





















 Информатика
ИнформатикаПохожие презентации:










Признаковая модель текста
1.
Признаковая модельтекста
Грацианова Татьяна Юрьевна
Ефремова Наталья Эрнестовна
2.
ПовторениеАбсолютная частота Fai – число
употреблений i-ого объекта в совокупности
текстов T
Относительная частота Fri: Fri = Fai / N,
где N – общее количество объектов в T
Словоупотребление – единица текста
Словоформа – единица частотного списка
Слово – единица словаря
2
3.
Повторение. ПримерЭта страница красного цвета.
Красное солнце. Красное лето.
Красная площадь флаги полощет.
Количество словоупотреблений в тексте
(вхождений словоформ) – 12
Количество различных словоформ – 11
Количество различных слов (лексем) – 9
Faплощадь = 1
Faкрасное = 2
Faкрасный = 4
Frплощадь = 1 / 12 ≈ 0,08
Frкрасное = 2 / 12 ≈ 0,1(6)
Frкрасный = 4 / 12 ≈ 0,(3)
Что еще можем посчитать?
3
4.
Повторение.Практическая работа
Тест в moodle
«Тест лингвистические ресурсы и пр.»
Абсолютная частота Fai – число употреблений
i-ого объекта в совокупности текстов T
Относительная частота Fri: Fri = Fai / N, где
N – общее количество уникальных объектов в T
Словоупотребление – единица текста
Словоформа – единица частотного списка
Слово – единица словаря
4
5.
Доклад Дарьи Кавериной иИгоря Рожкова
6.
Доклад Алины Афраковой7.
Доклад Екатерины Ветровой8.
СодержаниеМоделирование в КЛ
Признаковая модель текста. Виды
признаков
Модель «мешок слов» и
моделирование коллекции текстов.
Способы задания весов
Достоинства и недостатки модели
8
9.
Моделирование в КЛМодель – абстрактное представление реальности
Моделирование – построение и изучение моделей с
целью получения объяснений и предсказаний
В КЛ различаются модели языка в целом и текста и,
как следствие, коллекции текстов
Модель языка отвечает на вопрос, насколько
данная фраза типична/правильна для языка
Модель текста/коллекции текстов – это
представление формы и содержания путем
освобождения от несущественных для целей
исследования деталей
На их основе создаются алгоритмы и прикладные
программы
9
10.
Признаковая модель текстаДля части прикладных задач КЛ (классификация/
кластеризация, извлечение информации и др.) не
требуется полного понимания смысла текста,
достаточно правильно описать его содержание
не нужна модель всего языка, подойдет модель
обрабатываемого текста
Модель текста позволяет сравнивать тексты друг с
другом и единообразно обрабатывать их коллекции
Долгое время наиболее распространенной и
практически значимой была признаковая модель, где
текст представляется как неупорядоченный набор
(множество) информационных признаков (features)
10
11.
Виды признаковЛингвистические признаки:
слова: обычно значимые, не служебные; реже –
контексты слов и словосочетания
N-граммы (шинглы)
Статистические признаки текста:
количество слов с большой буквы
доля различных частей речи в тексте
доля сложных предложений
средняя длина слова/предложения и т.д.
Экстралингвистические признаки:
тип документа, автор, заголовок
дата публикации, источник информации
гиперссылки и пр.
Как еще могут быть признаки?
11
12.
Модель «мешок слов»(Bag of Words, BOW)
Признаки – значимые слова текста (terms)
Не учитываются:
связи между словами
порядок слов в тексте
грамматические формы слов
Если имеется N текстов и каждый текст – набор
слов:
wj = (wj1, …, wjm), где
wji – вес i-ого слов в j-ом тексте
m – число слов в текстах
По сути, имеем вектор в m-мерном пространстве
Вес может просто отображать наличие или
отсутствие слова (wji = 0 или 1)
12
13.
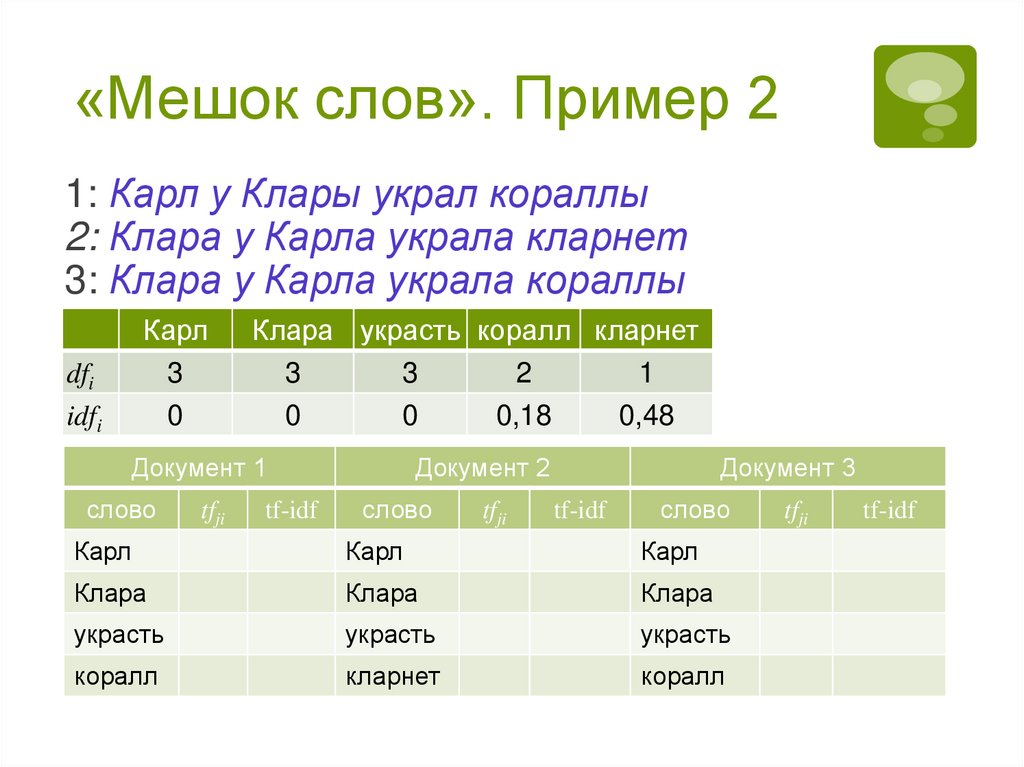
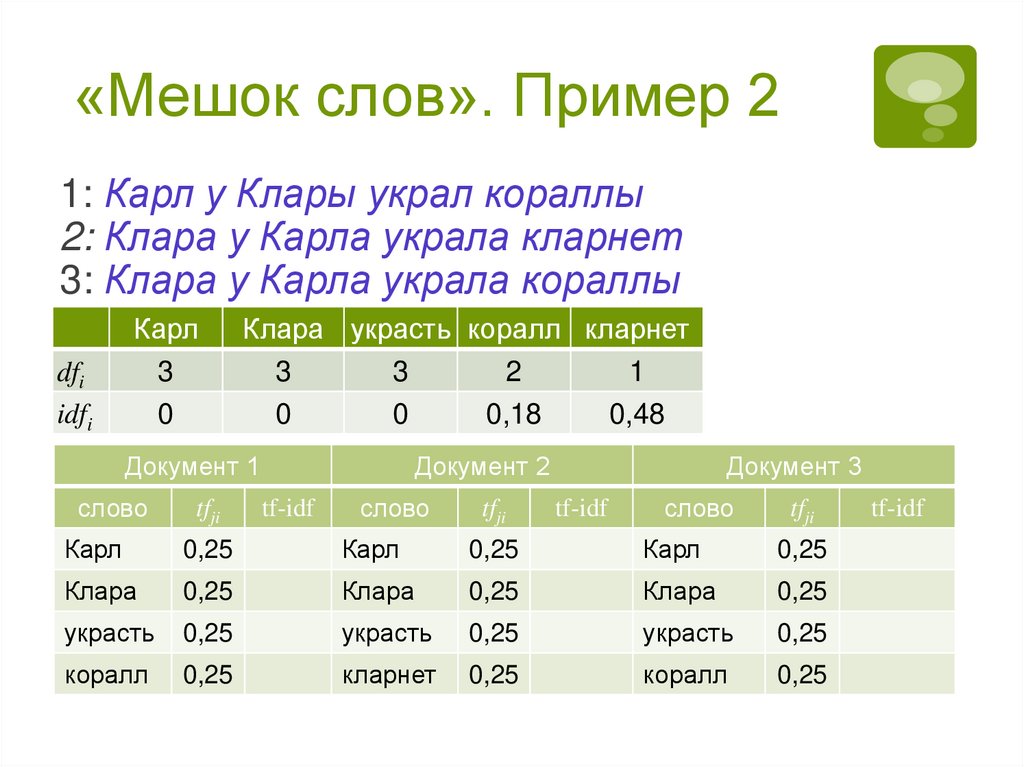
«Мешок слов». Пример 113
1: Карл у Клары украл кораллы
2: Клара у Карла украла кларнет
3: Клара у Карла украла кораллы
4: Простота – хуже воровства
Слова-признаки:
1Карл, 2Клара, 3украсть, 4коралл,
5кларнет, 6простота, 7хуже, 8воровство
Вес: присутствует признак в документе или нет
w1=
w2=
w3=
w4=
14.
«Мешок слов». Пример 114
1: Карл у Клары украл кораллы
2: Клара у Карла украла кларнет
3: Клара у Карла украла кораллы
4: Простота – хуже воровства
Слова-признаки:
1Карл, 2Клара, 3украсть, 4коралл,
5кларнет, 6простота, 7хуже, 8воровство
Вес: присутствует признак в документе или нет
w1=(1,1,1,1,0,0,0,0)
w2=(1,1,1,0,1,0,0,0)
w3=(1,1,1,1,0,0,0,0)
w4=(0,0,0,0,0,1,1,1)
15.
Задание весов признаковВ общем случае вес i-ого признака в j-ом тексте
задается следующим образом:
wji = lji gi nj, где
lji – локальный вес признака в тексте (например,
частота встречаемости i-ого признака в j-ом тексте)
gi – глобальный вес признака во всей коллекции
текстов (например, количество документов, в
которых признак встречается)
nj – нормирующий множитель для текста (например,
количество признаков в тексте)
Основой для задания весов обычно служит fji – частота
встречаемости i-ого признака в j-ом тексте
15
16.
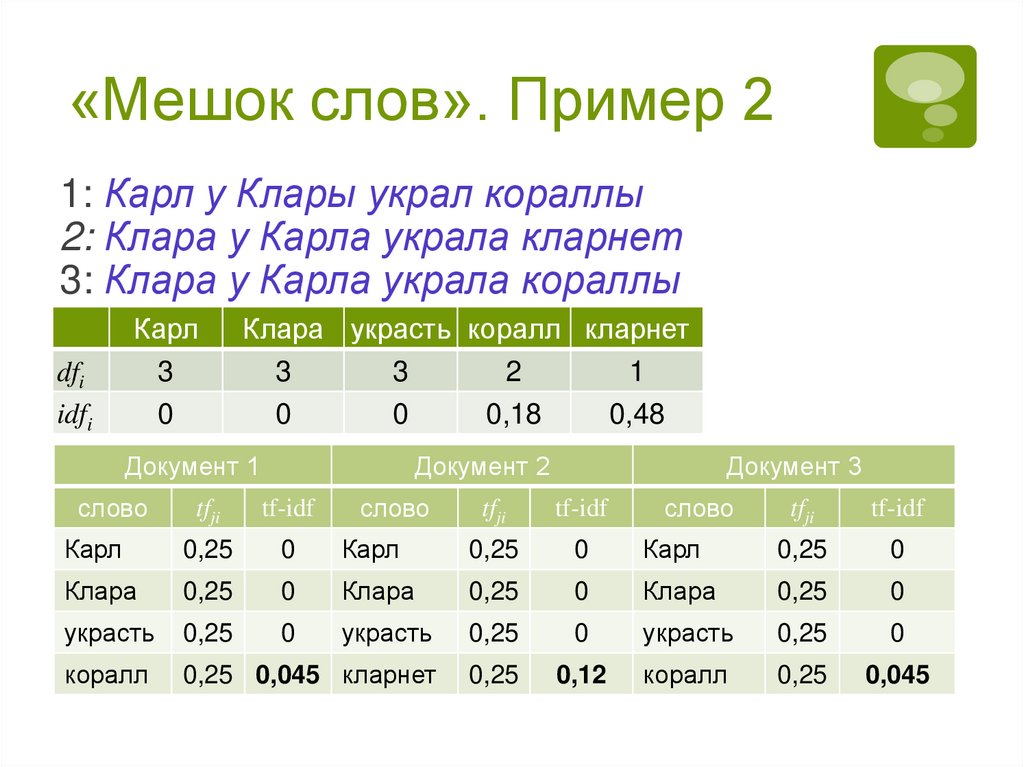
Задание весов признаков.Мера
tf-idf
16
Опирается на следующее предположение:
при обработке коллекции текстов частотные
признаки менее информативны, чем редкие
Веса частотных признаков должны быть ниже,
чем веса редких