


























































 Информатика
ИнформатикаПохожие презентации:



")


")


")
Этапы обработки текста. Часть 1
1.
Этапы обработкитекста. Часть 1
Грацианова Татьяна Юрьевна
Ефремова Наталья Эрнестовна
2.
СодержаниеОсновные этапы обработки текста
Графематический анализ и сегментация текста
Примеры графематических анализаторов
Морфологический анализ и синтез
Словарные и бессловарные модели
Примеры морфологических анализаторов
Синтаксический анализ
Деревья составляющих и деревья
зависимостей
Домашнее задание
Информация для домашнего изучения
2
3.
Основные этапыобработки текста
Какие этапы обработки текста
Вы помните?
3
4.
Этапы обработки текста (1)1. Графематический анализ и сегментация –
предобработка текста
2. Морфологический анализ:
нормализация словоформ или их стемминг
определение морфологических характеристик
3. Постморфологический анализ: разрешение
морфологической неоднозначности (снятие омонимии)
1-3 – предсинтаксический этап (предсинтаксис)
4. Синтаксический анализ – построение
синтаксической структуры предложения
5. Семантический и прагматический анализ –
построение семантического представления текста и
определение его смысла
4
5.
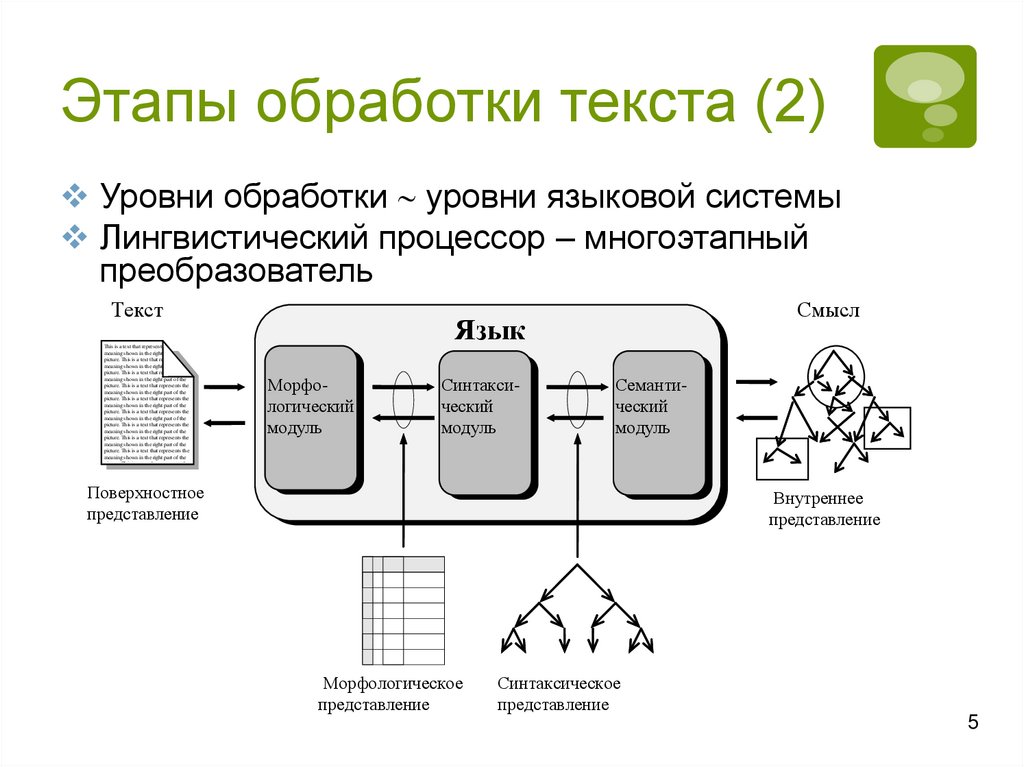
Этапы обработки текста (2)Уровни обработки уровни языковой системы
Лингвистический процессор – многоэтапный
преобразователь
Текст
This is a text that represents the
meaning shown in the right part of the
picture. This is a text that represents the
meaning shown in the right part of the
picture. This is a text that represents the
meaning shown in the right part of the
picture. This is a text that represents the
meaning shown in the right part of the
picture. This is a text that represents the
meaning shown in the right part of the
picture. This is a text that represents the
meaning shown in the right part of the
picture. This is a text that represents the
meaning shown in the right part of the
picture. This is a text that represents the
meaning shown in the right part of the
picture. This is a text that represents the
meaning shown in the right part of the
picture. This is a text that represents the
meaning shown in the right part of the
picture. This is a text that represents the
meaning shown in the right part of the
picture.
Смысл
Язык
Морфологический
модуль
Синтаксический
модуль
Семантический
модуль
Поверхностное
представление
Внутреннее
представление
Морфологическое
представление
Синтаксическое
представление
5
6.
Графематический анализ (ГА)Цель – выделение и классификация основных
единиц текста: слов, предложений, абзацев
Анализ уровня графем, посимвольная обработка
Графема – минимальная единица письменного
текста: буква, знак препинания и др. а, А, а, А, а
Близкое понятие – сегментация (segmentation),
т.е. разбиение текста на части (от символов до
разделов/глав)
Сегментация – более широкое понятие, но часто
используется как синоним
В случае обработки устной речи части
идентифицируются аудиально
6
7.
Сегментация нижнего уровня (low-level):Токенизация (tokenization) – выделение
минимальных лингвистически значимых
элементов текста (токенов); могут состоять из
нескольких графем
Разбиение текста на предложения
Сегментация высокого уровня (high-level):
Синтаксическая сегментация: выделение простых
предложений в составе сложного, выделение
синтаксических групп (именных, глагольных)
Макросинтаксический анализ: выделение
композиционных элементов (абзацев, заголовков,
разделов, сносок) и установление их иерархии
Используются сходные подходы
ГА в широком смысле
ГА в узком смысле
Виды сегментации
7
8.
Пример сложногопредложения (А. Милн)
Потом долгие годы он любил думать, что был в очень большой
опасности во время этого ужасного потопа, но единственная
опасность угрожала ему только в последние полчаса его
заключения, когда Сова уселась на ветку и, чтобы его морально
поддержать, стала рассказывать ему длиннейшую историю про
свою Тетку, которая однажды по ошибке снесла гусиное яйцо, и
история эта тянулась и тянулась (совсем как эта фраза), пока
Пятачок (который слушал Сову, высунувшись в окно), потеряв
надежду на спасение, начал засыпать и, естественно, стал
помаленьку вываливаться из окна; но, по счастью, в тот момент,
когда он держался только одними копытцами задних ног, Сова
громко вскрикнула, изображая ужас своей Тетки и ее крик, когда она
(Тетка) обнаружила, что яйцо было действительно гусиное, и
Пятачок проснулся и как раз успел юркнуть обратно в окно и
сказать: «Ах как интересно! Да что вы говорите!»— словом, вы
можете представить себе его радость, когда он увидел славный
Корабль «Мудрость Пуха» (Капитан — К.Робин, 1-й помощник — В.Пух), который плыл ему на выручку, а К. Робин и В.-Пух, в свою оче…
8
9.
Токенизация● Виды токенов (примеры):
Слова ЕЯ
я иду гулять
Знаки препинания
!–;
Числа
10 десять
Даты
13.09.2018
Буквенно-цифровые комплексы Boeing-747
Виды токенов зависят от прикладной задачи
● При выделении токенов опираемся на:
разделители: пробел, знак препинания, …
вид знака: буква латиницы/кириллицы, цифра, …
регистр букв
Определяем границы токена и его вид
Назовите синоним токена при компиляции программ
9
10.
Разделение напредложения
Что является маркером конца предложения?
Определенный символ и/или их
последовательность
Что является маркером начала
предложения?
Заглавная буква
Что означает многоточие в русском языке?
Мороз и солнце; день чудесный!
А сейчас поговорим о проблемах.
10
11.
Особенностиграфематического анализа
В общем случае разделители токенов и маркеры
конца/начала предложения неоднозначны
В связи с этим требуется:
учет прикладной задачи
анализ контекста знаков
использование дополнительной информации,
например, словарей предлогов, словосочетаний,
имен собственных, сокращений и пр.
15.03 я смотрел на Кота Б. Б. Кот смотрел на меня.
Я живу на ул. Ленина и меня зарубает время от
времени.
а ты знаешь что делать с субтитрами на ютьюб
даже не представляю а ты
11
12.
Подходы к реализацииграфематического анализа
Инженерный подход – регулярные выражения,
правила, словари
Машинное обучение – обучаем модель по
размеченным текстам
Гибридный подход
Как ставятся задачи токенизации и сегментации
на предложения в машинном обучении?
Нужно предсказать
является ли та или иная графема концом
токена/предложения
к какому из классов относится токен
12
13.
Графематическиеанализаторы
Сейчас повсеместно используются pipeline’ы,
реализующие все этапы обработки текста
✔ Natasha
✔ DeepPavlov
✔ spaCy
✔ Stanza
✔ UDPipe
Мы подробно рассмотрим один из первых pipeline
для русского языка: АОТ-Диалинг (проект aot.ru)
Отдельные анализаторы есть в NLTK, класс
tokenize
13
14.
Проект aot.ru (с 1997 года)«Этот сайт – музей автоматической обработки
текста, кунсткамера технологий рубежа
тысячелетий»
Лингвистический анализ текстов на русском языке
В том числе выполняет
графематический анализ
морфологический анализ
синтаксический анализ
семантический анализ
Инженерный подход
Программные модули с открытым кодом, C++
На сайте есть тестовый он-лайн интерфейс
14
15.
Графематика aot.ruМодуль выполняет
• токенизацию и сегментацию на предложения
• свертку словосочетаний
• анализ макроструктуры текста
При этом распознаются:
• слова, разделители и предложения
• аббревиатуры, ФИО, даты и числа,
электронные адреса, имена файлов
• тире и дефис
• устойчивые словосочетания
• абзацы, заголовки, перечисления (рубрики)
Вход модуля – текстовый файл (плейн-текст)
Выход – таблица токенов с дескрипторами
15
16.
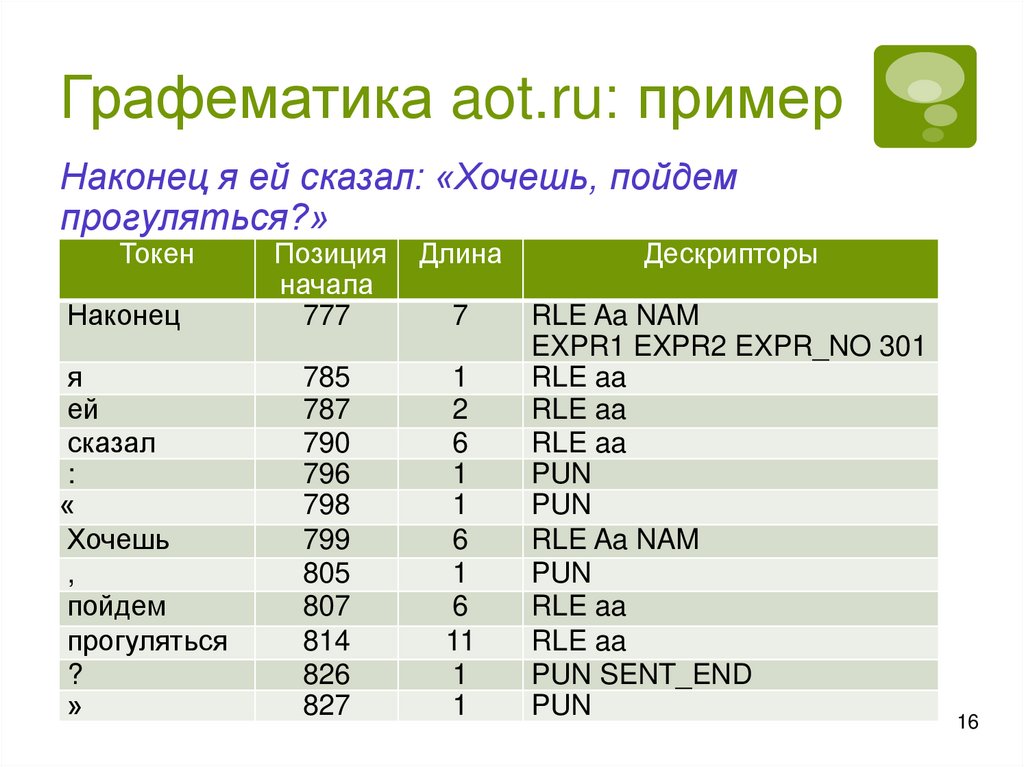
Графематика aot.ru: примерНаконец я ей сказал: «Хочешь, пойдем
прогуляться?»
Токен
Длина
Дескрипторы
Наконец
Позиция
начала
777
7
я
ей
сказал
:
«
Хочешь
,
пойдем
прогуляться
?
»
785
787
790
796
798
799
805
807
814
826
827
1
2
6
1
1
6
1
6
11
1
1
RLE Aa NAM
EXPR1 EXPR2 EXPR_NO 301
RLE aa
RLE aa
RLE aa
PUN
PUN
RLE Aa NAM
PUN
RLE aa
RLE aa
PUN SENT_END
PUN
16
17.
Примеры работыанализаторов в NLTK
Good muffins cost $3.88 in New York.
Please buy me two of them. Thanks.
wordpunct_tokenize
['Good', 'muffins', 'cost', '$', '3', '.', '88', 'in', 'New', 'York',
'.', 'Please', 'buy', 'me', 'two', 'of', 'them', '.', 'Thanks', '.’]
word_tokenize
['Good', 'muffins', 'cost', '$', '3.88', 'in', 'New', 'York', '.',
'Please', 'buy', 'me', 'two', 'of', 'them', '.', 'Thanks', ‘.’]
sent_tokenize
['Good muffins cost $3.88 in New York.', 'Please buy
me two of them.', 'Thanks.’]
17
18.
Графематический анализ исегментация текста: выводы (1)
Универсальных решений нет, поскольку от решаемой
задачи и специфики текста зависит:
какие виды сегментации нужны
какие последовательности графем потом будут
анализироваться как единое целое
Основная установка – ничего не потерять для
дальнейшего анализа текста в том числе рисунки,
врезки и пр.
Сегментация нижнего уровня: кажущаяся простота
✻ Для ЕЯ с развитым формообразованием (турецкий)
или словообразованием (немецкий) графематический
и морфологический анализы объединяются
18
19.
Графематический анализ исегментация текста: выводы (2)
При обоих подходах достигаемая точность – до
99% (https://github.com/natasha/razdel)
Почему?
Много современных реализаций – инженерный
подход
Почему?
Для улучшения результатов сегментации:
учет решаемой задачи и специфики текстов
токенизация и разделение на предложения
проводятся одновременно
более одного просмотра текста
Модули сегментации нижнего уровня
в общем случае
языково-зависимые компоненты
19
20.
Предмет морфологииМорфология как раздел лингвистики изучает слова
ЕЯ, включая:
внутреннюю структуру (устройство) слов,
т.е. уровень морфем – морфемика
внешние формы слов и их изменение в тексте, т.е.
собственно уровень слов – морфосинтаксис
Одна и та же информация в одном ЕЯ может быть
выражена морфологически, в другом – синтаксически:
говорю – hablo, буду говорить – hablare
Есть ЕЯ без морфологии: китайский (используются
служебные слова)
он получил – 他得到了, она получила – 她得到了
Есть ли аналог морфологии в ЯП?
20
21.
Что такое слово?В искусственных языках, формально:
слово – последовательность символов,
обозначающая переменную, число и др.: true, 12.7
выделяется в тексте разделителями (пробел и пр.)
Для слова ЕЯ формального критерия не существует
с синтаксической точки зрения – единицы,
из которых строятся предложения, текст
не обязательно выделяются пробелами
(древнерусский, японский, корейский языки)
могут включать знаки, не являющиеся
разделителями: куда-то, don’t
с семантической точки зрения – носители смысла
21
22.
Повторение (1)Словоформа
Лексема
Лемма, имя лексемы
Основа (stem)
Псевдооснова
22
23.
Слово в языке и тексте:основные термины
Словоформа – конкретная грамматическая форма
слова: носа, прибежал, синим
Лексема – множество всех словоформ слова,
обозначают одно понятие {нос, носа, носу, носом,
носе, носы, носов, носам, носами}
Лемма, имя лексемы – нормальная (базовая,
каноническая, словарная) форма лексемы: нос –
им. падеж, ед. число
Основа (stem) – часть слова без окончания и
постфикса, может изменяться: теленок – теленка
Псевдооснова – неизменяемая начальная часть
слова: теленок – теленка
23
24.
Словоизменительнаяпарадигма
Слово меняется в зависимости от его синтаксической
функции в предложении для выражения нужной
грамматической информации
Словоизменительная/морфологическая парадигма –
система форм слова, которая характеризуется:
изменением морфологических параметров (МП)
инвариантной частью (корень, основа)
перечнем изменяемых частей (флексий)
делать – делаю – делала – делай – делающий – делая
Бывают неизменяемые слова: и, всего, пальто
В парадигме могут отсутствовать некоторые формы:
ножницы, победить
Есть исключений: идти – шел
24
25.
Словоизменительнаяпарадигма: пример
Для слов нос, стол, завод и т.д.:
изменяется число и падеж
А что не изменяется?
перечень флексий (окончаний):
нос, носа, носу, нос, носом, носе,
носы, носов, носам, носы, носами, носах
Единственное число
им. род. дат. вин. тв.
а
у
ом
Множественное число
пр. им. род. дат. вин.
тв.
пр.
е
ами
ах
ы
ов
ам
ы
Словоизменительный/морфологический/флективный
класс – подкласс слов с одной морфопарадигмой
25
26.
Виды морфопроцессоровМорфологические процессоры – программы,
реализующие морфологическую обработку текста
Процессоры различаются:
направлением обработки (анализ/синтез)
функциями, в том числе возможностью
обрабатывать новые слова и разрешать
морфологическую неоднозначность
используемой моделью
Модели отличаются:
способом представления лингвистической
информации: словарные и бессловарные
полнотой учета разных морфологических явлений
(частей речи, флективных классов и значений МП)
26
27.
Морфологический синтезЦель – порождение нужной словоформы слова или его
парадигмы исходя из леммы/основы
Синтез всей парадигмы слова (лексемы)
Вход: лемма/основа слова
Выход: словоизменительная парадигма
лук → лук, лука, луку, лук, луком, луке
Синтез нужной словоформы
Вход: лемма/основа + набор конкретных значений
свободных морфологических параметров
Выход: словоформа
кипеть + ИЗЪЯВ. НАКЛ., НЕСОВ. ВИД, ПРОШ. ВР.,
ЕД.ЧИСЛО, МУЖ.РОД → кипел
Возможен синтез разных вариантов словоформы: (увидел)
оператор/оператора
Приложения: генерация текста, машинный перевод
27
28.
Морфологический анализ:теггинг
Термин используется в основном в западной КЛ,
означает буквально: проставление тегов к
словоформам
Чаще всего используется рart-of-speach (POS) tagging
– определение части речи словоформы
Вход: словоформа текста ЕЯ
Выход: словоформа и часть речи
красивее → ПРИЛ, process → N/V
Используется для распространенных
малофлективных индоевропейских языков Почему?
Использование: разметка текста, например, перед
синтаксическим анализом
28
29.
Морфологический анализ:стемминг
Стемминг (stem – основа слова) – отсечение
окончания слова
Вход: словоформа текста ЕЯ
Выход: основа/псевдооснова слова
белок → белок, белка → белк; белок, белка → бел
Важно! Словоформы, соответствующие одной
словоизменительной парадигме, должны получать
в результате стемминга одну и ту же (псевдо)основу
В основном используется для распространенных
малофлективных индоевропейских языков
Приложения: информационный поиск,
классификация и кластеризация текстов в коллекциях
29
30.
Морфологический анализ:лемматизация
Лемматизация (нормализация) – преобразование
окончания слова
Вход: словоформа текста ЕЯ
Выход: лемма (иногда и часть речи)
клею → клеить (ГЛ)
клеями → клей (СУЩ)
Происходит приведение слова к словарной форме
Принимается во внимание контекст слова Зачем?
Приложения: информационный поиск,
поддержка входа в электронные словари
Сравните стемминг и лемматизацию
30
31.
Полныйморфологический анализ
Определение для заданной словоформы
всех ее МП со значениями и приведение ее к
лемме (реже – основе)
Вход: словоформа текста ЕЯ
Выход:
часть речи
набор значений МП словоформы
лемма
синих → синий, ПРИЛ., МНОЖ. Ч., РОД. П.
Приложения: машинный перевод, извлечение
информации из текстов
31
32.
Повторение (2)Перечислите виды морфологического
анализа.
Какой из них больше подходит для
русского языка?
Почему?
32
33.
Словарные модели● Модели основаны на одном из видов словарей:
словаре словоформ или словаре основ
● Достоинства:
позволяют проводить синтез словоформ
реализуют полный морфоанализ словоформы,
распознавание морфоомонимии: после, косой,
стали, дома
простота реализации и поддержки процессора
● Недостатки:
проблема анализа новых слов
нет учета опечаток и других ошибок
трудоемкость построения и пополнения словарей
повторение информации и значительный объем
словарей, как следствие – невысокая скорость
33
34.
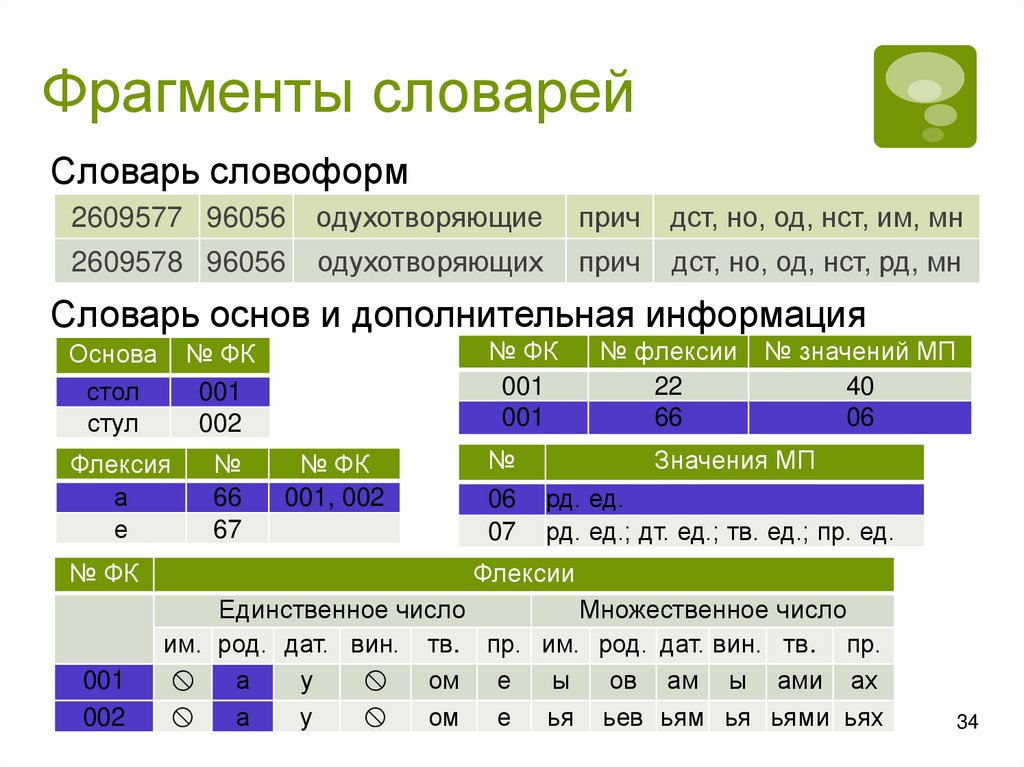
Фрагменты словарейСловарь словоформ
2609577 96056
одухотворяющие
прич
дст, но, од, нст, им, мн
2609578 96056
одухотворяющих
прич
дст, но, од, нст, рд, мн
Словарь основ и дополнительная информация
Основа
стол
стул
№ ФК
001
002
Флексия
а
е
№
66
67
№ ФК
001
001
№ ФК
001, 002
№
06
07
№ флексии
22
66
№ значений МП
40
06
Значения МП
рд. ед.
рд. ед.; дт. ед.; тв. ед.; пр. ед.
№ ФК
Флексии
001
002
Единственное число
Множественное число
им. род. дат. вин. тв. пр. им. род. дат. вин. тв. пр.
а
у
ом е
ы
ов ам ы ами ах
а
у
ом е ья ьев ьям ья ьями ьях
34
35.
Бессловарные модели.Инженерный подход (1)
● Отсутствуют большие словари, но используются:
словари псевдоокончаний/аффиксов, исключений и пр.
● Значения части речи и МП определяются по последним
буквам слова: -онок СУЩ, НЕОД., МР, ЕД.Ч., ИМ.П.
Достоинства:
Не зависят от объемных словарей
Дают возможность предсказания (с определенной
вероятностью) практически любого нового слова
Имеют хорошую скорость обработки словоформ
Недостатки:
Чувствительны к нерегулярному словоизменению и
коротким основам: шов, швы – ш?
Применимы в основном для стемминга в ограниченном
круге приложений
Почему?
35
36.
Бессловарные модели.Статистический подход
36
Идея: инвариантные части словоформ
(корни/основы) встречаются реже, чем аффиксы
Окончания слов и другие морфы определяются
автоматически (итеративно)
Идея универсальна, не зависит от конкретного
естественного языка (ЕЯ)
Для построения модели требуется обработка
больших объемов текстов
Чаще всего применяется для стемминга
Для РЯ работающей статистической модели нет
36
37.
Бессловарные модели.Машинное обучение
Нейронные сети используются часто, но не
всегда
Определение МП и снятие морфологической
омонимии происходит одновременно
Сильная зависимость от обучающего корпуса:
невозможно корректно обработать редкие
слова и исключительные случаи (например,
ошибки)
Производительность на несколько порядков
ниже, чем у методов на основе словарей
37
38.
Машинное обучение.Определение МП
Для определения МП (и части речи) часто
используются нейронные сети, обычно,
рекуррентные
Задача может ставится как задача
определения отдельной характеристики:
для каждой характеристики отдельный
полносвязный слой (классификатор)
определения всего набора характеристик:
наиболее вероятные наборы определяются,
например, с помощью логистической
регрессии
38
39.
Машинное обучение.Лемматизация
Может решаться независимо и рассматриваться как
задача:
преобразования одной последовательности букв в
другую (словоформы в лемму). При этом, например, на
вход нейронной сети подаются:
буквы обрабатываемой словоформы
ее морфологические характеристики
Зачем?
определения наиболее подходящего правила
преобразования (например, с помощью логистической
регрессии). Правила строятся автоматически по
размеченному корпусу
Лемматизация в наиболее современные системах
DeepPavlov и Natasha основана на словарной
морфологии из морфопроцессора pymorphy2
39
40.
Морфология aot.ruhttp://aot.ru/demo/morph.html
Базируется на словаре А.А. Зализняка (основ),
включает 174 тыс. лемм, можно править
При анализе выдается лемма, часть речи, значения МП
Синтезируется полная парадигма
Незнакомые слова обрабатываются по аналогии
Found Dict ID
Lemma
Grammems
Делай
+
пе, нс
ДЕЛАТЬ
Г дст,пвл,2л,ед
Печь
+
пе, нс
ПЕЧЬ
ИНФИНИТИВ, дст
+
но
ПЕЧЬ
С жр,вн,им,ед,
-
но
Покемон
ПОКЕМОН С мр,вн,им,ед
АНЕМОН
40
41.
Примеры работыморфоанализатора в NLTK
import nltk
from nltk.stem import WordNetLemmatizer
# Init the Wordnet Lemmatizer
lemmatizer = WordNetLemmatizer()
# Lemmatize Single Word
print(lemmatizer.lemmatize("bats")) #> bat
print(lemmatizer.lemmatize("feet")) #> foot
print(lemmatizer.lemmatize("are")) #> are
print(lemmatizer.lemmatize("are", 'v')) #> be
print(lemmatizer.lemmatize("stripes", 'v')) #> strip
print(lemmatizer.lemmatize("stripes", 'n')) #> stripe
41
42.
Морфологический анализи синтез: выводы (1)
Словарные морфопроцессоры до сих пор
используются, но при этом нужно помнить:
Словарная информация зависит от ЕЯ
Словари объемны, поэтому для улучшения
поиска нужно использовать специальные
структуры данных: хэш-таблицы, различные виды
деревьев
Снятие/разрешение омонимии
(постморфологический анализ) – отдельная
задача
42
43.
Морфологический анализи синтез: выводы (2)
Сейчас активно используется машинное
обучение, но при этом:
получаются громоздкие модели
для РЯ есть проблемы с покрытием всех
возможных вариантов
Современные МА многофункциональны:
графематика, морфология с разрешением
неоднозначности и разбором незнакомых слов
Точность определения леммы – до 96%,
точность определения МП – до 91%
(https://github.com/natasha/slovnet)
43
44.
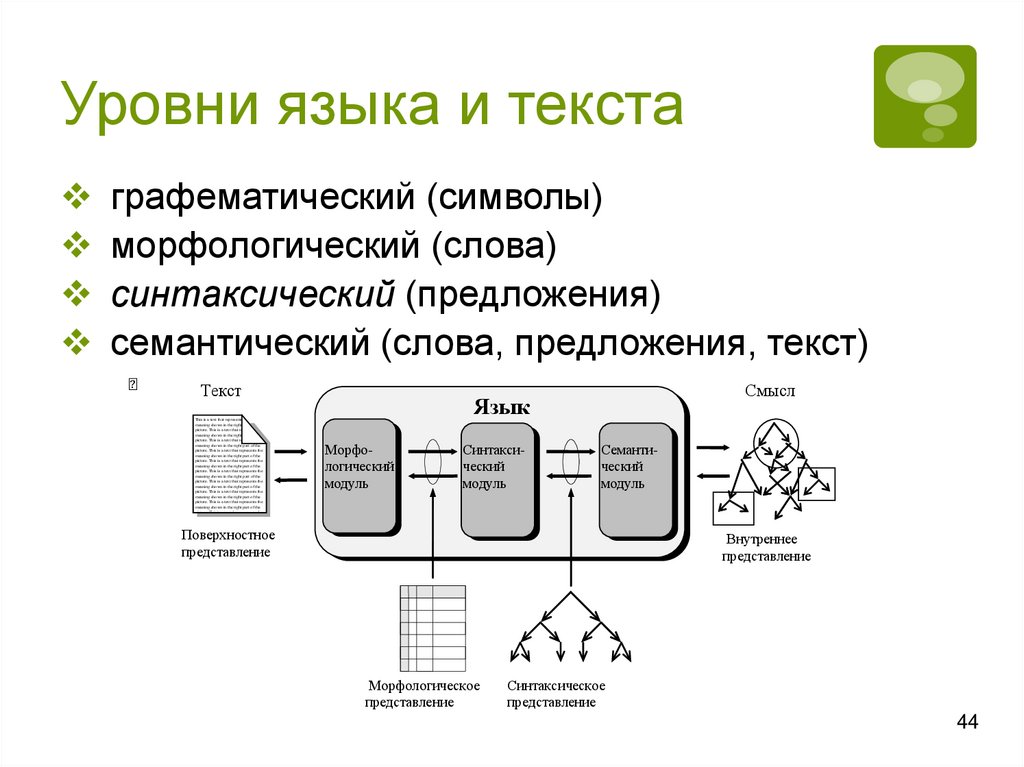
Уровни языка и текстаграфематический (символы)
морфологический (слова)
синтаксический (предложения)
семантический (слова, предложения, текст)
Текст
This is a text that represents the
meaning shown in the right part of the
picture. This is a text that represents the
meaning shown in the right part of the
picture. This is a text that represents the
meaning shown in the right part of the
picture. This is a text that represents the
meaning shown in the right part of the
picture. This is a text that represents the
meaning shown in the right part of the
picture. This is a text that represents the
meaning shown in the right part of the
picture. This is a text that represents the
meaning shown in the right part of the
picture. This is a text that represents the
meaning shown in the right part of the
picture. This is a text that represents the
meaning shown in the right part of the
picture. This is a text that represents the
meaning shown in the right part of the
picture. This is a text that represents the
meaning shown in the right part of the
picture.
Смысл
Язык
Морфологический
модуль
Синтаксический
модуль
Семантический
модуль
Поверхностное
представление
Внутреннее
представление
Морфологическое
представление
Синтаксическое
представление
44
45.
Графематика иморфология
Какую информацию мы получить
после графематического и
морфологического анализа для
предложения:
Скорый поезд под номером 1
следует из Казани, являющейся
столицей республики Татарстан, в
город-герой Москву.
45
46.
Что делать дальше?Скорый поезд под номером 1
следует из Казани, являющейся
столицей республики Татарстан, в
город-герой Москву.
Пункт отправления
Казань
Пункт назначения
Москва
Всегда ли важно только это?
46
47.
Синтаксический анализ (СА)Задача – установление связей между словами, а
также типов этих связей
Единица обработки – предложение (выражает
законченную мысль)
На входе: результат морфологического анализа
На выходе: синтаксическая структура
предложения
СА предшествует семантическому анализу
Иногда отдельно рассматриваются простые
предложения и словосочетания: частичный СА
Словосочетание – синтаксическая конструкция,
включающая несколько знаменательных слов
47
48.
Модели синтаксическогоанализа
Модель СА взаимосвязано включает:
способ представления синтаксической структуры
предложения
способ описания синтаксиса языка
способ его использования при анализе (синтезе)
Общее моделей: выход – синтаксическое дерево
Отличие моделей:
выделяемые синтаксические единицы
учитываемые синтаксические связи между ними
Разные ЕЯ разные подходы к моделированию
синтаксической структуры предложения
Почему на выходе дерево?
48
49.
Основные моделиДеревья составляющих (генеративный подход)
возникли в американской лингвистике
восходят к идеям порождающих грамматик Н.
Хомского
Деревья зависимостей/подчинения
возникли во французской и русской лингвистике
восходят к идеям Л. Теньера и А. Реформаторского
представлены в лингвистической модели
Смысл⇔Текст
Гибридные модели
попытки преодолеть ограничения первых двух
подходов
например, аппарат синтаксических групп Гладкого
49
50.
Модель синтаксиса:деревья составляющих
Происходит последовательное линейное членение
предложения на синтаксические единицы
● Единицы – непосредственные составляющие
(группы соседних слов текста)
● По факту, составляющие – словосочетания
(фразы), два крайних случая: слово и предложение
● Любые две составляющие либо не пересекаются,
либо одна целиком содержится в другой
● Связь составляющих: ненаправленное отношение
вложения
● Вложенность графически изображается как дерево
составляющих
50
51.
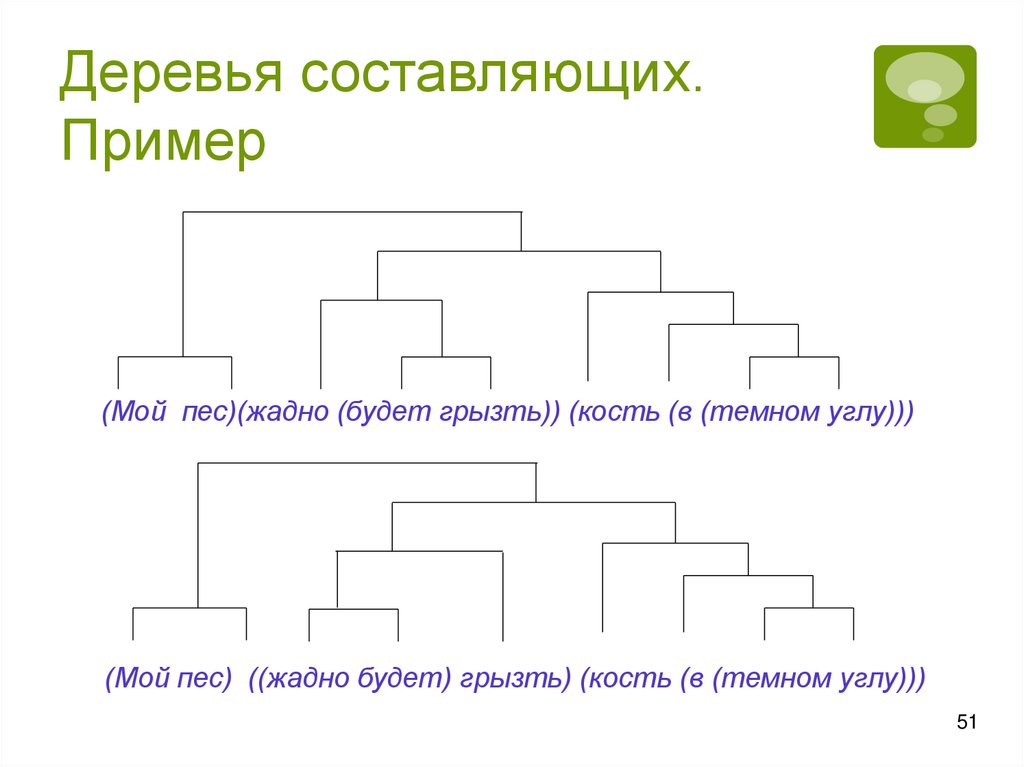
Деревья составляющих.Пример
(Мой пес)(жадно (будет грызть)) (кость (в (темном углу)))
(Мой пес) ((жадно будет) грызть) (кость (в (темном углу)))
51
52.
Деревья составляющих:грамматика
● Для одного предложения возможны разные
системы составляющих
● Среди множества систем составляющих только
некоторые правильны, т.е. отражают принятые в
лингвистике соглашения о синтаксической
структуре предложения
● Основа – контекстно-свободная (КС) грамматика,
описывающая правильную фразовую
(синтаксическую) структуру предложения
● Одновременно отражает и синтаксическую, и
линейную структуру предложения
52
53.
Деревья составляющих.Пример КС-грамматики
S → NP VP
NP → A N | Det N | N | N PP
VP → VP NP | AnV | Adv AnV
S – предложение
NP – именная группа
VP – глагольная группа
PP – предложная группа
AnV – аналитическая форма
глагола
AnV → Aux V
PP → Prep NP
Det – детерминатив
N – имя существительное
Adv – наречие
Aux – вспомогательный глагол
V – глагол
Prep – предлог
A – имя прилагательное
● Нетерминалы соответствуют типам фраз и
обозначениям частей речи слов
● А что есть терминалы?
53
54.
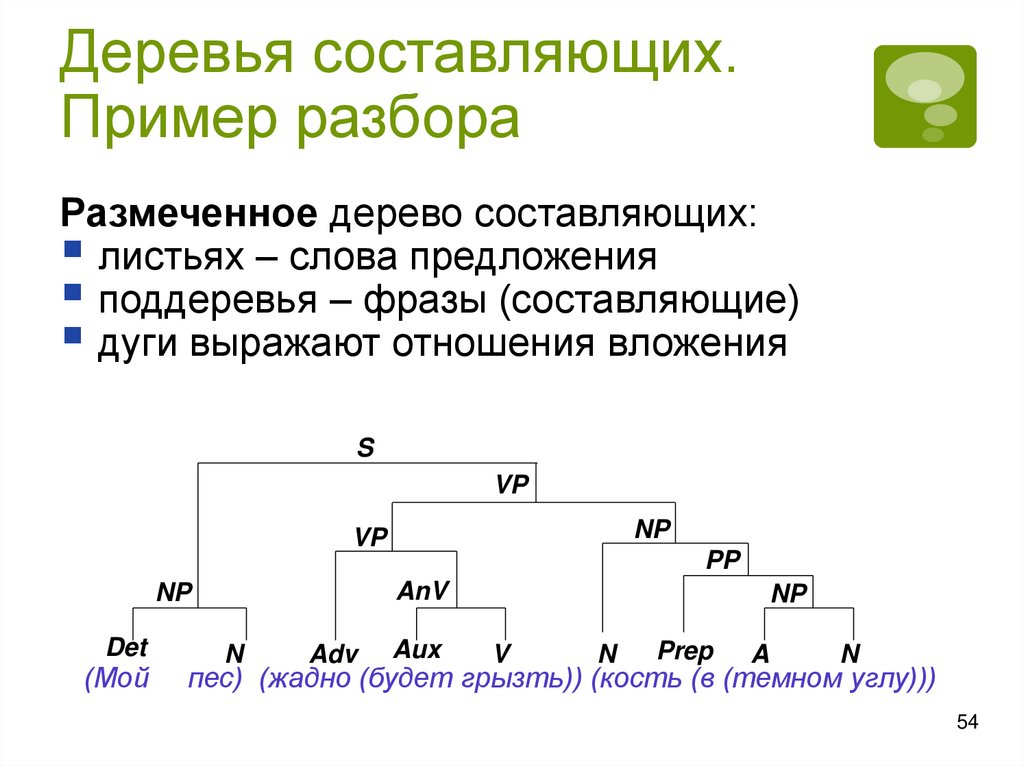
Деревья составляющих.Пример разбора
Размеченное дерево составляющих:
листьях – слова предложения
поддеревья – фразы (составляющие)
дуги выражают отношения вложения
S
VP
NP
VP
AnV
NP
Det
(Мой
PP
N
Adv
Aux
NP
V
N
Prep
A
N
пес) (жадно (будет грызть)) (кость (в (темном углу)))
54
55.
Деревья составляющих:дополнительные примеры
Пример 1 (об омонимии):
Декан назначен ректором.
(Декан) (назначен ректором).
S → NP VP
VP → VP NP | …
Пример 2 (о важности пунктуации):
– Дорогая, мне посуду мыть или ты сама
потом помоешь?
– Хорошо мой любимый.
((Хорошо), (мой любимый)).
((Хорошо), (мой), (любимый)).
((Хорошо мой), (любимый)).
55
56.
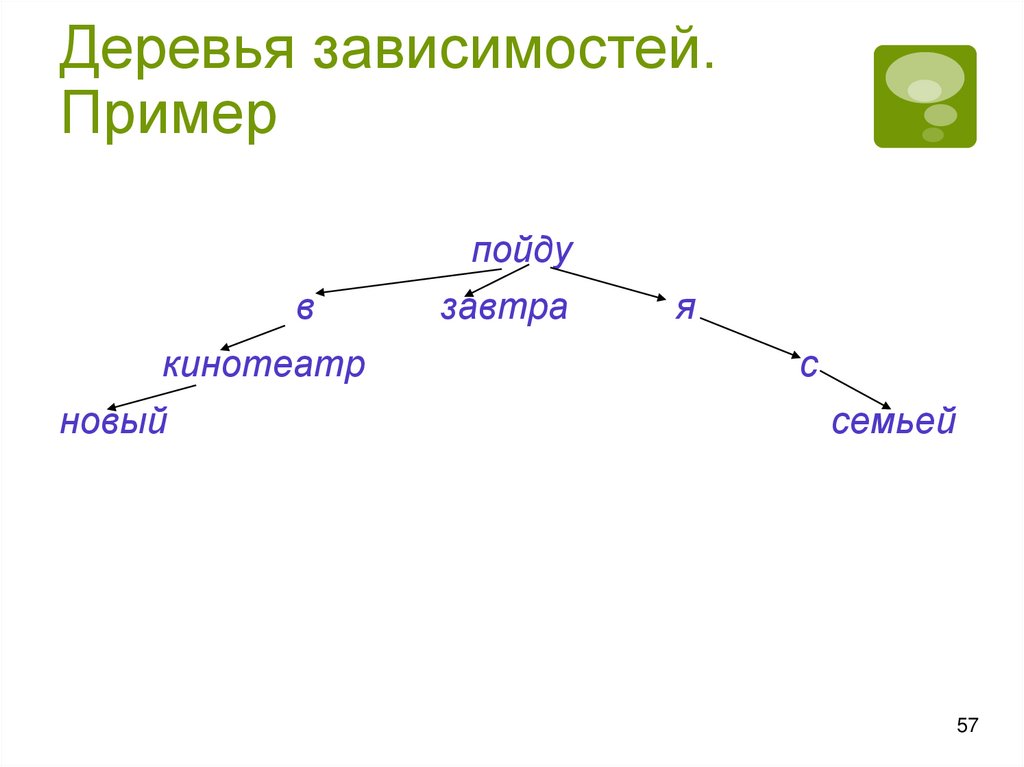
Модель синтаксиса:деревья зависимостей
Синтаксические единицы – слова,
синтаксическая связь – подчинение (зависимость)
Графическое представление – дерево
зависимостей (ДЗ):
вершины – слова (корень – глагол, сказуемое)
дуги – подчинительная связь (зависимость)
каждая вершина имеет ровно одну входящую
дугу (кроме корня)
существует уникальный путь от корня к каждой
вершине
Особенность: нужно задавать порядок слов
56
57.
Деревья зависимостей.Пример
пойду
в
кинотеатр
новый
завтра
я
с
семьей
57
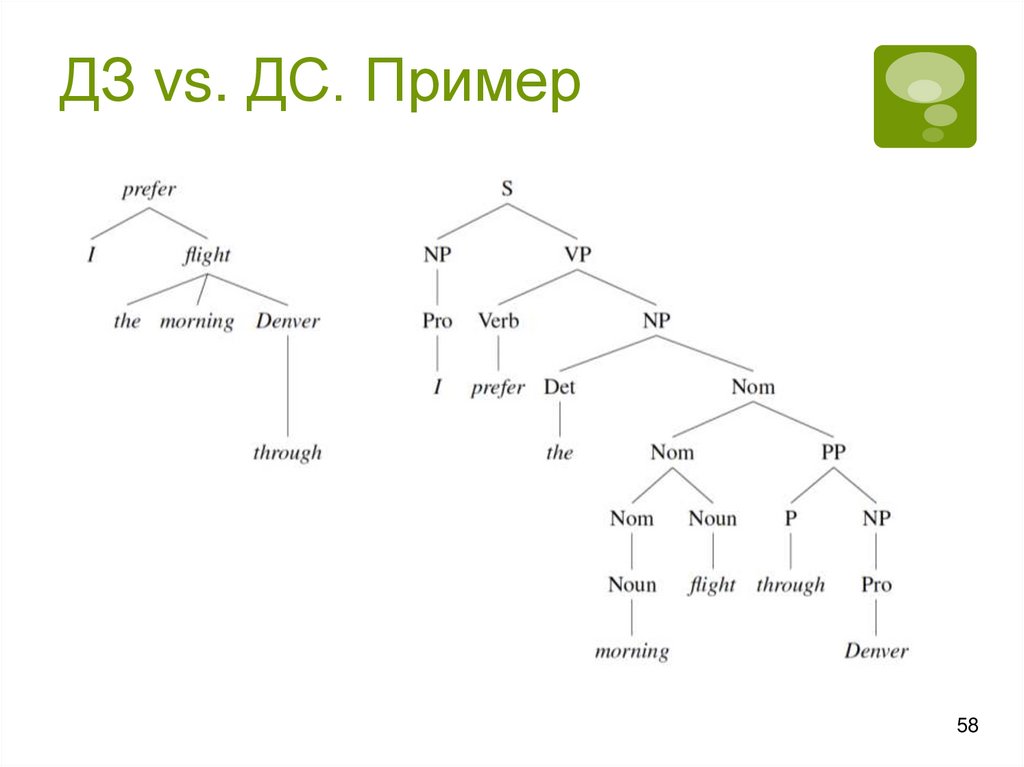
58.
ДЗ vs. ДС. Пример58
59.
Типы подчинительныхсвязей
В рамках модели ДЗ количество и набор типов связей
слов может варьироваться
Наиболее распространенные типы связей
предикат–субъект: спасатели ← обнаружили
прямообъектное: уделить → внимание
определительное: важный ← вопрос
отпредложное: в → здание
посессивное: книга → врача
Для установления связей – правила
Пример правила установления отпредложной связи
предлог (Prep) → существительное (N):
Если падеж N соответствует падежам предлога Prep,
то установить связь, сделав Prep главным словом
59
60.
Деревья зависимостей:проективность
Дерево зависимостей часто изображается в виде точек
на прямой, между которыми проведены направленные
дуги (зависимости)
Все дуги располагаются по одну сторону от прямой
Проективность («правильность» фразы) – возможность
изобразить зависимости слов так:
а) ни одна из дуг не пересекает другую дугу,
б) никакая дуга не накрывает вершину (корень дерева)
Содержательный смысл проективности: в тексте
синтаксически связанные слова близки к друг другу
Очень большой шар вполне может взлететь над домом
60
61.
Слабая проективность инепроективность
Большинство правильных предложений русского
языка проективны. Однако возможна:
Слабая проективность: дуги не пересекаются, но
допускается накрывание корня
Кубок все мечтают выиграть
Непроективные предложения встречаются
в художественной литературе и разговорной речи.
Усложняют автоматический СА
Кубок все выиграть мечтают
61
62.
Сравнение моделей САПредставление
ДС
ДЗ
Линейной структуры
естественное
отсутствует
Подчинительных
через вложение только между
связей (зависимостей)
словами
Неподчинительных
естественное неоднозначное
связей
Словосочетаний
явное
отсутствует
(фраз)
Отношений между
частичное
отсутствует
фразами
Разорванных единиц и
отсутствует
естественное
непроективности
ДС хороши для языков со строгим порядком слов,
ДЗ – для языков со свободным порядком
62
63.
Работа на семинаре (1)Приведите пример
словоформы
леммы
лексемы
основы
псевдоосновы
Проведите для слов после и семью
теггинг
стемминг
лемматизацию
полный морфологический разбор
63
64.
Работа на семинаре (2)Нарисовать дерево составляющих и дерево
зависимостей:
Добросовестные студенты читают
рекомендованную литературу по дискретной
математике.
Сколько различных деревьев зависимостей
возможны для фраз:
Вечером Марк съел быстро приготовленную на
кухне кашу с молоком
Определить проективность предложений:
Признанья нам его не нужно…
Икру я люблю красную…
Этому человеку мы будем обязаны всю жизнь.
64
65.
Домашнее задание пографематическому анализу
1. Исследовать ГА библиотеки NLTK
2. Используя их, написать свой ГА, который
осуществляет:
разбиение текста на токены ИЛИ
разбиение текста на предложения
3. Для выполнения задания использовать
регулярные выражения
4. Текст для тестирования дан
65
66.
Домашнее задание поморфологическому анализу
Посмотреть файл stemmer.py (для себя)
=====================================
Исследовать работу одного из МА (обращаем
внимание на pipeline’ы)
Для этого необходимо:
выбрать исследуемый МА
изучить и описать подход к построению
анализатора и его функциональность
запустить или подключить к своей программе
протестировать
описать особенности процесса запуска, данные и
результаты тестирования, сделать выводы
66