



")






















.")











 Математика
МатематикаПохожие презентации:



 регрессия в эконометрических расчетах")






Эконометрика. Парная регрессия
1. Э К О Н О М Е Т Р И К А
ЭКОНОМЕТРИКАКафедра СА и МЭП
Лектор:
доцент Концевая Наталья Валерьевна
Финуниверситет, 2015
2. Парная регрессия
1.2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
2
Понятия регрессионного анализа: зависимые и независимые
переменные.
Предпосылки применения метода наименьших квадратов (МНК).
Свойства оценок метода наименьших квадратов (МНК).
Линейная модель парной регрессии. Оценка параметров модели
с помощью метода наименьших квадратов (МНК).
Показатели качества регрессии модели парной регрессии.
Анализ статистической значимости параметров модели парной
регрессии.
Интервальная оценка параметров модели парной регрессии.
Проверка выполнения предпосылок МНК.
Интервалы прогноза по линейному уравнению парной регрессии.
(Прогнозирование с применением уравнения регрессии).
Понятие и причины гетероскедастичности. Последствия
гетероскедастичности. Обнаружение гетероскедастичности.
Нелинейная регрессия. Нелинейные модели и их линеаризация.
3. Типы переменных в эконометрической модели
Результирующая (зависимая, эндогенная) переменная YОна характеризует результат или эффективность функционирования
экономической системы. Значения ее формируются в процессе и
внутри функционирования этой системы под воздействием ряда
других переменных и факторов, часть из которых поддается
регистрации, управлению и планированию. По своей природе
результирующая переменная всегда случайна (стохастична).
Объясняющие (экзогенные, независимые) переменные X
Это — переменные, которые поддаются регистрации и описывают
условия функционирования реальной экономической системы.
Они в значительной мере определяют значения результирующих
переменных. Еще их называют факторными признаками. В
регрессионном анализе это аргументы результирующей функции
Y. По своей природе они могут быть как случайными, так и
неслучайными.
3
4. Регрессионный анализ
Предназначен для исследования зависимостиисследуемой переменной от различных факторов и отображения их взаимосвязи в форме
регрессионной модели.
Зависимая (объясняемая) переменная = > Y
Независимые (объясняющие) переменные
=>X
По виду функции различают модели:
линейные;
нелинейные.
По
количеству включенных факторов:
- однофакторные (парной регрессии);
5. Предпосылки применения метода наименьших квадратов (МНК)
Первое условие. Математическое ожидание случайной составляющей в любомнаблюдении должно быть равно нулю
Второе условие состоит в том, что возмущение
есть величина случайная.
(или зависимая переменная )
Третье условие предполагает отсутствие систематической связи между
значениями случайной составляющей в любых двух наблюдениях
M ( i , j ) = 0 (i j )
Четвертое условие означает, что дисперсия случайной составляющей должна
быть постоянна для всех наблюдений. Это условие гомоскедастичности.
Предположение о нормальности
Наряду с перечисленными условиями Гаусса— Маркова обычно также
предполагается нормальность распределения случайного члена.
6.
Свойства оценок метода наименьшихквадратов (МНК)
Оценки параметров регрессии должны быть несмещенными,
состоятельными и эффективными
Свойства
Интерпретация
Применение
Несмещенность
Математическое ожидание
остатков равно нулю
При большом числе
выборочных оцениваний
остатки не будут
накапливаться, оценки можно
сравнивать по разным
выборкам
Эффективность
Оценки считаются
Возможность перехода от
эффективными, если они
точечного оценивания к
характеризуются наименьшей
интервальному
дисперсией
Состоятельность
Вероятность получения
Состоятельность оценок
оценки на заданном
характеризует увеличение их
расстоянии от истинного
точности с увеличением
значения параметра близка к
объема выборки
единице.
7. Линейная парная регрессия
yi = a0 + a1 · xi + ε i ,где a 0 – постоянная величина,
a 1 – коэффициент регрессии, характери-зует угол
наклона линии регрессии.
Если a 1 > 0, то переменные x и y положительно
коррелированы, если a 1 < 0 – отрицательно.
a 0 + a 1 · x i - неслучайная составляющая;
ε i – случайная составляющая с нулевым
математическим ожиданием и постоянной
дисперсией, она учитывает неучтенные факторы,
8. Матричная форма оценки параметров уравнения регрессии МНК
Y=X·A+ε,
где Y – вектор-столбец (nx1) наблюдаемых
значений зависимой переменной;
X – матрица (nx2) значений факторов;
A – вектор-столбец (2x1) неизвестных
коэффициентов регрессии;
ε – вектор-столбец (nx1) ошибок
наблюдений
9.
y1...
Y yi
...
y
n
1
...
X 1
...
1
x1
...
xi
...
xn
a0
A
a1
ε1
...
ε εi
...
ε
n
Решение системы нормальных уравнений
в матричном виде: A = (X’·X)-1·X’·Y .
Для расчета вектора A необходимо:
1. Транспонировать матрицу X => [ ТРАНСП];
2. Умножить транспонированную матрицу на исходную
(X’X) => [МУМНОЖ];
3. Вычислить обратную матрицу (X’X)-1 => [МОБР];
10. Метод наименьших квадратов
Q( ,n
yi yˆi
i 1
2
n
( yi xi ) 2
i 1
n
n
n x i y i
i 1
i 1
n
n
n
2
xi xi y i x i .
i 1
i 1
i 1
n
A (X
X ) 1 X
Y n
xi
i 1
1
n
x
y
i i
ˆ
i 1
i 1
n
n
ˆ
2
xi
xi yi
i 1
i 1
n
11. Оценка параметров уравнения регрессии МНК
МНК минимизирует сумму квадратовотклонения фактических значений yi от
расчетных
n
a1=
Cov( x, y )
Var ( x )
=
x
i 1
i
x y i y n 1
S x2
x x y
=
x x
i
i
n
=
rx , y
Sy
Sx
y x y x
x x
2
2
=
y
i
i 1
n
__
xi n y x
2
2
x
n
x
i
i 1
__
a0 = y – a 1 · x .
y =a +a·x
y
i
2
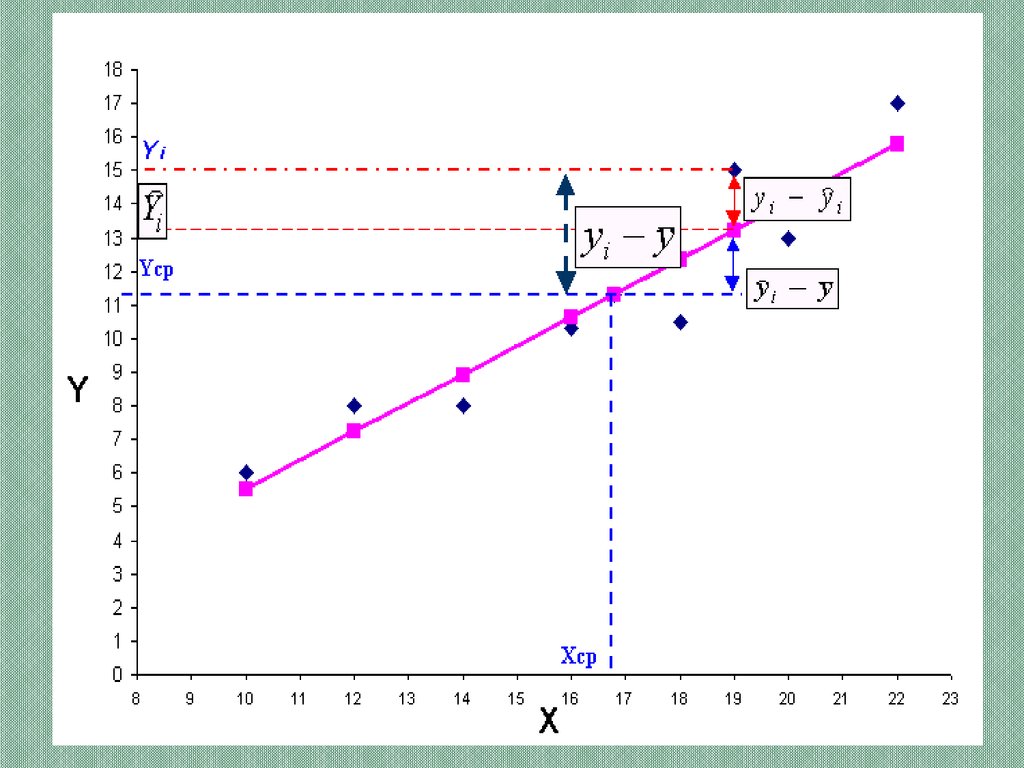
12. Оценка качества модели регрессии
Качество модели оценивается на основеанализа остаточной компоненты (εi = yi – yр ):
Качество модели регрессии оценивается по
следующим направлениям:
проверка качества всего уравнения регрессии;
проверка значимости всего уравнения
регрессии;
проверка статистической значимости
коэффициентов уравнения регрессии;
проверка выполнения предпосылок МНК.
13.
В основе анализа качества лежит теорема оразложении дисперсии на две составляющие:
n
n
( y y ) ( yˆ y )
2
i 1
i
i 1
дисперсия
2
i
n
yi yˆi ,
2
i 1
объясненная
необъясненная
Разделив обе части уравнения на левую получим:
n
1
( yˆ i y )
2
( yi y )
2
i 1
n
n
i 1
2
i
i 1
n
2
(
y
y
)
i
i 1
Коэффициент детерминации R2
Откуда, в окончательном виде имеем :
14.
nобъясняемая сумма квадратов
R
общая сумма квадратов
( yˆi y )
2
( yi y )
2
i 1
n
2
i 1
n
1
2
i
i 1
n
2
(
y
y
)
i
i 1
Коэффициент детерминации показывает долю
вариации результативного признака, находящегося под воздействием изучаемых факторов.
Чем ближе R2 к 1, тем выше качество модели.
Если R2 =0 ? – связь между признаками отсутствует
Если R2 = 1 ? - связь функциональная
Коэффициент множественной корреляции R
n
R = 1
i 2
i 1
n
( yi y )2
i 1
n
( yˆ
i 1
n
i
y )2
=
( yi y ) 2
i 1
Он отражает и тесноту связи и точность модели
15.
Основные свойствакоэффициента детерминации
1.
0 < R2 < 1.
2.
Чем ближе R2 к 1, тем лучше регрессия аппроксимирует
статистические данные, тем теснее линейная связь
между зависимой и объясняющими переменными.
3. Если R2 = 1, то статистические данные лежат на линии
регрессии, т.е. между зависимой и объясняющими
переменными имеется функциональная зависимость.
Если R2 = 0, то вариация зависимой переменной
полностью обусловлена воздействием неучтенных в
модели переменных.
4. В случае парной регрессии R2 = r 2.
16.
17.
Для однофакторной модели R = | ry,x |.Критерий
Фишера
используется
для
проверки значимости модели регрессии при
выбранном уровне α и степенях свободы k1 и
k2. Для однофакторной модели регрессии:
2
ry2, x
R
F=
(n 2) =
(n 2)
2
2
1 R
1 ry , x
Критерии точности модели
n
Средняя квадратическая ошибка –
(стандартная ошибка оценки)
n
S
2
i
i 1
n 2
S
- для однофакторной модели
2
i
i 1
n k 1
18.
Если Sε ≤ σy, то модель регрессии использоватьцелесообразно.
Средняя относительная ошибка
аппроксимации:
1 n y yˆ
1 n
A=
n
i 1
i
i
yi
100% =
A
n
y
i
i 1
100%
i
Если A ≤ 7%, то модель имеет хорошее качество.
Проверка гипотез о значимости
параметров уравнения регрессии.
Выдвигается H0 – гипотеза о незначимом отличии
параметра уравнения регрессии от нуля.
Для проверки этой гипотезы используется t –
статистика (имеющая распределение Стьюдента).
19.
Показатели качествакоэффициентов регрессии
1. Стандартные ошибки оценок (анализ точности
определения оценок).
2. Значения t-статистик (проверка гипотез
относительно коэффициентов регрессии).
3. Интервальные оценки коэффициентов
линейного уравнения регрессии.
4. Доверительные области для зависимой
переменной.
20.
Стандартные ошибки оценокОценки b0 и b1 являются случайными величинами.
Отсюда следует, что стандартные ошибки коэффициентов
регрессии - это средние квадратические отклонения
коэффициентов регрессии от их истинных значений.
2
21.
Свойства дисперсий оценок1. Дисперсии D[b0] и D[b1] прямо пропорциональны
дисперсии случайного отклонения
Следовательно, чем
больше фактор случайности, тем менее точными будут
оценки.
2. Чем
больше число наблюдений n, тем меньше дисперсии
оценок.
3. Чем больше дисперсия объясняющей переменной, тем
меньше дисперсия оценок коэффициентов регрессии.
Другими словами, чем шире область изменений
объясняющей переменной, тем точнее будут оценки (тем
меньше доля случайности в их определении).
Стандартная ошибка является оценкой среднего квадратического
отклонения коэффициента регрессии от его истинного значения
22.
Использование стандартныхошибок
Сравнивая значение коэффициента с его
стандартной ошибкой, можно судить о
значимости коэффициента
Коэффициент называется значимым, если есть
достаточно высокая вероятность того, что его
истинное значение отлично от нуля
Для стандартных ошибок оценок нет таблиц
критическихуровней — для точного суждения
используются t-статистики
23.
Типичные ошибки в использованиипоказателей качества регрессии
- Величина коэффициентов регрессии не указывает на силу
связи или силу влияния на зависимую переменную
- Значимость коэффициентов по t-тестам не позволяет
сделать вывод о справедливости тех или иных теорий
- t-статистики не указывают на относительную важность
коэффициентов регрессии
- t-статистики предназначены для использования
исключительно для выборки и бесполезны для анализа
всей совокупности
- Нельзя сравнивать t-статистики, F-статистики,
коэффициенты детерминации и др. у разных уравнений
24.
Расчетные значения t – критерия определяютсяпо формулам:
tb0 = |b0| / Sb0
S
где Sb0
Sb1
Здесь
S
и
x
n x ( x )
2
i
S
2
i
2
S
i
S n
ta1 = |b1| / Sb1 ,
x
2
i
n
x
n
S
2
2
n
x
n xi ( xi )
x
S 2 xi2
n
( xi x )2
S 2
2
(
x
x
)
i
2
(
x
x
)
i
n
tа0 или tа1>tтабл , то параметр значим
25.
Интервальная оценка параметров моделивыполняется для значимого уравнения по формулам:
a0 =[a0 ± tтабл·Sa0 ] – для свободного члена
a0 ;
a1 = [a1 ± tтабл·Sa1 ] – для параметра a1 .
где tтабл – критерий Стьюдента для k =n-2 степеней,
Sa0 ,Sa1 – стандартные отклонения
Прогнозирование по уравнению регрессии
Точечный прогноз получают подстановкой ожидаемого
значения xпрогн в уравнение:
yпрогн=a0+ a1·xпрогн
26.
21 ( xпрогн x )
yпрогн yпрогн S t 1 n
;
n
2
(
x
x
)
i
i 1
2
1 ( xпрогн x )
.
yпрогн S t 1 n
n
2
(
x
x
)
i
i 1
Интервальный
прогноз
=
Точечный ±
Средняя ошибка прогноза
прогноз
27. Графическая интерпретация результатов расчета
yВерхняя
доверительная
граница
Линия
регрессии
Нижняя
доверительная
граница
Доверительный
интервал
x
x
28.
Регрессионный анализпредназначен для исследования зависимости
исследуемой переменной от различных факторов и
отображения их взаимосвязи в форме регрессионной
модели.
В регрессионных моделях зависимая переменная Y
может быть представлена в виде функции f (Х), где Х1,Х2,…,Хm независимые (объясняющие) переменные,
или факторы.
Связь между переменной Y и m независимыми
факторами Х можно охарактеризовать функцией
регрессии Y= f (Х1,Х2,…,Хm ), которая показывает,
каково будет в среднем значение переменной yi, если
переменные Xi примут конкретные значения.
2
29. Регрессионные модели с переменной структурой (фиктивные переменные).
Построена регрессионная модель зависимостизаработной платы работника (Y) от возраста (Х) с
использованием фиктивной переменной по фактору
пол по 20 работникам одного предприятия
y 60, 71 6,98 x 17, 27 z
Из полученного уравнения регрессии следует, что при
одном и том же возрасте заработная плата у
работников мужчин на 17,27$ в месяц выше, чем у
женщин.
Из модели, включающей фиктивную переменную
можно получить частные уравнения регрессии для
работников мужчин (z=1) и женщин (z=0):
y 77,98 6,98 x
y 60, 71 6,98 x
2
( z 1)
( z 0).
30.
331.
ЗадачаАдминистрация страховой компании
приняла решение о введении нового
вида услуг – страхование на случай
пожара. С целью определения
тарифов по выборке из 10 случаев
пожаров анализируется зависимость
стоимости ущерба, нанесенного
пожаром от расстояния до
ближайшей пожарной станции.
3
32.
№1
2
3
4
5
6
7
8
9
Y-Общая
сумма
ущерба.
тыс.руб.
26.2
17.8
31.3
23.1
27.5
36
14.1
22.3
19.6
3
XРасстоян
ие до
ближайш
ей
станции.
км
3.4
1.8
4.6
2.3
3.1
5.5
0.7
3
2.6
33. Прогноз по модели Y=10,25+4,69X
Прогноз попо модели
модели
Прогноз
Y=10,25+4,69X
Y=10,25+4,69X
Прогноз Х
По исходным данным полагают, что расстояние до
ближайшей пожарной станции уменьшится на 5% от
своего среднего уровня
xкм
3.13
xкм
0.95 2.97
прогноз 3.13
Прогноз Y
)
yпрогноз a b
xтыс
10.25 4.69
2.97 24.2
прогноз руб
3
.
.
34. Построение доверительного интервала прогноза
ПостроениеПостроение доверительного
доверительного
интервала
интервала прогноза
прогноза
U = S yˆ × t α × 1+1/n+
(x прогноз -х ср) 2
n
2
(x
x
)
iср
i=1
1 0, 026
1,801 1,86 1
3,51
10 17,881
Стандартная ошибка 1.801
3
t(0,1; 8) 1,86
35. Построение доверительного интервала прогноза
U = S yˆ × t α × 1+1/n +(x прогноз -х ср) 2
n
(x
i=1
1,801 1,86 1
- x )2
iср
1 0, 026
3,51
10 17,881
Стандартная ошибка 1.801
Строим доверительный интервал прогноза ущерба с
вероятностью 0,90
(t=1,86). Из полученных результатов
видно, что интервал от 20,67 до 27,7 тыс. руб. ожидаемой
величины
ущерба
довольно
широкий.
Значительная
неопределенность прогноза линии регрессии, связана, прежде
всего с малым объемом выборки (n=10), а также тем, что по
мере удаления прогнозного знаения Х от среднего ширина
доверительного интервала увеличивается.
3
36. График прогноза
337. Нелинейная регрессия
При описании экономических процессов могутиспользоваться также и нелинейные функции.
Различают два класса нелинейных регрессий:
Нелинейные относительно объясняющих
переменных, но линейные по оцениваемым
параметрам:
Полиномы разных степеней
yi = a0 + a1·xi + a2·xi2 + a3·xi3 + … + ak·xik + εi
Равносторонняя гипербола yi
= a0 + a1 / xi + εi .
Нелинейные по оцениваемым параметрам:
Степенная
yi = a0 · xi a1 · εi
кривые спроса,предложения, Энгеля, производственные функции,
кривые освоения, зависимость вал. Нац. Прод. От уровня занятости
38.
Показательнаяyi = a0 · a1 xi · εi
Экспоненциальная
yi = e a0 + a1· xi · εi
Первый класс нелинейных моделей легко сводится к линейным путем замены нелинейных
переменных xk новыми линейными переменными zk и затем применяют МНК.
Во втором классе выделяют два подкласса:
Внутренне линейные – путем преобразований
сводятся к линейному виду;
Внутренне нелинейные – путем логарифмирования
приводятся к линейному виду, либо используются
итеративные процедуры оценки параметров.
Остальное см. практику
39.
Альтернативные функциональныеформы: правила выбора
Правила выбора формы зависимости:
1. Исходить из экономической теории.
2. Оценивать формальное качество модели.
3. Дополнительно проверять по нескольким содержательным
критериям.
4. Ответить на вопросы, возникающие при анализе модели:
- каковы признаки качественной модели;
- какие ошибки спецификации встречаются и каковы их последствия;
- как обнаружить ошибку спецификации;
- каким образом можно исправить ошибку спецификации и перейти к
более качественной модели.
40.
Признаки качественной модели1. Простота модели (из примерно одинаково отражающих
реальность моделей, выбирается та, которая содержит
меньше объясняющих переменных.
2. Единственность (для любых данных коэффициенты
модели должны вычисляться однозначно).
3. Максимальное соответствие (модель тем лучше, чем
больше скорректированный коэффициент детерминации).
4. Согласованность с теорией (уравнение регрессии должно
соответствовать теоретическим предпосылкам).
5. Прогнозные качества (прогнозы, полученные на основе
модели, должны подтверждаться реальностью).