








 Программное обеспечение
Программное обеспечениеПохожие презентации:










Spark. Распределенные системы
1.
Spark. Распределенныесистемы
2.
Когда объём данных растёт, и один компьютер с вычислениями уже несправляется, подключают распределённые системы (англ. Distributed File
Systems). Они хранят файлы с данными на нескольких компьютерах и
предоставляют доступ к данным. Файл делится на фрагменты, причём
каждый фрагмент может быть сохранён несколько раз на разных
компьютерах. Так гарантируется целостность данных.
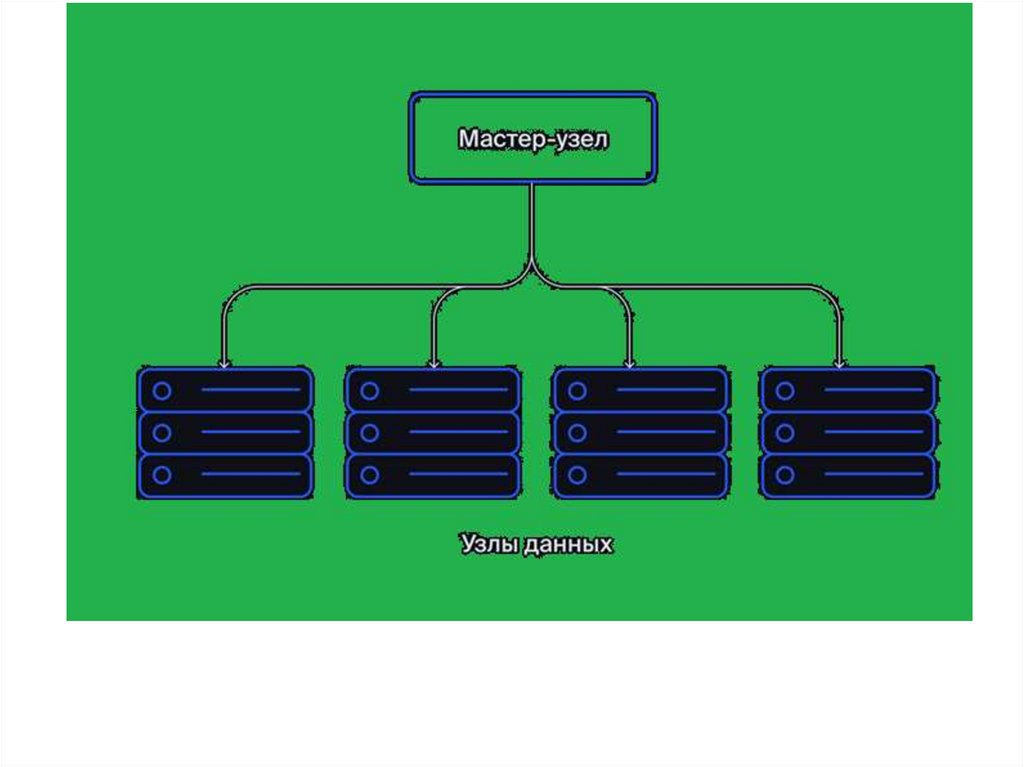
Распределённая система состоит из нескольких узлов (англ. nodes). Это
отдельные компьютеры с ресурсами вычисления и хранения данных.
Узлы бывают двух типов:
Мастер-узел, или ведущий узел (англ. Name Node). Он распределяет
файлы между компьютерами в кластере (англ. cluster) — наборе
связанных узлов.
Узлы данных (англ. Data Node). В них данные содержатся и
обрабатываются. Чтобы избежать потери информации, каждый файл
дублируется в нескольких узлах данных.
3.
4.
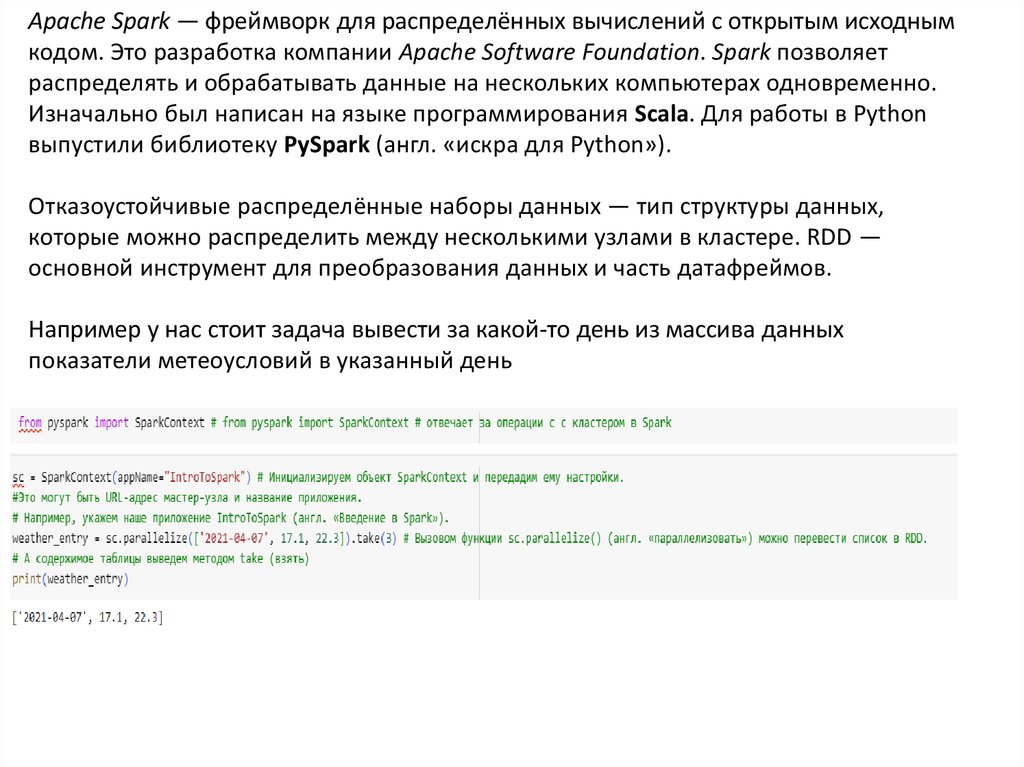
Apache Spark — фреймворк для распределённых вычислений с открытым исходнымкодом. Это разработка компании Apache Software Foundation. Spark позволяет
распределять и обрабатывать данные на нескольких компьютерах одновременно.
Изначально был написан на языке программирования Scala. Для работы в Python
выпустили библиотеку PySpark (англ. «искра для Python»).
Отказоустойчивые распределённые наборы данных — тип структуры данных,
которые можно распределить между несколькими узлами в кластере. RDD —
основной инструмент для преобразования данных и часть датафреймов.
Например у нас стоит задача вывести за какой-то день из массива данных
показатели метеоусловий в указанный день
5.
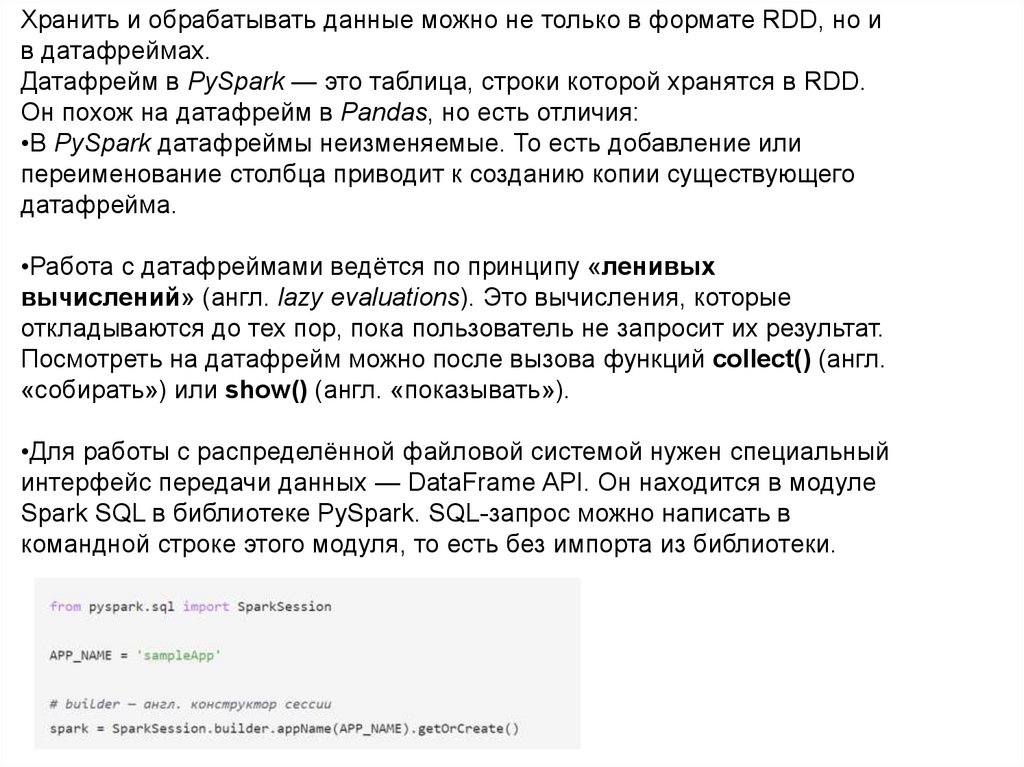
Хранить и обрабатывать данные можно не только в формате RDD, но ив датафреймах.
Датафрейм в PySpark — это таблица, строки которой хранятся в RDD.
Он похож на датафрейм в Pandas, но есть отличия:
•В PySpark датафреймы неизменяемые. То есть добавление или
переименование столбца приводит к созданию копии существующего
датафрейма.
•Работа с датафреймами ведётся по принципу «ленивых
вычислений» (англ. lazy evaluations). Это вычисления, которые
откладываются до тех пор, пока пользователь не запросит их результат.
Посмотреть на датафрейм можно после вызова функций collect() (англ.
«собирать») или show() (англ. «показывать»).
•Для работы с распределённой файловой системой нужен специальный
интерфейс передачи данных — DataFrame API. Он находится в модуле
Spark SQL в библиотеке PySpark. SQL-запрос можно написать в
командной строке этого модуля, то есть без импорта из библиотеки.
6.
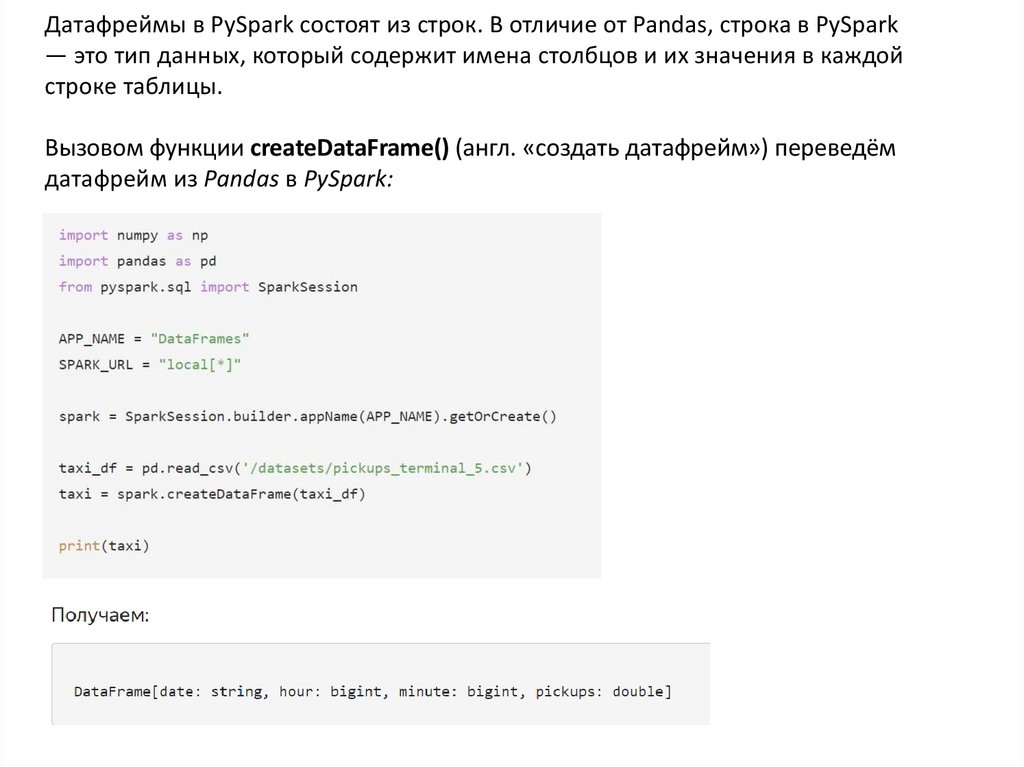
Датафреймы в PySpark состоят из строк. В отличие от Pandas, строка в PySpark— это тип данных, который содержит имена столбцов и их значения в каждой
строке таблицы.
Вызовом функции createDataFrame() (англ. «создать датафрейм») переведём
датафрейм из Pandas в PySpark:
7.
PySpark указал, какие типы имеют столбцы: дата — это строка, минута — целое число,допускающее большие значения (англ. bigint; big integer).
Для извлечения данных применим метод take()
8.
Чтобы загрузить датафрейм из csv-файла, у объекта SparkSessionвозьмём атрибут read (англ. «чтение»). Вызовем у атрибута функцию
load(). Эта функция принимает путь к файлу и параметры загрузки, а
возвращает датафрейм PySpark.
Прочитаем csv-файл. Обратите внимание: значения true и false
записываются строчными буквами.
9.
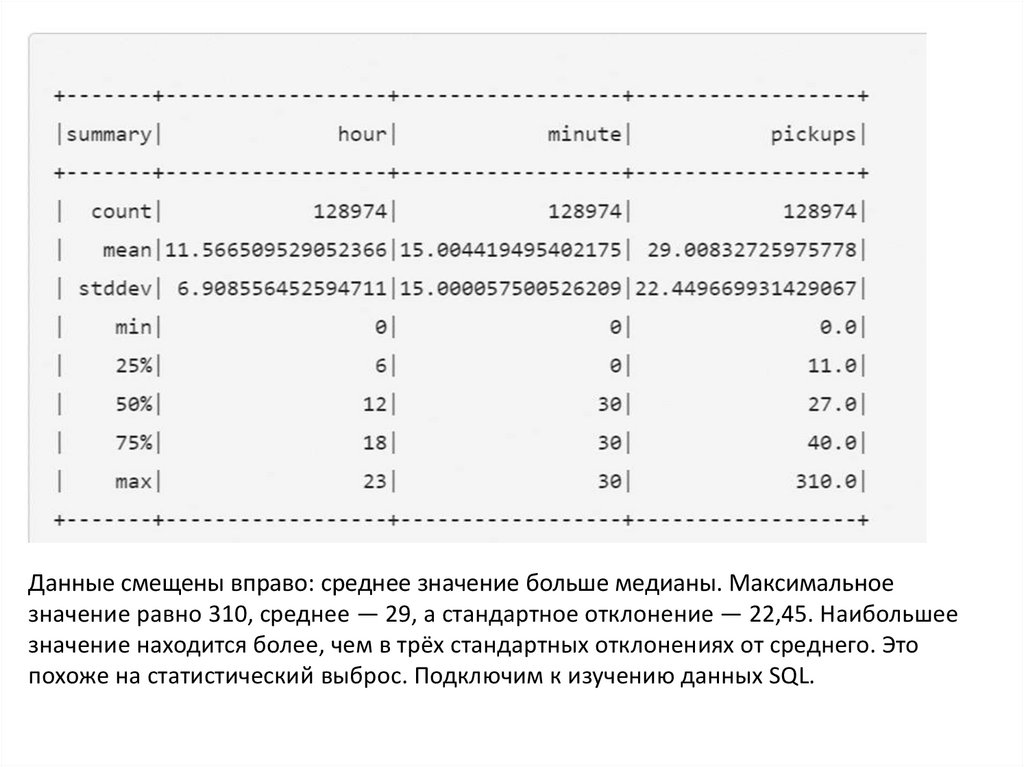
SQL запросы в датафреймахИзучим данные о заказах такси. Выведем на экран подробную
информацию о данных методом summary()
10.
Данные смещены вправо: среднее значение больше медианы. Максимальноезначение равно 310, среднее — 29, а стандартное отклонение — 22,45. Наибольшее
значение находится более, чем в трёх стандартных отклонениях от среднего. Это
похоже на статистический выброс. Подключим к изучению данных SQL.
11.
Напишем SQL-запрос в PySpark. Но сначала зарегистрируем временную таблицу(англ. Temp Table), то есть добавим датафрейм в базу данных:
Для выполнения SQL-запроса обратимся к объекту SparkSession. Нужно узнать,
много ли раз было более 100 заказов такси за 30 минут рядом с терминалом №5.
1431 раз было более 100 заказов такси за 30 минут рядом с терминалом №5.
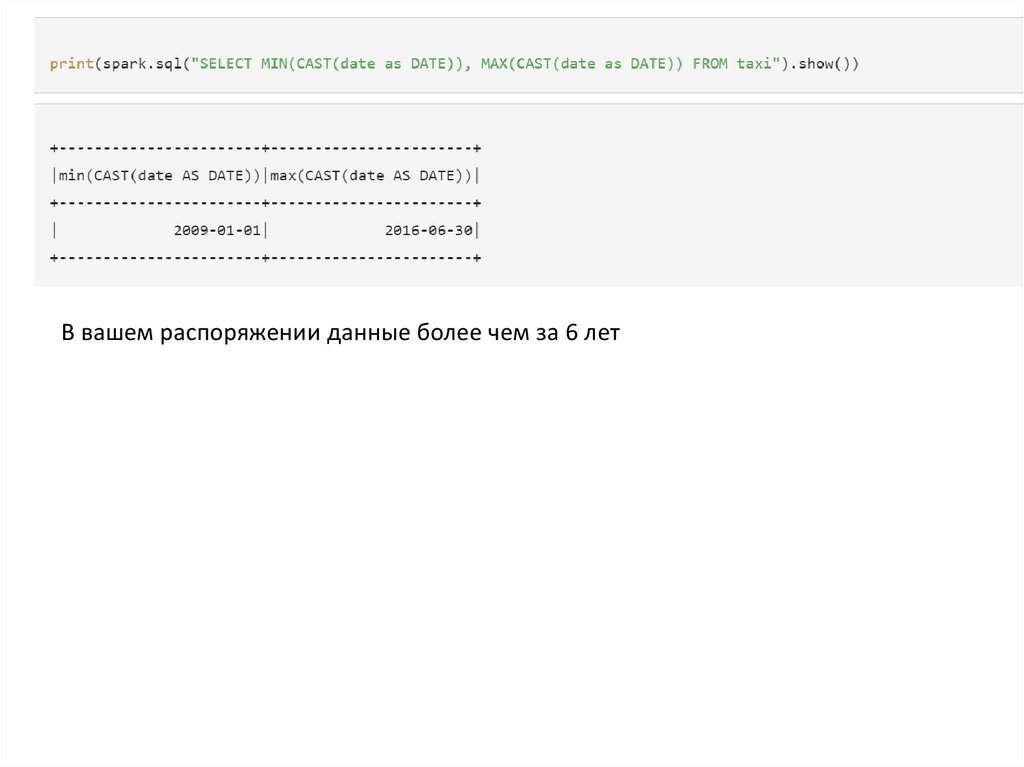
Узнаем, за какой период наши данные
12.
В вашем распоряжении данные более чем за 6 лет13.
GroupBy в PySparkПрименим к данным группировку и агрегирующие функции.
Рассмотрим, как в PySpark работает функция groupby(). Чтобы найти среднее
количество заказов в день за периоды в 30 минут, сгруппируем данные по датам
14.
Чтобы вычислить дни с самым большим в таблице средним арифметическимколичеством заказов, применим функцию sort()
15.
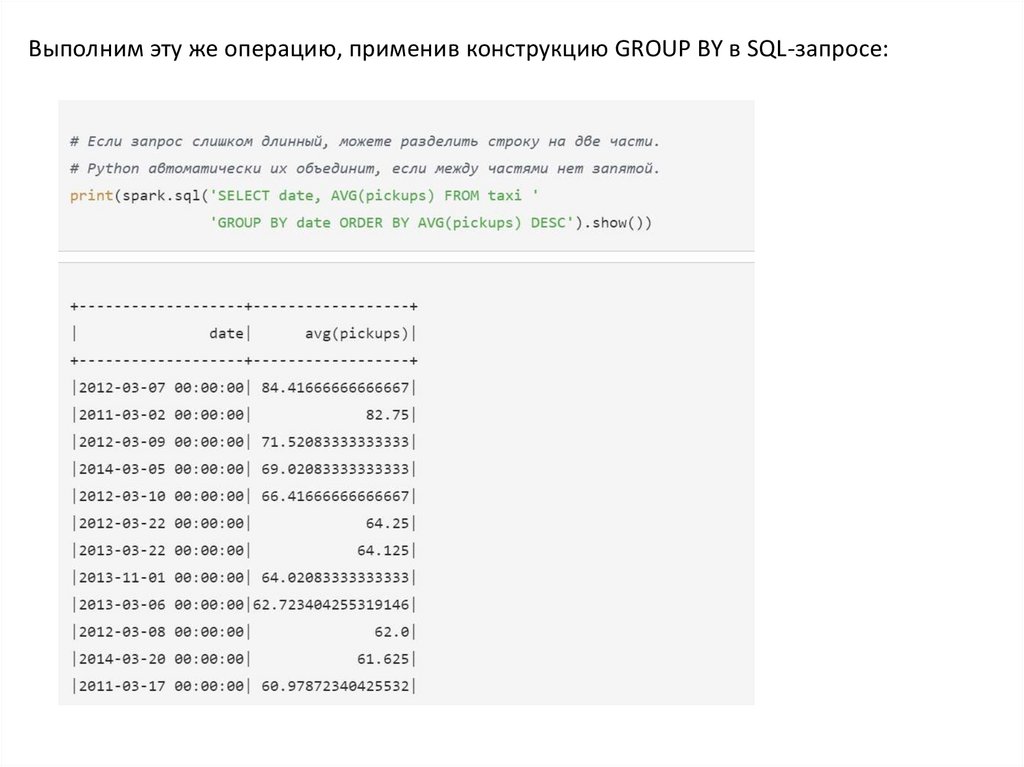
Выполним эту же операцию, применив конструкцию GROUP BY в SQL-запросе:16.
ЗаданиеВычислите среднее количество заказов за каждый час. Затем
отсортируйте данные по убыванию.
Выведите самые загруженные 10 часов и среднее количество заказов
такси в эти часы.