












































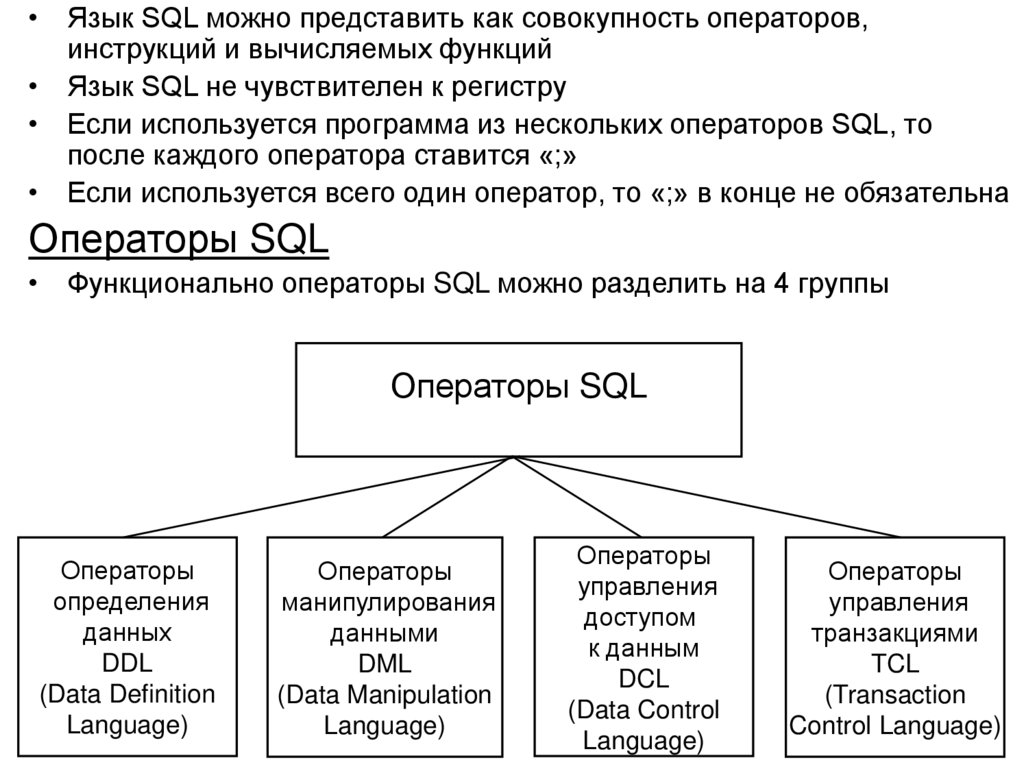
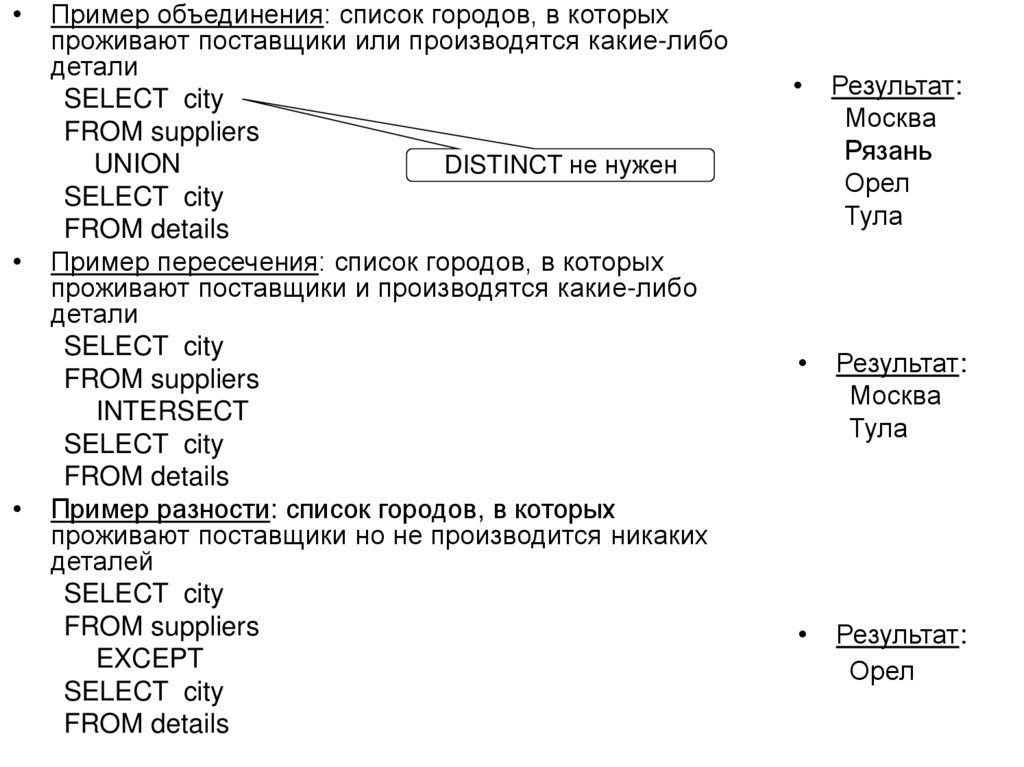
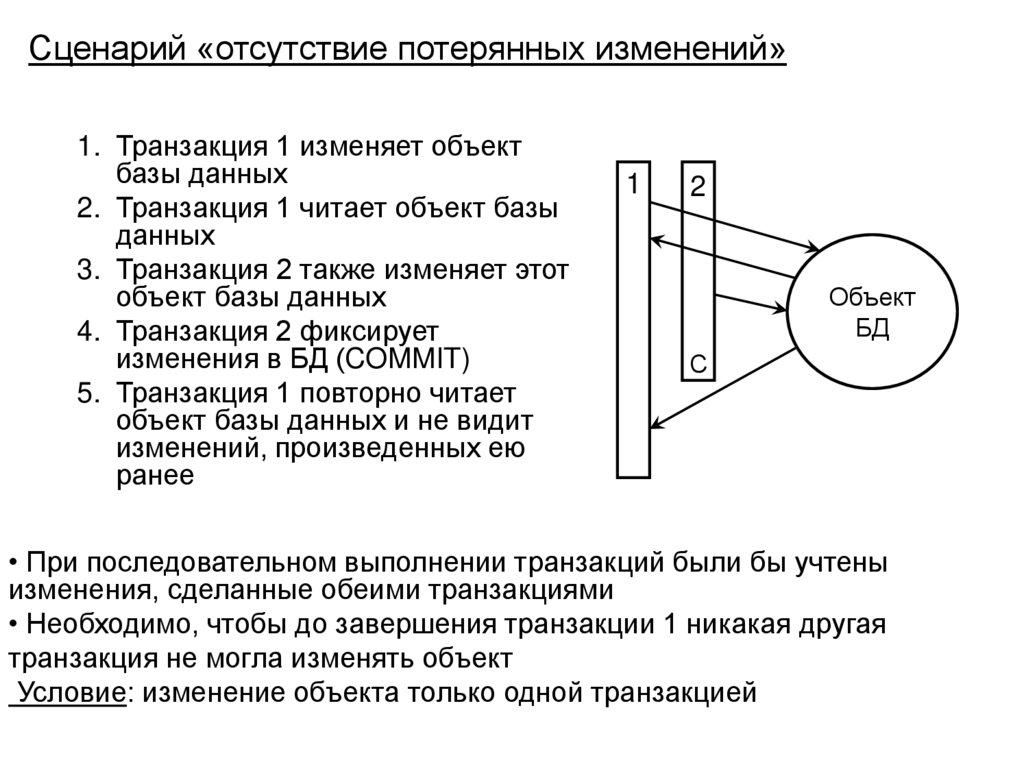
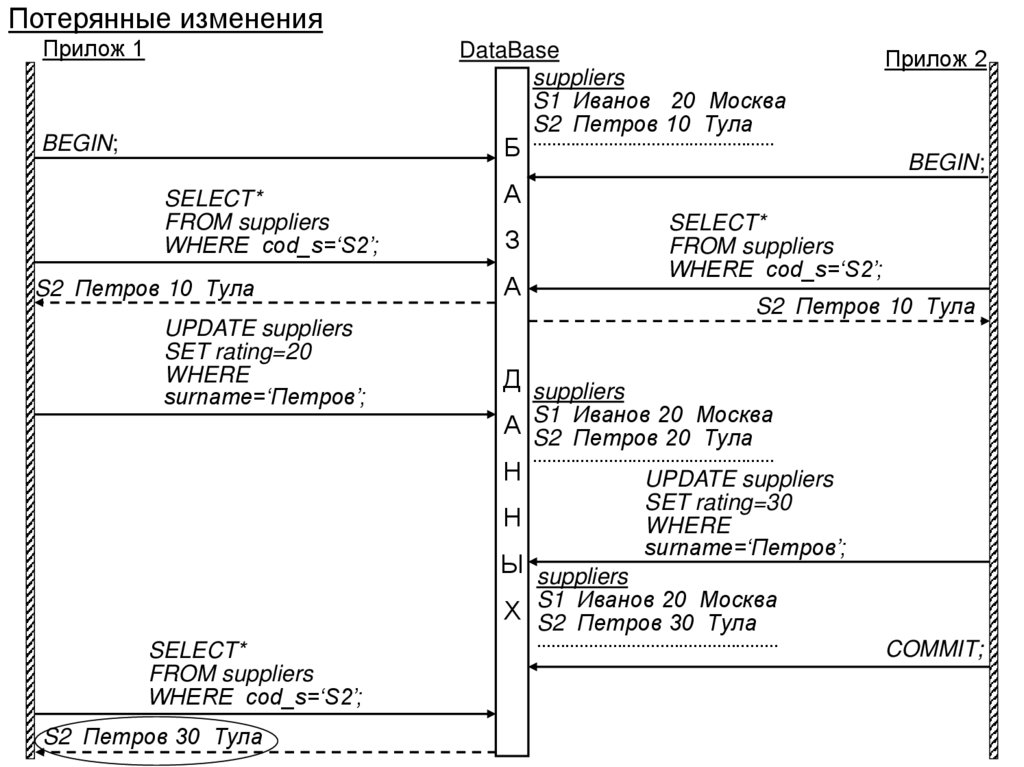
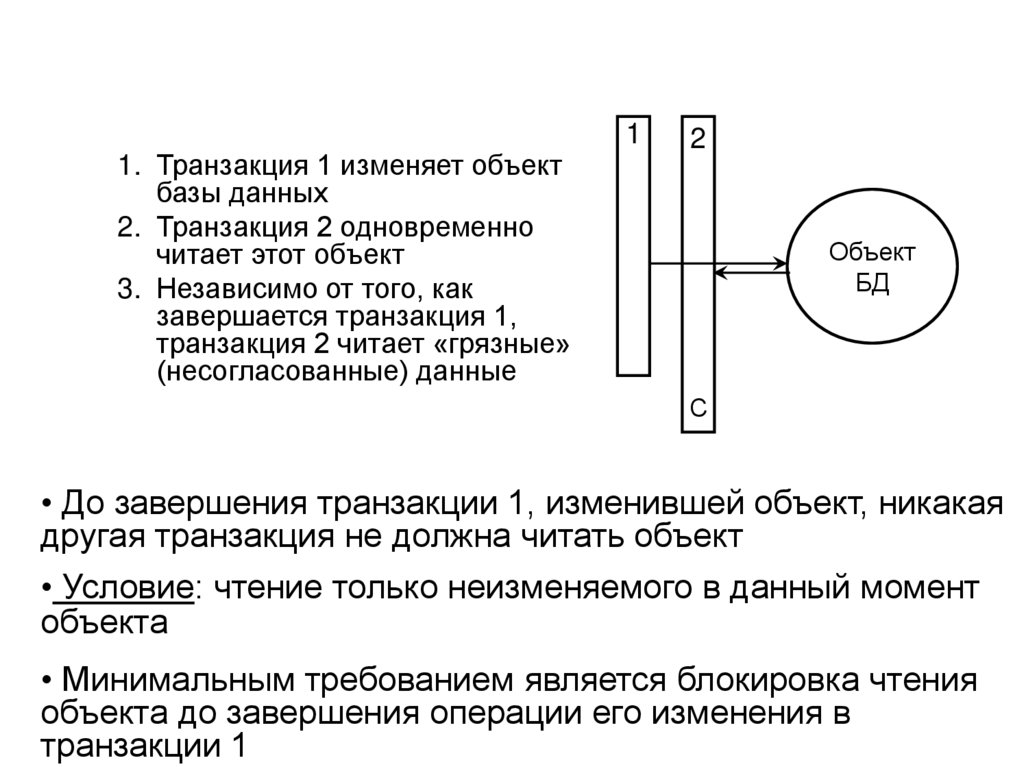
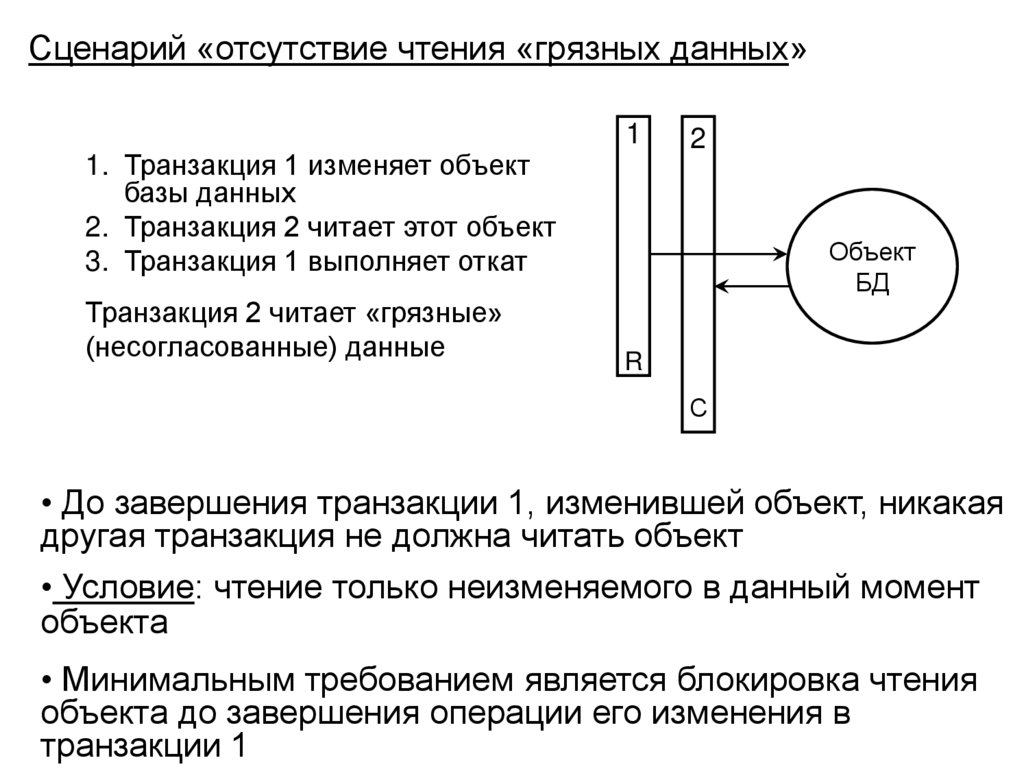
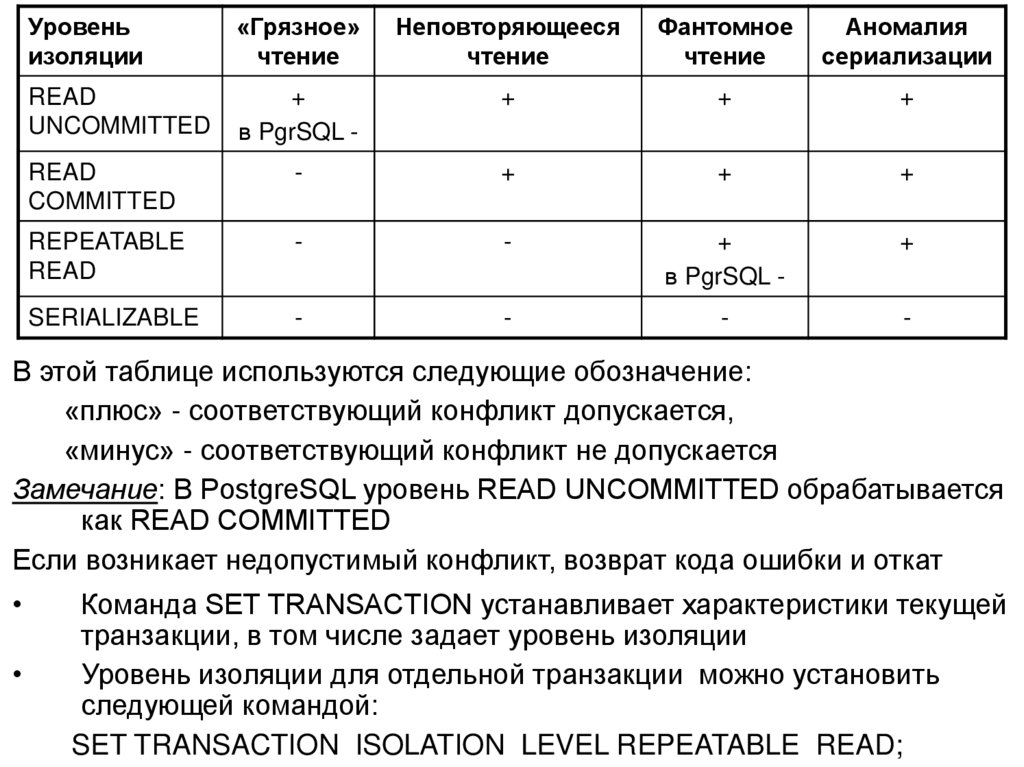
")

")









































")
")
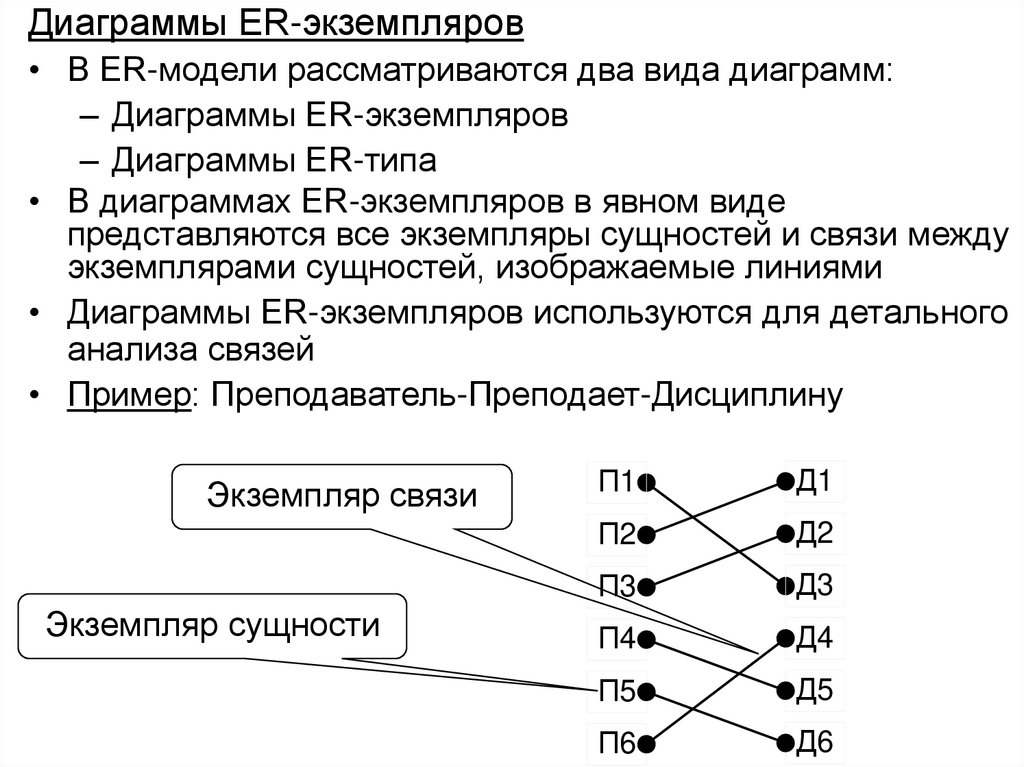
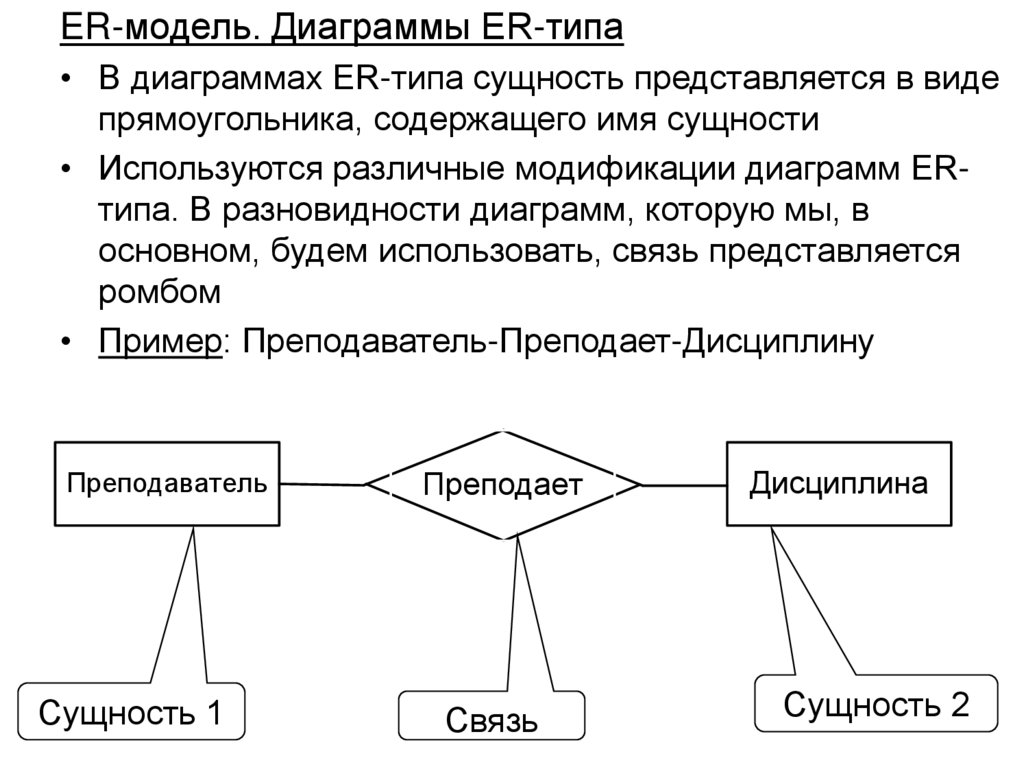



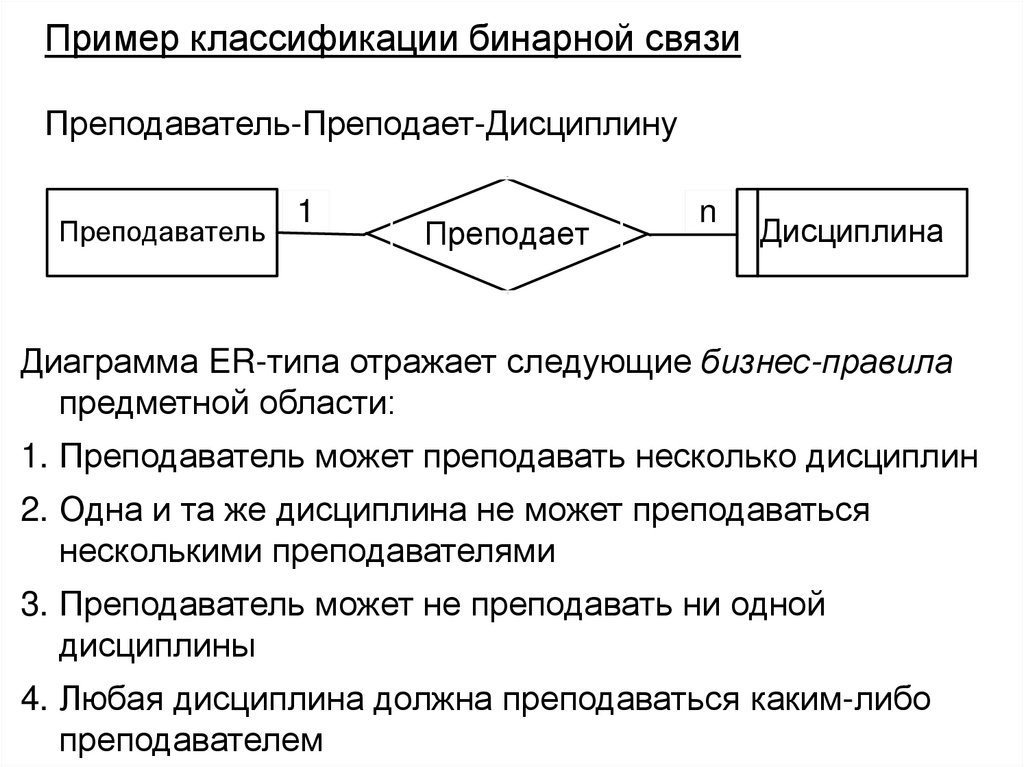













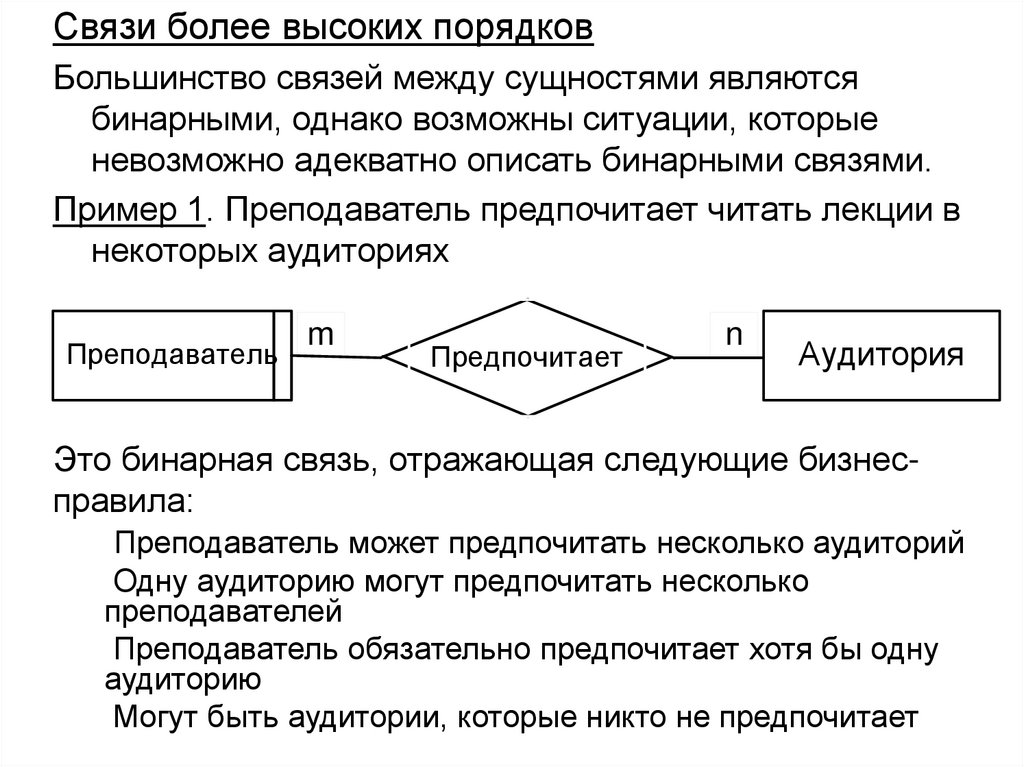


")















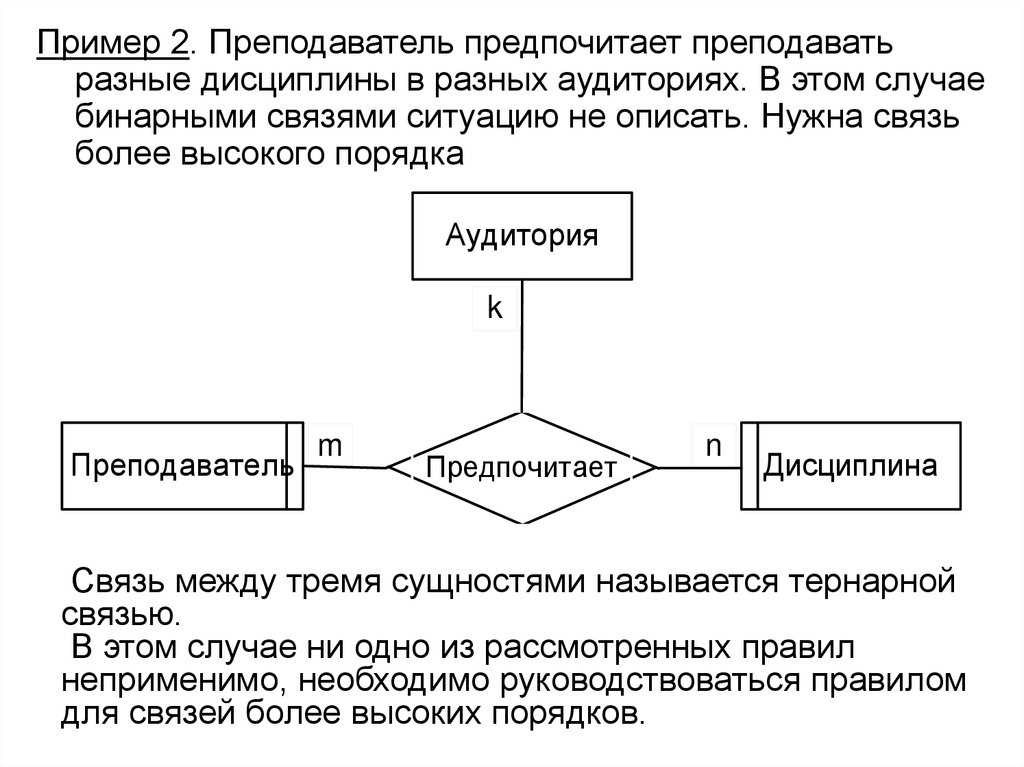
")












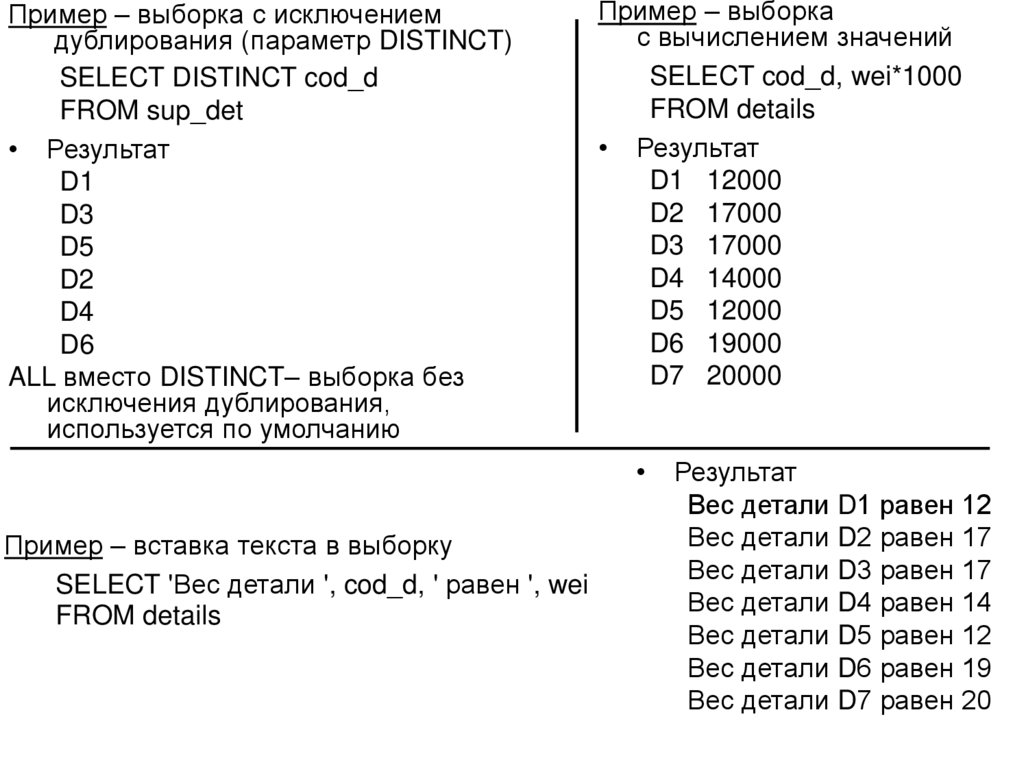



















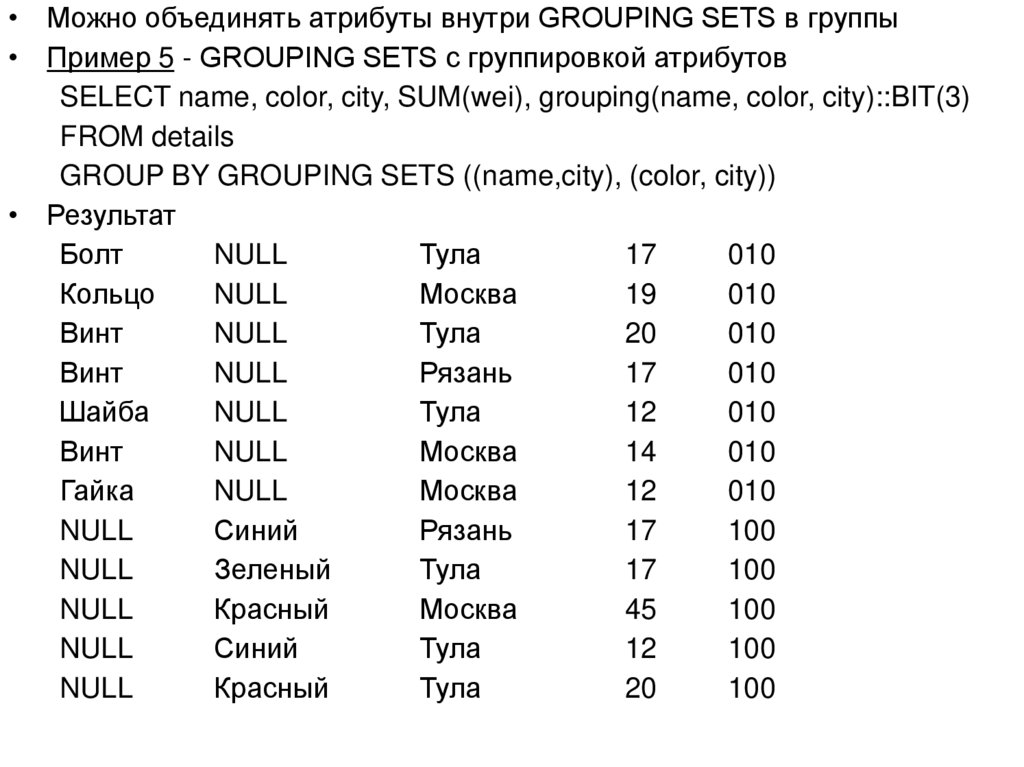


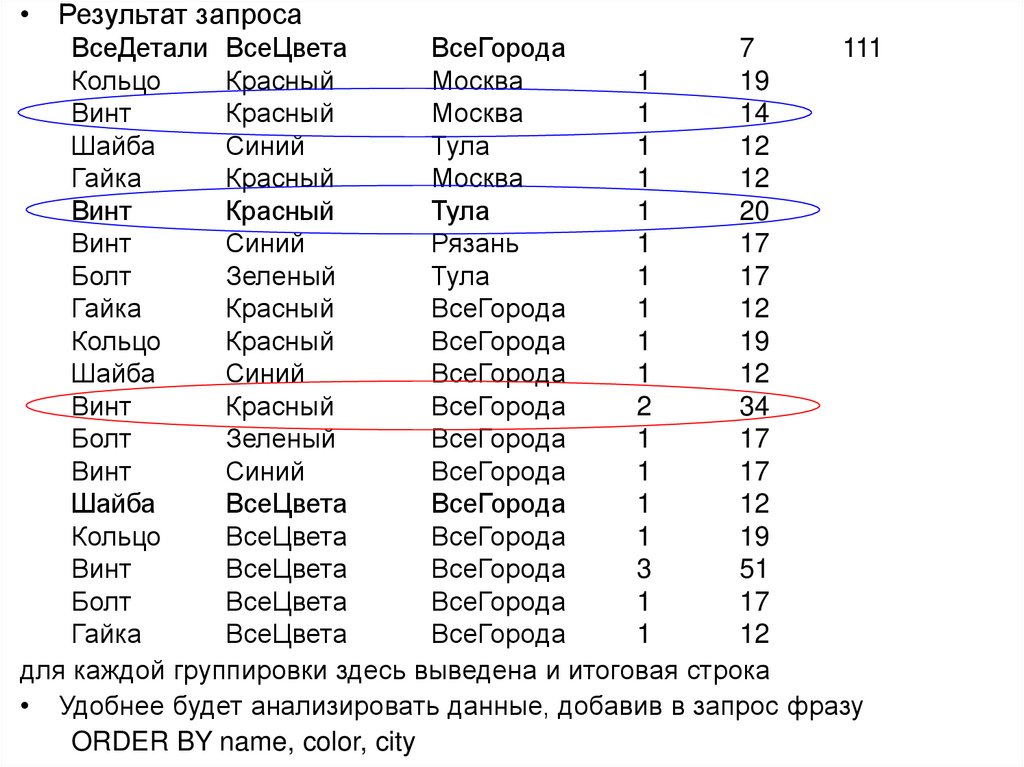
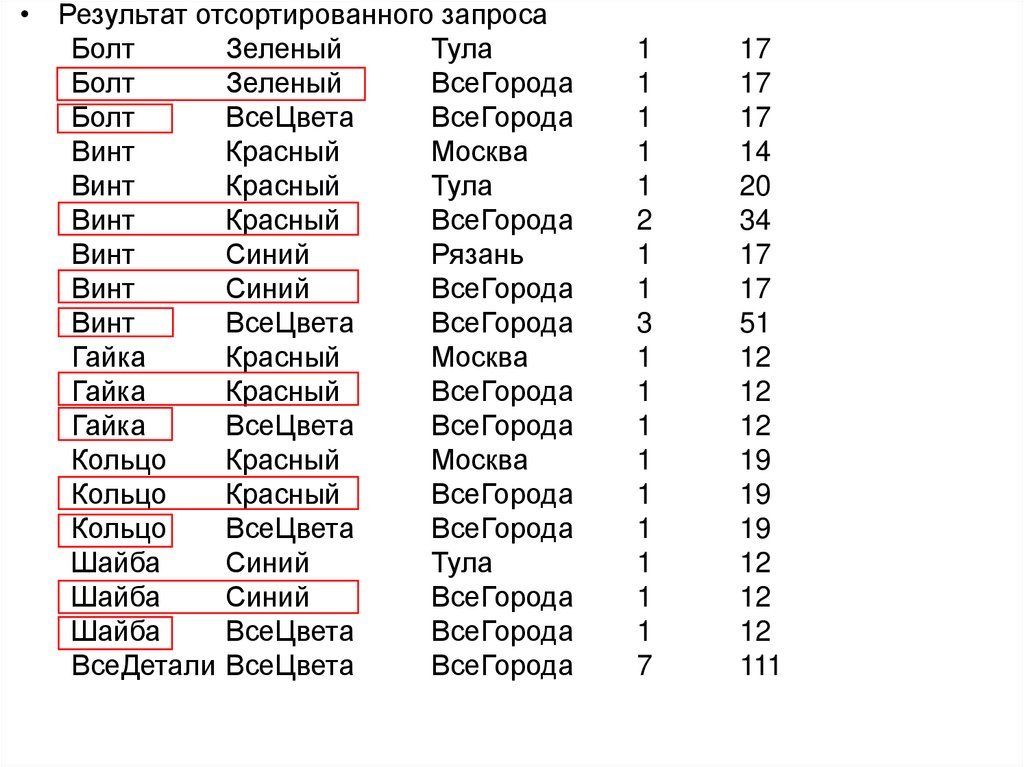



































































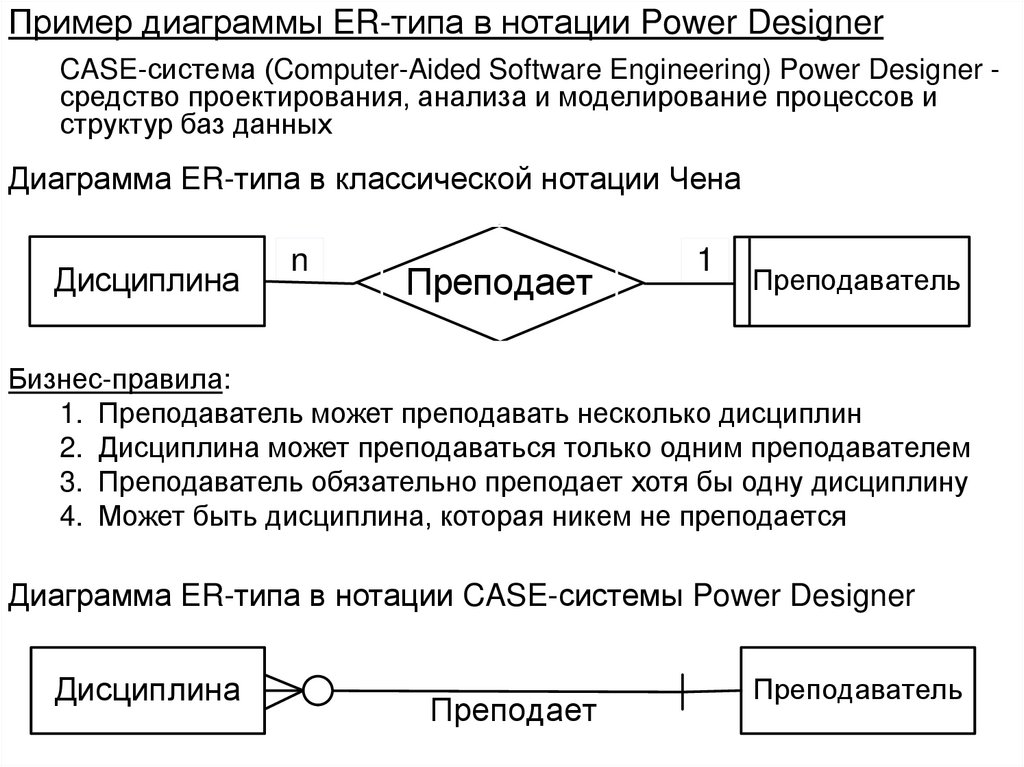
")


























































































 Базы данных
Базы данныхПохожие презентации:










Базы данных. Курс лекций
1. БАЗЫ ДАННЫХ
Курс лекций2. Структура учебной дисциплины
• Основные понятия, история и модели• Реляционная модель данных
• Проектирование реляционных баз данных
• Язык реляционных баз данных SQL
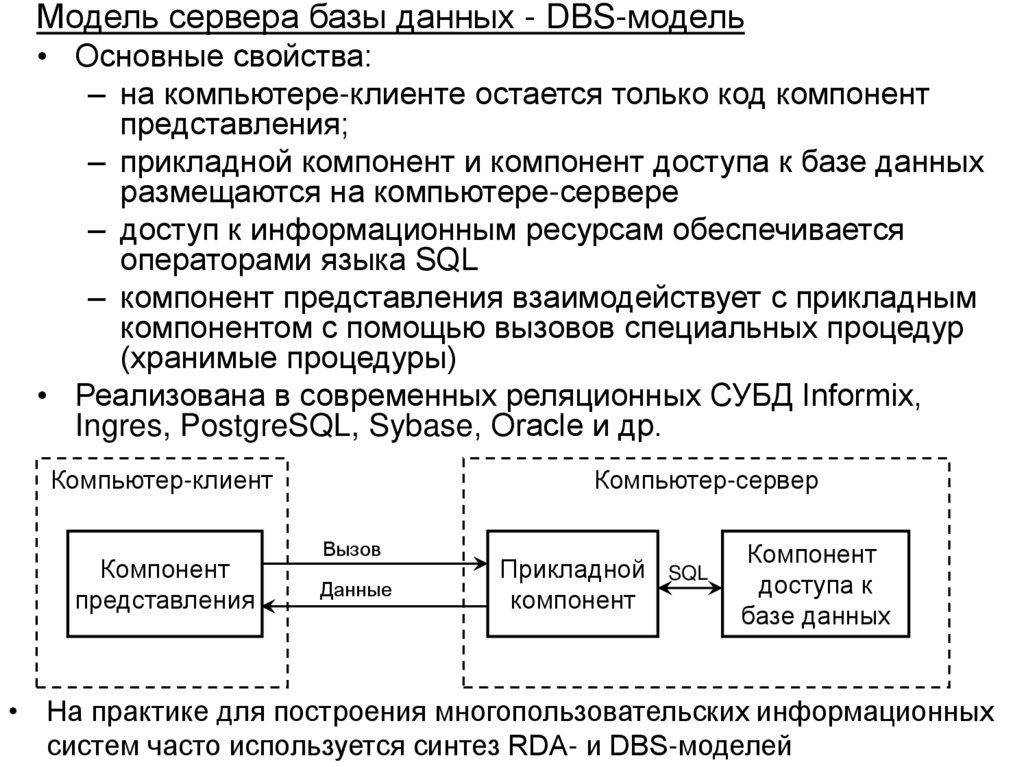
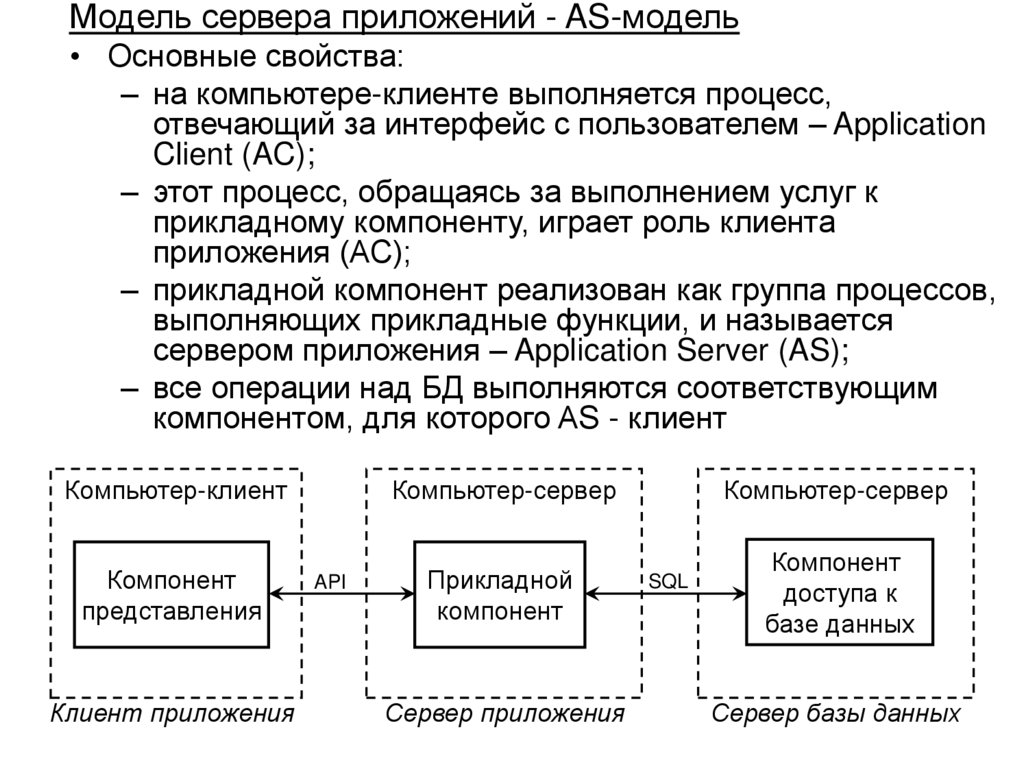
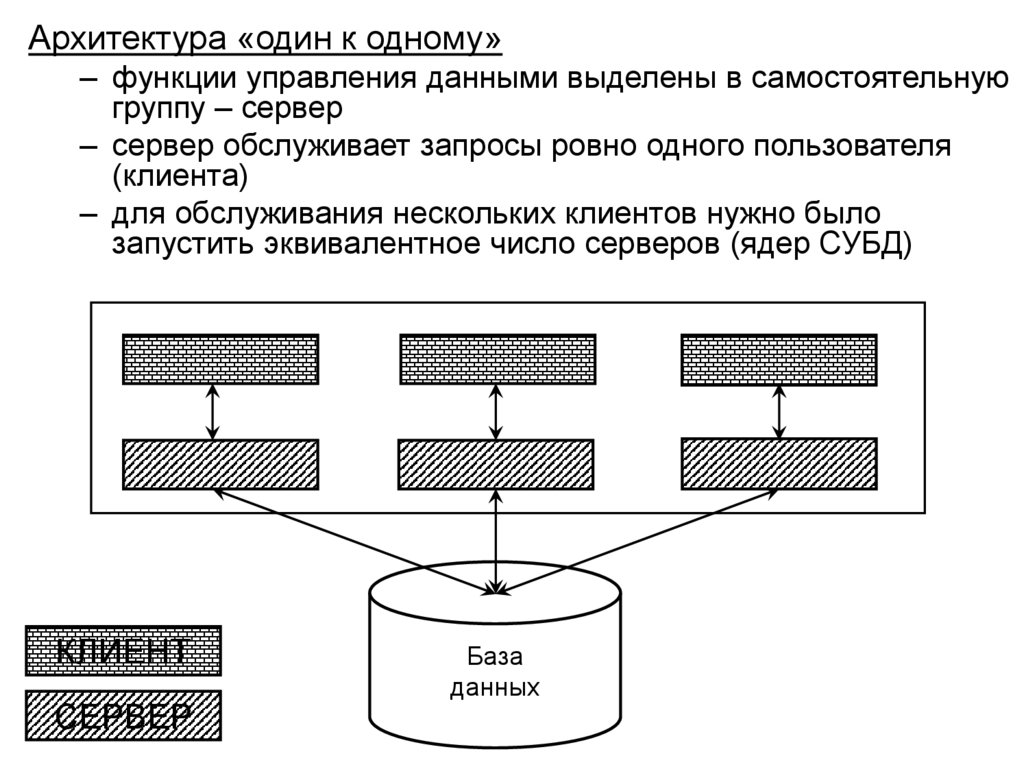
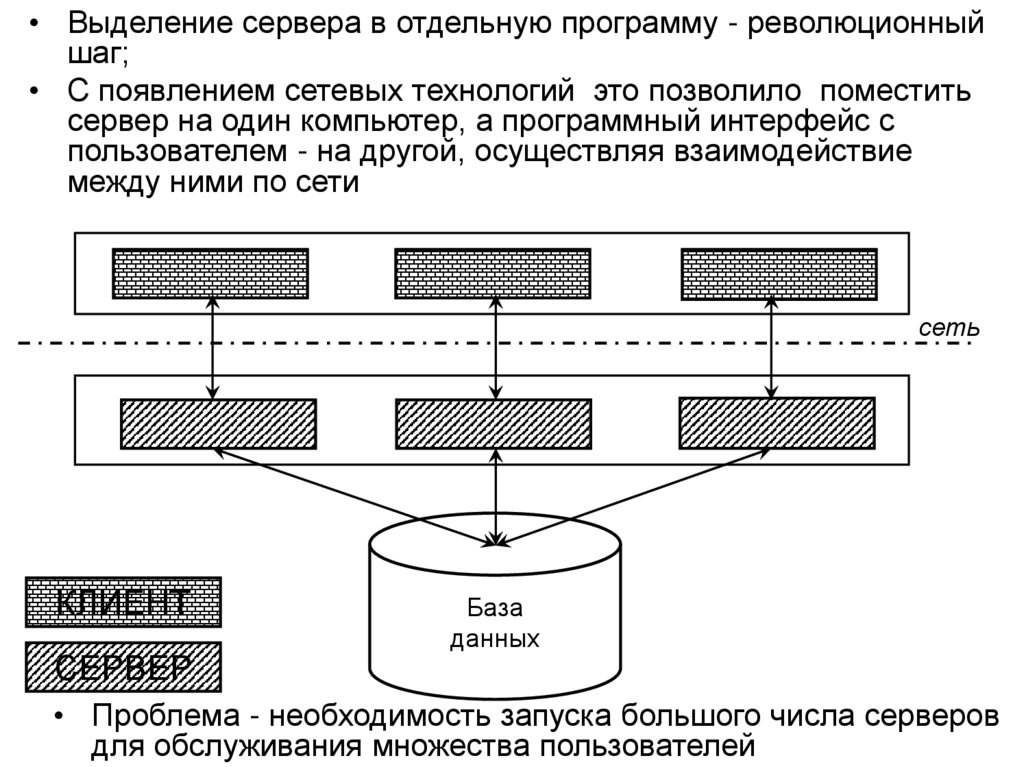
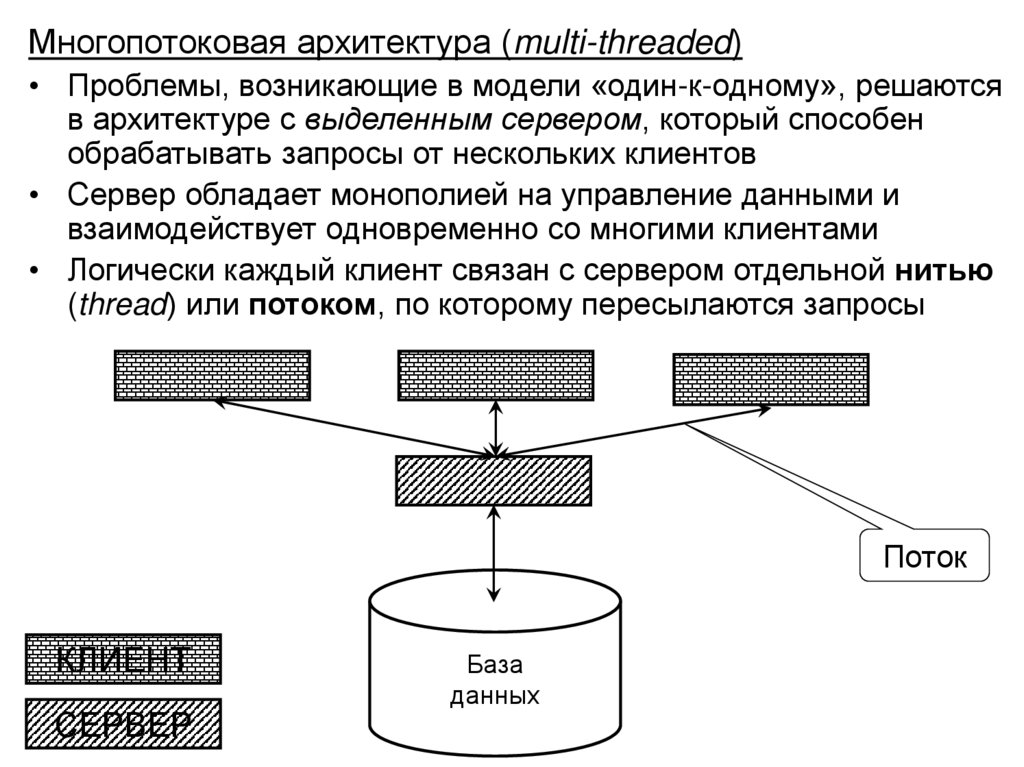
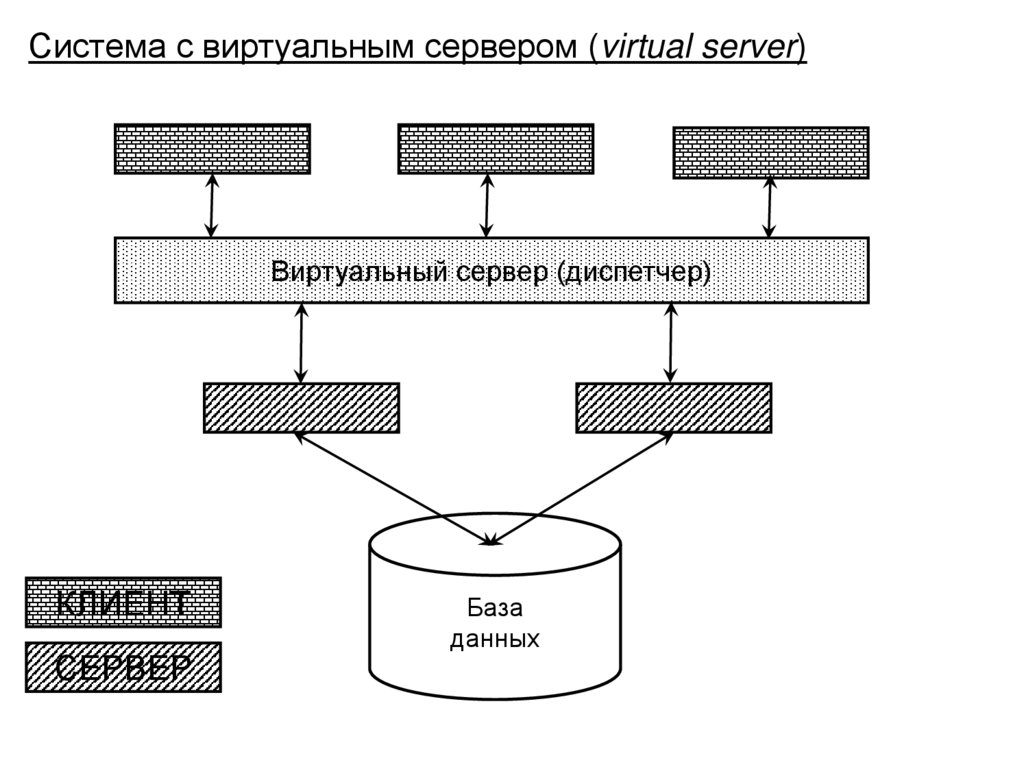
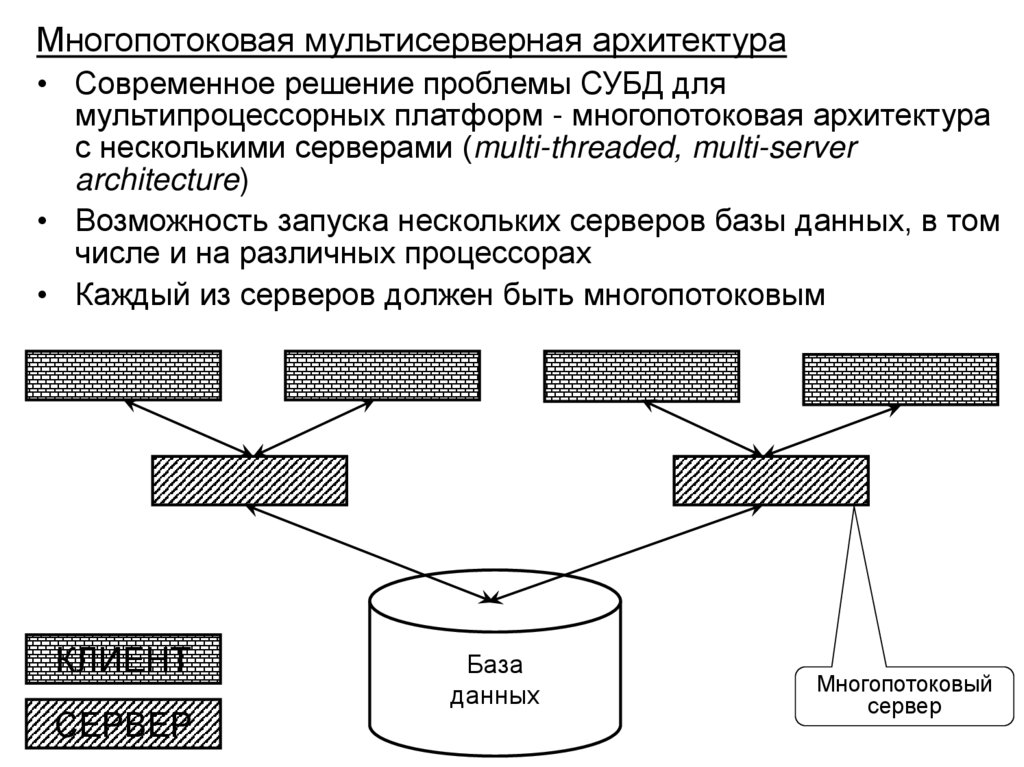
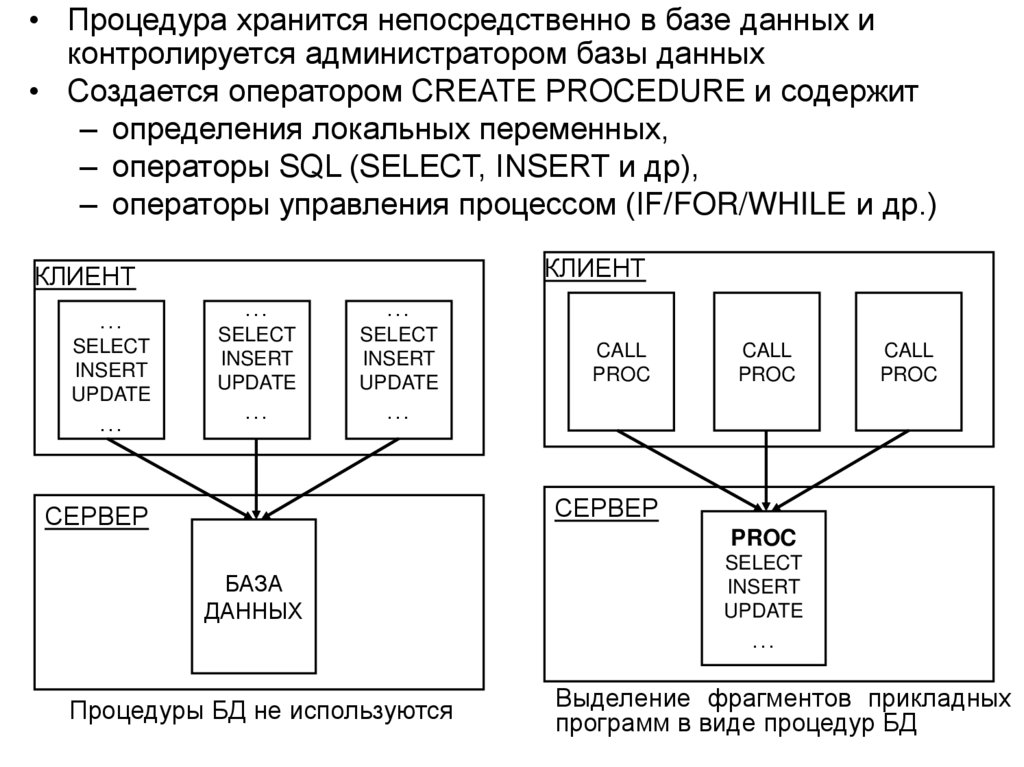
• Структура и функции СУБД
• Архитектура многопользовательских баз данных
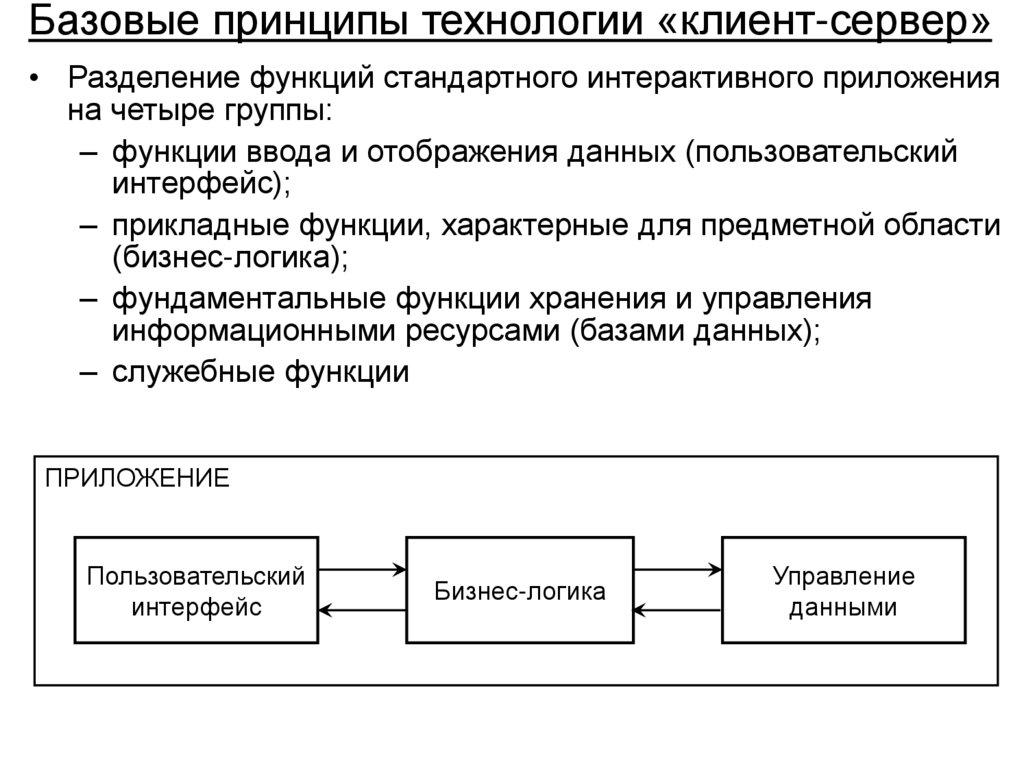
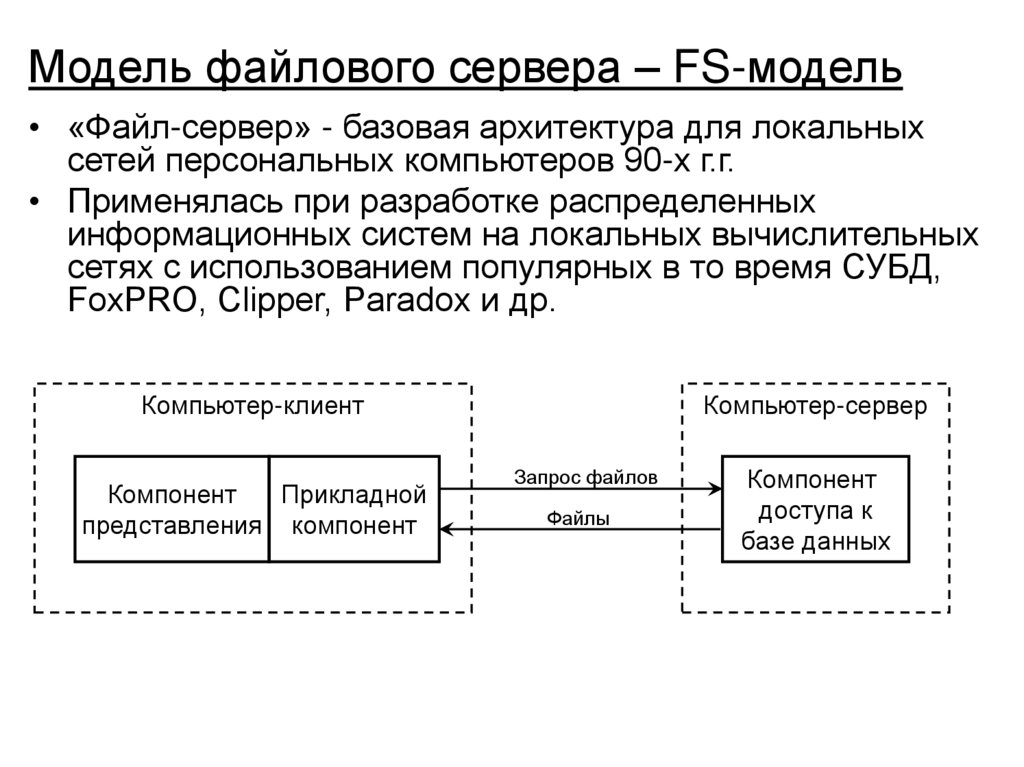
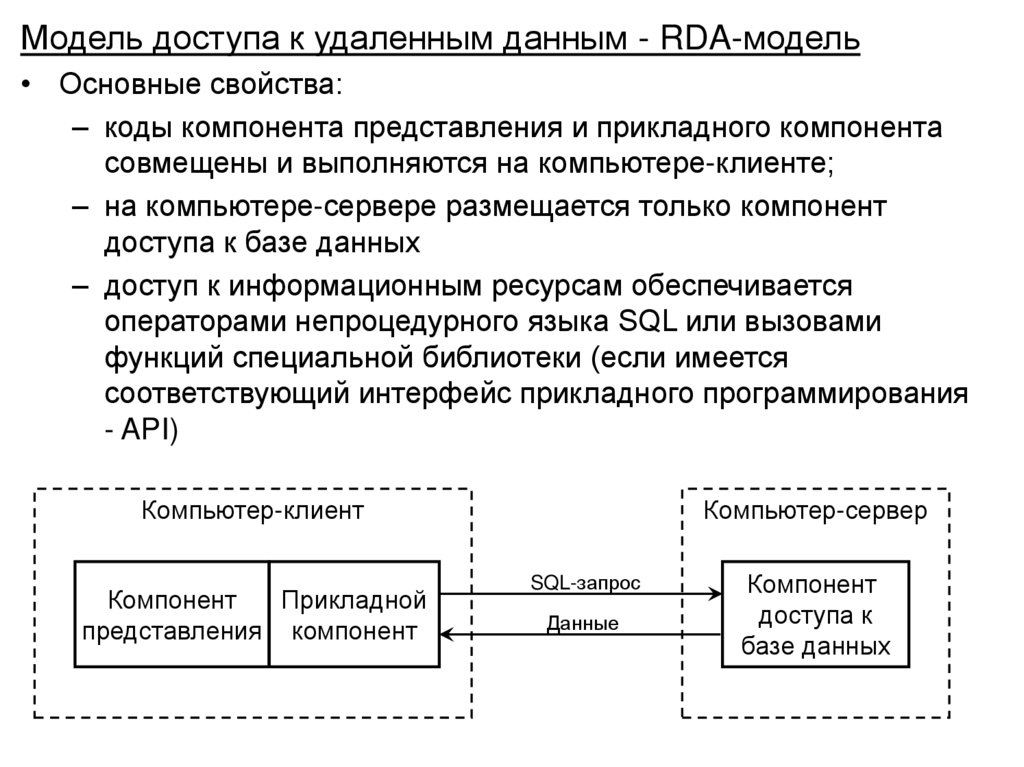
• Архитектура «клиент-сервер» в распределенной
вычислительной среде, варианты реализации
• Основные направления развития баз данных
3. Литература
Дейт К. Дж. Введение в системы баз данных. – Киев: Диалектика, 1998, 784 с.
Конноли Т., Бегг К., Страчан А. Базы данных: Проектирование, реализация и
сопровождение. Теория и практика, 2-е издание – М.– С./П.– К., Вильямс, 2000,
1111 с.
Карпова Т. С. Базы данных: модели, разработка, реализация. – С-П., ПИТЕР,
2002, 304 с.
Базы данных/ Под ред. проф. А.Д. Хомоненко. – С-П, КОРОНА принт, 2000.
Гарсиа-Молина Г., Ульман Дж., Уидом Дж. Системы баз данных. Полный курс.
М., –Вильямс, 2004, 1083 с.
Роб П., Коронел К. Системы баз данных: проектирование, реализация и
управление. – С-П., БХВ, 2004, 1024 с.
Грабер М. Введение в SQL. – М., ЛОРИ, 1994, 377 с.
Грофф Дж., Вайнберг П. Энциклопедия SQL. – С-П., ПИТЕР, 2003, 895с.
Джексон Г. Проектирование баз данных для использования с микроЭВМ. – М.,
Мир, 1991
Саймон А. Стратегические технологии баз данных. – М., Финансы и статистика,
1999, 478 с.
Д.Ульман, Д.Уидом. Введение в системы баз данных. – М., ЛОРИ, 2000.
Интернет-ресурсы, электронные библиотечные системы:
электронная библиотечная система «Университетская книга»
электронная библиотечная система университета на www.rsatu.ru
электронные ресурсы на сайте кафедры httD://www.rsatu.ru/sites/mзoevs/
www.citforum.ru
www.intuit.ru
4.
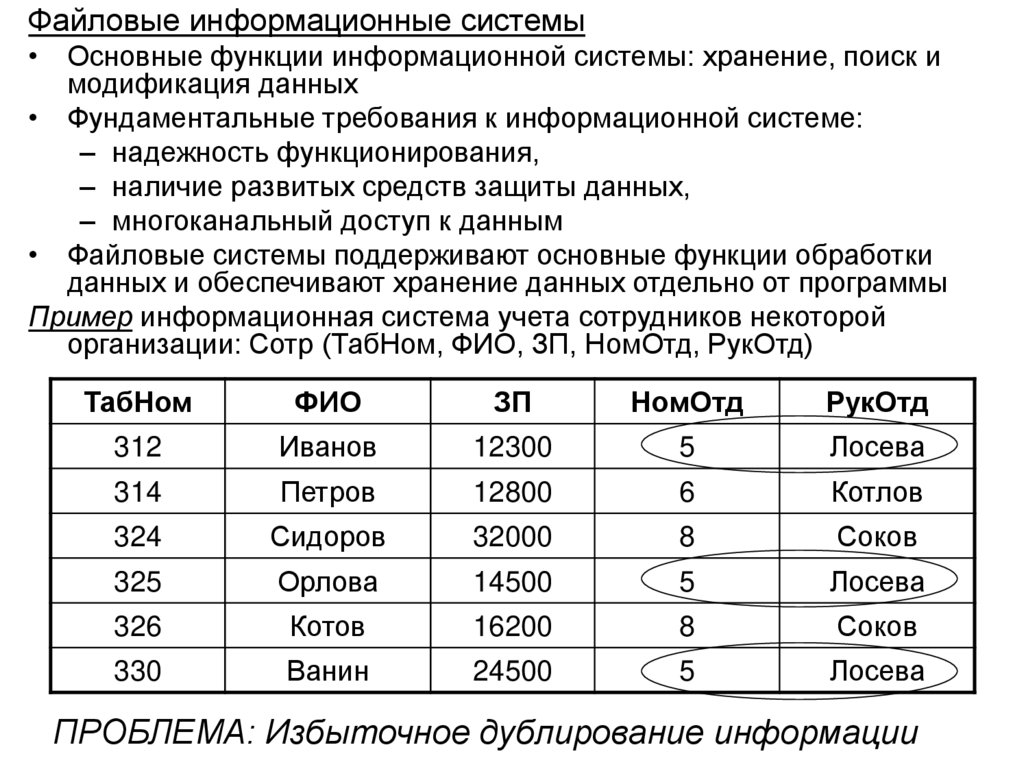
Файловые информационные системы• Основные функции информационной системы: хранение, поиск и
модификация данных
• Фундаментальные требования к информационной системе:
– надежность функционирования,
– наличие развитых средств защиты данных,
– многоканальный доступ к данным
• Файловые системы поддерживают основные функции обработки
данных и обеспечивают хранение данных отдельно от программы
Пример информационная система учета сотрудников некоторой
организации: Сотр (ТабНом, ФИО, ЗП, НомОтд, РукОтд)
ТабНом
ФИО
ЗП
НомОтд
РукОтд
312
Иванов
12300
5
Лосева
314
Петров
12800
6
Котлов
324
Сидоров
32000
8
Соков
325
Орлова
14500
5
Лосева
326
Котов
16200
8
Соков
330
Ванин
24500
5
Лосева
ПРОБЛЕМА: Избыточное дублирование информации
5.
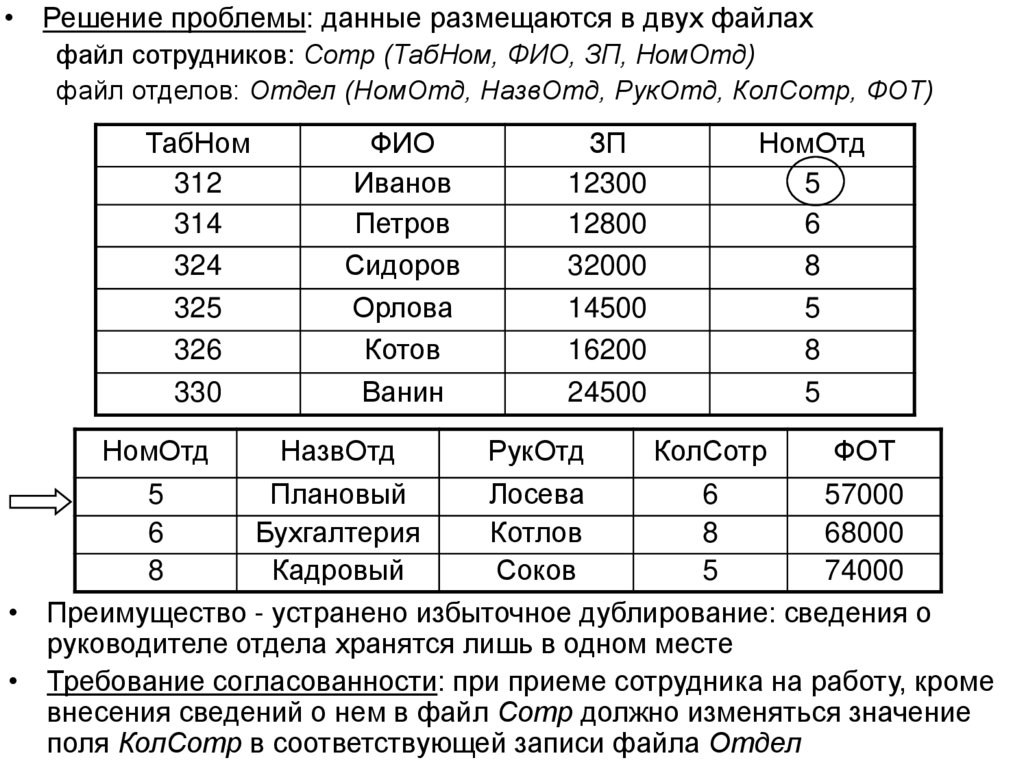
• Решение проблемы: данные размещаются в двух файлахфайл сотрудников: Сотр (ТабНом, ФИО, ЗП, НомОтд)
файл отделов: Отдел (НомОтд, НазвОтд, РукОтд, КолСотр, ФОТ)
ТабНом
312
314
324
325
326
330
НомОтд
ФИО
Иванов
Петров
Сидоров
Орлова
Котов
Ванин
НазвОтд
ЗП
12300
12800
32000
14500
16200
24500
РукОтд
НомОтд
5
6
8
5
8
5
КолСотр
ФОТ
5
Плановый
Лосева
6
57000
6
Бухгалтерия
Котлов
8
68000
8
Кадровый
Соков
5
74000
• Преимущество - устранено избыточное дублирование: сведения о
руководителе отдела хранятся лишь в одном месте
• Требование согласованности: при приеме сотрудника на работу, кроме
внесения сведений о нем в файл Сотр должно изменяться значение
поля КолСотр в соответствующей записи файла Отдел
6.
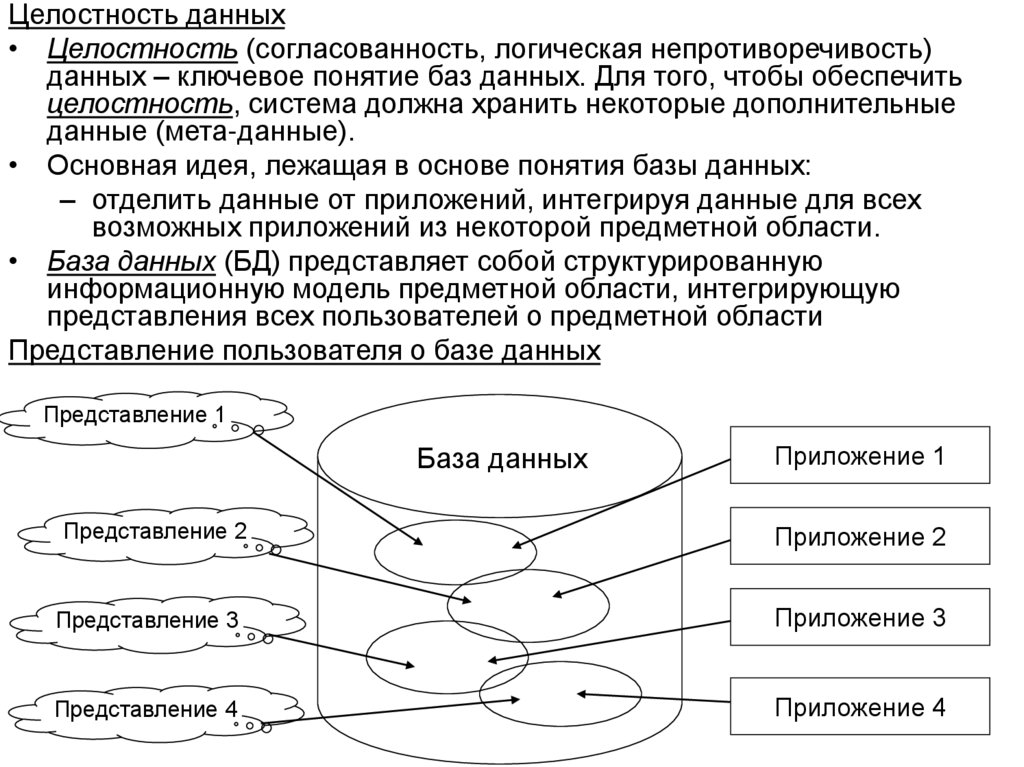
Целостность данных• Целостность (согласованность, логическая непротиворечивость)
данных – ключевое понятие баз данных. Для того, чтобы обеспечить
целостность, система должна хранить некоторые дополнительные
данные (мета-данные).
• Основная идея, лежащая в основе понятия базы данных:
– отделить данные от приложений, интегрируя данные для всех
возможных приложений из некоторой предметной области.
• База данных (БД) представляет собой структурированную
информационную модель предметной области, интегрирующую
представления всех пользователей о предметной области
Представление пользователя о базе данных
Представление 1
База данных
Приложение 1
Представление 2
Приложение 2
Представление 3
Приложение 3
Представление 4
Приложение 4
7.
• Вывод: каждый пользователь и прикладной программист имеет дело несо всей базой данных, а лишь с той ее частью, которая обеспечивает
решение необходимых ему задач, и использует лишь некоторое
подмножество всех возможностей и средств базы данных
Система управления базами данных
• Требования к современной базе данных:
– централизованное управление данными,
– отсутствие избыточного дублирования данных,
– поддержка целостности, т.е. логической непротиворечивости,
– удобство создания новых приложений,
– независимость приложений от данных, т.е. иммунитет приложений к
изменениям в структуре хранения и стратегии доступа к данным,
– многопользовательский доступ,
– защита от разрушения и несанкционированного доступа,
восстановление данных,
– поддержка существующих стандартов в области обработки данных.
• Стандартная файловая система не может обеспечить такой набор
свойств, поэтому для создания информационных систем на основе баз
данных используется специальная программная инструментальная
среда
• Система управления базами данных (СУБД) – это программная
инструментальная среда для создания баз данных и информационных
систем с указанными свойствами.
8.
Сведения из истории СУБД• GUAM (Generalized Update Access Method) - проект Appolo
• 1968 год - IMS (Information Management System) – IBM, Иерархическая
СУБД
• Середина 1960-х г.г., IDS (Integrated Data Store) – General Electric,
Сетевая СУБД
Стандартизация в области БД
1965 год – CODASYL (Conference on Data Systems Languages)
1967 год – DBTG (Data Base Task Group)
ANSI/SPARC, ACM SIGMOD
1971 год - DBTG определены термины Схема и Подсхема базы
данных:
– Схема - множество структур данных БД
– Подсхема - подмножество структур данных БД
• Сформулирована концепция общего языка баз данных,
обеспечивающего определение структур и свойств данных и
манипулирование данными:
– DDL – (Data Definition Language) - язык определения структур и
свойств данных
– DML – ( Data Manipulation Language) - язык манипулирования
данными
• 1973 год – ANSI/SPARC предложена трехуровневая модель
представления данных
9. Трехуровневая модель ANSI/SPARC
Представление 1Представление 2 …
Представление n
Внешний уровень
Концептуальный уровень
Физический уровень
Концептуальное
представление
Физическое
представление
СУБД
СУБД обеспечивает
независимую работу
с данными
на всех уровнях
Внешний уровень – это индивидуальный уровень пользователя,
представление базы данных для конкретного пользователя или группы
пользователей; может быть виртуальным
Концептуальный уровень – это представление всей базы данных, в котором
интегрированы все внешние представления, оно соответствует полному набору
структур, хранящихся в базе данных. На этом уровне используется некоторая
формализованная модель представления данных.
Внутренний (физический) уровень – это представление данных в виде
реальных структур, размещаемых на физических устройствах, на этом уровне с
данными работает сама СУБД, используя внутренние механизмы, скрытые от
пользователей
10.
Основные модели баз данных• Одним из центральных в концепции баз данных является понятие
«модель данных»
• Модель данных - это некоторый интегрированный набор базовых
понятий и средств для описания данных, связей между ними и
накладываемых на них ограничений
• Три типа (уровня) моделей представления данных:
– инфологическая,
– даталогическая,
– физическая.
Инфологическая модель отражает базовые понятия предметной области,
их свойства, связи между ними и ограничения.
• Инфологическая модель представляет собой семантическую модель
предметной области, построенную в рамках некоторого формализма.
• Инфологическая модель строится на ранних стадиях проектирования и
использует базовые структуры, которые не поддерживаются СУБД.
Даталогическая модель соответствует концептуальному уровню
представления и поддерживается системой управления базами
данных.
• Даталогическая модель или модель представления данных включает в
себя: набор поддерживаемых СУБД базовых структур, множество
операций над этими структурами, ограничения (иерархическая,
сетевая, реляционная, постреляционные)
Физическая модель – это низкоуровневое представление данных с
использованием внутренних механизмов СУБД
11.
Базовые понятия инфологической модели «Сущность-связь»• Сущность – это обобщающее смысловое понятие, конкретный
же представитель, относящийся к данной сущности, называется
экземпляром сущности
• Множество всех экземпляров некоторой сущности из данной
предметной области называется набором экземпляров
(например, набор студентов вуза).
• Каждая сущность имеет некоторые существенные признаки или
свойства, которые называются атрибутами сущности.
• Наборы атрибутов любых двух сущностей должны отличаться
хотя бы одним атрибутом – только в этом случае выполняется
основное свойство сущностей – различимость.
• Экземпляры одной сущности должны отличаться значениями
своих атрибутов (хотя бы одного) – это позволяет различать
экземпляры сущности
• Ключевой атрибут (ключ, первичный ключ) - атрибут
сущности, который однозначно идентифицирует экземпляр
сущности
12. Связи между сущностями
• В реальном мире сущности связаны между собой, т.е. междусущностями имеются связи или отношения.
Примеры
• Между сущностями Преподаватель и Студент имеется связь,
которую можно назвать Обучает
• Сущности Цех и Деталь связаны связью Выпускает
• Графически сущности и связи принято изображать на схемах
Цех
Выпускает
Деталь
• Типизация бинарных связей по характеру множественности:
– Один-к-одному (1:1)
– Один-ко-многим (1:n)
– Многие-ко-многим (m:n)
13. Связь один-к-одному
Определение• Связь между двумя сущностями называется простой
или связью один-к-одному (1:1), если любому
экземпляру одной сущности соответствует не более
одного экземпляра другой сущности.
Очевидно, такая связь является симметричной.
Пример
Пассажир
Имеет
1:1
Билет
14. Связь один-ко-многим
Определение• Связь между двумя сущностями называется
множественной связью один-ко-многим (1:n), если
некоторому экземпляру первой сущности может
соответствовать более одного экземпляра второй
сущности, но любому экземпляру второй сущности
соответствует не более одного экземпляра первой
Пример
Мать
Имеет
1:n
Ребенок
15. Связь многие-ко-многим
Определение• Связь между двумя сущностями называется
множественной связью многие-ко-многим (m:n),
если некоторому экземпляру одной сущности может
соответствовать более одного экземпляра другой
сущности.
Пример
Писатель
Написал
m:n
Книга
16. Даталогические модели
• Даталогическая модель или модельпредставления данных включает в себя:
– набор базовых структур,
– множество операций над этими структурами
– ограничения на данные
• Основные даталогические модели:
– Иерархическая
– Сетевая
– Реляционная
17. Иерархическая модель
Базовая структура – дерево; все данныепредставляются в виде деревьев
Первая СУБД - IMS (Information Management System),1968г.
Пример
Тип дерева
Отдел
Начальник
Сотрудник
Включает 3 типа сегментов
НомОтд
ТабНом
Фамилия
НазвОтд
Телефон
КолСотр
ТабНом
Фамилия
Зарплата
18. Иерархическая модель - Пример
Экземпляр типа дерева32
64
Сидоров
Плановый
283-446
5
72
Иванов
6300
74
Петров
7500
79
Орлова
8200
85
Семенов
7800
87
Котлова
8700
Фундаментальные свойства:
А) Любой экземпляр сегмента может иметь несколько
подчиненных, но не более одного предшественника.
В) Подчиненный экземпляр не может существовать без
своего предшественника
19. Неоднозначность иерархического представления
Вариант 1Предмет
Преподаватель
Студент
Вариант 2
Преподаватель
Предмет
Студент
20. Экземпляр типа дерева
Иванов112
Пр1
БазДан
Пр2
доцент
Физика
Пр3
Зач1
644
Зач2
128
Право
Орлов
Петров
С) У разных
экземпляров одного и
того же типа сегмента
может существовать
различное число
потомков
удовлетв
…
78
Фундаментальное
свойство:
отлично
Зач52
Зач54
Зач35
Смирнов
Сидоров
удовлетв
Перов
хорошо
отлично
…
Зач68
Зач85
Зач86
Котова
Клюев
удовлетв
удовлетв
Круглов
хорошо
…
Зач98
Павлов
хорошо
21.
Характерные особенности иерархической моделиЕстественно представляются связи 1:1 и 1:n
Сложности с представлением связи m:n
Необходимость введения искусственной иерархии
Необходимость введения «фиктивных» экземпляров сегментов
(добавление студента, пока ничего не изучающего или удаление
дисциплины может повлечь удаление изучавших ее студентов)
• Сложный низкоуровневый аппарат манипулирования данными
(работа с деревьями)
• Типичные запросы:
– найти указанный экземпляр дерева
– перейти от одного экземпляра дерева к другому
– перейти от одного типа сегмента к другому(от отдела к
сотруднику)
– обход дерева в порядке иерархии
– вставка нового экземпляра сегмента в указанное место
– удаление текущего экземпляра сегмента
• Недостаток: симметричные запросы
– найти всех студентов заданного преподавателя
– найти всех преподавателей заданного студента
обрабатываются ассиметрично
22. Сетевая модель
• Базовая структура – сеть (граф); все данныепредставляются в виде сети.
• Одна из первых СУБД - IDMS (Integrated Database Management
System, начало 70-х г.г. ХХ века, являющаяся развитием IDS
(Integrated Data Store)
• Обычно ограничиваются связями n:1, что сводит сеть к орграфу
Пример
Состоит
Сеть - орграф
Отдел
Сотрудник
Начальник
Работает
Возглавляется
Включает 3 типа записей
Состоит
НомОтд НазвОтд КолСотр
Возглавляется
ТабНом ФИО
Телефон
ТабНом ФИО
Работает
...
23. Типовые сетевые структуры
В сети выделяются типовые структуры – цепочкисотрудников каждого отдела
Сидоров
110
Иванов
...
111
Петров
...
112
31
Кадров
5
32
Плановый
3
33
Бухгалтерия 7
121
Котов
...
131
Котлов
...
141
Борина
...
122
Орлова
...
132
Клюева
...
142
Хромов
...
123
Петрова
...
133
Юдин
...
143
Васин
...
124
Ломов
...
144
Сокова
...
125
Синева
...
145
Лунин
...
146
Иванов
...
147
Орлова
...
...
24.
Характерные особенности сетевой моделиЕстественно представляется связь m:n
На физическом уровне реализуются в виде мультисписков
Как правило, не требуется поддержка ограничений целостности
Сложный низкоуровневый аппарат манипулирования данными
(работа с мультисписками)
• Типичные запросы:
– найти конкретную запись в наборе однотипных записей
(сотрудник Котлов)
– перейти от предка к первому потомку в некоторой связи (к
первому сотруднику отдела 32)
– перейти к следующему потомку в некоторой связи (от
Васина к Соковой)
– перейти от потомка к предку (от отдела к начальнику отдела)
– создать новый экземпляр записи
– удалить экземпляр записи
– модифицировать экземпляр записи
– включить экземпляр записи в связь (сотрудника в отдел)
– исключить экземпляр записи из связи (сотрудника из отдела)
25. Модель инвертированных таблиц
• СУБД Datacom/DB, конец 1960-х гг. и СУБД Adabas (ADAptableDAtabase System), 1971 г.
• Организация доступа к данным на основе инвертированных таблиц
используется практически во всех современных реляционных СУБД,
но в этих системах пользователи не имеют непосредственного
доступа к инвертированным таблицам (индексам)
• Базовой структурой данных является таблица, но в отличие от
реляционной модели пользователям видны и хранимые таблицы, и
пути доступа к ним
• Строки таблиц упорядочиваются системой в некоторой видимой
пользователям последовательности.
• Для каждой таблицы можно определить произвольное число ключей
поиска, для которых строятся индексы. Эти индексы автоматически
поддерживаются системой, но явно видны пользователям.
• Поддерживаются два класса операций:
– прямые поисковые операторы (например, установить адрес первой
записи таблицы по некоторому пути доступа);
– операторы, устанавливающие адрес записи при указании
относительной позиции от предыдущей записи по некоторому пути
доступа.
• Общие правила определения целостности БД отсутствуют. Вся
поддержка целостности данных возлагается на прикладную
программу.
26. Пример инвертированных таблиц
Исходная таблица Поставщики с даннымиКодПост
Имя
Рейтинг
Город
А1
Петров
20
Москва
А2
Котлов
10
Тула
А3
Соков
30
Тула
А4
Орлов
20
Москва
А5
Иванов
30
Орел
Инвертированные таблицы по атрибуту «Город»
Москва
А1
Орел
А5
Тула
А2
А4
А3
27.
Общие свойства дореляционных моделей• Некоторые из ранних систем используются даже в наше время,
накоплены громадные базы данных, и одной из актуальных
проблем информационных систем является использование этих
систем совместно с современными
• Все ранние системы не основывались на каких-либо
абстрактных моделях; понятие модели данных фактически
появилось только вместе с реляционным подходом
• Абстрактные представления ранних систем появились позже на
основе анализа и выявления общих признаков у различных
конкретных систем.
• В ранних системах доступ к базе данных производился на
уровне записей; пользователи осуществляли явную навигацию
в базе данных
• Навигационная природа ранних систем и доступ к данным на
уровне записей заставляли пользователей самих производить
всю оптимизацию доступа к базе данных, без какой-либо
поддержки системы
• Сложность использования, необходимость знаний о физической
организации данных
• Перегруженность пользовательского режима деталями
организации доступа к базе данных
28. Реляционная модель данных
Впервые основные понятия и ограниченияреляционной модели сформулировал
британский математик Эдгар Кодд в 1970 году
(Edgar F. Codd; 23.08.1923 – 18.04.2003)
Предложения Кодда были настолько эффективны для систем баз
данных, что за эту модель в 1981 году он был удостоен премии
Тьюринга «За фундаментальный вклад в теорию и практику
систем управления базами данных, в особенности за
реляционные базы данных»
Основной структурой данных в модели Кодда является отношение,
поэтому модель получила название реляционной (от
английского relation — отношение)
Достоинства реляционной модели:
– Простота и наглядность для пользователей представления данных
в виде плоских таблиц (отношений)
– Серьезное теоретическое обоснование и наличие строгого
математического аппарата манипулирования базовыми
структурами (реляционная алгебра и реляционное исчисление)
29.
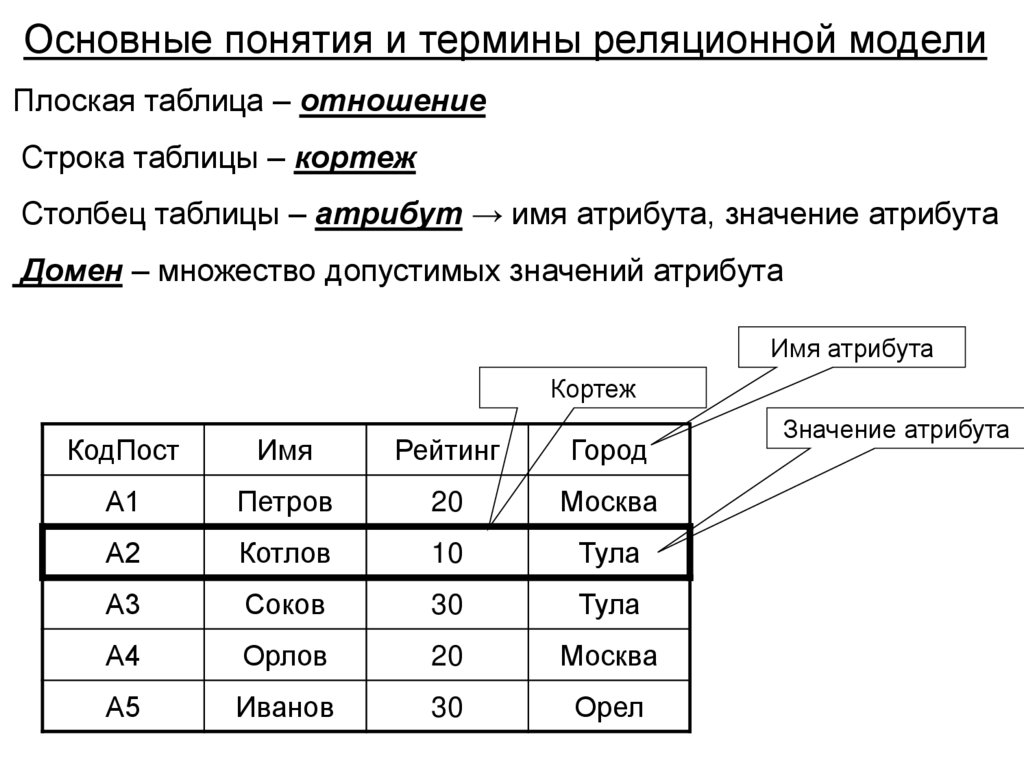
Основные понятия и термины реляционной моделиПлоская таблица – отношение
Строка таблицы – кортеж
Столбец таблицы – атрибут → имя атрибута, значение атрибута
Домен – множество допустимых значений атрибута
Имя атрибута
Кортеж
КодПост
Имя
Рейтинг
Город
А1
Петров
20
Москва
А2
Котлов
10
Тула
А3
Соков
30
Тула
А4
Орлов
20
Москва
А5
Иванов
30
Орел
Значение атрибута
30. Пример доменов отношения
Домен целыхчисел
Ключевой
атрибут
Домен имен
городов
Заголовок
отношения
Домен типов
самолетов
Номер
рейса
…
Пункт
прибытия
…
Тип автобуса
…
72
142
212
245
…
…
…
…
…
…
Сочи
Тула
Вятка
Орел
…
…
…
…
…
…
Yutong
КАВЗ-4238
КАВЗ-4238
НефАЗ-5299
…
…
…
…
…
…
45 72 84 128
142 154 212 236
245 320
Вятка Казань
Омск Орел
Сочи Тула Уфа
Имена
атрибутов
Тело
отношения
Yutong Hyundai
КАВЗ-4238 МАЗ-232
НефАЗ-5299
Понятие «Домен» схоже с понятием «Тип данных»
31. Сущности и связи в реляционной модели
СущностиПоставщики
Товар
КодПост
Имя
Рейтинг
Город
КодТов НаимТов Цена
Город
А1
Петров
20
Москва
В1
Мяч
5200
Тула
А2
Котлов
10
Тула
В2
Свитер
5100
Орел
А3
Соков
30
Тула
В3
Шапка
3300 Москва
А4
Орлов
20
Москва
В4
Сумка
4200 Москва
А5
Иванов
30
Орел
Связь
Поставки
КодПост КодТов КолТов
Связь между
сущностями
А1
В3
50
А1
В4
20
А2
В1
20
А3
В1
40
А4
В2
60
32.
Структурные понятия реляционной моделиСхема отношения - это именованное множество пар {имя
атрибута, имя домена}; если СУБД не поддерживает
понятие Домен, оно заменяется типом данных
Степень или "арность" схемы отношения - мощность
этого множества (количество атрибутов)
Кортеж, соответствующий данной схеме отношения, - это
множество пар {имя атрибута, значение}
Схема базы данных - это набор именованных схем
отношений
Отношение - это множество кортежей, соответствующих
одной схеме отношения
Кардинальное число отношения – это количество
кортежей этого отношения
Реляционная база данных - это множество всех
отношений-экземпляров, соответствующих схеме базы
данных
Все введенные понятия имеют простую интерпретацию
33. Сущности и связи в реляционной модели
ПоставщикиТовар
КодПост
Имя
Рейтинг
Город
А1
Петров
20
Москва
В1
Мяч
5200
Тула
А2
Котлов
10
Тула
В2
Свитер
5100
Орел
А3
Соков
30
Тула
В3
Шапка
3300 Москва
А4
Орлов
20
Москва
В4
Сумка
4200 Москва
А5
Иванов
30
Орел
КодТов НаимТов Цена
Схема отношения Поставщики
(КодПост, Имя, Рейтинг, Город)
Степень или "арность" = 4
Кардинальное число = 5
Кортеж отношения Поставщики:
(А2, Котлов, 10, Тула)
Схема базы данных:
Поставщики (КодПост, Имя, Рейтинг, Город)
Товар (КодТов, НаимТов, Цена, Город)
Поставки (КодПост, КодТов, КолТов)
Город
Поставки
КодПост КодТов КолТов
А1
В3
50
А1
В4
20
А2
В1
20
А3
В1
40
А4
В2
60
34.
Фундаментальные свойства отношенийОтсутствие кортежей-дубликатов
Из этого свойства вытекает наличие у каждого отношения первичного
ключа – минимального набора атрибутов, значения которых
однозначно идентифицируют кортеж отношения, понятие
первичного ключа исключительно важно в связи с определением
целостности базы данных
Отсутствие упорядоченности кортежей
Это свойство дает дополнительную гибкость СУБД при хранении баз
данных во внешней памяти и при выполнении запросов к базе
данных, например, можно потребовать сортировки
результирующей таблицы в соответствии со значениями некоторых
столбцов
Отсутствие упорядоченности атрибутов
Несмотря на это свойство в СУБД, как правило, в качестве неявного
порядка атрибутов используется их порядок в линейной форме
определения схемы отношения
Атомарность значений атрибутов
Это следует из определения домена как потенциального множества
значений простого типа данных, т.е. среди значений домена не
могут содержаться множества значений (отношения). Принято
говорить, что в реляционных базах данных допускаются только
нормализованные отношения или отношения, представленные в
первой нормальной форме (1НФ).
35.
• Согласно Кристоферу Дейтуреляционная модель состоит из трех
базовых частей, описывающих разные
аспекты реляционного подхода:
– структурной части,
– манипуляционной части,
– целостной части
• Структурный аспект - единственной структурой данных,
используемой в реляционных БД, является
нормализованное n-арное отношение
• Манипуляционный аспект модели рассматривает два
фундаментальных механизма манипулирования
отношениями в РБД:
– реляционная алгебра, которая базируется на
классической теории множеств
– реляционное исчисление, основанное на классическом
логическом аппарате исчисления предикатов первого
порядка
36. Понятие целостности в реляционной модели
Целостность сущности– любой кортеж любого отношения отличим от любого другого
кортежа этого отношения, т.е. в любом отношении должен
быть первичный ключ (простой или составной)
– гарантировано отсутствие в любом отношении кортежей с
одним и тем же значением первичного ключа
Первичный
ключ
ТабНом
ФИО
ЗарПл НомОтд
312
Иванов
12300
5
314
Петров
12800
6
324
Сидоров 32000
8
325
Орлова
14500
5
326
Котов
16200
8
330
Ванин
24500
5
37.
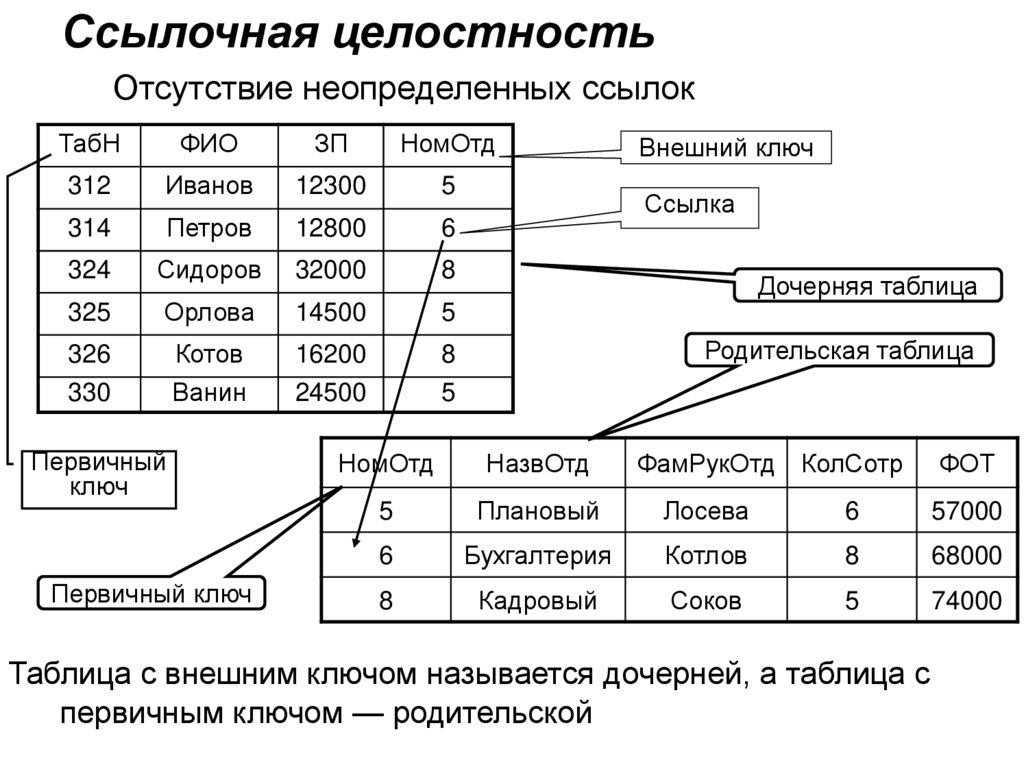
Ссылочная целостностьОтсутствие неопределенных ссылок
ТабН
ФИО
ЗП
НомОтд
312
Иванов
12300
5
314
Петров
12800
6
324
Сидоров
32000
8
325
Орлова
14500
5
326
Котов
16200
8
330
Ванин
24500
5
Первичный
ключ
Первичный ключ
Внешний ключ
Ссылка
Дочерняя таблица
Родительская таблица
НомОтд
НазвОтд
ФамРукОтд КолСотр
5
Плановый
Лосева
6
57000
6
Бухгалтерия
Котлов
8
68000
8
Кадровый
Соков
5
74000
Таблица с внешним ключом называется дочерней, а таблица с
первичным ключом — родительской
ФОТ
38.
• Целостность ссылок (ссылочная целостность)– Для каждого значения внешнего ключа в ссылающемся
(дочернем) отношении в отношении, на которое ведет
ссылка (родительском отношении), должен найтись кортеж с
таким же значением первичного ключа (либо значение
внешнего ключа должно быть неопределенным)
• Проблема удаления кортежей, на которые имеются
внешние ссылки
– Способы разрешения:
– Запрещается производить удаление кортежа, на который
существуют ссылки
– При удалении кортежа, на который имеются ссылки, во всех
ссылающихся кортежах значение внешнего ключа
автоматически становится неопределенным
– Из отношения, в котором имеются ссылки на удаляемый
кортеж, автоматически удаляются все ссылающиеся кортежи
(каскадное удаление)
Замечание: обычно в СУБД соответствующий режим удаления
кортежей можно указать явно или использовать режим по
умолчанию
39.
Механизмы манипулирования отношениямиДва базовых механизма: реляционная алгебра и реляционное исчисление
(исчисление доменов и исчисление предикатов)
Механизмы реляционной алгебры и реляционного исчисления
эквивалентны: для любого допустимого выражения реляционной
алгебры можно построить эквивалентную формулу реляционного
исчисления и наоборот
Выражения реляционной алгебры строятся на основе алгебраических
операций высокого уровня и имеют процедурную интерпретацию.
Формула реляционного исчисления только устанавливает условия,
которым должны удовлетворять кортежи результирующего отношения.
Поэтому языки реляционного исчисления являются декларативными
Замкнутость относительно понятия отношения: выражения реляционной
алгебры и формулы реляционного исчисления определяются над
отношениями и результатом вычисления также являются отношения
Большая выразительная мощность: очень сложные запросы к базе данных
могут быть выражены с помощью одного выражения реляционной
алгебры или одной формулы реляционного исчисления.
Язык манипулирования реляционными БД называется реляционно
полным, если любой запрос, записанный с помощью одного выражения
реляционной алгебры может быть выражен с помощью одного
оператора этого языка
Обычно (например, в SQL) язык реляционных баз данных основывается на
некоторой смеси алгебраических и логических конструкций.
40. Основы реляционной алгебры
Определение 1Пусть
D 1, D 2, D 3, D 4, … D n
– совокупность множеств, не обязательно различных
Декартовым произведением
D 1× D 2 × D 3 × D 4 × … × D n
этих множеств называется множество всех возможных
упорядоченных кортежей
(d1, d2, d3, d4, … dn ),
таких, что
d1 D 1 , d2 D 2 , d3 D 3 , d4 D 4 , … d n D n
Определение 2
Отношением R на множестве доменов
D 1, D 2, D 3, D 4, … D n
называется подмножество декартова произведения
D 1× D 2 × D 3 × D 4 × … × D n
этих доменов,
т.е. R D1× D2 × D3 × D4 × … × Dn
Здесь n – степень или арность отношения R,
а мощность множества R (количество кортежей) - кардинальное
число отношения R
41.
Операции реляционной алгебрыВ реляционную алгебру входит набор операций,
использующих отношения в качестве аргументовоперандов, и возвращающих отношения в качестве
результата.
Таким образом, операция реляционной алгебры может быть
представлена как функция отношений-аргументов:
R=f(R1, R2, R3, … Rn),
где R, R1, R2, R3, … Rn - отношения
Замкнутость реляционной алгебры:
реляционная алгебра является замкнутой - это означает, что
качестве аргументов в реляционные выражения можно
подставлять другие реляционные выражения, подходящие
по типу:
R=f(f1(R11, R12, R13, … R1n), f2(R21, R22, R23, … R2m), … fk(Rk1, Rk2, Rk3, … Rkl))
42.
Кодд рассматривал 8 операций реляционной алгебры, представленныхдвумя группами:
Теоретико-множественные операции:
– Объединение
– Пересечение
– Вычитание
– Декартово произведение
Специальные реляционные операции:
– Проекция
– Селекция (Выборка)
– Соединение
– Деление
Не все эти операции являются независимыми
К числу основных можно отнести 5 операций реляционной алгебры:
– Объединение
– Разность
– Декартово произведение
– Проекция
– Селекция
Дополнительная операция
– Соединение
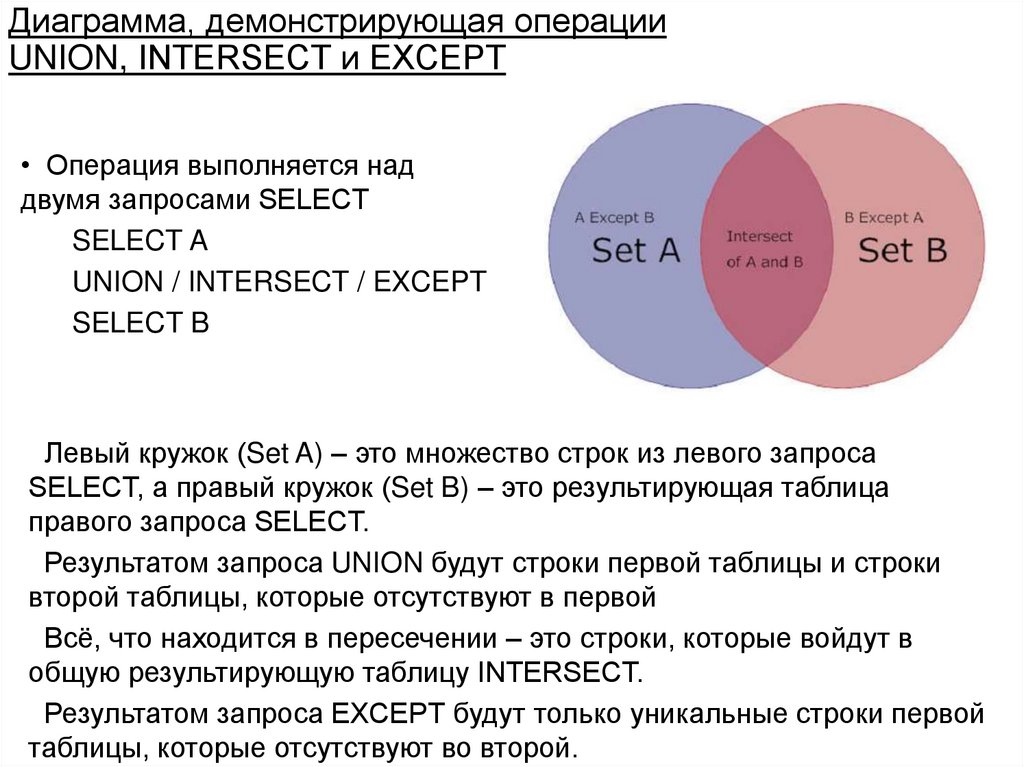
43. Объединение
ОпределениеПусть R и S – отношения одинаковой арности.
Объединением R U S называется множество кортежей,
принадлежащих либо R, либо S, либо обоим этим
отношениям
Операция выполняется над двумя совместимыми
таблицами R и S. В результате этой операции
строится новая таблица R U S, которая имеет тот же
состав атрибутов
• Пример
R: a b c
acd
ace
bad
S: a c d
bad
bae
RUS:abc
acd
ace
bad
bae
44. Пример объединения
Отношение RОтношение S
КодТов НаимТов Цена
Город
КодТов НаимТов Цена
Город
В1
Мяч
5200
Тула
В3
Шапка
3300 Москва
В2
Свитер
5100
Орел
В8
Мяч
3500
Тверь
В3
Шапка
3300 Москва
В9
Шайба
900
Орел
В4
Сумка
4200 Москва
Отношение R U S
КодТов НаимТов Цена
Условие: совместимость
отношений R и S
Город
В1
Мяч
5200
Тула
В2
Свитер
5100
Орел
В3
Шапка
3300 Москва
В4
Сумка
4200 Москва
В8
Мяч
3500
Тверь
В9
Шайба
900
Орел
45. Разность
Определение• Пусть R и S – отношения одинаковой арности. Разностью
R \ S называется множество кортежей, принадлежащих
R, но не принадлежащих S
• Операция выполняется над двумя совместимыми
таблицами R и S. В результате этой операции
строится новая таблица R \ S, которая как и
объединение имеет тот же состав атрибутов
• Пример
R: a b c
acd
ace
bad
S: a c d
bad
bae
R\S: abc
ace
Замечание: операция пересечения не является
независимой:
R ∩ S =R \ (R\ S)
46. Пример разности
Отношение RОтношение S
КодТов НаимТов Цена
Город
КодТов НаимТов Цена
Город
В1
Мяч
5200
Тула
В3
Шапка
3300 Москва
В2
Свитер
5100
Орел
В8
Мяч
3500
Тверь
В3
Шапка
3300 Москва
В9
Шайба
900
Орел
В4
Сумка
4200 Москва
КодТов НаимТов Цена
Город
Условие: совместимость
отношений R и S
Отношение R \ S
В1
Мяч
5200
Тула
В2
Свитер
5100
Орел
В4
Сумка
4200 Москва
Отношение R \ (R\ S)
КодТов НаимТов Цена
В3
Шапка
Город
3300 Москва
R∩S
47. Декартово произведение
Определение• Пусть R и S – отношения арности m и n соответственно. Декартовым
произведением R × S называется множество кортежей длиной m+n,
первые m компонентов которых образуют кортежи, принадлежащие R, а
последние n – кортежи, принадлежащие S
• Декартово произведение выполняется над двумя таблицами R и S,
которые имеют разный состав атрибутов: (r1, r2,..,rm) и (s1, s2, .. , sn).
• В результате операции образуется новая таблица R × S, которая
включает все атрибуты исходных таблиц (r1, r2,..,rm, s1, s2, .. , sn).
Результирующая таблица состоит из всевозможных сочетаний
кортежей исходных таблиц R и S. Число кортежей декартова
произведения равно произведению kr*ks количеств кортежей в
исходных таблицах.
• Пример
R: a b
ac
bd
S: b a c
dbe
R×S: abbac
acbac
bdbac
abdbe
acdbe
bddbe
48. Пример декартова произведения
Отношение RОтношение S
НомЗач
Имя
Город
КодДисц
С1
Иванов
Тула
Д1
С2
Петров
Орел
Д2
Физика
Зачет
С3
Котов
Москва
НаимДисц
Контроль
НаимДисц
Контроль
Математика Экзамен
Отношение R × S
НомЗач
Имя
Город
КодДисц
С1
Иванов
Тула
Д1
С1
Иванов
Тула
Д2
С2
Петров
Орел
Д1
С2
Петров
Орел
Д2
С3
Котов
Москва
Д1
С3
Котов
Москва
Д2
Математика Экзамен
Физика
Зачет
Математика Экзамен
Физика
Зачет
Математика Экзамен
Физика
Зачет
49. Проекция
• ПримерR: a b c
acd
ace
bad
¶1,3(R): a c
¶3,1(R): c a
ad
ae
bd
da
ea
db
Определение
• Пусть R – отношение арности k и пусть i1, i2, i3, … im –
множество различных целых чисел из диапазона от 1 до k.
• ¶ i , i , i , … i (R) – проекция R на атрибуты с номерами
1
2
3
m
• i1, i2, i3, … im есть множество кортежей a1, a2, a3, … am ,
• для каждого из которых существует кортеж b1, b2, b3, … bk из R,
такой, что aj= bij для j=1,2,…m.
• Алгоритм вычисления проекции: вычеркиваем лишние столбцы,
переупорядочиваем, исключаем дублирование кортежей
50. Пример проекции
Отношение RОтношение ¶НаимТов,Город(R)
КодТов НаимТов Цена
Город
НаимТов
Город
В1
Мяч
5200
Тула
Мяч
Тула
В2
Свитер
5100
Орел
Свитер
Орел
В3
Шапка
3300 Москва
Шапка
Москва
В4
Сумка
4200 Москва
Сумка
Москва
В8
Мяч
3500
Тула
Шайба
Орел
В9
Шайба
900
Орел
Мяч
Тверь
В10
Мяч
3500
Тверь
Замечание: Отношение-проекция содержит меньше кортежей, так
как после исключения из исходного отношения R ненужных
атрибутов образовались кортежи, которые дублируют друг друга
51. Селекция (Выбор)
Определение• Пусть R – отношение, а F – логическое выражение, в
которое могут входить константы, номера (имена)
атрибутов, знаки отношения, логические операции.
• Тогда селекцией σF(R) называется
• множество кортежей из R, для каждого из которых
выражение F принимает значение true.
• В результате операции селекции производится отбор
кортежей из исходной таблицы на основании некоторого
условия.
Результирующая таблица имеет ту же структуру, но
число ее кортежей будет меньше (или равно) числу
кортежей исходной таблицы
• Пример
R: a b
ac
bd
S: b a c
dbe
R×S: abbac
acbac
bdbac
abdbe
acdbe
bddbe
σ2>3 (R × S) : a c b a c
bdbac
52. Пример селекции
Отношение RОтношение σЦена>4000 (R)
КодТов НаимТов Цена
Город
КодТов НаимТов Цена
Город
В1
Мяч
5200
Тула
В1
Мяч
5200
Тула
В2
Свитер
5100
Орел
В2
Свитер
5100
Орел
В3
Шапка
3300 Москва
В4
Сумка
4200 Москва
В4
Сумка
4200 Москва
В8
Мяч
3500
Тула
В9
Шайба
900
Орел
В10
Мяч
3500
Тверь
Отношение-селекция содержит меньше кортежей, чем исходное
отношение R; отброшены кортежи не удовлетворяющие условию
отбора
53. Соединение (JOIN)
• Соединение выполняется для связывания данных двухотношений.
• Операция соединения формирует новое отношение,
структура которого представляет собой совокупность всех
атрибутов исходных таблиц
• В реляционной алгебре рассматривается 3 разновидности
операции соединения:
• Тэта-соединение
– Тета-соединение - это соединение с определенным
условием, в котором участвуют атрибуты каждого из
соединяемых отношений. Это условие означает что два
атрибута из разных отношений будут определенным образом
сравниваться. При сравнении может быть использована
любая из шести операций: =, , , , <=, >=
• Эквисоединение
– Эквисоединение – это разновидность тэта-соединения, в
котором при сравнении атрибутов используется операция «=»,
т.е атрибуты проверяются на совпадение значений
• Естественное соединение
– Естественное соединение – это соединение, которое строится
по условию совпадения одноименных атрибутов двух таблиц
54. Тэта-соединение
ОпределениеПусть R и S – отношения арности k1 и k2 соответственно.
Пусть i – целое число из диапазона от 1 до k1, j – целое число из
диапазона от 1 до k2 и пусть Θ – операция отношения.
Тогда соединением отношений R и S по атрибутам i и j называется
селекция декартова произведения этих отношений:
R ⊳⊲i Θ j S = σi Θ (k1+j)(R × S)
• Такое соединение называется Тэта-соедитением
• Для вычисления соединения сначала строится декартово
произведение R × S, а затем из полученного множества кортежей
отбрасываются те, у которых i-ый и (k1+j)-ый атрибуты не
удовлетворяют условию Θ
Пример
R: A B C S: D E
12 3
31
45 6
62
78 9
R × S : A B C D E R ⊳⊲ B<D S : A B C D
12 3 31 E
12 3 31
12 3 62
12 3 62
45 6 31
45 6 62
45 6 62
78 9 31
78 9 62
55. Эквисоединение
ОпределениеПусть R и S – отношения арности k1 и k2 соответственно.
Пусть i – целое число из диапазона от 1 до k1.
Тогда эквисоединением отношений R и S по атрибутам i и j называется
селекция декартова произведения этих отношений:
R ⊳⊲ i = j S = σi = (k1+j)(R × S)
• Эквисоединение является частным случаем тэта-соединения
• При построении эквисоединения также строится декартово
произведение R × S, а затем из полученного множества кортежей
отбрасываются те, у которых значения i-го и (k1+j)-го атрибутов не
совпадают
Пример
R: A B C
12 3
45 6
78 9
S: D E
31
62
R×S: ABCDE
12 3 31
12 3 62
45 6 31
45 6 62
78 9 31
78 9 62
R ⊳⊲ C=DS : A B C D E
12 3 31
45 6 62
56. Естественное соединение
Операция естественного соединения связывает два отношения, у
которых одноименные атрибуты имеют равные значения.
Определение
Пусть в отношениях R и S имеются одноименные атрибуты (имена некоторых
атрибутов отношения R совпадают с именами атрибутов отношения S).
Тогда естественным соединением R ⊳⊲ S называется соединение, в котором
оставлены только те кортежи декартова произведения R×S, у которых
значения одноименных атрибутов совпадают.
• Замечание. В полученном отношении R ⊳⊲ S одноименные атрибуты не
дублируются, поэтому, если m – арность отношения R, а n – арность
отношения S и k атрибутов у этих отношений имеют одинаковые имена
(очевидно, k<min(m,n)), то арность естественного соединения R ⊳⊲ S будет
m+n-k.
Пример
R: A B C
a bc
d bc
b bf
c ad
S: BCD
b c d
b c e
a d b
R ⊳⊲ S : A B C D
a bc d
a bc e
d bc d
d bc e
c ad b
57. Пример естественного соединения
Отношение RОтношение S
КодПост
Имя
Рейтинг
Город
А1
Петров
20
Москва
В1
Мяч
5200
Тула
А2
Котлов
10
Тула
В2
Свитер
5100
Орел
А3
Соков
30
Тула
В3
Шапка
3300 Москва
А4
Орлов
20
Москва
В4
Сумка
4200 Москва
А5
Иванов
30
Орел
КодПост КодТов
Имя
КодТов НаимТов Цена
Город
Отношение R ⊳⊲ S
Рейтинг НаимТов
Цена
Город
А1
В3
Петров
20
Шапка
3300
Москва
А1
В4
Петров
20
Сумка
4200
Москва
А2
В1
Котлов
10
Мяч
5200
Тула
А3
В1
Соков
30
Мяч
5200
Тула
А4
В3
Орлов
20
Шапка
3300
Москва
А4
В4
Орлов
20
Сумка
4200
Москва
А5
В2
Иванов
30
Свитер
5100
Орел
58. Общие сведения о реляционном исчислении
• Реляционное исчисление основывается на механизме исчисленияпредикатов первого порядка.
• Язык реляционного исчисления – это не процедурный язык,
поскольку его средствами можно выразить все, что необходимо и
необязательно указывать, как это получить.
• Выражение в реляционном исчислении описывает лишь свойства
желаемого результата, фактически не указывая, как его получить.
• Основными понятиями исчисления являются
– понятие переменной с некоторой областью допустимых
значений
– понятие правильно построенной формулы (WFF – well
formulated formula), составленной из предикатов, переменных и
кванторов
• В зависимости от области определения переменной различают
исчисление кортежей и исчисление доменов.
• В исчислении кортежей областью определения переменных
являются отношения базы данных, т.е. допустимым значением
каждой переменной является кортеж некоторого отношения.
• В исчислении доменов областью определения переменных
являются домены, на которых определены атрибуты отношений
базы данных, то есть допустимым значением каждой переменной
является значение некоторого домена
59. Проектирование реляционных баз данных
• Задачи проектирования– Возможность хранения всех необходимых данных в базе
данных.
– Исключение избыточного дублирования данных.
– Сведения числа данных, хранимых в базе данных, к
минимуму.
– Нормализация отношений для предотвращения аномалий
операций вставки, обновления, удаления.
– Нормализация – декомпозиция (разбиение) отношений.
• При манипулировании ненормализованными
отношениями потенциально могут возникнуть три вида
аномалий:
– Аномалия вставки (неопределенное значение атрибута)
– Аномалия обновления (нарушение целостности - логическая
противоречивость данных).
– Аномалия удаления (побочный эффект – удаление нужной
информации)
60.
Пример. Куратор студенческой группы постоянноконтролирует успеваемость студентов, проживающих в
общежитии
Ненормализованная таблица Куратор
НомЗач
Тел
еф
он
Дисци
пли
на
Сем
ес
тр
Оце
нк
а
1
3
382
Матем
ати
ка
БД
1
3
Физик
а
2
4
Матем
ати
ка
2
3
Матем
2
ати
3462
Ива
314
368
ка форме
Первый шагно
– приведение к первой нормальной
4
3215
Имя
Пет
ро
в
Ком
на
та
212
61. Нормализованное отношение Куратор
НомЗачИмя
Ком
на
та
Тел
еф
он
Дисци
плин
а
3215
Петр
ов
212
382
Матем
атик
а
1
3
3215
Петр
ов
212
382
БД
1
3
3215
Петр
ов
212
382
Физик
а
2
4
3215
Петр
ов
212
382
Матем
атик
а
2
3
3462
Сем Оце
ес
н
тр
к
а
Иван
314
368
Матем
2
ов
атик
Отношение находится в первой нормальной форме (1НФ) –
а
значения всех атрибутов атомарные
3462 Иван
314
368
Алгеб
3
4
5
62.
Аномалии вставки, обновления и удаления в отношенииКуратор
• При манипулировании данными в отношении Куратор
могут возникнуть:
– Аномалия вставки – появился студент, который еще не имеет
оценки по одной из дисциплин (не закончил изучение) –
неопределенное значение атрибута Оценка
– Аномалия обновления – Петров сообщил, что у него изменился
телефон, новый номер телефона занесли в 4 строки с его
фамилией, а Смирнов не сообщил – нарушена целостность:
несовпадение номера телефона в комнате 212).
– Аномалия удаления – Алексеев завершил изучение немецкого
языка и последний кортеж удален из отношения – при этом
удалена и информация о телефоне в комнате 325, и о том, в какой
комнате живет Алексеев
• Для того, чтобы избежать этих аномалий при
манипулировании данными необходим более высокий
уровень нормализации базы данных
• Нормализация отношений выполняется посредством их
декомпозиции (разбиения)
63.
Функциональная зависимость• В основе нормализации лежит понятие функциональной
зависимости
• Определение
• Пусть A и B –атрибуты. Если каждому значению атрибута A в
любой момент времени соответствует одно значение атрибута
B, то говорят, что B функционально зависит от A.
• Функциональная зависимость изображается так:
A→ B
или графически
A
B
Наличие функциональной зависимости означает, что в любых
кортежах, в которых имеются атрибуты A и B, одинаковым
значениям атрибута A соответствуют одинаковые значения
атрибута B.
Замечание A и B могут быть группами атрибутов (составными
атрибутами)
64. Функциональные зависимости отношения Куратор
ИмяНомер
НомЗач
НомЗач → Имя
НомЗач → Комната
НомЗач → Телефон
Комната → Телефон
Телефон → Комната
НомЗач, Дисциплина, Семестр → Оценка
Телефон
Комната
Дисциплина
Оценка
Семестр
Атрибут Оценка зависит только от составного
атрибута НомЗач, Дисциплина, Семестр.
Зависимости от любого из возможных
сочетаний этих трех атрибутов нет.
Определение. Функциональная зависимость
A→ B называется полной функциональной
зависимостью, если атрибут B не зависит ни
от какой части составного атрибута A.
Если A – не составной, зависимость полная.
65.
Нормализация отношений• Пример 1
• ПрепДисц (ТабНом, КодДисц, НаимДисц, Час, НомАуд, ФИО,
Должность, Оклад, Кафедра, Телефон)
• Отношение ПрепДисц находится в первой нормальной форме (1НФ)
Функциональные зависимости
ТабНом → ФИО
ТабНом → Должность
ТабНом → Кафедра
ТабНом → Телефон
КодДисц → НаимДисц
КодДисц → Час
Должность → Оклад
Кафедра → Телефон
Телефон → Кафедра
ТабНом, КодДисц → НомАуд
• Определение
Отношение находится во второй нормальной форме (2НФ), если оно
находится в первой нормальной форме, и все его атрибуты
функционально полно зависят от первичного ключа
• Вывод: Отношение ПрепДисц не находится в 2НФ
66.
Сведение отношения ко второй нормальной форме (2НФ)• Пример 1 - сведение отношения к 2НФ (устранение частичных
функциональных зависимостей)
ПрепДисц (ТабНом, КодДисц, НомАуд)
Преподаватель (ТабНом, ФИО, Должность, Оклад, Кафедра,
Телефон)
Дисциплина (КодДисц, НаимДисц, Час)
• Замечание. Если первичный ключ является простым, то 2НФ
обеспечивается автоматически
Определение
• Если А В и В С и А С, то А С называется транзитивной
функциональной зависимостью
Определение
• Отношение находится в третьей нормальной форме (3НФ), если оно
находится во 2НФ, и отсутствуют транзитивные зависимости
неключевых атрибутов от первичного ключа
• Вывод: Отношение Преподаватель не находится в 3НФ, т.к.
ТабНом → Должность → Оклад
ТабНом → Кафедра → Телефон
67.
Сведение отношения к третьей нормальной форме (3НФ)• Пример - сведение отношения к 3НФ (исключение транзитивных
зависимостей)
Преподаватель (ТабНом, ФИО, Должность, Кафедра)
ТабНом → ФИО
ТабНом → Должность
ТабНом → Кафедра
Должности (Должность, Оклад)
Должность → Оклад
Кафедра(Кафедра, Телефон)
Кафедра → Телефон
Дисциплина (КодДисц, НаимДисц, Час)
КодДисц → НаимДисц
КодДисц → Час
ПрепДисц (ТабНом, КодДисц, НомАуд)
ТабНом, КодДисц → НомАуд
• Каждый следующий уровень нормализации - это предыдущий уровень
плюс дополнительные требования.
68.
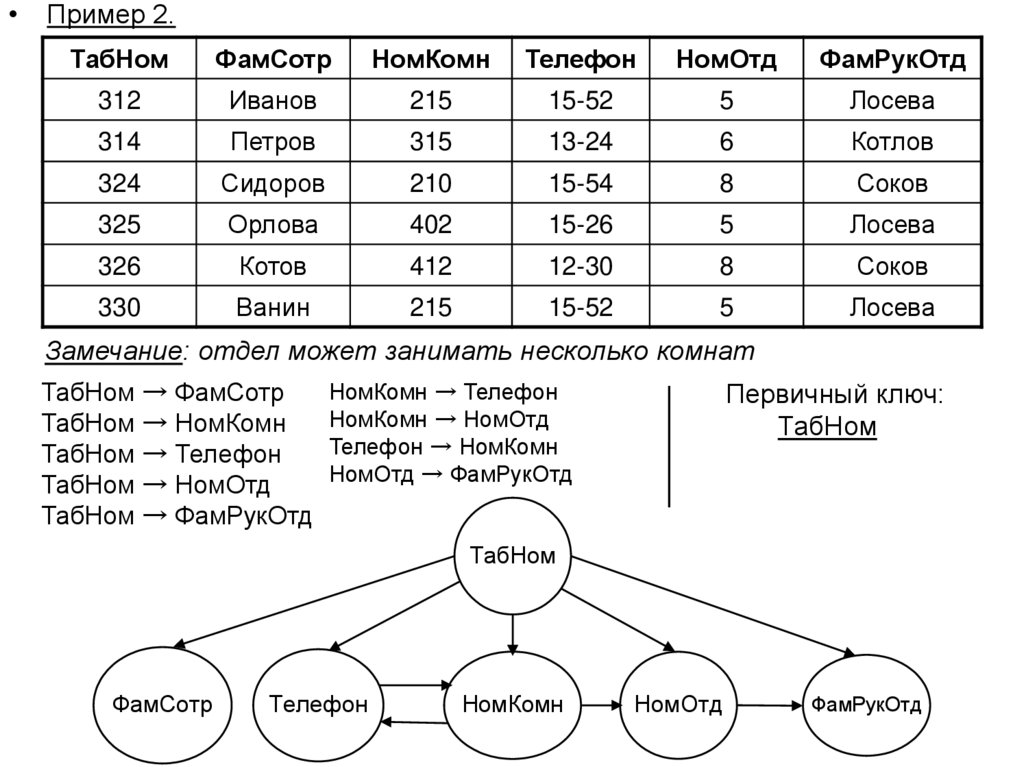
Пример 2.
ТабНом
ФамСотр
НомКомн
Телефон
НомОтд
ФамРукОтд
312
Иванов
215
15-52
5
Лосева
314
Петров
315
13-24
6
Котлов
324
Сидоров
210
15-54
8
Соков
325
Орлова
402
15-26
5
Лосева
326
Котов
412
12-30
8
Соков
330
Ванин
215
15-52
5
Лосева
Замечание: отдел может занимать несколько комнат
НомКомн → Телефон
ТабНом → ФамСотр
НомКомн → НомОтд
ТабНом → НомКомн
Телефон → НомКомн
ТабНом → Телефон
НомОтд → ФамРукОтд
ТабНом → НомОтд
ТабНом → ФамРукОтд
Первичный ключ:
ТабНом
ТабНом
ФамСотр
Телефон
НомКомн
НомОтд
ФамРукОтд
69.
Нормализация отношения Сотрудники• Отношение Сотрудники находится в первой нормальной форме (1НФ):
Сотрудники (ТабНом, ФамСотр, НомКомн, Телефон, НомОтд, ФамРукОтд)
ТабНом → ФамСотр
ТабНом → НомКомн
ТабНом → Телефон
ТабНом → НомОтд
ТабНом → ФамРукОтд
• Вывод: все атрибуты функционально полно зависят от первичного
ключа, отношение Сотрудники находится в 2НФ
• Транзитивные зависимости:
ТабНом → НомКомн → Телефон
ТабНом → НомКомн → НомОтд
ТабНом → НомОтд → ФамРукОтд ТабНом → Телефон → НомКомн
• Нормализация (декомпозиция) схемы до 3НФ:
Сотрудники (ТабНом, ФамСотр, НомКомн)
Комнаты (НомКомн, Телефон, НомОтд)
Отделы (НомОтд, НазвОтд, ФамРукОтд, …)
70.
Нормальная форма Бойса-Кодда• 3НФ является достаточно сильным уровнем нормализации,
которого во многих БД достаточно, однако есть и более
сильные уровни нормализации.
• На практике следует выполнять нормализацию до уровня
усиленной третьей нормальной формы или нормальной
формы Бойса-Кодда, которая практически гарантирует
отсутствие аномалий.
• Определение. Атрибут или набор атрибутов, который может
быть использован в данном отношении в качестве первичного
ключа, называется возможным ключом
• Определение. Если имеет место функциональная зависимость
• A → B, причем ни от какого подмножества A атрибут B
функционально не зависит (полная функциональная
зависимость), то атрибут A называется детерминантом
атрибута B.
• Определение. Отношение находится в нормальной форме
Бойса-Кодда (НФБК, BCNF) тогда и только тогда, когда каждый
детерминант отношения является возможным ключом.
• Замечание. НФБК называют еще усиленной третьей
нормальной формой.
• Кодд показал, что сведение всех отношений базы данных к
НФБК устраняет большинство аномалий.
71.
Анализ функциональных зависимостей отношения КураторФункциональные зависимости:
НомЗач → Имя
НомЗач → Комната
НомЗач → Телефон
Комната → Телефон
Телефон → Комната
НомЗач, Дисциплина, Семестр → Оценка
• Возможный ключ:
• Детерминанты:
• НомЗач, Дисциплина, Семестр
• НомЗач
• Комната
• Телефон
• НомЗач, Дисциплина, Семестр
Вывод: Отношение Куратор не находится в НФБК
Общая методика декомпозиции
Разработка отношения в 1НФ
Определение и запись всех функциональных зависимостей
Если не все детерминанты отношения являются возможными
ключами, разбиение (декомпозиция) на два отношения
4.
Повторение шагов 2 и 3 для каждого из двух полученных в
результате декомпозиции отношений
Проблема: Функциональных зависимостей много – как выполнять и с
чего начинать декомпозицию?
1.
2.
3.
72.
Решение проблемы: Декомпозиция универсального отношениявыполняется в соответствии с Правилом декомпозиции без
потерь
Правило декомпозиции (декомпозиция без потерь):
– Пусть R(A, B, C, D, E, …) – отношение, не находящееся в
нормальной форме Бойса-Кодда,
–
и пусть имеет место функциональная зависимость C → D,
причем C не является возможным ключом отношения R.
–
Тогда отношение R разбивается на 2 отношения: R1(A, B,
C, E, …) и R2(C, D):
R1(A, B, C, E, …)
R(A, B, C, D, E, …)
R2(C, D)
Очевидно, отношения R1 и R2 –это проекции отношения R на
соответствующие атрибуты.
Это правило называется декомпозицией без потерь при
естественном соединении.
73.
Исходное отношениеR: x y z
1 2 3
3 2 6
5 4 2
Исходное отношение
S: x y z
1 2 3
3 2 3
5 4 2
Декомпозиция на R1(x,y) и R2(y,z)
R1: x y
R2: y z
1 2
2 3
3 2
2 6
5 4
4 2
Декомпозиция на S1(x,y) и S2(y,z)
S1: x y
S2: y z
1 2
2 3
3 2
4 2
5 4
Естественное соединение
R1 ⊳⊲ R2: x y z
1 2 3
1 2 6
3 2 3
3 2 6
5 4 2
Естественное соединение
S1 ⊳⊲ S2: x y z
1 2 3
3 2 3
5 4 2
74. Пример: декомпозиция без потерь
Декомпозиция с потерямиДекомпозиция без потерь
Декомпозиция по ФЗ y→z
R1: x y
R2: y z
1 2
2 3
3 2
2 6
5 4
4 2
Декомпозиция по ФЗ y→z
R1: x y
R2: y z
1 2
2 3
3 2
4 2
5 4
Естественное соединение
R1 ►◄ R2: x y z
1 2 3
1 2 6
3 2 3
3 2 6
5 4 2
Естественное соединение
R1 ►◄ R2: x y z
1 2 3
3 2 3
5 4 2
• В отношении R нет
функциональной зависимости
y→z
• В отношении R есть
функциональная зависимость
y→z
Исходное отношение
R: x y z
1 2 3
3 2 6
5 4 2
Исходное отношение
R: x y z
1 2 3
3 2 3
5 4 2
75.
Правило транзитивной цепочки• В отношении Куратор атрибуты НомЗач, Комната, Телефон детерминанты, но не возможные ключи
• 5 вариантов выбора ФЗ для декомпозиции:
НомЗач → Имя
НомЗач → Комната
НомЗач → Телефон
Комната → Телефон
Телефон → Комната
• Правило транзитивной цепочки (правого крайнего):
– Если в отношении имеются функциональные зависимости,
которые образуют транзитивную цепочку A → B → C,
начинать декомпозицию надо с выделения в отдельное
отношение правой крайней функциональной зависимости в
этой цепочке
• В отношении Куратор можно выделить транзитивную цепочку
НомЗач → Комната → Телефон,
• поэтому на первом этапе разобьем его на 2 отношения,
выделив функциональную зависимость Комната → Телефон:
R1 (НомЗач, Имя, Комната,Дисциплина, Семестр, Оценка),
R2(Комната, Телефон)
76. Анализ функциональных зависимостей в R1 и R2
НомерИмя
НомЗач
Комната
Дисциплина
Оценка
• Отношение R1
• Детерминанты
НомЗач
НомЗач, Дисциплина, Семестр
• Возможный ключ
НомЗач, Дисциплина, Семестр
• Отношение не находится в НФБК
Семестр
• Отношение R2
Комната
Телефон
• Детерминанты
Комната
Телефон
• Возможные ключи
Комната
Телефон
• Отношение находится в НФБК
77.
Декомпозиция отношения R1• Функциональные зависимости
НомЗач → Имя и НомЗач → Комната
Можно рассматривать как единую ФЗ:
НомЗач → Имя, Комната
• Выполним декомпозицию отношения R1 по этой функциональной
зависимости на 2 отношения по правилу декомпозиции:
R3(НомЗач, Дисциплина, Семестр, Оценка)
R4(НомЗач, Имя, Комната)
• R3 и R4 добавляются к ранее полученному отношению R2,
находящемуся в НФБК
Анализ отношений R3 и R4:
• Отношение R3:
Детерминант и Возможный ключ - НомЗач, Дисциплина, Семестр
• Отношение R4:
Детерминант и Возможный ключ - НомЗач
• Отношения R3 и R4 находятся в НФБК
• Отношение Куратор сведено к 3 отношениям R2, R3, R4, каждое из
которых находится в НФБК и является проекцией отношения R:
R2= ¶Комната,Телефон(R)
R3= ¶НомЗач,Дисциплина,Семестр,Оценка(R)
R4= ¶НомЗач,Имя,Комната(R)
78. Нормализованные отношения БД Куратор
Отношение R3Отношение R4
НомЗач
Дисци
плин
а
Сем
ес
тр
Оце
нк
а
НомЗач
Имя
Ком
на
та
3215
Матем
атик
а
1
3
3215
Петр
ов
212
3462
314
3215
БД
1
3
Иван
ов
3215
Физик
а
2
4
3215
Матем
атик
а
2
3
3462
Матем
атик
а
2
4
Алгеб
3
3462
3567
СмирR2 212
Отношение
но
Комн вТеле
ата
фон
4756
Алек
325
212
се 382
ев 368
314
325
5
316
79.
Замечания к методу декомпозиции• Замечание1. Пусть имеется транзитивная цепочка
A → B → C.
• Согласно сформулированному правилу начинать декомпозицию
надо с ФЗ B → C.
• Рассмотрим на примере, к чему может привести несоблюдение
этого правила.
• Пример Рассмотрим отношение R(A, B, C), где A – ключевой
атрибут и имеется транзитивная функциональная зависимость
A → B → C.
• Согласно правилу транзитивной цепочки при декомпозиции на 2
отношения в отдельное отношение должна выделяться правая
ФЗ: B → C.
• Вопреки этому правилу выполним декомпозицию, выделив
левую ФЗ A → B.
• При этом отношение R разобьется на 2 отношения:
• R1(A, C) и R2(A,B).
Нетрудно видеть, что здесь утеряна ФЗ B → C.
80.
• Замечание 2. Пусть имеется отношение R(A, B, C) с двумяфункциональными зависимостями A → B и C → B, т.е. в
котором 2 детерминанта и один возможный ключ:
Детерминанты: A и C
Возможный ключ: A, C
• Если действовать обычным способом, выделив,
например, функциональную зависимость A→ B,
• отношение R разобьется на
– R1(A, C) и R2(A, B)
• При этом исчезла функциональная зависимость C → B
• Здесь необходимо правило, которое разобьет отношение
R на
– R1(A, B) и R2(C, B)
• Метод синтеза: Все функциональные зависимости с
одинаковыми детерминантами надо выделять в группы и
каждой группе отводить отдельное отношение
81.
Избыточные функциональные зависимости• Рассмотренная методика позволяет получить набор
отношений базы данных, находящихся в нормальной
форме Бойса-Кодда.
• Однако процесс декомпозиции может быть существенно
осложнен присутствием в рассматриваемом наборе
функциональных зависимостей для ненормализованного
отношения избыточных функциональных зависимостей.
• Определение.
• Функциональная зависимость, которая может быть
получена на основе других функциональных
зависимостей, называется избыточной.
• При проектировании базы данных прежде, чем
приступить к декомпозиции, необходимо устранить
избыточные функциональные зависимости. Для этого
используются так называемые правила вывода.
82.
Правила вывода• Строгий подход к вопросу избыточности в наборе функциональных
зависимостей включает в себя шесть правил вывода,
• три из которых:
– рефлексивность,
– транзитивность,
– пополнение
• вводятся как аксиомы Армстронга,
• а три остальные:
– объединение,
– декомпозиция,
– псевдотранзитивность
• выводятся из этих аксиом.
• Практически наибольший интерес представляют пять правил
вывода:
– транзитивность,
– пополнение
– объединение,
– декомпозиция,
– псевдотранзитивность
которые и рассмотрим
83. Удаление избыточных функциональных зависимостей
• Правило 1. Транзитивность• Если наряду с A → B и B → C в набор функциональных
зависимостей входит и транзитивная функциональная
зависимость A → C, то она избыточна.
• Пример
A
C
B
E
A
C
E
A
A→B
A→B
A→C
A→C
A→C
A
B→C
B→E
B→E
C→E
C→E
C
E
A→B
A→E
B→C
E
B
B
A→B
C
B→C
B→C
C→E
C→E
B
84.
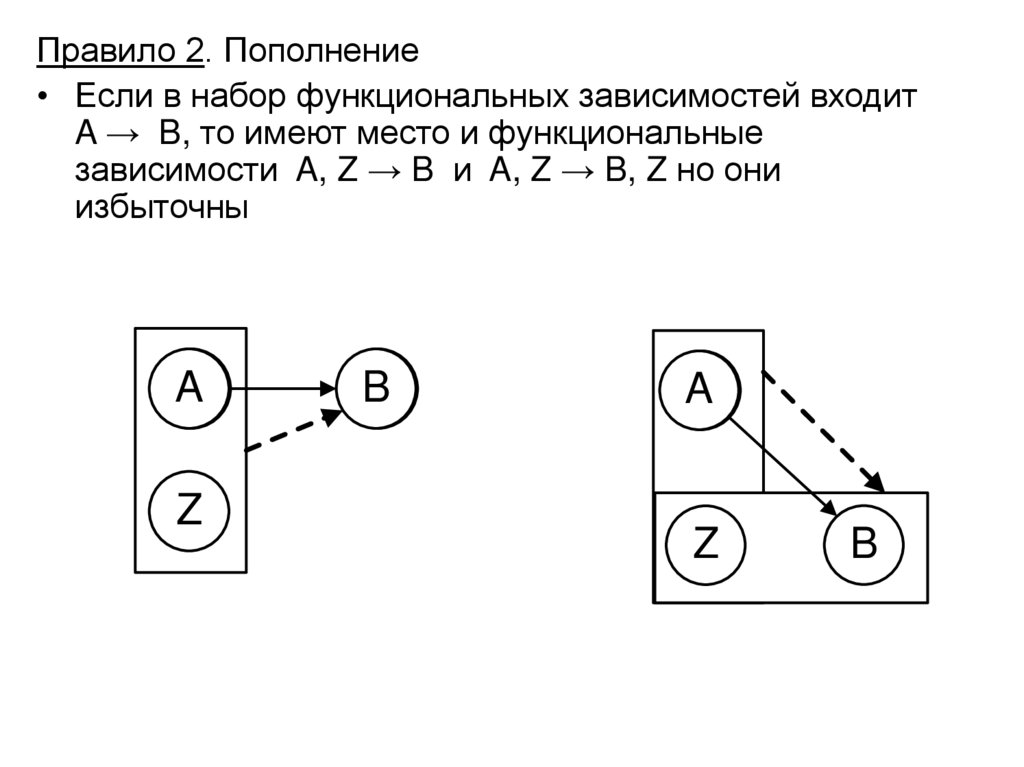
Правило 2. Пополнение• Если в набор функциональных зависимостей входит
A → B, то имеют место и функциональные
зависимости A, Z → B и A, Z → B, Z но они
избыточны
A
Z
B
A
Z
B
85.
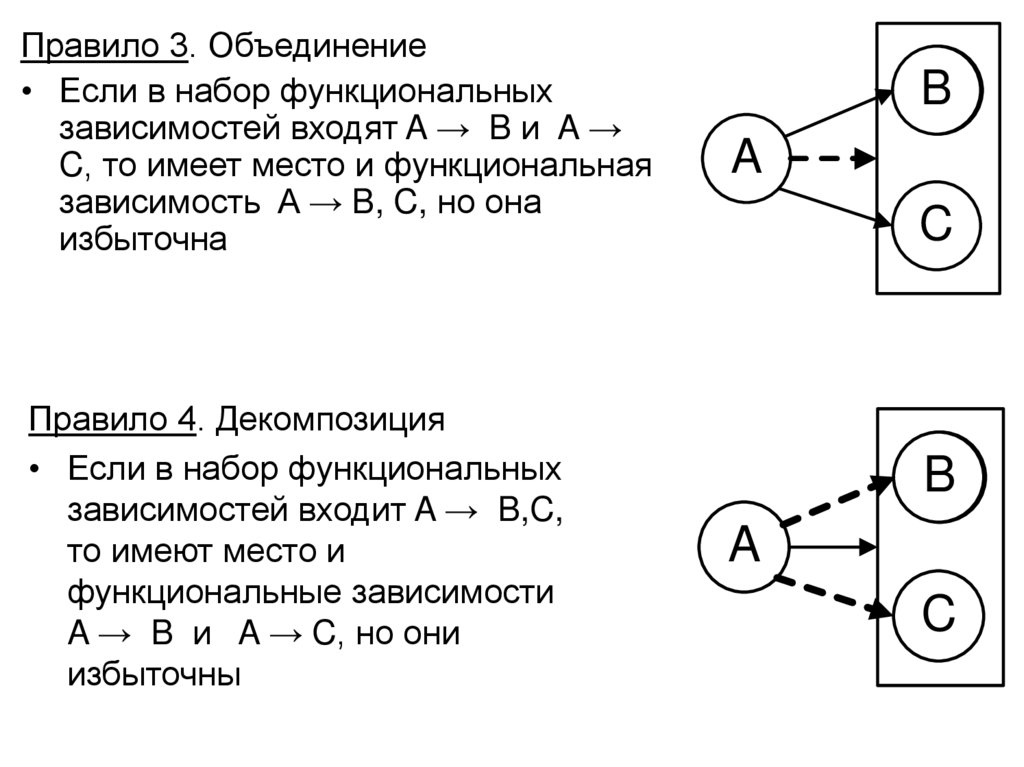
Правило 3. Объединение• Если в набор функциональных
зависимостей входят A → B и A →
C, то имеет место и функциональная
зависимость A → B, C, но она
избыточна
Правило 4. Декомпозиция
• Если в набор функциональных
зависимостей входит A → B,C,
то имеют место и
функциональные зависимости
A → B и A → C, но они
избыточны
B
A
A
C
B
A
A
C
86.
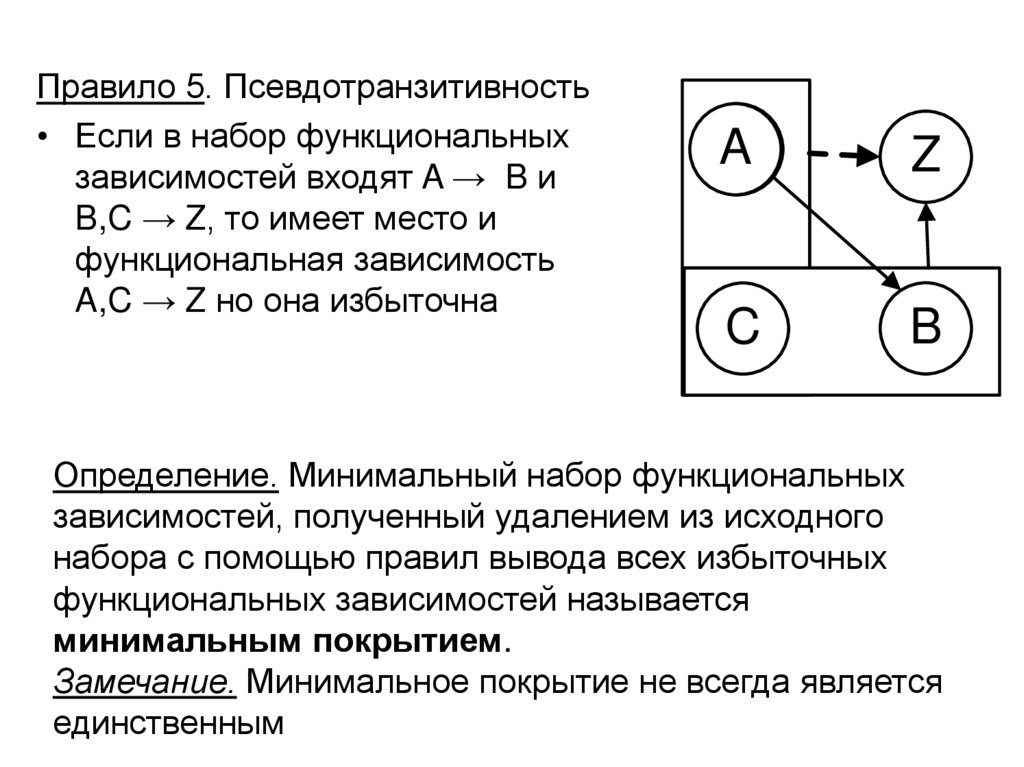
Правило 5. Псевдотранзитивность• Если в набор функциональных
зависимостей входят A → B и
B,C → Z, то имеет место и
функциональная зависимость
A,C → Z но она избыточна
A
Z
C
B
Определение. Минимальный набор функциональных
зависимостей, полученный удалением из исходного
набора с помощью правил вывода всех избыточных
функциональных зависимостей называется
минимальным покрытием.
Замечание. Минимальное покрытие не всегда является
единственным
87. Пример удаления избыточных функциональных зависимостей
AB
A
K
C
D
B
Пополнение
A
B
A
K
C
D
B
Транзитивность
A → B,C
A→D
A→K
K→C
B→D
B,C →
D
A→B
A→C
A→D
A→K
K→C
B→D
A
B
A
K
C
D
B
Декомпозиция
A
B
A
K
C
D
B
A → B,C
A→D
A→K
K→C
B→D
A→B
A→K
K→C
B→D
Минимальное покрытие
88.
• Уточненная методика проектирования БД наоснове анализа функциональных зависимостей:
• 1. Построение универсальных отношений
• 2. Определение всех функциональных зависимостей
• 3. Удаление всех избыточных ФЗ с помощью правил
вывода и получение минимального покрытия
• 4. Декомпозиция универсальных отношений в НФБК
• 5. Если может быть получено не одно минимальное
покрытие, выбор лучшего варианта
• 6. Проверка условия: набор функциональных
зависимостей для всех отношений совпадает с
минимальным покрытием
• 7. Удаление избыточных отношений.
• Замечание: Отношение R1 избыточно, если все его
атрибуты целиком входят в некоторое отношение R или в
некоторое соединение из других отношений.
89. Более высокие уровни нормализации
• Основные свойства нормальных форм:– каждая следующая нормальная форма в некотором
смысле лучше предыдущей;
– при переходе к следующей нормальной форме
свойства предыдущих нормальных форм
сохраняются.
• В основе процесса проектирования лежит метод
нормализации - декомпозиция отношения, находящегося
в предыдущей нормальной форме, в два или более
отношений, удовлетворяющих требованиям следующей
нормальной формы.
• Наиболее важные на практике нормальные формы
отношений основываются на фундаментальном в теории
реляционных баз данных понятии функциональной
зависимости.
• В следующих нормальных формах (4НФ и 5НФ)
учитываются не только функциональные, но и
многозначные зависимости между атрибутами
отношений.
90.
Многозначные зависимости и четвертая нормальная форма• Четвертая нормальная форма рассматривает отношения, в которых
имеются повторяющиеся наборы данных. Декомпозиция, основанная на
функциональных зависимостях, не приводит к исключению такой
избыточности. В этом случае используют декомпозицию, основанную на
многозначных зависимостях.
• Многозначная зависимость может рассматриваться как обобщение
функциональной зависимости основанное на соответствии между
множествами значений атрибутов.
• Пример (отношение моделирует сдачу экзаменов на сессии)
• В отношении R хранятся данные о предстоящих студентам в сессию
экзаменах
R(НомЗач, Группа, Дисциплина)
Детерминант - НомЗач, Группа, Дисциплина
Возможный ключ - НомЗач, Группа, Дисциплина
• Отношение R находится в НФБК, однако, аномалии возможны:
– мы не сможем хранить информацию о новой группе и перечне
дисциплин, которые должна пройти группа, пока в нее не будут
зачислены студенты
– если мы добавляем студента в уже существующую группу, то мы
должны добавить множество кортежей, соответствующих перечню
дисциплин для данной группы
• Перечень дисциплин, которые должен сдавать студент, однозначно
определяется не номером зачетной книжки, а группой, в которой он
обучается.
91.
Многозначные зависимостиОпределение
• В отношении R (A, B, C) существует многозначная
зависимость (MVD - multi valid dependence) A→→ B в том
и только в том случае, если множество значений B,
соответствующее паре значений A и C, зависит только от
A и не зависит от С.
• Здесь одному значению некоторого атрибута
соответствует некоторое постоянное множество значений
другого атрибута.
• Замечание. Можно обозначать MVD и так A ->> B
• В рассмотренном отношении R существуют две
многозначные зависимости:
• Группа →→ Дисциплина (группе соответствует список
дисциплин)
• Группа →→ НомЗач (группе соответствует список
студентов)
• При наличии многозначной зависимости возможна
дальнейшая нормализация до уровня четвертой (4НФ) и
пятой (5НФ) нормальных форм
92.
Четвертая нормальная форма (4НФ)• Дальнейшая нормализация подобных отношений основывается на
теореме Фейджина
• Определение. Проецирование отношения R на два отношения R1 и
R2 называется проецированием без потерь
• если естественное соединение проекций R1 и R2 полностью и без
избыточности совпадает с исходным отношением
• (восстановление исходного отношения путем естественного
соединения проекций).
Теорема Фейджина
• Отношение R(A, B, C) можно спроецировать без потерь в R1(A, B) и
R2(A, C) в том и только в том случае, когда существуют
многозначные зависимости A→→ B и A→→ C.
Определение.
• Отношение R находится в четвертой нормальной форме (4НФ) в том
и только в том случае, если оно находится в НФБК и в случае
существования многозначной зависимости A→→ B все остальные
атрибуты R функционально зависят от A.
• В рассмотренном примере можно выполнить декомпозицию
отношения R на два отношения:
R1(Группа, НомЗач)
R2(Группа, Дисциплина)
93. Пример многозначной зависимости
ДисциплиныПреподаватели
КодДисц
Наименование
Объем
(час.)
ТабНом
Имя
Должн.
Д1
Математика
П1
Петров
Доцент
200
Д2
Физика
П2
Котлов
СтПрепод
140
Д3
Англ.язык
П3
Соков
Доцент
220
Д4
Базы данных
П4
Орлов
Профессор
200
Д5
Защита данных
140
Аудитории
Распределение по аудиториям (Расписание)
КодАуд
Тип
КодДисц
ТабНом
КодАуд
А1
Лекц
Д2
П1
А1
А2
КомпАуд
Д2
П1
А2
А3
Лаборат
Д2
П3
А3
А4
Лекц
Д2
П3
А4
А5
КомпАуд
Д2
П4
А5
…..
94. Аномалии при многозначной зависимости
Аудитория подготовлена, апреподаватель еще не
назначен
Аудиторию пока не
подготовили
КодДисц
ТабНом
КодАуд
Д2
NULL
А1
Д2
П1
А2
Д2
П3
NULL
Д2
П3
А4
Д2
П4
А5
Наличие NULL-значений –
признак недостаточного
уровня нормализации
Аудитория на ремонте
может пропасть
информация о
преподавателе
95. Пример многозначной зависимости
Дисциплина ->> ПреподавательДисциплина ->> Аудитория
Одну дисциплину
могут читать
несколько
преподавателей
Одна дисциплина
может проводиться в
нескольких
аудиториях
Дисциплина ->> Преподаватель
Дисциплина ->> Аудитория
ТабНом
КодДисц
КодАуд
П1
Д2
А1
П1
Д2
А2
П3
Д2
А3
П3
Д2
А4
П4
Д2
А5
…..
Одна строка определяет сразу
несколько зависимостей
96. Декомпозиция при многозначной зависимости
В таблице должно быть не больше одноймногозначной зависимости
Выносим каждую многозначную зависимость в
отдельную таблицу
Преподаватели на Д4 еще не
назначены, а аудитории уже
зарезервированы
Преподавание
Размещение
КодДисц
ТабНом
КодДисц
КодАуд
Д2
П1
Д1
А1
Д2
П2
Д2
А2
Д3
П3
Д2
А3
Д3
П4
Д3
А4
Д5
П3
Д4
А5
Аудитория еще не готова, а
преподаватель на Д5 уже назначен
Аномалий нет!
97.
Понятие о пятой нормальной форме (5НФ)• Следующий уровень нормализации связан с новым видом
зависимости – зависимость проекции-соединения
Определение.
• Отношение R(X, Y, … Z) удовлетворяет зависимости проекциисоединения в том и только в том случае,
• если оно восстанавливается без потерь путем соединения
своих проекций на X, Y, … Z., где X, Y, … Z – наборы атрибутов
отношения R.
• Наличие такой зависимости (PJ-зависимость) создает
проблемы при модификации отношения.
Определение.
• Отношение R находится в пятой нормальной форме (5НФ или
PJ/NF - от ProjectJoin) в том и только в том случае,
• когда любая зависимость проекции-соединения в R
определяется наличием в этом отношении возможного ключа.
• Другими словами, каждая проекция такого отношения
содержит не менее одного возможного ключа и не менее
одного неключевого атрибута
• Замечание Шестая нормальная форма 6НФ – обобщение 5НФ
для хронологических (темпоральных) баз данных (введена К.
Дейтом)
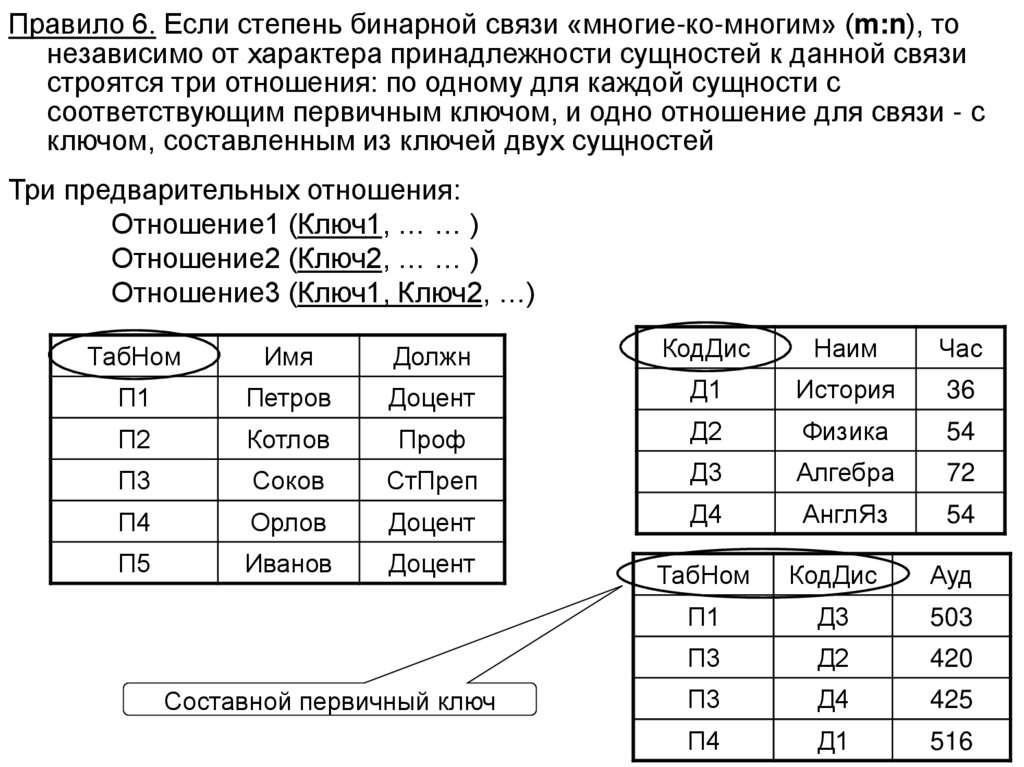
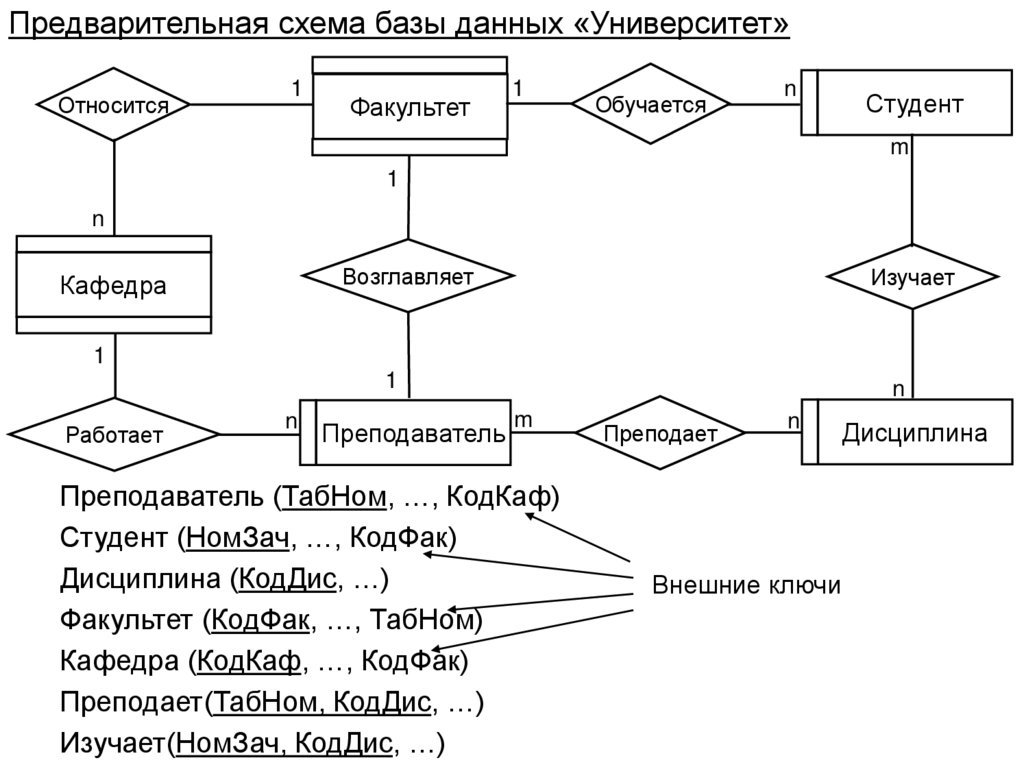
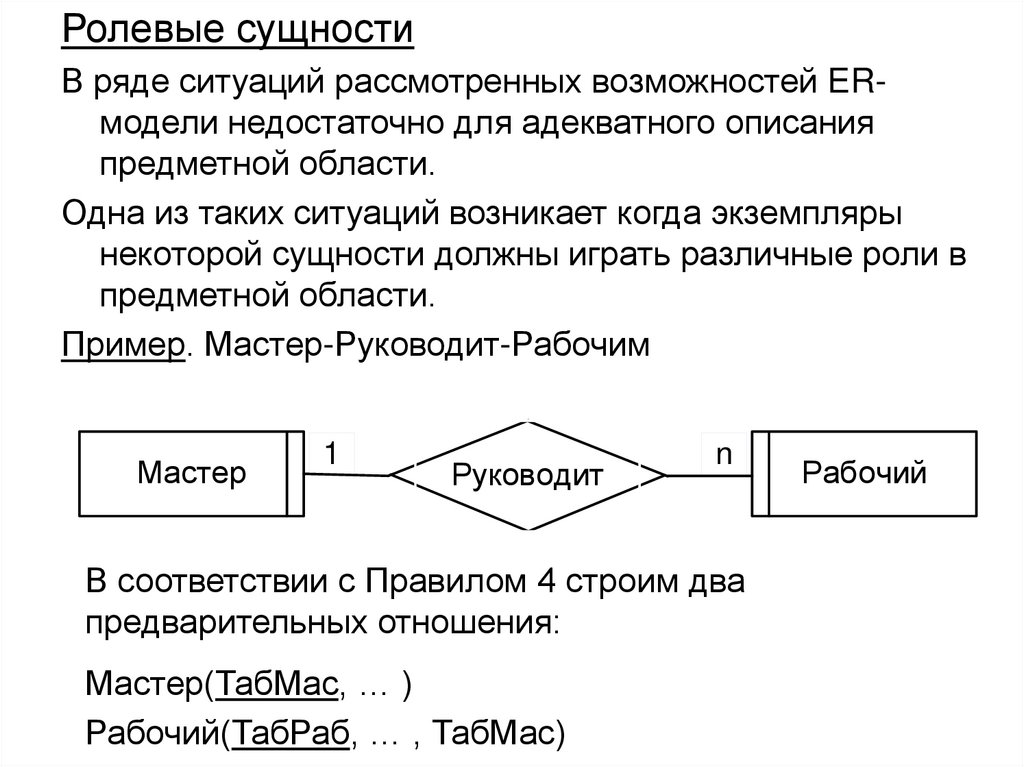
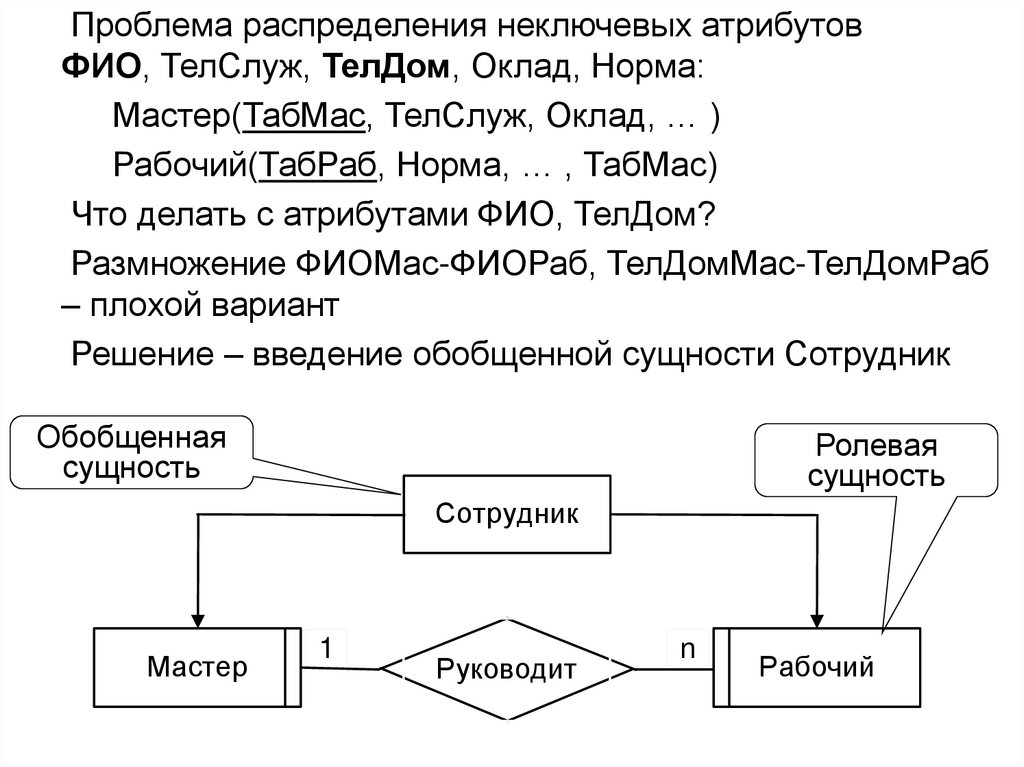
98. Проектирование баз данных на основе модели «Сущность-Связь»
• На первой стадии проектирования базы данныхвыполняется семантическое моделирование предметной
области. При этом в терминах семантической модели
разрабатывается концептуальная схема базы данных,
которая затем преобразуется к реляционной схеме.
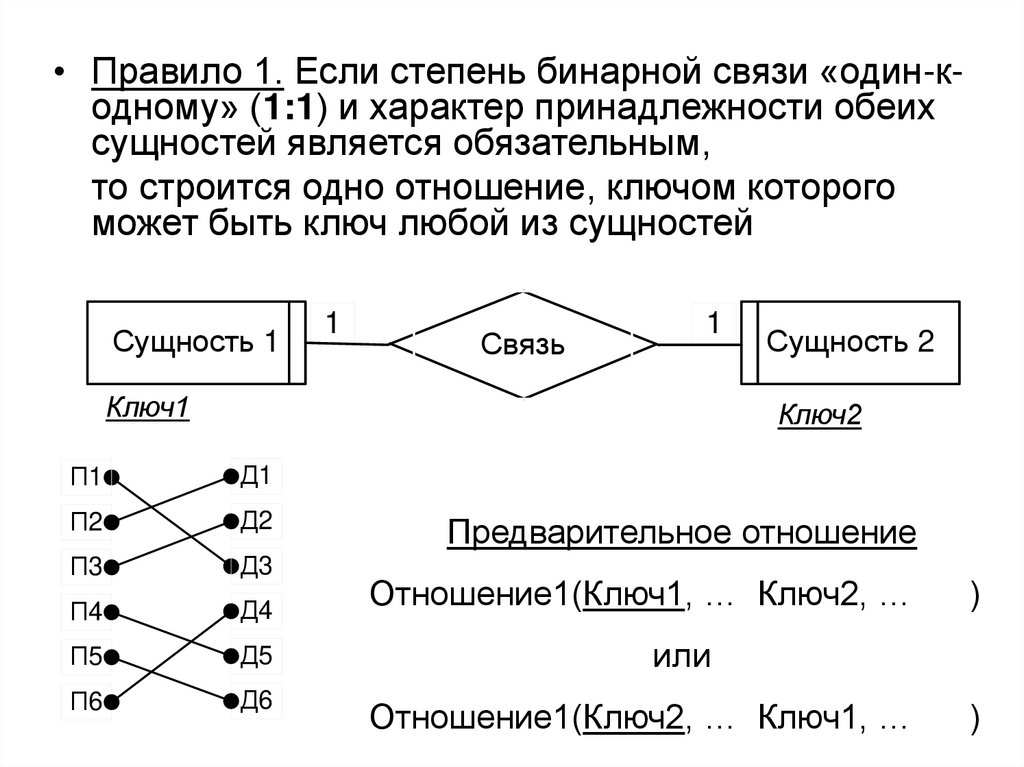
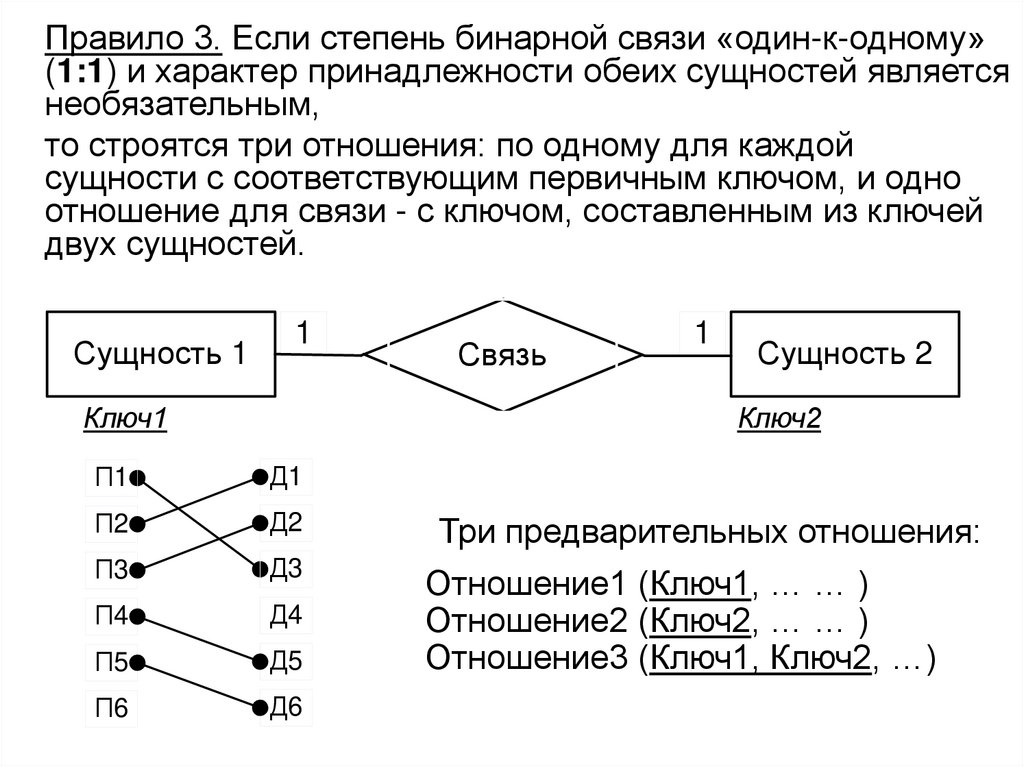
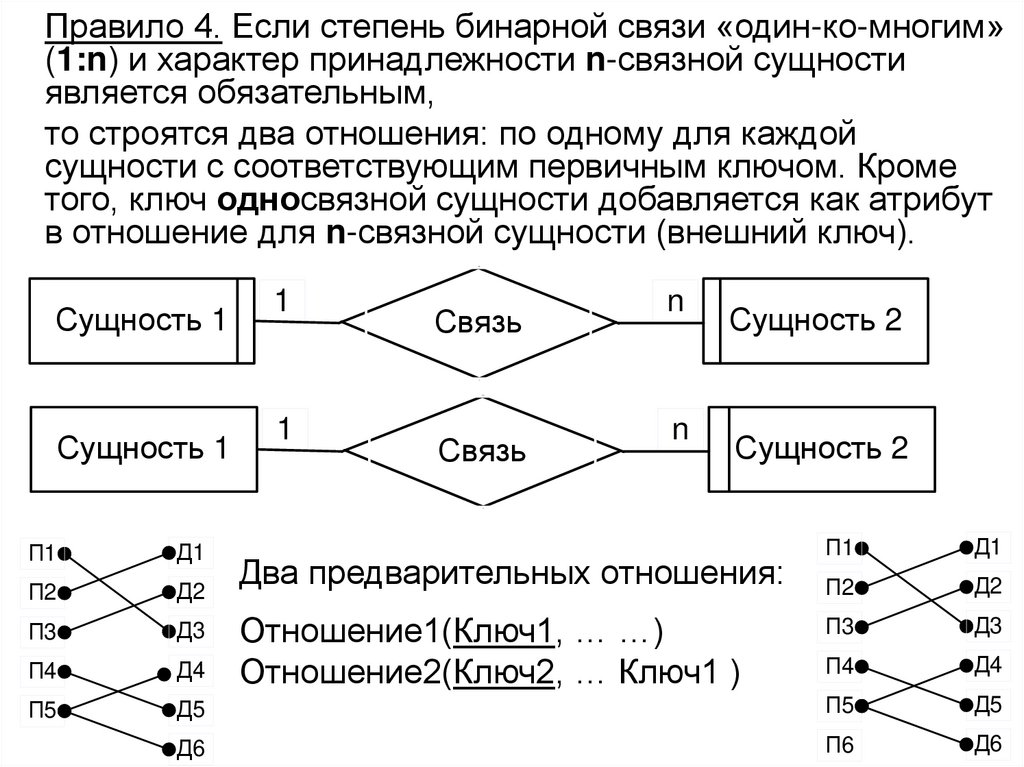
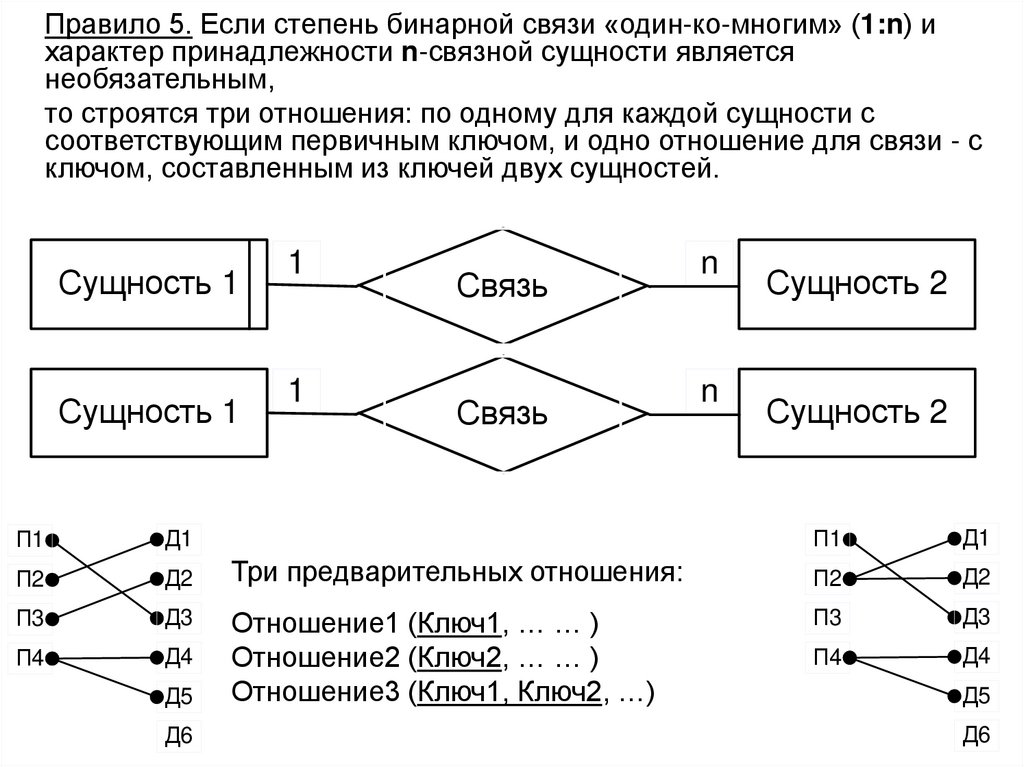
• Этот процесс выполняется в соответствии с методиками,
в которых достаточно четко описаны все этапы такого
преобразования.
• Соблюдение этих методик обеспечивает получение
реляционной схемы базы данных с достаточно высоким
уровнем нормализации (3НФ или НФБК).
• При построении семантической модели разработчик
взаимодействует с экспертами предметной области,
формализуя в семантической модели знания о
предметной области – бизнес-правила предметной
области.
99. Методика проектирования баз данных на основе модели «Сущность-Связь» (ER-модель, entity-relationship model, ERM)
Работа с экспертом,формализация бизнес-правил,
построение ER-диаграммы
Семантическая
модель
предметной
области
Формальные
правила
Набор
предварительных
отношений
Построение отношений
с ключевыми атрибутами
на основе четких правил
Схема базы данных
В НФБК
Распределение неключевых
атрибутов, проверка
выполнения условий НФБК
100. Модель Сущность-Связь (ER-модель)
• Большинство современных подходов кпроектированию реляционных баз данных
основано на использовании разновидностей ERмодели (entity-relationship model, ERM)
• ER-модель была предложена Питером Ченом (P.
Chen) в 1976 г.
• Моделирование предметной области в ER-модели
базируется на использовании графических диаграмм,
включающих небольшое число разнородных компонентов.
• ER-модели получили широкое распространение в системах
автоматизированного проектирования реляционных баз
данных - CASE-системах (Computer - Aided Software
Engineering )
• Основными понятиями ER-модели являются сущность,
связь и атрибут
• Связь - это графически изображаемая в ER-модели
ассоциация, устанавливаемая между сущностями.
• Связь между двумя разными сущностями – бинарная связь
• Связь между сущностью и ею же самой - рекурсивная связь
101.
Диаграммы ER-экземпляров• В ER-модели рассматриваются два вида диаграмм:
– Диаграммы ER-экземпляров
– Диаграммы ER-типа
• В диаграммах ER-экземпляров в явном виде
представляются все экземпляры сущностей и связи между
экземплярами сущностей, изображаемые линиями
• Диаграммы ER-экземпляров используются для детального
анализа связей
• Пример: Преподаватель-Преподает-Дисциплину
Экземпляр связи
Экземпляр сущности
П1
Д1
П2
Д2
П3
Д3
П4
Д4
П5
Д5
П6
Д6
102.
ER-модель. Диаграммы ER-типа• В диаграммах ER-типа сущность представляется в виде
прямоугольника, содержащего имя сущности
• Используются различные модификации диаграмм ERтипа. В разновидности диаграмм, которую мы, в
основном, будем использовать, связь представляется
ромбом
• Пример: Преподаватель-Преподает-Дисциплину
Преподаватель
Сущность 1
Преподает
Связь
Дисциплина
Сущность 2
103.
Классификация связей• При проектировании базы данных необходимо классифицировать
каждую связь по двум признакам:
– Характер множественности (степень) связи
Вопрос: может ли какой-либо экземпляр сущности быть связан с
несколькими экземплярами другой сущности
– Характер (класс) принадлежности сущностей к данной связи
Вопрос: может ли какой-либо экземпляр сущности не быть
связан ни с каким экземпляром другой сущности
• Эта классификация должна быть показана на диаграмме ER-типа,
т.е найти отражение в семантической модели.
• Классифицируя связи при построении семантической модели, мы
отражаем в ER-модели бизнес-правила предметной области,
которые должны поддерживаться при функционировании
информационной системы, в основе которой лежит проектируемая
база данных
• Большинство связей между сущностями можно представить как
бинарные, однако, возможны и более сложные ситуации связей
более высоких порядков
• Классифицируя бинарную связь по характеру множественности и
классу принадлежности, мы фиксируем в модели 4 бизнес-правила
предметной области
104. Классификация связей по характеру множественности
• Связь один-к–одному (1:1)Пример
Пассажир
1
Купил
1
Билет
n
Ребенок
n
Книга
• Связь один-ко-многим (1:n)
Пример
Мать
1
Имеет
• Связь многие-ко-многим (m:n)
Пример
Писатель
m
Написал
105.
Характер (класс) принадлежности сущности к связи• Определение.
• Если любой экземпляр некоторой сущности А
обязательно должен быть связан по крайней мере с
одним экземпляром сущности В, то характер
принадлежности (или класс принадлежности) сущности
А к данной связи называется обязательным
• Определение.
• Если допускается существование такого экземпляра
некоторой сущности А, который не связан ни с одним
экземпляром сущности В, то характер принадлежности
(или класс принадлежности) сущности А к данной
связи называется необязательным.
• Отражение характера принадлежности сущности к
связи на диаграмме ER-типа:
Сущность
необязательный
Сущность
обязательный
106.
Пример классификации бинарной связиПреподаватель-Преподает-Дисциплину
Преподаватель
1
Преподает
n
Дисциплина
Диаграмма ER-типа отражает следующие бизнес-правила
предметной области:
1. Преподаватель может преподавать несколько дисциплин
2. Одна и та же дисциплина не может преподаваться
несколькими преподавателями
3. Преподаватель может не преподавать ни одной
дисциплины
4. Любая дисциплина должна преподаваться каким-либо
преподавателем
107.
Пример построения ER-модели «Университет»• Сущности
– Декан (ТабНом)
– Факультет (КодФак)
– Преподаватель (ТабНом)
– Кафедра (КодКаф)
– Студент (НомЗач)
– Дисциплина (КодДис)
• Связи
– Декан-Возглавляет-Факультет
– Студент-Обучается на-Факультете
– Преподаватель-Работает на-Кафедре
– Кафедра-Входит в-Факультет
– Преподаватель-Преподает-Дисциплину
– Студент-Изучает-Дисциплину
108. Диаграмма ER-типа «Университет»
ДеканПРОБЛЕМА!
Декан не может
преподавать!
1
Возглавляет
1
Относится
1
Факультет
1
Обучается
n
Студент
m
n
Изучает
Кафедра
1
n
Работает
n
Преподаватель
m
Преподает
n
Дисциплина
109. Скорректированная диаграмма ER-типа «Университет»
ДеканВ этой семантической
модели нашли отражение
24 бизнес-правила
предметной области
1
Возглавляет
1
Относится
1
Факультет
1
Обучается
n
Студент
m
1
n
Возглавляет
Кафедра
Изучает
1
1
Работает
n
Преподаватель
n
m
Преподает
n
Дисциплина
110. Правила перехода от диаграммы ER-типа к предварительным отношениям базы данных
• Определение Предварительное отношение – это схемаотношения, в которой присутствуют только атрибуты,
которые являются первичным ключом и внешними
ключами
• В соответствии с методикой проектирования переход от
диаграммы ER-типа к набору предварительных
отношений базы данных выполняется на основе шести
правил
• Каждое из 6 правил соответствует определенному
характеру множественности и классу принадлежности
сущностей бинарной связи
• Наличие четких правил позволяет в CASE-системах
автоматизировать процесс проектирования схемы
реляционной базы данных
Замечание: CASE - computer-aided software engineering набор инструментов и методов программной инженерии
для проектирования программного обеспечения
111.
• Правило 1. Если степень бинарной связи «один-кодному» (1:1) и характер принадлежности обеихсущностей является обязательным,
• то строится одно отношение, ключом которого
может быть ключ любой из сущностей
Сущность 1
1
Связь
1
Ключ1
Сущность 2
Ключ2
П1
Д1
П2
Д2
П3
Д3
П4
Д4
П5
Д5
П6
Д6
Предварительное отношение
Отношение1(Ключ1, … Ключ2, …
)
или
Отношение1(Ключ2, … Ключ1, …
)
112. Связь «Один-к-одному». Правило 1
Две сущности и связь в одном отношенииТабНом
Имя
Должн
КодДис
Наим
Час
П1
Петров
Доцент
Д3
Алгебра
72
П2
Котлов
Проф
Д1
История
36
П3
Соков
СтПреп
Д4
АнглЯз
54
П4
Орлов
Доцент
Д2
Физика
54
113.
Правило 2. Если степень бинарной связи «один-к-одному»(1:1) и характер принадлежности одной из сущностей
является обязательным, а другой – необязательным,
то строятся два отношения: по одному для каждой
сущности с соответствующим первичным ключом.
Кроме того, ключ сущности с необязательным характером
принадлежности добавляется как атрибут в отношение для
сущности с обязательным характером принадлежности
(внешний ключ).
Сущность 1
Ключ1
1
Связь
1
Сущность 2
Ключ2
П1
Д1
П2
Д2
П3
Д3
Отношение1(Ключ1, … Ключ2)
П4
Д4
Отношение2(Ключ2, … … )
П5
Д5
Д6
Предварительные отношения
114. Связь «Один-к-одному». Правило 2
Два отношения для сущностей, связь через внешний ключВнешний ключ
ТабНом
Имя
Должн
КодДис
КодДис
Наим
Час
П1
Петров Доцент
Д3
Д1
История
36
П2
Котлов
Проф
Д1
Д2
Физика
54
П3
Соков
СтПреп
Д2
Д3
Алгебра
72
П4
Орлов
Доцент
Д5
Д4
АнглЯз
54
П5
Иванов Доцент
Д6
Д5
Химия
36
Д6
БазДан
72
115.
Правило 3. Если степень бинарной связи «один-к-одному»(1:1) и характер принадлежности обеих сущностей является
необязательным,
то строятся три отношения: по одному для каждой
сущности с соответствующим первичным ключом, и одно
отношение для связи - с ключом, составленным из ключей
двух сущностей.
Сущность 1
1
Ключ1
Связь
1
Сущность 2
Ключ2
П1
Д1
П2
Д2
Три предварительных отношения:
П3
Д3
П4
Д4
П5
Д5
Отношение1 (Ключ1, … … )
Отношение2 (Ключ2, … … )
Отношение3 (Ключ1, Ключ2, …)
П6
Д6
116. Связь «Один-к-одному». Правило 3
Два отношения для сущностей, отдельное отношение для связиТабНом
Имя
Должн
КодДис
Наим
Час
П1
Петров Доцент
Д1
История
36
П2
Котлов
Проф
Д2
Физика
54
П3
Соков
СтПреп
Д3
Алгебра
72
П4
Орлов
Доцент
Д4
АнглЯз
54
П5
Иванов Доцент
Отдельное отношение
для связи
ТабНом КодДис
Ауд
П1
Д1
503
П2
Д4
420
П3
Д3
425
П5
Д1
516
117.
Правило 4. Если степень бинарной связи «один-ко-многим»(1:n) и характер принадлежности n-связной сущности
является обязательным,
то строятся два отношения: по одному для каждой
сущности с соответствующим первичным ключом. Кроме
того, ключ односвязной сущности добавляется как атрибут
в отношение для n-связной сущности (внешний ключ).
Сущность 1
1
Сущность 1
1
Связь
Связь
n
Сущность 2
n
Сущность 2
П1
Д1
П2
Д2
П3
Д3
П4
Д4
Д5
П5
Д5
Д6
П6
Д6
П1
Д1
П2
Д2
П3
Д3
П4
Д4
П5
Два предварительных отношения:
Отношение1(Ключ1, … …)
Отношение2(Ключ2, … Ключ1 )
118. Связь «Один-ко-многим». Правило 4
Два отношения для сущностей, связь через внешний ключВнешний ключ
ТабНом
Имя
Должн
КодДис
Наим
Час
ТабНом
П1
Петров Доцент
Д1
История
36
П2
П2
Котлов
Проф
Д2
Физика
54
П4
П3
Соков
СтПреп
Д3
Алгебра
72
П4
П4
Орлов
Доцент
Д4
АнглЯз
54
П3
П5
Иванов Доцент
119.
Правило 5. Если степень бинарной связи «один-ко-многим» (1:n) ихарактер принадлежности n-связной сущности является
необязательным,
то строятся три отношения: по одному для каждой сущности с
соответствующим первичным ключом, и одно отношение для связи - с
ключом, составленным из ключей двух сущностей.
Сущность 1
1
Сущность 1
1
П1
Д1
П2
Д2
П3
Д3
П4
Д4
Д5
Д6
Связь
Связь
n
Сущность 2
n
Сущность 2
П1
Д1
Три предварительных отношения:
П2
Д2
Отношение1 (Ключ1, … … )
Отношение2 (Ключ2, … … )
Отношение3 (Ключ1, Ключ2, …)
П3
Д3
П4
Д4
Д5
Д6
120. Связь «Один-ко-многим». Правило 5
Два отношения для сущностей, отдельное отношение для связиТабНом
Имя
Должн
КодДис
Наим
Час
П1
Петров Доцент
Д1
История
36
П2
Котлов
Проф
Д2
Физика
54
П3
Соков
СтПреп
Д3
Алгебра
72
П4
Орлов
Доцент
Д4
АнглЯз
54
П5
Иванов Доцент
Отдельное отношение
для связи
ТабНом КодДис
Ауд
П1
Д1
503
П2
Д4
420
П3
Д3
425
П5
Д1
516
121. Связь «многие-ко-многим»
Сущность 1m
Сущность 1
m
Сущность 1
m
Связь
Связь
Связь
n
Сущность 2
n
Сущность 2
n
Сущность 2
П1
Д1
П1
Д1
П1
Д1
П2
Д2
П2
Д2
П2
Д2
П3
Д3
П3
Д3
П3
Д3
П4
Д4
П4
Д4
П4
Д4
П5
Д5
П5
Д5
П5
Д5
П6
Д6
П6
П6
Д6
122.
Правило 6. Если степень бинарной связи «многие-ко-многим» (m:n), тонезависимо от характера принадлежности сущностей к данной связи
строятся три отношения: по одному для каждой сущности с
соответствующим первичным ключом, и одно отношение для связи - с
ключом, составленным из ключей двух сущностей
Три предварительных отношения:
Отношение1 (Ключ1, … … )
Отношение2 (Ключ2, … … )
Отношение3 (Ключ1, Ключ2, …)
ТабНом
Имя
Должн
КодДис
Наим
Час
П1
Петров
Доцент
Д1
История
36
П2
Котлов
Проф
Д2
Физика
54
П3
Соков
СтПреп
Д3
Алгебра
72
П4
Орлов
Доцент
Д4
АнглЯз
54
П5
Иванов
Доцент
ТабНом
КодДис
Ауд
П1
Д3
503
П3
Д2
420
П3
Д4
425
П4
Д1
516
Составной первичный ключ
123.
Предварительная схема базы данных «Университет»Относится
1
Факультет
1
Обучается
n
Студент
m
1
n
Возглавляет
Кафедра
Изучает
1
1
Работает
n
Преподаватель
n
m
Преподаватель (ТабНом, …, КодКаф)
Студент (НомЗач, …, КодФак)
Дисциплина (КодДис, …)
Факультет (КодФак, …, ТабНом)
Кафедра (КодКаф, …, КодФак)
Преподает(ТабНом, КодДис, …)
Изучает(НомЗач, КодДис, …)
Преподает
n
Внешние ключи
Дисциплина
124.
Распределение неключевых атрибутовНа следующем этапе проектирования неключевые атрибуты
распределяются по предварительным отношениям
При этом выписываются и анализируются функциональные
зависимости и контролируется соблюдение условий НФБК
Возможные проблемы:
Не все отношения в достаточной степени нормализованы (не
находятся в НФБК)
Два отношения полностью совпадают
Некоторым неключевым атрибутам не находится логически
обоснованных мест
При возникновении этих проблем необходимо вернуться к диаграмме
ER-типа и скорректировать ее
При распределении неключевых атрибутов по предварительным
отношениям могут возникнуть и другие нестандартные ситуации, в
частности, когда некоторый атрибут является свойством нескольких
сущностей
125.
Ролевые сущностиВ ряде ситуаций рассмотренных возможностей ERмодели недостаточно для адекватного описания
предметной области.
Одна из таких ситуаций возникает когда экземпляры
некоторой сущности должны играть различные роли в
предметной области.
Пример. Мастер-Руководит-Рабочим
Мастер
1
Руководит
n
В соответствии с Правилом 4 строим два
предварительных отношения:
Мастер(ТабМас, … )
Рабочий(ТабРаб, … , ТабМас)
Рабочий
126.
Проблема распределения неключевых атрибутовФИО, ТелСлуж, ТелДом, Оклад, Норма:
Мастер(ТабМас, ТелСлуж, Оклад, … )
Рабочий(ТабРаб, Норма, … , ТабМас)
Что делать с атрибутами ФИО, ТелДом?
Размножение ФИОМас-ФИОРаб, ТелДомМас-ТелДомРаб
– плохой вариант
Решение – введение обобщенной сущности Сотрудник
Обобщенная
сущность
Ролевая
сущность
Сотрудник
Мастер
1
Руководит
n
Рабочий
127.
Правило ролей: Обобщенная сущность генерирует одноотношение с соответствующим ключом.
Ролевые сущности и связи между ними порождают
отношения в соответствии с ранее сформулированными
шестью правилами, где каждая роль трактуется как
обычная сущность.
Предварительные отношения:
Сотрудник(ТабСот, … )
Мастер(ТабМас, … )
Рабочий(ТабРаб, … ТабМас)
Теперь легко распределяются неключевые атрибуты:
Сотрудник(ТабСот, ФИО, ТелДом, … )
Мастер(ТабМас, ТелСлуж, Оклад, … )
Рабочий(ТабРаб, Норма, … ТабМас)
Замечание: в современных СУБД с объектноориентированным расширением реляционной модели
эту проблему можно решать иначе, определяя
отношение наследования между сущностями
128.
Связи более высоких порядковБольшинство связей между сущностями являются
бинарными, однако возможны ситуации, которые
невозможно адекватно описать бинарными связями.
Пример 1. Преподаватель предпочитает читать лекции в
некоторых аудиториях
Преподаватель
m
Предпочитает
n
Аудитория
Это бинарная связь, отражающая следующие бизнесправила:
Преподаватель может предпочитать несколько аудиторий
Одну аудиторию могут предпочитать несколько
преподавателей
Преподаватель обязательно предпочитает хотя бы одну
аудиторию
Могут быть аудитории, которые никто не предпочитает
129.
Пример 2. Преподаватель предпочитает преподаватьразные дисциплины в разных аудиториях. В этом случае
бинарными связями ситуацию не описать. Нужна связь
более высокого порядка
Аудитория
k
Преподаватель
m
Предпочитает
n
Дисциплина
Связь между тремя сущностями называется тернарной
связью.
В этом случае ни одно из рассмотренных правил
неприменимо, необходимо руководствоваться правилом
для связей более высоких порядков.
130.
Правило 7. Если связь между сущностями тернарная,необходимо строить 4 предварительных отношения –
по одному для каждой сущности с соответствующими
ключами и одно для связи с ключом, составленным из
ключевых атрибутов всех трех сущностей.
В соответствии с правилом 7 для рассматриваемого
примера имеем:
Преподаватель(ТабНом, … )
Дисциплина(КодДис, … )
Аудитория(НомАуд, … )
Предпочтение(ТабНом, КодДис, НомАуд, … )
Аналогичное правило действует и для n-арной связи:
строим n отношений для сущностей и одно –для nарной связи; при этом получаем n+1 предварительное
отношение
131. Нотация CASE-системы Power Designer для диаграмм ER-типа
СущностьОдин
Сущность
Многие
Сущность
Необязательный
Сущность
Обязательный
132.
Пример диаграммы ER-типа в нотации Power DesignerCASE-система (Computer-Aided Software Engineering) Power Designer средство проектирования, анализа и моделирование процессов и
структур баз данных
Диаграмма ER-типа в классической нотации Чена
Дисциплина
n
Преподает
1
Преподаватель
Бизнес-правила:
1. Преподаватель может преподавать несколько дисциплин
2. Дисциплина может преподаваться только одним преподавателем
3. Преподаватель обязательно преподает хотя бы одну дисциплину
4. Может быть дисциплина, которая никем не преподается
Диаграмма ER-типа в нотации CASE-системы Power Designer
Дисциплина
Преподает
Преподаватель
133. 12 правил Кодда (1985 г.)
• Правило 0: Основное правило (Foundation Rule):– Система, которая рекламируется или позиционируется как
реляционная система управления базами данных, должна быть
способна управлять базами данных, используя исключительно
свои реляционные возможности.
• Правило 1: Информационное правило (The Information Rule):
– Вся информация в реляционной базе данных на логическом
уровне должна быть явно представлена единственным способом:
значениями в таблицах.
• Правило 2: Гарантированный доступ к данным (Guaranteed
Access Rule):
– В реляционной базе данных каждое отдельное (атомарное)
значение данных должно быть логически доступно с помощью
комбинации имени таблицы, значения первичного ключа и имени
столбца.
• Правило 3: Систематическая поддержка отсутствующих
значений (Systematic Treatment of Null Values):
– Неизвестные, или отсутствующие значения NULL, отличные от
любого известного значения, должны поддерживаться для всех
типов данных при выполнении любых операций. Например, для
числовых данных неизвестные значения не должны
рассматриваться как нули, а для символьных данных — как
пустые строки.
134.
• Правило 4: Доступ к словарю данных в терминах реляционноймодели (Active On-Line Catalog Based on the Relational Model):
– Словарь данных должен сохраняться в форме реляционных
таблиц, и СУБД должна поддерживать доступ к нему при помощи
стандартных языковых средств, тех же самых, которые
используются для работы с реляционными таблицами,
содержащими пользовательские данные.
• Правило 5: Полнота подмножества языка (Comprehensive Data
Sublanguage Rule):
– Система управления реляционными базами данных должна
поддерживать хотя бы один реляционный язык, который
• (а) имеет линейный синтаксис,
• (б) может использоваться как интерактивно, так и в
прикладных программах,
• (в) поддерживает операции определения данных, определения
представлений, манипулирования данными (интерактивные и
программные), ограничители целостности, управления
доступом и операции управления транзакциями (begin, commit
и rollback).
• Правило 6: Возможность изменения представлений (View
Updating Rule):
– Каждое представление должно поддерживать все операции
манипулирования данными, которые поддерживают реляционные
таблицы: операции выборки, вставки, изменения и удаления
данных.
135.
• Правило 7: Наличие высокоуровневых операцийуправления данными (High-Level Insert, Update, and Delete):
– Операции вставки, изменения и удаления данных должны
поддерживаться не только по отношению к одной строке
реляционной таблицы, но и по отношению к любому
множеству строк.
• Правило 8: Физическая независимость данных (Physical
Data Independence):
– Приложения не должны зависеть от используемых
способов хранения данных на носителях, от аппаратного
обеспечения компьютеров, на которых находится
реляционная база данных.
• Правило 9: Логическая независимость данных (Logical
Data Independence):
– Представление данных в приложении не должно зависеть
от структуры реляционных таблиц. Если в процессе
нормализации одна реляционная таблица разделяется на
две, представление должно обеспечить объединение этих
данных, чтобы изменение структуры реляционных таблиц
не сказывалось на работе приложений.
136.
• Правило 10: Независимость контроля целостности(Integrity Independence):
– Вся информация, необходимая для поддержания
целостности, должна находиться в словаре данных.
Язык для работы с данными должен выполнять
проверку входных данных и автоматически
поддерживать целостность данных.
• Правило 11: Независимость от расположения
(Distribution Independence):
– База данных может быть распределённой, может
находиться на нескольких компьютерах, и это не
должно оказывать влияния на приложения. Перенос
базы данных на другой компьютер не должен
оказывать влияния на приложения.
• Правило 12: Согласование языковых уровней (The
Nonsubversion Rule):
– Если используется низкоуровневый язык доступа к
данным, он не должен игнорировать правила
безопасности и правила целостности, которые
поддерживаются языком более высокого уровня.
137. Язык реляционных баз данных SQL
• История развития SQL• SQL (Structured Query Language) — Структурированный Язык
Запросов — стандартный язык реляционных БД.
• Первые исследовательские проекты
– System R, начало 70-х г.г.– первый прототип реляционной
СУБД фирмы IBM Research, реализован язык SEQUEL
(Structured English Query Language), прототип SQL,
– Ingres - некоммерческая СУБД, Калифорнийский
университет, Беркли, реализован язык QUEL
– PostgreSQL возникла как некоммерческая линия развития
СУБД Ingres, сначала как Postgres (Post Ingres), а затем
PostgreSQL
• 1979 -1981 г.г. – первые коммерческие СУБД
– System/38 (SQL/DS), IBM объявила о первом, основанном
на SQL программном продукте
– Oracle V2, компания Relation Software (позже Oracle)
• 1987 год - первый стандарт языка SQL (SQL level /уровень/ 1)
принят Американским национальным институтом
стандартизации (ANSI)
138.
Стандартизация SQL• 1987 г., SQL-87 – первый стандарт языка
• 1989 г. SQL-89 (FIPS 127-1) – доработанный стандарт
• 1992 г., SQL-92 (SQL2, FIPS 127-2) – значительные изменения
стандарта SQL-89
• 1999 г., SQL:1999 – триггеры, нескалярные типы, некоторые
объектно-ориентированные возможности
• 2003 г., SQL:2003 (SQL3) – работа с XML-форматом, функции для
работы с OLAP-данными, генераторы последовательностей
• 2006 г., SQL:2006 – расширены возможности по работе с XMLформатом, возможность использовать в запросах SQL и XQuery
(язык запросов, разработанный для обработки данных в формате
XML)
• 2008 г., SQL:2008 – расширение возможностей по работе с OLAPданными, устранены неоднозначности, которые появились в
стандарте SQL:2003
• 2011 г., SQL:2011 – конвейерные процессы, темпоральные базы
данных
• 2016 г., SQL:2016 – полиморфные табличные функции, jsonформат
• Несмотря на наличие диалектов большинство SQL-запросов
достаточно легко переносятся из одной СУБД в другую
139.
Общая характеристика SQL• Целью разработки было создание простого непроцедурного языка,
которым мог воспользоваться любой пользователь, даже не имеющий
навыков программирования
• SQL основывается на исчислении кортежей, но включает также
некоторые элементы исчисления доменов, а также дополнительные
возможности
• С помощью SQL описывается только то, какие данные нужно извлечь
или модифицировать. То, каким образом это сделать, решает СУБД
непосредственно при обработке SQL-запроса
• Несмотря на наличие диалектов и различий в синтаксисе, в
большинстве своем тексты SQL-запросов, могут быть достаточно легко
перенесены из одной СУБД в другую
Структура языка
• В SQL определены два подмножества языка:
– SQL-DDL (Data Definition Language) - язык определения структур и
ограничений целостности баз данных.
– SQL-DML (Data Manipulation Language) - язык манипулирования
данными
• DDL – определение домена, базы данных, схемы отношения,
представления, индекса, описание свойств атрибутов, изменение
схемы отношения, определение удаление доменов, отношений,
индексов
• DML – запросы на выборку, вставку, удаление, модификацию данных
140.
• Язык SQL можно представить как совокупность операторов,инструкций и вычисляемых функций
• Язык SQL не чувствителен к регистру
• Если используется программа из нескольких операторов SQL, то
после каждого оператора ставится «;»
• Если используется всего один оператор, то «;» в конце не обязательна
Операторы SQL
• Функционально операторы SQL можно разделить на 4 группы
Операторы SQL
Операторы
определения
данных
DDL
(Data Definition
Language)
Операторы
манипулирования
данными
DML
(Data Manipulation
Language)
Операторы
управления
доступом
к данным
DCL
(Data Control
Language)
Операторы
управления
транзакциями
TCL
(Transaction
Control Language)
141.
• Операторы DDL - позволяют работать с метаданными (схемой базыданных)
– CREATE создает объект базы данных
– ALTER изменяет объект
– DROP удаляет объект
• Операторы DML - позволяют манипулировать данными в БД
– SELECT выбор данных из таблиц
– INSERT добавление новых данных
– UPDATE изменение существующих данных
– DELETE удаление данных
• Операторы DCL - определяют права доступа пользователей к данным
– GRANT предоставляет разрешения на определенные операции с
объектом
– REVOKE отзывает ранее выданные разрешения
– DENY задает запрет, имеющий приоритет над разрешением
• Операторы TCL - обеспечивают управление транзакциями
– COMMIT зафиксировать изменения, выполненные транзакцией
– ROLLBACK откатить все изменения, сделанные в контексте текущей
транзакции
– SAVEPOINT разделить транзакцию на более мелкие участки
– SET TRANSACTION ISOLATION LEVEL – устанавливает уровень
изолированности транзакций
142.
Инструкции и встроенные функции SQL• Инструкции используются при реализации процедурных
расширений SQL
– Хранимые процедуры
– Триггеры
– Функции, блоки, пакеты и пр.
• Встроенные функции позволяют осуществлять обработку
информации непосредственно при выполнении операторов DML
Типы данных в SQL
• Стандарт ISO - 6 групп скалярных типов данных:
– Символьный - Character
– Двоичный - Bit
– Точный числовой – Exact numeric
– Приближенный числовой – Approximate numeric
– Дата-Время - DateTime
– Интервальный – Interval
• Стандартом ISO определено общее для всех типов значение
NULL – «нет значения»
143.
Стандарт ISOСимвольные типы данных
• CHAR – символ (1 байт)
• CHAR(n) – строка длиной n байт; для хранения данных этого
типа всегда отводится n байт вне зависимости от реальной
длины строки
• VARCHAR(n) – строка переменной длины (n ≤ 255); отводится
число байт, соответствующее реальной длине строки
Точные числовые типы данных
• NUM[ERIC] (p, s) – вещественное число с фиксированной
десятичной точкой, p – максимальное количество цифр, s –
максимальное количество цифр после десятичной точки
• DEC[IMAL] [ p[, s] ] –полный аналог NUM[ERIC]
• INT[EGER] – стандартное целое (4 байта)
• SMALLINT – короткое целое число (2 байта)
Приближенные числовые типы данных
• FLOAT (n) – вещественное число с плавающей десятичной
точкой, n – точность мантиссы
• REAL – вещественное число с плавающей десятичной точкой
стандартной точности
• DOUBLE [PRECISION] – вещественное число с плавающей
десятичной точкой повышенной точности
144.
Битовые типы данных• BIT – один бит (0 V 1)
• BIT(n) – битовая последовательность фиксированной длины - n
бит; всегда отводится n бит вне зависимости от реальной длины
• BIT VARYING(n) – битовая последовательность переменной
длины; отводится число бит, соответствующее реальной длине
Типы данных Дата-Время
• DATE – дата (месяц/день/год)
• TIME (n) – время (час:мин:сек), n – точность, количество
десятичных знаков при задании секунд (1- до десятых, 2- до
сотых и т.д.)
• TIMESTAMP (n) – дата и время, эквивалент DATE+ TIME (n)
• Множество значений этих типов упорядочено, определены
константы CURDATE И CURTIME
• Распространенные форматы дат:
1999-01-08, January 8, 1999, 1/8/1999
• Распространенные форматы времени: 13:21, 1:21 pm, 1:21:34
Интервальный тип данных
• INTERVAL – интервал (отрезок) времени, возможно задание
точности и диапазона
• Замечание: обычно интервальный тип относят к группе типов
Дата-Время
145.
Приоритет операций в выражениях SQL1.
~ (побитовое НЕ)
2.
* , / , % (остаток от деления)
3.
+,4.
=, >, <, >=, <=, <>, !=
5.
NOT
6.
AND
7.
ALL, ANY, BETWEEN, IN, LIKE, OR, SOME
Пример:
выражение city ='Moskow' OR rating>20
эквивалентно выражению (city ='Moskow') OR (rating>20)
Группы типов данных в PostgreSQL
Числовые типы данных;
Символьные типы данных;
Типы для работы с датами и временем;
Типы для работы с валютой (денежными единицами);
Бинарные данные;
Логический (булев) тип;
Типы для представления интернет-адресов;
Геометрические типы;
Другие типы данных (форматы json, уникальный идентификатор uuid,
формат xml)
146.
Целые числовые типы данных в PostgreSQL• integer (int, int4): 4 байта, диапазон чисел -2147483648 ÷ +2147483647
• smallint (int2): 2 байта, диапазон чисел -32767 ÷ +32767
• bigint (int8): 8 байт, max число +9223372036854775807 (квинтиллионы)
Последовательные (автоинкрементные) типы данных
• serial: 4 байта, целое число с автоувеличением значения предыдущей
строки таблицы от 1 до 2147483647, используется для определения
идентификатора строки
• smallserial: 2 байта, целое число с автоувеличением от 1 до 32767
• bigserial: 8 байт, целое число с автоувеличением от 1 до
9223372036854775807 (более 9 квинтиллионов)
Вещественные числовые типы данных в PostgreSQL
Точные (до 131072 цифр до десятичной точки и до 16383 — после )
• numeric(p, s): p - точность, максимальное количество цифр числа и s –
масштаб, максимальное количество цифр после десятичной точки (для
числа 23.5141 p= 6, s=4), numeric(p) - по умолчанию s=0, numeric –
максимально допустимые системой
• decimal: полностью аналогичен типу numeric
Неточные (с плавающей десятичной точкой)
• real (float4): 4 байта, числа с плавающей точкой, диапазон от 1E-37 до
1E+37
• double precision (float8): 8 байт, числа с плавающей точкой, диапазон от
1E-307 до 1E+308
• float(p): без указания точности float эквивалентен double precision
147.
Символьные (строковые) типы данных PostgreSQL• Значения строкового типа заключается в одинарные кавычки
(апострофы): 'новый‘
• Если в строке содержится символ «‘» или «/», его надо удваивать
• character(n) или char(n): строка фиксированной длины, где n количество символов в строке, более короткие строки дополняются
пробелами, char трактуется как char(1),
• character varying(n) или varchar(n): строка ограниченной переменной
длины, где n – максимальное количество символов в строке, varchar
трактуется как строка любого размера
• text: текст произвольной длины
Замечание: рекомендуется использовать типы varchar и text
Типы данных для работы с датами и временем PostgreSQL
• Значение типа даты и времени в PostgreSQL заключаются в апострофы
• Даты могут представляться в различных форматах:
‘2015-11-05’, ‘2015-Nov-05’, ‘2015/11/05’, …
• При выводе даты используется установленный в системе формат,
который определяется значением параметра datestyle: YMD, DMY, MDY;
по умолчанию используется формат DMY
• Запросить текущее значение параметра datestyle можно командой
SHOW datestyle
• Время представляется в формате чч:мм:сс (21:14:02, 03:43:00)
148.
Если в некоторой SQL-конструкции необходимо указать, что символы в
апострофах – это не просто строка, а дата или время, используется
операция приведения типа «::», например, операторы
SELECT ’12-05-2021’::date;
SELECT ‘23:05:16’::time;
• выведут дату 12-05-2021 в установленном формате и время 23:05:16
• Функции current_date и current_time возвращают текущую дату и текущее
время соответственно, например, по запросу
SELECT current_date, current_time;
• будут выведены текущая дата и текущее время с указанием часового
пояса, причем секунды будут выведены с высокой точностью
• date: 4 байта, дата от 4713 г. до н.э. до 5874897 г. н.э., точность – 1 день
• time(p): 8 байт, время в сутках без указания часового пояса от 00:00:00 до
24:00:00 с точностью до 1 микросекунды
• time(p) with time zone: 12 байт, время в сутках с указанием часового пояса
от 00:00:00+1459 до 24:00:00-1459 с точностью до 1 мкс
• timestamp(p): 8 байт, дата от 4713 г до н.э. до 294276 г н.э. и время time
• timestamp(p) with time zone: 8 байт, timestamp + данные о часовом поясе
• interval(p): 16 байт, временной интервал от -178000000 до 178000000 лет с
точностью до 1 микросекунды
Замечание: типы с указанием часового пояса использовать не рекомендуется,
что, в частности, связано с проблемой учета перехода на летнее время
Денежный тип данных PostgreSQL
• money: 8 байт, точность дробной части определяется в конкретной БД
параметром lc_monetary, для точности два знака после запятой – значения
от -92233720368547758.08 до +92233720368547758.07
149.
Логический тип данных PostgreSQL• boolean: принимает значения true (TRUE, 't', 'true', 'y', 'yes', 'on', '1‘) или false
(FALSE, 'f', 'false', 'n', 'no', 'off', '0‘)
Бинарный тип данных PostgreSQL
• bytea: хранит бинарные строки - последовательность байт
Типы данных для представления интернет-адресов PostgreSQL
• cidr: интернет-адрес в формате IPv4 и IPv6 (192.168.0.1), от 7 до 19 байт
• inet: интернет-адрес в формате cidr/y, где y - количество бит в адресе
• macaddr (macaddr8): MAC-адрес, 6 байт (в формате EUI-64, 8 байт)
Битовые строки PostgreSQL
• bit(n): битовая строка фиксированной длины n бит, bit равносильно bit(1)
• bit varying(n): битовая строка переменной длины не более n, bit varying –
строка неограниченной длины
Геометрические типы данных PostgreSQL
• point: 16 байт, точка на плоскости в формате (x,y)
• line: 32 байта, линия неопределенной длины в формате {A,B,C} (Ax+By+C=0)
• lseg: 32 байта, отрезок в формате ((x1,y1),(x2,y2))
• box: 32 байта, прямоугольник в формате ((x1,y1),(x2,y2))
• path и polygon: типы данных для представления замкнутого многоугольника
• circle: 24 байта, окружность в формате <(x,y),r>
Другие типы данных PostgreSQL
• json (jsonb): данные в формате json в текстовом (бинарном) виде
• uuid: 32 байта, универсальный уникальный идентификатор (UUID, GUID)
• xml: данные в формате XML
150. Определение данных в SQL (DDL)
• Объекты базы данныхSCHEMA – база данных
DOMAIN - домен
TABLE – отношение (таблица)
VIEW - представление
INDEX - индекс
• Операторы
CREATE – создать объект БД
ALTER - изменить объект БД
DROP - удалить объект БД
• CREATE и DROP – с любым из объектов БД
• ALTER – только с DOMAIN и TABLE
151.
Создание базы данных• Создать БД
CREATE SCHEMA <имя_БД> AUTHORIZATION <ID>
• Удалить БД
DROP SCHEMA <имя_БД> [ RESTRICT | CASCADE ]
RESTRICT – не удалять, если есть данные (по умолчанию)
CASCADE – удалять вместе с данными
• Эквивалентные операторы
• Создать БД
CREATE DATABASE <имя_БД>
• Удалить БД
DROP DATABASE <имя_БД>
• Открыть БД
DATABASE <имя_БД>
• Закрыть БД
CLOSE DATABASE <имя_БД>
152.
Создание таблиц (отношений)• Создать таблицу
CREATE TABLE имя_таблицы
Ограничение на атрибут
(
имя_атрибута <тип> <ограничения>,
имя_атрибута <тип> <ограничения>,
………………………………………
имя_атрибута <тип> <ограничения> [,
<ограничения на таблицу>]
)
Полное имя таблицы:
Ограничение на таблицу
• <имя_схемы>.<имя_таблицы>
• Пример
CREATE TABLE suppliers
/*Объявление таблицы Поставщики*/
(
cod_s varchar(4), -- Код поставщика
surname varchar(20), -- Фамилия поставщика
rating smallint -- Рейтинг поставщика
)
комментарии
153.
Изменение и удаление таблиц• Добавление атрибутов
ALTER TABLE <имя_таблицы>
ADD <имя_атрибута> <тип>
• Замечание: Для уже имеющихся кортежей добавляемый атрибут
принимает значение NULL
• Пример
ALTER TABLE suppliers
ADD city varchar(20) -- добавление атрибута Город
• ALTER позволяет переименовать таблицу или атрибут, изменить тип
атрибута, добавить ограничения атрибута, изменить ограничения
таблицы
• Удаление таблицы:
DROP TABLE <имя_таблицы> [ RESTRICT | CASCADE ]
RESTRICT – не удалять, если на таблицу есть ссылки
CASCADE – удалять, вместе со ссылающимися таблицами
• Пример
DROP TABLE suppliers
Индексация
• Индекс - это упорядоченный список атрибутов или групп атрибутов в
таблице
• Индексация значительно ускоряет поиск данных по значению
проиндексированного атрибута, но замедляет некоторые операции
модификации
154.
Индексирование
CREATE INDEX <имя_индекса> ON <имя_таблицы>
(<имя_атрибута> [, <имя_атрибута> … ])
Пример
CREATE INDEX indcity ON suppliers (city)
Создание уникального индекса
CREATE UNIQUE INDEX …………….
Удаление индекса
DROP INDEX <имя_индекса>
Замечание: допускается создание трех типов индексов:
Уникальный индекс (Unique Index): этот индекс не позволяет
индексируемому атрибуту иметь повторяющиеся значения, для
первичного ключа уникальный индекс может быть создан
автоматически
Кластеризованный индекс (Clustered Index): этот индекс изменяет
физический порядок кортежей таблицы и выполняет поиск по
значению ключа; каждая таблица может иметь только один
кластеризованный индекс.
Некластеризованный индекс (Non-Clustered Index): этот индекс не
изменяет физический порядок кортежей таблицы, поддерживая
логический порядок; таблица может иметь много
некластеризованных индексов
155.
Ограничения на допустимые значения данных• Ограничения (Constraints) могут быть наложены на отдельные
атрибуты или на всю таблицу
• Ограничение на атрибут формулируется как свойство этого атрибута
• Ограничение на таблицу формулируется после описания последнего
атрибута, как правило, применяется к группе атрибутов
Виды ограничений в SQL:
– NOT NULL – исключение NULL-значений
– UNIQUE - поддержка уникальности значения
– PRIMARY KEY – определение первичного ключа
– CHECK - ограничение на значения атрибутов
– DEFAULT - значение по умолчанию
– FOREIGN KEY … REFERENCES – определение внешнего ключа
Исключение NULL-значений: NOT NULL
• Пример
CREATE TABLE suppliers
(
cod_s varchar(4) NOT NULL,
surname varchar(20) NOT NULL,
rating smallint,
city varchar(20)
)
156.
Поддержка уникальности значений: UNIQUE• Пример 1 – ограничение на атрибут
CREATE TABLE suppliers
(
cod_s varchar(4) NOT NULL UNIQUE,
surname varchar(20) NOT NULL,
rating smallint,
city varchar(20)
)
Замечание: Стандарты SQL:92, SQL:1999 и SQL: 2003 допускают повторение в
столбце значений NULL, но в некоторых СУБД ограничение UNIQUE
должно использоваться совместно с ограничением NOT NULL
• Пример 2 – ограничение на таблицу (в одном городе не должно быть
поставщиков с одинаковой фамилией)
CREATE TABLE suppliers
(
cod_s varchar(4) NOT NULL UNIQUE,
surname varchar(20) NOT NULL,
rating smallint,
city varchar(20) NOT NULL,
UNIQUE (surname, city)
)
Замечание: здесь также каждый из атрибутов, на комбинацию которых
накладывается ограничение, не должен принимать значение NULL
157.
Определение первичного ключа: PRIMARY KEY• Если ключ простой, ограничение накладывается на соответствующий
атрибут
Пример1 – определение простого ключа (ограничение на атрибут)
CREATE TABLE suppliers
(
cod_s varchar(4) NOT NULL PRIMARY KEY,
surname varchar(20) NOT NULL,
rating smallint,
city varchar(20) NOT NULL,
UNIQUE (Sname, city)
)
Замечание: в некоторых СУБД ограничение NOT NULL здесь обязательно
• Ограничений UNIQUE может быть несколько, PRIMARY KEY - только одно
Пример 2 – определение составного ключа (ограничение на таблицу)
CREATE TABLE suppliers
(
surname varchar(20) NOT NULL,
Birth smallint NOT NULL,
rating smallint,
city varchar(20),
PRIMARY KEY (surname, Birth) /*Составной ключ: Фамилия, ГодРожд*/
)
Замечание: ограничение NOT NULL накладывается на оба атрибута
158.
Ограничение на значения атрибутов: CHECK• Формулируется в виде
CHECK(<логическое выражение>)
• Если в логическое выражение входит только одно имя атрибута,
ограничение накладывается на соответствующий атрибут
• Если в логическое выражение входят имена нескольких атрибутов,
ограничение накладывается на таблицу
• Пример 1 – ограничение на значения атрибутов (ограничение на атрибут)
CREATE TABLE suppliers
(
cod_s varchar(4) NOT NULL PRIMARY KEY,
surname varchar(20),
rating smallint CHECK (rating>=10),
city varchar(20)
)
• Пример 2 – ограничение на значения атрибутов (ограничение на атрибут)
CREATE TABLE suppliers
(
cod_s varchar(4) NOT NULL PRIMARY KEY,
surname varchar(20),
rating smallint,
city varchar(20) CHECK (city IN ('Москва', 'Тула', 'Орел'))
)
159.
Пример 3 – ограничение на значения атрибутов (ограничение на таблицу)
CREATE TABLE suppliers
(
cod_s varchar(4) NOT NULL PRIMARY KEY,
surname varchar(20),
rating smallint CHECK (rating>=10),
city varchar(20),
CHECK(city='Москва' OR rating>20) /*живет в Москве или рейтинг>20*/
)
Задание значения по умолчанию: DEFAULT
• Ограничение накладывается на атрибут в виде :
DEFAULT <значение>
• Если для атрибута значение по умолчанию не задано, в качестве этого
значения используется NULL
• Пример
CREATE TABLE suppliers
(
cod_s varchar(4) NOT NULL PRIMARY KEY,
surname varchar(20) NOT NULL,
rating smallint DEFAULT 20,
city varchar(20) DEFAULT 'Тула'
)
• Замечание: нецелесообразно задавать DEFAULT для атрибута, на который
наложено ограничение UNIQUE или PRIMARY KEY
160.
Поддержка целостности по внешним ключам• Внешний ключ поддерживает ссылочную целостность, обеспечивая
связь между данными в двух таблицах.
• Внешний ключ в дочерней таблице ссылается на первичный ключ в
родительской таблице.
• Ограничение внешнего ключа предотвращает действия, которые
разрушают связи между дочерней и родительской таблицами.
• Если внешний ключ - простой атрибут, ограничение накладывается на
соответствующий атрибут в виде:
REFERENCES <имя_таблицы> (<имя_атрибута>)
• Если внешний ключ - составной атрибут, ограничение накладывается на
таблицу в виде:
– FOREIGN KEY(<список атрибутов>)
– REFERENCES имя_таблицы (<список атрибутов>)
• Пример 1 - внешний ключ – ограничение на атрибут
CREATE TABLE suppliers
Таблица со
(
списком городов,
cod_s varchar(4) NOT NULL PRIMARY KEY,
в которой city –
surname varchar(20) NOT NULL,
первичный ключ
rating smallint DEFAULT 20,
city varchar(20) DEFAULT 'Тула' REFERENCES AllCities(city)
)
161.
Если таблицы связаны по внешнему ключу, удаление строк родительской
таблицы, на которые имеются ссылки, запрещено по умолчанию
Однако реакцией системы на эту ситуацию можно управлять:
ON DELETE RESTRICT – запрещает удаление связанной строки
ON DELETE CASCADE – удалять все связанные строки
SET NULL – значение NULL для неопределенных ссылок
SET DEFAULT – значение DEFAULT для неопределенных ссылок
Пример 1а - внешний ключ – удаление связанных строк
CREATE TABLE suppliers (
cod_s varchar(4) NOT NULL PRIMARY KEY,
surname varchar(20) NOT NULL,
rating smallint DEFAULT 20,
city varchar(20) REFERENCES AllCities(city) ON DELETE CASCADE
)
Пример 2 - внешний ключ составной – ограничение на таблицу
CREATE TABLE OrderSales (
CodOrd varchar(4) NOT NULL PRIMARY KEY,
Productname varchar(20) NOT NULL,
quantProduct integer DEFAULT 100,
surname varchar(4) NOT NULL,
Birth smallint NOT NULL,
FOREIGN KEY(surname, Birth) REFERENCES suppliers(surname, Birth)
)
Если внешний ключ – простой атрибут, можно и как ограничение на таблицу
162.
Поставщикm
Поставляет
suppliers - Поставщики
n
Деталь
sup_det - Поставки
cod_s
surname
rating
city
S1
Иванов
20
Москва
cod_s
cod_d
quant
S2
Петров
10
Тула
S1
D1
100
S3
Сидоров
30
Тула
S1
D3
100
S4
Круглов
20
Москва
S1
D5
200
S5
Смирнов
30
Орел
S2
D2
300
S2
D4
200
S3
D2
300
S4
D5
100
S4
D6
400
S5
D1
200
S5
D3
200
S5
D4
100
details - Детали
cod_d
name
color
wei
city
D1
Гайка
Красный
12
Москва
D2
Болт
Зеленый
17
Тула
D3
Винт
Синий
17
Рязань
D4
Винт
Красный
14
Москва
D5
Шайба
Синий
12
Тула
D6
Кольцо
Красный
19
Москва
D7
Винт
Красный
20
Тула
163.
CREATE TABLE suppliers (cod_s varchar(4) NOT NULL PRIMARY KEY,
surname varchar(20) NOT NULL,
rating smallint DEFAULT 20,
details - Детали
city varchar(20) DEFAULT 'Тула'
cod_d name
color
)
suppliers - Поставщики
wei
city
D1
Гайка
Красный
12
Москва
cod_s
surname
rating
city
D2
Болт
Зеленый
17
Тула
S1
Иванов
20
Москва
D3
Винт
Синий
17
Рязань
S2
Петров
10
Тула
D4
Винт
Красный
14
Москва
S3
Сидоров
30
Тула
D5
Шайба
Синий
12
Тула
S4
Круглов
20
Москва
D6
Кольцо
Красный
19
Москва
S5
Смирнов
30
Орел
D7
Винт
Красный
20
Тула
CREATE TABLE details (
cod_d varchar(4) NOT NULL PRIMARY KEY,
name varchar(20) NOT NULL,
color varchar(20),
wei integer,
city varchar(20) DEFAULT 'Тула'
)
164.
CREATE TABLE sup_det(
cod_s varchar(4) NOT NULL,
ссылки?
cod_d varchar(4) NOT NULL,
quant smallint CHECK (quant <=1000),
PRIMARY KEY(cod_s, cod_d)
)
sup_det - Поставки
ID
cod_
d
quant
1
cod_
s
2
S1
D1
100
3
S1
D3
100
S1
D5
200
S2
D2
300
S2
D4
200
S3
D2
300
S4
D5
100
S4
D6
400
S5
D1
200
D3
200
D4
100
4
5
Суррогатный ключ
тип serial
6
7
8
9
10
CREATE TABLE sup_det
S5
11
(
S5
ID serial NOT NULL PRIMARY KEY,
cod_s varchar(4) NOT NULL REFERENSES suppliers (cod_s),
cod_d varchar(4) NOT NULL REFERENSES details (cod_d),
quant smallint CHECK (quant <=1000),
UNIQUE(cod_s, cod_d)
)
165.
Манипулирование данными в SQL (DML)• Подъязык манипулирования данными включает 4 оператора:
– SELECT выборка данных из таблиц – формирует отношение из
данных, выбираемых из базы данных; на основе оператора SELECT
строится язык запросов к базе данных
– INSERT добавление новых данных – добавляет кортеж к ранее
созданной таблице
– DELETE удаление данных – удаляет кортеж из ранее созданной
таблицы
– UPDATE изменение существующих данных изменяет значения
атрибутов в ранее размещенном в таблице кортеже
• SELECT не вносит изменений в базу данных
• INSERT, DELETE и UPDATE изменяют данные
Заполнение таблиц БД «Поставки» оператором INSERT
INSERT INTO suppliers VALUES ('S1', 'Иванов', 20, 'Москва');
…………………………………………………………………………
INSERT INTO details VALUES ('D1', 'Гайка', 'Красный', 12, 'Москва');
…………………………………………………………………………
INSERT INTO sup_det(cod_s, cod_d, quant) VALUES ('S1', 'D1', 100);
…………………………………………………………………………
Замечание: можно сразу несколько строк:
INSERT INTO suppliers VALUES
('S1', 'Иванов', 20, 'Москва'), ('S2', ‘Петров', 10, ‘Тула'), …;
166.
• Оператор SELECTОбщая структура запроса на выборку данных из таблицы с оператором
SELECT:
SELECT <список имен атрибутов>
FROM <имя_таблицы>
WHERE <предикат – условие истинности (условие отбора)>
Простая выборка
• Простая выборка – это выборка SELECT без условия отбора (WHERE):
SELECT *
-- звездочка в SELECT означает «все атрибуты таблицы»
FROM имя_таблицы
• Результат выборки – вся таблица
• Пример 1
SELECT cod_d
FROM sup_det
• Результат: столбец cod_d таблицы поставок sup_det
• Пример 2 – перестановка атрибутов
SELECT cod_d, cod_s
FROM sup_det
• Результат: переставленные столбцы cod_d, cod_s таблицы поставок sup_det
• Можно изменить название столбцов при выводе результата, назначив
именам атрибутов в предложении SELECT псевдонимы:
SELECT cod_d AS cod_detail, cod_s AS cod_supplier /*можно кириллицу*/
FROM sup_det
167.
Пример – выборка с исключениемдублирования (параметр DISTINCT)
SELECT DISTINCT cod_d
FROM sup_det
• Результат
D1
D3
D5
D2
D4
D6
ALL вместо DISTINCT– выборка без
исключения дублирования,
используется по умолчанию
Пример – выборка
с вычислением значений
SELECT cod_d, wei*1000
FROM details
• Результат
D1 12000
D2 17000
D3 17000
D4 14000
D5 12000
D6 19000
D7 20000
Пример – вставка текста в выборку
SELECT 'Вес детали ', cod_d, ' равен ', wei
FROM details
Результат
Вес детали D1 равен 12
Вес детали D2 равен 17
Вес детали D3 равен 17
Вес детали D4 равен 14
Вес детали D5 равен 12
Вес детали D6 равен 19
Вес детали D7 равен 20
168.
Выборка с ограничениями• Выборка с ограничениями – это выборка SELECT с условием отбора
WHERE
Пример: выбрать коды и фамилии поставщиков, проживающих в Туле и
имеющих рейтинг, больший 20
SELECT cod_s, surname
FROM suppliers
WHERE city = 'Тула' AND rating>20
• Результат
S3 Сидоров
Пример: какие цвета имеют детали, имеющие вес больше 17 или
наименование «Винт»
SELECT DISTINCT color
FROM details
WHERE wei > 17 OR name = 'Винт'
• Результат
Синий
Красный
Замечание: при отсутствии в запросе DISTINCT Красный цвет повторялся
бы трижды
169.
Пример: выбрать фамилии поставщиков с рейтингом выше 20, непроживающих в Москве
SELECT DISTINCT surname
FROM suppliers
WHERE NOT city = 'Москва' AND rating > 20
• Результат
Сидоров
Смирнов
Замечание: Последовательность операций в предложении WHERE: =, >, NOT,
AND; эквивалентное выражение (NOT (city = 'Москва')) AND (rating > 20)
Операция IN – принадлежность множеству значений
Пример: выбрать фамилии поставщиков, проживающих в Туле или Москве
SELECT surname
FROM suppliers
WHERE city IN ('Тула', 'Москва') -- вместо city='Тула‘ OR city= 'Москва'
• Результат
Иванов
Петров
Сидоров
Круглов
Замечание: можно с отрицанием NOT IN (не проживающих в Туле или Москве)
SELECT surname
FROM suppliers
WHERE city NOT IN ('Тула', 'Москва')
170.
Операция BETWEEN – принадлежность интервалу (включая границы)Пример: выбрать код и наименование деталей, вес которых попадает в
диапазон от 16 до 19
SELECT cod_d, name
FROM details WHERE wei BETWEEN 16 AND 19
• Результат
D2 Болт
D3 Винт
D6 Кольцо
Замечание: операцию BETWEEN можно использовать с отрицанием NOT:
SELECT cod_d, name
FROM details
WHERE wei NOT BETWEEN 16 AND 19
Операция LIKE – подобно шаблону (тип char, varchar)
LIKE <шаблон>
«_» - любой символ, «%» - любое количество символов
Пример: выбрать сведения о поставщиках, фамилия которых начинается с
буквы «С» и заканчивается буквой «в»
SELECT *
FROM suppliers WHERE surname LIKE 'С%в'
• Результат
S3 Сидоров
30
Тула
S5 Смирнов
30
Орел
171.
Замечание 1: операцию LIKE можно использовать с отрицанием NOT:SELECT *
FROM suppliers
WHERE surname NOT LIKE 'С%в '
Пример: выбрать сведения о поставщиках, с фамилией не менее, чем из 7
букв, начинающейся не на букву «С» и в которой отсутствует буква «н»
SELECT *
FROM suppliers
WHERE surname LIKE '_______%' -- 7 символов «_»
AND surname NOT LIKE 'С%'
AND surname NOT LIKE '%н%'
• Результат
S4
Круглов
20
Москва
Замечание 2: операция LIKE выполняет поиск с учетом регистра, ее аналог
ILIKE не учитывает регистр при поиске,
• Кроме оператора LIKE можно использовать SIMILAR TO, который
расширяет возможности LIKE, с помощью некоторых дополнительных
операторов так называемых регулярных выражений POSIX:
SELECT surname
FROM suppliers
WHERE surname SIMILAR TO ‘С%‘ –- выбрать фамилии на букву «С»
Замечание 3: можно и с отрицанием NOT SIMILAR TO
172.
Пример: выбрать сведения о поставщиках, с фамилией Смирнов или СидоровSELECT *
FROM suppliers
WHERE surname SIMILAR TO 'С(мирн|идор)ов'
• Для поиска по образцу можно использовать операторы для работы с
регулярными выражениями POSIX:
~ - оператор поиска совпадения с образцом с учетом регистра
~* - оператор поиска совпадения с образцом без учета регистра
символ «^» в начале образца – поиск образца в начале строки
символ «$» в конце образца – поиск образца в конце строки
(<образец1>|<образец2>) – поиск альтернативы
!~, !~* - отрицание, поиск несовпадения с образцом
Примеры:
SELECT surname
FROM suppliers
WHERE surname ~ '^С'
- фамилия начинается с буквы «С»
WHERE surname !~ '^И'
- фамилия не начинаются с буквы «И»
WHERE surname ~ 'ров$'
- фамилия заканчивается на «ров»
WHERE surname ~ 'рно'
- фамилия содержит «рно»
WHERE surname ~ 'с'
- фамилия содержит «с»
WHERE surname ~* ‘с'
- фамилия содержит «с» или «С»
WHERE surname ~* ('^К|н') - фамилия начинается с «К» или содержит «н»
173.
Пример: выбрать города, в которых производятся детали красного цвета, иназвание которых начинается не с буквы «в» и не содержит букву «а»
SELECT DISTINCT city
образец
FROM details
WHERE color='Красный'
AND name !~* '(^в|а)' -- * - без учета регистра
оператор
• Результат: Москва
Использование NULL-значений
• Использовать для сравнения с NULL операцию «=» нельзя; вместо этого
используется конструкция IS NULL
Пример: выбрать все коды деталей, для которых объем поставки не
определен
SELECT cod_d
FROM sup_det
WHERE quant IS NULL
• Результатом этого запроса будет пустая таблица
Замечание: здесь также можно с отрицанием NOT:
SELECT cod_d
FROM sup_det
WHERE quant IS NOT NULL
• Результатом этого запроса будут все коды деталей из таблицы sup_det
174.
Выборка с упорядочиванием• Упорядочить кортежи выборки:
ORDER BY <имя_атрибута> <параметр>, <имя_атрибута> <параметр> …
Значения параметра:
• ASC – по возрастанию (используется по умолчанию)
• DESC – по убыванию
Замечание: вместо имени атрибута можно указать его номер
Пример: выбрать наименование, цвет и вес деталей, производимых не в
Москве и не в Рязани, упорядочив по возрастанию веса, а при
одинаковом весе по убыванию цвета
SELECT name, color, wei
FROM details
WHERE city NOT IN ('Москва', 'Рязань')
ORDER BY wei, color DESC
• Результат
Шайба Синий
12
Болт Зеленый 17
Винт Красный 20
Замечание: если среди значений атрибута, по которому упорядочиваем,
есть NULL, соответствующие кортежи помещаются либо в начало, либо
в конец выборки
175.
Условные выражения• В качестве выводимого элемента в предложении SELECT можно
разместить условное выражение вида:
CASE
WHEN <лог.выражение> THEN <выражение>
WHEN <лог.выражение> THEN <выражение>
………………………..
ELSE <выражение>
END
• В этом случае значения соответствующего атрибута будут вычисляться
в ветви, соответствующей значению true логического выражения
Пример: для деталей красного цвета вывести название детали, город и
статус города (столица, регион)
SELECT name, city,
CASE
WHEN city = 'Москва' THEN 'Столица'
WHEN city IN ('Тула', 'Рязань') THEN 'Регион'
Винт
Москва Столица
ELSE 'Неизвестен'
END AS Статус_города
Винт
Тула
Регион
FROM details
Гайка Москва Столица
WHERE color='Красный'
Кольцо Москва Столица
ORDER BY name;
176.
Использование агрегированных функций• Агрегированная (агрегатная) функция вычисляет некоторое значение на
множестве значений атрибута - аргумента агрегированной функции
• Агрегированные функции SQL:
– COUNT – определяет количество кортежей или значений атрибута,
не являющихся NULL-значениями
– SUM – вычисляет сумму всех выбранных значений данного атрибута
– AVG - вычисляет среднее арифметическое всех выбранных
значений данного атрибута
– MAX - вычисляет наибольшее из всех выбранных значений данного
атрибута
– MIN - вычисляет наименьшее из всех выбранных значений данного
атрибута
• Структура простого запроса с функцией агрегирования:
SELECT <имя_функции> (<имя_атрибута>)
FROM <имя_таблицы>
Замечание 1: композиция функций запрещена
Замечание 2: аргументом функции может быть выражение
Замечание 3: для целочисленных аргументов результатом вычисления
функции AVG будет значение типа numeric, для аргументов, которые
представляют число с плавающей точкой, - значение типа double
177.
Пример 1: найти минимальный объем поставки (простой запрос)
SELECT MIN(quant)
FROM sup_det
• Результат: 100
• Пример 2: найти средний рейтинг поставщика, проживающего в Туле
(запрос с ограничением)
SELECT AVG(rating)
FROM suppliers
WHERE city = 'Тула'
• Результат: 20.0000000000000000
• В этом примере результат вычисления среднего значения будет иметь
приближенный числовой тип numeric, при выводе значения этого типа
автоматически определяемая точность по умолчанию будет достаточно
высокой, что, как правило, приводит к большому числу выводимых в
дробной части незначащих нулей, например, 20.0000000000000000
• Задать формат выводимого числового значения или даты в PostgreSQL
можно с помощью функции преобразования числа в текст
to_char(число, формат) или to_char(дата, формат)
to_char(12.1, '999.99') - число будет выведено с точностью до 3 знаков в целой
и 2 знака в дробной части: 12.10
to_char(дата, ‘DD.MM.YYYY') – дата будет выведена в указанном формате
Замечание: количество цифр 9 в шаблоне '999.99‘ должно быть достаточным
для выводимого числового значения
178.
• В последнем примере задать формат вывода среднего значения можно,изменив строку SELECT следующим образом:
SELECT to_char(AVG(rating), '999.99') /*теперь выведется 20.00*/
FROM suppliers
WHERE city = 'Тула'
Использование выражений в качестве аргумента агрегированной функции
• Пример 3: найти удвоенное среднее значение рейтинга
SELECT to_char(AVG(2*rating), '999.99')
FROM suppliers
• Результат: 44.00
Специфика использования функции COUNT
• Пример 4: найти количество поставщиков, имеющих рейтинг (не NULLзначение)
SELECT COUNT(rating)
FROM suppliers
• Результат: 5
• Пример 5: найти количество различных значений рейтинга
SELECT COUNT(DISTINCT rating)
FROM suppliers
• Результат: 3
179.
• Пример 6: найти количество кортежей в таблице поставщиковSELECT COUNT(*)
FROM suppliers
• Результат: 5
Замечание 1: учитываются и NULL-значения, и повторяющиеся значения
Использование параметра ALL
• Параметр ALL имеет смысл, противоположный DISTINCT : дубликаты
считаются, но NULL -значения игнорируются
• Пример 7: найти количество поставщиков, имеющих какой-либо
рейтинг
SELECT COUNT(ALL rating)
FROM suppliers
• Результат: 5
Замечание 2: этот запрос дает тот же результат, что и запрос из первого
примера
Замечание 3: DISTINCT можно использовать и с другими функциями
• Пример: найти среднее арифметическое неповторяющихся значений
рейтинга
SELECT to_char(AVG(DISTINCT rating), '999.99')
FROM suppliers
• Результат: 20.00
180. Группировка GROUP BY
• GROUP BY позволяет группировать кортежи по значенияматрибута и вычислять агрегированные функции от другого
атрибута отдельно для каждой группы
• Пример : для каждой детали выбрать поставку максимального
объема (группировка по одному атрибуту)
SELECT cod_d, MAX(quant)
FROM sup_det
GROUP BY cod_d
• Результат:
D1 200
D3 200
D5 200
D2 300
D4 200
D6 400
Замечание: в этом примере функция MAX вычисляется отдельно
для каждой группы с одинаковым значением атрибута cod_d
181.
• GROUP BY позволяетгруппировать кортежи и по
значениям нескольких атрибутов
• Пример : для каждого сочетания
наименования и цвета детали
выбрать деталь с максимальным
весом (группировка по
нескольким атрибутам)
SELECT name, color, MAX(wei)
FROM details
GROUP BY name, color
• Результат:
Гайка Красный 12
Болт Зеленый 17
Винт Синий
17
Винт Красный 20
Шайба Синий
12
Кольцо Красный 19
Замечание: все атрибуты, указанные
в SELECT и не входящие в
аргумент агрегированной
функции, должны быть указаны и
в GROUP BY
В запросе с группировкой может
присутствовать и условие WHERE,
при этом сначала отбираются
кортежи, удовлетворяющие
условию, а затем выполняется
группировка с вычислением
агрегированной функции для
каждой группы
• Пример : для каждого города
вычислить минимальный вес
детали красного цвета,
поставляемой из этого города
SELECT city, MIN(wei)
FROM details
WHERE color = 'Красный'
GROUP BY city
• Результат:
Москва 12
Тула
20
Замечание 1: по условию WHERE
кортежи отбираются до
группировки и вычисления
агрегированных функций
Замечание 2: условие WHERE не
позволяет отобрать группы, по
некоторому ограничению,
наложенному на группу в целом
182.
Использование HAVING в запросе с группировкойHAVING позволяет наложить ограничение на выбираемые группы кортежей
по некоторому дополнительному условию для отбираемой группы
• Это условие должно накладывать ограничение на значение некоторой
величины, характеризующей группу в целом
• Пример : для каждой группы деталей одинакового наименования
вычислить суммарный вес при условии, что он превосходит 18
SELECT name AS НаименованиеДетали, SUM(wei) AS СуммарныйВес
FROM details
GROUP BY name
HAVING SUM(wei) > 18
• Результат:
Винт 51
Кольцо 19
Замечание: в HAVING должно быть такое выражение, которое имеет одно
значение для всей группы, например, в последнем примере можно так:
HAVING name='Винт‘
• Иногда полезно бывает при выводе группировок добавлять суммирующую
строку. В PostgreSQL это можно сделать с помощью оператора ROLLUP:
SELECT city, COUNT(*), SUM(wei)
FROM details
GROUP BY ROLLUP (city)
ORDER BY SUM(wei)
Рязань
Москва
Тула
NULL
1
3
3
7
17
45
49
111
183.
Использование OFFSET и LIMIT в PostgreSQL• OFFSET позволяет пропустить несколько строк при выводе результата
выборки, LIMIT – задать количество выводимых строк
• Пример: для каждой группы деталей одинакового наименования
вычислить суммарный вес, отсортировав по наименованию детали
SELECT name, SUM(wei)
FROM details
GROUP BY name
ORDER BY name
Болт
Винт
Гайка
Кольцо
Шайба
• Добавив OFFSET, пропускаем 2 строки при выводе:
SELECT name, SUM(wei)
Гайка
FROM details
Кольцо
GROUP BY name
Шайба
ORDER BY name
OFFSET 2
• Вывести 3 строки, начиная со второй можно так:
SELECT name, SUM(wei)
FROM details
Винт
GROUP BY name
Гайка
ORDER BY name
Кольцо
OFFSET 1 LIMIT 3
17
51
12
19
12
12
19
12
51
12
19
184.
Mножественные группировки в одном запросеМножественные группировки удобно применять, если нужно сделать
несколько запросов к одной и той же таблице, отличающихся только
условием в GROUP BY
Для этого после фразы GROUP BY в качестве элемента группировки
указываются модификаторы GROUPING SETS, ROLLUP, CUBE
• Результат
Гайка Красный
Кольцо Красный
Шайба Синий
Винт
Красный
Болт
Зеленый
Винт
Синий
12
19
12
34
17
17
Пример 1 – простая группировка
SELECT name, color, SUM(wei)
FROM details
GROUP BY name, color
GROUPING SETS (имя_атр, имя_атр, …) – группировка отдельно по
каждому из указанных атрибутов, для остальных атрибутов - значение NULL
Пример 2 - GROUPING SETS-группировка
SELECT name, color, SUM(wei)
FROM details
GROUP BY GROUPING SETS (name, color)
Шайба NULL
Кольцо NULL
Винт
NULL
Болт
NULL
Гайка NULL
NULL Красный
NULL Синий
NULL Зеленый
12
19
51
17
12
65
29
17
185.
• Чтобы дополнительно получить строку с полной суммой безгруппировки можно добавить в GROUPING SETS пустую группировку (),
все поля атрибутов в которой будут заполнены NULL
• Пример 3 – дополнение полной суммы без группировки
SELECT name, color, SUM(wei)
FROM details
GROUP BY GROUPING SETS (name, color, ())
• Результат
NULL
NULL
111
Шайба
NULL
12
Кольцо
NULL
19
Винт
NULL
51
Болт
NULL
17
Гайка
NULL
12
NULL
Красный
65
NULL
Синий
29
NULL
Зеленый
17
• Добавив в список выбираемых атрибутов (фраза SELECT) функцию
grouping(имя_атр), можем узнать, какие атрибуты в данной строке
участвуют в группировке
• Функция grouping(имя_атр) возвращает 0, если указанный атрибут
участвует в группировке, в противном случае функция возвращает 1
186.
Пример 4 – добавление признака участия атрибута в группировке
SELECT name, color, SUM(wei), grouping(color)
FROM details
GROUP BY GROUPING SETS (name, color, ())
Результат
NULL
Шайба
Кольцо
Винт
Болт
Гайка
NULL
NULL
NULL
NULL
NULL
NULL
NULL
NULL
NULL
Красный
Синий
Зеленый
111
12
19
51
17
12
65
29
17
1
1
1
1
1
1
0
0
0
При участии в группировке двух атрибутов, приведем результат к типу bit(2):
SELECT name, color, SUM(wei), grouping(name, color)::BIT(2)
FROM details
GROUP BY GROUPING SETS (name, color, ())
Результат
NULL
Шайба
Кольцо
Винт
Болт
Гайка
NULL
NULL
NULL
NULL
NULL
NULL
NULL
NULL
NULL
Красный
Синий
Зеленый
111
12
19
51
17
12
65
29
17
11
01
01
01
01
01
10
10
10
→3
→1
→1
→1
→1
→1
→2
→2
→2
187.
• Можно объединять атрибуты внутри GROUPING SETS в группы• Пример 5 - GROUPING SETS с группировкой атрибутов
SELECT name, color, city, SUM(wei), grouping(name, color, city)::BIT(3)
FROM details
GROUP BY GROUPING SETS ((name,city), (color, city))
• Результат
Болт
NULL
Тула
17
010
Кольцо
NULL
Москва
19
010
Винт
NULL
Тула
20
010
Винт
NULL
Рязань
17
010
Шайба
NULL
Тула
12
010
Винт
NULL
Москва
14
010
Гайка
NULL
Москва
12
010
NULL
Синий
Рязань
17
100
NULL
Зеленый
Тула
17
100
NULL
Красный
Москва
45
100
NULL
Синий
Тула
12
100
NULL
Красный
Тула
20
100
188.
• Модификатор CUBE(имя_атр1, имя_атр2, имя_атр3,…) возвращаетгруппировки по всем возможным сочетаниям перечисленных в скобках
атрибутов
• Пример 6 – использование модификатора CUBE
SELECT name, color, city, COUNT(*), SUM(wei)
FROM details
GROUP BY CUBE (name, color, city)
• в этом примере будут возвращены 37 кортежей, включающие
следующие 8 вариантов группировки:
NULL, NULL, NULL - без группировки
name, color, city
- группировка по трем атрибутам
name, color, NULL - группировки по двум атрибутам
name, NULL, city
NULL, color, city
name, NULL, NULL - группировки по одному атрибуту
NULL, color, NULL
NULL, NULL, city
• Кроме того, группировка с модификатором CUBE выводит
суммирующую строку не только по всей таблице в целом (без
группировки), но и по каждой из групп в отдельности
189.
Модификатор ROLLUP(имя_атр1, имя_атр2, имя_атр3,…) генерирует
сочетания атрибутов, по которым выполняется группировка, убирая
атрибуты по одному с конца списка атрибутов в скобках (иерархически)
• Кроме того, ROLLUP, как и CUBE, выводит суммирующую строку не только
по всей таблице в целом, но и по каждой из групп в отдельности
• Пример 7 – использование модификатора ROLLUP
SELECT name, color, city, COUNT(*), SUM(wei)
FROM details
GROUP BY ROLLUP (name, color, city)
будут возвращены следующие 4 варианта сочетаний атрибутов:
NULL, NULL, NULL
name, color, city
name, color, NULL
name, NULL, NULL
из 8 сочетаний, по которым выполнит группировку CUBE.
• Используя в предложении SELECT функцию COALESCE(имя_атр, 'текст')
можно вместо NULL для данного атрибута выводить указанный текст:
SELECT
COALESCE(name, ‘ВсеДетали'),
COALESCE(color, ‘ВсеЦвета'),
COALESCE(city, ‘ВсеГорода'),
COUNT(*), SUM(wei)
FROM details
GROUP BY ROLLUP (name, color, city)
190.
• Результат запросаВсеДетали ВсеЦвета
ВсеГорода
7
111
Кольцо
Красный
Москва
1
19
Винт
Красный
Москва
1
14
Шайба
Синий
Тула
1
12
Гайка
Красный
Москва
1
12
Винт
Красный
Тула
1
20
Винт
Синий
Рязань
1
17
Болт
Зеленый
Тула
1
17
Гайка
Красный
ВсеГорода
1
12
Кольцо
Красный
ВсеГорода
1
19
Шайба
Синий
ВсеГорода
1
12
Винт
Красный
ВсеГорода
2
34
Болт
Зеленый
ВсеГорода
1
17
Винт
Синий
ВсеГорода
1
17
Шайба
ВсеЦвета
ВсеГорода
1
12
Кольцо
ВсеЦвета
ВсеГорода
1
19
Винт
ВсеЦвета
ВсеГорода
3
51
Болт
ВсеЦвета
ВсеГорода
1
17
Гайка
ВсеЦвета
ВсеГорода
1
12
для каждой группировки здесь выведена и итоговая строка
• Удобнее будет анализировать данные, добавив в запрос фразу
ORDER BY name, color, city
191.
• Результат отсортированного запросаБолт
Зеленый
Тула
Болт
Зеленый
ВсеГорода
Болт
ВсеЦвета
ВсеГорода
Винт
Красный
Москва
Винт
Красный
Тула
Винт
Красный
ВсеГорода
Винт
Синий
Рязань
Винт
Синий
ВсеГорода
Винт
ВсеЦвета
ВсеГорода
Гайка
Красный
Москва
Гайка
Красный
ВсеГорода
Гайка
ВсеЦвета
ВсеГорода
Кольцо
Красный
Москва
Кольцо
Красный
ВсеГорода
Кольцо
ВсеЦвета
ВсеГорода
Шайба
Синий
Тула
Шайба
Синий
ВсеГорода
Шайба
ВсеЦвета
ВсеГорода
ВсеДетали ВсеЦвета
ВсеГорода
1
1
1
1
1
2
1
1
3
1
1
1
1
1
1
1
1
1
7
17
17
17
14
20
34
17
17
51
12
12
12
19
19
19
12
12
12
111
192.
Соединения таблицНередко возникает необходимость в одном запросе получить данные сразу
из нескольких таблиц.
• В SQL предусмотрены несколько способов построения запроса данных с
использованием нескольких таблиц.
• Одним из таких способов является построение соединения таблиц с
последующей выборкой данных из соединения.
• При этом можно использовать две формы запроса с соединением таблиц:
неявное соединение и явное соединение (явная операция JOIN).
Неявное соединение таблиц
• При выборке данных с использованием неявного соединения таблиц в
предложении FROM через запятую указываются имена нескольких таблиц
• При дублировании имен в соединяемых таблицах полное имя атрибута:
имя_таблицы.имя_атрибута
• Пример 1: выбрать все фамилии поставщиков и наименования деталей
синего цвета, которые производятся в том же городе, где проживает
поставщик
• SELECT suppliers.surname, details.name /*или SELECT surname, name */
FROM suppliers, details
WHERE suppliers.city = details.city AND color = 'Синий'
• Результат:
Петров Шайба
Сидоров Шайба
Замечание: сначала вычисляется декартово произведение, затем
отбрасываются кортежи, не удовлетворяющие условию и столбцы, не
указанные в предложении SELECT
193.
• Пример 2: выбрать фамилию игород проживания поставщика
при условии, что у него есть
поставки объемом более 200
• SELECT DISTINCT surname, city
• FROM suppliers, sup_det
• WHERE
suppliers.cod_s = sup_det.cod_s
• AND sup_det.quant > 200
• Результат:
Петров Тула
Сидоров Тула
Круглов Москва
Замечание: параметр DISTINCT
здесь необходим, иначе каждый
кортеж будет повторяться в
полученной таблице столько раз,
сколько у данного поставщика
поставок, объемом более 200
• Пример 3: (соединение более 2
таблиц) выбрать поставки
поставщиков, которые проживают
не в том городе, где производятся
детали
• SELECT DISTINCT
– surname, name, quant
• FROM suppliers, details, sup_det
• WHERE
• sup_det.cod_s=suppliers.cod_s
• AND sup_det.cod_d= details.cod_d
AND suppliers.city <> details.city
• Результат:
Иванов Винт
100
Иванов Шайба 200
Петров Винт
200
Круглов Шайба 100
Смирнов Гайка 200
Смирнов Винт 200
Смирнов Винт 100
194.
Соединение копий одной таблицы (алиасов)Алиас – копия таблицы
Имя алиаса: имя_таблицы имя_алиаса_таблицы
Примеры имен алиасов:
suppliers first, suppliers second,
details a, details b,
пробел
sup_det sup_det1, sup_det sup_det2
Пример 1: (неявное соединение алиасов одной таблицы) найти все пары
поставщиков, имеющих одинаковый рейтинг
SELECT a.surname, b.surname, a.rating
FROM suppliers a, suppliers b
WHERE a.rating = b.rating
Результат:
Иванов
Иванов
20
Иванов
Круглов
20
Петров
Петров
10
Семантическое
Сидоров
Сидоров
30
дублирование!
Сидоров
Смирнов
30
Круглов
Иванов
20
Круглов
Круглов
20
Смирнов
Сидоров
30
Смирнов
Смирнов
30
Здесь DISTINCT не устранит семантическое дублирование
195.
• Пример 2: (устранение семантического дублирования)• SELECT a.surname, b.surname, a.rating
FROM suppliers a, suppliers b
WHERE a.rating = b.rating
AND a. surname < b.surname
• Результат:
Иванов Круглов
20
Сидоров Смирнов
30
• Пример 3: найти все возможные комбинации по три поставщика с
рейтингом 10, 20, 30 соответственно
• SELECT a.surname, b.surname, c.surname
FROM suppliers a, suppliers b, suppliers c
WHERE a.rating=10
AND b.rating=20
AND c.rating=30
• Результат:
Петров
Иванов Сидоров
Петров
Иванов Смирнов
Петров
Круглов Сидоров
Петров
Круглов Смирнов
Замечание: физически алиасы не создаются
196.
Явные операции соединения таблиц• В предложении FROM может быть указана явная операция соединения
двух и более таблиц
• Операция соединения по предикату (условию):
FROM <имя_таблицы_1> <операция_соединения> <имя_таблицы 2>
ON <предикат- условие отбора>
• Условие отбора определяет условие соединения кортежей из разных
таблиц (может отсутствовать)
• Виды соединений:
• INNER JOIN (JOIN) – внутреннее соединение
• OUTER JOIN – внешнее соединение
– LEFT OUTER JOIN (LEFT JOIN) – левое внешнее соединение
– RIGHT OUTER JOIN (RIGHT JOIN) – правое внешнее соединение
– FULL OUTER JOIN (FULL JOIN) – полное внешнее соединение
• CROSS JOIN – перекрестное соединение
• При любом соединении таблиц строится декартово произведение
соединяемых таблиц - каждый кортеж первой таблицы соединяется с
каждым кортежем второй таблицы, в результате получаем все
возможные сочетания кортежей двух таблиц (длинные кортежи-строки).
Затем «лишние» строки и столбцы отбрасываются
197.
CROSS JOIN• CROSS JOIN – формируется декартово произведение
• Операция CROSS JOIN используется без предиката в предложении
FROM, однако условие отбора (фильтрация) можно сформулировать в
предложении WHERE
• Пример Декартово произведение таблиц suppliers и details
SELECT * FROM suppliers CROSS JOIN details
что равносильно
SELECT * FROM suppliers, details
• Результат:
S1 Иванов
S1 Иванов
S1 Иванов
S1 Иванов
S1 Иванов
S1 Иванов
S1 Иванов
…
…
S5 Смирнов
20
20
20
20
20
20
20
…
30
Москва
Москва
Москва
Москва
Москва
Москва
Москва
…
Орел
D1
D2
D3
D4
D5
D6
D7
…
D7
Гайка
Болт
Винт
Винт
Шайба
Кольцо
Винт
…
Винт
Красный
Зеленый
Синий
Красный
Синий
Красный
Красный
…
Красный
12
17
17
14
12
19
20
20
Москва
Тула
Рязань
Москва
Тула
Москва
Тула
…
Тула
CROSS JOIN с условием:
SELECT * FROM suppliers CROSS JOIN details
WHERE suppliers.city = details.city /*условие WHERE, а не ON*/
Замечание: операция явного соединения CROSS JOIN полностью идентична
рассмотренной операции неявного соединения таблиц
198.
INNER JOIN• INNER JOIN (или просто JOIN) – внутреннее соединение, в
результирующий набор попадут только те соединения кортежей двух
таблиц, для которых выполнено условие отбора
• Условие отбора в операции INNER JOIN часто определяет соединение
таблиц по внешнему и первичному ключам
• Используя операцию внутреннего соединения, для рассмотренного
ранее запроса с неявным соединением:
– SELECT surname, name
– FROM suppliers, details
WHERE suppliers.city = details.city AND color = 'Синий'
• можно записать еще одну эквивалентную форму с INNER JOIN
– SELECT surname, name
FROM suppliers JOIN details ON suppliers.city = details.city
AND color = 'Синий‘ /*можно WHERE color = 'Синий‘ */
Пример 1: выбрать наименование и цвет деталей, которые поставляются в
объеме более 200
SELECT DISTINCT name, color
FROM details JOIN sup_det ON details.cod_d = sup_det.cod_d
WHERE quant>200;
• Результат:
Болт
Зеленый
Кольцо
Красный
199.
Пример 2: выбрать информацию о поставках с фамилиями поставщиков,наименованием деталей и объемом поставки
Сформируем этот запрос в 2 этапа, сначала свяжем по внешним ключам:
SELECT *
FROM sup_det JOIN suppliers ON suppliers.cod_s = sup_det.cod_s
JOIN details ON details.cod_d = sup_det.cod_d
• Результат:
1 S1 D1 100 S1 Иванов 20 Москва
D1 Гайка
Красный 12 Москва
2 S1 D3 100 S1 Иванов 20 Москва
D3 Винт
Синий
17 Рязань
3 S1 D5 200 S1 Иванов 20 Москва
D5 Шайба
Синий
12 Тула
4 S2 D2 300 S2 Петров 10 Тула
D2 Болт
Зеленый 17 Тула
5 …………………………………………………………………………………………..
11 S5 D4 100 S5 Смирнов 30 Орел
D4 Винт
Красный 14 Москва
Затем оставим только нужные нам атрибуты:
SELECT surname, name, quant
FROM sup_det
JOIN suppliers ON suppliers.cod_s = sup_det.cod_s
JOIN details ON details.cod_d = sup_det.cod_d
Иванов
Иванов
Иванов
Петров
Петров
Сидоров
Круглов
Круглов
Смирнов
Смирнов
Смирнов
Гайка 100
Винт
100
Шайба 200
Болт
300
Винт
200
Болт
300
Шайба 100
Кольцо 400
Гайка
200
Винт
200
Винт
100
200.
Пример 3: Выбрать фамилии поставщиков и наименование деталей дляпоставок, объем которых больше 300
SELECT surname, name
FROM sup_det
JOIN suppliers ON sup_det.cod_s=suppliers.cod_s
JOIN details ON sup_det.cod_d=details.cod_d
WHERE quant >300
• Результат:
Круглов
Кольцо
Пример 4: выбрать информацию о фамилиях поставщиков, наименованиях и
весе деталей по тем поставкам, в которых поставляются детали с весом
больше 14; результат отсортировать по фамилиям поставщика
SELECT surname AS Поставщик, name AS Деталь, wei AS Вес
FROM sup_det
JOIN suppliers ON suppliers.cod_s = sup_det.cod_s
JOIN details ON details.cod_d = sup_det.cod_d
WHERE wei>14
ORDER BY surname
• Результат:
Иванов
Винт
17
Круглов
Кольцо 19
Петров
Болт
17
Сидоров
Болт
17
Смирнов
Винт
17
201.
• Соединения можно использовать совместно с агрегатными функциямиПример 5: для каждого поставщика, у которого более одной поставки, выбрать
количество поставок; результат отсортировать по фамилиям поставщика
SELECT surname, COUNT(*)
FROM suppliers
JOIN sup_det ON suppliers.cod_s=sup_det.cod_s
GROUP BY surname
HAVING COUNT(*)>1
ORDER BY surname
• Результат:
Иванов
3
Круглов
2
Петров
2
Смирнов
3
Замечание: запрос из примера 5 можно было бы сформулировать с CROSS
соединением:
SELECT surname, COUNT(*)
FROM suppliers, sup_det
WHERE suppliers.cod_s=sup_det.cod_s
GROUP BY surname
HAVING COUNT(*)>1
ORDER BY surname
однако стандарт SQL ANSI рекомендует использовать операцию
INNER JOIN вместо CROSS JOIN
202.
• Пример 6: Выбрать фамилии поставщиков, в поставках которыхесть детали одинакового цвета с указанием для каждого цвета
количества поставок поставщика; результат отсортировать по
фамилиям поставщика
SELECT surname, color, COUNT(*)
FROM sup_det
JOIN suppliers ON suppliers.cod_s = sup_det.cod_s
JOIN details ON details.cod_d = sup_det.cod_d
GROUP BY surname, color
HAVING COUNT(*)>1
ORDER BY surname
• Результат:
Иванов
Синий
Смирнов Красный
2
2
Замечание: если надо выбрать фамилии поставщиков, в поставках
которых нет деталей одинакового цвета, в этом запросе надо
изменить фразу с HAVING:
HAVING COUNT(*)=1
203.
LEFT JOIN• LEFT JOIN – левое внешнее соединение, в результирующий набор
кроме кортежей, для которых выполняется условие, попадут все
остальные кортежи из первой (левой) таблицы; при этом отсутствующие
значения полей из правой таблицы будут заполнены NULL-значениями
• Пример: для каждой из фамилий поставщиков выбрать наименования
деталей синего цвета, которые производятся в том же городе, где
проживает поставщик
• SELECT surname, name
FROM suppliers LEFT JOIN details
ON suppliers.city = details.city AND color = 'Синий'
• Результат:
Иванов NULL
Петров Шайба
Сидоров Шайба
Круглов NULL
Смирнов NULL
204.
• Варианты запроса с левым соединением• SELECT surname, name
FROM suppliers LEFT JOIN details
ON suppliers.city = details.city
• Результат:
Иванов Гайка
Иванов Винт
Иванов Кольцо
Петров Болт
Петров Шайба
Петров Винт
Сидоров Болт
Сидоров Шайба
Сидоров Винт
Круглов Гайка
Круглов Винт
Круглов Кольцо
Смирнов NULL
AND color = 'Синий'
Иванов NULL
Петров Шайба
Сидоров Шайба
Круглов NULL
Смирнов NULL
WHERE color = 'Синий'
Петров Шайба
Сидоров Шайба
205.
RIGHT JOIN• RIGHT JOIN – правое внешнее соединение, в результирующий набор
кроме кортежей, для которых выполняется условие, попадут все
остальные кортежи из второй (правой) таблицы; при этом
отсутствующие значения полей из левой таблицы будут заполнены
NULL-значениями
• Пример: для каждого из наименований деталей выбрать все фамилии
поставщиков, которые проживают в том же городе, где производятся
детали, и имеют рейтинг, меньше 20
• SELECT surname, name
FROM suppliers RIGHT JOIN details
ON suppliers.city = details.city AND rating<20
• Результат:
NULL
Гайка
Петров Болт
NULL
Винт
NULL
Винт
Петров Шайба
NULL
Кольцо
Петров Винт
206.
FULL JOIN• FULL JOIN – полное внешнее соединение, в результирующий набор
кроме кортежей, для которых выполняется условие, попадут все
остальные кортежи из первой (левой) и второй (правой) таблиц; при
этом отсутствующие значения полей таблиц будут заполнены NULLзначениями
• Пример:
• SELECT surname, name
FROM suppliers FULL JOIN details
ON suppliers.city = details.city AND color = 'Синий'
• Результат:
Иванов NULL
Петров Шайба
Сидоров Шайба
Круглов NULL
Смирнов NULL
NULL
Гайка
NULL
Болт
NULL
Винт
NULL
Винт
NULL
Кольцо
NULL
Винт
207. Визуальное представление SQL Joins
INNER JOINFULL JOIN
LEFT JOIN
RIGHT JOIN
208.
Исключение пересечения множеств (разность)Пример: выбрать фамилии поставщиков которые проживают в городе, где
не производятся детали синего цвета
• Сначала левое соединение по условию,
Иванов
NULL
что синие детали в городе производятся
Петров
Шайба
SELECT surname, name
Сидоров
Шайба
FROM suppliers LEFT JOIN details
ON suppliers.city = details.city
Круглов
NULL
AND color = 'Синий‘
Смирнов
WHERE name IS NULL
Для фамилий, где такой детали не нашлось,
name имеет значение NULL
Поэтому добавляем к запросу условие
WHERE name IS NULL
details.name IS NULL
Пересечение (INNER JOIN)
NULL
209.
• С соединениями можно использоватьагрегированные функции
• Пример: Для каждой фамилии поставщика,
суммарный объем поставок которого превосходит
300, вычислить суммарный объем поставки,
упорядочив выборку по фамилиям
SELECT surname, SUM(quant)
• Результат:
FROM sup_det
Иванов
JOIN suppliers ON sup_det.cod_s=suppliers.cod_s
Круглов
GROUP BY surname
Петров
HAVING SUM(quant)>300
Смирнов
ORDER BY surname
• Пример: в предыдущем примере оставить только
поставщиков, в фамилии которых есть буква «н»
SELECT surname, SUM(quant)
• Результат:
FROM sup_det
Иванов
JOIN suppliers ON sup_det.cod_s=suppliers.cod_s
Смирнов
WHERE surname LIKE '%н%'
GROUP BY surname
HAVING SUM(quant)>300
ORDER BY surname
400
500
400
500
400
500
210.
Вложенные запросыSQL позволяет в предикате предложения WHERE запроса использовать
вложенный запрос (подзапрос), результат которого используется при
вычислении предиката.
Пример: выбрать все поставки болтов
Вариант 1 (запрос с соединением)
SELECT cod_s, sup_det.cod_d, quant
FROM sup_det JOIN details
ON sup_det.cod_d=details.cod_d AND name='Болт‘ /* WHERE name='Болт‘ */
Результат:
S2 D2
300
S3 D2
300
Вариант 2 (вложенный запрос)
SELECT cod_s, cod_d, quant
FROM sup_det
WHERE cod_d = (
SELECT cod_d FROM details WHERE name='Болт‘
)
• Сначала выполняется внутренний запрос, результат которого (D2)
подставляется в условие внешнего запроса, который затем выполняется
Замечание: запрос некорректен, если результатом внутреннего подзапроса
будет несколько значений кода детали
211.
• Вариант 3 (множественная операция IN)SELECT cod_s, cod_d, quant
FROM sup_det
WHERE cod_d IN
(SELECT cod_d FROM details WHERE name='Болт')
Замечание: запрос корректен даже если результатом внутреннего
подзапроса будет несколько значений кода детали
• Конструкция с вложенным запросом, как правило, реализуется СУБД
эффективнее, чем запрос с соединением таблиц:
– Если в обе таблицы из запроса входит n кортежей, в конструкции с
вложенным запросом просматривается 2n кортежей, т.е. оценка
алгоритма O(n)
– В запросе к соединению просматриваются все кортежи декартова
произведения таблиц, т.е. n2 кортежей, следовательно, и оценка
алгоритма в этом случае O(n2)
• Пример: выбрать поставщиков, которые поставляют деталь с кодом D2
SELECT * FROM suppliers
WHERE cod_s IN
(SELECT cod_s FROM sup_det WHERE cod_d = 'D2')
• Результат
S2 Петров
10
Тула
S3 Сидоров
30
Тула
212.
• Этот же запрос с соединением таблиц:SELECT suppliers.cod_s, surname, rating, city
FROM suppliers JOIN sup_det
ON suppliers.cod_s=sup_det.cod_s AND cod_d = 'D2'
Замечание: глубина вложения может быть большей
• Пример: выбрать поставщиков, которые поставляют гайки
• SELECT * FROM suppliers
WHERE cod_s IN (
SELECT cod_s FROM sup_det WHERE cod_d IN (
SELECT cod_d FROM details WHERE name = 'Гайка‘
)
)
• Результат
S1 Иванов
20
Москва
S5 Смирнов
30
Орел
• Этот же запрос с соединением таблиц:
SELECT suppliers.cod_s, surname, rating, suppliers.city
FROM suppliers
INNER JOIN sup_det ON suppliers.cod_s = sup_det.cod_s
INNER JOIN details ON details.cod_d = sup_det.cod_d
WHERE name = 'Гайка‘ /* или AND name = 'Гайка‘*/
213.
• Пример: выбрать поставщиков, которые поставляют детали,производимые в Туле
SELECT *
FROM suppliers
WHERE cod_s IN (
SELECT cod_s FROM sup_det WHERE cod_d IN
(SELECT cod_d FROM details WHERE city = 'Тула')
)
• Результат
S1
Иванов
20
Москва
S2
Петров
10
Тула
S3
Сидоров
30
Тула
S4
Круглов
20
Москва
• Этот же запрос с соединением таблиц:
SELECT suppliers.cod_s, surname, rating, suppliers.city
FROM suppliers
JOIN sup_det ON suppliers.cod_s = sup_det.cod_s
JOIN details ON details.cod_d = sup_det.cod_d
WHERE details.city = 'Тула‘
• В подзапросе можно использовать выражения, агрегированные
функции и HAVING. При этом подзапрос должен размещаться внутри
предложения HAVING
214.
• Пример: найти средний объем поставки для поставщиков, у которыхон превосходит 250
SELECT cod_s, to_char(AVG(quant), ‘9999.99')
FROM sup_det
GROUP BY cod_s
HAVING AVG (quant) > 250
Результат
S3 300.00
• Пример: найти средний объем поставки для поставщиков, у которых
он превосходит средний объем всех поставок
SELECT cod_s, to_char(AVG(quant), ‘9999.99')
FROM sup_det
GROUP BY cod_s
HAVING AVG (quant) >
(SELECT AVG(quant) FROM sup_det)
• Результат
S2 250.00
S3 300.00
S4 250.00
215.
• Пример: найти средний объем поставки для тех деталей, у которых онпревосходит средний объем поставок деталей, производимых в Туле
• SELECT cod_d, to_char(AVG(quant), '9999.99')
FROM sup_det
GROUP BY cod_d
HAVING AVG(quant) > (
SELECT AVG(quant) FROM sup_det WHERE cod_d IN
(SELECT cod_d FROM details WHERE city = 'Тула')
)
• Результат
D2 300.00
D6 400.00
• Средний объем поставки из Тулы во внутреннем подзапросе можно
вычислить с использованием INNER JOIN:
SELECT AVG(quant)
FROM sup_det JOIN details
ON sup_det.cod_d=details.cod_d AND city = 'Тула'
• Отличительная черта всех рассмотренных примеров с вложенными
запросами:
– внутренний подзапрос не ссылается на таблицы, которые указаны в
предложении FROM внешнего подзапроса
– внутренний подзапрос может выполняться независимо от внешнего,
отсюда следует оценка O(n)
216.
Пример1: Найти фамилии поставщиков с рейтингом большем 10,
проживающих в городе, где производятся какие-либо детали
SELECT DISTINCT surname, suppliers.city
FROM suppliers
JOIN details ON suppliers.city=details.city
WHERE rating>10
• Результат:
Сидоров
Тула
Иванов
Москва
Круглов
Москва
Анализ: сначала соединение:
SELECT surname, suppliers.city
FROM suppliers
JOIN details ON suppliers.city=details.city
• Результат:
S1
Иванов 20
Москва …
D1
…
S1
Иванов 20
Москва …
D4
…
S1
Иванов 20
Москва …
D6
…
S2
Петров 10
Тула
…
D2
…
S2
Петров 10
Тула
…
D5
…
…………………………………………………………………..
S3
Сидоров 30
Тула
…
D2
…
…………………………………………………………………..
S4
Круглов 20
Москва …
D1
…
…………………………………………………………………..
217.
Пример 2: Найти поставщиков с рейтингом большем 10, проживающих в
городе, где не производится никаких деталей
SELECT DISTINCT surname, suppliers.city
FROM suppliers
JOIN details ON suppliers.city!=details.city
WHERE rating>10
• Результат:
ОШИБКА!!!
Сидоров
Тула
Иванов
Москва
Круглов
Москва
Смирнов
Орел
Анализ: сначала соединение:
SELECT surname, suppliers.city
FROM suppliers
JOIN details ON suppliers.city!=details.city
• Результат:
S1
Иванов 20
Москва …
D2
…
Тула
S1
Иванов 20
Москва …
D3
…
Рязань
S1
Иванов 20
Москва …
D5
…
Тула
S1
Иванов 20
Москва …
D7
…
Тула
S2
Петров 10
Тула
…
D1
…
Москва
S2
Петров 10
Тула
…
D5
…
Рязань
…………………………………………………………………………………..
S5
Смирнов 20 Орел …
D1
…
Москва
…………………………………………………………………………………..
218.
Решение (найти поставщиков с рейтингом большем 10, проживающих в
городе, где не производится никаких деталей):
SELECT surname, city
FROM suppliers
WHERE rating>10
AND city NOT IN (
SELECT DISTINCT city
FROM details
)
можно без DISTINCT
• Результат:
Смирнов
Орел
Анализ Шаг 1: вложенный запрос:
SELECT DISTINCT city FROM details
• Результат:
Москва
Рязань
Тула
Шаг 2: внешний запрос
SELECT surname, city
FROM suppliers
WHERE rating>10
AND city NOT IN (‘Москва’, ‘Рязань’, ‘Тула’)
• Результат:
Смирнов
Орел
219.
Связанные (коррелированные) подзапросы• Во внутреннем подзапросе в предикате предложений WHERE или
HAVING можно ссылаться на таблицы из предложения FROM внешнего
подзапроса
• В этом случае подзапросы связаны между собой и не могут быть
выполнены последовательно независимо один от другого, в отличие от
рассмотренных ранее несвязанных (некоррелированных) подзапросов
• Пример: найти фамилии поставщиков с суммарным объемом поставок
больше 450
• SELECT surname
FROM suppliers
WHERE 450 < (
SELECT SUM(quant) FROM sup_det
WHERE suppliers.cod_s = sup_det.cod_s
)
• Результат
Петров
Круглов
Смирнов
Замечание: здесь подзапросы связаны, поэтому внутренний подзапрос
выполняется многократно с фиксированным значением suppliers.cod_s
на каждом шаге
• Оценка в этом случае как и для запроса с соединением O(n2)
220.
Пример: найти всех поставщиков, имеющих поставки объемом 200
деталей
• SELECT *
FROM suppliers
WHERE 200 IN (
SELECT quant FROM sup_det
WHERE suppliers.cod_s = sup_det.cod_s)
• Результат
S1
Иванов
20
Москва
S2
Петров
10
Тула
S5
Смирнов
30
Орел
• Соответствующий запрос с соединением таблиц можно записать так:
• SELECT DISTINCT suppliers.cod_s, surname, rating, city
FROM suppliers JOIN sup_det
ON suppliers.cod_s = sup_det.cod_s WHERE quant= 200
• Параметр DISTINCT здесь необходим, поскольку могут быть
повторяющиеся кортежи
Замечание: для рассмотренного примера можно построить более
эффективный запрос, в котором внутренний подзапрос независим от
внешнего
• SELECT *
• FROM suppliers
• WHERE cod_s IN (
– SELECT cod_s FROM sup_det WHERE quant = 200)
221.
Пример: найти все поставки с объемом большим, чем средний объем
поставки для данной детали
SELECT cod_s, cod_d, quant
FROM sup_det out
WHERE quant > (
SELECT AVG(quant) FROM sup_det inn
WHERE inn.cod_d = out.cod_d
)
Результат
S1 D5
200
S2 D4
200
S5 D1
200
S5 D3
200
Связанные запросы можно использовать и с HAVING
Пример: Найти максимальный вес деталей каждого из наименований, для
тех деталей, у которых максимальный вес больше 17
SELECT name, MAX(wei)
FROM details
GROUP BY name
HAVING MAX(wei) > 17
Результат
Кольцо
19
Винт
20
222.
Пример: Найти максимальный вес деталей каждого из наименований, у
которых максимальный вес более, чем на 10% превосходит средний вес
детали этого наименования
– SELECT name, MAX(wei)
– FROM details a
– GROUP BY name
– HAVING MAX(wei) > (
• SELECT 1.1*AVG(wei) FROM details b
WHERE b.name = a.name )
• Результат
Винт
20
• Пример: Найти средний объем поставки для каждого из кодов деталей,
производимых в Рязани, средний объем поставки которых меньше
максимального объема поставки болтов
– SELECT cod_d, to_char(AVG(quant), '9999.99')
– FROM sup_det WHERE cod_d IN
• (SELECT cod_d FROM details WHERE city='Рязань')
– GROUP BY cod_d
– HAVING AVG (quant) < (
• SELECT MAX(quant) FROM sup_det WHERE cod_d IN
(SELECT cod_d FROM details WHERE name = 'Болт')
)
• Результат
D3 150.00
Замечание: Подзапросы в последнем примере не связаны между собой
223.
Использование EXISTS• Операция EXISTS применяется к подзапросу SELECT и возвращает
значение TRUE, если выборка не пуста, и значение FALSE, если
выборка пуста
• Пример: выбрать фамилии и рейтинг всех поставщиков, если хотя бы
один поставщик проживает в Москве
• SELECT surname AS Фамилия, rating AS Рейтинг
FROM suppliers
WHERE EXISTS (
SELECT * FROM suppliers WHERE city = 'Москва‘
)
• Результат
Иванов
20
Петров
10
Сидоров 30
Круглов
20
Смирнов 30
• Несмотря на то, что во внутреннем и внешнем запросах делается
выборка из одной и той же таблицы suppliers, они не связаны между
собой
• EXISTS можно использовать и в связанных подзапросах, в этом случае
EXISTS вычисляется отдельно для каждого кортежа внешнего
подзапроса
224.
• Пример: найти коды тех поставщиков,которые имеют несколько поставок
• SELECT DISTINCT cod_s
Пример – вариант 2 запроса
FROM sup_det out
SELECT DISTINCT cod_s
WHERE EXISTS (
FROM sup_det out
SELECT * FROM sup_det inn
WHERE 1<(
WHERE inn.cod_s = out.cod_s
SELECT COUNT(*)
AND inn.cod_d <> out.cod_d
FROM sup_det inn
)
WHERE inn.cod_s =
• Результат
out.cod_s
S1
)
S2
S4
S5
• Очевидно, запрос с NOT
• SELECT DISTINCT cod_s
• FROM sup_det out
• WHERE NOT EXISTS (
SELECT * FROM sup_det inn
WHERE inn.cod_s = out.cod_s
AND inn.cod_d <> out.cod_d
)
найдет поставщиков с одной поставкой (S3)
225.
• В подзапросе, к которому непосредственно применяется операцияEXISTS, нельзя использовать агрегатные функции
• Пример: найти данные обо всех поставщиках, поставляющих детали,
для которых имеется несколько поставок
• SELECT *
• FROM suppliers
• WHERE EXISTS (
SELECT * FROM sup_det a
WHERE suppliers.cod_s = a.cod_s
AND 1 < (
SELECT COUNT(*) FROM sup_det b
WHERE a.cod_d = b.cod_d
)
)
• Результат
S1 Иванов
20
Москва
S2 Петров
10
Тула
S3 Сидоров
30
Тула
S4 Круглов
20
Москва
S5 Смирнов
30
Орел
Замечание: в этом примере функция COUNT вычисляется во вложенном
запросе, а не в том, к которому непосредственно применяется
операция EXISTS
226.
Использование ANY, SOME и ALL• Операции ANY, SOME и ALL, как и EXISTS, применяются к вложенному
подзапросу, однако, синтаксис несколько иной – они комбинируются с
операцией отношения
• ANY и SOME идентичны, они возвращают значение TRUE, если хотя бы
одно из выбранных значений удовлетворяет отношению, а FALSE, если
ни одно значение не удовлетворяет отношению
• Пример: найти данные обо всех поставщиках, которые проживают в том
городе, где производятся детали
SELECT *
FROM suppliers
WHERE city = ANY
(SELECT city FROM details)
• Результат
S1 Иванов
20
Москва
S2 Петров
10
Тула
S3 Сидоров
30
Тула
S4 Круглов
20
Москва
Замечание: Смирнов проживает в Орле, где не производятся никакие
детали
227.
• Для этого примера можно предложить варианты и без ANY• Вариант 1 (с операцией IN):
SELECT *
FROM suppliers
WHERE city IN (SELECT city FROM details)
• Вариант 2 (с операцией EXISTS):
SELECT *
FROM suppliers
WHERE EXISTS
(SELECT * FROM details WHERE suppliers.city = details.city)
Замечание: очевидно второй вариант менее эффективен, поскольку в нем
присутствуют связанные подзапросы
• При использовании ANY могут возникнуть неоднозначные ситуации,
связанные с переводом с английского: «какой-нибудь» не значит
«каждый», а значит «хотя бы один»
• Пример: найти данные обо всех поставщиках, рейтинг которых больше,
чем рейтинг хотя бы одного поставщика, проживающего в Москве
• SELECT *
FROM suppliers
WHERE rating > ANY
(SELECT rating FROM suppliers WHERE city=‘Москва’)
• Результат
S3 Сидоров
30
Тула
S5 Смирнов
30
Орел
228.
• Пример: найти данные обо всех деталях, вес которых меньше весакакой-либо из деталей синего цвета
• SELECT *
• FROM details
• WHERE wei < ANY
• (
– SELECT wei FROM details WHERE color='Синий‘
• )
• Результат
D1 Гайка
Красный 12 Москва
D4 Винт
Красный 14 Москва
D5 Шайба Синий
12 Тула
Замечание: условие wei<ANY равносильно wei<MAX, поэтому запрос из
последнего примера может быть сформулирован без ANY:
• SELECT *
• FROM details
• WHERE wei < (
– SELECT MAX(wei) FROM details WHERE color='Синий‘
)
• ANY может использоваться и в конструкции со связанными запросами
229.
• Пример: найти данные обо всех деталях, вес которых меньше весакакой-либо детали того же цвета Вариант 2
• SELECT * FROM details a
SELECT * FROM details a
• WHERE wei < ANY
WHERE wei <
(SELECT wei FROM details b
(SELECT MAX(wei) FROM details b
WHERE a.color = b.color)
WHERE a.color = b.color)
• Результат
D1 Гайка
Красный
12
Москва
D4 Винт
Красный
14
Москва
D5 Шайба
Синий
12
Тула
D6 Кольцо
Красный
19
Москва
• Операция ALL возвращает значение TRUE, если все выбранные
значения удовлетворяют отношению, а FALSE, если хотя бы одно
значение не удовлетворяет отношению
• Пример: найти данные обо всех поставщиках, рейтинг которых выше
рейтинга любого из поставщиков, проживающих в Москве
• SELECT *
• FROM suppliers
• WHERE rating > ALL
(SELECT rating FROM suppliers WHERE city = 'Москва')
• Результат
S3 Сидоров
30
Тула
S5 Смирнов
30
Орел
230.
• Как правило, ALL используется с неравенствами, в том числе и соперацией «<>»
• Использовать ALL с операцией «=» нецелесообразно, поскольку
результат получим только, если все выбранные в подзапросе значения
будут одинаковы
• Пример: найти данные обо всех деталях, вес которых отличается от
веса любой из деталей красного цвета
• SELECT *
FROM details
WHERE wei <> ALL (
SELECT wei FROM details WHERE color = 'Красный‘
)
• Результат
D2 Болт
Зеленый 17 Тула
D3 Винт
Синий
17 Рязань
• Пример: найти данные обо всех деталях, цвет которых отличается от
цвета любого из винтов
• SELECT *
FROM details
WHERE color <> ALL (
SELECT color FROM details WHERE name = 'Винт‘
)
• Результат
D2 Болт
Зеленый 17 Тула
231.
Запросы с WITH (общие табличные выражения)• WITH позволяет определять в запросе временные (виртуальные)
таблицы, существующие только для этого запроса (Общие табличные
выражения, Common Table Expressions, CTE), присоединяя затем к
WITH основной запрос, в котором можно ссылаться на определенную в
WITH таблицу.
• К основному запросу можно присоединить несколько виртуальных
таблиц, разделяя их определения в WITH запятыми.
• Общий вид такой конструкции с двумя временными таблицами
выглядит так:
WITH <имя табл1> AS( -- определение временной таблицы табл1
SELECT …………….
FROM ……………….
………………………..
), <имя табл2> AS( -- определение временной таблицы табл2
SELECT …………….
FROM ……………….
………………………..
)
SELECT ……………. -- основной запрос
FROM ……………….
………………………..;
• В основном запросе в этой конструкции можно ссылаться не только на
базовые таблицы, но и на временные таблицы табл1 и табл2
232.
Пример 1: вычислить средний рейтинг поставщиков, для каждого изгородов, в которых проживают поставщики и производятся детали
красного цвета, упорядочив выборку по названиям городов
WITH sup_detcity AS( -- временная таблица
SELECT surname, rating, name, suppliers.city, color
FROM suppliers
JOIN details ON suppliers.city=details.city
WHERE color='Красный'
)
SELECT city, to_char(AVG(rating), '999.99') -- основной запрос
FROM sup_detcity
GROUP BY city
ORDER BY city;
• Результат
Москва
20
Тула
20
Замечание: здесь в основном запросе выборка делается из временной
таблицы sup_detcity, в которой атрибут city встречается лишь один раз,
поэтому, указывая в предложении SELECT запроса этот атрибут, нет
необходимости ссылаться на базовые таблицы
• Использование WITH позволяет упростить структурно сложные и
громоздкие запросы
233.
Пример 2: Выбрать сведения о поставщиках, в поставках которых есть
детали одинакового цвета; выборку упорядочить по фамилиям.
WITH Tab1 AS ( -- sup_det + Цвет деталей
SELECT cod_s, sup_det.cod_d, color
FROM sup_det
JOIN details ON details.cod_d = sup_det.cod_d
), Tab2 AS ( -- Коды поставщиков, с поставками дет. одинакового цвета
SELECT a.cod_s
FROM Tab1 a
JOIN Tab1 b ON a.cod_s = b.cod_s
AND a.color = b.color
AND a.cod_d != b.cod_d
)
SELECT * FROM suppliers
WHERE cod_s IN (SELECT * FROM Tab2)
ORDER BY surname;
• Результат
S1
Иванов
20
Москва
S5
Смирнов
30
Орел
Замечание: в этом примере последовательно создаются 2 временные
таблицы
• Если необходимо выбрать сведения о поставщиках, поставляющих только
детали разных цветов фразу WHERE формулируем так:
WHERE cod_s NOT IN (SELECT * FROM Tab2)
234. Операции UNION, INTERSECT и EXCEPT
• Каждый запрос SELECT возвращает некоторое множество кортежей(строк). Операторы UNION, INTERSECT и EXCEPT позволяют
выполнять операции над несколькими выборками SELECT.
• Оператор UNION реализует операцию реляционной алгебры
объединение множеств,
• Оператор INTERSECT - реализует операцию пересечение множеств,
• Оператор EXCEPT - реализует операцию разность множеств.
• В качестве множеств-операндов выступают результаты двух запросов
(множества кортежей Set A и Set B) .
– UNION возвращает те кортежи, которые возвращает первый (Set A)
или второй (Set B), или оба запроса;
– INTERSECT возвращает те кортежи, которые возвращает и первый
(Set A), и второй (Set B) запросы;
– EXCEPT возвращает те кортежи, которые возвращает первый
запрос (Set A), но которых нет среди кортежей, возвращаемых
вторым запросом (Set B).
• Очевидно, эти определения соответствуют операциям объединения,
пересечения и разности из теории множеств
• Для того, чтобы могли быть выполнены эти операции, запросы должны
быть совместимы по объединению: должны совпадать число столбцов,
порядок их следования и типы
235.
Диаграмма, демонстрирующая операцииUNION, INTERSECT и EXCEPT
• Операция выполняется над
двумя запросами SELECT
SELECT A
UNION / INTERSECT / EXCEPT
SELECT B
Левый кружок (Set A) – это множество строк из левого запроса
SELECT, а правый кружок (Set B) – это результирующая таблица
правого запроса SELECT.
Результатом запроса UNION будут строки первой таблицы и строки
второй таблицы, которые отсутствуют в первой
Всё, что находится в пересечении – это строки, которые войдут в
общую результирующую таблицу INTERSECT.
Результатом запроса EXCEPT будут только уникальные строки первой
таблицы, которые отсутствуют во второй.
236.
Пример объединения запросов• Операция UNION позволяет объединить результаты нескольких
запросов в одну таблицу
• Необходимо, чтобы объединяемые отношения были совместимы по
количеству, порядку следования и типу атрибутов
• Операция UNION автоматически исключает дублирование кортежей,
поэтому не имеет смысла использовать DISTINCT в объединяемых
запросах
• Пример: найти фамилии и рейтинг поставщиков, проживающих в Туле
и/или имеющих поставки объемом 200 деталей
• SELECT surname, rating
Можно и без объединения
• FROM suppliers WHERE city='Тула'
SELECT surname, rating
UNION
FROM suppliers
SELECT surname, rating
WHERE city='Тула' OR cod_s IN
FROM suppliers WHERE cod_s IN
(SELECT cod_s FROM
(SELECT cod_s FROM sup_det
sup_det
WHERE
quant=200
WHERE quant=200
)
)
• Результат
Петров
10
Сидоров 30
Иванов
20
Смирнов 30
237.
Пример объединения: список городов, в которых
проживают поставщики или производятся какие-либо
детали
SELECT city
FROM suppliers
UNION
DISTINCT не нужен
SELECT city
FROM details
Пример пересечения: список городов, в которых
проживают поставщики и производятся какие-либо
детали
SELECT city
FROM suppliers
INTERSECT
SELECT city
FROM details
Пример разности: список городов, в которых
проживают поставщики но не производится никаких
деталей
SELECT city
FROM suppliers
EXCEPT
SELECT city
FROM details
Результат:
Москва
Рязань
Орел
Тула
Результат:
Москва
Тула
Результат:
Орел
238. Обновление данных в базе данных
• Оператор SELECT только выбирает данные из базы данных, неизменяя их
• Обновление данных в базе данных выполняют операторы
INSERT
DELETE
UPDATE
Оператор INSERT добавляет в таблицу базы данных кортежи
• Общий вид оператора INSERT:
INSERT INTO <имя_таблицы> (<список_имен_атрибутов>)
VALUES (<список_значений>)
• Пример: добавить в таблицу suppliers информацию о новом
поставщике
INSERT INTO suppliers
VALUES ('S6', 'Стеклов', 10, 'Орел')
Замечание: в списке значений выражения недопустимы, но можно
указывать NULL-значения
• Пример: добавить в таблицу suppliers информацию о новом
поставщике, для которого пока не определен рейтинг
INSERT INTO suppliers
VALUES ('S7', 'Соков', NULL, 'Орел')
239.
• В списке значений могут присутствовать не все атрибуты,отсутствующие значения формируются по умолчанию
• Пример:
INSERT INTO details (cod_d, city)
VALUES ('D8', 'Рязань')
• Можно не указывать список имен атрибутов, указав в
соответствующих местах списка значений NULL-значения:
• Пример:
INSERT INTO details
VALUES ('D8', NULL, NULL, NULL, 'Рязань')
Замечание: для атрибутов name, color и wei не должен быть задан
параметр NOT NULL и DEFAULT
• Порядок имен атрибутов может быть произвольным, но
соответствующие значения должны быть указаны в том же
порядке
• Пример:
INSERT INTO details (cod_d, city, name, wei)
VALUES ('D8', 'Рязань', 'Шайба', 10)
Замечание: значение атрибута color будет сформировано по
умолчанию
240.
В таблицу могут быть добавлены кортежи, выбранные из других таблиц
Пример:
INSERT INTO sup_det (cod_s, cod_d)
SELECT cod_s, cod_d FROM suppliers, details
WHERE suppliers.city = details.city
Замечание: значение атрибута quant будет сформировано по умолчанию
Оператор DELETE удаляет из таблицы базы данных кортежи
• Общий вид оператора DELETE:
DELETE FROM <имя_таблицы>
WHERE <условие>
• Пример: удалить все поставки, объем которых превосходит 200
DELETE FROM sup_det
WHERE quant > 200
• Пример: удалить всех поставщиков, проживающих в Москве и имеющих
рейтинг меньше 20
DELETE FROM suppliers
WHERE city = 'Москва' AND rating < 20
• Если предикат отсутствует, удаляются все кортежи
• Пример: удалить все поставки
DELETE FROM sup_det
Замечание 1: пустая таблица sup_det в базе данных остается
Замечание 2: удалить сразу все строки в таблице можно оператором
TRUNCATE TABLE <имя_таблицы> --или DELETE FROM <имя_таблицы>
241.
Оператор UPDATE изменяет значения атрибутов в имеющихся в таблице базыданных кортежах
Общий вид оператора UPDATE:
UPDATE <имя_таблицы>
SET
<имя_атрибута>=<выражение>, …
WHERE <условие>
Может использоваться без предиката
Пример: всем поставщикам установить значение рейтинга равным 30
UPDATE suppliers
SET
rating = 30
Предикат накладывает ограничения на кортежи, в которых надо изменить
значения атрибутов
Пример: у всех поставщиков с рейтингом 20 повысить рейтинг до 30
UPDATE suppliers
SET
rating = 30
WHERE rating = 20
Можно сразу изменить значения нескольких атрибутов
Пример: всех проживающих в Москве поставщиков с рейтингом меньше
30, перевести в Томск, повысив им рейтинг до 30
UPDATE suppliers
SET
rating = 30, city ='Томск'
WHERE city ='Москва' AND rating < 30
242.
В предложении SET можно использовать выражения
Пример: всем поставщикам, не проживающим в Москве, увеличить
значение рейтинга на 10
UPDATE suppliers
SET
rating = rating + 10 WHERE
city <> 'Москва'
В качестве присваиваемого значения можно использовать NULL
Пример: аннулировать рейтинг поставщиков, не проживающих в Москве
UPDATE suppliers
SET
rating = NULL WHERE city <> 'Москва'
В операторах обновления можно использовать подзапросы
Пример: пусть оператором CREATE создана таблица suppliersDetMsk
такой же структуры, что и таблица suppliers;
надо поместить в таблицу suppliersDetMsk сведения о поставщиках,
поставляющих детали, производимые в Москве, независимо от того, где
проживает поставщик
INSERT INTO suppliersDetMsk
SELECT * FROM suppliers
WHERE cod_s IN
(
SELECT cod_s FROM sup_det WHERE cod_d IN
(SELECT cod_d FROM details WHERE city='Москва')
)
Замечание: вложенные подзапросы в этом примере не связаны между собой,
поэтому они могут быть выполнены последовательно
243.
Пример: (DELETE) удалить все поставки деталей из Тулы
DELETE FROM sup_det WHERE cod_d = ANY
(SELECT cod_d FROM details WHERE city='Тула')
Замечание: в этом примере вложенный подзапрос также не связан с внешним
запросом, поэтому оператор SELECT выполняется однократно
Пример: (UPDATE) повысить на 10 рейтинг поставщиков, имеющих более
двух поставок
UPDATE suppliers SET rating = rating + 10
WHERE 2 < (SELECT COUNT(*) FROM sup_det
WHERE sup_det.cod_s = suppliers.cod_s)
Замечание: в этом примере вложенный подзапрос связан с внешним
запросом, поэтому оператор SELECT выполняется многократно для
каждого фиксированного значения кода поставщика
Ограничение на использование подзапросов в операторах обновления:
– в предложении FROM вложенного подзапроса SELECTнельзя
ссылаться на обновляемую таблицу оператора обновления
Пример: удалить всех поставщиков с рейтингом ниже среднего
Неверное решение
DELETE FROM suppliers WHERE rating <
(SELECT AVG(rating) FROM suppliers)
Верное решение
– Шаг 1: SELECT AVG(rating) FROM suppliers
Результат: число A (в нашем примере А=22)
– Шаг 2: DELETE FROM suppliers WHERE rating < A
244.
RETURNING - возврат данных из изменённых строк• Предложение RETURNING позволяет получать данные из
модифицируемых строк при выполнении команд INSERT, UPDATE и
DELETE.
• Использование RETURNING позволяет обойтись без дополнительного
запроса к базе для контроля данных, получая измененные строки при
выполнении этих команд
• В предложении RETURNING можно указывать те же имена атрибутов
изменяемой таблицы или выражения над этими атрибутами, что и в
предложении SELECT
• Можно использовать и краткую запись RETURNING *, выбирающую все
атрибуты изменяемой таблицы
• В команде UPDATE предложение RETURNING возвращает новое
содержимое изменённой строки:
1
S1
D1
200
UPDATE sup_det
2
S1
D3
200
SET quant = quant * 2
7
S4
D5
200
WHERE quant < 200
11
S5
D4
200
RETURNING *;
• В команде DELETE предложение RETURNING возвращает содержимое
удалённой строки:
300
DELETE FROM sup_det
300
WHERE quant >= 300
400
RETURNING quant;
245.
• Создаем таблицу sup_det200 той же структуры, что и sup_det:CREATE TABLE sup_det200
(
ID serial NOT NULL PRIMARY KEY,
cod_s varchar(4) NOT NULL REFERENCES suppliers (cod_s),
cod_d varchar(4) NOT NULL REFERENCES details (cod_d),
quant smallint CHECK (quant <=1000),
UNIQUE(cod_s, cod_d)
);
• Переносим в sup_det200 строки, удаляемые из sup_det
WITH quant200 AS ( -- quant200 – временная таблица
DELETE FROM sup_det
WHERE quant>200
RETURNING * -- возвращает удаляемые строки в quant200
)
INSERT INTO sup_det200 SELECT * FROM quant200; -- вставляем строки
• Выводим содержимое созданной таблицы sup_det200
SELECT cod_s, cod_d, quant FROM sup_det200;
• Результат
Строки перенесены
S2
D2
300
из sup_det в sup_det200
S3
D2
300
S4
D6
400
246.
• Создать новую таблицу с занесением в нее данных из других таблицможно с помощью модифицированного оператора SELECT INTO
• Например, таблицу sup_det200 можно создать и заполнить данными из
sup_det следующим образом:
SELECT * INTO sup_det200
FROM sup_det WHERE quant>200;
• В отличие от предыдущего примера кортежи были не перенесены, а
скопированы в новую таблицу sup_det200 из таблицы sup_det
Замечание: стандарт рекомендует создавать новую таблицу явно
оператором CREATE TABLE, однако на практике часто удобнее
использовать модификацию SELECT INTO
• Иногда при работе с базой данных возникает необходимость удалить
какую-либо таблицу (например, sup_det200), но по каким-то причинам у
нас нет уверенности, что эта таблице была создана ранее или не была
уже удалена
• Используя в этом случае обычный оператор
DROP TABLE sup_det200
мы рискуем получить сообщение об ошибке (таблица отсутствует)
• В этом случае можно использовать условную форму оператора:
DROP TABLE IF EXISTS sup_det200
• Теперь, если таблица sup_det200 в базе данных отсутствует, ситуация
не будет диагностирована как ошибка
247. Представления в SQL
Представления в SQL
Представление VIEW – виртуальное отношение (таблица), как правило,
создается для работы с базой данных из приложений
Представления ограничивают доступ к базе данных из приложений
Создание представления:
CREATE VIEW <имя_представления>
AS <выборка SELECT>
Пример: создать представление suppliersNotMsk, в которое поместить
данные о поставщиках, не проживающих в Москве
CREATE VIEW suppliersNotMsk AS
SELECT *
FROM suppliers WHERE city <> ‘Москва’
Замечание: на самом деле таблица suppliersNotMsk в базе данных не
создается; создавая представление мы как бы накладываем на базовую
таблицу S маску, через которую часть кортежей из S становятся
недоступными в представлении
Можно сделать недоступными в представлении и часть атрибутов
базовой таблицы
Пример: создать представление suppliersNotrating , в которое поместить
все данные о поставщиках, кроме рейтинга
CREATE VIEW suppliersNotrating AS
SELECT cod_s, surname, city FROM suppliers
248.
Представления могут создаваться и из нескольких базовых таблиц
Пример: создать представление с данными о поставках, в котором
будут указаны фамилия поставщика и наименование детали
CREATE VIEW namesup_det
AS SELECT surname, name, quant
FROM sup_det
JOIN suppliers ON sup_det.cod_s=Supliers.cod_s
JOIN details ON SuppDet.cod_d= details.cod_d
Можно создавать групповые представления, используя агрегатные
функции
Пример: создать представление suppliersStat, в которое поместить
статистические данные о поставках по каждому поставщику:
количество поставок, суммарный объем и средний объем поставки
CREATE VIEW suppliersStat AS
SELECT cod_s, COUNT(*), SUM(quant), AVG(quant)
FROM sup_det
GROUP BY cod_s
Имея это представление, можно простым запросом получить
статистические данные о поставках:
SELECT * FROM suppliersStat
Для удаления представления используется оператор DROP:
DROP VIEW <имя_представления>
Пример: удалить представление NRS
DROP VIEW suppliersNotrating
249.
Представление можно модифицировать, при этом изменяются данные и
в базовой таблице
Пример: увеличить на 10 рейтинг у поставщика S2, используя
представление suppliersNotMsk
UPDATE suppliersNotMsk
SET rating = rating+10 WHERE cod_s=‘S2’
Замечание: рейтинг поставщика S2 увеличился в таблице suppliers
При обновлении данных в представлениях могут возникать
неоднозначности
Пример: создать представление, в которое поместить все возможные
города, в которых проживают поставщики и производятся детали из
таблиц suppliers и details
CREATE VIEW city_Sup_and_Det (citySD) AS
SELECT DISTINCT suppliers.city
FROM suppliers JOIN details ON suppliers.city = details.city;
SELECT * FROM city_Sup_and_Det;
Результат – два кортежа представления city_Sup_and_Det:
Москва
Тула
Замечание: поскольку в запросе есть DISTINCT, невозможно установить, из
каких кортежей получилась, например, Москва, поэтому невозможно
однозначно определить, что удалять из базовых таблиц при удалении
этого города из представления
250.
В последнем примере мы получили представление, которое нельзя
обновлять в силу неоднозначности в определении кортежей базовых
таблиц Supplies и details
city_Sup_and_Det - это представление типа read-only - «только для
чтения»
Критерии обновляемости (updatable) представлений:
–
–
–
–
–
–
–
–
–
–
–
представление определено на одной базовой таблице
в представление входит первичный ключ базовой таблицы
в определении представления нет DISTINCT
в представлении нет атрибутов, полученных как функции
агрегирования
в определении представления нет фраз GROUP BY и HAVING
в определении представления нет фраз WITH, OFFSET, LIMIT
в определении представления нет UNION, EXCEPT, INTERSECT
в определении представления нет подзапросов
представление может быть определено на базе другого
представления, но последнее должно быть обновляемым
в списке выбираемых атрибутов нет выражений
для оператора INSERT необходимо, чтобы в представление
входили все атрибуты базовой таблицы, для которых задан
параметр NOT NULL
251.
Пример: создать представление с количеством поставок для каждого
поставщика
CREATE VIEW Sup(cod_s, QPost) AS
SELECT cod_s, COUNT(*)
FROM sup_det
GROUP BY cod_s
Замечание: представление только для чтения, поскольку в нем
присутствуют функция COUNT и группировка GROUP BY
Пример: создать представление с данными о деталях, производимых
в Москве
CREATE VIEW detailsInMsk AS
SELECT *
FROM details WHERE city = ‘Москва’
Замечание: представление обновляемое, поскольку удовлетворяет всем
критериям обновляемости
Пример: создать представление с кодом, фамилией и городом
поставщиков, среди поставок которых есть поставки объемом 200
CREATE VIEW Supquant200 AS
SELECT cod_s, surname, city
FROM Supplies
WHERE cod_s IN
(SELECT cod_s FROM sup_det WHERE quant=200)
Замечание: представление только для чтения, поскольку в нем
присутствует подзапрос
252.
Пример: создать представление с данными о деталях, производимых в
Москве с весом большим 12
CREATE VIEW DetMsk12 AS
SELECT *
FROM detailsInMsk WHERE wei > 12
Замечание: представление обновляемое, поскольку обновляемым является
базовое представление detailsInMsk
С обновляемыми представлениями связаны некоторые аномалии,
которые могут возникать при их обновлении
Пример: создать представление с данными о поставщиках, рейтинг
которых равен 30
– CREATE VIEW SupplRat30 AS
SELECT *
FROM Supplies WHERE rating = 30
Замечание: это обновляемое представление, которое ограничивает
видимость кортежей в таблице Supplies
Добавим в представление еще один кортеж:
INSERT INTO SupplRat30
VALUES(‘S7’, ‘Орлов’, 20, ‘Калуга’)
Кортеж будет добавлен в базовую таблицу Supplies, но в представлении
его не окажется, т.е. он будет недоступен для приложения, которое,
работая с представлением SupplRat30, внесло это изменение
Невозможен контроль корректности выполненных действий
Замечание: аналогичная ситуация возникла бы в рассмотренном примере с
изменением рейтинга поставщика с кодом S2 в представлении
suppliersNotMsk, если бы этот поставщик проживал в Москве
253.
Для того, чтобы запретить обновление, результат которого не виден в
обновляемом представлении, в определение представления
добавляют предложение WITH CHECK OPTION
Оператор создания представления SupplRat30 будет выглядеть так:
– CREATE VIEW SupplRat30 AS
SELECT *
FROM Supplies WHERE rating = 30
WITH CHECK OPTION
Теперь вставка кортежа, в котором рейтинг отличен от 30, будет
невозможна
Однако не во всех ситуациях проблема может быть решена с
помощью WITH CHECK OPTION
Пример: создать представление с данными о поставщиках,
проживающих в Москве
CREATE VIEW suppliersInMsk AS
SELECT cod_s, surname, rating
FROM S WHERE city = ‘Москва’
Замечание: сохранять атрибут city здесь нецелесообразно, поскольку его
значение во всех кортежах одинаково
254.
Добавим в созданное представление suppliersInMsk кортеж:
INSERT INTO suppliersInMsk
VALUES(‘S7’, ‘Орлов’, 20)
В базовую таблицу suppliers также будет добавлен кортеж, в котором
значение атрибута city будет сформировано по умолчанию
Однако, если по умолчанию задано не значение ‘Москва’,
добавленный кортеж не будет виден в представлении
Замечание: если для атрибута city задано ограничение NOT NULL,
добавление кортежа будет невозможно
Добавление предложения
WITH CHECK OPTION
в этом случае не даст результата, поскольку добавляемый кортеж не
противоречит определению представления - он становится
невидимым только после формирования в базовой таблице suppliers
значения атрибута city
В этой ситуации следует сохранить в представлении атрибут city, хотя
он и будет одинаков у всех кортежей
Тогда при добавлении кортежа в представление мы должны будем
указать атрибут city и, если это не Москва, параметр
– WITH CHECK OPTION
запретит выполнение операции
255. Механизмы защиты данных в SQL
Два типа угроз:
– Внесение некорректных изменений
– Несанкционированный доступ (нарушение
конфиденциальности)
Локальные средства поддержания целостности
данных – ограничения на атрибуты и таблицы,
внешние ключи и т.д.
Глобальные механизмы защиты данных в SQL:
– Представления
– Привилегии
– Транзакции
Представления ограничивают доступ к базе
данных из приложений
256. Система привилегий в SQL
Контроль прав доступа данного пользователя к таблицам БД
производится на основе механизма привилегий
Базовые принципы
Каждый пользователь (user) в среде SQL, имеет специальное
идентификационное имя или номер (ID пользователя)
Вход в систему пользователь может выполнить только под своим ID,
зарегистрированным в системе
Возможно поддержание в системе некоторого общего ID: USER
Каждому пользователю (ID пользователя) назначается некоторый набор
привилегий – действий, которые ему доступны
Операторы SQL для системы привилегий:
– GRANT – назначить привилегию
– REVOKE – лишить привилегии
Типы привилегий:
– Системные привилегии
– Объектные привилегии
Системные привилегии определяют иерархию пользователей, устанавливая
несколько уровней прав пользователя по отношению к базе данных
CONNECT – право входить в систему и создавать представления
RESOURSE – право создавать базовые таблицы
DBA – право выполнять любые действия (привилегия
суперпользователя, администратора базы данных)
Замечание: в ряде систем выделяется уровень системного администратора
SYS или SYSADM, который выше, чем DBA
257.
Назначение системной привилегии:
GRANT <уровень_привилегии> TO <ID пользователя>
Например, DBA назначает привилегию пользователю:
GRANT RESOURSE TO Ivanov
Если пользователю надо разрешить создать конкретную базовую
таблицу, указывается ее имя:
GRANT RESOURSE ON suppliers TO Ivanov
Создать нового пользователя DBA может так:
GRANT CONNECT TO Ivanov IDENTIFIED BY Password
Механизм объектных привилегий - для выполнения любого действия над
таблицей пользователь должен обладать соответствующей привилегией
Пользователь, создавший таблицу, является ее владельцем и обладает
всеми привилегиями на выполнение операций над этой таблицей
В число привилегий владельца таблицы входит привилегия на передачу
всех или некоторых привилегий на данную таблицу другому
пользователю, включая привилегию на передачу привилегий
Стандартный набор объектных привилегий (ANSI)
SELECT – право использовать таблицу для выборки данных в
операторе SELECT
INSERT – право добавлять в таблицу кортежи
DELETE – право удалять кортежи из таблицы
UPDATE – право изменять значения атрибутов в имеющихся в
таблице кортежах
REFERENCES – право использовать атрибуты таблицы в качестве
родительских ключей при определении внешних ключей других
таблиц
258.
Могут быть определены нестандартные привилегии объекта:
INDEX - право создавать индекс в таблице
SYNONYM - право создавать синоним для объекта
ALTER - право выполнять команду ALTER TABLE
Назначение объектной привилегии:
GRANT <привилегия> ON <имя_таблицы>TO <ID>
Замечание: здесь может быть список привилегий и/или список ID
пользователей
Например, владелец таблицы suppliers назначает привилегию
SELECT пользователю Petrov:
GRANT SELECT ON suppliers TO Petrov
Можно сразу назначить несколько привилегий:
GRANT INSERT, DELETE ON sup_det TO Ivanov
Можно назначить привилегии сразу нескольким пользователям:
GRANT SELECT, UPDATE ON suppliers TO Ivanov, Petrov
Можно назначить привилегию не на всю таблицу, а только на
отдельные атрибуты:
GRANT UPDATE ON sup_det(quant) TO Orlov
или
GRANT UPDATE ON sup_det(cod_s, cod_d) TO Ivanov
Замечание: атрибуты могут быть указаны в любом порядке
259.
Используя параметр ALL PRIVILEGES (ALL), который группирует все
привилегии пользователя, можно передать все свои привилегии на
таблицу:
GRANT ALL PRIVILEGES ON suppliers TO Orlov, Kotov
или
GRANT ALL ON sup_det TO Sidorov
Параметр PUBLIC группирует всех пользователей, что позволяет
пользователю сделать свою привилегию или все свои привилегии
общедоступными:
GRANT UPDATE ON sup_det TO PUBLIC
или
GRANT ALL ON details TO PUBLIC
Замечание: Любой подключившийся ID сразу получает эти привилегии
Владелец таблицы, назначая привилегию, может предоставить право
передавать эту привилегию другим пользователям, добавив фразу
WITH GRANT OPTION
Пример: Ivanov - владелец таблицы suppliers, назначая привилегию
SELECT пользователю Petrov, предоставляет ему право передавать
эту привилегию другим пользователям
GRANT SELECT ON suppliers TO Petrov
WITH GRANT OPTION
260.
Теперь Petrov может передать эту привилегию пользователю Sidorov,
но при этом он должен указать ID владельца таблицы:
GRANT SELECT ON Ivanov.suppliers TO Sidorov
Замечание: если бы Petrov предоставил пользователю Sidorov право
GRANT OPTION, то передавая эту привилегию другому пользователю
(Kotlov), Sidorov должен ссылаться не на того, кто предоставил ему
это право (Petrov.suppliers), а на владельца таблицы:
GRANT SELECT ON Ivanov.suppliers TO Kotlov
Привилегии ограничивают права пользователей на создание
представлений (VIEW), поскольку для того, чтобы пользователь имел
право создать представление, он должен иметь привилегию SELECT
на все таблицы, на базе которых создается представление
Лишить пользователя объектной привилегии можно командой
REVOKE:
REVOKE <привилегия> ON <имя_таблицы> FROM <ID>
Например, владелец таблицы suppliers лишает привилегий INSERT и
DELETE пользователя Petrov:
REVOKE INSERT, DELETE ON suppliers FROM Petrov
Как правило, в СУБД действует каскадный принцип отмены
привилегий:
– привилегия отменяется не только у тех пользователей, которые
указаны в команде REVOKE, но и у всех, кому эти пользователи
передали привилегию
261.
Механизм транзакций в SQLМеханизм транзакций обеспечивает возможность восстановления
целостного состояния базы данных после ошибок пользователя,
программных или аппаратных сбоев
Транзакция в SQL – это группа логически связанных операторов SQL,
которые должны быть либо выполнены все вместе, либо не должен
быть выполнен ни один из них
Основное свойство транзакции: до начала выполнения транзакции и
после ее завершения база данных должна находиться в целостном
состоянии - транзакция переводит базу данных из одного целостного
состояния в другое
Транзакция может рассматриваться как минимальная единица
активности пользователя по отношению к базе данных
Пример: удалить из базы данных поставщика с кодом S2
Очевидно, необходимо сначала решить вопрос с поставками,
например, передать их поставщику S4, поэтому операции передачи
поставок другому поставщику и удаления поставщика из таблицы
необходимо объединить в одну транзакцию
Транзакция удаления из базы данных поставщика с кодом S2 :
UPDATE sup_det
SET cod_s = 'S4'
WHERE cod_s = 'S2‘;
DELETE FROM suppliers
WHERE cod_s = 'S2';
262.
Первая транзакция начинается с начала сеанса работы с базой данных
на SQL
Каждая следующая транзакция начинается сразу после завершения
предыдущей
Транзакция должна заканчиваться одной из двух команд:
COMMIT; – фиксирует в базе данных все изменения, сделанные в
ходе выполнения транзакции
ROLLBACK; – отменяет все изменения, сделанные в ходе выполнения
транзакции, не фиксируя их в базе данных (откат)
В PostgreSQL транзакция определяется набором SQL-команд,
окружённым командами BEGIN и COMMIT/ROLLBACK
BEGIN; -- открываем транзакцию
UPDATE sup_det
SET cod_s = 'S4'
WHERE cod_s = 'S2‘;
DELETE FROM suppliers
WHERE cod_s = 'S2';
COMMIT; -- закрываем транзакцию (или ROLLBACK; )
На самом деле PostgreSQL отрабатывает каждый SQL-оператор как
транзакцию и, если вы не вставите команду BEGIN, то каждый отдельный
оператор будет неявно окружён командами BEGIN и COMMIT
Если последовательно выполняемые в сеансе работы с базой данных
операторы логически не связаны и каждый из них не нарушает
целостности, каждый оператор выделяется в отдельную транзакцию
263.
Если последовательно выполняемые в сеансе работы с базой
данных операторы логически не связаны и каждый из них не
нарушает целостности, то каждый оператор выделяется в
отдельную транзакцию
При работе с базой данных в прикладной программе можно
использовать режим автофиксации транзакций AUTOCOMMIT
По умолчанию программы со встраиваемым SQL работают не в
режиме автофиксации, поэтому в определённые моменты нужно
явно выполнять COMMIT
Команда SET AUTOCOMMIT устанавливает режим автофиксации
для текущего сеанса использования базы данных
SET AUTOCOMMIT может переключить сеанс в режим
автофиксации, когда автоматически фиксируется в базе данных
результат каждого отдельного оператора
Включение/отключение режима AUTOCOMMIT:
SET AUTOCOMMIT ON – установить режим AUTOCOMMIT
SET AUTOCOMMIT OFF – отменить режим AUTOCOMMIT
При возникновении аварийной ситуации для текущей транзакции
автоматически выполняется откат
264.
Проблема параллельных транзакцийВ многопользовательском режиме возможны ситуации, когда
одновременно поступает запрос к одной и той же таблице - при этом
могут возникать конфликтные ситуации
Пример конфликтной ситуации:
SELECT AVG(rating)
FROM suppliers
UPDATE suppliers
SET rating = rating*2
Для управления параллельными транзакциями в SQL может
использоваться механизм блокировок (locks)
Блокировки накладывают ограничение на выполнение некоторых
операций над данными, если в этот момент активны другие операции,
при этом блокируемые операции выстраиваются в очередь
Виды блокировок:
S- locks – разделяемые блокировки: в единицу времени может
выполняться несколькими пользователями
X- locks – исключительные блокировки: запрещается доступ к
данным всем пользователям, кроме того, чья блокировка в
данный момент активна
Уровень изолированности транзакций определяет, в какой мере в
результате выполнения логически параллельных транзакций
допускается получение несогласованных данных
265. Использование SQL в языках программирования (встроенный SQL)
Проблема:–
SQL – декларативный язык, что накладывает на него ряд
ограничений
– Отсутствуют операторы управления процессом обработки
данных (присваивание-ветвление-цикл)
– Интерактивный SQL выполняет по одной команде в каждый
момент времени
Назначение встроенного SQL – комбинировать достоинства
императивных языков высокого уровня с SQL, давая
возможность обращаться к БД через SQL из программы на
процедурном языке высокого уровня
Встраиваемые в код приложения SQL-операторы могут
вставляться статически или формироваться динамически в
процессе выполнения программы
Программа со встроенным SQL представляет собой смесь
SQL-операторов и кода на базовом языке программирования
(HOST-языке), поэтому ее нельзя просто скомпилировать с
помощью компилятора базового языка
266.
Доступ к базе данных из прикладной программыВозможные варианты обращаться к базе данных из программы на
языке высокого уровня:
– встраивание в код языка программирования SQL-операторов
(статический SQL)
– формирование кода SQL-операторов в процессе выполнения
программы на языке программирования и дальнейшее их
выполнение (динамический SQL)
– вызов из программ, написанных на других языках
программирования, SQL-модулей, которые представляют собой
код на языке SQL
– использование интерфейса прикладного программирования API
(Application Programming Interface), позволяющего реализовать
работу с базой данных через предоставляемый набор APIфункций:
• целевой API - предоставляется производителем СУБД для
работы именно с этой базой данных
• межплатформенный API - включает унифицированные
средства доступа к СУБД различных производителей ODBC
(Open DataBase Connectivity), JDBC (Java Database
Connectivity), соответствующих стандарту SQL/CLI (SQL Call
Level Interface)
• REST API (RESTfull) – современная технология создания API
для взаимодействия веб-приложения с базой данных на
сервере
267.
Стандартом SQL-92 предусматривалась возможность
встраивания SQL-операторов в следующие процедурные
языки программирования: C, Pascal, Java (SQLJ), Ada,
Cobol, Fortran, PL/1, PL/M
Базовые принципы:
– операторы SQL помещаются в исходный текст
программы
– каждому SQL-оператору предшествует фраза-флаг
EXEC SQL (EXECute SQL)
– определяются дополнительные операторы, которые
являются специальными для встроенной формы SQL
– исходный код программы со встроенным SQL- кодом
обрабатывается прекомпилятором (препроцессором)
– прекомпилятор формирует модуль доступа, заменяя в
исходном коде операторы SQL на вызов внешних
процедур модуля доступа
– связанный с программой ID доступа, должен иметь все
привилегии, чтобы выполнять операции SQL в
программе
268.
Процесс обработки программного кода со встроенным SQL-кодомИсходный код
Препроцессор
Создание
модуля доступа
Замена SQL-кода
на вызовы подпрограмм
Компиляция
Линкование
Выполняемый код
Связывание
План доступа
269.
Использование переменных языка высокого уровня во встраиваемыхSQL-операторах
Переменные базового языка программирования во встроенном SQL
можно использовать:
– в выражениях;
– как INTO-переменные;
– как переменные связи (bind-переменные);
– как индикаторные переменные.
Требования к переменным языка высокого уровня, используемым во
встраиваемых операторах SQL:
– должны быть объявлены в разделе объявления типов SQL
DECLARE SECTION
– должны иметь совместимый тип данных с их функциями в
операторе SQL (например, числовой тип, если он вставляется в
числовое поле)
– к моменту их использования в операторе SQL должны иметь
значения, независимо от того, что оператор SQL может
формировать значение
– когда переменная упоминается в операторе SQL, перед ее
именем ставится символ «двоеточие» (это дает возможность
использовать имена атрибутов таблиц в качестве имен
переменных)
270.
Все переменные, на которые есть ссылки в операторах SQL, должны
быть объявлены в разделе объявления типов SQL DECLARE
SECTION
В программе может быть несколько таких разделов и они
размещаются в любых местах, в которых синтаксис основного языка
допускает объявление переменных, но обязательно до использования
объявляемых переменных в операторах SQL
Для работы с данными из таблицы поставщиков suppliers раздел
объявления типов может выглядеть так:
EXEC SQL BEGIN DECLARE SECTION;
char cod_s[4], surname[20], city[20];
int rating;
EXEC SQL END DECLARE SECTION;
Замечание 1: внутри раздела используется нотация языка высокого
уровня, в который встраивается SQL (в данном примере C++)
Замечание 2: дополнительно объявлять в программе переменные,
описанные в разделе DECLARE SECTION, не надо
Переменные связи
Для передачи значений в базу данных используются переменные
связи (bind-переменные)
Эти переменные могут использоваться в предложении WHERE для
вычисления условия или в операторах INSERT, DELETE и UPDATE
Пример: добавить поставщика в таблицу suppliers
EXEC SQL INSERT INTO suppliers
VALUES (:cod_s, :surname, :rating, :city);
271.
В таблицу можно добавить несколько кортежей, использовав оператор
цикла языка высокого уровня (например, C++)
Пример: добавить в таблицу suppliers поставщиков, данные о которых
вводятся c клавиатуры
cout <<"Введите код поставщика "; cin >>cod_s;
while (cod_s[0]!='0') {
cout <<"Введите Фамилию Рейтинг Город ";
cin >>surname >>rating >>city;
EXEC SQL INSERT INTO suppliers
VALUES (:cod_s, :surname, :rating, :city);
cout <<"Код следующего поставщика "; cin >>cod_s;
}
Пример: добавить поставщиков с рейтингом большим 20
cout <<"Введите код поставщика "; cin >>cod_s;
while (cod_s[0]!='0') {
cout <<"Введите Фамилию Рейтинг Город ";
cin >>surname >>rating >>city;
if (rating > 20) then EXEC SQL INSERT INTO suppliers
VALUES (:cod_s, :surname, :rating, :city);
cout <<"Код следующего поставщика "; cin >>cod_s;
}
272.
Во встроенном SQL для извлечения данных из результирующей выборки
в переменные основного языка программирования можно использовать
модифицированный оператор SELECT и INTO-переменные
В операторе SELECT можно добавить предложение INTO, сразу указав
имена переменных, в которые будут занесены результаты запроса; такие
переменные называются INTO-переменными.
Ограничения при использование INTO-переменных:
– результатом выборки должен быть только один кортеж, если выбрано
несколько кортежей, операция считается ошибочной
– INTO-переменные должны соответствовать выбираемым атрибутам
по количеству, порядку следования и типам
Результирующая выборка будет гарантированно возвращать только один
кортеж в следующих случаях:
– при использовании в предикате значения поля, являющегося
уникальным в силу объявления его как PRIMARY KEY или UNIQUE;
– при агрегировании данных всей таблицы, когда в списке полей
указывается агрегирующая функция, а фраза GROUP BY отсутствует;
– если структура используемых таблиц и синтаксис оператора SELECT
однозначно определяют возвращаемую строку
Пример: выбрать из таблицы suppliers данные о поставщике с кодом S2,
присвоив значения атрибутов переменным языка высокого уровня
EXEC SQL SELECT cod_s, surname, rating, city
INTO :cod_s, :surname, :rating, :city
FROM suppliers WHERE cod_s = ‘S2’;
Замечание: в данном примере единственность выбранного кортежа
обеспечивается тем, что он выбирается по значению первичного ключа
273.
Для извлечения значений переменных из базы данных можно
использовать и запросы, результатом которых является
несколько кортежей
С этой целью в SQL используется понятие курсора
Курсор (cursor) SQL – это связанная с запросом буферная
переменная, которая принимает значение множества
кортежей, удовлетворяющих запросу.
Объявление курсора
EXEC SQL DECLARE SupplsInMsk CURSOR FOR
SELECT *
FROM suppliers
WHERE CITY = ‘Москва’;
Эта инструкция не выполняется, она лишь объявляет курсор с
именем SupplsInMsk, который определен на указанной
выборке поставщиков, проживающих в Москве, т.е. связывает
курсор с запросом SELECT
Для того, чтобы курсор принял значение множества выбранных
кортежей, необходимо выполнить оператор открытия курсора:
EXEC SQL OPEN CURSOR SupplsInMsk;
274.
Оператор OPEN CURSOR выполняет выборку
SELECT, для которой объявлен курсор, и делает
доступным для считывания в программу первый
кортеж выбранной таблицы
курсор
cod_
surname rating
s
city
Иванов
Москва
S1
20
S4 Круглов
20 Москва
Считывание текущего кортежа и перемещение курсора к
следующему из выбранных кортежей выполняется
оператором FETCH:
EXEC SQL FETCH SupplsInMsk
INTO :cod_s, :surname, :rating, :city;
курсор
cod_
surname rating
s
city
Иванов
Москва
S1
20
275.
Пример: написать на C++ фрагмент кода, который выводит на
дисплей данные о поставщиках, проживающих в Москве,
используя объявленный ранее курсор SupplsInMsk
EXEC SQL OPEN CURSOR SupplsInMsk;
char flag[3]="да";
while (flag=="да") {
EXEC SQL FETCH SupplsInMsk
INTO :cod_s, :surname, :rating, :city;
cout <<cod_s <<‘ ‘ << surname <<‘ ‘ << rating <<‘ ‘ << city <<endl;
cout <<"Продолжить просмотр (да/нет)? ";
cin >>flag;
}
EXEC SQL CLOSE CURSOR SupplsInMsk;
Последний оператор
EXEC SQL CLOSE CURSOR SupplsInMsk;
завершает работу с курсором, разрывая связь курсора с текущим
значением выборки
276.
Обработка ошибок• Стандартом SQL-92 определены две переменные, значения
которых автоматически формируются СУБД при выполнении
SQL-оператора:
– SQLSTATE, тип char(5) - содержит информацию о классе (два
старших символа) и подклассе (3 младших символа),
описывающих состояние выполненного SQL-оператора
– SQLCODE, целочисленный тип - содержит код завершения
последнего выполненного SQL-оператора
• Статус выполнения SQL-оператора может быть следующим:
– успешное завершение, SQLSTATE ='00000' (класс '00'),
SQLCODE = 0
– успешное завершение с предупреждением (класс состояния
'02' - предупреждение 'NOT FOUND‘, класс '01' предупреждение, специфицируемое подклассом)
– завершение с ошибкой, классы '03' и более описывают как
стандартные, так и определяемые приложением ошибочные
ситуации, специфицируемые подклассом
• 'NOT FOUND' - SQL-оператор без ошибки, но не вернул
ожидаемого результата, например, не выбрано ни одного
кортежа, или оператор UPDATE не изменил ни одного кортежа
277.
Переменные SQLCODE и SQLSTATE часто используются в
операторе while для завершения цикла и для выхода из него в
случае возникновения ошибки
Для операторов OPEN и FETCH значение SQLCODE=0
означает, что курсор не пуст
Пример: написать фрагмент кода, который выводит на экран
дисплея данные обо всех поставщиках, проживающих в Москве
EXEC SQL OPEN CURSOR SupplsInMsk;
while (!SQLCODE) {
EXEC SQL FETCH SupplsInMsk
INTO :cod_s, :surname, :rating, :city;
cout <<cod_s <<‘ ‘ << surname <<‘ ‘ << rating <<‘ ‘ << city <<endl;
}
EXEC SQL CLOSE CURSOR SupplsInMsk;
Замечание: нарушение условия SQLCODE==0 означает, что
последний из выбранных кортежей уже был считан и выведен
на экран
278.
Программирование реакции на ошибки• Встроенный SQL поддерживает оператор WHENEVER,
определяющий действия, которые будут выполнены при
возникновении ситуации с появлением ошибки
• Этот оператор следует указывать до выполнения того SQLоператора, чья обработка ошибок будет "перехватываться"
• Оператор WHENEVER может определять, например, метку, на
которую будет выполнен переход при возникновении ошибки:
EXEC SQL WHENEVER SQLERROR GOTO Err_1;
• или действие типа CONTINUE (продолжение выполнения):
EXEC SQL WHENEVER NOT FOUND CONTINUE;
• или
– EXEC SQL WHENEVER SQLWARNING CONTINUE;
• или действие типа BREAK
EXEC SQL WHENEVER NOT FOUND BREAK; //завершить цикл
• или некоторую процедуру обработки ошибок
279.
Обработка NULL-значений• При необходимости распознавания NULL-значения в
извлекаемом кортеже или внесения NULL-значения в
таблицу используются индикаторные переменные
• Если в результате выполнения оператора извлекаемые
данные принимают значение NULL, считается, что SQLоператор выполнен с ошибкой
• Для предотвращения таких ситуаций применяются
индикаторные переменные, указываемые после имени
переменной через двоеточие (или INDICATOR:)
• До выполнения оператора индикаторной переменной по
умолчанию присваивается значение 0, если после
выполнения оператора она принимает отрицательное
значение, значит выбрано значение NULL
• Если в операторе INSERT или UPDATE требуется указать,
что используемая переменная может содержать значение
NULL, то после этой переменной через двоеточие следует
записать индикаторную переменную; в этом случае при
отрицательном значении индикаторной переменной в базу
данных будет занесено значение NULL
280.
• Пример 1: выборка из базы данныхИндикаторная
переменная
EXEC SQL OPEN CURSOR SupplsInMsk;
while (!SQLCODE) {
EXEC SQL FETCH SupplsInMsk
INTO :cod_s, :surname, :rating :Rat_ind, :city;
if (Rat_ind<0) then rating=0;
cout <<cod_s <<‘ ‘ << surname <<‘ ‘ << rating <<‘ ‘ << city <<endl;
}
EXEC SQL CLOSE CURSOR SupplsInMsk;
• Пример 2: занесение в базу данных
Rat_ind= …;
EXEC SQL UPDATE suppliers
SET rating = :rating :Rat_ind
WHERE cod_s=‘S3’;
• В примере 2, если значение индикаторной переменной Rat_ind
меньше нуля, у атрибута rating в базе данных будет сформировано
значение NULL, в противном случае атрибут rating получит значение
переменной rating
Замечание Индикаторная переменная Rat_ind должна быть описана в
разделе DECLARE SECTION как переменная типа integer
281. Динамический SQL
Создание операторов динамического SQL• Операторы динамического SQL - в отличие от операторов
встроенного SQL - формируются не на этапе компиляции,
а на этапе выполнения приложения
• Динамический SQL может применяться совместно с API
ODBC или SQL/CLI
• Начальный уровень поддержки динамического SQL
соответствия стандарту SQL-92 не требует
• Операторы динамического SQL формируются в программе
как строковые переменные, например,
• Stmt = "SELECT * FROM suppliers"
• Для динамического формирования оператора можно
выполнять конкатенацию строк
• Операторы динамического SQL можно использовать:
–
–
однократно, производя за один шаг компиляцию и выполнение
оператора (одношаговым интерфейс);
многократно, разделяя процесс компиляции оператора, при
котором строится план выполнения, и процесс непосредственного
выполнения оператора (многошаговый интерфейс).
282.
Одношаговый интерфейсОдношаговый интерфейс реализуется SQL-оператором:
EXECUTE IMMEDIATE :<имя строковой переменной>
На SQL-оператор, значение которого имеет указанная строковая
переменная, накладываются некоторые ограничения в части
использования переменных (INTO-переменные и переменные связи
или bind-переменные)
Пример динамического SQL с одношаговым интерфейсом:
St = "INSERT INTO sup_det VALUES (:cod_s, :cod_d, :quant) “;
EXEC SQL EXECUTE IMMEDIATE :St;
Многошаговый интерфейс
Многошаговый интерфейс, реализуемый операторами PREPARE и
EXECUTE, используется при необходимости неоднократного
выполнения одного и того же SQL-оператора, но с различными
параметрами
Оператор PREPARE компилирует указанный SQL-оператор без его
выполнения
Для выполнения откомпилированного SQL-оператора используется
оператор EXECUTE
При каждом выполнении оператора EXECUTE используется уже
«откомпилированный» SQL-оператор, что значительно повышает
производительность.
283. Структура и функции СУБД
Типовая структура СУБД
СУБД
ЯДРО
Компиляторы
Подсистема
поддержки
времени
выполнения
Утилиты
Ядро - основная резидентная часть, обеспечивающая
реализацию основных функций СУБД
Компиляторы – компиляция операторов непроцедурного
языка БД в некоторый исполняемый внутренний
машинно-независимый код
Подсистема поддержки времени выполнения –
интерпретатор внутреннего исполняемого кода СУБД
Утилиты – загрузка и выгрузка БД, сбор статистики,
глобальная проверка целостности и т.д
284.
Типовые функции и структура ядра СУБДЯдро СУБД
Функции ядра>
Управление
данными во
внешней
памяти
Управление
буферами
оперативной
памяти
Управление
транзакциями
Управление
журналами
(журнализация)
Структура ядра>
Менеджер
данных
Менеджер
буферов
Менеджер
транзакций
Менеджер
журналов
285.
Управление данными во внешней памяти• Обеспечение работы со структурами внешней памяти
– для хранения данных, непосредственно входящих в
базу данных
– для служебных целей, например, для ускорения
доступа к данным
• В конкретных реализациях СУБД возможны два подхода:
– активное использование возможностей существующих
файловых систем
– собственная система работы с данными на всех
уровнях вплоть до уровня устройств внешней памяти
• В любом случае
– пользователь не обязан знать, использует ли СУБД
файловую систему, и если использует, то как
организованы файлы
– СУБД поддерживает собственную систему именования
объектов базы данных
286.
Управление буферами оперативной памяти• СУБД обычно работают с базой данных, существенно
превосходящей доступный объем оперативной памяти
• Если при обращении к любому элементу данных будет
производиться обмен с внешней памятью, то вся система
будет работать со скоростью устройства внешней памяти
• Основным способом реального увеличения скорости
является буферизация данных в оперативной памяти
• Как правило, СУБД поддерживается собственный набор
буферов оперативной памяти с собственной дисциплиной
замены буферов, даже если операционная система
производит общесистемную буферизацию
• Одно из направлений развития СУБД ориентировано на
постоянное присутствие в оперативной памяти всей базы
данных, т.е. предполагается, что объем оперативной
памяти настолько велик, что позволяет не беспокоиться о
буферизации
287.
Управление транзакциями• Транзакция - это последовательность операций над БД,
рассматриваемых СУБД как единое целое
• Транзакция либо успешно выполняется, и СУБД
фиксирует (COMMIT) изменения БД, произведенные этой
транзакцией, во внешней памяти, либо ни одно из этих
изменений никак не отражается на состоянии БД.
• Понятие транзакции необходимо для поддержания
логической целостности БД
• Каждая транзакция начинается при целостном состоянии
БД и оставляет это состояние целостным после своего
завершения
• Транзакция может рассматриваться как единица
активности пользователя по отношению к базе данных
• Понятие транзакции особенно важно в
многопользовательских СУБД
• При управлении параллельно выполняющимися
транзакциями каждый из пользователей должен ощущать
себя единственным пользователем базы данных
288.
Управление транзакциями в многопользовательских СУБДACID-требования к транзакционным системам:
Атомарность (atomicity) - любая транзакция должна быть либо
выполнена и зафиксирована в базе данных полностью, либо ее
частичное выполнение не должно оставлять никаких следов ни в базе
данных, ни в результатах работы приложений.
СУБД должна устранять последствия неполного выполнения
транзакций, приложения не должны выводить какие-либо результаты,
зависящие от не полностью выполненных транзакций.
Согласованность (consistency) – в результате выполнения
транзакции база данных должна быть переведена из одного
целостного (логически непротиворечивого) состояния в другое
Изолированность (isolation) - СУБД должна обеспечить выполнение
без помех со стороны других транзакций; нарушение изоляции
транзакций может приводить к появлению некорректных результатов
и состояний базы данных (аномалии конкурентного выполнения).
Требование изоляции транзакций может вступать в противоречие с
требованием высокой пропускной способности, поэтому довольно
часто используются ослабленные условия изоляции транзакций.
Долговечность (durability) - никакие изменения, выполненные
завершенными транзакциями, не могут быть потеряны, что бы ни
происходило с сервером базы данных или вычислительной системой,
на которой этот сервер работает (отказоустойчивость базы данных).
289.
Сериализация транзакций• С управлением транзакциями в многопользовательской
СУБД связаны важные понятия сериализации транзакций
и сериального плана выполнения смеси транзакций
• Под сериализаций параллельно выполняющихся
транзакций понимается такой порядок планирования их
работы, при котором суммарный эффект смеси
транзакций эквивалентен эффекту их некоторого
последовательного выполнения.
• Сериальный план выполнения смеси транзакций - это
такой план, который приводит к сериализации транзакций.
• Сериальное выполнение смеси транзакций должно
обеспечивать для каждого пользователя, по инициативе
которого выполняется транзакция, незаметность
присутствия других транзакций
• Существует несколько базовых алгоритмов сериализации
транзакций; наиболее распространены алгоритмы,
основанные на синхронизационных захватах объектов БД
290.
Взаимодействие параллельных транзакцийПри использовании любого алгоритма сериализации
возможны ситуации конфликтов между двумя или более
транзакциями по доступу к объектам БД
Практические методы сериализации транзакций
основаны на учете следующих видов конфликтов:
– W-W - транзакция 2 пытается изменять объект,
измененный не закончившейся транзакцией 1
– W-R - транзакция 2 пытается читать объект,
измененный не закончившейся транзакцией 1
– R-W - транзакция 2 пытается изменять объект,
прочитанный не закончившейся транзакцией 1
Замечание: очевидно, ситуация R-R параллельного чтения
двумя транзакциями одного объекта базы данных не
является конфликтной, в этом случае транзакции могут
быть выполнены в любом порядке с сохранением
сериальности
291.
Важнейшая задача многопользовательской системы – обеспечение
изолированности пользователей, создание у каждого пользователя
надежной иллюзии монопольной работы с базой данных
Поскольку основным свойством транзакции является сохранение
целостности БД, транзакции рассматриваются как единицы
изолированности пользователей
Рассматриваются несколько базовых проблемных ситуаций, в которых
проявляется эффект конкурирующей транзакции, и которые должны
учитываться при управлении параллельными транзакциями:
– потерянные изменения (lost update) – одна транзакция
перезаписала данные, обновленные и зафиксированные другой
транзакцией
– «грязное чтение» или чтение «грязных данных» (dirty read) –
чтение частичных (uncommited) изменений
– неповторяющееся чтение (non-repeatable read) – повторное чтение
показывает другие (измененные) данные
– фантомное чтение (phantom read) – при повторном чтении
появляются/исчезают «кортежи-фантомы»
– аномалия сериализации (serialization anomaly) – результат
параллельного выполнения транзакций не совпадает с
результатом какого-либо их последовательного выполнения
(последовательность выполнения влияет на результат)
Каждой ситуации можно сопоставить некоторый сценарий
взаимодействия параллельных транзакций
292.
Сценарий «отсутствие потерянных изменений»1. Транзакция 1 изменяет объект
базы данных
2. Транзакция 1 читает объект базы
данных
3. Транзакция 2 также изменяет этот
объект базы данных
4. Транзакция 2 фиксирует
изменения в БД (COMMIT)
5. Транзакция 1 повторно читает
объект базы данных и не видит
изменений, произведенных ею
ранее
1
2
Объект
БД
С
• При последовательном выполнении транзакций были бы учтены
изменения, сделанные обеими транзакциями
• Необходимо, чтобы до завершения транзакции 1 никакая другая
транзакция не могла изменять объект
Условие: изменение объекта только одной транзакцией
293.
Потерянные измененияПрилож 1
DataBase
suppliers
S1 Иванов 20 Москва
S2 Петров 10 Тула
Б ……………………………………………
BEGIN;
SELECT*
FROM suppliers
WHERE cod_s=‘S2’;
S2 Петров 10 Тула
UPDATE suppliers
SET rating=20
WHERE
surname=‘Петров’;
Прилож 2
BEGIN;
А
SELECT*
FROM suppliers
WHERE cod_s=‘S2’;
З
А
S2 Петров 10 Тула
Д suppliers
Иванов 20 Москва
А S1
S2 Петров 20 Тула
Н
……………………………………………
Н
Ы suppliers
UPDATE suppliers
SET rating=30
WHERE
surname=‘Петров’;
Иванов 20 Москва
Х S1
S2 Петров 30 Тула
SELECT*
FROM suppliers
WHERE cod_s=‘S2’;
S2 Петров 30 Тула
……………………………………………
COMMIT;
294.
1. Транзакция 1 изменяет объектбазы данных
2. Транзакция 2 одновременно
читает этот объект
3. Независимо от того, как
завершается транзакция 1,
транзакция 2 читает «грязные»
(несогласованные) данные
1
2
Объект
БД
С
• До завершения транзакции 1, изменившей объект, никакая
другая транзакция не должна читать объект
• Условие: чтение только неизменяемого в данный момент
объекта
• Минимальным требованием является блокировка чтения
объекта до завершения операции его изменения в
транзакции 1
295.
Сценарий «отсутствие чтения «грязных данных»1. Транзакция 1 изменяет объект
базы данных
2. Транзакция 2 читает этот объект
3. Транзакция 1 выполняет откат
Транзакция 2 читает «грязные»
(несогласованные) данные
1
2
Объект
БД
R
С
• До завершения транзакции 1, изменившей объект, никакая
другая транзакция не должна читать объект
• Условие: чтение только неизменяемого в данный момент
объекта
• Минимальным требованием является блокировка чтения
объекта до завершения операции его изменения в
транзакции 1
296.
«Грязное чтение»Прилож 1
DataBase
suppliers
S1 Иванов 20 Москва
S2 Петров 10 Тула
Прилож 2
Б ……………………………………………
BEGIN;
BEGIN;
А
UPDATE suppliers
SET rating=30
WHERE
surname=‘Петров’;
З
А
suppliers
S1 Иванов 20 Москва
S2 Петров 30 Тула
Д ……………………………………………
А
Н
Н
Ы
ROLLBACK;
Х
SELECT*
FROM suppliers
WHERE cod_s=‘S2’;
S2 Петров 30 Тула
suppliers
S1 Иванов 20 Москва
S2 Петров 10 Тула
……………………………………………
COMMIT;
297.
Сценарий «отсутствие неповторяющихся чтений»1. Транзакция 1 читает объект базы
данных
2. До завершения транзакции 1
транзакция 2 изменяет объект
3. Tранзакция 2 успешно
завершается
4. Транзакция 1 повторно читает
объект и видит его измененное
состояние
1
2
Объект
БД
C
• Чтобы избежать неповторяющихся чтений, до завершения
транзакции 1 никакая другая транзакция не должна
изменять объект
• Условие: изменение только нечитаемого в данный момент
объекта
• Во многих СУБД это является максимальным требованием
к синхронизации транзакций
298.
Неповторяющееся чтениеПрилож 1
DataBase
suppliers
S1 Иванов 20 Москва
S2 Петров 10 Тула
Прилож 2
Б ……………………………………………
BEGIN;
BEGIN;
А
З
А
UPDATE suppliers
SET rating=30
WHERE
surname=‘Петров’;
SELECT*
FROM suppliers
WHERE cod_s=‘S2’;
S2 Петров 10 Тула
Д
suppliers
А S1 Иванов 20 Москва
S2 Петров 30 Тула
Н ……………………………………………
COMMIT;
Н
Ы
SELECT*
FROM suppliers
WHERE cod_s=‘S2’;
S2 Петров 30 Тула
Х
COMMIT;
299.
Проблема «кортежей-фантомов»1. Транзакция 1 выполняет оператор A
выборки строк таблицы R,
удовлетворяющих условию S
2. Транзакция 2 вставляет в таблицу R
новую строку, удовлетворяющую
условию S
3. Транзакция 2 успешно завершается
4. Транзакция 1 повторно выполняет
оператор A, в результате появляется
строка, которая отсутствовала при
первом выполнении оператора
1
2
Удовл S
Таблица R
C
• Чтобы избежать появления кортежей-фантомов, требуется
более высокий логический уровень синхронизации
транзакций - предикатные синхронизационные захваты
300.
Фантомное чтениеПрилож 1
DataBase
suppliers
S1 Иванов 20 Москва
S2 Петров 10 Тула
Б ……………………………………………
BEGIN;
SELECT surname
FROM suppliers
WHERE rating=20;
Иванов
Круглов
Прилож 2
BEGIN;
А
З
А
INSERT INTO suppliers
VALUES (‘S7’,’Орлов’,20,‘Тула’)
suppliers
Д S1 Иванов 20 Москва
S2 Петров 10 Тула
А ……………………………………………
S7 Орлов 20 Тула
Н
SELECT surname
FROM suppliers
WHERE rating=20;
Иванов
Круглов
Орлов
Н
Ы
Х
COMMIT;
301.
Аномалия сериализации
Пусть параллельно выполняются следующие 2
транзакции:
Транзакция 1
Транзакция 2
BEGIN;
SELECT COUNT(*)
FROM suppliers
WHERE city=‘Тула’;
BEGIN;
SELECT COUNT(*)
FROM suppliers
WHERE city=‘Москва’;
INSERT INTO suppliers
VALUES(‘S6’, ‘Котов’, 20, ‘Москва’);
COMMIT;
INSERT INTO suppliers
VALUES(‘S7’, ‘Орлов’, 20, ‘Тула’);
COMMIT;
Два варианта последовательности выполнения COMMIT:
– Транзакция 1, Транзакция 2
SELECT в Транзакции 1 возвращает значение 2
SELECT в Транзакции 2 возвращает значение 3
– Транзакция 2, Транзакция 1
SELECT в Транзакции 1 возвращает значение 3
SELECT в Транзакции 2 возвращает значение 2
Результат зависит от последовательности выполнения транзакций
302.
Стандарт определяет некоторую шкалу уровней изолированности
транзакций
Всего в стандарте SQL предусмотрено четыре уровня, при этом
каждый более высокий уровень включает в себя все возможности
предыдущего.
Уровень 1: READ UNCOMMITTED (чтение незафиксированных данных)
— самый низкий уровень изоляции, согласно стандарту SQL, на этом
уровне допускается чтение «грязных» данных
Замечание: в PostgreSQL чтение «грязных» данных на этом уровне не
допускается.
Уровень 2: READ COMMITTED (чтение зафиксированных данных) — не
допускается чтение «грязных» данных, транзакция может видеть
только те незафиксированные изменения данных, которые
произведены в ходе выполнения ее самой.
Уровень 3: REPEATABLE READ (повторяющееся чтение) — не
допускается чтение «грязных» данных и неповторяющееся чтение
Замечание: в PostgreSQL на этом уровне не допускается также фантомное
чтение
Уровень 4: SERIALIZABLE (сериализуемость) — не допускается ни одна
из перечисленных ситуаций, в том числе и аномалии сериализации,
результат выполнения транзакций должен быть эквивалентен
некоторому их последовательному выполнению
303.
Уровеньизоляции
«Грязное»
чтение
Неповторяющееся
чтение
Фантомное
чтение
Аномалия
сериализации
READ
UNCOMMITTED
+
в PgrSQL -
+
+
+
READ
COMMITTED
-
+
+
+
REPEATABLE
READ
-
-
+
в PgrSQL -
+
SERIALIZABLE
-
-
-
-
В этой таблице используются следующие обозначение:
«плюс» - соответствующий конфликт допускается,
«минус» - соответствующий конфликт не допускается
Замечание: В PostgreSQL уровень READ UNCOMMITTED обрабатывается
как READ COMMITTED
Если возникает недопустимый конфликт, возврат кода ошибки и откат
Команда SET TRANSACTION устанавливает характеристики текущей
транзакции, в том числе задает уровень изоляции
Уровень изоляции для отдельной транзакции можно установить
следующей командой:
SET TRANSACTION ISOLATION LEVEL REPEATABLE READ;
304.
Управление журналами ивосстановлением базы данных после сбоев
Надежность хранения данных во внешней памяти одно из
основных требований к СУБД
СУБД должна быть в состоянии восстановить последнее
согласованное состояние БД после любого аппаратного или
программного сбоя.
Обычно рассматриваются два вида аппаратных сбоев:
– мягкие сбои, которые можно трактовать как внезапную
остановку работы компьютера, например, аварийное
выключение питания
– жесткие сбои, характеризуемые потерей информации на
носителях внешней памяти
Примеры программных сбоев:
– аварийное завершение работы СУБД (ошибка в
программе или аппаратный сбой) - ситуация трактуется
как особый вид мягкого аппаратного сбоя
– аварийное завершение прикладной программы, в
результате чего некоторая транзакция остается
незавершенной - в этом случае требуется ликвидировать
последствия только одной транзакции
305.
Для восстановления БД нужно располагать некоторой
дополнительной информацией, т.е. поддержание надежности
хранения данных в БД требует избыточности хранения данных
Данные, которые используются для восстановления, должны
храниться особо надежно
Основной метод поддержания такой избыточной информации ведение журнала изменений БД.
Журнал - это особая часть БД, недоступная пользователям и
поддерживаемая с особой тщательностью, в которую
поступают записи обо всех изменениях основной части БД
Иногда поддерживаются две копии журнала, располагаемые на
разных физических дисках
В разных СУБД изменения БД журнализуются на разных
уровнях:
– иногда запись в журнале соответствует некоторой
логической операции изменения БД (например, операции
удаления строки из таблицы реляционной БД),
– иногда - минимальной внутренней операции модификации
страницы внешней памяти; в некоторых системах
одновременно используются оба подхода
306.
Во всех случаях придерживаются стратегии «упреждающей»
записи в журнал (так называемого протокола Write Ahead Log
- WAL), согласно которой запись об изменении любого
объекта БД должна попасть во внешнюю память журнала
раньше, чем измененный объект попадет во внешнюю
память основной части БД.
Корректное соблюдение протокола WAL позволяет с
помощью журнала решить все проблемы восстановления БД
после любого сбоя.
Самая простая ситуация восстановления - индивидуальный
откат транзакции, для этого не требуется общесистемный
журнал изменений БД; достаточно для каждой транзакции
поддерживать локальный журнал операций модификации
БД и производить откат транзакции, следуя от конца
локального журнала
В большинстве СУБД локальные журналы не
поддерживаются, а индивидуальный откат транзакции
выполняют по общесистемному журналу, для чего все
записи от одной транзакции связывают обратным списком
307.
Восстановление базы данных после мягкого сбояПри мягком сбое во внешней памяти основной части БД могут:
– находиться объекты, модифицированные транзакциями, не
закончившимися к моменту сбоя
– отсутствовать объекты, модифицированные транзакциями,
которые к моменту сбоя успешно завершились (при мягком
сбое пропадает содержимое буферов оперативной памяти)
Целью процесса восстановления после мягкого сбоя является
состояние внешней памяти основной части БД, которое
возникло бы при фиксации во внешней памяти изменений всех
завершившихся транзакций и которое не содержало бы никаких
следов незаконченных транзакций
При восстановлении базы данных после мягкого сбоя
последовательно выполняются два шага:
– сначала производят откат незавершенных транзакций (undo)
– затем повторно воспроизводят (redo) те операции
завершенных транзакций, результаты которых не
отображены во внешней памяти
Этот процесс содержит много тонкостей, связанных с общей
организацией управления буферами и журналом
308.
Восстановление базы данных после жесткого сбояДля восстановления БД после жесткого сбоя используют
журнал и архивную копию базы данных
• Необходимым условием восстановления базы данных
после жесткого сбоя является сохранность журнала во
внешней памяти в СУБД
Архивная копия - это полная копия БД к моменту начала
заполнения журнала
• В процессе восстановления, исходя из состояния БД в
архивной копии, по журналу последовательно
воспроизводится выполнение всех транзакций, которые
закончились к моменту сбоя
• Процесс восстановления после жесткого сбоя является
достаточно длительным, поэтому, как правило, не
воспроизводится выполнение незавершенных к моменту
сбоя транзакций – после восстановления эти транзакции
должны быть выполнены пользователями повторно
309. Архитектура многопользовательских баз данных
• Многопользовательская база данных:– централизованная архитектура
– распределенная архитектура с сетевым клиент-серверным
взаимодействием
Система с централизованной архитектурой
• Централизованная
архитектура вычислительных систем
была распространена в 70-х и 80-х годах и
реализовывалась на базе мейнфреймов
(например, IBM-360/370) или их
отечественных аналогов серии ЕС ЭВМ,
либо на базе мини-ЭВМ (например, PDP11 или их отечественного аналога СМ-4)
• Характерная особенность
централизованной архитектуры –
полная «неинтеллектуальность»
Мейнфрейм или
терминалов; они лишь обеспечивают
мини-ЭВМ
доступ к мощной центральной ЭВМ (хостБаза данных и
ЭВМ), которая полностью управляет их
все приложения
работой, – «многотерминальный доступ»
(бизнес-логика)
310.
Особенности систем с централизованной архитектурой• Достоинства:
– пользователи совместно используют дорогие ресурсы
ЭВМ и дорогие периферийные устройства;
– централизация ресурсов и оборудования облегчает
обслуживание, эксплуатацию и администрирование
вычислительной системы
• Недостатки:
– пользователь полностью зависит от администратора
хост-ЭВМ
– пользователь не может настроить рабочую среду под
свои потребности - все используемое программное
обеспечение является коллективным (ВЦКП)
– центральная ЭВМ должна иметь большую память и
высокую производительность, чтобы обеспечивать
комфортную работу большого числа пользователей.
311.
Распределенная архитектура «клиент-сервер»«Клиент-сервер» - это модель взаимодействия компьютеров в сети
Как правило, один компьютер в сети располагает информационновычислительными ресурсами, такими как процессоры, файловая
система, почтовая служба, служба печати, база данных, другие же
компьютеры пользуются ресурсами.
Компьютер, управляющий тем или иным ресурсом, принято называть
сервером этого ресурса
Компьютер, желающий воспользоваться ресурсом, которым он не
обладает, - клиентом
Конкретный сервер характеризуется видом ресурса, которым он
владеет:
– если ресурсом являются базы данных, то речь идет о сервере баз
данных, назначение которого - обслуживать запросы клиентов,
связанные с обработкой данных;
– если ресурс - это файловая система, то говорят о файловом
сервере или файл-сервере и т.д.
Этот же принцип распространяется и на взаимодействие процессов
(программ): если один из процессов выполняет некоторые функции,
предоставляя другим соответствующий набор услуг, такой процесс
рассматривается в качестве сервера.
Процессы, пользующиеся этими услугами, принято называть
клиентами
312.
• Сервер базы данных представляет собой многопользовательскуюверсию СУБД, параллельно обрабатывающую запросы, поступившие
со всех рабочих станций
• Задача сервера:
– реализация логики обработки транзакций с применением
необходимой техники синхронизации - поддержки протоколов
блокирования ресурсов,
– обеспечение, предотвращение и/или устранения тупиковых
ситуаций
• Программное обеспечение рабочей станции при такой архитектуре
может играть роль только внешнего интерфейса (Front - end)
централизованной системы управления данными.
• Это позволяет существенно уменьшить сетевой трафик, сократить
время на ожидание блокированных ресурсов данных в
мультипользовательском режиме, разгрузить рабочие станции
• Как правило, клиент и сервер территориально отделены друг от
друга, и в этом случае они образуют систему распределенной
обработки данных
• Если информационная система имеет архитектуру «клиент-сервер»,
то это означает, что реализованные в ее рамках прикладные
программы могут иметь распределенный характер, т.е. часть функций
приложений будет реализована в программе-клиенте, другая - в
программе-сервере
313.
Базовые принципы технологии «клиент-сервер»• Разделение функций стандартного интерактивного приложения
на четыре группы:
– функции ввода и отображения данных (пользовательский
интерфейс);
– прикладные функции, характерные для предметной области
(бизнес-логика);
– фундаментальные функции хранения и управления
информационными ресурсами (базами данных);
– служебные функции
ПРИЛОЖЕНИЕ
Пользовательский
интерфейс
Бизнес-логика
Управление
данными
314.
• Исходя из этого деления любое приложение может состоять изследующих компонентов:
– компонент представления (presentation), реализующий функции
первой группы;
– прикладной компонент (business application), поддерживающий
функции второй группы;
– компонент доступа к информационным ресурсам (resource access)
или менеджер ресурсов (resource manager), поддерживающий
функции третьей группы
• Различия определяются четырьмя факторами:
– какие виды программного обеспечения входят в логические
компоненты;
– какие механизмы программного обеспечения используются для
реализации функций трех групп;
– как логические компоненты распределяются между компьютерами
в сети;
– какие механизмы используются для связи компонент между собой
• Четыре подхода, реализованные в модели «клиент-сервер»:
– модель файлового сервера (File Server) – FS-модель;
– модель доступа к удаленным данным (Remote Data Access) – RDAмодель;
– модель сервера баз данных (DataBase Server) – DBS-модель;
– модель сервера приложений (Application Server) – AS-модель.
315.
Модель файлового сервера – FS-модель• «Файл-сервер» - базовая архитектура для локальных
сетей персональных компьютеров 90-х г.г.
• Применялась при разработке распределенных
информационных систем на локальных вычислительных
сетях с использованием популярных в то время СУБД,
FoxPRO, Clipper, Paradox и др.
Компьютер-клиент
Компонент
Прикладной
представления компонент
Компьютер-сервер
Запрос файлов
Файлы
Компонент
доступа к
базе данных
316.
• Основные свойства FS-модели:– выделяется файл-сервер для реализации услуг по
обработке файлов других узлов сети;
– работает под управлением сетевых ОС;
– сервер играет роль компонента доступа к информационным
ресурсам;
– в остальных узлах функционирует приложение, в кодах
которого совмещены компоненты представления и
прикладной;
– протокол обмена - набор низкоуровневых вызовов.
• Технология:
– запрос направляется на файловый сервер, который
передает СУБД, размещенной на компьютере-клиенте,
требуемый блок данных;
– вся обработка осуществляется на компьютере-клиенте
• Недостатки:
– очень высокий сетевой трафик;
– небольшое число операций манипулирования;
– недостаточный уровень безопасности
317.
Модель доступа к удаленным данным - RDA-модель• Основные свойства:
– коды компонента представления и прикладного компонента
совмещены и выполняются на компьютере-клиенте;
– на компьютере-сервере размещается только компонент
доступа к базе данных
– доступ к информационным ресурсам обеспечивается
операторами непроцедурного языка SQL или вызовами
функций специальной библиотеки (если имеется
соответствующий интерфейс прикладного программирования
- API)
Компьютер-клиент
Компонент
Прикладной
представления компонент
Компьютер-сервер
SQL-запрос
Данные
Компонент
доступа к
базе данных
318.
• Технология RDA-модели :– клиентский запрос направляется на сервер, где
функционирующее ядро СУБД обрабатывает запрос и
возвращает результат (блок данных) клиенту
– ядро СУБД выполняет пассивную роль;
– инициатор манипуляций с данными - программы на
компьютере-клиенте.
• Достоинства:
– процессор сервера загружается операциями обработки
данных;
– уменьшается загрузка сети, т.к. по сети передаются
запросы на высокоуровневом языке SQL;
– унификация интерфейса «клиент-сервер» в виде языка
SQL; использование его в качестве стандарта общения
клиента и сервера.
• Недостатки:
– удовлетворительное администрирование приложений
в RDA-модели невозможно из-за совмещения в одной
программе различных по своей природе функций
(представления и прикладных)
319.
Модель сервера базы данных - DBS-модель• Основные свойства:
– на компьютере-клиенте остается только код компонент
представления;
– прикладной компонент и компонент доступа к базе данных
размещаются на компьютере-сервере
– доступ к информационным ресурсам обеспечивается
операторами языка SQL
– компонент представления взаимодействует с прикладным
компонентом с помощью вызовов специальных процедур
(хранимые процедуры)
• Реализована в современных реляционных СУБД Informix,
Ingres, PostgreSQL, Sybase, Oracle и др.
Компьютер-клиент
Компонент
представления
Компьютер-сервер
Вызов
Данные
Прикладной
компонент
SQL
Компонент
доступа к
базе данных
• На практике для построения многопользовательских информационных
систем часто используется синтез RDA- и DBS-моделей
320.
• Основные свойства DBS-модели:– основа модели - механизм хранимых процедур, средство
программирования SQL-сервера;
– процедуры хранятся в словаре базы данных, разделяются
между несколькими клиентами и выполняются на
компьютере, где функционирует SQL-сервер;
– компонент представления выполняется на компьютереклиенте;
– прикладной компонент и ядро СУБД на компьютере-сервере
базы данных.
• Достоинства:
– возможность централизованного администрирования;
– возможность разделения процедуры между несколькими
приложениями
– вместо SQL-запросов по сети передаются вызовы хранимых
процедур, что ведет к снижению сетевого трафика.
• Недостатки:
– в большинстве СУБД недостаточно возможностей для
отладки и типизирования хранимых процедур;
– ограниченность средств для написания хранимых процедур.
321.
Модель сервера приложений - AS-модель• Основные свойства:
– на компьютере-клиенте выполняется процесс,
отвечающий за интерфейс с пользователем – Application
Client (AC);
– этот процесс, обращаясь за выполнением услуг к
прикладному компоненту, играет роль клиента
приложения (АС);
– прикладной компонент реализован как группа процессов,
выполняющих прикладные функции, и называется
сервером приложения – Application Server (AS);
– все операции над БД выполняются соответствующим
компонентом, для которого AS - клиент
Компьютер-клиент
Компонент
представления
Клиент приложения
Компьютер-сервер
API
Прикладной
компонент
Сервер приложения
Компьютер-сервер
SQL
Компонент
доступа к
базе данных
Сервер базы данных
322.
Особенности AS-модели• RDA- и DBS-модели имеют в основе двухзвенную схему
разделения функций приложения.
– в RDA-модели прикладные функции отданы клиенту,
прикладной компонент сливается с компонентом
представления
– в DBS-модели их реализация осуществляется через ядро
СУБД, прикладной компонент интегрируется в компонент
доступа к ресурсам.
• В AS-модели:
– реализована трехзвенная схема разделения функций
– прикладной компонент выделен как важнейший
изолированный элемент приложения, имеющий
стандартизированные интерфейсы с двумя другими
компонентами
• AS-модель:
– обобщается на n-звенную модель клиент-серверного
взаимодействия
– является фундаментом для мониторов обработки
транзакций (Transaction Processing Monitors - TPM), которые
выделяются как особый вид программного обеспечения
323.
Преимущества модели сервера приложений• Целостность данных и кода
– Выделяя бизнес-логику на отдельный сервер или на небольшое
количество серверов, можно гарантировать обновления и
улучшения приложений для всех пользователей. Отсутствует риск,
что старая версия приложения получит доступ к данным или
сможет их изменить старым несовместимым образом.
• Централизованная настройка и управление
– Изменения в настройках приложения, таких, как изменение сервера
базы данных или системных настроек, могут производиться
централизованно.
• Безопасность
– Сервер приложений действует как центральная точка, используя
которую, можно управлять доступом к данным и частям самих
приложений, что считается преимуществом для защиты данных.
Это, в частности, позволяет перенести ответственность за
аутентификацию с потенциально небезопасного уровня клиента на
уровень сервера приложений, при этом дополнительно скрывая
уровень базы данных
• Поддержка транзакций
– Транзакция представляет собой неделимую единицу активности, во
время которой выполняется изменение данных. Конечные
пользователи при этом могут выиграть от стандартизованного
поведения системы, от уменьшения времени на разработку и от
снижения стоимости.
324.
Примеры некоторых современных Java-серверов приложений• Apache Tomcat
Apache Tomcat - это программное обеспечение с открытым исходным кодом,
разработанное фондом Apache; написан на Java выпущен впервые в 1999
году. Его называют контейнером сервлетов - специальных модулей,
которые обрабатывают запросы от пользователей и возвращают результат
Tomcat позволяет запускать веб-приложения и часто используется вместе с
конфигурационным файлом Apache HTTPD (Apache Hypertext Transfer
Protocol Server daemon)
Tomcat может исполнять Java-сервлеты (java-программы, которые
выполняются на серверной стороне Web-приложения ), доставлять
клиентам страницы в кодах Java Server Page, может обслуживать
приложения Java EE (Java Enterprise Edition).
• Oracle WebLogic
Сервер Oracle WebLogic – сервер для распределённых приложений с
использованием стандартов Java EE; полностью интегрирован с
продуктами и облачными сервисами Oracle
• Glassfish
Glassfish – сервер приложений с открытым кодом на Java EE, который
поддерживает Java-сервлеты
Glassfish поддерживает разработку серверных компонентов с бизнес-логикой
EJB (Enterprise JavaBeans)
• JBoss
JBoss – сервер приложений с открытым кодом для создания, развёртывания и
хостинга приложений на языке Java
JBoss может работать на разных платформах и в любой операционной
системе с поддержкой Java
325. Эволюция серверов баз данных
• Сервер базы данных – ядро СУБД (программное обеспечение)• Изначально в архитектуре систем не было адекватного механизма
организации взаимодействия типа Клиент-сервер
Централизованная архитектура
– управление данными (функция Сервера) и взаимодействие с
пользователем совмещены в одной программе
КЛИЕНТ
СЕРВЕР
База
данных
326.
Архитектура «один к одному»– функции управления данными выделены в самостоятельную
группу – сервер
– сервер обслуживает запросы ровно одного пользователя
(клиента)
– для обслуживания нескольких клиентов нужно было
запустить эквивалентное число серверов (ядер СУБД)
КЛИЕНТ
СЕРВЕР
База
данных
327.
• Выделение сервера в отдельную программу - революционныйшаг;
• С появлением сетевых технологий это позволило поместить
сервер на один компьютер, а программный интерфейс с
пользователем - на другой, осуществляя взаимодействие
между ними по сети
сеть
КЛИЕНТ
СЕРВЕР
База
данных
• Проблема - необходимость запуска большого числа серверов
для обслуживания множества пользователей
328.
Многопотоковая архитектура (multi-threaded)• Проблемы, возникающие в модели «один-к-одному», решаются
в архитектуре с выделенным сервером, который способен
обрабатывать запросы от нескольких клиентов
• Сервер обладает монополией на управление данными и
взаимодействует одновременно со многими клиентами
• Логически каждый клиент связан с сервером отдельной нитью
(thread) или потоком, по которому пересылаются запросы
Поток
КЛИЕНТ
СЕРВЕР
База
данных
329.
• Достоинства многопотоковой архитектуры:– значительно уменьшается нагрузка на операционную
систему, возникающую при работе большого числа
пользователей (trashing)
– возможность взаимодействия с одним сервером многих
клиентов позволяет в полной степени использовать
разделяемые объекты, что значительно уменьшает
потребности в памяти и общее число процессов
операционной системы
• Проблема многопотоковой архитектуры :
– сервер выполняется только на одном процессоре, что
не позволяет эффективно использовать СУБД на
мультипроцессорных платформах, поскольку СУБД
используют только один из процессоров, не загружая
оставшиеся
• Одно из решений этой проблемы - замена выделенного
сервера на диспетчер или виртуальный сервер
330.
Система с виртуальным сервером (virtual server)Виртуальный сервер (диспетчер)
КЛИЕНТ
СЕРВЕР
База
данных
331.
• Свойства системы с виртуальным сервером• Виртуальный сервер теряет право монопольно
распоряжаться данными, выполняя только функции
диспетчеризации запросов к актуальным серверам
• В архитектуру системы добавляется новый слой, который
размещается между клиентом и сервером:
– увеличиваются затраты ресурсов на поддержку баланса
загрузки (load balancing)
– ограничиваются возможности управления
взаимодействием "клиент-сервер"
• во-первых, становится невозможным направить запрос
от конкретного клиента конкретному серверу,
• во-вторых, серверы становятся равноправными - нет
возможности устанавливать приоритеты для
обслуживания запросов
• Архитектура систем с диспетчеризацией не может
эффективно применяться в системах оперативной обработки
транзакций, где особенно важен учет приоритета клиентов
332.
Многопотоковая мультисерверная архитектура• Современное решение проблемы СУБД для
мультипроцессорных платформ - многопотоковая архитектура
с несколькими серверами (multi-threaded, multi-server
architecture)
• Возможность запуска нескольких серверов базы данных, в том
числе и на различных процессорах
• Каждый из серверов должен быть многопотоковым
КЛИЕНТ
СЕРВЕР
База
данных
Многопотоковый
сервер
333. Активный сервер
• Изначально во взаимодействии клиент-сервер серверуотводится пассивная роль – он активизируется только в
ответ на запрос клиента
• Поскольку база данных не просто статичное хранилище
данных, а информационная модель предметной
области, как части реального мира, в ней должны
отражаться причинно-следственные связи и процессы
реального мира
• Для этого в базе данных, помимо собственно данных и
непосредственных связей между ними, должны
храниться знания о данных (мета-данные), а сама база
данных должна адекватно отражать процессы,
происходящие в реальном мире
• Необходимость иметь средства хранения и управления
такой информацией привела к развитию концепции
активного сервера, как эффективного инструмента
построения глобальных информационных систем
334.
Актуальные задачи• Во-первых, необходимо, чтобы база данных в любой момент
правильно отражала состояние предметной области - данные
должны быть взаимно непротиворечивыми
– Пример: каждый сотрудник должен работать в реально
существующем отделе, если отдел расформируется, все его
сотрудники переводятся в другие отделы и т.д.
• Во-вторых, база данных должна отражать некоторые правила
предметной области, законы, по которым она функционирует
(business rule)
– Пример: предприятие может нормально работать, только в том
случае, если на складе имеется достаточный запас деталей
определенной номенклатуры; как только это правило нарушается,
предприятие должно закупить детали в нужном количестве
• В-третьих, необходим постоянный контроль за состоянием
базы данных, отслеживание всех изменений и адекватная
реакция на них
– Пример: в автоматизированной системе управления
производством датчики контролируют температуру инструмента;
как только температура инструмента превышает максимально
допустимое значение, он отключается.
335.
• В-четвертых, необходимо, чтобы возникновение некоторойситуации в базе данных четко и оперативно влияло на ход
выполнения прикладной программы; нужен механизм
оперативного оповещения приложений о происходящих в
базе данных изменениях
– Пример: в системах автоматизированного управления
производством необходимо моментально уведомлять
программы о любых изменениях параметров
технологических процессов, например, об изменении
температуры
• Важная проблема СУБД - контроль типов данных
– В базе данных можно хранить только данные стандартных
типов; в реальной жизни требуется хранить и обрабатывать
данные в значительно более широком диапазоне плоскостные и пространственные координаты, единицы
различных метрик, графические изображения и т.д.
336.
Подходы в рамках RDA-модели:• Знания о предметной области включаются непосредственно в
прикладные программы, при этом серверу отводится пассивная
роль поставщика и хранителя данных, а вся интеллектуальная
часть реализуется в приложениям
• Недостатки:
– реализация правил перегружает прикладную программу и
усложняет ее написание и понимание
– любое изменение бизнес-правила должно быть отражено во
многих прикладных программах с пересмотром логики их
выполнения и, зачастую, полным переписыванием приложения
– бизнес-правила не должны противоречить друг другу, что
нельзя гарантировать, когда их реализует группа разработчиков
– практически невозможно обеспечить централизованный
контроль за взаимным соответствием бизнес-правил, если они
разбросаны по многим программам
• Целесообразно оставить за прикладными программами только
базовые алгоритмы управления данными, а часто меняющиеся
правила, которые действуют во внешнем мире, вынести за рамки
прикладных программ
• Правила должен формулировать и контролировать один человек администратор базы данных
337.
• В рамках RDA-модели задача контроля за состоянием базыданных и уведомления прикладных программ о происходящих в
системе событиях опирается на механизмы опроса (polling)
прикладными программами базы данных
• Недостатки:
– прикладная программа не может непрерывно опрашивать
базу данных, так как это приведет к перегрузке сервера
постоянными запросами
– опрос производится через интервалы времени, которые
определяет программист
– если в базе данных происходят какие-либо изменения, то
они выявляются не сразу, а через какое-то время
– не обеспечивается оперативность оповещения, что является
ключевым требованием для прикладных программ,
работающих в реальном времени
– постоянный опрос базы данных существенно сказывается на
производительности системы - программы, опрашивающие
базу данных, перегружают своими запросами сервер и сеть
– логические конструкции, реализующие опрос в тексте
прикладной программы, серьезно затрудняют ее написание
и понимание
338.
• В рамках RDA-модели проблема синхронизации работы несколькихпрограмм, обращающихся к базе данных, обеспечивается
стандартными средствами многозадачной операционной системы
• Такая синхронизация может быть связана с изменениями,
происходящими в базе данных, только посредством постоянного
опроса несколькими приложениями таблицы, в которой фиксируется
некоторое событие (например, поступление денег на счет
фиксируется в таблице «Платежи» и работа нескольких прикладных
программ синхронизируется этим событием)
• Недостатки:
– взаимосвязь программ обеспечивается на уровне операционной
системы, тогда как эту функцию, безусловно, должна выполнять
СУБД
– приходится использовать механизм опроса (polling), недостатки
которого уже обсуждались
• В рамках RDA-модели общепринятый способ преодоления
ограничения на типы данных в СУБД - приведение данных новых
типов к стандартным
• Функции преобразования данных в рамках RDA-модели могут быть
реализованы только в прикладных программах:
– программа извлекает из базы данных данные новых типов,
представленные как стандартные,
– преобразует и обрабатывает их,
– затем вновь преобразует и передает серверу для хранения
339.
• Сервер в обработке данных новых типов при такой схемеучастия не принимает - он рассматривает их как
стандартные и обрабатывает как стандартные
• Такой подход делает принципиально невозможным
контроль целостности данных хотя бы потому, что
различные программы могут интерпретировать данные
новых типов по-разному - централизованный контроль
типов данных, являющийся функцией сервера базы
данных не поддерживается
• Таким образом, в рамках RDA-модели решение всех
рассмотренных задач ложится целиком на прикладные
программы, поскольку в модели взаимодействия "клиентсервер" серверу отводится в основном пассивная роль:
– сервер базы данных лишен функций хранения и
обработки знаний о предметной области.
– сервер не может контролировать состояние базы
данных и инициировать реакцию на ее изменения
– пассивный сервер не имеет средств отслеживания
событий в базе данных, а также средств воздействия на
работу прикладных программ и возможностей их
синхронизации
340.
• Предпосылки к активизации роли сервера появляются вDBS и AS моделях, поскольку при этом на сервере могут
быть запущены процессы, активизируемые самим
сервером, а не как реакция на запрос клиента
Технология активного сервера
• Знания выносятся за рамки прикладных программ и
оформляются как объекты базы данных;
• Функции использования знаний начинает выполнять
непосредственно сервер базы данных.
• Такая архитектура реализует концепцию активного
сервера, которая опирается на четыре основных
механизма:
– хранимые процедуры (процедуры базы данных)
– триггеры (правила)
– события в базе данных
– типы данных, определяемые пользователем
341.
Хранимые процедуры (процедуры базы данных)• Хранимая процедура - это механизм, который позволяет
организовать бизнес логику
• В различных СУБД процедуры баз данных носят название хранимых
(stored), присоединенных, разделяемых и т.д.
• Использование хранимых процедур преследует следующие цели:
– обеспечивается независимый уровень централизованного
контроля доступа к данным, осуществляемый администратором
базы данных
– одна процедура может использоваться несколькими
прикладными программами - это позволяет существенно
сократить время написания программ за счет оформления их
общих частей в виде хранимых процедур, доступных для
многократных вызовов, что также существенно экономит
вычислительные ресурсы системы
– использование хранимых процедур позволяет значительно
снизить трафик сети, поскольку прикладная программа,
вызывающая процедуру, передает серверу лишь ее имя и
параметры; сеть не перегружается многократной посылкой
полных SQL-запросов
– хранимые процедуры в сочетании с триггерами (правилами)
предоставляют администратору мощные средства поддержки
целостности базы данных
342.
• Процедура хранится непосредственно в базе данных иконтролируется администратором базы данных
• Создается оператором CREATE PROCEDURE и содержит
– определения локальных переменных,
– операторы SQL (SELECT, INSERT и др),
– операторы управления процессом (IF/FOR/WHILE и др.)
КЛИЕНТ
КЛИЕНТ
…
SELECT
INSERT
UPDATE
…
…
…
SELECT
INSERT
UPDATE
SELECT
INSERT
UPDATE
…
…
CALL
PROC
CALL
PROC
CALL
PROC
СЕРВЕР
СЕРВЕР
PROC
БАЗА
ДАННЫХ
SELECT
INSERT
UPDATE
…
Процедуры БД не используются
Выделение фрагментов прикладных
программ в виде процедур БД
343.
Хранимые процедуры в MySQL• Пример: разработать процедуру, которая будет показывать нам список
поставщиков из города, который мы передадим в качестве аргумента
DELIMITER // -- изменяем разделитель
CREATE PROCEDURE get_suppliers (city_arg CHAR(20) )
BEGIN
SELECT suppliers.cod_s, suppliers.surname, suppliers.rating
FROM suppliers
WHERE city = city_arg;
END //
DELIMITER ; -- возвращаем разделитель
• Замечания:
– Процедура обязательно должна начинаться с BEGIN и
заканчиваться END.
– Оператор DELIMITER задает новый знак-разделитель, это
необходимо для того, чтобы запрос создания процедуры
заканчивался после ключевого слова END, в противном случае,
запрос закончится на точке с запятой, после основного тела
процедуры
– Название города является параметром процедуры city_arg и
передается ей при вызове из прикладной программы
– Вызов созданной процедуры выполняется оператором CALL
следующим образом:
• CALL get_suppliers(‘Москва’);
344.
• Пример: разработать процедуру, которая будет показыватьпоставки из города, который мы передадим в качестве
аргумента, объем которых превосходит заданное в
качестве аргумента число
DELIMITER //
CREATE PROCEDURE get_deliveries (city_arg CHAR(20), quant_arg int )
BEGIN
SELECT sup_det.cod_s, sup_det.cod_d, sup_det.quant
FROM sup_det INNER JOIN details
ON sup_det.cod_d = details.cod_d AND details.city = city_arg
AND sup_det.quant > quant_arg;
END //
DELIMITER ;
• Замечания:
– Процедура выбирает данные, используя соединение двух таблиц
details и sup_det
– Вызов созданной процедуры выполняется оператором CALL
следующим образом:
• CALL get_deliveries (‘Тула’, 200);
345.
Пример: разработать процедуру, которая находит фамилию и рейтинг
проживающего в заданном городе поставщика, лучшего по суммарному
объему поставок деталей заданного цвета
DELIMITER //
CREATE PROCEDURE best_supplier (city_arg char(20), color_arg char(20))
BEGIN
SELECT surname, SUM(quant)
FROM suppliers
INNER JOIN sup_det ON sup_det.cod_s=suppliers.cod_s
INNER JOIN details ON sup_det.cod_d = details.cod_d
WHERE suppliers.city = city_arg
AND details.color = color_arg
GROUP BY surname
ORDER BY SUM(quant) DESC
LIMIT 1;
END //
DELIMITER ;
Замечания:
– Процедура выбирает данные, используя соединение трех таблиц
suppliers, details и sup_det, при этом возвращает только одну строку
– Вызов созданной процедуры выполняется оператором CALL
следующим образом:
• CALL best_supplier (“Москва", “Красный”);
346.
Триггеры (правила)• Механизм триггеров позволяет программировать обработку
ситуаций, возникающих при любых изменениях в базе данных.
• Триггер придается таблице базы данных и применяется при
выполнении над ней операций добавления, удаления или
обновления данных
• Применение триггера заключается в проверке
сформулированных в нем условий, при выполнении которых
происходит вызов специфицированной внутри триггера
процедуры обработки данных
• Триггер может быть применен как до, так и после выполнения
операции обновления, следовательно, триггер может отменить
операцию
• Триггер позволяет определить реакцию сервера на любое
изменение состояния базы данных
• Триггеры по своей сути являются обработчиками событий
• Триггеры (так же, как и процедуры) хранятся непосредственно в
базе данных независимо от прикладных программ.
• Одна из целей механизма триггеров - отражение бизнес-правил
предметной области и обеспечение целостности базы данных, в
частности, целостности по ссылкам (referential integrity)
347.
Создание триггера в MySQL– CREATE TRIGGER <имя триггера>
–
<время срабатывания> <операция>
– ON <имя таблицы>
– FOR EACH ROW BEGIN
• <алгоритм обработки данных>
– END
• Замечания:
– < время срабатывания>: BEFORE или AFTER
– < операция>: INSERT, DELETE или UPDATE
– FOR EACH ROW – цикл обработки всех изменяемых строк
– При ссылке на атрибуты изменяемых строк в алгоритме
обработки данных используются ключевые слова OLD и NEW:
- NEW — это ссылка на значение, которое должно появиться
после обновления или вставки данных;
с помощью триггера можно изменить это новое значение
- OLD — это ссылка на значение, которое уже было в
таблице, либо перед удалением, либо перед обновлением.
348.
• Пример Триггер вставки, который вызывается при выполнении командыINSERT в таблице поставок sup_det :
если объем добавляемой поставки превосходит 500, рейтинг
соответствующего поставщика в таблице suppliers увеличивается на 10
• DELIMITER //
• CREATE TRIGGER ins_sup_det
• AFTER INSERT ON sup_det
• FOR EACH ROW
• BEGIN
DECLARE n NUMERIC(6);
DECLARE Cod CHAR(2);
SET n = New.quant;
SET Cod = New.cod_s
IF n>500 THEN
UPDATE suppliers SET rating = rating+10
WHERE cod_s = Cod;
END IF;
• END //
• DELIMITER ;
• Замечание: здесь n и Cod - локальные переменные
349.
События в MySQL• MySQL поддерживает события (events), начиная с версии 5.1.
События используются, если нам нужно выполнять запросы или
отдельные процедуры по расписанию. Внутри события можно
запускать SQL-команды или просто вызывать процедуру.
• Событие MySQL - это запланированная задача, которая работает
в соответствии с заданным расписанием. В отличие от триггера
событие вызывается в зависимости от времени, а не в
зависимости от обновления таблицы, поэтому иногда его
называют «временной триггер».
• События MySQL могут использоваться, например, для
оптимизации таблиц базы данных, очистки журналов, архивации
данных или составления комплексных отчетов во время
непиковой нагрузки.
• Синхронизация события может быть одноразовая (выполняется
только один раз) или текущая (периодически повторяет действие
с заданным интервалом)
• По умолчанию событие начинается, как только создано, и
продолжается неопределенно долго, пока оно не будет
заблокировано или удалено.
350.
Событиями в MySQL управляет Планировщик событий.
Для выполнения всех запланированных событий MySQL использует
специальный поток заданий, который называется «поток планировщика
событий»
Поток
планировщика
Сервер
Время
события
Поток
события
Обычные
потоки
За работу планировщика событий в MySQL отвечает глобальная
переменная event_scheduler, которая может принимать одно из 3-х
значений:
– OFF (или 0): Планировщик остановлен, никакие планируемые события не
выполняются; OFF является значением по умолчанию для event_scheduler.
– ON (или 1): Планировщик работает, поток планировщика выполняется сам и
выполняет все планируемые события.
– DISABLED: планировщик неактивный, поток планировщика не выполняется.
351.
Включить планировщик событий:
– SET GLOBAL event_scheduler = ON;
Создать событие, задавая время выполнения
– CREATE EVENT <имя события>
– ON SCHEDULE AT <дата-время>
– DO <SQL-запрос>;
или периодичность выполнения (расписание)
– CREATE EVENT <имя события>
– ON SCHEDULE EVERY <число>
–
< SECOND | MINUTE | HOUR | DAY | MONTH | YEAR | WEEK>
– DO <SQL-запрос>;
После фразы ON SCHEDULE задается график (когда и как часто
выполнять)
– если событие является единичным, используется синтаксис:
AT timestamp [+ INTERVAL].
– если событие периодическое, используется условие EVERY:
EVERY interval STARTS timestamp [+INTERVAL]
ENDS timestamp [+INTERVAL];
Дополнительный параметр:
– ON COMPLETION PRESERVE - задание после выполнения сохраняется
– ON COMPLETION NOT PRESERVE - задание выполняется один раз
Удаление события: DROP EVENT <имя события>
352.
Пример Создать событие, для еженедельного удаления из таблицыsup_det поставок с нулевым объемом (сборка мусора)
• Включаем планировщик:
– SET GLOBAL event_scheduler=ON;
• Создаем событие:
CREATE EVENT clean_sup_det
– ON SCHEDULE
– EVERY 1 WEEK STARTS CURRENT_TIMESTAMP
– ON COMPLETION PRESERVE
– DO
– DELETE FROM sup_det WHERE quant=0;
• Если мы хотим выполнить такую очистку однократно через 20 минут:
CREATE EVENT clean_sup_det
– ON SCHEDULE
– AT CURRENT_TIMESTAMP + INTERVAL 20 MINUTE
– ON COMPLETION PRESERVE
– DO
– DELETE FROM sup_det WHERE quant=0;
Замечание: можно объединять интервалы, например:
• AT CURRENT_TIMESTAMP + INTERVAL 3 WEEK + INTERVAL 2 DAY
эквивалентно «три недели и два дня от этого времени»
353.
Типы данных, определяемые пользователем• Проблемы с типами данных решаются за счет интеграции в сервер
новых типов данных
• Не все современные СУБД поддерживают типы данных,
определенные пользователем
• Введение новых типов данных является по существу изменением
ядра СУБД
• Для определения нового типа данных, например, в СУБД Ingres
необходимо:
– написать и откомпилировать функции на языке С
– собрать редактором связей необходимые модули Ingres
– в Ingres типы данных, определяемые пользователем, могут
быть параметризованными.
• Определение нового типа данных сводится к указанию в его
имени, размера и идентификатора в глобальной структуре,
описывающей типы данных
• Чтобы с новым типом данных можно было использовать функции,
которые реализуют стандартные операции (сравнение,
преобразование в различные форматы, и т.д.), программист
должен разработать их самостоятельно, используя стандартный
интерфейс функций
• Как только новый тип данных определен, все операции
выполняются над ним, как над данными стандартного типа
354.
Интерфейс программирования приложений API• API (application programming interface) представляет собой
библиотеки функций, разработанные для обеспечения связи
прикладной программы с СУБД посредством вызова APIфункций
• Прикладная программа вызывает специальные функции
библиотеки для передачи в СУБД SQL-запроса в текстовом
виде и для получения результатов выполнения запросов, а
также различной служебной информации.
• Применение подобного подхода приводит к тому, что
прикладной программист пишет код приложения на языке
более высокого уровня по сравнению с SQL, вызывая лишь
функции специальной API-библиотеки
• Механизм использования API в программировании применяется
достаточно широко (например, библиотека Windows API) применение его для общения с ядром СУБД еще одно
применение этого механизма
• По схеме компиляции и выполнения программа, содержащая
вызовы функций специализированной API-библиотеки, ничем
не отличается от обычной программы, в частности, в этом
случае не требуется обработка кода специализированным
препроцессором с механизмом раздельной компиляции, как в
случае со встроенным SQL-кодом
355.
Схема работы приложения совместно с SQL API:– программа получает доступ к базе данных путем вызова
одной или нескольких API-функций, подключающих
программу к СУБД и к конкретной базе данных;
– для пересылки инструкций SQL в СУБД программа
формирует инструкцию в виде текстовой строки и затем
передает эту строку в качестве параметра при вызове APIфункции;
– программа вызывает выполнение API-функции для проверки
состояния переданной в СУБД инструкции и обработки
ошибок;
– если инструкция SQL представляет собой запрос на
выборку, то, вызывая API-функции, программа записывает
результаты запроса в свои переменные; обычно за один
вызов возвращается одна строка или столбец данных;
– свое обращение к базе данных программа заканчивает
вызовом API-функции, отключающей ее от СУБД.
356.
• Пример: библиотека DB-Library реализует интерфейспрограммирования приложений для совместной работы с СУБД
Microsoft SQL Server
• Содержит более 100 функций, в частности:
– dblogin(); dbopen() - подключение к БД;
– dbopen(); dbexit() - установка/разрыв соединения с БД;
– dbcmd() - передача инструкции (пакета инструкций) SQL в
СУБД в текстовом виде;
– dbsqlexec() - требование к СУБД выполнить текущий пакет
инструкций (пакет – последовательность SQL-команд);
– dbcancel() - прекращение выполнения пакета инструкций
SQL;
– dbresults() - получение результатов выполнения очередной
инструкции SQL в текущем пакете;
– dbbind(), dbdata(), dbnextrow(), dbnumcols(), dbdatlen() и др. обработка результатов запросов на выборку данных
• Основная проблема, связанная с разработкой приложений с
использованием API-библиотек, состоит в том, что каждая
СУБД имеет собственный программный интерфейс доступа к
API-функциям
357.
Протокол ODBC• ODBC (Open Database Connectivity - открытый доступ к базам
данных) - универсальный интерфейс программирования
приложений для доступа к базам данных, разработан компанией
Microsoft
• Цель - стандартизация механизмов взаимодействия с СУБД
• Основная идея - разработка универсального интерфейса на уровне
семейства операционных систем Windows, который мог бы быть
поддержан в разных СУБД
• Структура программного обеспечения ODBC:
– интерфейс вызовов функций ODBC - верхний уровень ODBC,
содержащий API, который используется непосредственно
приложениями; реализован в виде Dll-библиотеки динамической
компоновки и входит в состав операционной системы Windows;
– драйверы ODBC - нижний уровень ODBC, содержащий набор
драйверов для различных СУБД, поддерживающих протокол
ODBC; ODBC-драйвер является промежуточным звеном между
прикладной программой и API, транслируя вызовы функций API в
вызовы внутренних специализированных функций СУБД;
– диспетчер драйверов ODBC - средний уровень ODBC,
программный механизм, управляющий процессом загрузки
необходимых драйверов
358.
Протокол JDBC• JDBC (Java Database Connectivity) представляет собой API для
выполнения SQL-запросов к базам данных из программ,
написанных на языке Java
• Основная причина разработки программного интерфейса JDBC
– возрастание роли языка Java как средства создания
приложений, в частности, Интернет-приложений, работающих с
базами данных
• Первоначально интерфейс JDBC был разработан компанией
Sun Microsystems, в настоящее время JDBC поддерживается
всеми ведущими коммерческими СУБД.
• Версия JDBC 1.0 содержала средства доступа к данным,
напоминающие аналогичный функциональный аппарат
протокола ODBC:
– диспетчер драйверов для подключения к разным СУБД;
– механизм управления сеансами для одновременной
работы с несколькими СУБД;
– механизм передачи инструкций SQL на выполнение в
СУБД;
– механизм работы с курсорами для передачи результатов
выполнения запросов из СУБД в приложение
359.
• Начиная с версии JDBC 2.0 интерфейс идеологически разделен на двеосновные части: Core API - основные возможности и Extensions API расширения
• Основные параметры JDBC:
– Пакетные операции. Программа на Java может осуществить
обновление базы данных в пакетном режиме, т.е. одна функция
JDBC может добавить в базу данных несколько записей, что
положительно сказывается на производительности программ.
– Курсоры с произвольным доступом. В JDBC 2.0 существует
средство, позволяющее перемещаться по результатам запроса
произвольным образом.
– Обновляемые курсоры. В JDBC 2.0 курсоры, наряду с функцией
возврата результата запроса, выполняют еще и роль обновления
базы данных. Обновления производятся при добавлении или
изменении одной из строк в результатах запроса.
– Организация связного пула. Несколько программ на языке Java
могут пользоваться совместным доступом к базе данных, уменьшая
затраты на подключения к базе данных и отключения от нее.
– Поддержка JNDI (Java Naming and Directory Interface) — это Java
API, организованный в виде службы каталогов, который позволяет
Java-клиентам открывать и просматривать данные и объекты по их
именам
– Распределенные транзакции, объектно-реляционные
расширения SQL и т.д.
360.
Протоколы ODBC и JDBC – схема выполнения программПрикладная программа / на Java
Интерфейс вызовов функций ODBC/JDBC API
Диспетчер драйверов ODBC/JDBC
Драйвер
ODBC/JDBC
Драйвер
ODBC/JDBC
Драйвер
ODBC/JDBC
СУБД
СУБД
СУБД
База
данных
361.
• Архитектура JDBC берет свое начало от ODBC и в существеннойчасти повторяет ее
• Отличие драйверов JDBC от драйверов ODBC
– Драйверы JDBC подразделяются на четыре типа:
– По местонахождению API СУБД
• размещенные на клиентской СУБД
• размещенные на серверной СУБД
– По способу доступа к базе данных:
• доступ через собственный API СУБД
• доступ через ODBC
• Протокол OCI компании Oracle
• Интерфейс вызовов OCI (Oracle Call Interface) - специальный
инструмент, представляющий собой программный интерфейс в
СУБД Oracle
• Данный API-интерфейс появился еще в ранних версиях Oracle и
продолжает развиваться от версии к версии
• В старых версиях функции OCI очень похожи на функции
динамического SQL, многие из вносимых в более поздние версии
изменений идеологически заимствованы из ODBC
362. Постреляционные СУБД
• Уже в середине 80-ых годов в области системуправления данными возник ряд задач, для которых
реляционная модель была недостаточно эффективна
• Сформировалось несколько направлений развития
СУБД, значительно различающихся целевыми
проблемами и подходом к модели БД
– активные СУБД
– многомерные БД и хранилища данных
– объектно-реляционные СУБД
– объектно-ориентированные СУБД
– темпоральные СУБД
– noSQL СУБД (MongoDB, DynamicDB, Tarantool )
– дедуктивные (логические) СУБД
• Все они в совокупности сформировали третье
поколение СУБД
363. Технология многомерных баз данных
• Источником и теоретической основой для многомерных баз данныхявляется алгебра многомерных матриц, которая использовалась для
ручного анализа данных с конца XIX столетия.
• В конце 60-х годов компании IRI Software и Comshare начали
разрабатывать систему управления многомерными базами данных
• В конце 70-х и начале 80-х годов корпорацией Oracle был куплен
инструментарий маркетингового анализа IRI Express - средство
оперативной аналитической обработки информации
• На базе системы Comshare был создан инструментарий System W, в 80х годах активно применявшийся для финансового планирования,
анализа и формирования отчетов
• В 1991 году компания Arbor Software (теперь Hyperion Solutions) начала
работу по созданию многопользовательских серверов многомерных баз
данных; результатом этих работ стала система Essbase, которая позже
была интегрирована корпорацией IBM в СУБД DB2
• В 1993 году Э.Ф. Кодд ввел термин OLAP (OnLine Analytical Processing)
• В начале 90-х сложилась технология хранилищ данных (Data
Warehouse), что позволило для реализации многомерных баз данных
использовать технологию реляционных баз данных.
• В 1998 году корпорация Microsoft выпустила OLAP Server, первую
многомерную систему, предназначенную для массового рынка
• Сегодня такие системы, как правило, поставляются вместе с системами
управления реляционными базами данных
364.
• Области применения многомерных моделей для анализаданных:
– Хранилище данных (Data Warehouse) интегрирует и
хранит информацию из нескольких источников для
дальнейшего ее анализа
– Системы оперативной аналитической обработки OLAP
(online analytical processing) позволяют оперативно
получить ответы на запросы о тенденциях,
охватывающие большие объемы данных
– Приложения извлечения знаний (добычи данных) служат
для выявления знаний за счет полуавтоматического
поиска ранее неизвестных шаблонов и связей в базах
данных
• Многомерные базы данных рассматривают данные как кубы
(OLAP-кубы), которые являются обобщением плоских
таблиц на любое число измерений
• OLAP-кубы поддерживают иерархию измерений и формул;
набор составляет многомерную базу данных (или
хранилище данных)
• На практике обычно OLAP-кубы данных имеют от 4 до 12
измерений
365.
• Пример OLAP-куба с данными о продажах продуктов в двух городах:• В соответствующих ячейках хранятся данные об объеме продаж
• Факт — непустая ячейка, содержащая соответствующий числовой
параметр
• Для каждой комбинации время, продукт, город в ячейке
размещаются числовые значения параметра (объем продаж),
связанного с фактом
Хлеб
Молоко
62
86
Факт
Тула
59
82
Рязань
57
64
2018
2019
68
Измерения
366.
• Измерения — ключевая концепция многомерных баз данных• Многомерное моделирование предусматривает использование
измерений для предоставления максимально возможного
анализа для фактов
• Измерения используются для выбора и агрегирования данных на
требуемом уровне детализации
• Измерения организуются в иерархию, состоящую из нескольких
уровней, каждый из которых представляет уровень детализации,
требуемый для соответствующего анализа
• Факты
• Факты представляют некий шаблон или событие, которые
необходимо проанализировать
• В большинстве многомерных моделей данных факты однозначно
определяются комбинацией значений измерений
• Факт существует только тогда, когда ячейка для конкретной
комбинации значений не пуста.
• Большинство многомерных моделей также требуют, чтобы
каждому факту соответствовало одно значение на более низком
уровне каждого измерения
367.
Типы запросов• Многомерная база данных естественным образом предназначена для
определенных типов запросов.
– Запросы вида slice-and-dice осуществляют выбор, сокращающий
размерность куба, например, можно рассмотреть сечение куба,
рассмотрев только те ячейки, которые касаются хлеба, а затем еще
больше сократить его, оставив ячейки, относящиеся только к 2018
году; фиксация значения измерения сокращает размерность куба,
но при этом возможны и более общие операции выбора.
– Запросы вида drill-down (детализация) и roll-up (свертывание) —
взаимообратные операции, которые используют иерархию
измерений и параметры для агрегирования. Обобщение до высших
в иерархии значений соответствует уменьшению размерности
(свертка), например, свертка от уровня «Город» до уровня «Страна»
агрегирует значения для Тулы и Рязани в одно значение — Россия
– Запросы вида drill-across комбинируют кубы, которые имеют одно
или несколько общих измерений. С точки зрения реляционной
алгебры такая операция выполняет соединение (join).
– Запросы вида ranking возвращают только те ячейки, которые
появляются в верхней или нижней части упорядоченного
определенным образом списка, например, 10 самых продаваемых
продуктов в Рязани в 2019 году.
– Поворот (rotating) куба дает пользователям возможность увидеть
данные, сгруппированные по другим измерениям
368.
Хранилища данных• Хранилище данных (Data Warehouse) — предметноориентированная информационная база данных, специально
разработанная и предназначенная для подготовки отчётов и
бизнес-анализа с целью поддержки принятия решений в
организации; данные, поступающие в хранилище данных, как
правило, доступны только для чтения.
• OLTP-система (Online Transaction Processing), транзакционная
система — система обработки транзакций в реальном времени,
работает с небольшими по размерам транзакциями, но идущими
большим потоком, и при этом для клиента достигается
минимальное время отклика системы
• Данные из OLTP-системы копируются в хранилище данных таким
образом, чтобы при построении отчётов и OLAP-анализе не
использовались ресурсы транзакционной системы и не
нарушалась её стабильность
• Используются два варианта обновления данных в хранилище:
– полное обновление данных, при котором сначала старые данные
удаляются, потом происходит загрузка новых данных; процесс
происходит с определённой периодичностью, при этом актуальность
данных может несколько отставать от OLTP-системы;
– инкрементальное обновление, когда обновляются только те данные,
которые изменились в OLTP-системе
369.
• Хранилища данных, как правило, содержат три типа фактов:– События (event), как правило, моделируют события реального мира,
при этом каждый факт представляет определенный экземпляр
изучаемого явления (продажи, щелчки мышью на Web-странице,
движение товаров на складе и т.д.)
– Мгновенные снимки (snapshot) моделируют состояние объекта в
данный момент времени (уровни наличия товаров в магазине или на
складе, число пользователей Web-сайта и т.д.), причем один и тот же
экземпляр явления реального мира, например, конкретный продукт,
может возникать в нескольких фактах.
– Совокупные мгновенные снимки (cumulative snapshot) содержат
информацию о деятельности организации за определенный отрезок
времени (совокупный объем продаж за предыдущий период)
• Параметры
• Параметры состоят из двух компонентов:
– численная характеристика факта (цена, доход от продаж и т.д.);
– формула, обычно простая агрегатная функция, скажем, сумма,
которая может отображать несколько значений параметров в одно
• В многомерной базе данных параметры, как правило, представляют
свойства факта, который пользователь хочет изучить
• Параметры принимают различные значения для разных комбинаций
измерений
370.
NoSQL базы данных
Термин NoSQL, впервые он стал использоваться в конце 90-х, но
современный смысл приобрел только в середине 2009 г., обычно термин
расшифровывается как Not Only SQL
Как оказалось, реляционные базы данных неважно приспособлены к
работе с очень большими объемами данных, для распределённой работы
на нескольких машинах удобнее использовать другие технологии
При использовании реляционной базы данных на нескольких машинах
обычно используются два метода: репликация и шардинг.
Репликация чтения – каждое обновление базы данных распространяется
на несколько машин, которые могут обрабатывать только запросы на
чтение.
Все изменения выполняются одним сервером - ведущим узлом, другие
сервера - реплики чтения, лишь поддерживают копии данных.
Пользователь может читать с любой из машин, но изменять данные лишь
через ведущий узел.
Удобный и популярный метод, но он позволяет лишь обрабатывать больше
запросов на чтение, не решая задачу обработки требуемых объемов
данных.
Шардинг – используется несколько экземпляров реляционной базы
данных, каждый из которых обрабатывает операции записи и чтения для
части данных. Например, одна машина может обрабатывать все запросы о
поставщиках, чьи имена начинаются на A, другая – хранить все данные о
поставщиках, чьи имена начинаются на Б, и так далее.
Хотя шардинг позволяет записывать больше данных, управление такой
базой данных в части масштабирования и выравнивания данных по
машинам на практике очень затруднено
371.
• Согласно доказанной в 1999 году теореме CAP (теорема Брюера)работающая на нескольких машинах распределенная база данных
может обладать тремя свойствами:
– Согласованностью (Consistency) –любая операция чтения
возвращает результат последней операции записи, после записи
новых данных, прочитать старые уже невозможно.
– Доступностью (Availability) – распределенная система в любой
момент может обслужить запрос и вернуть не ошибочный ответ.
– Устойчивостью к нарушению связности (Partition tolerance) –
база данных продолжает отвечать на запросы на чтение и запись
даже в случае, когда часть её серверов временно неспособны
взаимодействовать друг с другом (возможный сбой - нарушение
связности сети).
• Теорема CAP утверждает, что одновременное выполнение всех
трёх свойств — невозможно.
• В реляционных базах данных свойства согласованности и доступности
должны поддерживаться одновременно, поэтому они плохо
приспособлены к работе в распределенной среде.
• Базы данных NoSQL придают основное значение масштабируемости и
производительности, в них обычно не поддерживаются понятия
соединения и транзакции, а модель данных оказывается в чем-то более
ограниченной
• Масштабируемость - способность системы увеличивать свою
производительность при добавлении ресурсов
• Это дает возможность хранения больших объемов данных и обработки
большего числа запросов, чем было возможно когда-либо ранее
372.
NoSQL базы данных делятся на четыре основные категории:Документно-ориентированные базы данных - предоставляют
возможность хранения сложных вложенных документов, в в большинстве
реляционных баз данных эта возможность всё еще отсутствует, однако
например, в PostgreSQL документно-ориентированное хранилище тоже
поддерживается
Базы данных типа «ключ/значение» - реализуют простейшую NoSQLмодель, как распределенную хэш-таблицу, позволяющую записывать данные
по ключу и читать их с его помощью; легко масштабируются и отличаются
значительно более низкой задержкой.
Графовые базы данных - хотя граф можно представить и с помощью
реляционной базы данных, лучше воспользоваться специализированной
графовой базой данных, которая может хранить информацию о графе в
распределенной среде и эффективно реализовывать алгоритмы на графах.
Столбцовые базы данных – данные хранятся на диске не в виде таблиц, а
в виде отдельных столбцов таблиц, что позволяет агрегировать данные и
выполнять определенные запросы более эффективно
Наиболее популярные NoSQL СУБД:
MongoDB. Гибкое хранилище документов с хорошим набором
инструментария, достаточно стабильное и надежное
DynamoDB. Надежная, масштабируемая база данных с низкой задержкой,
богатым набором возможностей и интеграцией с множеством других
сервисов Amazon (AWS), которую не нужно развертывать самостоятельно;
настроить масштабируемый кластер DynamoDB, способный обрабатывать
тысячи запросов, можно очень легко (несколько щелчков мышью)
Neo4j. Самая распространенная масштабируемая и стабильная графовая
база данных.
Redis. Redis применяется в основном для реализации кэша и хранения
вспомогательных данных часто в тандеме с перечисленными базами данных
373.
Характеристики NoSQL баз данныхОбщих характеристик для всех NoSQL немного, Многие характеристики
свойственны только определенным NoSQL базам
1. Не используется SQL
Имеется в виду ANSI SQL DML, так как многие базы пытаются использовать
query languages похожие на общеизвестный SQL-синтаксис, но полностью
его реализовать не удалось никому
2. Неструктурированные (schemaless)
В NoSQL базах в отличие от реляционных структура данных не
регламентирована (или слабо типизирована, если проводить аналогии с
языками программирования) — в отдельной строке или документе можно
добавить произвольное поле без предварительного декларативного
изменения структуры всей таблицы. Таким образом, если появляется
необходимость поменять модель данных, то единственное достаточное
действие — отразить изменение в коде приложения.
3. Представление данных в виде агрегатов (aggregates)
Работа с большими, часто денормализованными, объектами чревата
многочисленными проблемами при попытках произвольных запросов к
данным, когда запросы не укладываются в структуру агрегатов
4. Слабые ACID свойства
АСИД (атомарность, согласованность, изолированность и долговечность)
Все реляционные базы обеспечивают тот или иной уровень изоляции —
либо за счет блокировок при изменении и блокирующего чтения, либо за
счет undo-логов. С появлением огромных массивов информации и
распределенных систем стало ясно, что обеспечить для них
транзакционность набора операций и получить при этом высокую
доступность и быстрое время отклика невозможно
374. Темпоральные базы данных
• При разработке информационных систем часто приходитсясталкиваться с требованиями о необходимости хранения не только
актуального состояния данных, но и истории их изменения.
• В теории баз данных решением этой задачи занимается отдельное
направление – темпоральные (или временные) базы данных
• Основной идеей модели темпоральных баз данных является
расширение реляционной таблицы таким образом, что она становится
трехмерной
• В этой модели изменение значения атрибута приводит к появлению
нового элемента данных без уничтожения старого. При этом все старые
значения элемента данных также могут быть получены из таблицы
• Темпоральные базы данных реализуют расширение языка запросов
SQL - SQL/Temporal
• Событие, отражением которого является новое значение элемента
данных в базе данных, в реальной жизни часто происходит раньше того
момента, когда оператор вводит информацию в базу данных.
• С событием в темпоральной базе данных ассоциируется две
временные отметки:
– время наступления события в реальной жизни - действительное
время
– время внесения изменения в базу данных - время транзакции.
• Темпоральная СУБД должна хранить в базе данных оба значения
времени и позволять делать поиск по обоим значениям
375.
• Добавление времени в реляционную модель темпоральнойбазы данных
376.
• Темпоральные данные – это данные, которые явно или неявносвязаны с определенными датами или промежутками времени
• Даже если нет явной зависимости от времени для какого-нибудь
факта или события, то все равно для него имеется неявная
зависимость от времени, так как когда-то стало известно, что такой
факт существует и всегда есть вероятность, что в будущем факт
будет пересмотрен
• Темпоральные базы данных – это базы данных, хранящие
темпоральные данные.
• Такие БД и содержащиеся в них данные могут рассматриваться как
темпоральные только в том случае, если известно правило
интерпретации временных меток и интервалов для конкретной
системы управления базами данных (СУБД).
• В темпоральной СУБД учитываются специфическая природа
времени и изменчивость данных с течением времени; обычные
реляционные СУБД не будут попадать в категорию темпоральных.
• Принято считать, что впервые идеи управления темпоральными
данными появились в работе Джакоба Бен-Зви (Jacob Ben-Zvi) в
1982 г.
• В 80-е годы прошлого века начали появляться работы по
темпоральной логике и использованию данных, зависимых от
времени, их представлению внутри системы и визуализации для
пользователя. С тех пор предлагались различные модели,
создавались прототипы систем темпоральных БД.
377.
• В темпоральных БД хранятся данные, изменяющиеся с течениемвремени.
• В стандартном языке запросов SQL отсутствует адекватная и
эффективная поддержка работы с темпоральными БД.
• Традиционная реляционная БД хранит информацию лишь о
текущем состоянии, и СУБД не предоставляет возможности
работать с данными, привязанными к определенным датам или
интервалам времени (то есть темпоральными данными).
• Поэтому в реляционных БД поддержка работы с такими данными
обеспечивается усилиями программистов и администраторов,
которые используют для решения задач громоздкие конструкции
языка SQL.
• В реляционной БД может сохраняться информация о событиях и
интервалах времени, соответствующих различным представлениям
и связям.
• Если обработкой подобных данных занимается сам пользователь,
то используемый тип времени можно назвать временем,
определяемым пользователем. Его отличительным признаком
служит отсутствие интерпретации со стороны СУБД, так как
обработка данных, связанных со временем, полностью возлагается
на пользователя.
• Практически все современные СУБД обеспечивают поддержку
подобной разновидности времени, например, с помощью введения
типов данных DATA или TIMESTAMP.
378.
• В общем случае можно выделить два вида данных дляпредставления времени:
– время фиксации определенного события или факта
– время выполнения какого-либо действия или операции.
• Если рассматривать данные, представленные в БД, как некоторое
отражение текущего состояния действительности для
моделируемого мира, то каждая запись может восприниматься как
некоторый факт, который является истинным в определенный
момент или интервал времени.
• При переходе к темпоральной БД для каждого факта можно указать
тот промежуток времени, когда этот факт являлся истинным в
моделируемом мире, представленном в базе данных.
• Такое представление времени, когда с данными связывается
промежуток времени их актуальности (с точки зрения
моделируемого мира), называется временем фиксации факта (valid
time).
• Значениями данного типа времени могут быть моменты времени как
в прошлом, так и в будущем. Кроме того, эти значения могут
изменяться, то есть истинность факта в определенные моменты
времени может приниматься или отклоняться.
• Например, любое предложение естественного языка, которое имеет
значением истину или ложь и представляет собой факт, связано со
временем, когда этот факт становится истинным (в прошлом,
настоящем или будущем)
379.
• Другим типом времени, который рассматривается в темпоральныхБД, является время операции, или транзакционное время.
• В любой СУБД каждой записи БД можно сопоставить тот
промежуток времени, когда данная запись была представлена в БД,
т.е. промежуток времени между моментами добавления записи и ее
удаления из БД.
• При этом операция обновления, которая вносит изменения в запись,
понимается как составная операция удаления старой записи и
добавления новой.
• В подавляющем числе СУБД время операции используется
журналом восстановления системы для работы с блокировками. В
некоторых системах администраторы даже могут применять
специальные расширения языка SQL, позволяющие получить
доступ ко времени операции и истории изменений записей в БД.
• Таким образом, момент времени, когда факт актуализируется в БД,
является временем выполнения операции.
• Время операции может быть связано с любой сущностью БД, а не
только с фактами.
• Хотя все сущности могут быть связаны с временем операции,
проектировщик может решить не рассматривать временной аспект
для некоторых сущностей БД.
• Время операции, которое отражает время изменения состояния
объектов БД или приложений, записывается как значение атрибута
сущности БД.
380.
• При моделировании временных данных обычно применяютследующие интерпретации временных меток:
– Время фиксации события или факта (Valid time), т.е. так называемая
действительная дата — это временная метка, которая
представляет время события или состояния предметной области
(например, это дата подписи на документе, показания времени,
снятые с контролирующих приборов, дата отгрузки проданного
товара со склада и т.д.)
– Время операции (Transaction time) — это временная метка,
представляющая время, когда была выполнена операция
деятельности организации (операция предметной области)
– Время сбора данных (Capture time) — это временная метка,
представляющая время, когда данные были извлечены или собраны
из источника данных (возможно, некоторой внешней БД).
– Время актуализации данных (Apply time) — это временная метка,
связанная со временем загрузки данных в хранилище данных.
– Время, определяемое пользователем (User-defined time) – это
временная метка, представляющая момент или моменты времени,
которые пользователь намерен хранить в атрибуте сущности, но
непосредственно не связанные с фиксацией временной
зависимости в модели данных. Например, атрибуты "День
рождения", "День государственного праздника" и т.п.
• Два вида временных меток: моментальные и интервальные
381.
КОНЕЦПРЕЗЕНТАЦИИ