













 Информатика
ИнформатикаПохожие презентации:










Кодирование информации (2лекция)
1.
Кодирование информации2.
Информационное сообщение• Информация бывает разного рода: текстовой,
числовой, звуковой, видео и т.д. Кодирование –
переход от одной формы представления
информации к другой, более удобной для
хранения, передачи или обработки. Обратный
процесс называется декодированием. В
вычислительной технике используется двоичная
система кодирования.
3.
Кодирование текстовойинформации
• С помощью 1 бита можно закодировать 2
возможных символа, с помощью двух – 4, с
помощью трех – 8 символов, m<=2h
Например, в некоторой стране автомобильный
номер длиной 5 символов состоит из заглавных
букв (30 различных букв) и любых десятичных
цифр в любом порядке. Определите объем
памяти, отводимый для записи 50 номеров.
М=30+10=40 различных символов. М=40<=26
H=6 бит – вес одного символа в битах. К=5*6=30
бит=3,75 байт≈4 байт. H=4*50 ≈200 байт.
4.
Системы кодирования текстовойинформации
Для кодирования текстовой информации каждому символу ставится в
соответствие определенное целое число (код символа) – специальные кодовые
таблицы. Стандарты разрабатывались Американским национальным
институтом стандартизации (ANSI), впоследствии была создана
Международная организация стандартизации (ISO). Основой для
компьютерных стандартов послужил американский стандартный код для
обмена информации, разработанный в 1960 г. - ASCII. В нем закреплены две
таблицы: базовая и расширенная. Базовая закрепляет значения кодов от 0 до
127 и используется для английского языка, расширенная относится к
символам с кодами от 128 до 255 для русского языка. Для русского языка
наиболее распространенными являются однобайтовые кодировки CP-866
(Code page MS-DOS), CP-1251 (Windows-1251), КОИ-8 (КОИ8-R),
предназначенных для кодирования русских и латинских букв. В них первые
128 символов совпадают с ASCII, а вторая часть для кодирования русских
букв во всех кодировках различна.
5.
Системы кодирования текстовойинформации
• Например, десятичный код слова ДИСК в разных кодировках
будет выглядеть по-разному:
• КОИ-8: 228201211203
• CP-1251: 196232241234
• CP-866: 132168225170
• Несовпадение кодовых таблиц приводит к тому, что текст,
набранный в одной кодировке, будет нечитабельным в другой. В
1993 г. Был разработан новый стандарт кодирования 2-х
байтный, который описывает алфавиты всех языков - 16
разрядная система кодирования UNICODE позволяет
закодировать 65536 различных символов, используя 2 байта на
символ. Оценить информационный объем сообщения: Ученье свет, а неученье - тьма в кодировке КОИ8-R и Unicode.
6.
Равномерные коды• Равномерные коды (для кодирования
используют все символы исходного алфавита и
одинаковое количество знаков на символ)
позволяют однозначно декодировать
сообщение (ASCII, UNICODE и др.).
• Главный недостаток: избыточное кодирование.
• Эффективное кодирование осуществляется с
применением неравномерных кодов, в
которых более короткие кодовые комбинации
соответствуют более вероятным символам
сообщения, а более длинные — менее
вероятным символам.
7.
Основные требования кэффективному коду
• однозначность декодирования, т. е.
каждому символу кодируемого сообщения
должна соответствовать своя кодовая
комбинация и для всех символов
комбинации должны быть различны;
• никакая более короткая комбинация
эффективного кода не должна являться
началом другой, более длинной
комбинации.
8.
Префиксный код• Префиксный код – это код переменной длины, в
котором ни одно кодовое слово не является
началом другого кодового слова, например,
• А 01
• Б 100
• В 110
• И 101
• О 00
• Е 111
• Сообщение 1100011001 однозначно декодируется.
9.
Префиксный код• Определить, какой код является
префиксным:
• X1 0
x1 0
• X2 10
x2 10
• X3 11
x3 11
x4 100
10.
Префиксный код• Сообщения, закодированные префиксным
кодом, можно декодировать сразу, не
дожидаясь получения всего сообщения
целиком. Префиксные коды используются
для кодирования аудио и видео файлов, а
также используются в архиваторах.
Рассмотрим построение эффективного кода
на примере кода Шеннона-Фано и кода
Хаффмена.
11.
Методика Шеннона-Фано• 1 этап. Записываются сообщения ai в порядке убывания их
вероятностей (более вероятные вверху, менее вероятные внизу).
• 2 этап. Все сообщения делятся на две группы, таким образом, чтобы
в каждой группе суммарные вероятности были примерно равны.
Верхней группе присваивается ноль нижней единица. Затем каждая
группа разбивается на две подгруппы, также, по возможности, с
равными суммарными вероятностями. Верхней подгруппе
присваивается ноль, нижней единица, и т. д. Деление подгрупп
производится до тех пор, пока в каждой подгруппе не окажется по
одному элементу ai.
• 3 этап. Записываются кодовые комбинации, соответствующие
каждому элементу сообщения, при этом 1-я группа соответствует
старшему разряду, 2-я следующему и т. д. по всем столбцам. Если в
столбце элемента ai отсутствует символ «0» или «1», то в
соответствующем разряде кодовой комбинации он не пишется.
12.
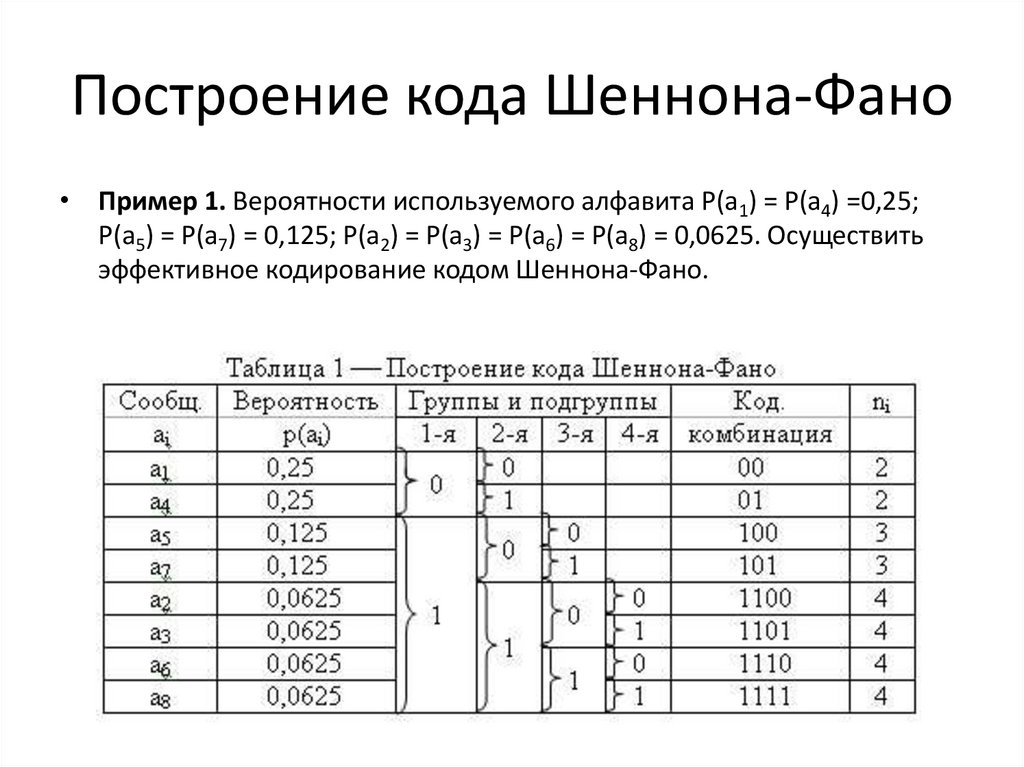
Построение кода Шеннона-Фано• Пример 1. Вероятности используемого алфавита Р(а1) = Р(а4) =0,25;
Р(а5) = Р(а7) = 0,125; Р(а2) = Р(а3) = Р(а6) = Р(а8) = 0,0625. Осуществить
эффективное кодирование кодом Шеннона-Фано.
13.
Методика Хаффмана• В основе лежит идея кодирования битовыми
группами. Сначала проводится частотный
анализ входной последовательности, т.е.
устанавливается частота вхождения каждого
символа. Затем символы сортируются по
уменьшению частоты вхождения. Чем чаще
встречается символ, тем меньшим
количеством бит он кодируется. Результат
кодирования заносится в словарь. Две
последние частоты объединяются и
суммируются и выстраиваются в новый
столбец в порядке убывания.
14.
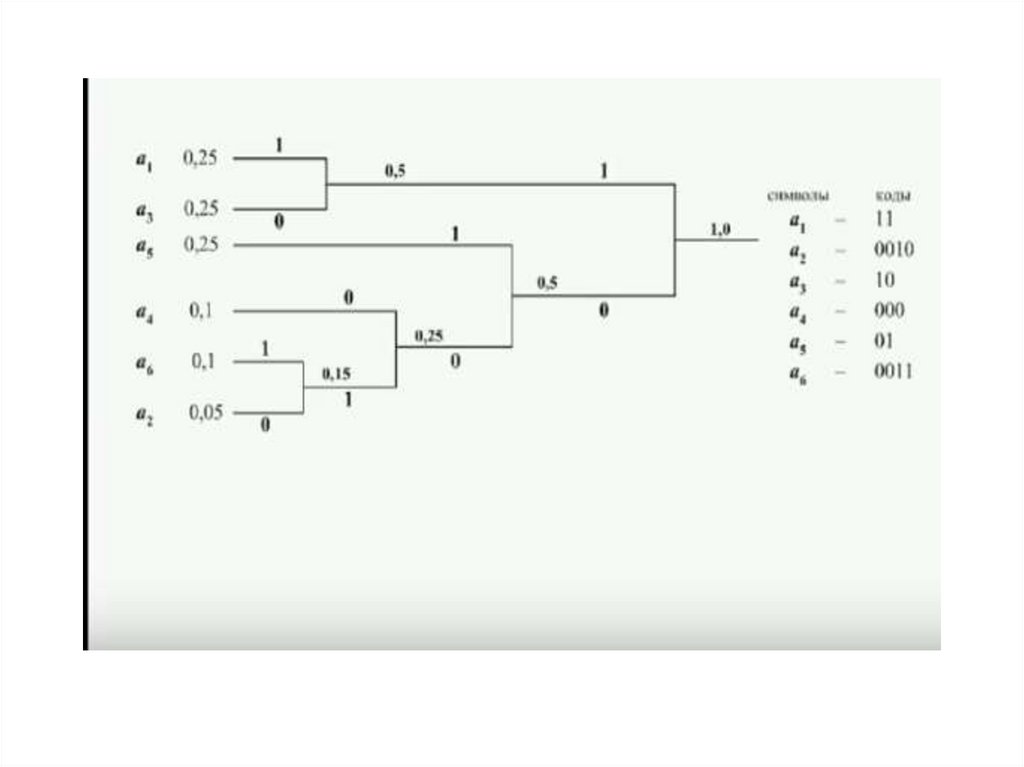
Методика Хаффмена• 1 этап. Записываются сообщения ai в порядке убывания их
вероятностей .
• 2 этап. Строится дерево кода, для этого два сообщения с
наименьшей вероятностью (снизу таблицы) объединяются в
группу. Ветви с наибольшей вероятностью присваивается
единица, с наименьшей - ноль. Если четыре символа имеют
одинаковую минимальную вероятность, то организуются две
одинаковые группы.
• Такая организация групп продолжается до тех пор, пока не
образуется последняя группа с элементом имеющим
наибольшую вероятность ( в самом верху таблицы).
• 3 этап. Формируются кодовые комбинации, для этого
записывают значение ветвей графа справа налево.