










































 АЛГОРИТМОВ КОМПРЕССИИ")
 Информатика
ИнформатикаПохожие презентации:








")

Эффективное кодирование сообщений
1. ЭФФЕКТИВНОЕ КОДИРОВАНИЕ СООБЩЕНИЙ
Постановка задачи кодирования источникаБазовые стратегии компрессии данных
Кодовые слова фиксированной длины
Неравномерные коды
Методы оптимального кодирования без
памяти
Методы трансформации данных
Методики сравнения алгоритмов. Наборы
тестовых данных
2. ПОСТАНОВКА ЗАДАЧИ КОДИРОВАНИЯ ИСТОЧНИКА
При кодировании, в соответствии с определеннымправилом (кодом) f последовательность ui
преобразуется в конечную последовательность
(кодовое слово) xi = (x1, x2, ..., xk), формируемую из
букв алфавита D=(d1, ..., dm) кодового словаря X.
Если множество конечных последовательностей
источника обозначить как U*, а множество
конечных кодовых слов – как X*, то кодирование –
это отображение
f : U* X*,
а код последовательности ui или кодовое слово xi –
как xi = f(ui).
3. ПОСТАНОВКА ЗАДАЧИ КОДИРОВАНИЯ ИСТОЧНИКА
Кодыпеременной
длины
Коды
фиксированной
длины
Типы кодирования источника:
- слова источника ui различной длины ni -> кодовые слова
xi одинаковой длины ki=k=const;
- слова источника ui одинаковой длины ni=n=const ->
кодовые слова xi одинаковой длины ki=k=const;
- слова источника ui одинаковой длины ni=n=const ->
кодовые слова xi различной длины ki;
- слова источника переменной длины ui -> кодовые слова
xi переменной длины ki.
Эффективное кодирование обеспечивает увеличение
средней информационной нагрузки на кодовое слово
(символ кодового словаря).
4. БАЗОВЫЕ СТРАТЕГИИ КОМПРЕССИИ ДАННЫХ
1. Статистическое кодирование:- блочное, когда статистика хранится с
данными
- поточное, когда статистика постоянно
обновляется
2. Трансформация потока (словарные
методы)
3. Трансформация блока
5. КОДОВЫЕ СЛОВА ФИКСИРОВАННОЙ ДЛИНЫ
Блоковое кодирование сопоставляет уникальнуюпоследовательность из R кодовых символов каждому
из L символов дискретного источника.
Число двоичных символов кодера на один символ
источника
R=[log2L]+1.
Поскольку H(X) log2L, то R H(X). Эффективность
кодирования определяется отношением H(X)/R.
Если L равно степени 2 и символы источника
равновероятны, то R=H(X).
Если L не является степенью 2, но символы
источника все еще равновероятны, R отличается от
H(X) самое большее на 1 символ.
6. КОДОВЫЕ СЛОВА ФИКСИРОВАННОЙ ДЛИНЫ
Пример. Передача числового сообщения длиной N, состоящего изцифр от 0 до 9 (L=10).
Каждая цифра может содержать информацию, равную самое
большее log210 3,32193 бит.
Цифр в
блоке
Битов
на
блок
Ср.
число
битов на
цифру
Разность
Распределение
1
4
4
4-3,32
p(0)=25/40=0,6250;
p(1)=15/40=0,3715
2
7
3,5
3,5-3,32
p(0)=384/700=0,5486;
p(1)=316/700=0,4514
3
10
3,33
3,33-3,32
p(0)=5312/10000=0,5312
p(1)=4688/10000=0,4688
Теорема о кодировании источника
кодами фиксированной длины
log L k log L 1
log m J log m J
7. НЕРАВНОМЕРНЫЕ КОДЫ
Применение:при неравных вероятностях сообщений источника.
Требования к кодам переменной длины:
- свойство однозначности (единственности декодирования);
- отсутствие префикса (возможность мгновенного
декодирования).
Условие существование мгновенного кода – неравенство
Крафта:
Необходимое и достаточное условие для существования
двоичного кода с кодовыми символами длины k1 k2 ... kL,
удовлетворяющего условию отсутствия префикса
L
L
1
1
ki
i 1 2
или
k ki
L
2
2
i 1
8. НЕРАВНОМЕРНЫЕ КОДЫ
Префиксному коду сопоставляется бинарноеориентированное дерево.
Если имеет место строгое неравенство, то код является
неэффективным.
9. НЕРАВНОМЕРНЫЕ КОДЫ
Обобщенная теорема кодирования источника:Дискретный источник без памяти U имеет алфавит из L букв
A=(a1,...,aL) с вероятностями p(a1), ..., p(aL).
Обозначим через m количество возможных символов в
кодовом алфавите, а ki – число букв в кодовом слове,
соответствующем ai. Тогда среднее число букв в кодовом
слове на одну букву источника
будет определяться как
L
k p (ai )ki
i 1
При заданном конечном ансамбле источника U с энтропией
H(U) и кодовом алфавите из m символов существует
возможность создать код, который отвечает префиксному
требованию условию и имеет среднюю длину,
H (U )
H (U )
удовлетворяющую условию
k
1
log m
log m
10. КОДИРОВАНИЕ ИСТОЧНИКОВ БЕЗ ПАМЯТИ
Метод ШеннонаРасположим все сообщения ui длиной J в порядке убывания их
вероятностей, пусть это будут вероятности
p1, p2, ..., pN, где
S 1
N=LJ – число сообщений ui. Пусть Qs pi- накопленная
i 1
вероятность до ps-1 включительно. Закодируем сначала все
сообщения в двоичную систему (m=2). Двоичный код для
сообщения us получается путем записи дробной части
разложения Qs как двоичного числа (с учетом того, что при
S=1 Qs=0). Разложение производится до позиции ms, где ms –
целое число, удовлетворяющее соотношению
1
1
log 2
ms 1 log 2
ps
ps
11. КОДИРОВАНИЕ ИСТОЧНИКОВ БЕЗ ПАМЯТИ
Метод Шеннона1
2
Сообщ.
ps
Двоичное
Qs
Qs
S
ms
ps
log2(1/ps)
1
2ms 1
log2(1/ps) ms < 1+log2(1/ps)
1+log2(1/ps)
1/2^ms
Код
a (00)
0.5
1
0
0,0000
1
2
1
0.5
0
b (01)
0.25
2
0.5
0,1000
2
3
2
0.25
10
c (10)
0.125
3
0.75
0,1100
3
4
3
0.125
110
d (11)
0.125
4
0.875
0,1110
3
4
3
0.125
111
kJ
2 бит
HJ(U)
1,75 бит
1*0.5+2*0.25+3*0.125+3*0.125 = 1,75 бит
12. КОДИРОВАНИЕ ИСТОЧНИКОВ БЕЗ ПАМЯТИ
Статический метод ХаффманаЛемма. Пусть вероятности букв (символов) алфавита
источника упорядочены по убыванию
p(a1) p(a2) ... p(aL).
Тогда существует оптимальный код, длина слов которого не
убывают, а две наименее вероятные буквы имеют коды
одинаковой длины:
|f(a1)| |f(a2)| ... |f(aL-1)| = |f(aL)|.
13. КОДИРОВАНИЕ ИСТОЧНИКОВ БЕЗ ПАМЯТИ
Статический метод ХаффманаПример построения дерева Хаффмана (H-дерева).
Средняя длина кода равна
0,3*2+0,2*2+0,15*3+0,15*3+0,1*3+0,1*3=
0,6+0,4+0,45+0,45+0,3+0,3=1+0,9+0,6=2,5).
14. КОДИРОВАНИЕ ИСТОЧНИКОВ БЕЗ ПАМЯТИ
Статический метод ХаффманаНеоднозначности при построении дерева
Вариант 1 (перекошенное)
x1
x2
x3
x4
x5
Вариант 2 (сбалансированное)
p(ai)
f(ai)
|f(ai)|
0,4
0,2
0,2
0,1
0,1
0
10
110
1110
1111
1
2
3
4
4
0,2
0,4
0,6
1,0
x1
x2
x3
x4
x5
p(ai)
0,4
0,2
0,2
0,1
0,1
0,6
1,0
0,2
0,4
f(ai)
00
01
10
110
111
|f(ai)|
2
2
2
3
3
Средняя длина кодового слова одинакова: 2,2 бита
Дисперсии длин:
D1=0,4(1-2,2)2 + 0,2(2-2,2)2 + 0,2(3-2,2)2 + 0,1(4-2,2)2 + 0,1(4-2,2)2 = 1,36;
D2=0,4(2-2,2)2 + 0,2(2-2,2)2 + 0,2(2-2,2)2 + 0,1(3-2,2)2 + 0,1(3-2,2)2 = 0,16.
15. КОДИРОВАНИЕ ИСТОЧНИКОВ БЕЗ ПАМЯТИ
Адаптивный метод ХаффманаКОДЕР
ИнициализироватьМодель();
Пока не конец Сообщения
Символ = ВзятьСледующийСимвол();
Закодировать(Символ);
ОбновитьМодельСимволом(Символ);
Конец Пока
Пример упорядоченного
дерева (W – вес узла, N –
порядковый номер):
ДЕКОДЕР
ИнициализироватьМодель();
Пока не конец БитовогоПотока
Символ = РаскодироватьСледующийСимвол();
ВыдатьСимвол(Символ);
ОбновитьМодельСимволом(Символ);
Конец Пока
16. КОДИРОВАНИЕ ИСТОЧНИКОВ БЕЗ ПАМЯТИ
Адаптивный метод ХаффманаОбновление дерева выполняется в 2 этапа:
1-й этап: увеличивается вес листа дерева,
соответствующего последнему считанному и
закодированному символу. Затем увеличивается вес его
родителя, родителя родителя и т.д. до тех пор, пока не
дойдем до корня дерева;
После кодирования
символа "А"
17. КОДИРОВАНИЕ ИСТОЧНИКОВ БЕЗ ПАМЯТИ
Адаптивный метод Хаффмана2-й этап обновления дерева – перестановка узлов
дерева – требуется тогда, когда увеличение веса узла
приводит к нарушению свойства упорядоченности.
Нарушение
упорядоченности
после "АА"
о
ан
ст
ре
Пе
а
вк
После
кодирования
"АААА"
18. КОДИРОВАНИЕ ИСТОЧНИКОВ БЕЗ ПАМЯТИ
Адаптивный метод ХаффманаПроблемы адаптивного кодирования:
- инициализация модели (специальные символы EOF и
ESCAPE);
- переполнение.
Метод расширяющегося префикса (splay trees)
Класс алгоритмов расширяющегося префикса
(расширяющихся деревьев – splay trees), в которых деревья,
используемые при сжатии данных, могут не иметь
постоянной упорядоченности.
Это существенно упрощает процедуры обработки дерева и
позволяет повысить быстродействие алгоритма при
незначительной потере эффективности кодирования.
19. КОДИРОВАНИЕ ИСТОЧНИКОВ БЕЗ ПАМЯТИ
Метод ХаффманаНедостаток: метод Хаффмана присваивает каждому символу
алфавита код с целым числом битов.
20. КОДИРОВАНИЕ ИСТОЧНИКОВ БЕЗ ПАМЯТИ
Арифметическое кодированиеФормирование одного (длинного) кода для всего потока
символов.
Сообщение: ДЛИННОШЕЕЕ
Символ
Вероятность
Интервал
Д
1/10
[0.00...0.10)
Е
3/10
[0.10...0.40)
И
1/10
[0.40...0.50)
Л
1/10
[0.50...0.60)
Н
2/10
[0.60...0.80)
О
1/10
[0.80...0.90)
Ш
1/10
[0.90...1.00)
21. КОДИРОВАНИЕ ИСТОЧНИКОВ БЕЗ ПАМЯТИ
Арифметическое кодированиеКодер
НижняяГраница = 0.0;
ВерхняяГраница = 1.0;
ПОКА ((ОчереднойСимвол=ВзятьОчереднойСимвол()) != EOF)
Интервал = ВерхняяГраница – НижняяГраница;
НижняяГраница = НижняяГраница + Интервал *
НижняяГраницаИнтервала(ОчереднойСимвол);
ВерхняяГраница = НижняяГраница + Интервал *
ВерхняяГраницаИнтервала(ОчереднойСимвол);
КОНЕЦ ПОКА;
Выдать(НижняяГраница);
Интервал
НижняяГраница
ВерхняяГраница
0.0
1.0
Д
1.0
0.0 + 1.0*0.0 = 0.0
0.0 + 1.0*0.1 = 0.1
Л
0.1
0.0 + 0.1*0.5 = 0.05
0.0 + 0.1*0.6 = 0.06
И
0.01
0.05 + 0.01*0.4 = 0.054
0.05 + 0.01*0.5 = 0.055
Н
0.001
0.054+0.001*0.6=0.0546
0.054+0.001*0.8=0.0548
Н
0.0002
0.0546+0.0002*0.6=0.05472
0.0546+0.0002*0.8=0.05476
О
0.00004
0.05472+0.00004*0.8=0.054752
0.05472+0.00004*0.9=0.054756
Ш
0.000004
0.054752+0.000004*0.9=0.0547556
0.054752+0.000004*1.0=0.054756
Е
0.0000004
0.0547556+0.0000004*0.1=0.05475564
0.0547556+0.0000004*0.4=0.05475576
Е
0.00000012
0.05475564+0.00000012*0.1=0.054755652
0.05475564+0.00000012*0.4=0.054755688
Е
0.000000036
0.054755652+0.000000036*0.1=0.0547556556
0.054755652+0.000000036*0.4=0.0547556664
22. КОДИРОВАНИЕ ИСТОЧНИКОВ БЕЗ ПАМЯТИ
Арифметическое кодированиеДекодер
Число = ПрочитатьЧисло();
ВСЕГДА
Символ = НайтиСимволВИнтервалКоторогоПопадаетЧисло(Число);
Выдать(Символ);
Интервал = ВерхняяГраницаИнтервала(Символ) – НижняяГраницаИнтервала(Символ);
Число = Число – НижняяГраницаИнтервала(Символ);
Число = Число / Интервал;
КОНЕЦ ВСЕГДА;
Число
Символ
НижняяГраница
ВерхняяГраница
Интервал
0.0547556556
Д
0.0
0.1
0.1
0.547556556
Л
0.5
0.6
0.1
0.47556556
И
0.4
0.5
0.1
0.7556556
Н
0.6
0.8
0.2
0.778278
Н
0.6
0.8
0.2
0.89139
О
0.8
0.9
0.1
0.9139
Ш
0.9
1.0
0.1
0.139
Е
0.1
0.4
0.3
0.13
Е
0.1
0.4
0.3
0.1
Е
0.1
0.4
0.3
0.0
23. КОДИРОВАНИЕ ИСТОЧНИКОВ БЕЗ ПАМЯТИ
Арифметическое кодирование.Целочисленная реализация
Границы (Low, High)
Интервал
Целочисленные
границы
Выходной поток
(перенос)
Сдвиг
(нормализация)
Интервал
L = 0.0
H = 1.0
1.0
L = 0000
H = 9999
Д
L = 0.0 + 1.0 * 0.0 = 0.0
H = 0.0 + 1.0 * 0.1 = 0.1
0.1
L = 0000
H = 0999
"0"
0000
9999
[0..1)
Л
L = 0.0 + 1.0 * 0.5 = 0.5
H = 0.0 + 1.0 * 0.6 = 0.6
0.1
L = 5000
H = 5999
"5"
0000
9999
[0..1)
И
L = 0.0 + 1.0 * 0.4 = 0.4
H = 0.0 + 1.0 * 0.5 = 0.5
0.1
L = 4000
H = 4999
"4"
0000
9999
[0..1)
Н
L = 0.0 + 1.0 * 0.6 = 0.6
H = 0.0 + 1.0 * 0.8 = 0.8
0.2
L = 6000
H = 7999
Н
L = 0.6 + 0.2 * 0.6 = 0.72
H = 0.6 + 0.2 * 0.8 = 0.76
0.04
L = 7200
H = 7599
"7"
2000
5999
[0.2...0.6)
О
L = 0.2 + 0.4 * 0.8 = 0.52
H = 0.2 + 0.4 * 0.9 = 0.56
0.04
L = 5200
H = 5599
"5"
2000
5999
[0.2...0.6)
Ш
L = 0.2 + 0.4 * 0.9 = 0.56
H = 0.2 + 0.4 * 1.0 = 0.6
0.04
L = 5600
H = 5999
"5"
6000
9999
[0.6...1.0)
Е
L = 0.6 + 0.4 * 0.1 = 0.64
H = 0.6 + 0.4 * 0.4 = 0.76
0.12
L = 6400
H = 7599
Е
L = 0.64 + 0.12 * 0.1 = 0.652
H = 0.64 + 0.12 * 0.4 = 0.688
0.036
L = 6520
H = 6879
"6"
5200
8799
[0.52...0.88)
Е
L = 0.52 + 0.36 * 0.1 = 0.556
H = 0.52 + 0.36 * 0.4 = 0.664
0.108
L = 5560
H = 6639
"5560"
[0..1)
24. КОДИРОВАНИЕ ИСТОЧНИКОВ БЕЗ ПАМЯТИ
i = 0;delitel = b[clast];
// delitel = 10
FIRST_QTR = (High0+1) / 4;
// 16384 = 010000000..
HALF = FIRST_QTR * 2;
// 32768 = 100000000..
THIRD_QTR = FIRST_QTR * 3;
// 49152 = 110000000..
cntr = 0;
while not eof()
{
c = ReadSymbol();
// Взять входной символ
j = IndexForSymbol(c); // Индекс по таблице
i++;
Interval = Highi-1 – Lowi-1 + 1;
// Текущий интервал
Lowi = Lowi-1 + b[j-1]*Interval / delitel;
// Нижняя граница
Highi = Lowi-1 + b[j]*Interval / delitel - 1;
// Верхняя граница
for ( ; ; )
// Обрабатываем варианты
{
if (Highi < HALF)
// у обоих границ старший
бит = 0
OutputBitPlusFollow(0);
else if (Lowi > HALF)
// у обоих границ старший
бит = 1
{
OutputBitPlusFollow(1);
Lowi -= HALF;
// обнуляем старший бит
Highi -= HALF;
}
else if ((Lowi >= FIRST_QTR) && (Highi <=THIRD_QTR)) // сближаются!
{
cntr ++;
// наращиваем счетчик
Lowi -= FIRST_QTR;
// расширяем интервал
Highi -= FIRST_QTR;
}
else
// диапазон еще достаточно
широк
break;
Lowi = 2 * Lowi;
Highi = 2 * Highi + 1;
}
}
void OutputBitPlusFollow(int bit)
{
WriteStreamBit(bit);
for (; cntr>0; cntr--)
WriteStreamBit(!bit);
}
КОДИРОВАНИЕ ИСТОЧНИКОВ
БЕЗ ПАМЯТИ
Арифметическое кодирование. Кодер
25. КОДИРОВАНИЕ ИСТОЧНИКОВ БЕЗ ПАМЯТИ
Low0 = 0; High0 = 65535;i = 0;
delitel = b[clast];
FIRST_QTR = (High0+1) / 4;
HALF = FIRST_QTR * 2;
THIRD_QTR = FIRST_QTR * 3;
// delitel = 10
// 16384 = 010000000..
// 32768 = 100000000..
// 49152 = 110000000..
КОДИРОВАНИЕ ИСТОЧНИКОВ
БЕЗ ПАМЯТИ
Value = Read16Bit();
Interval = Highi-1 – Lowi-1 + 1;
Cum = (Value – Lowi + 1) * delitel – 1) / Interval;
for (j=1; b[j]<Cum; j++);
// Чтение из потока первого слова
// Текущий интервал
// Накопленная сумма
// Нашли соответствующий символ
// Пересчитать границы
Lowi = Lowi-1 + b[j-1]*Interval / delitel;
// Нижняя граница
Highi = Lowi-1 + b[j]*Interval / delitel - 1;
// Верхняя граница
// Удаление символа из входного потока
for ( ; ; )
{
if (Highi < HALF)
// старший бит = 0 – ничего не делать
{
}
else if (Lowi >= HALF)
{
Value -= HALF;
// обнуляем старший бит
Lowi -= HALF;
Highi -= HALF;
}
else if ((Lowi >= FIRST_QTR) && (Highi <=THIRD_QTR)) // сближаются!
{
Value -= FIRST_QTR;
// обнуляем второй слева бит
Lowi -= FIRST_QTR;
Highi -= FIRST_QTR;
}
else
// диапазон еще достаточно широк
break;
Lowi = 2 * Lowi;
Highi = 2 * Highi + 1;
Value = 2 * Value + ReadNextBit(); // Читаем следующий бит из потока
}
Арифметическое кодирование. Декодер
26. КОДИРОВАНИЕ ИСТОЧНИКОВ БЕЗ ПАМЯТИ
Integer Coding (целочисленноекодирование, SEM-кодирование с
разделение экспонент и мантисс и т.п.)
Основная идея - отдельно описывать порядок значения
элемента (экспоненту) и отдельно – значащие цифры
значения (мантиссу).
Цель – закодировать число произвольной величины, когда
верхняя граница чисел потока источника (которую
необходимо знать, чтобы выбрать фиксированное
количество битов на число) заранее неизвестна.
Примеры (монотонных) кодов: код Левенштейна (1968),
Райса (1979), Голомба (1966), Фибоначчи (1939), серия
кодов Элайеса (1975).
27. КОДИРОВАНИЕ ИСТОЧНИКОВ БЕЗ ПАМЯТИ
Integer CodingУнарный код неотрицательного целого числа n состоит из (n1) нулей (единиц), за которыми следует одна единица
(ноль), например, унарный код числа 4 = 0001 или 1110,
числа 9 = 000000001 или 111111110.
Монотонный код представляет собой префиксно-свободный
код с минимальными длинами кодовых слов, в котором если
X1>X2, то длина кодового слова S(X1) S(X2) для любых X1,
X2, принадлежащих алфавиту источника, т.е. малые
значения получают более короткие кодовые слова, чем
большие значения.
28. КОДИРОВАНИЕ ИСТОЧНИКОВ БЕЗ ПАМЯТИ
Коды ЭлайесаГамма-код Элайеса числа n представляет собой комбинацию
унарного кода числа и бинарного кода числа n без старшей
единицы: (гамма-код Элайеса для 1 равен 1).
Дельта-кодами Элайеса называются гамма-коды, в которых
унарная часть также закодирована гамма-кодами.
Омега-коды Элайеса рекурсивно кодируют свой префикс,
поэтому иногда называются рекурсивными кодами Элайеса.
29. КОДИРОВАНИЕ ИСТОЧНИКОВ БЕЗ ПАМЯТИ
Коды ЭлайесаЧисло
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
Гамма-код
20
21
21
22
22
22
22
23
23
23
23
23
23
23
23
24
24
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
0
0
1
0
1
2
3
0
1
2
3
4
5
6
7
0
1
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
=
1
010
011
00100
00101
00110
00111
0001000
0001001
0001010
0001011
0001100
0001101
0001110
0001111
000010000
000010001
Дельта-код
20
21
21
22
22
22
22
23
23
23
23
23
23
23
23
24
24
=> N' = 0, N =
+ 0 => N' = 1,
+ 1 => N' = 1,
+ 0 => N' = 2,
+ 1 => N' = 2,
+ 2 => N' = 2,
+ 3 => N' = 2,
+ 0 => N' = 3,
+ 1 => N' = 3,
+ 2 => N' = 3,
+ 3 => N' = 3,
+ 4 => N' = 3,
+ 5 => N' = 3,
+ 6 => N' = 3,
+ 7 => N' = 3,
+ 0 => N' = 4,
+ 1 => N' = 4,
1
N
N
N
N
N
N
N
N
N
N
N
N
N
N
N
N
=> 1
= 2 =>
= 2 =>
= 3 =>
= 3 =>
= 3 =>
= 3 =>
= 4 =>
= 4 =>
= 4 =>
= 4 =>
= 4 =>
= 4 =>
= 4 =>
= 4 =>
= 5 =>
= 5 =>
Омега-кода
0100
0101
01100
01101
01110
01111
00100000
00100001
00100010
00100011
00100100
00100101
00100110
00100111
001010000
001010001
0
10
11
10
10
10
10
11
11
11
11
11
11
11
11
10
10
0
0
100 0
101 0
110 0
111 0
1000 0
1001 0
1010 0
1011 0
1100 0
1101 0
1110 0
1111 0
100 10000 0
100 10001 0
30. КОДИРОВАНИЕ ИСТОЧНИКОВ БЕЗ ПАМЯТИ
Еще один вариант кода Элайеса...elias(i) = ( unar ( |bin' (|bin'(i)|)|+2 ), bin' (|bin'(i)|), bin'(i) )
где bin'(i) – двоичная запись натурального числа i без первой единицы.
Унарный код unar(i) сопоставляет числу i двоичную комбинацию виде 1i-10
(например, unar(1) = 0, unar(2) = 10, unar(3) = 110 и т.д.).
i
elias(i)
length
1
0
1
2
10 0
3
3
10 1
3
4
110 0 00
6
5
110 0 01
6
6
110 0 10
6
7
110 0 11
6
8
110 1 000
7
...
...
...
15
110 1 111
7
31. КОДИРОВАНИЕ ИСТОЧНИКОВ БЕЗ ПАМЯТИ
Код ЛевенштейнаКод Левенштейна для числа n получается путем обращения
последовательности битов в двоичной записи этого числа и
добавления перед каждым битом, кроме последнего, флагового
бита "0". Последним флаговым битом является бит "1",
который совпадает с самым старшим битом в исходной
двоичной записи числа n.
Декодирования числа заканчивается, как только на месте
флагового бита встречается "1" – это и будет последний
информационный бит числа (в его реверсивной записи).
Например: 13 = 1101 => 1011 => 0100011. Подчеркнуты
флаговые биты, выделены информационные биты.
32. КОДИРОВАНИЕ ИСТОЧНИКОВ С ПАМЯТЬЮ
Кодирование длин серий (RLE)Предположим, что для представления длины серии решено
послать двоичное число, состоящее из k цифр.
В соответствии с алгоритмом кодирования, это можно сделать
только в том случае, если длина серии находится между 0 и 2k2. Приемник генерирует указанное число нулей и затем одну 1.
Если получено число 0, то приемник просто генерирует 1.
Если послано число 2k-1, приемник генерирует 2k-1 нулей, за
которыми не следует 1. Если после этого послано 0, то
генерируется 1; для любого другого числа генерируется
указанное число нулей и затем единица (если это не снова 2k-1).
Таким образом, передав достаточное число k-значных двоичных
чисел, можно указать любую длину серии, состоящей из нулей.
33. КОДИРОВАНИЕ ИСТОЧНИКОВ С ПАМЯТЬЮ
Словарное сжатиеВходной алфавит A={0,1,...,|A|-1}.
x – слово, xji - сегмент xixi+1...xj слова.
Разобьем слово x последовательно на несовпадающие подслова (парсинг):
n
x xnn01 1 xnn12 1 xn pp 11 , n0 0, n p 1 n x
таким образом, что все слова, за исключением, возможно, последнего,
различны и для каждого j=1,2,...,p+1 при nj-nj-1>1 существует i, i<j такое,
n j 1
ni
что xni 1 1 xn j 1 1
Конкатенация кодов всех слов образует слово f(x), для длины которого
p
имеем
| f ( x) | [log j | A |]
j 1
С учетом того, что максимальное число C(x) слов, на которые разбивается
x, может лишь превзойти p (C(x) p), имеем
| f ( x) | C ( x) log C ( x)(1 o(1))
34. КОДИРОВАНИЕ ИСТОЧНИКОВ С ПАМЯТЬЮ
Алгоритм LZ77В качестве модели данных используется "скользящее" по сообщению
окно, разделенное на две неравные части (словарь и lookaheadбуфер).
for (i=0; i<MAX-1; i++)\r for (j=i+1; j
<MAX; j++)\r
Обработанная часть сообщения (словарь)
Буфер Look-ahead
Алгоритм LZ77 выдает коды, состоящие из трех элементов:
- смещение в словаре относительно начала буфера, совпадающей с
содержимым буфера (i);
- длина подстроки (j);
- первый символ в буфере, следующий за подстрокой (s).
Дополнительные соглашения:
- нулевое смещение зарезервировано для обозначения конца кодирования;
- последний символ словаря соответствует единичному смещению относительно символа
начала буфера;
- если имеется несколько фраз с одинаковой длиной, то выбирается ближайшая к буферу;
- в неопределенных ситуациях – когда длина совпадения нулевая – смещению (для
определенности) присваивается, например, единичное значение.
35. КОДИРОВАНИЕ ИСТОЧНИКОВ С ПАМЯТЬЮ
Алгоритм LZ77.Шаг
Сжатие фразы "кот_ломом_колол_слона"
Скользящее окно
Совпадающая фраза
Буфер (7)
Словарь (буфер поиска)
(30)
1
Закодированные
данные
i
j
s
кот_лом
-
1
0
'к'
2
к
от_ломо
-
1
0
'о'
3
ко
т_ломом
-
1
0
'т'
4
кот
_ломом_
-
1
0
'_'
5
кот_
ломом_к
-
1
0
'л'
6
кот_л
омом_ко
о
4
1
'м'
7
кот_лом
ом_коло
ом
2
2
'_'
8
кот_ломом_
колол_с
ко
10
2
'л'
9
кот_ломом_кол
ол_слон
ол
2
2
'_'
10
кот_ломом_колол_
слона
-
1
0
'с'
11
кот_ломом_колол_c
лона
ло
5
2
'н'
12
кот_ломом_колол_cлон
а
-
1
0
'а'
Размер исходной фразы: 21 симв. х 8 бит = 168 бит
Размер кода LZ77 (без доп. компрессии кодов): 12 шагов х (5 + 3 + 8) бит = 192 бита
36. КОДИРОВАНИЕ ИСТОЧНИКОВ С ПАМЯТЬЮ
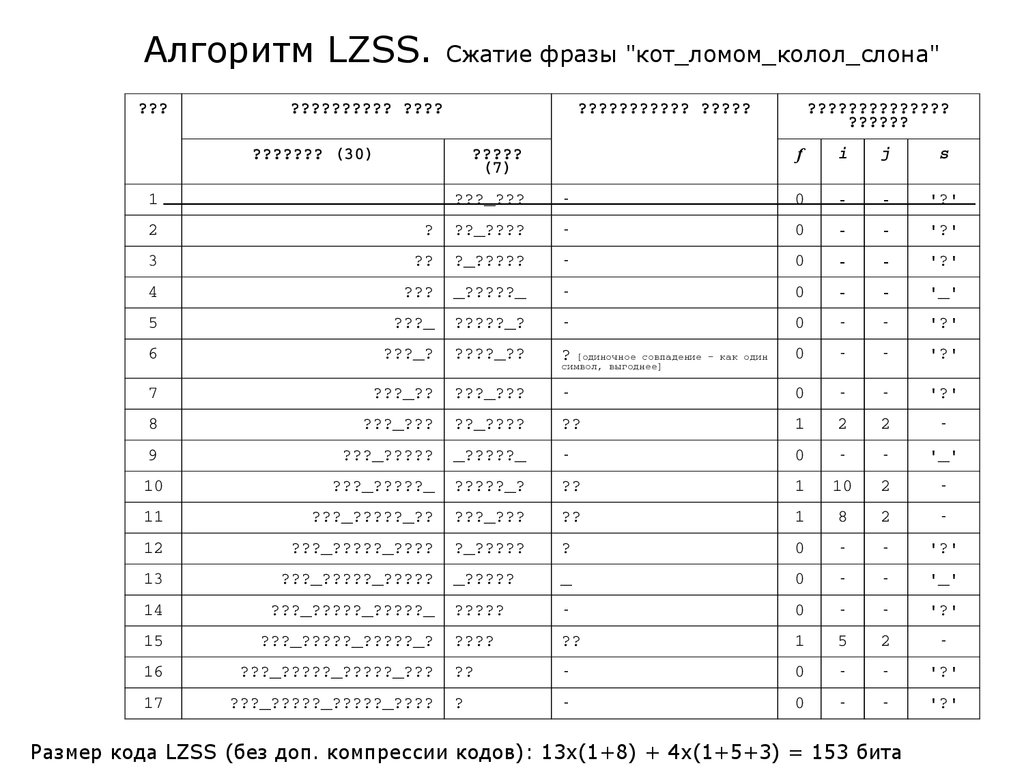
Алгоритм LZSSОсновная идея алгоритма заключается в добавлении к
каждому указателю и символу однобитового префикса f,
позволяющего различать эти объекты. Иначе говоря,
однобитовый префикс указывает тип и, соответственно длину
непосредственно следующих за ним данных. Такая техника
позволяет:
- записывать символы в явном виде, когда соответствующий им
код имеет большую длину, и, следовательно, словарное
кодирование только вредит;
- обрабатывать ни разу не встреченные до текущего момента
символы.
37.
Алгоритм LZSS.???
Сжатие фразы "кот_ломом_колол_слона"
?????????? ????
??????????? ?????
??????? (30)
?????
(7)
1
??????????????
??????
f
i
j
s
???_???
-
0
-
-
'?'
2
?
??_????
-
0
-
-
'?'
3
??
?_?????
-
0
-
-
'?'
4
???
_?????_
-
0
-
-
'_'
5
???_
?????_?
-
0
-
-
'?'
6
???_?
????_??
? [одиночное
0
-
-
'?'
7
???_??
???_???
-
0
-
-
'?'
8
???_???
??_????
??
1
2
2
-
9
???_?????
_?????_
-
0
-
-
'_'
10
???_?????_
?????_?
??
1
10
2
-
11
???_?????_??
???_???
??
1
8
2
-
12
???_?????_????
?_?????
?
0
-
-
'?'
13
???_?????_?????
_?????
_
0
-
-
'_'
14
???_?????_?????_
?????
-
0
-
-
'?'
15
???_?????_?????_?
????
??
1
5
2
-
16
???_?????_?????_???
??
-
0
-
-
'?'
17
???_?????_?????_????
?
-
0
-
-
'?'
совпадение – как один
символ, выгоднее]
Размер кода LZSS (без доп. компрессии кодов): 13х(1+8) + 4х(1+5+3) = 153 бита
38. КОДИРОВАНИЕ ИСТОЧНИКОВ С ПАМЯТЬЮ
Алгоритм LZ78На каждом шаге в словарь вставляется новая фраза, которая
представляет собой сцепление (конкатенацию) одной из фраз
S словаря, имеющей самое длинное совпадение со строкой
буфера, и символа s. Символ s является символом, следующим
за строкой буфера, для которой найдена совпадающая фраза
S.
В словаре не может быть совпадающих фраз.
Кодер порождает только последовательность кодов фраз.
Каждый код состоит из номера (индекса) n "родительской"
фразы S или префикса, и символа s. В начале обработки
словарь пуст.
Дополнительные соглашения:
- фраза с номером 0 обозначает конец сжатой строки;
- фраза с номером 1 задает пустую фразу словаря.
39. КОДИРОВАНИЕ ИСТОЧНИКОВ С ПАМЯТЬЮ
Алгоритм LZ78.???
??????????? ?
??????? ?????
????
?????
Сжатие фразы "кот_ломом_колол_слона"
?????
???????????
????? S
?? ?????
(0..14)
?????????????? ??????
n
s
1
?
2
???_???
-
1
'?'
2
?
3
??_????
-
1
'?'
3
?
4
?_?????
-
1
'?'
4
_
5
_?????_
-
1
'_'
5
?
6
?????_?
-
1
'?'
6
??
7
????_??
?
3
'?'
7
??_
8
??_????
??
7
'_'
8
??
9
?????_?
?
2
'?'
9
??
10
???_???
?
6
'?'
10
?_
11
?_?????
?
6
'_'
11
?
12
?????
-
1
'?'
12
???
13
????
??
10
'?'
13
?
14
?
-
1
'?'
Размер кода LZ78 (без доп. компрессии кодов): 13(4+8) = 156 битов.
40. ПРЕОБРАЗОВАНИЕ БЛОКОВ ДАННЫХ
Преобразование Барроуза-Уиллера (BWT)Цель обработки – преобразовать входной блок
(последовательность символов) в более удобный для сжатия
вид.
Вариант схемы кодирования (последовательное применение
алгоритмов):
- преобразование BWT;
- преобразование MTF;
- статистический кодер для сжатия данных, полученных в
результате последовательного применения двух предыдущих
преобразований.
Алгоритм BWT оперирует сразу всем сообщением или
значительным по объему блоком данных, что осложняет его
применения в системах поточного кодирования данных
(системах реального времени).
41. ПРЕОБРАЗОВАНИЕ БЛОКОВ ДАННЫХ
Преобразование Барроуза-Уиллера (BWT)Процедура преобразования выполняется следующим образом:
- выделяется блок из исходного потока;
- формируется матрица всех перестановок, полученных в
результате циклического сдвига блока;
- все перестановки сортируются в соответствии с
лексикографическим порядком символов каждой
перестановки;
- на выход подается последний столбец матрицы и номер
строки, соответствующей оригинальному блоку.
42. ПРЕОБРАЗОВАНИЕ БЛОКОВ ДАННЫХ
Преобразование Барроуза-Уиллера (BWT)43. ПРЕОБРАЗОВАНИЕ БЛОКОВ ДАННЫХ
Преобразование Барроуза-Уиллера (BWT)44. ПРЕОБРАЗОВАНИЕ БЛОКОВ ДАННЫХ
Преобразование Барроуза-Уиллера (BWT)Важно, что при добавлении любого столбца перемещения являются
одинаковыми.
Чтобы получить вектор обратного преобразования следует определить
порядок получения символов первого столбца из символов
последнего, т.е. отсортировать матрицу по номерам новых строк:
Полученные значения номеров строк T = {2,5,6,7,8,9,10,1,3,0,4} – и
есть искомый вектор, содержащий номера позиций символов в
строке, которую надо декодировать.
45. МЕТОДЫ АНАЛИЗА (СРАВНЕНИЯ) АЛГОРИТМОВ КОМПРЕССИИ
Наборы тестовых данныхПринято измерять эффективности компрессоров с помощью
стандартизованных наборов файлов:
- набор Calgary Compression Corpus (CalgCC) из 14 файлов (+4
дополнительных), большая часть из которых представляет собой
тексты на английском языке (художественные, технические, с
большим количеством опечаток и т.п.) или языках программирования
(программы на С, Лисп, Pascal). Имеются также геофизические
данные, объектные файлы, факсимильные изображения;
- Canterbury Compression Corpus (CantCC) – предложен той же группой
исследователей, что и CalgCC и является альтернативой морально
устаревшему CalgCC (с точки зрения типов обрабатываемых данных);
- наборы файлов из Archive Comparison Test (ACT) – текстовые файлы,
исполняемые файлы, звуковые файлы, полноцветные изображения;
- наборы файлов из тестов Art Of Lossless Data Compression (ARTest) –
полноцветные изображения, текстовые файлы, разнородные файлы;
- файлы из Compression Comparison Вадима Юткина (VYCCT) – 8
файлов разных типов.