


















 Программное обеспечение
Программное обеспечениеПохожие презентации:










Nets compression and speedup
1.
Deep neural networks compressionAlexander Chigorin
Head of research projects
VisionLabs
a.chigorin@visionlabs.ru
2.
Deep neural networks compression. MotivationNeural net architectures and size
Architecture
VGG-16
# params
(millions)
138
Size in MB
552
Accuracy on
ImageNet
71%
AlexNet
ResNet-18
GoogleNet V1
61
~34
~5
244
138
20
57%
68%
69%
GoogleNet V4
~40
163
80%
Too much for some types of devices (mobile phones, embedded).
Some models can be compressed up to 50x without loss of accuracy.
3.
Deep neural networks compression. OverviewMethods to review:
• Learning both Weights and Connections for Efficient Neural Networks
• Deep Compression: Compressing Deep Neural Networks with Pruning,
Trained Quantization and Huffman Coding
• Incremental Network Quantization: Towards Lossless CNNs with LowPrecision Weights
4.
Networks Pruning5.
Networks Pruning. Generic idea2
6.
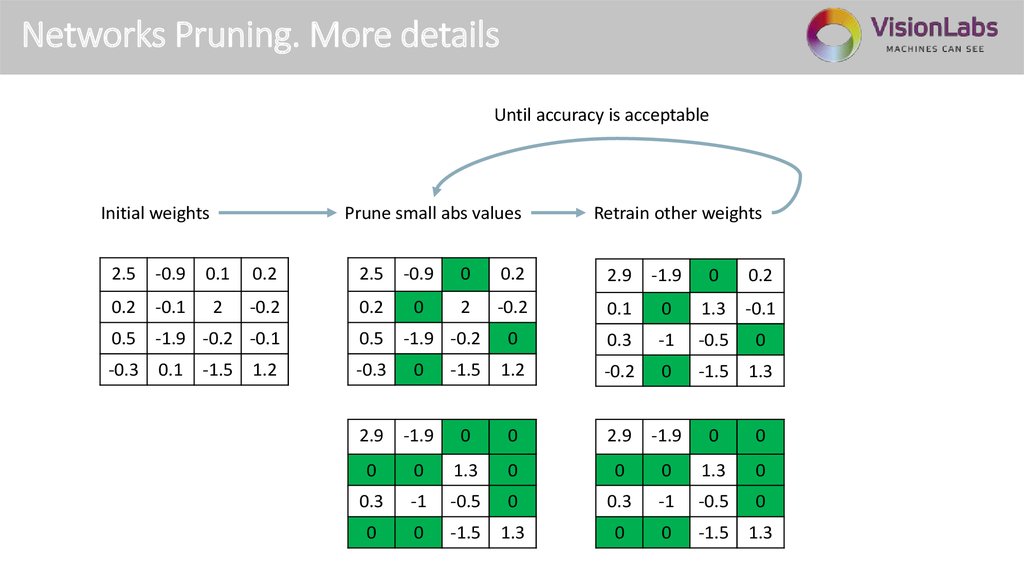
Networks Pruning. More detailsUntil accuracy is acceptable
Initial weights
Prune small abs values
Retrain other weights
2.5
-0.9
0.1
0.2
2.5
-0.9
0
0.2
2.9
-1.9
0
0.2
0.2
-0.1
2
-0.2
0.2
0
2
-0.2
0.1
0
1.3
-0.1
0.5
-1.9 -0.2 -0.1
0.5
0
0.3
-1
-0.5
0
-0.3
0.1
-0.3
0
-1.5
1.2
-0.2
0
-1.5
1.3
2.9
-1.9
0
0
2.9
-1.9
0
0
0
0
1.3
0
0
0
1.3
0
0.3
-1
-0.5
0
0.3
-1
-0.5
0
0
0
-1.5
1.3
0
0
-1.5
1.3
-1.5
1.2
-1.9 -0.2
7.
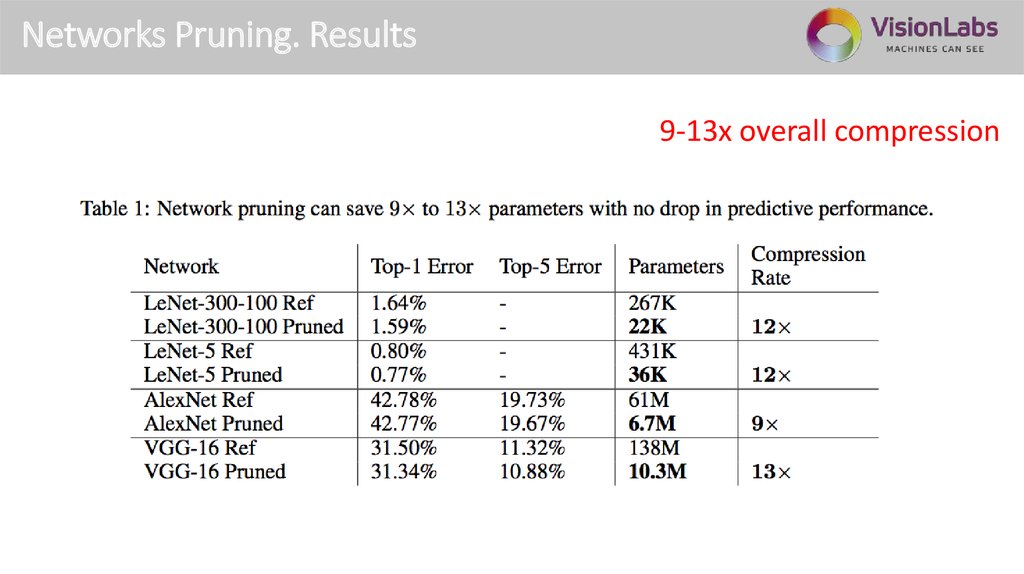
Networks Pruning. Results9-13x overall compression
2
8.
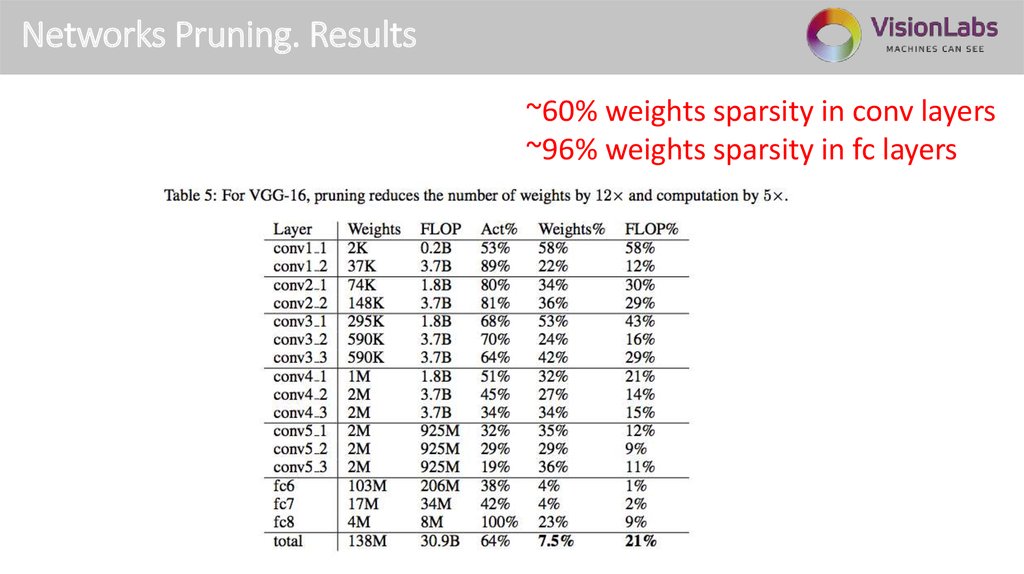
Networks Pruning. Results~60% weights sparsity in conv layers
~96% weights sparsity in fc layers
2
9.
Deep CompressionICLR 2016 Best Paper
2
10.
Deep Compression. OverviewAlgorithm:
• Iterative weights pruning
• Weights quantization
• Huffman encoding
2
11.
Deep Compression. Weights pruningAlready discussed
12.
Deep Compression. Weights quantizationInitial weights
Cluster weights
2.5
-0.9
0.1
0.2
0
3
1
1
2
0.2
-0.1
2
-0.2
1
2
0
2
0.2
0.5
-1.9 -0.2 -0.1
1
3
2
2
-0.3
0.1
2
1
3
0
-1.5
1.2
Write to the disk.
Each index can be
compressed to 2 bits
Fine-tuned
centroids
Centroids
Retrain with
weights
sharing
Final weights
2.5
2.5
-1.6
0.2
0.2
0.1
0.2
-0.2
2.5
-0.2
-0.2
-0.2
0.2
-1.6 -0.2 -0.2
-1.5
-1.6
-0.2
0.2
-1.6
Write to the disk.
Only ¼ of original weights
~4x reduction
2.5
13.
Deep Compression. Huffman codingDistribution of the weight indexes. Some indexes are more frequent
than the others!
Huffman coding – lossless compression. Output is
The variable-length code table for encoding a source
symbol.
Frequent symbols are encoded with less bits.
2
14.
Deep Compression. Results35-49x overall compression
15.
Deep Compression. Results~13x reduction (pruning)
~31x reduction (quantization)
~49x reduction (Huffman coding)
16.
Incremental Network Quantization17.
Incremental Network Quantization. IdeaIdea:
• let’s quantize weights incrementally (as we do during pruning)
• let’s quantize to the power of 2
18.
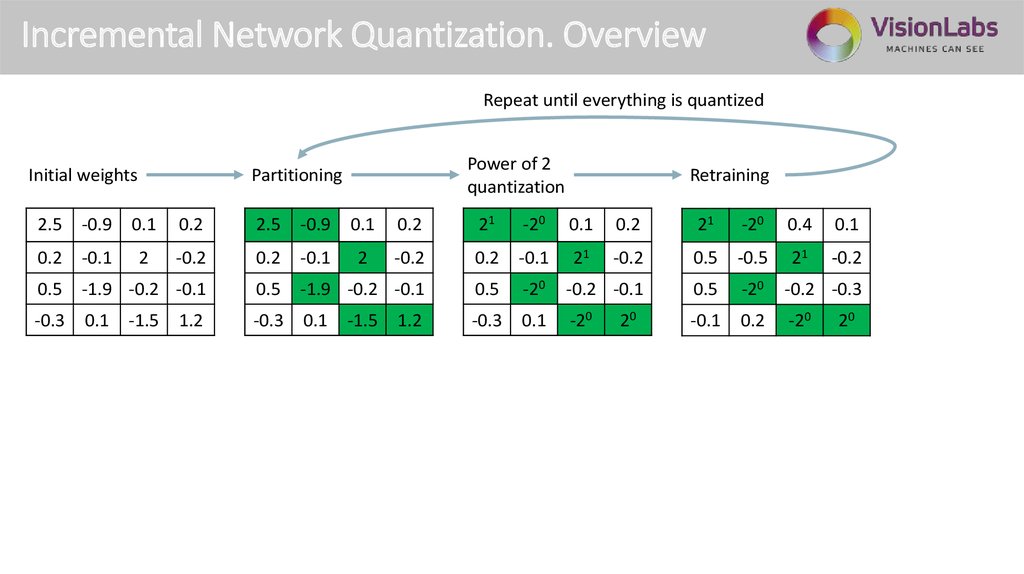
Incremental Network Quantization. OverviewRepeat until everything is quantized
Initial weights
Power of 2
quantization
Partitioning
Retraining
2.5
-0.9
0.1
0.2
2.5
-0.9
0.1
0.2
21
-20
0.1
0.2
21
-20
0.4
0.1
0.2
-0.1
2
-0.2
0.2
-0.1
2
-0.2
0.2
-0.1
21
-0.2
0.5
-0.5
21
-0.2
0.5
-1.9 -0.2 -0.1
0.5
-1.9 -0.2 -0.1
0.5
-20
-0.2 -0.1
0.5
-20
-0.2 -0.3
-0.3
0.1
-0.3
0.1
-0.3
0.1
-20
-0.1
0.2
-20
-1.5
1.2
-1.5
1.2
20
20
19.
Incremental Network Quantization. OverviewRepeat until everything is quantized
Initial weights
Power of 2
quantization
Partitioning
Retraining
2.5
-0.9
0.1
0.2
21
-20
0.4
0.1
21
-20
2-1
0.1
21
-20
2-1
0.4
0.2
-0.1
2
-0.2
0.5
-0.5
21
-0.2
2-1
-2-1
21
-0.2
2-1
-2-1
21
-0.1
0.5
-1.9 -0.2 -0.1
0.5
-20
-0.2 -0.3
2-1
-20
-0.2 -0.3
2-1
-20
-0.2 -0.1
-0.3
0.1
-0.1
0.2
-20
-0.1
0.2
-20
-0.4
0.2
-20
-1.5
1.2
20
20
20
20.
Incremental Network Quantization. OverviewInitial weights
Power of 2
quantization
Partitioning
21
0.4
2-1
2-1
-0.1
2-1
-2-1
21
-2-3
Write to the disc.
Powers of 2 set: {-3, -2, -1, 0, 1}
Can be represented with 3 bits.
~10x reduction (3 bits instead of 32)
-0.9
0.1
0.2
0.2
-0.1
2
-0.2
2-1
-2-1
0.5
-1.9 -0.2 -0.1
2-1
-20
-0.2 -0.1
2-1
-20
-2-2
-2-3
-0.3
0.1
-0.4
0.2
-20
-2-1
2-2
-20
20
1.2
2-1
-20
2.5
-1.5
-20
21
21
20
2
21.
Incremental Network Quantization. Results~7x reduction, accuracy increased (!)
22.
Incremental Network Quantization. ResultsNo big drop in accuracy even with 3 bits
for ResNet-18
2
23.
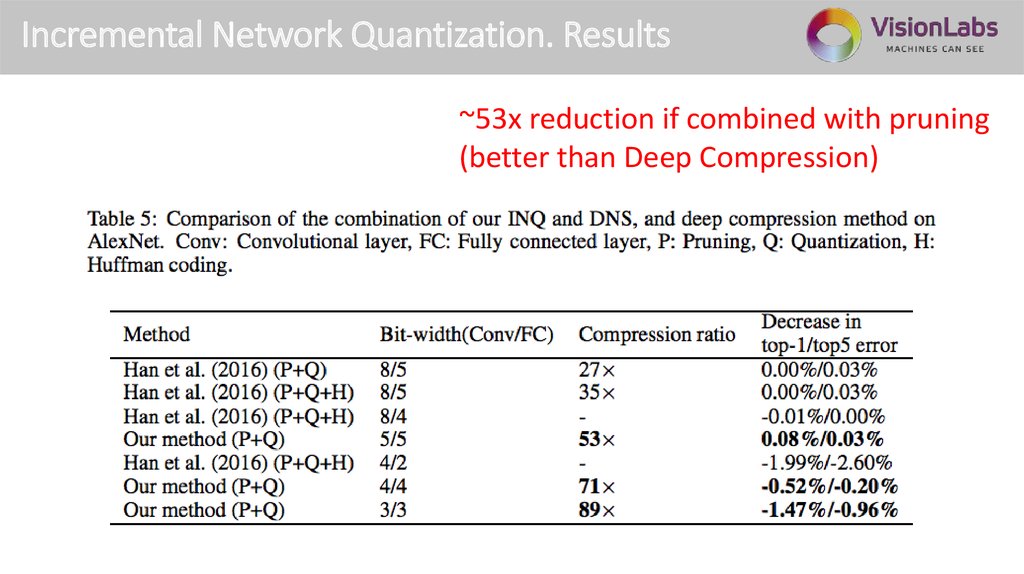
Incremental Network Quantization. Results~53x reduction if combined with pruning
(better than Deep Compression)
24.
Future: native hardware support25.
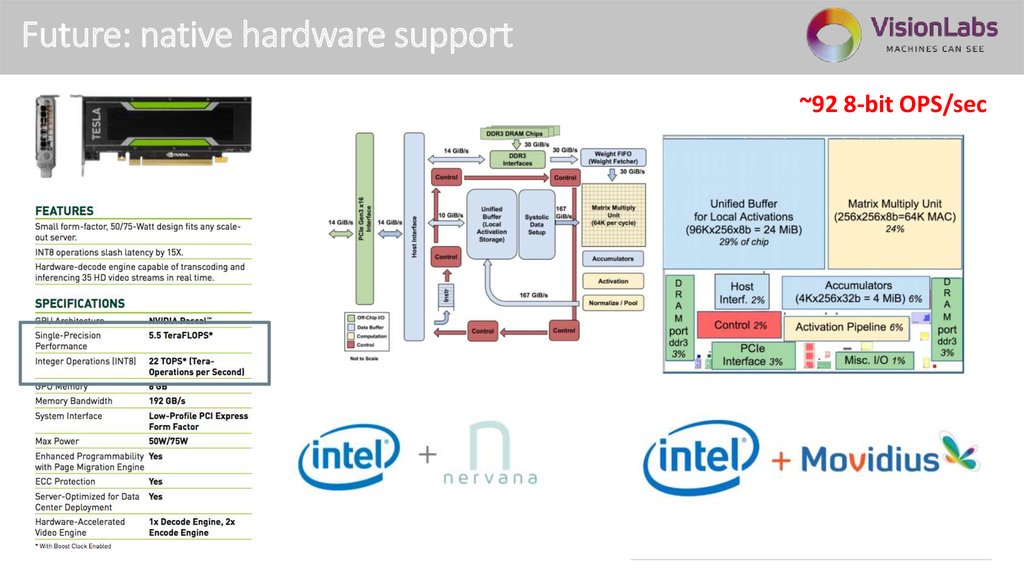
Future: native hardware support~92 8-bit OPS/sec
26.
Этапы типового внедрения платформы26
Alexander Chigorin
Head of research projects
VisionLabs
a.chigorin@visionlabs.ru