
























 Информатика
ИнформатикаПохожие презентации:



")






NLP. Типы задач
1.
NLP2.
Типы задач-
Классификация (спам/нет, содержит призыв к чему-то/нет)
Кластеризация (новости/категории)
Машинный перевод (все понятно, но является одним из основных
двигателей прогресса)
3.
Извлечение сущностей4.
Вопросно-ответные системы5.
NLP сложности…
Полисемия: стол, остановка
Омонимия: лук, замок
press space bar to continue (космический бар пресс …)
Анафора: Дворник мел снег. Он устал
Эллипсис: Маша ела красное яблоко, Петя зеленое
6.
Пайплайн-
На первом шаге необходимо разбить документ
Классический подход: текст на предложения, предложения на токены.
(сегментация/токенизация)
Токены и документа в вектора, вектора подаем на вход алгоритму МО
7.
Токенизация на предложения-
Надо разбить на токены поступивший текст
Вначале делаем сегментацию (разбиваем на предложения)
Идея 1: Давайте разбивать по знакам препинания
Идея 2: Давайте сделаем классификатор, который будет по символу
угадывать конец ли это предложения или нет
Вопрос: Зачем нужна идея 2, когда есть идея 1?
8.
Токенизация на предложения-
Надо разбить на токены поступивший текст
Вначале делаем сегментацию (разбиваем на предложения)
Идея 1: Давайте разбивать по знакам препинания
Идея 2: Давайте сделаем классификатор, который будет по символу
угадывать конец ли это предложения или нет
Вопрос: Зачем нужна идея 2, когда есть идея 1?
С вам 2.5$, уважаемый!
9.
Токенизация на предложения-
Надо разбить на токены поступивший текст
Вначале делаем сегментацию (разбиваем на предложения)
Идея 1: Давайте разбивать по знакам препинания
Идея 2: Давайте сделаем классификатор, который будет по символу
угадывать конец ли это предложения или нет
Идея 3: На основе регулярных выражений (TreebankWordTokenizer из nltk.
Используется в DeepPavlov)
10.
Токенизация предложения на слова-
Тут проще, обычно хватает просто пробелов и регулярок
nltk.word_tokenize
11.
Лемматизация и стемминг-
Процесс нормализации слов
dog, dogs, dog’s, dogs’ => dog
the boy’s dogs are different sizes => the boy dog be differ size
-
Стемминг - просто отрезает от корня лишнее
Лемматизация - использует словарь и морфологический анализ, чтобы
привести слово к канонической форме
12.
Лемматизация и стемминг-
Процесс нормализации слов
dog, dogs, dog’s, dogs’ => dog
the boy’s dogs are different sizes => the boy dog be differ size
-
Слово good – это лемма для слова better. Стеммер не увидит эту связь, так как
здесь нужно сверяться со словарем.
13.
Итог предыдущих слайдов-
Получили текст
-
Разбили его на предложение
-
Предложения разбили на токены
14.
Итог предыдущих слайдов-
Получили текст
-
Разбили его на предложение
-
Предложения разбили на токены
-
Что дальше?
15.
Итог предыдущих слайдов-
Получили текст
-
Разбили его на предложение
-
Предложения разбили на токены
-
Что дальше?
-
Нужно получить какое-то представление, которое будет понятно компьютеру
16.
Bag of words-
Каждое слово - вектор совпадающий с длиной словаря
-
Для iго слова на iй позиции стоит 1
-
Плюсы: интерпретируемая, неплохо показывает себя на простейших задачах
-
Минусы: при маленьком словаре работает не очень, тк такое представление не умеет
работать с новыми словами, при большом словаре сильно большая разреженность. Не
учитывает близость слов
17.
Простейшая модель текста-
Для документов вектор состоит из 0/1 (нет слова в документе/есть)
-
Неплохо справляется с задачами классификации, тк есть явный указатель на
ключевые слова
18.
Счетная модель текста-
Состоит из натуральных чисел (сколько раз слово встречается в тексте)
-
Чтобы работать с текстами разной длины - можно делить на длину документа
-
Можно считать не отдельно слова, а n-граммы
19.
tf-idf-
tf - term frequency, сколько раз терм t встречается в документе делить на количество
слов в документе
-
idf - inverse document frequency, логарифм отношения кол-ва всех документов к кол-во
документов, в которых встречается терм t
20.
Недостатки упомянутых выше методов-
Полученный представления большие
Из-за этого может страдать качество модели
Близость термов по смысле никак не учитывается
21.
Недостатки упомянутых выше методов-
Полученный представления большие
Из-за этого может страдать качество модели
Близость термов по смысле никак не учитывается
22.
Дистрибутивная гипотеза-
Лингвистические единицы встречающиеся в схожих контекстах, имеют
близкие значения
23.
Дистрибутивная гипотеза-
Лингвистические единицы встречающиеся в схожих контекстах, имеют
близкие значения
Мы принимаем эту гипотезу на веру
Нам нужно померить совстречаемость
24.
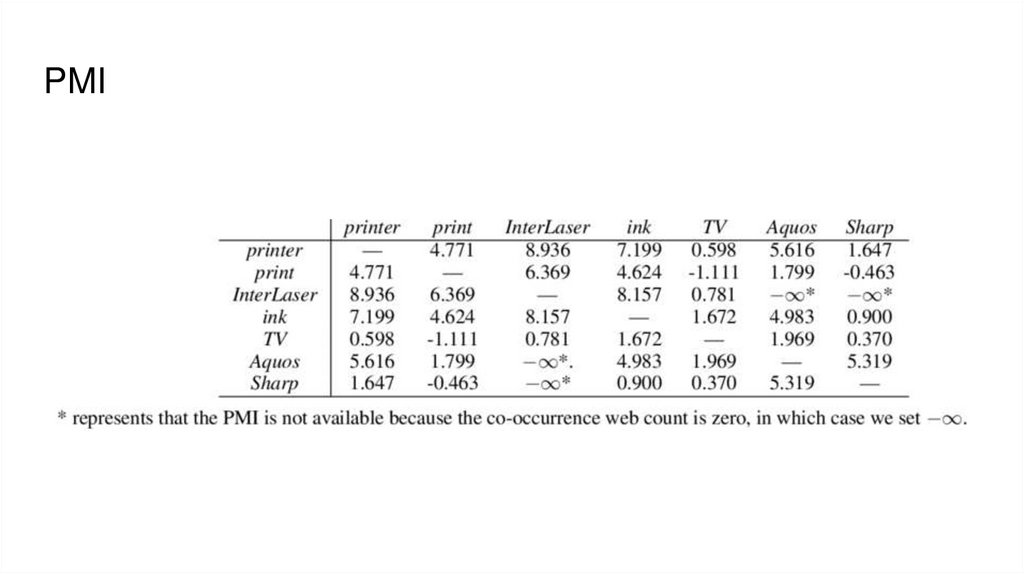
PMI (pointwise mutual information)25.
PMI26.
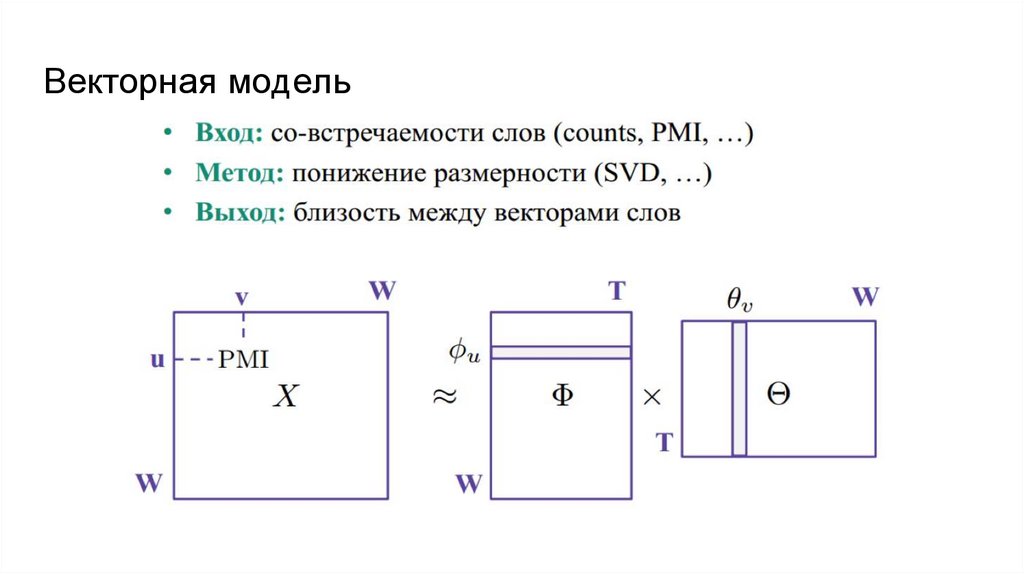
Векторная модель27.
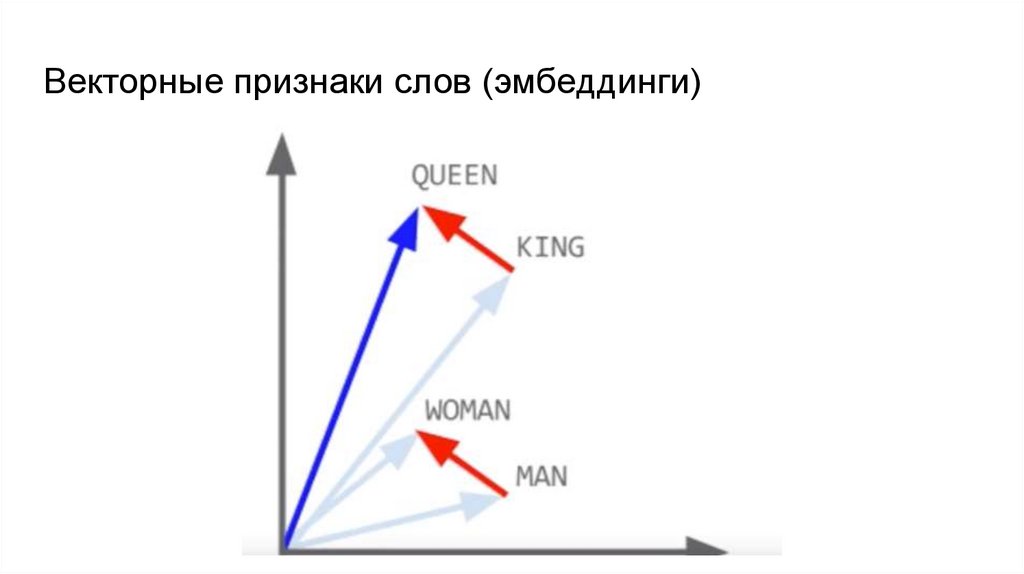
Векторные признаки слов (эмбеддинги)28.
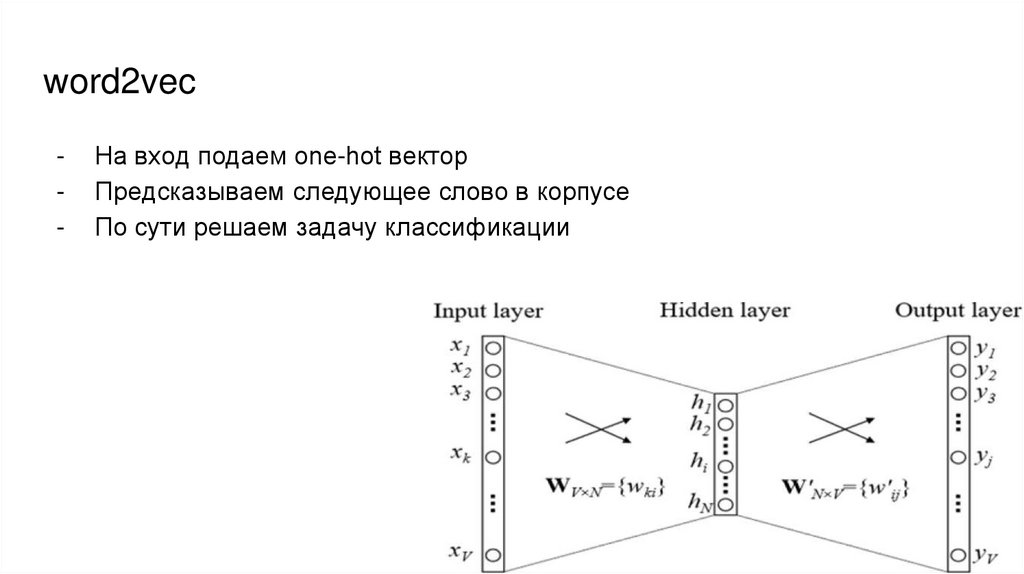
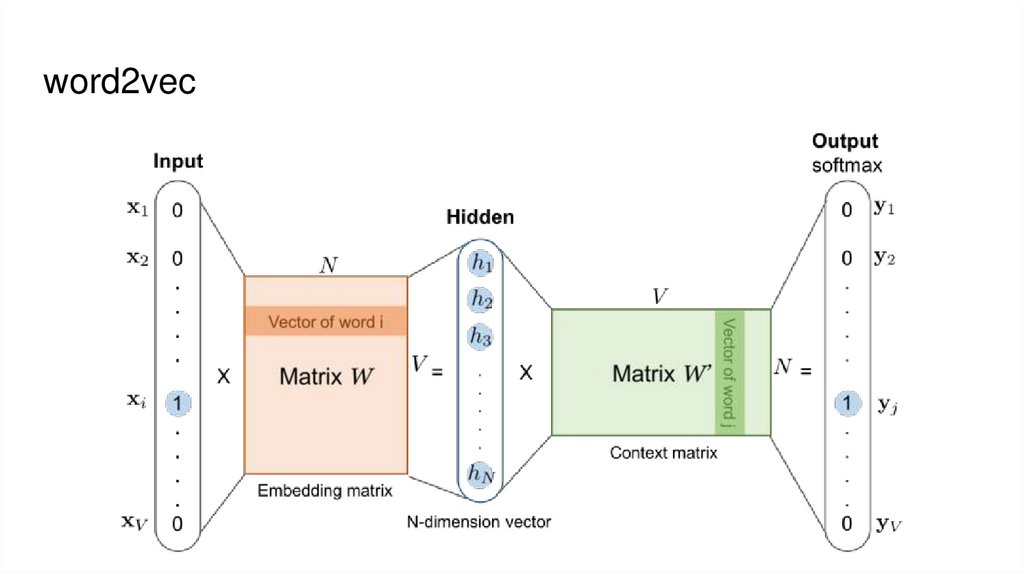
word2vec-
На вход подаем one-hot вектор
Предсказываем следующее слово в корпусе
По сути решаем задачу классификации
29.
word2vec30.
cbow-
На вход подаем one-hot вектор
Предсказываем центральное слово
По сути решаем задачу классификации
31.
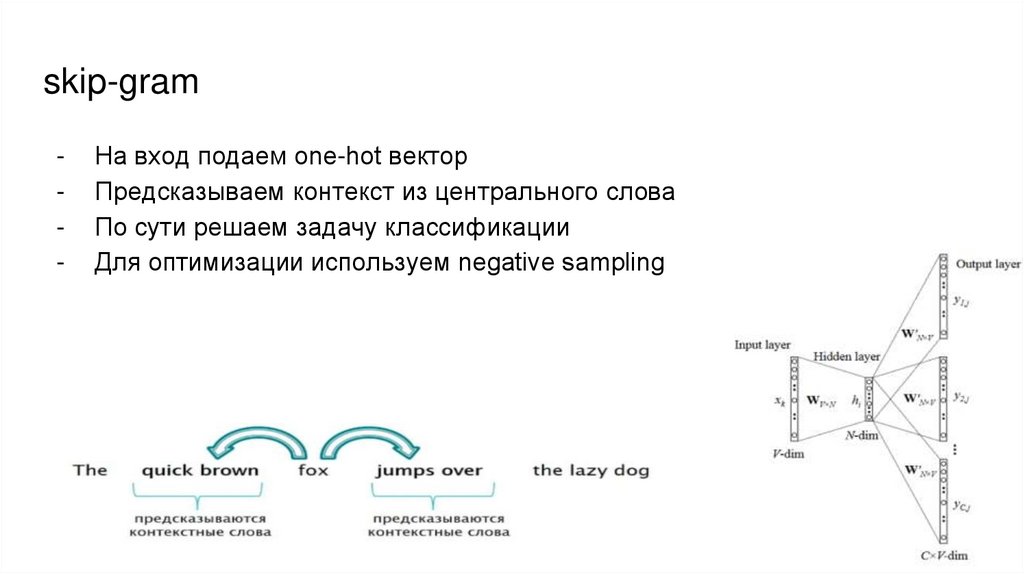
skip-gram-
На вход подаем one-hot вектор
Предсказываем контекст из центрального слова
По сути решаем задачу классификации
Для оптимизации используем negative sampling