






























 Информатика
ИнформатикаПохожие презентации:
")
")
")
")
")
")




Классификация вычислительных систем
1.
Классификациявычислительных систем
2.
В соответствии с наиболее известнойклассификацией архитектур ВС,
предложенной в 1966 году М.Флинном и
базирующейся на понятии потока, под
которым понимается последовательность
элементов, команд или данных,
обрабатываемая процессором, выделают
четыре типа архитектур ВС: SISD, MISD,
SIMD, MIMD:
3.
SISD(single instruction, single data)
• - одиночный поток команд и одиночный
поток данных. К этому классу относятся,
прежде всего, классические последовательные
машины, или иначе, машины фоннеймановского типа, например, PDP-11 или
VAX 11/780. В таких машинах есть только один
поток команд, все команды обрабатываются
последовательно друг за другом и каждая
команда инициирует одну операцию с одним
потоком данных.
4.
SIMD(single instruction, multiple data)
• - одиночный поток команд и множественный
поток данных. В архитектурах подобного рода
сохраняется один поток команд, включающий,
в отличие от предыдущего класса, векторные
команды. Это позволяет выполнять одну
арифметическую операцию сразу над
многими данными - элементами вектора. В
таких системах обычно очень много модулей
обработки (от 1024 до 16384), которые и
позволяют за одну инструкцию обрабатывать
несколько данных.
5.
MISD(multiple instruction, single data)
• - множественный поток команд и одиночный
поток данных. Определение подразумевает
наличие в архитектуре многих процессоров,
обрабатывающих один и тот же поток данных.
Однако ни Флинн, ни другие специалисты в
области архитектуры компьютеров до сих пор
не смогли представить убедительный пример
реально существующей вычислительной
системы, построенной на данном принципе.
6.
MIMD(multiple instruction, multiple data)
• - множественный поток команд и
множественный поток данных. Этот класс
предполагает, что в вычислительной системе
есть несколько устройств обработки команд,
объединенных в единый комплекс, каждое из
которых работает со своим потоком команд и
данных. Основное отличие этих систем от
многопроцессорных SIMD-машин состоит в
том, что инструкции и данные связаны, потому
что они относятся к одной и той же
исполняемой задаче.
7.
Классификация ДжонсонаЕ. Джонсон предложил проводить
классификацию MIMD-архитектур на
основе структуры памяти и
реализации механизма
взаимодействия и синхронизации
между процессорами.
8.
• По структуре оперативной памяти существующиевычислительные системы делятся на две большие
группы: либо это системы с общей памятью, прямо
адресуемой всеми процессорами, либо это системы
с распределенной памятью, каждая часть которой
доступна только одному процессору.
Одновременно с этим и для межпроцессорного
взаимодействия существуют две альтернативы:
через разделяемые (общие) переменные или с
помощью механизма передачи сообщений. Исходя
из таких предположений, можно получить четыре
класса MIMD-архитектур, уточняющих систематику
Флинна
9.
общаяПамять
GMSV - General Memory-Shared variables
(Общая память - разделяемые переменные)
Класс 1 ≪Системы с разделяемой памятью≫
GMMP - General Memory, Message propagation
(Общая память - передача сообщений)
10.
Распределенная ПамятьDMSV - Distributed Memory, Shared variables
(Распределенная память - разделяемые
переменные)
Класс 2. ≪Гибридная архитектура≫
DMMP - Distributed Memory, Message
propagation) (Распределенная память - передача сообщений)
Класс 3 ≪Архитектуры с передачей сообщений≫
11.
Классификация БазуПо мнению А. Базу (A. Basu), любую
параллельную вычислительную систему
можно однозначно описать
последовательностью решений, принятых на
этапе ее проектирования, а сам процесс
проектирования представить в виде дерева.
Корень дерева — это вычислительная система
и последующие ярусы дерева, фиксируя
уровень параллелизма, метод реализации
алгоритма, параллелизм инструкций и способ
управления, последовательно дополняют друг
друга, формируя описание системы.
12.
Классификация Дункана• конвейеризацию на этапе подготовки и выполнения команды
(instruction pipelining), т. е. частичное перекрытие таких этапов, как дешифрация команды, вычисление адресов операндов, выборка операндов, выполнение команды и сохранение
результата;
• наличие в архитектуре нескольких функциональных устройств, работающих независимо, в частности, возможность
параллельного выполнения логических и арифметических
операций;
• наличие отдельных процессоров ввода/вывода, работающих
независимо и параллельно с основными процессорами.
13.
Классификация Кришнамарфидля классификации параллельных
вычислительных систем предлагает
использовать четыре характеристики,
похожие на характеристики классификации
А. Базу :
• • степень гранулярности;
• • способ реализации параллелизма;
• • топологию и природу связи процессоров;
• • способ управления процессорами.
14.
Классификация СкилликорнаПредлагается рассматривать архитектуру любого компьютера,
как абстрактную структуру, состоящую из четырех компонент:
• процессор команд (IP — Instruction Processor) — функциональное устройство, работающее, как интерпретатор команд; в
системе, вообще говоря, может отсутствовать;
• процессор данных (DP — Data Processor) — функциональное
устройство, работающее как преобразователь данных, в соответствии с арифметическими операциями;
• иерархия памяти (IM — Instruction Memory, DM — Data
Memory) — запоминающее устройство, в котором хранятся
данные и команды, пересылаемые между процессорами;
• переключатель — абстрактное устройство, обеспечивающее
связь между процессорами и памятью.
15.
Классификация ХендлераПредложенная классификация базируется на различии между
тремя уровнями обработки данных в процессе выполнения программ:
• уровень выполнения программы: опираясь на счетчик команд
и некоторые другие регистры, устройство управления (УУ)
производит выборку и дешифрацию команд программы;
• уровень выполнения команд: арифметико-логическое устройство компьютера (АЛУ) исполняет команду, выданную ему
устройством управления;
• уровень битовой обработки: все элементарные логические схемы процессора (ЭЛС) разбиваются на группы, необходимые
для выполнения операций над одним двоичным разрядом.
16.
Классификация ХокниОсновная идея классификации состоит в
следующем.
Множественный поток команд может быть
обработан двумя способами: либо одним
конвейерным устройством обработки,
работающем в режиме разделения
времени для отдельных потоков, либо
каждый поток обрабатывается своим
собственным устройством
17.
Первая возможностьиспользуется в MIMD-компьютерах,
которые автор называет
конвейерными
18.
Архитектуры, использующие вторую возможность, всвою очередь опять делятся на два класса:
• • MIMD-компьютеры, в которых возможна прямая
связь каждой пары процессоров, которая
реализуется с помощью переключателя;
• • MIMD-компьютеры, в которых прямая связь
каждого процессора возможна только с
ближайшими соседями по сети, а взаимодействие
удаленных процессоров поддерживается
специальной системой маршрутизации через
процессоры-посредники.
19.
Классификация Шорапредставляет собой попытку выделения типичных
способов компоновки вычислительных систем
на основе фиксированного числа базисных блоков:
устройства управления, арифметико-логического
устройства, памяти команд и памяти данных.
Дополнительно предполагается, что выборка из
памяти данных может осуществляться словами, т. е.
выбираются все разряды одного слова и/или
битовым слоем — по одному разряду из одной и
той же позиции каждого слова (иногда этих два
способа называют горизонтальной и вертикальной
выборками соответственно)
20.
Примеры некоторых архитектурвычислительных систем
21.
• асимметричная многопроцессорная(мультипроцессорная)обработка (архитектура);
• массивно-параллельная архитектура;
• симметричная многопроцессорная архитектура;
• гибридная архитектура с неоднородным доступом к
памяти;
• параллельная архитектура с векторными
процессорами;
• кластерная архитектура.
22.
Асимметричнаямультипроцессорная обработка —
ASymmetric Multiprocessing (ASMP)
Это архитектура суперкомпьютера, в которой каждый
процессор имеет свою оперативную память
Передача сообщений может осуществляться через общую шину
(МРР-архитектура) либо благодаря межпроцессорным
связям. В последнем случае процессоры связаны либо непосредственно, либо через друг друга.
Непосредственные связи используются при небольшом числе
процессоров.
23.
МРР-архитектура (massive parallelprocessing) — массивно-параллельная архитектура
24.
Система состоит из однородных вычислительных узлов, включающих:1. один или несколько центральных процессоров (обычно RISC),
2. локальную память (прямой доступ к памяти других узлов невозможен),
Архитек 3. коммуникационный процессор или сетевой адаптер
тура
4. иногда - жесткие диски (как в SP) и/или другие устройства В/В
К системе могут быть добавлены специальные узлы ввода-вывода и
управляющие узлы. Узлы связаны через некоторую коммуникационную среду
(высокоскоростная сеть, коммутатор и т.п.)
Пример
IBM RS/6000 SP2, Intel PARAGON/ASCI Red, SGI/CRAY T3E, Hitachi SR8000,
ы
транспьютерные системы Parsytec.
Масшта
Общее число процессоров в реальных системах достигает нескольких тысяч
бируемость (ASCI Red, Blue Mountain).
Существуют два основных варианта:
1. Полноценная ОС работает только на управляющей машине (front-end), на
каждом узле работает сильно урезанный вариант ОС, обеспечивающие только
Операци
работу расположенной в нем ветви параллельного приложения. Пример: Cray
онная
T3E.
система
2. На каждом узле работает полноценная UNIX-подобная ОС (вариант, близкий
к кластерному подходу). Пример: IBM RS/6000 SP + ОС AIX, устанавливаемая
отдельно на каждом узле.
Модель
программи
рования
Программирование в рамках модели передачи сообщений ( MPI, PVM, BSPlib)
25.
Симметричнаямультипроцессорная обработка
Symmetric Multiprocessing (SMP)
26.
Система состоит из нескольких однородных процессоров и массива общей памяти (обычно из несколькихнезависимых блоков). Все процессоры имеют доступ к любой точке памяти с одинаковой скоростью.
Архитектура
Процессоры подключены к памяти либо с помощью общей шины (базовые 2-4 процессорные SMP-сервера),
либо с помощью crossbar-коммутатора (HP 9000). Аппаратно поддерживается когерентность кэшей.
Примеры
HP 9000 V-class, N-class; SMP-cервера и рабочие станции на базе процессоров Intel (IBM, HP, Compaq,
Dell, ALR, Unisys, DG, Fujitsu и др.).
Наличие общей памяти сильно упрощает взаимодействие процессоров между собой, однако накладывает
Масштабиру
сильные ограничения на их число - не более 32 в реальных системах. Для построения масштабируемых
емость
систем на базе SMP используются кластерные или NUMA-архитектуры.
Вся система работает под управлением единой ОС (обычно UNIX-подобной, но для Intel-платформ
Операционн
поддерживается Windows NT). ОС автоматически (в процессе работы) распределяет процессы/нити по
ая система
процессорам (scheduling), но иногда возможна и явная привязка.
Модель
Программирование в модели общей памяти. (POSIX threads, OpenMP). Для SMP-систем существуют
программирова
сравнительно эффективные средства автоматического распараллеливания.
ния
27.
Гибридная архитектура (NUMA).Организация когерентности
многоуровневой иерархической
памяти
28.
Система состоит из однородных базовых модулей (плат), состоящих из небольшого числа процессоров и блока памяти.Модули объединены с помощью высокоскоростного коммутатора. Поддерживается единое адресное пространство, аппаратно
поддерживается доступ к удаленной памяти, т.е. к памяти других модулей. При этом доступ к локальной памяти в несколько
Архитектура
раз быстрее, чем к удаленной.
В случае, если аппаратно поддерживается когерентность кэшей во всей системе (обычно это так), говорят об архитектуре
cc-NUMA (cache-coherent NUMA)
Примеры
HP HP 9000 V-class в SCA-конфигурациях, SGI Origin2000, Sun HPC 10000, IBM/Sequent NUMA-Q 2000, SNI RM600.
Масштабируемость NUMA-систем ограничивается объемом адресного пространства, возможностями аппаратуры
Масштабируе
поддежки когерентности кэшей и возможностями операционной системы по управлению большим числом процессоров. На
мость
настоящий момент, максимальное число процессоров в NUMA-системах составляет 256 (Origin2000).
Обычно вся система работает под управлением единой ОС, как в SMP. Но возможны также варианты динамического
Операционна
"подразделения" системы, когда отдельные "разделы" системы работают под управлением разных ОС (например, Windows NT
я система
и UNIX в NUMA-Q 2000).
Модель
программирован
ия
Аналогично SMP.
29.
PVP-архитектура(Parallel Vector Process)
30.
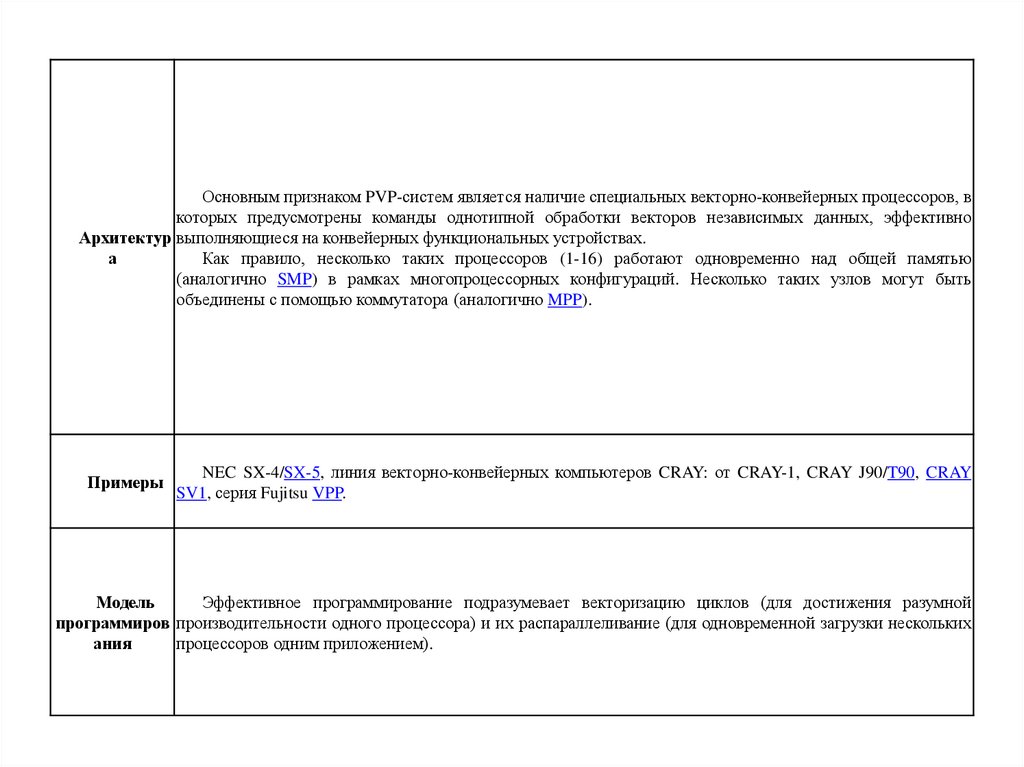
Основным признаком PVP-систем является наличие специальных векторно-конвейерных процессоров, вкоторых предусмотрены команды однотипной обработки векторов независимых данных, эффективно
Архитектур выполняющиеся на конвейерных функциональных устройствах.
а
Как правило, несколько таких процессоров (1-16) работают одновременно над общей памятью
(аналогично SMP) в рамках многопроцессорных конфигураций. Несколько таких узлов могут быть
объединены с помощью коммутатора (аналогично MPP).
Примеры
NEC SX-4/SX-5, линия векторно-конвейерных компьютеров CRAY: от CRAY-1, CRAY J90/T90, CRAY
SV1, серия Fujitsu VPP.
Модель
Эффективное программирование подразумевает векторизацию циклов (для достижения разумной
программиров производительности одного процессора) и их распараллеливание (для одновременной загрузки нескольких
ания
процессоров одним приложением).
31.
Кластерная архитектура32.
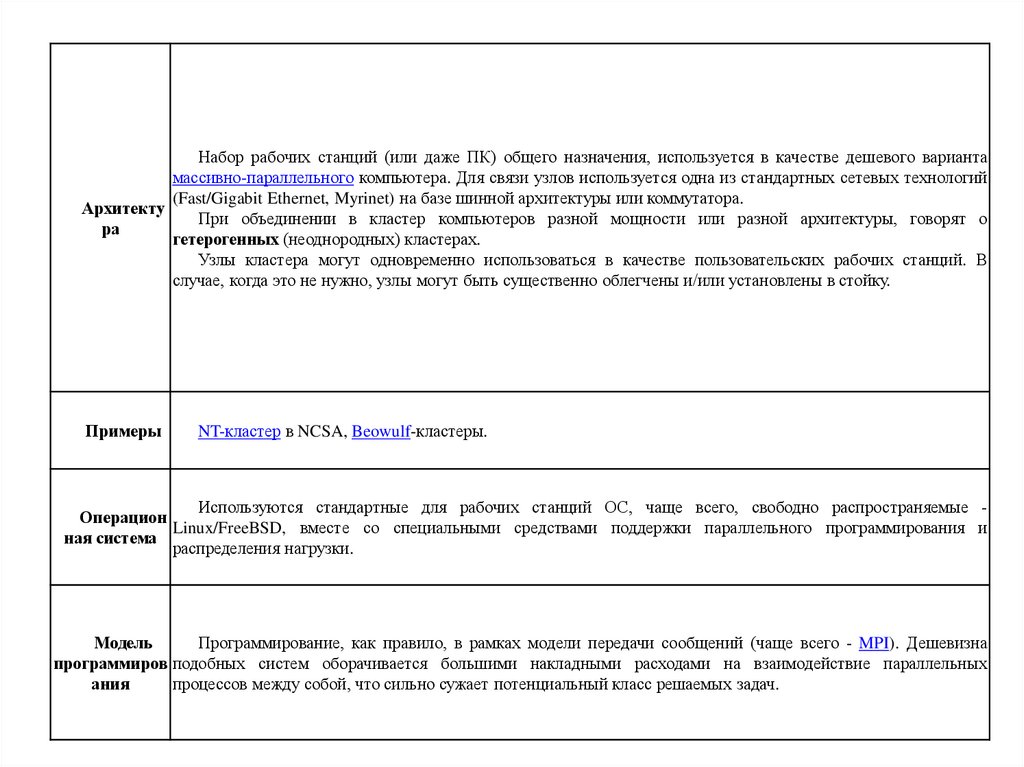
Набор рабочих станций (или даже ПК) общего назначения, используется в качестве дешевого вариантамассивно-параллельного компьютера. Для связи узлов используется одна из стандартных сетевых технологий
(Fast/Gigabit Ethernet, Myrinet) на базе шинной архитектуры или коммутатора.
Архитекту
При объединении в кластер компьютеров разной мощности или разной архитектуры, говорят о
ра
гетерогенных (неоднородных) кластерах.
Узлы кластера могут одновременно использоваться в качестве пользовательских рабочих станций. В
случае, когда это не нужно, узлы могут быть существенно облегчены и/или установлены в стойку.
Примеры
NT-кластер в NCSA, Beowulf-кластеры.
Используются стандартные для рабочих станций ОС, чаще всего, свободно распространяемые Операцион
Linux/FreeBSD, вместе со специальными средствами поддержки параллельного программирования и
ная система
распределения нагрузки.
Модель
Программирование, как правило, в рамках модели передачи сообщений (чаще всего - MPI). Дешевизна
программиров подобных систем оборачивается большими накладными расходами на взаимодействие параллельных
ания
процессов между собой, что сильно сужает потенциальный класс решаемых задач.