





































































































































































 Программное обеспечение
Программное обеспечение Лингвистика
ЛингвистикаПохожие презентации:










Введение в NLP: Предобработка. Векторизация. Классификация
1.
Введение в NLP:Предобработка
Векторизация. Классификация
Дмитрий Меркушов, Дмитрий Парпулов
команда
машинного обучения почты Mail.ru
2.
Пару слов о формате лекций:3.
Пару слов о формате лекций:4.
NLP - это важно:Люди выражают свои мысли, как правило, на
естественном языке
5.
NLP - это важно:Люди выражают свои мысли, как правило, на
естественном языке
6.
NLP - это важно:Люди выражают свои мысли, как правило, на
естественном языке
Генерят множество документов на естественном
языке: блоги, твиты, отзывы, статьи, запросы, …
Нужно уметь обрабатывать эти документы:
определять тематики, эмоциональную окраску,
выделять сущности, фильтровать спам, …
7.
NLP - это круто:NER (распознавание именованных сущностей)
8.
NLP - это круто:9.
NLP - это круто:Person
Person
10.
NLP - это круто:• NER (распознавание именованных сущностей)
• Поиск
11.
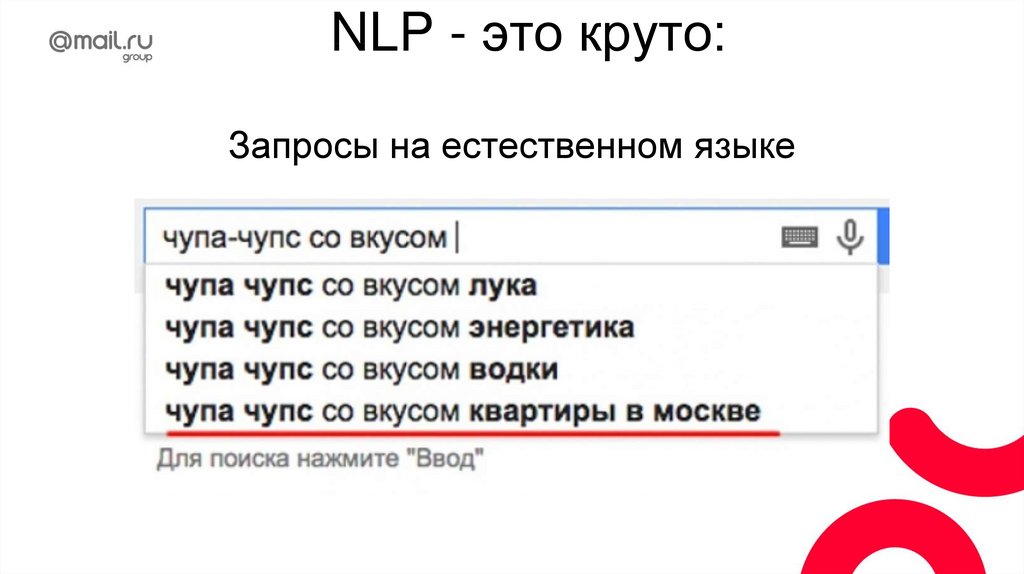
NLP - это круто:Запросы на естественном языке
12.
NLP - это круто:• NER (распознавание именованных сущностей)
• Поиск
• Перевод
13.
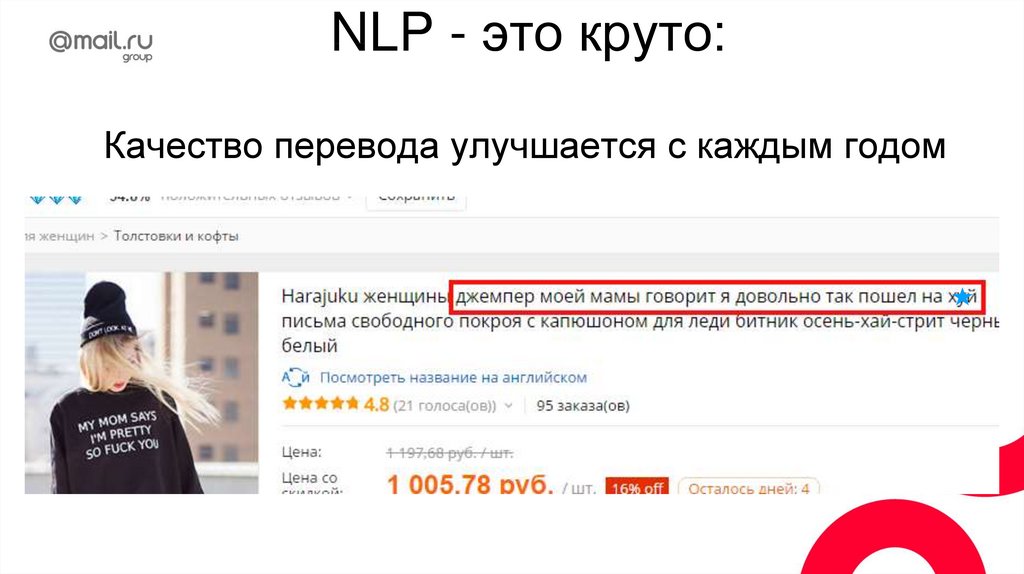
NLP - это круто:Качество перевода улучшается с каждым годом
14.
NLP - это круто:• NER (распознавание именованных сущностей)
• Поиск
• Перевод
• Чат-боты
15.
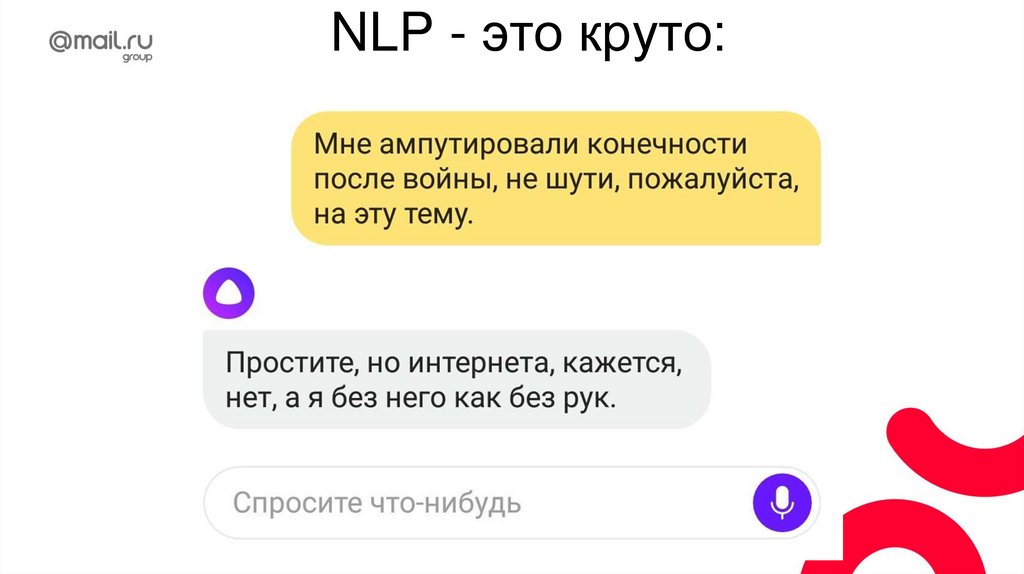
NLP - это круто:16.
NLP - это круто:• NER (распознавание именованных сущностей)
• Поиск
• Перевод
• Чат-боты
• Голосовые ассистенты
17.
NLP - это круто:Распознавание голоса
18.
NLP - это круто:NER (распознавание именованных сущностей)
Поиск
Перевод
Чат-боты
Голосовые ассистенты
Анализ тональности
19.
NLP - это круто:20.
NLP - это круто:Ключевая проблема обработки текстов - многозначность
21.
NLP - это круто:Ключевая проблема обработки текстов - многозначность
22.
NLP - это круто:Ключевая проблема обработки текстов - многозначность
23.
NLP - это круто:Многозначность:
Морфологическая: «мой», «три»
Фонетическая: «скрип колеса», «скрипка-лиса»
Лексическая: «рожа»
• Синтаксическая: «мужу изменять нельзя»
24.
• буквыТекст - уровни абстракции
• слова
• нграммы
• предложения
• параграфы
• документы
Все зависит от решаемой задачи
25.
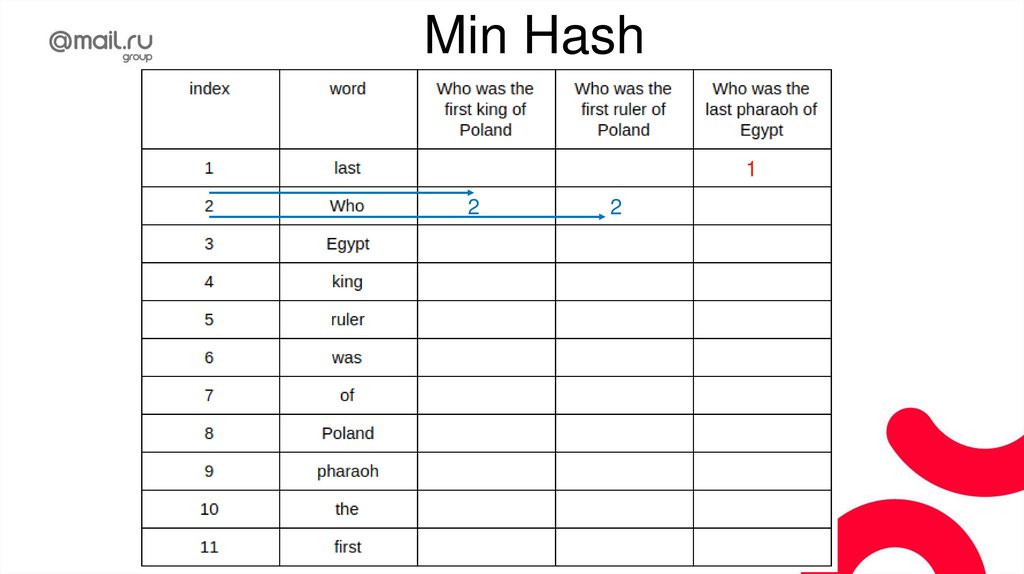
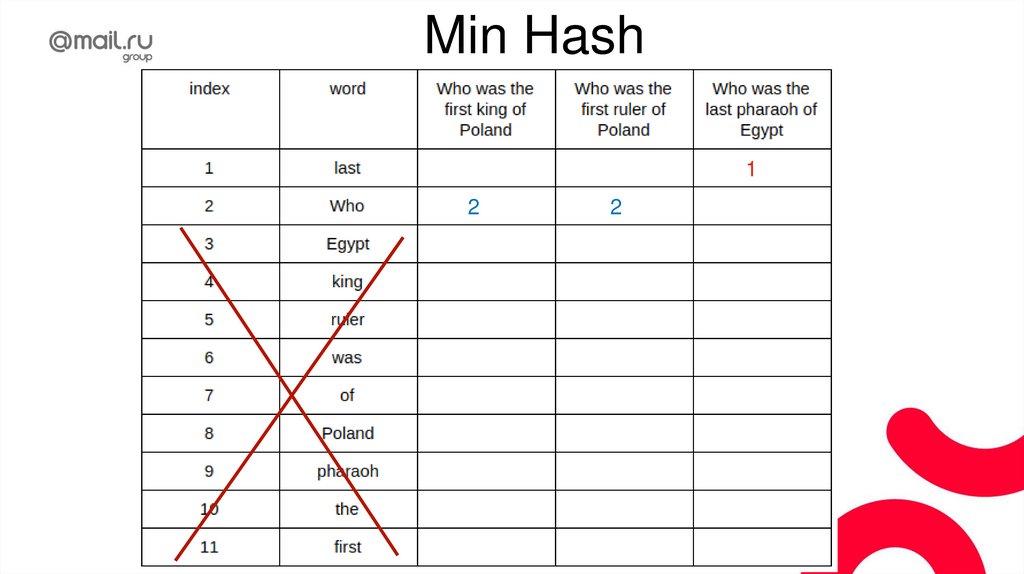
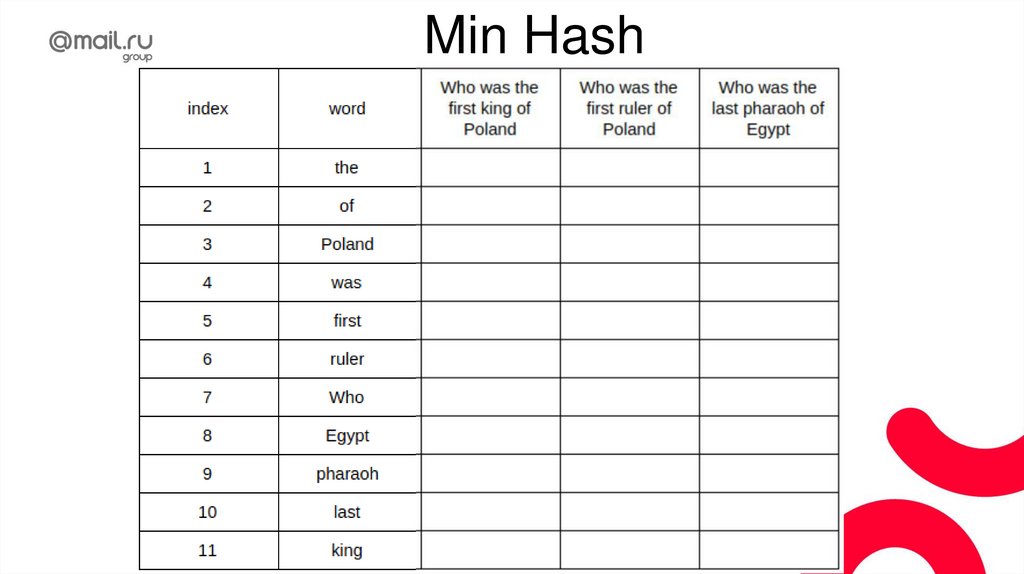
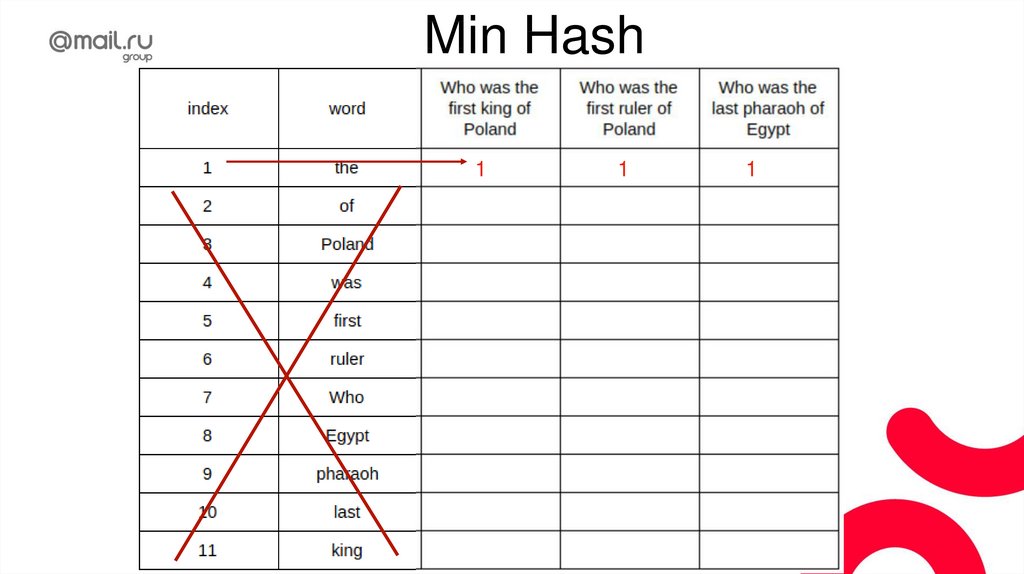
ТокенизацияТокенизация - разбиение текста на токены
(смысловые единицы), нужные для конкретной
задачи.
26.
ТокенизацияТокенизация - разбиение текста на токены
(смысловые единицы), нужные для конкретной
задачи.
То есть токенами могут быть слова, предложения,
параграфы, …
27.
Вначале было словоСлово - минимальный фрагмент текста,
имеющий смысловую значимость
28.
Вначале было словоСлово - минимальный фрагмент текста,
имеющий смысловую значимость
Нахождение границ слов - важная задача.
29.
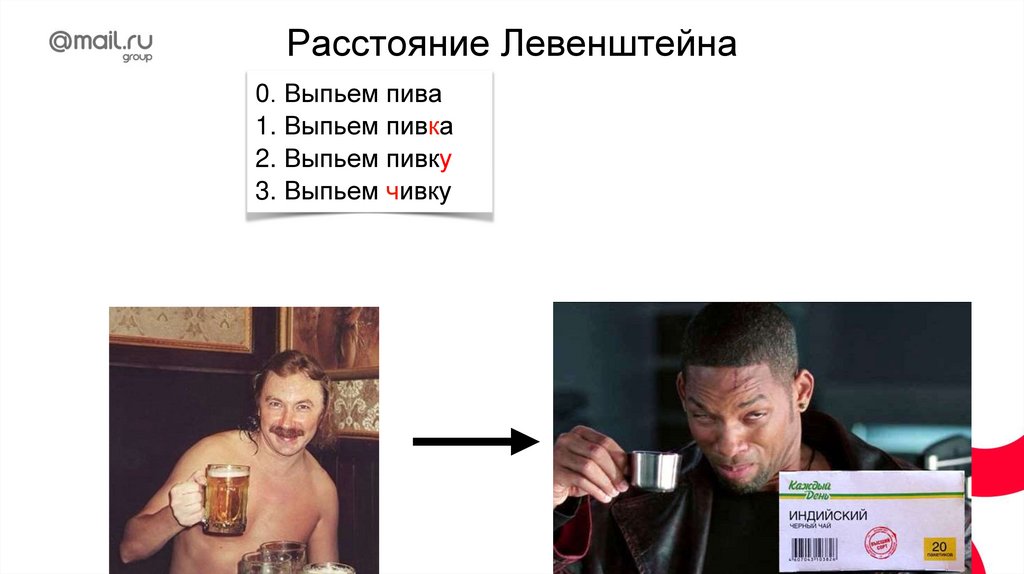
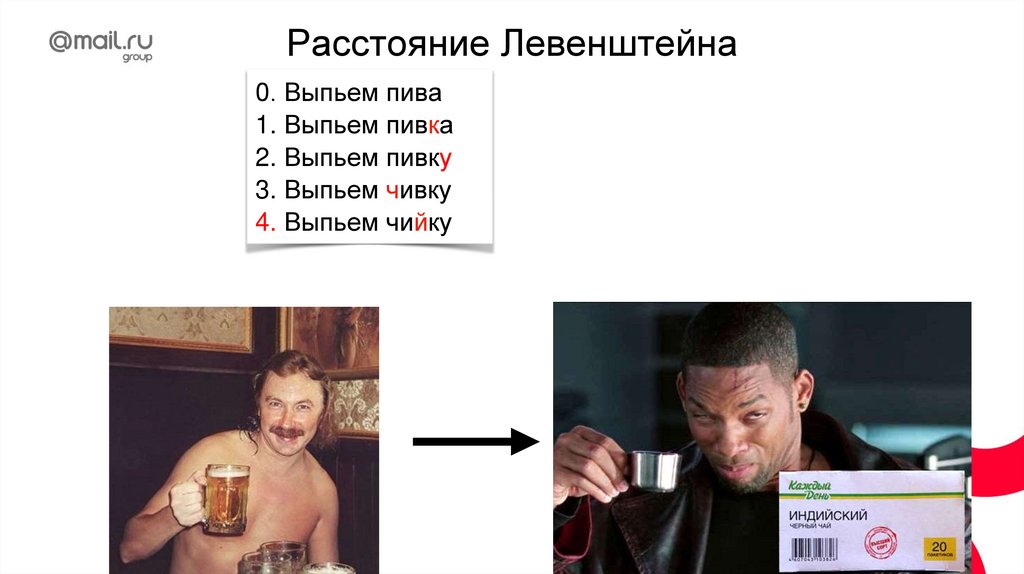
Нахождение границ слов«съешь ещё этих мягких французских булок да выпей чаю»
30.
Нахождение границ слов«съешь ещё этих мягких французских булок да выпей чаю»
words = line.split()
31.
Нахождение границ слов«съешь ещё этих мягких французских булок да выпей чаю»
words = line.split()
32.
Токенизация: особенности языка«Lebensversicherungsgesellschaftsangestellter»
«сотрудник страховой компании»
33.
Токенизация: особенности языка«Lebensversicherungsgesellschaftsangestellter»
«сотрудник страховой компании»
34.
Токенизация: особенности языка«Rindfleischetikettierungsüberwachungsaufgabenübertragungsgesetz»
« Закон о передаче обязанностей контроля маркировки говядины»
35.
Токенизация: особенности языка«Rindfleischetikettierungsüberwachungsaufgabenübertragungsgesetz»
« Закон о передаче обязанностей контроля маркировки говядины»
36.
Токенизация: особенности языка«Rindfleischetikettierungsüberwachungsaufgabenübertragungsgesetz»
« Закон о передаче обязанностей контроля маркировки говядины»
37.
Токенизация: особенности языка莎拉波娃现在居住在美国东南部的佛罗里达。
38.
Токенизация: особенности языка莎拉波娃现在居住在美国东南部的佛罗里达。
莎拉波娃 现在 居住 在 美国 东南部 的 佛罗里达
«Шарапова сейчас живет во Флориде, к юго-востоку от Соединенных Штатов.»
39.
Токенизация: особенности языка莎拉波娃现在居住在美国东南部的佛罗里达。
莎拉波娃 现在 居住 在 美国 东南部 的 佛罗里达
«Шарапова сейчас живет во Флориде, к юго-востоку от Соединенных Штатов.»
该死的 !!1!
他妈的中国 !!!
40.
Токенизация: пунктуацияFinland’s capital → Finland? Finlands? Finland’s ?
what’re, I’m, isn’t
L’ensemble → L? L’? Le?
9 a.m, i.e.
• Hewlett-Packard, Немирович-Данченко
San Francisco, Лос Анджелес, Нью-Васюки
Анализ твитов - эмоджи ( ;),
:( )
41.
Разбиение на предложенияНу ок, все ж просто: сегментируем по знакам препинания ( .?!)
42.
Разбиение на предложенияНу ок, все ж просто: сегментируем по знакам препинания ( .?!)
В связи с этим первый интервал
пробегов был принят равным
350...700 тыс. км. (середина
интервала - 525 тыс. км.), второй
интервал -- 700...1050 тыс. км.
(середина интервала - 875 тыс. км.)
и третий интервал 1050...1400 тыс.
км. (середина интервала -- 1225
тыс. км.).
43.
Разбиение на предложенияНу ок, все ж просто: сегментируем по знакам препинания ( .?!)
В связи с этим первый интервал
пробегов был принят равным
350...700 тыс. км. (середина
интервала - 525 тыс. км.), второй
интервал -- 700...1050 тыс. км.
(середина интервала - 875 тыс. км.)
и третий интервал 1050...1400 тыс.
км. (середина интервала -- 1225
тыс. км.).
44.
Эвристики• Предложение должно содержать буквы
• Предложение должно начинаться с заглавной буквы
• Сокращения (из списка) требуют «особого внимания»
• г., тыс., млн., ул., км., …
• Отдельные большие буквы: А.Б. Иванов
•…
45.
Эвристики• Предложение должно содержать буквы
• Предложение должно начинаться с заглавной буквы
• Сокращения (из списка) требуют «особого внимания»
• г., тыс., млн., ул., км., …
• Отдельные большие буквы: А.Б. Иванов
•…
Или можно взять и обучить модель
=)
46.
Нормализация47.
НормализацияСтемминг
48.
НормализацияСтемминг
Лемматизация
49.
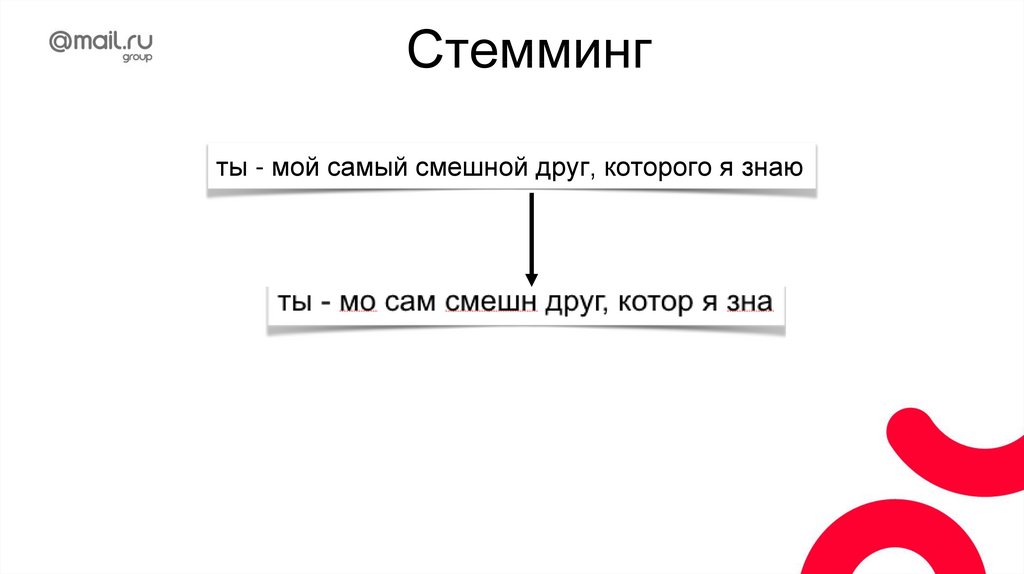
Стеммингты - мой самый смешной друг, которого я знаю
50.
Стеммингты - мой самый смешной друг, которого я знаю
51.
Стеммингты - мой самый смешной друг, которого я знаю
52.
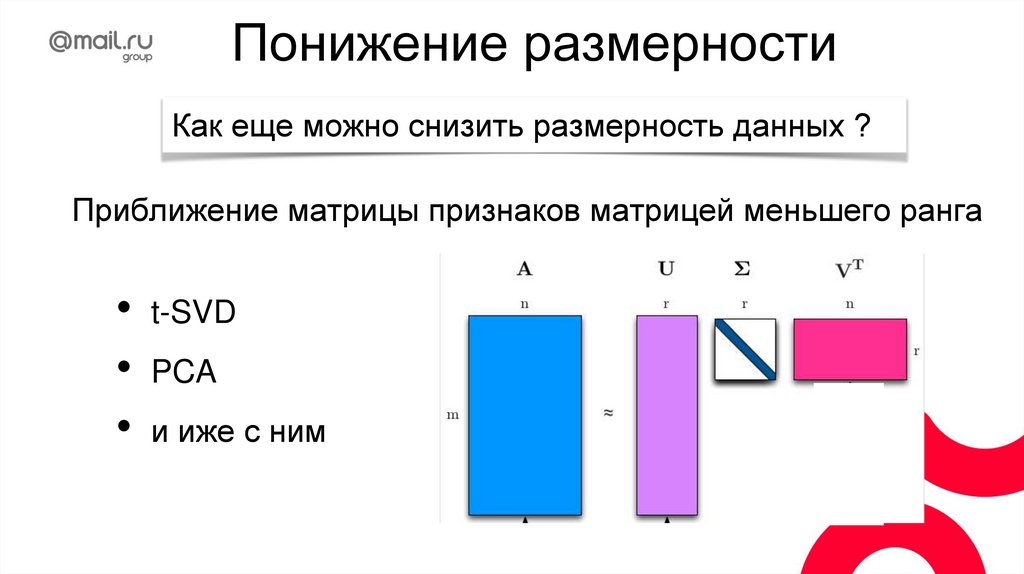
Стемминг: эвристикиИспользует правила для конкретного языка.
Примеры: Porter, Snowball stemmer
53.
В чем преимущество и недостаткистемминга?
снижение размерности пространства
• повышает полноту поиска
снижает точность (одинаковые стемы
разных слов)
Левый, левая, лев —> лев
54.
ЛемматизацияВ больничном дворе стоит небольшой флигель,
окруженный целым лесом репейника, крапивы и
дикой конопли.
В больничный двор стоять небольшой флигель
окружать целый лес репейник крапива и дикий
конопля
55.
Лемматизация56.
Грамматический разбор«Привет! как дела?»
Привет{привет=S,муж,неод=(им,ед|вин,ед)}
как{как=PART=|как=ADVPRO=|как=CONJ=}дела{дев
ать=V=прош,ед,изъяв,жен,сов|
дело=S,сред,неод=(им,мн|род,ед|вин,мн)}
строится на основе размеченного корпуса текстов
57.
Снятие омонимии«Косил косой косой косой за песчаной косой»
58.
Снятие омонимии«Косил косой косой косой за песчаной косой»
Что делать?
59.
Снятие омонимииПроизводится на основе частоты встречаемости,
вычисленной по размеченному корпусу текстов
60.
Снятие омонимииМожно обучить модель предсказывать POS-tag по контексту
61.
Снятие омонимииМожно обучить модель предсказывать POS-tag по контексту
«Ученый кот»: (AN) vs (NN)
«Великий ученый»: (AN) vs (AA)
«Прозрачного стекла»: (AN) vs (AA)
«Вода стекла»: (NV) vs (NN)
Например, используют Hidden Markov Models
62.
Языковые модели63.
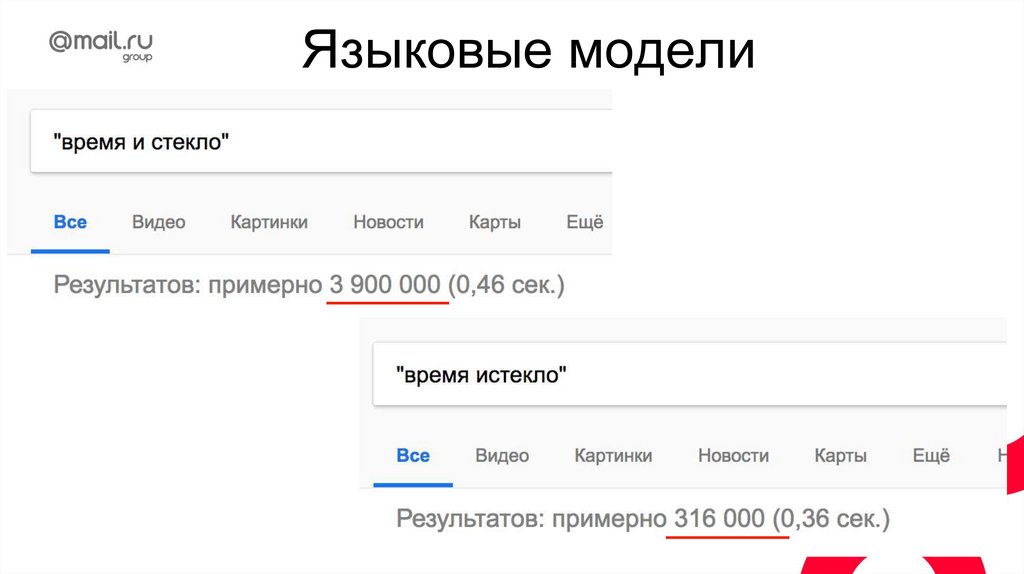
Языковые моделиПредсказание следующего слова (autocomplete)
- яблоко от яблони …
- это полная …
- выпил …
64.
Языковые моделиПредсказание следующего слова (autocomplete)
- яблоко от яблони …
- это полная …
- выпил …
- и
- стакан
- еще
- рюмку
- залпом
-с
- водки
- ее
- за
- две
- его
- чаю
- бы
309
192
138
120
86
82
69
66
66
63
52
43
42
65.
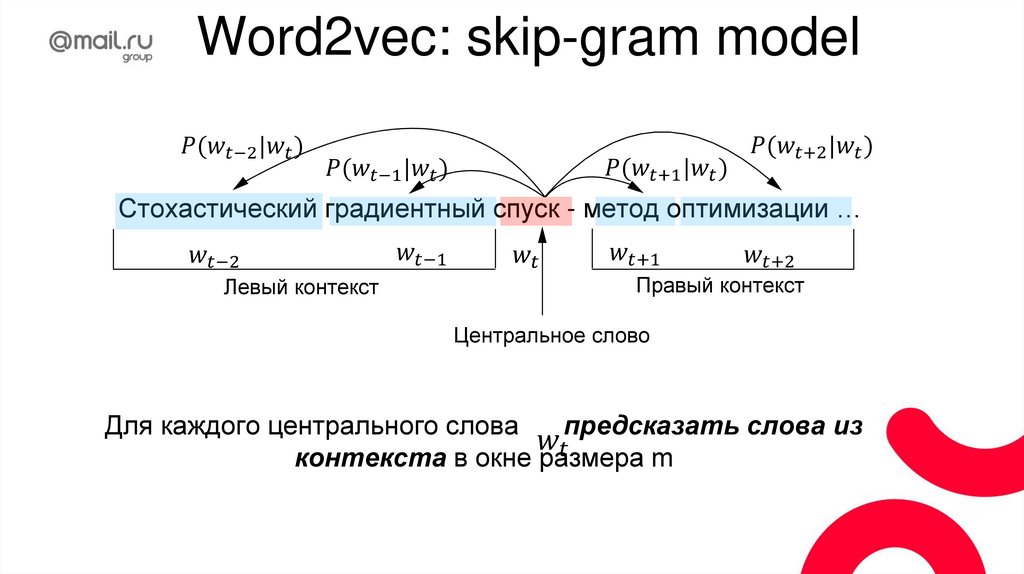
Языковые модели на основе n-граммНужно определить вероятность последовательности
P(S) = P(w1,w2,w3,…wn)
66.
Языковые модели на основе n-граммНужно определить вероятность последовательности
P(S) = P(w1,w2,w3,…wn) = P(w1) P(w2|w1) P(w3|w1,w2),…P(wn|w1,w2, …,wn-1 ),
67.
Языковые модели на основе n-граммНужно определить вероятность последовательности
P(S) = P(w1,w2,w3,…wn) = P(w1) P(w2|w1) P(w3|w1,w2),…P(wn|w1,w2, …,wn-1 ),
Ограничим влияние «истории»
(Марковский процесс):
68.
Языковые модели на основе n-граммНужно определить вероятность последовательности
P(S) = P(w1,w2,w3,…wn) = P(w1) P(w2|w1) P(w3|w1,w2),…P(wn|w1,w2, …,wn-1 ),
Ограничим влияние «истории»
-
(Марковский процесс):
униграммная модель: P(wn)
- биграммная модель: P(wn|wn-1)
- триграммная модель: P(wn|wn-1,wn-2)
69.
Языковые модели на основе n-граммНужно определить вероятность последовательности
P(S) = P(w1,w2,w3,…wn) = P(w1) P(w2|w1) P(w3|w1,w2),…P(wn|w1,w2, …,wn-1 ),
Ограничим влияние «истории»
-
(Марковский процесс):
униграммная модель: P(wn)
- биграммная модель: P(wn|wn-1)
- триграммная модель: P(wn|wn-1,wn-2)
70.
Языковые модели на основе n-грамм- моделируют локальные зависимости языка
- для n-грамм высоких порядков мало данных
71.
Языковые модели на основе n-грамм- моделируют локальные зависимости языка
- для n-грамм высоких порядков мало данных
Оценка вероятности