
















 Информатика
ИнформатикаПохожие презентации:










Искусственный интеллект, машинное обучение, глубокое обучение, нейронные сети
1. Машинное обучение. Обучающая выборка
2. Машинное обучение
Машинное обучение (англ. machine learning, ML) — класс методовискусственного интеллекта, характерной чертой которых является не прямое
решение задачи, а обучение за счёт применения решений множества сходных
задач. Алгоритмы машинного обучения превращают набор данных в модель.
У метода машинного обучения есть множество различных алгоритмов:
линейная регрессия,
логистическая регрессия,
система рекомендаций,
дерево решений,
метод опорных векторов,
сигмоида и другие.
Нейросети – один из способов машинного обучения, самый сложный и самый
дорогой.
3. Искусственный интеллект, машинное обучение, глубокое обучение, нейронные сети
4.
Задачи, решаемые с помощью машинного обучения1. Пример задачи, которую не следует решать методами машинного обучения.
Найти точку минимума функции:
2. Обычно выделяют следующие категории задач, решаемых методами МО:
задачи классификации - это когда требуется входные данные отнести к тому или иному
классу;
задачи регрессии - когда делают прогнозы в виде вещественных чисел на основе
входных данных;
задачи ранжирования - подразумевает упорядочивание (по некоторому критерию)
входного набора данных. Пример – это поисковые системы, которые ранжируют
поисковую выборку по релевантности для каждого конкретного пользователя.
задачи классификации.
5.
Обучающая выборкаОбучающая выборка – это исходные данные, прямые результаты измерений, которые удобно представлять в
виде векторов.
Длина
чашелистика
5,2
4,9
Ширина
чашелистика
3,5
3
Длина
Ширина
лепестка лепестка Класс
1,4
0,2
1
1,4
0,25
1
4,4
5
5,1
5,3
5
7
5,9
6
3,2
3,5
3,8
3,7
3,3
3,5
3
2,2
1,3
1,6
1,9
1,5
1,4
4,7
4,2
4
0,2
0,6
0,4
0,2
0,2
1,4
1,5
1
1
1
1
1
1
2
2
2
5,1
5,7
6,3
5,8
7,1
6,3
2,5
2,8
3,3
2,7
3
2,9
3
4,1
6
5,1
5,9
5,6
1,1
1,3
2,5
1,9
2,1
1,8
2
2
3
3
3
3
Измерение некоего i-го объекта.
Измерение 8-го объекта (8-ой строки).
Xi = [7,3.5,4.7,1.4]T
6.
Обучающая выборкаОбучающая выборка – это исходные данные, прямые результаты измерений, которые удобно представлять в
виде векторов.
Матрица X составлена из l векторов
и каждый вектор содержит n чисел
Длина
Ширина
Длина
Ширина
лепестка лепестка Класс
1,4
0,2
1
1,4
0,25
1
чашелистика
5,2
4,9
чашелистика
3,5
3
4,4
5
5,1
5,3
5
7
5,9
6
3,2
3,5
3,8
3,7
3,3
3,5
3
2,2
1,3
1,6
1,9
1,5
1,4
4,7
4,2
4
0,2
0,6
0,4
0,2
0,2
1,4
1,5
1
1
1
1
1
1
2
2
2
5,1
5,7
6,3
5,8
7,1
6,3
2,5
2,8
3,3
2,7
3
2,9
3
4,1
6
5,1
5,9
5,6
1,1
1,3
2,5
1,9
2,1
1,8
2
2
3
3
3
3
Первые 3 строчки матрицы данных по Ирисам. В
каждой строке n = 4 значения. Всего строк l = 150.
5,2 3,5 1,4 0,2
1,4 0,25
Х = 4,9 3
4,4 3,2 1,3 0,2
7.
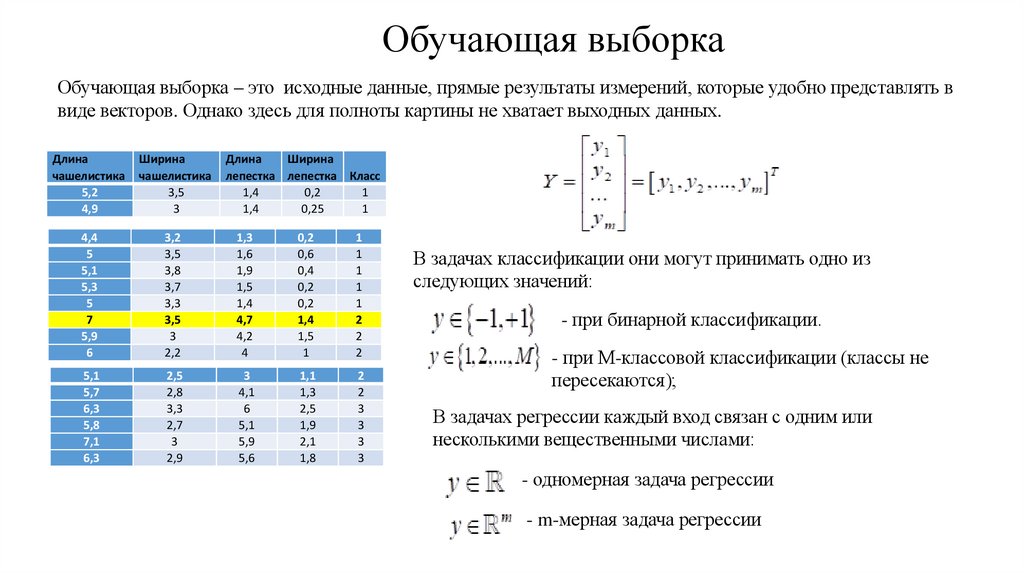
Обучающая выборкаОбучающая выборка – это исходные данные, прямые результаты измерений, которые удобно представлять в
виде векторов. Однако здесь для полноты картины не хватает выходных данных.
Длина
чашелистика
5,2
4,9
Ширина
чашелистика
3,5
3
Длина
Ширина
лепестка лепестка Класс
1,4
0,2
1
1,4
0,25
1
4,4
5
5,1
5,3
5
7
5,9
6
3,2
3,5
3,8
3,7
3,3
3,5
3
2,2
1,3
1,6
1,9
1,5
1,4
4,7
4,2
4
0,2
0,6
0,4
0,2
0,2
1,4
1,5
1
1
1
1
1
1
2
2
2
5,1
5,7
6,3
5,8
7,1
6,3
2,5
2,8
3,3
2,7
3
2,9
3
4,1
6
5,1
5,9
5,6
1,1
1,3
2,5
1,9
2,1
1,8
2
2
3
3
3
3
В задачах классификации они могут принимать одно из
следующих значений:
- при бинарной классификации.
- при M-классовой классификации (классы не
пересекаются);
В задачах регрессии каждый вход связан с одним или
несколькими вещественными числами:
- одномерная задача регрессии
- m-мерная задача регрессии
8.
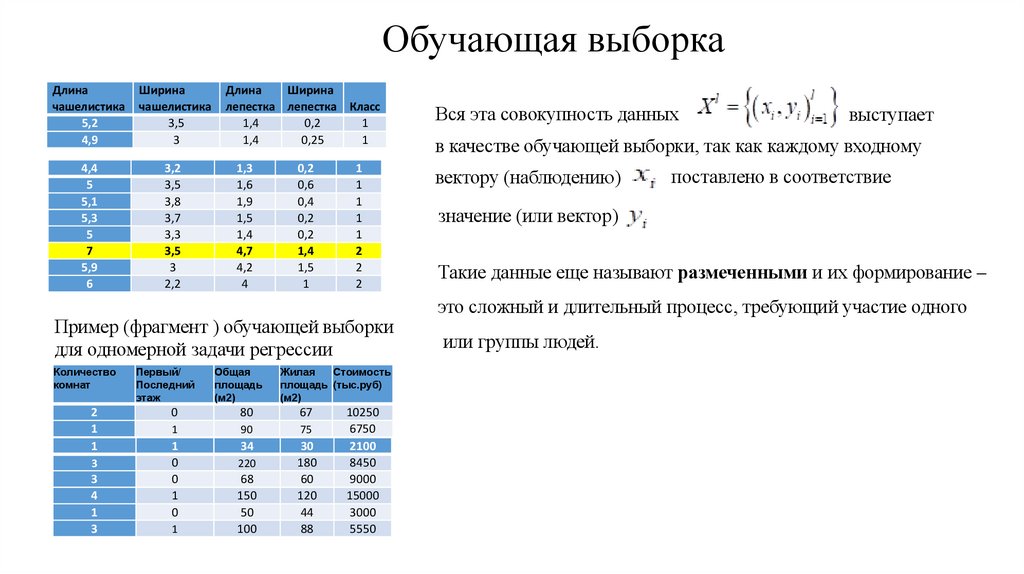
Обучающая выборкаДлина
чашелистика
5,2
4,9
Ширина
чашелистика
3,5
3
4,4
5
5,1
5,3
5
7
5,9
6
3,2
3,5
3,8
3,7
3,3
3,5
3
2,2
Длина
Ширина
лепестка лепестка Класс
1,4
0,2
1
1,4
0,25
1
1,3
1,6
1,9
1,5
1,4
4,7
4,2
4
0,2
0,6
0,4
0,2
0,2
1,4
1,5
1
1
1
1
1
1
2
2
2
Пример (фрагмент ) обучающей выборки
для одномерной задачи регрессии
Количество
комнат
2
1
1
3
3
4
1
3
Первый/
Последний
этаж
Общая
площадь
(м2)
Жилая
Стоимость
площадь (тыс.руб)
(м2)
0
80
67
1
90
75
1
0
0
1
0
34
30
180
60
120
44
88
1
220
68
150
50
100
10250
6750
2100
8450
9000
15000
3000
5550
Вся эта совокупность данных
выступает
в качестве обучающей выборки, так как каждому входному
вектору (наблюдению)
поставлено в соответствие
значение (или вектор)
Такие данные еще называют размеченными и их формирование –
это сложный и длительный процесс, требующий участие одного
или группы людей.
9.
Вторичные признакиИсходные результаты измерений могут иметь сложную структуру (например, при
кодировании текстов, звуков или изображений) и трудно интерпретируемыми самими алгоритмами.
Например, до появления глубоких нейронных сетей (deep learning) в задачах классификации
изображений инженеры формировали, так называемые, вторичные признаки: выделяли различные
монотонные области, границы объектов с помощью различных фильтров или набрасывали на
изображение случайные линии и пытались, затем, вычислять различные соотношения площадей.
И такие подходы в разных задачах давали определенные результаты.
По-английски это называется feature extraction и feature engineering – непростой и
творческий процесс, создания более информативных признаков.
Математически извлечение признаков из сырых исходных данных можно представить в виде
функционального преобразования:
, где x – это вектор результатов исходных
измерений, который затем, переводится в набор признаков, причем k - любое число, не обязательно
равное n (исходному числу признаков – длине вектора X).
В результате, можно записать матрицу F, содержащую эти выделенные признаки:
Получаем новое признаковое пространство F, упрощающее работу алгоритмов машинного
обучения.
10.
Подготовка обучающей выборкидля оптимизации нейросети
1.Сбор данных. Необходимо собрать достаточное количество данных, чтобы модель
могла обучиться и обобщать информацию.
2.Очистка данных. Включает удаление дубликатов, заполнение пропущенных значений
и исправление ошибок.
3.Анализ и визуализация данных. Анализ данных помогает понять структуру и
особенности датасета.
4.Преобразование и нормализация данных. Преобразование данных включает
изменение формата данных для удобства их использования в модели.
5. Кодирование - превращение категориальных признаков в числовые формы.
6. Разделение данных на обучающую и тестовую выборки. Это важный шаг для
оценки производительности модели.
7. Валидационная выборка. Помогает настроить гиперпараметры модели и избежать
переобучения.
11.
Подготовка обучающей выборкидля оптимизации нейросети
1. Сбор данных. Первый шаг — это сбор исходных данных, которые будут
использоваться для обучения. Качество и репрезентативность данных имеют огромное
значение для успешной тренировки нейросети. Важно, чтобы данные были
разнообразными и охватывали весь спектр возможных ситуаций, с которыми модель
будет сталкиваться в будущем. Кроме того, необходимо собрать достаточное количество
данных, чтобы модель могла обучиться и обобщать информацию.
Репрезентативность — свойство выборочной совокупности представлять
характеристики генеральной совокупности (объекта в целом).
Это понятие используется в статистике и социологии для оценки,
насколько результаты исследования, полученные на основе выборки,
можно обобщить на всю генеральную совокупность.
12.
Подготовка обучающей выборкидля оптимизации нейросети
2. Очистка данных. Включает удаление дубликатов, заполнение пропущенных значений
и исправление ошибок.
13.
Подготовка обучающей выборкидля оптимизации нейросети
3. Анализ и визуализация данных. Анализ данных помогает понять структуру и особенности
датасета.
Датасет (от англ. dataset) — это структурированный набор данных,
организованный для определённой цели.
Проще говоря, это коллекция информации,
собранная в одном месте и подготовленная для анализа или обработки.
Чаще всего датасеты выглядят как таблицы со строками и столбцами.
В строках содержится информация об объектах наблюдения,
например, пользователи, транзакции, товары.
А в столбцах — их характеристики: возраст, дата покупки и др.
Иногда данные бывают несбалансированными, то есть один класс представлен гораздо чаще
других. Это может привести к смещению модели в сторону доминирующего класса. Для устранения
этой проблемы используют методы балансировки, такие как oversampling (увеличение количества
экземпляров меньших классов) или undersampling (уменьшение количества экземпляров
доминирующих классов).
14.
Подготовка обучающей выборкидля оптимизации нейросети
4. Преобразование и нормализация данных. Преобразование данных включает изменение
формата данных для удобства их использования в модели.
Нормализация полезна для данных, которые имеют разные масштабы и диапазоны
значений, помогает избежать доминирования признаков с большими значениями над
признаками с меньшими. Поэтому на практике выполняют предварительную нормализацию
входных значений, например, по формуле:
Здесь max, min – максимальное и минимальное значения входных данных по всему
обучающему множеству. В результате, входные данные при обучении будут находиться в
диапазоне от 0 до 1.
Раз сеть обучена на нормированных значениях, то и потом, при ее работе, данные
также нужно нормировать. Кроме того, нормировку следует делать через те же самые
параметры min и max, которые были использованы в обучающей выборке, а не
пересчитывать их заново.
15.
Подготовка обучающей выборкидля оптимизации нейросети
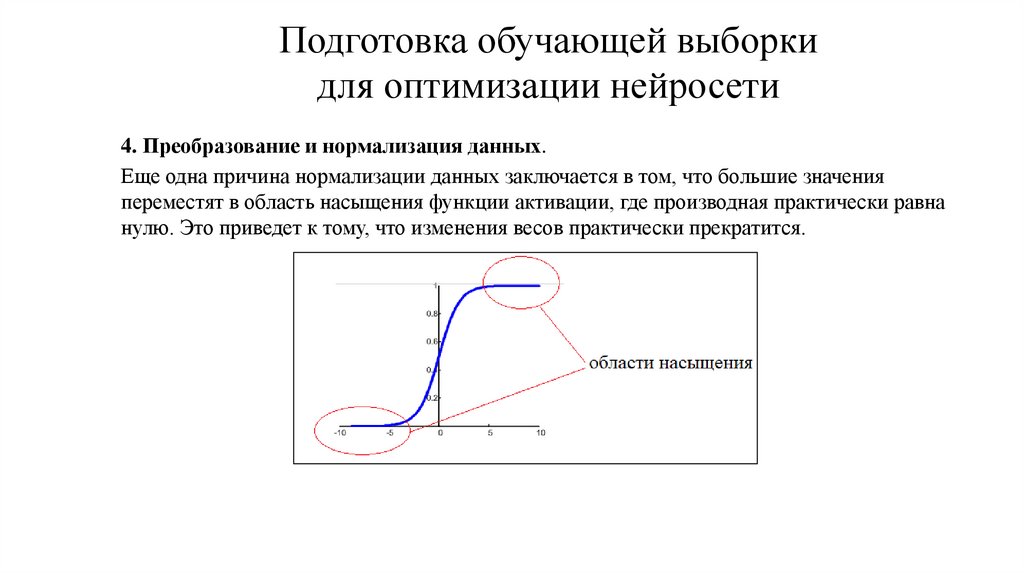
4. Преобразование и нормализация данных.
Еще одна причина нормализации данных заключается в том, что большие значения
переместят в область насыщения функции активации, где производная практически равна
нулю. Это приведет к тому, что изменения весов практически прекратится.
16.
Подготовка обучающей выборкидля оптимизации нейросети
5. Кодирование
One Hot Encoding — это метод преобразования категориальных данных в числовой формат,
понятный алгоритмам машинного обучения.
Суть метода: каждая уникальная категория становится отдельным бинарным признаком,
который принимает значение 1, если объект принадлежит к этой категории, и 0 — если нет.
Label encoding (кодирование меток) — это метод преобразования категориальных данных в
числовой формат. Простыми словами, это процесс, при котором каждой категории в
категориальной переменной присваивается уникальное целое число. Это позволяет
использовать данные в алгоритмах машинного обучения, требующих числового ввода. Способ
полезен, когда категории имеют некоторую иерархию или порядок (например, «Низкий»,
«Средний», «Высокий») — числовое представление сохраняет связь между категориями
17.
Подготовка обучающей выборкидля оптимизации нейросети
6. Разделение данных на обучающую и тестовую выборки. Это важный шаг для
оценки производительности модели.
7. Валидационная выборка. Помогает настроить гиперпараметры модели и избежать
переобучения.
Деление датасета на обучающую, тестовую и валидационную выборки — это
важнейший этап подготовки данных для обучения нейросети. Цель деления — разделить
данные таким образом, чтобы модель обучалась на одних данных, проверялась на других
и окончательно тестировалась на независимых данных.
18.
Подготовка обучающей выборкидля оптимизации нейросети
1.Обучающая выборка (Training Set):
1. Составляет большую часть датасета (обычно ~60%-80%).
2. Используется для непосредственной тренировки модели.
3. На этих данных модель обучается, корректирует свои параметры и запоминает шаблоны и
закономерности.
2.Валидационная выборка (Validation Set):
1. Занимает примерно 10%-20% данных.
2. Служит для тонкой настройки гиперпараметров модели (например, количества слоев,
размеров батчей, скоростей обучения).
3. Помогает отслеживать, не происходит ли переобучение (overfitting), и выбирать лучшую
конфигурацию модели.
3.Тестовая выборка (Test Set):
1. Обычно составляет 10%-20% данных.
2. Применяется для финального независимого тестирования модели.
3. Показывает, как модель поведёт себя на данных, которые она не видела во время обучения.
19.
Подготовка обучающей выборкидля оптимизации нейросети
Один из способов деления — использование библиотек, таких как scikit-learn (sklearn) в Python.
Пример кода для деления датасета:
1
2
3
4
5
6
7
from sklearn.model_selection import train_test_split
# Разделим данные на обучающую и тестовую выборки
X_train_val, X_test, y_train_val, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Разделим обучающую выборку на обучающую и валидационную
X_train, X_val, y_train, y_val = train_test_split(X_train_val, y_train_val, test_size=0.2, random_state=42)
20.
Источники датасетовОткрытый портал данных Российской Федерации (data.gov.ru)
www.Kaggle.com - популярная платформа для соревнований и обмена датасетами.
Содержит тысячи наборов данных для различных задач: от обработки изображений и
текстов до временных рядов и научных исследований. Бесплатная регистрация и открытый
доступ к данным.