






 Медицина
Медицина Информатика
ИнформатикаПохожие презентации:










Применение Stable Diffusion для аугментации данных и сегментации медицинских изображений
1.
МИНОБРНАУКИ РОССИИФЕДЕРАЛЬНОЕ ГОСУДАРСТВЕННОЕ
БЮДЖЕТНОЕ ОБРАЗОВАТЕЛЬНОЕ УЧРЕЖДЕНИЕ
ВЫСШЕГО ОБРАЗОВАНИЯ
«ВОРОНЕЖСКИЙ ГОСУДАРСТВЕННЫЙ
УНИВЕРСИТЕТ»
(ФГБОУ ВО «ВГУ»)
Кафедра математических методов исследования операций
Выпускная квалификационная работа на тему:
«Применение Stable Diffusion для аугментации данных и
сегментации медицинских изображений»
Студент Доровской А.А.
Руководитель Каширина И.Л.
1
2.
Актуальность и проблемаАктуальность: Медицинская диагностика в современных
условиях всё чаще опирается на автоматизированные системы
анализа изображений (МРТ, КТ, рентген). Такие системы
помогают ускорить процесс диагностики и повысить её
точность.
Для обучения высокоэффективных моделей сегментации
требуется большое количество размеченных данных.
Проблема: Ограниченность и неравномерность медицинских
датасетов ведет к переобучению моделей и снижению их
обобщающей способности.
Необходимость в методах, позволяющих увеличивать объем
обучающих данных без затрат времени и ресурсов на сбор и
разметку.
2
3.
Объект, предмет и цель исследованияОбъект исследования: рентген-снимки переломов
костей и суставов рук.
Предмет исследования:Методы увеличения и
расширения набора данных с помощью генеративных
моделей, таких как Stable Diffusion.
Цель работы: Разработать подход по использованию
генеративных моделей для синтеза реалистичных
изображений переломов суставов. Исследовать
эффективность синтетических данных в сравнении с
традиционными методами аугментации и исходными
наборами данных.
3
4.
ЗадачиАнализ существующих методов аугментации
и генеративных моделей.
Разработка и внедрение метода
аугментации с использованием Stable
Diffusion.
Обучение модели сегментации на
расширенных данных.
Оценка эффективности метода по метрикам
IoU и Accuracy.
4
5.
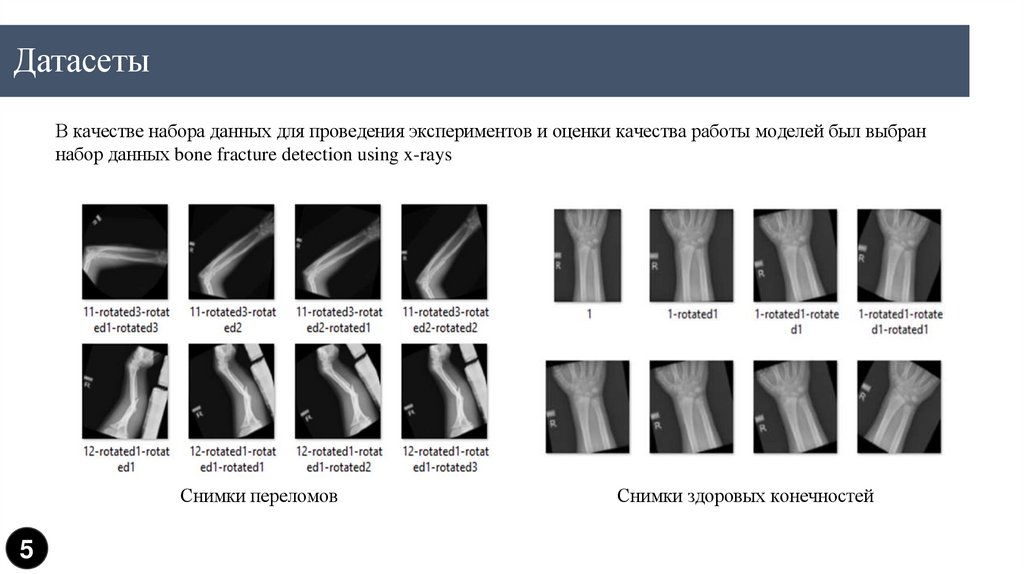
ДатасетыВ качестве набора данных для проведения экспериментов и оценки качества работы моделей был выбран
набор данных bone fracture detection using x-rays
Снимки переломов
5
Снимки здоровых конечностей
6.
Методы и архитектурыВ данной работе используется сборка Stable Diffusion от Automatic1111 – Stable Diffusion Web UI. Данная
сборка имеет браузерный интерфейс, основанный на библиотеке Gradio, а также она доступна для развертывания
на локальной машине с поддержкой GPU путем клонирования репозитория с GitHub. WebUI создает виртуальное
окружение Python, устанавливает все необходимые зависимости и запускает локальный веб-сервер.
Для решения задачи семантической сегментации выбрана полносверточная нейронная сеть U-Net. Оценка
эффективности моделей осуществляется с помощью метрик IoU и Accuracy.
6
7.
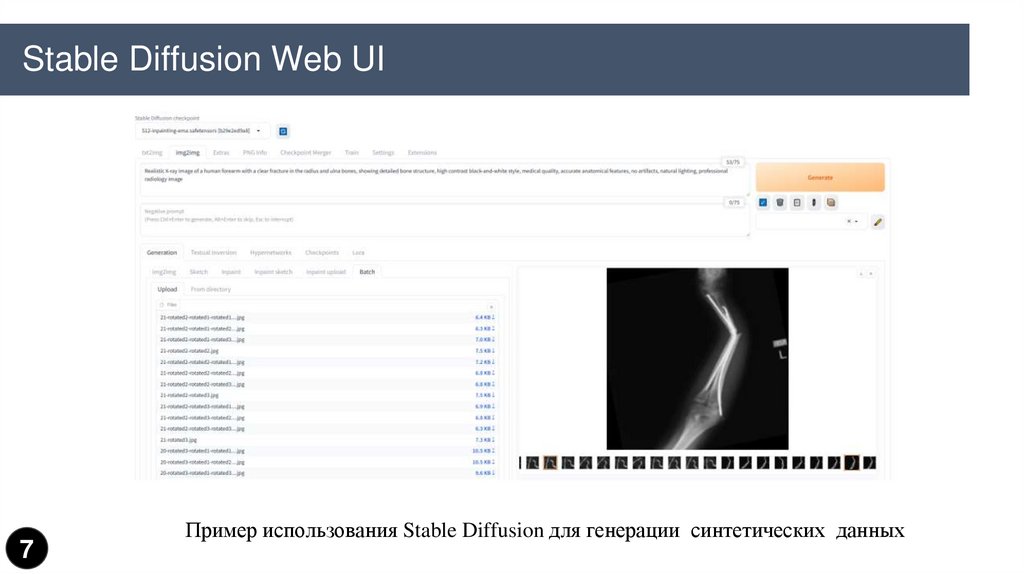
Stable Diffusion Web UI7
Пример использования Stable Diffusion для генерации синтетических данных
8.
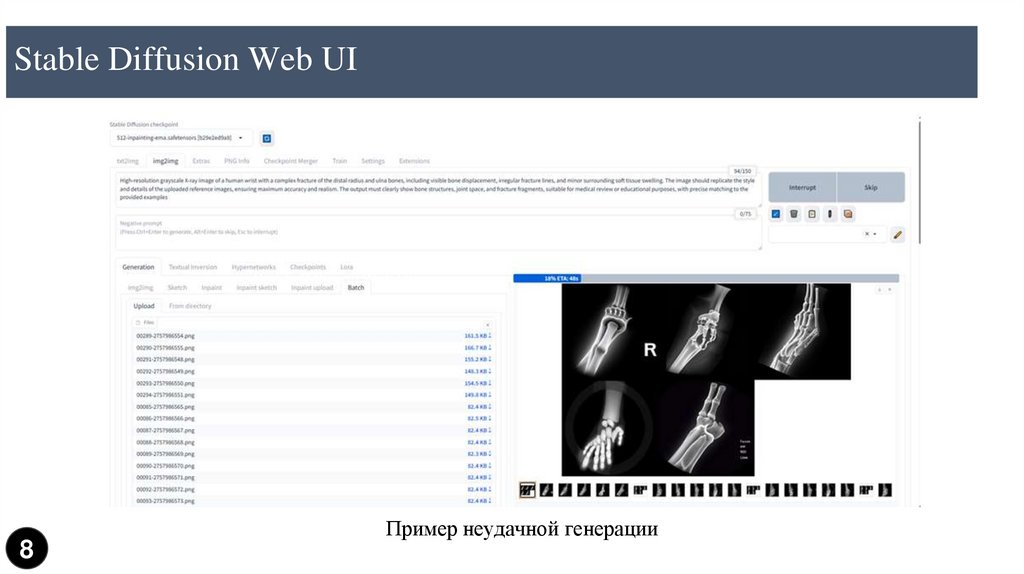
Stable Diffusion Web UIStable Diffusion Web UI
8
Пример неудачной генерации
9.
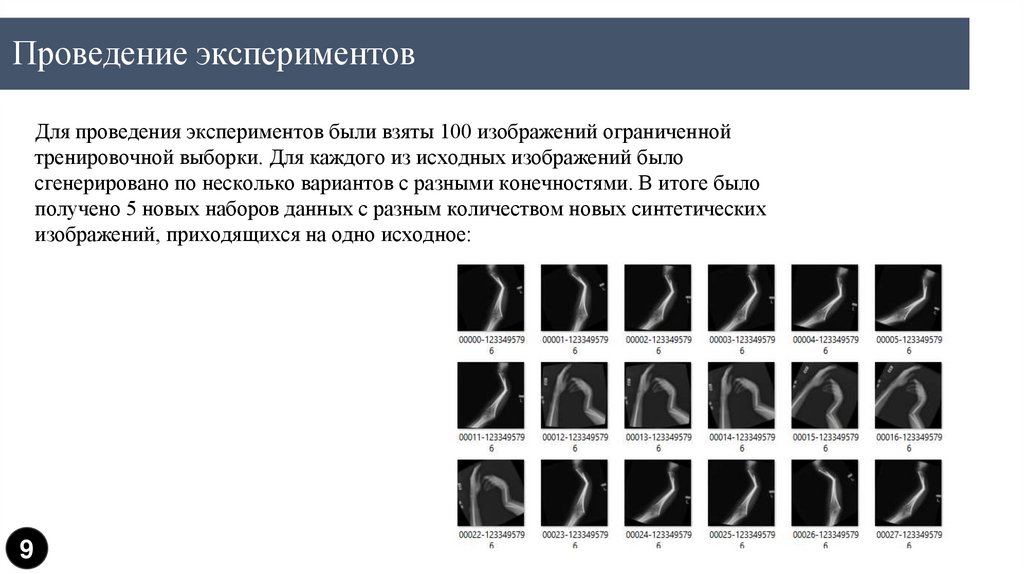
Проведение экспериментовДля проведения экспериментов были взяты 100 изображений ограниченной
тренировочной выборки. Для каждого из исходных изображений было
сгенерировано по несколько вариантов с разными конечностями. В итоге было
получено 5 новых наборов данных с разным количеством новых синтетических
изображений, приходящихся на одно исходное:
9
10.
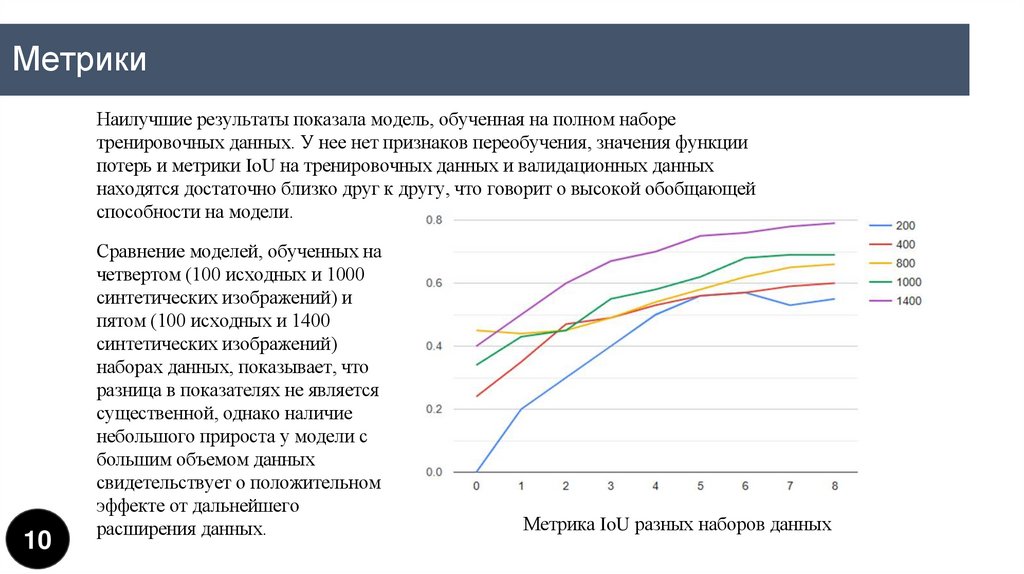
МетрикиНаилучшие результаты показала модель, обученная на полном наборе
тренировочных данных. У нее нет признаков переобучения, значения функции
потерь и метрики IoU на тренировочных данных и валидационных данных
находятся достаточно близко друг к другу, что говорит о высокой обобщающей
способности на модели.
10
Сравнение моделей, обученных на
четвертом (100 исходных и 1000
синтетических изображений) и
пятом (100 исходных и 1400
синтетических изображений)
наборах данных, показывает, что
разница в показателях не является
существенной, однако наличие
небольшого прироста у модели с
большим объемом данных
свидетельствует о положительном
эффекте от дальнейшего
расширения данных.
Метрика IoU разных наборов данных
11.
Значение метрикВ таблице представлены показатели работы
нескольких моделей: одна, обученная на
полной тренировочной выборке, и другие —
на ограниченной по объему выборке, а также
на наборах с разным количеством созданных
синтетических изображений. Такой
сравнительный анализ позволяет оценить,
насколько расширение данных помогает
повысить качество модели и подтвердить
гипотезу о преимуществах синтеза
изображений для повышения точности и
устойчивости модели при работе с
ограниченными исходными данными.
Набор данных
Полная обучающая выборка (8 600
Accuracy
IoU
0,883
0,784
0,831
0,508
0,847
0,569
0,854
0,6565
0,8572
0,671
0,862
0,683
0,863
0,756
изображений)
Ограниченная обучающая выборка
(100 изображений)
Ограниченная выборка и синтетические
данные (100 + 200
изображений)
Ограниченная выборка и
синтетические данные (100 + 400
изображений)
Ограниченная выборка и
синтетические данные (100 + 800
изображений)
Ограниченная выборка и
синтетические данные (100 + 1000
изображений)
Ограниченная выборка и
синтетические данные (100 + 1400
11
изображений)
12.
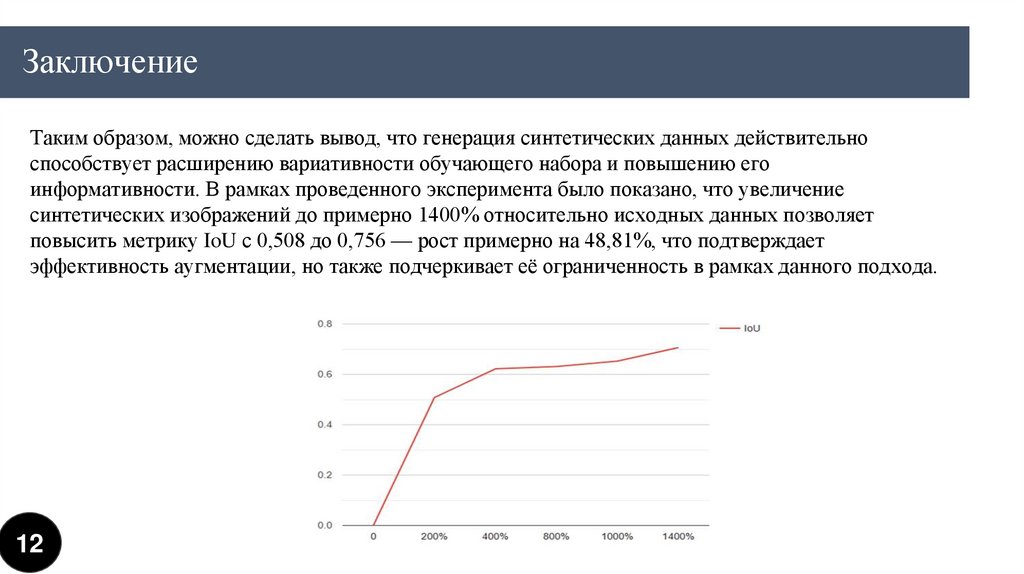
ЗаключениеТаким образом, можно сделать вывод, что генерация синтетических данных действительно
способствует расширению вариативности обучающего набора и повышению его
информативности. В рамках проведенного эксперимента было показано, что увеличение
синтетических изображений до примерно 1400% относительно исходных данных позволяет
повысить метрику IoU с 0,508 до 0,756 — рост примерно на 48,81%, что подтверждает
эффективность аугментации, но также подчеркивает её ограниченность в рамках данного подхода.
12
13.
МИНОБРНАУКИ РОССИИФедеральное государственное бюджетное
образовательное учреждение
высшего образования
«МИРЭА – Российский технологический университет»
РТУ МИРЭА
Институт искусственного интеллекта (ИИИ)
Кафедра технологий искусственного
интеллекта (ТИИ)
Выпускная квалификационная работа на тему:
«Классификация переломов тазобедренного
сустава»
Студент группы КВМО-02-23 Волков Н.П.
Руководитель Куликов А.А.
12