




























































































































 Базы данных
Базы данныхПохожие презентации:





")
")



База данных. Реляционные БД
1.
База данных–логически структурированная совокупность постоянно
хранимых данных, характеризующих актуальное состояние
некоторой
предметной
области
и
используемых
прикладными программными системами какого-либо
предприятия
• Включает также метаданные (словарь данных/системный
каталог) и другую служебную информацию.
• В зависимости от способа логической организации
(структурирования и представления) данных различают:
Реляционные базы данных
Нереляционныебазы данных
2.
Реляционные БДКонцепция впервые была опубликована
в 1970 Эдгаром Франком Коддом
База данных –совокупность двумерных таблиц,
связанных друг с другом с помощью ключей(Primary Key /
Foreign Key)
• Каждая таблица хранит информацию об объектах
предметной области
• Каждая запись в таблице имеет одинаковую структуру
• Стандартный язык для работы с данными -SQL
Oracle, MySQL, Microsoft SQL Server, PostgreSQL
3.
Нереляционные БДХранилища ключей и значений
Простейшая модель. Данные можно легко распределять в
кластере. Для сложных запросов не подходят (Redis, Riak)
Колоночные
Данные хранятся не по строкам, а по столбцам. Хорошо подходят
для BigData (Hbase, Clickhouse, Vertica)
Документоориентированные
Хранение коллекций документов с произвольным набором
атрибутов (полей) (CouchDB, Couchbase, MongoDB)
Графовые. Упор на установление произвольных связей между
данными (OrientDB, Neo4j)
http://nosql-database.org
4.
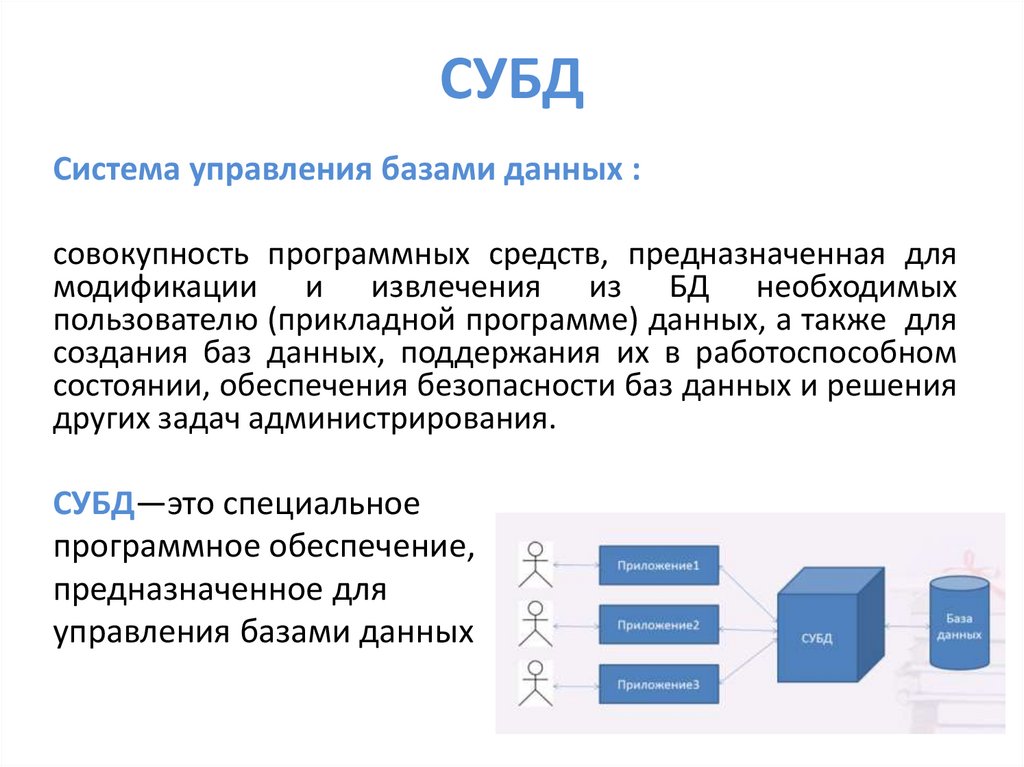
СУБДСистема управления базами данных :
совокупность программных средств, предназначенная для
модификации и извлечения из БД необходимых
пользователю (прикладной программе) данных, а также для
создания баз данных, поддержания их в работоспособном
состоянии, обеспечения безопасности баз данных и решения
других задач администрирования.
СУБД—это специальное
программное обеспечение,
предназначенное для
управления базами данных
5.
Классификация систем баз данных по способуорганизации (архитектуре)
Централизованные(локальные) –все компоненты находятся на одном компьютере
Распределенные–все компоненты распределены по нескольким компьютерам
Файл-серверные:
На файловом сервере – БД;
На рабочих станциях – СУБД и клиентские приложения
Клиент-серверные:
На сервере – СУБД и БД;
На рабочих станциях – клиентские приложения (вкл. Библиотеки)
Многозвенные:
Двухзвенные:
1 звено – СУБД и БД;
2 звено – сервер приложений;
3 звено – клиентские
приложения
1 звено – БД;
2 звено – клиентские
приложения
6.
Основы архитектуры PostgreSQL—это открытая,
BSD*-лицензированная система
управления объектно-ориентированными
реляционными базами данных
*Berkeley Software Distribution license
Использует модель клиент/сервер
Использует многопроцессорность вместо многопоточности
для обеспечения стабильности системы
Сбой в одном из процессов не повлияет на остальные
система продолжит функционировать
и
7.
Преимущества и особенности СУБДPostgreSQL
• Надежность
• Производительность
• Расширяемость
• Поддержка SQL
• Поддержка многочисленных типов данных
8.
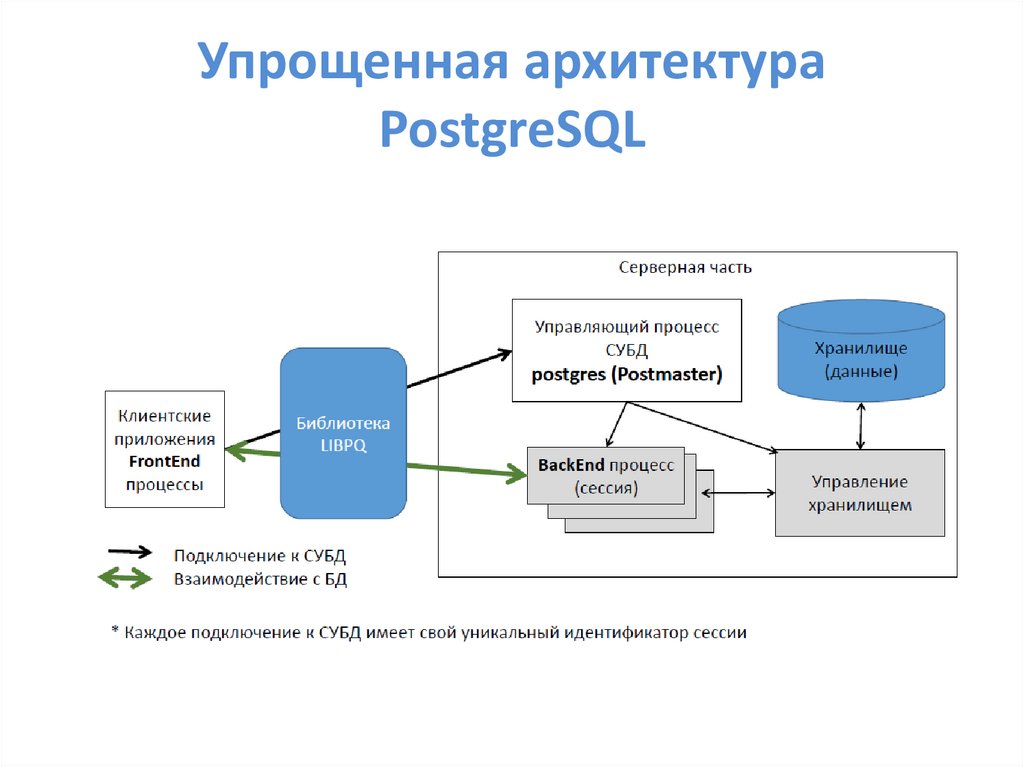
Упрощенная архитектураPostgreSQL
9.
Основные процессы• FrontEnd процессы -клиентские приложения:
используют PostgreSQL в качестве менеджера баз данных
соединение может происходить через TCP/IP или локальные
сокеты
• Демон postmaster-это основной процесс PostgreSQL:
прослушивание через порт/сокет входящих клиентских
подключений
создание BackEnd процессов и выделение им ресурсов
• BackEnd процессы:
аутентификация клиентских подключений
управление запросами и отправка результатов клиентским
приложениям
выполнение внутренних задач (служебные процессы)
10.
Взаимодействие с БДДля работы с реляционной СУБД существует два
подхода:
• работа с библиотекой, которая соответствует
конкретной СУБД и позволяет использовать для
работы с БД язык БД
• работа с ORM (Object-Relational Mapping), которая
использует объектно-ориентированный подход
для работы с БД и автоматически генерирует код
на языке БД
*используется программистами клиентских
приложений
11.
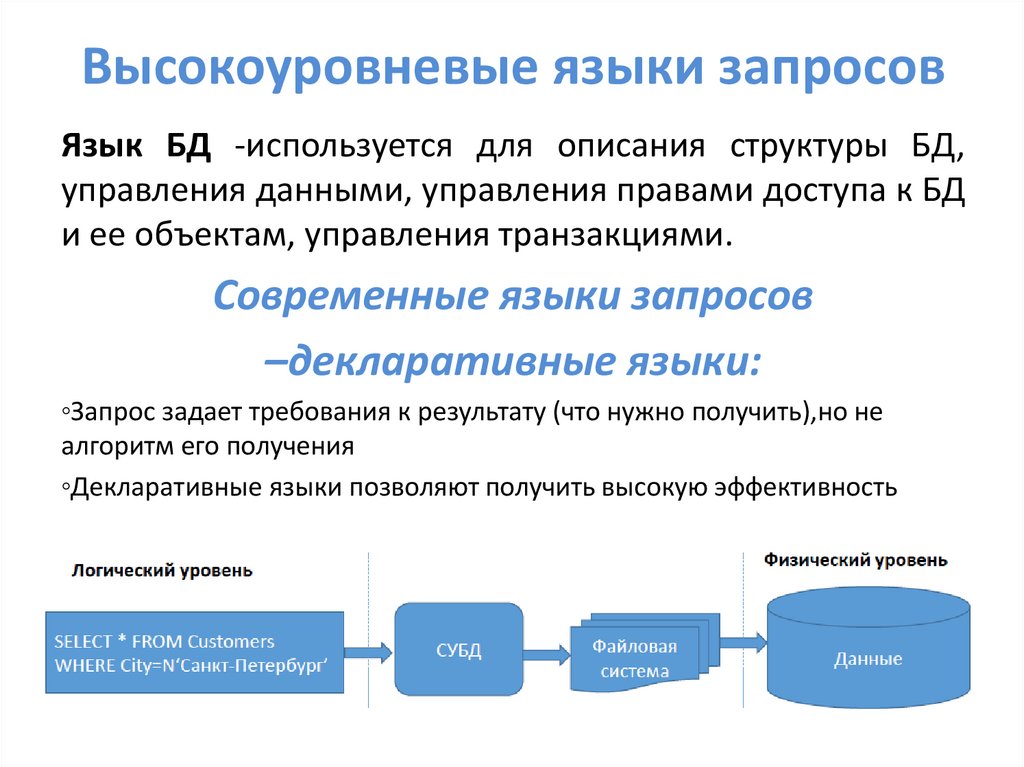
Высокоуровневые языки запросовЯзык БД -используется для описания структуры БД,
управления данными, управления правами доступа к БД
и ее объектам, управления транзакциями.
Современные языки запросов
–декларативные языки:
◦Запрос задает требования к результату (что нужно получить),но не
алгоритм его получения
◦Декларативные языки позволяют получить высокую эффективность
12.
Три стадии проектирования базыданных
Концептуальное (инфологическое) проектирование
• анализ требований к данным
• построение обобщённой концептуальной модели предметной
области
Логическое (даталогическое) проектирование
• преобразование требований к данным в СУБД ориентированную
структуру базы данных
• построение логической модели данных
Физическое проектирование
• определение особенностей хранения данных, методов доступа и
т.д.
• создание схемы базы данных для конкретной СУБД и программноаппаратной платформы
13.
Предметная областьПредметная область - это часть реального мира,
подлежащая изучению для достижения поставленной цели
(автоматизации, управления, создания базы данных и пр).
Предметная область представляется множеством
фрагментов. Каждый фрагмент предметной области
характеризуется множеством объектов и процессов,
использующих объекты, а также множеством пользователей,
характеризуемых различными взглядами на предметную
область.
Например, предметная область ВМФ - базы, корабли,
заводы …
Корабль - тип, порт приписки, траектория движения.
14.
Модель предметной областиконцептуальная (семантическая модель,
инфологическая) модель, предназначенная
для представления семантики предметной
области
на самом высоком уровне
абстракции.
• Наиболее известным представителем
класса семантических моделей является
модель «сущность-связь» (ER-модель).
15.
Данные, информация, знанияДанные (в концепции баз данных)- это набор конкретных
значений параметров или факторов, характеризующих объект,
условие, ситуацию и т.д.
Примеры: Петров Николай Степанович, $3000 и т.д.
Информация - совокупность данных, упорядоченная с
определенной целью, придающей им смысл.
Пример: Сотрудник Петров Николай Степанович получает
зарплату $3000
Знания – это закономерности (принципы, связи, законы)
предметной области, позволяющие специалистам ставить и
решать задачи в этой области.
Пример: Если животное млекопитающее и оно ест мясо,
то это хищник.
16.
Анализ предметной области иопределение требований данным
Назначение ИС и границы проекта
• абстрагирование от неважного
• сосредоточение на важном
Определение основных пользователей системы
(действующих лиц) и их целей
Определение бизнес-правил и ограничений
• Отношения между информационными объектами
• Ограничения на значения определённых характеристик
Определение требований обработки данных
• Защита
• Время отклика
• Темпы увеличения объемов данных
17.
Отношения – свойства:1.Таблицы в реляционных базах данных имеют уникальные имена
2.Столбцы каждой таблицы имеют уникальные имена внутри одной
таблицы
3.Порядок расположения строк и столбцов в таблице – произвольный
4.Данные в столбце должны быть однотипными.
Примеры типов данных:
• Символьные
• Текстовые
• Числовые
• Дата/Время
• Логические
5.Данные в ячейках должны быть атомарными
6.Не рекомендуется избыточно дублировать данные в столбцах
таблицы. При дублировании информации может быть нарушена
целостность данных
7.В таблицах базы данных строки не должны повторяться
18.
Целостность базы данных:DATABASE INTEGRITY содержащаяся информация в базе
соответствует информации предметной области
Непротиворечивость - невозможность сделать
разные выводы об одном и том же объекте или явлении
реального мира на основании информации,
представленной различными сущностями.
Ограничение целостности (integrity constraint) –
явное или неявное правило, применяющееся при любой
попытке изменения данных в базе для гарантированного
сохранения целостности.
Примеры: в базе не должна храниться информация об
одном и том же студенте дважды, студент должен быть
причислен к какой-то группе.
* Соответствие действительности средствами
реляционной модели данных можно обеспечить только
до некоторой степени.
19.
Ограничения целостностиВ теории реляционных баз данных принято выделять четыре типа
ограничений целостности:
1. Ограничением базы данных называется ограничение на значения,
которые разрешено принимать указанной базе данных.
2. Ограничением переменной отношения называется ограничение
на значения, которые разрешено принимать указанной
переменной отношения.
3. Ограничением атрибута называется ограничение на значения,
которые разрешено принимать указанному атрибуту.
4. Ограничение типа представляет собой определение множества
значений, из которых состоит данный тип.
Примером распространённого ограничения уровня переменной
отношения является потенциальный ключ;
Примером распространённого ограничения уровня базы данных
является внешний ключ.
20.
СуперключСуперключ (SK) – один или несколько столбцов,
значения в которых позволяет однозначно
отличить одну запись в таблице от другой.
• обладает свойством уникальности – в
таблице не может быть двух записей с
одинаковым значением SK,
• совокупность всех столбцов всегда должна
являться суперключом (т.к. строки в таблице
не должны повторяться)
21.
Потенциальный ключПотенциальный ключ – это подвид суперключа,
который дополнительно обладает свойством
неизбыточности:
т.е. из потенциального ключа нельзя исключить ни
один атрибут без потери свойства уникальности
оставшихся
Ограничение UNIQUE не позволяет значениям
соответствующих столбцов повторяться
Неключевые атрибуты - не входят в состав ни
одного из потенциальных ключей
22.
Какие бываютпотенциальные ключи:
Один из потенциальных ключей выбирается для
быстрого и однозначного определения записи в
таблице. Этот ключ будет называться первичным.
Должен быть:
• минимальным
• обязательным
• постоянным
Ограничение типа PRIMARY KEY: значения не
повторяются и не содержат NULL
Альтернативный ключ - оставшиеся потенциальные
ключи:
ограничение типа UNIQUE - не позволяет значениям
соответствующих столбцов повторяться
23.
Суррогатный ключтакой ключ, который не имеет представительства
в реальности.
Напрмер:
ID_студента – суррогатный ключ
№студенческого_билета – естественный ключ
001 Петров Иван Федорович ИБ-21
002 Петров Иван Федорович ИБ-21
24.
Суррогатные ключи:• Искусственно создаются
• Удовлетворяют всем характеристикам хороших
первичных ключей
• Могут поддерживаться автоматически
• Обеспечивают хорошую производительность при
отображении информации из нескольких сущностей
(используются в OLAP-системах)
• Занимают дополнительное место
• На самом деле не позволяют отличить один
реальный экземпляр сущности от другого и
избежать ошибок при вводе данных
25.
Естественные ключи• Выбираются из числа реальных характеристик
сущности
• Не всегда хорошо подходят на роль первичного ключа
• Значения вносятся «вручную»
• Часто негативно влияют на производительность при
отображении информации из нескольких сущностей
(плохо подходят для OLAP-систем)
• Позволяют однозначно отличить один реальный
экземпляр сущности от другого
• в т.ч. могут быть использованы для поиска сущностей
по их реальным характеристикам
26.
Ключи27.
Виды связейБинарные связи соединяют между собой две
таблицы
Унарные связи служат для соединения таблицы
с собой
1:1 (один-к-одному)
1:М (один-ко-многим)
M:N (многие-ко-многим).
28.
Виды связей в реляционной моделиСвязь между таблицами А и В называется связью
один-к-одному, если каждой записи таблицы А
соответствует не более одной записи таблицы B, и
каждой записи таблицы B соответствует не более одной
записи таблицы A.
Связь между таблицами А и В называется связью
один-ко-многим, если каждой записи таблицы А
соответствует ноль, одна или несколько записей
таблицы B, но каждой записи таблицы B соответствует
не более одной записи таблицы A.
Связь между таблицами А и В называется связью
многие-ко-многим, если каждой записи таблицы А
соответствует ноль, одна или несколько записей
таблицы B, и каждой записи таблицы B соответствует
ноль, одна или несколько записей таблицы A.
Связи М:N (многие-ко-многим) реализуются при
помощи дополнительной (ассоциативной) таблицы и
двух связей 1:М.
29.
Ассоциативная таблицаСостоит минимум из 2-х атрибутов:
Ссылка на PK первой таблицы
Ссылка на PK второй таблицы
Первичный ключ составной (оба столбца)
30.
Внешний ключТаблица, в которой содержатся исходные данные для
связывания, называется главной (родительской) таблицей,
вторая – подчиненной (дочерней).
Главная таблица всегда находится со стороны «один» в
связи.
Тот столбец (или столбцы) в дочерней таблице, которые
ссылаются на главную таблицу, называют внешним ключом
(Foreign Key).
Внешний ключ дочерней таблицы - «копия» потенциального
ключа главной таблицы:
• состоит ровно из такого же количества атрибутов, что и
потенциальный ключ родительской таблицы,
• определен на тех же доменах что и соответствующий
потенциальный ключ родительской таблицы
31.
Ограничение внешнего ключаFOREIGN KEY делает известные значения столбцов
подчиненной таблицы «ссылками» на значения из
столбцов первичного ключа главной таблицы. Т.е.
значения столбцов внешнего ключа подчиненной
таблицы могут либо совпадать со значениями первичного
ключа главной таблицы, либо быть неизвестными (NULL)
Логическая связь 1:1 на уровне базы данных
обеспечивается наложением ограничения уникальности
(т.е. первичного или альтернативного ключа) на
атрибуты, входящие в состав внешнего ключа, т.е.
внешний ключ может быть одновременно и
потенциальным.
32.
Ссылочная целостностьОперации с родительской
таблицы
Вставка строки в таблицу
• возникает новое значение атрибутов потенциального ключа родительской таблицы
• т.к. допустимо существование экземпляров родительской таблицы, с которыми не
связаны экземпляры дочерней, то ссылочная целостность не нарушается
! Обновление строки таблицы
• может измениться значение атрибутов потенциального ключа родительской
таблицы
• если есть экземпляры дочерней таблицы, связанные с обновляемым экземпляром
родительской, то значения атрибутов их внешних ключей могут стать
некорректными => может возникнуть нарушение ссылочной целостности
! Удаление строки из таблицы
• удаляется некоторое значение атрибутов потенциального ключа родительской
таблицы
• если есть экземпляры дочерней таблицы, связанные с удаляемым экземпляром
родительской, то значения их внешних ключей станут некорректными => может
возникнуть нарушение ссылочной целостности
33.
Ссылочная целостностьОперации с дочерней таблицей
! Вставка строки в таблицу
добавляется некоторое значение атрибутов внешнего ключа дочерней таблицы
значение атрибута внешнего ключа добавляемого экземпляра может не
совпадать ни с одним из значений потенциального ключа родительской
таблицы => может возникнуть нарушение ссылочной целостности
! Обновление строки таблицы
может измениться значение атрибутов внешнего ключа дочерней таблицы
новое значение атрибутов внешнего ключа может не соответствовать ни одному
значению потенциального ключа в родительской таблицы => может
возникнуть нарушение ссылочной целостности
Удаление строки из таблицы
удаляется значение атрибутов внешнего ключа дочерней таблицы
мы не ссылаемся на значения атрибутов внешнего ключа => ссылочная
целостность не нарушается
34.
Типы данных и доменыДля каждого атрибута должны быть определены:
Домен – определяет множество всех
допустимых значений атрибута (область
определения)
Предопределённые домены соответствуют
общим типам данных: BLOB, DateTime, Number,
String
Тип данных атрибута – характеризует вид
хранящихся данных (символьные строки,
бинарные строки, целые числа, логические
значения, дата, время и др.)
35.
Нормализация реляционных базданных
Нормализация - формальная процедура, проверки и
реорганизации отношений, в ходе которой создается
оптимизированная структура БД, позволяющая
избежать различных видов аномалий
Подразумевает декомпозицию отношения на два
или более, обладающих лучшими свойствами при
добавлении, изменении и удалении данных
Задачи нормализации:
• Исключение из таблиц повторяющейся
информации.
• Создание структуры, в которой предусмотрена
возможность ее будущих изменений и с
минимальным влиянием на приложения
36.
Дублирование- заключается в хранении идентичных данных
Необходимое:
важен сам факт идентичности данных - для
поддержки ссылочной целостности (связей
между сущностями)
Избыточное:
—ведет к аномалиям, которые не являются
неразрешимыми в принципе, но существенно
усложняют обработку
—при избыточном дублировании могут
возникать противоречия данных
37.
Аномалия данных– это такая ситуация в базе данных, которая приводит к
противоречиям в базе данных, либо существенно усложняет
обработку данных.
Виды аномалий:
Аномалия модификации данных. Необходимость
изменения одного значения приводит к необходимости
просмотра всей таблицы (для исключения
противоречий).
Аномалия удаления данных. Состоит в том, что удаление
данных из таблицы приводит к удалению информации не
связанной напрямую с удаляемыми данными.
Аномалия вставки данных. Нельзя добавить одни
данные без наличия других или же для вставки данных
необходимо просмотреть всю таблицу (для исключения
противоречий).
* Основная причина аномалий - хранение в одном
отношении разнородной информации.
38.
Нормализация. Нормальные формыСуществует 6 нормальных форм:
• 1НФ - Первая нормальная форма
• 2НФ - Вторая нормальная форма
• 3НФ - Третья нормальная форма
• НФБК - нормальная форма Бойса-Кодда (усиленная третья
нормальная форма)
• 4НФ - Четвертая нормальная форма
• 5НФ - Пятая нормальная форма
Свойства НФ:
• Каждая последующая НФ сохраняет свойства предыдущей;
• каждая следующая НФ добавляет свои свойства к
полученным от предыдущей.
39.
Первая нормальная формаОтношение находится в первой нормальной форме тогда и
только тогда, когда:
все столбцы имеют уникальные имена,
определён его первичный ключ – отсутствуют
повторяющиеся строки,
все атрибуты отношения содержат атомарные значения, в
т.ч. нет многозначных атрибутов
нет упорядочивания строк сверху-вниз - порядок строк не
несет в себе никакой информации,
нет упорядочивания столбцов слева-направо - порядок
столбцов не несет в себе никакой информации.
Для приведения отношения к 1 НФ следует:
разделить сложные атрибуты на атомарные
«повторяющиеся» атрибуты совместить в один
определить первичный ключ отношения
40.
ДекомпозицияКак правило, для приведения отношения к 1НФ не
нужно разбивать его на несколько новых, однако
эта необходимость обязательно возникает на
дальнейших этапах нормализации
Не будут ли данные потеряны в ходе декомпозиции?
Можно ли вернуться обратно к исходным отношениям,
если будет принято решение отказаться от
декомпозиции, восстановятся ли при этом данные?
Приведение отношения к любой НФ в дальнейшем
должно основываться на декомпозиции без
потерь
41.
Вторая нормальная формаОпределение:
Отношение находится во второй нормальной
форме (2НФ), тогда и только тогда, когда оно
находится в 1НФ, и каждый его неключевой атрибут
функционально полно зависит от первичного ключа
*Если первичный ключ отношения состоит из одного
атрибута, оно автоматически находится во 2НФ
Для приведения отношения к 2НФ следует:
выделить неключевые атрибуты, которые зависят
только от части первичного ключа и перенести их в
новое отношение вместе с той частью ключа, от
которой они зависят.
42.
Функциональная зависимостьФункциональная зависимость (ФЗ) – возникает, когда по
значениям одних данных в предметной области можно
определить значения других данных.
Множество атрибутов Y некоторого отношения А
функционально зависит от множества атрибутов X того же
отношения тогда и только тогда, когда для всех экземпляров,
имеющих одинаковые значения атрибутов X, значения атрибутов
Y также совпадают в любом состоянии отношения A (т.е. для
каждого значения X есть только одно возможное значение Y)
• X однозначно определяет Y: X→Y
• X–детерминант функциональной зависимости
• Y–зависимая часть
• Любой потенциальный ключ является детерминантом
некоторой ФЗ
43.
Третья Нормальная формаОтношение находится в третьей нормальной
форме тогда и только тогда, когда оно находится в
2НФ и не содержит транзитивных функциональных
зависимостей между неключевыми атрибутами и
каким-либо потенциальным ключом.
Не должно наблюдаться функциональных
зависимостей между неключевыми атрибутами.
Примечание:
Отношение автоматически находится в 3НФ, если
содержит не более одного неключевого атрибута.
44.
Транзитивная функциональнаязависимость
ФЗ X → Y называется транзитивной, если
существует такой атрибут Z этого же отношения,
что имеются ФЗ X → Z и Z → Y и отсутствует ФЗ Z →
X.
Например, зависимость
• Group(X) -> SpecName(Y)
является транзитивной, т.к.
• Group (X) -> SpecID(Z) и SpecID(Z) -> SpecName(Y),
но ФЗ
• SpecID(Z) -> Group (X)
не существует (по одной специальности может
обучаться несколько групп)
45.
Для приведения отношения к 3НФследует для каждой ФЗ, нарушающей
требования 3НФ:
1. Создать новое отношение, схема которого
будет включать все атрибуты ФЗ-нарушителя.
2. Первичным ключом нового отношения станет
детерминант переносимой ФЗ
3. Из исходного отношения удалить все атрибуты
зависимой части переносимой ФЗ
4. Копия атрибутов, входящих в детерминант
переносимой ФЗ, должна остаться в исходном
отношении для обеспечения его связи с новым
отношением
46.
Теорема ХезаПусть R(X,Y,Z) является отношением, и X,Y,Z
– атрибуты или множества атрибутов этого
отношения.
Если имеется функциональная
зависимость
X->Y,
то отношения R1(X,Y) и R2(X,Z) образуют
декомпозицию без потерь
47.
НФБКУсиленная 3НФ или нормальная форма Бойса-Кода
Отношение находится в нормальной форме БойсаКодда (НФБК) тогда и только тогда, когда оно находится в
3НФ и любая полная ФЗ имеет в качестве детерминанта
некоторый потенциальный ключ данного отношения.
НФБК может нарушаться, если имеется ФЗ между
ключевыми атрибутами (т.к. все зависимости неключевых
атрибутов от каких-либо других уже были устранены на
этапе приведения к 3НФ).
Проверять отношение на нарушение НФБК следует, если в
нём есть пересекающиеся потенциальные ключи
*Отношение автоматически находится в НФБК, если оно
содержит только один потенциальный ключ.
48.
4 НФОтношение находится в четвёртой
нормальной форме тогда и только тогда, когда
оно находится в НФБК и не содержит
нетривиальных многозначных зависимостей
Проверять отношение на нарушение 4НФ
следует, если оно состоит как минимум из трёх
атрибутов и все его атрибуты – ключевые
*Отношение автоматически находится в 4НФ,
если:
• содержит менее 3-х атрибутов и/или
• содержит не ключевые атрибуты
49.
Многозначная зависимостьМногозначная зависимость (МЗ) –
является обобщением функциональной
зависимости и рассматривает соответствие
одному значению детерминанта МЗ
некоторого множества значений зависимого
атрибута.
В отношении R(X,Y,Z) существует
многозначная зависимость X->->Y тогда и
только тогда, когда множество значений
атрибута Y, соответствующее паре
значений атрибутов X и Z, зависит только
от X и не зависит от Z
50.
Многозначная зависимостьСогласно лемме Фейджина (Фейгина), если в
таком отношении имеется МЗ X->->Y, то обязательно
имеется и МЗ X->->Z, что записывается как X->->Y|Z
• X называется детерминантом МЗ
• Х,Y,Z – могут быть группами атрибутов
Aтрибуты Y и Z многозначно зависят от атрибута X
тогда и только тогда, когда из того, что в отношении R
содержатся кортежи
• r1=(x,y,z1) и r2=(x,y1,z)
следует, что в отношении R присутствует кортеж
• r3=(x,y,z) и r4=(x,y1,z1)
т.е. имеются все возможные сочетания значений Y и Z,
соответствующие некоторому значению атрибута X, т.к.
Y и Z не зависят друг от друга
51.
5НФОтношение находится в пятой нормальной
форме тогда и только тогда, когда оно находится
в 4НФ и не содержит нетривиальных
зависимостей соединения
Проверять отношение на нарушение 5НФ
следует, если оно состоит как минимум из трёх
атрибутов и все его атрибуты – ключевые
*Отношение автоматически находится в 5НФ,
если:
• Содержит менее 3-х атрибутов и/или
• Содержит неключевые атрибуты
52.
Зависимость соединенияЗависимость соединения (ЗС )– является обобщением
многозначной зависимости.
В отношении R(X,Y,Z) существует зависимость
соединения *(X,Y,Z) тогда и только тогда, когда декомпозиция
отношения R на R1(X,Y), R2(Y,Z) и R3(X,Z) происходит без
потерь.
Х,Y,Z – могут быть группами атрибутов
Между атрибутами X, Y и Z существует зависимость
соединения тогда и только тогда, когда из того, что в
отношении R содержатся кортежи
r1=(x,y1,z),r2=(x,y,z1) и r3=(x1,y,z)
следует, что в отношении R присутствует кортеж r4=(x,y,z),
т.е. если существуют попарные сочетания значений трёх
атрибутов:
(x,y), (y,z) и (x,z),
то все эти значения обязательно должны встретиться в одном
кортеже (некая зависимость наблюдается между всеми
атрибутами).
53.
Сущность (entity)– это именованное множество подобных
уникальных экземпляров (instances) –
объектов, событий, концепций – информация
о которых должна храниться в базе данных.
Имя сущности – существительное, как
правило, в единственном числе (по имени
одного экземпляра).
Примеры сущностей: множества Студент,
Предмет, Сессия.
54.
Сущность (entity)подразделяются на:
• обычные,
• слабые.
Слабой называется такая сущность,
существование которой зависит от другой
сущности, т.е. она не может существовать, если
этой другой сущности не существует
55.
Экземпляр сущности. АтрибутЭкземпляр сущности – конкретный представитель
сущности.
Сущность «Студент» - экземпляр сущности «Селиванов»
Атрибут (attribute) – именованное и неотъемлемое
свойство всех экземпляров сущности, значимое для
рассматриваемой предметной области.
Свойство в целом (например, «фамилия") присуще
всем экземплярам сущности, но его значение
(например, «Петров") может быть своим для каждого из
экземпляров.
Имя атрибута – существительное. Обычно, в
единственном числе.
Экземпляр сущности можно рассматривать как
сочетание конкретных значений атрибутов сущности,
описывающих её реальное проявление.
56.
Атрибут сущности• Составной – может быть разделен на несколько
отдельных атрибутов, допустим в самом начале
моделирования.
• Атомарный –
степень атомарности определяется
разработчиком, зависит от задачи:
- обязательно дальнейшее разбиение составного
атрибута на простые, если предполагается
самостоятельное использование его частей при
изменении информации или в случае, если какаялибо часть является детерминантом
функциональной зависимости
57.
Атрибут сущностиАтрибуты, изначально присущие сущности
Появившиеся в результате связи с другой сущностью
Однозначные / многозначные (множественные)
• однозначный – содержит только одно значение для
каждого экземпляра сущности в конкретный
момент времени
− у сотрудника может быть только одна дата
рождения
• многозначный – содержит несколько значений
− у одного отделения компании может быть
несколько контактных телефонов
* «Какая информация должна храниться о…?»
(определение атрибута)
58.
Атрибут сущности - определениеАтрибуты указываются только для сущностей. Если у связи
имеются атрибуты, то это указывает на тот факт, что связь
можно определить как сущность
• Сначала выделяют только атрибуты сущности - те, которые
есть у неё всегда, вне связи с остальными. В дальнейшем у
сущности появятся атрибуты, характеризующие её связи.
*Например, у сущности Студент нет собственного
атрибута Группа, этот атрибут появится только после
того, как мы рассмотрим связь сущности Студент и
сущности Группа.
• В одной сущности не должно быть атрибутов с одинаковым
именем
• Необходимо определить ключевые атрибуты для каждой
сущности
• При определении атрибутов стоит ориентироваться на
документооборот организации, бизнесс-прпоцессы.
59.
Типы данныхДомен - определение множества всех
допустимых значений атрибута
Предопределённые домены соответствуют
общим типам данных: BLOB, DateTime,
Number, String
Тип данных атрибута – характеризует вид
хранящихся данных (символьные строки,
бинарные строки, целые числа, логические
значения, дата, время и др.)
Имя атрибута
Домен
Тип данных
Фамилия
String
Varchar
60.
Потенциальный ключCandidate Key – неизбыточный набор
атрибутов, совокупность значений которых
позволяет уникально идентифицировать каждый
экземпляр сущности.
Неизбыточность – нельзя удалить хотя бы
один атрибут из набора так, чтобы оставшиеся
продолжали подходить на роль уникального
идентификатора для каждого экземпляра
сущности.
• Один выбирается как первичный - PK, Primary
key,
• остальные становятся альтернативными - AK,
Alternate Key
61.
Первичный ключВсе потенциальные ключи, и первичный и
альтернативные - равнозначны!
Должен обладать следующими характеристиками:
• минимальным - не только по количеству
атрибутов, но и по суммарной длине
значения
• Обязательным - иметь значения для всех
возможных экземпляров сущности
• постоянным – значения такого атрибута
никогда не должны меняться
62.
Суррогатные и естественныепервичные ключи
на концептуальном уровне можно выбирать
только
естественные (при возможности
полностью отделить этот уровень от
остальных при проектировании).
На последующих уровнях проектирования,
допускается
использование
суррогатных
ключей,
при
условии,
что
имеется
естественный ключ в роли альтернативного
63.
Требования к ключам сущности• Каждая сущность должна обладать первичным ключом
• Каждая сущность может обладать любым числом
альтернативных ключей
• Первичный или альтернативный ключ может состоять из
одного или нескольких атрибутов
• Отдельный атрибут может быть частью более чем одного
ключа, первичного или альтернативного
• Например, некоторая сущность, описывающая мебельные
ткани, может иметь два потенциальных ключа:
1) Название ткани + Название цвета и
2) Название ткани + Код цвета.
• Таким образом, один и тот же атрибут, Название цвета,
входит в состав сразу двух ключей
64.
Связи- обеспечение целостности
Связь – ассоциирование экземпляров двух или
более сущностей
Имя связи – обычно глагол или фраза на основе
глагола, которая определяет семантику связи и
выражает некоторое бизнес-правило.
Связь может быть поименована в две стороны:
Студент <учится в> Группе,
Группа <состоит из> Студентов
65.
Внешний ключИспользуется для связи между сущностями
в одну из них необходимо добавить информацию о другой
так, чтобы можно было однозначно определить связанные
экземпляры
Для установки связи атрибуты одного из потенциальных
ключей (по умолчанию – первичного) одной сущности
мигрируют (копируются) в другую, где становятся внешним
ключом
сущность, из которой был скопирован ключ, называется
родительской
сущность, в которую были добавлены новые атрибуты
(внешний ключ) – дочерней
Значения внешнего ключа должны быть точной копией
того потенциального ключа, на который они ссылаются
Домен, тип данных, размер данных – обязательно
должны совпадать!
66.
Обеспечение связиИндексы – это специальная структура в базе данных,
использующаяся для ускорения поиска по значениям
атрибута (или атрибутов), на основе которых он построен.
Индекс похож на алфавитный указатель терминов в
конце книги: берутся все значения некоторого
атрибута, сохраняются отдельно в отсортированном
виде и рядом с каждым проставляется указатель на
те строки таблицы, где данное значение встречается.
Индекс может быть уникальным (значения атрибута,
на базе которого построен индекс, в таблице не
повторяются, т.е. одно значение может встретиться
только в одной строке) и неуникальным (одно и то
же значение может встретиться в нескольких
строках).
67.
Характеристики связейКаждая связь имеет три характеристики:
Кратность (кардинальность, мощность)
Сила
Модальность
В совокупности эти характеристики выражают
существующие ограничения предметной
области.
68.
Характеристики связейКратность (кардинальность, мощность) – показывает,
какое количество экземпляров одной сущности
участвует в связи с одним экземпляром другой.
один-к-одному (1:1)
один-ко-многим (1:М) / многие-к-одному
(М:1)
многие-ко-многим (М:М)
Сила – идентифицирующая, не идентифицирующая
Модальность:
Модальность «может»
Модальность «должен»
69.
Категориальнаясвязь
это особая разновидность связи, которая используется для описания структур, в
которых сущность является типом (категорией) другой сущности.
При этом родительская сущность содержит общие свойства, присущие дочерним
(категориальным) сущностям - иерархия наследования (категории),
Делится на суперклассы и подклассы.
• не существует в реляционной модели, поэтому в ходе дальнейшего
проектирования должна быть разрешена
Родительской сущностью (суперклассом, супертипом) является та, которую
можно разделить на подклассы (категории, подтипы), каждый из которых
будет являться дочерней сущностью:
• в родительскую сущность выносятся все общие атрибуты, с ней устанавливаются
общие связи
• в дочерних сущностях остаются атрибуты, характеризующие только эти сущности
(характеристики, отличающие их от других подтипов этого же супертипа) и их
«личные» связи с другими сущностями
• в родительской сущности вводится атрибут-дискриминатор, позволяющий
распределять её экземпляры по категориям
70.
Категориальная связь• Эксклюзивная – каждому экземпляру
родового предка может соответствовать
экземпляр только в одном из потомков
• Инклюзивная – каждому экземпляр
родового предка могут соответствовать
экземпляры нескольких потомков
В нотации IE:
71.
Унарнаясвязь
(рекурсивная)
Связывает сущность саму с собой.
• Иерархическая (тип 1:1 или 1:М)
− всегда необязательная
• атрибут внешнего ключа может содержать NULL
(необходимо для внесения информации об
экземпляре, являющимся корнем иерархии)
− всегда неидентифицирующая
• для некоторого экземпляра в «дочерней» копии
сущности не будет существовать экземпляра в
«родительской»
Пример: связь между сотрудникомподчинённым и сотрудникомначальником
• Сетевая (тип М:М)
Пример: связь между родственниками
72.
Сетевая рекурсияЧеловек из сущности «Человек», может
быть как отцом, так и матерью для
ребенка из сущности «Ребенок»
73.
Индекс— это отдельная структура данных, которая
ускоряет извлечение данных из таблицы
за счет дополнительных операций записи и
хранения для ее обслуживания.
74.
Типы индексовB-tree,
Hash,
GiST,
SP-GiST,
GIN,
BRIN.
Каждый тип индекса использует разную структуру хранения
и алгоритм для обработки разных типов запросов.
CREATE INDEX - без указания типа индекса умолчанию Bдерева.
75.
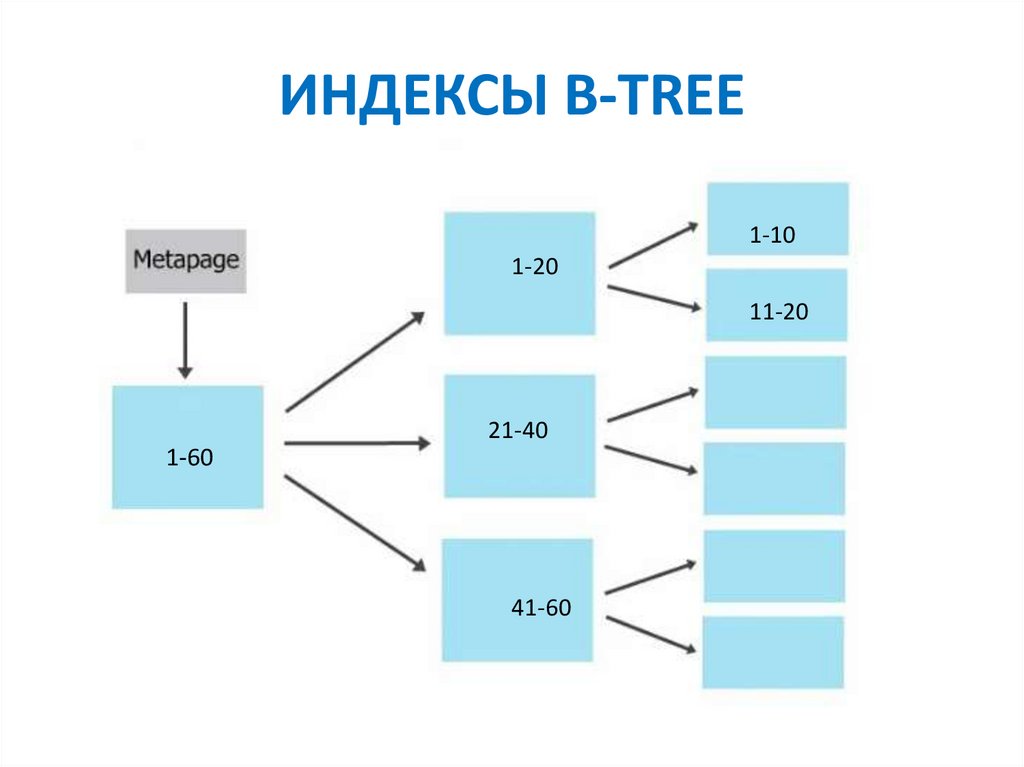
ИНДЕКСЫ B-TREE1-10
1-20
11-20
21-40
1-60
41-60
76.
ИНДЕКСЫ B-TREEкогда столбцы индекса участвуют в сравнении
используется один из следующих операторов:
<
<=
=
>=
BETWEEN
IN
IS NULL
IS NOT NULL
77.
ИНДЕКСЫ B-TREEоператор сопоставления с шаблоном
LIKE
~
если шаблон является константой и привязан к
началу шаблона, например:
• column_name LIKE 'foo%'
• column_name LKE 'bar%'
• column_name ~ '^foo'
78.
ИНДЕКСЫ B-TREEILIKE если ~*
шаблон начинается с неалфавитного символа,
то есть символов, на которые не влияет
преобразование верхнего/нижнего регистра.
• B-tree используется по умолчанию
79.
ИНДЕКСЫ B-TREEОсобенности
Можно:
Поиск по полному значению;
Поиск по самому левому префиксу;
Поиск по префиксу столбца;
Поиск по диапазону значений;
Поиск по полному совпадению одной части и диапазону в
другой части;
Запросы только по индексу.
Нельзя:
Поиск без использования левой части ключа;
Нельзя пропускать столбцы;
Оптимизация после поиска в диапазоне.
80.
HASH -индексыХэш-индексы
могут обрабатывать только простое сравнение
на равенство (=).
Чтобы создать хэш-индекс, вы используете
CREATE INDEX оператор с HASH-типом индекса в
USING предложении:
CREATE INDEX index_name
ON table_name USING HASH (indexed_column);
81.
HASH -индексызанимают больше места, чем индексы b-tree.
Проиндексировать 4 миллиона целочисленных
значений:
Для b-tree требуется около 90 МБ
Для хеш-индекса требуется 125 МБ
пространства.
82.
Индексы GIN(Generalized Inverted Index)
применяются для
полнотекстового поиска,
поиска по массивам,
JSON,
и триграммам.
Пример создания GIN-индекса для
полнотекстового поиска:
CREATE INDEX example_gin ON example_table
USING gin (to_tsvector('english', column_name));
83.
BRINиндексы диапазона блоков
BRIN намного меньше и менее затратен в
обслуживании по сравнению с индексом Bдерева.
• BRIN позволяет использовать индекс для
очень большой таблицы.
• BRIN часто используется для столбца с
линейным порядком сортировки, например
для столбца даты создания таблицы заказов на
продажу.
84.
ИНДЕКСЫ GIST«обобщенное дерево поиска»
позволяют создавать общие древовидные
структуры.
Полезны:
• при индексировании геометрических типов
данных
• и полнотекстовом поиске.
85.
ИНДЕКСЫ SP-GISTразделенный на пространство GiST.
поддерживает секционированные деревья поиска,
которые облегчают разработку широкого спектра
различных несбалансированных структур данных.
наиболее полезны для данных, которые имеют
естественный элемент кластеризации и не являются
одинаково сбалансированным деревом, например
ГИС, мультимедиа, телефонная маршрутизация и IPмаршрутизация.
86.
PostgreSQL CREATE INDEX87.
PostgreSQL DROP INDEX88.
UNIQUE ИНДЕКС• только индексы B-дерева могут быть
объявлены как уникальные индексы.
Определяем:
• первичный ключ
• ограничение уникальности для таблицы
PostgreSQL автоматически создает
соответствующий UNIQUEиндекс.
89.
UNIQUE ИНДЕКСПРИМЕР НЕСКОЛЬКИХ СТОЛБЦОВ
90.
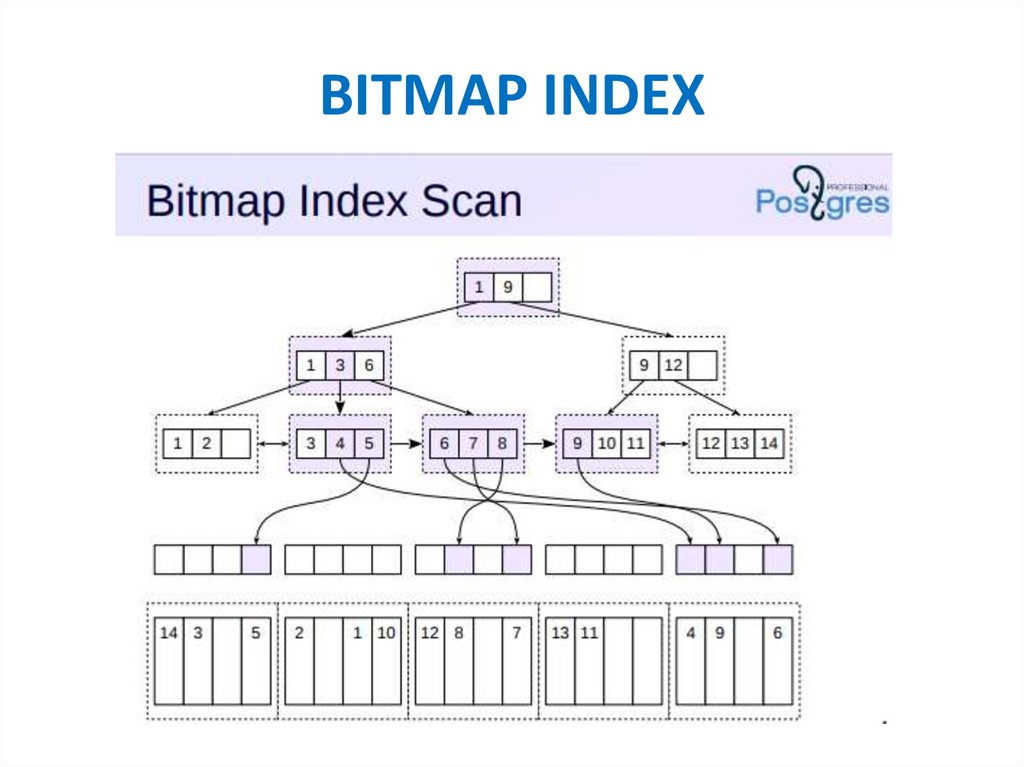
BITMAP INDEXБитовая карта
Мало уникальных значений
Много повторений
Read чаще чем Update
Не подходит для OLTP
В WHERE при использовании OR/AND
CREATE INDEX my_bitmap_index ON my_table USING bitmap (flag1, flag2,
flag3);
Подходит, например, для индексирования таких полей как «Пол», где
только 2 значения «М»/«Ж»
https://edu.postgrespro.ru/qpt/qpt_05_bitmapscan.pdf
91.
BITMAP INDEX92.
Bitmap Indexпохож на обычный индексный доступ, но происходит в два
этапа.
• сканируется индекс (Bitmap Index Scan)
в локальной памяти процесса строится битовая карта
отмечаются те строки, которые должны быть
прочитаны.
• начинается сканирование таблицы (Bitmap Heap Scan).
страницы читаются последовательно
каждая страница просматривается ровно один раз.
93.
ИНДЕКСЫне всегда являются положительным
фактором
При вставке, обновлении или удалении
данных, индексы должны быть обновлены
важно тщательно анализировать и выбирать
индексы
94.
КОГДА НЕ ИСПОЛЬЗУЕМ ИНДЕКСЫ• В результате выборки большой объем
данных
• Если есть партиционирование и
сегментация
• Если частое обновление (вставка данных)
талицы
– При загрузке данных, рекомендуется удалять
индекс, затем делать вставку, снова добавить
индекс
95.
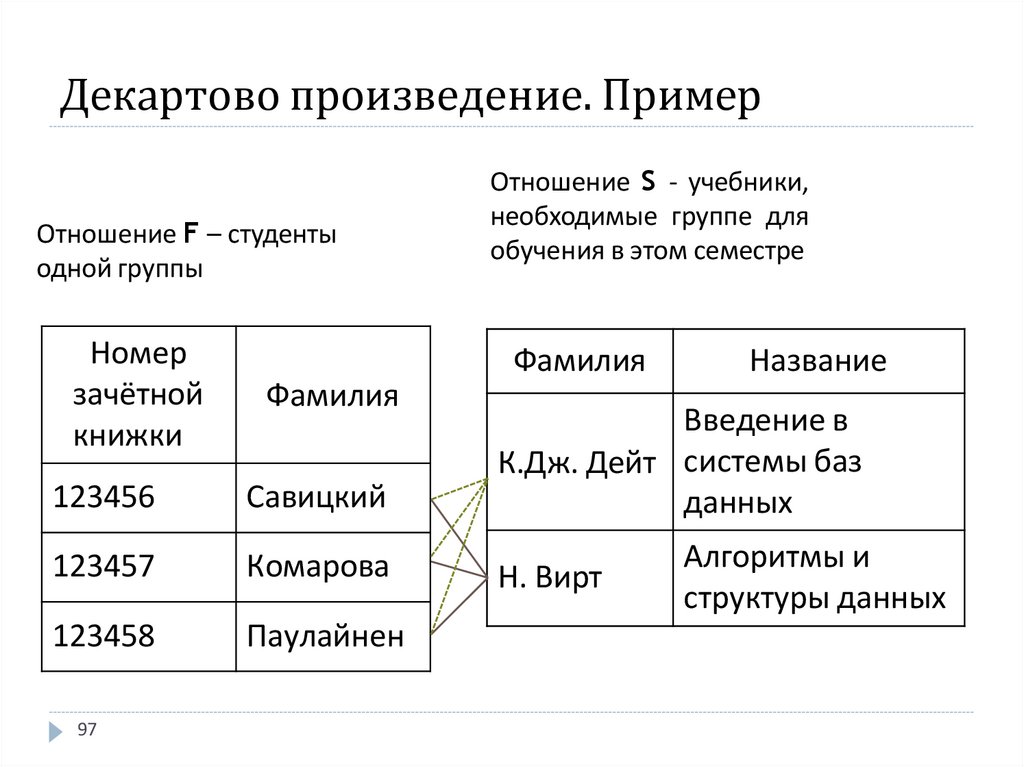
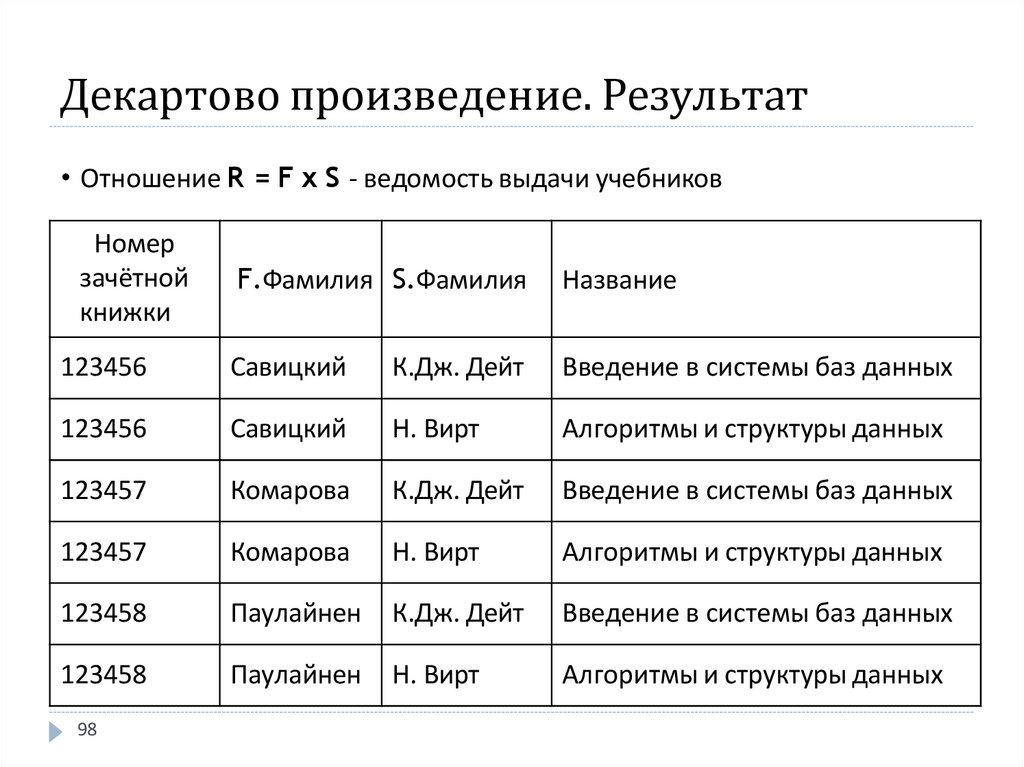
Декартово произведение. ОпределениеДекартовым произведением отношений
F, состоящего из атрибутов {F1, F2,…, Fn} и
S, состоящего из атрибутов {S1, S2, …, Sm}
называется отношение R,