









































 Математика
МатематикаПохожие презентации:










Основные понятия. Описательная статистика. Занятие 1
1.
Занятие 1Основные понятия.
Описательная
статистика.
2.
Данные – результаты некоторого количества измеренийкакой-либо ПЕРЕМЕННОЙ (переменных) – variable, такой,
как:
- вес, длина тела, пол, окрас, температура тела .....
наблюдение
популяция =
генеральная совокупность
выборка
Важнейший вопрос: что мы можем сказать обо всей ПОПУЛЯЦИИ,
если всё, что у нас есть, это лишь ВЫБОРКА из неё?
3.
ПЕРЕМЕННЫЕКачественные
nominal
Ранговые
Количественные
ordinal
(качественные, могут быть Дискретные
выстроены в
discrete Непрерывные
последовательность)
continuous
4.
Непрерывные переменные:рост, вес Ани, Тани и Мани
1. Не нужно писать много знаков после запятой
(ориентируются на точность измерений).
2. Если почему-то необходимо округлить числа, чётные
округляют в меньшую сторону, нечётные – в большую (2.5 в
2, 3.5 в 4);
5.
Три основные концепции в анализе данных:1. Что такое РАСПРЕДЕЛЕНИЕ переменной и как его
описывать
2. Что такое распределение ВЫБОРОЧНЫХ СРЕДНИХ
и как оно связано с распределением переменной
3. Что такое СТАТИСТИКА КРИТЕРИЯ
Необходимо для обдумывания и обсуждения данных
6.
Частотное распределение переменной (frequency distribution)На примере непрерывной переменной
Взвешиваем N кроликов
7.
Частотное распределение переменной (frequency distribution)1. Упорядочим по возрастанию значения переменной
(выстроим кроликов от меньшего к большему);
2. Напротив значений напишем, сколько раз они
встретились в выборке (для непрерывной
переменной разобьём их на группы по равным
интервалам).
Частотное распределение (frequency distribution) – это
соответствие между значениями нашей переменной и
их вероятностями
8.
Частотное распределение переменной (frequency distribution)Частота – то, сколько раз встретилось данное значение переменной
Гистограмма – графическое представление частотного
Интервалы
должны быть:
Частота
распределения, разбитого по интервалам, где высота столбика
отражает ЧАСТОТУ
•одного размера,
•не должны иметь
общих точек.
Масса кролика, кг
9.
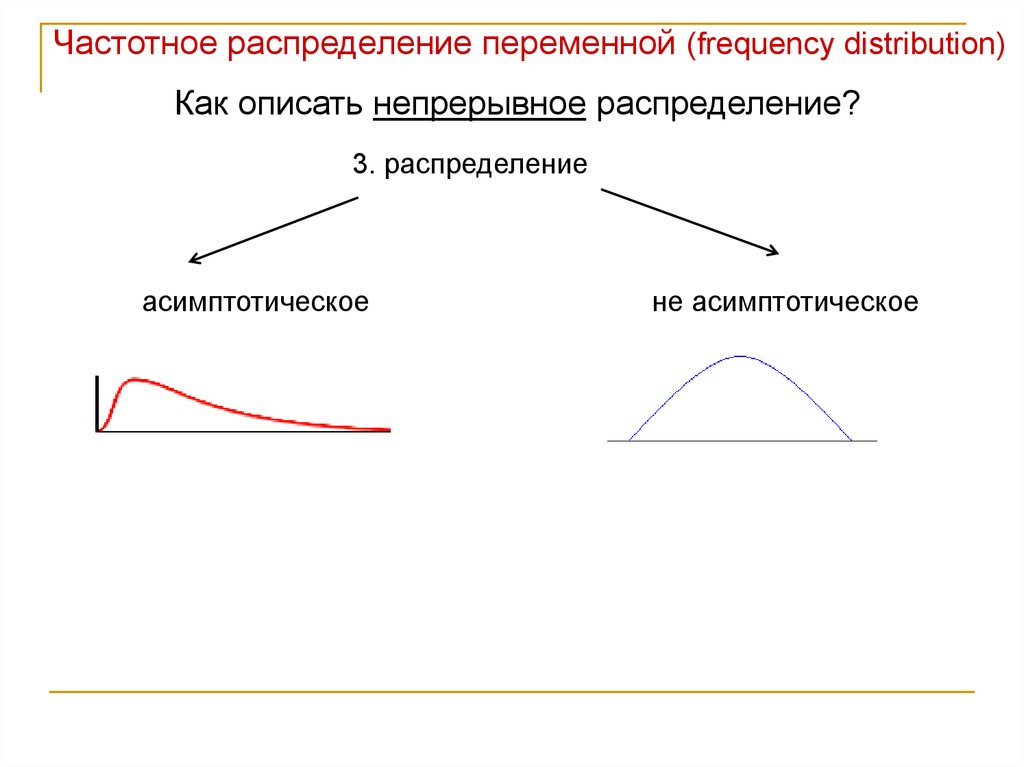
Частотное распределение переменной (frequency distribution)Как описать непрерывное распределение?
1. По количеству «максимумов» (мод):
мультимодальное
унимодальное
бимодальное
обычно возникают, если популяция имеет
естественные обособленные подгруппы
10.
Частотное распределение переменной (frequency distribution)Как описать непрерывное распределение?
2. По признаку симметрии:
Симметричное
Скошенное (skewed)
negatively
positively
11.
Частотное распределение переменной (frequency distribution)Как описать непрерывное распределение?
3. распределение
асимптотическое
не асимптотическое
12.
Частотное распределение переменной (frequency distribution)Нормальное распределение (Гауссово):
первое знакомство
Унимодальное
Симметричное
Асимптотическое
Это
непрерывное
распределение
Высота деревьев, масса тела новорожденных, IQ, скорость
прохождения лабиринта крысами и многие, многие другие переменные
13.
Частотное распределение переменной (frequency distribution)Картинка распределения качественных или ранговых
переменных
трава
корни плоды листва
Виды пищи
Оставим на некоторое время качественные и ранговые
переменные и обратимся только к КОЛИЧЕСТВЕННЫМ
14.
Частотное распределение переменной (frequency distribution)Три ОСНОВНЫЕ ХАРАКТЕРИСТИКИ, которыми можно почти
полностью описать большинство распределений
1. «Середина» распределения;
2. «Ширина» распределения;
3. Форма распределения
«Середина»
Мода
(mode)
Медиана
(median)
Среднее значение
(mean)
15.
Частотное распределение переменной (frequency distribution)«Середина» распределения
Мода (mode) – наиболее часто встречающееся
значение
существует и для качественных, и
для ранговых переменных
16.
Частотное распределение переменной (frequency distribution)«Середина» распределения
Медиана (median)– значение, которое делит
распределение пополам (его площадь в т.ч.): половина
значений больше медианы, половина – не больше.
1 2
3 4
5
6
7
8
9
10
11
Номера кроликов
Медиана = (11+1)/2 = 6
Имеет смысл для ранговых и количественных переменных,
но не для качественных
17.
Частотное распределение переменной (frequency distribution)«Середина» распределения
Среднее значение – сумма всех значений переменной,
делённая на количество значений
*«balancing point» method
Среднее для выборки
X
X
i
n
i
Среднее для популяции
X
N
18.
Частотное распределение переменной (frequency distribution)«Середина» распределения
Мода, медиана и среднее СОВПАДАЮТ для
симметричного унимодального распределения
ЗАРПЛА ЧАСТ
ТА, $
ОТА
200000
1
20000
1
19000
1
14000
3
К появлению перекоса чувствительнее
всего среднее значение
19.
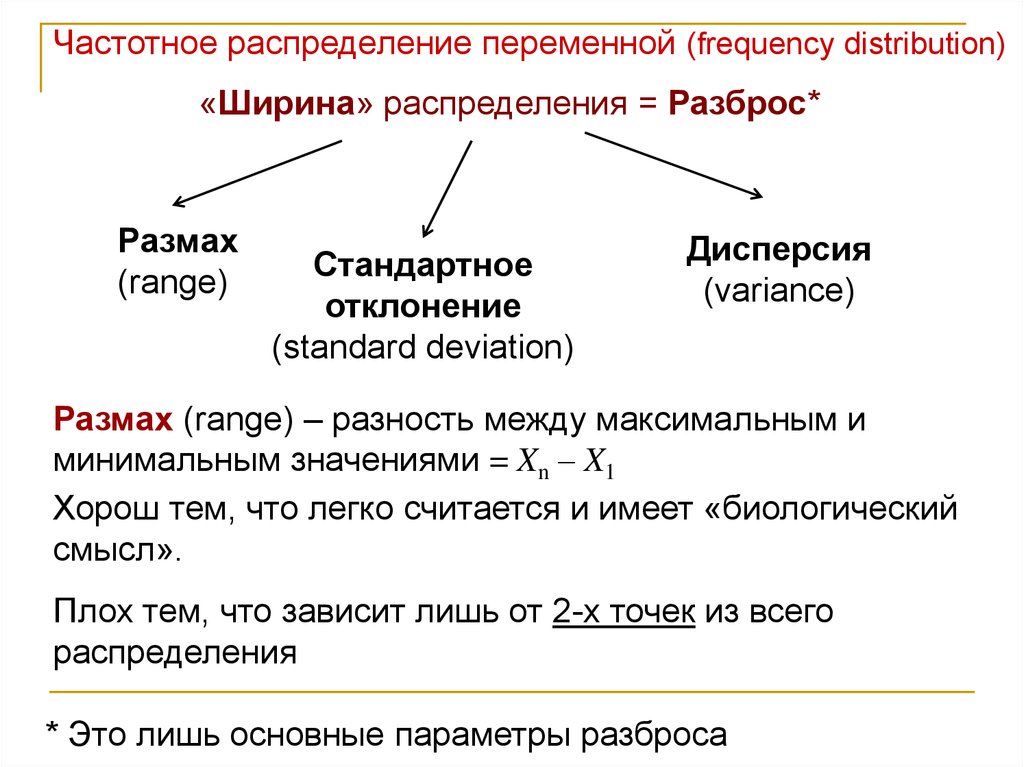
Частотное распределение переменной (frequency distribution)«Ширина» распределения = Разброс*
Размах
(range)
Стандартное
отклонение
(standard deviation)
Дисперсия
(variance)
Размах (range) – разность между максимальным и
минимальным значениями = Xn – X1
Хорош тем, что легко считается и имеет «биологический
смысл».
Плох тем, что зависит лишь от 2-х точек из всего
распределения
* Это лишь основные параметры разброса
20.
Частотное распределение переменной (frequency distribution)Разброс распределения
Стандартное отклонение (standard deviation)
Для выборки:
s
(X
i
X)
i
n 1
Поправка на то, что в
выборке разброс
всегда будет меньше,
чем во всей популяции
Для популяции:
2
(x
i
)
2
i
n
Сумма квадратов
(sum of squares = SS)
Стандартное отклонение зависит ото всех значений
переменной
21.
Частотное распределение переменной (frequency distribution)Разброс распределения
Стандартное отклонение (standard deviation):
для нормального распределения = дистанции от среднего
значения до каждой из точек перегиба
Стандартное
отклонение
измеряется в тех же
единицах, что и
переменная!
s
s
22.
Частотное распределение переменной (frequency distribution)Разброс распределения
Дисперсия (variance)
Для выборки:
s
2
2
(
X
X
)
i
i
n 1
Для популяции:
2
2
(
x
)
i
i
n
Равна стандартному отклонению в квадрате и содержит
почти ту же информацию; измеряется в единицах
переменной, возведённых в квадрат (что не всегда
удобно).
Дисперсия используется скорее в различных статистических тестах, а
не в описательной статистике
23.
Частотное распределение переменной (frequency distribution)Другие параметры распределения:
Процентили
Квартили (quartiles) делят распределение на
четыре части так, что в каждой из них оказывается
поровну значений (2-я квартиль = медиана).
1-я квартиль = 25% процентиль
3-я квартиль = 75% процентиль
Интерквартильный размах – разница между
третьей и первой квартилями.
Коэффициент вариации
(Coefficient of variation)
s 100
CV
X
24.
ЧастотаЧастотное распределение переменной (frequency distribution)
6
5
4
3
2
1
25% 25% 25%
Квартиль 1
25%
Квартиль 3
медиана
Значение
переменной
25.
Частотное распределение переменной (frequency distribution)Процентили и z-оценка
95% процентиль – значение переменной, левее
которого находится 95% значений переменной
95%
26.
Частотное распределение переменной (frequency distribution)Процентили и z-оценка
Z-оценка (z-scores) – переменная, соответствующая
количеству стандартных отклонений относительно
среднего значения
выборка
точка
перегиба
X X
z
s
популяция
z
Z-оценка
X
27.
Частотное распределение переменной (frequency distribution)«Площадь распределения»
Площадь, которую занимает график распределения,
соответствует количеству измерений в выборке.
частота
Отрезая часть распределения на графике, мы
отделяем эквивалентную часть от выборки
16% площади
распределения ~
16% объёма
выборки
масса, кг
28.
Частотное распределение переменной (frequency distribution)Площадь нормального распределения
Нормальное распределение определяется лишь 2-мя
параметрами – μ и σ .
1
f
e
2
1 X 2
(
)
2
Необыкновенное свойство:
Относительные площади под участками нормального
распределения всегда одинаковы!
29.
Частотное распределение переменной (frequency distribution)Площадь нормального распределения
Откладывая от среднего значения стандартное
отклонение (в ту или другую сторону) мы всегда отрезаем
строго определённую долю популяции, приблизительно:
Z-оценка
(количество стандартных
отклонений)
Пример с IQ (μ=100, σ=15)
30.
Частотное распределение переменной (frequency distribution)Площадь нормального распределения
31.
Распределение выборочных средних (sampling distributionof the means)
Три основные концепции в анализе данных:
1. Что такое РАСПРЕДЕЛЕНИЕ переменной и как его
описывать
2. Что такое распределение ВЫБОРОЧНЫХ СРЕДНИХ
и как оно связано с распределением переменной
3. Что такое СТАТИСТИКА КРИТЕРИЯ
популяция
выборка
Мы ловим 4-х кроликов и считаем их среднюю массу; ловим ещё
4-х, снова считаем среднюю массу, опять ловим….
популяция
32.
Распределение выборочных средних (sampling distributionof the means)
Выборка должна быть РЕПРЕЗЕНТАТИВНОЙ, т.е. её
свойства должны отражать свойства популяции.
Для этого она должна быть СЛУЧАЙНОЙ (random) – т.е.,
все особи в популяции должны иметь одинаковые шансы
клетка
попасть в неё.
Пример: если в одну группу поместить зверьков, которые первыми
вышли из клетки, а в другую – тех, кто в ней остался, выборки буду
неслучайными
33.
Распределение выборочных средних (sampling distributionof the means)
Ещё раз центральный статистический вопрос: что мы можем
сказать обо всей ПОПУЛЯЦИИ, если всё, что у нас есть, это лишь
ВЫБОРКА из неё?
На ферме живёт 1000
кроликов, которые
содержатся в 25-и вольерах
по 22 зверька.
Средняя масса кролика –
μ=50 кг, σ = 4 кг.
Посчитаем средние массы
для каждой вольеры!
…..
Форма распределений маленьких выборок не обязательна
должна удовлетворять критериям нормального распределения.
34.
Распределение выборочных средних (sampling distributionof the means)
Мы посчитали средние массы кроликов в КАЖДОЙ
вольере, и теперь построим распределение из этих
СРЕДНИХ значений!
1.2
5
40 45 50 55 60
50
Оно будет намного УЖЕ распределения всех кроликов на ферме,
и уже, чем каждое из распределений из отдельных вольер
Это и будет распределение выборочных средних (sampling
distribution of the means)
35.
Распределение выборочных средних (sampling distributionof the means)
Популяция
Выборка
Распределение
(вся ферма) (из вольеры) выборочных средних
стандартное
отклонение
среднее
X
X
s
>>
X
Стандартная
ошибка среднего
(Standard error = SE)
36.
Распределение выборочных средних (sampling distributionof the means)
ЦЕНТРАЛЬНАЯ ПРЕДЕЛЬНАЯ ТЕОРЕМА
Определяет форму, среднее и разброс в
распределении выборочных средних
• Форма: с увеличение размера выборок (вольер)
распределение выборочных средних приближается к
нормальному распределению (независимо от формы
распределения популяции).
• Среднее: среднее значение в распределении средних
равно среднему значению в популяции, т.е., X
• Разброс: распределение выборочных средних уже
распределения популяции на n , где n – объём выборки,
т.е.
SE X
Пример с монеткой
n
37.
Распределение выборочных средних (sampling distributionof the means)
Следствие:
если некоторая величина отклоняется от среднего под
воздействием слабых, независимых друг от друга
факторов, она имеет нормальное распределение.
Поэтому оно так широко распространено в природе!
38.
Распределение выборочных средних (sampling distributionof the means)
Использование распределения выборочных средних
Из нашей выборки мы получили среднее значение X.
Насколько оно близко истинному среднему значению
во всей популяции?
Мы знаем, что для нормального распределения
существует z-оценка, значениям которой соответствуют
однозначно определённые площади распределения.
Но мы также знаем, что выборочные средние
образуют нормальное распределение!!
39.
Распределение выборочных средних (sampling distributionof the means)
1.2
5
-2
-1
0
1
2 Z - оценка
0
Z - оценка
Вопрос: какая часть ОСОБЕЙ имеет
массу больше 55 кг?
Другой вопрос: какая часть ВЫБОРОК
имеет СРЕДНЮЮ массу больше 55 кг?
Пример про бутылки с кока-колой
40.
Оценка параметров популяции на основе свойстввыборки
Мы посчитали среднюю массу кроликов в одной
вольере, но на самом деле нас интересует средняя
масса всех кроликов!
Решим обратную задачу:
Пусть мы изначально знаем среднюю массу кроликов на ферме и
стандартное отклонение в популяции. Как оценить среднюю массу в
одной из вольер?
Построим распределение выборочных средних! Вспомним, что оно –
нормальное, а его среднее значение соответствует среднему в
популяции.
Зная стандартное отклонение в нем
1.2
(=SE!!) можем рассчитать
интервал, в который попадёт 95%
(99%) всех средних масс в
вольерах:
zcv0.05 1.96
-2 -1 0 1
μ
2
cv – critical value
41.
Оценка параметров популяции на основе свойстввыборки
95% доверительный интервал (95% confidence interval):
интервал значений переменной, который с вероятностью
95% содержит нужный параметр.
Т.е., расстояние от выборочного среднего до среднего
значения в популяции в 95% выборок не больше 1.96 SE
Вернёмся к исходной задаче:
Как оценить среднюю массу в популяции, если нам
известно среднее в выборке??
Расстояние от среднего в выборке до (неизвестного)
среднего в популяции с вероятностью 95% не больше
1.96 SE
42.
Оценка параметров популяции на основе свойстввыборки
Вопрос: где расположено μ?
Ответ: я точно не знаю, но наиболее вероятно – в
пределах ± 2-х стандартных ошибок среднего (SE)
X zcv0.05 ( X ) X zcv0.05 ( X )
Чем больше уровень достоверности – 99%, 99,9%... (=
доверительный уровень) тем ШИРЕ будет интервал
Вопрос: где расположено μ?
Ответ: я совершенно уверен, что оно лежит в
пределах... от до
В примере нам было известно σ, но на
практике оно обычно неизвестно!
43.
Оценка параметров популяции на основе свойстввыборки
Мы не знаем стандартное отклонение в популяции, и
оцениваем его через стандартное отклонение в выборке
– поэтому, доверительный интервал должен быть ШИРЕ,
чем при известном σ. И поправка (t вместо z-оценки)
будет зависеть от РАЗМЕРА ВЫБОРКИ (число степеней
свободы df = n-1)
s
(X
i
X)
i
n 1
df
2
s
SE s X
n
(x
i
)
i
n
2
44.
t-распределение (Стьюдента)df=k
t df
При больших (>30) размерах выборок приближается к нормальному