


























 Математика
Математика Информатика
ИнформатикаПохожие презентации:







")


Кластерный анализ SAS
1.
SAS ENTERPRISE MINERКЛАСТЕРИЗАЦИЯ
Cop yr i g h t © 2 0 12 , SAS In s ti tu t e I n c . A ll r i g h ts r es er ve d .
2.
КОНЦЕПЦИЯ SEMMAS
ample
Cop yr i g h t © 2 0 12 , SAS In s ti tu t e I n c . A ll r i g h ts r es er ve d .
E
xplore
M
odify
M
odel
A
ssess
3.
ЧТО ЕСТЬ КЛАСТЕР?Кластер: группа «похожих» объектов
Кластерный анализ
Разбиение множество объектов на группы (кластеры)
Тип моделей:
«похожих» между собой в группе (внутриклассовое расстояние)
«не похожих» на объекты других групп
Определение неформальное, формализация зависит от метода
«описательный» (descriptive) Data mining => одна из задач наглядное представление кластеров
«прогнозный» (predictive) Data mining => разбиение на кластеры,
а затем «классификация» новых объектов
Тип обучения:
всегда «без учителя» (unsupervised) => тренировочный набор не
размечен
Cop yr i g h t © 2 0 12 , SAS In s ti tu t e I n c . A ll r i g h ts r es er ve d .
4.
ПРИМЕНЕНИЕ МЕТОДОВ КЛАСТЕРИЗАЦИИ ВЗАДАЧАХ АНАЛИЗА ДАННЫХ
Кластеризация ради кластеризации:
Выявление и описание групп (человек не способен «осознать» более 10
объектов в одной задаче, как обработать выборку с миллионами?)
«Сжатие» информации (особенно в обработке мультимедиа)
• Построение различных поисковых индексов (сравниваем не со всеми, а
начинаем с прототипов кластеров)
Мощнейшее средство предобработки данных:
Дискретизация
• Уменьшение размера выборки (от больших объемов к «реальным»)
• Обработка пропущенных значений (инициализируем и итерационно
«улучшаем» пропуски)
• Поиск исключений и артефактов (что не в кластере, то под
«подозрением»)
Cop yr i g h t © 2 0 12 , SAS In s ti tu t e I n c . A ll r i g h ts r es er ve d .
5.
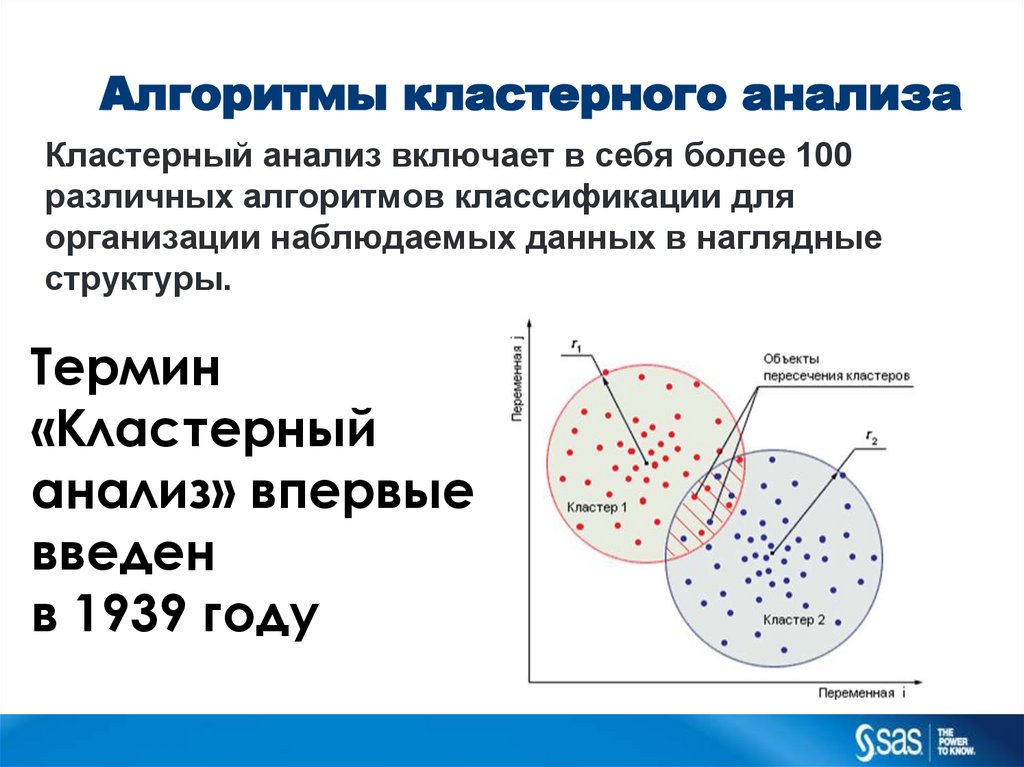
Алгоритмы кластерного анализаКластерный анализ включает в себя более 100
различных алгоритмов классификации для
организации наблюдаемых данных в наглядные
структуры.
Термин
«Кластерный
анализ» впервые
введен
в 1939 году
6.
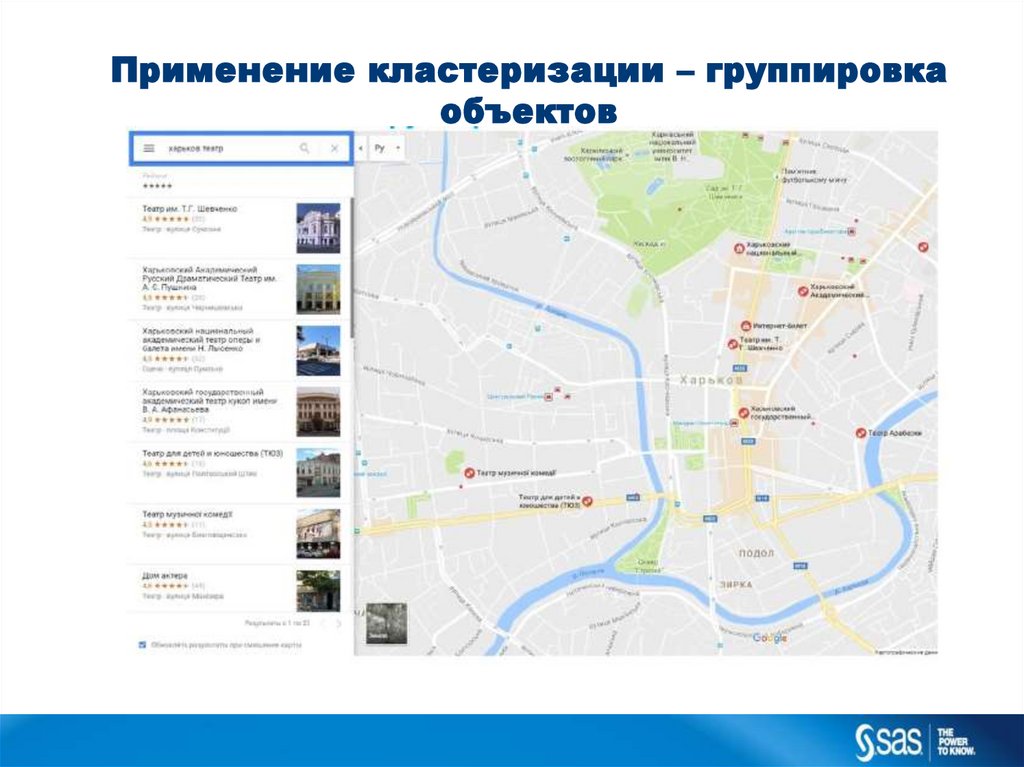
Применение кластеризации – группировкаобъектов
7.
Применение кластеризации –распознавание образов
8.
Применение кластеризации – классификациярезультатов поиска
9.
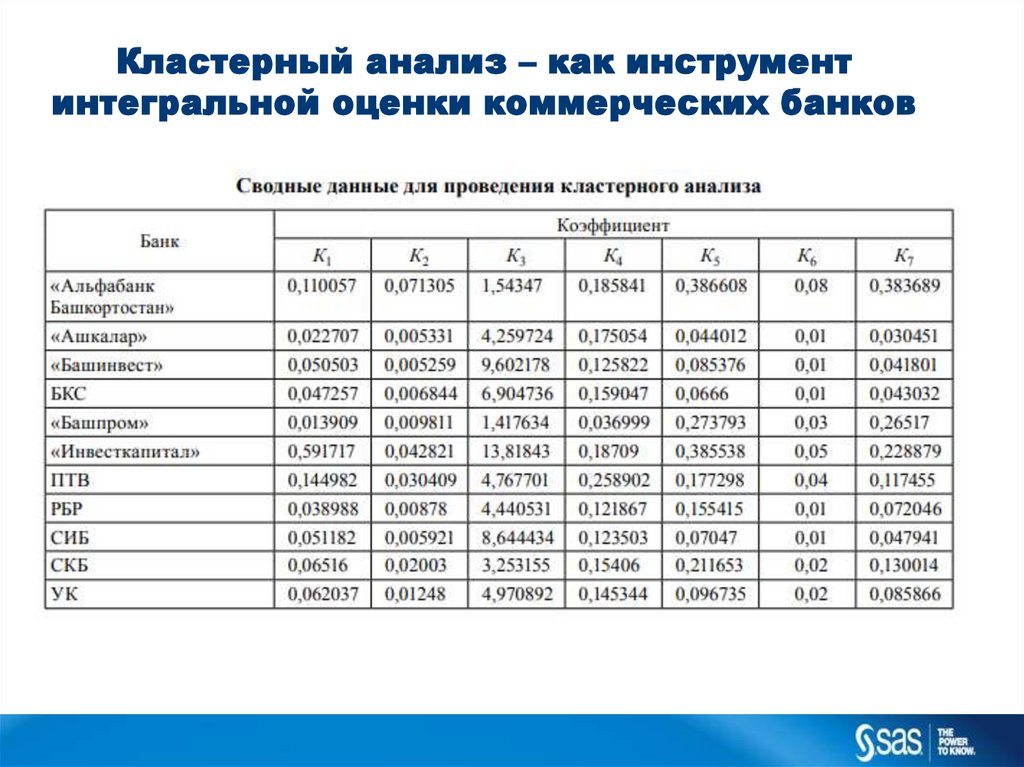
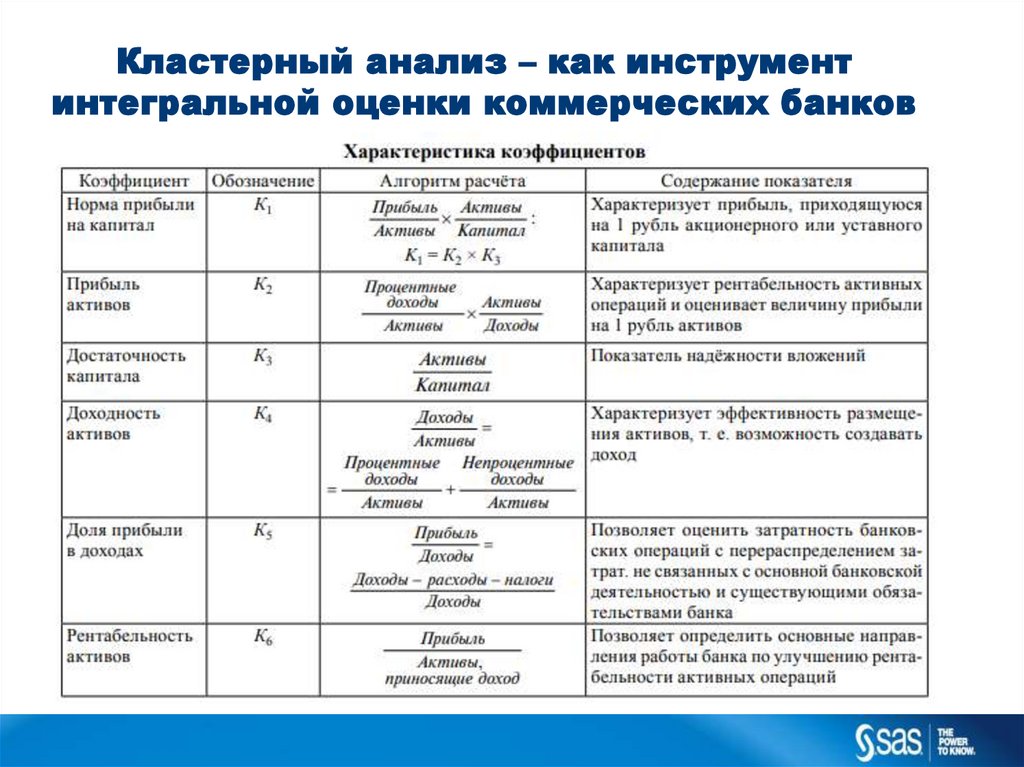
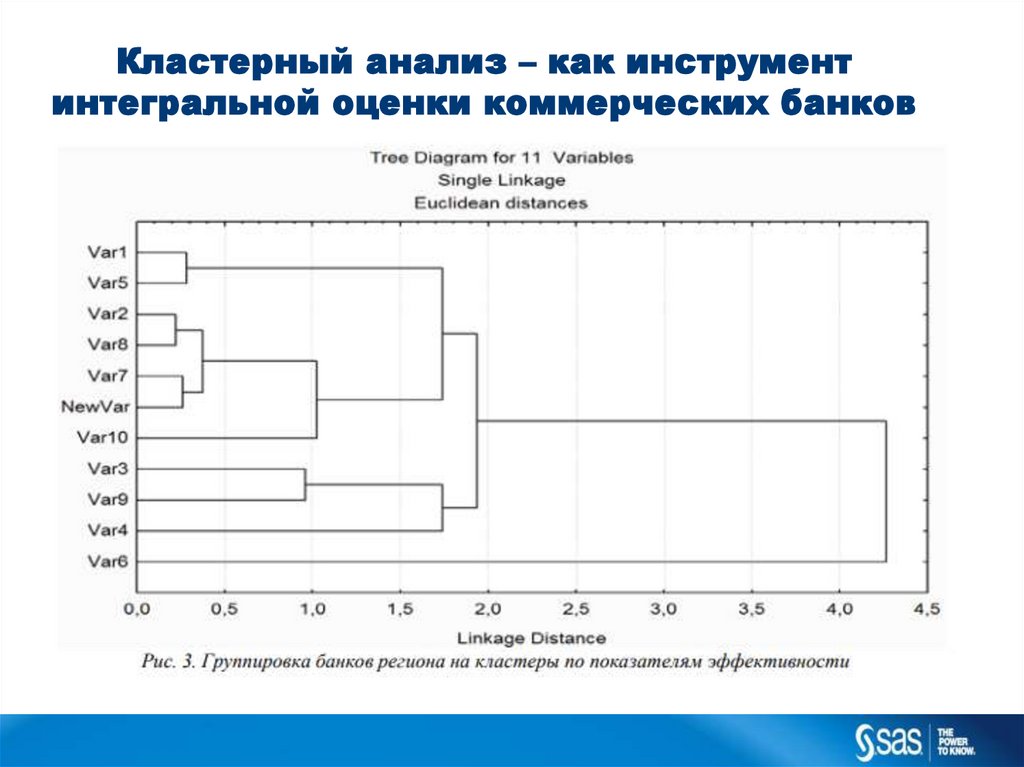
Кластерный анализ – как инструментинтегральной оценки коммерческих банков
10.
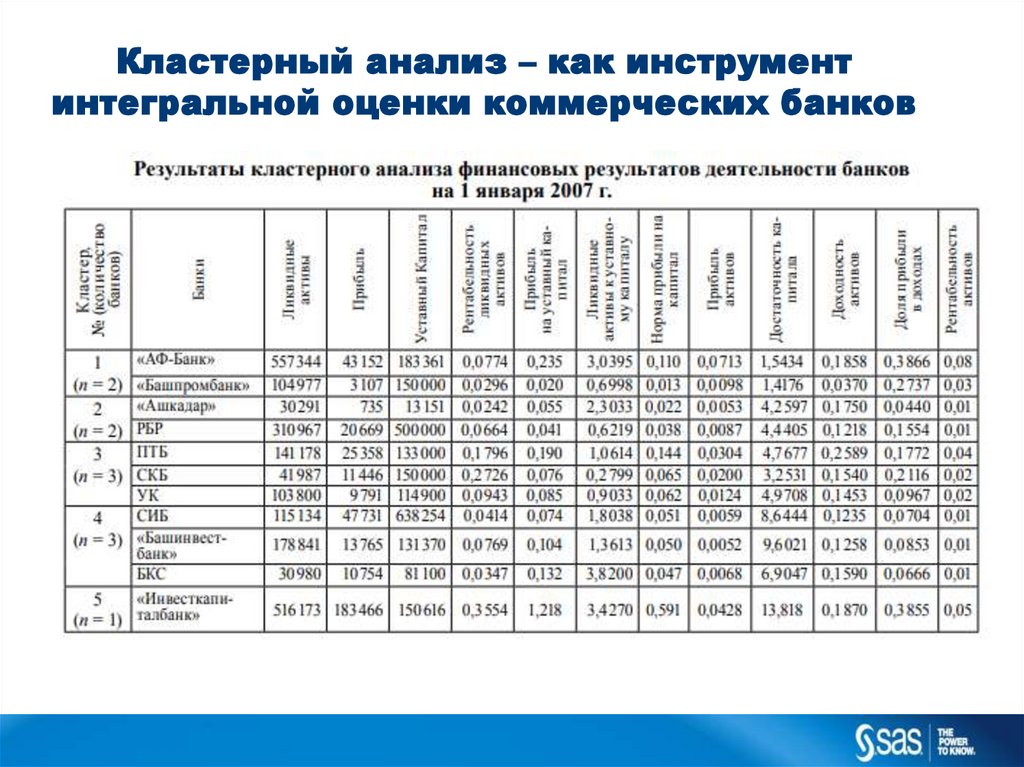
Кластерный анализ – как инструментинтегральной оценки коммерческих банков
11.
Кластерный анализ – как инструментинтегральной оценки коммерческих банков
12.
Кластерный анализ – как инструментинтегральной оценки коммерческих банков
13.
Кластерный анализ – как инструментинтегральной оценки коммерческих банков
14.
КАЧЕСТВО КЛАСТЕРИЗАЦИИХороший метод кластеризации находит кластеры
c высоким «внутриклассовым» сходством объектов
и низким «межклассовым» сходством объектов
Оценка качества кластеризации (нет понятия «точность»)
необходима, так как влияет на выбор параметров метода
определяется либо экспертом – субъективная величина
либо «перекрестной» проверкой целевой функции кластеризации
Качество кластеризации зависит:
от метода кластеризации
от меры сходства (или расстояния)
Cop yr i g h t © 2 0 12 , SAS In s ti tu t e I n c . A ll r i g h ts r es er ve d .
15.
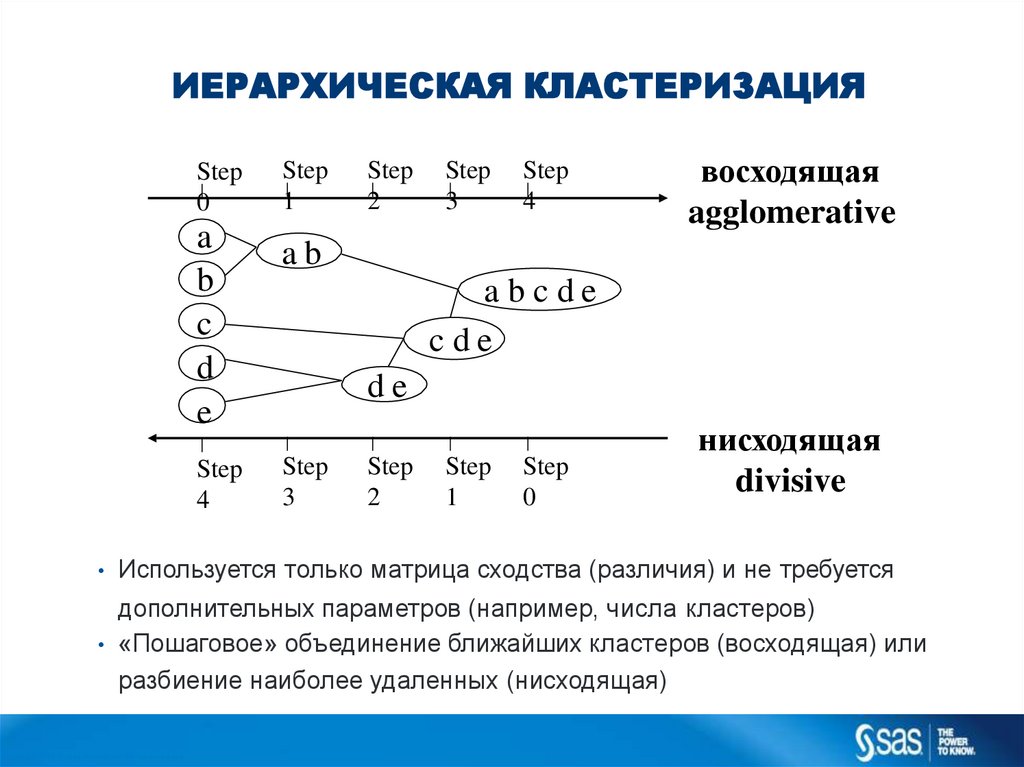
ИЕРАРХИЧЕСКАЯ КЛАСТЕРИЗАЦИЯStep
0
a
b
c
d
e
Step
4
Step
1
Step
2
Step
3
Step
4
восходящая
agglomerative
ab
abcde
cde
de
Step
3
Step
2
Step
1
Step
0
нисходящая
divisive
Используется только матрица сходства (различия) и не требуется
дополнительных параметров (например, числа кластеров)
«Пошаговое» объединение ближайших кластеров (восходящая) или
разбиение наиболее удаленных (нисходящая)
Cop yr i g h t © 2 0 12 , SAS In s ti tu t e I n c . A ll r i g h ts r es er ve d .
16.
ПРЕДСТАВЛЕНИЕ ИЕРАРХИЧЕСКИХКЛАСТЕРОВ - ДЕНДРОГРАММА
бинарное дерево,
описывающее все шаги
разбиения
Корень – общий кластер,
листья - элементы
«Высота» ветвей (до
пересечения) – порог
расстояния «склейки»
(«разделения»)
Cop yr i g h t © 2 0 12 , SAS In s ti tu t e I n c . A ll r i g h ts r es er ve d .
Результат кластеризации
– «срез» дендрограммы
17.
ИЕРАРХИЧЕСКАЯ КЛАСТЕРИЗАЦИЯ - DEMOCop yr i g h t © 2 0 12 , SAS In s ti tu t e I n c . A ll r i g h ts r es er ve d .
18.
УРОВНИ КЛАСТЕРИЗАЦИИCop yr i g h t © 2 0 12 , SAS In s ti tu t e I n c . A ll r i g h ts r es er ve d .
19.
ОЦЕНКА БЛИЗОСТИ КЛАСТЕРОВРасчет расстояния на основе попарных
расстояний между элементами различных
кластеров:
Полное связывание: наибольшее попарное
расстояние. Дает компактные сферические
кластеры.
Среднее связывание: усредненное попарное
расстояние. Редко используется.
Единственное связывание: наименьшее
попарное расстояние. Дает «растянутые» кластеры
сложной формы.
Центроидное связывание: расстояние между
центрами (мат. ожидание) кластеров.
Другие методы (например метод Ward’а –
минимизирует внутрикластерные дисперсии или
другую целевую функцию)
Cop yr i g h t © 2 0 12 , SAS In s ti tu t e I n c . A ll r i g h ts r es er ve d .
20.
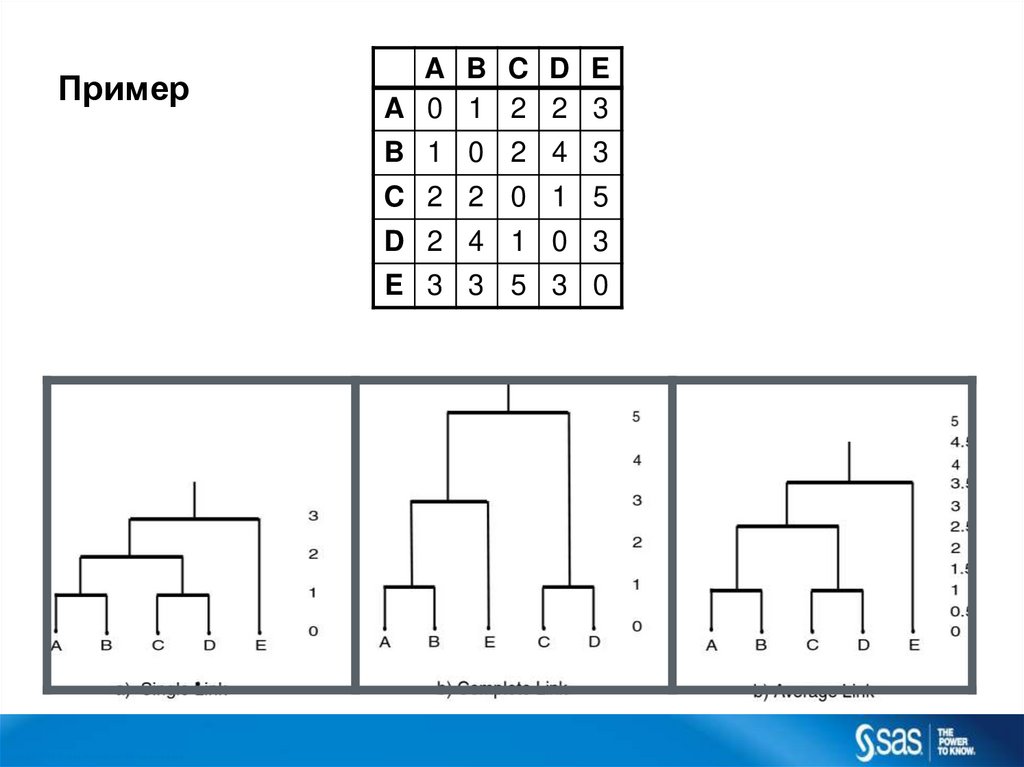
ПримерA B C D E
A 0 1 2 2 3
B 1 0 2 4 3
C 2 2 0 1 5
D 2 4 1 0 3
E 3 3 5 3 0
Cop yr i g h t © 2 0 12 , SAS In s ti tu t e I n c . A ll r i g h ts r es er ve d .
21.
КЛАСТЕРИЗАЦИЯ НА ОСНОВЕ СТРОГОЙ
ГРУППИРОВКИ (PARTITIONING):
Основная задача:
Найти такое разбиение C исходного множества X из N объектов
на K непересекающихся подмножеств Ck, покрывающих X, чтобы
внутриклассовое расстояние было минимальным:
min
Ci C j , Ci X
Точное решение – перебор с отсечением
K
i 1
x Ci x Ci d (x, x )
метод «ветвей и границ», но число комбинаций неприемлемо
даже для 100 объектов:
K
Эвристические методы:
K N
1
K i
S(N , K )
( 1) K
K ! i 1
i
K-means (прототип кластера – мат. ожидание m), K-medoids
(прототип кластера – средний элемент)
min
ищется локальный минимум
Cop yr i g h t © 2 0 12 , SAS In s ti tu t e I n c . A ll r i g h ts r es er ve d .
Ci C j , Ci X
K
i 1
x Ci d (mi , x)
22.
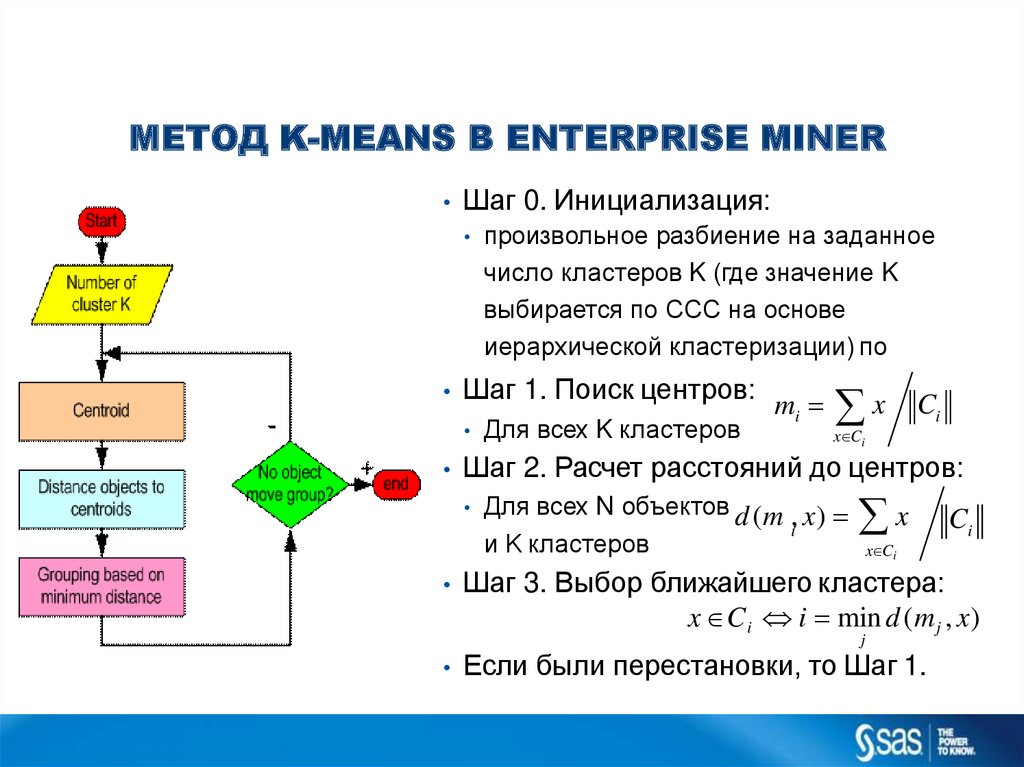
МЕТОД K-MEANS В ENTERPRISE MINERШаг 0. Инициализация:
Шаг 1. Поиск центров:
Для всех K кластеров
mi
x
Ci
x Ci
Шаг 2. Расчет расстояний до центров:
произвольное разбиение на заданное
число кластеров K (где значение K
выбирается по ССС на основе
иерархической кластеризации) по
Для всех N объектов d (m , x)
i
и K кластеров
x
x Ci
Шаг 3. Выбор ближайшего кластера:
x C i i min d (m j , x)
j
Cop yr i g h t © 2 0 12 , SAS In s ti tu t e I n c . A ll r i g h ts r es er ve d .
Ci
Если были перестановки, то Шаг 1.
23.
АЛГОРИТМ КЛАСТЕРИЗАЦИИ K-MEANSTraining Data
1. Выбор переменных.
2. Выбор k центров
кластеров.
3. Выбор ближайшего
центра для каждого
примера.
4. Пересчет центров.
5. Переход на шаг 3 пока
процесс не сошелся
Cop yr i g h t © 2 0 12 , SAS In s ti tu t e I n c . A ll r i g h ts r es er ve d .
24.
АЛГОРИТМ КЛАСТЕРИЗАЦИИ K-MEANSTraining Data
1. Выбор переменных.
2. Выбор k центров
кластеров.
3. Выбор ближайшего
центра для каждого
примера.
4. Пересчет центров.
5. Переход на шаг 3 пока
процесс не сошелся
Cop yr i g h t © 2 0 12 , SAS In s ti tu t e I n c . A ll r i g h ts r es er ve d .
25.
АЛГОРИТМ КЛАСТЕРИЗАЦИИ K-MEANSTraining Data
1. Выбор переменных.
2. Выбор k центров
кластеров.
3. Выбор ближайшего
центра для каждого
примера.
4. Пересчет центров.
5. Переход на шаг 3 пока
процесс не сошелся
Cop yr i g h t © 2 0 12 , SAS In s ti tu t e I n c . A ll r i g h ts r es er ve d .
...
26.
АЛГОРИТМ КЛАСТЕРИЗАЦИИ K-MEANSTraining Data
1. Выбор переменных.
2. Выбор k центров
кластеров.
3. Выбор ближайшего
центра для каждого
примера.
4. Пересчет центров.
5. Переход на шаг 3 пока
процесс не сошелся
Cop yr i g h t © 2 0 12 , SAS In s ti tu t e I n c . A ll r i g h ts r es er ve d .
...
27.
АЛГОРИТМ КЛАСТЕРИЗАЦИИ K-MEANSTraining Data
1. Выбор переменных.
2. Выбор k центров
кластеров.
3. Выбор ближайшего
центра для каждого
примера.
4. Пересчет центров.
5. Переход на шаг 3 пока
процесс не сошелся
Cop yr i g h t © 2 0 12 , SAS In s ti tu t e I n c . A ll r i g h ts r es er ve d .
...
28.
АЛГОРИТМ КЛАСТЕРИЗАЦИИ K-MEANSTraining Data
1. Выбор переменных.
2. Выбор k центров
кластеров.
3. Выбор ближайшего
центра для каждого
примера.
4. Пересчет центров.
5. Переход на шаг 3 пока
процесс не сошелся
Cop yr i g h t © 2 0 12 , SAS In s ti tu t e I n c . A ll r i g h ts r es er ve d .
...
29.
АЛГОРИТМ КЛАСТЕРИЗАЦИИ K-MEANSTraining Data
1. Выбор переменных.
2. Выбор k центров
кластеров.
3. Выбор ближайшего
центра для каждого
примера.
4. Пересчет центров.
5. Переход на шаг 3 пока
процесс не сошелся
Cop yr i g h t © 2 0 12 , SAS In s ti tu t e I n c . A ll r i g h ts r es er ve d .
...
30.
АЛГОРИТМ КЛАСТЕРИЗАЦИИ K-MEANSTraining Data
1. Выбор переменных.
2. Выбор k центров
кластеров.
3. Выбор ближайшего
центра для каждого
примера.
4. Пересчет центров.
5. Переход на шаг 3 пока
процесс не сошелся
Cop yr i g h t © 2 0 12 , SAS In s ti tu t e I n c . A ll r i g h ts r es er ve d .
...
31.
АЛГОРИТМ КЛАСТЕРИЗАЦИИ K-MEANSTraining Data
1. Выбор переменных.
2. Выбор k центров
кластеров.
3. Выбор ближайшего
центра для каждого
примера.
4. Пересчет центров.
5. Переход на шаг 3 пока
процесс не сошелся
Cop yr i g h t © 2 0 12 , SAS In s ti tu t e I n c . A ll r i g h ts r es er ve d .
...
32.
АЛГОРИТМ КЛАСТЕРИЗАЦИИ K-MEANSTraining Data
1. Выбор переменных.
2. Выбор k центров
кластеров.
3. Выбор ближайшего
центра для каждого
примера.
4. Пересчет центров.
5. Переход на шаг 3 пока
процесс не сошелся
Cop yr i g h t © 2 0 12 , SAS In s ti tu t e I n c . A ll r i g h ts r es er ve d .
...
33.
АЛГОРИТМ КЛАСТЕРИЗАЦИИ K-MEANSTraining Data
1. Выбор переменных.
2. Выбор k центров
кластеров.
3. Выбор ближайшего
центра для каждого
примера.
4. Пересчет центров.
5. Переход на шаг 3 пока
процесс не сошелся
Cop yr i g h t © 2 0 12 , SAS In s ti tu t e I n c . A ll r i g h ts r es er ve d .
...
34.
АЛГОРИТМ КЛАСТЕРИЗАЦИИ K-MEANSTraining Data
1. Выбор переменных.
2. Выбор k центров
кластеров.
3. Выбор ближайшего
центра для каждого
примера.
4. Пересчет центров.
5. Переход на шаг 3 пока
процесс не сошелся
Cop yr i g h t © 2 0 12 , SAS In s ti tu t e I n c . A ll r i g h ts r es er ve d .
...
35.
АЛГОРИТМ КЛАСТЕРИЗАЦИИ K-MEANSTraining Data
1. Выбор переменных.
2. Выбор k центров
кластеров.
3. Выбор ближайшего
центра для каждого
примера.
4. Пересчет центров.
5. Переход на шаг 3 пока
процесс не сошелся
Cop yr i g h t © 2 0 12 , SAS In s ti tu t e I n c . A ll r i g h ts r es er ve d .
...
36.
ОПРЕДЕЛЕНИЕ ЧИСЛА КЛАСТЕРОВSAS Cubic Clustering Criterion (CCC) (Sarle, 1983)
Основная идея: сравнение R2 (для отображения матрицы данных
с помощью индикаторной матрицы в прототипы кластеров) для
заданной модели кластеризации с E(R2) для равномерно
распределенного множества прототипов кластеров (как наихудший
возможный вариант):
1 E(R 2 )
CCC ln
K
2
1
R
clust
Cop yr i g h t © 2 0 12 , SAS In s ti tu t e I n c . A ll r i g h ts r es er ve d .
37.
ОПРЕДЕЛЕНИЕ ЧИСЛА КЛАСТЕРОВСлучайно выбираются центры
для большого (50 по
умолчанию) числа кластеров
Все наблюдения
объединяются в эти
случайные кластеры
Решается задач восходящей
иерархической кластеризации,
на каждом шаге считается
CCC
По определенным правилам
выбирается оптимальное
число кластеров:
1.
2.
3.
4.
Первый локальный пик …
Cop yr i g h t © 2 0 12 , SAS In s ti tu t e I n c . A ll r i g h ts r es er ve d .