изделий. Случайная величина
распределена по нормальному закону с неизвестными
параметрами.
х i , мм
ni
0,3 0,5
6
9
0,7
26
0,9
25
1,1
30
1,3
26
1,5
21
1,7
24
1,9
20
2,2
8
2,3
5
ni - количество изделий, имеющих отклонение х i
Найти числовые характеристики закона распределения случайной
величины
1
Pn (k )
е
2 D
1
f ( x)
е
2
( k m )2
2 D
( x m )2
2σ 2
,
,
где mξ=np; Dξ=npq
4.
Метод максимального правдоподобияМетод максимального правдоподобия - метод
нахождения статистических оценок неизвестных
параметров распределения. Предполагается, что
результаты наблюдений x1, х2,...хn являются взаимно
независимыми случайными величинами,
принадлежащими одному закону распределения
вероятностей.
Рассмотрим случай, когда распределение вероятностей
зависит от одного параметра ν. В качестве оценок
выбирают то значение параметра ν, при котором
полученные результаты "наиболее вероятны".
5.
Смысл принципа "наибольшей вероятности" рассматриваемогометода заключается в следующем.
Вводится функция правдоподобия
L(xb x2ν. .xn,ν) = f(x1,ν) f(x2,ν).. .f(xn,ν),
где f(xi,v) в случае непрерывного распределения есть плотность
вероятности рассматриваемой случайной величины X, а в
дискретном случае есть вероятность того, что случайная величина
X примет значение xi
Оценкой максимального правдоподобия параметра ν называют такое
его значение ˆ ˆ( x1 , x 2 ,... x n ), при котором функция L(x1, х2,...х,ν)
достигает наибольшего значения.
Для удобства определения максимума функции L(x1, х2,...хn,v),
рассматривают логарифм этой функции InL, так как максимум InL и
максимум самой функции L совпадают.
Уравнение правдоподобия
d
ln L( x1 , x 2 x n ...v) 0
dv
ln f ( xi , v) 0
i 1 v
n
L(xb x2ν. .xn,ν) = f(x1,ν)-f(x2,ν).. .f(xn,ν)
6.
Пример 3. Наблюдалось N изделий, из них n изделий отказало.Искомый параметр
v = Р - вероятность безотказной работы.
Функция правдоподобия L(n,P) = PN-n (1-P)n
L N n
[ P (1 P) n ] 0
P P
L
( N n) P N n 1 (1 P) n P N n n(1 P) n 1
P
Разделив каждый член на PN-n-1(1-P)n-1
(N-n)(1-P)-P·n=0
N-n=NP
N n
n
Pˆ
1
N
N
7.
Пример 4. Имеем x1,x2,…xn случайных величин (наблюдений),распределение которых предполагается экспоненциальным, т.е.
F ( x) е x
Определить параметр этого закона по значениям
экспериментальных данных.
n
n
n
n
1
n
x
ln
е
[ln xi ] [ xi ] xi 0
i 1
i 1
i 1
i 1
n
n
x
i 1
i
8.
Показательный закон распределенияПоказательное распределение – это распределение интервалов
между соседними событиями в простейшем потоке событий
Событие состоит в том, что в интервале (0, t) не произойдет ни
одного события. Эта вероятность определяется по формуле Бернулли
для редких явлений:
λt 0 λt
Р (ξ 0) Р (τ t )
e e λt .
0!
F (t ) P (τ t ) 1 P (τ t ) 1 e λt
1 e λt
F (t )
0
e λt
f (t )
0
1
mτ ;
λ
t 0;
при t 0;
при
F(t), f(t)
1
t 0;
при t 0.
при
1
D 2 ;
λ
F(t)
λ
1
σ
λ
f(t)
t
9.
Дисперсионный анализДисперсионный анализ – анализ изменчивости признака под
влиянием каких-либо контролируемых переменных факторов.
(В зарубежной литературе именуется ANOVA – «Analisis of Variance»)
Обобщенно задача дисперсионного анализа состоит в том, чтобы
из общей вариативности признака выделить три частные
вариативности:
-Вариативность, обусловленную действием каждой из исследуемых
независимых переменных.
- Вариативность, обусловленную взаимодействием исследуемых
независимых переменных.
- Вариативность случайную, обусловленную всеми неучтенными
обстоятельствами.
Вариативность,
обусловленная
действием
исследуемых
переменных и их взаимодействием соотносится со случайной
вариативностью. Показателем этого соотношения является F –
критерий Фишера
10.
FэмпА = Вариативность, обусловленная действием переменной А /Случайная вариативность
FэмпБ = Вариативность, обусловленная действием переменной Б /
Случайная вариативность
FэмпАБ = Вариативность, обусловленная взаимодействием А и Б /
Случайная вариативность
Чем в большей степени вариативность признака обусловлена
исследуемыми переменными или их взаимодействием, тем выше
эмпирические значения критерия F.
В отличие от корреляционного анализа, в дисперсионном исследователь
исходит из предположения, что одни переменные выступают как влияющие
(именуемые факторами или независимыми переменными), а другие
(результативные признаки или зависимые переменные) – подвержены
влиянию этих факторов.
11.
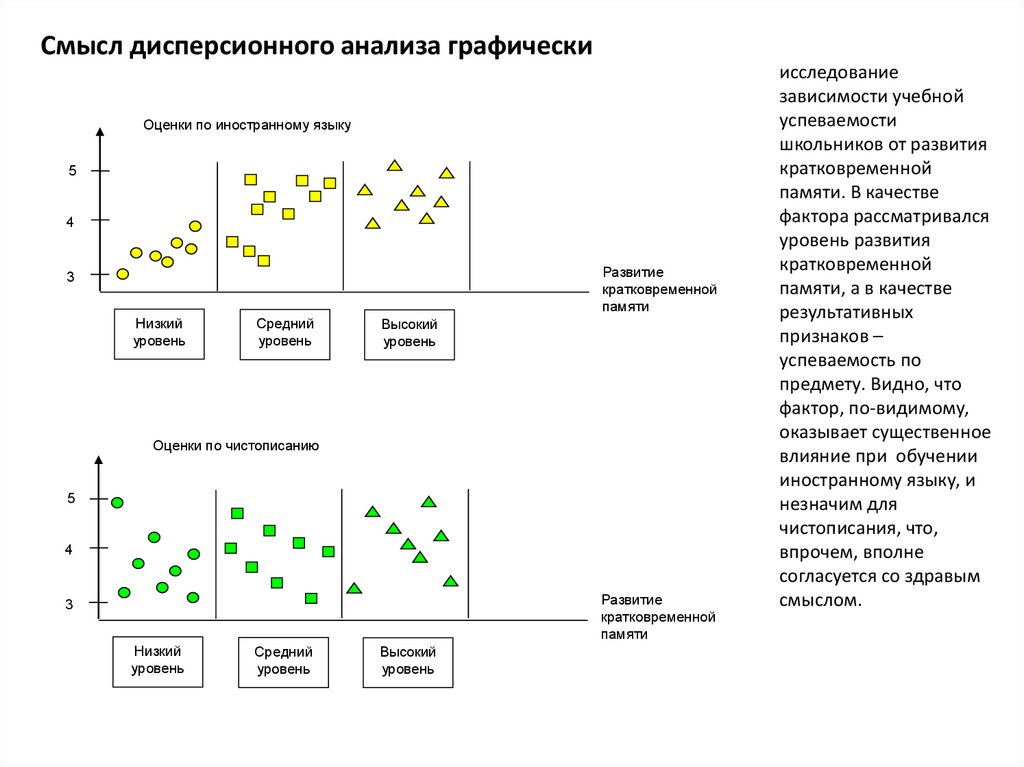
Смысл дисперсионного анализа графическиОценки по иностранному языку
5
4
Развитие
кратковременной
памяти
3
Низкий
уровень
Средний
уровень
Высокий
уровень
Оценки по чистописанию
5
4
Развитие
кратковременной
памяти
3
Низкий
уровень
Средний
уровень
Высокий
уровень
исследование
зависимости учебной
успеваемости
школьников от развития
кратковременной
памяти. В качестве
фактора рассматривался
уровень развития
кратковременной
памяти, а в качестве
результативных
признаков –
успеваемость по
предмету. Видно, что
фактор, по-видимому,
оказывает существенное
влияние при обучении
иностранному языку, и
незначим для
чистописания, что,
впрочем, вполне
согласуется со здравым
смыслом.
12.
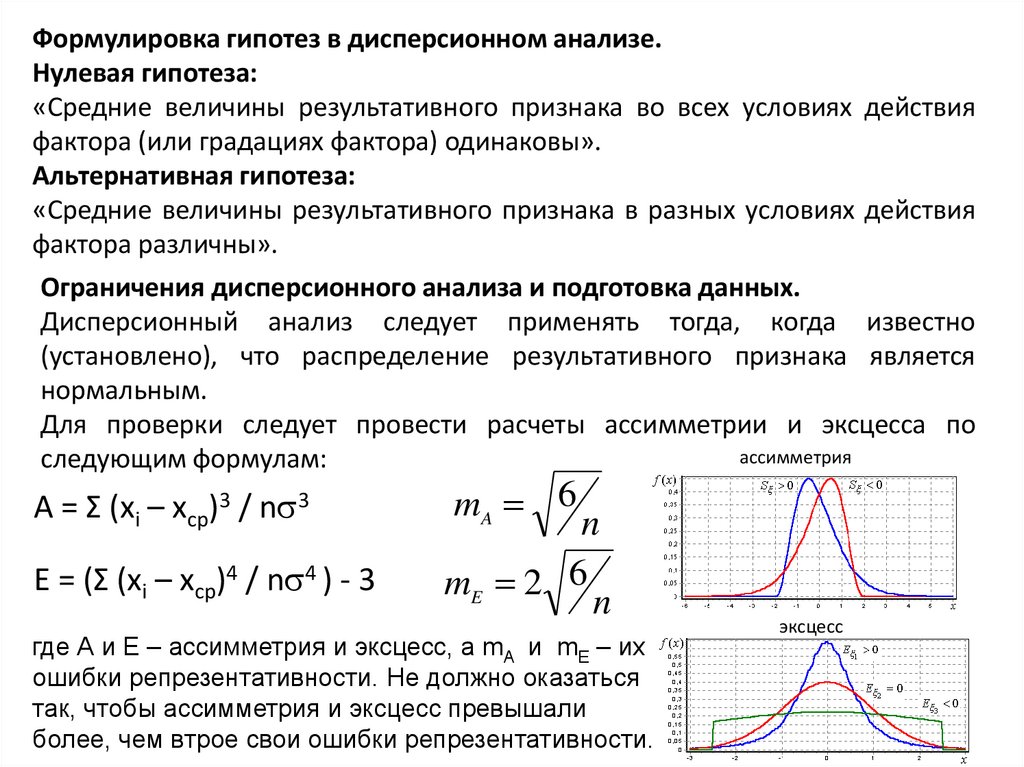
Формулировка гипотез в дисперсионном анализе.Нулевая гипотеза:
«Средние величины результативного признака во всех условиях действия
фактора (или градациях фактора) одинаковы».
Альтернативная гипотеза:
«Средние величины результативного признака в разных условиях действия
фактора различны».
Ограничения дисперсионного анализа и подготовка данных.
Дисперсионный анализ следует применять тогда, когда известно
(установлено), что распределение результативного признака является
нормальным.
Для проверки следует провести расчеты ассимметрии и эксцесса по
ассимметрия
следующим формулам:
A = Σ (xi – xср)3 / n 3
E = (Σ (xi – xср)4 / n 4 ) - 3
mA 6
n
mE 2 6
n
где А и Е – ассимметрия и эксцесс, а mA и mE – их
ошибки репрезентативности. Не должно оказаться
так, чтобы ассимметрия и эксцесс превышали
более, чем втрое свои ошибки репрезентативности.
эксцесс
13.
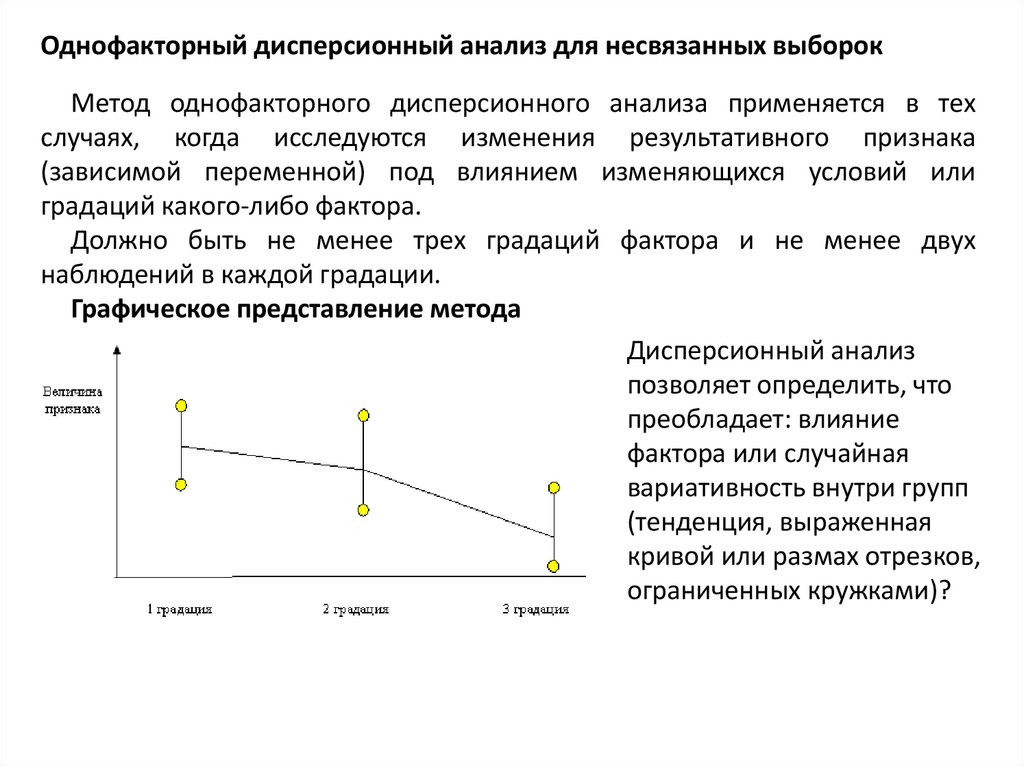
Однофакторный дисперсионный анализ для несвязанных выборокМетод однофакторного дисперсионного анализа применяется в тех
случаях, когда исследуются изменения результативного признака
(зависимой переменной) под влиянием изменяющихся условий или
градаций какого-либо фактора.
Должно быть не менее трех градаций фактора и не менее двух
наблюдений в каждой градации.
Графическое представление метода
Дисперсионный анализ
позволяет определить, что
преобладает: влияние
фактора или случайная
вариативность внутри групп
(тенденция, выраженная
кривой или размах отрезков,
ограниченных кружками)?
14.
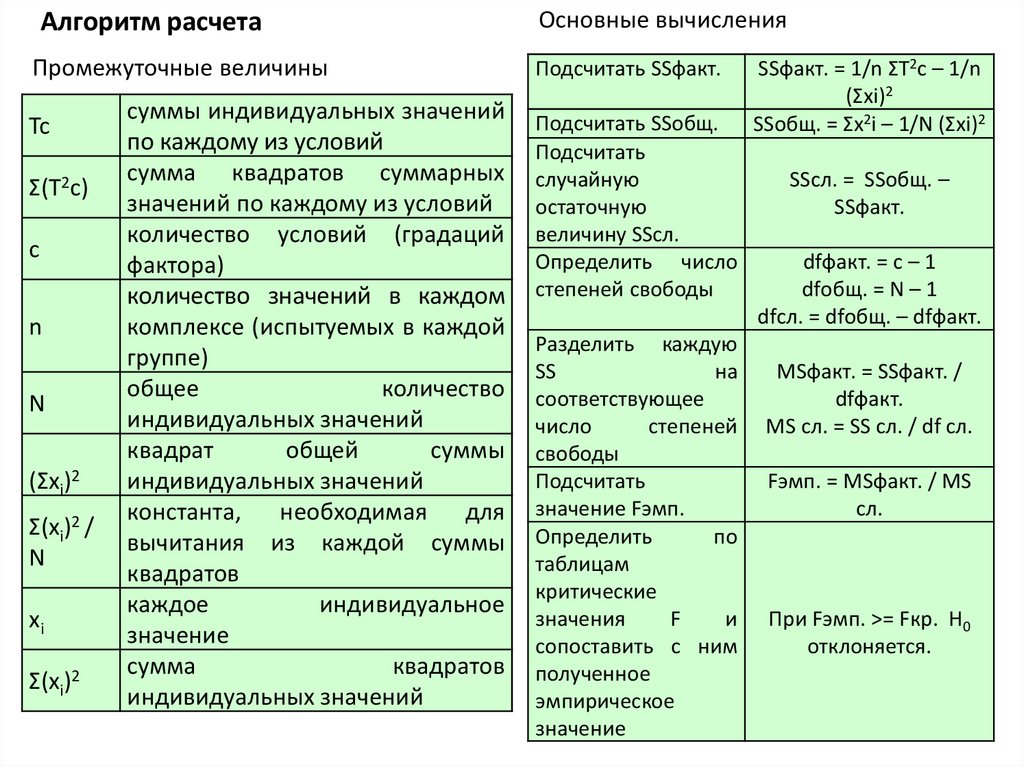
Алгоритм расчетаОсновные вычисления
Промежуточные величины
Подсчитать SSфакт.
Tc
Σ(T2c)
с
n
N
(Σxi)2
Σ(xi)2 /
N
xi
Σ(xi)2
суммы индивидуальных значений
по каждому из условий
сумма квадратов суммарных
значений по каждому из условий
количество условий (градаций
фактора)
количество значений в каждом
комплексе (испытуемых в каждой
группе)
общее
количество
индивидуальных значений
квадрат
общей
суммы
индивидуальных значений
константа, необходимая для
вычитания из каждой суммы
квадратов
каждое
индивидуальное
значение
сумма
квадратов
индивидуальных значений
Подсчитать SSобщ.
Подсчитать
случайную
остаточную
величину SSсл.
Определить число
степеней свободы
Разделить каждую
SS
на
соответствующее
число
степеней
свободы
Подсчитать
значение Fэмп.
Определить
по
таблицам
критические
значения
F
и
сопоставить с ним
полученное
эмпирическое
значение
SSфакт. = 1/n ΣT2c – 1/n
(Σxi)2
SSобщ. = Σx2i – 1/N (Σxi)2
SSсл. = SSобщ. –
SSфакт.
dfфакт. = с – 1
dfобщ. = N – 1
dfсл. = dfобщ. – dfфакт.
MSфакт. = SSфакт. /
dfфакт.
MS сл. = SS сл. / df сл.
Fэмп. = MSфакт. / MS
сл.
При Fэмп. >= Fкр. H0
отклоняется.
15.
Однофакторный дисперсионный анализ для связанных выборокМетод применяется в тех случаях, когда исследуется влияние разных
условий действия фактора (градаций фактора) на одну и ту же выборку.
(Одни и те же респонденты (испытуемые) в разных условиях.)
Условий (градаций) должно быть не менее трех. Индивидуальных значений
по каждому условию должно быть не менее двух.
В этом случае различия могут быть вызваны не только влиянием фактора, но
и индивидуальными различиями между респондентами.
В расчеты вводятся дополнительные компоненты – суммы квадратов сумм
индивидуальных значений.
16.
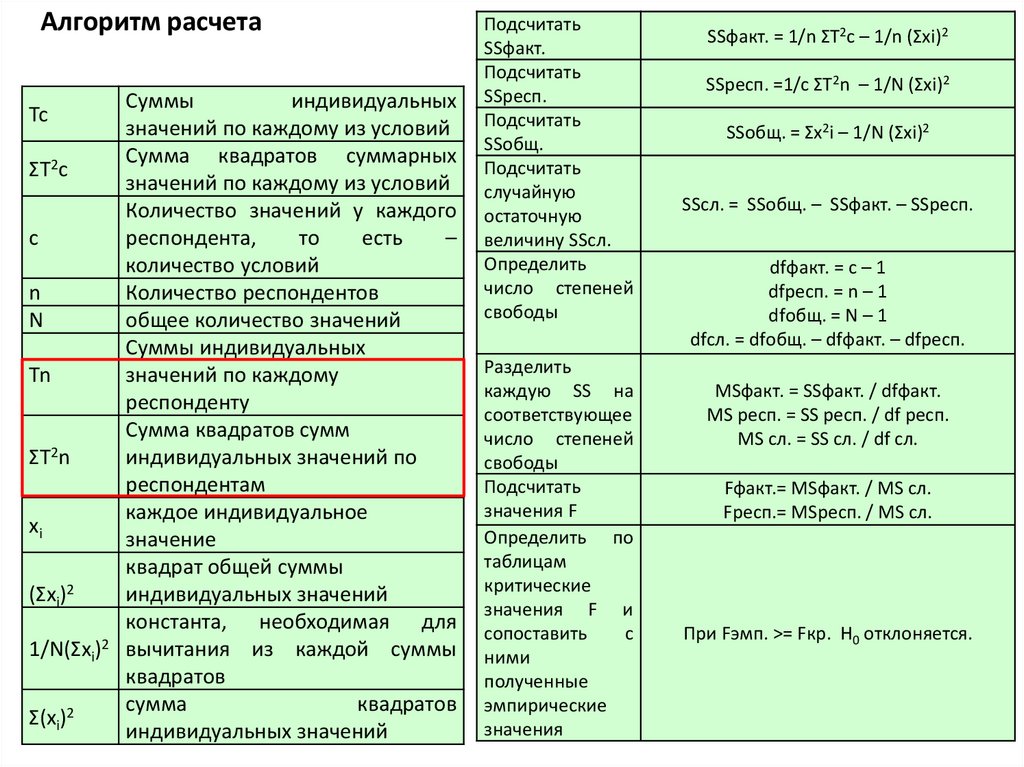
Алгоритм расчетаTc
ΣT2c
с
n
N
Tn
ΣT2n
xi
(Σxi)2
1/N(Σxi)2
Σ(xi)2
Суммы
индивидуальных
значений по каждому из условий
Сумма квадратов суммарных
значений по каждому из условий
Количество значений у каждого
респондента,
то
есть
–
количество условий
Количество респондентов
общее количество значений
Суммы индивидуальных
значений по каждому
респонденту
Сумма квадратов сумм
индивидуальных значений по
респондентам
каждое индивидуальное
значение
квадрат общей суммы
индивидуальных значений
константа, необходимая для
вычитания из каждой суммы
квадратов
сумма
квадратов
индивидуальных значений
Подсчитать
SSфакт.
Подсчитать
SSресп.
Подсчитать
SSобщ.
Подсчитать
случайную
остаточную
величину SSсл.
Определить
число степеней
свободы
Разделить
каждую SS на
соответствующее
число степеней
свободы
Подсчитать
значения F
Определить по
таблицам
критические
значения F и
сопоставить
с
ними
полученные
эмпирические
значения
SSфакт. = 1/n ΣT2c – 1/n (Σxi)2
SSресп. =1/c ΣT2n – 1/N (Σxi)2
SSобщ. = Σx2i – 1/N (Σxi)2
SSсл. = SSобщ. – SSфакт. – SSресп.
dfфакт. = с – 1
dfресп. = n – 1
dfобщ. = N – 1
dfсл. = dfобщ. – dfфакт. – dfресп.
MSфакт. = SSфакт. / dfфакт.
MS респ. = SS респ. / df респ.
MS сл. = SS сл. / df сл.
Fфакт.= MSфакт. / MS сл.
Fресп.= MSресп. / MS сл.
При Fэмп. >= Fкр. H0 отклоняется.
17.
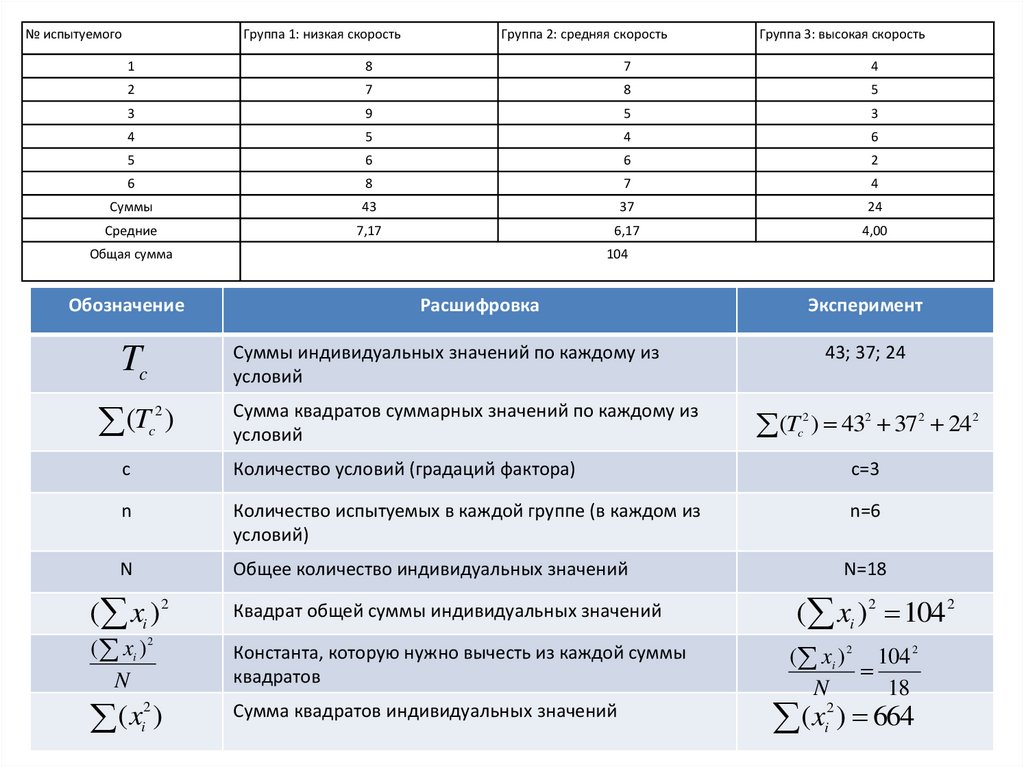
Пример решенияТри различные группы из шести испытуемых получили списки из десяти слов.
Первой группе слова предъявлялись с низкой скоростью -1 слово в 5 секунд,
второй группе со средней скоростью - 1 слово в 2 секунды, и третьей группе с
большой скоростью - 1 слово в секунду. Было предсказано, что показатели
воспроизведения будут зависеть от скорости предъявления слов
№ испытуемого
Группа 1:
низкая скорость
1
2
3
4
5
6
Суммы
Средние
Общая сумма
8
7
9
5
6
8
43
7,17
Группа 2:
Группа 3:
средняя скорость высокая скорость
7
8
5
4
6
7
37
6,17
104
4
5
3
6
2
4
24
4,00
18.
№ испытуемогоГруппа 1: низкая скорость
Группа 2: средняя скорость
Группа 3: высокая скорость
1
8
7
4
2
7
8
5
3
9
5
3
4
5
4
6
5
6
6
2
6
8
7
4
Суммы
43
37
24
Средние
7,17
6,17
4,00
Общая сумма
Обозначение
104
Расшифровка
Эксперимент
Суммы индивидуальных значений по каждому из
условий
Tc
(T )
2
c
Сумма квадратов суммарных значений по каждому из
условий
43; 37; 24
(T ) 43 37 24
2
c
2
c
Количество условий (градаций фактора)
c=3
n
Количество испытуемых в каждой группе (в каждом из
условий)
n=6
N
Общее количество индивидуальных значений
N=18
( xi )2
( x )
2
i
N
2
(
x
i)
2
Квадрат общей суммы индивидуальных значений
( xi )2 104 2
Константа, которую нужно вычесть из каждой суммы
квадратов
( xi ) 2 104 2
N
18
Сумма квадратов индивидуальных значений
( x ) 664
2
i
2
19.
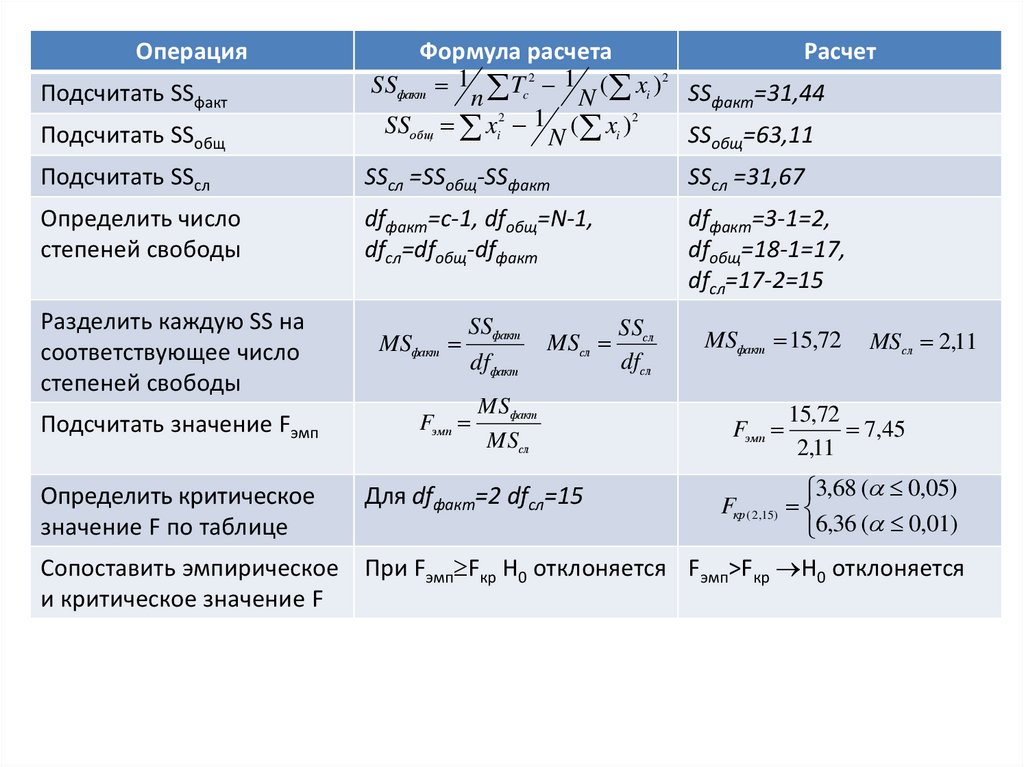
ОперацияПодсчитать SSобщ
Формула расчета
Расчет
SSфакт 1 Tc2 1 ( xi ) 2 SS
n
N
факт=31,44
2
2
SSобщ xi 1 ( xi )
SSобщ=63,11
N
Подсчитать SSсл
SSсл =SSобщ-SSфакт
SSсл =31,67
Определить число
степеней свободы
dfфакт=с-1, dfобщ=N-1,
dfсл=dfобщ-dfфакт
dfфакт=3-1=2,
dfобщ=18-1=17,
dfсл=17-2=15
Разделить каждую SS на
соответствующее число
степеней свободы
MSфакт
Подсчитать значение Fэмп
Fэм п
Подсчитать SSфакт
Определить критическое
значение F по таблице
SSфакт
dfфакт
MSсл
MSфакт
MSсл
Для dfфакт=2 dfсл=15
SSсл
dfсл
MSфакт 15,72
Fэмп
MS сл 2,11
15,72
7,45
2,11
3,68 ( 0,05)
Fкр ( 2,15)
6,36 ( 0,01)
Сопоставить эмпирическое При Fэмп Fкр H0 отклоняется Fэмп>Fкр H0 отклоняется
и критическое значение F
20.
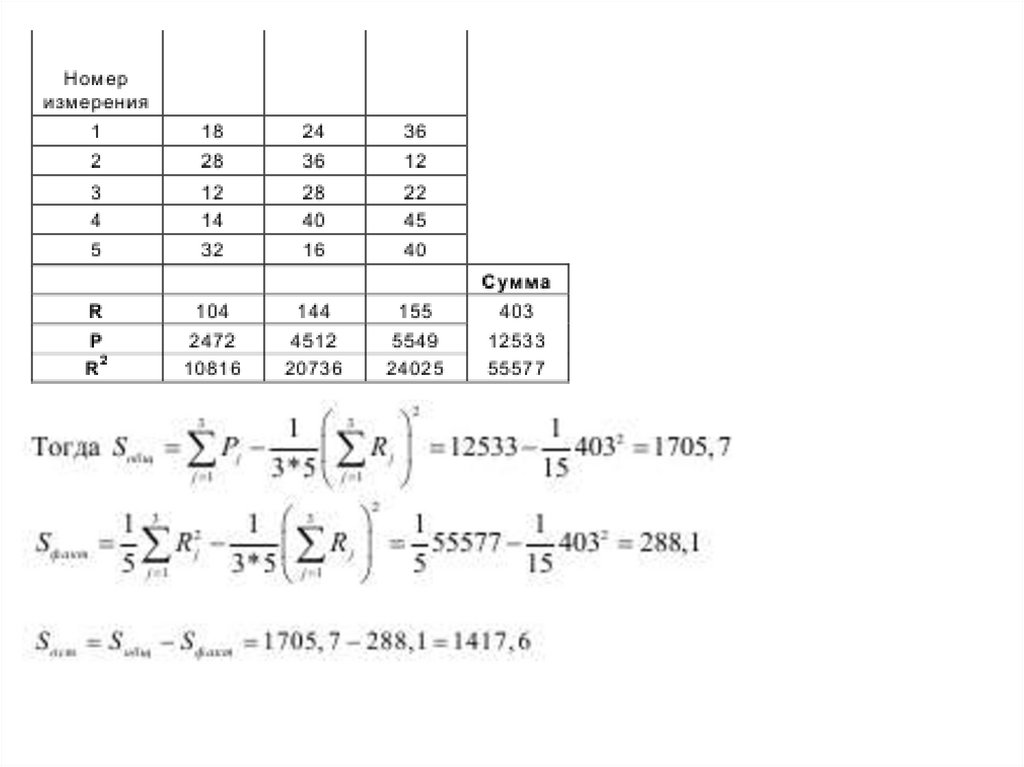
ЗАДАНИЕ. При уровне значимости α =0, 05 методом дисперсионного анализапроверить нулевую гипотезу о влиянии фактора на качество объекта на основании
пяти измерений для трех уровней фактора Ф1 – Ф3