




 Информатика
ИнформатикаПохожие презентации:










Кодирование сообщений
1.
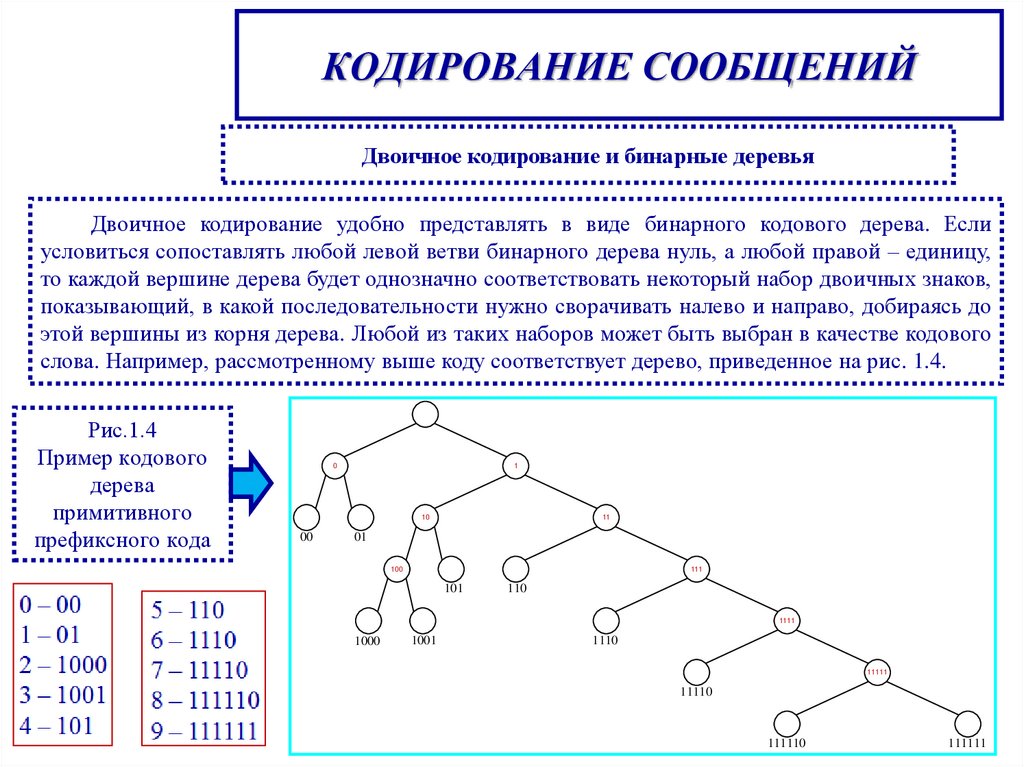
КОДИРОВАНИЕ СООБЩЕНИЙДвоичное кодирование и бинарные деревья
Двоичное кодирование удобно представлять в виде бинарного кодового дерева. Если
условиться сопоставлять любой левой ветви бинарного дерева нуль, а любой правой – единицу,
то каждой вершине дерева будет однозначно соответствовать некоторый набор двоичных знаков,
показывающий, в какой последовательности нужно сворачивать налево и направо, добираясь до
этой вершины из корня дерева. Любой из таких наборов может быть выбран в качестве кодового
слова. Например, рассмотренному выше коду соответствует дерево, приведенное на рис. 1.4.
Рис.1.4
Пример кодового
дерева
примитивного
префиксного кода
0
1
10
00
11
01
100
111
101
110
1111
1000
1001
1110
11111
11110
111110
111111
2.
КОДИРОВАНИЕ СООБЩЕНИЙДвоичное кодирование и бинарные деревья
Очевидно, что условие префиксности кода в терминологии бинарных деревьев можно
сформулировать следующим образом: никакие две вершины, изображающие некоторую пару
кодовых слов, не лежат на одном пути из корня кодового дерева.
Процесс двоичного кодирования можно интерпретировать следующим образом. На каждом
шаге движения по кодовому дереву, начиная от корня, происходит выбор одного из двух
поддеревьев: правого и левого. Это соответствует разбиению множества знаков алфавита на два
подмножества – правое и левое – с присвоением им очередных двоичных знаков (единицы и
нуля). Так, в рассмотренном примере множество {0,…,9} было разбито на два подмножества
{0,1} и {2,3,…,9}. При дальнейшем движении вправо множество {2,3,…,9} в свою очередь было
разбито на два подмножества {2,3,4} и {5,6,…,9}, а при движении влево множество {0,1} было
разбито на два подмножества {0} и {1} и т.д. до тех пор, пока во всех подмножествах не
осталось по одному элементу.
Таким образом, двоичные коды, соответствующие вершинам кодового дерева,
характеризуют «историю» последовательного разбиения исходного множества знаков на правые
и левые подмножества.
3.
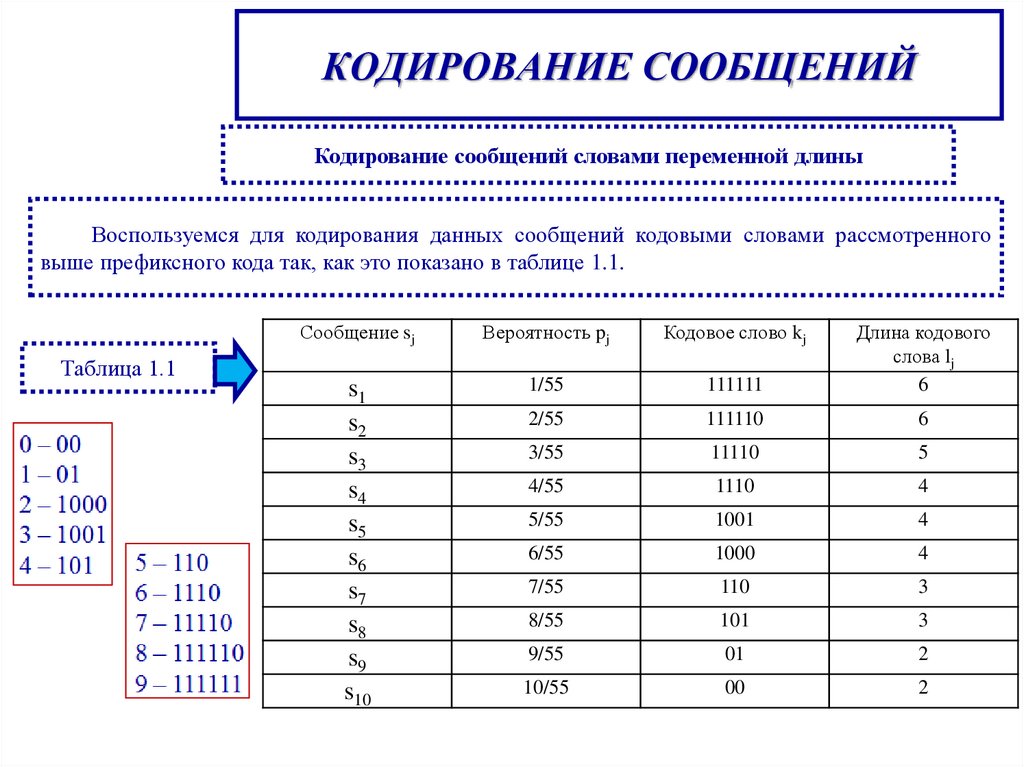
КОДИРОВАНИЕ СООБЩЕНИЙКодирование сообщений словами переменной длины
4.
КОДИРОВАНИЕ СООБЩЕНИЙКодирование сообщений словами переменной длины
Воспользуемся для кодирования данных сообщений кодовыми словами рассмотренного
выше префиксного кода так, как это показано в таблице 1.1.
Таблица 1.1
Сообщение sj
Вероятность pj
Кодовое слово kj
s1
s2
s3
s4
s5
s6
s7
s8
s9
s10
1/55
111111
Длина кодового
слова lj
6
2/55
111110
6
3/55
11110
5
4/55
1110
4
5/55
1001
4
6/55
1000
4
7/55
110
3
8/55
101
3
9/55
01
2
10/55
00
2
5.
КОДИРОВАНИЕ СООБЩЕНИЙКодирование сообщений словами переменной длины
6.
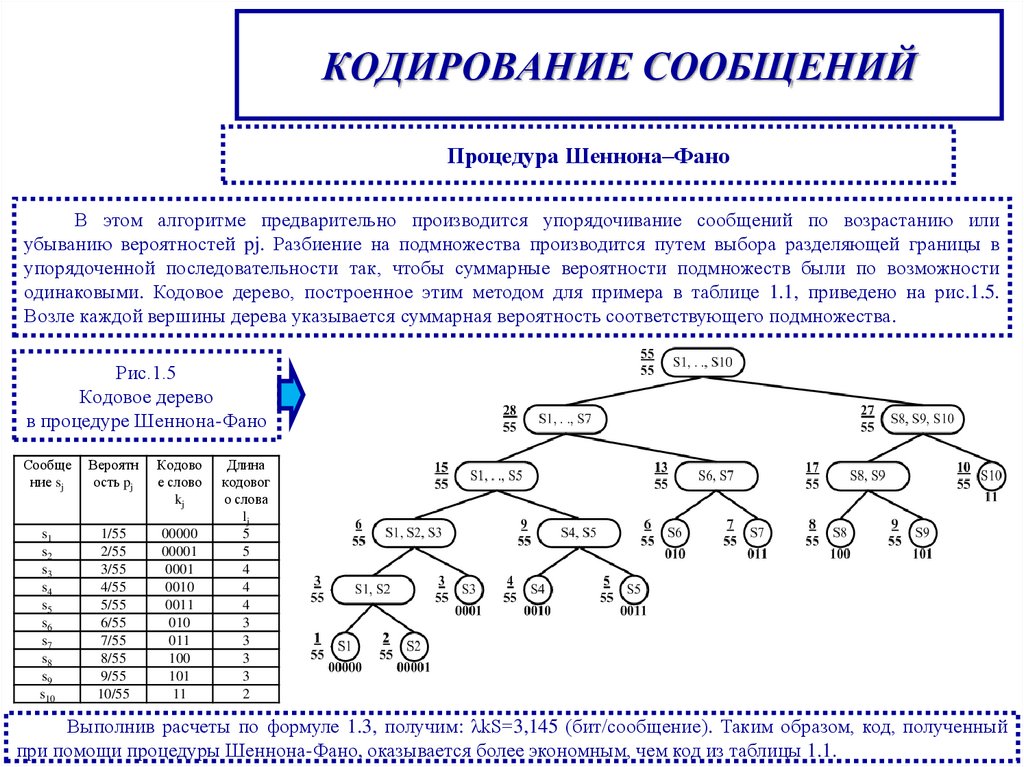
КОДИРОВАНИЕ СООБЩЕНИЙПроцедура Шеннона–Фано
В этом алгоритме предварительно производится упорядочивание сообщений по возрастанию или
убыванию вероятностей pj. Разбиение на подмножества производится путем выбора разделяющей границы в
упорядоченной последовательности так, чтобы суммарные вероятности подмножеств были по возможности
одинаковыми. Кодовое дерево, построенное этим методом для примера в таблице 1.1, приведено на рис.1.5.
Возле каждой вершины дерева указывается суммарная вероятность соответствующего подмножества.
Рис.1.5
Кодовое дерево
в процедуре Шеннона-Фано
Сообще
ние sj
Вероятн
ость pj
Кодово
е слово
kj
s1
s2
s3
s4
s5
s6
s7
s8
s9
s10
1/55
2/55
3/55
4/55
5/55
6/55
7/55
8/55
9/55
10/55
00000
00001
0001
0010
0011
010
011
100
101
11
Длина
кодовог
о слова
lj
5
5
4
4
4
3
3
3
3
2
Выполнив расчеты по формуле 1.3, получим: λkS=3,145 (бит/сообщение). Таким образом, код, полученный
при помощи процедуры Шеннона-Фано, оказывается более экономным, чем код из таблицы 1.1.
7.
КОДИРОВАНИЕ СООБЩЕНИЙПроцедура Хафмана
Рассмотренная процедура Шеннона-Фано является простым, но не всегда оптимальным
алгоритмом построения экономного кода. Причина состоит в том, что способ разбиения на
подмножества ограничен: вероятности сообщений, отнесенных к первому подмножеству, всегда
больше или всегда меньше вероятностей сообщений, отнесенных ко второму подмножеству.
Оптимальный алгоритм, очевидно, должен учитывать все возможные комбинации при разбиении
на равновероятные подмножества. Это обеспечивается в процедуре Хафмана.
Процедура Хафмана представляет собой рекурсивный алгоритм, который строит бинарное
дерево «в обратную сторону», т.е. от конечных вершин к корню. Основная идея алгоритма состоит
в том, чтобы объединить два сообщения с наименьшими вероятностями – например, p1 и p2 – в
одно множество и далее решать задачу с m-1 сообщениями и вероятностями p1’ = p1 + p2; p2’ = p3;
… ; pm-1’ = pm. Кодовое дерево, построенное процедурой Хафмана для рассматриваемого
примера, приведено на рис.1.6.
8.
КОДИРОВАНИЕ СООБЩЕНИЙПроцедура Хафмана
Рис.1.6
Кодовое дерево в процедуре Хафмана
Расчеты по формуле 1.3
дают среднее значение
длины кодового слова
λkS=3,145
(бит/сообщение), что
совпадает с результатом
применения процедуры
Шеннона-Фано. Это
означает, что для данного
примера процедура
Шеннона-Фано также
оказалась оптимальной.