








 Информатика
ИнформатикаПохожие презентации:









")
Нефинансовая отчетность
1.
ПРОЕКТ В Rгруппа 3 l нефинансовая
отчетность
Выполнили:студенты 1 курса магистратуры
ДЭКФ23-1м
Колекина Н.В.
Убайдуллаева М.А.
Скобникова В.К.
Филиппенко В.И.
Лягушкина О.И.
2.
Гипотезы исследования01
Степень раскрытия компанией нефинансовой
информации в соответствии со стандартами GRI
прямо положительно коррелирует с увеличением
инвестиционной привлекательности компании на
финансовом рынке.
02 Полнота раскрытия компанией информации о
благотворительной деятельности, социальной
ответственности, инновациях и научнотехническом развитии, не затрагиваемая
стандартами GRI, также оказывает воздействие
на привлекательность компании для инвесторов.
компании.
Федорова Е.А., Хрустова Л.Е., Демин
И.С. Полнота раскрытия
нефинансовой информации
российскими компаниями: влияние
на инвестиционную
привлекательность // Российский
журнал менеджмента. - 2020. - №18
(1) . - С. 51-72..
https://cyberleninka.ru/article/n/vliya
nie-kachestva-raskrytiya-nefinansovoyinformatsii-rossiyskimi-kompaniyamina-ih-investitsionnuyu-privlekatelnost
3.
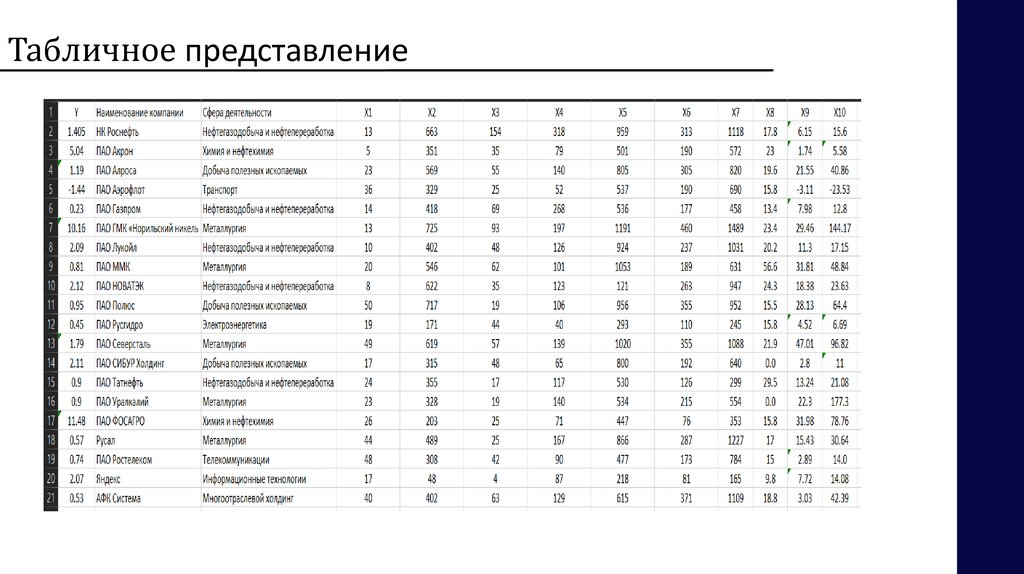
Подготовка массива и переменные01
Был собран массив из 20 российских компаний, которые специализируются в
различных отраслях
02
При анализе были использованы следующие показатели :
Y: Коэффициент Тобина
X1: Индекс раскрытия информации о благотворительной и спонсорской
деятельности
X2: Индекс раскрытия информации о политике в области управления персоналом
X3: Индекс раскрытия информации об инновационном и научно техническом
развитии
X4: Индекс раскрытия информации о социальной ответственности
X5: Индекс раскрытия информации об экологической ответственности
X6: Индекс раскрытия информации об экономической результативности
X7: Индекс раскрытия общей информации о корпоративном управлении
X8: wacc
X9: ROA
X10: ROE
4.
МетодологияБыла взята отчётность компаний за 2022 г.
01
1.Внесли данные в R,выбрав слова/словосочетания, по
которым будем совершен поиск
2. Полученное количество слов, которые встречаются в
отчетности компаний, были использованы для составления
индексов
install.packages("devtools")
devtools::install_github("dmafanasyev/rulexicon")
keytable<-rulexicon::key_nonfinance_report_standard
text_2<-readLines("C:/Skobnikova/2/Rostelecom.txt",encoding =
'UTE-8') %>% paste(collapse = ' ') %>%
tolower
library(stringr)
occurencies<-str_count(text_2,keytable$regex)
sum(keytable$section * occurencies)
by(occurencies, keytable$section, sum)
Такие показатели, как
коэффициент Тобина, ROA, ROE и
WACC были рассчитаны вручную
также на основе данных отчётности
компаний.
«Яндекс»
«Polus»
5.
Табличное представление6.
Корректировка данных и сводная статистикаПреобразуем неправильно определенные
переменные, исключив при этом столбцы с
названием компаний и их сфере деятельности
library (readxl)
df=read_excel("C:/Skobnikova/project.xlsx")
str(df)
df$Y <- as.numeric(df$`Y`)
str(df)
df$X8 <- as.numeric(df$`X8`)
str(df)
df$X9 <- as.numeric(df$`X9`)
str(df)
df$X10 <- as.numeric(df$`X10`)
str(df)
df_reg=df[ , -2] #исключение буквенного столбца
df_reg
df_reg1=df_reg[ , -2] #исключение буквенного столбца
df_reg1
summary(df_reg1)
7.
Описательная статистикаИндекс по переменным: ('X2', 'X5', 'X6', 'X7')
df_reg1$row_sum=rowSums(df_reg1[ , c('X2',
'X5', 'X6', 'X7')]) #индекс
df_reg1
Индекс по переменным: ('X1', 'X3', 'X4')
df_reg1$row_sum_1=rowSums(df_reg1[ ,
c('X1', 'X3', 'X4')])
df_reg1
library("memisc")
library("psych")
library("dplyr")
library("ggplot2")
df_reg1 <- na.omit(df_reg1)
qplot(data = df_reg1, Y, geom =
"histogram")
qplot(data = df_reg1, 1, Y, geom =
"boxplot") +
geom_boxplot(outlier.color = "red")
Удаляем пропуски и строим
гистограмму по Y:
boxplot.stats(df_reg1$Y)$stats
df_1 <- as.numeric(quantile(df_reg1$Y,
probs = 0.75) + 1.5*IQR(df_reg1$Y))
df_reg1 <- df_reg1[df_reg1$Y <= df_1,]
qplot(data = df_reg1, Y, geom =
"histogram")
8.
Кореляционный анализизlibrary (ggcorrplot)
ggcorrplot(cor(df_reg1))
9.
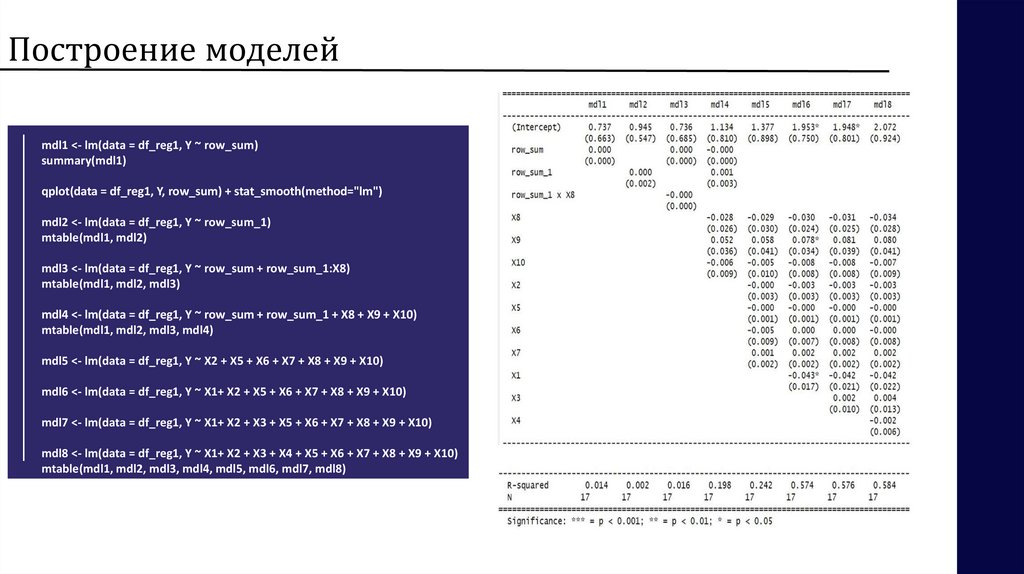
Построение моделейmdl1 <- lm(data = df_reg1, Y ~ row_sum)
summary(mdl1)
qplot(data = df_reg1, Y, row_sum) + stat_smooth(method="lm")
mdl2 <- lm(data = df_reg1, Y ~ row_sum_1)
mtable(mdl1, mdl2)
mdl3 <- lm(data = df_reg1, Y ~ row_sum + row_sum_1:X8)
mtable(mdl1, mdl2, mdl3)
mdl4 <- lm(data = df_reg1, Y ~ row_sum + row_sum_1 + X8 + X9 + X10)
mtable(mdl1, mdl2, mdl3, mdl4)
mdl5 <- lm(data = df_reg1, Y ~ X2 + X5 + X6 + X7 + X8 + X9 + X10)
mdl6 <- lm(data = df_reg1, Y ~ X1+ X2 + X5 + X6 + X7 + X8 + X9 + X10)
mdl7 <- lm(data = df_reg1, Y ~ X1+ X2 + X3 + X5 + X6 + X7 + X8 + X9 + X10)
mdl8 <- lm(data = df_reg1, Y ~ X1+ X2 + X3 + X4 + X5 + X6 + X7 + X8 + X9 + X10)
mtable(mdl1, mdl2, mdl3, mdl4, mdl5, mdl6, mdl7, mdl8)
10.
Тестирование предпосылокlibrary(lmtest)
resettest(mdl8)
Тестирование предпосылки Ожидаемые значения случайных
возмущений = 0 тестом Рэмзи:
P-value = 0,9648 => 0,9648>0,05 можно сделать вывод, что предпосылка
принимается.
library(lmtest)
dwtest(mdl8)
Тестирование предпосылки 3 об отсутствии автокорреляции случайных
возмущений
Для тестирования предпосылки теоремы Гаусса-Маркова
использована команда dwtest. В данном случае получается, что p-value
= 0,075. Это больше 0,05, следовательно, гипотеза об отсутствии
автокорреляции случайных возмущений соблюдается.
11.
СПАСИБО ЗАВНИМАНИЕ!