
















































 Информатика
ИнформатикаПохожие презентации:







")

 — Chapter 1 — Farid Feyzi")
Data storage and manipulation
1.
KARAGANDA STATE TECHNICAL UNIVERSITYDEPARTMENT OF INFORMATION TECHNOLOGY AND SECURITY
SLIDE LECTURE
SUBJECT: DATA STORAGE AND
MANIPULATION
DISCIPLINE: INFORMATION AND COMMUNICATION
TECHNOLOGIES
SENIOR LECTURER KLYUEVA E.G.
ASSOCIATE PROFESSOR, KAN O.A.
2.
1. Bases of database systems: concept, characteristic,architecture;
2. Data models;
3. Normalization;
4. Integrity constraint on data;
5. Fundamentals of SQL;
6. Parallel processing of data and their restoration;
7. Design and development of databases;
8. Technology of programming of ORM;
9. The distributed, parallel and heterogeneous databases.
3.
Databases and database technology are having a majorimpact on the growing use of computers.
It is fair to say that databases play a critical role in
almost all areas where computers are used, including
business, electronic commerce, engineering, medicine, law,
education, and library science, to name a few.
4.
A database is a collection of related data.By data, we mean known facts that can be recorded
and that have implicit meaning.
For example, consider the names, telephone numbers,
and addresses of the people you know. This is a collection
of related data with an implicit meaning and hence is a
database.
5.
A database has the following implicit properties:- a database represents some aspect of the real world,
sometimes called the miniworld or the universe of
discourse (DoD). Changes to the miniworld are reflected in
the database;
- a database is a logically coherent collection of data
with some inherent meaning. A random assortment of data
cannot correctly be referred to as a database;
- a database is designed, built, and populated with data
for a specific purpose.
6.
A database can be of any size and of varyingcomplexity.
A database may be generated and maintained manually
or it may be computerized. A computerized database may
be created and maintained either by a group of application
programs written specifically for that task or by a database
management system.
7.
A database management system (DBMS) is acollection of programs that enables users to create and
maintain a database.
The DBMS is hence a general-purpose software system
that facilitates the processes of defining, constructing,
manipulating, and sharing databases among various users
and applications.
8.
The database system contains not only the databaseitself but also a complete definition or description of the
DB structure and constraints.
This definition is stored in the DBMS catalog, which
contains information such as the structure of each file, the
type and storage format of each data item, and various
constraints on the data.
The information stored in the catalog is called metadata, and it describes the structure of the primary database.
9.
The architecture of DBMS packages has evolved fromthe early monolithic systems, where the whole DBMS
software package was one tightly integrated system, to the
modern DBMS packages that are modular in design, with a
client/server system architecture.
In a basic client/server DBMS architecture, the system
functionality is distributed between two types of modules.
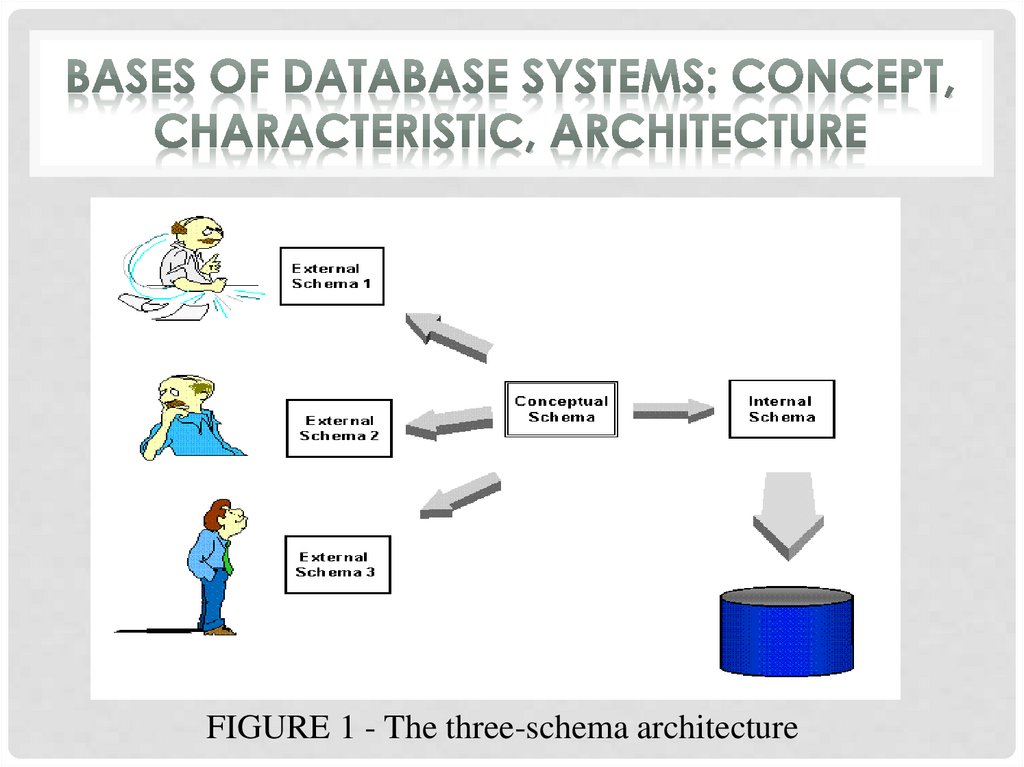
Now we specify an architecture for database systems,
called the three-schema architecture that was proposed
to help achieve and visualize these characteristics.
10.
FIGURE 1 - The three-schema architecture11.
By structure of a database, we mean the data types,relationships, and constraints that should hold for the data.
Most data models also include a set of basic operations
for specifying retrievals and updates on the database. In
addition to the basic operations provided by the data
model, it is becoming more common to include concepts in
the data model to specify the dynamic aspect or behavior
of a database application. This allows the database
designer to specify a set of valid userdefined operations
that arc allowed on the database objects.
12.
Common logical data models for databases include:- Hierarchical database model;
- Network model;
- Relational model;
- Post-relational database models;
- Object model;
- Multidimensional model.
13.
The hierarchical model organizes data into a tree-likestructure, where each record has a single parent or root.
Sibling records are sorted in a particular order. That order
is used as the physical order for storing the database.
This model is good for describing many real-world
relationships.
This model was primarily used by IBM’s Information
Management Systems in the 60s and 70s, but they are
rarely seen today due to certain operational inefficiencies.
14.
15.
The network model builds on the hierarchical modelby allowing many-to-many relationships between linked
records, implying multiple parent records. Based on
mathematical set theory, the model is constructed with sets
of related records. Each set consists of one owner or parent
record and one or more member or child records. A record
can be a member or child in multiple sets, allowing this
model to convey complex relationships.
It was most popular in the 70s after it was formally
defined by the Conference on Data Systems Languages
(CODASYL).
16.
17.
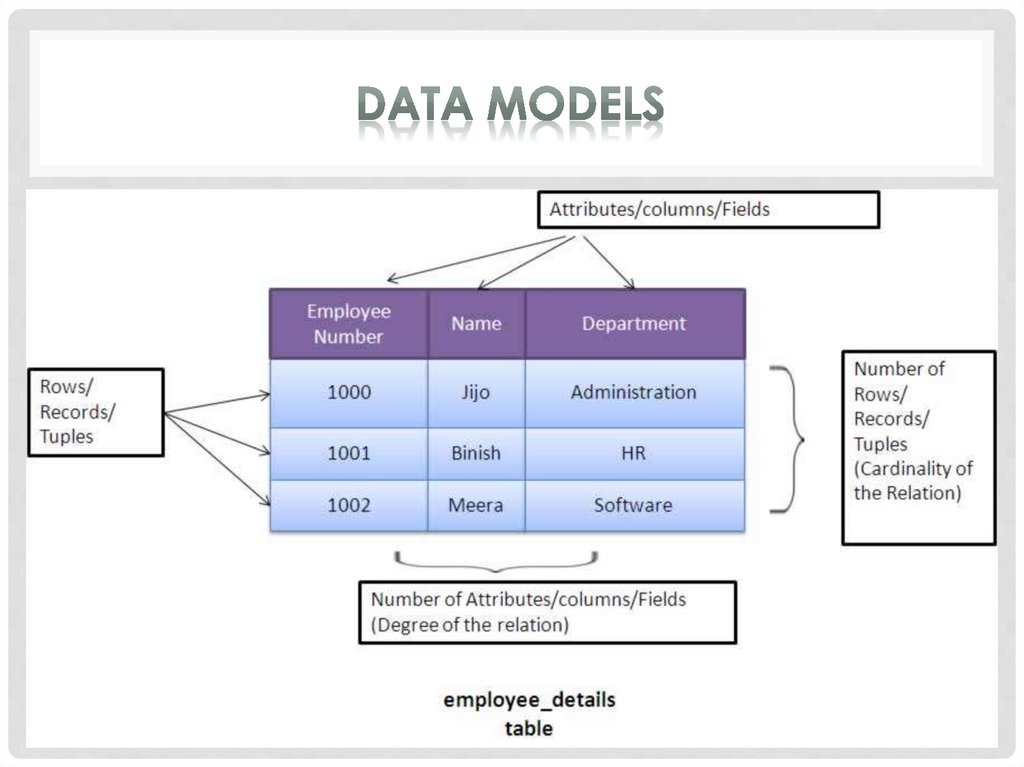
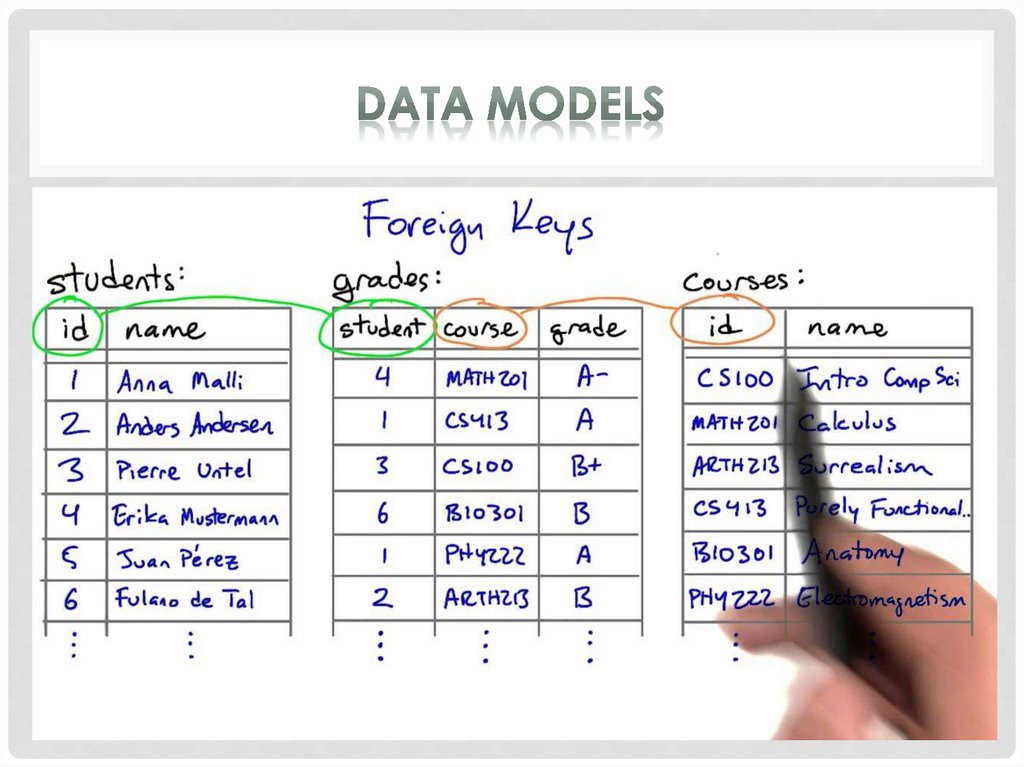
The most common model, the relational model sortsdata into tables, also known as relations, each of which
consists of columns and rows. Each column lists an
attribute of the entity in question, such as price, zip code,
or birth date. Together, the attributes in a relation are called
a domain. A particular attribute or combination of
attributes is chosen as a primary key that can be referred to
in other tables, when it’s called a foreign key.
Each row, also called a tuple, includes data about a
specific instance of the entity in question, such as a
particular employee.
18.
19.
The model also accounts for the types of relationshipsbetween those tables, including one-to-one, one-to-many,
and many-to-many relationships.
Within the database, tables can be normalized, or
brought to comply with normalization rules that make the
database flexible, adaptable, and scalable. When
normalized, each piece of data is atomic, or broken into the
smallest useful pieces.
Relational databases are typically written in Structured
Query Language (SQL). The model was introduced by E.F.
Codd in 1970.
20.
21.
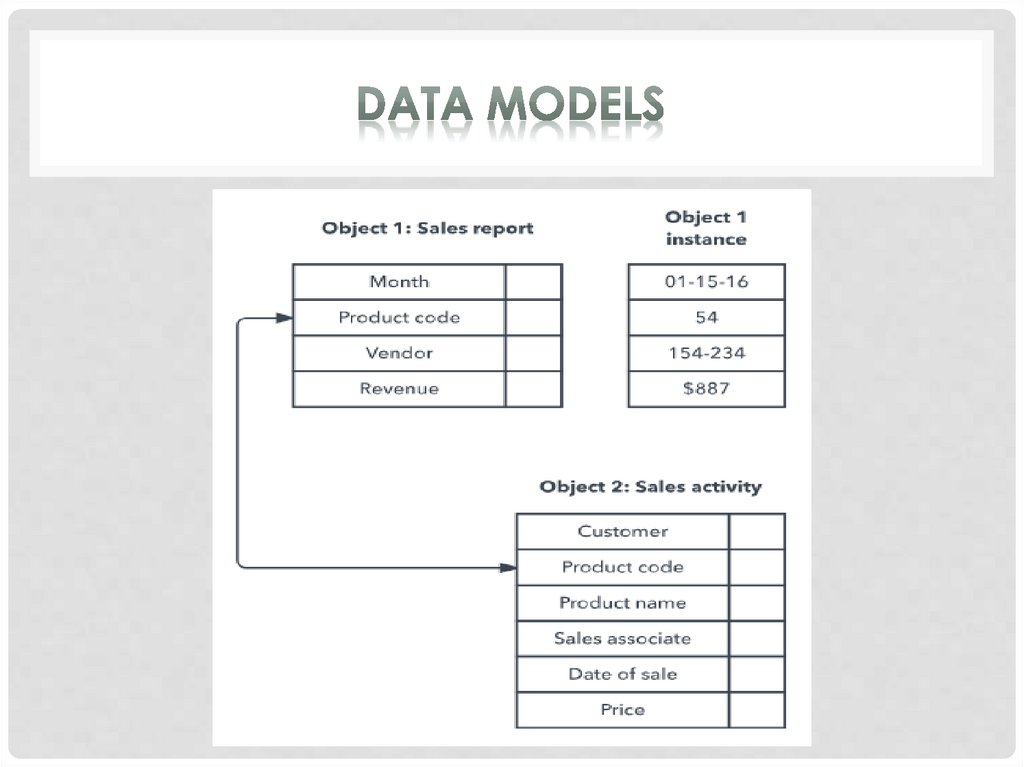
Object-oriented database model defines a database asa collection of objects, or reusable software elements, with
associated features and methods.
The object-oriented database model is the best known
post-relational database model, since it incorporates tables,
but isn’t limited to tables. Such models are also known as
hybrid database models. This models combines the
simplicity of the relational model with some of the
advanced functionality of the object-oriented database
model. In essence, it allows designers to incorporate
objects into the familiar table structure.
22.
23.
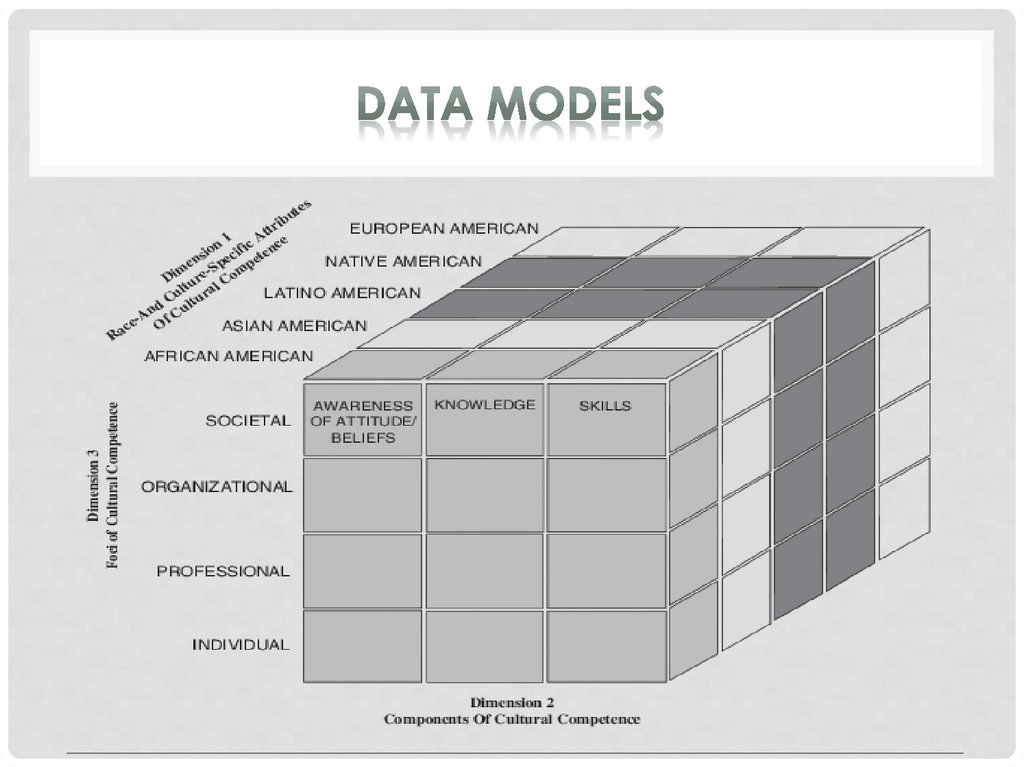
Multidimensional modelis a variation of the
relational model designed to facilitate improved analytical
processing. While the relational model is optimized for
online transaction processing (OLTP), this model is
designed for online analytical processing (OLAP).
Each cell in a dimensional database contains data about
the dimensions tracked by the database. Visually, it’s like a
collection of cubes, rather than two-dimensional tables.
24.
25.
Normalization is the process of efficiently organizingdata in a database.
There are two goals of the normalization process:
eliminating redundant data (for example, storing the same
data in more than one table) and ensuring data
dependencies make sense (only storing related data in a
table).
Both of these are worthy goals as they reduce the
amount of space a database consumes and ensure that data
is logically stored.
26.
The normalization process, as first proposed by Codd(1972), takes a relation schema through a series of tests to
"certify" whether it satisfies a certain normal form.
The database community has developed a series of
guidelines for ensuring that databases are normalized.
These are referred to as normal forms and are
numbered from one (the lowest form of normalization,
referred to as first normal form or 1NF) through five (fifth
normal form or 5NF). In practical applications, you'll often
see 1NF, 2NF, and 3NF along with the occasional 4NF.
Fifth normal form is very rarely seen.
27.
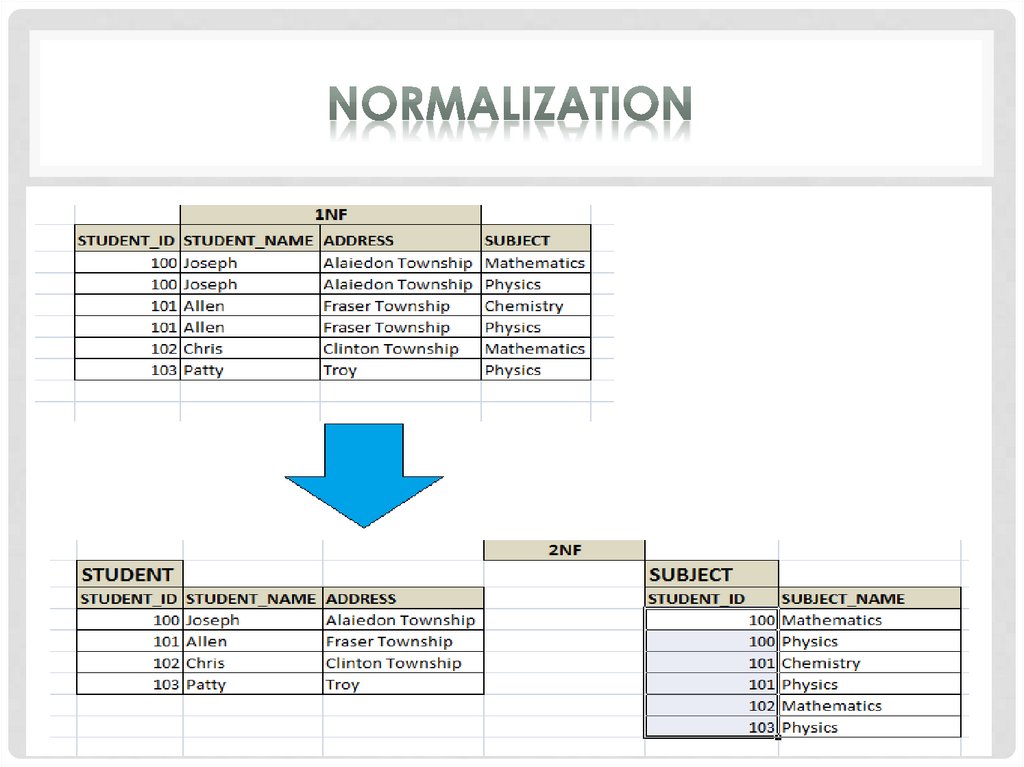
First normal form (1NF) sets the very basic rules foran organized database:
- eliminate duplicative columns from the same table;
- create separate tables for each group of related data
and identify each row with a unique column or set of
columns (the primary key).
28.
Second normal form (2NF) further addresses theconcept of removing duplicative data:
- meet all the requirements of the first normal form;
- remove subsets of data that apply to multiple rows of
a table and place them in separate tables;
- create relationships between these new tables and
their predecessors through the use of foreign keys.
29.
30.
Third normal form (3NF) goes one large step further:- meet all the requirements of the second normal form;
- remove columns that are not dependent upon the
primary key.
31.
The Boyce-Codd Normal Form, also referred to as the"third and half (3.5) normal form", adds one more
requirement:
- meet all the requirements of the third normal form;
- every determinant must be a candidate key.
32.
The fourth normal form (4NF) has one additionalrequirement:
- meet all the requirements of the third normal form;
- a relation is in 4NF if it has no multi-valued
dependencies.
33.
A database is said to be in the fifth normal form(5NF), if and only if:
- meet all the requirements of the fourth normal form;
- joining two or more decomposed table should not
lose records nor create new records.
34.
Constraints are the conditions forced on the columnsof the table to meet the data integrity.
There are the domain integrity, the entity integrity, the
referential integrity and the foreign key integrity
constraints.
35.
Domain integrity means the definition of a valid set ofvalues for an attribute. You define:
- data type;
- lenght or size;
- is null value allowed;
- is the value unique or not for an attribute.
You may also define the default value, the range
(values in between) and/or specific values for the attribute.
Some DBMS allow you to define the output format and/or
input mask for the attribute.
36.
The entity integrity constraint states that primary keyscan't be null. There must be a proper value in the primary
key field.
This is because the primary key value is used to
identify individual rows in a table. If there were null values
for primary keys, it would mean that we could not
indentify those rows.
37.
The referential integrity constraint is specified betweentwo tables and it is used to maintain the consistency among
rows between the two tables. The rules are:
1. You can't delete a record from a primary table if
matching records exist in a related table.
2. You can't change a primary key value in the primary
table if that record has related records.
3. You can't enter a value in the foreign key field of the
related table that doesn't exist in the primary key of the primary
table.
4. However, you can enter a Null value in the foreign key,
specifying that the records are unrelated.
38.
The most common query language used with therelational model is the Structured Query Language (SQL).
SQL defines the methods used to create and manipulate
relational databases on all major platforms.
SQL commands can be divided into two main
sublanguages.
The Data Definition Language (DDL) contains the
commands used to create and destroy databases and database
objects.
The Data Manipulation Language (DML) to insert,
retrieve and modify the data contained within it.
39.
The CREATE command can be used to establish eachof these databases on your platform. For example, the
command:
CREATE DATABASE employees
CREATE TABLE personal_info (first_name char(20)
not null, last_name char(20) not null, employee_id int not
null)
The USE command allows you to specify the database
you wish to work with within your DBMS.
USE employees
40.
The ALTER command allows you to make changes tothe structure of a table without deleting and recreating it:
ALTER TABLE personal_info
ADD salary money null
The DROP allows us to remove entire database objects
from our DBMS.
DROP TABLE personal_info
DROP DATABASE employees
41.
The INSERT command in SQL is used to add records toan existing table.
INSERT INTO personal_info
values('bart','simpson',12345,$45000)
The SELECT command allows database users to
retrieve the specific information they desire from an
operational database.
SELECT *
FROM personal_info
42.
The UPDATE command can be used to modifyinformation contained within a table, either in bulk or
individually.
UPDATE personal_info
SET salary = salary * 1.03
DELETE command is similar to that of the other DML
commands. The DELETE command with a WHERE clause
can be used to remove his record from the personal_info
table:
DELETE FROM personal_info
WHERE employee_id = 12345
43.
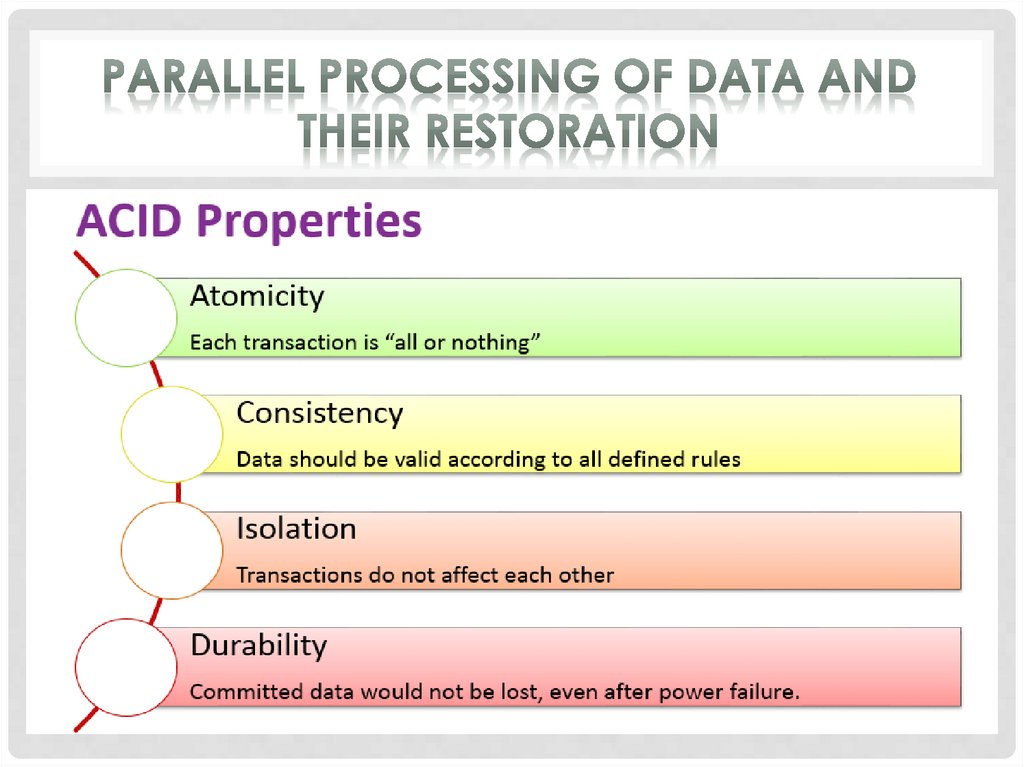
A transaction is a unit of work that you want to treat as"a whole". It has to either happen in full, or not at all.
A classical example is transferring money from one bank
account to another. To do that you have to first withdraw the
amount from the source account, and then deposit it to the
destination account. The operation has to succeed in full. If
you stop halfway, the money will be lost, and that is Very
Bad.
44.
In modern databases transactions also do some otherthings - like ensure that you can't access data that another
person has written halfway.
But the basic idea is the same - transactions are there to
ensure, that no matter what happens, the data you work with
will be in a sensible state.
They guarantee that there will NOT be a situation where
money is withdrawn from one account, but not deposited to
another.
45.
The effects of all the SQL statements in a transaction canbe either all committed (applied to the database) or all rolled
back (undone from the database).
46.
47.
When multiple transactions are being executed by theoperating system in a multiprogramming environment, there
are possibilities that instructions of one transactions are
interleaved with some other transaction.
Schedule − chronological execution sequence of a
transaction. A schedule can have many transactions in it,
each comprising of a number of instructions/tasks.
Serial Schedule − It is a schedule in which transactions
are aligned in such a way that one transaction is executed
first. When the first transaction completes its cycle, then the
next transaction is executed. Transactions are ordered one
after the other.
48.
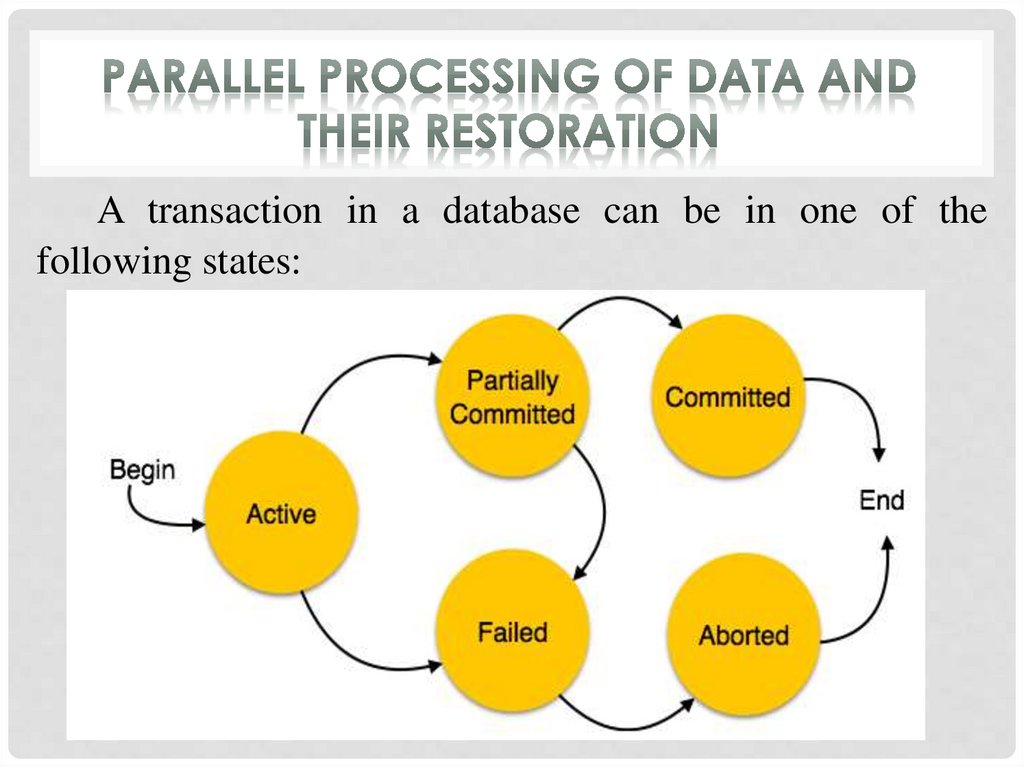
A transaction in a database can be in one of thefollowing states:
49.
Active − in this state, the transaction is being executed.This is the initial state of every transaction.
Partially Committed − when a transaction executes its
final operation, it is said to be in a partially committed state.
Failed − a transaction is said to be in a failed state if any
of the checks made by the database recovery system fails. A
failed transaction can no longer proceed further.
50.
Aborted − if any of the checks fails and the transactionhas reached a failed state, then the recovery manager rolls
back all its write operations on the database to bring the
database back to its original state where it was prior to the
execution of the transaction. Transactions in this state are
called aborted. The database recovery module can select one
of the two operations after a transaction aborts:
- re-start the transaction;
- kill the transaction.
Committed − if a transaction executes all its operations
successfully, it is said to be committed. All its effects are
now permanently established on the database system.
51.
52.
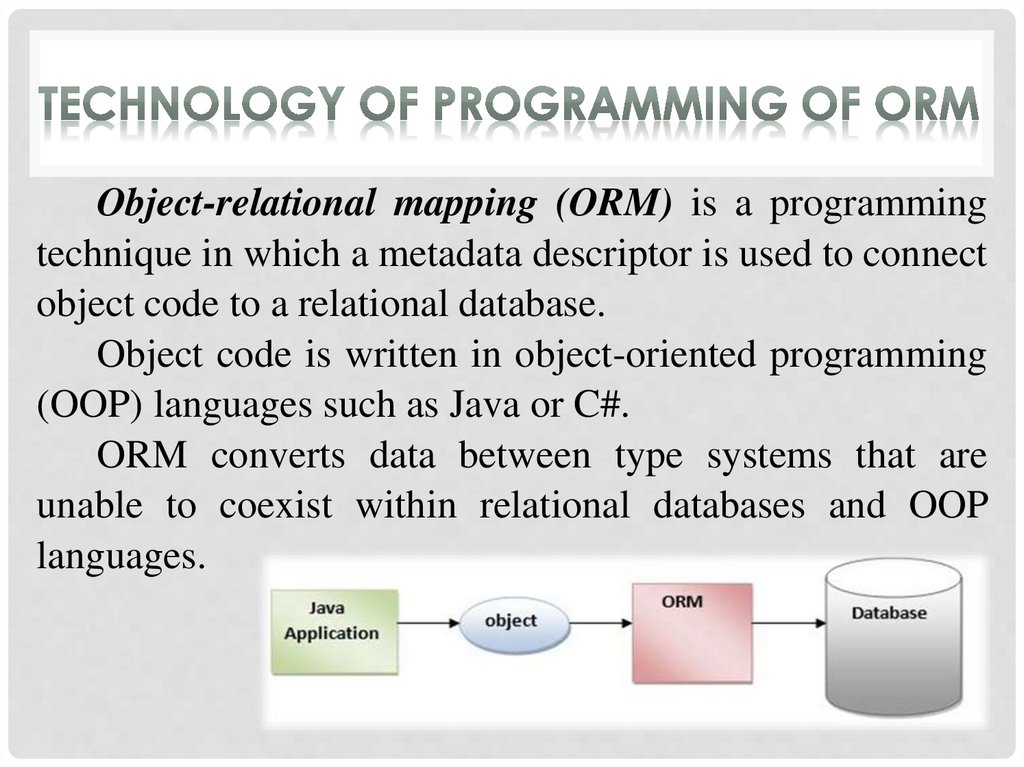
Object-relational mapping (ORM) is a programmingtechnique in which a metadata descriptor is used to connect
object code to a relational database.
Object code is written in object-oriented programming
(OOP) languages such as Java or C#.
ORM converts data between type systems that are
unable to coexist within relational databases and OOP
languages.
53.
Compared to traditional techniques of exchangebetween an object-oriented language and a relational
database, ORM often reduces the amount of code that
needs to be written.
Disadvantages of ORM tools generally stem from the
high level of abstraction obscuring what is actually
happening in the implementation code. Also, heavy
reliance on ORM software has been cited as a major factor
in producing poorly designed databases.
54.
Another approach is to use an object-oriented databasemanagement system (OODBMS) or document-oriented
databases such as native XML databases that provide more
flexibility in data modeling.
OODBMSs are databases designed specifically for
working with object-oriented values. Using an OODBMS
eliminates the need for converting data to and from its SQL
form, as the data is stored in its original object representation
and relationships are directly represented, rather than
requiring join tables/operations.
The equivalent of ORMs for Document-oriented
databases are called Object-Document Mappers (ODMs).
55.
A distributed database is a database in which storagedevices are not all attached to a common processor. It may
be stored in multiple computers, located in the same
physical location; or may be dispersed over a network of
interconnected computers.
Unlike parallel systems, in which the processors are
tightly coupled and constitute a single database system, a
distributed database system consists of loosely coupled
sites that share no physical components.
56.
Two processes ensure that the distributed databasesremain up-to-date and current: replication and duplication.
Replication involves using specialized software that
looks for changes in the distributive database. Once the
changes have been identified, the replication process makes
all the databases look the same.
Duplication basically identifies one database as a master
and then duplicates that database. The duplication process is
normally done at a set time after hours. This is to ensure that
each distributed location has the same data. In the
duplication process, users may change only the master
database. This ensures that local data will not be overwritten.
57.
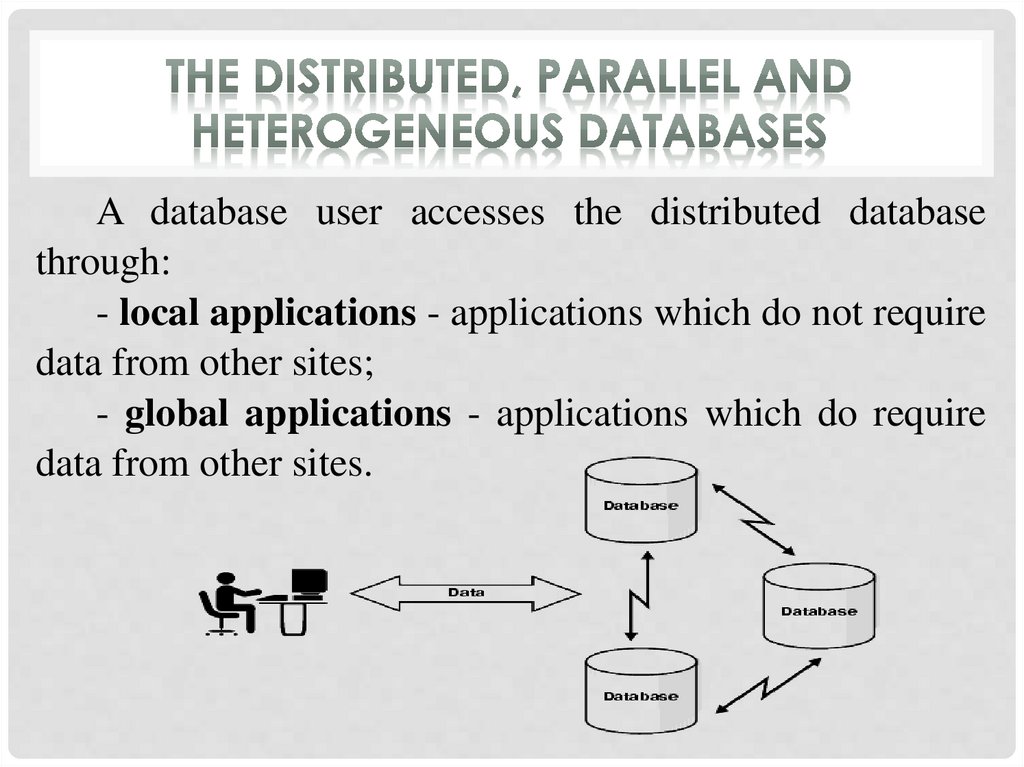
A database user accesses the distributed databasethrough:
- local applications - applications which do not require
data from other sites;
- global applications - applications which do require
data from other sites.
58.
A homogeneous distributed database has identicalsoftware and hardware running all databases instances, and
may appear through a single interface as if it were a single
database.
A heterogeneous distributed database may have
different hardware, operating systems, database
management systems, and even data models for different
databases.
59.
A parallel database system seeks to improveperformance through parallelization of various operations,
such as loading data, building indexes and evaluating
queries.
Although data may be stored in a distributed fashion,
the distribution is governed solely by performance
considerations.
Parallel databases improve processing and input/output
speeds by using multiple CPUs and disks in parallel.
60.
1. An Introduction to Database Systems by C.J. Date.2. Database Systems: The Complete Book by Jeffrey
D. Ullman, Jennifer Widom.
3.
Distributed
Database
Systems
(ebook)
by Chhanda Ray.
61.
1. What is the meant by thedatabase? What is the difference
between a database and a simple set
of data?
2. What is the database system?
3. What is the normalization?
4. What are the basic commands
of the SQL?
62.
THE LECTURE IS OVERTHANK YOU FOR ATTENTION