































 Программное обеспечение
Программное обеспечениеПохожие презентации:


")







Импорт наборов данных
1.
Импорт наборов данныхЛекция 6
Преподаватель: Сатыбалдиева Рысхан Жакановна, к.техн.наук, ассоц.проф. Кафедры
«Программная Инженерия»
r.satybaldiyeva@satbayev.university
Сатыбалдиева Р.Ж.
2.
Содержание• Начальное изучение данных
• Пакеты Python для обработки и анализа данных
• Импорт и экспорт данных в Python
Сатыбалдиева Р.Ж.
3.
• Набор данных, или набор набор данных обычно находитсяв формате CSV, который разделяет каждое из значений
запятыми, что делает его очень легко импортировать в
большинстве инструментов или приложений.
• Каждая строка представляет строку в наборе данных.
Начальное
изучение
данных
• Иногда первая строка является заголовком, который
содержит имя столбца для каждого из столбцов.
• Скачайте набор данных – data set по адресу
https://archive.ics.uci.edu/ml/datasets/automobile
(создатель Jeffrey C. Schlimmer)
Сатыбалдиева Р.Ж.
4.
Пакеты Python для обработки и анализаданных
• Библиотека Python представляет собой набор функций и методов,
которые позволяют выполнять множество действий без
написания кода
• Библиотеки обычно содержат встроенные модули,
обеспечивающие различные функциональные возможности,
которые вы можете использовать напрямую.
Сатыбалдиева Р.Ж.
5.
Библиотеки Python для анализа данных• Можно условно разделить библиотеки анализа данных Python на
три группы:
• научно вычислительные библиотеки;
• библиотеки для визуализации данных;
• алгоритмические библиотеки задач машинного обучения
Сатыбалдиева Р.Ж.
6.
Pandas• Pandas предлагает структуру данных и инструменты для
эффективной обработки и анализа данных.
• Он предоставляет факты, доступ к структурированным
данным.
• Основным инструментом Pandas является двухмерная
таблица, состоящая из столбцов и строк меток, которые
называются фреймом данных.
• Он предназначен для обеспечения простой
функциональности индексации.
Сатыбалдиева Р.Ж.
7.
Библиотека NumPy• использует массивы для своих
входов и выходов.
• Он может быть расширен на
объекты для матриц и с
незначительными изменениями
кодирования, разработчики
могут выполнять быструю
обработку массива.
Сатыбалдиева Р.Ж.
8.
SciPy• включает функции для
• некоторых продвинутых
математических задач, а также
визуализацию данных.
Сатыбалдиева Р.Ж.
9.
Библиотеки позволяющие создаватьграфики, диаграммы и карты
• Использование методов визуализации данных является лучшим
способом общения с другими.
• Пакет Matplotlib является самой известной библиотекой для
визуализации данных.
• Это отлично подходит для создания графиков и сюжетов.
• Графики также очень быстро настраиваются.
• Еще одной библиотекой визуализации высокого уровня является
Seaborn.
• Он основан на Matplotlib.
• Очень легко создавать различные сюжеты, такие как тепловые карты,
временные ряды и скрипки.
Сатыбалдиева Р.Ж.
10.
Алгоритмымашинного
обучения
С помощью алгоритмов машинного обучения мы можем
разработать модель, используя наш набор данных и
получать прогнозы.
Алгоритмические библиотеки решают задачи машинного
обучения от базового до сложного.
Здесь мы представляем два пакета, библиотека Scikitlearn содержит инструменты статистического
моделирования, включая регрессию, классификацию,
кластеризацию и так далее.
Эта библиотека построена на NumPy, SciPy и Matplotib.
Statsmodels также является модулем Python, который
позволяет пользователям исследовать данные, оценивать
статистические модели и выполнять статистические тесты.
Сатыбалдиева Р.Ж.
11.
Сбор данных — это процесс загрузки и чтения данных вблокнот из различных источников. Чтобы прочитать любые
данные с помощью пакета Python pandas, необходимо
учитывать два важных фактора: формат и путь к файлу.
Импорт и
экспорт
данных в
Python
Формат — это способ кодирования данных. Обычно мы
можем определить различные схемы кодирования, взглянув
на окончание имени файла. Некоторые распространенные
кодировки: CSV, JSON, XLSX, HDF и так далее.
С каждой точкой данных связано большое количество
свойств.
формат данных — CSV, что означает значения, разделенные
запятыми.
Сатыбалдиева Р.Ж.
12.
Импортирование CSV в PythonImport pandas as pd
url = “https://archive.ics.uci.edu/ml/machine-learningdatabases/autos/imports-85.data”
df = pd.read_csv(url)
Сатыбалдиева Р.Ж.
13.
Метод read_CSV• В pandas метод read_CSV может считывать файлы со столбцами,
разделенными запятыми, во фрейм данных pandas.
• Чтение данных в pandas можно быстро выполнить в три строки.
• Сначала импортируйте pandas, затем определите переменную с
путем к файлу, а затем используйте метод read_CSV для импорта
данных.
• Однако read_CSV предполагает, что данные содержат заголовок.
• данные могут и не имеют заголовков столбцов.
• Тогда нужно указать read_CSV, чтобы не назначать заголовки,
установив для заголовка значение none.
Сатыбалдиева Р.Ж.
14.
Импортирование CSV без заголовкаimport pandas as pd
url = “https://archive.ics.uci.edu/ml/machine-learning-databases/autos/imports85.data”
df = pd.read_csv(url, header = None)
• После прочтения набора данных рекомендуется взглянуть на фрейм данных,
чтобы получить лучшее представление и убедиться, что все произошло так,
как вы ожидали.
• Поскольку печать всего набора данных может занять слишком много
времени и ресурсов для экономии времени, мы можем просто использовать
dataframe.head для отображения первых n строк фрейма данных.
Сатыбалдиева Р.Ж.
15.
Печать кадра данных в Python• печать всего набора данных может занять слишком много
времени – не рекомендуется для большого набора данных
• df.head(n) выводит первые n строк набора данных
• df.tail(n) показывает нижние конечные n строк набора данных
Сатыбалдиева Р.Ж.
16.
dataframe.tail• dataframe.tail показывает нижние конечные
строки фрейма данных. Здесь мы распечатали
первые пять строк данных. Похоже, набор
данных был успешно прочитан.
• Мы можем видеть, что pandas автоматически
устанавливает заголовок столбца как список
целых чисел, потому что мы устанавливаем
заголовок равным none при чтении данных.
• Трудно работать с фреймом данных, не имея
осмысленных имен столбцов.
• Однако мы можем назначать имена столбцов
в pandas. В случае если оказалось, что есть
имена столбцов в отдельном файле онлайн,
сначала необходимо поместить имена
столбцов в список, называемый заголовками,
затем мы устанавливаем df.columns равные
заголовки, чтобы заменить целочисленные
заголовки по умолчанию списком.
Сатыбалдиева Р.Ж.
17.
Метод head• метод head, выводит заголовки
• метод to_CSV позволяет экспортировать свой фрейм данных
pandas в новый файл CSV.
• Для этого укажите путь к файлу, который включает имя файла, в
который вы хотите записать. Например, если вы хотите сохранить
кадр данных df как automobile.CSV на свой компьютер, вы можете
использовать синтаксис df.to_CSV.
Сатыбалдиева Р.Ж.
18.
Добавить заголовок - Метод head• заменить заголовок по умолчанию (на df.columns = headers)
Сатыбалдиева Р.Ж.
19.
Экспортировать набор данных Pandas в CVS• сохранить прогресс в любое время, сохранив измененный набор
данных, используя
• path = ”C:/Windows/…./automobile.csv"
• df.to_csv(path)
Сатыбалдиева Р.Ж.
20.
Экспортирование различных форматов вPandas
• В этом курсе мы будем читать и сохранять только файлы CSV.
• pandas также поддерживает импорт и экспорт с различными
форматами наборов данных.
• Синтаксис кода для чтения и сохранения других форматов
данных очень похож на чтение или сохранение файла CSV.
Формат данных
Чтение
Сохранение
csv
pd.read_csv()
df.to_csv()
json
pd.read_json()
df.to_json()
Excel
pd.read_excel()
df.to_excel()
sql
pd.read_sql()
df.to_sql()
Сатыбалдиева Р.Ж.
21.
Типы данных• Pandas имеет несколько встроенных методов, которые можно
использовать для понимания типа данных или функций или
для просмотра распределения данных внутри набора данных.
• Используя эти методы, дает обзор набора данных, а также
указывает на возможные проблемы, такие как неверный тип
данных функций, которые могут потребоваться решить позже.
• Данные имеют различные типы.
• Основными типами, хранящимися в объектах Pandas, являются
объект, float, Int и datetime.
Сатыбалдиева Р.Ж.
22.
Типы данных• Хотя тип datetime Pandas, является очень полезным типом для обработки
данных временных рядов.
• Есть две причины для проверки типов данных в наборе данных.
• Pandas автоматически назначает типы на основе кодировке, которую он
обнаруживает из исходной таблицы данных.
• По ряду причин это назначение может быть неправильным.
Сатыбалдиева Р.Ж.
23.
Ограничения к данным• Например, должно быть неловко, если столбец цены автомобиля,
который будет содержать непрерывные числовые
числа, присваивается тип данных объекта. Было бы более
естественным для него иметь тип float.
• Вторая причина заключается в том, что он позволяет опытным
ученым по данным увидеть, какие функции Python могут быть
применены к определенному столбцу.
• Например, некоторые математические функции могут быть
применены только к числовым данным.
Сатыбалдиева Р.Ж.
24.
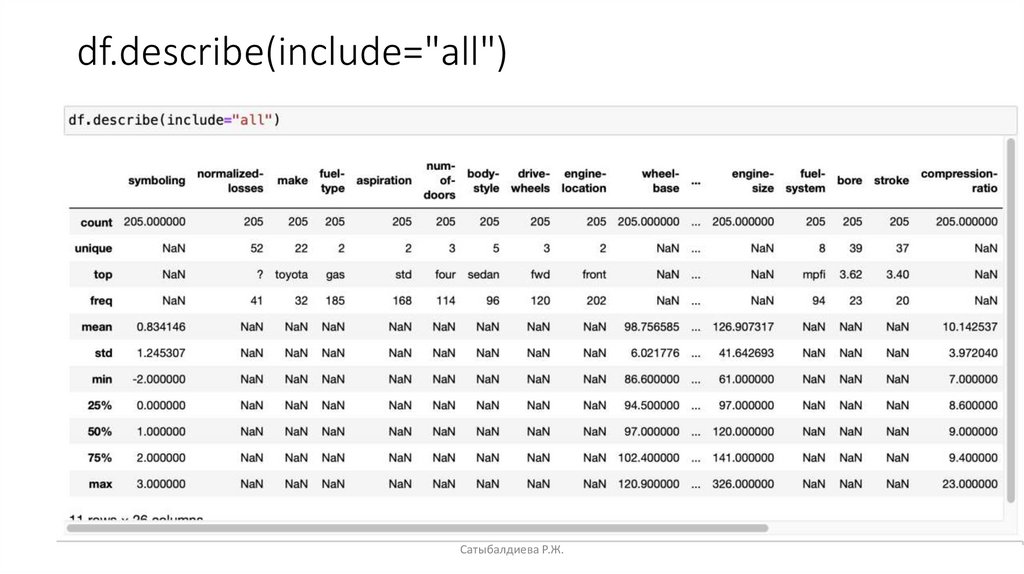
Метод описания• Чтобы получить быструю статистику, мы используем метод описания.
• Он возвращает количество терминов в столбце как количество,
среднее значение столбца как среднее, стандартное отклонение
столбца как стандартное значение, максимальные минимальные
значения, а также границу каждого из квартилей.
• По умолчанию функции dataframe.describe пропускают строки и
столбцы, не содержащие чисел.
• Можно заставить метод описания работать и для столбцов типа
объекта. Чтобы включить сводку по всем столбцам, мы могли бы
добавить аргумент. include = all внутри скобки описания функции.
Теперь результат показывает сводку по всем 26 столбцам, включая
атрибуты объектного типа.
Сатыбалдиева Р.Ж.
25.
df.describe(include="all")Сатыбалдиева Р.Ж.
26.
Для столбцов типа объекта• для столбцов типа объекта вычисляется другой набор статистики, как
уникальный, верхний и частотный
• Unique - это количество различных объектов в столбце.
• Top является наиболее часто встречающимся объектом, и freq - количество
раз, когда верхний объект появляется в столбце.
• Некоторые значения в таблице показаны здесь как NaN, что означает не
число.
• Это связано с тем, что эта конкретная статистическая метрика не может быть
рассчитана для данного типа данных столбца.
• Другой метод, который вы можете использовать для проверки набора
данных, - это функция dataframe.info.
• Эта функция показывает верхние 30 строк и нижние 30 строк фрейма
данных.
Сатыбалдиева Р.Ж.
27.
Доступ к базамданных с
использованием
Python
• Так обычный пользователь обращается к базам
данных с помощью кода Python, написанного на
блокноте Jupyter, веб-редакторе.
• Существует механизм, с помощью которого
программа Python взаимодействует с СУБД.
• Код Python подключается к базе данных с
помощью вызовов API.
Сатыбалдиева Р.Ж.
28.
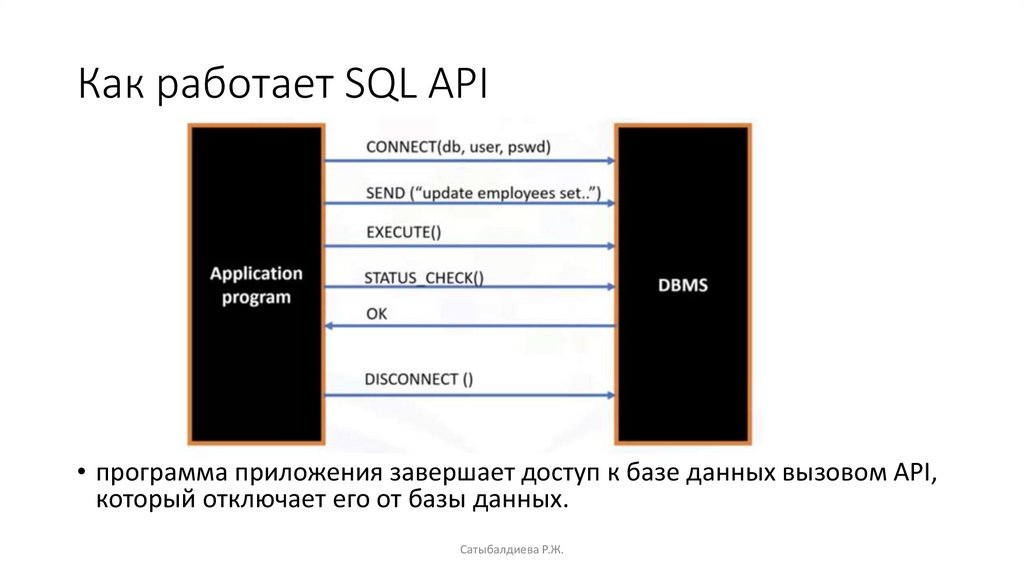
SQL API• Интерфейс прикладного программирования представляет собой набор функций, которые
можно вызвать для получения доступа к некоторым типам серверов.
• SQL API состоит из вызовов библиотечных функций в качестве интерфейса прикладного
программирования, API, для СУБД.
• Чтобы передать SQL-инструкции в СУБД, прикладная программа вызывает функции в API,
и вызывает другие функции для получения результатов запроса и информации о состоянии
из СУБД.
• Основная операция типичного SQL API проиллюстрирована на следующем слайде.
• Программа приложения начинает доступ к базе данных одним или несколькими вызовами
API, которые подключают программу к СУБД.
• Чтобы отправить инструкцию SQL в СУБД, программа строит инструкцию в виде текстовой
строки в буфере, а затем выполняет вызов API для передачи содержимого буфера в СУБД.
• Приложенная программа делает вызовы API для проверки состояния запроса СУБД и для
обработки ошибок
Сатыбалдиева Р.Ж.
29.
Как работает SQL API• программа приложения завершает доступ к базе данных вызовом API,
который отключает его от базы данных.
Сатыбалдиева Р.Ж.
30.
DB-API• DB-API является стандартным API Python для доступа к
реляционным базам данных.
• Это стандарт, который позволяет писать одну программу, которая
работает с несколькими видами реляционных баз данных вместо
того, чтобы писать отдельную программу для каждой из них.
• Итак, если вы изучите функции DB-API, то вы можете применить
эти знания для использования любой базы данных с Python.
Сатыбалдиева Р.Ж.
31.
Объекты соединения и объекты курсора.• Двумя основными понятиями в Python DB-API являются объекты
соединения и объекты запросов.
• Объекты подключения используются для подключения к базе данных
и управления транзакциями.
• Объекты курсора используются для выполнения запросов.
• Вы открываете объект курсора, а затем запускаете запросы.
• Курсор работает подобно курсору в системе обработки текста, где вы
прокручиваете в результирующем наборе и получаете ваши данные в
приложение.
• Курсоры используются для сканирования результатов базы данных.
Сатыбалдиева Р.Ж.
32.
Методы, используемые с объектамисоединения
• Метод cursor () возвращает новый объект курсора, используя
соединение.
• Метод commit () используется для фиксации любой ожидающей
транзакции в базе данных.
• Метод rollback () приводит к откату базы данных к началу любой
ожидающей транзакции.
• Метод close () используется для закрытия соединения с базой
данных.
Сатыбалдиева Р.Ж.
33.
Алгоритм применения DB-API для запросабазы данных.
• Сначала вы импортируете свой модуль базы данных с помощью API подключения
из этого модуля.
• Чтобы открыть подключение к базе данных, вы используете функцию подключения
и передаете параметры, которые являются именем базы данных, именем
пользователя и паролем.
• Функция connect возвращает объект соединения.
• После этого вы создаете объект курсора на объекте соединения.
• Курсор используется для выполнения запросов и получения результатов.
• После выполнения запросов с помощью курсора, мы также используем курсор для
получения результатов запроса.
• Наконец, когда система завершит выполнение запросов, она освобождает все
ресурсы, закрыв соединение.
• Помните, что всегда важно закрывать соединения, чтобы избежать неиспользуемых
соединений, занимающих ресурсы.
Сатыбалдиева Р.Ж.
34.
Применение
DB-API
для
запрос
а базы
данных
.
Сатыбалдиева Р.Ж.
35.
Заключение• В данной лекции рассмотрены вопроса импортирования и
соединения наборов данных в Python
Сатыбалдиева Р.Ж.