














 Интернет
Интернет Образование
ОбразованиеПохожие презентации:










Әлеуметтік жүйелердегі онлайн экстремизм анықтау үшін машиналық оқыту тәсілдерін құрастыру
1.
Қ.И.Сәтбаев атындағы Қазақ Ұлттық Техникалық зерттеу университетіАвтоматика және ақпараттық технологиялар институты
Киберқауіпсіздік, ақпаратты өңдеу және сақтау кафедрасы
«Әлеуметтік жүйелердегі онлайн
экстремизм анықтау үшін машиналық
оқыту тәсілдерін құрастыру»
Орындаған: Алдаберген Ж.Қ
Ғылыми етекші: Тлетай Ш.Т
2.
Жұмыстың мақсаты:1
Бұл жұмыс әлеуметтік жүйелерде экстремистік
мәтінді анықтау мәселесін шешуге бағытталған
машиналық оқыту әдістерін зерттеуге және әзірлеуге
арналған.
3.
“Зерттеу обекъектілері:
Әлеуметтік желідегі экстремизм
Әлеуметтік желілердің API жұмысы
NLP (Natural Language Processing) және мәтінді
семантикалық талдау
Машиналық оқыту әдістері
3
4.
“Дипломдық жұмыстың негізгі зерттеу
әдістері:
Стемминг
және Лемматизация әдістерін қолданып
мәтінді бір формаға келтіру.
Мәтінді классификация жасайтын машиналық оқыту
моделін құрастыру.
4
5.
Дипломдық жұмыс 3 тараудан тұрады1-тарауда: Әлеуметтік желілердегі онлайн экстремизмнің түрлері мен
2
сипаттары қаратырылады.
2-тарауда: Компьютерлік лингвистиканы пайдаланып деректерді талдау
және өңдеу әдістері мен құралдары сипатталады.
3-тарауда: Машиналық оқыту алгоритмдері зерттеледі. Экстремистік
мәтінді анықтайтын машиналық оқыту модельдерін құрастырамыз.
5
6.
Әлеуметтік желілердегі онлайнэкстремизм
⬥ Интернетті пайдалану – еркін және ашық ресурс – кез-келген
ақпаратты жылдам және жасырын түрде таратуға мүмкіндік
береді. Осыған байланысты әлеуметтік желілер зиянды
ниетпен жиі қолданылады. Солардың бірі – онлайн
экстремизм – желі қолданушыларын азғыру және
экстремистік идеологияны насихаттау болып табылады.
6
7.
Экстремизм және оның түрлері⬥ Қазіргі әлемде экстремизм мен терроризмнің өсуі адамдар өмірінің
тұрақтылығы мен қоғам қауіпсіздігіне айтарлықтай қауіп төндіреді.
Қазіргі зерттеулер экстремизмді қоғамдық-саяси өмірдегі жағымсыз
құбылыс ретінде түсіну 100 жыл бұрын қалыптасқанын айтады.Көп
жағдайда, жалпы экстремизм (латын тілінен аударғанда extremus «төтенше») түсінігі – қоғамда қалыптасқан нормалар мен ережелерді
түбегейлі жоққа шығаратын радикалды көзқарастар мен әрекеттер
жиынтығы. Бұл кез-келген, тіпті ең тұрақты және өркендеген қоғамды
сілкіндіретін өте үлкен қауіп.
7
8.
Компьютерлік лингвистика әдістері менқұралдарын пайдаланып деректерді өңдеу
⬥ Табиғи тілді өңдеу (NLP) – бұл компьютерлерге адамның
тілін түсінуге көмектесетін жасанды интеллект (AI)
саласы. Ол тілдің ережелері мен құрылымын зерттеу
үшін лингвистика мен информатиканың мүмкіндіктерін
біріктіреді және мәтін мағынасын түсінуге, талдауға
және ажыратуға қабілетті интеллектуалды жүйелер
құрады.
8
9.
Табиғи тілді өңдеуді (NLP) қолданып машиналар менадамдар арасындағы әдеттегі өзара қарым-қатынас
орнату келесідей сипатқа ие:
1. Адам машинамен сөйлеседі.
2. Машина дыбысты қабылдайды.
3. Дыбысты мәтінге түрлендіреді.
4. Мәтін өңдеуден өтеді.
5. Мәтінді аудиоға түрлендіреді.
6. Құрылғы тиісті әрекетті орындап, дұрыс құрылған сөйлем
негізінде кері байланыс орнатып, жауап қатады. Осының
барлығы 5 секунд ішінде орындалады.
9
10.
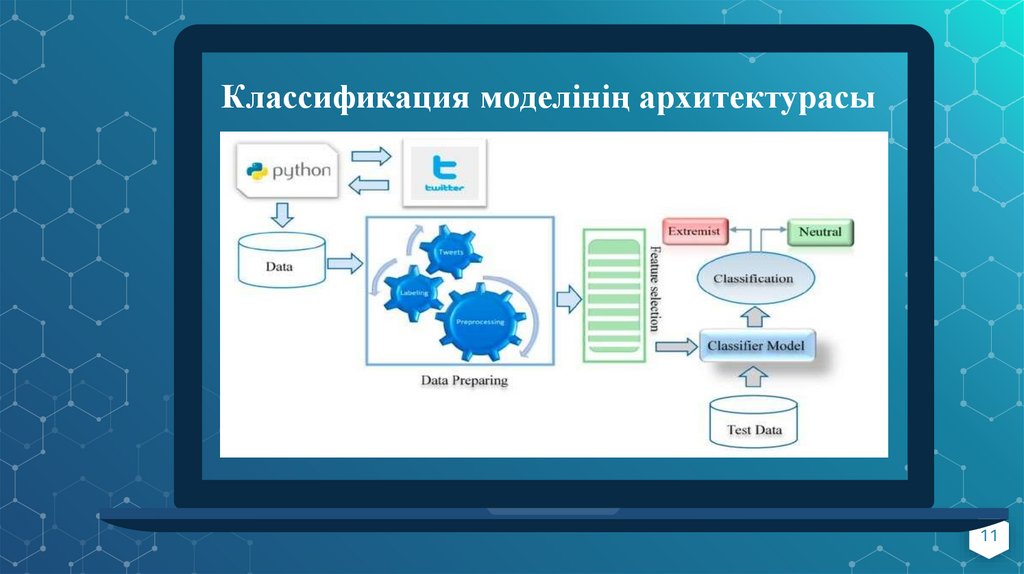
Экстремистік мәтінді анықтайтынмашиналық оқыту модельдерін құру
Машиналық оқыту моделін құруға дейін келесі қадамдар
орындалады:
Деректер жіктеу
Деректерді нейтралды және экстремистік деп таңбалау (0 және 1)
Деректерді алдын-ала өңдеу
Мәтінді векторға түрлендіру
Деректерді train және test бөліктерге бөлу
10
11.
Классификация моделінің архитектурасыPlace your screenshot here
11
12.
Деректерді машиналық оқытуға дайындауБіздің жағдайда деректер ретінде мәтін қарастырылады, сондықтан
деректерді дайындау үшін біз сүзгілеу мен векторизацияны қарастырамыз.
Мәтінді сүзу шу мен шығындыларды азайту үшін жасалады, оны екі жолмен
жүзеге асыруға болады:
Сөзді қалыпты формаға келтіру – стемминг және лемматизация
алгоритмдерін пайдаланып сөздің түбір формасын (негізін) анықтау. Әдістің
жүзеге асырылуына байланысты бірқатар оң және теріс аспектілер бар. Теріс
аспектілерінің бірі - әртүрлі сөз табындағы түбірлес сөздердің негізін анықтау
кезінде түбірі бірдей болып қалуы мүмкін, осылайша оның бірегейлігі
төмендейді. Екінші жағынан, егер сүзгілеу жеткіліксіз болса, сіз жазылуы
жағынан әр түрлі бірақ мағынасы жағынан бірдей сөздерді ала аласыз.
12
13.
Тұрақты өрнектерТұрақты өрнек (regexp, regex) бұл іздеу үлгісін
анықтайтын таңбалар тізбегі. Мысалға:
. - жол берілімінен басқа кез-келген таңба;
\w - бір әріп немесе сан;
\d - бір сан;
\s - бір бос орын;
\W - не әріп емес, не сан емес таңба;
\D - сан емес таңба;
\S - бос орын емес;
[abc] - көрсетілген таңбалардың кез-келгенін a, b немесе c сәйкес
келетінін табады;
[^ abc] - көрсетілгендерден басқа кез-келген таңбаны табады; • [ag] - a-дан g-ге дейінгі диапазондағы таңбаны табады.
13
14.
Деректерді алдын-ала өңдеуДеректер таңбалар, сілтемелер және тыныс белгілері түріндегі
«шу» немесе «керексіз деректерден» тұратын өңделмеген түрінде
болады. Деректердегі керек емес артық символдар модель үшін
пайдасыз және классификаторлардың көрсеткішін төмендетуі
мүмкін. Мұндай қажетсіз символдарды корпустан алып тастау үшін,
біз
төменде
сипатталған
деректерді
өңдеудің
бірнеше
тапсырмаларын орындаймыз.
14
15.
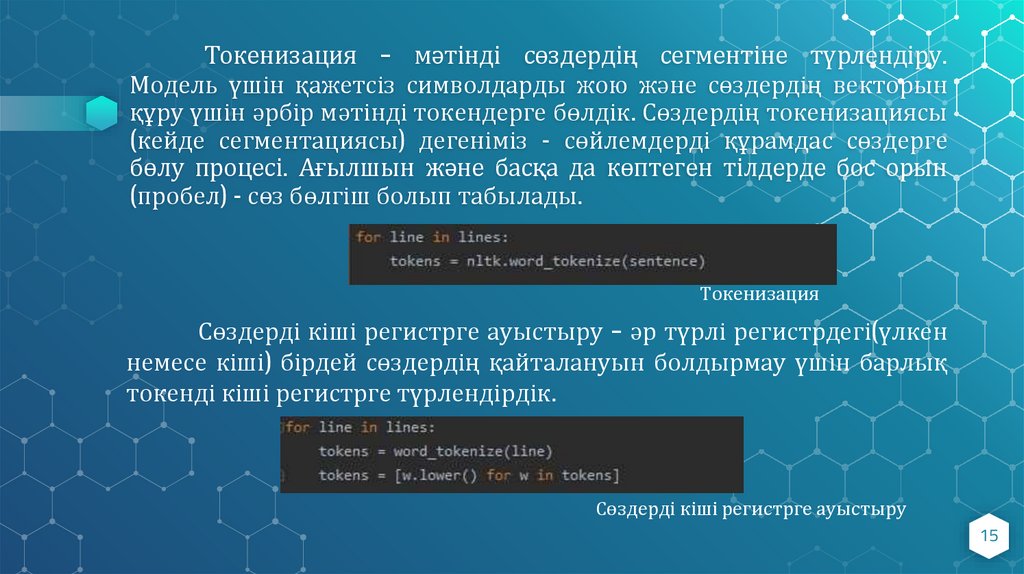
Токенизация – мәтінді сөздердің сегментіне түрлендіру.Модель үшін қажетсіз символдарды жою және сөздердің векторын
құру үшін әрбір мәтінді токендерге бөлдік. Сөздердің токенизациясы
(кейде сегментациясы) дегеніміз - сөйлемдерді құрамдас сөздерге
бөлу процесі. Ағылшын және басқа да көптеген тілдерде бос орын
(пробел) - сөз бөлгіш болып табылады.
Токенизация
Сөздерді кіші регистрге ауыстыру – әр түрлі регистрдегі(үлкен
немесе кіші) бірдей сөздердің қайталануын болдырмау үшін барлық
токенді кіші регистрге түрлендірдік.
Сөздерді кіші регистрге ауыстыру
15
16.
Деректерді өңдеу нәтижесі16
17.
Назарларыңызғарахмет!
17