












 Информатика
ИнформатикаПохожие презентации:





")




Тематическое моделирование. Формальные модели в лингвистике
1.
Формальные модели в лингвистикеЛекция 11. Тематическое моделирование
МАМАЕВ И.Д.,
ПРЕПОДАВАТЕЛЬ КАФЕДРЫ Р7
2.
Тематическое моделированиеТематическое моделирование — «способ построения модели текстовой коллекции,
отражающий переход от совокупности документов, совокупности слов в документах
коллекции к набору тем, характеризующих текстовую коллекцию». [Митрофанова 2013].
Тематические модели — модели со скрытыми переменными (факторами), задающими
тематику текстов. Для выявления этих скрытых переменных лучше всего применять
нечеткую кластеризацию — разбиение текстов на пересекающиеся классы.
В тематических моделях используется подход к обработке текстовых данных,
называемый bag-of-words: способ упорядочения слов внутри документов не имеет
значения.
3.
Темы, выделенные для корпусаиздательства Associated Press
А как же сочетания длиной 2 и более?
4.
Типы тематических моделейВ практических разработках последних лет широко используется ряд методов
тематического моделирования.
Среди алгебраических моделей текста, на которые опираются процедуры тематического
моделирования, наиболее распространены стандартная векторная модель текста VSM
(Vector Space Model) и латентно-семантический анализ LSA (Latent Semantic Analysis).
Среди вероятностных (генеративных) моделей наиболее всего применяются
вероятностный латентно-семантический анализ pLSA (probalilistic Latent Semantic
Analysis), латентное размещение Дирихле LDA (Latent Dirichlet Allocation).
5.
Vector Space ModelВ VSM текст описывается матрицей совместной встречаемости «термы-термы» или
«термы-документы».
Словам или текстам ставятся в соответствие вектора в n-мерном пространстве.
Cравнение векторов (как правило, определение косинуса угла между векторами)
позволяет оценить, насколько слово характерно для некого документа, насколько
связаны слова между собой в документе, насколько близки документы.
Недостатки VSM связаны с неудобством использования d работе с текстами больших
объемов, с невозможностью учесть синонимические отношения между словами и их
многозначность.
6.
Latent Semantic AnalysisМодель LSA наследует основные характеристики VSM, однако в LSA для сокращения
размерности признакового пространства и для выявления наиболее значимых слов в
текстах используется сингулярное разложение матрицы совместной встречаемости
(Singular Value Decomposition, SVD).
В отличие от VSM, модель LSA пригодна для описания больших текстовых
коллекций и позволяет частично учесть контекстную синонимию, однако не
справляется с многозначностью.
Также в LSA сложно заранее задать ожидаемое число тем, приписать метку темы,
используя какое-либо ключевое слово из этой темы.
7.
Singular Value Decomposition8.
pLSA и LDAМодель pLSA являет собой вероятностную модификацию LSA. В pLSA порождение
документа, характеризующих его тем, ключевых слов в этой теме производится в
соответствии с методом Байеса. Модель pLSA отчасти учитывает многозначность слов
(т. е. в разных значениях многозначные слова могут представлять разные темы).
Основные недостатки pLSA связаны с риском переобучения модели, а также со
сложностью добавления новых документов в текстовую коллекцию.
Модель LDA сглаживает шероховатости, имеющиеся в предыдущих моделях. В модели
LDA, опирающейся на распределение Дирихле, каждая тема характеризуется
вероятностным распределением на множестве слов в текстовой коллекции, а документы
описываются семейством распределений тем. LDA позволяет описывать корпуса текстов
очень большого объема, в одну тему могут попадать слова разных частей речи, однако
данная модель не предусматривает установление связей между темами.
9.
Примерыисследований
лингвистических
[Кирина 2022].
Корпус русского рассказа первой трети XX в. разрабатывается с целью сохранения
национального
литературного
наследия,
построения
модели
литературнохудожественной системы в рамках одного жанра и проведения различных пилотных
экспериментов [Martynenko, Sherstinova, 2020]. Аннотированный подкорпус, на базе
которого проводится данное исследование, включает в себя 310 рассказов, написанных
300 авторами, и содержит метаинформацию в соответствие со следующими
историческими периодами: период I (1900–1913): предреволюционные годы, Русскояпонская война; период II (1914–1922): Первая мировая война, Февральская и
Октябрьская
революции,
Гражданская
война;
период
III
(1923–1930):
послереволюционные годы с окончания Гражданской войны до 1930-х гг.
10.
Примерыисследований
лингвистических
[Кирина 2022].
Корпус русского рассказа первой трети XX в. разрабатывается с целью сохранения
национального
литературного
наследия,
построения
модели
литературнохудожественной системы в рамках одного жанра и проведения различных пилотных
экспериментов [Martynenko, Sherstinova, 2020]. Аннотированный подкорпус, на базе
которого проводится данное исследование, включает в себя 310 рассказов, написанных
300 авторами, и содержит метаинформацию в соответствие со следующими
историческими периодами: период I (1900–1913): предреволюционные годы, Русскояпонская война; период II (1914–1922): Первая мировая война, Февральская и
Октябрьская
революции,
Гражданская
война;
период
III
(1923–1930):
послереволюционные годы с окончания Гражданской войны до 1930-х гг.
11.
Примерыисследований
лингвистических
12.
Примерыисследований
лингвистических
Тема t_3 «ЗАКЛЮЧЕНИЕ В ТЮРЬМЕ И КАЗНЬ» объединяет тематически связанные
«Рассказ о семи повешенных» Л. Андреева и рассказы «Тюрьма» М. Горького и
«Баррикада» Г. Яблочкова. Стоит также отметить, что слово лагерь, несмотря
значительную связность других терм топика, здесь не указывает на лагерь, например,
военнопленных, а используется для обозначения больших групп людей, в том числе
массовых сборищ:
«Произвольно и несправедливо всё это... Разве можно делить людей только на два
лагеря?.. А например – я? Ведь, в сущности, я – не господин и не раб!» (М. Горький
«Тюрьма»)
…идут толпами, – что там уже толпа, – целый лагерь, с ночлегами и чуть ли даже не с
палатками (Ф. Сологуб «В толпе»).
13.
Примерыисследований
лингвистических
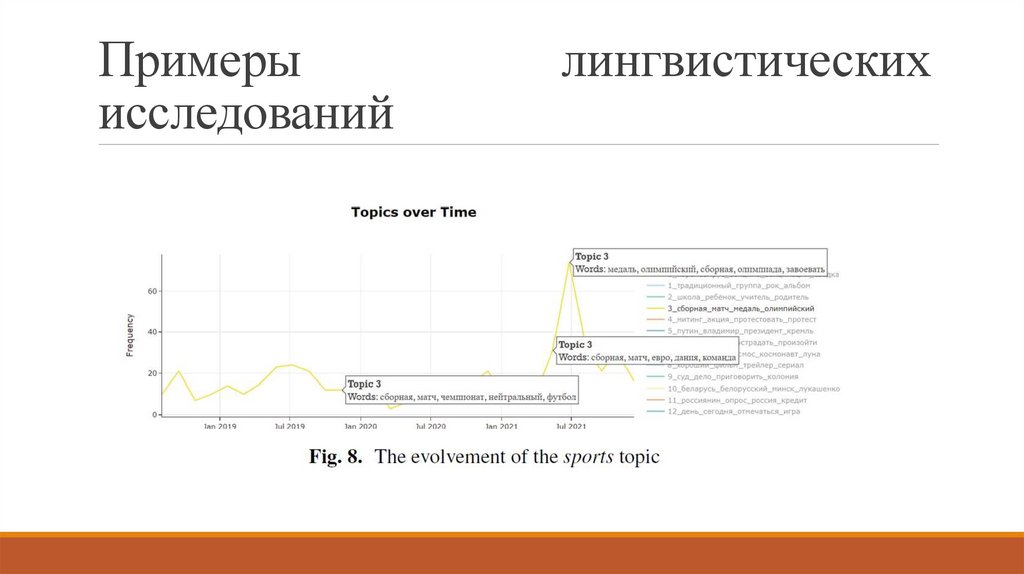
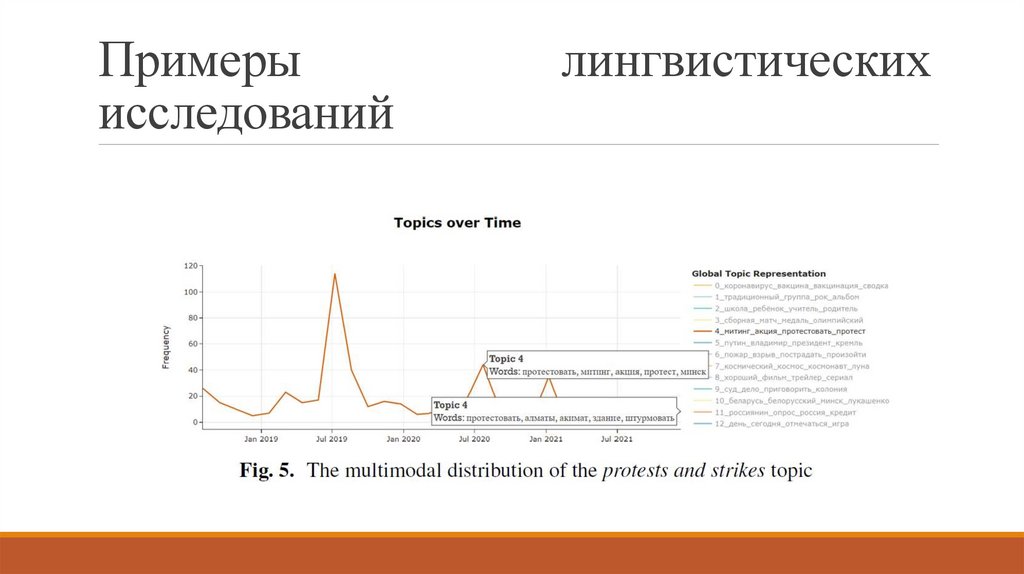
[Mamaev, Mamaeva, Aksenova 2023].
Тематическое моделирование как инструмент изучения семантических сдвигов.
Семантический сдвиг в узком понимании — изменение лексического значения слова со
временем под влиянием нелингвистических факторов.
Семантический сдвиг в широком понимании — изменение тематического набора слов
рубрики со временем под влиянием нелингвистических факторов.
Корпус социальной сети «Лентач» с начала 2019 по начало 2022 гг.
14.
Примерыисследований
лингвистических
15.
Примерыисследований
лингвистических