







































 Образование
ОбразованиеПохожие презентации:
")






 система управления обучением")


Обучение с подкреплением Reinforcement Learning
1.
Обучение с подкреплениемReinforcement Learning
kamakovejchuk@fa.ru
2.
Обучение с учителем и обучение с подкреплениемОбучение с подкреплением отличается от обучения с учителем, еще одного
вида обучения, который изучается в большинстве современных работ по
машинному обучению. В случае обучения с учителем имеется обучающий
набор
помеченных
внешним
учителем.
примеров,
Каждый
подготовленный
пример
квалифицированным
представляет
собой
описание
ситуации и спецификацию – метку – правильного действия, которое
система должна предпринять в этой ситуации. Часто метка определяет
категорию, которой принадлежит ситуация. Цель такого обучения
–
добиться, чтобы система смогла экстраполировать, или обобщить, свою
реакцию на ситуации, которые не были предъявлены в обучающем
наборе.
3.
Это важный вид обучения, но, взятый сам по себе, он не подходит дляобучения с помощью взаимодействия. В интерактивных задачах часто
практически
невозможно
получить
примеры
желаемого
поведения,
которые правильно представляли бы все ситуации, в которых агенту
предстоит действовать. На неизведанной территории – там, где от
обучения как раз и ожидают плодов, – агент должен уметь действовать,
исходя из своего опыта.
Обучение с подкреплением отличается и от так называемого обучения без
учителя, которое обычно имеет целью обнаружение структуры, скрытой
в
наборе непомеченных данных. Кажется, что термины «обучение
с учителем» и «обучение без учителя» исчерпывают все возможные
парадигмы машинного обучения, однако это не так.
4.
Может возникнуть представление, что обучение с подкреплением –разновидность обучения без учителя, поскольку отсутствуют примеры
правильного
поведения.
Но
в
действительности
цель
обучения
с подкреплением – максимизировать вознаграждение, а не выявить
скрытую структуру. Выявление структуры в опыте агента, конечно, может
быть полезно, но само по себе не решает задачу максимизации
вознаграждения, стоящую перед обучением с подкреплением. Поэтому
можно считать обучение с подкреплением третьей парадигмой машинного
обучения наряду с обучением с учителем, без учителя и, возможно, еще
какими-то парадигмами.
5.
Отличие отдругих подходов
ИДЕЯ
• Обучение с учителем
Стремиться
к действиям, ведущим
к награде, избегать
действий, ведущих к
неудачам
есть база, есть размеченные
ответы
• Обучение без учителя
есть база, нет размеченных
ответов
• Обучение с подкреплением
нет базы, нет размеченных
ответов
6.
Один из вызовов, стоящих перед обучением с подкреплением, но отсутствующийв других видах обучения, – нахождение компромисса между исследованием
и
использованием. Чтобы получить большое вознаграждение, обучающийся
с
подкреплением
агент
должен
предпочитать
действия,
которые
были
испробованы в прошлом и принесли вознаграждение. Но чтобы найти такие
действия, он должен пробовать действия, которые раньше не выбирал.
Агент
должен
использовать
уже
приобретенный
опыт,
чтобы
получить
вознаграждение, но должен продолжать исследования, чтобы выбирать более
эффективные действия в будущем.
Дилемма состоит в том, что одного лишь исследования или использования
недостаточно для успешного решения задачи. Агент должен пробовать разные
действия и неуклонно отдавать предпочтение тем, которые кажутся наилучшими.
7.
Областьприменения
• Игры (особенно
логические)
• Роботы-манипуляторы
• Навигация машин, роботов
• Боты(трейдинг, чат, игровые)
• И т.д ...
8.
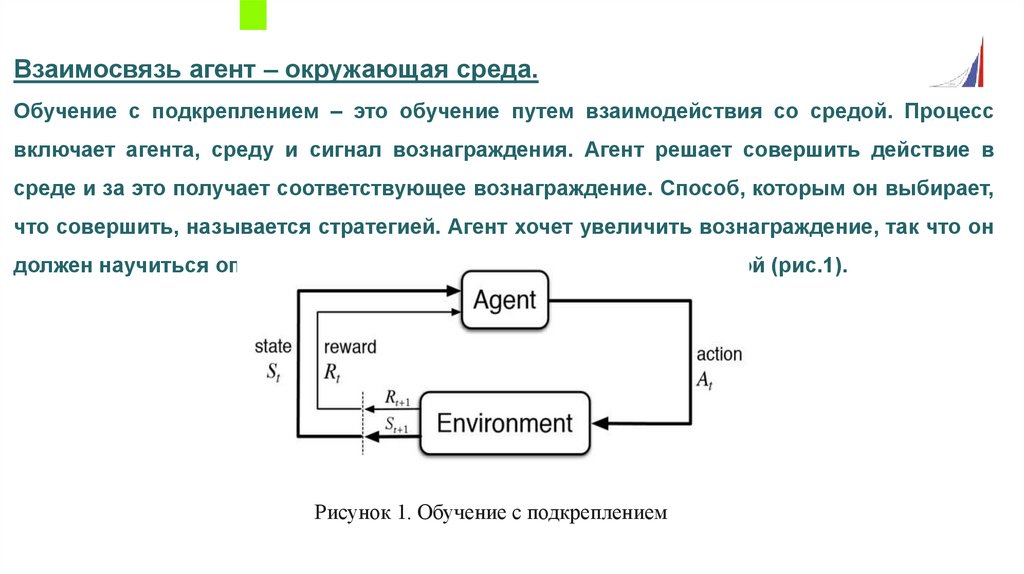
Взаимосвязь агент – окружающая среда.Обучение с подкреплением – это обучение путем взаимодействия со средой. Процесс
включает агента, среду и сигнал вознаграждения. Агент решает совершить действие в
среде и за это получает соответствующее вознаграждение. Способ, которым он выбирает,
что совершить, называется стратегией. Агент хочет увеличить вознаграждение, так что он
должен научиться оптимальной стратегии взаимодействия со средой (рис.1).
Рисунок 1. Обучение с подкреплением
9.
Постановка задачи обучения с подкреплениемОбучение с подкреплением (Reinforcement Learning, RL) - это область
машинного обучения, где агент учится принимать решения, взаимодействуя
со своей средой. Основные компоненты задачи обучения с подкреплением:
1. Агент: Сущность, которая принимает решения или действия в среде.
2. Среда: Мир, в котором агент действует.
3. Состояние (State): Конкретное условие или конфигурация среды и агента
в определенный момент времени.
4. Действие (Action): Это то, что агент может совершить в каждом состоянии.
Множество всех возможных действий обычно обозначается как A.
10.
5. Награда (Reward): После выполнения действия агент получает награду(или штраф, который является отрицательной наградой) от среды. Цель
агента - максимизировать сумму полученных наград.
6. Политика (Policy): Это стратегия агента, которая определяет, какое
действие следует предпринять в каждом состоянии.
Цель обучения с подкреплением - найти оптимальную политику, которая
максимизирует ожидаемую кумулятивную награду. Однако это сложная
задача, поскольку награда может зависеть не только от текущего действия,
но и от всех будущих действий. Кроме того, агенту часто приходится
балансировать
между
исследованием
неизвестных
состояний
(для
обучения) и использованием своих текущих знаний (для получения
награды), что известно как дилемма исследования и использования.
11.
Таким образом, в обучении с подкреплением существует агент (agent) взаимодействует с окружающей средой(environment), предпринимая действия (actions). Окружающая среда дает награду (reward) за эти действия, а
агент продолжает их предпринимать.
Алгоритмы с частичным обучением пытаются найти стратегию, приписывающую состояниям (states)
окружающей среды действия, одно из которых может выбрать агент в этих состояниях.
Ниже приведены основные элементы обучения с подкреплением:
Состояние (State): полное описание мира. Это может быть позиция, фиксированная или динамическая. Как
правило, такие состояния записываются в виде массивов, матриц или тензоров высшего порядка.
Действие (Action): множество допустимых действий агента записывается в пространстве, именуемом
«пространство действий». Как правило, количество действий в пространстве конечно.
Среда (Environment): это место, в котором агент существует и с которым взаимодействует. Для различных
сред используются различные типы вознаграждений, стратегий, т.д.
Вознаграждение и выигрыш (Reward): отслеживать
функцию вознаграждения
R при обучении
с
подкреплением нужно постоянно. Она критически важна при настройке алгоритма, его оптимизации, а также при
прекращении обучения. Она зависит от текущего состояния мира, только что предпринятого действия и
следующего состояния мира.
Стратегии: это правила, в соответствии с которыми агент избирает следующее действие.
12.
Неформализованная постановка задачи RL:требуется определить наиболее важные аспекты реальной проблемы,
стоящей перед обучающимся агентом, который взаимодействует во
времени
с
окружающей
средой
для
достижения
некоторой
цели.
Обучающийся агент должен уметь в какой-то степени воспринимать
состояние среды и предпринимать действия, изменяющие это состояние.
У агента также должна быть цель или несколько целей, как-то связанных
с состоянием окружающей среды. Любой метод, подходящий для решения
таких
задач,
будет
с подкреплением.
рассматриваться
нами
как
метод
обучения
13.
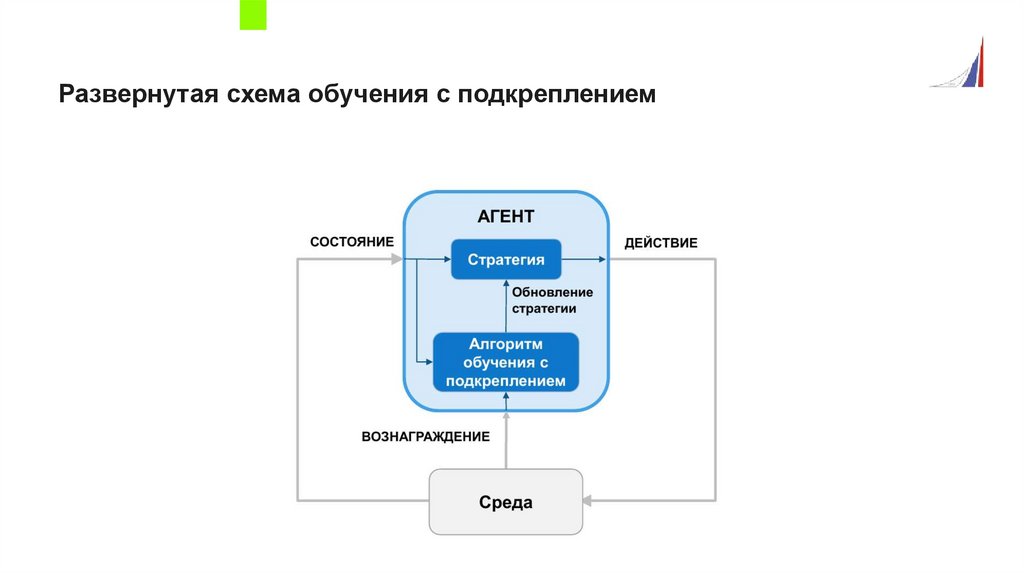
Развернутая схема обучения с подкреплением14.
Опыт• За счёт совершения различных действий в среде
агент набирается опыта.
• Опыт – в каком состоянии было совершено
какое действие, какая награда была за это
получена и в какое новое состояние в
результате агент попал.
<s, a, r, s’>
• Опыт должен быть максимально разнообразным:
желательно побывать в наибольшем числе
состояний и попробовать в каждом из них как
можно больше различных действий.
15.
НаградаАгент оценивает ситуацию – пару «состояниедействие» при помощи скалярной награды
(действительного числа).
Награда показывает, насколько полезно
было совершить определённое действие в
данном состоянии
Задание инженером правильного метода
формирования награды играет
определяющую роль в успехе обучения
16.
СтратегияАгент руководствуется некоторой стратегией
действий.
Стратегия определяет в каком состоянии
будет совершено какое действие.
17.
Пример: обучение беспилотного автомобиляБортовой компьютер обучается вождению...
(агент)
с помощью данных с датчиков (камеры и LIDAR),...
(состояние)
которые отображают дорожные условия, положение автомобиля,...
(среда)
генерирует команды рулевого управления, торможения и газа, ...
(действие)
и, согласно соответствию «состояние-действие», ...
(стратегия)
пытается оптимизировать комфорт водителя и эффективность
расхода топлива...
(вознаграждение)
Алгоритм действия обновляется методом проб и ошибок с помощью
алгоритма обучения с подкреплением
18.
Пример: обучение роботов ходьбе19.
Задача об одноруком бандите20.
21.
22.
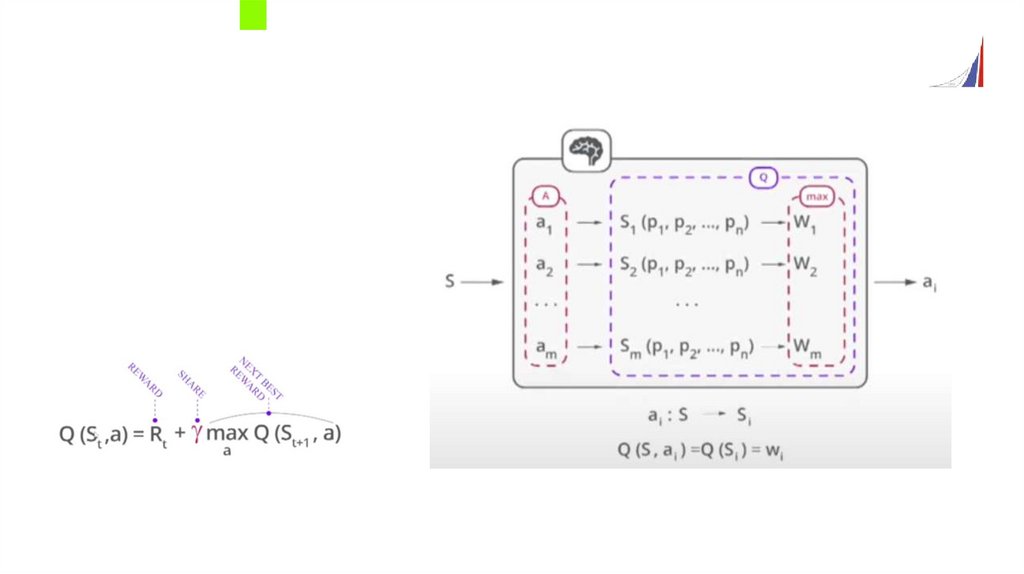
Q-обучениеСамый простой популярный алгоритм обучения с подкреплением.
В основе лежит определение оценки функции полезности (Q-функции) для конечного числа
действий.
Функция полезности действия
Каждое действие в каждом состоянии можно оценить при помощи функцией полезности Qπ(s, a) –
ожидаемой суммой наград при совершении агентом действия a в состоянии s и совершении
последующих действий в соответствии со стратегией π.
Процесс обучения – определение функции полезности в процессе функционирования агента.
Функция полезности показывает, насколько большую награду можно получить за определённое
действие, а также насколько данное действие является перспективным.
Т.е. сколько ещё наград можно будет собрать в будущем, если при движении из нового состояния,
используя текущую стратегию.
На сколько сильно будет учитываться перспектива получения наград в будущем, инженер задаёт с
помощью коэффициента дисконтирования γ :
0<γ<1
23.
Стратегия действий агента при Q-обученииСтратегия действий – выбор действия с максимальной текущей оценкой полезности.
Хранение оценок полезности действий в таблице:
s1
s2
…
sm
a1
a2
Q(s1, a1) Q(s1, a2)
Q(s2, a1) Q(s2, a2)
…
…
Q(sm, a1) Q(sm, a2)
…
…
…
…
…
an
Q(s1, an)
Q(s2, an)
…
Q(sm, an)
24.
Функция ценности и Q-функция. Оптимизация политики и Q-learning. Policygradients.
1. Функция ценности (V-функция): Это функция, которая оценивает,
насколько хорошо агент выполняет задачу, находясь в определенном
состоянии. Она вычисляет ожидаемую награду, которую агент получит,
следуя определенной стратегии.
2. Q-функция: Это расширение функции ценности, которое учитывает не
только состояние, но и действие, которое агент предпринимает в этом
состоянии. Q-функция оценивает ожидаемую награду для пары состояниедействие, следуя определенной стратегии.
25.
3. Оптимизация политики: Это процесс улучшения стратегии агента путеммаксимизации функции ценности или Q-функции. Один из способов
оптимизации политики - это использование Q-learning.
4. Q-learning: Это метод обучения с подкреплением, который использует Qфункцию для оптимизации политики. Q-learning итеративно обновляет Qфункцию и использует ее для выбора действий, которые максимизируют
ожидаемую награду.
5. Policy gradients: Это другой метод оптимизации политики, который
использует градиентный подход. Вместо того, чтобы искать оптимальную
политику напрямую, Policy gradients обновляют политику в направлении,
которое увеличивает ожидаемую награду.
26.
Подход на основе Policy Gradient. Подход на основе Q-learning.Policy Gradient - это подход к обучению с подкреплением, который напрямую
оптимизирует параметризованную стратегию управления с помощью варианта
градиентного спуска. Эти методы относятся к классу техник поиска стратегий,
которые максимизируют ожидаемый возврат стратегии из фиксированного
класса, в отличие от подходов с приближением функции ценности. Они
позволяют прямо включать знания о предметной области в параметризацию
стратегии; часто оптимальная стратегия представляется более компактно, чем
соответствующая
функция
ценности;
многие
такие
сходимость хотя бы к локально оптимальной стратегии.
методы
гарантируют
27.
POLICY GRADIENT(градиенты политики, стратегии)
Схожа с обучением с учителем, но:
• Вместо правильных меток - метка
выиграл/проиграл
• Если выиграл в эпизоде - все действия в нем
получают позитивную метку(и наоб.)
• Функция потерь - кросс-энтропия, в которую
вводим вознаграждение (умножаем его на
логарифм)
• Делаем тренировку из ряда игровых
эпизодов, обновляем веса по этой
функции, делаем следующую тренировку
28.
Q-learning - это алгоритм обучения с подкреплением, который находит лучшуюпоследовательность действий на основе текущего состояния агента. "Q" означает
качество. Качество представляет собой ценность действия для максимизации
будущих наград. Алгоритмы, основанные на моделях, используют функции
перехода и награды для оценки оптимальной стратегии и создания модели. В
отличие от них, алгоритмы без модели учатся последствиям своих действий
через опыт без функции перехода и награды.
29.
Q-learning30.
31.
32.
Подходы RL, основанные на моделяхПодходы к обучению с подкреплением (RL), основанные на моделях,
используют модель окружающей среды для планирования. Вот некоторые
ключевые аспекты:
1. Моделирование окружения: Модель окружения предсказывает, что
произойдет в следующем состоянии, исходя из текущего состояния и
действия.
Это
наблюдаемым
может
быть
состоянием,
наблюдаемым состоянием.
простым
или
как
в
задачах
сложным
в
задачах
с
полностью
с
частично
33.
2. Планирование с использованием модели: С помощью модели окружения агентможет планировать, просматривая возможные последовательности действий и
выбирая ту, которая приведет к наиболее положительному результату. Это может
быть реализовано с помощью различных методов, таких как поиск по дереву
Monte Carlo.
3. Обучение модели: Модель окружения обычно обучается на основе истории
взаимодействий агента с окружающей средой. Это может быть реализовано с
помощью методов обучения с учителем, таких как регрессия.
4. Смешанные подходы: В некоторых случаях агенты могут использовать
комбинацию подходов, основанных на моделях и без моделей, чтобы достичь
лучших
результатов.
Например,
они
могут
использовать
модель
для
планирования в новых областях пространства состояний, а затем переключаться
на подход без модели, когда они достаточно исследовали область.
34.
Алгоритмы, основанные на использовании модели средыАлгоритмы, основанные на использовании модели среды, относятся к классу
методов машинного обучения и искусственного интеллекта. Они используют модель,
которая описывает поведение среды. Эти алгоритмы обучаются в процессе
взаимодействия с динамическим, часто стохастическим, объектом управления
(средой)
социально-экономической
природы
с
целью
максимизации
общего
вознаграждения.
В процессе моделирования возникает проблема выбора таких алгоритмов обучения,
которые адекватно отражают стохастическую динамику моделируемого объекта, и
имеют высокую производительность. Однако, эти алгоритмы не чувствительны к
особенностям системы, таким как разнообразие шкал характеристик изучаемых
объектов, неоднородность выборок данных, неполнота и пропуски в данных,
стохастичность данных, их мультиколлинеарность и гетероскедастичность.
35.
Использование обучения с подкреплением для разработки чат-ботаВ контексте разработки чат-бота, глубокое обучение с подкреплением может быть
использовано для моделирования будущих вознаграждений в диалоге с чат-ботом.
Диалоги моделируются с помощью двух виртуальных агентов.
С помощью градиентных методов можно вознаграждать последовательности, содержащие
такие важные атрибуты разговора, как связность, информативность и простота ответа.
Однако, для эффективного обучения чат-бота требуется большое количество обучающих
данных.
36.
Цикл обучения модели с симулятором пользователяОбучение модели с симулятором пользователя - это процесс, в котором модель обучается
на основе взаимодействия с симулятором, который имитирует поведение пользователя.
Этот процесс обычно включает в себя следующие этапы:
Подготовка данных: Сначала подготавливается набор данных с аннотациями,
сделанными людьми.
Адаптация модели: Затем языковая модель адаптируется к этим данным.
Обучение с подкреплением: Модель затем дообучается, используя метод, который
называется «обучение с подкреплением на основе отзывов людей» (Reinforcement
Learning from Human Feedback, RLHF).
Этот цикл обучения используется в мощных языковых моделях, таких как ChatGPT, GPT-4
и Claude. Благодаря этому такие модели лучше отражают наши ожидания в плане их
поведения, они лучше соответствуют тому, как мы собираемся их использовать.
37.
Задача о перевернутом маятнике• Простая задача для апробации методов обучения с
подкреплением.
• Целевое
состояние
маятника:
стабилизация
в
вертикальном положении (нулевой угол отклонения от
вертикальной оси, нулевая угловая скорость).
• Чем ближе положение маятника к вертикальному, больше
награда.
• В
точке
подвеса
–
мотор.
Действие
управляющий
момент,
создаваемый
мотором.
38.
Используемый инструментарий39.
До обученияРезультаты обучения маятника
Время
обучения –
порядка 5 – 10
минут
40.
41.
Марковский процесс принятия решенийВ ранней истории обучения с подкреплением есть два основных направления, которые
долго и плодотворно развивались независимо, прежде чем переплелись в современном
обучении с подкреплением. Одно направление связано с обучением методом проб
и ошибок, оно уходит корнями в психологию обучения животных. Это направление можно
проследить в самых ранних работах по искусственному интеллекту, и оно привело
к возрождению обучения с подкреплением в начале 1980-х годов. Второе направление
связано с задачей оптимального управления и ее решением с помощью функций ценности
и
динамического
программирования.
По
большей
части
оно
не
соприкасается
с обучением. Оба направления были практически независимы, но оказались в какой-то
мере взаимосвязаны в третьем, не столь отчетливо выделяющемся направлении,
связанном с методами на основе временных различий типа того, что мы применили
в примере с крестиками и ноликами. Все три направления сошлись в конце 1980-х годов,
когда сформировалась современная дисциплина обучения с подкреплением.
42.
Направление, ставящее во главу угла обучение методом проб и ошибок, – то, чему посвященообучение с подкреплением в традиционном понимании.
Термин «оптимальное управление» вошел в обиход в конце 1950-х годов и применялся для
описания
задачи
о
проектировании
устройства
управления,
которое
должно
было
минимизировать или максимизировать некоторую характеристику поведения динамической
системы во времени. Один из подходов к решению этой задачи был разработан в середине
1950-х годов Ричардом Беллманом и другими учеными путем обобщения теории Гамильтона–
Якоби, созданной в
XIX веке. В этом подходе понятия состояния динамической системы
и функции ценности, или «оптимальной функции выгоды», используются для вывода
функционального уравнения, которое теперь часто называют уравнением Беллмана. Класс
методов решения задач оптимального управления путем решения этого уравнения называется
динамическим программированием (Bellman, 1957a). В работе Bellman (1957b) описана также
дискретная стохастическая версия задачи оптимального управления, известная под названием
«марковский процесс принятия решений» (МППР, англ. MDP). В работе Ronald Howard (1960)
предложен метод итерации по стратегиям для МППР. Все это – существенные элементы,
лежащие в основе теории и алгоритмов современного обучения с подкреплением.
43.
Все работы по оптимальному управлению в какой-то мере являются работами пообучению с
подкреплением. Метод обучения с подкреплением можно определить как
любой эффективный способ решения задач обучения с подкреплением, и теперь понятно,
что эти задачи тесно связаны с задачами оптимального управления, особенно со
стохастическими, подобными формулируемым в терминах МППР. Соответственно, мы
должны
считать
методы
решения
задач
оптимального
управления,
например
динамическое программирование, также методами обучения с подкреплением. Поскольку
почти все традиционные методы требуют полного знания об управляемой системе,
кажется не вполне естественным говорить, что они часть обучения с
подкреплением.
С другой стороны, многие алгоритмы динамического программирования инкрементные
и итеративные. Как и методы обучения, они постепенно приходят к правильному ответу
путем последовательных приближений.
44.
Марковский процесс принятия решений (МППР) — это математический формализмдля марковского дискретного стохастического процесса управления. Он служит
основой для моделирования последовательного принятия решений в ситуациях,
где результаты частично случайны и частично зависят от лица, принимающего
решение.
МППР
используется
во
множестве
областей,
включая
робототехнику,
автоматизированное управление, экономику и производство. Подход обучения с
подкреплением, основанный на данной модели, применяется, например, в
нейронной сети AlphaZero.
45.
Марковские процессы принятия решений представляют собой инструмент дляпостановки задачи обучения, где достижение цели осуществляется через
взаимодействие и последовательное принятие решений. Окружающая среда (или
просто среда), представляет собой сторону, с которой взаимодействует агент.
Агент выбирает действия, в то время как среда реагирует на эти действия и
предоставляет новые ситуации для агента. Кроме того, среда генерирует
вознаграждения
—
числовые
значения,
которые
агент
стремится
максимизировать с течением времени путем выбора действий.
Марковские процессы принятия решений включают все три аспекта –
восприятие, действие и цель – в простейшей возможной форме, не сводя,
однако, ни один аспект к тривиальному.