























 Лингвистика
ЛингвистикаПохожие презентации:








: мова як предмет дослідження")

Прикладні аспекти статистичної лінгвістики
1. Прикладні аспекти статистичної лінгвістики.
2.
1. Проблематика статистичноїлінгвістики з теоретичного та прикладного
поглядів.
2. Основні галузі використання
структурно-ймовірнісної моделі мови.
3. Психолінгвістика як практичне
застосування лінгвістики
3.
Статистична лінгвістика міждисциплінарний напрямок уприкладних дослідженнях, у яких
основним інструментом вивчення мови
використовуються кількісні чи
статистичні методи аналізу.
Іноді статистичну (чи кількісну чи
квантитативну лінгвістику)
протиставляють комбінаторній
лінгвістиці. В останній домінантну роль
посідає «некількісний» математичний
апарат – теорія множин, математична
логіка, теорія алгоритмів тощо.
4.
Для вдосконалення системистенографії первісно був
призначений і частотний словник
німецької мови Кедінґа (його
уклали на матеріалі 11 млн. слів
6000 працівників), виданий у
Берліні 1898 р.
5.
Р. Елрідж, керівник невеликої фабрики,за 2 роки опрацював 250 статей
загальною довжиною 44 000
слововживань і 1911р. видав "Шість
тисяч загальновживаних англійських
слів" для своїх робітників-емігрантів, що
вивчають англійську мову.
6.
У 1928 р. побачив світ "Німецький частотнийсловник" (German frequency Word Book)
Морґана, роком пізніше — "Німецький
словник ідіом" (A German Idiom List) Xayxa, у
цьому руслі також працювали науковці
Пфеффер та Веґлер. Також з'явився
"Порівняльний частотний словник першої
тисячі слів англійської, французької, німецької
та іспанської мов" (Comparative Frequency list
on the First Thousand words in English, French,
German and Spanish) Ітона, де наведено 1000
найчастотніших слів названих чотирьох
європейських мов.
7.
Увійшов в історію англійськиймовознавець та педагог Палмер, що
відібрав три тисячі слів, які дають змогу
розуміти 95% тексту.
Під час воєн зростає потреба передати
інформацію так, щоб її не міг зрозуміти
противник. Тому посилилася увага до
криптографії — науки про
зашифровування та розшифрування
повідомлень, "ламання кодів".
8.
Основні поняття та категорійнийапарат статистичної лінгвістики:
вибірка, частота, розподіл, похибка.
Однорідний масив (корпус) певних
одиниць, які потрібно обстежити,
називають генеральною сукупністю
(ГС).
9.
Вибірка — це певна кількість матеріалу,на підставі дослідження якого можна
зробити правильні висновки про всю
генеральну сукупність. Основні вимоги
до вибірки: репрезентативність та
однорідність.
10.
Щоби бути репрезентативною, вибіркамає
1) рівномірно розподілятися по
генеральній сукупності та
2) мати достатньо великий обсяг, якого
вистачає для правильних висновків про
ГС.
11.
Розрізняють два типи однорідностівибірки: лінгвістична та
статистична.
У межах лінгвістичної однорідності
вибірки виділяють:
1) хронологічну (тексти вибірки повинні
мати хронологічні межі);
2) жанрову (тексти вибірки мають бути
жанрово обмежені);
3) тематичну (тексти мають бути
тематично обмежені).
12.
Статистично однорідною вважаютьвибірку, в якій досліджувані одиниці
мають статистичну поведінку, яка
суттєво між собою не відрізняється.
Якщо середня частота явища (літери,
морфеми, слова, довжини слова,
довжини речення і т.ін.) в одній вибірці
суттєво не відрізняється від його
частоти в інших вибірках, то ці вибірки
статистично однорідні стосовно цього
явища.
13.
За способом організації виділяють такірізновиди вибірок:
1) механічна — організована з
урахуванням рівномірності розподілу
досліджуваної одиниці по генеральній
сукупності. Всі тексти генеральної
сукупності перенумеровують, а потім,
наприклад, з кожного п'ятого, десятого,
двадцятого тексту вибирають відрізок
необхідної довжини.
14.
2) випадкова — організована шляхомвипадкового вибору текстів з генеральної
сукупності. В основі такого методу організації
вибірки лежить гіпотеза про те, що досить
велика кількість навздогад відібраних
одиниць з генеральної сукупності має
адекватно її представляти. Тож кожна
сторінка, розділ чи інша одиниця тексту
генеральної сукупності повинні мати
однаковий шанс потрапити до вибірки. Тому,
як правило, випадкова вибірка ґрунтується на
таблиці випадкових чисел.
15.
3) зональна (типова) — організованана основі лінгвістично однорідної
сукупності текстів, тобто зони. Зоною
залежно від мети дослідження
вважають прозу, поезію та драму в
художній літературі; твори одного
автора або конкретний твір; сукупність
слів певної морфемної структури
(наприклад, префіксальних або
одноморфемних) тощо.
16.
Вибірка може бути структурною, тобтоскладатися із менших частин, які
називають підвибірками, та
неструктурною, тобто суцільною.
17.
Абсолютна частота — це кількість вживаньпевної одиниці (літери, слова, словоформи,
словосполучення, речення тощо) в
обстеженому матеріалі.
Відносна частота — відношення абсолютної
частоти певної одиниці у вибірці до обсягу
вибірки. Вимірюється у відсотках (%) або в
частках 1 (наприклад, 25% або 0,25).
Так, у реченні Говорили око в око абсолютна
частота слова око — 2, а відносна — 2/4 = 0,5
або 50%.
18.
Проте в різних підвибірках частотаодиниці звичайно неоднакова. У таких
випадках належить оперувати
середньою частотою. Це відношення
суми абсолютних частот певної
одиниці у підвибірках до кількості
підвибірок.
Наприклад, якщо у трьох підвибірках, з
яких складається вибірка, слово
"яскраво" має абсолютні частоти 4, 6 і 8,
то його середня частота у вибірці буде
(4 + 6 + 8) / 3 = 6.
19.
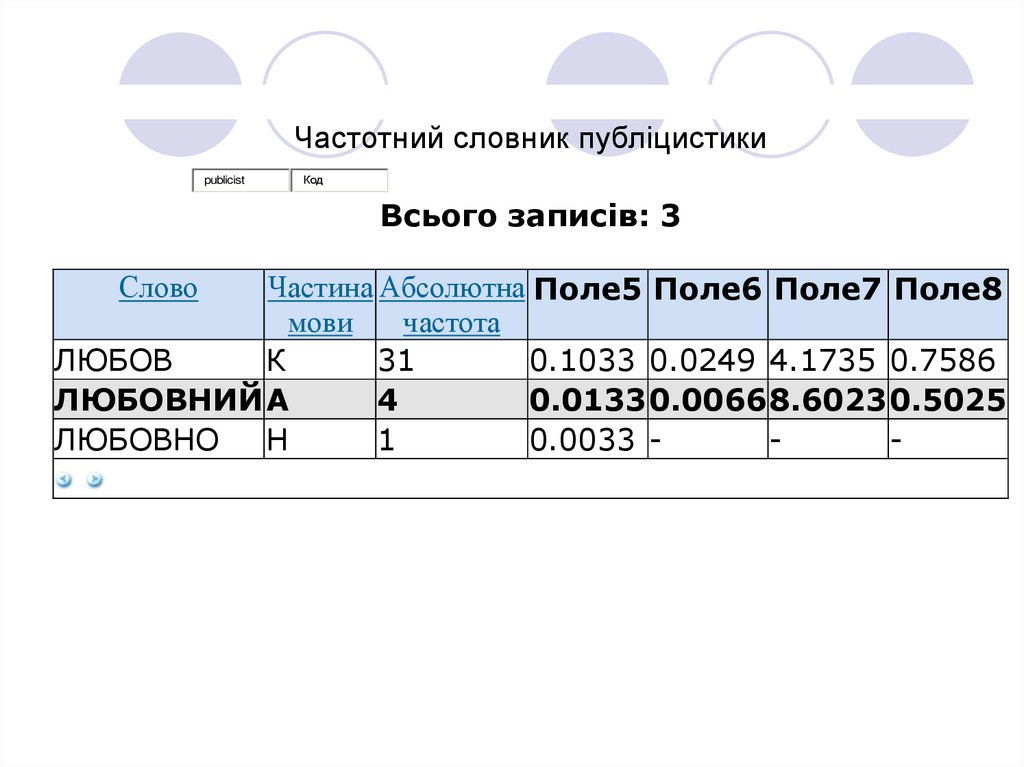
Частотний словник публіцистикиpublicist
Код
Всього записів: 3
Частина Абсолютна Поле5 Поле6 Поле7 Поле8
мови
частота
ЛЮБОВ
К
31
0.1033 0.0249 4.1735 0.7586
ЛЮБОВНИЙ А
4
0.0133 0.0066 8.6023 0.5025
ЛЮБОВНО
Н
1
0.0033 Слово
20.
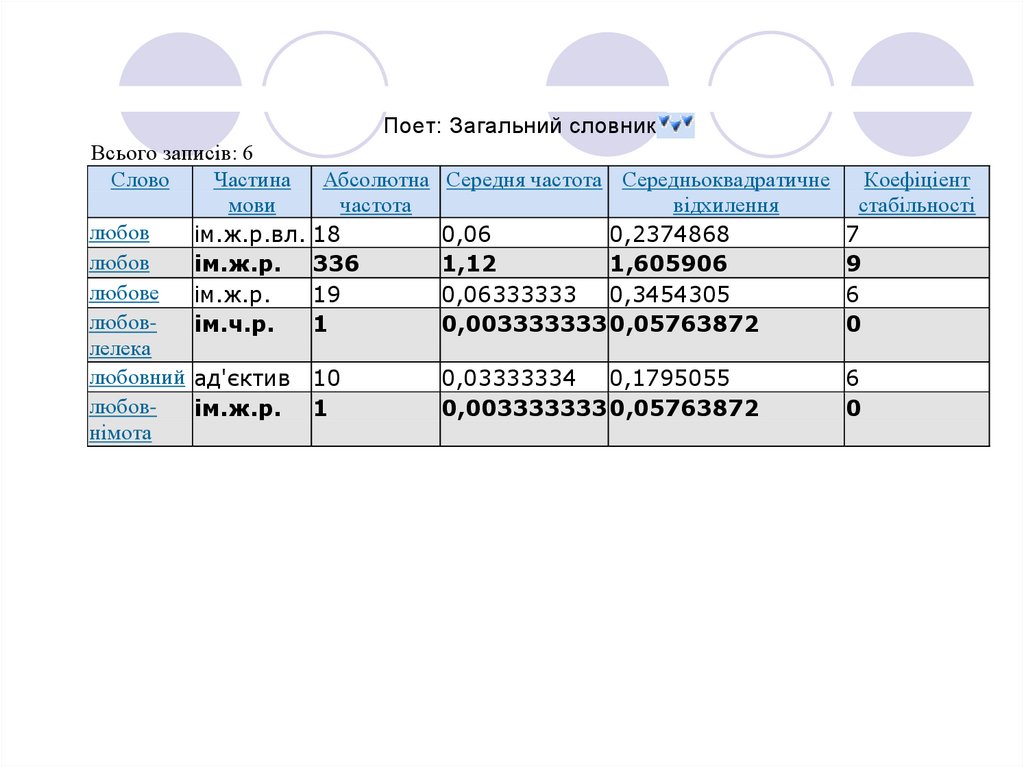
Поет: Загальний словникВсього записів: 6
Слово
Частина Абсолютна
мови
частота
любов
ім.ж.р.вл. 18
любов
ім.ж.р. 336
любове
ім.ж.р.
19
любовім.ч.р.
1
лелека
любовний ад'єктив 10
любовім.ж.р. 1
німота
Середня частота Середньоквадратичне
відхилення
0,06
0,2374868
1,12
1,605906
0,06333333 0,3454305
0,003333333 0,05763872
Коефіціент
стабільності
7
9
6
0
0,03333334 0,1795055
0,003333333 0,05763872
6
0
21.
Технологія лінгвістичногоспостереження ґрунтується на двох
вихідних твердженнях:
по-перше, на регулярності і
періодичності аналізованих даних, і,
по-друге, на достатньо великому
обсязі використовуваного матеріалу,
на репрезентативності вибірки даних.
22.
Інформація про статистичнізакономірності функціювання мовної
системи лежить в основі деяких методик
аналіз даних, розроблюваних у
політичній лінгвістиці. До них належить,
зокрема, методика контент-аналізу,
використовувана для виявлення
структури і стану суспільної свідомості.
23.
Комп’ютерне моделювання мови тамовлення.
Авторизація/атрибуція тексту.
24.
Психолінгвістика, галузь лінгвістики,що вивчає мову насамперед як
феномен психіки. З погляду
психолінгвістики, мова існує тією мірою,
якою існує внутрішній світ мовця і
слухача, людини, яка пише і читає.
Тому психолінгвістика не займається
вивченням «мертвих» мов - таких, як
старослов'янська або грецька, де
нам доступні лише тексти, але не
психічні світи їх творців.
25.
Ось питання, які традиційно займають розумипсихолінгвістів:
1. Чи симетрично влаштований процес розпізнавання
мовлення, яке звучить, і процес його породження?
2. Чим відрізняються механізми оволодіння рідною
мовою від механізмів оволодіння мовою іноземною?
3. Які механізми забезпечують процес читання?
4. Чому за певних уражень мозку виникають ті чи інші
дефекти мови?
5. Яку інформацію про особу мовця можна отримати,
вивчаючи певні аспекти її мовної поведінки?
26.
Прийнято вважати, що психолінгвістикавиникла близько 40 років тому в США.
Дійсно, сам термін психолінгвістика
був запропонований американськими
психологами в кінці 1950-х років з метою
надати формальний статус уже
сформованому саме в США науковому
напрямку.
27.
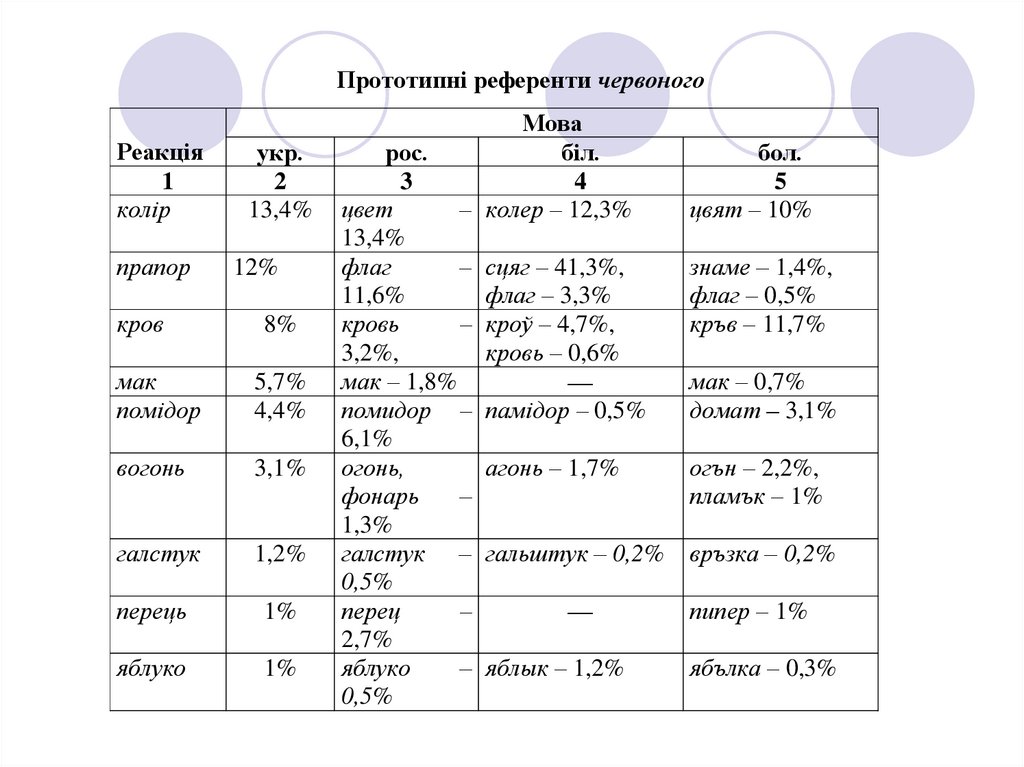
Прототипні референти червоногоРеакція
1
колір
прапор
кров
укр.
2
13,4%
12%
8%
мак
помідор
5,7%
4,4%
вогонь
3,1%
галстук
1,2%
перець
1%
яблуко
1%
Мова
біл.
4
– колер – 12,3%
рос.
3
цвет
13,4%
флаг
–
11,6%
кровь
–
3,2%,
мак – 1,8%
помидор –
6,1%
огонь,
фонарь
–
1,3%
галстук –
0,5%
перец
–
2,7%
яблуко
–
0,5%
бол.
5
цвят – 10%
сцяг – 41,3%,
флаг – 3,3%
кроў – 4,7%,
кровь – 0,6%
—
памідор – 0,5%
знаме – 1,4%,
флаг – 0,5%
кръв – 11,7%
агонь – 1,7%
огън – 2,2%,
пламък – 1%
гальштук – 0,2%
връзка – 0,2%
—
яблык – 1,2%
мак – 0,7%
домат – 3,1%
пипер – 1%
ябълка – 0,3%