








 Программирование
ПрограммированиеПохожие презентации:


")







Конвейерный процессор. Лекция №11
1.
Лекция №11. Конвейерный процессорВопросы:
1. Принципы построения конвейерного процессора.
2. Конвейерный тракт данных.
3. Конвейерное устройство управления.
4. Конфликты и их разрешение.
Литература. Цифровая схемотехника и архитектура компьютера, Дэвид М.
Харрис и Сара Л. Харрис, второе издание, Издательство Morgan Kaufman, English
Edition 2013, с. 1007- 1040.
2.
1. Принципы построения конвейерного процессора.Микропроцессоры выполняют миллионы и миллиарды команд в секунду, так что
производительность важнее, чем время ожидания тех или иных операций.
Конвейеризация требует определенных дополнительных расходов, но при
конвейеризации преимуществ много, а обходится она дешево. Поэтому все современные
высокопроизводительные микропроцессоры – конвейерные.
Наибольшие задержки в в трактах обработки команд процессора создают Чтение и
Запись в память и регистровый файл, а также Использование АЛУ..
Конвейер создадим из типовых стадий обработки команд таким образом, чтобы
каждая из этих стадий включала ровно одну из операций обработки команд.
Назовем типовые стадии обработки команд следующим образом:
Fetch (F выборка), Decode (D дешифрация), Execute (E выполнение), Memory
(M доступ к памяти) и Writeback (W обратная запись результатов).
Они похожи на пять этапов выполнения команды lw в многотактном процессоре.
В стадии Fetch процессор читает команду из памяти команд.
В стадии Decode процессор читает операнды из регистрового файла и дешифрует
команду, чтобы установить управляющие сигналы.
В стадии Execute процессор выполняет вычисления в АЛУ.
В стадии Memory процессор читает или пишет в память данных.
В стадии Writeback процессор записывает результат в регистровый файл
3.
1.1. Выполнение команд в однотактном процессоре.На рис. (а) приведена временная диаграмма однотактного без конвейерного процессора.
По горизонтальной оси отложено время (в пикосекундах – pc, 1рс= 10-12с ), по
вертикальной – команды. Задержками мультиплексоров и регистров пренебрежем.
В однотактном процессоре, показанном на рис. (a), первая команда выбирается
из памяти в момент времени 0 рс (F I); далее процессор читает операнды из регистрового
файла (D R); далее АЛУ выполняет необходимые вычисления (E ALU); происходит
чтение памяти данных (M R/W); результат записывается в регистровый файл (WR).
Время исполнения одной команды составило 950 pс:
250 (F I) + 150 (D R) + 200 (E ALU)+ 250 (M R/W) + 100 (WR) = 950 рс,
Выполнение команды 2 начинается после того, как закончена команда 1.
Таким образом, однотактный без конвейерный процессор обеспечивает выполнение 2-х
команд за время, равное:
2 х 950 рс = 1900 рс
4.
1.2. Выполнение команд в конвейерном процессоре.В конвейерном процессоре, на рис. (b), длина самой медленной стадии определяется
стадией доступа к памяти (Fetch- загрузка или Memory - память) и равна равна 250 рс.
В начальный момент времени команда1 instr1 загружается из памяти. Через 250 pс,
команда 1 попадает в стадию Decode, но команда 2 instr2 загрузится из памяти только
через 500 рс (столько времени теперь требуется на выборку 2-х команд), следовательно
для дешифровки команды 1 можно отвести большее время или немного задержать
дешифровку команды 1, пока не загрузится команда 2 и т.д.
ВЫВОДЫ:
1. Пропускная способность 3-х команд в конвейерном процессоре больше, чем в
однотактном, потому что стадии конвейера не идеально сбалансированы, то есть не
содержат абсолютно одинаковое количество логики.
2. Пропускная способность процессора с пяти стадийным (F,D,E,M,W) конвейером
не в пять раз больше, чем у однотактного (2 команды исполняются за 1350 рс, а у без
конвейерного однотактного процессора исполнялись за 1900 рс ).
3. Увеличение пропускной способности весьма значительно. За время 1600рс прошло
3 команды в конвейерном П, а в однотактном П потребовалось бы 3х950 рс = 2850 рс.
5.
1.3. Абстрактное представление работающего конвейераFetch
Decode
Execute
Memory
Writeback
Абстрактное представление работающего конвейера показывает продвижение команд по конвейеру.
Каждая стадия обозначена главным компонент стадии – память команд (instruction memory, IM, стадия Fetch),
чтение регистрового файла ( register file, RF, стадия Decodre), АЛУ
, (стадия Execute) память данных (DM,
стадия Memory) и запись в регистровый файл ( register file, RF, стадия Writeback). Таким образом, каждая стадия
привязана к ее главному копоненту.
Строки определяют на каком такте команда находится в той или иной стадии.
Например, команда sub загружается из памяти (IM) на третьем такте и выполняется на пятом (АЛУ).
Столбцы определяют чем заняты стадии конвейера на конкретном такте.
Например, на шестом такте команда or загружается из памяти команд (IM) .
Цвет главного компонента стадии закрашен серым, если он используются и белым, если не используется и
простаивает. Например, память данных DM в командах add, sub, and и or не используется. Память команд RF и
АЛУ используются на каждом такте. Память команд RF может использоваться в первой или во второй половине
стадии: цвет серо-белый или наоборот.
Главная проблема в конвейерных системах – разрешение конфликтов (hazards-опасности ), которые возникают,
когда результаты одной из команд требуются для выполнения последующей команды до того, как первая
завершится.
6.
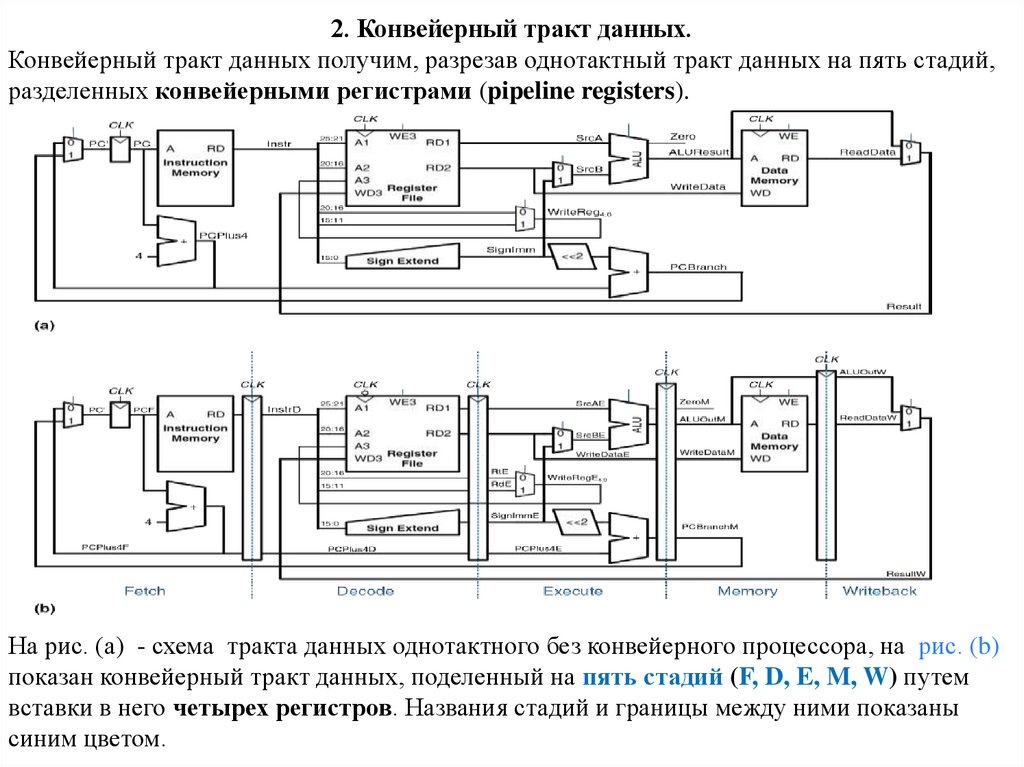
2. Конвейерный тракт данных.Конвейерный тракт данных получим, разрезав однотактный тракт данных на пять стадий,
разделенных конвейерными регистрами (pipeline registers).
На рис. (а) - схема тракта данных однотактного без конвейерного процессора, на рис. (b)
показан конвейерный тракт данных, поделенный на пять стадий (F, D, E, M, W) путем
вставки в него четырех регистров. Названия стадий и границы между ними показаны
синим цветом.
7.
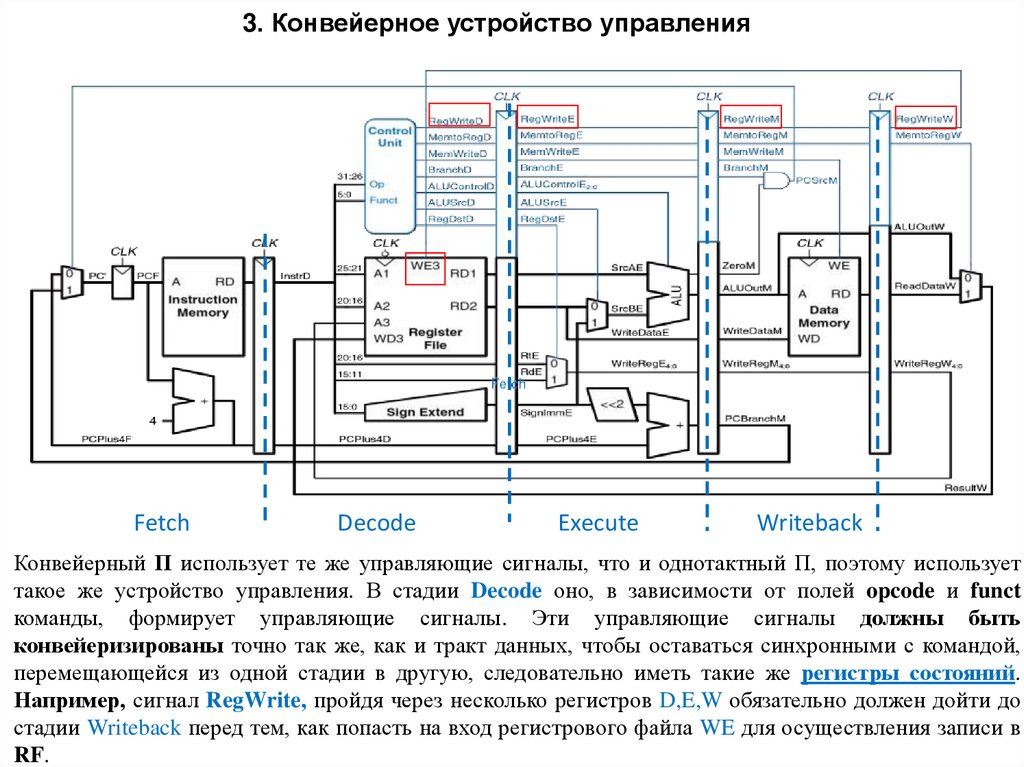
3. Конвейерное устройство управленияFetch
Decode
Execute
Writeback
Конвейерный П использует те же управляющие сигналы, что и однотактный П, поэтому использует
такое же устройство управления. В стадии Decode оно, в зависимости от полей opcode и funct
команды, формирует управляющие сигналы. Эти управляющие сигналы должны быть
конвейеризированы точно так же, как и тракт данных, чтобы оставаться синхронными с командой,
перемещающейся из одной стадии в другую, следовательно иметь такие же регистры состояний.
Например, сигнал RegWrite, пройдя через несколько регистров D,E,W обязательно должен дойти до
стадии Writeback перед тем, как попасть на вход регистрового файла WE для осуществления записи в
RF.
8.
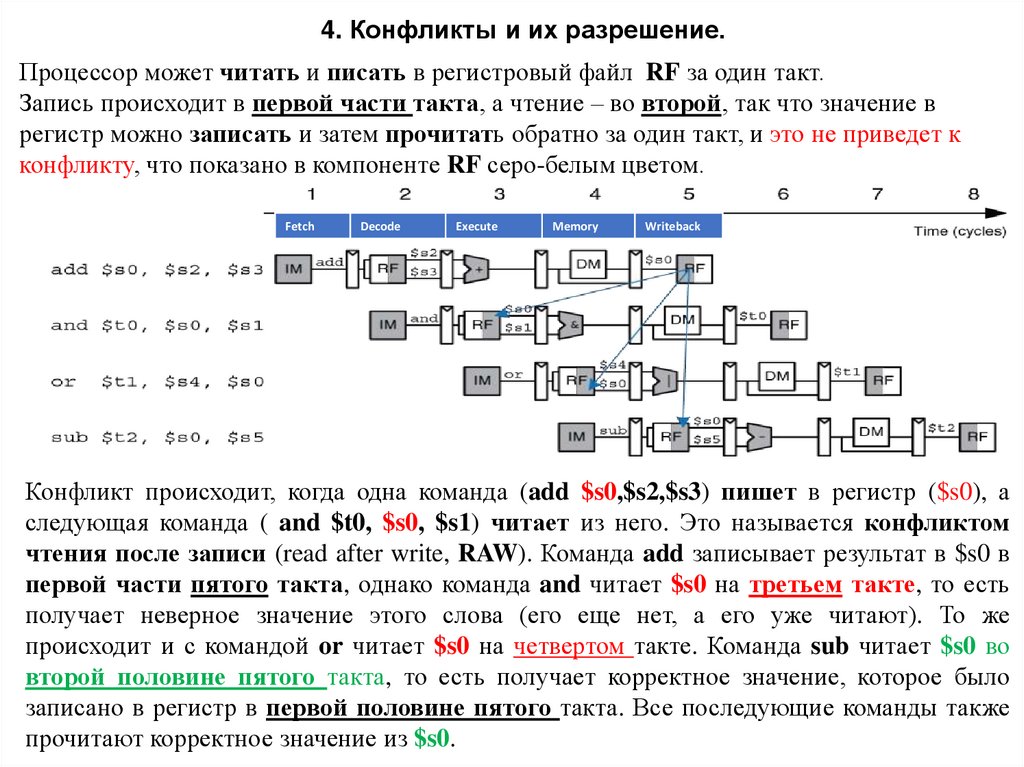
4. Конфликты и их разрешение.Процессор может читать и писать в регистровый файл RF за один такт.
Запись происходит в первой части такта, а чтение – во второй, так что значение в
регистр можно записать и затем прочитать обратно за один такт, и это не приведет к
конфликту, что показано в компоненте RF серо-белым цветом.
Fetch
Decode
Execute
Memory
Writeback
Конфликт происходит, когда одна команда (add $s0,$s2,$s3) пишет в регистр ($s0), а
следующая команда ( and $t0, $s0, $s1) читает из него. Это называется конфликтом
чтения после записи (read after write, RAW). Команда add записывает результат в $s0 в
первой части пятого такта, однако команда and читает $s0 на третьем такте, то есть
получает неверное значение этого слова (его еще нет, а его уже читают). То же
происходит и с командой or читает $s0 на четвертом такте. Команда sub читает $s0 во
второй половине пятого такта, то есть получает корректное значение, которое было
записано в регистр в первой половине пятого такта. Все последующие команды также
прочитают корректное значение из $s0.
9.
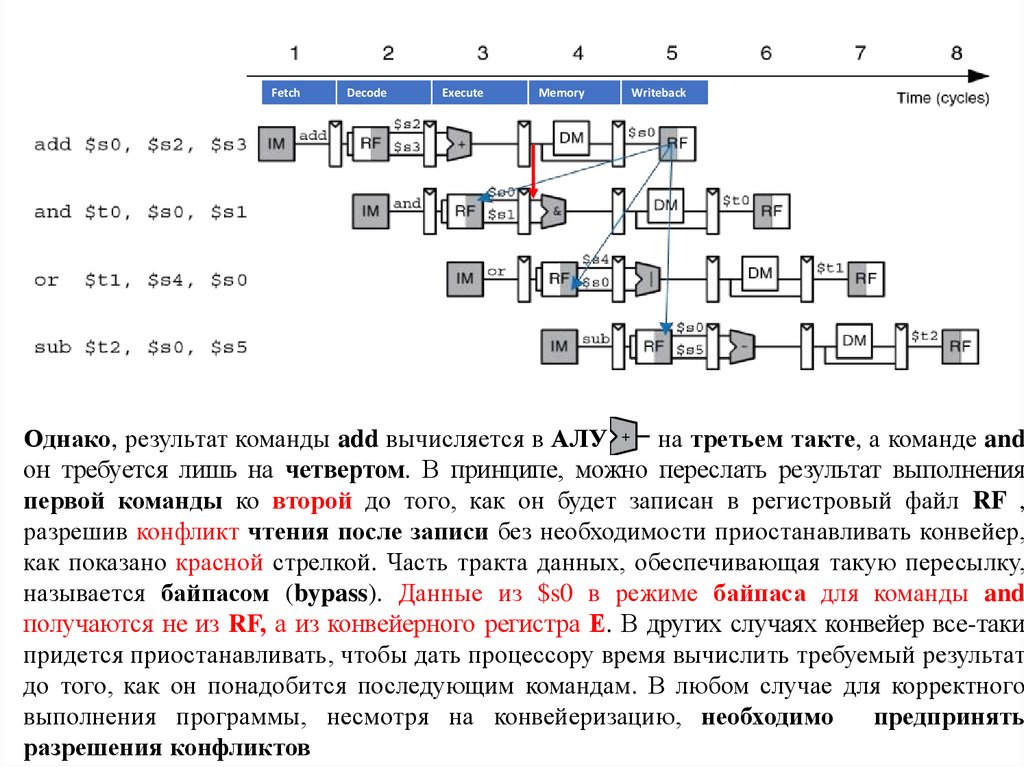
FetchDecode
Execute
Memory
Writeback
Однако, результат команды add вычисляется в АЛУ
на третьем такте, а команде and
он требуется лишь на четвертом. В принципе, можно переслать результат выполнения
первой команды ко второй до того, как он будет записан в регистровый файл RF ,
разрешив конфликт чтения после записи без необходимости приостанавливать конвейер,
как показано красной стрелкой. Часть тракта данных, обеспечивающая такую пересылку,
называется байпасом (bypass). Данные из $s0 в режиме байпаса для команды and
получаются не из RF, а из конвейерного регистра Е. В других случаях конвейер все-таки
придется приостанавливать, чтобы дать процессору время вычислить требуемый результат
до того, как он понадобится последующим командам. В любом случае для корректного
выполнения программы, несмотря на конвейеризацию, необходимо
предпринять
разрешения конфликтов
10.
Конфликты можно разделить на конфликты данных (data hazards – данныеопасностей) и конфликты управления (control hazards - управляющие опасности).
Конфликт данных происходит, когда команда пытается прочитать из регистра значение,
которое еще не было записано предыдущей командой.
Конфликт управления происходит, когда процессор выбирает из памяти следующую
команду раньше, чем именно эта команду потребуется.
Для разрешения конфликтов в процессор добавляется блок разрешения конфликтов
(hazard unit), который будет выявлять и разрешать конфликты таким образом, чтобы
процессор выполнял программы корректно.
4.1. Разрешение конфликтов пересылкой через байпас.
Конфликты данных можно разрешить путем пересылки результата через байпас
(bypassing или forwarding) из стадий Memory или Writeback в ожидающую этот
результат команду, находящуюся в стадии Execute. Для организации байпаса добавим
мультиплексоры перед АЛУ ( синие стрелы), что бы операнд можно было получать
либо из регистрового файла RF, либо напрямую из стадий Memory или Writeback.
Fetch
Decode
Execute
Memory
Writeback
11.
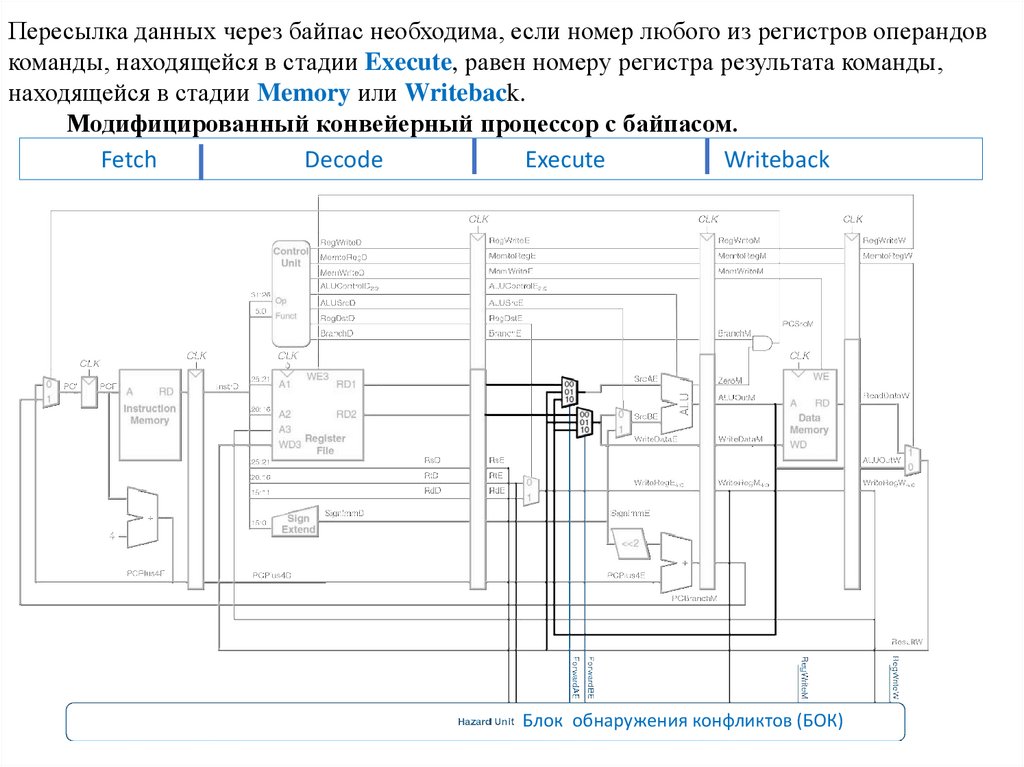
Пересылка данных через байпас необходима, если номер любого из регистров операндовкоманды, находящейся в стадии Execute, равен номеру регистра результата команды,
находящейся в стадии Memory или Writeback.
Модифицированный конвейерный процессор с байпасом.
Fetch
Decode
Execute
Writeback
Блок обнаружения конфликтов (БОК)
12.
У П появился блок обнаружения конфликтов (БОК) и два новых мультиплексора.БОК получает на свой вход номера регистров, хранящих операнды команды, находящейся в стадии
Execute, а также номера регистров результатов команд, находящихся в стадиях Memory и Writeback,
а также сигналы RegWrite из стадий Memory и Writeback. Эти сигналы показывают, нужно ли на
самом деле писать результат в регистр или нет (например, команды sw и beq не записывают свои
результаты в регистровый файл, поэтому их результаты пересылать не нужно). На схеме сигналы
RegWriteМ и RegWriteW , подключенные к блоку обнаружения конфликтов, изображены как
короткие линии с названиями сигналов ни к чему не соединенные.
Предполагается, что все линии с одинаковыми названиями сигналов соединены между собой.
БОК управляет мультиплексорами байпаса (forwarding multiplexers), которые определяют, взять ли
операнды из регистрового файла или переслать их напрямую из стадии Memory или Writeback.
Если в одной из этих стадий происходит запись результата в регистр и номер этого регистра
совпадает с номером регистра операнда следующей команды, то используется байпас.
Регистр $0 –исключение, он всегда содержит ноль, поэтому его нельзя пересылать.
Если номера регистров результатов в стадиях Memory и Writeback одинаковы, то приоритет
отдается стадии Memory, так как она содержит более новую команду.
Функция, определяющая логику пересылки данных в операнд SrcA и логику для операнда SrcB
(ForwardBE) одинаковы за исключением того, что она проверяет поле rt, а не rs и имеет вид:
if ((rsE != 0) AND (rsE == WriteRegM) AND RegWriteM) then ForwardAE = 10
else if ((rsE != 0) AND (rsE == WriteRegW) AND RegWriteW) then ForwardAE = 01
else ForwardAE = 00
13.
4.2. Разрешение конфликтов данных приостановками конвейера.Например, команда lw не может прочитать данные раньше, чем в конце стадии Memory,
поэтому ее результат нельзя переслать в стадию Execute следующей команды and.
В этом случае будем считать, что длительность записи команды lw равна двум тактам,
поэтому зависимая команда and не может использовать результат lw раньше, чем через
два такта.
Fetch
Decode
Execute
Memory
Writeback
Несчастье -
Команда lw получает данные из памяти в конце четвертого такта. Однако команде and
эти данные требуются в качестве операнда уже в самом начале четвертого такта.
Пересылка данных через байпас не поможет разрешить этот конфликт. Приостановим
конвейер, задержав все операции до тех пор, пока данные не станут доступны.
Приостановим зависимую команду (and) в стадии Decode, которая попадает в эту стадию
на третьем такте и оставим ее там на четвертом такте. Следующая команда (or)
должна, соответственно, оставаться в стадии Fetch в течение третьего и четвертого
тактов, так как стадия Decode занята командой and.
14.
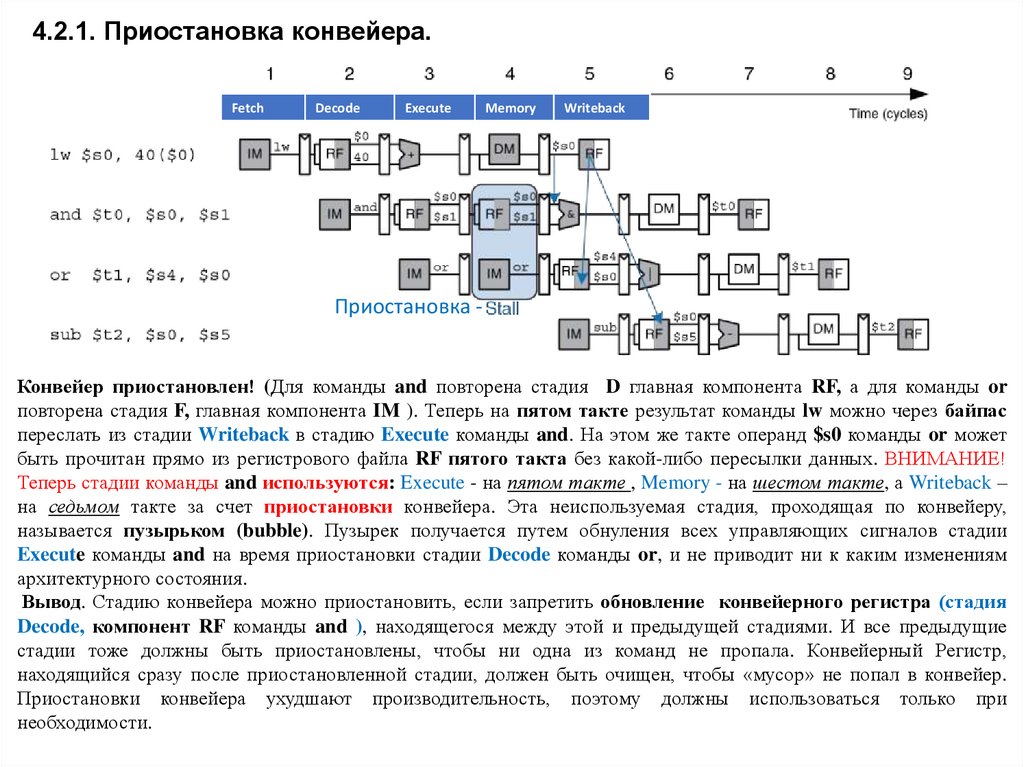
4.2.1. Приостановка конвейера.Fetch
Decode
Execute
Memory
Writeback
Приостановка Конвейер приостановлен! (Для команды and повторена стадия D главная компонента RF, а для команды or
повторена стадия F, главная компонента IM ). Теперь на пятом такте результат команды lw можно через байпас
переслать из стадии Writeback в стадию Execute команды and. На этом же такте операнд $s0 команды or может
быть прочитан прямо из регистрового файла RF пятого такта без какой-либо пересылки данных. ВНИМАНИЕ!
Теперь стадии команды and используются: Execute - на пятом такте , Memory - на шестом такте, а Writeback –
на седьмом такте за счет приостановки конвейера. Эта неиспользуемая стадия, проходящая по конвейеру,
называется пузырьком (bubble). Пузырек получается путем обнуления всех управляющих сигналов стадии
Execute команды and на время приостановки стадии Decode команды or, и не приводит ни к каким изменениям
архитектурного состояния.
Вывод. Стадию конвейера можно приостановить, если запретить обновление конвейерного регистра (стадия
Decode, компонент RF команды and ), находящегося между этой и предыдущей стадиями. И все предыдущие
стадии тоже должны быть приостановлены, чтобы ни одна из команд не пропала. Конвейерный Регистр,
находящийся сразу после приостановленной стадии, должен быть очищен, чтобы «мусор» не попал в конвейер.
Приостановки конвейера ухудшают производительность, поэтому должны использоваться только при
необходимости.
15.
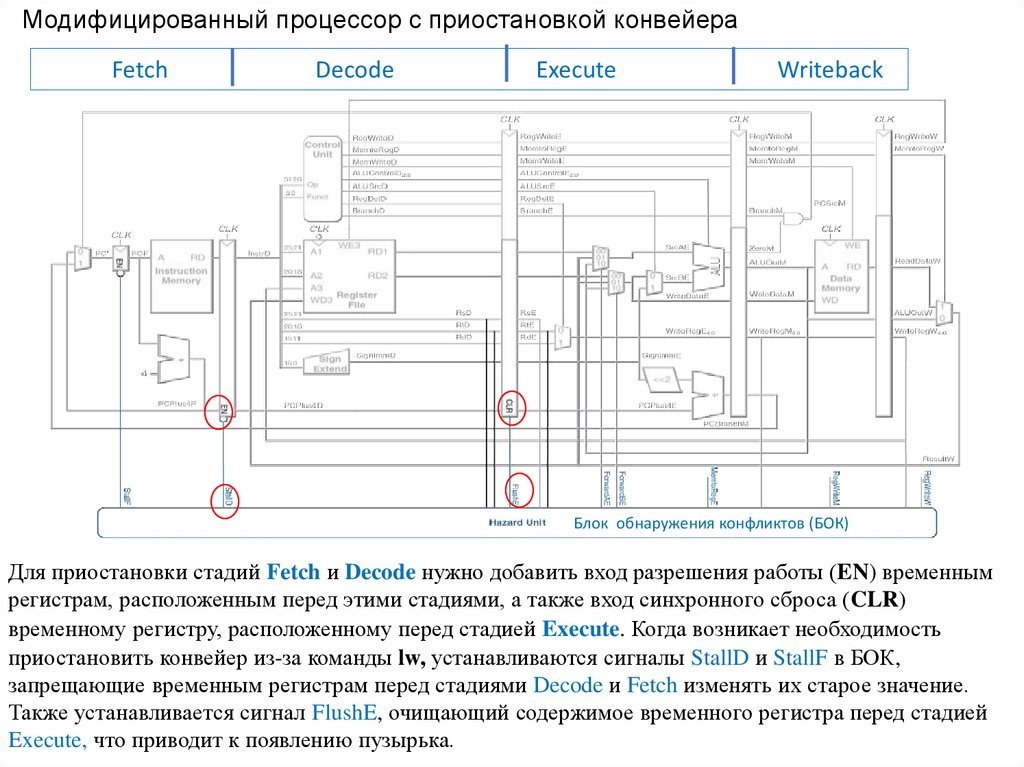
Модифицированный процессор с приостановкой конвейераFetch
Decode
Execute
Writeback
Блок обнаружения конфликтов (БОК)
Для приостановки стадий Fetch и Decode нужно добавить вход разрешения работы (EN) временным
регистрам, расположенным перед этими стадиями, а также вход синхронного сброса (CLR)
временному регистру, расположенному перед стадией Execute. Когда возникает необходимость
приостановить конвейер из-за команды lw, устанавливаются сигналы StallD и StallF в БОК,
запрещающие временным регистрам перед стадиями Decode и Fetch изменять их старое значение.
Также устанавливается сигнал FlushE, очищающий содержимое временного регистра перед стадией
Execute, что приводит к появлению пузырька.
16.
4.3. Разрешение конфликтов управленияВыполнение команды beq приводит к конфликту управления: конвейерный
процессор не знает, какую команду выбрать следующей, поскольку в этот момент еще
не ясно, нужно ли будет выполнить условный переход или нет (выполнение условия ?).
Способы разрешения этого конфликта:
1. Приостановка конвейера .
До тех пор , пока не будет вычислен адрес перехода, происходит торможение
конвейера. Конвейер приостанавливается до тех пор, пока не будет принято нужное
решение (т.е. до тех пор, пока не будет вычислен требуемый сигнал счетчика команд
PCSrc). Решение принимается в стадии Memory, так что для каждой команды
условного перехода придется приостанавливать конвейер на три такта (состояния:
Fetch, Decode, Execute).
2. Предсказание перехода и начало выполнения команд перехода.
Как только условие перехода будет вычислено, процессор может прервать эти команды,
если предсказание было неверны. Допустим, что условный переход не будет выполнен,
и продолжили выполнять команды в порядке следования. А если окажется, что переход
должен был быть выполнен, то конвейер должен быть очищен (flushed – смыть ,
очистить) от трех команд, идущих сразу за командой перехода, путем очистки
соответствующих временных регистров конвейера. Зря потраченные в этом случае
такты называются простоем из-за неправильно предсказанного перехода (branch
misprediction penalty).
.
17.
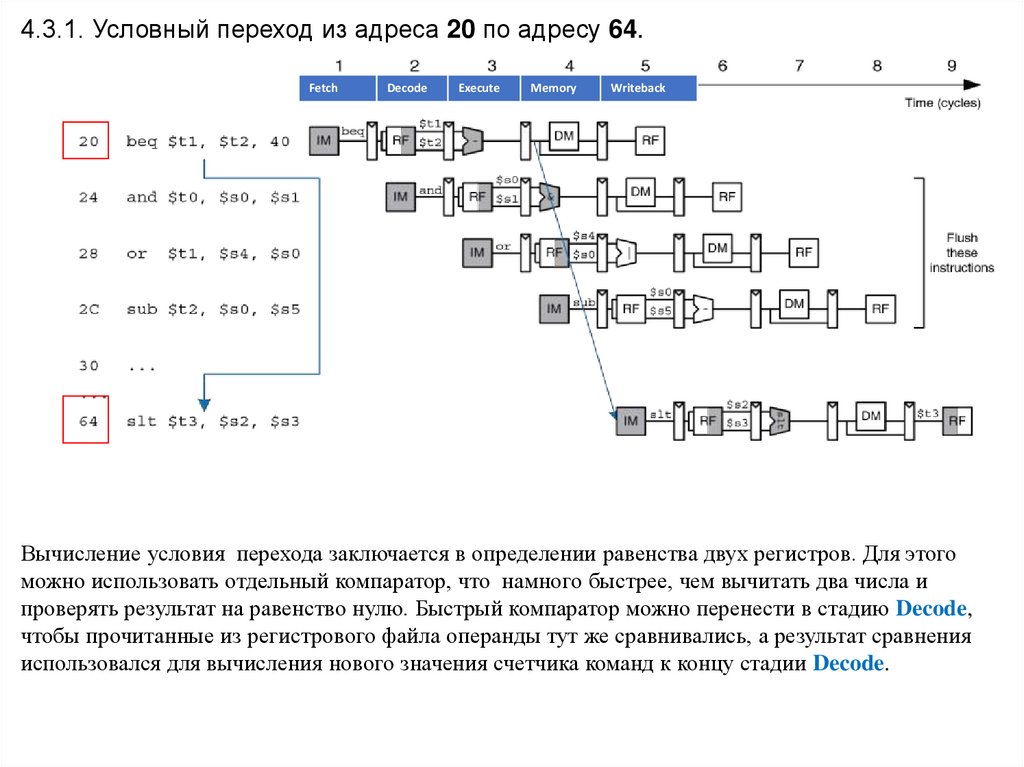
4.3.1. Условный переход из адреса 20 по адресу 64.Fetch
Decode
Execute
Memory
Writeback
Вычисление условия перехода заключается в определении равенства двух регистров. Для этого
можно использовать отдельный компаратор, что намного быстрее, чем вычитать два числа и
проверять результат на равенство нулю. Быстрый компаратор можно перенести в стадию Decode,
чтобы прочитанные из регистрового файла операнды тут же сравнивались, а результат сравнения
использовался для вычисления нового значения счетчика команд к концу стадии Decode.
18.
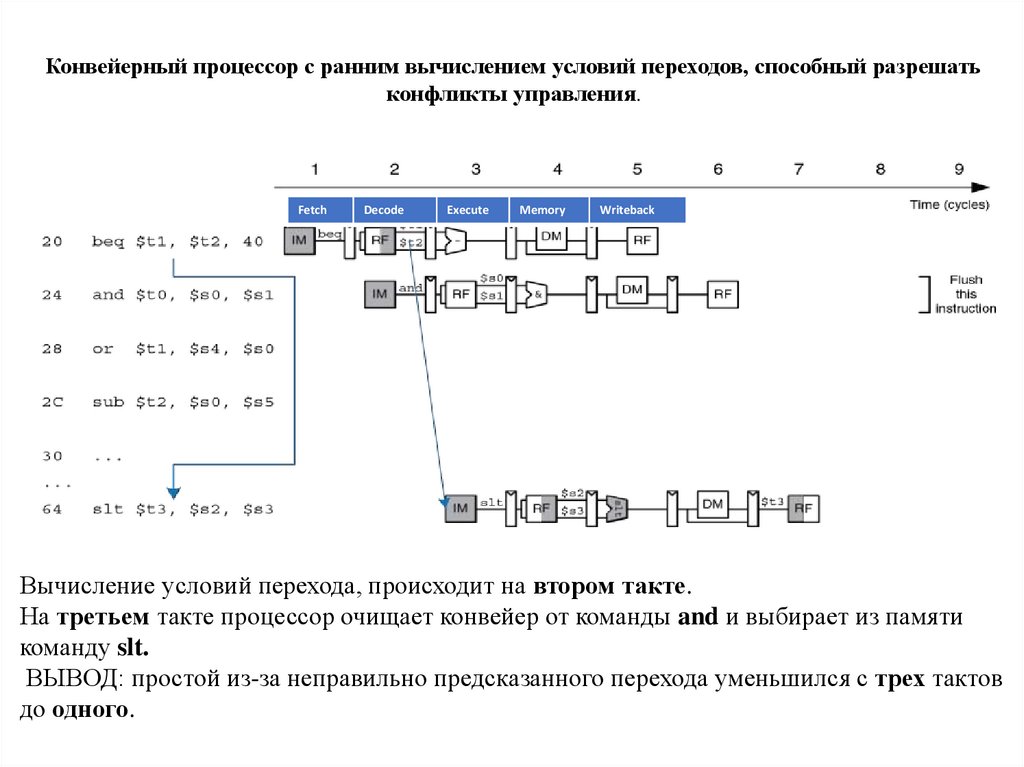
Конвейерный процессор с ранним вычислением условий переходов, способный разрешатьконфликты управления.
Fetch
Decode
Execute
Memory
Writeback
Вычисление условий перехода, происходит на втором такте.
На третьем такте процессор очищает конвейер от команды and и выбирает из памяти
команду slt.
ВЫВОД: простой из-за неправильно предсказанного перехода уменьшился с трех тактов
до одного.
19.
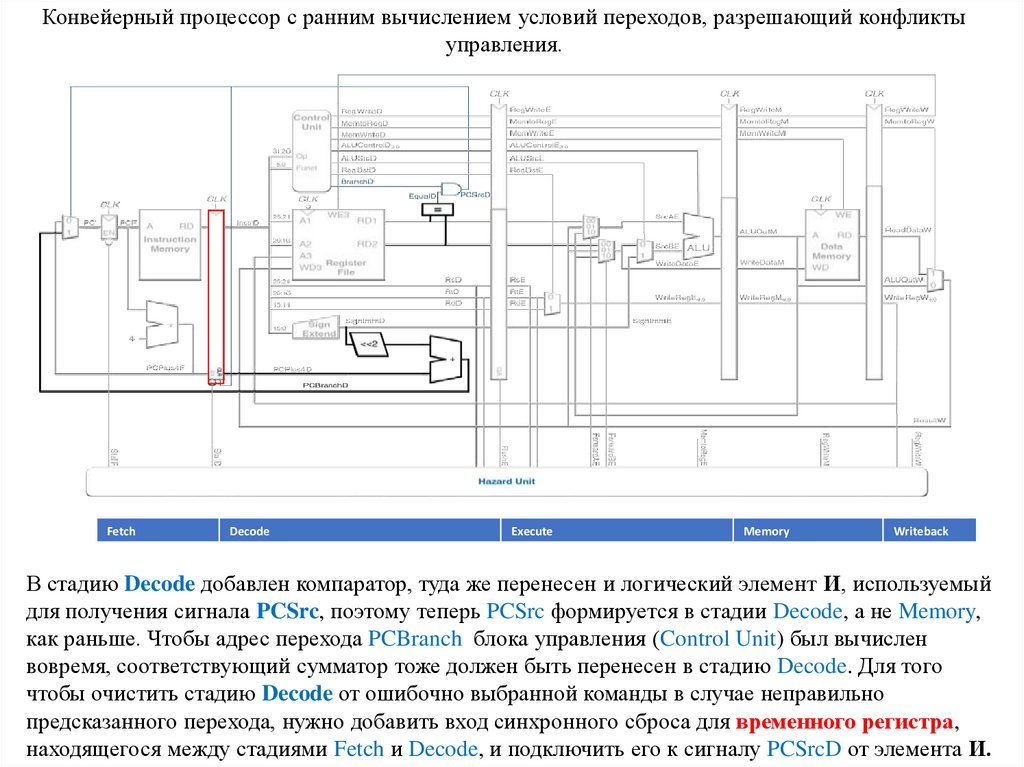
Конвейерный процессор с ранним вычислением условий переходов, разрешающий конфликтыуправления.
Fetch
Decode
Execute
Memory
Writeback
В стадию Decode добавлен компаратор, туда же перенесен и логический элемент И, используемый
для получения сигнала PCSrc, поэтому теперь PCSrc формируется в стадии Decode, а не Memory,
как раньше. Чтобы адрес перехода PCBranch блока управления (Control Unit) был вычислен
вовремя, соответствующий сумматор тоже должен быть перенесен в стадию Decode. Для того
чтобы очистить стадию Decode от ошибочно выбранной команды в случае неправильно
предсказанного перехода, нужно добавить вход синхронного сброса для временного регистра,
находящегося между стадиями Fetch и Decode, и подключить его к сигналу PCSrcD от элемента И.