






")

")





")






















")



")
")
")
")



")
")


")
")







 հրամաններ")





")
















")
")


")




")
")
")
")

")

")
")


")


")








")
")
")


")
")





")





")








: Converting TLP into ILP")



")


")

")

")


")




















")





 Английский язык
Английский языкПохожие презентации:










Computer System Architecture
1. Computer System Architecture
III course2. Von-Neumann-ի Ճարտարապետություն
Հիմնական հասկացություններ• Հիշողությունում պահվող ծրագիրը
• ծրագրային կառավարման սկզբունք
• Երկուական կոդը
• Հասցեավորում
• Միասնական հիշողություն հրամանների և
տվյալների համար
3. Benefits and Drawbacks SW and HW
BenefitsDrawbacks
HW
Fast, low power consumption
Inflexible, unadaptable,
complete to build and
test
SW
Flexible, adaptable, simple to build Slow, high power
and test
consumption
4. Classes of Parallelism
I.Data-Level Parallelism (DLP) - there are many data items that can be operated
at the same time
II. Task-Level Parallelism (TLP) – task of work can operate independently and
largely in parallel.
Computer hardware can exploit thesе two kinds in 4 ways:
1. Instruction-Level Parallelism: pipelining, speculation, out-of-order execution
2. Vector architectures and Graphic Processor Units (GPUs) exploit DLP, using SIMD
processing
3. Thread-Level Parallelism
Exploits DLP or TLP (with interaction among parallel threads)
4. Request-Level Parallelism
Parallelism among largely decoupled tasks specified by the programmer or OS.
(WSC exploits request-level parallelism and data-level parallelism).
5. Քոմփյութերների դասակարգում
Ըստ Ֆլիննի:
– ունիվերսալ չէ, սակայն պարզ
– չափսերը՝ մեկ հրաման (SI-Single Instruction), բազմակի հրամաններ(MIMultiple Instructions),
• մեկ տվյալ (SD – Single Data), բազմակի տվյալներ(MD – Multiple Data)
SISD – մեկպրոցեսորան ի (uniprocessor)
Data SD
MD
SIMD – վեկտորային պրոցեսորներ
Instr.
MISD – չկիրառվող տարբերակ
SI
SISD
SIMD
Fault-tolerant computers,
Near memory computing (Micron Automata
MI
MISD
MIMD
processor).
MIMD – մուլտիպրոցեսոր +
բազմահոսք, մուլտիքոմփյութեր,
Many Cores processors (Intel Xeon
Phi)
Այս դասակարգումը չի ներառում տվյալների հոսքի ղեկավարումը
This classification does not envelope data driven processing.
6. Զուգահեռ գործողության քոմփյութերների դասակարգումը
Քոմփյութերային զուգահեռ ճարտարապետություններSIMD
SISD
Վեկտորային
պրոցեսոր
UMA
Շինային
կազմակերպմամբ
MISD
Մատրիցային
պրոցեսոր
COMA
Կոմուտացիայով
MIMD
Մուլտիքոմփյութերնհեր
Մուլտիպրոցեսորներ
MPP
NUMA
CC-NUMA
NC-NUMA
Ցանց
COW
Հիպեր
խորհանարդ
7. CISC architecture
The most common are three types of architectures: CISC, RISC, VLIW.CISC architecture (Complete Instruction Set Computers) reduces the semantic gap between
high-level languages (HLL) and machine instructions.
Examples: processors of x86-64 architecture (AMD, Intel).
Properties
• a relatively small number of general purpose registers (8, 16).
• a large number of machine instructions, some of which are implemented by hardware
operators of high-level languages (HLL – High Level Language).
• ISA includes instructions of different lengths (in the x86 architecture, command lengths
vary from one to 15 bytes)
• variety of addressing methods
• register-register and register-memory instruction formats
• 2-operands instructions
Software Succession
8. RISC Architecture (Load/Store)
RISC architecture (Reduced Instruction Set Computers)The difference between RISC processors and CISC:
• More general purpose registers (from 32 in ARM to 128 in IA-64 architecture).
• The same length of instructions
• 3-operand instructions for arithmetic and logic operations (oper rd,rs1,rs2)
• Memory operations are performed by the Load and Store instructions.
• Fewer instruction formats and operand addressing methods.
Circumstances contributing to the emergence of RISC processors:
RISC պրոցեսորների առաջացմանը նպաստող հանգամանքները.
• compilers rarely use complex instructions
• acceleration of instruction pipeline
կոմպիլյատորները հազվադեպ են օգտագործում բարդ հրամաններ
• հրամանների կոնվեյերի արագացում
9. Comparison CISC and RISC Processors
CISC processorRISC processor
Instruction
fetch
Instruction
fetch
Decoding
Decoding
Translation to RISC
Execution
Execition RISC uops
Low Power
CISC processors from Intel and AMD
are superpipelined superscalar
microprocessors based on the CISC
architecture with a RISC core.
ARM RISC processors are
superpipelined superscalar
microprocessors based on the RISC
architecture.
10. Superscalar and VLIW Processors (ILP)
Superscalar processor:Detects parallelism through hardware
Pipelining (super- and hyper pipeline)
• Superscalar (multi-issue)
• Out-of-order execution (dynamic scheduling)
Very long instruction word (VLIW) and the explicitly parallel instruction computer (EPIC) used wide
instructions with multiple independent operations bundled together in each instruction.
Like the RISC approach, VLIW and EPIC shifted work from the hardware to the compiler
(IA- 64)
The compiler generates a program that can be executed without dependency
determination in the pipeline.
Featchers :
Very long instruction word
Very large register set
Predication
Control and data speculation
Software pipelining
11. Instruction Bundles
i2i1
opcode
predicate r1
i0
r2
Template
r3
• Template field is set during code generation, by a compiler, or the
assembler
• The template points
–
–
–
–
i0 i1 i2 all instr. are executed in parallel
i0 || i1 i2 first i0, then i1 and i2 in parallel
i0 i1 || i2 first i0 & i1 in parallel then i2
i0 || i1 || i2
first i0 then i1 after i2
12. Comparison of Superscalar and VLIW-Processors
Comparison of Superscalar and VLIWProcessors (Static scheduling)Traditional architecture
(dynamic scheduling)
Hardware
compiler
Implicitly
parallel
Parallel
Machine Code
Original
Source
Code
Itaniumbased
compiler
Sequential Machine
Code
Multiple execution units
resources used less efficiently
.. .. .. ..
. . . .
..
.
..
.
..
.
Massive
Resources
..
.
13.
14.
15.
16. NPU – Neural Processing Unit
Нейро́нный проце́ссор — это специализированный класс микропроцессоров исопроцессоров, используемый для аппаратного ускорения работы алгоритмов
искусственных нейронных сетей, компьютерного зрения, распознавания по
голосу, машинного обучения и других методов искусственного интеллекта.
An AI accelerator, deep learning processor or neural processing unit (NPU) is a
class of specialized hardware accelerator or computer system designed to
accelerate artificial intelligence and machine learning applications, including
artificial neural networks and computer vision.
AI արագացուցիչը, խորը ուսուցման պրոցեսորը կամ նեյրոնային մշակման
միավորը (NPU) մասնագիտացված ապարատային արագացուցիչի կամ
համակարգչային համակարգի դաս է, որը նախատեսված է
արհեստական ինտելեկտի և մեքենայական ուսուցման ծրագրերը, ներառյալ
արհեստական նեյրոնային ցանցերը և համակարգչային տեսլականը
արագացնելու համար:
17. NPU (Neural Processing Unit )
После процессоров и графических процессоров NPU — это новая мода, икаждая компания использует возможности NPU для предоставления функций и
возможностей генеративного искусственного интеллекта. Компьютеры
Copilot+ оснащены процессорами Qualcomm серии Snapdragon X,
оснащенными мощным NPU, обеспечивающим производительность до 45
TOPS (триллионов операций в секунду).
NPU означает «модуль нейронной обработки» и специально разработан для
выполнения задач, связанных с искусственным интеллектом.
NPU может обрабатывать нейронные сети, задачи машинного обучения и
рабочие нагрузки ИИ.
Для задач ИИ выполняются определенные типы математических вычислений,
наиболее распространенным из которых является умножение матриц (также
называемое «matmul»). NPU предназначены для сверхбыстрого выполнения
операций умножения матриц.
18. NPU
Յուրաքանչյուր ընկերություն օգտագործում է NPU-ի հզորությունը՝գեներացնող AI-ի առանձնահատկություններն ու
հնարավորությունները մատուցելու համար:
Copilot+ համակարգիչներն աշխատում են Qualcomm Snapdragon X-series
պրոցեսորներով, որոնք ունեն հզոր NPU, որն ապահովում է մինչև 45
TOPS (տրիլիոն գործողություններ վայրկյանում):
NPU-ն նշանակում է Նյարդային մշակման միավոր և հատուկ
նախագծված է AI-ի հետ կապված առաջադրանքներ կատարելու
համար:
NPU-ն կարող է կարգավորել նեյրոնային ցանցերը, մեքենայական
ուսուցման առաջադրանքները և AI աշխատանքային
ծանրաբեռնվածությունը:
AI առաջադրանքների համար կատարվում են որոշակի տեսակի
մաթեմատիկական հաշվարկներ, որոնցից ամենատարածվածը
մատրիցային բազմապատկումն է (նաև կոչվում է «matmul»): NPU-ները
նախատեսված են գերարագ մատրիցային բազմապատկման
գործողություններ կատարելու համար:
19.
Ամփոփելու համար, NPU-ները հատուկ նախագծված են AI-ի առաջադրանքներիհամար, որտեղ կենտրոնացված է զուգահեռությունը բացելու, matmul
գործողությունների չափազանց արագ գործարկման և մասշտաբայնության
ապահովման վրա: Հիշեք, որ տարբեր ընկերություններ NPU-ները տարբեր
կերպ են անվանում: Google-ն այն անվանում է TPU (Tensor Processing Unit), իսկ
Apple-ը՝ Նյարդային շարժիչ:
To summarize, NPUs are specifically designed for AI tasks where the focus is on
unlocking parallelism, performing matmul operations extremely fast, and providing
scalability. Keep in mind that different companies call NPUs by different names.
Google calls it TPU (Tensor Processing Unit), while Apple calls it Neural Engine.
20.
Как работает NPU:1. Моделирование нейронов: NPU моделирует работу человеческих
нейронов и синапсов на уровне схемы, что позволяет ему эффективно
обрабатывать большие объемы данных и выполнять сложные
вычисления.
2. Оптимизация для AI задач: NPU использует специализированные
инструкции и архитектуру, которые позволяют ему быстро и
эффективно выполнять задачи, связанные с машинным обучением,
такие как обучение моделей и вывод данных.
3. Энергоэффективность: Благодаря своей специализированной
архитектуре, NPU может выполнять AI задачи с меньшим
энергопотреблением по сравнению с традиционными процессорами.
21. CPU
22. Պրոցեսորի կառուցվածքը
AB DB CBControl
Unit
Memory
BIU
IF.1
IP
Instruction Pointer
Instruction Register
Opcode
R1
IF.2
А2
Data
D
Decoder
Instructions
OF.1
Operands Addressing
OA
GPRs
Status Register
ALU
EX
R1
R2
OF.2
I/O modules
AB – address bus, DB – data bus, CB – control bus.
23. Պրոցեսորի ընդհանուր կառուցվածքը
IP – instruction pointer or program counter(Հրամանի հաշվիչ, պարունակում է ընթացիկ հրամանի հասցեն) :
IR – instruction register, պարունակում է ընթացիկ հրաման
GPRs – General Purpose Registers
Status register or “flags “ - Ստատուս ռեգիստր կամ «դրոշակներ»
•ցույց է տալիս պրոցեսորի վիճակը ընթացիկ ծրագրի վերաբերյալ :
24. Instruction Execution Stages
• IF - Instruction Fetch (Հրամանի ընտրում)• D – Decoding (վերծանում)
• OA - Generate Operands Addresses
OF - Operands Fetch
• EX - Execution
• S - Store
25. Պրոցեսորի աշխատանքի ալգորիթմ
BeginRun?
No
Yes
Հրամանի
Instruction ընտրում
fetch
Օպերանդների
Հրամանի
ընտրում
վերծանում
ALU_oper
Operands
Exit
Instruction
fetch
(Halt)
Decode
Branch_instr.
Execution
Branch
Taken?
Yes
PC=PC+1
PC=Br․address
No
End
PC=PC+1
Անցում դեպի
հաջորդ հրաման
26. Հարվարդ ճարտարապետություն
Հիմնական տարբերությունը՝• Von-Neumann-ի ճարտարապետություն
Միասնական հիշողություն հրամանների և տվյալների համար
(հետևաբար ընդհանուր շինա հրամանների և տվյալների համար)։
Առավելություններ՝
հիշողության առավել արդյունավետ օգտագործումը
Պարզ իրականացումը
Թերություններ՝
Հրամանների և տվյալների հաջորդական ընտրում (bottleneck )
• Harvard-ի ճարտարապետություն՝
Հիշողությունը բաժանված է երկու մասի՝ հրամանների (ծրագրերի) հիշողությունը
և տվյալների հիշողությունը.
Կան մի քանի շինա (տվյալների և հրամանները շինաներ):
Առավելություններ՝
Հրամանների և տվյալների զուգահեռ ընտրանք (արտադրողականությունը
բարձրանում է)
Թերություններ՝
բարդ իրականացումը
27. Հարվարդ ճարտարապետություն
Հրամանների շինաՀրամանների
հիշողություն
Պրոցեսոր
Տվյալների
հիշողություն
Տվյալների շինա
Արտաքին
սարքեր
28. Instruction Execution Stages
• IF - Instruction Fetch (Հրամանի ընտրում)• D – Decoding (վերծանում)
• OA - Generate Operands Addresses
(Առաջացնել օպերանդներից հասցեները)
• OF - Operands Fetch
• EX - Execution
• S - Storage
29. Latency Numbers Every Engineer Should Know
Latency Comparison Numbers ------------• 3GHz CPU cycle – 0.3 ns• L1 cache reference -0.5 ns
• Branch mispredict - 3 ns
• L2 cache reference 5 ns, 10x L1 cache
• Mutex lock/unlock ~20ns. – используется для синхронизации одновременно
выполняющихся потоков
• Main memory reference 100 ns, 20x L2 cache, 200x L1 cache
• Compress 1K bytes with Zippy: 2,000 ns ,2 us
• Send 1K bytes over 1 Gbps network: 10,000 ns 10 us
• Read 4K randomly from SSD* 150,000 ns = 150 us. ~1GB/sec SSD
• Read 1 MB sequentially from memory : 250,000 ns = 250 us
• Round trip within same datacenter: 500,000 ns = 500 us
• Read 1 MB sequentially from SSD*: 1,000,000 ns = 1,000 us = 1 ms =4xmemory
• Disk seek – 10,000,000 = 10xround trip DC
• Read 1 MB seq from disk 20,000,000 = 80xmemory = 20xSSD
Notes-----1 ns = 10^-9 seconds
1 us = 10^-6 seconds = 1,000 ns
1 ms = 10^-3 seconds = 1,000 us = 1,000,000 ns
30. Latency Numbers Every Programmer Should Know
• Disk seek - 10,000,000 ns 10,000 us 10 ms 20x datacenter roundtrip• Read 1 MB sequentially from disk : 20,000,000 ns 20,000 s 20 ms 80x
memory, 20x SSD
• Send packet CA->Netherlands->CA 150,000,000 ns : 150,000 s = 150 ms
Notes
----1 ns = 10^-9 seconds
1 us = 10^-6 seconds = 1,000 ns
1 ms = 10^-3 seconds = 1,000 s = 1,000,000 ns
By Jeff Dean: http://research.google.com/people/jeff/
Originally by Peter Norvig: http://norvig.com/21-days.html#answers
31. Simple RISC Processor
Control UnitAB DB CB
Main Memory
BIU
PC
Programs
SP
IR
OpCode
Instruction
Address
R1
R2
R3
Stack
DC
ALU
Operand1
+
Operand2
x
Result
-
-
R0
R1
GPRs
Data
Область
данных
R15
SF OF PF ZF CF
Flags
Input/Output
Ports
I/OBus
I/O
I/O
32. Instruction Execution Stages
1. IP AB2. Read
3. DB IR
Instruction:
4. Decoding
Instruction Decoding - D
5. A1 AB
6. Read
7. DB Reg__ALU
8. A2 AB
9. Read
10. DB Reg_ALU
Add R1, A2; R1 (R1)+(A2)
Instruction Fetch - IF
Operands Fetch - OF
11. ADD
Operation Execution - EX
12. Result DB
13. A1 AB
14. Write
15. IP+Length IP
Writing result to memory - S
Next IP generation
33. Конвейеризация вычислений
Наиболее важный архитектурный прием повышенияпроизводительности – конвейеризация вычислений.
Конвейерная обработка в общем случае основана на разделении
подлежащей исполнению функции на более мелкие части,
называемые ступенями (стадиями) конвейера и выделении для
каждой из них отдельного блока аппаратуры.
Конвейеризацию используют для повышения
производительности таких устройств как операционные
устройства, оперативная память.
Наибольший эффект достигается при конвейеризации машинного
цикла – этапов выполнения команд. Ступени разделяются с
помощью буферных регистров или буферной памяти.
33
34. Հաշվարկումների կոնվեյերացում
Հաշվարկումների կոնվեյերացումը կիրառվում է արտադրողականությանբարձրացման համար:
Ընդհանրապես կոնվեյերային մշակումը հիմնված է կատարման
ենթակա ֆունկցիայի (հրամանի) բաժանմանը ավելի փոքր մասերի,
որոնք կոչվում են կոնվեյերի աստիճաններ (փուլեր) և որոնցից
յուրաքանչյուրին համապատասխանեցվում է առանձին ապարատային
բլոկ:
Կոնվեյերացումը օգտագործվում է այնպիսի սարքերի
արտադրողականության բարձրացման համար, ինչպիսին են
օպերացիոն սարքերը, օպերատիվ հիշողությունը:
Մեծ էֆեկտ է ստացվում մեքենայական ցիկլի` հրամանների կատարման
փուլերի կոնվեյերացման ժամանակ: Աստիճանները առանձնացվում են
բուֆերային ռեգիստրների և բուֆերային հիշողության օգնությամբ:
34
35. Pipelining
• Instruction processing consists of K sequential stages. Unpipelined:IF
OA OF EX
D
S
IF
D
OA OF EX
S
• Pipelining allows overlapping different instructions at different stages.
IF
I
I+1
D
OA OF EX
IF
D
OA OF
IF
D
OA OF EX
IF
D
OA
IF
D OA
I+2
I+3
I+4
IF
ID
OA
S
EX
OF
S
S
OF EX
S
OF EX
EX
S
S
36. Определение эффективности конвейеров.
Для характеристики эффективности используют три метрики:ускорение, эффективность и производительность.
Ускорение S – отношение времени обработки без конвейера к
времени обработки с конвейером.
Наилучшее время TKOН обработки N команд входного потока на
конвейере из K стадий и тактовымևпериодом можно определить
следующим способом:
TKOН =(K + (N-1)) .
В процессоре без конвейера общее время выполнения
TБЕЗ КОН = NK .
S = NK/(K + (N-1)).
При N ускорение S K.
36
37. Կոնվեյերի էֆեկտիվության որոշում
Էֆեկտիվության բնութագրման համար օգտագործվում են երեք մետրիկա `արագացում, էֆեկտիվություն, արտադրողականություն:
S արագացումը` դա առանց կոնվեյերի մշակման ժամանակի
հարաբերությունը կոնվեյերով մշակված ժամանակին:
Մուտքային հոսքի N հրամանների K փուլից բաղկացած կոնվեյերային
մշակման լավագույն Tpipe ժամանակը և տակտի տևողությամբ որոշվում է
հետևյալ ձև`
Tpipe=(K + (N-1)) .
Առանց կոնվեյերի պրոցեսորում կատարման ընդհանուր ժամանակը`
Twithout_pipe= NK .
Այսինքն`
S = NK/(K + (N-1)), եթե N , ապա S K.
37
38. Метрики конвейера
Эффективность E – доля ускорения, приходящаяся на однуступень конвейера.
E = S/K = N/(K+(N-1)).
Третьей метрикой является пропускная способность или
производительность P .
P = E/ = N/(K+(N-1) ).
При N эффективность стремится к 1, а производительность – к
частоте тактирования.
38
39. The Structure of Four-Stage Pipelined Processor
F/DPC
Instr.
Mem.
PC0
Op.
code
Branch
0
NextPC
DC
R3
D/EX
E/WB WB
Op.
code
Op.
code
R1
R1
R2
PC+1
EX(Mem)
ID
IF
GPRs
Op1
Branch
address
ALU
Op2
Mem/
Addr
1
R1
Data
Mem.
Result,
Flags
40. Կոնվեյերի կառուցվածքը (RISC-processor)
IP(PC)F/D
D/EX
IM
EX/Mem
DM
Mem/WB
r2
r3
Instruction
Fetch
Clock
Read
Write
Op.code
r1
Կոնվեյեր ունի 5 աստիճան: Կոնվեյերի փուլերը առանձնացվում
են կոնվեյերային ռեգիստրներով` IP(PC), F/D, D/EX, EX/mem, Mem/WB) : ALU
IP/PC հրամանի հասցեի հաշվիչ
40
41. Abstract Veiw of Pipeline in Operation
12
3
4
5
IM
RF
ALU
DM
RF
load r1, addr1
RF
sub r4, r5,r6
and r7, r11,r9
or r8, r2,r6
store r4, addr2
IM
7
8
9
10
DM is used
>
IM
6
ALU
>
DM
RF
ALU
>
DM
RF
IM
RF
ALU
>
DM
RF
IM
RF
ALU
>
DM
RF
DM is not used
IM – Instruction Memory (Icache), DM – Data Memory (Dcache).
Number of cycles – 9.
RF
RF is not used
42. Կոնվեյերում առաջացվող կոնֆլիկտները
CPI` Cycles Per Instructions –Կոնվեյերի CPI = Իդեալական կոնվեյերի CPI +
Կառուցվածքային հապաղում + տվյալների ռիսկի
հապաղում + Ղեկավարման ռիսկի հապաղում
Pipeline CPI = Ideal pipeline CPI + Structural stalls + Data hazards stalls +
+Control hazards stalls
Բանաձևի աջ կողմի յուրաքանչյուր մեծության արժեքի
նվազեցումը կբերի կոնվեյերի CPI –ի մինիմացմանը և այդպիսով
կբարձրացվի IPC (Instruction Per Clock).
Կառուցվածքային կոնֆլիկտները առաջանում են ռեսուրսների
անբավարար լինելու պատճառով (օրինակ` օպերացիոն սարքերի,
հրամանների կամ տվյալների համար ՕՀ-ին միաժամանակ դիմելու
և այլն) :
42
43. Կառուցվածքային կոնֆլիկտներ
Երկու տարբեր հրամանները, որոնք գտնվում են կոնվեյերի առանձինփուլերում փորձում են օգտագործել միևնույն ռեսուրսը (հիշողությունը):
I և I+3 հրամանները դիմում են քեշ-ին:
I
I+1
I+2
I+3
I+4
IF
D
OA
OF
EX
S
IF
D
OA
OF
EX
S
IF
D
OA
OF
EX
S
IF
D
OA
OF
EX
S
IF
D
OA
OF
EX
S
43
44. Structural Hazards (2)
II+1
I+2
I+3
I+4
IF
D
OA
OF EX
S
IF
D
OA OF
EX
S
OF
Stall
EX S
stall Stall Stall
Stall
IF
IF D
OA
Stall
D
Stall Stall Stall Stall
OA OF EX S
IF
D OA OF EX S
Avoiding structural hazards:
• Replicate the contended resource
• Pipeline the contended resources
For example: separated ICache and DCache, large number of ALU,
pipelined ALU.
44
45. Կառուցվածքային ռիսկ (2)
II+1
I+2
I+3
I+4
IF
D
OA
OF EX
S
IF
D
OA OF
EX
S
OF
Stall
EX S
Stall Stall
Stall
stall
IF D
IF
OA
Stall
D
Stall Stall Stall Stall
OA OF EX S
IF
D OA OF EX S
Կառուցվածքային ռիսկից խուսափելու համար`
• ռեսուրսների ավելացում,
• Pipeline the contended resources:
Օրինակ` առանձնացված ICache և DCache , մեծ քանակի
ԹՏՍ-ներ:
45
46. Data Hazards (1)
Bernstein’s Conditions:RAW : O(i) I(j) = ;
WAR: I(i) O(j) = ;
WAW: O(i) O(j) = ;
Two different instructions i and j use the same registers (or storage location) and
i comes earlier than j.
RAW – j tries to read a source before i writes it.
It is true dependence (dataflow).
Example:
add R1, R2, R3 //R1 (R2)+(R3)
sub R2, R4, R1 //R2 (R4)-(R1)
or R1, R6, R3
//R1 (R6) || (R3)
• problem: sub reads R1 before add has written it
46
47. Ըստ տվյալների կոնֆլիկտներ(1)
Բեռնստեյնի պայմաններըRAW : O(i) I(j) = ;
WAR: I(i) O(j) = ;
WAW: O(i) O(j) = ;
i և j տարբեր հրամանները օգտագործում են նույն ռեգիստրները (կամ
հիշողության հատվածը) և i հրամանը մշակվում է ավելի շուտ քան j
հրամնը:
RAW – j հրամանը փորձում է կարդալ արժեքը, մինչ i հրամանը գրանցում է
այն:
Դա իրական կախվածություն է: (dataflow).
Օրինակ`
add R1, R2, R3 //R1 (R2)+(R3)
sub R2, R4, R1 //R2 (R4)-(R1)
or R1, R6, R3
//R1 (R6) || (R3)
• կոնֆլիկտը` sub հրամանը ընթերցում է R1-ից ավելի շուտ, քան add
հրամանը կհասցնի գրանցել այնտեղ
47
48. RAW-dependences
add R1, R2, R3sub R2, R4, R1
or R1, R6, R3
IF
D
EX
WB
IF
D
Stall
EX
WB
IF
stall D
EX
WB
The following tasks should be decided:
• RAW detection at the decode stage
• Insert stalls after decoding
• Reducing RAW-stalls
1. S/W: compiler schedules (moves) instruction to reduce stalls.
2. H/W: data bypassing and data forwarding.
48
49. RAW-կախվածություններ
add R1, R2, R3sub R2, R4, R1
or R1, R6, R3
IF
D
EX
WB
IF
D
Stall
EX
WB
IF
D
EX
WB
Կառուցվածքային
ռիսկ?
Հապաղումների կրճատման համար անհրաժեշտ է լուծել հետևյալ
խնդիրները`
•RAW –ը հայտնաբերել վերծանման փուլում,
• վերծանումից հետո կատարել սպասումներ /stalls/,
• կրճատել RAW-stalls
1. S/W:/ծրագրային լուծում/ կոմպիլյատորը նախատեսում է
դադարումներ մինչև հրամանի կատարման ավարտը:
2. H/W: /ապարատային լուծում/ տվյալների կոնվեյերացում և
ինֆորմացիայի արագացված անցում -data forwarding.
49
50. RAW – dependences: data bypassing and data forwarding
EXD
M
U
X
M
U
X
WB
ALU
DCache
50
51. Data hazards (2)
WAR – j tries to write an operand before it is read by i.It is anti-dependence (artificial).
Example:
add R1, R2, R3
sub R2, R4, R1
or R1, R6, R3
• problem: add could use wrong value of R2.
WAW – j tries to write an operand it is written to i.
Output dependences (artificial).
Example:
add R1, R2, R3
sub R2, R4, R1 problem: later instruction that reads R1 would
or R1, R6, R3 get wrong value.
51
52. Ըստ տվյալների ռիսկեր (2)
WAR – j հրամանը փորձում է գրանցել օպերանդը մինչ iհրամանը կընթերցի այն: Սա հակակախվածություն է
/արհեստական/
Օրինակ`
add R1, R2, R3
sub R2, R4, R1
or R1, R6, R3
• կոնֆլիկտը` add-ը կարող է օգտագործել R2-ի սխալ արժեքը
WAW – j հրամանը փորձում է գրանցել օպերանդը, որը
գրանցվում է նաև I հրամանով:
Ելքային կախվածություն (արհեստական).
Example:
add R1, R2, R3
sub R2, R4, R1 վերջին հրամանը, որը կարդում է R1 կունենա սխալ արժեք
or R1, R6, R3
52
53. Registers Renaming
Register renaming (in h/w)• change registers names to eliminate WAR and WAW hazards
“Key: think of architectural registers as names not locations”
Locations – internal register file.
Names dynamically map to internal register file by the usage of
map tables (Register allocation tables).
Map table holds the current mapping .
The same architectural register can be mapped to more than
one internal registers.
53
54. Ռեգիստրների վերանվանում
Ռեգիստրների վերանվանումը վերացնում է WAR և WAW ռիսկերը:• Ծրագրավորողը աշխատում է տրամաբանական GPRs հետ:
• Ներքին ռեգիստրային ֆայլի ռեգիստրների քանակը ավելի մեծ է քան
GPR-ի քանակը:
Ընդհանուր նշանակւթյան ռեգիստրները դինամիկ արտապատկերվում
են ֆիզիկական ռեգիստրների վրա ռեգիստրների վերանվանման
աղյուսակի միջոցով:
Աղյուսակը պահպանում է ընթացիկ արտապատկերումը:
Map table holds the current mapping .
The same architectural register can be mapped to more than one internal
registers.
54
55. Registers Renaming (Example)
K1:K2:
mov
WAW
eax,
17;
RAW
add
eax,
ecx;
K3:
mov
mem1, eax;
K4:
mov
eax,
K5:
sub
eax,
WAR
eax 17
eax (eax)+(ecx)
mem1 eax
edx;
eax edx
ecx;
eax (eax)-(ecx)
K6:
mov mem2, eax;
After renaming
K1:
mov r2,
17
K2:
add r2,
r3
K3:
mov mem1, r2
K4:
mov r4,
r5
K5:
sub
r4,
r3
K6:
mov mem2, r4
mem2 eax
r0
r1
r2
r3
r4
r5
eax K1
ecx K2
eax K4
edx K5
r39
Instructions can be executed in parallel
К1, К4
К2, К5
К3, К6
55
56. Registers Renaming (Example)
K1:K2:
mov
WAW
add
eax,
eax,
17;
eax 17
RAW
ecx;
eax (eax)+(ecx)
K3:
mov
mem1, eax; mem1 eax
K4:
mov
eax,
K5:
sub
eax,
WAR
edx; eax edx
ecx; eax (eax)-(ecx)
ro
r1
r2
r3
r4
r5
r5
eax K1
ecx K2
eax K4
ecx K5
edx K4
…
K6:
mov mem2, eax; mem2 eax
Վերանվանումից հետո
K1:
mov r2,
17
K2:
add r2,
r3
K3:
mov mem1, r2
Հրամանները կարող են կատարվել
K4:
mov r4,
r5
К1, К4
զուգահեռ
K5:
sub r4,
r3
К2, К5
K6:
mov mem2, r4
К3, К6
56
57. Կոնվեյերի օրինակ
Ենթադրենք ունենք պարզ RISC-պրոցեսոր.Հրամանների հավաքածու` ամբողջ թվերի, սահող ստորակետով թվերի
թվաբանություն, տրամաբանական գործողությունների, անցման
հրամաններ, Load/Store հրամաններ և այլն:
Թվաբանական հրամանները ունեն 3-հասցեանի “register-register”
ֆորմատ, ինչը բնորոշ է RISC-պրոցեսորների համար:
Հրամանների կատարման փուլերը
• IF – instruction fetch` հրամանի ընտրում ICache –ից:
• ID – decoding ` հրամանի կոդի վերծանում:
• EX – execution` կատարում (ԹՏՍ, Load/Store գործողությունների
հասցեավորում )
• MEM – Load/store գործողություններ
• WB – write back (write result from ALU or Load to register file)
57
58. Example of Pipeline
PC+4
MEM
EX/OA
D/X
F/D
Instr.
Cache
WB
X/M
ALU
MUX
PC
D
Reg.
file
Branch
M/W
Data
Cache
MUX
IF
Load
Stages divided by pipeline registers/latches.
Pipeline registers: PC, F/D, D/X, X/M, M/W
58
59. Կոնվեյերի օրինակ
DK+4
Instr.
Cache
WB
K+3
K+2
K+1
K
F/D
D/X
X/M
M/W
ALU
MUX
PC
PC+
4
MEM
EX/OA
Reg.
file
Data
Cache
Branch
Կոնվեյերի փուլերը առանձնացվում են կոնվեյերային
ռեգիստրներով` IP(PC), F/D, D/Mem, Mem/EX, S(WB) :
IP/PC հրամանի հասցեի հաշվիչ
MUX
IF
Load
59
60. Implementing Bypassing
PC+4
Instr.
Cache
D/X
WB
MEM
M/W
X/M
F/D
ALU
Reg.
file
Data
Cache
MUX
EX/OA
Read Reg
MUX
PC
D
IF
MUX
Branch
60
61. RAW Dependences
IFD
EX
MEM WB
add r1,r2,r3
IF
Stall Stall Stall D
EX MEM WB
Stall Stall Stall
D
sub r4, r1,r5
IF
EX MEM WB
and r6, r1,r7
Stall Stall Stall IF
or r8, r1,r9
D EX
MEM WB
62. RAW Dependences
ICacheGPR
ALU
MEM
WB
ALU
MEM
WB
ALU
MEM
WB
ALU
MEM
>
add r1,r2,r3
ICache
GPR
>
sub r4, r1,r5
ICache
GPR
>
and r6, r1,r7
ICache
or r8, r1,r9
GPR
>
WB
63. Implementing Bypassing
K+3K+4
MUX
ICache
IP
D
Op.
Code
r5
EX/OA
Op.
Code
==
Read
r1
GPRs
r3
MUX
Operand1
ALU
>
r2
Write
Operand2
K+1 MEM
K
WB
r4
r1
Taken
branch
K+2
MUX
==
Op.
Code
Op.
Code
r1
r2
Result
Addr
DCache
+4
Result
64. Անցումների (ճյուղավորումների) հրամաններ
Քոմփյութերայինծրագրերով
իրականացված
ալգորիթմների
մեծամասնությունը ժամանակ առ ժամանակ կատարում է արդյունքների
վերլուծություն, որից կաղված ընտրում է ալգորիթմի այս կամ այն ճյուղը:
Նմանատիպ գործողությունները կարելի է իրագործել այնպիսի
հրամանների օգնությամբ, որոնք փոխում են ծրագրի կատարման բնական
ընթացքը: Այդ հրամանները կոչվում են անցումների հրամաններ:
Նրանք ստիպողաբար փոխում են հրամաննրի հաշվիչի (СчК),
պարունակությունը, որտեղ մշտական պահվում է հերթական կատարվող
հրամանի հասցեն:
Այս տիպի հրամանները ներմուծվում են պրոցեսորի կազմում ելնելով
հետևյալ նկատառումներից`
1. Հաճաղ անհրաժեշտ է լինում կրկնակի կատարել ծրագրի որոշակի
հատվածները, ընդ որում նրանց կրկնումների քանակը կարող է լինել շատ
մեծ, օրինակ տվյալների աղյուսակի մշակում: Եթե այդպիսի հրաման չկա,
ապա անհրաժեշտ է ընդօրինակել ծրագրում հրամանների ողջ
հաջորդականությունը, ինչը շատ մեծացնում է ծրագրի հրամնների
64
ծավալը:
65. Անցման հրամաններ 2
Պայմանական անցման հրամանը կատարվում է միայնորոշակի պայմանների կատարման դեպքում: Այն
բաղկացած է հետևյալ փուլերից.
1. Անցման պայմանի կատարման ստուգում ( սովորաբար
դա դրոշակների կամ որևէ ռեգիստրի վիճակն է ).
2. Անցման հասցեի ձևավորում
3. Անցման դեպքում ղեկավարման փոխանցումը (Անցման
հասցե СчК).
Եթե անցում չի կատարվում, ապա СчК СчК +1.
Անցումը կարող է լինել ինչպես առաջ, այնպես էլ հետ:
Ենթածրագրերի հետ աշխատանքի համար պետք է
օգտագործվեն երկու տիպի հրաման` ենթածրագրի կանչի
հրաման (Call) և ենթածրագրից վերադարձի հրաման
(Return):
65
66.
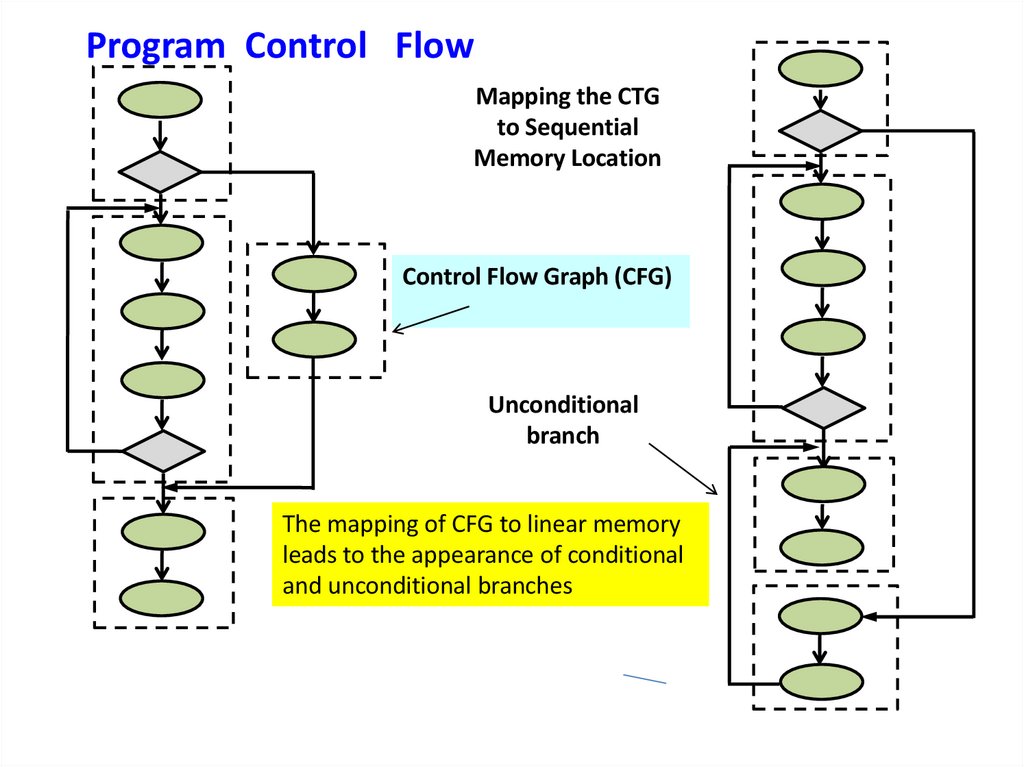
Program Control FlowMapping the CTG
to Sequential
Memory Location
Control Flow Graph (CFG)
Unconditional
branch
The mapping of CFG to linear memory
leads to the appearance of conditional
and unconditional branches
67. Branch Instructions
1.cmp r1,r2 ; compare a and b
jgt L1
; if (a>=b) skip if block
add r3, r3, r4 ; if(a<b) y=y+c
L1: sub r3, r3, r2 ; y=y-b
if operator
if (a<b)
y=y+c;
y=y-b;
2. if-else operator
if (a==b)
y=y+c;
else y=y-d;
c=a*d;
L1:
L2:
cmp r1,r2
; compare a and b
jnz L1
; if (a b) skip if block
add r4, r4, r3 ; if block, y=y+c
jmp L2
; if (a==b) skip else block
sub r3, r3, r2 ; else block, y=y-d
mul r3,r1,r4
...
68. Operators While, For
r1 –b, r2 – x;int b = 1;
int x = 0;
while (b != 128)
{
b = b * 2;
x = x + 1;
}
cycle:
done:
For
int sum = 0;
for (i = 0; i != 10; i = i + 1) {
sum = sum + i ;
}
mov r1, 1 ; b=1
mov r2, 0
; x=0
cmp r1,128 ;
je
done;
mul r1,2
;
add
x,1
jmp cycle
cycle:
Done;
mov r1, 10 ;
mov r2, 0 ; sum=0
mov r0, 0 ; i=0
cmp r0, r1 ; compare i and 10
je
done ;
add r2,r2,r0; sum=sum=I
jmp cycle
69. Օպերատոր IF-Then-Else
After compilationExample:
. . .
If(a==b)
y=y+1;
else y=y-1;
c=c+d;
. . .
. . .
L1:
L2
OF SF
ZF AF PF
CF
cmp eax, ebx
jnz
L1
inc
y
jmp
L2
dec
y
add
ecx,edx
. . .
Status Register (Flags)
70. Checking of the Branch Condition
Conditional BranchK:
Br.cond
CC
K+instr.
length
Branch Address
0
1
check of the
condition
CC- Condition Code
1
JC – 0001
JZ - 0011
JP - 0010
JGE- 0101
JMP- 0000
<0
0
1
2
3
4
5
…
>=0
OF S
Z
P
C
Flags
Branch
Taken/not taken
71. Control Dependencies (1)
The most problems arise if an instruction defines which instructionexecutes the next. Instructions, that can change consequence of computing, are
the following: conditional branch, jump, procedure call, return.
The methods of overcoming control hazards
1. The most simple method: waiting.
Naive solution: stall until outcome is available (end of execution).
1
Ins1
Ins2
Ins3
Ins15
Ins16
Ins17
2
IF
D
IF
3
4
5
OA
OF EX
D OA
OF
IF D
OA
IF stall
stall
Instruction 4
6
7
8
9
10
11
12
13
14 15
S
EX
S
OF EX S
stall stall IF D OA
stall stall stall IF
D
stall stall stall stall IF
OF
OA
D
EX
OF
OA
S
EX
OF
S
EX
S
Անցման հրամանը Instruction 15
71
72. Branch Prediction. Static Prediction
Branch prediction is the most efficient method of fight against stallsfrom control hazard.
Static (compiler) branch prediction
Some static prediction options
• predict always not-taken
+ very simple, since the target is already known – most branches (~65%)
are taken
• predict always taken
+ better performance
– more difficult, must know target before branch is decoded
• prediction based on branch offset: predict backward branches(as) “taken” and
forward branches what “not taken”??
• predict specific opcodes taken
• use profiles to predict on per-static branch basis
73. Предсказание переходов
Предсказание переходов является одним из наиболее эффективных способовборьбы с конфликтами по управлению.
Идея заключается в том, что еще до момента выполнения команды условного
перехода или же сразу после ее поступления делается предположение о
наиболее вероятном результате выполнения такой команды (переход
произойдет или нет). Последующие команды подаются на конвейер в
соответствии с предсказанием.
При ошибочном предсказании конвейер необходимо вернуть к состоянию, с
которого началась выборка ненужных команд, т.е. очистить конвейер, что
эквивалентно приостановке конвейера. Цена ошибки может быть достаточно
высокой, но при правильном предсказании имеем большой выигрыш –
конвейер функционирует ритмично, без остановок. Выигрыш тем больше,
чем выше точность предсказания.
74. Անցումների կանխատեսում
Անցումների կանխատեսում հանդիսանում է մեկն այնեղանակներից, որոնք պայքարում են ղեկավարման
կոնֆլիկտների դեմ:
Միտքը կայանում է նրանում, որ մինչ պայմանական
անցուման հրամանի կատարումը կամ կատարումից
անմիջապես հետո արվում է կանխատեսում այդ
հրամանի կատարման ամենահավանական արդյունքի
մասին (անցում կլինի,թե ոչ): Հաջորդ հրամանները
տրվում են կանխորոշման համապատասխան
կոնվեյերին:
Սխալ կանխատեսման դեպքում կոնվեյերը պետք է
վերադարձնել այն վիճակից, որից սկսվել է վերցնել ոչ
ճիշտ հրաման, դատարկել կոնվեյերը, որը էկվիվալենտ է
կոնվեյերի կանգին:
Ինչքան ճիշտ լինի կանխորոշումը, այնքան մեծ կլինի
օգուտը:
75. Статическое предсказание
Статическое предсказание делается на этапе компиляциипрограммы.
Используют следующие стратегии:
• Переход происходит всегда (ПВ);
• Переход не происходит никогда (ПН);
• Предсказание определяется по результатам профилирования;
• Предсказание определяется кодом операции команды
перехода;
• Предсказание зависит от направления перехода;
• При первом выполнении команды переход имеет место
всегда.
76. Точность предсказания
Точность предсказания – процентное отношениеправильных предсказаний к их общему количеству.
числа
Доказано, что для того, чтобы снижение производительности
конвейера из-за приостановок по управлению не превысило 10%,
точность предсказания должна быть выше 97,7%.
В зависимости от того, когда и на основе какой информации
делается предсказание, используют два подхода: статический и
динамический.
77. Точность предсказания
Точность предсказания – процентное отношениеправильных предсказаний к их общему количеству.
числа
Доказано, что для того, чтобы снижение производительности
конвейера из-за приостановок по управлению не превысило 10%,
точность предсказания должна быть выше 97,7%.
В зависимости от того, когда и на основе какой информации
делается предсказание, используют два подхода: статический и
динамический.
78. Точность предсказания
Точность предсказания – процентное отношениеправильных предсказаний к их общему количеству.
числа
Доказано, что для того, чтобы снижение производительности
конвейера из-за приостановок по управлению не превысило 10%,
точность предсказания должна быть выше 97,7%.
В зависимости от того, когда и на основе какой информации
делается предсказание, используют два подхода: статический и
динамический.
79. Կանխատեսման ճշգրտությունը
Կանխատեսման ճշգրտությունը ճիշտ կանխատեսումներիքանակի տոկոսն է դրանց ընդհանուր թվին:
Ապացուցված է, որ որպեսզի ղեկավարման ընդհատումների
պատճառով կոնվեյերի արտադրողականության նվազումը
չգերազանցի 10%-ը, կանխատեսման ճշգրտությունը պետք է
լինի 97,7%-ից բարձր:
Կախված նրանից, թե երբ և ինչ տեղեկատվության հիման
վրա է արվում կանխատեսումը, օգտագործվում են երկու
մոտեցում՝ ստատիկ և դինամիկ։
80. Ստատիկ կանխատեսում 1
Ստատիկ կանխատեսումը կատարվում է ծրագրիկոմպիլացիայի փուլում: Օգտագործվում են հետևյալ
ռազմավարությունները (ստրատեգիաները).
• Անցումը կատարվում է միշտ (ԱՄ);
• Անցում երբեք չի կատարվում (ԱԵ);
• Կանխատեսումը որոշվում է արդյունքներով
• Կանխատեսումը որոշվում է հրամանների անցումների
գործողության կոդով
• Կանխատեսումը կախված է անցման ուղղությունից
• Հրամանի առաջին կատարման դեպքում անցումը
միշտ տեղ ունի
81. Ստատիկ կանխատեսում 1
При предсказании на основе кода операции предполагается, что для однихкоманд переход произойдет, а для других – нет.
Стратегия ПВ – для команд перехода по условию <0,>=0,=0,
a ПН – всем остальным командам. Стратегия приводит к успеху более, чем в
75% (по Смиту – 86%).
Эффективность предсказания зависит от характера программы.
Исходя из направления перехода – переходу “назад” назначается стратегия
ПВ, а переходу “вперед” – ПН.
Для перехода “назад” фактический переход имеет место в 85% случаев, а для
перехода “вперед” – 65%.
В последней стратегии при первом выполнении команды перехода
предсказывается, что переход обязательно будет. Точность выше, чем у
всех предшествующих. Но этот метод практически нереализуем при больших
объемах программ.
82. Ստատիկ կանխատեսում 2
Գործողության կոդի հիման վրա կանխատեսումը ենթադրվում է,որ որոշ հրամանների համար անցում կկատարվի, մյուսների
համար ոչ:
Անցում Միշտ (ԱՄ) ստրատեգիան <0, >=0,=0 պայմանով անցման
հրամանի համար է, իսկ (ԱԵ)Անցում Երբեք ` մնացած բոլորի
համար: Ստրատեգիան ունի ավելի քան 75 % առավելություն
(ըստ Սմիտի– 86%).
Կանխորոշման էֆեկտիվությունը կախված է ծրագրի բնույթից:
Անցումների ուղղությունից ելնելով <<հետ>> անցումը նշանակում
է ԱՄ , իսկ <<առաջ>> անցումը` ԱԵ:
<<Հետ>> անցման համար անցումը տեղի է ունենում 85% դեպքում,
իսկ <<առաջ>> ` 65%:
Վերջին ստրատեգիայի ժամանակ անցման հրամանի առաջին
կատարման դեպքում կանխատեսվում է, որ անցում անպայման
կլինի: Ճշությունը ավելի բարձր է, քան նախորդ դեպքերում: Բայց այս
մեթոդը չի իրականացվում մեծ ծավալով ծրագրերի դեպքում:
83. Branch Prediction
Ветвления бывают случайные и регулярные.Регулярные ветвления довольно хорошо предсказываются на
основе предыдущей статистики их выполнения.
Случайные ветвления в принципе невозможно предсказать на
основании сбора предыдущей статистики их выполнения.
84. Դինամիկ կանխատեսում
Դինամիկ կանխատեսումը ենթադրում է նախորդողանցումների մասին ինֆորմացիայի կուտակում:
Դինամիկ կանխատեսումը համեմատած ստատիկի հետ
ապահովում է կանխատեսման ավելի մեծ ճշտություն:
Ճյուղավորման դինամիկ կանխատեսումը անցկացնում
է անցման հրամանի կատարման նախապատմության
վերլուծություն: Յուրաքանչյուր անցման հրամանին
համապատասխանեցվում է կանխատեսման մեկ կամ
մի քանի բիթեր:
Պարզագույն դեպքում դիտարկվում է վերջին կատարված
հրամանի արդյունքը (ճյուղավորման կանխատեսման
մեկ բիթանի սխեմա): Ճյուղավորման կանխատեսման
բիթը մեկ բիթանի սխեմայում կոչում են փոխանջատիչ
– “ճիշտ է/ճիշտ չէ”–(taken /not taken).
85. Dynamic Branch Predictor
• Dynamic Branch Predictor работает на стадии выборки команд изпамяти (Instruction Fetch)
• Определяет, какую команду выбирать на следующем такте.
• Если результат предсказания “Taken”, то процессор выбирает
команду из ячейки памяти , адрес которой находится в BTB
(Branch Target Buffer).
• Для типичных программ точность хороших предсказателей
переходов превышает 90%.
86. Dynamic Branch Prediction
The idea of dynamic prediction assumes accumulation of history about previousbranches - Pattern History Table.
Each instruction is corresponded to one or more bits of branch history.
One-bit predictor
Taken (“false”)
Not taken
(“true”)
0
1
Taken
(“true”)
Not taken(“false”)
0 – prediction “not taken”, 1 – prediction “taken”.
Not taken, Taken – feedback from branch unit
“+” - simple, “-” - two misprediction per loop.
The one-bit scheme works well for patterns like TTTTTTTT... or NNNNNNN..., but
will produce incorrect predictions for a branch stream where most of the
transitions occur but one of them does not, ...TTTNTTT....
The accuracy of the prediction is insufficient, the direction of branch is predicted
incorrectly 2 times in a cycle.
87. Մեկ բիթանի կանխատեսման սխեմա
taken (“ճիշտ չէ”)Not taken
(“ճիշտ է”)
0
1
taken
(“ճիշտ է”)
not taken (“ճիշտ չէ”)
“0” վիճակ – կանխատեսում է, որ անցում չի լինի (Not taken)
“1” վիճակ – կանխատեսում, որ անցում կլինի
Մեկ բիթանոց սխեման լավ է աշխատում T T T T T T T T... կամ
NNNNNNN... օրինակների համար, բայց սխալ կանխատեսումներ
կստեղծի ճյուղային հոսքի համար, որտեղ անցումներից շատերը
տեղի են ունենում, բայց դրանցից մեկը՝ ոչ, ...T T T N T T T...
Կանխատեսման ճշտությունը անբավարար է, անցման
ուղղությունը ցիկլում 2 անգամ կանխատեսվում է սխալ:
88. Improvement: Two-bit counters (Smith)
Taken(“true”
Not taken(“false”)
11
Taken
(“false”)
10
Taken (“true”)
Not taken
(“false”)
Prediction:
00 – strong “not taken”
01 – weak “not taken”
11– strong “taken”
10 – weak “taken”
Not taken(“true”)
01
00
Taken (“false”)
Incorrectly predicts
Not taken patterns such as
(“true”) NTNTNTNTNT... or
NNTNNTNNT...
2-bit saturating counter to implement hysteresis.
Not taken, Taken – feedback signals from branch unit.
Only one misprediction per loop
89. Երկբիթանի կանխատեսման սխեմա (Սմիթի պրեդիկտոր)
Not taken (“ճիշտ է”) Taken (“ճիշտ չէ”)Taken
(“ճիշտ է» )
11
taken
(“ճիշտ չէ”)
taken
(“ճիշտ է”)
10
Not Taken (“ճիշտ
չէ”)
Not taken (“ճիշտ
է”)
01
00
Not taken
(“ճիշտ է”)
ПВ (“ճիշտ չէ”)
00 – Անցման շատ փոքր հավանականություն (ուժեղ կանխատեսում)
01 – Անցման փոքր հավանականություն (թույլ կանխատեսում)
11 – Անցման շատ մեծ հավանականություն (ուժեղ կանխատեսում)
10 – Անցման մեծ հավանականություն (թույլ կանխատեսում):
Ցիկլի կատարելիս կանխատեսման սխեման թույլ է տալիս մեկ սխալ։
Սխալ կերպով կանխատեսում է այնպիսի օրինաչափություններ, ինչպիսիք
են NTNTNTNTNT... կամ NNTNNTNNT...
90.
Երբ ավտոմատը գտնվում է 00 վիճակում, ապա կանխատեսվումէ, որ անցում չի լինելու (not taken). Եթե իրականում անցում
կկատարվի, ապա ավտոմատը կանցնի 01 վիճակ: Դա
նշանակում է, որ երբ տվյալ անցման հրամանը կհանդիպի
հերթական անգամ, հրամանների ընտրման բլոկը նորից
կկանխատեսի, որ անցում չկա:
Եթե այս անգամ ևս
կանխատեսումը սխալ է կատարվել, ապա ավտոմատը
կանցնի 11 վիճակ: Դրանից հետո կկանխատեսվի է անցման
կատարում (taken): Այսպիսով, կանխատեսող սարքը կփոխի
կանխատեսման արժեքը այն դեպքում, երբ 2 անգամ կանի ոչ
ճիշտ կանխատեսում: Ավտոմատի ճիշտ վիճակի ընտրման
համար ցիկլ մտնելիս կարելի է օգտագործել ստատիկ
կանխատեսում ավտոմատի սկզբնական վիճակ ընդունելով
11: Այդ դեպքում կանխատեսումը միշտ կլինի ճիշտ, բացի
ցիկլի վերջին իտեռացիայից: Վերջին սխալ կանխատեսումը
անխուսափելի է: Կանխատեսման ճշտությունը դիտարկված
10 իտեռացիաներով ցիկլի համար կլինի 90%.
91. Dynamic Branch Prediction
The idea of dynamic prediction assumes accumulation of history about previousbranches.
Pattern History Table.
Each instruction is corresponded to one or more bits of branch history.
One-bit predictor
Taken (“false”)
Not taken
(“true”)
0
1
Not taken(“false”)
0 – prediction “not taken”, 1 – prediction “taken”.
Not taken, Taken – feedback from branch unit
“+” - simple, “-” - two misprediction per loop.
Taken
(“true”)
92. Improvement: Two-bit counters (Smith)
Taken(“true”
Not taken(“false”)
11
Taken
(“false”)
10
Taken (“true”)
Not taken
(“false”)
Not taken(“true”)
01
00
Not taken
(“true”)
Taken (“false”)
2-bit saturating counter to implement hysteresis.
Not taken, Taken – feedback signals from branch unit.
Only one misprediction per loop
Prediction:
00 – strong “not taken”
01 – weak “not taken”
11– strong “taken”
10 – weak “taken”
93. Two-Bit Predictor
Prediction:00 – strong “not taken”
01 – weak “not taken”
11 – strong “taken”
10 – weak “taken”
94. Branch Target Buffer 1
IPIP on instr. to fetch
Tags
Comparators
IP1
==
IP2
==
IP3
==
IPk
==
BHT
Branch Address
1
B TB - Ասոցիատիվ բուֆերը
Prediction
Predict
Return
Address
Stack
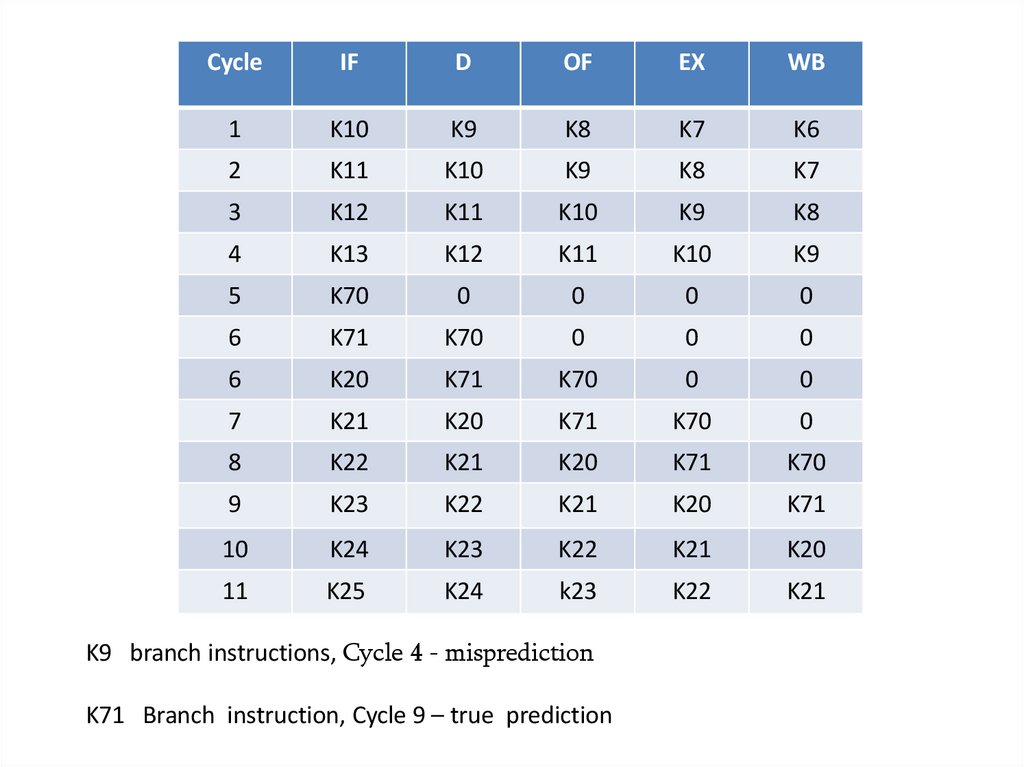
95. Օրինակ
Գոյություն ունի հինգ աստիճան կոնվեյերը։Կոնվեյերի վրա գտնվում են К10, К9, К8, К7, К6 հրամանները:
K9 հրամանը պայմանական անցման հրաման է:
Կանխատեսման արդյունքը հանդիսանում է К10 հրամանը:
Ինչպիսին կլինի հրամանների հաջորդականությունը 10 տակտ հետո,
եթե տեղի ունի misprediction և եղել է անցում К70 հասցեով:
Ինչպիսին կլինի հրամանների հաջորդականությունը, եթե
կանխատեսումը կատարվել է ճիշտ: К9 հրամանից հետո չի եղել
անցման կանխատեսում:
96.
CycleIF
D
OF
EX
WB
1
K10
K9
K8
K7
K6
2
K11
K10
K9
K8
K7
3
K12
K11
K10
K9
K8
4
K13
K12
K11
K10
K9
5
K70
0
0
0
0
6
K71
K70
0
0
0
6
K20
K71
K70
0
0
7
K21
K20
K71
K70
0
8
K22
K21
K20
K71
K70
9
K23
K22
K21
K20
K71
10
K24
K23
K22
K21
K20
11
K25
K24
k23
K22
K21
K9 branch instructions, Cycle 4 - misprediction
K71 Branch instruction, Cycle 9 – truе prediction
97. Example
Assume that a branch has the following sequence of taken (T) and not taken (N)outcomes: T, T, T, N, N, T, T, T, N, N, N,N
What is the prediction accuricy for a 2-bit counter (Smith predictor) for this sequence
assuming an initial state of strongly taken.
state
prediction
outcome result
11
T
T
+
11
T
T
+
11
T
T
+
11
T
N
-
10
T
N
-
00
N
T
-
01
N
T
-
11
T
T
+
11
T
N
-
10
T
N
-
00
N
N
+
00
N
N
+
98. Երկմակարդակ կանխատեսման սխեմա (1)
Մեկ մակարդականի սխեմաների կանխատեսումըկողմնորոշված են այն պայմանական անցման
հրամանների վրա, որոնց արդյունքը կախված է
իրենց նախորդող արդյունքներից:
Միևնույն ժամանակ շատ հրամանների համար
դիտարկվում է ուժեղ կախվածություն ոչ թե իրենց
արդյունքներից, այլ նրանց նախորդող ուրիշ
ճյուղավորման հրամանների կատարման
արդյունքներից:
Այս իրավիճակը հաշվի է առնվում երկմակարդականի
ադապտատիվ պրեդիկտորներում: Դրանք անվանում
են կոռելացված, քանի որ նրանք արտապատկերում
են անցումների հրամանների միջև
փոխկապակցվածությունը:
99. Երկմակարդակ կանխատեսման սխեմա (2)
Դիտարկենք ծրագրի հատված (երկբիթանի սխեմայիհամար վատագույն դեպքը):
• if (a= = 2)
• a=0;
• if (b= = 2)
• b=0;
• if (a !=b) { …
100. Երկմակարդակ կանխատեսման սխեմա (3)
Կարելի է հետևել, թե կատարվել են արդյոք վերջին k անցմանհրամանները, հաշվի չառնելով ` ինչ անցումների հրամաններ
են եղել: Դրա համար օգտագործում են k-բիթանի թիվ, որը
պահվում է գլոբալ նախապատմության k-բիթանի
տեղաշարժող ռեգիստրում: Գլոբալ նախապատմության kբիթանի յուրաքանչյուր կոմբինացիային համապատասխանում
է n բիթանի կանխատեսման աղյուսակ:
Կանխատեսման սխեման կոչվում է (k,n) կանխատեսում, եթե այն
օգտագործում է վերջին k պայմանական անցման հրամանների
վարքը 2k կանխատեսման սխեմաներից մեկի ընտրման
համար, որոնցից յուրաքանչյուրը իրենից ներկայացնում է n
բիթանի կանխատեսման սխեմա յուրաքանչյուր առանձին
անցման համար:
Երկմակարդակ կանխատեսման սխեման տալիս է
կանխատեսման ավելի բարձր տոկոս և օգտագործում է ոչ մեծ
քանակությամբ լրացուցիչ սարքավորումներ:
101. Correlating/Two-Level Predictors (Patt,Yeh)
Bi-mode (one-level) predictors:Some branch instructions have a tendency to outcome repetition (the
prediction depends on its own outcome history).
Alternative: some branch outcomes are correlated.
Example: some condition
if (d==0)
. . .
if (d!=0)
Example: related condition
if (d==0)
b=1;
if (b==1)
The prediction depends on the outcome of only 1 branch
which may produce bad prediction.
102. Two-Level Predictors
YesB1
a=2?
No
a=0
Yes
b=0
B2
b=2?
No
B3
a b?
if (a= =2)
a=0;
if (b= =2)
b=0;
if (a !=b) { …
If branch B1 & B2 are taken,
branch B3 is not taken;
a 2-bit saturating counter
cannot predict this behavior.
103. Correlating/Two-Level Predictors (Patt,Yeh)
Bi-mode (one-level) predictors:Որոշ հրամաններ հակված են կրկնել արդյունքները (the prediction
depends on its own outcome history).
Alternative: որոշ անցման հրամաններ փոխկապակցված են
Example: some condition
if (d==0)
. . .
if (d!=0)
Example: related condition
if (d==0)
b=1;
…
if (b==1)
The prediction depends on the outcome of only 1 branch
which may produce bad prediction.
104. Two-Level Predictors
General idea of correlated branch prediction:• put the global branch history in a global history register
• use its value to access a pattern history table (PHT) of 2-bit
saturating counters.
PHT
Global history register
of last m branches executed
nt nt nt
nt
m bit
t
t
2m entries of 2-bit counters
0
1
2
3
4
.
.
.
105. Two Level Predictor (2,2)
PCGHR
Биты предсказания
Branch
outcome
0
1
2
3
Исследования
показали, что с
увеличением числа
битов глобальной
истории точность
предсказания
значительно
увеличивается.
(Экспоненциально
относительно числа
битов GHR)
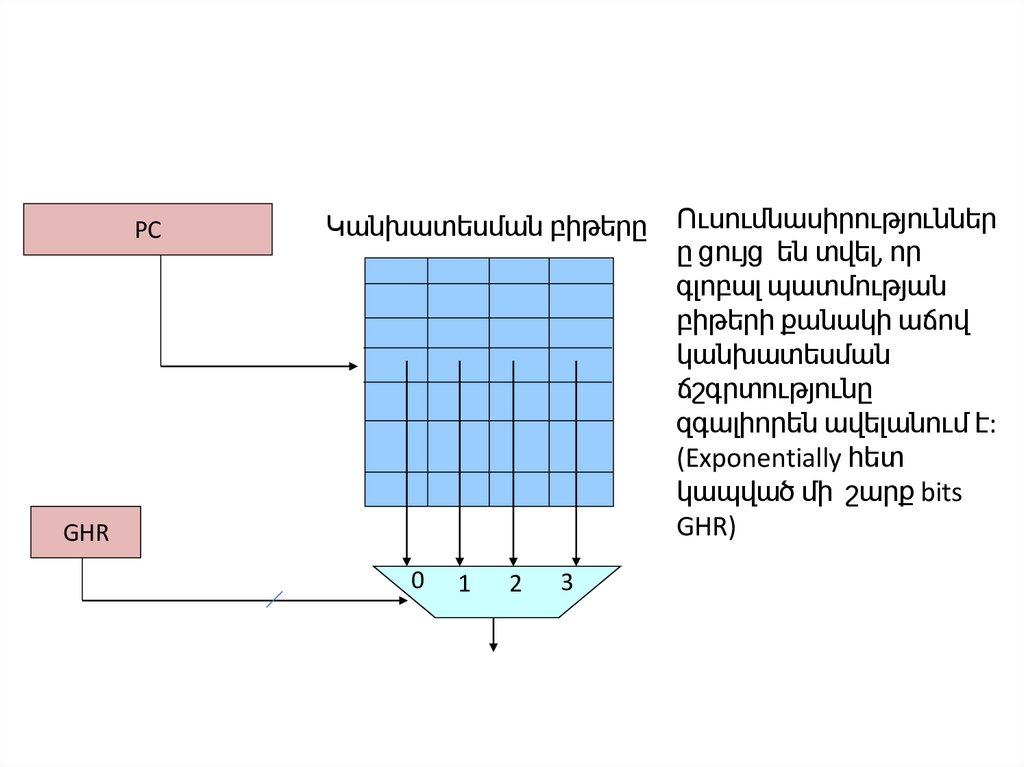
106.
PCԿանխատեսման բիթերը
GHR
0
1
2
3
Ուսումնասիրություններ
ը ցույց են տվել, որ
գլոբալ պատմության
բիթերի քանակի աճով
կանխատեսման
ճշգրտությունը
զգալիորեն ավելանում է:
(Exponentially հետ
կապված մի շարք bits
GHR)
107. Tournament Predictor (M’cFarling)
SelectorIP
Predictor 0
0
1
Predictor 1
Multiplexer
Prediction
108. Селектор
00 – оба предиктора предсказали неправильно.11 – оба предиктора предсказали правильно.
10 – предсказание первого верно, второго – неверно.
01 – предсказание первого предиктора неверно, второго –
верно.
Выбор предиктора осуществляется старшим разрядом счетчика,
который поступает на управляющий вход мультиплексора.
Если состояния 00 01 – выбирается первый предиктор (P0),
если 10 11 – выбирается второй предиктор (P1).
По имеющимся оценкам, точность предсказания гибридных схем
повышается по сравнению с бимодальными до 97%.
109. Սելեկտորի աշխատանկը
00 – 2 պրեդիկտորն էլ սխալ են կանխատեսել11 – 2 պրեդիկտորն էլ ճիշտ են կանխատեսել
10 - առաջին պրեդիկտորը կանխատեսել է ճիշտ է,
երկրորդը` սխալ
01 – առաջին պրեդիկտորի կանխատեսել է սխալ, երկրորդը`
ճիշտ
Պրեդիկտորի ընտրությունը իրականանում է հաշվիչի բարձր
կարգով, որը գալիս է մուլտիպլեքսորի ղեկավարող
մուտքին:
Եթե 00 01 վիճակն է – ընտրվում է P0 պրեդիկտոր
Եթե 10 11 վիճակն է – ընտրվում է P1 պրեդիկտոր
Հիբրիդային սխեմաների կանխատեսումը համեմետած
բիմոդալ սխեմաների հետ ճշտությունը բարձրանում է
մինչև 97%:
110. Hybrid/Competitive/Tournament Predictors (McFarling)
Motivation: Different schemes work better for different branches.Tournament predictors use two (or more) predictors, for
example, the 1-st, based on global history and the 2-d based on
local history, and combined by a selector.
Selector tries to select right predictor for right prediction.
Մոտիվացիան. Տարբեր սխեմաներն ավելի լավ են
աշխատում տարբեր ճյուղերի համար:
Մրցաշարի պրեդիկտորներ օգտագործում են երկու
(կամ ավելի) պրեդիկտորներ, օրինակ ՝ 0-ինը ՝ հիմնված
գլոբալ պատմության վրա և 1-ինը ՝ հիմնվելով տեղական
պատմության վրա, և զուգորդվում են սելեկտորի
կողմից:
Սելեկտորը փորձում է ճիշտ կանխատեսման համար
ընտրել ճիշտ պրեդիկտոր։
111. Селектор
Обычно для выбора селектора используют 2-битный счетчик снасыщением.
Граф переходов автомата Мура, описывающего поведение
селектора:
00 11 01
00 11
10
11
10
01
01
10
10
01
00
01
00 11 10
00 11
112. Սելեկտորի գրաֆ
Հիմնականում սելեկտորի ընտրման համար օգտագործումեն 2-բիթանի հագեցած հաշվիչ:
Մուրի ավտոմատի, որը նկարագրում է սելեկտորի վարքը,
անցման գրաֆը։
00 11 01
00 11
10
11
10
01
01
01
10
10
00
01
00 11 10
00 11
113. Branch Target Buffer (2)
PCBTB contains all branch instructions (taken and not
taken). BHT (Branch History Table) is also located in BTB
Tag 1
Tag 2
Tag 3
==
==
==
Tag n
==
Branch Target Address Prediction
bits
Predict?
Branch Predictor
1
+4
0
Taken
Not Taken
History update
(from branch unit)
1
0
114. Branch Target Buffer
PCTags
Tag 1
Tag 2
Tag 3
==
==
==
Tag n
==
Branch Target Address
Prediction bits
Predict?
Branch Predictor
Taken
Not Taken
History update
(from branch unit)
1
+4
Predicted PC
0
1
0
Alternative
PC
115.
Form signalsto correct
misprediction
Taken branch, first
executed
Misprediction
==
X/M
F/D
PC M_icode Target Predicted PC Alternative PC PD Direction
PC D_icode
Predicted PC Alternative PC PD Direction
Predicted Direction (tkn/ntk)
ICache
IF
+4
BTB
Correction history
PC
0
0
MUX
Misprediction
1
MUX
1
Not predicted taken
branch, first executed
Predict?
0
MUX
1
Predicted PC
116. Form Address to Reload Pipeline
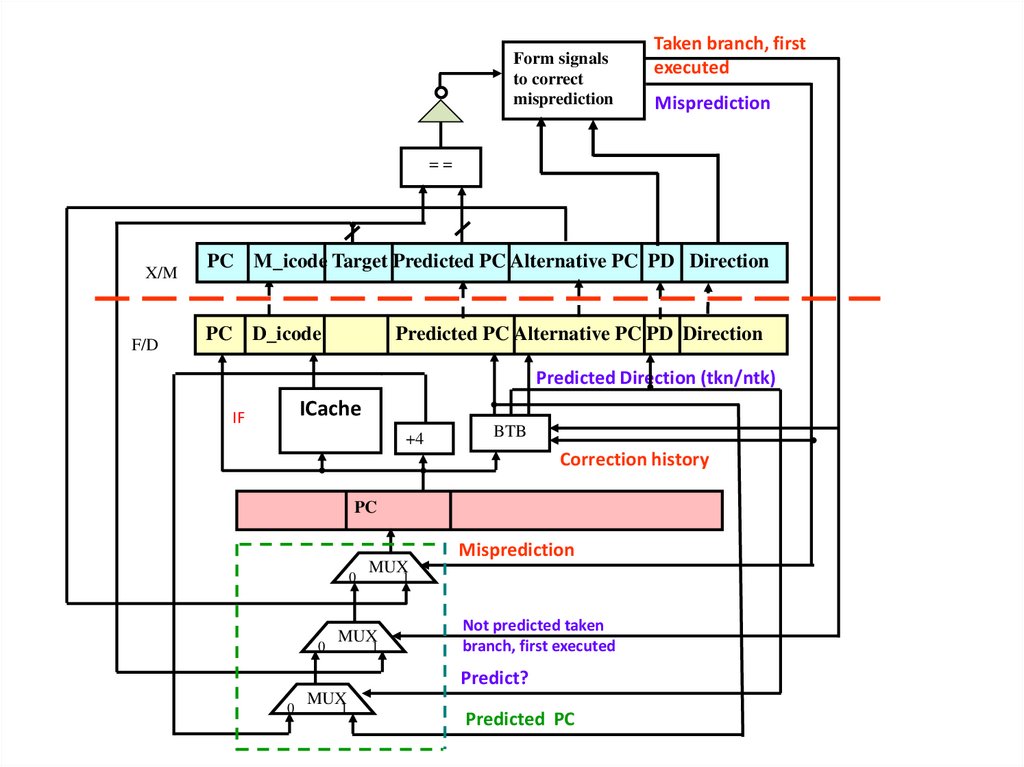
DPC
D_icode Pre-
Alternate PC
PD
F/D
diction
ICache
BTB
Predicted Direction (PD)
+4
IF
PC
0
MUX
Misprediction
Prediction
1
Form Address to reload
pipeline
Branch
+4
Tkn/
ntkn
X/M
Form signals
to correct
misprediction
Prediction
1
MUX
0
MUX
Misprediction
M
PC
M_icode Pred.
direct.
Branch addr.
Tkn/
ntkn
117. Instruction Pipeline. Check Prediction
Next PCCheck
prediction
X/M
PC
+4
Misprediction
Instr.
Cache
1
T/Ntk
BTB
D
S
Prediction
PC
Target Branch
PC
addr
MUX
PC
MUX
Predicted Address
PC
0
EX
F/D
0
1
D
D
S
PC
+4
0
1
MUX
IF
BTB
update
Correct
misprediction
Misprediction
True Address
Pr- prediction; D - Direction (Taken/Not taken) S-speculation
118. Neuropredictors
Предсказание переходов— это важная технология, которая помогает улучшитьпроизводительность процессоров, предсказывая, будет ли выполнен условный
переход в программе.
Одним из методов предсказания переходов является использование персептронов.
1. Входные данные:
Персептрон получает на вход несколько битов истории переходов, которые
представляют собой последовательность предыдущих переходов (например,
выполнен или не выполнен).
2. Веса:
Каждому входному биту соответствует вес. Эти веса настраиваются в процессе
обучения.
3. Суммирование:
Входные биты умножаются на соответствующие веса и суммируются. К этой сумме
добавляется смещение (bias).
4. Активационная функция:
Полученная сумма передается через активационную функцию, которая решает,
будет ли переход выполнен или нет. В простейшем случае используется пороговая
функция: если сумма превышает определенное значение, предсказывается
выполнение перехода, иначе — нет.
119.
NeuropredictorsBranch prediction՝ կարևոր տեխնոլոգիա է, որն օգնում է բարելավել
պրոցեսորի աշխատանքը՝ կանխատեսելով, թե արդյոք ծրագրի
պայմանական ճյուղը կկատարվի: Անցումների կանխատեսման
մեթոդներից մեկը պերցեպտրոնների օգտագործումն է:
Անցումների կանխատեսման մեթոդներից մեկը պերցեպտրոնների
օգտագործումն է:
1․Մուտքային տվյալներ. Պերցեպտրոնը որպես մուտք է ստանում
անցումային պատմության մի քանի բիթ, որոնք ներկայացնում են
նախորդ անցումների հաջորդականությունը (global history)։
2. Կշիռներ:
Յուրաքանչյուր մուտքային բիթ ունի իր հետ կապված կշիռ: Այս
կշիռները ճշգրտվում են մարզման գործընթացում:
3. Գումարում։
Մուտքային բիթերը բազմապատկվում են համապատասխան
կշիռներով և գումարվում: Այս գումարին ավելացվում է
կողմնակալություն:
120.
4. Ակտիվացման ֆւնկցիա:Ստացված գումարը փոխանցվում է ակտիվացման ֆունկցիայի
միջոցով, որը որոշում է՝ անցումը կկատարվի, թե ոչ։ Ամենապարզ
դեպքում օգտագործվում է շեմային ֆունկցիա՝ եթե գումարը
գերազանցում է որոշակի արժեք, ապա անցումը կանխատեսվում է,
հակառակ դեպքում՝ ոչ։
Սովորում (Կրթություն)
Գործողության ընթացքում պերցեպտրոնը կարգավորում է իր
կշիռները՝ հիմնվելով կանխատեսման ժամանակ թույլ տված
սխալների վրա: Եթե կանխատեսումը սխալ է, կշիռները ճշգրտվում են
այնպես, որ հաջորդ անգամ կանխատեսումն ավելի ճշգրիտ լինի:
Գործողության ընթացքում պերցեպտրոնը կարգավորում է իր
կշիռները՝ հիմնվելով կանխատեսման ժամանակ թույլ տված
սխալների վրա: Եթե կանխատեսումը սխալ է, կշիռները ճշգրտվում են
այնպես, որ հաջորդ անգամ կանխատեսումն ավելի ճշգրիտ լինի:
121. Perceptron-Based Branch Prediction
Dynamic branch prediction with neural methods1
x1
w0
w1
x2
..
.
xi
w2
wi
wn
...
xn
Perceptron
y
=0
n
y w0 xi wi
i 1
Out
If y 0, then prediction is “taken”
else prediction is “not taken”.
if (xi) y=y+wi; else y=y-wi
122. Perceptron-ի հիմնված ճյուղավորումների կանխատեսումը
Նեյրոնային մեթոդներով դինամիկ պրեդիկտոր1
w0
n
y w0 xi wi
i 1
x1
x2
...
xi
w1
w2
wi
wn
=0
y
...
xn
Perceptron
If y 0, then prediction is “taken”,
else prediction is “not taken”.
if (xi) y=y+wi; else y=y-wi
123. Prediction with Perceptron (Dynamic Neural Network Predictor)
Perceptron from BTBW0
-w1
GHR
W2
W1
1
W3
1
1
1
0
0
0
-w2
X1
GHR – Global History Register
-w3
X2
X3
Adder
Y Prediction
(Sign bit)
The result of the last
branch instruction
124. Perceptron Update (Training)
GHR1
0
1
X1
X2
0
The outcome of the last
branch instruction
(previous)
X3
The outcome of
the branch instruction
(from EX stage) 1
Check prediction
==
==
w0+1 1
w1+1 1
0
w0-1
=0
Y=2+3-3=2
Taken
True prediction
0
w2+1 1
0
==
w3+1
w3-1
1000- 0
1008-1
1020-0
1
0
w1-1
w2-1
2
3
-3
W0
W1
W2
W3
3
2
-2
-1
Write in BTB
Perceptron Training
0
W0 =2
W1=3
W2=-3
W3=0
Pridicted instr.
2000 – not taken
(0)
125. Perceptron Update (Training)
GHR1
0
1
X1
X2
0
The outcome of the last
branch instruction
(previous)
X3
The outcome of
the branch instruction
(from EX stage) 0
Check prediction
==
==
w0+1 1
w1+1 1
0
w0-1
=0
Y=2+3-3=2
Taken
True prediction
0
w2+1 1
0
==
w3+1
w3-1
1000- 0
1008-1
1020- 0
1
0
w1-1
w2-1
2
3
-3
W0
W1
W2
W3
1
4
-4
1
Write in BTB
Perceptron Training
0
W0 =2
W1=3
W2=-3
W3=0
Pridicted instr.
2000 – not taken
(0)
126. Example
w0=w1=1w2=w3=0
Example
w0
w1 w2 w3 x0
x1
x2
x3
y
pred out
1
1
0
0
1
0
0
1
1
T
T
+
2
0
-1
-1
1
0
0
1
3
T
T
+
3
-1
-2
0
3
1
2
3
6
T
T
+
4
-2
-3
1
10
T
N
-
3
-1
-2
0
3
1
2
-1
5
T
N
-
2
0
-1
-1
2
0
1
-1
3
T
T
+
3
-1
0
0
3
1
0
0
4
T
T
+
4
-2
-1
1
6
T
N
-
3
-1
0
-3
1
T
N
-
2
0
1
-4
-5
N
N
+
1
1
2
-5
-6
N
T
-
0
2
3
-6
-11
N
N
+
127. The Perceptron Predictor
Table of Perceptron weightsBranch Address
w0 w1 w2 w3
wn-1 wn
X
X X
Updated weight values
Global history register
xn
x1
x2
x3
1
x0
bias
X
X
X
Recompute
weights
Addition tree
y
Sign bit
Branch
prediction
Branch
outcome
128. Perceptron Update (2: >0)
Perceptron Update (2: >0)• After executing branch instruction weights of perceptron are updated. Let
t= -1, if the branch is not taken, t=1, if the branch is taken. Let >0 be
training threshold
Yout=
1
if Y>
0
if - Y
-1
Y< -
• If Yout is not equal to t , all the weights are updated as wi = wi +txi, i (0,
1,…n}. - Y indicate, that the perceptron has not been trained to
a state where the predictions are made with high confidence. Weights will
be updated.
• Empirically derived = 1,93 h + 14, where h – history length
129. Perceptron Update (2: >0)
Perceptron Update (2: >0)• Անցման հրամանը կատարելյուց հետո պերսեպտրոնի կշիռները
թարմացվում են։ Ընդունենք որ t=-1, եթե անցումը չի
կատարվել և t=1, եթե կատարվել է։ Թող ուսուցման շեմը լինի
>0:
1
if Y>
Yout=
0
if - Y
-1
Y< -
• Եթե Yout հավասար չէ t-ի բոլոր կշիռները թարմացվում են
որպես wi = wi + t: , i (0, 1,…n}.
- Y ցույց է տալիս, որ պերսեպտրոնը ուսուցված չէ այն
վիճակի, որտեղ կանխատեսումները կարող են արվել մեծ
վստահությամբ ։
Կշիռները թարմացվելուեն:
• Empirically derived = 1,93 h + 14, where h – history length
130. Կանխատեսման բլոկ
PCPHT
Branch
direction
predictor
Tag
Tag
Tag
==
==
==
==
==
Target Address
Target Address
==
Instruction
Length
CD
Adder
MUX
Prediction
Not-taken
Target
0
MUX
1
Predicted Address
Taken
Target
131. Преимущества и недостатки нейропредикторов
Преимущества персептронных предсказателей:• Адаптивность:
Они могут адаптироваться к различным паттернам переходов в программах
• Точность:
Персептронные предсказатели могут достигать высокой точности
предсказаний, особенно в сложных сценариях.
Недостатки:
• Сложность:
Реализация и обучение персептронов могут быть сложными и требовать
значительных вычислительных ресурсов.
• Задержки:
В некоторых случаях использование персептронов может приводить к
дополнительным задержкам в конвейере.
132. Նեյրոպրեդիկտորների առավելություններն ու թերությունները
Պերցեպտրոնի կանխատեսիչների առավելությունները.• Հարմարվողականություն.
Նրանք կարող են հարմարվել ծրագրերի անցումային
տարբեր օրինաչափություններին
• Ճշգրտություն: Պերցեպտրոնի կանխատեսիչները կարող են
հասնել կանխատեսման բարձր ճշգրտության, հատկապես
բարդ սցենարներում: Թերություններ.
• Դժվարություն. Պերցեպտրոնների ներդրումը և
վերապատրաստումը կարող են լինել բարդ և հաշվարկային
առումով ինտենսիվ:
• Ուշացումներ. Որոշ դեպքերում պերցեպտրոնների
օգտագործումը կարող է լրացուցիչ ուշացումներ առաջացնել
խողովակաշարում:
133. Advantages and Disadvantages of Neuropredictors
Advantages of perceptron predictors:• Adaptability:
They can adapt to different transition patterns in programs
• Accuracy:
Perceptron predictors can achieve high prediction accuracy,
especially in complex scenarios.
Disadvantages:
• Complexity:
Implementing and training perceptrons can be complex and require
significant computational resources.
• Latency:
In some cases, using perceptrons can introduce additional latency in
the pipeline.
134. Տվյալների հոսքի վերահսկում
Example: ax2 + bx +c =0; x1,2 = (-b (b2 -4ac))/2aa
b
2
K1
2a
K2
x
x
4
c
K3
neg
K4
x
ac -b
x K5
Tag
b2
Tag
4ac
b2-4ac
K8
+
-
K9
K10
/
/
K11
x1
x2
K6
K7
Opcode Where Where
From
From
11/6=1,8
1.K1,K2,K3,K4
2.K5
3.K6
4.K7
5.K8,K9
6.K10,K11
135. Dennis Machine (MIT)
K1K2
x
K10 K11
1
1
a
2
x
K5
1
a
c
1
K3
K4
neg K8
1
-
b
-
x
K6
1
b
b
1
K5
x
K6
0
K2
4
1
-
K6
K9
-
K7
K8
0
K7
K4
0
K5
K9
K10
K8
0
K6
-
-
+
K10 -
0
K3
K7
0
K9
K11
-
K11 -
0
0
K3
K7
/
x1
0
0
K8
K1
/
x2
0
K9
K1
0
-
-
136. Տվյալների հոսքի համակարգի կառուցվածքը
EUsComm2
K1
+
K2
+
K3
Comm1
x
x
Neg
K11
Control Unit
137. Տվյալների հոսքի վերահսկում
Հոսքային մեքենաների վրա հրամանը կատարելու համար բավարար էերկու պայման.
• տվյալների առկայություն, որոնց վրա կատարվում է սահմանված
գործողությունը.
• առկայությունը ազատ օպերացիոն սարքի որը նախատեսված է դրա
իրականացման համար:
Տվյալների հոսքի վերահսկմամբ ճարտարապետություններում գոյություն
չունի «հրամանների հաջորդականություն» հասկացություն, չկա
հրամանների հաշվիչ, չկա նույնիսկ հասցեական հիշողություն ՝
սովորական իմաստով:
• Հոսքային համակարգում գտնվող ծրագիրը ոչ թե հրամանների
հավաքածուն է, այլ հաշվարկային գրաֆը:
• Գրաֆի յուրաքանչյուր հանգույց ներկայացնում է օպերատոր կամ
օպերատորների հավաքածու, իսկ ճյուղերը ներկայացնում են
հանգույցների տվյալներին կախվածությունը
138. O-O-O Execution
Команды могут выполняться не в том порядке, в котором они содержатся впрограмме.
Идея:
• если выполнение отдельной команды задерживается, потому что входные
данные для команды еще не доступны, тогда микропроцессор попытается
найти более поздние инструкции, которые он может сделать в первую
очередь, если исходные данные для последующих инструкций готовы
• Очевидно, что микропроцессор должен проверить, нужны ли для более
поздних инструкций рeзультаты предыдущей инструкции.
• Если каждая инструкция зависит от результата предыдущей инструкции
(RAW-зависимости), то у нас нет возможностей для выполнения вне порядка.
Это называется цепочкой RAW зависимостей.
139. Pentium Pro Pipelining
In-OrderFront End
IF1
IF2
BTB0
BTB1
Next IP
Decode
D0 D1 D2…
Ops
queue
Out-Of-Order
Renaming
Allocate
Schedule
Dispatch
Execute
In-Order
Retirement
Retire
Re-order Buffer
140. O-O-O Execution
Սահմանափակ հոսքի վերահսկումՄիտք՝
• Եթե առանձին հրամանի կատարումը հետաձգվում է,
որովհետև հրամանի համար մուտքային տվյալները դեռ
հասանելի չեն, այդ ժամանակ պրոցեսորը կփորձի գտնել
ավելի ուշ հրամաններ, որոնք ունեն պատրաստի տվյալներ:
• Պրոցեսորը պետք է ստուգի, թե արդյոք անհրաժեշտ են
նախորդ հրամանի արդյունքները ավելի ուշ հրամանների
համար:
• Եթե ամեն հրամանը կախված է նախորդ հրամանի
արդյունքից (RAW-կախվածություն), ապա մենք չունենք
հնարավորություն կատարել հրամանները ոչ
հերթականությամբ։
Դա անվանվում է RAW- կախվածությունը
141. Out-of-Order Execution (O-o-O)
Register renaming and allocationRe-order buffer and retirement unit are combined in a single unit:
first is reordered instructions
retirement block is switched on when should give the result.
Unified scheduler forms ops queue and dispatch ops to one of
the 8 ports of EU.
• Micro-ops are executed by EU and then results are sent back to
any waiting reservation station (RS) as well as retirement unit.
• The entry, corresponding to instruction in ROB is marked as
complete.
Out-of-Order clusters use physical register file (PRF) which store
operands.
ops store only pointers to operands (this reduces the area and
saves energy)
Per cycle may be performed up to eight operations
142. O-o-O Execution
Instructions are split into μops•All instructions are translating into micro-operations - abbreviated μops or
uops.
• A simple instruction such as ADD EAX,EBX generates only 1 μop,
• ADD EAX,[MEM1] may generate 3 μops,
agu - address generate (to read into r1)
load r2, [r1] - load from memory operand
add r4,r2,r3 r4 – the name of eax after renaming (r2+r3 r4)
• ADD [MEM1], EAX may generate 4 uops
agu - address generate (to read into r1)
load r2, [r1]
add r4,r2,r3
store [r1], r4 - Store r4 (eax) into memory
The advantage of this is that the μops can be executed out of order.
143. O-o-O Execution
Внеочередное исполнение команд (Out-of-order execution, dynamicscheduling, OОOE)
• сокращениe простоев конвейера (stall) за счет внеочередного выполнения
инструкций по готовности их данных (ограниченная форма data flowвычислений)
1. Инструкция выбирается из памяти (одна или несколько)
2. Инструкция направляется (dispatch) в очередь инструкций (instruction
queue, instruction buffer, reservation station)
3. Находясь в очереди инструкция ожидает пока её операнды станут
доступными. После чего инструкция может покинуть очередь раньше более
старых команд.
4. Инструкция направляется на подходящее исполняющее устройство
5. Результаты выполнения инструкции помещаются в очередь
6. Инструкция записывает данные в регистровый файл, только после того
как более старые инструкции сохранили свои результаты(retire stage)
144. O-O-O
Հրամանների ոչ կարգավորված կատարումը(Out-of-order execution, dynamic scheduling)
• կոնվեյերի հապաղումների (stalls) փոքրացում ոչ կարգավորված
հրամանների կատարման հաշվին պատրաստի տվյալների
դեպքում (սահմանափակ հաշվարկներ data flow)
1. Հրամանն ընտրվում է հիշողությունից (մեկ կամ մի քանի)
2. Հրամանն ուղարկվում է հրամանի կատարման հերթ (dispatch)
(instruction queue, instruction buffer, reservation station)
3. Հերթում գտնվելու ժամանակ հրամանը սպասում է, մինչև դրա
օպերանդները հասանելի դառնան: Որից հետո հրամանը կարող է
թողնել հերթը ավելի հին հրամաններից առաջ:
4. Հրամանը ուղարկվում է համապատասխան կատարողական
սարքին
5. Հրամանի կատարման արդյունքները հերթագրվում են
6. Հրամանը տվյալները գրում է ռեգիստրի ֆայլում միայն այն բանից
հետո, երբ ավելի հին հրամանները կպահեն իրենց արդյունքները
(retire stage)
145.
FrontEndL1 ICache
Branch Prediction
Microcode
ITLB
Instr.Fetch
Instr.Queue
5-way decode
opsCache
Common
Data Bus
(CDB)
MUX
Allocation Queue
CDB
Retirement
Unit
ReOrder Buffer
Scheduler
EU
Memory
Subsystem
EU
EU
Load Buffer
Execution
Engine
Store Buffer
L1 DCache
DTLB
L2 Cache
GPRs
146. Superscalar Processor
Скалярныe процессоры относятся к классу SISD.Векторные процессоры и GPU – класс SIMD.
Многоядерные и мультитредовые процессоры – к классу MIMD.
Обычно на машинах MIMD работает одна программа, которая
использует все или часть ядер.
Этот стиль программирования называется парадигмой
“ одна программа – много данных”
Single Program – multiple Data, SPMD.
Тракт данных суперскалярного процессора содержит несколько копий
функциональных блоков, что позволяет ему выполнять несколько
команд одновременно.
Диаграмма 2-конвейерного процессора (2-way), который производит
выполнение двух команд за 1 такт, представлена на следующем
слайде.
Суперскалярные и суперконвейерные процессоры используют ILP
(Instruction Level Parallelism).
147. Superscalar Processor Data Path
IFCLK
D
CLK
Register file
Icache
dcache
CLK
A1 RD1
A2 RD4
A3
A4 RD2
A5 RD5
A6
WR3
WR6
EX
RD1
RD2
CLK
CLK
Mem
A1
A2
RD3
WB
RD1
RD2
Dcache
RD4
Superscalar պրոցեսորի տվյալների
Заուղի
один такт выполняется 2 команды
• Из памяти Icache выбирается сразу 2 команды
• Register file имеет 6 портов: A1,RD1, A2, RD2, A3, WR3 – порты команды1,
A4,RD4, A5, RD5, A6, WR6 – порты команды 2.
• В каждом такте читается 4 операнда из RegFile и записывается в Regfile 2 результата.
• При выполнении команд load и store чтение и запись операндов осуществляется в
Dcache. Адреса операндов вычисляются на стадии Execution.
148. Multithreading
• Superscalar and VLIW processors exploit ILP• Իրական ծրագրերը բավականին ցածր ILP
ունեն
• With the increase of performance one can achieve
exploiting thread-level parallelism within a processor
• Three methods are used:
– Chip multiprocessing (CMP)
– Multithreading
– Chip multiprocessing and multithreading (CMT)
149. Multithreaded Processors
• Superscalar and VLIW-uniprocessors have one instruction pointer• The instructions are bound to IP with the execution window (in
superscalar) or instruction bundle (in VLIW)
Idea: two or more processes (threads) share one pipeline and execution
units.
• Processor must duplicate the independent state of each thread (separate
copy of GPRs, IP, Page Table, etc.). The memory itself can be shared
through the virtual memory mechanism (which means
multiprogramming).
• Stateless structures are not replicated: Caches, EUs, buses, etc.
• Hardware switch of threads must be fast
• Thread level parallelism (TLP)
150. Two Multithreading Approaches
Coarse-grained multithreading:• Used in processors with short pipeline
• Switch threads with long stalls (i.e. L2 cache misses)
• Threads which doesn’t interfere with each other much
The utilization of L1 cache misses or branch misprediction cannot be improved in
coarse-grained multithreading (e.g. IBM Northstar/Pulsar (2 threads))
Fine-grained multithreading:
• N thread contexts
• Switch threads on each instruction
Instructions of each thread are assigned to execute on each N-cycle. Processor
throughput is increased by partially hiding the latencies of execution of some long
instructions (e.g. MTA Tera).
151. Simultaneous Multithreading (SMT): Converting TLP into ILP
• SMT – particulars of fine-grained multithreading• Motivation:
– Modern multiple-issue processors have more available functional units than a
single thread
• The properties of SMT:
“+” improves utilization of EUs
“-” individual thread performances suffer due to interference
• Implement on top of multiple-issue, dynamic scheduling processor.
• SMT uses TLP to hide long-latency events in a processor, thereby
increasing the usage of functional units.
152. Simple Multithreaded Pipeline
I Fetch0
1
2
3
P
C
F/D
Op
Code
GPRs
GPRs
GPRs
GPRs
r5
ICache
r6
r7
Thread
select
+1
T
C
Thread 3
Thread 2
Decoding
2
Thread
number
Thread 1
Op
Code
EX
X
ALU
Thread 0
Op
Code
Y
Z
r3
r3
Thread select
Read Write
2
2
• Each thread has architecture state (GPRs, PC, APIC)
• Thread select – round robin
Z= XopY
• One copy Software (e.g., OS) perceives multiple, slower CPUs. Individual
thread performance
•s is reduced.
153. Multi-Core Architecture
• Trend in computer architecture– Replicate multiple processor cores on a single die
• The cores run in parallel
• Within each core, threads are time-sliced
Interaction with the Operating System
• OS perceives each core as a separate processor
• OS scheduler maps threads/processes to different cores
• Most major OS support multi-core today: Windows, Linux,
Mac OS X, Solaris, etc.
154. Instruction-Level Parallelism
Parallelism at the machine-instruction level• The processor can re-order, pipeline instructions, split them
into microinstructions, do aggressive branch prediction, etc.
• Instruction-level parallelism enabled rapid increases in
processor speeds the last 30 years
• Reasons for use multi-core processors (The first 2-core
processor: 2001, IBM, Power PC)
• The use of long pipelines brings a lot of problems:
Heat problems, difficult design and verification etc.
• Many new applications are multithreaded
General trend in computer architecture (shift towards more
parallelism)
155. SPARC Core Pipeline (Т1)
FetchSelect
Decode
Execute
ICache
ITLB
Thread
Select
Mux
Instr
Buffer
PC
Logic
Decode
Logic
Thread
Select
Logic
WriteBack
Crypto
Coprocessor
Reg
Files
Thread
Select
Mux
Memory
ALU
MUL
DIV
SHIFT
DCache
DTLB
StBuffer
Instruction Type
Cache Misses
Traps and Interrupts
Resource Conflicts
Crossbar
interface
156. Intel Hyper-Threading
The first processor with HT – Intel Xeon (Prestonia, 2003)OS perceives each thread as a separate processor
HT – virtual two-processing
One physical processor – two logical: LP0, LP1
• Instructions from threads are put into pipeline by turns
• Threads have no priorities
• Both LP compete for resources of core.
Growth of performance ~35%
Increase of die size: about 5% (almost free of cost).
157. Intel Hyper-Threading
В случае, когда несколько тредов претендуют на одни и те же ресурсы, либо одиниз тредов ждет данных, программисту необходимо использовать специальную
команду “Pause”. Это требует перекомпиляции программ.
Впервые технология HT была реализована в процессорах Intel Xeon (Prestonia) и
Xeon MP, затем Prescott и т.д.
Идея этой технологии проста. Один физический процессор представляется
операционной системе как два логических процессора, и операционная система
не видит разницы между одним SMT процессором или двумя обычными
процессорами. В обоих случаях операционная система направляет потоки как на
двухпроцессорную систему. Далее все вопросы решаются на аппаратном уровне
Гипертредовая обработка использует потенциал таким образом, чтобы
функциональные блоки процессора были максимально загружены.
158. Hyperthreading (HT)
Without HTArchitectural
State 0
With HT
Thread 0
Architectural
State 0
Thread 1
Architectural
State 1
159. Example
Thread AThread B
ALU
ALU
FPU
S/L
ALU
ALU
FPU
S/L
1
2
3
4
5
1
2
Execution without hyperthreading
S/L
1
2
3 4 5 6 7
Processor Cycles
8
9 10
3
4
5
160. Example (2)
Thread AThread B
ALU
ALU
FPU
S/L
ALU
ALU
FPU
S/L
1
2
3
4
1
5
Execution with HT
ALU
ALU
FPU
S/L
1
2
3
4
Processor Cycles
5
2
3
4
5
161. Processor’s Resources
• Two modes are provided: single-task (ST) and multi-task (MT).• In MT mode resources are divided into:
– Duplicate
IP, GPRs, RAT, ITLB, APIC.
– Partitioned
Static and dynamic shared queues, trace cache (LP0 and LP1 are
gained access to TC by turns)
– Fully shared – determinative type:
Functional units. They do not know whether LP instruction is entered
from Internal registers or Cache memory.
162. Hyper-Threading (x86-32/64)
Sharedresources
Decode
Decode
Duplicated
resources
Shared
Duplicated
163. Multi-Core Architecture
• Trend in computer architecture– Replicate multiple processor cores on a single die
• The cores run in parallel
• Within each core, threads are time-sliced
Interaction with the Operating System
• OS perceives each core as a separate processor
• OS scheduler maps threads/processes to different cores
• Most major OS support multi-core today: Windows, Linux,
Mac OS X, Solaris, etc.
164. Instruction-Level Parallelism
Parallelism at the machine-instruction level• The processor can re-order, pipeline instructions, split them into
microinstructions, do aggressive branch prediction, etc.
• Instruction-level parallelism enabled rapid increases in processor speeds
the last 20 years
• Reasons for use multi-core processors
• The use of long pipelines brings a lot of problems:
Heat problems, difficult design and verification etc.
• Many new applications are multithreaded
General trend in computer architecture (shift towards more parallelism)
165. Thread-level Parallelism (TLP)
This is parallelism on a more coarser scale• Server can serve each client in a separate thread (Web server,
database server)
• Single-core superscalar processors cannot fully exploit TLP
• Multi-core architectures are the next step in processor
evolution: explicitly exploiting TLP
166. Multi-core Processors
• Multi-core processor is a special kind of a multiprocessor:– All processors are on the same chip
• Multi-core processors are MIMD system:
– Different cores execute different threads (Multiple Instructions),
operating on different parts of memory (Multiple Data)
• Multi-core is a shared memory multiprocessor:
– All cores share the same memory
• Many-cores processors: Example Intel Xeon Phi
• 60 cores
167. Multiprocessors on a Single Chip
MIMD - organization of main memory: shared and distributed(կիսվում և բախշվում)
Shared memory – processors can communicate via memory directly (loads,
stores)
Պրոցեսորները կարող են ուղղակիորեն հաղորդակցվել հիշողության
միջոցով
Example
–
–
UMA – Uniform Memory Access
NUMA – Non-Uniform Memory Access
Distributed memory: each processor has its own memory and can address
only to it (multicomputers, clusters, warehouse-scale computers)
յուրաքանչյուր պրոցեսոր ունի իր հիշողությունը և կարող է դիմել
միայն դրան,
Processors can communicate via messages (message passing).
Վերամշակողները կարող են հաղորդակցվել
հաղորդագրությունների միջոցով
168. Interaction with the OS
OS perceives each core as a separate processorOS scheduler maps threads/processes to different cores
Most major OS support multi-core today:
Windows, Linux, Mac OS …
169. Applications that Benefit from Multi-Core
Database servers• Web servers (Web commerce)
• Compilers
• Multimedia applications
• Scientific applications, CAD/CAM
• In general, applications with Thread-level parallelism (as
opposed to instruction level parallelism)
170. Multiprocessors on a Single Chip
MIMD - organization of main memory: shared and distributed.• Shared memory – processors can communicate via memory directly
(loads, stores).
• Example
–
–
UMA – Uniform Memory Access
NUMA – Non-Uniform Memory Access
• Distributed memory: each processor has its own memory and can address
only to it (multicomputers, clusters, warehouse-scale computers)
Processors can communicate via messages (message passing).
171. Single Thread Running
L1 Dcache, DTLBThe processor pipeline
can get stalled:
• Waiting for the result of a long
floating point (or integer) operation
• Waiting for data to arrive from
memory
Other execution units wait unused
Integer
Floating Point
Schedulers
Retirement
Unit
Rename/Allocate
Ops queues
Decoder
L2Cache
Ops ROM
BTB, ITLB
Thread 1, Floating Point
172. Single Thread Running
L1 Dcache, DTLBInteger
Floating Point
Schedulers
Retirement
Unit
Rename/Allocate
Ops queues
Decoder
L2Cache
BTB, ITLB
Thread 2, Integer
Ops ROM
173. Hyperthreading
L1 Dcache, DTLBBoth threads can run
concurrently
Integer
Floating Point
Schedulers
Retirement
Unit
Rename/Allocate
Ops queues
Decoder
L2Cache
BTB, ITLB
Thread 1, Thread 2
Ops ROM
174. Dual Core Processor
L1 Dcache, DTLBInteger EUs
L1 Dcache, DTLB
Floating Point EUs
Schedulers
Retirement
unit
Floating Point
Schedulers
Rename/Allocate
Rename/Allocate
Ops queues
Ops queues
Decoder
L2Cache
Integer
BTB, ITLB
Thread 1, Thread 2
Ops ROM
Retirement
unit
Decoder
L2Cache
BTB, ITLB
Thread 1, Thread 2
Ops ROM
175. Core i7 Structure
Core 1Core 2
Core 3
Core 4
L3 Cache
DRAM
Integrated IGP
Memory
Controller
QPI1
QPI2
Power and
Clock
UnCore
QPI – Quick Path Interconnect 25,6 GB/s or 6,4 GТ/s (GigaTransfer)
IGP – Integrated Graphics Processor
176. Example: SunnyCove Microarchitecture
BPUI-TLB +32KB Icache
Microcode
4 ops
Front
End
ops cache
6 ops
Decode
5 ops
op Queue
RS
Port1
Port0
ALU
LEA
Shift
JMP
FM
ALU
Shift
FDIV
Port6
Port5
ALU
LEA
iMUL
iDIV
FMA
ALU
Shift
Shuffle
ALU
LEA
Branch
LEA
iMUL
Shift
JMP
FMA
RS
RS
P4 P9
P2
Store
Dara
RS
P8
Store Load
Dcache (48KB)
Shuffle
Execution Engine
P7
AGU AGU AGU AGU
LD
STA LD
STA
Load
O-o-O
P3
SOC
512KB L2
Store
Renam
e/
Allocate
/
Retirem
ent
Unit
177. Sunny Cove Microarchitecture
178. Intel Core Processor Structure
L1 ICacheITLB
Instr.Fetch
Instr.Queue
5-way decode
FrontEnd
Branch Prediction
Microcode
opsCache
Common
Data Bus
(CDB)
MUX
Allocation Queue
Retirement
Unit
ReOrder Buffer
CDB
Scheduler
EU
Memory
Subsystem
EU
Load Buffer
Execution
Engine
EU
Store Buffer
L1 DCache
DTLB
L2 Cache
GPRs
179. Zen Block Diagram
180. MIMD-համակարգեր: UMA
Symmetric Shared-MemoryMultiprocessor (SMP):
• uniform memory access,
• uniform I/O access
• from P0 same latency to M0
as Mk
• data placement is easy for
software (load, store
instructions)
Memory
Latency
Hardware – shared memory,
OS – shared memory
M0
M1
M2
..
Mk
P2
...
Pn
Interconnect
P0
P1
181. NUMA System
Hardware – distributed memory, OS– shared memory
Interconnect
long latency
M0
M1
M2
…
Mk
P0
P1
P2
…
Pk
short latency
The latency from P0 to M0 is shorter than from P0 to Mk
P0- ից M0- ի հապաղումը ավելի կարճ է, քան P0- ից Մկ
(-) data placement is hard for software
տվյալների տեղադրումը դժվար է ծրագրային ապահովման համար
Less contentions (non-local only)
Ավելի քիչ հակասություններ
Typically used in larger multiprocessors
182. MIMD System with Distributed Memory
M0M1
M2
…
Mk
P0
P1
P2
…
Pk
Interconnect
• Hardware: distributed memory (բաշխված հիշողություն)
• Software: distributed memory (բաշխված հիշողություն)
• Communicate via message passing
183. Amdahl’s Law
TSfTS
(1-f)TS
Serial part
TP
Parallel part
fTS/n
184. Amdahl’s Law
• Իդեալում, n պրոցեսորների համակարգը կարող է արագացնելհաշվարկները n անգամ:
Իրականում դա անհնար է:
• Որպես կանոն, յուրաքանչյուր ծրագիր ունի կոդերի հատված, որը
պետք է իրականացվի հաջորդաբար:
Սա պահանջում է մեկ պրոցեսոր:
• Problems arise and with that part of the task, which is amenable to
parallelization. Processors can not be loaded equally frequently.
Խնդիրներ են առաջանում և առաջադրանքի այն մասով,
որը ենթակա է զուգահեռացման։ Պրոցեսորները չեն կարող
հավասարապես հաճախակի բեռնվել:
Ts - time of solving the task by a single processor
f - the proportion of parallel computations
1-f - the proportion of serial computations
185. Amdahl’s Law
• Իդեալում, n պրոցեսորների համակարգը կարող է արագացնելհաշվարկները n անգամ:
Իրականում դա անհնար է:
• Որպես կանոն, յուրաքանչյուր ծրագիր ունի կոդերի հատված, որը
պետք է իրականացվի հաջորդաբար:
Սա պահանջում է մեկ պրոցեսոր:
• Problems arise and with that part of the task, which is amenable to
parallelization. Processors can not be loaded equally frequently.
Խնդիրներ են առաջանում և առաջադրանքի այդ մասի հետ կապված,
ինչը զուգահեռին ենթակա է: Պրոցեսորները չեն կարող հաճախակի
հավասարաչափ բեռնվել
Ts - time of solving the task by a single processor
f - the proportion of parallel computations
1-f - the proportion of serial computations
186. Amdahl’s Law (2)
Amdahl’s
Law
(2)
T = (1-f)T + f T /n
S = TS/TP = n/(n-f(n-1))= 1/(1-f+f/n)
P
S
S
• Lim S =1/(1-f) (при n )
• Եթե n , ապա S 1/(1-f) և հաջորդական հաշվարկի մասը
10% է (1-f = 0,1), ապա պրոցեսորների քանակից անկախ,
արագազունը կարող է լինել ոչ ավելի, քան 10 անգամ:
• Example: achieve speedup of 50 using 100 processors
50 = 100/(100-99f); f 98%.
• Only 2% of work can be serial.
• 30=100/(100-99f)
• 3=10/(100-99f)
• f=290/297 97%
• 1-f 3%
187. Օրինակ 1
Ենթադրենք, որ անհրաժեշտ է արագագործությունը մեծացնել մինչև 90,100 պրոցեսորների համար: Որոշել, քանի տոկոս է կազմում սկզբնական
հաշվարկները, որոնք կարող են կատարվել հաջորդական ռեժիմում:
S = 1/(1-fEnchanced + fEnchanced/SEnchanced)
fEnchanced – զուգահեռ հաշվարկների մասը նշանակենք x-ով:
90 = 1/(1-x+x/100); 1/(1-0,99x)=90; 90(1-0,99x)=1;
x= 89/89,1 =0,999.
Հաջորդական հաշվարկների մասը` 1-0,999=0,001
Ինչը կազմում է – 0,1%
188. Superscalar Processors
• Definition:– Multiple instructions are issued per cycle and multiple results are
generated by multiple pipelines per cycle
– Superscalar processors expose and exploit parallelism by hardware
• The ways to exploit ILP:
– Pipelining (super- and hyper pipeline)
– Superscalar (multi-issue)
– Out-of-order execution (dynamic scheduling)
189. Speculative Execution
Speculative Execution
Instructions are decoded and executed, but the results are not retired into the
permanent register file, and memory writes are pending until the branch instruction is
finally resolved.
• If the wrong branch was executed speculatively (misprediction), then the pipeline is
flushed, the results of the speculative execution are discarded and the other branch is
fed into the pipeline.
The result is that several clock cycles are wasted. The number of wasted clock cycles is
approximately equal to the length of the pipeline.
What happens if a speculative instruction raises an exception?
• Example 1
Load instruction is executed and there is a cache miss.
In some cases, a special instruction called Speculative Load is introduced,
which attempts to read data from the cache
If it is not there, it stops reading.
If in the future it turns out that this value is simply not necessary, then there are no
losses.
190. Speculative Execution
• Example 2.Operator if (x> 0) z = y / x and Floating point division
If x = 0, then execution ends with an attempt to divide by 0 (Exception).
• This is a failure in a properly executed program.
One possible solution is special versions of those instructions that may cause
exceptions.
In addition, a special bit (poison bit) is added to the registers.
• If the speculative instruction fails, then poison bits are written to the
registers.
• If then this bit is used by a ordinary instruction, an interruption occurs
(Exception).
If this result is not used, then the poison bits are reset.
191. O-o-O Execution
Instructions are split into μops• All instructions are translating into micro-operations - abbreviated μops or uops.
A simple instruction such as ADD EAX,EBX generates only 1 μop
ADD EAX,[MEM1] may generate 3:
–
–
–
agu - address generate (to read into r1)
load r2, [r1] - load from memory operand
add r4,r2,r3 r4 – the name of eax after renaming (r2+r3 r4)
ADD [MEM1], eax may generate 4 uops
–
agu - address generate (to read into r1)
– load r2, [r1]
– add r4,r2,r3
– store [r1], r4 - Store r4 (eax) into memory
The advantage of this is that the μops can be executed out of order.