







 Программное обеспечение
Программное обеспечениеПохожие презентации:










ML-анализатор для разделения содержательной и бессодержательной частей аудиовыступлений и докладов
1.
МИНОБРНАУКИ РОССИИФедеральное государственное бюджетное образовательное учреждение
высшего образования
«МИРЭА – Российский технологический университет»
РТУ МИРЭА
Институт кибербезопасности и цифровых технологий
Кафедра КБ-3 «Разработка программных решений и системное программирование»
Выпускная квалификационная работа
«ML-анализатор для разделения содержательной и бессодержательной частей
аудиовыступлений и докладов»
Студент БСБО-09-20 Ибрагимов Магомедрасул Омарович
Руководитель: к.т.н., доцент, Нурматова Е.В.
Москва, 2024 г.
2.
Актуальность темыНеобходимость в оптимизации процесса обучения предметам;
Рост объема получаемой информации;
Недостаток времени для изучения материалов;
Интеграция с существующими системами.
2
3.
Цель и задачи, решаемые в выпускной работеЦель:
Разработать
приложение-анализатор
для
сокращения
аудиовыступлений путем удаления несодержательной части.
объема
Задачи:
Проанализировать предметную область;
Выбрать необходимые инструменты;
Выбрать модели для обучения, реализовать приложение на их основе;
Разработать интерфейс анализатора.
3
4.
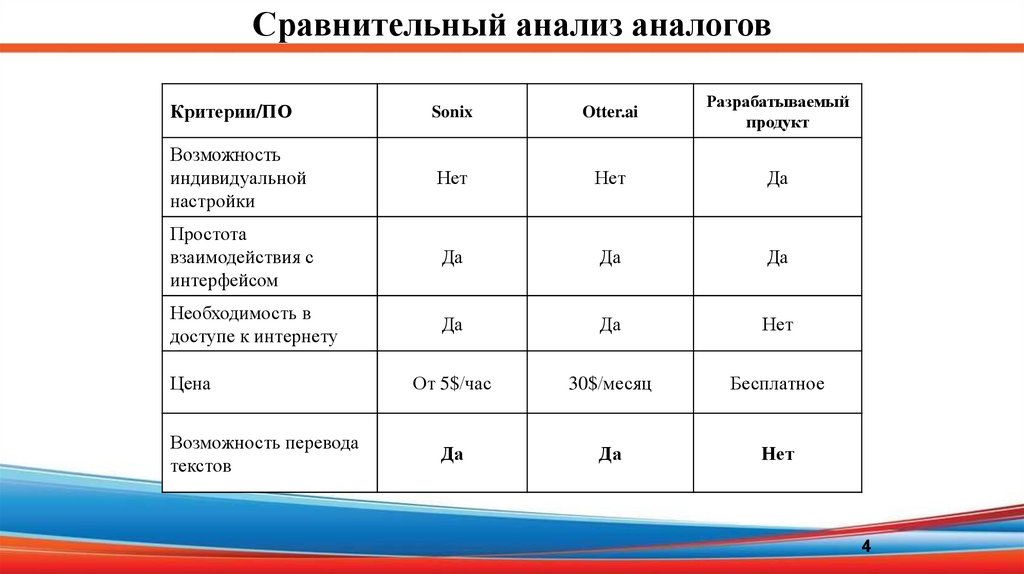
Сравнительный анализ аналоговКритерии/ПО
Sonix
Otter.ai
Разрабатываемый
продукт
Возможность
индивидуальной
настройки
Нет
Нет
Да
Простота
взаимодействия с
интерфейсом
Да
Да
Да
Необходимость в
доступе к интернету
Да
Да
Нет
От 5$/час
30$/месяц
Бесплатное
Да
Да
Нет
Цена
Возможность перевода
текстов
4
5.
Обзор выбранных инструментовЯзык программирования:
Python
Среда разработки и работы с данными:
PyCharm, JupyterNotebook
Библиотеки:
Tkinter,Whisper(набор библиотек), NLTK(набор библиотек),
Librosa, Joblib, scikit-learn
5
6.
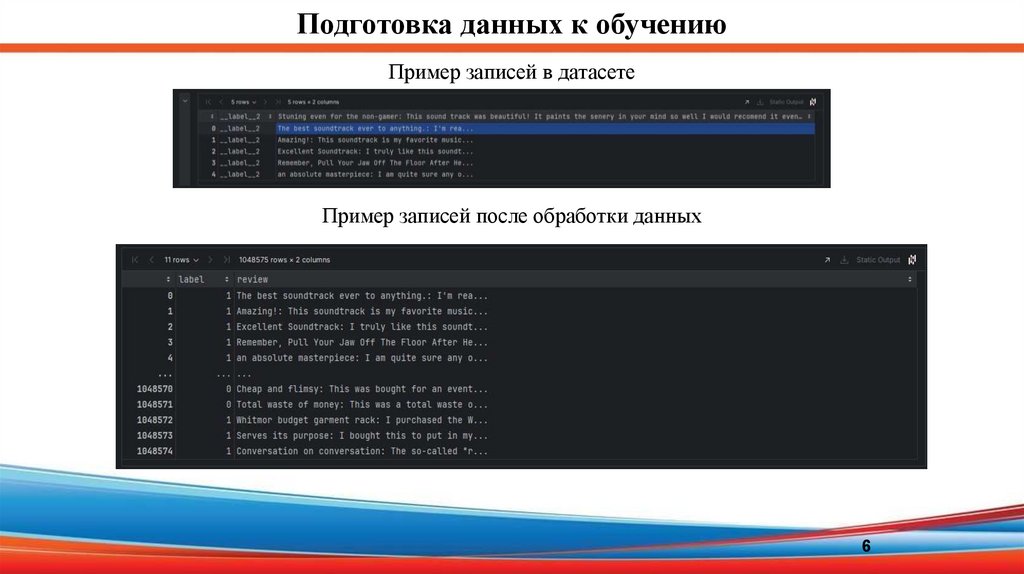
Подготовка данных к обучениюПример записей в датасете
Пример записей после обработки данных
6
7.
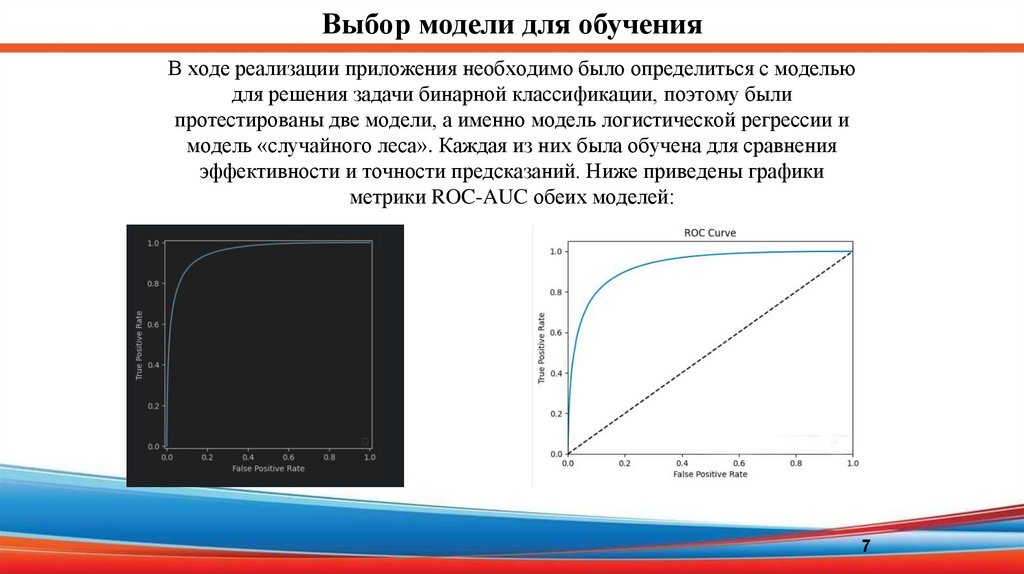
Выбор модели для обученияВ ходе реализации приложения необходимо было определиться с моделью
для решения задачи бинарной классификации, поэтому были
протестированы две модели, а именно модель логистической регрессии и
модель «случайного леса». Каждая из них была обучена для сравнения
эффективности и точности предсказаний. Ниже приведены графики
метрики ROC-AUC обеих моделей:
7
8.
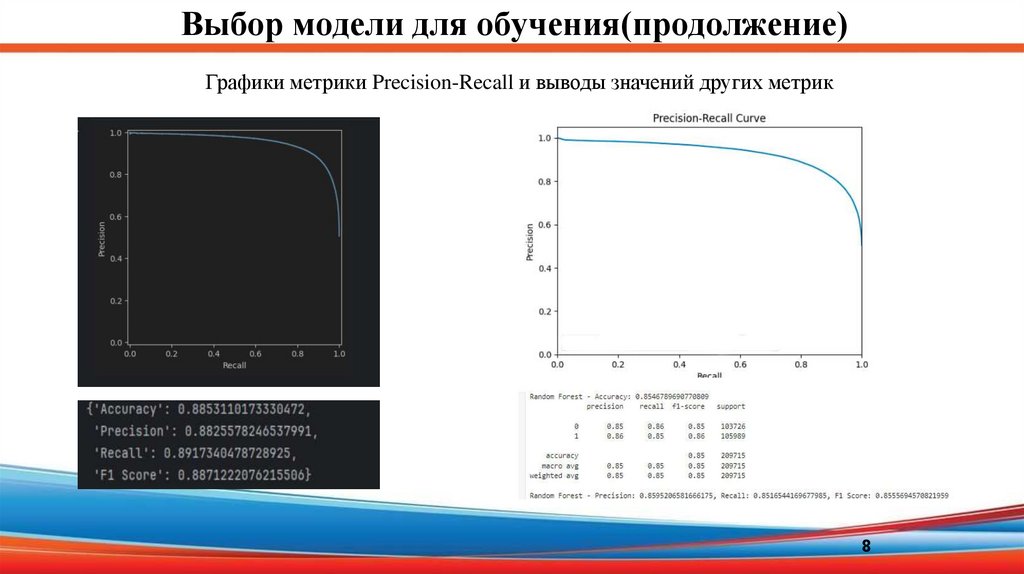
Выбор модели для обучения(продолжение)Графики метрики Precision-Recall и выводы значений других метрик
8
9.
Преимущества выбранной моделиПреимущества модели логистической регрессии:
• Простота и легкость интерпретации;
• Регуляризация, позволяющая избежать переобучения;
• Невысокие требования к вычислительным ресурсам;
• Меньшее время вычислений по сравнению с иными моделями;
9
10.
Векторизатор• TF-IDF — это статистическая мера, используемая для оценки важности слова в
контексте документа и в коллекции документов.
• В программе TF-IDF используется для векторизации текстов, чтобы их можно
было использовать в модели машинного обучения (в данном случае, в
логистической регрессии).
• TF-IDF помогает выделить важные слова в тексте и уменьшить вес часто
встречающихся, но менее информативных слов (например, предлогов и
союзов). Это позволяет модели классификации фокусироваться на
действительно значимых признаках текста, что улучшает точность
предсказаний. Это помогает эффективно различать содержательные и
бессодержательные предложения в транскрибированном тексте аудио.
10
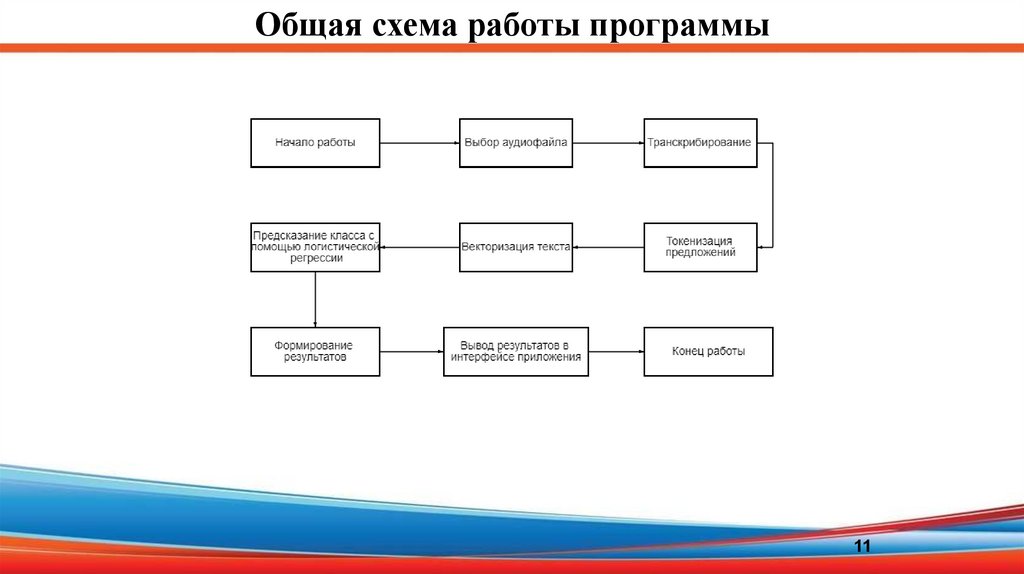
11.
Общая схема работы программы11
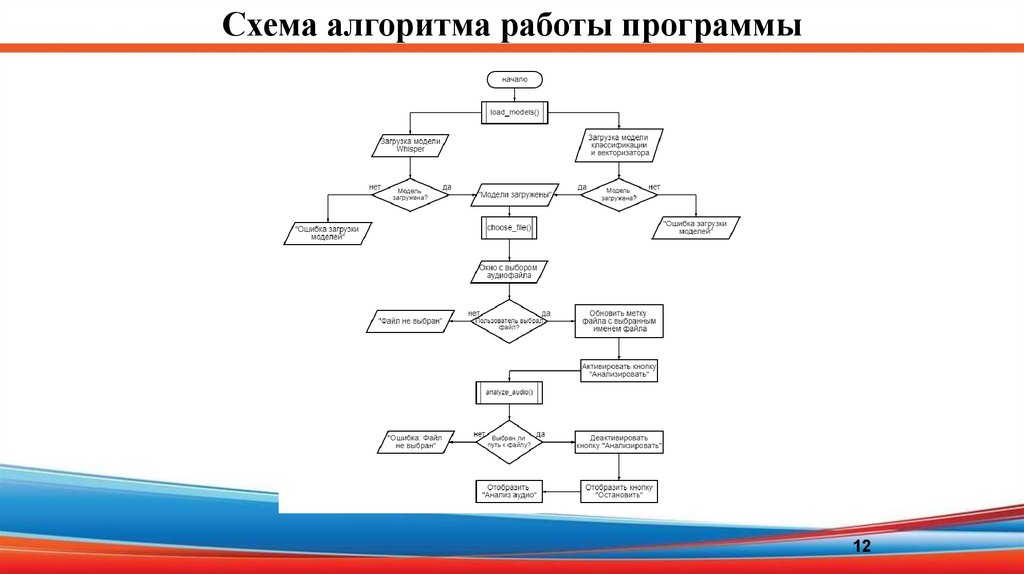
12.
Схема алгоритма работы программы12
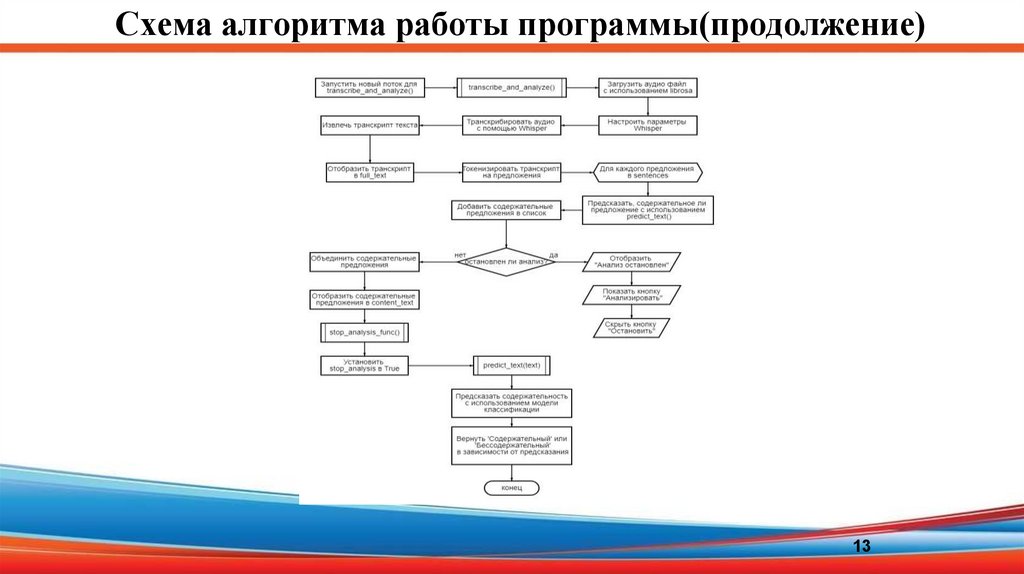
13.
Схема алгоритма работы программы(продолжение)13
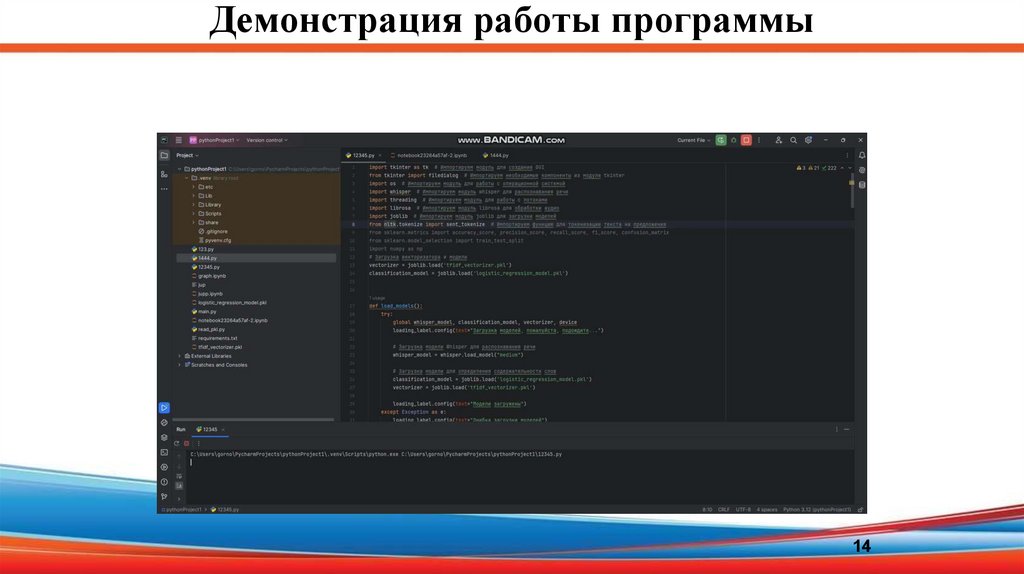
14.
Демонстрация работы программы14
15.
Заключение• В ходе работы над выпускной квалификационной работой были:
• 1) изучены модели машинного обучения для решения задачи бинарной
классификации
• 2) подготовлен датасет для обучения моделей;
• 3) проанализированы метрики моделей;
• 4) разработан и реализован ML-анализатор;
• 5) разработан пользовательский интерфейс;
15
16.
Благодарю за внимание!Москва, 2024 г.