








































 Математика
МатематикаПохожие презентации:










Математическая статистика
1. Основы математической статистики
Математическая статистика позволяетобрабатывать результаты опытов, измерений и
т.д. Математическая статистика использует
методы теории вероятности.
2. Случайные события
• Событие называется детерминированным, если в результатеопыта оно происходит или не происходит наверняка. В
детерминированном случае мы точно знаем, что данная причина
приведет к единственному, вполне определенному следствию.
• Событие называется случайным, если в результате опыта мы не
можем заранее предсказать - произойдет событие или нет. При
этом предполагается, что опыт можно повторять неограниченное
число раз при неизменных условиях.
3.
•События A и B называются несовместными, если появлениеодного исключает появление другого.
•Событие B следует из события A, если событие B происходит
всегда, когда произошло событие A .
Это обозначается тем же символом, что и подмножество: A B .
•Будем говорить о равенстве двух событий A и B, если из A следует
B и из B следует A.
•Событие называется невозможным, если оно не может произойти
никогда при данных условиях.
•Событие называется достоверным, если оно происходит всегда при
данных условиях.
4.
•Пусть случайный эксперимент проводится раз n, и событие Aпроизошло m раз. Тогда говорят, что относительная частота
события A есть n(A)=m/n .
•Частота события связана с его вероятностью.
Относительную частоту называют еще эмпирической
вероятностью потому, что по частоте события мы оцениваем
возможность его появления в будущем.
• Для любого случайного события A
0 Pn(A) 1
n - количество случайных экспериментов.
5. Две теоремы о вероятности суммы событий и произведении
1. Если события несовместны, то вероятность суммы событийравна сумме вероятностей:
P(A+B) = P(A) + P(B)
2. Если события независимы, то вероятность произведения
событий равна произведению вероятностей:
P(A B) = P(A) P(B)
6. Классическое определение
•Вероятностью Р(А) события называется отношение числаблагоприятных исходов m(А) к общему числу несовместных
равновозможных исходов:
m( A)
P ( A)
N
Свойства вероятности.
•I. Для любого случайного события А 0 P(A) 1
•2. Пусть события A и B несовместны. Тогда P(A+B)=P(A)+P(B)
Например: бросание кубика. Всего исходов 6, число исходов,
благоприятных выпадению четного числа – 3. P(A)=1/2
7.
Дискретная случайная величина1
p1
2
...
p2
...
n
, p1 p 2 ... p n 1
pn
Будем предполагать, что все числа xk различны.
Случайная величина принимает значение xk , если
произошел исход wk, вероятность которого равна pk
Точнее: вероятность события {x(wk)=xk} равна pk
Дискретная случайная величина полностью
определяется своими значениями и их вероятностями.
8. Дисперсия
Дисперсией конечной случайной величины x называется числоD M M
2
по определению математического ожидания, дисперсия вычисляется
по следующей формуле
D xi M pi
2
i
Дисперсию иногда обозначают как s2(x) или 2
D
называется среднеквадратичным отклонением
или стандартным отклонением случайной
величины
9. Функция распределения
Функция действительной переменнойF ( x) P x
называется функцией распределения случайной величины x .
1.
2.
Свойства функции распределения
P x 1 F x
P a b F (b) F (a)
3. При любом х выполняется неравенство.
0 F ( x) 1
Это справедливо, поскольку функция распределения есть
вероятность
4. Функция распределения есть неубывающая функция.
10.
5. При x событие стремится к невозможному ивероятность соответственно, стремится к нулю. При x
событие становится достоверным
6. Функция распределения непрерывна слева, то есть
lim F ( x) F ( x0 )
x x0 0
Случайная величина x называется непрерывной случайной
величиной, если существует функция f (x) такая, что
b
P a, b f ( x)dx
a
Функция f (x)называется плотностью вероятности или
плотностью распределения случайной величины x
11. Распределение Гаусса
Говорят, что случайная величина x , распределена по нормальномузакону (имеет нормальное распределение) с параметрами m и s,
(s>0) если она имеет плотность распределения
2
2
x
m
t m
x
1
f ( x)
2
e
2 2
На рисунке представлены
графики стандартного (при
m=0 и s=1) нормального
распределения Гаусса
(черный) и его плотности
(красный)
F ( x)
1
2
e
2 2
dt
12. Статистика
Генеральной совокупностью называется вся совокупность
исследуемых объектов
• Выборочной совокупностью или просто выборкой называют
совокупность случайно отобранных из генеральной
совокупности объектов
• Объемом совокупности называют число объектов этой
совокупности
Способы формирования выборочной совокупности
• Повторный – после измерений объект возвращают в
генеральную совокупность
• Бесповторный – после измерений объект в генеральную
совокупность не возвращается
Выборка должна быть репрезентативной - представительной. Для
этого объекты из генеральной совокупности должны отбираться
случайно.
13. Выборка и ее обработка
•Упорядочивание. Элементы выборки x1 , x 2 ,..., x n располагаются впорядке возрастания.
•Частотный анализ. Пусть выборка содержит k различных значений
. z1 , z 2 ,..., z k , причем zi встречается ni (i=1,2,…,k) Число ni называют
частотой элемента zi ,
k
n
i 1
i
n
•Совокупность пар (zi, ni ) называют статистическим рядом
выборки. Часто его представляют в виде таблицы – в первой строке
zi, во второй ni.
•Величина ni = ni /n называется относительной частотой
•Накопленная частота значения zi равна n1+n2+…+ni.
•Относительная накопленная частота n1+n2+…+ni
14. Эмпирическая функция распределения
Каждой выборке {x1 , x2 ,..., xn } можно поставить в соответствиеконечную случайную величину, принимающую эти значения с
равными вероятностями 1/n
x1
n 1
n
x 2 ...
1 ...
n
xn
1
n
Это распределение называется выборочным, или эмпирическим,
распределением. Как и для любой конечной случайной величины,
для эмпирической случайной величины можно построить
ступенчатую функцию распределения; она называется выборочной
функцией распределения. Кроме того, можно вычислить числовые
характеристики выборочной случайной величины xnматематическое ожидание, дисперсию.
15.
выборочное математическое ожидание (его обычно называютвыборочным средним), выборочная дисперсия, выборочная медиана
и т.д. Например, выборочное среднее (его обозначают через ) есть
не что иное как среднее арифметическое значений выборки x
x1 x2 ... xn
M n x
n
Соответственно выборочная дисперсия s2 равна
n
1
2
D n s x i x
n i 1
2
16. ОЦЕНКА ФУНКЦИИ РАСПРЕДЕЛЕНИЯ
Пусть в нашем распоряжении имеется выборка {x1 , x2 ,...xn }из генеральной совокупности с функцией распределения
F(x). Функция распределения F * ( x) эмпирической
n
случайной величины
x1 x 2 ... x n
n 1 1
1
n
n n
17.
Поскольку каждое значение из выборки есть случайнаявеличина с функцией распределения, то вероятность успеха равна
p=F(x) . Число успехов равно mn(x) , а относительная частота успеха
равна mn(x)/n и совпадает с выборочной функцией распределения.
Следовательно, выборочная функция распределения представляет
собой относительную частоту успеха, а функция распределения
генеральной совокупности - вероятность успеха. Из предыдущего
нам известно, что относительная частота есть несмещенная
состоятельная оценка вероятности. Значит, выборочная функция
распределения действительно является несмещенной,
состоятельной и эффективной оценкой функции распределения:
MFn* ( x) F ( x)
lim P Fn* ( x) F ( x) 1
n
18. Выборочные квантили
Выборочный квантиль определяются по выборке.•Квантиль – левее должно располагаться кол-во значений,
соответствующее индексу квантили. Например, для квантили x0.8
Левее должно располагаться 80% значений выборки.
19. Распределение Стьюдента
На рисунке красным выделено нормальное распределение,черным – распределение Стьюдента.
20. Свойства распределения Стьюдента
• Распределение Стьюдента симметрично, причем Mt(k) = 0.• При больших k распределение Стьюдента близко к стандартному
нормальному распределению N(0,1).
21. Доверительный интервал математического ожидания.
Случайная величина U распределена по нормальному законуx m
~ N (0,1)
n
Случайная величина
x m
~ t (n 1)
S n
распределена по закону Стьюдента, а доверительный интервал
математического ожидания примет вид ( - квантиль
распределения Стьюдента, 1 2 )
S
S
, x
x
n
n
22. Пример
Вычислим доверительные интервалы для нашей выборки.Интервал для математического ожидания. Случай 1. Будем считать,
что несмещенная оценка дисперсии – точное значение.
Выберем уровень значимости 0.95 . По таблице найдем
квантиль стандартного распределения u0.975 1.96 . Подставим в
формулу
u(1 ) / 2
n
m=0.51735, s=0,288955, n=49. После вычислений получим
0,0809074.
Интервал будет 0.51735- 0,0809074<m< 0.51735+ 0,0809074
0,4364426<m<0,5982574.
23. Пример. Интервал для дисперсии
S2=0,0834952
S 2 n 1
S
n 1
2
2
2
1 2 (n 1)
1 2 (n 1)
2
2
Находим квантили распределения 1 2 и 1 2 .
02.975 71.4 02.025 42.85
Находим интервал 0,056131<s2<0,09353
Интервал для математического ожидания. Случай 2.
Используем распределение Стьюдента. Формула та же, что и
раньше, но вместо квантиля нормального распределения
используется квантиль распределения Стьюдента. t (48)0.975 2.0105
После вычислений получим
0.51735- 0,082992 <m< 0.51735+ 0,082992
0,434358<m<0,600342
24. Статистическая гипотеза
Любое утверждение о виде илисвойствах закона распределения
наблюдаемых случайных величин
Всякий раз предполагаем, что у
нас имеются две
взаимоисключающие гипотезы:
основная и альтернативная
24
25.
Нулевой (основной) гипотезой - H0называют какое-либо конкретное
предположение о теоретической функции
распределения или предположение,
влекущее за собой важные практические
последствия
Альтернативная гипотеза H1 - любая
гипотеза, исключающая нулевую
25
26.
Задача проверки статистическойгипотезы состоит в том, чтобы,
используя статистические данные
(выборку)
X1, X2, …, Xn,
принять или отклонить нулевую
гипотезу
26
27.
Нулевые и альтернативные гипотезыформулируются как утверждение о
принадлежности функций
распределения некоторой случайной
величины определенному классу
распределений
,
, 0
0
1
1
0
1
HF
; HF
0: x
0
1: x
1
28.
Гипотеза называется простой, еслисоответствующий класс
распределений содержит лишь
одно распределение, в противном
случае гипотеза будет сложной.
Гипотезы о параметрах
распределений называются
параметрическими
28
29.
Статистикой критерияназывается функция от выборки
TX
значение которой для заданной
выборки служит основанием принятия
или отклонения основной гипотезы
29
30.
Статистический критерий -правило, позволяющее только по
результатам наблюдений
X1, X2, …, Xn
принять или отклонить нулевую
гипотезу
H0
30
31.
Каждому критерию отвечаетразбиение области значений
статистики критерия на две
непересекающихся части:
• критическую область 1
• область принятия гипотезы 0
31
32. Критические области
Односторонние1
0
1
Двусторонняя
t
c
t
0
1
c1
Неправдоподобно
маленькие значения
0
c
1
c2
Приемлемые значения
t
Неправдоподобно
большие значения
32
32
33.
Если значение статистикикритерия попадает в область
принятия гипотезы 0 , то
принимается нулевая гипотеза, в
противном случае она отвергается
(принимается альтернативная
гипотеза)
33
34.
Задать статистический критерийзначит:
• задать статистику критерия
• задать критическую область
34
35.
В ходе проверки гипотезы H0 можноприйти к правильному выводу, либо
совершить два рода ошибок:
• ошибку первого рода -- отклонить H0,
когда она верна
• ошибку второго рода -- принять H0,
когда она не верна.
35
36.
Так как статистика критерияTX
есть случайная величина со своим
законом распределения, то
попадание её в ту или иную область
характеризуется соответствующими
вероятностями:
• вероятностью ошибки первого рода
• вероятностью ошибки второго рода
36
37.
Ошибку первого рода ещё называютуровнем значимости критерия.
Часто пользуются понятием мощности
критерия W -- вероятности попадания
в критическую область при условии
справедливости альтернативной
гипотезы
W
1
37
38.
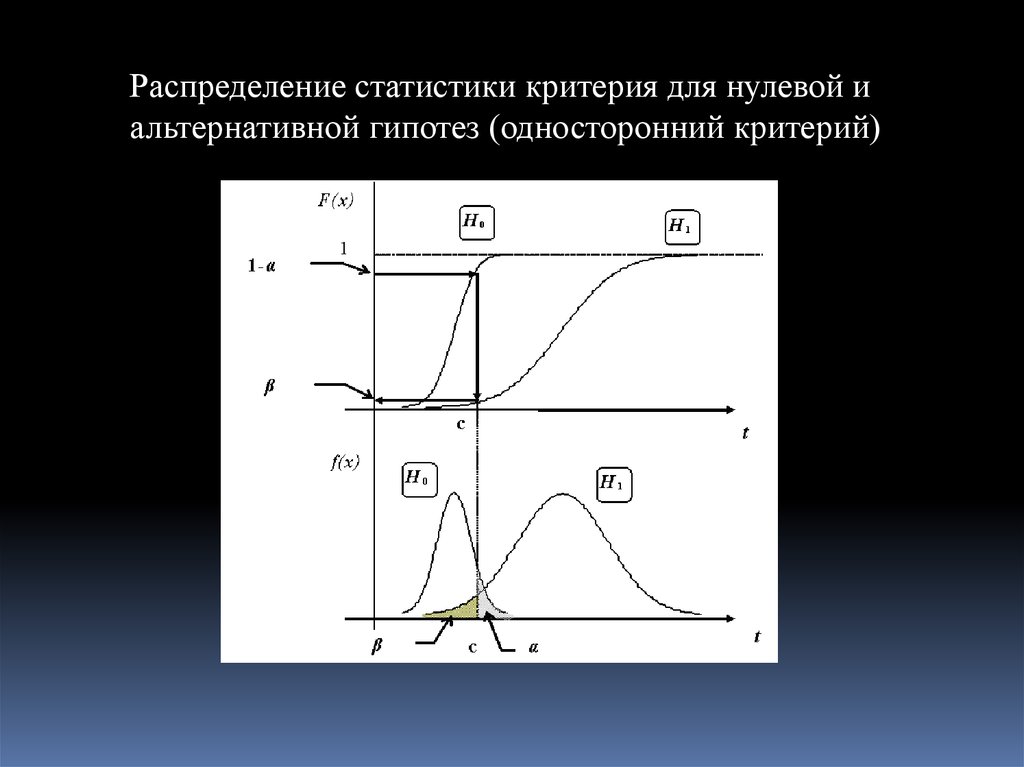
Распределение статистики критерия для нулевой иальтернативной гипотез (односторонний критерий)
39. Пять шагов проверки гипотезы
1 шаг – выдвигается основная гипотезаH0
2 шаг – задается уровень значимости
α
3 шаг – задается статистика критерия T(X) с
известным законом распределения
39
40.
4 шаг – из таблиц распределениястатистики критерия находятся квантили,
соответствующие границам критической
области
5 шаг – для данной выборки
рассчитывается значение статистики
критерия
41.
Если значение статистики критерияпопадает в область принятия гипотезы,
то нулевая гипотеза принимается на
уровне значимости α.
В противном случае принимается
альтернативная гипотеза (отвергается
нулевая гипотеза)