






 Программное обеспечение
Программное обеспечениеПохожие презентации:





")




ML Flow Optuna
1.
ML FlowOptuna
2.
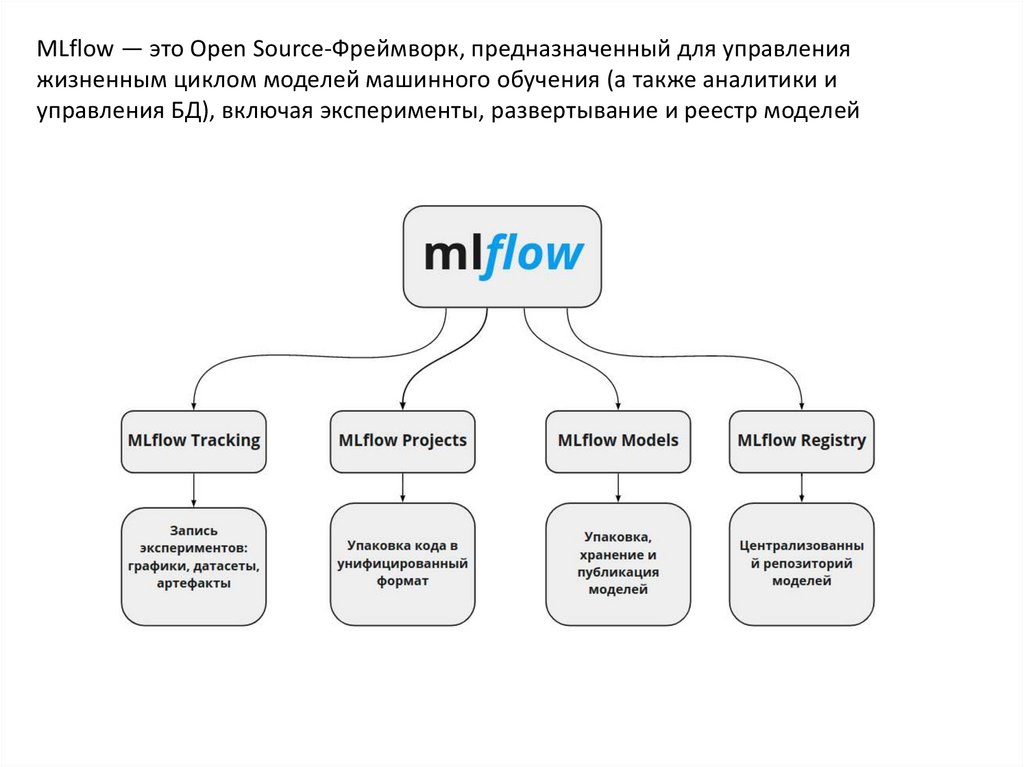
MLflow — это Open Source-Фреймворк, предназначенный для управленияжизненным циклом моделей машинного обучения (а также аналитики и
управления БД), включая эксперименты, развертывание и реестр моделей
3.
• Основное предназначение данного инструмента —упростить жизнь ML-разработчика, администратора
баз данных и инженера данных, ведь с ростом колва моделей и экспериментов возникает хаос в их
хранении, упорядочивании и версионировании:
нужно помнить, с какими параметрами обучалась
модель, а если было несколько переобучений, то
добавляются различные версии моделей. Их как-то
нужно сравнивать, чтоб отобрать лучший вариант.
Также нужно хранить саму модель и отслеживать
основные показатели и метрики. И иметь
возможность простым способом воспроизвести
эксперименты, в случае если хотите поделиться
своими наработками.
4.
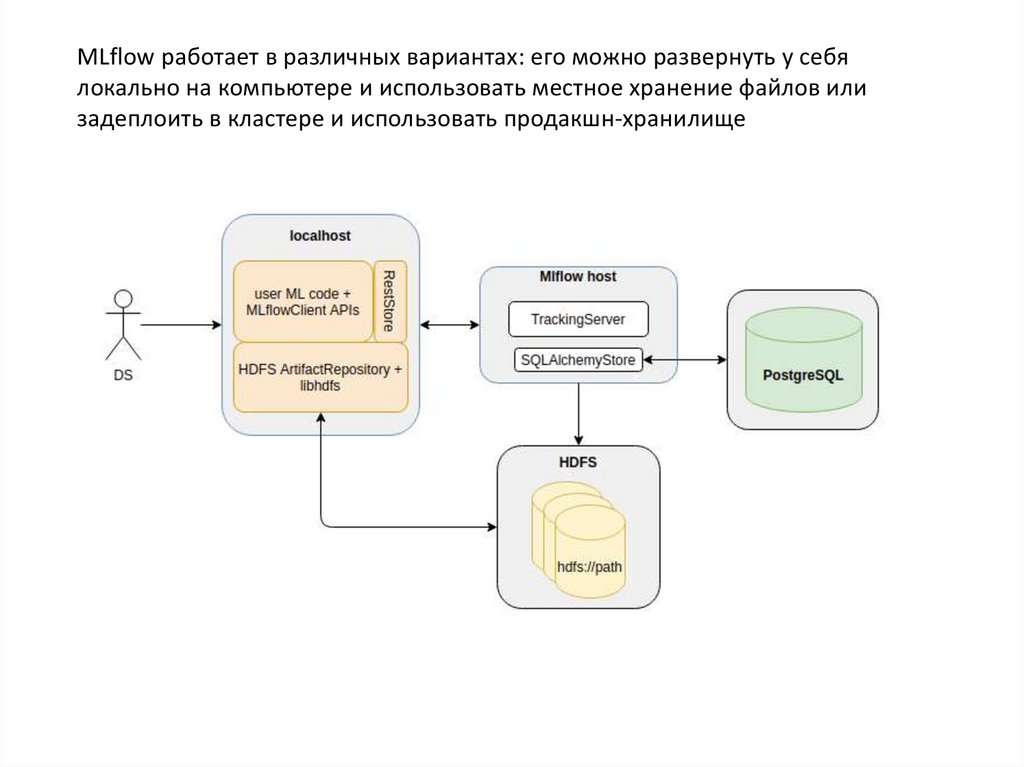
MLflow работает в различных вариантах: его можно развернуть у себялокально на компьютере и использовать местное хранение файлов или
задеплоить в кластере и использовать продакшн-хранилище
5.
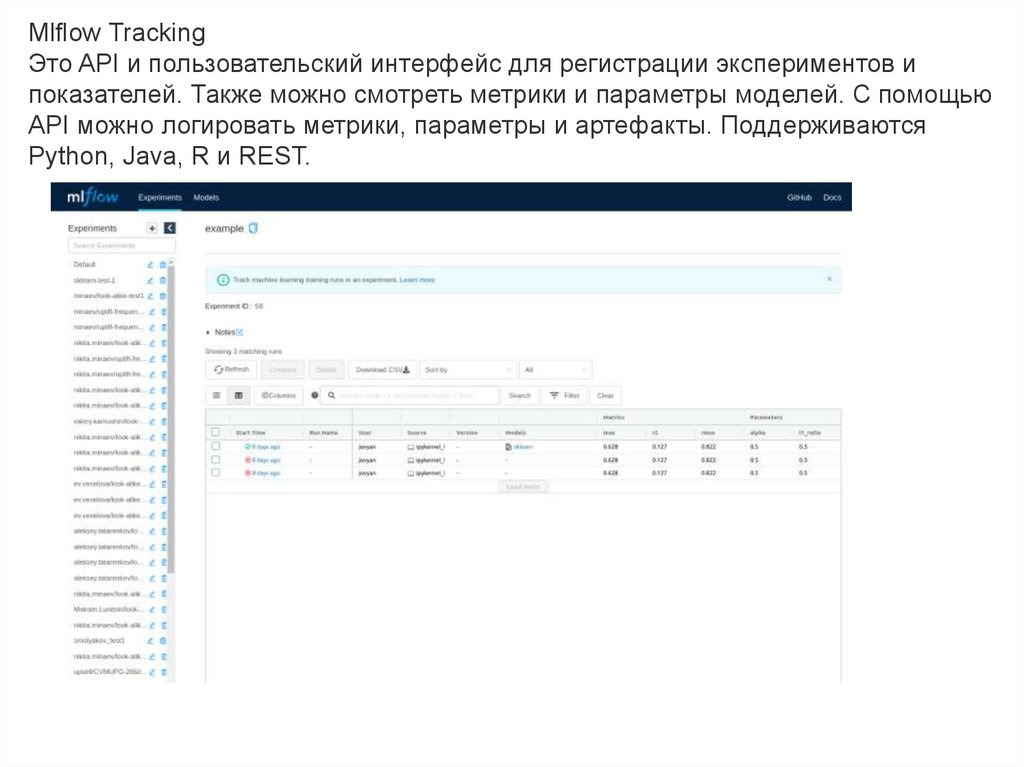
Mlflow TrackingЭто API и пользовательский интерфейс для регистрации экспериментов и
показателей. Также можно смотреть метрики и параметры моделей. С помощью
API можно логировать метрики, параметры и артефакты. Поддерживаются
Python, Java, R и REST.
6.
В MLflow Tracking есть две важных концепции: runs и experiments.Run — это единичный запуск эксперимента. При каждом запуске
эксперимента создается новая запись с текущими параметрами модели.
Experiment объединяет несколько Run в одну группу.
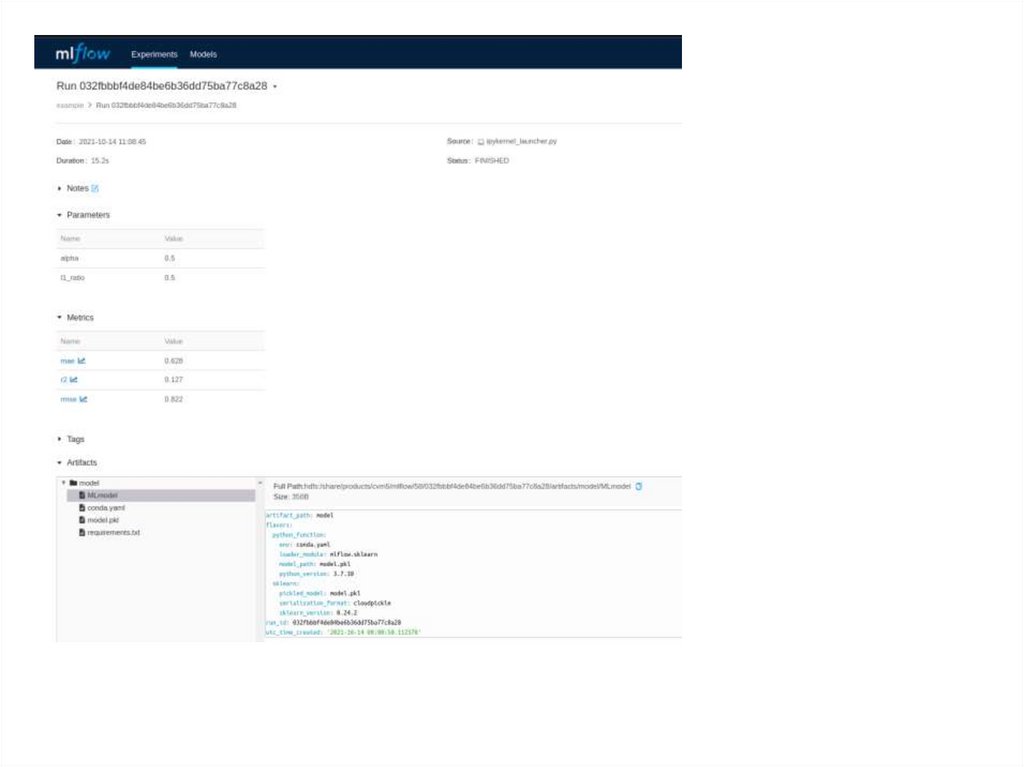
Если провалиться в один из экспериментов, то можно увидеть основную
мета-информацию запуска:
Параметры, с которыми было запущено обучение модели.
Метрики качества модели.
Артефакты, что мы залогировали (это могут быть картинки,
конфигурационные файлы, переменные окружения и т. п.).
Есть возможность добавлять описание и тэгировать эксперимент, чтобы
кастомизировать внутреннюю организацию.
7.
8.
MLflow ProjectsЭто формат упаковки кода для многократного использования и воспроизведения
эксперимента. Каждый проект описывается файлом MLProject в формате yaml.
Основными параметрами проекта являются: имя, окружение и библиотеки.
MLflow Models
Это формат для упаковки моделей машинного обучения, что позволяет использовать
модель как сервис. Например, для стриминговых запросов через REST API или при
батч обработка через Apache Spark.
С помощью MLflow Models можно упаковывать модель в Docker-образ для
последующего использования в Kubernetes.
MLflow Registry
Этот централизованное хранилище моделей. Оно включает в себя UI, который
позволяет управлять полным жизненным циклом модели. Также он позволяет
сравнивать разные модели между собой, например, чтобы увидеть отличия в
параметрах.
Всё это позволяет удобно управлять выкаткой моделей.
9.
ПреимуществаУнификация метрик моделей.
Масштабируемость — неважно сколько моделей, вся информация
задокументирована (записана).
Централизованное, безопасное и масштабируемое хранилище.
Вся полезная информация по экспериментам структурирована и упорядочена.
Возможность сохранения (логирования) любых типов файлов (картинки, csv,
html, графики).
Простая и понятная документация и API (низкий порог вхождения).
Простое подключение к «безграничному» хранилищу артефактов для
сохранения огромных датасетов.
Недостатки MLflow
Одно пространство экспериментов для всех (используется шаблон имени
эксперимента user/model/task).
Отсутствие разделения по ролям (Viewer, User) и авторизации.
10.
OptunaГиперпараметры — это параметры, которые не учатся в процессе обучения модели. Они
задаются заранее. От выбора гиперпараметров напрямую зависит качество и
эффективность модели, а их оптимизация может улучшить результаты предсказаний.
Традиционный подход к оптимизации гиперпараметров включает в себя grid search и
random search, иногда они могут быть неэффективными и времязатратными, особенно
когда пространство гиперпараметров велико.
Optuna решает проблему оптимизации гиперпараметров, предоставляя легковесный
фреймворк для автоматизации поиска оптимальных гиперпараметров. Она использует
алгоритмы, такие как TPE, CMA-ES, и даже поддерживает пользовательские алгоритмы.
11.
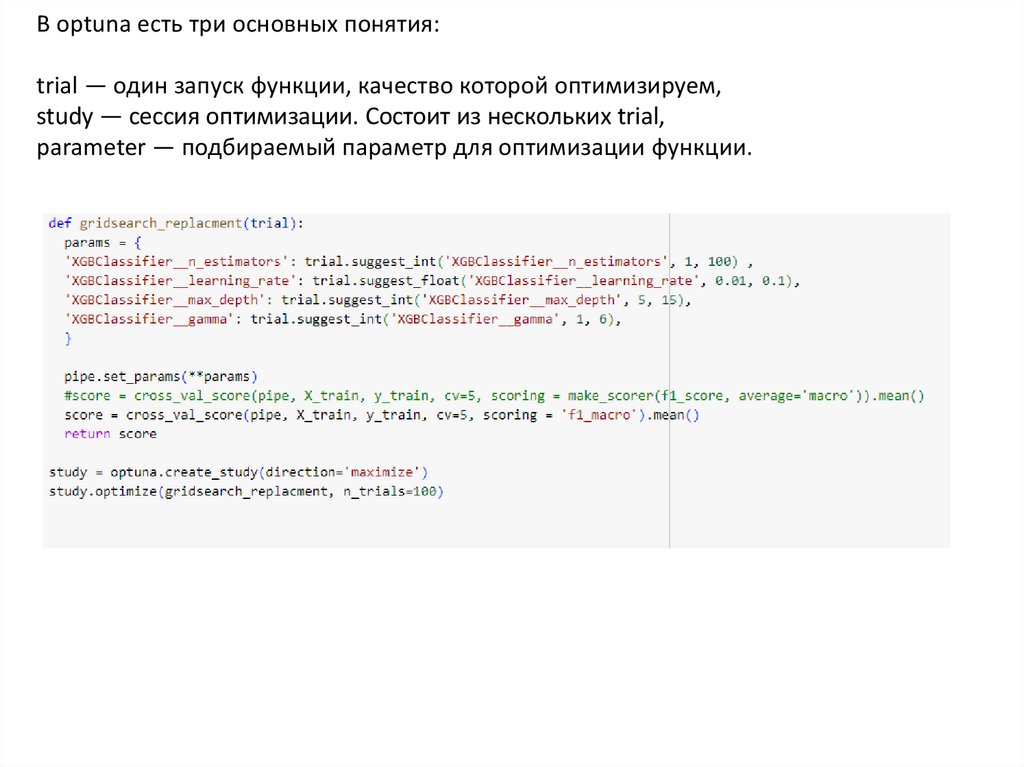
В optuna есть три основных понятия:trial — один запуск функции, качество которой оптимизируем,
study — сессия оптимизации. Состоит из нескольких trial,
parameter — подбираемый параметр для оптимизации функции.
12.
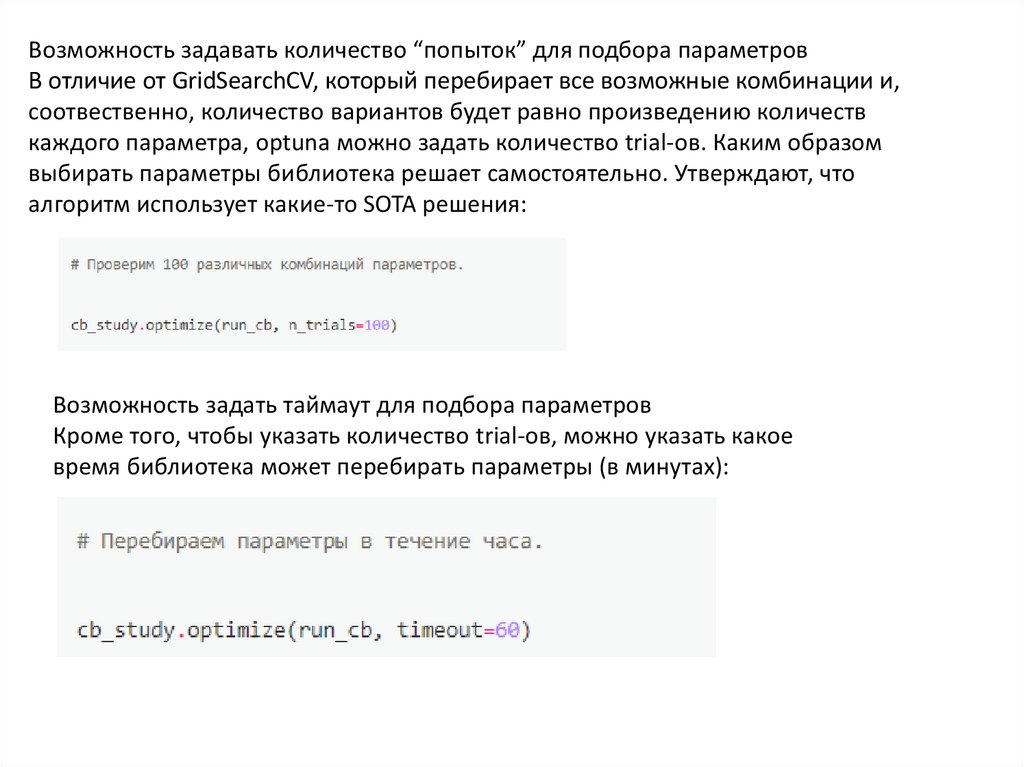
Возможность задавать количество “попыток” для подбора параметровВ отличие от GridSearchCV, который перебирает все возможные комбинации и,
соотвественно, количество вариантов будет равно произведению количеств
каждого параметра, optuna можно задать количество trial-ов. Каким образом
выбирать параметры библиотека решает самостоятельно. Утверждают, что
алгоритм использует какие-то SOTA решения:
Возможность задать таймаут для подбора параметров
Кроме того, чтобы указать количество trial-ов, можно указать какое
время библиотека может перебирать параметры (в минутах):
13.
14.
• Продолжайте работать с вторым заданием (Используйте в пайплайнеXGBclasiifier)
• data = pd.read_csv('/content/drive/MyDrive/bank.csv', sep=';')
• y = data[['y']].apply(lambda x: 1 if x.y == 'yes' else 0, axis=1)
• X = data.drop('y', axis = 1)
• C помощью команды pip установите mlflow и optuna
• В пайплайне закомментируйте все что касается gridsearch, а также fit и
predict модели
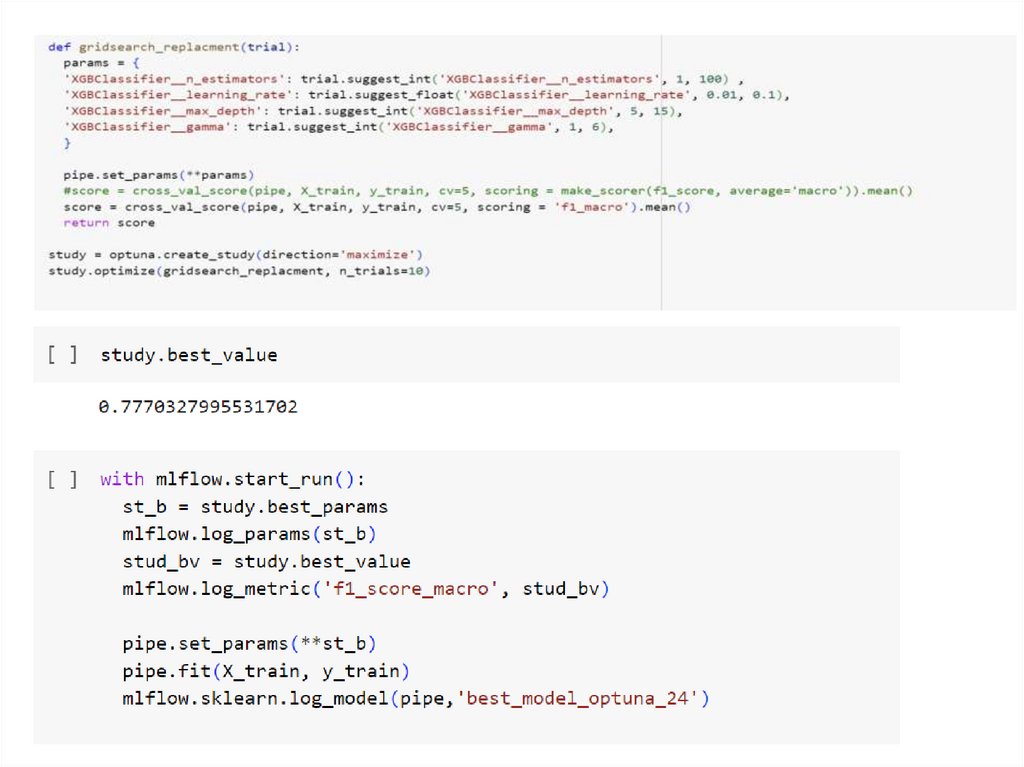
• Напишите функцию по замене gridsearch на optuna, примените
гиперпарметры которые Вы указывали в 2-ой работе
• Сохраните полученные результаты в ML flow