
































 Информатика
ИнформатикаПохожие презентации:










Области применения ИТ в лингвистике
1.
Области применения ИТ влингвистике
1. Автоматический анализ и синтез звучащей речи
2. Автоматическое реферирование и аннотирование текста
3. Автоматический анализ и синтез текста
2.
Анализ и синтез звучащей речиЗадача ИТ в Л – дигитализация
текстов - переведение языкового
материала, существующего в
печатном или устном виде, в
цифровую форму.
Роль компьютера:
• преобразование текстов,
• выделение из них отдельных
элементов и
• создание (синтеза) аналогичных
текстов.
• Автоматический анализ
звучащей речи –
преобразование речи в
печатный текст.
• Автоматический синтез
звучащей речи –
преобразование печатного
текста в звучащий текст
естественного языка.
3.
Этапы автоматического анализа1. Ввод звучащей речи в
компьютер с помощью
микрофона.
2. Выделение компьютерной
программой в звуковом
потоке отдельных знаков.
3. Идентификация выделенных
знаков звучащей речи со
знаками языка.
• Минимальный знак звучащей
речи – звук, создаваемый
артикуляционным аппаратом.
• Звук можно измерить по
частоте, высоте и т.д. с
помощью спец.приборов
(осциллографом).
4.
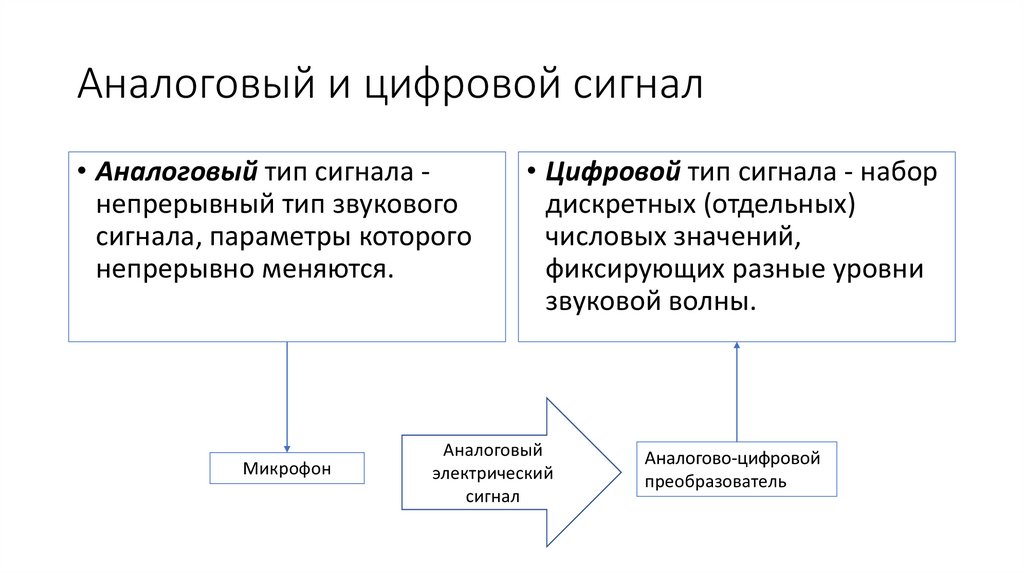
Аналоговый и цифровой сигнал• Аналоговый тип сигнала непрерывный тип звукового
сигнала, параметры которого
непрерывно меняются.
Микрофон
• Цифровой тип сигнала - набор
дискретных (отдельных)
числовых значений,
фиксирующих разные уровни
звуковой волны.
Аналоговый
электрический
сигнал
Аналогово-цифровой
преобразователь
5.
Автоматическое распознавание речиПо словам
Ограничения:
• личность говорящего: автомат
распознает речь только опреде
ленного говорящего,
• запас слов: автомат распознает
только ограниченное количество
слов,
• подготовленность речи:
автомат распознает речь, лишь
если она подготовлена.
По фонемам
Акустические признаки звуков:
• длительность и динамика
звучания
• чередование сигнала и пауз
выводятся из артикуляционных
признаков.
Ограничения:
• неуниверсальность акустических
признаков,
• отсутствие слогоделения,
акцентуации и ритма.
6.
Автоматическое распознавание речиСпектрограмма –
фотографическое изображение
звука.
• 4 частоты – 4 форманты –
активны при произнесении
звуков.
Форманта – максимум
концентрации энергии в спектре
звука.
Задача анализа - перевод
спектрограмм в фонологическую
транскрипцию.
«И» «У»
Подробнее по ССЫЛКЕ.
7.
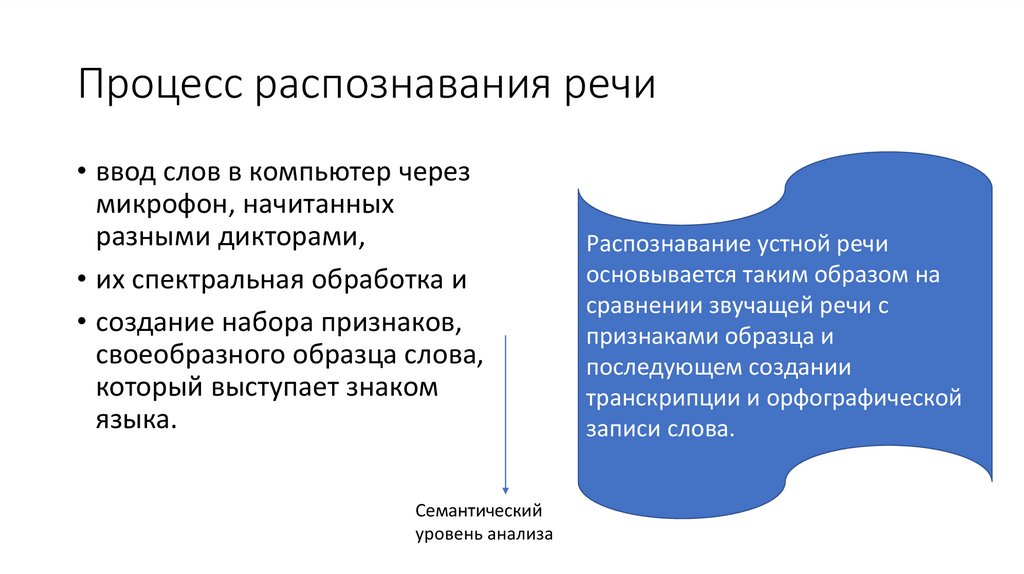
Процесс распознавания речи• ввод слов в компьютер через
микрофон, начитанных
разными дикторами,
• их спектральная обработка и
• создание набора признаков,
своеобразного образца слова,
который выступает знаком
языка.
Семантический
уровень анализа
Распознавание устной речи
основывается таким образом на
сравнении звучащей речи с
признаками образца и
последующем создании
транскрипции и орфографической
записи слова.
8.
Семантический уровень автоматическогоанализа звучащей речи
• машина устанавливает, что введенные предложения
многозначны и правдоподобны;
• машина прогнозирует, что в определенных речевых контекстах
могут возникать определенные типы общения; в зависимости от
такого прогнозируемого типа общения машина интерпретирует
предложение.
• ССЫЛКА на обзор программ и сервисов для
автоматического распознавания звучащей
речи.
• Пока Google впереди планеты всей, но
конкуренты у него уже есть.
9.
Автоматический синтез речиГде мы встречаемся с
синтезом звучащей речи?
Компилятивный синтез –
Воспроизведение заранее
записанных слов и фраз.
Формантно-голосовой метод –
Моделирование речевого тракта
человека.
Пример.
10.
Вопросы для обсуждения1. Что такое знак? В чем различие между знаками языка и
знаками речи?
2. В каких сферах ограничениями пословного распознавания
звучащей речи можно пренебречь? Для каких сфер эти
ограничения будут принципиально важными?
3. Какие артикуляционные признаки звуков вам известны?
4. Представители каких профессий должны быть задействованы в
создании сложных систем анализа звучащей речи?
11.
Автоматическое реферирование ианнотирование
Для чего нужно автоматическое реферирование?
Для Быстрой обработки большого количества текстовой
информации.
12.
(Автоматическое) Реферирование ианнотирование текста
Вторичный документ
Реферат
(передает суть исх.текста)
Аннотация
(сигнальная функция)
Связный текст, который кратко
выражает не только центральную
тему или предмет какого-либо
документа (статьи, монографии,
книги, патента и др.), но и цель,
применяемые методы, основные
результаты описанного
исследования или разработки.
• Реферирование – процесс
составления реферата.
Краткое изложение
содержания документа,
дающее общее
представление о его теме.
• Аннотирование –
процесс составления
аннотации.
13.
Виды рефератов• связный текст — новое текстовое образование, порождаемое
на основе логико-смыслового анализа исходного текста
(требуются более сложные программы);
• реферат-клише — модификация заданной клишированной
струк туры, пустые ячейки которой заполняются после анализа
задан ного текста;
• квазиреферат — перечень наиболее информативных предложе
ний текста.
14.
Этапы (автоматического) реферирования ианнотирования
Чтобы
сформулировать
задачу
автоматического
реферировани,
необходимо
рассмотреть
процесс
реферирования
человеком, то есть
ручное
реферирование.
1. Подготовительный – референт определяет
тематическую направленность текста и пытается
понять и осмыслить текст в целом,
2. аналитический – референт делит текст на некоторые
фрагменты (абзацы, аспекты). В каждом фрагменте
выделяются смысловые единицы (предложения,
словосочетания, слова), на основе которых
составляется план реферата,
3. построение реферата или аннотации –
выделенные ранее смысловые единицы (их
комбинации или преобразования) располагаются в
единый вторичный текст в соответствии с планом
реферата/аннотации.
15.
Этап 2. Выделение смысловых единиц• Ключевое
(опорное) слово это термин,
относящийся к
основному
содержанию
текста и
повторяющийся в
нем несколько раз
(с учетом всех
возможных
синонимов).
• Ключевое
словосочетание
– это сочетание
слов, среди
которых есть
одно или
несколько
ключевых.
• Ключевое
предложение –
содержит два и
более
ключевых
слова или
ключевых
словосочетания
.
16.
Этап 2, план реферата / аннотацииСмысловые ориентиры:
• основные темы и подтемы исходного текста,
• основные аспекты исследования,
• основные ключевые предложения, словосочетания, слова.
Выбор ориентиров зависит от типа реферата / аннотации.
17.
Этап 3, создание реферата / аннотацииСмысловые единицы реферата:
• полные (без изменений) ключевые предложения исх.текста,
• перефразированные ключевые предложения исх.текста (синонимы
разных уровней, конверсивы, замены «вид-род», «часть-целое» и др.),
• предложения, составленные из ключевых слов или словосочетаний
исх.текста с помощью специальных связующих элементов,
(посредством логико-смысловых скреп: потому что, в то время как,
поэтому, вследствие и т.д.),
• Предложения, обобщающие несколько предложений исх.текста
(совершенно другие слова).
18.
Компьютер должен уметь1. Находить в тексте ключевые
слова, словосочетания и
предложения.
2. Находить менее важные
единицы.
3. Составлять из первых
смысловые единицы
реферата.
4. Составлять из этих единиц
текст реферата / аннотации.
Последовательность
ключевых предложений
квазитекст.
Список ключевых слов и
словосочетаний
табличный реферат или
таблица.
19.
Методы поиска смысловых единиц висходном тексте
Статистические –
ключевые слова в
тексте всречаются
наибольшее кол-во раз
и определяются по
коээфценту. Ключевые
предложения содержат
несколько кл.слов,
расположенных на
небольшом расстоянии
друг от друга.
Позиционные
– ключевые
слова и
предложения
содержатся
заголовках,
подзаголовках,
в начале и в
конце текста.
Список онлайн-рефераторов
Логико-семантические методы
опираются на исследование
структуры и семантики
текстов. Цель этого метода —
выделить из конкретного текста
предложения с наибольшим
функциональным весом.
Величина эта зависит от
многих факторов: наличия в
исследуемом предложении
специальных семантически
значимых слов, связи этого
предложения с другими
предложениями текста
синтаксического типа самого
предложения и т.д.
20.
Вопросы для обсуждения1. Опишите этапы составления реферата текста.
2. Представьте известные вам системы автоматического
реферирования и ан нотирования текстов.
3. Какие задачи являются перспективными для систем
автоматического реферирования и аннотирования текстов?
21.
Автоматический анализ исинтез текста
22.
Основные понятияАвтоматический анализ
текста – это последовательное
преобразование в
• лексемно-морфологические,
• синтаксические и
• семантические представления,
понятные компьютеру.
Автоматический синтез
текста – это процесс
преобразования
• лексемно-морфологических,
• синтаксических и
• семантических компьютерных
представлений
в текст на естественном языке.
23.
Этапы автоматического анализа текста1. графематический анализ: выделение границ слов,
предложений, абзацев и других элементов текста (например,
врезок в газетном тексте);
2. морфологический анализ: определение исходной формы
каждого использованного в тексте слова и набора
морфологических характеристик этого слова;
3. синтаксический анализ: выявление грамматической структуры
предложений текста;
4. семантический анализ: определение смысла фраз.
24.
Графематический анализ – токенизация• выделение границ слов,
предложений, абзацев и
других элементов текста.
• Англ. token = отдельное слово,
фраза или любой другой
значимый элемент текста.
НО! Устойчивые выражения
невозможно разделить
Формальные сигналы границ:
• пробелы,
• прописные буквы и знаки
препинания, обозначающие
границы между
предложениями и составными
частями предложений,
• абзацные отступы,
обозначающие границы между
связанными по смыслу
группами предложений
25.
Морфологический анализИспользованное в тексте слово
возводится к его исходной
форме и определяется набор
морфологических характеристик
текстовой формы слова: часть
речи; род, число и т.д.
Каждое употребленное в тексте
слово называется словоформой
(или словоупотреблением).
Для связности текста некоторые
слова в тексте повторяются.
Исходные формы словоформ:
• Лемма – словарная исходная
форма.
• Машинная основа - ядерная
часть слова без
словоизменительных морфем.
26.
«Машинная основа» в морфологическоманализе
Это квазиоснова. Пример.
Существуют разные
словоформы
• сидеть – сижу
• друг – друзья
Они имеют машинную
(квази)основу
«си» и «дру».
Возведение разных словоформ
к одной квазиоснове называется
«стемминг».
• Определение машинной
основы (квазиосновы):
последовательность букв от
начала словоформы, общая для
всех словоформ, входящих в
формообразовательную
парадигму данного слова.
27.
Частеречный тэгингЧастеречный тэгинг - это определение частеречной
принадлежности слова и его морфологических характеристик.
• Как определить принадлежность слова к той или иной части
речи?
С помощью словоизменительных элементов слова – «машинные
окончания».
28.
Машинные окончанияЭто элементы, описывающие формоизменение конкретной
лексемы и представляемые в виде парадигм.
Машинные окончания зафиксированы в типовой парадигме
лексемы.
Бывают:
Совпадения типовых парадигм
(машинных окончаний):
• ручка – кочка
Совпадение машинных основ
лексем, имеющих разные
типовые парадигмы:
• лож#
ложиться или ложь
29.
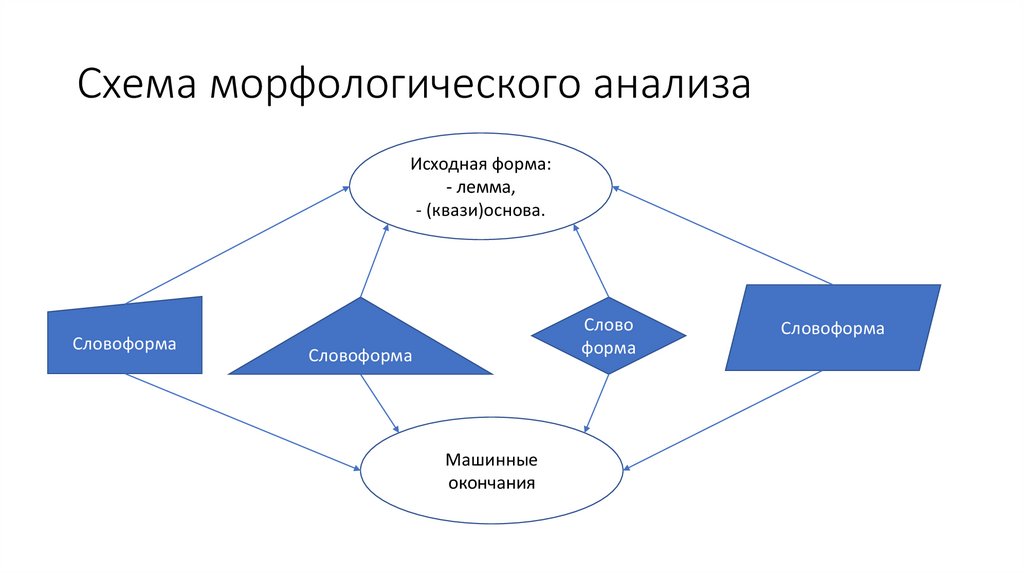
Схема морфологического анализаИсходная форма:
- лемма,
- (квази)основа.
Словоформа
Слово
форма
Словоформа
Машинные
окончания
Словоформа
30.
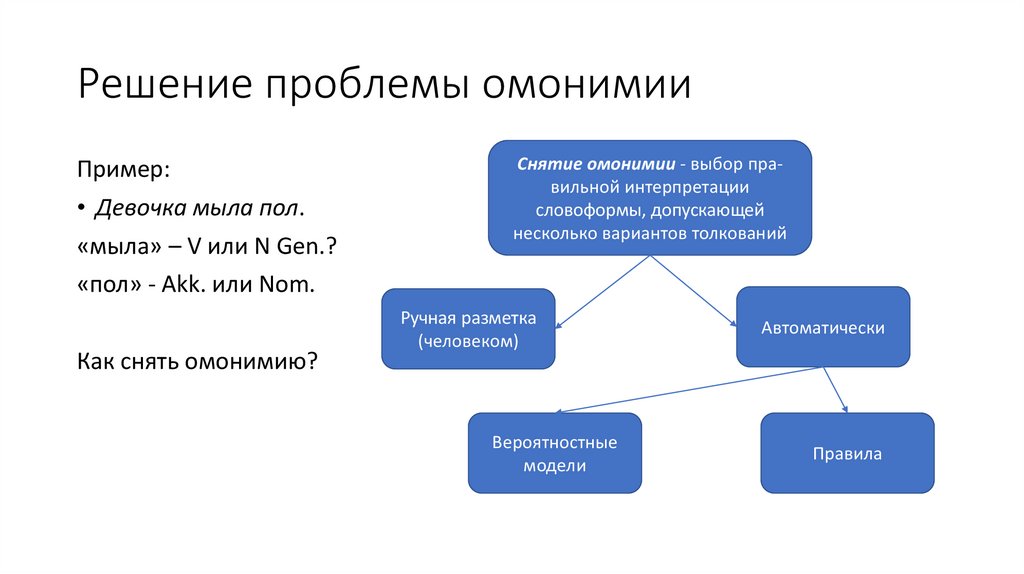
Решение проблемы омонимииПример:
• Девочка мыла пол.
«мыла» – V или N Gen.?
«пол» - Akk. или Nom.
Как снять омонимию?
Снятие омонимии - выбор правильной интерпретации
словоформы, допускающей
несколько вариантов толкований
Ручная разметка
(человеком)
Вероятностные
модели
Автоматически
Правила
31.
Этапы морфологического анализа1. нормализация словоформ, имеющая вид лемматизации, т.е.
сведения различных словоформ к некоторому единому
представлению — к исходной форме (лемме) или стемминга,
т.е. возведения разных словоформ к одной квазиоснове;
2. частеречный тэгинг, т.е. указание части речи для каждой словоформы в тексте;
3. полный морфологический анализ — приписывание
грамматических характеристик словоформе.
32.
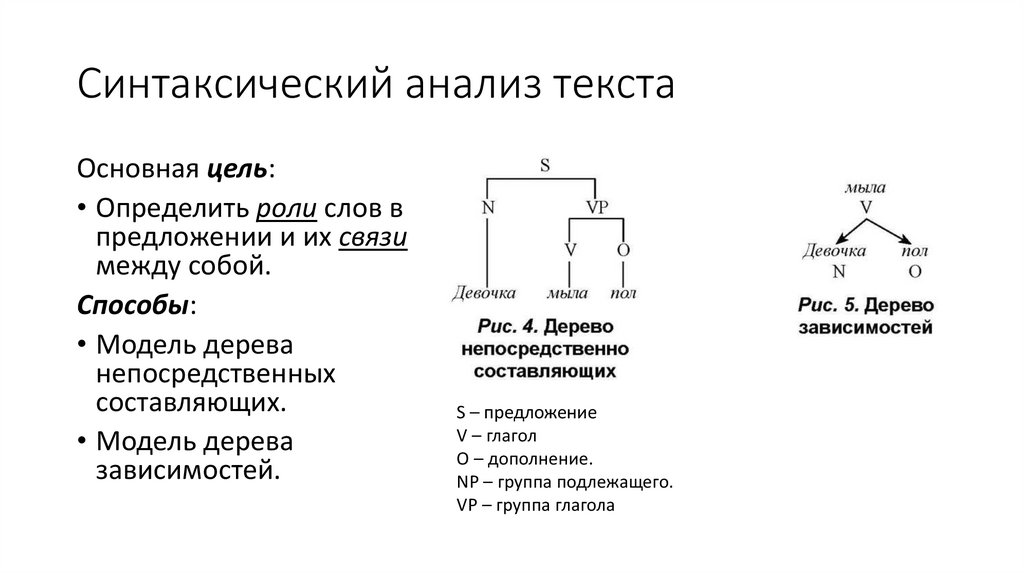
Синтаксический анализ текстаОсновная цель:
• Определить роли слов в
предложении и их связи
между собой.
Способы:
• Модель дерева
непосредственных
составляющих.
• Модель дерева
зависимостей.
S – предложение
V – глагол
O – дополнение.
NP – группа подлежащего.
VP – группа глагола
33.
Причины синтаксической многозначностипредложений
• Лексико-морфологическая многозначность: (одна и та же
словоформа может восходить к различным исходным формам
или к разным морфологическим формам одной лексемы),
• Неоднозначность правил синтаксич. разбора, которые могут
требовать разные представления синтаксич.структуры: в виде
дерева составляющих или в виде дерева зависимостей.
Чтобы избежать синтаксической омонимии, обратимся к
семантическому анализу.
34.
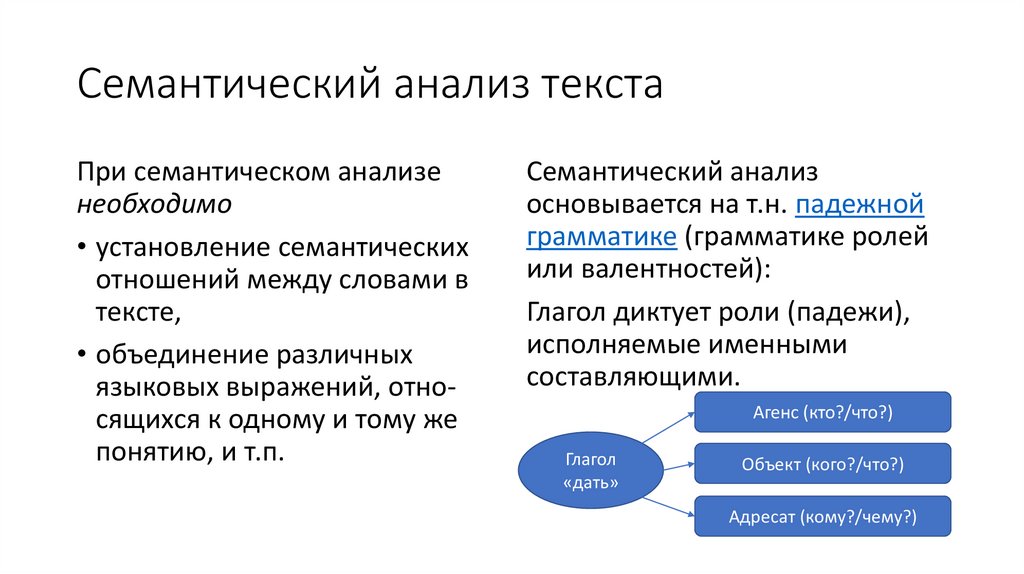
Семантический анализ текстаПри семантическом анализе
необходимо
• установление семантических
отношений между словами в
тексте,
• объединение различных
языковых выражений, относящихся к одному и тому же
понятию, и т.п.
Семантический анализ
основывается на т.н. падежной
грамматике (грамматике ролей
или валентностей):
Глагол диктует роли (падежи),
исполняемые именными
составляющими.
Агенс (кто?/что?)
Глагол
«дать»
Объект (кого?/что?)
Адресат (кому?/чему?)
35.
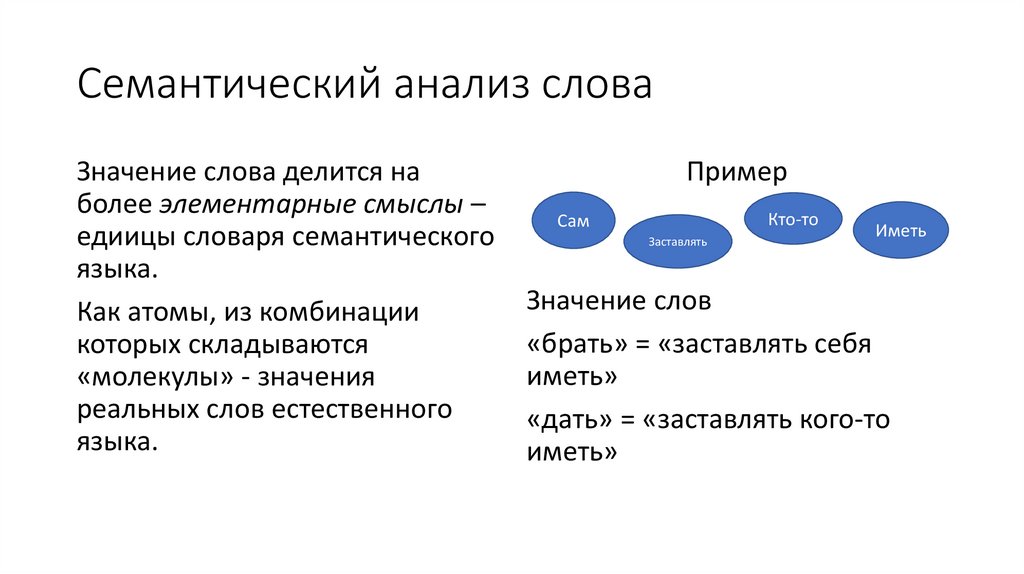
Семантический анализ словаЗначение слова делится на
более элементарные смыслы –
едиицы словаря семантического
языка.
Как атомы, из комбинации
которых складываются
«молекулы» - значения
реальных слов естественного
языка.
Пример
Кто-то
Сам
Заставлять
Иметь
Значение слов
«брать» = «заставлять себя
иметь»
«дать» = «заставлять кого-то
иметь»
36.
Омонимия на разных уровнях• Лексическая омонимия: совпадение звучания и/или написания слов, не
имеющих общих элементов смысла, например, рожа — лицо и вид болезни.
• Морфологическая омонимия: совпадение форм одного и того же слова
(лексемы), например, словоформа пол соответствует именительному и
винительному падежам существительного пол.
• Лексико-морфологическая омонимия (наиболее частый вид омонимии):
совпадение словоформ двух разных лексем, например, мыла — глагол мыть
в единственном числе женского рода прош. вр. и существительное мыло в
единственном числе, родительном падеже.
• Синтаксическая омонимия: неоднозначность синтаксической структуры,
имеющей несколько интерпретаций, например: Эти типы стали есть в цехе
(словоформа стали может интерпретироваться как существительное или как
глагол).
37.
Автоматический синтез текстаЭто процесс производства
связного текста, отдельные
этапы которого являются теми
же, что и при
морфологическом анализе, но
применяются в обратном
порядке: сначала
осуществляется семантический
синтез, затем синтаксический,
морфологический и
графематический.
Семантический
синтез
Синтаксический
синтез
Лексикоморфологический
Смысловая запись фразы
Синтаксическая структура
Цепочка лексикограм.характкристик слова
Реальная словоформа
Графематический синтез объединяет слова в единый
текст, следит за соответствием фрагментов входного
текста фрагментам выходного текста.
38.
Программа «Элиза» 1966 г.• Эта программа имитировала
диалог с психотерапевтом,
реализуя технику активного
слушания.
• целью программы было не
моделирование мышления в
точном смысле, а
моделирование речевого
поведения, что было
обусловлено ограниченными
программными ресурсами, а
также начальным уровнем
лингвистического анализа и
синтеза.
Программа включала:
1. комплекс ключевых слов,
которые актуализируют
некоторые устойчивые
речевые формулы,
2. способность
трансформировать
предыдущее высказывание в
общий вопрос.
39.
Виртуальные агенты или ботыСегодня используются более сложные алгоритмы. Например, создан
специальный язык разметки для
искусственного интеллекта AIML
(Artificial Intelligence Markup Lan
guage) для создания виртуальных
агентов (или ботов).
Боты, моделируют диалог с
собеседником, используются в
• компьютерных играх и
• на корпоративных вебстраницах, например, для
ответов на вопросы пользователя
о возможностях мобильного
оператора или торговой сети.
Пример современного бота:
https://www.eviebot.com/en/
40.
Вопросы для обсуждения1. Назовите и кратко охарактеризуйте уровни естественного языка,
релевантные для морфологического анализа и синтеза текста.
2. Дайте определения основным понятиям автоматического анализа
текста: слово, словоформа, лемма, машинная основа, стемминг,
частеречный тэгинг.
3. Назовите и дайте краткую характеристику этапам автоматического
анализа текста.
4. Назовите и дайте краткую характеристику этапам автоматического
синтеза текста.
5. Охарактеризуйте системы компьютерного моделирования диалогов,
в том числе роботы-автоответчики. Как происходит обучение
роботов? Как распознать робот-автоответчик?