











")
















")



")


")
")
")
")
")



































































































 Информатика
ИнформатикаПохожие презентации:


")

")


")


Організація обчислювальних систем та мереж. Апаратні складові ЕОМ. (Лекція 6)
1.
ОРГАНІЗАЦІЯ ОБЧИСЛЮВАЛЬНИХСИСТЕМ ТА МЕРЕЖ
Лекція 6. Апаратні складові ЕОМ
2. Конвейерная обработка данных
Конвейерная организация процессораозначает,
что
многие
сложные
действия разбиваются на этапы с
небольшим временем выполнения.
Каждый этап выполняется в отдельном
устройстве (блоке).
Конвейеризация
позволяет
нескольким внутренним блокам МП
работать одновременно, совмещая
дешифрование команды, операции
АЛУ,
вычисление
эффективного
адреса и циклы шины нескольких
команд.
3. Конвейерная обработка данных
В составе МП 80286 есть 4 конвейерных устройства:BU (Bus Unit) – шинный блок (считывание из
памяти и портов ввода/вывода);
IU
(Instruction
Unit)
–
командный
блок
(дешифрация команд);
EU
(Executive Unit) – исполнительный блок
(выполнение команд);
AU (Address Unit) – адресный блок (вычисляет все
адреса, формирует физический адрес).
4. Конвейерная обработка данных в ЦП 80286
BUСчитывание
0 команды
Считывание
1 команды
Считывание
2 команды
Считывание
3 команды
IU
Дешифрация
-1 команды
Дешифрация
0 команды
Дешифрация Дешифрация 2
1 команды
команды
EU
Исполнение
-2 команды
Исполнение
-1 команды
Исполнение 0
команды
Исполнение 1
команды
AU
Адрес 1
команды
Адрес 2
команды
Адрес 3
команды
Адрес 4
команды
5. Конвейерная обработка данных в ЦП 80486
В ЦП 80486 – пятиступенчатый конвейер дляобработки данных:
предвыборка команд (PF –Perfect);
декодирование команды (D1 – Instruction Decode);
формирование адреса (D2 – Address Generate);
выполнение команды в АЛУ и доступ к кэш-памяти
(EX – Execute);
обратная запись (WB – Write Back).
6. Конвейерная обработка данных
Можно выделить два наиболее важных проявленияконвейерной организации процессора — прохождение
инструкции (операции) от момента считывания из кэша
инструкций до полного завершения (отставки), и
прохождение
операции
через
функциональное
устройство.
Первое проявление обычно называют «конвейером процессора»
либо «конвейером непредсказанного перехода» (что более правильно).
Длина этого конвейера влияет на производительность только в случае
неправильного предсказания перехода в программе, когда происходит
отмена работы, выполненной во всех этапах, начиная с этого перехода
(сброс конвейера).
7. Конвейерная обработка данных
Длина конвейера функционального устройства, в свою очередь,определяет время ожидания результатов операции другой
операцией, использующей эти результаты в качестве операндов.
Такое
старт-стопное
время
выполнения
операции
функциональном устройстве называют латентностью.
в
Обращение к кэшам всех уровней и к оперативной памяти
также производится конвейерным образом. Большинство простых
операций
целочисленной
арифметики
и
логики
имеют
латентность, равную единице — то есть они выполняются в
функциональных устройствах синхронно, без конвейеризации.
8. ЦП Pentium
Схема предсказанияперехода
64 – разрядная шина
КЭШ команд, 8К
Буфер предвыборки, 32 бита
U (5+3ступ.)
V (5 ступ.)
АЛУ
АЛУ
(целочисл.)
(целочисл.)
Блок регистров
КЭШ данных, 8К
Конвейерный
блок
FPU
Умножитель
Сложитель
Делитель
9. ЦП Pentium
Суперскалярная архитектура – это способ построенияпроцессора с двумя или более конвейерами, позволяющий
выполнять параллельно 2 или более выбранные команды.
U – конвейер основной (команды целочисленные и с плавающей
точкой).
V – конвейер (команды, которые выполняются за один такт).
Спаривание – это процесс параллельного выполнения 2-х
команд, независящих по данным или ресурсам.
10. Конвейеры ЦП Pentium
11. Основные отличия ЦП Pentium
Увеличен размер страничной памяти. Механизм страничнойорганизации памяти позволяет работать одновременно со страницей
4 Мбайт.
64-разрядная ШД.
Конвейеризация машинного цикла.
Суперскалярная архитектура.
Контроль четности адреса и данных.
Раздельные блоки кэш-памяти для данных и кода.
Блок прогнозирования ветвлений.
Средства
управления
питанием
(снижение
мощности
потребления).
12. Структура микропроцессора Pentium Pro
Кэш 2-го уровня, 256 Кбайт(монтируется в один корпус с ЦП)
Внешняя
64-разрядная
синхронная
шина
Буфер
запросов
Синхронная
64-разрядная
шина
Буфер
данных
Интерфейс памяти
Блок интерфейса с памятью
За 1 такт выбираются 2 строки кэша
(строка – 32 байта)
Блок выборки
инструкций
Блок
предсказания
переходов
(512 входов)
Дешифратор команд
Дешифратор,
1 микрооперация
за такт
Дешифратор,
1 микрооперация
за такт
Дешифратор,
4 микрооперации
Блок
микропрограммного
управления
Блок резервирования
Блок формирования адреса
Буфер команд,
8 Кбайт
Блок формирования адреса
Арифметическое устройство
с фиксированной точкой
Арифметическое устройство
с фиксированной точкой
Арифметическое устройство
с плавающей точкой
Пул инструкций
Таблица переименования регистров
Блок удаления
13. ЦП Pentium Pro (P6)
Термин динамическое исполнение программы определил3 способа обработки данных:
Глубокое предсказание ветвлений (с вероятностью >
90% можно предсказать 10 - 15 ближайших переходов).
Анализ потока данных (на 20-30 шагов вперед посмотреть
программу и определить зависимость команд по данным или
ресурсам).
Опережающее (внеочередное) исполнение команд.
14. ЦП Pentium MMX
Основные черты MMX (MultiMediaeXtention) технологии:SIMD архитектура (одна команда над многими данными);
57 новых инструкций;
8 64-разрядных регистра MMX (ММ0-ММ7 – это мантиссы 8
регистров блока арифметики с плавающей точкой);
4 новых типа данных:
упакованный байт 64=8х8
упакованное слово 64=4х16
упакованное двойное слово 64=2х32
учетверенное слово 64=1х64
15. ЦП Pentium II
2 кэша I уровня (16 Кб).Кэш II уровня (512 Кб).
Двойная независимая шина (300-разрядная) 2 независимых канала передачи данных:
для связи ЦП с кэш II уровня;
для связи ЦП с оперативной памятью.
16. ЦП Pentium III
Используется расширение SSE (Streaming SIMD Extensions) – потоковыеSIMD расширения для вещественных чисел.
70 новых инструкций.
8 новых 128-разрядных регистров данных: XMM0, XMM1,…, XMM7.
32-битный регистр управления/состояния MXCSR используется для
маскирования исключений, выбора режимов и определения состояния
флагов.
Новый тип данных - упакованные числа с плавающей запятой
одинарной точности. В одном 128-разрядном регистре 4 новых типа данных.
Все команды SSE доступны из любых режимов работы ЦП:
реального, защищенного и виртуального.
17. ЦП Pentium IV
В МП Pentium 4 была представлена технология SSE2, дополняющаяSSE новыми типами данных и новыми инструкциями. Инструкции SSE2
также оперируют 128-битными регистрами XMM0-XMM7, но при этом
добавлены пять новых типов данных:
упакованные двойной точности (2 х 64 бит IEEE-754 double precision),
упакованные байты (16 x 8 бит),
упакованные слова (8 х 16 бит),
упакованные двойные слова (4 х 32 бит),
упакованные четверные слова (2 х 64 бит).
Все команды MMX, SSE и SSE2 доступны в любом режиме работы
процессора: реальном, защищенном, виртуальном.
18.
Net-Burst – архитектура:Изменение последовательности выполнения команд.
2. Буфер предсказания переходов – 4Кб (вероятность удачного предсказания
93-94%).
3. Окно команд (можно выбирать 126 команд для внеочередного выполнения).
4. Трассирующий КЭШ – команд I уровня находится после дешифратора
и содержит микрокоманды готовые к исполнению (объем кэша - 12000
микрокоманд).
5. Используются
SIMD расширения, включая 144 новых инструкции,
использующие 128-разрядные XMM - регистры.
6. АЛУ работает на удвоенной частоте ЦП.
7. Применена
Quad-pumped 400 МГц системная шина, обеспечивающая
пропускную способность 3,2 Гбайта/с.
8. Кэш L2 – 256 Кбайт работает на частоте процессора.
9. Кэш L1 – 8Кбайт.
1.
19. Линейка процессоров Intel Core 2 Duo
Линейка процессоров Intel Core 2 Duo основана на полностьюобновлённой микроархитектуре.
Intel говорит не просто об изменениях в новой микро-архитектуре
процессоров Core 2 Duo, а о кардинальном обновлении. Инженеры компании
взяли некоторые элементы текущей микроархитектуры PentiumD NetBurst и
добавили к ней ингредиенты, сделавшие мобильные процессоры Pentium M и
Core Duo столь популярными на рынке, в результате чего и родилась новая
микро-архитектура Core 2. Ключевой целью было достижение идеального
соотношения между производительностью и энергопотреблением.
Снижение разрядности шин.
Хотя все шины имеют ширину 128 бит, она не всегда бывает
востребована. Intel решила добавить функцию, позволяющую
разделять шины, выключая их часть. Для передачи восьми байт
достаточно ширины 64 бита, поэтому
вторая половина шины не
работает, что экономит энергию.
20. Процессоры Intel Core i7
Intel выпустила процессоры для десктопов Core i7архитектуры Nehalem: Intel Core i7-965 Extreme
Edition (тактовая частота 3.4 ГГц, стоимость единицы
в партии от 1000 штук - $999), Intel Core i7- 940 (2.93
ГГц, цена - $562) и Intel Core i7- 920 (2.66 ГГц, $284).
"Экстремальная" модель отличается повышенной
скоростью обмена данными между процессорными
ядрами (6.4 GT/sec против 4.8 GT/sec в других двух
моделях). В остальном архитектура одинакова:
производимые по 45-нм техпроцессу
Core i7
оснащены 8 MB кэш-памяти третьего уровня,
поддерживают оперативную память DDR3-1066, а
энергопотребление при пиковой загрузке составляет
130 Вт.
21.
22.
23.
24. Процессоры компании AMD
Развитие современных микроархитектур в компании AMDначалось с создания в 1999 г. процессора Athlon (K7). Это был
первый
полноценный
суперскалярный
конвейерный
микропроцессор с внеочередным исполнением операций,
разработанный в компании.
Следующий процессор компании Athlon 64 / Opteron (K8),
увидевший свет в 2003 г., мало отличается от своего
предшественника K7 по микроархитектуре. При его создании
основной упор был сделан на две ключевые технологии: 64битный режим целочисленной и адресной арифметики AMD64
(x86-64), и интегрированный контроллер оперативной памяти,
25. Процессоры компании AMD
ОднакоK8
значительно
уступает
новому
процессору P8 (Intel Core), особенно в игровых и
десктопных применениях. Превосходство процессора
P8 в производительности обусловлено в первую
очередь динамической организацией его архитектуры,
имеющей увеличенную ширину запуска и обработки
инструкций, полночастотным выполнением упакованных
128-битных операций SSE, увеличенным размером L2кэша, более совершенным предсказателем переходов и
улучшенной подсистемой предвыборки данных.
В связи с появлением столь серьёзного конкурента,
компания AMD объявила о планах создания нового
процессора
с
улучшенной
и
расширенной
микроархитектурой, известного под названием K8L.
26. Многоядерный процессор -
Многоядерный процессорцентральный процессор, содержащий два и более
вычислительных ядра на одном процессорном кристалле или в
одном корпусе.
Ядром процессора - это система исполнительных устройств
(набор арифметико-логических устройств), предназначенных для
обработки данных.
27. Кэш- сверхоперативная память
В многоядерных процессорах кэш первого уровня у каждогоядра своя, а кэш 2-го уровня существует в нескольких
вариантах
:
разделяемый — кэш расположен на одном с обеими
ядрами кристалле и доступен каждому из них в полном
объёме (процессоры семейств Intel Core).
индивидуальный — отдельные кэш равного объёма,
интегрированные в каждое из ядер. Обмен данными из кэш
L2 между ядрами осуществляется через контроллер памяти
— интегрированный (Athlon 64 X2) или внешний (Pentium D).
28. Производительность.
В приложениях, оптимизированных под многопоточность,
наблюдается прирост производительности на двухъядерном
процессоре.
Старые
приложения
(не
оптимизированные
под
многопоточность),
либо
приложения,
которым
многопоточность не нужна или невозможна не будут получать
практически никакой выгоды от дополнительных ядер, и
могут даже выполняться медленнее, чем на процессоре с
меньшим количеством ядер, но большей тактовой частотой.
29. Наращивание количества ядер.
На сегодняшний день основными производителямипроцессоров — Intel и AMD дальнейшее увеличение числа
ядер процессоров признано как одно из приоритетных
направлений увеличения производительности. Уже освоено
производство 8-ядерных процессоров для домашних
компьютеров, а также 16-ядерных в серверных системах.
30. Одновременная многопоточность (Simultaneous multithreading)
Одновременная многопоточность(Simultaneous multithreading – SMT, hardware multithreading) — технология, позволяющая выполнять
инструкции из нескольких потоков выполнения (программ) на одном суперскалярном конвейере
Одновременная многопоточность (Simultaneous multithreading)
Thread 1
Thread 2
Потоки разделяют один суперскалярный конвейер процессора
(ALU, FPU, Load/Store)
SMT позволяет повысить эффективность использования модулей
суперскалярного процессора (ALU, FPU, Load/Store) за счет наличия
большего количества инструкций из разных потоков выполнения
(ниже вероятность зависимости по данным)
Superscalar pipeline
Примеры реализации:
IBM ACS-360 (1968 г.), DEC Alpha 21464 (1999 г., 4-way SMT)
Intel Pentium 4 (2002 г., Intel Hyper-Threading, 2-way SMT)
Разделение
ресурсов ALU, FPU,
Load/Store
Intel Xeon Phi (4-way SMT), Fujitsu Sparc64 VI (2-way SMT), IBM POWER8 (8-way SMT)
31. Intel Hyper-Threading Technology
Логический процессорArchitectural State
Frontend
(Fetch, Decode)
Логический процессор
Architectural State
ILP
Backend
Вычислительное ядро
(Execution Engine)
Architectural state + Interrupt controller
(LAPIC) = Logical processor
2 потока разделяют суперскалярный
конвейер
Ускорение (Speedup) ~ 30 %
Кеш-память
(Cache)
Architectural state:
Регистры общего назначения
(RAX, RBX, RCX, …)
Chip
Сегментные регистры (CS, DS, …),
Управляющие регистры (RFLAGS, RIP,
GDTR)
X87 FPU-регистры,
MMX/XMM/YMM-регистры
MSR-регистры, Time stamp counter
32. Проблемы многоядерности.
Многоядерные и Hyper-Threading процессоры не только увеличивают
производительность, но и порождают многочисленные проблемы - некоторые
приложения (драйвера) начинают работать нестабильно, выбрасывая критические
ошибки или обрушивая систему в голубой экран смерти.
Основной "удар" различий одно- и многопроцессорных машин операционная
система и BIOS берут на себя.
Прикладное приложение или драйвер устройства, спроектированный для
однопроцессорной системы, не требует никакой адаптации для переноса на
многопроцессорную систему, если, конечно, он спроектирован правильно. Многие
типы ошибок (и, в особенности, ошибки синхронизации) могут годами не
проявляться
в
однопроцессорных
конфигурациях,
но
заваливают
многопроцессорную машину каждые десять минут, а то и чаще.
33. Проблемы многоядерности.
Многопроцессорные системы создают много проблем и далеко не
все из них разрешимы в рамках простой переделки программ.
Получив возможность создавать потоки, программисты далеко не
сразу осознали, что отлаживать многопоточные программы на
порядок сложнее, чем однопоточные. С другой стороны, уже
сейчас
мы
приходим
к распределенным
системам
и
распределенному программированию. Разбив цикл с большим
количеством итераций на два цикла, исполняющихся в разных
потоках/процессах, на двухпроцессорной машине мы удвоим
производительность! А это слишком значительный выигрыш,
чтобы позволить себе пренебрегать им.
34. Параллелизм уровня данных (Data Parallelism – DP)
2835. Векторные процессоры
Векторный процессор (Vector processor) – процессор поддерживающийна уровне системы команд операции для работы с векторами (SIMD-инструкции)
Векторные процессоры
Векторные вычислительные системы
o CDC STAR-100 (1972 г., векторы до 65535 элементов)
o Cray Research Inc.: Cray-1 (векторные регистры), Cray-2, Cray X-MP, Cray Y-MP
Source
1
X1
X2
…
XN
Source
2
Y1
Y2
…
YN
+
+
Сложение
двух векторов
Destination
X1 + Y1
X2 + Y2
+
…
XN + YN
36. Векторные процессоры
Максимальное ускорение (Speedup)линейно зависит от числа элементов в векторном регистре
(использование векторных инструкций может привести к сокращению количества команд в программе, а это
процессоры
может обеспечить Векторные
более эффективное
использование кеш-памяти)
Векторный процессор (Vector processor) – процессор поддерживающий
на уровне системы команд операции для работы с векторами (SIMD-инструкции)
Векторные вычислительные системы
o CDC STAR-100 (1972 г., векторы до 65535 элементов)
o Cray Research Inc.: Cray-1 (векторные регистры), Cray-2, Cray X-MP, Cray Y-MP
Source
1
X1
X2
…
XN
Source
2
Y1
Y2
…
YN
+
+
Сложение
двух векторов
Destination
X1 + Y1
X2 + Y2
+
…
XN + YN
37. Параллелизм уровня потоков (Thread Level Parallelism – TLP)
3338. Многопроцессорные SMP-системы (Symmetric multiprocessing)
Shared memory (RAM)System bus
Bus
Arbiter
Cache
Cache
Cache
CPU 1
CPU 2
CPU N
I/O
Процессоры SMP-системы имеют одинаковое время доступа к разделяемой
памяти (симметричный доступ)
Системная шина (System bus) – это узкое место, ограничивающее
масштабируемость вычислительного узла
39. Многопроцессорные SMP-системы (Symmetric multiprocessing)
40. Многопроцессорные NUMA-системы (AMD)
NUMA (Non-Uniform Memory Architecture) – это архитектура вычислительной системыс неоднородным доступом к разделяемой памяти
Процессоры сгруппированы в NUMA-узлы со своей локальной памятью
Доступ к локальной памяти NUMA-узла занимает меньше времени по сравнению
с временем доступом к памяти удаленных процессоров
4-х процессорная NUMA-система
Remote access
(slow)
Local access
(fast)
Каждый процессор имеет
интегрированный контроллер
и несколько банков памяти
Процессоры соединены шиной
Hyper-Transport
(системы на базе процессоров
AMD)
Доступ к удаленной памяти
занимает больше времени
(для Hyper-Transport ~ на
30%, 2006 г.)
41. Многопроцессорные NUMA-системы (Intel)
CPU 0CPU 1
Memory
4-х процессорная
NUMA-система
Каждый процессор имеет
интегрированный
контроллер и несколько
банков памяти
Процессоры соединены
шиной
Intel QuickPath Interconnect
(QPI)
– решения на базе процессоров
Intel
Memory
Intel Nehalem based systems with QPI
2-way Xeon 5600 (Westmere) 6-core, 2 IOH
42. Политики управления памятью NUMA-системы
Политики управления памятью можноПолитикиBIOS/UEFI:
управления памятью NUMA-системы
задавать в настройках
NUMA Mode – в системе присутствует несколько
NUMA-узлов, у каждого узла имеется своя
локальная память (local), операционная система
учитывает топологию системы при выделении
памяти
Node Interleave – память циклически выделяется со
всех NUMA-узлов (чередование), операционная
система “видит” NUMA-систему как SMP-машину
Memory latency and bandwidth accessing local, remote memory for a
PowerEdge R610 server (Dual Intel Xeon X5550 Nehalem, 6 x 4GB
1333 MHz RDIMMS)
43. Современные системы на базе многоядерных процессоров
4344. Современные системы на базе многоядерных процессоров
45.
Современные системы на баземногоядерных процессоров
Intel Xeon Phi (Intel MIC): 64 cores Intel P54C
(Pentium)
Pipeline: in-order, 4-way SMT, 512-bit SIMD
Кольцевая шина (1024 бит, ring bus) для связи
ядер и контроллера памяти GDDR5
Устанавливается в PCI Express слот
SMP-система
256
логических
процессоров
46.
Современные системы на баземногоядерных процессоров
Graphics Processing Unit (GPU) – графический процессор, специализированный
многопроцессорный ускоритель с общей памятью
Большая часть площади чипа занята элементарными ALU/FPU/Load/Store
модулями
Устройство управления (Control unit) относительно простое по сравнению
с CPU
NVIDIA GeForce GTX 780
(Kepler, 2304 cores, GDDR5 3 GB)
AMD Radeon HD 8970
(2048 cores, GDDR5 3 GB)
47. Современные системы на базе многоядерных процессоров
Sony Playstation 3IBM Cell
(2-way SMT
PowerPC core + 6
SPE)
Tilera TILEPro64
(64 cores, VLIW, mesh)
Microsoft XBox 360
IBM Xenon
(3 cores with 2-way
SMT)
Cisco Routers
MIPS
Multi-core processors
48. Принципы функционирования ЭВМ
Система команд49.
Функциональная и структурная организацияЭВМ
Принципы
функционирования
ЭВМ,
т.е.
коды,
система команд, алгоритмы выполнения машинных
операций, технология выполнения различных
процедур и взаимодействия аппаратной части и
программного обеспечения, способы использования
устройств при организации их совместной работы,
образуют функциональную организацию ЭВМ.
50.
Функциональная и структурная организацияЭВМ
Принципы функционирования ЭВМ могут
быть реализованы:
аппаратными,
программно-аппаратными
программными средствами.
51.
Функциональная и структурная организацияЭВМ
При аппаратной и программно-аппаратной реализации могут
быть применены регистры, дешифраторы, сумматоры; блоки
жесткого аппаратного управления или микропрограммного с
управлением подпрограммами (комплексами микроопераций);
устройства или комплексы устройств, реализованные в виде
автономных систем (программируемых или с жестким
управлением) и др.
При программной реализации могут быть применены
различные виды программ.
52.
Функциональная и структурная организацияЭВМ
ЭВМ
представляет
собой
совокупность
устройств,
выполненных
на
больших
интегральных схемах, каждая из которых имеет
свое функциональное назначение.
Комплект интегральных схем, из которых
состоит ЭВМ, называется микропроцессорным
комплектом.
53.
Функциональная и структурная организацияЭВМ
В основной состав микропроцессорных комплектов входят:
системный таймер,
микропроцессор,
сопроцессоры,
контроллер прерываний,
контроллер прямого доступа к памяти,
контроллеры устройств ввода-вывода.
54.
Функциональная и структурная организацияЭВМ
Все устройства ЭВМ делятся на
центральные и периферийные.
Центральные устройства — полностью электронные.
Периферийные устройства могут быть либо электронными, либо
электромеханическими с электронным управлением.
55.
Функциональная и структурная организацияЭВМ
В состав центральных устройств ЭВМ входят:
центральный процессор,
основная память
ряд дополнительных узлов, выполняющих
служебные функции:
контроллер прерываний,
таймер и контроллер прямого доступа к
памяти (ПДП).
56.
Функциональная и структурная организацияЭВМ
Периферийные устройства делятся на два вида:
–
внешние запоминающие устройства (ЗУ)
–
НМД
НГМД
НМЛ
устройства ввода-вывода (УВВ):
клавиатура
дисплей
принтер
мышь
адаптер каналов связи (КС) и др.
57.
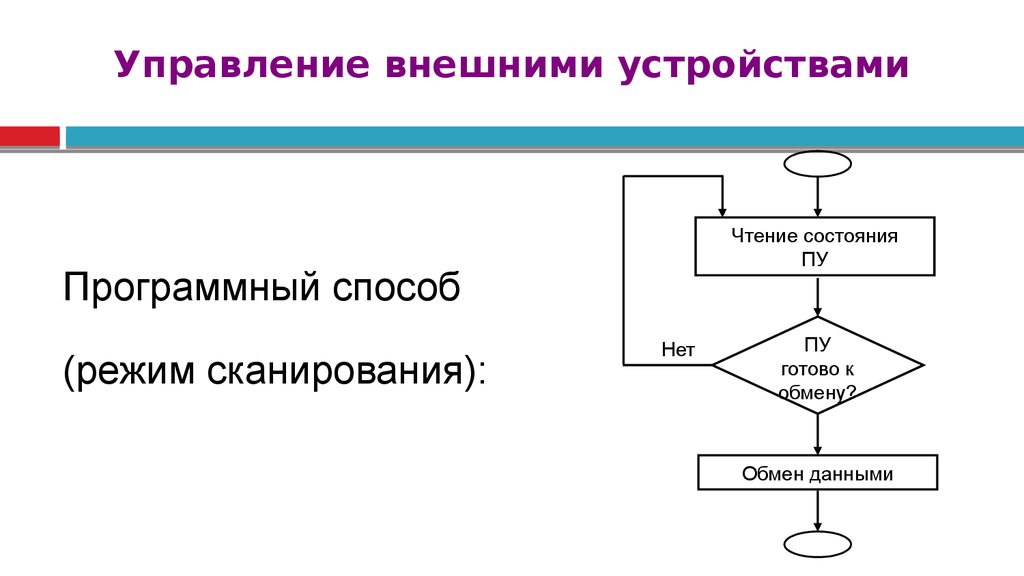
Алгоритм работы ЭВМ1)
2)
3)
4)
5)
6)
7)
8)
9)
10)
11)
12)
13)
14)
Загрузка выполняемой программы
Передача адреса 1 выполняемой команды в счетчик команд
Адрес из счетчика команд на шину адреса системной магистрали (СМ)
На шину управления – «Выборка из оперативной памяти (ОП)»
Содержимое соотв. ячейки ОП на шину данных
Одновременно на шину управления сигнал о выполнении выборки из ОП
Процессор считывает с шины данных и передает в регистр команд
В регистре команд – разделение на кодовую и адресную части
Код команды настраивает МП на выполнение заданной операции
Адрес следующей команды заносится в счетчик команд
Адресная часть команды выставляется на шину адреса СМ
Одновременно на шину управления – «Выборка из ОП»
Выбранная из ОП информация вводится в арифметическое устройство
(АУ) и начинается ее выполнение в АУ.
Результат на шину данных, на шину адреса – адрес ОП, на шину
58.
Алгоритм работы ЭВМПроцесс передачи команды другому устройству предусматривает следующие
действия:
a)
ЦП выставляет на шину адреса СМ адрес интересующего его устройства;
b)
по шинам управления передается сигнал “Поиск устройства”;
c)
d)
e)
все устройства, подключенные к системной магистрали, получив этот сигнал, читают
номер устройства с шины адреса и сравнивают его со своим номером. Устройства, для
которых эти номера не совпадают, на эту команду не реагируют. Устройство с
совпавшим номером, вырабатывает сигнал отклика по шине управления;
ЦП, получив сигнал отклика, в простейшем случае выставляет имеющуюся у него
команду на шину данных и сопровождает ее по шине управления сигналом “Передаю
команду”;
получив сигнал о приеме команды, ЦП переходит к выполнению очередной своей
команды, выставляя на шину адреса содержимое счетчика команд.
59. Центральные устройства ЭВМ
Память60. VIII. Организация памяти ЭВМ
Центральныеустройства
ЭВМ. Память
VIII. Организация
памяти ЭВМ
Памятью ЭВМ называется совокупность устройств,
служащих для запоминания, хранения и выдачи
информации.
Характеристики памяти ЭВМ:
-Назначение.
-Информационная емкость.
-Информационная емкость читаемого слова.
-Способ доступа.
61.
Центральные устройства ЭВМ.Классификация ЗУ
Адресные ЗУ:
• Постоянные ЗУ, ПЗУ (ROM)
• ЗУ c произвольным
доступом (RAM)
Ассоциативные ЗУ:
• Полностью ассоциативные ЗУ
• Ассоциативные ЗУ с прямым размещением
• Наборно-ассоциативные ЗУ
Последовательные ЗУ:
FIFO
LIFO
Файловые
Циклические
62.
Центральные устройства ЭВМ.Классификация ЗУ
63.
Центральные устройства ЭВМ. ПамятьОсновная память включает два
типа устройств:
оперативное запоминающее устройство
(ОЗУ или RAM - Random Access Memory)
постоянное запоминающее устройство
(ПЗУ или ROM - Read Only Memory)
64.
Центральные устройства ЭВМ. ПамятьОЗУ предназначено для хранения переменной
информации и допускает изменение своего
содержимого в ходе выполнения процессором
вычислительных операций с данными и может
работать в режимах записи, чтения и хранения.
65.
Центральные устройства ЭВМ. ПамятьПЗУ содержит информацию, которая не должна
изменяться в ходе выполнения процессором
вычислительных операций, например
стандартные программы и константы.
Чаще всего информация заносится в ПЗУ перед
установкой микросхемы в ЭВМ, но есть и
перезаписываемые ПЗУ.
Основными операциями, которые может
выполнять ПЗУ, являются чтение и хранение.
ПЗУ является энергонезависимым элементом
66.
Обобщенная схема адресного ЗУ67.
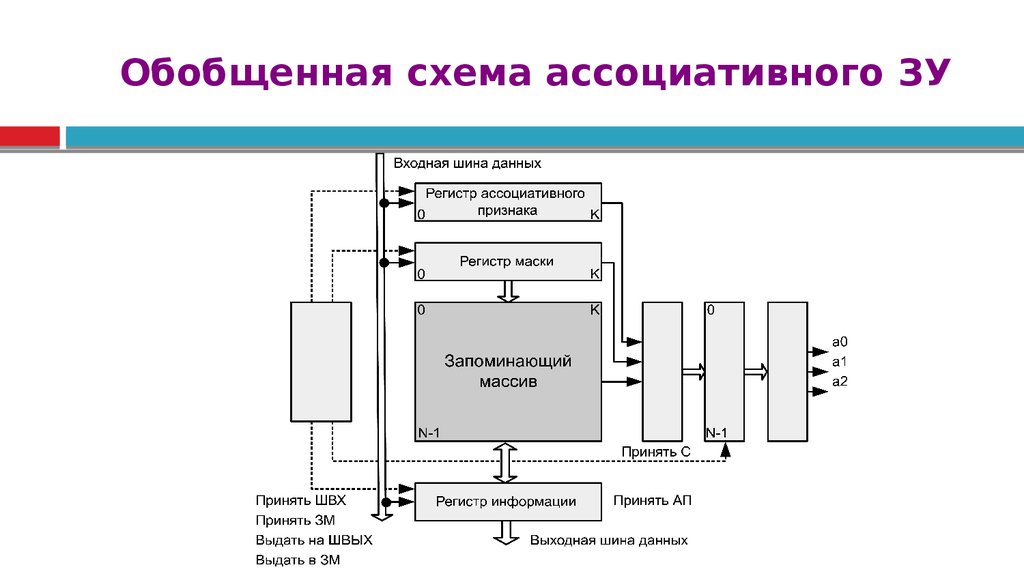
Обобщенная схема ассоциативного ЗУ68.
Обобщенная схема последовательного ЗУСтек (память типа LIFO)
69.
Обобщенная схема последовательного ЗУБуфер (память типа FIFO)
70.
ЗУ(RA c п
M) рои
зв
ол
ьн
ым
Постоянные ЗУ, ПЗУ (ROM)
до
сту
по
м
Адресные ЗУ
Динамические ЗУПД (DRAM)
Статические ЗУПД (SRAM)
71. Постоянные и перепрограммируемые ЗУ
Преимущества ROM по сравнению RAM:- Аппаратная простота.
- Высокая плотность размещения ЗЭ.
- Энергонезависимость.
- Большое быстродействие.
72. Структура ROM
73. Структура ППЗУ
РПЗУ-УФ, ОПРРПЗУ-УФ(EPROM, EPROM-OTP)
РПЗУ-ЭС (EEPROM), FLASH
74. Модели оперативной памяти.
Сегментированная модель. Программевыделяются непрерывные области памяти
(сегменты) - она может обращаться только к
данным, которые находятся в этих сегментах.
• Страничная модель. ОЗУ рассматривается как
совокупность блоков фиксированного размера
(4 Кбайт). Основное применение этой модели
связано с организацией виртуальной памяти,
что позволяет ОС использовать для работы
75. Особенности использования и реализации моделей памяти зависят от режима работы микропроцессора:
Модели оперативной памяти.• Особенности использования и реализации моделей
памяти зависят от режима работы микропроцессора:
Режим реальных адресов.
Защищенный режим.
Режим виртуального 8086.
Режим системного управления.
76. Сегментация - это механизм адресации, обеспечивающий существование нескольких независимых адресных пространств как в пределах одной зада
Сегментация памятиСегментация - это механизм адресации,
обеспечивающий существование нескольких
независимых адресных пространств как в
пределах одной задачи, так и в системе в
целом для защиты задач от взаимного
влияния.
В основе механизма сегментации лежит понятие
сегмента, который представляет собой независимый,
поддерживаемый на аппаратном уровне блок памяти.
77.
Сегментация памяти.- Адрес начала сегмента хранится в
соответствующем сегментном регистре.
- Внутри сегмента программа обращается к
адресам относительно начала сегмента линейно,
т.е. начиная с 0 и заканчивая адресом, равным
размеру сегмента. Этот относительный адрес, или
смещение, который микропроцессор использует
для доступа к данным внутри сегмента,
называется эффективным.
78. Формирование физического адреса
- Диапазон изменения физического адреса в реальномрежиме от 0 до 1 Мбайт. Эта величина определяется
тем, что шина адреса i8086 имела 20 линий.
- Максимальный размер сегмента
64 Кбайт. Это объясняется 16-разрядной архитектурой
регистров. Максимальное значение, которое может
содержать 16-ти разрядный регистр равно:
2^16-1 = 65535 = 64 Кбайт
79. Формирование физического адреса.
В сегментном регистре содержаться только старшие 16 битфизического адреса начала сегмента.
Недостающие младшие 4 бита 20-битного адреса
получаются сдвигом в сегментном регистре влево на 4
разряда.
Эта операция сдвига выполняется аппаратно и для
программного обеспечения абсолютно прозрачна.
80. Формирование физического адреса.
Получившееся 20-битное значение и является настоящимфизическим адресом, соответствующим началу сегмента.
К нему, также аппаратно, прибавляется вторая
составляющая адреса, смещение, которое может
содержаться явно в команде либо косвенно в одном из
регистров общего назначения.
81. Схема страничного преобразования
V - признак присутствиястраницы в физ. памяти.
R - признак использования
страницы.
M - признак модификации.
A - признак права
доступа.
82. Сегментная организация
Программа отображается впамять блоками различного
размера – сегментами.
Преобразование логического
адреса в физический
осуществляется с помощью
таблицы сегментов.
83. Сегментно-страничная организация памяти
Программа отображается впамять блоками различного
размера – сегментами, каждый
из которых целое число
страниц.
Преобразование логического
адреса в физический
осуществляется с помощью
таблицы сегментов и таблицы
страниц сегмента.
84. Формирование физического адреса
Адрес ячейки памяти для удобства принято записывать вшестнадцатиричной системе счисления.
Каждой шестнадцатиричной цифре соответствует 4 бита:
0
1
2
3
4
5
6
7
-
0000
0001
0010
0011
0100
0101
0110
0111
8 1000
9 1001
A1010
B1011
85. Пример формирования физического адреса:
- Пусть содержимое сегментного регистра равно: 1А62hПосле сдвига влево на 4 разряда получим: 1А620h
Смещение пусть равно: 01B5h
К физическому адресу начала сегмента прибавляется смещение:
1А620h
+
01B5h
-----------
86.
Размещение информации в основной памятиIBM PC
В младших адресах
располагаются блоки
операционной системы
(векторы прерываний,
зарезервированная область
памяти BIOS, драйверы
устройств, дополнительные
обработчики прерываний DOS
и BIOS, командный процессор
87.
Размещение информации в основной памятиIBM PC
После операционной системы располагается
область памяти, отведенная пользователю.
Область памяти пользователя заканчивается
адресом 9FFFF.
Этот адрес является физической границей
оперативного ЗУ, последним адресом 640Кбайтовой основной памяти.
Остальное адресное пространство (128 Кбайт с
адреса АОООО по BFFFF) отведено под
видеопамять, которая физически размещается
не в ОП, а в адаптере дисплея.
88.
Размещение информации в основной памятиIBM PC
После видеопамяти расположено адресное
пространство (256 Кбайт) постоянного
запоминающего устройства (ПЗУ),
хранящего программы базовой системы
ввода-вывода (BIOS — Basic Input-Output
System).
Эта часть ОП еще называется ROM-BIOS.
Из отведенных 256 Кбайт непосредственно
ПЗУ занимает 64 Кбайта, а остальные 192
Кбайта оставлены для расширения ПЗУ.
89.
Размещение информации в основной памятиIBM PC
Запись в ОП (и чтение из нее) может осуществляться не
только байтами, но и машинными словами.
Старший байт
Младший байт
7 6 5 4 3 2 1 0 7 6 5 4 3 2 1 0
Номера разрядов
в байтах
Машинное слово характеризуется не всеми адресами
занятых байтов, а только одним - адресом младшего байта
слова.
При записи слова младший байт размещается по адресу,
который является адресом машинного слова, старший
байт машинного слова размещается в следующем по
порядку байте ОП, имеющем номер, увеличенный на 1
90.
Размещение информации в основной памятиIBM PC
При чтении из ОП двух следующих подряд байтов машинного слова
их принято размещать слева направо: сначала первый из
прочитанных байтов (с меньшим адресом), а затем — следующий. В
результате происходит «вращение» байтов.
Младший байт
Старший байт
7 6 5 4 3 2 1 0 7 6 5 4 3 2 1 0
Номера разрядов
в байтах
91.
Размещение информации в основной памятиIBM PC
При записи отдельных байтов каждый байт располагается в ОП по своему
адресу, при чтении никакого вращения не происходит.
При записи же в ОП единиц информации; имеющих в своем составе больше
одного байта, адресом информационной единицы является адрес самого
младшего байта, запись в ОП ведется побайтно, начиная с самого младшего
байта, каждый последующий байт располагается в ячейке, адрес которой на
1 больше предыдущего.
Иными словами, запись машинного или двойного слова производится справа
налево, тогда как при чтении считанные байты обычно располагаются слева
направо — происходят «вращение» байтов, перестановка их местами, что
необходимо учитывать при работе с ОП на физическом уровне.
92. Программирование процессора
Конструкциями машинного языка являютсяконстанты и команды. Команды содержат код
команды и адреса данных, которые используются в
командах
93. Основные тенденции развития ЭВМ
- Повышение степени интеграции элементной базы-Увеличение набора команд
-Увеличение степени аппаратной поддержки
- Наличие семантического разрыва
Проблема семантического разрыва
Технология программирования непрерывно развивается, что позволяет увеличивать
функциональность программ и сокращать время их разработки.
Создание проблемноориентированных языков высокого уровня усугубляет принципиальное отличие языка
машинных команд, реализуемого компьютером, от языков, используемых при написании
программ. Данная проблема носит название "семантического разрыва" и выражается в
неоправданном падении производительности вычислительной системы.
94. Архитектура системы команд
В команде указывается, какуюоперацию выполнять (КОП),
над какими операндами
выполнять операцию, а также
куда поместить операнд.
Организация ЭВМ
ИУ6
RISC – Reduced Instruction Set Computer;
CISC – Complex Instruction Set Computer;
VLIW – Very Long Instruction Word;
ROSC - Removed Operand Set Computer
13
95. Сравнение CISC, RISC и VLIW архитектур СК
ХарактеристикаCISC
RISC
VLIW
Длина команды
Различная
Одинаковая
Одинаковая
Расположение
полей в
командах
Различное
Одинаковое
Одинаковое
Количество
регистров
Малое. Регистры
специализированн
ые
Большое.
Регистры
универсальные
Большое.
Регистры
универсальные
Доступ к памяти
Кодируется в
команде.
Выполняется по
микрокоманде
Выполняется по
специальной
команде
Выполняется по
специальной
команде
Различная
Одинаковая (для
большинства
команд)
Различная
Длительность
выполнения
команд
96.
Стековая архитектура СК(+) При размещении операндов в стековой памяти (LIFO) архитектура
команд упрощается (большое количество действий выполняется
аппаратно)
Операции:
- занесение в стек (PUSH);
- извлечение из стека (POP);
- выполнение действий на стеком (извлечение операндов из вершины
стека, выполнение действий, помещение результата в вершину стека)
Для выполнение арифметических операций их преобразуют к
постфиксной форме (Польской записи).
Пример: a = a + b * (c -d); Постфиксная форма: abcd-*+;
Действия: PUSH a; PUSH b; PUSH c; PUSH d; SUB; MUL; ADD; POP a.
(-) Отсутствие прямого доступа к памяти ограничивает область применения.
(-) Сложность организации параллельной обработки.
97.
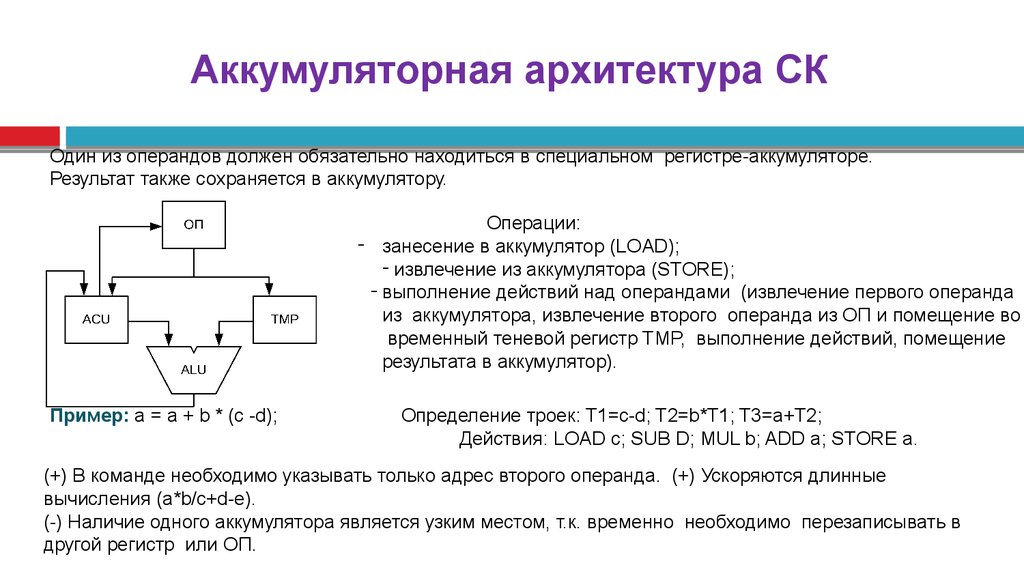
Аккумуляторная архитектура СКОдин из операндов должен обязательно находиться в специальном регистре-аккумуляторе.
Результат также сохраняется в аккумулятору.
Операции:
- занесение в аккумулятор (LOAD);
- извлечение из аккумулятора (STORE);
- выполнение действий над операндами (извлечение первого операнда
из аккумулятора, извлечение второго операнда из ОП и помещение во
временный теневой регистр TMP, выполнение действий, помещение
результата в аккумулятор).
Пример: a = a + b * (c -d);
Определение троек: T1=c-d; T2=b*T1; T3=a+T2;
Действия: LOAD c; SUB D; MUL b; ADD a; STORE a.
(+) В команде необходимо указывать только адрес второго операнда. (+) Ускоряются длинные
вычисления (a*b/c+d-e).
(-) Наличие одного аккумулятора является узким местом, т.к. временно необходимо перезаписывать в
другой регистр или ОП.
98.
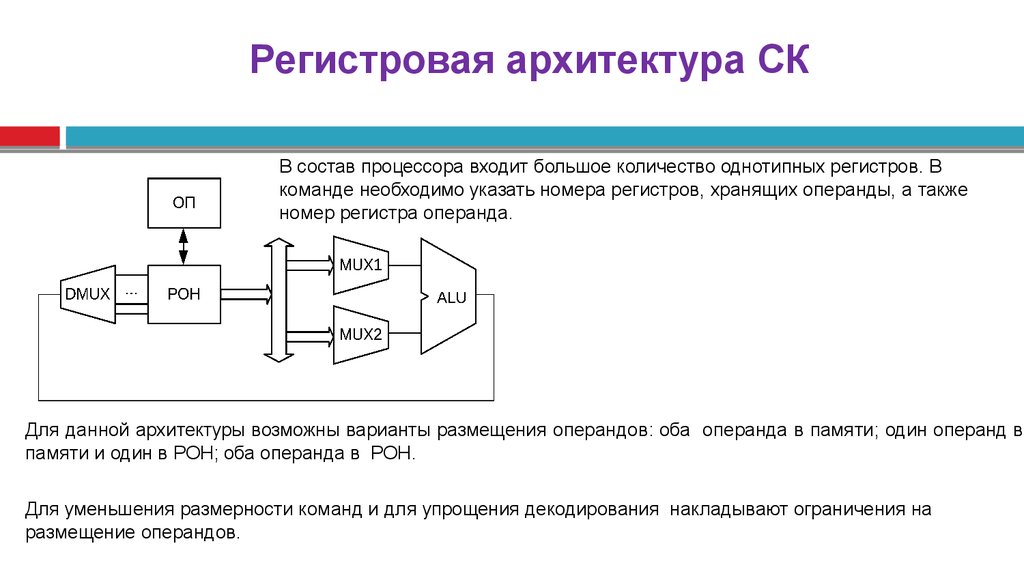
Регистровая архитектура СКВ состав процессора входит большое количество однотипных регистров. В
команде необходимо указать номера регистров, хранящих операнды, а также
номер регистра операнда.
Для данной архитектуры возможны варианты размещения операндов: оба операнда в памяти; один операнд в
памяти и один в РОН; оба операнда в РОН.
Для уменьшения размерности команд и для упрощения декодирования накладывают ограничения на
размещение операндов.
99. Типы команд
Команды пересылки данных.• регистр-регистр
• регистр-память
• память-память
Команды арифметической и логической обработки (сложение, вычитание, умножение,
деление, инкремент, декремент, сравнение, операции над ЧПЗ, логические операции,
операции сдвига).
Сдвиг: логический, арифметический, циклический, циклический через
дополнительным разряд.
Команды работы со строками (могут быть реализованы набором других команд,
однако удобны при работе с символьной информацией).
Команды векторной обработки (позволяет выполнять однотипные действия над
большим количеством однородных данных).
Команды преобразования: служат для табличного преобразования данных из
одной системы кодов в другую (2-10 <-> 2)
100.
Типы командКоманды ввода/вывода. Служат для управления, проверки состояния и обмена данными с
периферийными устройствами.
Команды вывода в порт
Команды ввода из порта.
Команды управления потоком команд. Данные команды служат для указания очередности
выполняемых команд.
Вычисление адреса очередной команды может выполняться несколькими способами:
увеличением адреса на длину исполненной (естественный порядок).
изменением адреса на длину следующей (перешагивание)
изменением адреса на значение, указанное в текущей команде (короткий переход).
непосредственное указание следующей команды (длинный переход).
Перечисленные команды могут выполняться лишь по некоторому условию (уловные переходы).
Команды условного перехода составляют 80% команд управления.
Команды безусловного перехода: вызовы и возвраты из процедур, и.т.д.
101. Формати команд
Операційна частинаАдресна частина
Структура 4-х адресної команди
Код операції
1 дані
2 дані
Результат
Структура 3-х адресної команди
Код команди
1 дані
2 дані
Результат
Адреса
наступної
команди
102. Структура 2-х адресної команди
Командний режим роботи процесораСтруктура 2-х адресної команди
Код операції
1 дані ( результат)
2 дані
або
Код операції
1 дані
2 дані (результат)
Структура 1 адресної команди
Код операції
Адреса даних