













 Электроника
ЭлектроникаПохожие презентации:


")






")
Циклы обмена. Лекция 7
1. Циклы обмена
2.
Циклы обменаСистемная магистраль является самым главным системообразующим элементом в
микропроцессорной системе с помощью которой производится обмен информацией между
основными компонентами микропроцессорной системы.
Обмен информацией в микропроцессорной системе происходит в циклах обмена.
Под циклом обмена информацией понимается временной интервал, в течении которого
происходит выполнение одной элементарной операции обмена по шине данных.
Во время каждого цикла обмена устройства, участвующие в обмене информацией, передают
друг другу информационные и управляющие сигналы в строго установленном порядке,
который называется протокол обмена информацией.
Длительность цикла обмена может быть постоянной или переменной, но всегда включает в
себя несколько тактов синхронизации. Поэтому даже в идеальной системе частота чтения или
записи данных меньше тактовой частоты системы.
В зависимости от архитектуры системной магистрали циклы чтения команд и пересылки
данных могут происходить как одновременно, так и последовательно.
Типы циклов обмена:
1.
2.
3.
4.
5.
Цикл записи (вывода).
Цикл чтения (ввода).
Цикл чтение-модификация-запись.
Цикл обработки прерывания.
Цикл прямого доступа к памяти (ПДП).
3.
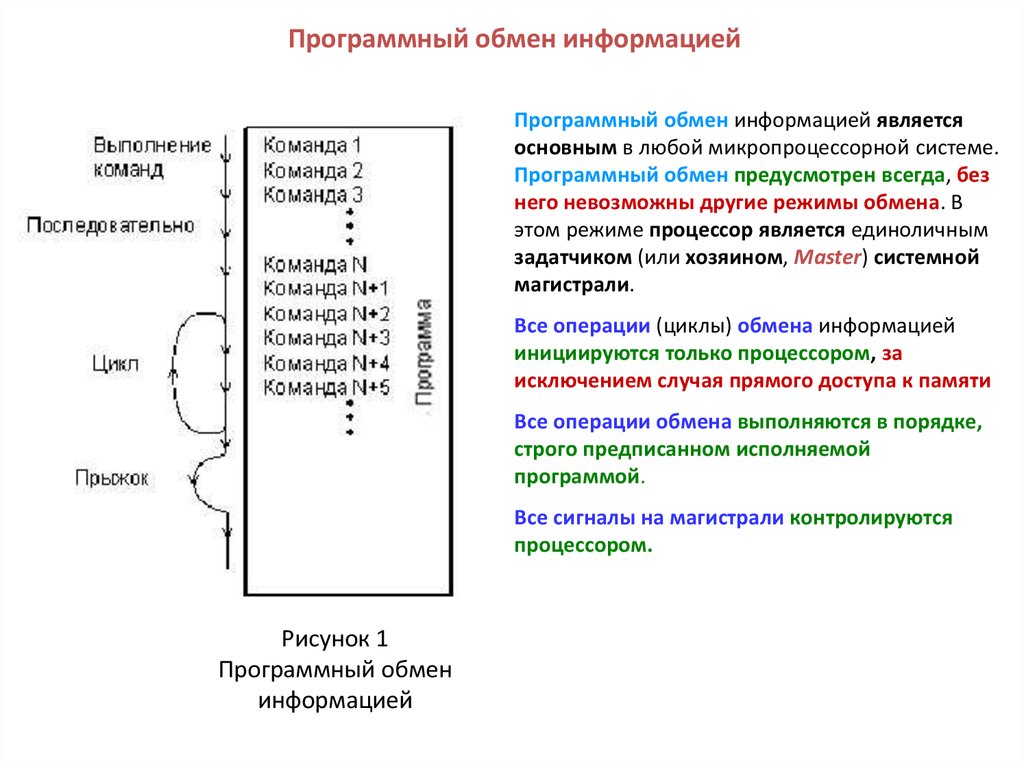
Программный обмен информациейПрограммный обмен информацией является
основным в любой микропроцессорной системе.
Программный обмен предусмотрен всегда, без
него невозможны другие режимы обмена. В
этом режиме процессор является единоличным
задатчиком (или хозяином, Master) системной
магистрали.
Все операции (циклы) обмена информацией
инициируются только процессором, за
исключением случая прямого доступа к памяти
Все операции обмена выполняются в порядке,
строго предписанном исполняемой
программой.
Все сигналы на магистрали контролируются
процессором.
Рисунок 1
Программный обмен
информацией
4.
Шины обмена данными Q-BUSQ-Bus — одна из разновидностей шин, применяемых в компьютерах PDP-11 и MicroVAX фирмы
Digital Equipment Corporation. (Магистральный параллельный интерфейс МПИ, СССР).
Q-Bus использует мультиплексирование, так что линии данных и адреса использовали те же
самые контакты. Это позволяло как уменьшить размер так и удешевить конструкцию, при
сохранении практически такой же функциональности.
Q-Bus использует:
– Ввод-вывод с отображением на память означает, что при обмене данными между любыми
двумя устройствами на шине, такими как ЦП, память, порты ввода-вывода, используются
одни и те же протоколы.
– Адресацию с точностью до байта означает, что минимальной адресуемой единицей на
шине является 8-ми битный байт.
– Строгие отношения главный-подчинённый на шине означает, что в каждый текущий
момент времени только одно устройство может быть в состоянии Главный (Master или
Ведущий) на шине. Ведущее устройство инициирует операцию на шине и ему отвечает
максимум одно ведомое устройство. Ведущее устройство может инициировать любую
операцию — чтение или запись.
– Асинхронный протокол взаимодействия означает что длина цикла шины не зафиксирована
во времени; продолжительность каждого отдельного цикла на шине определяется
исключительно взаимодействием Ведущего и Ведомого устройств в текущем цикле. Эти
устройства используют специальные сигналы готовности (RPLY) для управления
длительностью цикла шины. Кроме того, специальная логика Ведущего устройства
ограничивает максимальную длительность цикла для предотвращения зависания.
5.
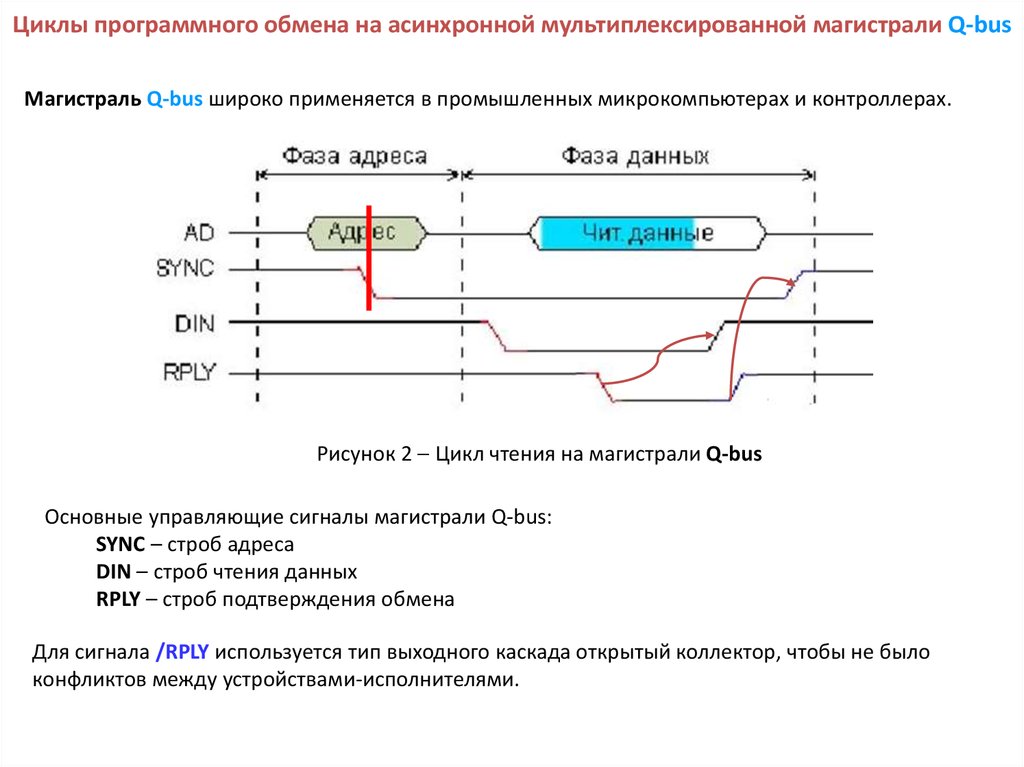
Циклы программного обмена на асинхронной мультиплексированной магистрали Q-busМагистраль Q-bus широко применяется в промышленных микрокомпьютерах и контроллерах.
Рисунок 2 Цикл чтения на магистрали Q-bus
Основные управляющие сигналы магистрали Q-bus:
SYNC – строб адреса
DIN – строб чтения данных
RPLY – строб подтверждения обмена
Для сигнала /RPLY используется тип выходного каскада открытый коллектор, чтобы не было
конфликтов между устройствами-исполнителями.
6.
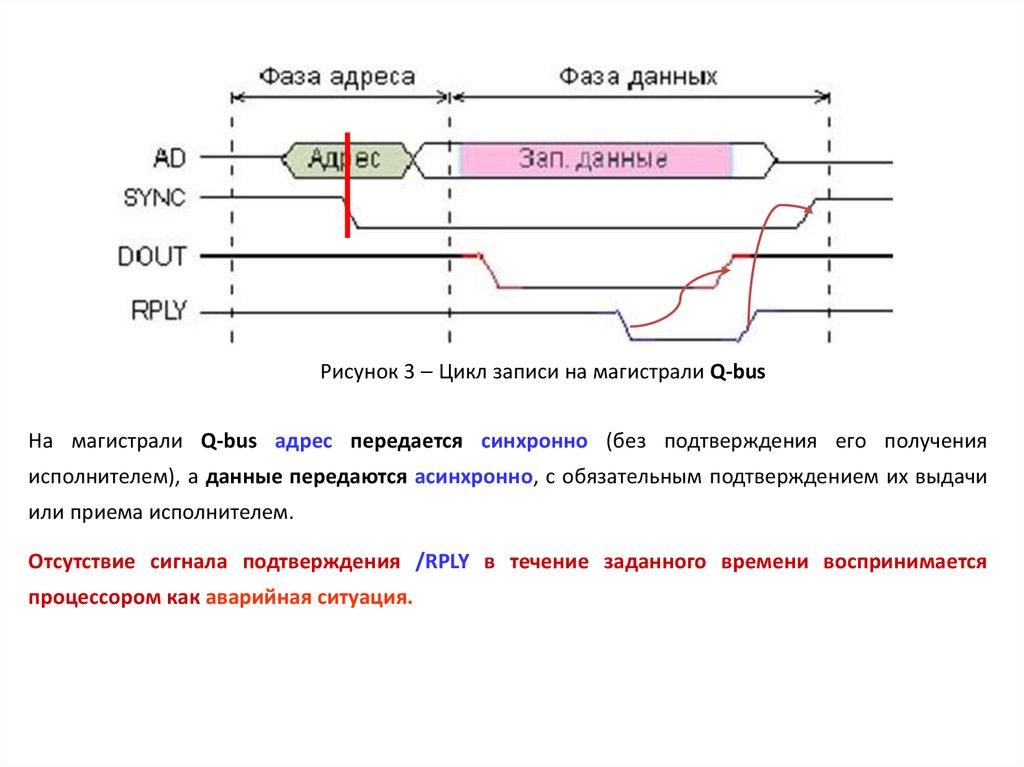
Рисунок 3 Цикл записи на магистрали Q-busНа магистрали Q-bus адрес передается синхронно (без подтверждения его получения
исполнителем), а данные передаются асинхронно, с обязательным подтверждением их выдачи
или приема исполнителем.
Отсутствие сигнала подтверждения /RPLY в течение заданного времени воспринимается
процессором как аварийная ситуация.
7.
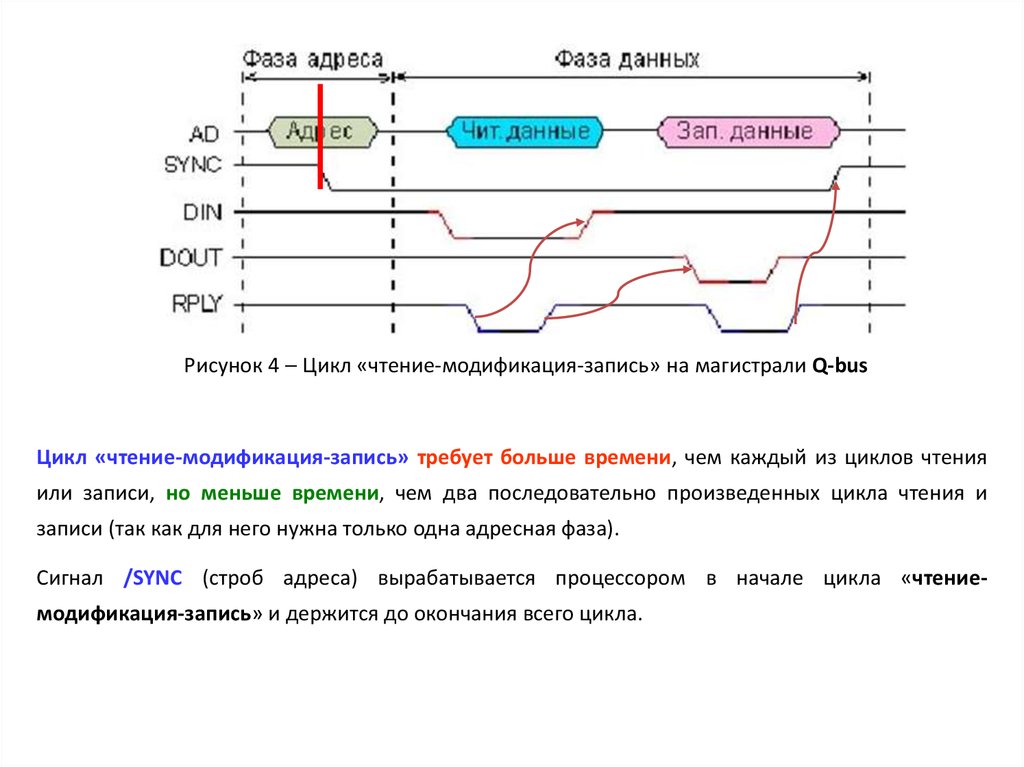
Рисунок 4 Цикл «чтение-модификация-запись» на магистрали Q-busЦикл «чтение-модификация-запись» требует больше времени, чем каждый из циклов чтения
или записи, но меньше времени, чем два последовательно произведенных цикла чтения и
записи (так как для него нужна только одна адресная фаза).
Сигнал /SYNC (строб адреса) вырабатывается процессором в начале цикла «чтениемодификация-запись» и держится до окончания всего цикла.
8.
Шины обмена данными ISAISA bus (от англ. Industry Standard Architecture) — 8- или 16-разрядная шина ввода-вывода IBM PCсовместимых компьютеров. Служит для подключения плат расширения стандарта ISA. Для
встроенных систем существует вариант компоновки шины ISA — шина PC/104. Электрически она
полностью совместима с шиной ISA, но отличается от неё конструкцией разъёмов.
В классическом варианте шина имела разрядность 8 бит данных и 20 бит адреса, 8 линий питания
и представляла собой синхронную 8-битную шину с контролем четности и двухуровневыми
прерываниями (trigger-edge interrupts), при использовании которых устройства запрашивают
прерывания, изменяя состояние линии соответствующего IRQ с 0 на 1 или обратно. Такая
организация запросов прерываний позволяет использовать каждое прерывание только одному
устройству.
Единственными устройствами, управляющими шиной, были процессор и контроллер прямого
доступа к памяти на материнской плате.
Шина ISA превосходила потребности среднего пользователя образца 1984 года, а производители
плат расширения приняли ISA за стандарт. Такая популярность шины привела к тому, что слоты ISA
до сих пор присутствуют на многих системных платах промышленных компьютеров, и платы ISA до
сих производятся.
9.
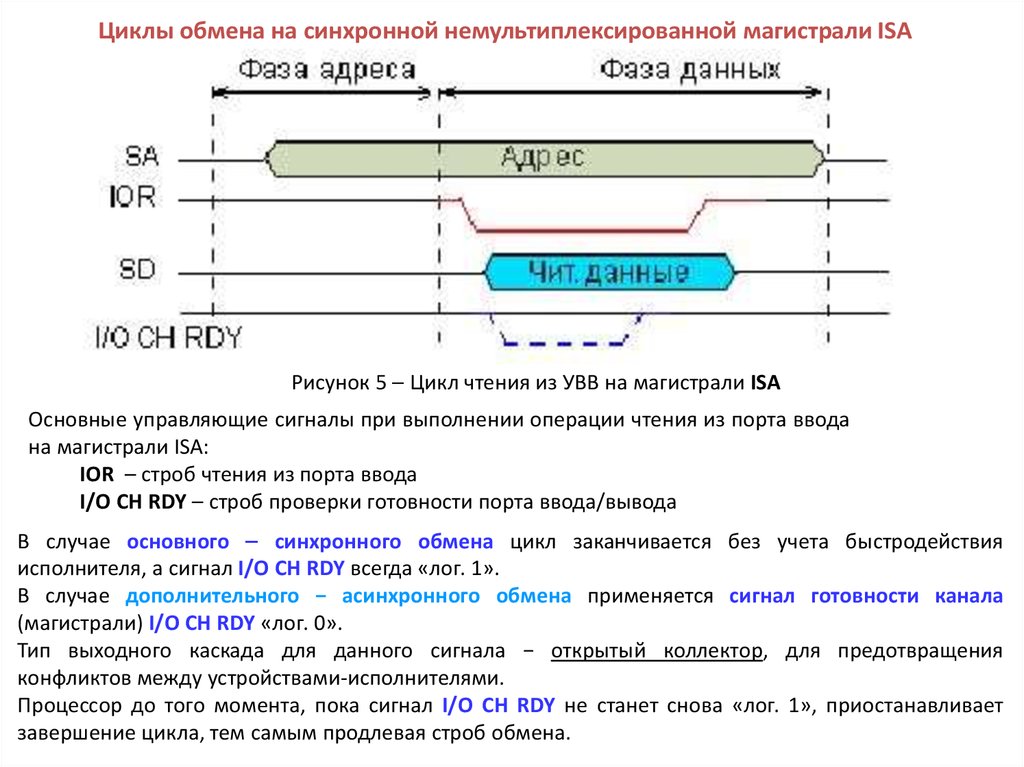
Циклы обмена на синхронной немультиплексированной магистрали ISAРисунок 5 Цикл чтения из УВВ на магистрали ISA
Основные управляющие сигналы при выполнении операции чтения из порта ввода
на магистрали ISA:
IOR – строб чтения из порта ввода
I/O CH RDY – строб проверки готовности порта ввода/вывода
В случае основного синхронного обмена цикл заканчивается без учета быстродействия
исполнителя, а сигнал I/O CH RDY всегда «лог. 1».
В случае дополнительного − асинхронного обмена применяется сигнал готовности канала
(магистрали) I/O CH RDY «лог. 0».
Тип выходного каскада для данного сигнала − открытый коллектор, для предотвращения
конфликтов между устройствами-исполнителями.
Процессор до того момента, пока сигнал I/O CH RDY не станет снова «лог. 1», приостанавливает
завершение цикла, тем самым продлевая строб обмена.
10.
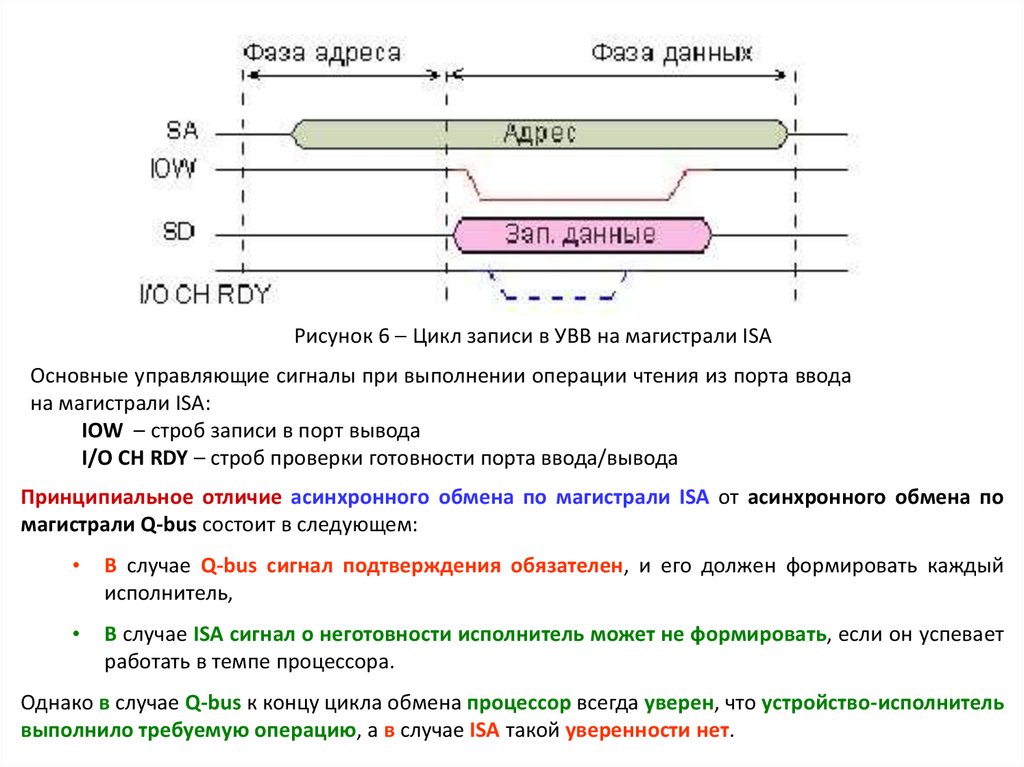
Рисунок 6 Цикл записи в УВВ на магистрали ISAОсновные управляющие сигналы при выполнении операции чтения из порта ввода
на магистрали ISA:
IOW – строб записи в порт вывода
I/O CH RDY – строб проверки готовности порта ввода/вывода
Принципиальное отличие асинхронного обмена по магистрали ISA от асинхронного обмена по
магистрали Q-bus состоит в следующем:
В случае Q-bus сигнал подтверждения обязателен, и его должен формировать каждый
исполнитель,
В случае ISA сигнал о неготовности исполнитель может не формировать, если он успевает
работать в темпе процессора.
Однако в случае Q-bus к концу цикла обмена процессор всегда уверен, что устройство-исполнитель
выполнило требуемую операцию, а в случае ISA такой уверенности нет.
11.
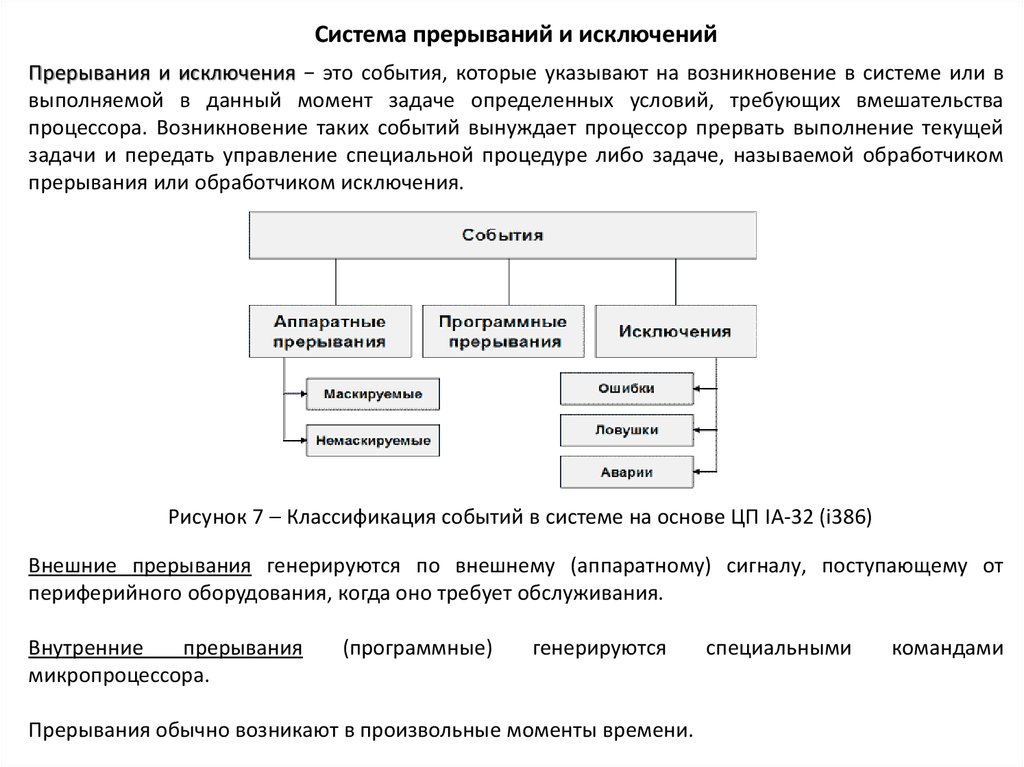
Система прерываний и исключенийПрерывания и исключения − это события, которые указывают на возникновение в системе или в
выполняемой в данный момент задаче определенных условий, требующих вмешательства
процессора. Возникновение таких событий вынуждает процессор прервать выполнение текущей
задачи и передать управление специальной процедуре либо задаче, называемой обработчиком
прерывания или обработчиком исключения.
Рисунок 7 Классификация событий в системе на основе ЦП IA-32 (i386)
Внешние прерывания генерируются по внешнему (аппаратному) сигналу, поступающему от
периферийного оборудования, когда оно требует обслуживания.
Внутренние
прерывания
микропроцессора.
(программные)
генерируются
Прерывания обычно возникают в произвольные моменты времени.
специальными
командами
12.
Прерывания делятся на аппаратные и программныеАппаратные прерывания используются для организации взаимодействия с внешними
устройствами. Запросы аппаратных прерываний поступают на специальные входы
микропроцессора.
Они бывают:
скрытые (маскируемые), процессор может не откликаться на факт запроса
на обслуживание прерывания;
открытые (немаскируемые), процессор не может не откликнуться на факт
запроса на обслуживание прерывания;
Программные прерывания вызываются следующими ситуациями:
особый случай (исключение), возникший при выполнении команды и
препятствующий нормальному продолжению программы (переполнение,
нарушение защиты памяти, отсутствие нужной страницы в оперативной памяти
и т.п.);
наличие в программе специальной команды прерывания INT n (RST n),
используемой
обычно
программистом
при
обращениях
к
специальным
функциям операционной системы (API) для ввода-вывода информации.
Каждому запросу прерывания в компьютере присваивается свой номер, который
используется для определения адреса первой команды подпрограммы обработчика
прерывания.
13.
При поступлении запроса прерывания компьютер выполняет следующую последовательностьдействий:
Аппаратная часть
1. определение наиболее приоритетного незамаскированного запроса на прерывание (если
одновременно поступило несколько запросов);
2. определение типа выбранного запроса;
3. сохранение текущего состояния счетчика команд и регистра флагов;
4. определение адреса обработчика прерывания по типу прерывания и передача управления
первой команде этого обработчика;
Программная часть
5. выполнение программы − обработчика прерывания;
Аппаратная часть
6. восстановление сохраненных значений счетчика команд и регистра флагов прерванной
программы;
Программная часть
7. продолжение выполнения прерванной программы.
Задача программиста − составить программу − обработчик прерывания, которая выполняла бы
действия, связанные с обслуживанием запроса данного типа.
Программа-обработчик должна начинаться с сохранения состояния тех регистров процессора,
которые будут ею изменяться, и заканчиваться восстановлением состояния этих регистров.
Программа-обработчик должна завершаться специальной командой, указывающей процессору
на необходимость возврата в прерванную программу.
14.
Исключения это внутренние события процессора, которые сигнализируют о каких-либоошибочных условиях при выполнении той или иной инструкции.
Источниками исключений являются три типа событий:
– генерируемые программой исключения, позволяющие программе контролировать
определенные условия в заданных точках программы (например, INT0 – проверка на
переполнение, INT3 – контрольная точка, BOUND – проверка границ массива);
– исключения машинного контроля (#18), возникающие в процессе контроля операций
внутри чипа и транзакций на шине процессора (Pentium 6 и Pentium 4);
– обнаруженные процессором ошибки в программе (например, деление на ноль, нарушение
правил защиты области данных, отсутствие страницы и т.п.)
Исключения процессора, в зависимости от способа генерации и возможности рестарта
(перезапуска) вызвавшей исключение команды, подразделяются на нарушения, ловушки и аварии.
Нарушение (отказ) – это исключение, которое обнаруживается либо перед исполнением, либо во
время исполнения команды. При этом процессор переходит в состояние, позволяющее
осуществить рестарт команды. В качестве адреса возврата в стек обработчика исключения
заносится адрес вызвавшей исключение команды.
Ловушка возникает на границе команд сразу же после команды, вызвавшей это исключение.
Например, если ловушка сработала на команде безусловного перехода JMP, то в стеке
запоминаются значения регистров CS и EIP, указывающие на ссылку команды JMP.
Авария не позволяет осуществить рестарт программы, и зачастую нельзя точно локализовать
команду, вызвавшую это исключение. Исключения типа "авария" генерируются при обнаружении
серьезных ошибок, таких как неразрешенные или несовместимые значения в системных таблицах
или аппаратные сбои.
15.
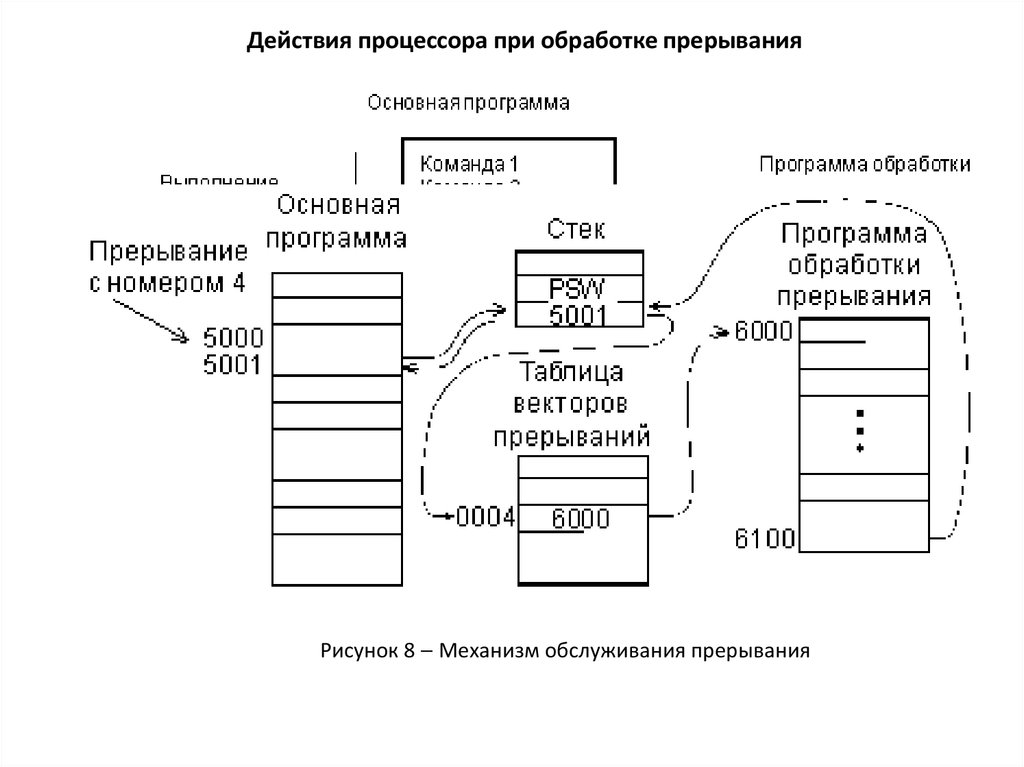
Действия процессора при обработке прерыванияRETI
Рисунок 8 Механизм обслуживания прерывания
16.
Обмен по прерываниям в микропроцессорной системеМеханизм прерывания используются тогда, когда необходима реакция микропроцессорной
системы на какое-то внешнее событие, например, приход внешнего сигнала.
Существуют два метода реакции микропроцессора на внешние события:
1. Метод опроса (polling) специального бита (флага) в специальном регистре. Используется
программный способ постоянного контроля факта наступления события (например,
установка или сброс соответствующего флага). Реализуется в микропроцессорной системе
постоянным считыванием информации из устройства ввода/вывода, которое связано с тем
внешним устройством, на поведение которого необходимо срочно реагировать.
2. Метод запроса с помощью прерывания, то есть насильственного перевода процессора с
выполнения текущей программы на выполнение экстренно необходимой программы.
Получив запрос на обслуживане прерывания от внешнего устройства (часто называемый
IRQ — Interrupt ReQuest), процессор заканчивает выполнение текущей команды и
переходит к специальной программе обработки прерывания. Закончив выполнение
программы обработки прерывания, процессор возвращается к исходной (прерванной)
программе с той точки, где его прервали.
17.
Типы прерыванийПрерываний в микропроцессорной системе обычно бывает много. Поэтому процессору
необходима информация о номере (адресе или векторе) конкретного прерывания.
Прерывания в микропроцессорных системах бывают двух основных типов:
1. векторные прерывания;
2. радиальные прерывания.
Векторные прерывания обеспечивают системе большую гибкость, так как в системе их может
быть очень много. Однако, они требуют проведения отдельного цикла чтения вектора (номера)
обработчика прерывания по магистрали, что приводит к усложнению аппаратурных узлов во
всех устройствах запрашивающих прерывания для обслуживания циклов безадресного чтения.
Радиальные прерывания не требуют никакого цикла обмена по магистрали, но требуется
введение в систему специального устройства – контроллера прерываний и, следовательно,
введение отдельной дополнительной линии в шину управления системной магистрали для
каждого радиального прерывания .
В системе обычно не очень много (от 1 до 16), но работать с радиальными прерываниями проще,
так как все сводится только к выработке единственного сигнала запроса прерывания IRQ, и
никаких циклов обмена по магистрали не требуется.
18.
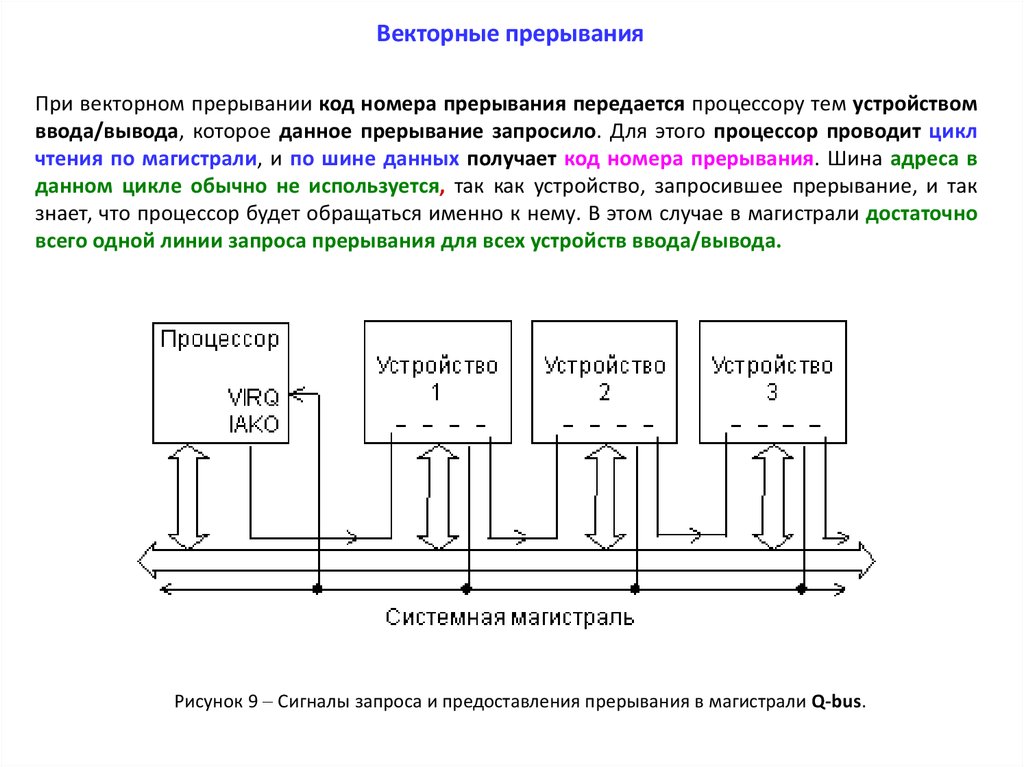
Векторные прерыванияПри векторном прерывании код номера прерывания передается процессору тем устройством
ввода/вывода, которое данное прерывание запросило. Для этого процессор проводит цикл
чтения по магистрали, и по шине данных получает код номера прерывания. Шина адреса в
данном цикле обычно не используется, так как устройство, запросившее прерывание, и так
знает, что процессор будет обращаться именно к нему. В этом случае в магистрали достаточно
всего одной линии запроса прерывания для всех устройств ввода/вывода.
Рисунок 9 Сигналы запроса и предоставления прерывания в магистрали Q-bus.
19.
Рисунок 10 Цикл запроса/предоставления векторного прерывания на магистрали Q-bus/VIRQ – запрос прерывания. Тип выходного каскада для этого сигнала – ОК, чтобы избежать
конфликтов между запрашивающими прерывания устройствами.
/DIN – строб чтения данных
IAKO – сигнал подтверждения прерывания последовательно проходит через все устройства, которые
могут запрашивать прерывания. Устройство запросившее прерывание, не пропускает через себя этот
сигнал. Если прерывания одновременно запросили два или более устройств, то сигнал
предоставления прерывания получит только то устройство, которое ближе к процессору. Такой
механизм разрешения конфликтов называется иногда географическим приоритетом (или
цепочечным приоритетом, Daisy Chain).
Затем процессор проводит цикл безадресного чтения номера прерывания. В ответ на полученные
сигналы /DIN и IAKO устройство, которому предоставлено прерывание, должно выдать на шину
адреса/данных AD код номера прерывания (адрес вектора прерывания) и выставить сигнал
подтверждения /RPLY. Процессор читает код номера прерывания и заканчивает цикл безадресного
чтения снятием сигналов /DIN и IAKO
20.
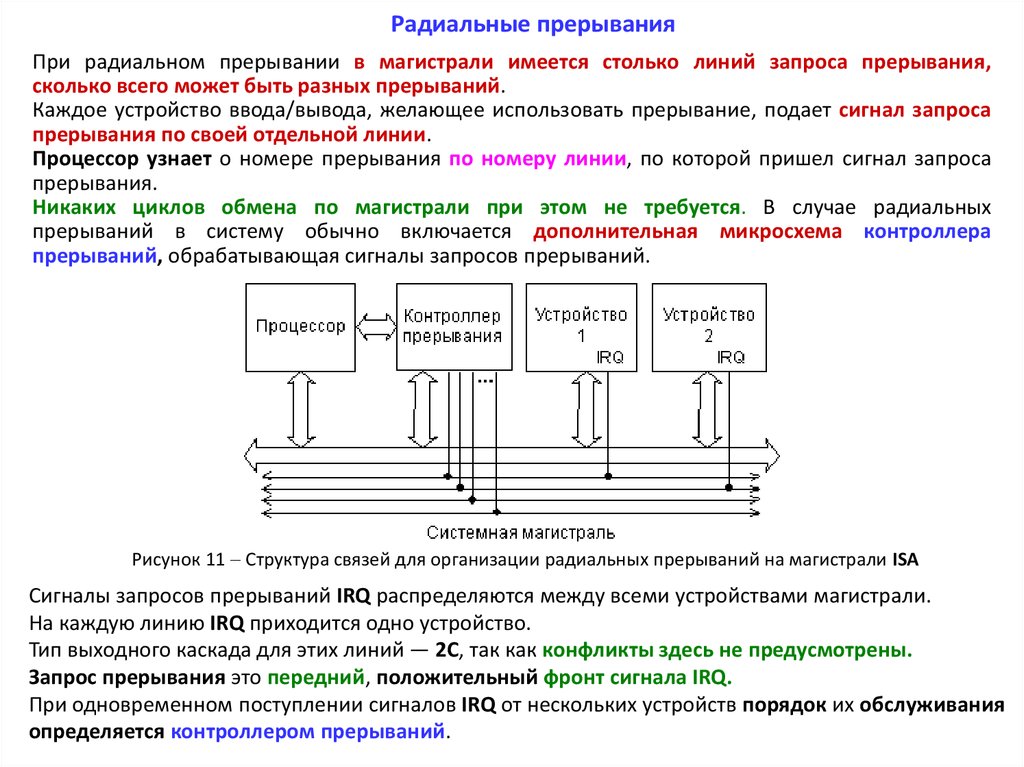
Радиальные прерыванияПри радиальном прерывании в магистрали имеется столько линий запроса прерывания,
сколько всего может быть разных прерываний.
Каждое устройство ввода/вывода, желающее использовать прерывание, подает сигнал запроса
прерывания по своей отдельной линии.
Процессор узнает о номере прерывания по номеру линии, по которой пришел сигнал запроса
прерывания.
Никаких циклов обмена по магистрали при этом не требуется. В случае радиальных
прерываний в систему обычно включается дополнительная микросхема контроллера
прерываний, обрабатывающая сигналы запросов прерываний.
Рисунок 11 Структура связей для организации радиальных прерываний на магистрали ISA
Сигналы запросов прерываний IRQ распределяются между всеми устройствами магистрали.
На каждую линию IRQ приходится одно устройство.
Тип выходного каскада для этих линий — 2С, так как конфликты здесь не предусмотрены.
Запрос прерывания это передний, положительный фронт сигнала IRQ.
При одновременном поступлении сигналов IRQ от нескольких устройств порядок их обслуживания
определяется контроллером прерываний.
21.
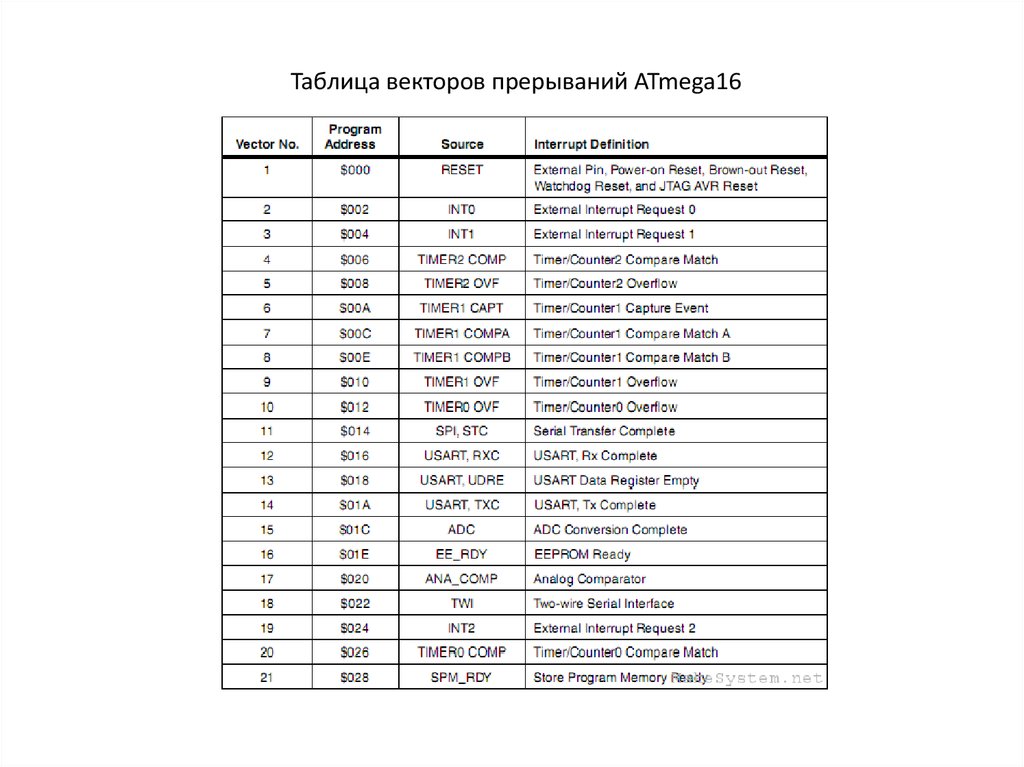
Таблица векторов прерываний ATmega1622.
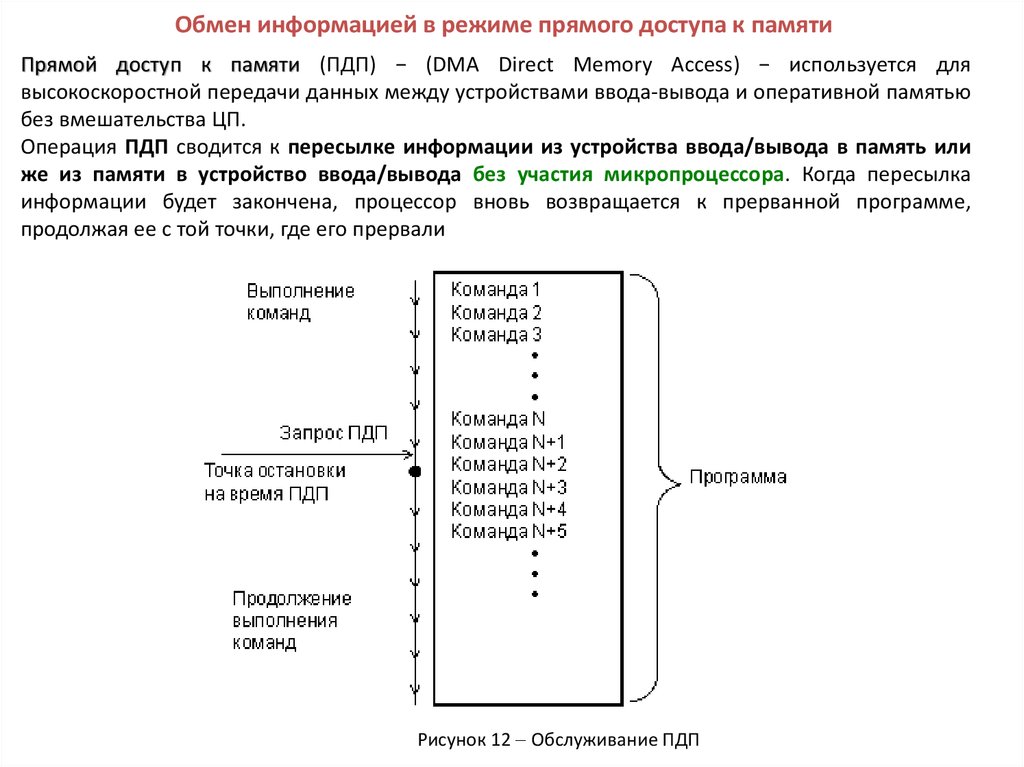
Обмен информацией в режиме прямого доступа к памятиПрямой доступ к памяти (ПДП) − (DMA Direct Memory Access) − используется для
высокоскоростной передачи данных между устройствами ввода-вывода и оперативной памятью
без вмешательства ЦП.
Операция ПДП сводится к пересылке информации из устройства ввода/вывода в память или
же из памяти в устройство ввода/вывода без участия микропроцессора. Когда пересылка
информации будет закончена, процессор вновь возвращается к прерванной программе,
продолжая ее с той точки, где его прервали
Рисунок 12 Обслуживание ПДП
23.
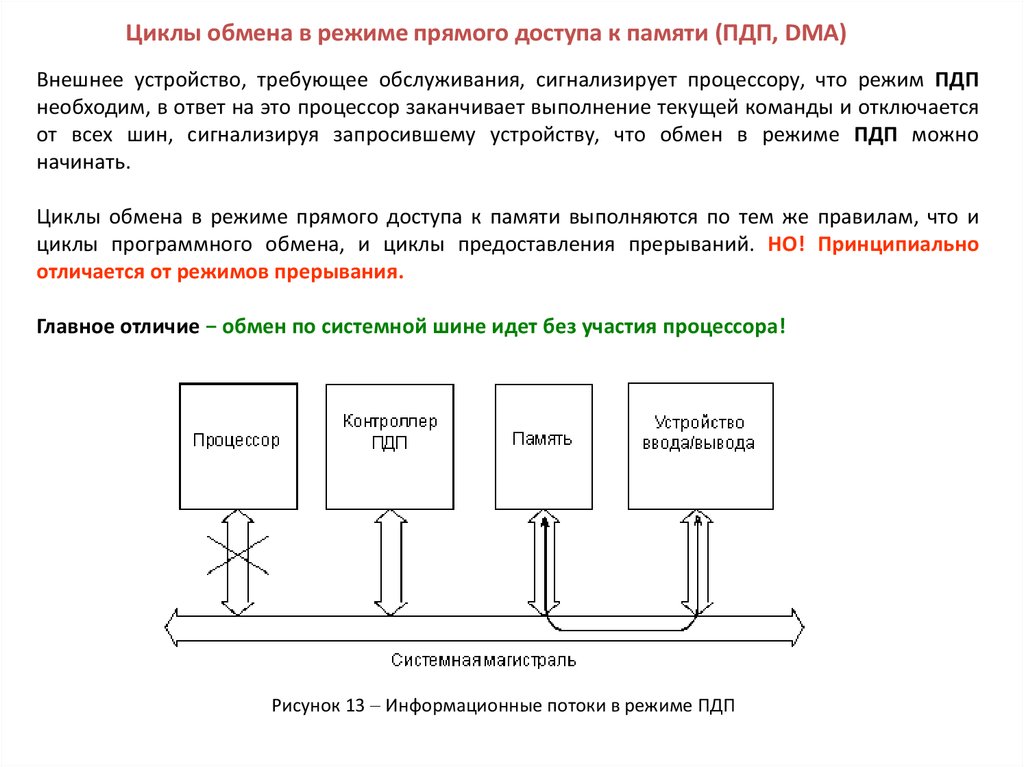
Циклы обмена в режиме прямого доступа к памяти (ПДП, DMA)Внешнее устройство, требующее обслуживания, сигнализирует процессору, что режим ПДП
необходим, в ответ на это процессор заканчивает выполнение текущей команды и отключается
от всех шин, сигнализируя запросившему устройству, что обмен в режиме ПДП можно
начинать.
Циклы обмена в режиме прямого доступа к памяти выполняются по тем же правилам, что и
циклы программного обмена, и циклы предоставления прерываний. НО! Принципиально
отличается от режимов прерывания.
Главное отличие − обмен по системной шине идет без участия процессора!
Рисунок 13 Информационные потоки в режиме ПДП
24.
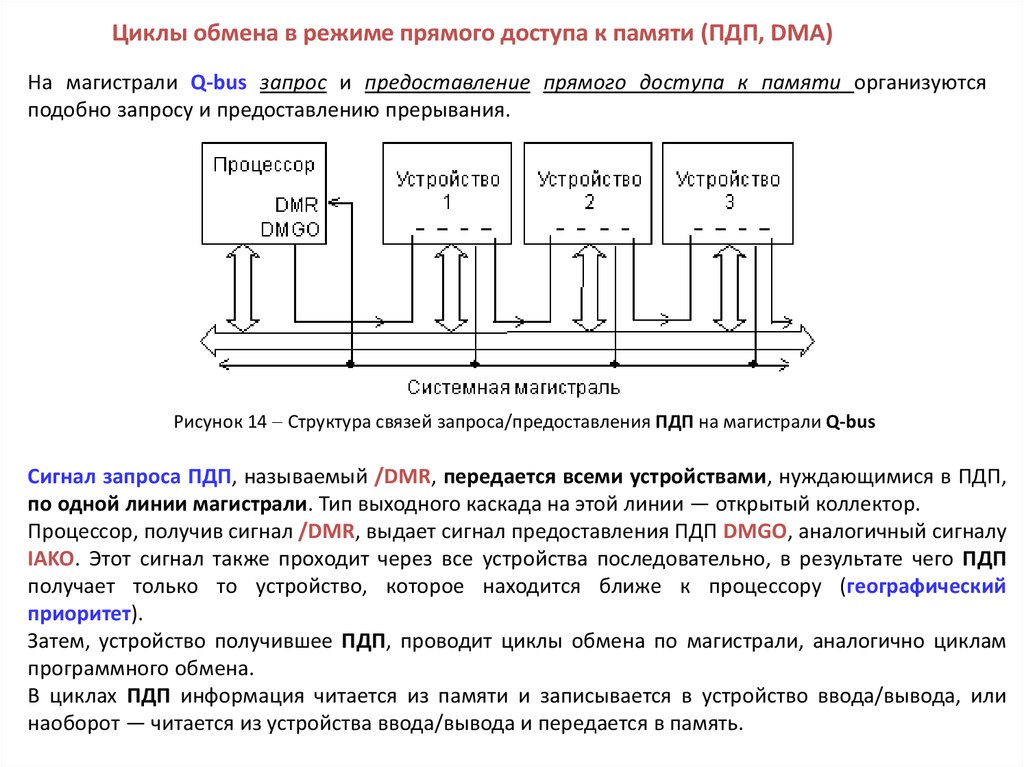
Циклы обмена в режиме прямого доступа к памяти (ПДП, DMA)На магистрали Q-bus запрос и предоставление прямого доступа к памяти организуются
подобно запросу и предоставлению прерывания.
Рисунок 14 Структура связей запроса/предоставления ПДП на магистрали Q-bus
Сигнал запроса ПДП, называемый /DMR, передается всеми устройствами, нуждающимися в ПДП,
по одной линии магистрали. Тип выходного каскада на этой линии — открытый коллектор.
Процессор, получив сигнал /DMR, выдает сигнал предоставления ПДП DMGO, аналогичный сигналу
IAKO. Этот сигнал также проходит через все устройства последовательно, в результате чего ПДП
получает только то устройство, которое находится ближе к процессору (географический
приоритет).
Затем, устройство получившее ПДП, проводит циклы обмена по магистрали, аналогично циклам
программного обмена.
В циклах ПДП информация читается из памяти и записывается в устройство ввода/вывода, или
наоборот — читается из устройства ввода/вывода и передается в память.
25.
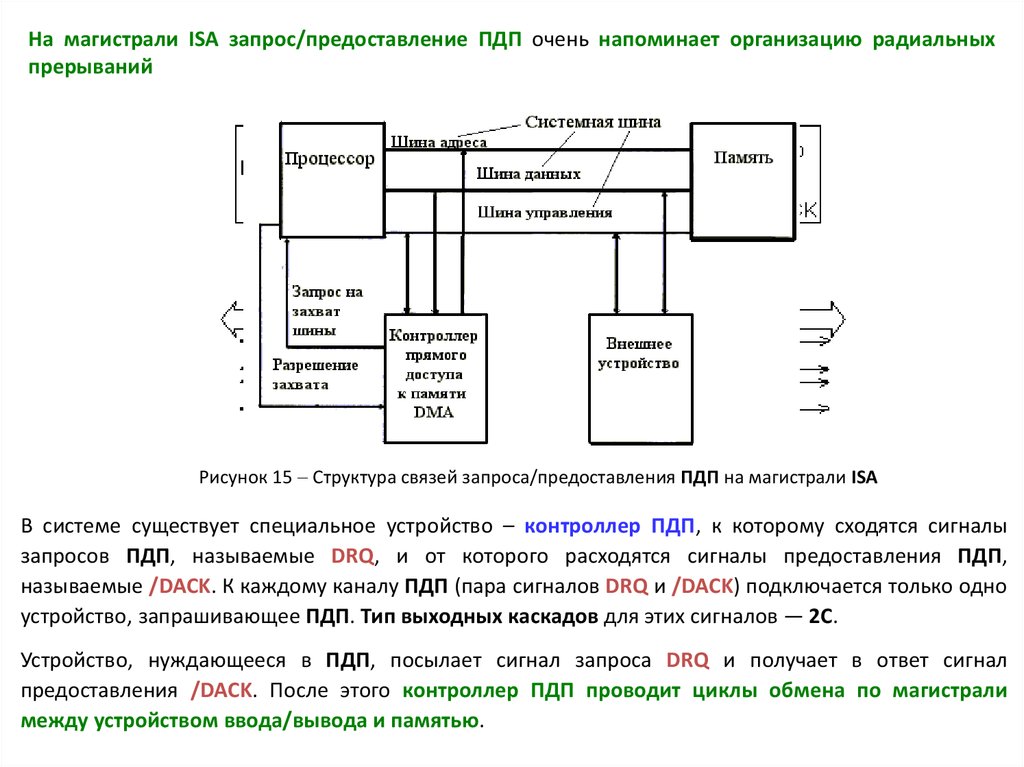
На магистрали ISA запрос/предоставление ПДП очень напоминает организацию радиальныхпрерываний
Рисунок 15 Структура связей запроса/предоставления ПДП на магистрали ISA
В системе существует специальное устройство – контроллер ПДП, к которому сходятся сигналы
запросов ПДП, называемые DRQ, и от которого расходятся сигналы предоставления ПДП,
называемые /DACK. К каждому каналу ПДП (пара сигналов DRQ и /DACK) подключается только одно
устройство, запрашивающее ПДП. Тип выходных каскадов для этих сигналов — 2С.
Устройство, нуждающееся в ПДП, посылает сигнал запроса DRQ и получает в ответ сигнал
предоставления /DACK. После этого контроллер ПДП проводит циклы обмена по магистрали
между устройством ввода/вывода и памятью.
26.
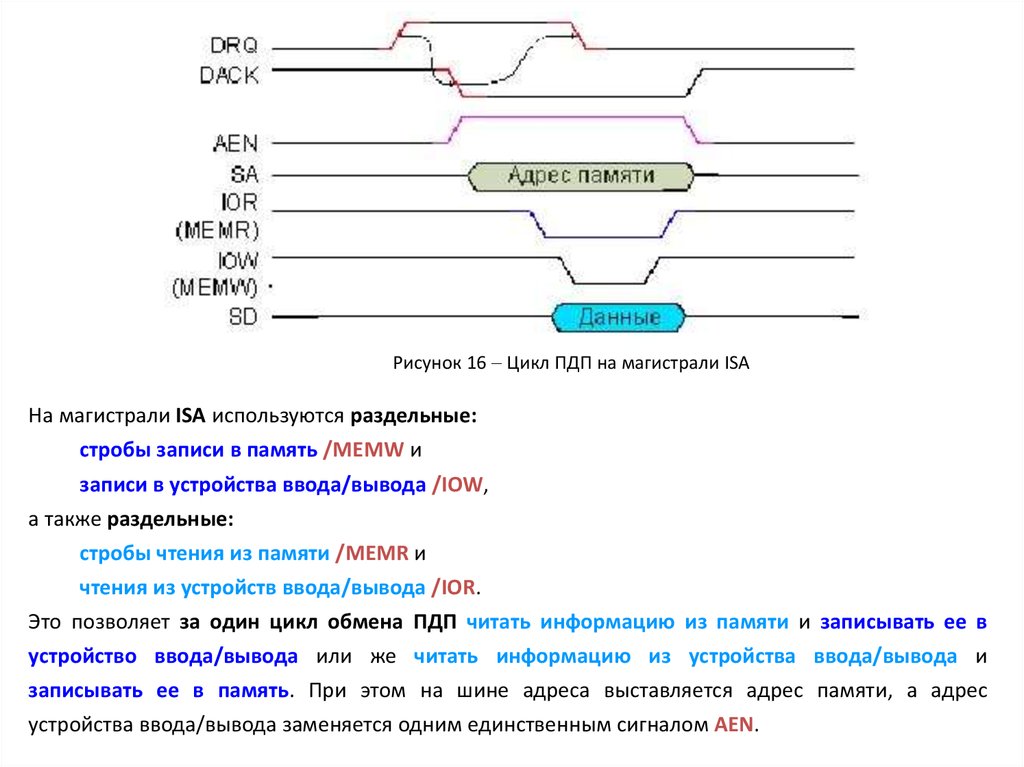
Рисунок 16 Цикл ПДП на магистрали ISAНа магистрали ISA используются раздельные:
стробы записи в память /MEMW и
записи в устройства ввода/вывода /IOW,
а также раздельные:
стробы чтения из памяти /MEMR и
чтения из устройств ввода/вывода /IOR.
Это позволяет за один цикл обмена ПДП читать информацию из памяти и записывать ее в
устройство ввода/вывода или же читать информацию из устройства ввода/вывода и
записывать ее в память. При этом на шине адреса выставляется адрес памяти, а адрес
устройства ввода/вывода заменяется одним единственным сигналом AEN.
27.
Теоретически обмен с помощью ПДП может обеспечить более высокую скорость передачиинформации, чем программный обмен, так как процессор может передавать данные медленнее,
чем специализированный контроллер ПДП.
Однако на практике это преимущество реализуется далеко не всегда.
Как и в случае прерываний, реакция на внешнее событие при ПДП существенно медленнее, чем
при программном режиме.
Скорость обмена в режиме ПДП обычно ограничена возможностями магистрали.
Рациональное использование прямого доступа к памяти (ПДП) позволяет существенно ускорить
работу программ, в ходе выполнения которых необходимы регулярные пересылки массивов
данных между модулями микроконтроллера. Ускорение происходит как за счёт большой скорости
пересылки, так и за счёт освобождения от участия в ней процессора, который в это время может
выполнять другие фрагменты программы.
Одновременное функционирование в системе нескольких активных элементов может приводить к
конфликтам между ними при одновременном обращении к одному и тому же пассивному
элементу. Результат конфликта один остановка работы обоих конфликтующих элементов и
обычно вычислительного процесса в целом
Доступные для обращений со стороны нескольких активных элементов пассивные элементы
принято именовать общими ресурсами вычислительной системы. Типичный пример – память.
Для предотвращения конфликтов шину доступа к общему ресурсу оборудуют арбитром шины, в
который заложена шкала приоритетов всех возможных обращений к этому ресурсу.
Программные меры предотвращения конфликтов сводятся к такой организации вычислительного
процесса, при которой продолжительность занятия общего ресурса каждым активным элементом
минимальна, в результате чего вероятность конфликта предельно снижена.
28.
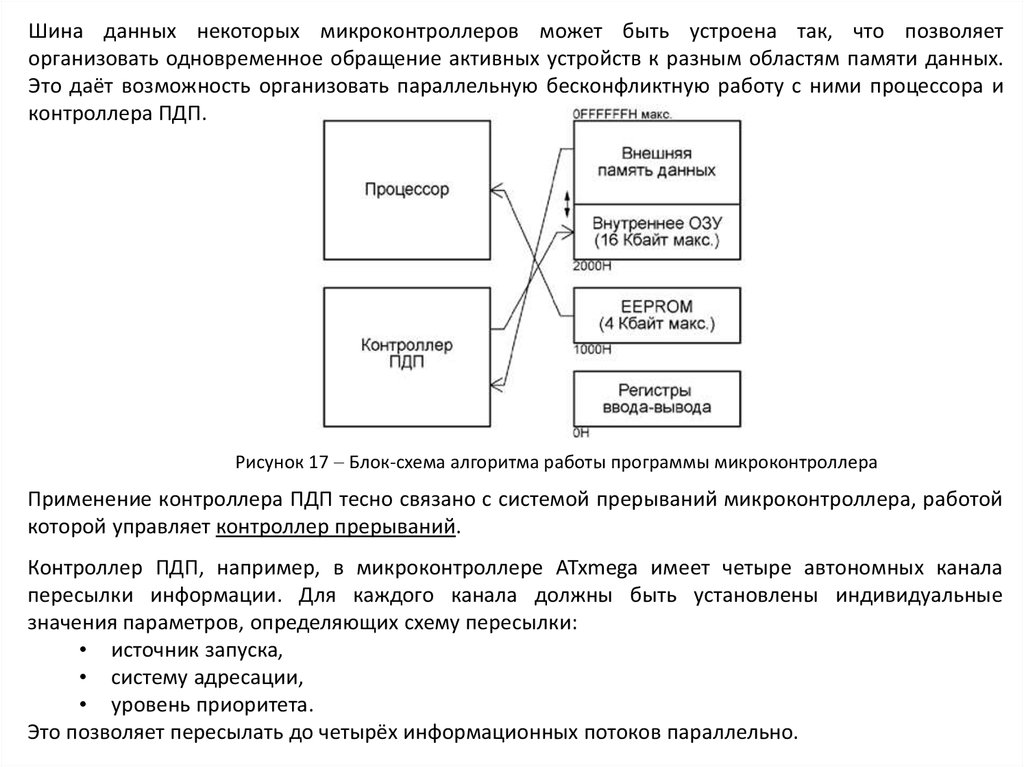
Шина данных некоторых микроконтроллеров может быть устроена так, что позволяеторганизовать одновременное обращение активных устройств к разным областям памяти данных.
Это даёт возможность организовать параллельную бесконфликтную работу с ними процессора и
контроллера ПДП.
Рисунок 17 Блок-схема алгоритма работы программы микроконтроллера
Применение контроллера ПДП тесно связано с системой прерываний микроконтроллера, работой
которой управляет контроллер прерываний.
Контроллер ПДП, например, в микроконтроллере ATxmega имеет четыре автономных канала
пересылки информации. Для каждого канала должны быть установлены индивидуальные
значения параметров, определяющих схему пересылки:
• источник запуска,
• систему адресации,
• уровень приоритета.
Это позволяет пересылать до четырёх информационных потоков параллельно.
29.
Пересылка массива информации по каналу ПДП называется транзакцией.Транзакция (max 16 Мб) выполняется блоками (max 64 кб), а передача блока, в свою очередь,
может происходить пакетами из одного, двух, четырёх или восьми байтов.
При блочной схеме пересылки контроллер ПДП захватывает шину на всё время передачи блока,
при пакетной только на время передачи пакета. Столь сложная структура транзакции позволяет с
минимальными простоями обслуживать обращения процессора и контроллера ПДП к одной и той
же области памяти.
Пример. Пусть в ходе выполнения некоторой программы контроллер ПДП должен переслать
последовательность результатов работы АЦП в ОЗУ. Причём АЦП выдаёт новый однобайтовый
результат каждую микросекунду, а всего нужно переслать 2000 результатов (выборок размером 1
байт каждая). Если эту транзакцию осуществить одним блоком такого объёма, то контроллер ПДП,
получив доступ к ОЗУ, не освободит его до завершения передачи всего блока. Поэтому в течение
2000 мкс ОЗУ будет недоступно процессору.
Это неразумно, поскольку между пересылками по каналу ПДП двух смежных байтов проходит 1 мкс, а
операция записи байта в ОЗУ выполняется за один машинный такт (около 0,03 мкс при тактовой
частоте 32 МГц). Другими словами, лишь 3 % времени транзакции ОЗУ будет занято операциями
записи, а в течение оставшихся 97 % будет бесполезно простаивать, оставаясь недоступным для
процессора. Ему придётся ждать завершения транзакции. Понятно, что это сильно замедлит
работу программы.
В рассматриваемом случае целесообразно настроить контроллер ПДП на пакетную передачу,
задав размер пакета 1 байт. Контроллер ПДП станет захватывать шину каждую микросекунду всего
на один машинный такт. В оставшуюся часть микросекунды ОЗУ будет свободно для обращений к
нему процессора.
30.
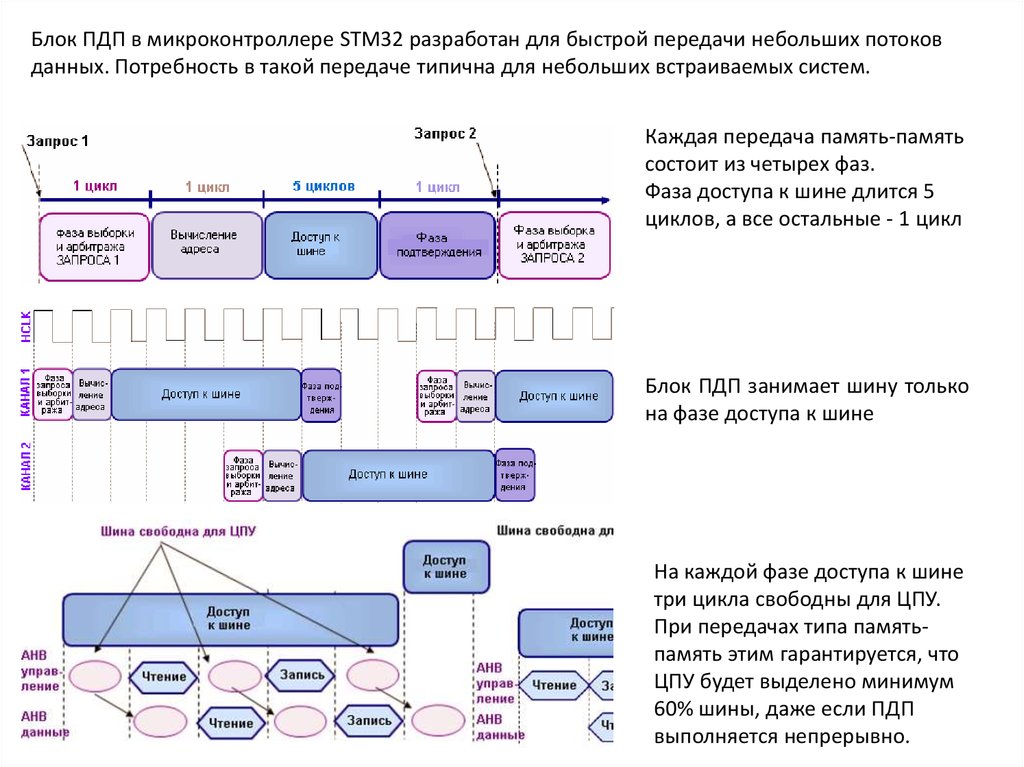
Блок ПДП в микроконтроллере STM32 разработан для быстрой передачи небольших потоковданных. Потребность в такой передаче типична для небольших встраиваемых систем.
Каждая передача память-память
состоит из четырех фаз.
Фаза доступа к шине длится 5
циклов, а все остальные - 1 цикл
Блок ПДП занимает шину только
на фазе доступа к шине
На каждой фазе доступа к шине
три цикла свободны для ЦПУ.
При передачах типа памятьпамять этим гарантируется, что
ЦПУ будет выделено минимум
60% шины, даже если ПДП
выполняется непрерывно.
31.
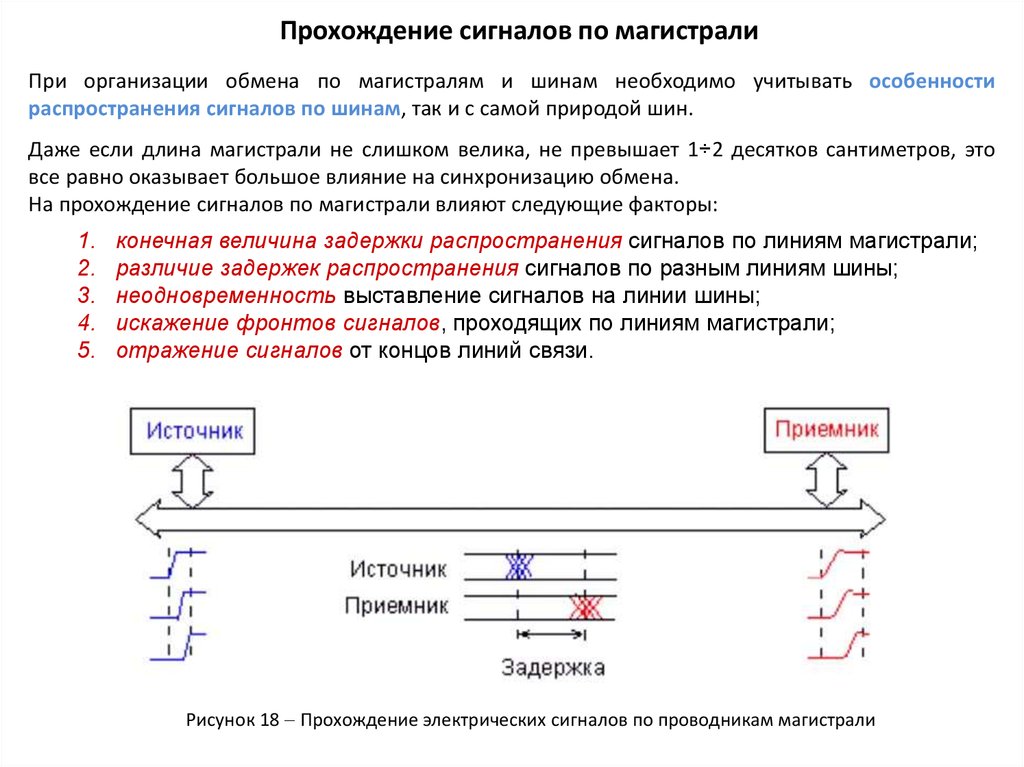
Прохождение сигналов по магистралиПри организации обмена по магистралям и шинам необходимо учитывать особенности
распространения сигналов по шинам, так и с самой природой шин.
Даже если длина магистрали не слишком велика, не превышает 1÷2 десятков сантиметров, это
все равно оказывает большое влияние на синхронизацию обмена.
На прохождение сигналов по магистрали влияют следующие факторы:
1.
2.
3.
4.
5.
конечная величина задержки распространения сигналов по линиям магистрали;
различие задержек распространения сигналов по разным линиям шины;
неодновременность выставление сигналов на линии шины;
искажение фронтов сигналов, проходящих по линиям магистрали;
отражение сигналов от концов линий связи.
Рисунок 18 Прохождение электрических сигналов по проводникам магистрали
32.
Для учета всех вышеперечисленных факторов разработчики стандартных магистралей обменаи стандартных протоколов обмена всегда закладывают необходимые задержки между
сигналами, участвующими в обмене, причём, задержки между сигналами выбираются таким
образом, чтобы устройство, которому адресован тот или иной сигнал, имело достаточно времени
для его обработки.
Опасно, не изменяя протокола обмена, пытаться увеличить длину магистрали, увеличивая
тем самым задержки распространения сигналов по линиям и шинам. Особенно чувствительны к
такого рода «модернизациям» синхронные магистрали, в которых не предусмотрено
обязательное подтверждение выполнения каждой операции.
Длительность фазы адреса в цикле обмена выбирается так, чтобы в течении адресной фазы
все сигналы всех разрядов кода адреса, пусть даже и сформированные процессором не
одновременно, должны дойти до устройства-исполнителя по своим проводам шины. А устройствоисполнитель должно этот код адреса принять и обработать (то есть отличить свой адрес от чужого).
Длительность фазы данных в цикле чтения должна выбираться такой, чтобы устройствоисполнитель успело получить строб чтения и выдать код читаемых данных на шину данных. Затем
этот код должен успеть дойти до процессора и процессор должен успеть его прочитать. После чего
процессор снимает сигнал строба чтения, этот задний фронт сигнала доходит с задержкой до
устройства-исполнителя, которое также с задержкой снимает свой код данных. Аналогично и в
цикле записи.
33.
Для улучшения формы сигналов, распространяющихся по магистрали, иногда применяютоконечные согласователи (терминаторы) на концах линий магистрали.
Особенно важно их применение в случае, когда допустимая длина магистрали превышает
несколько метров. Или частота сигналов передаваемых по шине превышает несколько сотен МГц.
Например, в случае магистрали Q-bus применяются два типа согласователей: 120-омный и 250омный.
Рисунок 19 Оконечные согласователи на магистрали Q-bus
Включение согласователей предъявляет дополнительные требования к нагрузочной способности
передатчиков, работающих на линии магистрали.
Выходные каскады передатчиков, работающих на линии магистрали, должны обеспечивать
высокие выходные токи, т.к. к магистрали может подключаться несколько устройств, каждое из
которых потребляет входной ток.
Типичные величины требуемых выходных токов магистральных передатчиков находятся в
пределах 20-30 мА.
Входные токи магистральных приемников должны быть малыми, чтобы не перегружать
передатчики. Типичные величины допустимых входных токов магистральных приемников лежат в
пределах 0,2-0,8 мА.