






 Программирование
ПрограммированиеПохожие презентации:



")
")




")
RISC-V Processor with “F” Extension
1.
RISC-V Processor with “F”Extension
Kathy Camenzind and Miguel Gomez
2.
Outline● Background
● Implementation Strategy
○
○
○
Combinational
Multicycle
4-stage pipeline
● Microarchitecture
● Testing
○
○
Connectal
Compliance tests
● Results
● Notable bugs & lessons learned
3.
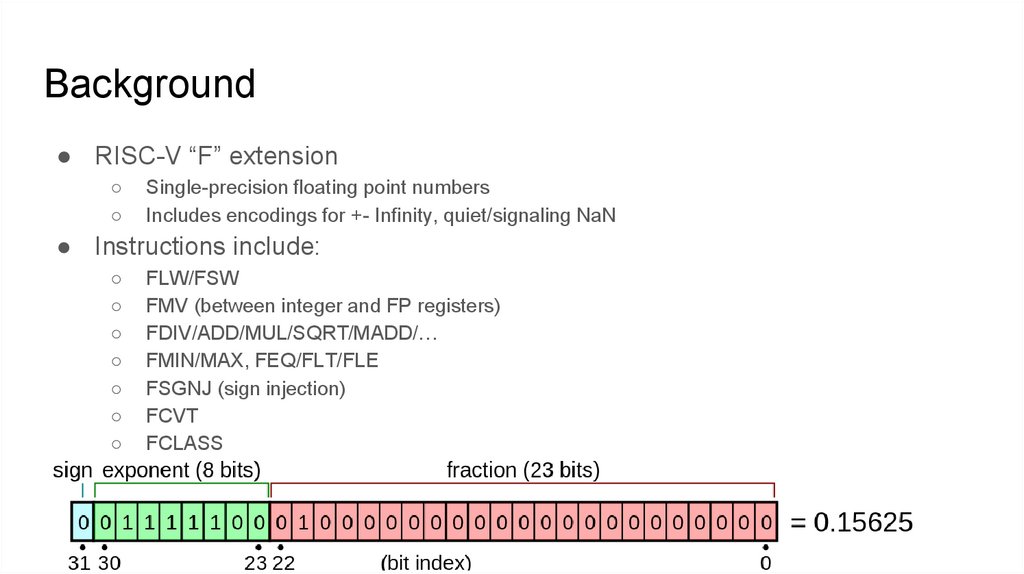
Background● RISC-V “F” extension
○
○
Single-precision floating point numbers
Includes encodings for +- Infinity, quiet/signaling NaN
● Instructions include:
○
○
○
○
○
○
○
FLW/FSW
FMV (between integer and FP registers)
FDIV/ADD/MUL/SQRT/MADD/…
FMIN/MAX, FEQ/FLT/FLE
FSGNJ (sign injection)
FCVT
FCLASS
4.
Overview of Required Modifications● Based on Lab 5 Processor
● CSR instructions
○
○
Basic CSR reads and swaps
FCSR (rounding mode)
● Extending the Decode and Execute stages to handle new instructions
● Integrating Bluespec’s built in FloatingPoint library
● Adding tests that use floating point instructions
5.
Implementation Strategy● Combinational
○
○
Executes floating-point operations in single cycle
Very long critical path
● Multicycle
○
○
Executes floating-point operations in multiple cycles
One instruction passes through processor at a time
● 4-Stage Pipeline with Bypassing
○
○
Executes floating-point operations in multiple cycles
Pipelining based on ThreeStageBypass from lab 5, with added writeback stage
● 4-Stage Superscalar Pipeline with Bypassing
○
○
Can execute multiple instructions at a time in different functional units
Preserves commit order within integer operations and floating point operations
6.
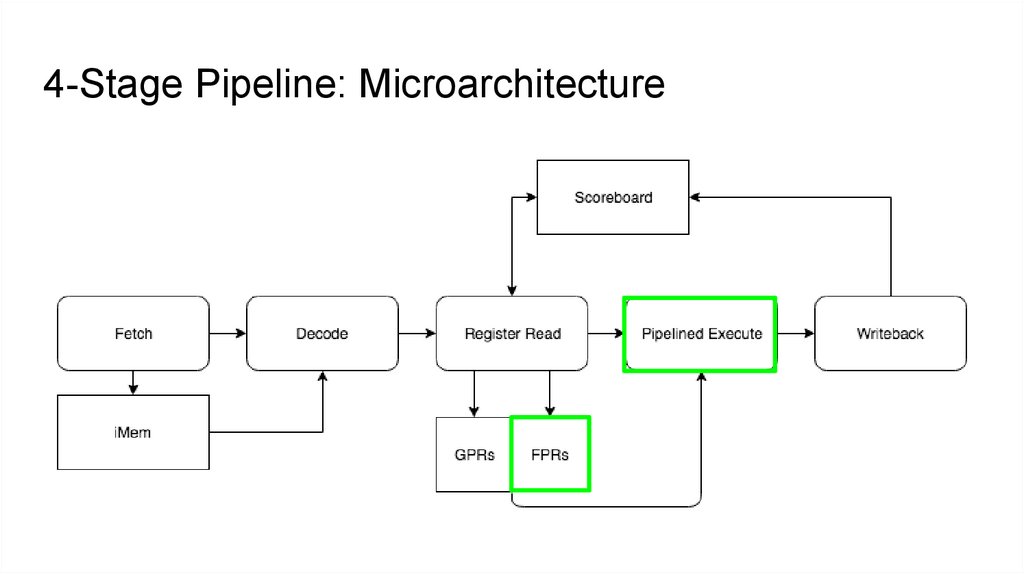
4-Stage Pipeline: Microarchitecture7.
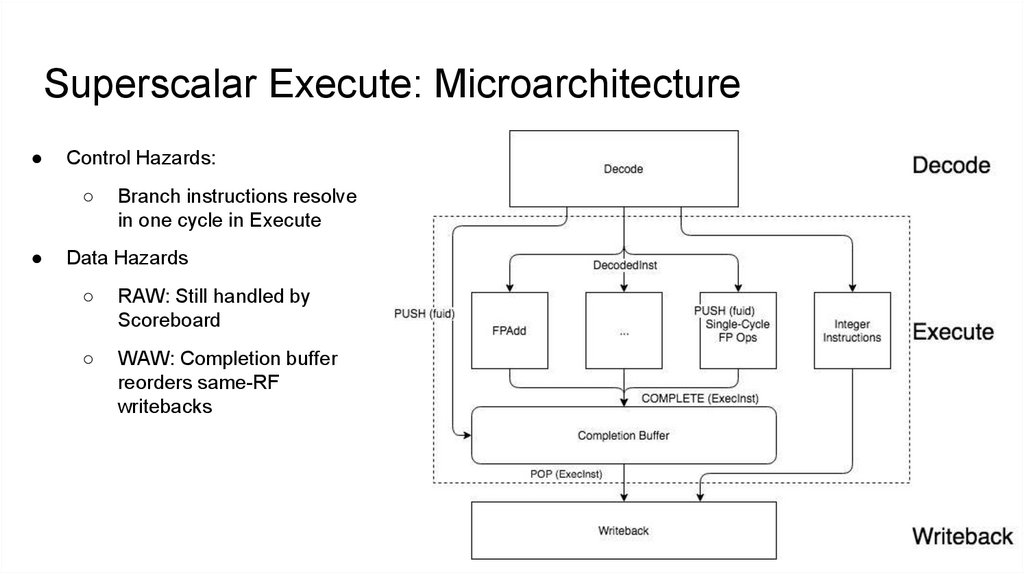
Superscalar Execute: MicroarchitectureControl Hazards:
○
Branch instructions resolve
in one cycle in Execute
Data Hazards
○
RAW: Still handled by
Scoreboard
○
WAW: Completion buffer
reorders same-RF
writebacks
8.
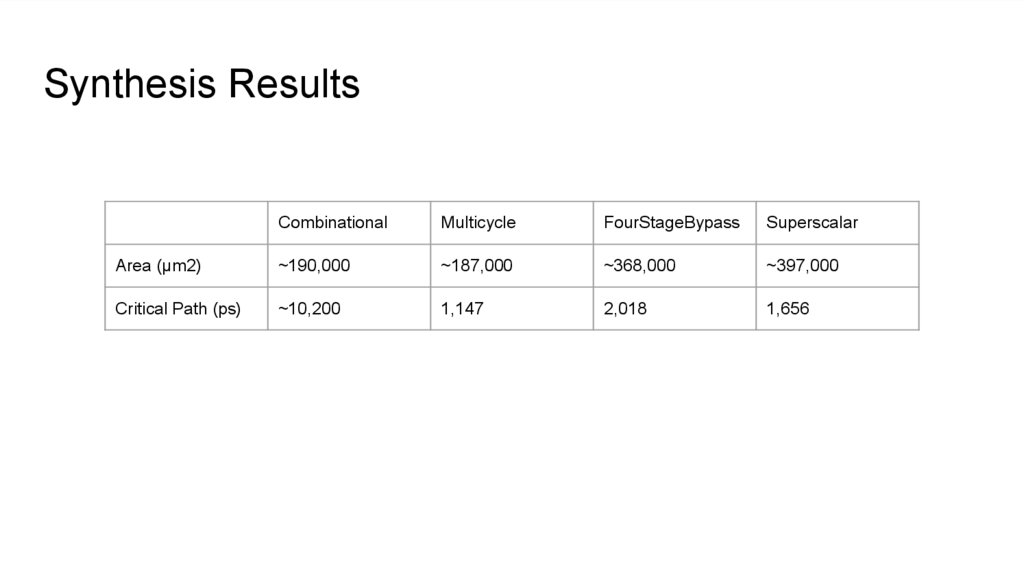
Synthesis ResultsCombinational
Multicycle
FourStageBypass
Superscalar
Area (μm2)
~190,000
~187,000
~368,000
~397,000
Critical Path (ps)
~10,200
1,147
2,018
1,656
9.
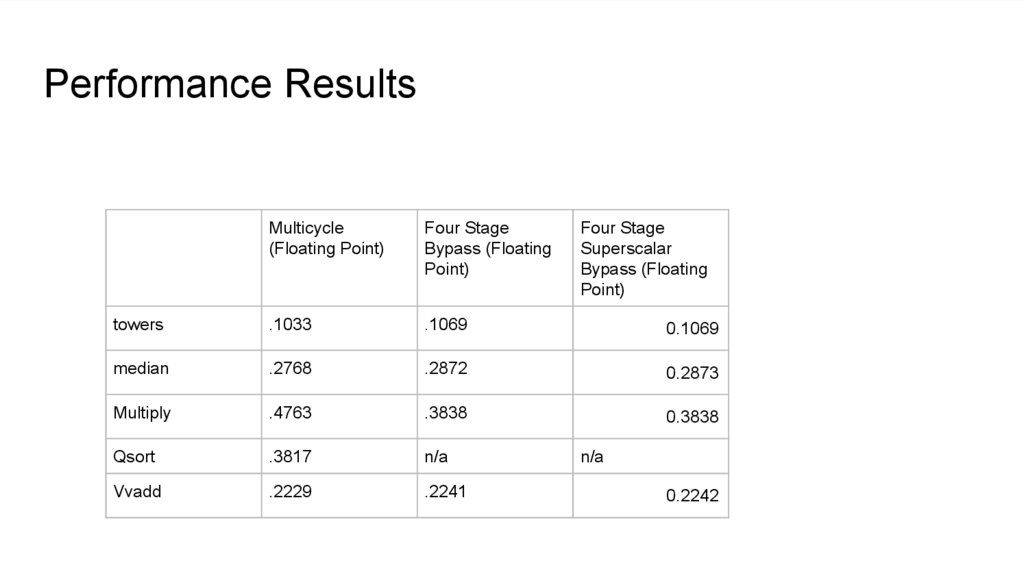
Performance ResultsMulticycle
(Floating Point)
Four Stage
Bypass (Floating
Point)
Four Stage
Superscalar
Bypass (Floating
Point)
towers
.1033
.1069
0.1069
median
.2768
.2872
0.2873
Multiply
.4763
.3838
0.3838
Qsort
.3817
n/a
Vvadd
.2229
.2241
n/a
0.2242
10.
Running on FPGA11.
Notable Bugs● Functionally incorrect functions in FloatingPoint.bsv
● Compliance tests that were non-compliant :)
○
Mostly centered around NaN operations
● Debugging
○
○
○
Implemented showInst for new instructions
Printed which stages were executing which instructions
Printing the current state of the completion buffer
12.
Conclusion / Things Learned● Efficient pipelining is difficult
● Fixing edge cases should be a second priority, completing the bigger picture
is first
● Simulations can sometimes be unreliable
● Libraries can be incorrect