
















")



































")
")




 Информатика
Информатика Электроника
ЭлектроникаПохожие презентации:
")


")
")





Микросхемы процессоров и шины
1. Микросхемы процессоров и шины
2. Микросхемы процессоров
Выводы микросхемы ЦП:• адресные
• информационные
• управляющие
Эти выводы связаны с соответствующими выводами на микросхемах памяти
и микросхемах УВВ через набор параллельных проводов (так называемую
шину)
ЦП обменивается информацией с памятью и УВВ, подавая сигналы на
выводы и принимая сигналы на входы.
[Другого способа обмена информацией не существует]
3. Микросхемы процессоров
Вызов команды:1. ЦП посылает в память адрес этой команды по адресным выводам.
2. Затем ЦП задействует одну или несколько линий управления, чтобы
сообщить памяти, что ему нужно (например, прочитать слово).
3. Память помещает требуемое слово на информационные выводы ЦП и
посылает сигнал о том, что это сделано.
4. Когда ЦП получает этот сигнал, он считывает слово и выполняет
вызванную команду.
4. Микросхемы процессоров
Производительность ЦП определяется:•числом адресных выводов
m адресных выводов =>м/обратиться к 2^m ячеек памяти
[т = 16, 32, 64]
•числом информационных выводов
n информационных выводов => м/ считывать (записывать) nразрядное слово за одну операцию [ n =8, 32, 64]
ЦП с 8 информационными выводами понадобится 4 операции, чтобы считать 32разрядное слово, а ЦП, имеющий 32 информационных вывода, может сделать ту
же работу в рамках одной операции =>микросхема с 32 информационными
выводами работает гораздо быстрее, но и стоит гораздо дороже
5. Микросхемы процессоров
Управляющие выводы позволяют регулировать и синхронизировать потокданных к процессору и от него, а также выполнять другие функции.
Основные категорий управляющих выводов:
• управление шиной
[выходы из ЦП в шину, позволяют сообщить, что процессор хочет считать (записать)
информацию из памяти или сделать что-нибудь еще];
• прерывания
[входы из УВВ в процессор. ЦП может дать сигнал УВВ начать операцию, а затем
приступить к какому-нибудь другому действию, пока УВВ выполняет свою работу. Когда
УВВ ее завершит, контроллер ввода-вывода посылает сигнал на один из выводов прерывания, чтобы прервать работу ЦП и заставить его обслужить УВВ (например, проверить
ошибки ввода-вывода)]
6. Микросхемы процессоров
• арбитраж шины [выводы арбитража нужны для регулировки потока информации вшине, т.е. для исключения таких ситуаций, когда два устройства пытаются
воспользоваться шиной одновременно];
• сигналы сопроцессора [обмен информацией между процессором и сопроцессором,
например, с графическими процессорами, процессорами для обработки вещественных
данных и т. п. ];
• cостояние [принимают информацию о состоянии];
• разное [например, выводы для перезагрузки компьютера, обеспечение совместимость
со старыми микросхемами устройств ввода-вывода].
Все процессоры содержат выводы для питания (обычно +1,2 В или +1,5 В),
заземления и синхронизирующего сигнала (меандра).
7. Микросхемы процессоров
Стрелками обозначены входные ивыходные сигналы, а короткими
диагональными линиями – наличие
нескольких выводов данного типа.
Цоколевка типичного ЦП.
Цоколевка – значение сигналов на различных выводах
8. Компьютерные шины
Шина – это несколько проводников, соединяющих несколько устройств:могут быть внутренними по отношению к процессору и служить для
передачи данных в АЛУ и из АЛУ,
могут быть внешними по отношению к процессору и связывать
процессор с памятью или устройствами ввода-вывода.
Современные персональные компьютеры обычно содержат специальную
шину между ЦП и памятью, системную,
и по крайней мере еще одну шину для УВВ
9. Компьютерные шины
Компьютерная система с несколькими шинамиКогда тип всех битов одинаков, например все адресные или все информационные, рисуется обычная
стрелка. Когда включаются адресные линии, линии данных и управления, используется жирная стрелка
10. Компьютерные шины
Протокол шины – правила о том, как работает шина и все устройства,связанные с шиной, должны подчиняться этим правилам, чтобы платы,
которые выпускаются сторонними производителями, подходили к
системной шине
Примеры шин :
• Omnibus [PDP-8]
• Unibus [PDP-11]
• Multibus [8086]
• VME [оборудование для
физической лаборатории]
• IBM PC [PC/XT]
• ISA [PC/AT]
• EISA [80386]
MicroChannel [PS/2]
Nubus [Macintosh]
PCI [различные персональные компьютеры]
SCSI [различные персональные компьютеры
и рабочие станции]
• Universal Serial Bus
[современные персональные компьютеры]
• Fire Wire [бытовая электроника]
11. Компьютерные шины
Как работают шины: некоторые устройства, соединенные с шиной, являютсяактивными и могут инициировать передачу информации по шине, тогда
как другие являются пассивными и ждут запросов.
Активное устройство называется задающим, пассивное – подчиненным.
Задающее устройство
Подчиненное устройство
Пример
Центральный процессор
Память
Вызов команд и данных
Центральный процессор
Устройство ввода-вывода
Инициализация передачи данных
Центральный процессор
Сопроцессор
Передача команды от процессора к
сопроцессору
Память
Прямой доступ к памяти
Центральный процессор
Вызов сопроцессором операндов из
центрального процессора
Устройство ввода-вывода
Сопроцессор
12. Компьютерные шины
Задающие устройства обычно связаны с шиной через микросхему,которая называется драйвером шины (является цифровым усилителем)
Подчиненные устройств связаны с шиной приемником шины
Для устройств, которые могут быть и задающим, и подчиненным
устройством, используется приемопередатчик, или трансивер шины
Являются устройствами
с тремя состояниями,
что дает им
возможность
отсоединяться, когда
они не нужны
Устройства могут подсоединятся к шине через открытый коллектор, тогда требуют доступа к
шине в одно и то же время, результатом является булева операция ИЛИ над всеми этими
сигналами. Такое соглашение называется монтажным ИЛИ.
В большинстве шин одни линии являются устройствами с тремя состояниями, а другие,
которым требуется свойство монтажного ИЛИ – открытым коллектором.
Как и процессор, шина имеет адресные, информационные линии и управляющие линии [между
выводами процессора и сигналами шины может не быть взаимно однозначного соответствия]
13. Ширина шины
Ширина (количество адресных линий) шины – самый очевидный параметрпри проектировании.
Чем больше адресных линий содержит шина, тем к большему объему памяти
может обращаться процессор [n адресных линий => 2п ячеек памяти]
Проблема:
• для широких шин требуется больше проводов, чем для узких
• широкие шины занимают больше физического пространства и для них
нужны разъемы большего размера
Система с шиной, содержащей 64 адресные линии, и памятью в 232 байт будет стоить дороже,
чем система с шиной, содержащей 32 адресные линии, и такой же памятью в 232 байт.
14. Ширина шины
1 Мбайт памяти16 Мбайт памяти
Расширение адресной шины с течением времени
15. Ширина шины
Пропускную способность шины можно увеличить двумя способами:• сократить время цикла шины (сделать большее количество передач в
секунду)
• увеличить ширину шины данных (то есть увеличить количество битов,
передаваемых за цикл).
Проблемы в случае увеличения скорости работы шины:
• сигналы на разных линиях передаются с разной скоростью, это
явление называется расфазировкой шины, поэтому чем быстрее
работает шина, тем больше расфазировка.
• шина становится несовместимой с предыдущими версиями
16. Ширина шины
Решение: мультиплексная шина.• нет разделения на адресные и информационные линии
Может быть, например, 32 линии и для адресов, и для данных. Сначала эти
линии используются для адресов, затем — для данных. Чтобы записать
информацию в память, нужно сначала передавать в память адрес, а потом —
данные.
В случае с отдельными линиями адреса и данные могут передаваться вместе.
17. Синхронизация шины
В зависимости от их синхронизацииСинхронная шина содержит линию, которая запускается кварцевым
генератором:
• cигнал – меандр с частотой обычно от 5 до 133 МГц
• любое действие шины занимает целое число, т. наз. циклов шины.
Асинхронная шина не содержит задающего генератора.
• циклы шины могут быть произвольными и не обязательно
одинаковыми для всех пар устройств.
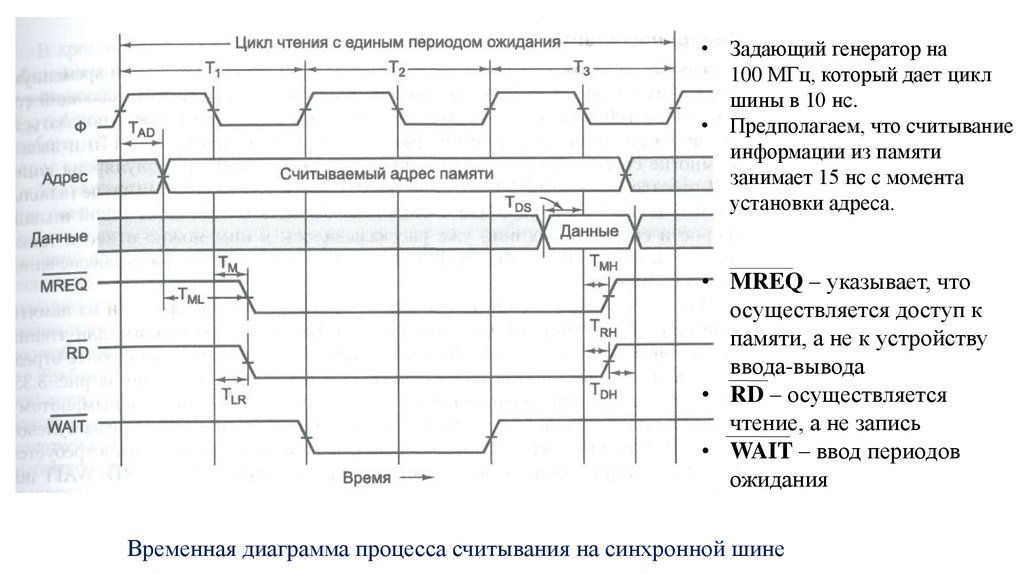
18.
• Задающий генератор на100 МГц, который дает цикл
шины в 10 нс.
• Предполагаем, что считывание
информации из памяти
занимает 15 нс с момента
установки адреса.
• MREQ – указывает, что
осуществляется доступ к
памяти, а не к устройству
ввода-вывода
• RD – осуществляется
чтение, а не запись
• WAIT – ввод периодов
ожидания
Временная диаграмма процесса считывания на синхронной шине
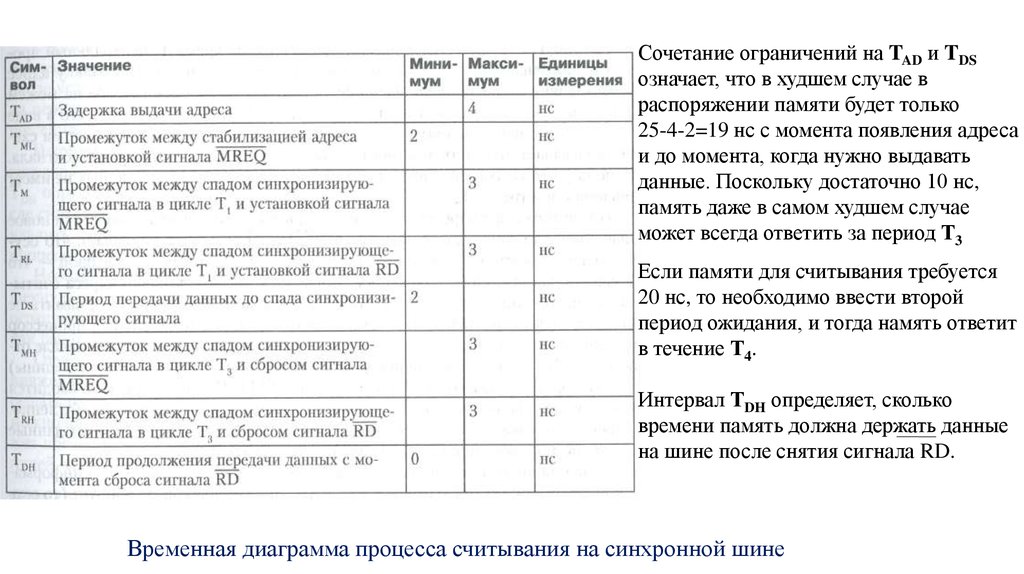
19.
Сочетание ограничений на TAD и TDSозначает, что в худшем случае в
распоряжении памяти будет только
25-4-2=19 нс с момента появления адреса
и до момента, когда нужно выдавать
данные. Поскольку достаточно 10 нс,
память даже в самом худшем случае
может всегда ответить за период Т3
Если памяти для считывания требуется
20 нс, то необходимо ввести второй
период ожидания, и тогда намять ответит
в течение Т4.
Интервал ТDH определяет, сколько
времени память должна держать данные
на шине после снятия сигнала RD.
Временная диаграмма процесса считывания на синхронной шине
20. Синхронные шины (пример)
Для чтения слова понадобится три цикла шины:1. За время Т1 центральный процессор помещает адрес нужного слова на адресные линии
2. Устанавливаются сигналы MREQ и RD
3. Поскольку после установки адреса считывание информации из памяти занимает 15 нс,
память не может передать требуемые данные за период Т2 => чтобы центральный
процессор не ожидал поступления данных, память устанавливает сигнал WAIT в начале
отрезка Т2
4. В начале отрезка Т3, когда есть уверенность в том, что память получит данные в течение
текущего цикла, сигнал WAIT сбрасывается.
5. Во время первой половины отрезка Т3 память помещает данные на информационные
линии. На спаде отрезка Т3 центральный процессор стробирует (т.е. считывает)
информационные линии, сохраняя их значения во внутреннем регистре.
6. Считав данные, центральный процессор сбрасывает сигналы MREQ и RD.
21. Синхронные шины
Plus:• удобно использовать благодаря дискретным временным интервалам
• синхронную систему построить проще, чем асинхронную
• разработку синхронных шин вложено очень много ресурсов
Minus:
• если процессор и память способны закончить передачу за 3,1 цикла, они
вынуждены продлить ее до 4,0 цикла, поскольку неполные циклы запрещены
• трудно делать технологические усовершенствования
• если синхронная шина соединяет ряд устройств, одни из которых работают
быстро, а другие медленно, шина подстраивается под самое медленное устройство, а более быстрые не могут использовать свой потенциал полностью
=> асинхронные шины, то есть шины без задающего генератора
22. Асинхронные шины
• Работа асинхронной шины непривязывается к генератору.
• Когда задающее устройство
устанавливает адрес, сигнал MREQ,
RD или любой другой требуемый
сигнал, он выдает специальный
синхронизирующий сигнал MSYN
(Master SYNchronization).
• Когда подчиненное устройство получает этот сигнал, оно начинает выполнять свою работу
настолько быстро, насколько это возможно. Когда работа заканчивается, подчиненное
устройство выдает сигнал SSYN (Slave SYNchronization).
23. Асинхронные шины
• Сигнал SSYN сообщает задающемуустройству, что данные доступны. Он
фиксирует их, а затем сбрасывает
адресные линии вместе с сигналами
MREQ, RD и MSYN.
• Сброс сигнала MSYN означает для
подчиненного устройства, что цикл
закончен, поэтому устройство
сбрасывает сигнал SSYN, и все
возвращается к первоначальному
состоянию, когда все сигналы
сброшены.
24. Асинхронные шины
Набор таких взаимообусловленных сигналов называется полнымквитированием:
1. Установка сигнала MSYN.
2. Установка сигнала SSYN в ответ на сигнал MSYN.
3. Сброс сигнала MSYN в ответ на сигнал SSYN.
4. Сброс сигнала SSYN в ответ на сброс сигнала MSYN.
Взаимообусловленность сигналов не является синхронной. Каждое событие
вызывается предыдущим событием, а не импульсами генератора. Если какая-то
пара устройств (задающее и подчиненное) работает медленно, это никак не
влияет на другую пару устройств, которая может работать гораздо быстрее.
25. Арбитраж шины
Что происходит, когда задающим устройством шины становятся два илиболее устройств одновременно?
[микросхемы вода-вывода, cопроцессоры]
=> используется механизм – арбитраж шины.
Арбитраж:
• централизованный
• децентрализованный
26. Арбитраж шины
Шина содержит одну линию запроса(монтажное ИЛИ), которая может
запускаться одним или несколькими
устройствами в любое время.
Арбитр не может определить,
сколько устройств запрашивают
Одноуровневый централизованный арбитраж шины с
шину (определяет только факт
последовательным опросом
наличия или отсутствия запросов).
Когда арбитр обнаруживает запрос шины, он устанавливает линию предоставления шины,
которая последовательно связывает все устройства ввода-вывода.
Когда физически ближайшее к арбитру устройство получает сигнал предоставления шины, это
устройство проверяет, нет ли запроса шины:
Если запрос есть => устройство пользуется шиной,
Если запроса нет => устройство передает сигнал следующему устройству.
Такая система называется системой последовательного опроса
Ближайшее к арбитру устройство обладает наивысшим приоритетом
27. Арбитраж шины
двухуровневый централизованный арбитражЧтобы приоритеты устройств не
зависели от расстояния от арбитра, в
некоторых шинах поддерживается
несколько уровней приоритета.
На каждом уровне приоритета есть
линия запроса шины и линия
предоставления шины
Каждое устройство связано с одним из уровней запроса шины, причем чем выше уровень
приоритета, тем больше устройств привязано к этому уровню.
Если одновременно запрашивается несколько уровней приоритета, арбитр предоставляет шину
самому высокому уровню.
Среди устройств одинакового приоритета реализуется система последовательного опроса.
В случае конфликта устройство 2 «побеждает» устройство 4, а устройство 4 «побеждает»
устройство 3. Устройство 5 имеет низший приоритет, поскольку оно находится в самом конце
самого нижнего уровня
28. Арбитраж шины
Некоторые арбитры содержат третью линию, которая устанавливается, как толькоустройство принимает сигнал предоставления шины, и получает шину в свое
распоряжение:
Как только эта линия подтверждения приема устанавливается, линии
запроса и предоставления шины могут быть сброшены.
В результате другие устройства могут запрашивать шину, пока первое
устройство ее использует.
Когда закончится текущая передача, следующее задающее устройство уже
будет выбрано.
Это устройство может начать работу, как только будет сброшена линия
подтверждения приема.
29. Арбитраж шины
В системах, где память связана с главной шиной, ЦП должен конкурировать совсеми устройствами ввода-вывода практически на каждом цикле шины:
ЦП устанавливают самый низкий приоритет
[ЦП всегда может подождать, а устройства ввода-вывода должны получить
доступ к шине как можно быстрее, чтобы не потерять данные]
Во многих современных компьютерах для решения этой проблемы память помещается на
одну шину, а устройства ввода-вывода – на другую, поэтому им не приходится завершать
работу, чтобы предоставить доступ к шине.
30. Арбитраж шины
Децентрализованный арбитраж шиныНапример, компьютер может содержать 16 приоритетных линий запроса
шины. Когда устройству нужна шина, оно устанавливает свою линию запроса.
Все устройства отслеживают все линии запроса, поэтому в конце каждого
цикла шины каждое устройство может определить, обладает ли оно в данный
момент наивысшим приоритетом и, следовательно, разрешено ли ей
пользоваться шиной в следующем цикле
Minus: число устройств ограничивается числом линий запроса.
31. Арбитраж шины
Децентрализованный арбитраж шиныДецентрализованный арбитраж шины (II): используются только три линии
независимо от того, сколько устройств имеется в наличии:
Первая линия – монтажное ИЛИ. Она требуется для запроса шины.
Вторая линия называется BUSY и означает занятость. Она запускается текущим
задающим устройством шины.
Третья линия служит для арбитража шины. Онапоследовательно соединяет все
устройства
32. Арбитраж шины
• Когда шина не требуется ни одному из устройств, линия арбитража передаетсигнал всем устройствам.
• Чтобы получить доступ к шине, устройство сначала проверяет, свободна ли шина
и установлен ли сигнал арбитража IN.
• Если сигнал IN не установлен, устройство не может стать задающим
устройством шины. В этом случае оно сбрасывает сигнал OUT.
• Если сигнал IN установлен, устройство также сбрасывает сигнал OUT, в
результате чего следующее устройство не получает сигнала IN и, в свою очередь,
сбрасывает сигнал OUT => все следующие по цепи устройства не получают
сигнал IN и сбрасывают сигнал OUT.
В результате остается только одно устройство, у которого сигнал IN установлен, а
сигнал OUT сброшен. Оно становится задающим устройством шины, устанавливает
линию BUSY и сигнал OUT, после чего начинает передачу данных.
33. Принципы работы шины
• Передача блоками может быть более эффективна, чем последовательная передачаинформации, когда за раз передается одно слово
[При использовании кэш-памяти желательно сразу вызывать всю строку кэш-памяти (то
есть 16 последовательных 64-разрядных слов]
• Когда начинается чтение блока, задающее устройство сообщает подчиненному
устройству, сколько слов нужно передать (например, помещая общее число слов
на информационные линии в период Т1 ) => задающее устройство выдает одно
слово в течение каждого цикла до тех пор, пока не будет передано требуемое
количество слов.
34. Принципы работы шины
BLOCK – указывает, чтозапрашивается передача
блока.
В данном примере считывание блока из четырех слов
занимает 6 циклов вместо 12-ти.
35. Принципы работы шины
Системы с двумя или несколькими ЦП на одной шине:• в конкретный момент только один ЦП может использовать
определенную структуру данных в памяти.
• в памяти содержится переменная, которая принимает значение 0, когда
ЦП использует структуру данных, и 1, когда структура данных не
используется.
• если центральному процессору нужно получить доступ к структуре
данных, он должен считать переменную, и если она равна 0, придать ей
значение 1.
В мультипроцессорных системах предусмотрен специальный цикл шины,
который дает возможность любому процессору считать слово из памяти,
проверить и изменить его, а затем записать обратно в память; весь этот
процесс происходит без освобождения шины =>
другие ЦП не используют шину и не мешают работе первого процессора
36. Принципы работы шины
Цикл обработки прерываний:• Когда центральный процессор командует устройству ввода-вывода
произвести какое-то действие, он ожидает прерывания после
завершения работы.
• Для сигнала прерывания нужна шина.
Разрешение конфликтных ситуаций
• несколько устройств одновременно захотят выполнить прерывание
• каждому устройству приписывают определенный приоритет
• для распределения приоритетов поддерживать централизованный
арбитраж.
Стандартный, широко используемый интерфейс прерываний:
микросхема Intel 8259А
37. Принципы работы шины
Контроллер прерываний 8259А• До восьми контроллеров вводавывода могут быть
непосредственно связаны с
восемью входами IRx (Interrupt
Request — запрос прерывания)
микросхемы 8259А.
• Когда любое из устройств решит
произвести прерывание, оно запускает свою линию входа.
• При активизации одного или нескольких входов контроллер 8259А выдает сигнал INT
(INTerrupt - прерывание), который подается на соответствующий вход ЦП.
38. Принципы работы шины
• Если ЦП способен обработатьпрерывание, он посылает
микросхеме 8259А импульс
через вывод INTA (INTerrupt
Acknowledge – подтверждение
прерывания).
Контроллер прерываний 8259А
• Микросхема 8259А определяем, на какой именно вход поступил сигнал прерывания и
помещает номер входа на информационную шину. Эта операция требует особого цикла
шины.
• ЦП использует этот номер для обращения к таблице указателей, которую называют
таблицей векторов прерываний, чтобы найти адрес процедуры обработки этого
прерывания.
39. Принципы работы шины
• Микросхема 8259А содержит несколько регистров, которые ЦП может считывать изаписывать, используя обычные циклы шины и выводы RD (ReaD – чтение), WR (WRite –
запись), CS (Chip Select – выбор элемента памяти) и А0.
• Когда программное обеспечение обработало прерывание и готово получить следующее,
оно записывает специальный код в один из регистров, который вызывает сброс сигнала
INT микросхемой 8259А, если не появляется другое прерывание.
• Регистры также могут записываться для того, чтобы перевести микросхему 8259А в один
из нескольких режимов, и для выполнения некоторых других функций.
40. Принципы работы шины
• При наличии более 8 устройств ввода-вывода, микросхемы 8259А могут соединятьсякаскадом. [все 8 входов могут быть связаны с выходами еще 8 микросхем 8259А, соединяя до 64
устройств ввода-вывода в двухступенчатую систему обработки прерываний].
• Контроллер-концентратор ввода/вывода Intel ICH10 I/O, одна из микросхем чипсета
Core i7, содержат два контроллера прерываний 8259А.
ICH10 имеет 15 внешних прерываний - на 1 меньше 16 прерываний двух контроллеров 8259А,
так как одно из прерываний используется для каскадного подключения второго контроллера 8259А.
41. Цоколевка процессора Core i7
Из 1155 контактов Core i7 длясигналов используются 447, для
питания (с различным напряжением)
— 286, для «земли» — 360; еще 62
зарезервированы на будущее
С левой стороны – 5 основных групп
сигналов шины памяти; с правой
стороны – прочие сигналы.
Цоколевка процессора Core i7
42. Цоколевка процессора Core i7
=>Каналы памяти DDR № 1, № 2: используются для взаимодействия сDDR3-совместимой динамической памятью. Группа сигналов
предоставляет банку динамической памяти адрес, данные,
управляющую информацию и синхронизацию
=> Интерфейс PCI: предназначен для прямой связи периферийных
устройств с центральным процессором Core i7.
=> Интерфейс DMI (Direct Media Interface): используется для связи
процессора Core i7 с комплектным чипсетом
Чипсет Core i7 состоит из микросхем:
Р67 – обеспечивает поддержку интерфейсов SATA, USB, аудио, PCIe и
флэш-памяти
ICH10 – обеспечивает поддержку наследных интерфейсов, включая
интерфейс PCI и функциональность контроллера прерываний 8259А
43. Цоколевка процессора Core i7
Прерывания Core i7:может осуществлять тем же способом, что и 8088 (это требуется в
целях совместимости), или использовать новую систему прерывания с
устройством APIC (Advanced Programmable Interrupt Controller — усовершенствованный программируемый контроллер прерываний).
Группа сигналов температурного контроля позволяет процессору
оповещать окружающие устройства об опасности перегрева (t>130 °С).
Если внутренние датчики обнаруживают, что процессор вскоре перегреется, они
запускают терморегуляцию — механизм, быстро снижающий выделение тепла за счет
того, что процессор работает только на каждом N-м такте. Чем выше значение N,
тем сильнее замедляется процессор и тем быстрее он остывает
44. Цоколевка процессора Core i7
Группа сигналов тактовой частоты отвечает за определение частотысистемной шины.
Группа диагностических сигналов предназначена для тестирования и
отладки систем согласно стандарту IEEE 1149.1 JTAG.
Группа сигналов инициализации обслуживает загрузку (запуск) системы.
Сигнал СК используется процессором для генерирования различных
тактовых импульсов с частотой, кратной или дробной по отношению к
частоте системного генератора. Для этого применяется устройство,
называемое системой автоподстройки по задержке, или DLL
(Delay-Locked Loop)
45. Конвейерный режим шины памяти DDR3 процессора Core i7
Запросы к памяти состоят из трех этапов:1. Фаза активизации (ACT) памяти «открывает» строку динамической памяти, делая
ее готовой для последующих обращений.
2. В фазе чтения (READ) или записи (WRITE) могут происходить обращения к
отдельным словам открытой строки динамической памяти или к последовательным
словам текущей строки динамической памяти с использованием пакетного режима.
3. Фаза предзаряда (PCHRG) «закрывает» текущую строку динамической памяти и
готовит память к следующей команде активизации.
46. Конвейерный режим шины памяти DDR3 процессора Core i7
Идея работы:Динамическая память DDR3 состоит из нескольких банков (до 8 банков)
Банк представляет собой блок динамической памяти, к которому процессор может
обращаться параллельно с другими банками, даже находящимися на той же
микросхеме.
47. Конвейерный режим шины памяти DDR3 процессора Core i7
Интерфейс памяти DDR3 имеетчетыре основных сигнальных
канала:
• синхронизация шины (СК),
• команда шины (CMD),
• адрес (ADDR)
• данные (DATA).
Core i7 выдает 3 обращения к трем разным банкам DDR3. Обращения полностью перекрываются, так
что операции чтения на микросхеме динамической памяти выполняются параллельно. Связь между
командами и последующими операциями на временной диаграмме обозначается стрелками.
48. Конвейерный режим шины памяти DDR3 процессора Core i7
СК – управляет всей работойшины.
CMD – указывает, какая
операция запрашивается у
динамической памяти.
ACT – задает адрес строки
динамической памяти, открытой
сигналом ADDR.
PCHRG – указывает банк, к
которому применяется операция
предзаряда, через сигналы
ADDR.
При выполнении команды READ адрес столбца динамической памяти задается с использованием
сигналов ADDR, а динамическая память выдает прочитанное значение спустя фиксированное
время через сигналы DATA.
49. Конвейерный режим шины памяти DDR3 процессора Core i7
В нашем примере:=> команда ACT должна предшествовать первой команде READ для того же банка на
два цикла шины DDR3, а данные выдаются через один цикл после команды READ.
Операция PCHRG должна произойти по крайней мере на два цикла позже последней
операции READ с тем же банком динамической памяти.
=> параллелизм запросов памяти проявляется в перекрытии запросов READ к разным
банкам динамической памяти. Первые два обращения READ к банкам 0 и 1 полностью
перекрываются, производя результаты в циклах шины 3 и 4 соответственно. Обращение
к банку 2 частично перекрывается с первым обращением к банку 1, и наконец, второе
чтение из банка 0 частично перекрывается с обращением к банку 2.
50. Шина PCI
PCI (Peripheral ComponentInterconnect — взаимодействие
периферийных компонентов),
[1990 г, компания Intel]
Шина PCI несовместима со всеми
старыми платами ISA => Intel решила
разрабатывать компьютеры с тремя и
более шипами
ISA – 16,7 Мбайт/с
EISA – 33,3 Мбайт/с
Архитектура типичной системы первых поколений Pentium. PCI –133 Мбайт/с =>528 Мбайт/с
[толщина линий шины обозначает ее пропускную способность =>
чем толще линия, тем выше пропускная способность]
51. Шина PCI
Платы PCI отличаются:• потребляемой мощностью
[cтарые компьютеры обычно используют напряжение 5 В, а новые — 3,3 В, поэтому шина PCI
поддерживает то и другое]
• разрядностью
[32-разрядные платы содержат 120 выводов; 64-разрядные платы содержат те же 120 выводов
плюс 64 дополнительных вывода]
• синхронизацией
[могут работать на частоте либо 33 МГц, либо 66 МГц, контакты идентичны, один из выводов
связывается либо с источником питания, либо с землей]
52. Шина PCI
• Р67 предоставляет интерфейс кнескольким современным высокопроизводительным интерфейсам вводавывода.
[8 дополнительных линий PCI Express и
дисковые интерфейсы SATA, 15
интерфейсов USB 2.0, 10G Ethernet и
аудиоинтерфейс]
• Микросхема ICН10 обеспечивает
поддержку интерфейсов старых
устройств
[PCI, 1G Ethernet, порты USB ports и
старые версии PCI Express и SATA]
В новых системах ICH10 микросхема может отсутствовать.
Структура шин в современной системе Core i7
53. Работа шины PCI
Шины PCI являются синхроннымиВсе транзакции в шине PCI осуществляются между задающим и подчиненным
устройствами
Адресные и информационные линии объединяются:
Минимальная транзакция занимает три цикла [операция чтения]:
цикл 1: задающее устройство передает адрес на шину
цикл 2: задающее устройство удаляет адрес, и шина переключается таким образом,
чтобы подчиненное устройство могло ее использовать.
цикл 3: подчиненное устройство выдает запрашиваемые данные.
При записи шине не нужно переключаться, поскольку задающее устройство передает
в нее и адрес, и данные.
Если подчиненное устройство не может дать ответ в течение трех циклов, то
вводится режим ожидания.
54. Арбитраж шины PCI
REQ# – запрос шиныGNT# – получение разрешения на
доступ к шине.
У шины PCI имеется централизованный арбитр
1. PCI-устройство (в том числе ЦП) устанавливает сигнал REQ# и ждет, пока арбитр не установит сигнал GNT#.
2. Если арбитр установил сигнал GNT#, то устройство может использовать шину в следующем
цикле.
Допустимы циклический арбитраж, приоритетный арбитраж, а также другие схемы арбитража
55. Арбитраж шины PCI
Транзакции:• шина предоставляется для одной транзакции
[продолжительность транзакции теоретически не ограничена]
• между транзакциями требуется вставлять пустой цикл
[при отсутствии конкуренции на доступ к шине устройство может совершать
последовательные транзакции без пустых циклов между ними]
• если задающее устройство выполняет очень длительную передачу, а какое-нибудь
другое устройство выдало запрос на доступ к шине, арбитр может сбросить сигнал
на линии GNT#
[задающее устройство следит за линией GNT#, и при сбросе сигнала устройство должно
освободить шину в следующем цикле]
56. Обязательные сигналы шины PCI (32-разрядные сигналы)
КоличествПодчиЗадающее
о
ненное
устройство
лини
устройство
й
CLK
1
AD
32
Да
PAR
1
Да
С/ВЕ#
4
Да
Да
Комментарий
Управление шиной
[тактовый генератор (33 МГц или 66 МГц)]
Объединенные адресные и информационные линии
[адрес устанавливается во время первого цикла, а данные
— во время третьего]
Бит четности для адреса или данных
[т.е. для АD]
Во время первого цикла – команда шине (считать одно
слово, считать блок и т. п.).
Во время второго цикла – битовый массив, который
показывает, какие байты из слова нужно считать (или
записать)
57. Обязательные сигналы шины PCI (32-разрядные сигналы)
КоличествПодчиЗадающее
о
ненное
устройство
лини
устройство
й
FRAME#
1
Да
IRDY#
1
Да
IDSEL
1
Да
DEVSEL#
1
Да
Комментарий
Указывает, что установлены сигналы AD и С/ВЕ
[сообщает подчиненному устройству, что адрес и
команды действительны]
При чтении – задающее устройство готово принять
данные [устанавливается одновременно с FRAME# ];
При записи – что данные находятся в шине
[устанавливается, когда данные уже переданы в шину]
Считывание конфигурационного пространства
[256 байт, содержит характеристики устройства, которые
другие устройства могут считывать]
Подчиненное устройство распознало свой адрес и ждет
сигнала
58. Обязательные сигналы шины PCI
КолиПодчиЗадающеечество
ненное
устройство
линий
устройство
Комментарий
TRDY#
1
Да
При чтении – данные находятся на линиях AD;
При записи – что подчиненное устройство готово принять
данные
STOP#
1
Да
Подчиненное устройство требует немедленно прервать
текущую транзакцию
PERR#
1
Обнаружена ошибка четности данных
SERR#
1
Обнаружена ошибка четности адреса или системная
ошибка
59. Обязательные сигналы шины PCI
КолиПодчиЗадающеечество
ненное
устройство
линий
устройство
КомментарийR
REQ#
1
Арбитраж шины – запрос на доступ к шине
GNT#
1
Арбитраж шины – предоставление шины
RST#
1
Перезагрузка системы и всех устройств
60. Транзакции на шине PCI
Цикл Т1 :• сигнала задающее устройство помещает
адрес на линии AD и команду на линии
С/ВЕ#.
• задающее устройство устанавливает
сигнал FRAME#, чтобы начать
транзакцию.
Цикл Т2 :
• задающее устройство переключает шину,
чтобы подчиненное устройство могло
воспользоваться ею во время цикла Т3
• задающее устройство изменяет сигнал
С/ВЕ#, чтобы указать, какие байты в
слове ему нужно считать
Примеры 32-разрядных транзакций на шине PCI.
Во время первых трех циклов происходит операция чтения, затем идет
пустой цикл, а следующие три цикла — операция записи
61. Транзакции на шине PCI
Цикл Т3 :• подчиненное устройство устанавливает сигнал DEVSEL#.
[этот сигнал сообщает задающему устройству, что подчиненное устройство получило адрес и
собирается ответить]
• Подчиненное устройство помещает данные на линии AD и выдает сигнал TRDY#, который сообщает
задающему устройству о данном действии.
Если подчиненное устройство не может ответить быстро, оно не снимает сигнал DEVSEL#, извещающий
о присутствии этого устройства, но при этом не устанавливает сигнал TRDY# до тех пор, пока не сможет
передать данные. При такой процедуре вводится один или несколько периодов ожидания.