













 законом и вероятностью есть внутренняя зависимость")

")







![Эта методика предусматривает решение следующих задач [49. С. 51]:](https://cf.ppt-online.org/files/slide/b/BEM9SDpGkTZ47hnXgRd6w31cxt8lvj0VUONm2Y/slide-24.jpg "Эта методика предусматривает решение следующих задач [49. С. 51]:")


")


")
")


.")
 выборка")
 выборка")

")













 Лингвистика
ЛингвистикаПохожие презентации:










Понятие и сущность лингвостатистического анализа. Ключевые понятия квантитативной лингвистики
1. Квантитативная лингвистика Лекция 2
ПОНЯТИЕ И СУЩНОСТЬЛИНГВОСТАТИСТИЧЕСКОГО
АНАЛИЗА.
КЛЮЧЕВЫЕ ПОНЯТИЯ
КВАНТИТАТИВНОЙ
ЛИНГВИСТИКИ
2. 2.1. Условия успешного осуществления лингвостатистического анализа
• Основная задача: получение достоверной(объективной) информации об изучаемых
явлениях
целесообразно проводить
лингвостатистический анализ или
статистический анализ языковых структур,
используя метод статистического и
вероятностного моделирования
• !!! важно правильно установить, что
считать, зачем считать и как считать
3. Что считать?
• Определение единицы лингвостатистическогоисследования
• союз статистики с традиционными методиками
качественного анализа языка
• Статистика (опираясь на результаты уже
осуществленного лингвистами качественного
анализа языковых элементов) показывает
закономерности их функционирования и развития и
дает основу для качественных оценок уже на новом
уровне исследования.
4. А.М. Агапов отмечает:
• существует два способа выраженияинформации об объективной реальности
(описательный и количественный), которые
сами по себе могут характеризовать лишь
видимые черты и свойства исследуемых
объектов, но не их внутреннюю, чаще всего
скрытую суть.
• суть раскрывается в результате сущностносодержательного, качественного анализа на
основе описательной или количественной
информации
5. Зачем считать?
• типы лингвистических задач, решаемых набазе статистики, возможности статистики в
разных областях языковой структуры и на
разных ступенях исследовательской
абстракции от конкретного языкового или
речевого материала
6. Л.А. Турыгина примеры возможных целевых вопросов при подготовке к лингвостатистическому исследованию
1. Какие задачи можно и должно решать при помощистатистической методики в области фонетики языка и звуковой
организации речи?
2. Есть ли уверенность в том, что статистика даст положительные
результаты в изучении лексики и лексической семантики?
3. Как очерчивается круг главных задач статистического изучения
морфологии и синтаксиса?
4. Возможно ли применение статистики в исследовании языковых
и речевых стилей?
5. Как статистически подойти к вопросам речевой культуры и
возможны ли объективные, статистические оценки таких
качеств речи, как богатство, разнообразие, выразительность и
т.д.?
6. Каковы углы статистического зрения на проблемы истории
языка?
7. Как считать?
• знакомство исследователя с минимальнонеобходимыми для этого статистическимиинструментами
8. 2.2. Понятие статистического закона и вероятности
• понятия «статистический закон» и«вероятность».
• Толковый переводоведческий словарь:
«статистический закон — выраженная в
количественных показателях вероятностная
зависимость между изучаемыми
явлениями» [47]
9. А.Н. Головин в своей книге «Язык и статистика».
все сложные и очень сложные системы(структуры) подчиняются в своем
функционировании и развитии статистическим
законам. Очень часто в действительности то
или иное явление изменяется (функционально
или генетически) под влиянием многих
воздействий (причин) одновременно, причем
эти многие воздействия меняют в некоторых
пределах равнодействующую величину
совокупного влияния. Но равнодействующая,
все же, определена в границах своих
колебаний и подчинена закону [18].
10. Пример
• подбрасывание игрального кубика• Если подбросим игральный кубик 600 раз, то
каждая его сторона выпадет приблизительно по 100
раз, с некоторыми отклонениями от этого
идеального случая.
• действует одна и та же совокупность причин,
влияний, среди которых вес подбрасываемого
предмета, его форма, степень однородности его
физической структуры, сопротивление воздуха,
высота подбрасываний, движение руки человека и
т.д.
11.
• Таким образом, равнодействующая величинасовокупного влияния многих воздействий все время
колеблется, но эти колебания случайны и не
выходят за некоторые небольшие пределы.
• Причем, чем больше отклонение от идеального
случая, тем реже оно встречается. А это означает,
что в то время как сами отклонения в величине
совокупного влияния возникают случайно, т.е.
вследствие не учитываемого для каждого
отдельного подбрасывания изменения в сочетании
многих воздействий, то величина этих отклонений
подчинена определенному статистическому
закону, который может быть установлен и описан с
помощью математики.
12.
по нескольким пробам, выборкам
можно судить о той большой совокупности
явлений, которая нас интересует. Построив
некоторую гипотезу о действии того или
иного статистического закона, мы можем,
если гипотеза имеет обоснование, говорить
о вероятности изучаемого явления или
«события».
13.
• В толковом переводоведческомсловаре:
«вероятность» или «вероятностная
мера» — численная мера возможности
наступления некоторого события [47].
Таким образом, в общем смысле
вероятность может пониматься как доля
изучаемого явления в некотором ряду
явлений, ожидаемая на основе гипотезы
или предшествующего опыта.
14. Вероятность
• Измеряется вероятность отношением числапоявлений интересующего нас события в
опыте к числу всех событий нашего опыта.
• где A — исследуемое событие;
• P — вероятность его наступления;
• m — количество случаев наступления
события А;
• n — количество всех наступивших событий.
15. Между статистическим (вероятностным) законом и вероятностью есть внутренняя зависимость
–– сама вероятность закономерна;–– действие изучаемого закона как раз и
выражается в сохранении определенной
вероятности;
–– изменение вероятности будет говорить и
об изменении статистического закона.
16.
если мы, изучая методами
статистики язык и речь, можем какимлибо образом обнаружить вероятность
изучаемых фактов и установить,
сохраняется или нарушается эта
вероятность, то мы тем самым получаем
объективное свидетельство действия
некоторых законов в функционировании и
развитии языка, а, следовательно, можем
прогнозировать сохранение и изменение
этих законов.
17. Л.А. Турыгина (методика)
1) формулирование цели исследования;2) определение единицы анализа или
единицы счета;
3) методика сбора информации;
4) вопрос о представительности
(репрезентативности) выборки;
5) вопрос о рациональном объеме выборки.
18. 2.3. Понятие цели и единицы лингвостатистического анализа
• ЯЗЫКОЗНАНИЕ: единицей анализа станетлингвостатистическая, языковая единица.
• Цель статистического анализа языковых
структур: исследование совокупности
однородных лингвистических объектов
(лингвистических единиц), обладающих
признаками, которые составляют предмет
проводимого анализа [49. С. 42].
19. В зависимости от цели исследования лингвистическими единицами могут быть
буквы,
фонемы,
морфемы,
словоформы,
слова,
словосочетания,
предложения,
текст,
печатный знак и т.п.
в квантитативной лингвистике: единицы
счета.
20. Единицы анализа
• В период становленияквантитативной
лингвистики
обращалось внимание
на вычисления:
– отношений числа
гласных к числу
согласных в тексте,
– определение числа
фонем в слоге, слове.
• В настоящее время
объектом
пристального
внимания ученых
лингвистов является:
– лексика
– синтаксис
21. вопрос о границах единицы
• Важно знать принадлежит лилингвистическая единица к той или иной
категории.
– Например, при работе со звуками важно
решить, считать ли отдельными звуками
аллофоны (вариант фонемы, обусловленный
конкретным фонетическим окружением) или
только фонемы (минимальная
смыслоразличительная единица языка).
22. Рассмотрим специфику лексико-статистических исследований
Рассмотрим специфику лексикостатистических исследований• массовое статистическое обследование
лингвистических единиц может быть
осуществлено только на базе формальной
процедуры (А.М. Агапов)
– Например, слово — сумма семантически и
грамматически связанных между собой
словоформ; лемма — словарная словоформа.
Словоупотребление является единицей текста
(речи), слово — единицей словаря (язык).
23. 2.4. Методика сбора информации для лингвостатистического анализа
• Первичным материалом, информацией влингвистической статистике является текст,
рассматриваемый как последовательность
лингвистических единиц заданного уровня: букв
или фонем, морфов или морфем, словоформ или
лексем, словосочетаний, предложений.
• Изучаются: количественные характеристики
лингвистических форм — их употребительность,
совместная встречаемость, законы
распределения в тексте, их физические размеры
24.
описываются свойства текста,
формулируются гипотезы о механизмах его
образования и устройстве системы языка
• Следовательно, в случае лингвостатистических
исследований решение проблемы выбора
методики сбора информации сводится к решению
проблемы выбора методики сбора или подбора
текстов.
25. Эта методика предусматривает решение следующих задач [49. С. 51]:
• 1) качественное и количественное распределениематериала по темам, подтемам, разделам (обычно
подсказывается композицией и содержанием
исследуемой совокупности текстов и консультацией со
специалистами (экспертами) данной области знаний);
• 2) установление хронологических рамок источников и
документов (связано с определением хронологических
рамок исследуемых документов; два требования:
• надежная репрезентация тематических выборок в
достаточно широком диапазоне времени
• представление материала, отображающего
основные свойства данного подъязыка).
26. ВАЖНО!
обратиться к вопросам опредставительности (репрезентативности) и
о рациональном объеме выборки
27. 2.5. Минимально-необходимые статистические инструменты: частота, генеральная и выборочная совокупности
• Основные понятия и категории вквантитативной лингвистике: частота,
средняя частота и отклонение от
средней частоты, а также генеральная
и выборочная совокупности
28. Частотой (f)
• какого-либо явления (факта, «события»)называют «число его появлений в
наблюдаемом отрезке действительности.
• Этим отрезком может быть любая
совокупность считаемых единиц и любая
среда, в которой появляются или находятся
факты, поддающиеся счету» [36. С. 12].
– НАПРИМЕР, таким отрезком может быть и текст
большего или меньшего объема, большей или
меньшей длины
– если мы возьмем текст длиной в 500 знаменательных
слов и насчитаем в нем 100 глаголов, это число мы и
назовем наблюдавшейся частотой глагола.
29.
• Подсчет частот лингвистических единицзачастую практически невозможен во всей
так называемой «генеральной
совокупности» (например, во всех текстах
поэтов Серебряного века, если изучается
статистически язык таковых), поэтому
используется метод выборочного
наблюдения.
30. Выборочное наблюдение
• — это «несплошное наблюдение, прикотором исследуется не вся совокупность
языковых единиц, называемая
генеральной лингвистической
совокупностью (ГЛС), а лишь
определенная часть, называемая
выборочной лингвистической
совокупностью (ВЛС) или выборкой» [18.
С. 25].
31. Выборочная лингвистическая совокупность (ВЛС)
• — это часть генеральной совокупности, аименно: объединенная общим признаком
совокупность языковых единиц, выбранная
из генеральной совокупности при
проведении выборочного наблюдения [34].
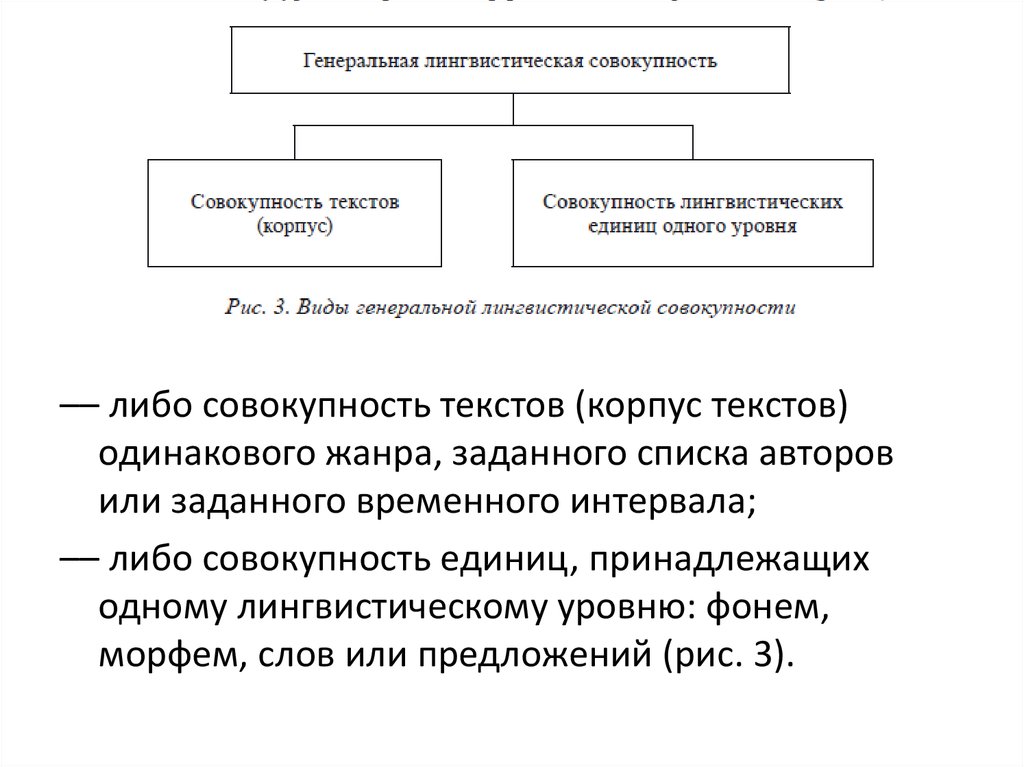
32. Генеральная лингвистическая совокупность (ГЛС)
- совокупность однородных лингвистическихобъектов (лингвистических единиц),
обладающих признаком/признаками,
составляющим/и предмет лингвистического
анализа [Там же].
33.
–– либо совокупность текстов (корпус текстов)одинакового жанра, заданного списка авторов
или заданного временного интервала;
–– либо совокупность единиц, принадлежащих
одному лингвистическому уровню: фонем,
морфем, слов или предложений (рис. 3).
34. Виды выборочных лингвистических совокупностей
• По объему содержащихся в выборкахединиц различают малые ,средние и
большие выборки.
• Выборка считается малой, если ее объем
менее 30 единиц, средней при объеме от
30 до 100 единиц и большой в объеме
более 100 единиц
35.
• По способу отбора выборки делятся надва типа:
–– вероятностные: случайная выборка
(простой случайный отбор), механическая
(систематическая) выборка, серийная
(гнездовая или кластерная) выборка,
типическая и др.;
–– невероятностные: квотная выборка, метод
снежного кома, стихийная выборка и т.д.
36. Случайная выборка (простой случайный отбор).
• Такая выборка предполагает однородностьгенеральной совокупности, одинаковую
вероятность доступности всех элементов,
наличие полного списка всех элементов.
• При отборе элементов, как правило,
используется таблица случайных чисел.
Данный вид реже других используется в
лингвистике.
37. Механическая (систематическая) выборка
• Разновидность случайной выборки,упорядоченная по какому-либо признаку.
Первый элемент отбирается случайно,
затем, с шагом n отбирается каждый k
элемент.
• Размер генеральной совокупности при этом
N = nk.
38. Серийная (гнездовая или кластерная) выборка
• При серийной выборке вся генеральнаясовокупность разбивается на серии, гнезда.
• Затем производят случайный или
механический отбор, единицами которого
выступают не сами объекты, а группы
(кластеры или гнезда).
• Объекты внутри групп обследуются
сплошняком.
39. Типическая выборка
• При типическом отборе в выборочном методегенеральная совокупность разбивается на группы,
однородные в качественном отношении, а затем
внутри каждой группы производится случайный
отбор.
• Типический отбор организовать сложнее, чем
случайный, так как необходимы определенные
знания о составе и свойствах генеральной
совокупности, но зато он даст более точные
результаты.
40. В лингвистике (А.М. Агапов)
• Типический отбор чаще всего сочетается ссерийным, например, текстовые базы
данных (корпуса), где количество серий,
извлекаемых из каждой тематической
группы, определяется удельным весом этой
группы в генеральной совокупности [2].
41. Список рекомендуемой литературы
1. Апресян Ю.Д. Идеи и методы современной структурнойлингвистики: краткий очерк. URL:
http://www.classes.ru/grammar/151.new-in-linguistics-4/source/
worddocuments/2. htm
2. Арапов М.В. Квантитативная лингвистика. М.: Наука, 1988. 211 с.
3. Головин Б.Н. Язык и статистика. М.: Высш. шк., 1977. 193 с.
4. Носенко А.И. Статистика для лингвистов. М.: Прогресс, 1983. 154 с.
5. Турыгина Л.А. Моделирование языковых структур средствами
вычисительной техники. М.: Высш. шк., 1988. 231 с.
6. StatSoft Inc. (2001). Электронный учебник по статистике. URL:
http://www.statsoft.ru/home/textbook/de- fault.htm
42. Практические задания Задание 1. Знакомство с работой программы «Wordstat»
1. Краткая справка.Программа «Wordstat» предназначена для
статистического анализа текстов.
Обработать можно любой текст,
предварительно сохранив его в формате txt
или html. В результате работы программы
пользователь получает список слов из
заданного текста с указанием частоты их
употребления в заданном тексте.
43. 2. На основе программы «Wordstat» определите частоту слов в данном тексте.
Дом, который построил ДжекВот дом,
Который построил Джек. А это пшеница,
Которая в темном чулане хранится В доме,
Который построил Джек.
(файл оставлю в VK)
44. Для решения подобных задач можно использовать следующий алгоритм.
• Для начала создайте файл в html формате с текстомодного автора (откройте «Блокнот»; загрузите нужный
текст; в меню «Файл» выберите «Сохранить как...» и
назовите файл text1.html) и сохраните файл в одной папке
с текстом. Затем откройте программу (wordstat.exe) и
скопируйте туда текст. Если вам необходимо обработать
несколько текстов одного автора, обработайте все файлы
по очереди (следите, чтобы была включена опция
«накапливать сумму результатов»). Автоматически
откроется файл (по умолчанию) под названием
wordstat.txt. В нем вы обнаружите результаты.
• Скачать: http://www.bestfree.ru/soft/obraz/word-count.php
45. Задание 2. Отработка процедуры лингвостатистического анализа.
• Выполните следующие действия напримере конкретного авторского текста,
обоснуйте полученные результаты.
Результаты представьте в виде файла
программы «MS Word».
46.
• 1. Пусть в нашем распоряжении оказалоськакое-то количество произведений одного
писателя (ваше исследование). Для
удобства упорядочьте их хронологически
(т.е. в порядке написания) и для краткости
назовите получившуюся генеральную
лингвистическую совокупность текстом
«данного автора». Таким образом, текст
автора (в данном определении) может
состоять из нескольких различных
произведений — романов, повестей,
рассказов и т.п
47.
• 2. Выделите из этого текста отдельныефрагменты (выборки одинакового объема или
выборочные лингвистические совокупности),
состоящие из одного и того же количества слов
(фиксированного заранее).
• Это количество слов естественно назвать
объемом выборки. Эти равновеликие (равные по
объему) выборки выделяйте из текста через
равные интервалы, т.е. таким образом, чтобы
каждые две соседние выборки были отделены
друг от друга примерно одним и тем же
количеством слов. Это «расстояние», интервал
между соседними выборками называют шагом.
Объем выборок и их шаг можно варьировать в
зависимости от поставленных задач.
48.
• Итак, последовательно двигаясь по текстуодного автора, через каждые, например, 10
страниц стандартного книжного текста
делайте выборки одного и того же объема,
например, в 2000 слов. Чем длиннее
исследуемый текст, тем больше выборок вы
сможете сделать. Для коротких
произведений число выборок будет
невелико, что усложняет анализ, делает
результаты неустойчивыми.
49.
• 3. Выберите какой-либо лингвистическийпараметр, например, частоту употребления
писателем предлога «в». Изучите
эволюцию этого параметра вдоль всего
текста, состоящего, быть может, из
нескольких отдельных произведений,
выстроенных нами в ряд. Для этого
сделайте последовательные выборки и
подсчитайте для каждой из них значение
интересующего вас лингвистического
параметра. В результате для каждой
выборки (порции) получим свое число. От
выборки к выборке оно будет меняться.
50.
4. Постройте график, отложив по горизонтали целыечисла 1, 2, 3 и т.д., являющиеся номерами
последовательных выборок, а по вертикали —
значения изучаемой нами лингвистической
характеристики. В результате эволюция данного
параметра вдоль всего исследуемого текста
изобразится некоторой ломаной линией. Она
наглядно показывает поведение исследуемого
параметра вдоль произведений данного автора.
Такие графики очень удобны при поиске
характерных черт данного автора — авторских
инвариантов.
51.
5*. Теперь задача может быть переформулирована так:требуется найти такой лингвистический параметр и такой
оптимальный объем выборок, чтобы соответствующие
им графики изображались бы для каждого автора
практически горизонтальными линиями (прямыми), т.е.
слабо колеблющимися ломаными. Другими словами, это
будет означать, что числовые значения найденного
инварианта мало отклоняются от своего среднего
значения вдоль произведений каждого отдельного автора.
Это явление — сглаживание ломаной кривой и ее
стремление к горизонтальной прямой — назовем
стабилизацией лингвистического параметра. Эта черта
может быть названа характерной чертой данного автора
или авторским инвариантом.
Такая исследовательская находка, возможно, ляжет в основу
вашего научного проекта.
52.
• Deadline: October 20, 2016 (15.00)• !!!Next lecture: OCTOBER 13 (next week!!!)