



























































 Образование
ОбразованиеПохожие презентации:


")







Машинное обучение и нейросетевые технологии
1.
МАШИННОЕ ОБУЧЕНИЕ ИНЕЙРОСЕТЕВЫЕ ТЕХНОЛОГИИ
2.
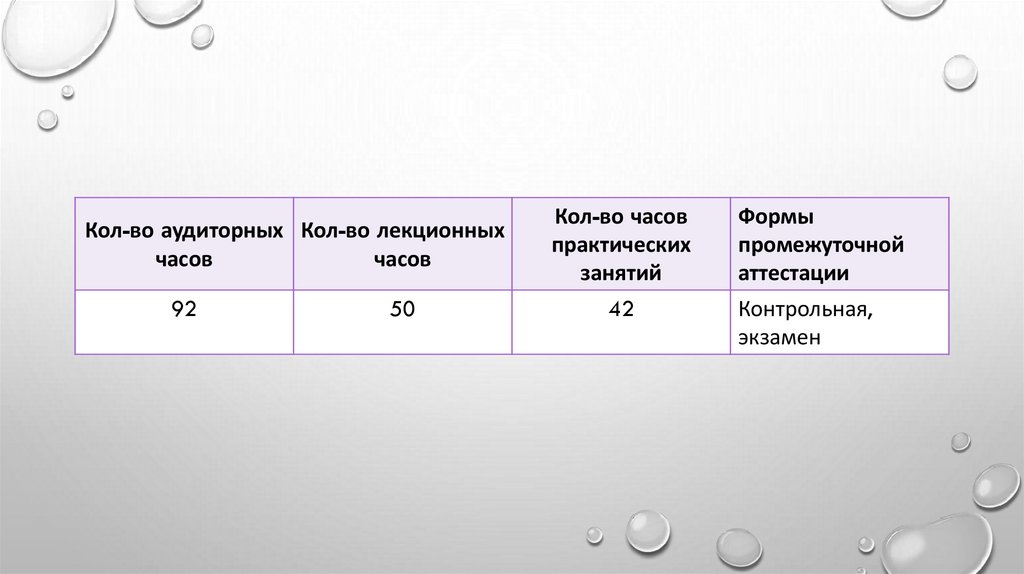
Кол-во аудиторных Кол-во лекционныхчасов
часов
92
50
Кол-во часов
практических
занятий
Формы
промежуточной
аттестации
42
Контрольная,
экзамен
3.
ВВЕДЕНИЕ1959 году компания IBM опубликовала в
журнале IBM journal of research and
development статью, автор которой
артур самуэль - сотрудник IBM,
исследовал вопрос о применении
машинного обучения в контексте игры в
шашки «для проверки того факта, что
компьютер можно запрограммировать
таким образом, чтобы он научился
играть в шашки лучше, чем человек,
написавший программу».
4.
ВВЕДЕНИЕХотя в первоначальном определении Артура Самуэля
понятие машинного обучения не было рассмотрено,
ключевая характеристика машинного обучения — это
концепция самообучения.
Она подразумевает применение статистического
моделирования для выявления закономерностей и
повышения производительности на основе данных и
эмпирической информации без использования прямых
команд. Артур Самуэль назвал это способностью
обучаться без явного программирования. Он не имел в
виду, машины способны выполнять поставленную задачу,
используя входные данные, а не входную команду.
5.
ВВЕДЕНИЕРешения генерируются путем выявления
существующих в данных взаимосвязей и
закономерностей с помощью вероятностных
рассуждений (проб и ошибок) и применения других
вычислительных методов.
Выход модели принятия решений определяется
содержанием входных данных, а не правилами,
заранее определенными программистом. При этом
программист отвечает за:
• подачу данных на вход модели,
• выбор подходящего алгоритма,
• настройку параметров алгоритма для
уменьшения ошибки прогнозирования.
6.
ВВЕДЕНИЕПример самообучающейся модели — система выявления
спама в электронных сообщениях. После получения
входных данных эта модель учится отмечать письма с
подозрительными темами и текстом, содержащим ключевые
слова, которые сильно коррелируют со спамом, отмеченным
пользователями в прошлом. К признакам спама могут
относиться такие слова, как: дорогой друг, бесплатно, счет,
PayPal, казино, платеж, банкротство и победитель. По мере
анализа все большего количества данных модель может
сталкиваться с исключениями и делать ошибочныt прогнозы.
Например, система может ошибочно классифицировать
тему письма как спам: «Сервис PayPal получил ваш платеж
за фильм „Казино Рояль“, купленный на eBay».
7.
ВВЕДЕНИЕХотя процесс самообучения модели зависит от данных, большее их
количество не всегда приводит к лучшим решениям. В своей книге Брюс
Шнайер пишет: «когда вы ищете иголку, последнее, что вам следует делать, это
наваливать на нее как можно больше сена». Это означает, что увеличение
количества нерелевантных данных может помешать в достижении желаемого
результата, количество входных данных должно быть совместимо с
имеющимися вычислительными и временными ресурсами.
8.
ВВЕДЕНИЕИскусственный интеллект – свойство интеллектуальных систем выполнять
творческие функции, которые традиционно считаются прерогативой человека;
наука и технология создания интеллектуальных машин, особенно
интеллектуальных компьютерных программ.
Машинное обучение – класс методов
искусственного интеллекта, характерной чертой
которых является не прямое решение задачи, а
обучение за счёт применения решений множества
сходных задач.
Машинное обучение (МО) – это подмножество
методов искусственного интеллекта, которое
позволяет компьютерным системам учиться на
предыдущем опыте и улучшать свое поведение для
выполнения определенной задачи.
9.
ВВЕДЕНИЕНейронные сети (НС) или искусственные НС являются подмножеством методов
МО, имеющим некоторую косвенную связь с биологическими нейронными сетями.
Они обычно описываются как совокупность связанных единиц, называемых
искусственными нейронами, организованными
слоями.
Глубокое обучение (ГО) – это подмножество НС,
которое обеспечивает расчеты для многослойной
НС. Типичными архитектурами НС являются
глубокие нейронные сети, сверточные нейронные
сети (СНС), рекуррентные нейронные сети
(РНС), порождающие состязательные сети (ПСНС),
и др.
10.
ВВЕДЕНИЕМашинное обучение [] — это дисциплина, в которой компьютеры
строят вероятностные статистические модели на основе данных и
используют их для прогнозирования и анализа данных.
Машинное обучение также известно как статистическое
машинное обучение.
Герберт А. Саймон однажды определил «обучение» как
«способность системы улучшать свою производительность
путем выполнения процесса».
Cтатистическое машинное обучение — это машинное обучение,
в котором компьютерные системы улучшают производительность системы, используя
данные и статистические методы.
11.
ВВЕДЕНИЕОсновные характеристики машинного обучения:
1) машинное обучение основано на компьютере и сети.
2) машинное обучение — это дисциплина, основанная на данных, которая использует
данные в качестве объекта изучения.
3) цель машинного обучения — прогнозировать и анализировать данные.
4) машинное обучение ориентировано на метод, при этом методы машинного обучения
создают и применяют модели для прогнозирования и анализа.
5) машинное обучение — это междисциплинарный предмет вероятности, статистики,
информации, вычислений, оптимизации, информатики и т.д.
12.
МЕТОДЫ МАШИННОГО ОБУЧЕНИЯМетоды МО создают вероятностные статистические модели на основе данных для
прогнозирования и анализа данных.
МО начинается с заданного набора ограниченных обучающих данных для обучения
и предполагает, что
данные независимо и одинаково распределены;
обучаемая модель принадлежит набору функций, который называется пространством
гипотез;
оптимальная модель выбирается из пространства гипотез на основе определенного
критерия оценки, чтобы сделать оптимальное предсказание доступных обучающих
данных и неизвестных тестовых данных;
выбор оптимальной модели осуществляется алгоритмом.
Таким образом, метод МО включает пространство гипотез модели, критерии выбора
модели и алгоритм обучения модели, стратегию и алгоритм для краткости.
13.
МЕТОДЫ МАШИННОГО ОБУЧЕНИЯШаги для реализации метода машинного обучения следующие:
(1) получить ограниченный набор обучающих данных;
(2) определить пространство гипотез, которое содержит все возможные модели,
то есть набор моделей обучения;
(3) определить критерии выбора модели (стратегию обучения);
(4) реализовать алгоритм для решения оптимальной модели (алгоритм обучения);
(5) выбрать оптимальную модель с помощью методов обучения;
(6) использовать изученную оптимальную модель для прогнозирования или
анализа новых данных.
14.
ИССЛЕДОВАНИЯ МАШИННОГО ОБУЧЕНИЯИсследования машинного обучения обычно делятся на три части:
методы машинного обучения - исследования методов машинного обучения
направлены на разработку новых методов обучения,
теория машинного обучения исследует эффективность и результативность
методов машинного обучения и фундаментальные теоретические вопросы
машинного обучения,
применение машинного обучения к практическим задачам для решения задач.
15.
ДОСТИЖЕНИЯ МАШИННОГО ОБУЧЕНИЯПримеры:
распознавании образов,
интеллектуальный анализ данных,
обработка естественного языка,
обработка речи,
вычислительное зрение,
поиск информации, и др.
16.
НЕОБХОДИМОСТЬ МАШИННОГО ОБУЧЕНИЯВажность машинного обучения в науке и технике в основном отражается в
следующих аспектах:
1) Машинное обучение является эффективным способом обработки больших
объемов данных.
2) Машинное обучение является эффективным средством компьютерной
интеллектуализации. Применение машинного обучения для имитации
человеческого интеллекта является наиболее эффективным средством, несмотря
на определенные ограничения.
3) Если считать, что компьютерная наука состоит из трех измерений: системы,
вычисления и информации. Машинное обучение в основном относится к
информационному измерению и играет центральную роль
17.
КЛАССИФИКАЦИЯ МАШИННОГО ОБУЧЕНИЯМашинное обучение обычно подразделяется на три основные группы:
• контролируемое обучение,
• неконтролируемое обучение,
• обучение с подкреплением.
Иногда оно также включает полуконтролируемое обучение и активное обучение.
18.
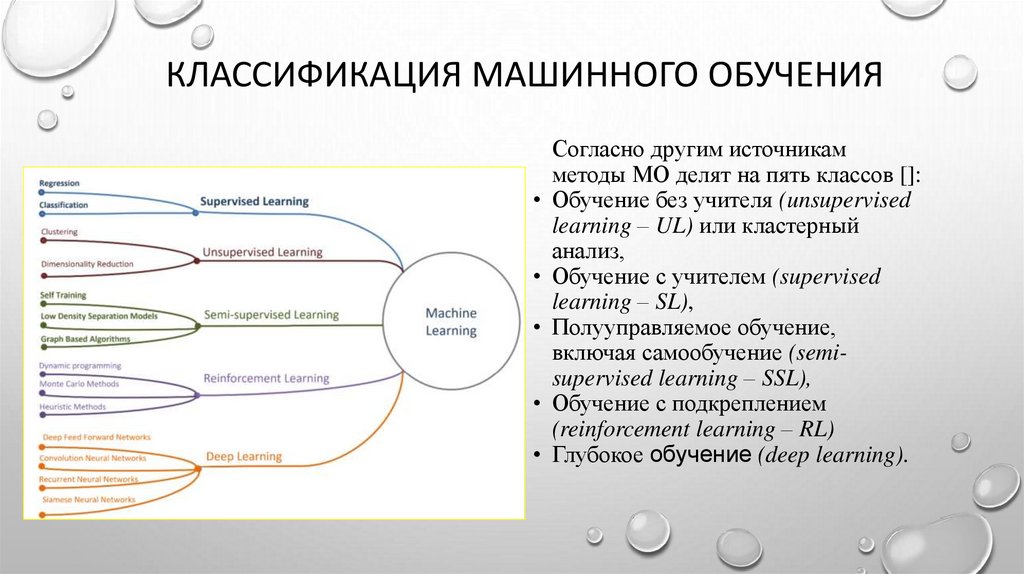
КЛАССИФИКАЦИЯ МАШИННОГО ОБУЧЕНИЯСогласно другим источникам
методы МО делят на пять классов []:
• Обучение без учителя (unsupervised
learning – UL) или кластерный
анализ,
• Обучение с учителем (supervised
learning – SL),
• Полууправляемое обучение,
включая самообучение (semisupervised learning – SSL),
• Обучение с подкреплением
(reinforcement learning – RL)
• Глубокое обучение (deep learning).
19.
ОБУЧЕНИЕ С УЧИТЕЛЕММетоды обучения с учителем решают задачу классификации или регрессии.
Регрессией называется задача обработки данных, когда по некоторому объему
исходных данных, описывающих, например, предысторию развития процесса,
необходимо определить его будущее состояние в пространстве или времени или
предсказать его состояние при ранее не встречавшемся сочетании параметров.
Классификацией называется задача обработки данных, когда определенный
объект нужно отнести к одному из ранее определенных классов.
Задача классификации возникает тогда, когда в потенциально бесконечном
множестве объектов выделяются конечные группы некоторым образом
обозначенных объектов. Обычно формирование групп выполняется экспертом.
Алгоритм классификации, используя эту первоначальную классификацию как
образец, должен отнести следующие не обозначенные объекты к той или иной
группе, исходя из свойств этих объектов.
20.
ОБУЧЕНИЯ С УЧИТЕЛЕММетоды обучения с учителем часто разделяются на линейные и нелинейные в
зависимости от формы (гиперплоскости или гиперповерхности), разделяющей
классы объектов.
В двумерном случае линейные классификаторы разделяют классы единственной
прямой, тогда как нелинейные классификаторы – линией.
21.
ОБУЧЕНИЯ С УЧИТЕЛЕМКонтролируемое обучение — это метод машинного обучения, в котором модели
прогнозирования получаются из маркированных данных.
Маркированные данные представляют собой связь между входом и выходом, а
модель прогнозирования генерирует соответствующий выход для заданного входа.
Суть контролируемого обучения заключается в изучении статистического закона
отображения входов и выходов.
В контролируемом обучении набор всех возможных входных и выходных
значений называется входным пространством и выходным пространством
соответственно.
Входное и выходное пространство могут быть:
набором конечных элементов или всем евклидовым пространством.
одинаковыми или разными, но выходное пространство обычно намного меньше
входного пространства.
22.
ОБУЧЕНИЯ С УЧИТЕЛЕМКаждый конкретный вход является экземпляром, который обычно представлен
вектором признаков.
В это время пространство, в котором существуют все векторы признаков,
называется пространством признаков.
Каждое измерение пространства признаков соответствует признаку.
Иногда входное пространство и пространство признаков являются одним и тем
же пространством и не различаются; иногда предполагается, что входное
пространство и пространство признаков являются разными пространствами, и
экземпляр отображается из входного пространства в пространство признаков.
Модель определяется в пространстве признаков.
23.
ОБУЧЕНИЯ С УЧИТЕЛЕМВ контролируемом обучении входные и выходные данные являются значениями
случайных величин, определенных во входном (признаковом) пространстве и
выходном пространстве. Входные и выходные переменные представлены
заглавными буквами.
Обычно входная переменная записывается как X, а выходная переменная
записывается как Y.
Значения входных и выходных переменных выражаются строчными буквами; то
есть значение входной переменной записывается как x, а значение выходной
переменной записывается как y.
Переменные могут быть скалярными или векторными.
24.
ОБУЧЕНИЯ С УЧИТЕЛЕМСистема обучения (а именно алгоритм обучения) пытается изучить модель через
информацию, полученную от образцов (xi, yi) в обучающем наборе данных. В
частности, для входных данных xi определенная модель y = f (x) может генерировать
выходные данные f (xi), а соответствующие выходные данные в обучающем наборе
данных — yi.
Разница между выходными данными обучающей выборки yi и выходными
данными модели f (xi) должна быть достаточно мала, чтобы гарантировать наиболее
точный прогноз модели.
Обучающая система выбирает лучшую модель посредством непрерывных
попыток сделать достаточно точное предсказание на обучающем наборе данных.
25.
ОБУЧЕНИЕ БЕЗ УЧИТЕЛЯСуть неконтролируемого обучения заключается в изучении статистических законов или
потенциальных структур в данных. Неконтролируемое обучение обычно обучает или
тренирует модель, используя большой объем немаркированных данных. Здесь комбинации
входных и выходных переменных — неизвестными. Обучающие данные выражаются как
U = {x1, x2, . . . xN}, где xi,i = 1, 2, . . . , N .
Неконтролируемое обучение может использоваться для анализа существующих данных и
прогнозирования будущих данных. Модель может реализовать кластеризацию, снижение
размерности или оценку вероятности данных.
26.
ОБУЧЕНИЕ БЕЗ УЧИТЕЛЯПреимущество неконтролируемого обучения заключается в том, что оно
позволяет обнаружить в данных еще не известные закономерности (например,
существование двух доминирующих типов клиентов) и создает базу для проведения
анализа после выявления новых групп.
Неконтролируемое обучение оказывается особенно полезным в сфере
обнаружения мошенничества, где наиболее опасные атаки — те, которые еще только
предстоит классифицировать.
27.
ПОЛУУПРАВЛЯЕМОЕ ОБУЧЕНИЕПолуконтролируемое обучение представляет собой гибрид контролируемого и
неконтролируемого обучения, которое предполагает использование наборов,
содержащих размеченные и неразмеченные данные.
Цель SSL — это использование неразмеченных данных для повышения надежности
предсказательной модели.
Один из методов заключается в том, чтобы построить исходную модель на основе
размеченных данных (контролируемое обучение), а затем использовать ее для
маркировки неразмеченных данных. Затем модель можно переобучить на более
крупном наборе. Или итеративно переобучать модель, используя вновь размеченные
данные, которые соответствуют заданному порогу достоверности, и добавляя их в
тренировочный набор после достижения ими соответствия установленному пороговому
значению точности. Нет гарантии, что модель SSL обучения превзойдет модель,
обученную на меньшем количестве исходных размеченных данных.
28.
ОБУЧЕНИЕ С ПОДКРЕПЛЕНИЕМПредполагает построение предсказательной модели на основе обратной связи,
получаемой в результате случайных проб и ошибок, знаний, приобретенных в ходе
предыдущих итераций.
Цель обучения с подкреплением — достижение конкретного выхода путем
случайного перебора огромного количества возможных комбинаций, входных данных и
оценки их эффективности.
Как обучение студента, по мере продвижения в течении учебы студент оценивает
полезность различных действий в разных условиях и изучает способы успешно
закончить учебу. Полученные в ходе этого процесса знания влияют на последующее
поведение и успешную сдачу сессии, результативность постепенно улучшается
благодаря обучению и наработке опыта.
29.
ОБУЧЕНИЕ С ПОДКРЕПЛЕНИЕМАналогичным образом алгоритмы обучения с подкреплением обеспечивают
непрерывную тренировку модели.
Стандартная модель обучения с подкреплением предусматривает измеримые
критерии, по которым оценивается ее эффективность.
В случае со студентом это, например, способность избежать пересдачи, а в случае с
игры — способность избежать поражения.
30.
ГЛУБОКОЕ ОБУЧЕНИЕВ 2006 году Джеффри Хинтон в соавторстве с другими
специалистами опубликовал работу, посвященную
распознаванию рукописных цифр с помощью глубокой
нейронной сети, в которой был введен термин «глубокое
обучение».
Глубокое обучение — это обучение сложных нейронных
сетей (состоящих не менее чем из 5-10 слоев).
Самый популярный и мощный из методов глубокого
обучения сверточные сети.
Популярный пример моделей глубокого обучения — это
система распознавания объектов в беспилотных
автомобилях, предназначенная для распознавания пешеходов
и транспорта, в которой используется более 150 слоев.
31.
ГЛУБОКОЕ ОБУЧЕНИЕК другим областям применения методов глубокого
обучения относится:
анализ временных рядов, направленный на изучение
динамики изменения различных показателей за
определенные периоды (интервалы) времени,
распознавание речи,
задачи обработки текста, включая анализ настроений,
тематическую сегментацию и распознавание именованных
сущностей.
32.
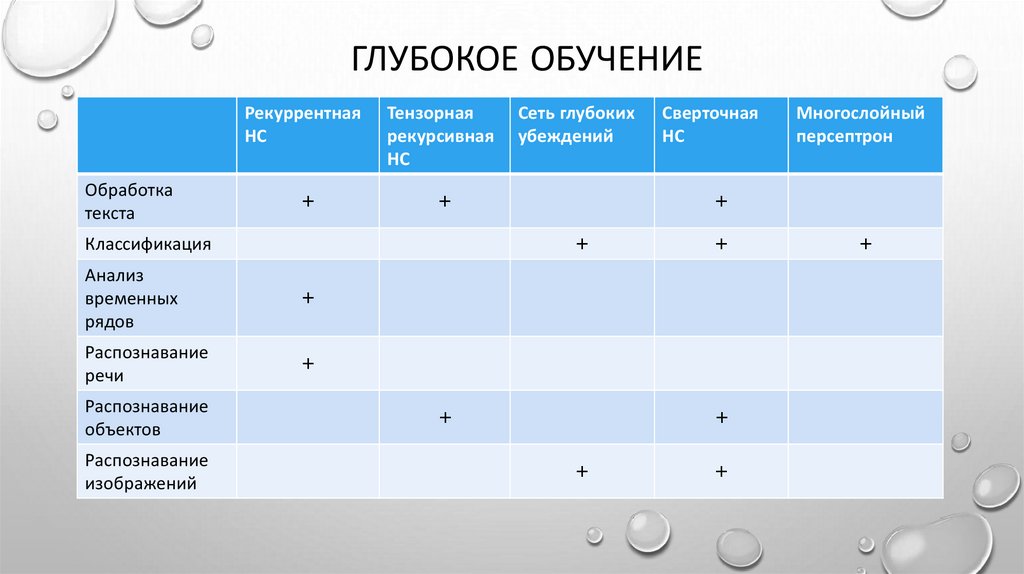
ГЛУБОКОЕ ОБУЧЕНИЕОбработка
текста
Рекуррентная
НС
Тензорная
рекурсивная
НС
+
+
Анализ
временных
рядов
+
Распознавание
речи
+
Распознавание
изображений
Сверточная
НС
Многослойный
персептрон
+
+
Классификация
Распознавание
объектов
Сеть глубоких
убеждений
+
+
+
+
+
+
33.
Машинное обучение применяет математические модели к данным, чтобыделать аналитические выводы или прогнозы.
Такие модели принимают на вход признаки.
Признаки – это числовое представление некоторого аспекта данных.
Конструирование признаков – это извлечение признаков из необработанных
данных и приведение их к формату, пригодному для обработки моделью
машинного обучения. Конструирование признаков – один из важных этапов
процесса. Правильно выбранные признаки облегчают сложное моделирование и
способствуют получению более качественных результатов. Подходящие признаки
можно выявить только в контексте конкретной модели и данных, по этой причине
выявить общий алгоритм конструирования признаков для разных проектов сложно.
34.
• МЫ БУДЕМ УЧИТСЯ ТОМУ КАК• ПРЕДСТАВИТЬ ТЕКСТОВЫЕ ДАННЫЕ ИЛИ ИЗОБРАЖЕНИЯ?
• КАК УМЕНЬШИТЬ РАЗМЕРНОСТЬ СГЕНЕРИРОВАННЫХ ПРИЗНАКОВ?
• КОГДА И КАК НОРМАЛИЗОВАТЬ ПРИЗНАКИ?
• ПРЕИМУЩЕСТВА И НЕДОСТАТКИ РАЗНЫХ ПОДХОДОВ МО.
35.
• НА ПРАКТИЧЕСКИХ ЗАНЯТИЯХ БУДЕТ ИСПОЛЬЗОВАТЬСЯ ЯП PYTHON И ТАКИЕ БИБЛИОТЕКИКАК
• NUMPY
• MATPLOTLIB
• PANDAS
• SEABORN
• SCIKIT-LEARN
36.
ДАННЫЕДАННЫЕ ЭТО НАБЛЮДЕНИЯ ЗА ЯВЛЕНИЯМИ РЕАЛЬНОГО МИРА.
ПРИВЕДИТЕ ПРИМЕРЫ ДАННЫХ?
ДОХОДЫ КОМПАНИЙ
КУРС ВАЛЮТ
СТОИМОСТЬ АКЦИЙ
БИОМЕТРИЧЕСКИЕ ДАННЫЕ (ИЗМЕНЕНИЕ СЕРДЕЧНОГО РИТМА, ДАВЛЕНИЕ, ИЗМЕНЕНИЕ УРОВНЯ
САХАРА В КРОВИ И ТД)
КАЖДЫЙ НАБОР ТАКИХ ДАННЫХ ЯВЛЯЕТ РЕАЛЬНУЮ КАРТИНУ СОБЫТИЙ В НЕКОТОРЫЙ МОМЕНТ
ВРЕМЕНИ, НО ВСЕ ДАННЫЕ ВМЕСТЕ ТЯЖЕЛЫ ДЛЯ ВОСПРИЯТИЯ И АНАЛИЗА. КАЖДЫЙ НАБОР
МОЖЕТ ВКЛЮЧАТЬ НЕКОТОРУЮ ПОГРЕШНОСТЬ ИЛИ НЕПОЛНОТУ. ТО ЕСТЬ ИХ СЛЕДУЕТ
ПРЕДВАРИТЕЛЬНО ПОДГОТОВИТЬ ПЕРЕД ИСПОЛЬЗОВАНИЕМ.
37.
ДАННЫЕОбработка данных (если у вас имеется некоторый опыт) – многоэтапный и
цикличный процесс.
Данные могут быть избыточными, недостающими, неверными.
Избыточные данные содержат повторную информацию.
Недостающие данные содержат пустые фрагменты.
Неверные данные возникают при ошибке при измерениях.
38.
МАТЕМАТИЧЕСКАЯ МОДЕЛЬМатематическая модель данных описывает отношения различных аспектов данных.
Математические формулы связывают численные величины между собой.
Данные часто представлены не числами, то есть нужны признаки для интерпретации
таких данных.
Признаки – это числовое представление исходных данных.
Конструирование признаков – процесс формулирования наиболее подходящих
признаков на основе данных информации, модели и задачи. Имеет значение и число
признаков, если их недостаточно, модель не сможет выполнить свою задачу. Если же
признаков будет много и они не будут относится к решаемой задаче, то модель будет
сложной в обучении и потребуется большие вычислительные силы.
39.
КЛАССИФИКАЦИЯ МОДЕЛЕЙРазница между вероятностными и невероятностными моделями заключается
не в отображении отношений между входом и выходом, а во внутренней структуре
модели.
Вероятностная модель
Невероятностная модель
Контролируемое
обучение
Форма условного распределения
вероятностей P(y|x)
Функциональная форма y=f(x)
Неконтролируемое
обучение
Форма условного распределения
вероятностей P(z|x) или P(x|z)
Функциональная форма z=g(x)
Модели
Логистическая регрессия, алг-м Байеса,
скрытая марковская модель (HMM),
условное случайное поле (CRF),
вероятностный латентносемантический анализ (PLSA),
скрытое распределение Дирихле (LDA),
модель гауссовой смеси (GMM), и тд.
Логистическая регрессия,
метод опорных векторов (SVM),
k-ближайших соседей (KNN),
k-средних,
AdaBoost адаптивный бустинг,
латентно-семантический анализ
(LSA), нейронные сети.
40.
КЛАССИФИКАЦИЯ МОДЕЛЕЙВозможно преобразование форм из условного распределения вероятностей (для
контролируемого обучения P(y|x) и для неконтролируемого обучения P(z|x) или
P(x|z)) в функциональную (для контролируемого обучения) – надо максимизировать
условного распределения вероятностей и наоборот – просто нормализовать
функцию. Для наглядности можно условно представить это в следующей форме:
Контролируемое
обучение
max(