





















 Электроника
ЭлектроникаПохожие презентации:



")



")

")
Применение вычислительного конвейера и критерии его оптимизации. Лекция 12
1. Применение вычислительного конвейера и критерии его оптимизации
2.
Конвейер — способ организации вычислений, используемый в современныхпроцессорах и микроконтроллерах с целью повышения их производительности,
например, за счёт увеличения числа инструкций, выполняемых в единицу времени
(организация параллелизма на уровне исполнения инструкций).
Вычислительный конвейер — один из вариантов организации параллельной обработки
информации в микропроцессоре. Различные этапы вычислительного процесса
выполняются в отдельных узлах (ступенях конвейера), связанных последовательно друг
с другом так, чтобы обеспечить одновременное выполнение этих этапов.
Вычислительный конвейер один из наиболее перспективных структурных методов
повышения производительности, который получил самое широкое распространение в
быстродействующих вычислительных средствах.
Конвейеры классифицируют:— по функциональным возможностям;
— по структурной конфигурации.
Функциональные возможности
Однофункциональный конвейер — это конвейер, способный к вычислению базовой
функции только одного вида. Такой конвейер выполняет без изменений одни и те же
операции над каждым набором входных данных.
Многофункциональный конвейер — это конвейер, способный к вычислению функций
различных типов.
3.
Структурные конфигурации выделяют статические и динамические конвейеры.В конвейере статического типа
• время выполнения каждого этапа вычислительного процесса фиксировано и
не зависит от набора входных данных,
• на каждой ступени конвейера выполняется один и тот же набор
алгоритмических действий, а
• процесс обработки информации на данной ступени не зависит от результатов
вычислений на последующих ступенях конвейера.
Если хотя бы одно из вышеперечисленных условий не выполняется, то конвейер
является динамическим.
Однофункциональный конвейер, как правило, имеет статическую конфигурацию.
Такие конвейеры применяются, например, при построении вычислительных средств
цифровой обработки сигналов (ЦОС) на базе специализированных БИС –
процессоров DSP (digital signal processor), структура которых реализует естественный
параллелизм операторов преобразования. При этом на вход конвейера данные
поступают в структурированном виде и обрабатываются обычно итеративно.
Многофункциональный
динамический
конвейер
характерен
для
микропроцессоров с универсальной структурой, выполняющих широкий набор
команд.
4.
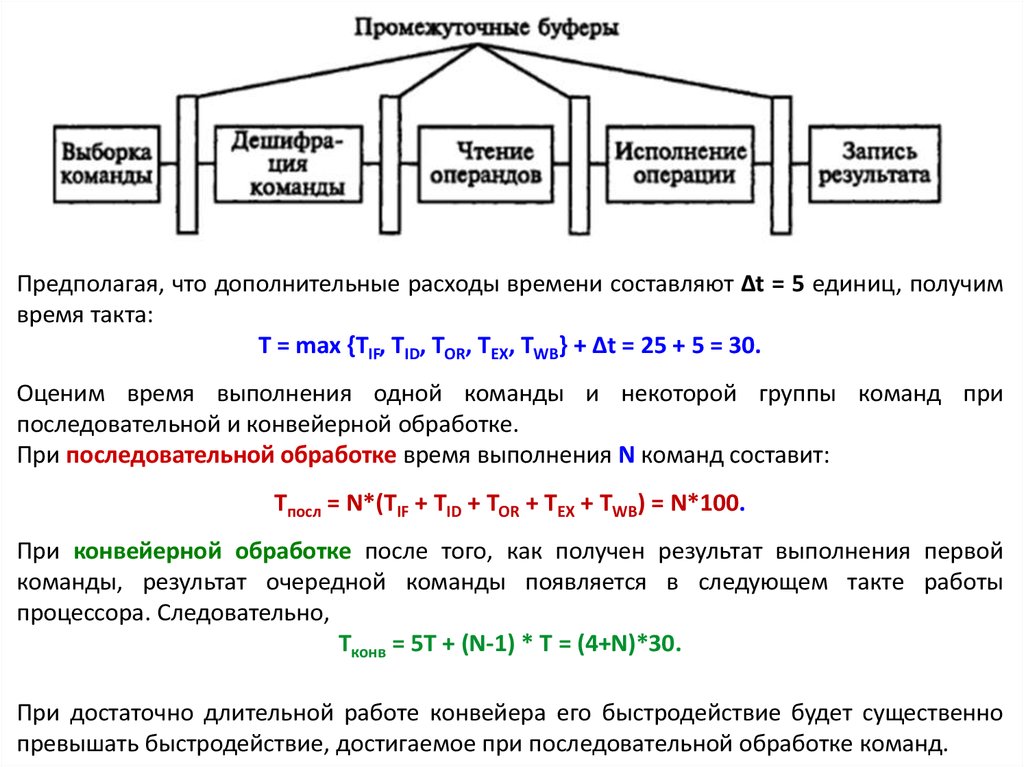
Принципы конвейерной обработки информацииВыполнение команды на примере пятиступенчатого конвейера процессора i486
складывается из следующих этапов:
1.
2.
3.
4.
5.
IF (Instruction Fetch) – считывание команды в процессор;
ID (Instruction Decoding) – декодирование команды;
OR (Operand Reading) – считывание операндов;
EX (Executing) – выполнение команды;
WB (Write Back) – запись результата.
Так как в каждом такте могут выполняться различные стадии обработки команд, то
длительность такта выбирается исходя из максимального времени выполнения всех
стадий.
Пример. Пусть для выполнения отдельных стадий обработки требуются следующие
затраты времени (в некоторых условных единицах):
TIF = 20, TID = 15, TOR = 20, TEX = 25, TWB = 20.
Задание. Вычислить время исполнения потока команд при последовательной и
конвейерной обработке.
Примечание. Необходимо также учитывать, что для передачи команды с одной стадии
на другую требуется определенное дополнительное время (Δt), связанное с записью
промежуточных результатов обработки в буферные регистры.
5.
Предполагая, что дополнительные расходы времени составляют Δt = 5 единиц, получимвремя такта:
T = max {TIF, TID, TOR, TEX, TWB} + Δt = 25 + 5 = 30.
Оценим время выполнения одной команды и некоторой группы команд при
последовательной и конвейерной обработке.
При последовательной обработке время выполнения N команд составит:
Tпосл = N*(TIF + TID + TOR + TEX + TWB) = N*100.
При конвейерной обработке после того, как получен результат выполнения первой
команды, результат очередной команды появляется в следующем такте работы
процессора. Следовательно,
Tконв = 5T + (N-1) * T = (4+N)*30.
При достаточно длительной работе конвейера его быстродействие будет существенно
превышать быстродействие, достигаемое при последовательной обработке команд.
6.
Эффект конвейеризации при выполнении 3-х командУвеличение скорости обработки данных будет тем больше, чем меньше длительность
такта конвейера и чем больше количество выполненных команд.
7.
СуперскалярностьСуперскалярность — архитектура вычислительного ядра, использующая несколько
конвейеров, которые могут содержать множество исполнительных блоков.
Планирование исполнения потока команд является динамическим и осуществляется
самим вычислительным ядром. Если в процессе работы команды, обрабатываемые
конвейером, не противоречат друг другу, и одна не зависит от результата другой, то
такое устройство может осуществить параллельное выполнение команд.
В суперскалярных системах решение о запуске инструкции на исполнение принимает
сам вычислительный модуль, а это требует много ресурсов.
8.
Суперскалярный процессор (англ. — superscalar processor) — процессор, способныйвыполнять несколько инструкция одновременно (поддерживающий так называемый
параллелизм на уровне инструкций) за счёт включения в состав его
вычислительного ядра нескольких одинаковых функциональных узлов (таких
как АЛУ, FPU, умножитель (integer multiplier), сдвигающее устройство (integer shifter) и
другие устройства). Планирование исполнения потока инструкций осуществляется
динамически вычислительным ядром (не статически компилятором).
Существуют разные способы увеличения производительности, которые могут
использоваться совместно, например:
Использование конвейера.
При использовании конвейера количество узлов остаётся прежним;
увеличение производительности достигается за счёт одновременной работы
узлов, ответственных за разные стадии обработки инструкций одного потока.
Суперскалярность (увеличение количества функциональных узлов процессора).
При использовании суперскалярности увеличение производительности
достигается за счёт одновременной работы большего количества одинаковых
узлов, независимо обрабатывающих инструкции одного потока (в том числе, и
большего количества конвейеров).
Многоядерность (увеличение количества ядер).
При использовании нескольких ядер каждое ядро выполняет инструкции
отдельного потока, может быть суперскалярным и/или конвейерным.
Многопроцессорность (увеличение количества процессоров).
При использовании нескольких процессоров каждый процессор может быть
многоядерным.
9.
В суперскалярном процессоре инструкция извлекается из потока инструкций(находящегося в памяти), определяется наличие или отсутствие зависимости
инструкции по данным от других инструкций, затем инструкция выполняется.
Одновременно, в течение одного такта, может выполняться несколько независимых
инструкций.
По классификации Флинна:
• одноядерные суперскалярные процессоры относят к группе
процессоров SISD (англ. single instruction stream, single data stream — один
поток инструкций, один поток данных).
• Подобные процессоры, но поддерживающие инструкции для работы с
короткими векторами, могут быть отнесены к
группе SIMD (англ. single instruction stream, multiple data streams — один поток
инструкций, несколько потоков данных).
• Многоядерные суперскалярные процессоры относят к
группе MIMD (англ. multiple instruction streams, multiple data streams —
несколько потоков инструкций, несколько потоков данных).
В суперскалярных процессорах задача распределения между вычислительными
конвейерами решается аппаратно. Это сильно усложняет конструкцию процессора, и
может быть чревато ошибками, поэтому, например, в процессорах с VLIW
архитектурой задача распределения решается во время компиляции и в инструкциях
явно указано, какое вычислительное устройство должно выполнять какую команду.
10.
Конфликты в вычислительном конвейере испособы минимизации их влияния на
производительность процессора
11.
Конфликты − это такие ситуации в конвейерной обработке, которые препятствуютвыполнению очередной команды в предназначенном для нее такте.
Конфликты снижают реальную производительность конвейера, которая могла бы
быть достигнута в идеальном случае.
Существуют три класса конфликтов:
1. Структурные конфликты, которые возникают из-за конфликтов по
вычислительным ресурсам, когда аппаратные средства не могут
поддерживать все возможные комбинации команд в режиме
одновременного выполнения с совмещением.
2. Конфликты по данным, возникающие в случае, когда выполнение одной
команды зависит от результата выполнения предыдущей команды.
3. Конфликты по управлению, которые возникают при конвейеризации
команд переходов и других команд, которые изменяют значение счетчика
команд.
Конфликты в конвейере приводят к необходимости приостановки выполнения
команд (pipeline stall).
В простейших конвейерах, если приостанавливается какая-либо команда, то все
следующие за ней команды также приостанавливаются. Команды, предшествующие
приостановленной, могут продолжать выполняться, но во время приостановки не
выбирается ни одна новая команда.
12.
Структурные конфликты и способы их минимизацииСовмещенный режим выполнения команд в общем случае требует конвейеризации
функциональных устройств и дублирования ресурсов для разрешения всех возможных
комбинаций команд в конвейере.
Если какая-нибудь комбинация команд не может быть принята из-за конфликта по
ресурсам, то говорят, что в машине имеется структурный конфликт.
Причины возникновения структурных конфликтов
1. В процессорах с не полностью конвейерными функциональными устройствами
время работы такого устройства может составлять несколько тактов
синхронизации конвейера. В этом случае последовательность команд, которые
используются в данном функциональном устройство, не может поступать в него в
каждом такте.
2. Недостаточное дублирование некоторых ресурсов, препятствует выполнению
произвольной последовательности команд в конвейере без его приостановки
Когда последовательность команд наталкивается на структурный конфликт, конвейер
приостанавливает выполнение одной из команд до тех пор, пока не станет
доступным требуемое устройство.
13.
Недостаточное дублирование некоторых ресурсовОдним из типичных примеров служит конфликт из-за доступа к запоминающим
устройствам.
Борьба с конфликтами такого рода проводится путем увеличения количества
однотипных функциональных устройств, которые могут одновременно выполнять одни
и те же или схожие функции.
Конфликты из-за исполнительных устройств обычно сглаживаются введением в состав
микропроцессора дополнительных блоков. Так, в микропроцессоре Pentium-4
предусмотрено 4 АЛУ для обработки целочисленных данных.
Методом преодоления структурного конфликта является введение суперскалярности, то
есть увеличение количества вычислительных конвейеров.
Недостатком суперскалярных процессоров является необходимость синхронного
продвижения команд в каждом из конвейеров.
Для обеспечения правильной работы суперскалярного процессора при возникновении
“затора” в одном из конвейеров ему нужно приостанавливать работу других,
параллельных конвейеров. В противном случае может нарушиться исходный порядок
завершения команд программы.
Такие приостановки
процессора.
существенно
снижают
быстродействие
суперскалярного
14.
Пример структурного конфликтаСтруктурный конфликт может возникать в процессоре у которого имеется единственный конвейер
памяти для команд и данных.
Когда одна из команд обращается к памяти за данными, то она может конфликтовать с выборкой
более поздней команды из памяти.
Чтобы разрешить эту ситуацию, нужно приостановить конвейер на один такт в момент, когда
происходит обращение к памяти за данными. Подобная приостановка часто называются
"конвейерным пузырем", поскольку такая приостановка проходит по конвейеру, занимая место и
время, но не выполняя никакой полезной работы.
Пример. Во 2-м такте обработка фиолетовой инструкции
задерживается, и на стадии декодирования в третьем
такте теперь находится “пузырёк”.
Все инструкции, следующие «за» фиолетовой
инструкцией, задерживаются на один такт, тогда как
инструкции, находящиеся «перед» фиолетовой
инструкцией, продолжают исполняться.
Очевидно, что наличие “пузырька” в конвейере даёт
суммарное время исполнения в 8 тактов вместо 7 на
схеме исполнения.
Пузырек в третьем такте обработки
задерживает исполнение
Исполнительные устройства должны выполнять какое-то действие на каждом такте. “Пузырьки”
являются способом создания задержки при обработке инструкции без прекращения работы
конвейера. При их выполнении не происходит полезной работы на стадиях выборки,
декодирования, исполнения и записи результата. Они могут быть выражены при помощи
инструкции NOP (not operation) ассемблера.
15.
Разрешение этой ситуации состоит в том, чтобы дать возможность выполнятьсякомандам в одном конвейере вне зависимости от ситуации в других конвейерах.
Но это приводит к неупорядоченному выполнению команд. При этом команды,
стоящие в программе позже, могут завершиться ранее команд, стоящих впереди.
Аппаратные средства микропроцессора должны гарантировать, что результаты
выполненных команд будут записаны в приемник в том порядке, в котором команды
записаны в программе. Для этого в микропроцессоре результаты этапа выполнения
команды обычно сохраняются в специальном буфере восстановления
последовательности команд. Запись результата очередной команды из этого буфера
в приемник результата проводится лишь после того, как выполнены все
предшествующие команды и записаны их результаты
16.
Конфликты по управлению возникают при конвейеризации команд переходов идругих команд, изменяющих значение счетчика команд.
Вероятность возникновения конфликта по управлению тем выше, чем больше
ступеней конвейера. В инженерных задачах примерно каждая шестая команда
является командой условного перехода, поэтому приостановки конвейера при
выполнении команд переходов до определения истинного направления перехода
существенно скажутся на производительности процессора
Наиболее эффективным методом снижения потерь от конфликтов по управлению
служит предсказание переходов.
При выполнении команды условного перехода специальный блок микропроцессора
(блок предсказания перехода) определяет наиболее вероятное направление перехода,
не дожидаясь формирования признаков, на основании анализа которых этот переход
реализуется
Если после формирования анализируемых признаков оказалось, что направление
перехода выбрано верно, все полученные результаты переписываются из буфера по
месту назначения, а выполнение программы продолжается в обычном порядке, иначе
буфер результатов очищается. Также очищается и конвейер, содержащий команды,
находящиеся на разных этапах обработки, следующие за командой условного
перехода. При этом аннулируются результаты всех уже выполненных этапов этих
команд и конвейер полностью перегружается новыми данными.
17.
Методы предсказания переходов делятся на: статические и динамические.При использовании статических методов до выполнения программы для каждой
команды условного перехода указывается направление наиболее вероятного
ветвления. Это указание делается или программистом с помощью специальных
средств, имеющихся в некоторых языках программирования, по опыту выполнения
аналогичных программ либо результатам тестового выполнения программы, или
программой-компилятором по заложенным в ней алгоритмам.
Методы динамического прогнозирования учитывают направления переходов, уже
реализовывавшиеся этой командой при выполнении программы. Например,
подсчитывается количество переходов, выполненных ранее по тому или иному
направлению, и на основании этого определяется направление перехода при
следующем выполнении данной команды.
В современных микропроцессорах вероятность
направления переходов достигает 90-95 %!
правильного
предсказания
18.
Динамической аппаратной технике планирования загрузки конвейера при наличиизависимостей по данным соответствует и динамическая техника для эффективной обработки
переходов. Эта техника используется для двух целей:
• для прогнозирования того, будет ли переход выполняемым, и
• для возможно более раннего нахождения целевой команды перехода.
Эта техника называется аппаратным прогнозированием переходов.
Простейшей схемой динамического прогнозирования направления условных переходов
является буфер прогнозирования условных переходов или таблица "истории" условных
переходов.
Буфер прогнозирования условных переходов представляет собой небольшую память,
адресуемую с помощью младших разрядов адреса команды перехода. Каждая ячейка этой
памяти содержит один бит, который говорит о том, был ли предыдущий переход
выполняемым или нет. Это простейший вид такого рода буфера. В нем отсутствуют теги, и он
оказывается полезным только для сокращения задержки перехода в случае, если эта
задержка больше, чем время, необходимое для вычисления значения целевого адреса
перехода. В действительности не известно, является ли прогноз корректным (этот бит в
соответствующую ячейку буфера могла установить совсем другая команда перехода, которая
имела то же самое значение младших разрядов адреса). Но это не имеет значения.
Прогноз это только предположение, которое рассматривается как корректное, и выборка
команд начинается по прогнозируемому направлению. Если же предположение окажется
неверным, бит прогноза инвертируется.
Такой буфер можно рассматривать как кэш-память, каждое обращение к которой является
попаданием, и производительность буфера зависит от того, насколько часто прогноз
применялся и насколько он оказался точным.
19.
Простая однобитовая схема прогноза имеет недостаточную производительность.Например, команда условного перехода в цикле, которая являлась выполняемым
переходом последовательно девять раз подряд, а затем однажды невыполняемым.
Направление перехода будет неправильно предсказываться при первой и при
последней итерации цикла.
Неправильный прогноз последней итерации цикла неизбежен, поскольку бит прогноза
будет говорить, что переход "выполняемый" (переход был девять раз подряд
выполняемым).
Неправильный прогноз на первой итерации происходит из-за того, что бит прогноза
инвертируется при предыдущем выполнении последней итерации цикла, поскольку в
этой итерации переход был невыполняемым.
Таким образом, точность прогноза для перехода, который выполнялся в 90% случаев,
составила только 80% (2 некорректных прогноза и 8 корректных).
В общем случае, для команд условного перехода, используемых для организации
циклов, переход является выполняемым много раз подряд, а затем один раз
оказывается невыполняемым.
Поэтому однобитовая схема прогнозирования будет неправильно предсказывать
направление перехода дважды (при первой и при последней итерации).
20.
Для исправления этого положения часто используется схема двухбитового прогноза.В двухбитовой схеме прогноз должен быть сделан неверно дважды, прежде чем он
изменится на противоположное значение.
Двухбитовая схема прогнозирования в действительности является частным случаем
более общей схемы, которая в каждой строке буфера прогнозирования имеет n-битовый
счетчик. Этот счетчик может принимать значения от 0 до 2n - 1.
Схема прогноза будет следующей:
• Если значение счетчика меньше, чем 2n-1 (точка на середине интервала), то
переход прогнозируется как выполняемый. Если направление перехода
предсказано правильно, к значению счетчика добавляется единица (если только
оно не достигло максимальной величины); если прогноз был неверным, из
значения счетчика вычитается единица.
• Если значение счетчика больше или равно 2n-1, то переход прогнозируется как
невыполняемый. Если направление перехода предсказано правильно, из
значения счетчика вычитается единица (если только не достигнуто значение 0);
если прогноз был неверным, к значению счетчика добавляется единица.
Исследования n-битовых схем прогнозирования показали, что двухбитовая схема
работает почти также хорошо, и поэтому в большинстве систем применяются
двухбитовые схемы прогноза, а не n-битовые.
Буфер прогнозирования переходов может быть реализован в виде небольшой
специальной кэш-памяти, доступ к которой осуществляется с помощью адреса команды
во время стадии выборки команды в конвейере, или как пара битов, связанных с
каждым блоком кэш-памяти команд и выбираемых с каждой командой.
21.
Конфликты по данным, остановы конвейера и реализация механизмаобходов
Конфликты по данным возникают в случаях, когда выполнение одной команды
зависит от результата выполнения предыдущей команды
1. Конфликты типа RAW (Read After Write): команда N (Next – последующая) пытается
прочитать операнд прежде, чем команда P (Previous – предыдущая) запишет на это
место свой результат. При этом команда N может получить некорректное старое
значение операнда.
Пусть выполняемые команды имеют следующий вид:
Команда P –
ADD R1, R2
; R1 = R1 + R2
Команда N –
SUB R3, R1
; R3 = R3 – R1
Уменьшение влияния конфликта типа RAW обеспечивается методом обхода
(продвижения) данных. В этом случае результаты, полученные на выходах
исполнительных устройств, помимо входов приемника результата передаются также на
входы всех исполнительных устройств микропроцессора. Если устройство управления
обнаруживает, что данный результат требуется одной из последующих команд в
качестве операнда, то этот результат сразу же, параллельно с записью в приемник
результата, передается на вход исполнительного устройства для использования
следующей командой.
Конфликты типа RAW обусловлены именно конвейерной организацией обработки
команд.
22.
2. Конфликты типа WAR (Write After Read): команда N пытается записать результат вприемник, прежде чем он считается оттуда командой P, При этом команда P может
получить некорректное новое значение операнда:
Команда P –
Команда N –
ADD R1, R2
SUB R2, R3
; R1 = R1 + R2
; R2 = R2 – R1
Этот конфликт возникнет в случае, если команда N вследствие неупорядоченного
выполнения завершится раньше, чем команда P прочитает старое содержимое регистра
R2.
3. Конфликты типа WAW (Write After Write): команда N пытается записать результат в
приемник, прежде чем в этот же приемник будет записан результат выполнения
команды P, то есть запись заканчивается в неверном порядке, оставляя в приемнике
результата значение, записанное командой P:
Команда P –
Команда N –
ADD R1, R2
...
SUB R1, R3
; R1 = R1 + R2
; R1 = R1 – R3
Устранение конфликтов по данным типов WAR и WAW достигается путем отказа от
неупорядоченного исполнения команд, но чаще всего путем введения буфера
восстановления последовательности команд.
23.
Наличие конфликтов приводит к значительному снижению производительностимикропроцессора.
Определенные типы конфликтов требуют приостановки конвейера. При этом
останавливается выполнение всех команд, находящихся на различных стадиях
обработки (до 20-ти команд в Pentium-4).
Другие конфликты, например, при неверном предсказанном направлении перехода,
ведут к необходимости полной перезагрузки конвейера. Потери будут тем больше, чем
более длинный конвейер используется в микропроцессоре.
Такая ситуация явилась одной из причин сокращения числа ступеней в
микропроцессорах последних моделей. Так, в микропроцессоре Itanium конвейер
содержит всего 10 ступеней. При этом его тактовая частота составляет около 1 ГГц.
Однако за счёт большей структурной избыточности на каждой ступени выполняется
больше функциональных действий, чем в прицессоре Pentium-4.