
















 Образование
ОбразованиеПохожие презентации:










Улучшение нормализатора
1.
Улучшениенормализатора
1
2.
Введение● Используется небольшой трансформер
● Модель обучена на 3,2 млн. пар src-dst
● Иногда возникают проблемы: “988 г. н. э” - “988 грамм н.э”; “1000 экз. тысяча экз” и т. д.
2
3.
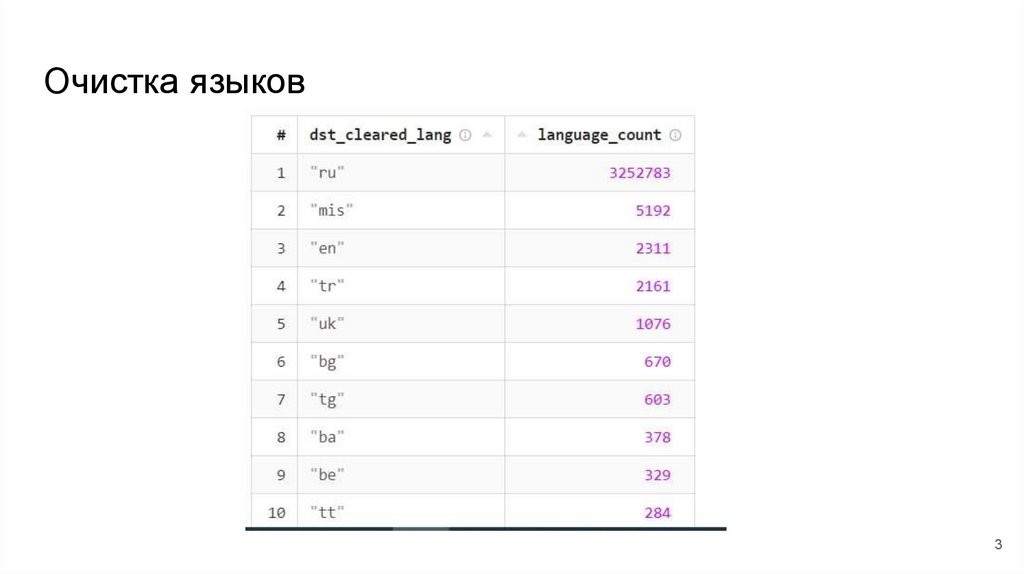
Очистка языков3
4.
Очистка языков● Оставляем только такие примеры, в которых все слова содержатся в
логах Алисы
● Турецкие удаляем все
4
5.
Использование GPTПроблемный срез на “г. - год - грамм - город”:
5
6.
Использование GPT● Собрали голденсет (~3300 размеченных пар src-dst, из них 12.5%
ошибочных )
● Инструкции для нормализации
● Chain of thought + few shot
● Просим определить некорректные пары src-dst
6
7.
Использование GPT: chain of thoughtПромпт:
src: "1996 год - Джорджтаунский университет, г. Вашингтон, США."
dst: "тысяча девятьсот девяносто шестой год - джорджтаунский
университет , г . вашингтон , сша ."
Result: Mistake
Explanation: "г." stands for the city, so the correct
transformation is "тысяча девятьсот девяносто шестой год джорджтаунский университет , город вашингтон , сша ."
7
8.
Использование GPT: результаты (1)GPT-3.5: recall=0.294, precision=0.356
GPT-4 (общие примеры для CoT): recall=0.443, precision=0.352
GPT-4 (специально выбрали примеры на “г.” для CoT): recall=0.628,
precision=0.364)
GPT-4 (специальные примеры + self-consistency): recall=0.606,
precision=0.561
8
9.
Использование GPT● Теперь просим GPT выдать нам правильную нормализацию
● Если нормализация GPT совпала с вариантом из датасета, то пара
правильная
GPT-4 (специальные примеры): recall=0.83, precision=0.567
9
10.
Использование GPT: проблемы● Долго подбирать примеры для chain of thought
● Проблемы с парсингом
● Нужно подбирать гиперпараметры (температура, количество задач в
одном запросе)
10
11.
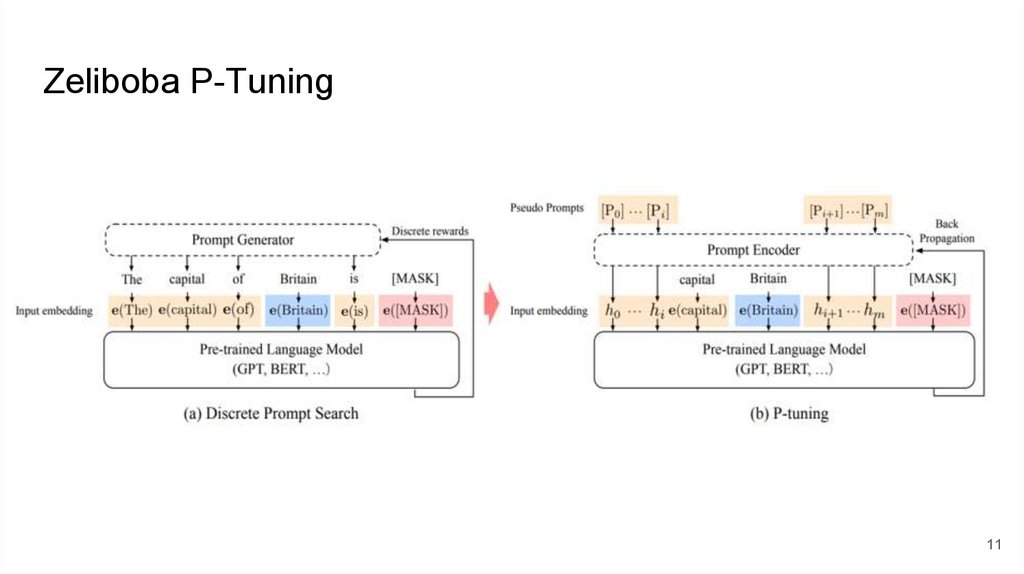
Zeliboba P-Tuning11
12.
Zeliboba P-TuningДля обучения взято 1.5к пар src-dst из голденсета на “г.”
Zeliboba 7B NG3 T0 (классификация): recall=0.556, precision=0.815
Zeliboba 7B NG3 T0 (генерация): recall=0.735, precision=0.609
Zeliboba 33B NG3 T0 (генерация): recall=0.768, precision=0.651
12
13.
Оценки улучшений● Сравниваем SER для старой и новой модели на диффе
● Для двух фиксированных корзинок делаем нормализацию старой и
новой моделью, генерируем аудио и отправляем на SBS
13
14.
Оценки улучшений: аккураси-тесты● 6 наборов тестов под разные кейсы
● Ожидается, что новая модель будет не хуже старой на всех наборах
тестов
Уже есть улучшения:
● ALICE-29597: accuracy from 0.879 to 0.989 (номера телефонов)
● ALICE-10980: accuracy from 0.928 to 0.948 (‘s на конце слов)
● ALICE-21999 accuracy from 0.931 to 0.940 (3-х, 4-х)
14
15.
Полная прочистка датасетаУвеличили трейнсет для Зелибобы до 30к пар src-dst
Проверяем прочистку с помощью трёх моделей:
● Zeliboba 33B NG3 T0 P-Tuning на трейнсете из 30к пар
● Zeliboba 33B NG3 T0 fine-tuning на трейнсете из 30к пар
● Zeliboba 33B NG3 T0 fine-tuning на всём датасете (3 млн. пар)
15
16.
Сравнение LLMНа вручную размеченной выборке из 100 примеров:
● P-Tuning на 30к парах: accuracy=91.92%
● Fine-tuning на 30к парах: accuracy=91.92%
● Fine-tuning на всём датасете: accuracy=76.78%
● Нормализатор из транка: accuracy=71.72%
16
17.
Прочистка с помощью ЗелибобыFine-tuning 30k:
Удалено 158632 пар src-dst (~5% датасета)
Результаты на аккураси-тестах как у модели из транка
Улучшение на SBS для двух корзинок (нормализацию новой модели выбирают на 10-13% чаще)
P-Tuning 30k:
Удалено 192505 пар src-dst (~6% датасета)
Результаты на аккураси-тестах как у модели из транка
Слабое улучшение на SBS для первой корзинки, небольшое ухудшение для второй
17
18.
Увеличение датасетаИдея: собрать ~3 млн. текстов из логов Алисы и получить для них
нормализацию с помощью Зелибобы
● Берутся только самые часто встречающиеся тексты
● Большие тексты были обработаны чанкером
● В датасет добавляются только тексты, нуждающиеся в нормализации
● Для получения нормализации рассматриваются три вышеупомянутые
дообученные модели
18
19.
Результаты● Датасет обучения нормализатора очищен от лишних языков
● Есть улучшения на половине аккураси-тестов
● Дообучена LLM (fine-tuning на 30к парах) для прочистки и генерации
новых объектов в датасете
TODO:
● Сравнить использование разных LLM для увеличения датасета
● Улучшить трейнсет для файн-тюнинга Зелибобы
19