























































































































 Программное обеспечение
Программное обеспечение Электроника
ЭлектроникаПохожие презентации:


")
")
")
")


")

Цифровая схемотехника и архитектура компьютера. Микроархитектура. (Глава 7)
1.
Глава 7Цифровая схемотехника и архитектура
компьютера, второе издание
Дэвид М. Харрис и Сара Л. Харрис
Глава 7 <1>
2.
Цифровая схемотехника и архитектура компьютераЭти слайды предназначены для преподавателей, которые читают
лекции на основе учебника «Цифровая схемотехника и
архитектура компьютера» авторов Дэвида Харриса и Сары
Харрис. Бесплатный русский перевод второго издания этого
учебника можно загрузить с сайта компании Imagination
Technologies:
https://community.imgtec.com/downloads/digital-design-andcomputer-architecture-russian-edition-second-edition
Процедура регистрации на сайте компании Imagination
Technologies описана на станице:
http://www.silicon-russia.com/2016/08/04/harris-and-harris-2/
Глава 7 <2>
3.
БлагодарностиПеревод данных слайдов на русский язык был выполнен командой
сотрудников университетов и компаний из России, Украины, США в составе:
Александр Барабанов - доцент кафедры компьютерной инженерии факультета радиофизики,
электроники и компьютерных систем Киевского национального университета имени Тараса
Шевченко, кандидат физ.-мат. наук, Киев, Украина;
Антон Брюзгин - начальник отдела АО «Вибро-прибор», Санкт-Петербург, Россия.
Евгений Короткий - доцент кафедры конструирования электронно-вычислительной аппаратуры
факультета электроники Национального технического университета Украины «Киевский
Политехнический Институт», руководитель открытой лаборатории электроники Lampa, кандидат
технических наук, Киев, Украина;
Евгения Литвинова – заместитель декана факультета компьютерной инженерии и управления,
доктор технических наук, профессор кафедры автоматизации проектирования вычислительной
техники Харьковского национального университета радиоэлектроники, Харьков, Украина;
Юрий Панчул - старший инженер по разработке и верификации блоков микропроцессорного
ядра в команде MIPS I6400, Imagination Technologies, отделение в Санта-Кларе, Калифорния, США;
Дмитрий Рожко - инженер-программист АО «Вибро-прибор», магистр Санкт-Петербургского
государственного автономного университета аэрокосмического приборостроения (ГУАП), СанктПетербург, Россия;
Владимир Хаханов – декан факультета компьютерной инженерии и управления, проректор по
научной работе, доктор технических наук, профессор кафедры автоматизации проектирования
вычислительной техники Харьковского национального университета радиоэлектроники, Харьков,
Украина;
Светлана Чумаченко – заведующая кафедрой автоматизации проектирования вычислительной
техники Харьковского национального университета радиоэлектроники, доктор технических наук,
профессор, Харьков, Украина.
Глава 7 <3>
4.
Глава 7 :: ТемыВведение
Анализ производительности
Однотактный процессор
Многотактный процессор
Конвейерный процессор
Исключения
Улучшение микроархитектуры
Глава 7 <4>
5.
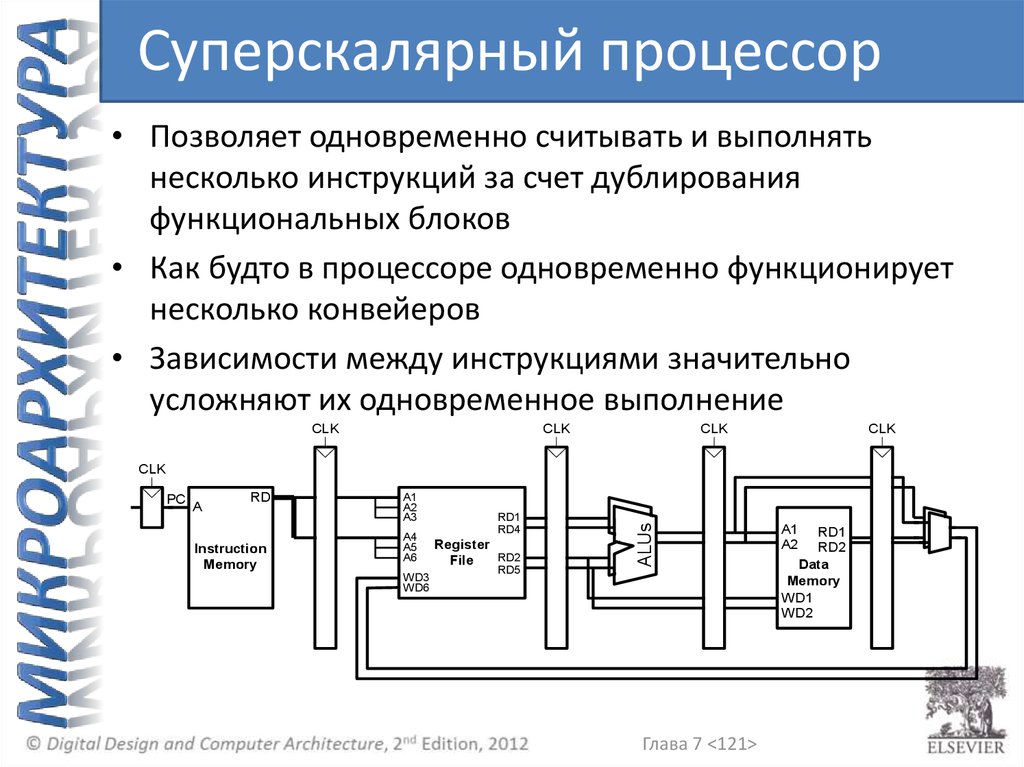
Введение• Микроархитектура:
аппаратная реализация
архитектуры в виде схемы
• Процессор:
– Тракт данных: функциональные
блоки обработки и передачи
данных (арифметико-логическое
устройство, регистровый файл,
мультиплексоры и т.д.)
– Устройство управления:
формирует управляющие
сигналы для функциональных
блоков
Глава 7 <5>
Application
Software
programs
Operating
Systems
device drivers
Architecture
instructions
registers
Microarchitecture
datapaths
controllers
Logic
adders
memories
Digital
Circuits
AND gates
NOT gates
Analog
Circuits
amplifiers
filters
Devices
transistors
diodes
Physics
electrons
6.
Микроархитектура• Несколько аппаратных реализаций одной
и той же архитектуры:
– Однотактная реализация: каждая
инструкция выполняется за один такт
– Многотактная реализация: каждая
инструкция разбивается на несколько шагов
и выполняется за несколько тактов
– Конвейерная реализация: каждая
инструкция разбивается на несколько шагов
и несколько инструкций выполняются
одновременно
Глава 7 <6>
7.
Производительность процессора• Время выполнения программы
Execution Time = (#instructions)(cycles/instruction)(seconds/cycle)
Время выполнения = (#инструкции)(такты/инструкция)(секунды/такт)
• Определения:
– CPI: Количество тактов на выполнение инструкции
(Cycles/instruction)
– Период тактовой частоты: секунды/такт
– IPC: Количество инструкций выполняемых за такт
(instructions/cycle = IPC = 1 / CPI)
• Необходимо удовлетворять следующие
ограничения:
–
–
–
–
Стоимость
Площадь на кристалле
Энергопотребление
Производительность
Глава 7 <7>
8.
MIPS процессор• Будем рассматривать подмножество
инструкций MIPS:
– Инструкции R-типа: and, or, add, sub, slt
– Инструкции работы с памятью: lw, sw
– Инструкции переходов: beq, j
Глава 7 <8>
9.
Архитектурное состояние• Определяется:
– Содержимым счетчика команд (PC)
– Содержимым 32-х регистров общего
назначения
– Содержимым памяти
Глава 7 <9>
10.
Элементы, хранящие состояние MIPSCLK
CLK
PC'
PC
32
32
32
A
RD
Instruction
Memory
5
32
5
5
32
A1
A2
A3
WD3
CLK
WE3
RD1
RD2
WE
32
32
Register
File
Глава 7 <10>
32
32
A
RD
Data
Memory
WD
32
11.
Однотактный MIPS процессор• Тракт данных
• Устройство управления
Глава 7 <11>
12.
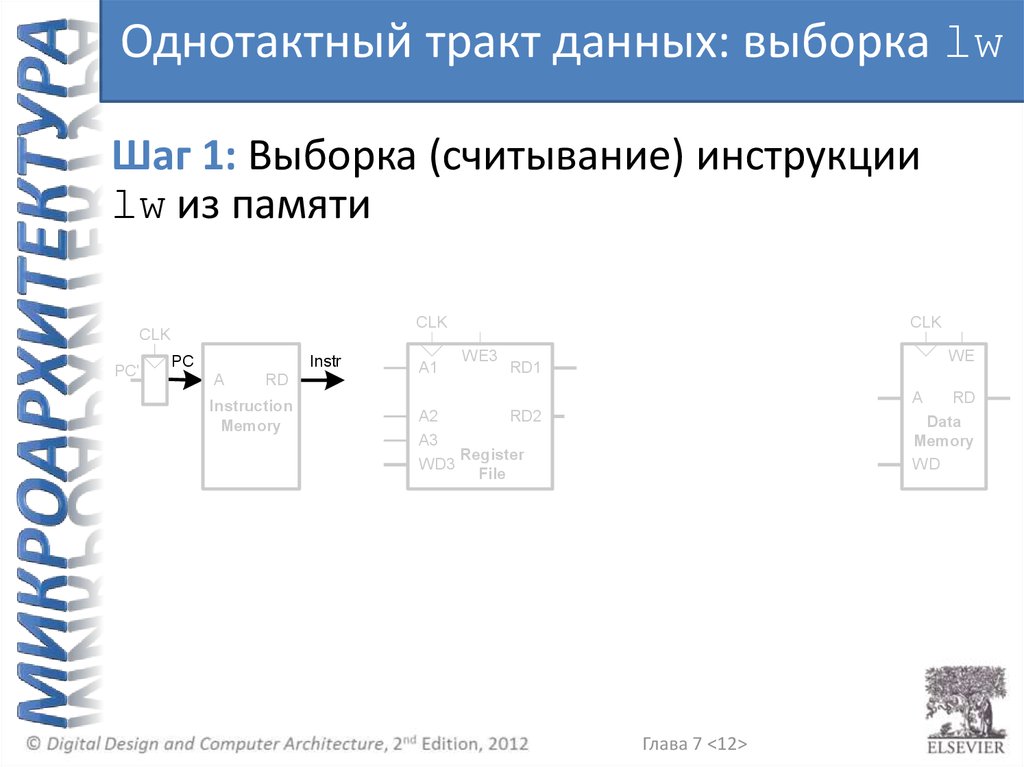
Однотактный тракт данных: выборка lwШаг 1: Выборка (считывание) инструкции
lw из памяти
CLK
CLK
PC'
PC
Instr
A
RD
Instruction
Memory
A1
CLK
WE3
WE
RD1
A
A2
A3
WD3
RD
Data
Memory
WD
RD2
Register
File
Глава 7 <12>
13.
Однотактный тракт данных: чтение регистровШаг 2: считывание операндов-источников
из регистрового файла
CLK
CLK
CLK
25:21
PC'
PC
A
RD
WE
RD1
A
Instruction
Memory
A2
A3
WD3
lw
WE3
A1
Instr
RD
Data
Memory
WD
RD2
Register
File
rt, imm(rs)
I-Type
op
6 bits
rs
5 bits
rt
imm
5 bits
16 bits
Глава 7 <13>
14.
Однотактный тракт данных: расширение константыШаг 3: расширение 16-битной константы
до 32-х разрядов битом знака
CLK
CLK
PC'
PC
A
RD
Instr
25:21
A1
CLK
WE3
WE
RD1
A
Instruction
Memory
A2
A3
WD3
RD
Data
Memory
WD
RD2
Register
File
SignImm
15:0
Sign Extend
Глава 7 <14>
15.
Однотактный тракт данных: вычисление адресаШаг 4: Вычисление адреса ячейки в
памяти
ALUControl2:0
PC
A
RD
Instr
25:21
Instruction
Memory
A1
A2
A3
WD3
WE3
RD2
SrcB
Register
File
SignImm
15:0
CLK
Zero
SrcA
RD1
ALU
PC'
010
CLK
CLK
Sign Extend
Глава 7 <15>
ALUResult
WE
A
RD
Data
Memory
WD
16.
Однотактный тракт данных: считывание из памяти• Шаг 5: считываем данные из памяти и записываем их
в регистр, номер которого хранится в коде инструкции
RegWrite
ALUControl2:0
1
PC
A
RD
Instruction
Memory
Instr
25:21
20:16
A1
A2
A3
WD3
CLK
WE3
Zero
SrcA
RD1
RD2
ALU
PC'
010
CLK
CLK
SrcB
ALUResult
Register
File
WE
A
RD
Data
Memory
WD
SignImm
15:0
Sign Extend
I-Type
lw
rt, imm(rs)
op
6 bits
rs
5 bits
rt
imm
5 bits
16 bits
Глава 7 <16>
ReadData
17.
Однотактный тракт данных: увеличение PCШаг 6: Вычисляем адрес следующей
инструкции
RegWrite
ALUControl2:0
1
PC
A
RD
Instr
Instruction
Memory
25:21
A1
A2
20:16
A3
+
WD3
CLK
WE3
Zero
SrcA
RD1
RD2
SrcB
ALU
CLK
PC'
010
CLK
ALUResult
Register
File
WE
A
RD
Data
Memory
WD
ReadData
PCPlus4
SignImm
4
15:0
Sign Extend
Result
Глава 7 <17>
18.
Однотактный тракт данных: swЗапись содержимого регистра rt в память
RegWrite
ALUControl2:0
0
010
1
CLK
PC
A
RD
Instr
Instruction
Memory
25:21
A1
WE3
A2
20:16
A3
Zero
SrcA
RD1
20:16
WD3
+
CLK
RD2
SrcB
ALU
CLK
PC'
MemWrite
WE
ALUResult
WriteData
Register
File
A
RD
Data
Memory
WD
ReadData
PCPlus4
SignImm
4
15:0
Sign Extend
Result
I-Type
sw
rt, imm(rs)
op
6 bits
rs
5 bits
rt
imm
5 bits
16 bits
Глава 7 <18>
19.
Однотактный тракт данных: R-Тип• Считываем операнды из регистров rs и rt
• Записываем ALUResult в регистр с номером из поля rd
инструкции (для инструкций I-типа результат записывается
в регистр с номером rt)
RegWrite
RegDst
1
1
0
A
RD
Instr
Instruction
Memory
25:21
20:16
CLK
WE3
A1
A2
0 SrcB
RD2
A3
WD3
1
Register
File
20:16
+
ALUResult
WriteData
MemtoReg
0
0
WE
A
RD
Data
Memory
WD
ReadData
0
1
0
15:11
WriteReg4:0
PCPlus4
Zero
SrcA
RD1
ALU
PC
MemWrite
varies
CLK
CLK
PC'
ALUSrc ALUControl2:0
1
SignImm
4
15:0
Sign Extend
Result
R-Type
op
6 bits
rs
5 bits
rt
rd
shamt
funct
5 bits
5 bits
5 bits
6 bits
Глава 7 <19>
20.
Однотактный тракт данных: beq• Проверяем на равенство регистры rs и rt
• Рассчитываем адрес для условного перехода:
BTA = (sign-extended immediate << 2) + (PC+4)
PCSrc
RegWrite
RegDst
0
110
PC
1
A
RD
Instr
Instruction
Memory
25:21
20:16
A1
A2
A3
WD3
WE3
RD2
0 SrcB
1
Register
File
+
MemtoReg
x
0
WE
ALUResult
WriteData
A
RD
Data
Memory
WD
ReadData
0
1
0
15:11
WriteReg4:0
PCPlus4
1
SignImm
Sign Extend
<<2
+
15:0
Zero
SrcA
RD1
20:16
4
MemWrite
1
CLK
ALU
PC'
0
CLK
CLK
0
ALUSrc ALUControl2:0 Branch
x
PCBranch
Result
Assembly Code
Field Values
op
beq $t0, $0, else
(beq $t0, $0, 3)
rs
4
6 bits
rt
8
5 bits
imm
0
5 bits
3
5 bits
5 bits
6 bits
Глава 7 <20>
21.
Однотактный процессор31:26
5:0
MemtoReg
Control
MemWrite
Unit
Branch
ALUControl2:0
Op
ALUSrc
Funct
RegDst
PCSrc
RegWrite
CLK
PC'
PC
1
A
RD
Instr
Instruction
Memory
25:21
20:16
A1
A2
A3
WD3
WE3
RD2
0 SrcB
1
Register
File
20:16
+
WriteReg4:0
15:0
WriteData
A
RD
Data
Memory
WD
ReadData
0
1
1
SignImm
4
ALUResult
WE
0
15:11
PCPlus4
Zero
SrcA
RD1
ALU
0
CLK
Sign Extend
<<2
+
CLK
PCBranch
Result
Глава 7 <21>
22.
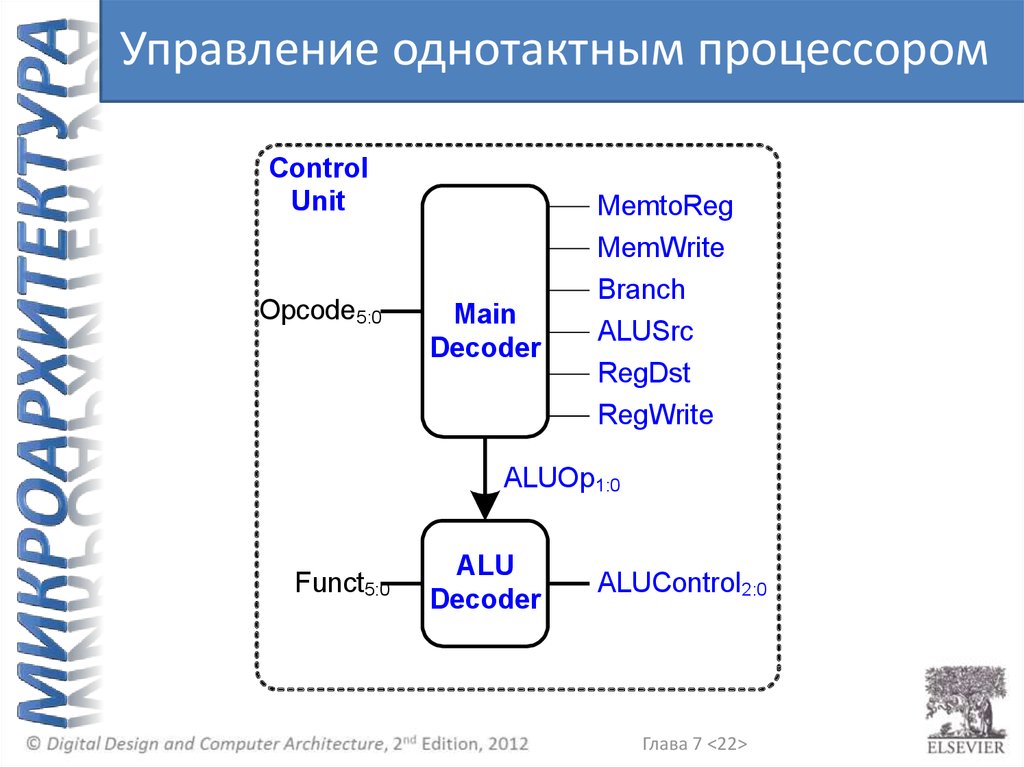
Управление однотактным процессоромControl
Unit
MemtoReg
MemWrite
Opcode5:0
Main
Decoder
Branch
ALUSrc
RegDst
RegWrite
ALUOp1:0
Funct5:0
ALU
Decoder
ALUControl2:0
Глава 7 <22>
23.
Вспомним принцип работы АЛУA
B
N
N
ALU
N
Y
F
3
F2:0
Функция
000
A&B
001
A|B
010
A+B
011
Не исп.
100
A & ~B
101
A | ~B
110
A-B
111
SLT
Глава 7 <23>
24.
Вспомним принцип работы АЛУA
B
N
N
N
0
1
F2
N
Cout
+
[N-1] S
Zero
Extend
N
N
N
N
0
1
2
3
2
F1:0
N
Y
Глава 7 <24>
25.
Управляющее устройство: Дешифратор АЛУALUOp1:0
Действие
00
Сложение
01
Вычитание
10
Определяется полем Funct
11
Не используется
ALUOp1:0 Funct
ALUControl2:0
00
X
010 (Сложение)
X1
110 (Вычитание)
1X
X
100000 (add)
1X
100010 (sub)
110 (Вычитание)
1X
100100 (and)
000 (И)
1X
100101 (or)
001 (ИЛИ)
1X
101010 (slt)
111 (SLT)
010 (Сложение)
Глава 7 <25>
26.
Управляющее устройство: основной дешифраторInstruction
Op5:0
RegWrite
R-type
000000
lw
100011
sw
101011
beq
000100
31:26
5:0
RegDst
AluSrc
Branch
MemtoReg
Control
MemWrite
Unit
Branch
ALUControl2:0
Op
ALUSrc
Funct
RegDst
MemWrite
MemtoReg
PCSrc
RegWrite
CLK
PC'
PC
1
A
RD
Instr
Instruction
Memory
25:21
20:16
A1
A2
A3
WD3
SrcA
RD1
RD2
0 SrcB
1
Register
File
20:16
+
WriteReg4:0
15:0
WriteData
A
RD
Data
Memory
WD
ReadData
0
1
1
SignImm
4
ALUResult
WE
0
15:11
PCPlus4
Zero
ALU
0
CLK
WE3
Sign Extend
<<2
+
CLK
PCBranch
Result
Глава 7 <26>
ALUOp1:0
27.
Управляющее устройство: основной дешифраторInstruction
Op5:0
RegWrite
RegDst
AluSrc
Branch
MemWrite
MemtoReg
ALUOp1:0
R-type
000000
1
1
0
0
0
0
10
lw
100011
1
0
1
0
0
0
00
sw
101011
0
X
1
0
1
X
00
beq
000100
0
X
0
1
0
X
01
31:26
5:0
MemtoReg
Control
MemWrite
Unit
Branch
ALUControl2:0
Op
ALUSrc
Funct
RegDst
PCSrc
RegWrite
CLK
PC'
PC
1
A
RD
Instr
Instruction
Memory
25:21
20:16
A1
A2
A3
WD3
WE3
RD2
0 SrcB
1
Register
File
20:16
+
WriteReg4:0
15:0
WriteData
WE
A
RD
Data
Memory
WD
ReadData
0
1
1
SignImm
4
ALUResult
0
15:11
PCPlus4
Zero
SrcA
RD1
ALU
0
CLK
Sign Extend
<<2
+
CLK
PCBranch
Result
Глава 7 <27>
28.
Однотактный тракт данных: or31:26
5:0
MemtoReg
Control
MemWrite
Unit
Branch
ALUControl2:0
Op
ALUSrc
Funct
RegDst
0
PCSrc
RegWrite
0
CLK
CLK
PC'
PC
1
A
RD
Instr
25:21
WE3
A1
CLK
1
001
SrcA
RD1
0
Instruction
Memory
20:16
A2
RD2
A3
WD3
0 SrcB
1
Register
File
+
WriteReg4:0
WriteData
A
RD
Data
Memory
WD
ReadData
0
1
1
SignImm
Sign Extend
<<2
+
15:0
ALUResult
0
WE
0
15:11
4
Zero
0
1
20:16
PCPlus4
ALU
0
PCBranch
Result
R-Type
op
6 bits
rs
5 bits
rt
rd
shamt
funct
5 bits
5 bits
5 bits
6 bits
Глава 7 <28>
29.
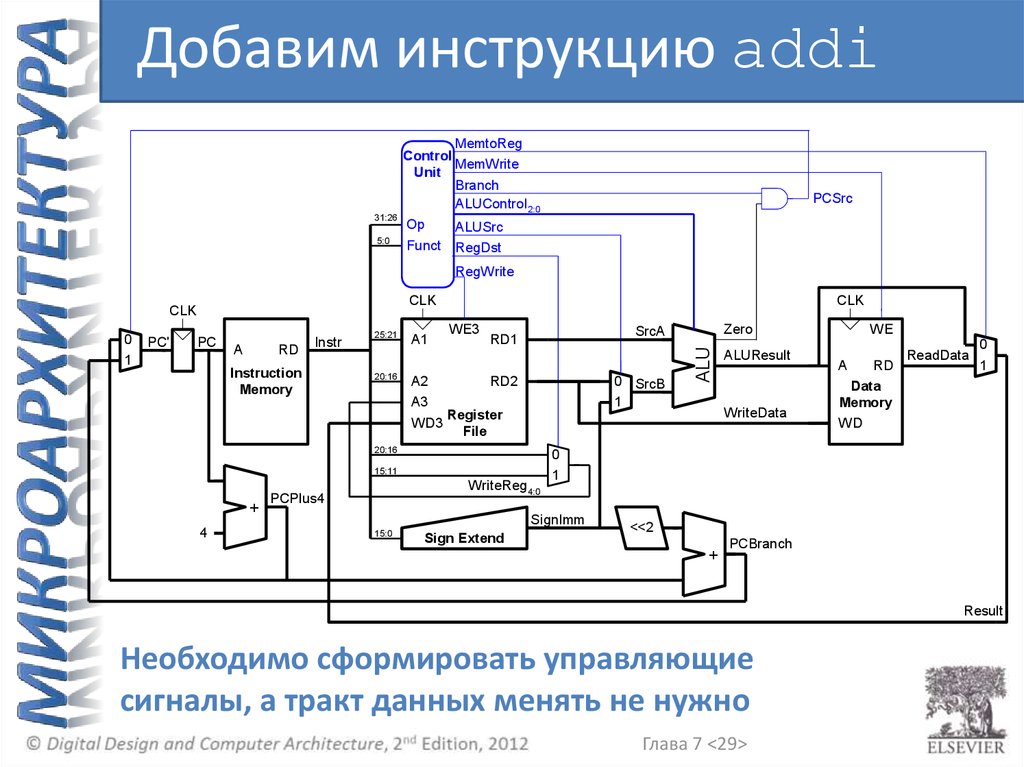
Добавим инструкцию addi31:26
5:0
MemtoReg
Control
MemWrite
Unit
Branch
ALUControl2:0
Op
ALUSrc
Funct
RegDst
PCSrc
RegWrite
CLK
0
PC'
PC
1
A
RD
Instr
Instruction
Memory
25:21
20:16
A1
A2
A3
WD3
CLK
WE3
RD2
0 SrcB
1
Register
File
20:16
+
WriteReg4:0
Sign Extend
RD
Data
Memory
WD
0
1
<<2
+
15:0
WriteData
A
ReadData
1
SignImm
4
ALUResult
WE
0
15:11
PCPlus4
Zero
SrcA
RD1
ALU
CLK
PCBranch
Result
Необходимо сформировать управляющие
сигналы, а тракт данных менять не нужно
Глава 7 <29>
30.
Управляющее устройство: addiInstruction
Op5:0
RegWrite
RegDst
AluSrc
Branch
MemWrite
MemtoReg
ALUOp1:0
R-type
000000
1
1
0
0
0
0
10
lw
100011
1
0
1
0
0
1
00
sw
101011
0
X
1
0
1
X
00
beq
000100
0
X
0
1
0
X
01
addi
001000
Глава 7 <30>
31.
Управляющее устройство: addiInstruction
Op5:0
RegWrite
RegDst
AluSrc
Branch
MemWrite
MemtoReg
ALUOp1:0
R-type
000000
1
1
0
0
0
0
10
lw
100011
1
0
1
0
0
1
00
sw
101011
0
X
1
0
1
X
00
beq
000100
0
X
0
1
0
X
01
addi
001000
1
0
1
0
0
0
00
Глава 7 <31>
32.
Добавим функционала: jJump
31:26
5:0
MemtoReg
Control
MemWrite
Unit
Branch
ALUControl2:0
Op
Funct
PCSrc
ALUSrc
RegDst
RegWrite
CLK
0
1
0
1
PC'
PC
A
RD
Instr
Instruction
Memory
25:21
20:16
A1
A2
A3
WD3
CLK
WE3
RD2
0 SrcB
1
Register
File
20:16
PCJump
+
15:11
WriteReg4:0
PCPlus4
Sign Extend
WriteData
<<2
+
15:0
ALUResult
0
1
SignImm
4
Zero
SrcA
RD1
ALU
CLK
27:0
PCBranch
31:28
25:0
<<2
Глава 7 <32>
WE
A
RD
Data
Memory
WD
ReadData
0 Result
1
33.
Управляющее устройство: jInstruction
Op5:0
R-type 000000
RegWrite
RegDst
AluSrc
Branch
MemWrite
MemtoReg
ALUOp1:0
Jump
1
1
0
0
0
0
10
0
lw
100011
1
0
1
0
0
1
00
0
sw
101011
0
X
1
0
1
X
00
0
beq
000100
0
X
0
1
0
X
01
0
j
000100
Глава 7 <33>
34.
Управляющее устройство: jInstruction
Op5:0
R-type 000000
RegWrite
RegDst
AluSrc
Branch
MemWrite
MemtoReg
ALUOp1:0
Jump
1
1
0
0
0
0
10
0
lw
100011
1
0
1
0
0
1
00
0
sw
101011
0
X
1
0
1
X
00
0
beq
000100
0
X
0
1
0
X
01
0
j
000100
0
X
X
X
0
X
XX
1
Глава 7 <34>
35.
Вернемся к вопросу производительностиВремя выполнения программы
= (#инструкции)(такты/инструкция)(секунды/такт)
= # инструкции x CPI x TC
Глава 7 <35>
36.
Производительность однотактного процессора31:26
5:0
MemtoReg
Control
MemWrite
Unit
Branch
ALUControl 2:0
0
0
PCSrc
Op
ALUSrc
Funct RegDst
RegWrite
0
PC'
PC
1
A
RD
Instr
Instruction
Memory
25:21
A1
CLK
1
WE3
010
SrcA
RD1
1
20:16
A2
A3
WD3
RD2
0 SrcB
1
Register
File
+
WriteReg4:0
WriteData
1
A
RD
Data
Memory
WD
ReadData
0
1
1
SignImm
Sign Extend
<<2
+
15:0
ALUResult
0
WE
0
15:11
4
Zero
0
20:16
PCPlus4
ALU
CLK
CLK
PCBranch
Result
CPI = 1
TC определяется цепью с наибольшей задержкой (lw)
Глава 7 <36>
37.
Производительность однотактного процессора• Задержка самой длинной цепи
комбинационной логики:
Tc = tpcq_PC + tmem + max(tRFread, tsext + tmux) + tALU +
tmem + tmux + tRFsetup
• Обычно на длительность периода
больше всего влияют:
– память, АЛУ, регистровый файл
– Tc = tpcq_PC + 2tmem + tRFread + tmux + tALU + tRFsetup
Глава 7 <37>
38.
Посчитаем производительностьоднотактного процессора
Параметр
Обозначение Задержка (пс)
Время записи в регистр tpcq_PC
30
Время предустановки
регистра
tsetup
20
Задержка
мультиплексора
tmux
25
Задержка АЛУ
tALU
200
Задержка считывания
из памяти
tmem
250
Задержка считывания
из регистрового файла
tRFread
150
Время предустановки
регистрового файла
tRFsetup
20
Tc = ?
Глава 7 <38>
39.
Посчитаем производительностьоднотактного процессора
Параметр
Обозначение
Задержка (пс)
Время записи в регистр
tpcq_PC
30
Время предустановки
регистра
tsetup
20
Задержка мультиплексора
tmux
25
Задержка АЛУ
tALU
200
Задержка считывания из
памяти
tmem
250
Задержка считывания из
регистрового файла
tRFread
150
Время предустановки
регистрового файла
tRFsetup
20
Tc = tpcq_PC + 2tmem + tRFread + tmux + tALU + tRFsetup
= [30 + 2(250) + 150 + 25 + 200 + 20] пс
= 925 пс
Глава 7 <39>
40.
Посчитаем производительностьоднотактного процессора
Предположим, в программе 100 миллиардов
инструкций:
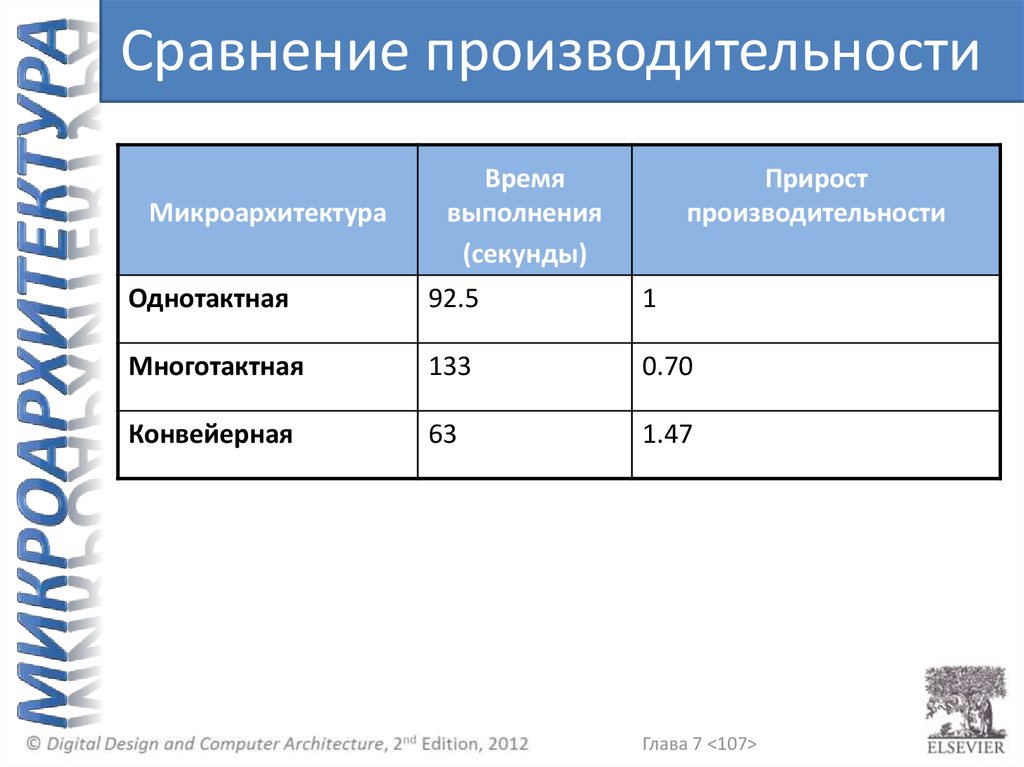
Время выполнения = # инструкции x CPI x TC
= (100 × 109)(1)(925 × 10-12 с)
= 92.5 секунд
Глава 7 <40>
41.
Многотактный MIPS процессор• Однотактный:
+ Простой
- Период тактовой частоты ограничен инструкцией с
самой длинной цепью комбинационной логики (lw)
- Несколько сумматоров & 2 отдельных памяти
• Многотактный:
+ Выше тактовая частота
+ Простые инструкции выполняются быстрее (за
меньше тактов)
+ Повторное использование аппаратурных ресурсов в
разных тактах
- Значительно усложняется устройство управления
• Этапы разработки: тракт данных и устройство
управления
Глава 7 <41>
42.
Элементы хранящие состояние многотактногопроцессора
• Вместо отдельной памяти для инструкций и данных
будем использовать одну общую память
CLK
CLK
PC'
PC
EN
A
CLK
WE
RD
Instr / Data
Memory
A1
A2
A3
WD
WD3
WE3
RD1
RD2
Register
File
Глава 7 <42>
43.
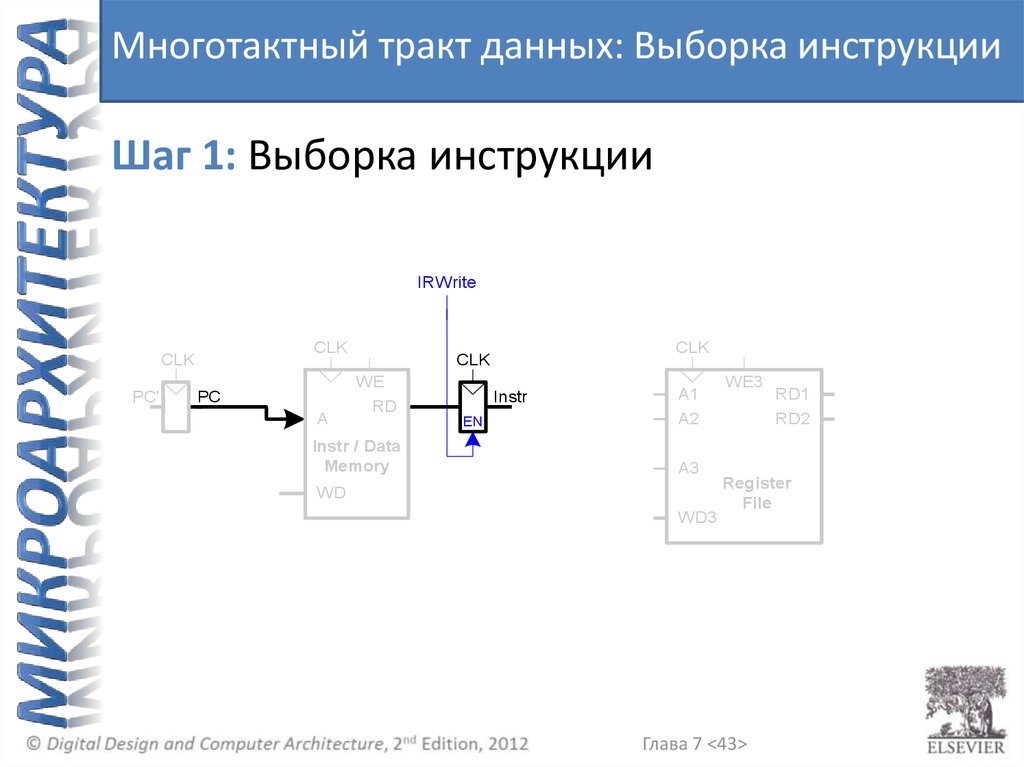
Многотактный тракт данных: Выборка инструкцииШаг 1: Выборка инструкции
IRWrite
CLK
CLK
CLK
CLK
WE
PC'
b
PC
A
Instr
RD
Instr / Data
Memory
EN
A1
WE3
A2
A3
WD
WD3
RD1
RD2
Register
File
Глава 7 <43>
44.
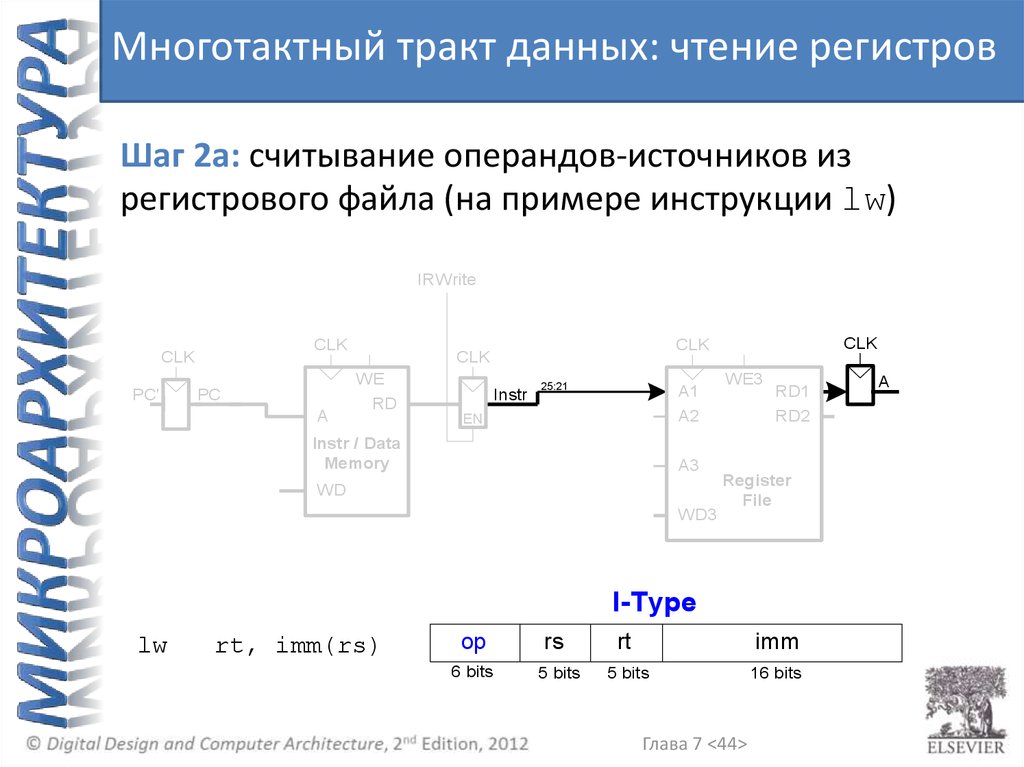
Многотактный тракт данных: чтение регистровШаг 2a: считывание операндов-источников из
регистрового файла (на примере инструкции lw)
IRWrite
CLK
CLK
WE
PC'
b
PC
A
Instr
RD
CLK
CLK
CLK
25:21
A1
WE3
A2
EN
Instr / Data
Memory
A3
WD
WD3
RD1
RD2
Register
File
I-Type
lw
rt, imm(rs)
op
6 bits
rs
5 bits
rt
imm
5 bits
16 bits
Глава 7 <44>
A
45.
Многотактный тракт данных: расширениеконстанты
Шаг 2b: расширение 16-битной константы
до 32-х разрядов битом знака
IRWrite
CLK
CLK
WE
PC'
b
PC
A
Instr
RD
CLK
CLK
CLK
25:21
A1
WE3
A2
EN
Instr / Data
Memory
A3
WD
WD3
RD1
A
RD2
Register
File
SignImm
15:0
Sign Extend
Глава 7 <45>
46.
Многотактный тракт данных: вычисление адресаШаг 3: Вычисление адреса ячейки в
памяти
IRWrite
WE
PC'
b
PC
A
Instr
RD
CLK
CLK
CLK
25:21
A1
A2
EN
WE3
RD1
A
RD2
SrcB
Instr / Data
Memory
A3
WD
WD3
Register
File
SignImm
15:0
Sign Extend
Глава 7 <46>
CLK
SrcA
ALU
CLK
CLK
ALUControl2:0
ALUResult
ALUOut
47.
Многотактный тракт данных: считывание изпамяти
Шаг 4: считываем данные из памяти
IRWrite
CLK
CLK
ALUControl2:0
WE
PC'
b
PC
0
1
Adr
A
Instr / Data
Memory
WD
Instr
RD
CLK
CLK
CLK
25:21
A1
A2
EN
WE3
RD1
A
RD2
SrcB
A3
CLK
Data
WD3
Register
File
SignImm
15:0
Sign Extend
Глава 7 <47>
CLK
SrcA
ALU
IorD
ALUResult
ALUOut
48.
Многотактный тракт данных: запись в регистрШаг 5: записываем считанное из памяти 32-битное
число в регистр общего назначения, номер которого
хранится в поле rt инструкции
IRWrite
CLK
CLK
RegWrite
WE
PC'
b
PC
0
1
Adr
A
Instr / Data
Memory
WD
Instr
RD
CLK
CLK
CLK
25:21
A1
WE3
A2
EN
ALUControl2:0
A
RD1
RD2
SrcB
20:16
CLK
A3
Data
WD3
Register
File
SignImm
15:0
Sign Extend
I-Type
lw
rt, imm(rs)
op
6 bits
rs
5 bits
rt
imm
5 bits
16 bits
Глава 7 <48>
CLK
SrcA
ALU
IorD
ALUResult
ALUOut
49.
Многотактный тракт данных: увеличиваем PCШаг 6: вычисляем адрес следующей
инструкции и записываем в PC
IorD
IRWrite
CLK
CLK
RegWrite
WE
PC'
b
EN
PC
0
1
Adr
A
Instr / Data
Memory
WD
Instr
RD
CLK
CLK
CLK
25:21
A1
A2
EN
ALUSrcA ALUSrcB1:0 ALUControl2:0
WE3
0
RD1
A
RD2
00
4
20:16
CLK
Data
A3
WD3
SrcA
1
01
SrcB
10
Register
File
11
SignImm
15:0
Sign Extend
Глава 7 <49>
CLK
ALU
PCWrite
ALUResult
ALUOut
50.
Многотактный тракт данных: swЗапись содержимого регистра rt в память
IorD
MemWrite IRWrite
CLK
CLK
RegWrite
WE
PC'
b
PC
EN
0
1
Adr
A
Instr / Data
Memory
WD
Instr
RD
CLK
CLK
CLK
EN
25:21
A1
20:16
A2
20:16
A3
ALUSrcA ALUSrcB1:0 ALUControl2:0
WE3
0
A
RD1
B
RD2
00
4
CLK
Data
WD3
SrcA
1
01
SrcB
10
Register
File
11
SignImm
15:0
Sign Extend
I-Type
sw
rt, imm(rs)
op
6 bits
rs
5 bits
rt
imm
5 bits
16 bits
Глава 7 <50>
CLK
ALU
PCWrite
ALUResult
ALUOut
51.
Многотактный тракт данных: R-Тип• Считываем операнды из регистров rs и rt
• Записываем ALUResult в регистр с номером из поля rd
инструкции (для инструкций I-типа результат записывается
в регистр с номером rt)
IorD
MemWrite IRWrite
CLK
CLK
RegDst MemtoReg
b
PC
EN
0
1
Adr
A
Instr
RD
EN
Instr / Data
Memory
25:21
A1
20:16
A2
20:16
15:11
CLK
WD
WE3
0
RD1
RD2
A
0
A3
1
1
WD3
SrcA
1
B
00
4
0
Data
ALUSrcA ALUSrcB1:0 ALUControl2:0
CLK
CLK
CLK
WE
PC'
RegWrite
01
10
Register
File
11
SignImm
15:0
Sign Extend
R-Type
op
6 bits
rs
5 bits
rt
rd
shamt
funct
5 bits
5 bits
5 bits
6 bits
Глава 7 <51>
SrcB
CLK
ALU
PCWrite
ALUResult
ALUOut
52.
Многотактный тракт данных: beq• rs == rt?
• BTA = (sign-extended immediate << 2) + (PC+4)
PCEn
MemWrite IRWrite
CLK
CLK
PC'
b
PC
EN
1
Adr
A
Instr
RD
EN
Instr / Data
Memory
WD
RegWrite
CLK
25:21
A1
20:16
A2
20:16
0
15:11
1
WE3
0
A
RD1
B
RD2
A3
WD3
1
SrcA
1
00
4
0
Data
ALUSrcA ALUSrcB1:0 ALUControl2:0 Branch PCWrite
01
10
Register
File
11
<<2
SignImm
15:0
Sign Extend
Assembly Code
Field Values
op
beq $t0, $0, else
(beq $t0, $0, 3)
rs
4
6 bits
rt
8
5 bits
PCSrc
CLK
CLK
CLK
WE
0
RegDst MemtoReg
imm
0
5 bits
3
5 bits
5 bits
6 bits
Глава 7 <52>
SrcB
Zero
ALU
IorD
CLK
0
ALUResult
ALUOut
1
53.
Многотактный процессорCLK
PCWrite
PCEn
Branch
IorD Control PCSrc
ALUControl2:0
Unit
ALUSrcB1:0
IRWrite
MemWrite
5:0
PC
EN
0
1
Adr
A
Instr
RD
25:21
20:16
EN
Instr / Data
Memory
WD
MemtoReg
CLK
WE
PC'
RegWrite
Funct
RegDst
CLK
CLK
ALUSrcA
Op
CLK
0
15:11
1
WE3
0
RD1
RD2
A
A3
1
WD3
SrcA
1
B
00
4
0
Data
A1
A2
20:16
CLK
CLK
01
10
Register
File
11
<<2
SignImm
15:0
Sign Extend
Глава 7 <53>
SrcB
Zero
ALU
31:26
CLK
0
ALUResult
ALUOut
1
54.
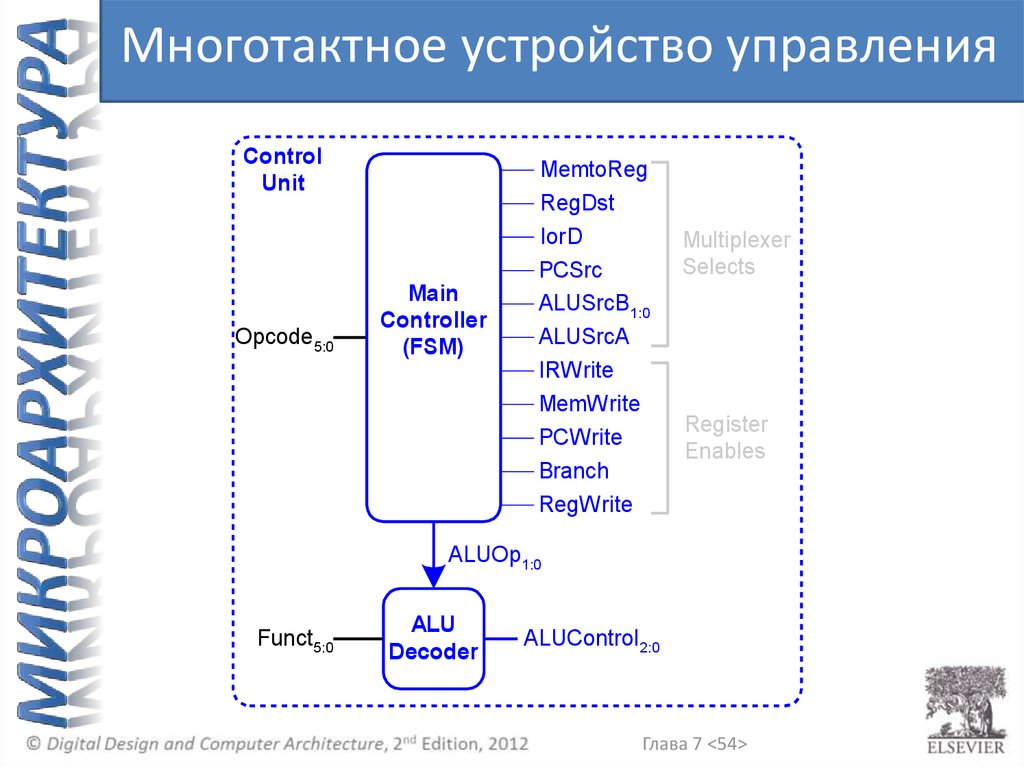
Многотактное устройство управленияControl
Unit
Opcode5:0
MemtoReg
RegDst
IorD
Main
Controller
(FSM)
PCSrc
ALUSrcB1:0
ALUSrcA
IRWrite
MemWrite
Multiplexer
Selects
Register
Enables
PCWrite
Branch
RegWrite
ALUOp1:0
Funct5:0
ALU
Decoder
ALUControl2:0
Глава 7 <54>
55.
Основной управляющий автомат: ВыборкаS0: Fetch
Reset
CLK
1
PCWrite
0
Branch
PCEn
IorD Control PCSrc
ALUControl2:0
Unit
MemWrite
ALUSrcB1:0
IRWrite
5:0
PC
EN
1
0
1
CLK
WE
Adr
A
Instr / Data
Memory
WD
Instr
RD
MemtoReg
0
PC'
0
RegWrite
Funct
RegDst
CLK
CLK
ALUSrcA
Op
25:21
20:16
EN
CLK
20:16
0
15:11
1
WE3
0
CLK
0
0
RD1
RD2
A
A3
X
1
WD3
B
01
00
01
10
Register
File
11
<<2
SignImm
15:0
SrcA
1
4
0
Data
A1
A2
X
1
CLK
Sign Extend
Глава 7 <55>
SrcB
010
ALU
31:26
Zero
CLK
0
0
ALUResult
ALUOut
1
56.
Основной управляющий автомат: Выборка• Сигналы разрешения записи будем показывать
только если они не равны нулю
• Одновременно со считыванием инструкции при
помощи АЛУ увеличиваем на 4 содержимое PC
S0: Fetch
CLK
1
PCWrite
0
Branch
PCEn
IorD Control PCSrc
ALUControl2:0
Unit
MemWrite
ALUSrcB1:0
IRWrite
31:26
5:0
PC
EN
1
0
1
CLK
WE
Adr
A
Instr / Data
Memory
WD
Instr
RD
MemtoReg
0
PC'
0
RegWrite
Funct
RegDst
CLK
CLK
ALUSrcA
Op
25:21
20:16
EN
CLK
20:16
0
15:11
1
0
CLK
0
WE3
0
RD1
RD2
A
A3
X
1
WD3
B
01
00
01
10
Register
File
11
<<2
SignImm
15:0
SrcA
1
4
0
Data
A1
A2
X
1
CLK
Sign Extend
Глава 7 <56>
SrcB
010
ALU
Reset
IorD = 0
AluSrcA = 0
ALUSrcB = 01
ALUOp = 00
PCSrc = 0
IRWrite
PCWrite
Zero
CLK
0
0
ALUResult
ALUOut
1
57.
Основной управляющий автомат: ДекодированиеS0: Fetch
IorD = 0
AluSrcA = 0
ALUSrcB = 01
ALUOp = 00
PCSrc = 0
IRWrite
PCWrite
Reset
• Будем указывать только те управляющие
сигналы, которые имеют смысл на
конкретном этапе выполнения команды
• На этом этапе выполняется считывание
из регистрового файла, расширение
константы и декодирование операции
S1: Decode
CLK
0
PCWrite
0
Branch
PCEn
IorD Control PCSrc
ALUControl2:0
Unit
MemWrite
ALUSrcB1:0
IRWrite
5:0
PC
EN
0
0
1
CLK
WE
Adr
A
Instr / Data
Memory
WD
Instr
RD
MemtoReg
X
PC'
0
RegWrite
Funct
RegDst
CLK
CLK
ALUSrcA
Op
25:21
20:16
EN
CLK
20:16
0
15:11
1
WE3
X
CLK
0
0
RD1
RD2
A
SrcA
1
B
XX
00
4
A3
X
0
Data
A1
A2
X
0
CLK
1
WD3
01
SrcB
XXX
Zero
ALU
31:26
10
Register
File
11
<<2
SignImm
15:0
Sign Extend
Глава 7 <57>
CLK
X
0
ALUResult
ALUOut
1
58.
Основной управляющий автомат: АдресS0: Fetch
IorD = 0
AluSrcA = 0
ALUSrcB = 01
ALUOp = 00
PCSrc = 0
IRWrite
PCWrite
Reset
S1: Decode
Op = LW
or
Op = SW
S2: MemAdr
CLK
0
PCWrite
0
Branch
PCEn
IorD Control PCSrc
ALUControl2:0
Unit
ALUSrcB1:0
IRWrite
MemWrite
5:0
PC
EN
0
0
1
CLK
WE
Adr
A
Instr / Data
Memory
WD
Instr
RD
MemtoReg
X
PC'
0
RegWrite
Funct
RegDst
CLK
CLK
ALUSrcA
Op
25:21
20:16
EN
CLK
20:16
0
15:11
1
WE3
1
CLK
0
0
RD1
RD2
A
A3
X
1
WD3
SrcA
1
B
10
00
4
0
Data
A1
A2
X
0
CLK
01
10
Register
File
11
<<2
SignImm
15:0
Sign Extend
Глава 7 <58>
SrcB
010
ALU
31:26
Zero
CLK
X
0
ALUResult
ALUOut
1
59.
Основной управляющий автомат: АдресS0: Fetch
Reset
S2: MemAdr
S1: Decode
IorD = 0
AluSrcA = 0
ALUSrcB = 01
ALUOp = 00
PCSrc = 0
IRWrite
PCWrite
Op = LW
or
Op = SW
CLK
0
PCWrite
0
Branch
PCEn
IorD Control PCSrc
ALUControl2:0
Unit
ALUSrcB1:0
IRWrite
ALUSrcA = 1
ALUSrcB = 10
ALUOp = 00
MemWrite
5:0
PC
EN
0
0
1
CLK
WE
Adr
A
Instr / Data
Memory
WD
Instr
RD
MemtoReg
X
PC'
0
RegWrite
Funct
RegDst
CLK
CLK
ALUSrcA
Op
25:21
20:16
EN
CLK
20:16
0
15:11
1
WE3
1
CLK
0
0
RD1
RD2
A
A3
X
1
WD3
B
10
00
01
10
Register
File
11
<<2
SignImm
15:0
SrcA
1
4
0
Data
A1
A2
X
0
CLK
Sign Extend
Глава 7 <59>
SrcB
010
ALU
31:26
Zero
CLK
X
0
ALUResult
ALUOut
1
60.
Основной управляющий автомат: lwS0: Fetch
IorD = 0
AluSrcA = 0
ALUSrcB = 01
ALUOp = 00
PCSrc = 0
IRWrite
PCWrite
Reset
S2: MemAdr
S1: Decode
Op = LW
or
Op = SW
ALUSrcA = 1
ALUSrcB = 10
ALUOp = 00
Op = LW
S3: MemRead
IorD = 1
S4: Mem
Writeback
RegDst = 0
MemtoReg = 1
RegWrite
Глава 7 <60>
61.
Основной управляющий автомат: swS0: Fetch
IorD = 0
AluSrcA = 0
ALUSrcB = 01
ALUOp = 00
PCSrc = 0
IRWrite
PCWrite
Reset
S2: MemAdr
S1: Decode
Op = LW
or
Op = SW
ALUSrcA = 1
ALUSrcB = 10
ALUOp = 00
Op = SW
Op = LW
S5: MemWrite
S3: MemRead
IorD = 1
IorD = 1
MemWrite
S4: Mem
Writeback
RegDst = 0
MemtoReg = 1
RegWrite
Глава 7 <61>
62.
Основной управляющий автомат: R-ТипS0: Fetch
IorD = 0
AluSrcA = 0
ALUSrcB = 01
ALUOp = 00
PCSrc = 0
IRWrite
PCWrite
Reset
S2: MemAdr
S1: Decode
Op = LW
or
Op = SW
Op = R-type
S6: Execute
ALUSrcA = 1
ALUSrcB = 10
ALUOp = 00
ALUSrcA = 1
ALUSrcB = 00
ALUOp = 10
Op = SW
Op = LW
S5: MemWrite
S3: MemRead
IorD = 1
IorD = 1
MemWrite
S7: ALU
Writeback
RegDst = 1
MemtoReg = 0
RegWrite
S4: Mem
Writeback
RegDst = 0
MemtoReg = 1
RegWrite
Глава 7 <62>
63.
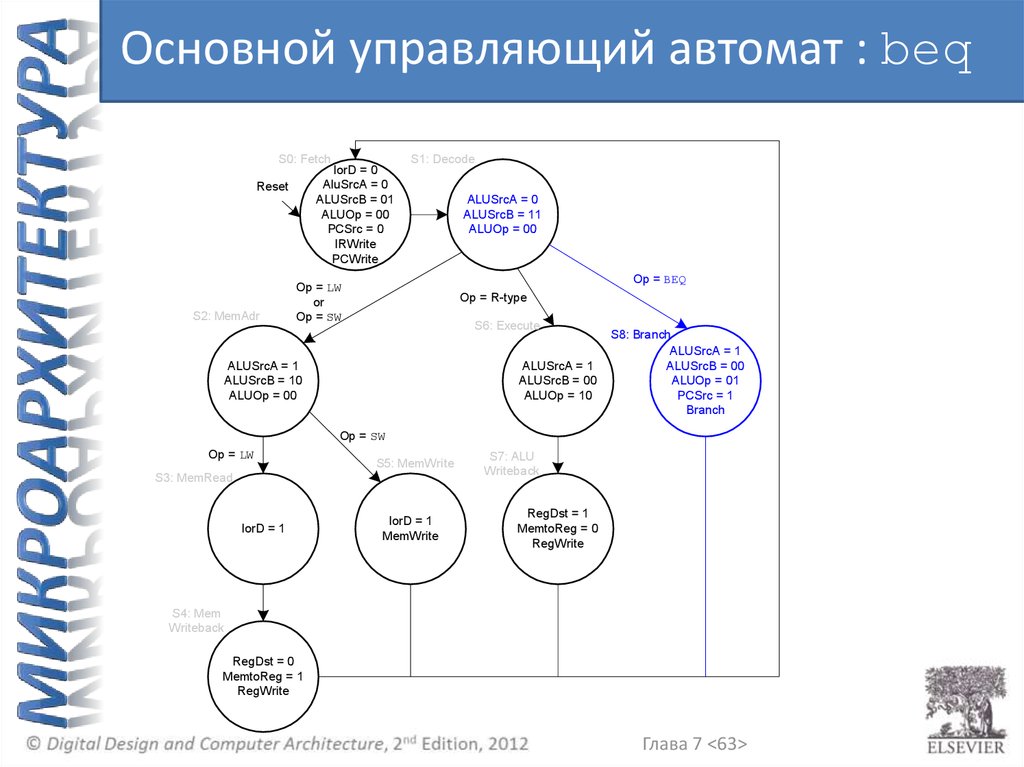
Основной управляющий автомат : beqS0: Fetch
IorD = 0
AluSrcA = 0
ALUSrcB = 01
ALUOp = 00
PCSrc = 0
IRWrite
PCWrite
Reset
S2: MemAdr
S1: Decode
ALUSrcA = 0
ALUSrcB = 11
ALUOp = 00
Op = BEQ
Op = LW
or
Op = SW
Op = R-type
S6: Execute
ALUSrcA = 1
ALUSrcB = 10
ALUOp = 00
ALUSrcA = 1
ALUSrcB = 00
ALUOp = 10
S8: Branch
ALUSrcA = 1
ALUSrcB = 00
ALUOp = 01
PCSrc = 1
Branch
Op = SW
Op = LW
S5: MemWrite
S3: MemRead
IorD = 1
IorD = 1
MemWrite
S7: ALU
Writeback
RegDst = 1
MemtoReg = 0
RegWrite
S4: Mem
Writeback
RegDst = 0
MemtoReg = 1
RegWrite
Глава 7 <63>
64.
Основной управляющий автоматS0: Fetch
IorD = 0
AluSrcA = 0
ALUSrcB = 01
ALUOp = 00
PCSrc = 0
IRWrite
PCWrite
Reset
S2: MemAdr
S1: Decode
ALUSrcA = 0
ALUSrcB = 11
ALUOp = 00
Op = BEQ
Op = LW
or
Op = SW
Op = R-type
S6: Execute
ALUSrcA = 1
ALUSrcB = 10
ALUOp = 00
ALUSrcA = 1
ALUSrcB = 00
ALUOp = 10
S8: Branch
ALUSrcA = 1
ALUSrcB = 00
ALUOp = 01
PCSrc = 1
Branch
Op = SW
Op = LW
S5: MemWrite
S3: MemRead
IorD = 1
IorD = 1
MemWrite
S7: ALU
Writeback
RegDst = 1
MemtoReg = 0
RegWrite
S4: Mem
Writeback
RegDst = 0
MemtoReg = 1
RegWrite
Глава 7 <64>
65.
Добавим функционала: addiS0: Fetch
IorD = 0
AluSrcA = 0
ALUSrcB = 01
ALUOp = 00
PCSrc = 0
IRWrite
PCWrite
Reset
S2: MemAdr
S1: Decode
ALUSrcA = 0
ALUSrcB = 11
ALUOp = 00
Op = BEQ
Op = LW
or
Op = SW
Op = ADDI
Op = R-type
S6: Execute
ALUSrcA = 1
ALUSrcB = 10
ALUOp = 00
ALUSrcA = 1
ALUSrcB = 00
ALUOp = 10
S8: Branch
ALUSrcA = 1
ALUSrcB = 00
ALUOp = 01
PCSrc = 1
Branch
S9: ADDI
Execute
Op = SW
Op = LW
S5: MemWrite
S3: MemRead
IorD = 1
IorD = 1
MemWrite
S7: ALU
Writeback
S10: ADDI
Writeback
RegDst = 1
MemtoReg = 0
RegWrite
S4: Mem
Writeback
RegDst = 0
MemtoReg = 1
RegWrite
Глава 7 <65>
66.
Основной управляющий автомат: addiS0: Fetch
IorD = 0
AluSrcA = 0
ALUSrcB = 01
ALUOp = 00
PCSrc = 0
IRWrite
PCWrite
Reset
S2: MemAdr
S1: Decode
ALUSrcA = 0
ALUSrcB = 11
ALUOp = 00
Op = BEQ
Op = LW
or
Op = SW
Op = ADDI
Op = R-type
S6: Execute
ALUSrcA = 1
ALUSrcB = 10
ALUOp = 00
ALUSrcA = 1
ALUSrcB = 00
ALUOp = 10
S8: Branch
ALUSrcA = 1
ALUSrcB = 00
ALUOp = 01
PCSrc = 1
Branch
S9: ADDI
Execute
ALUSrcA = 1
ALUSrcB = 10
ALUOp = 00
Op = SW
Op = LW
S5: MemWrite
S3: MemRead
IorD = 1
IorD = 1
MemWrite
S7: ALU
Writeback
S10: ADDI
Writeback
RegDst = 1
MemtoReg = 0
RegWrite
RegDst = 0
MemtoReg = 0
RegWrite
S4: Mem
Writeback
RegDst = 0
MemtoReg = 1
RegWrite
Глава 7 <66>
67.
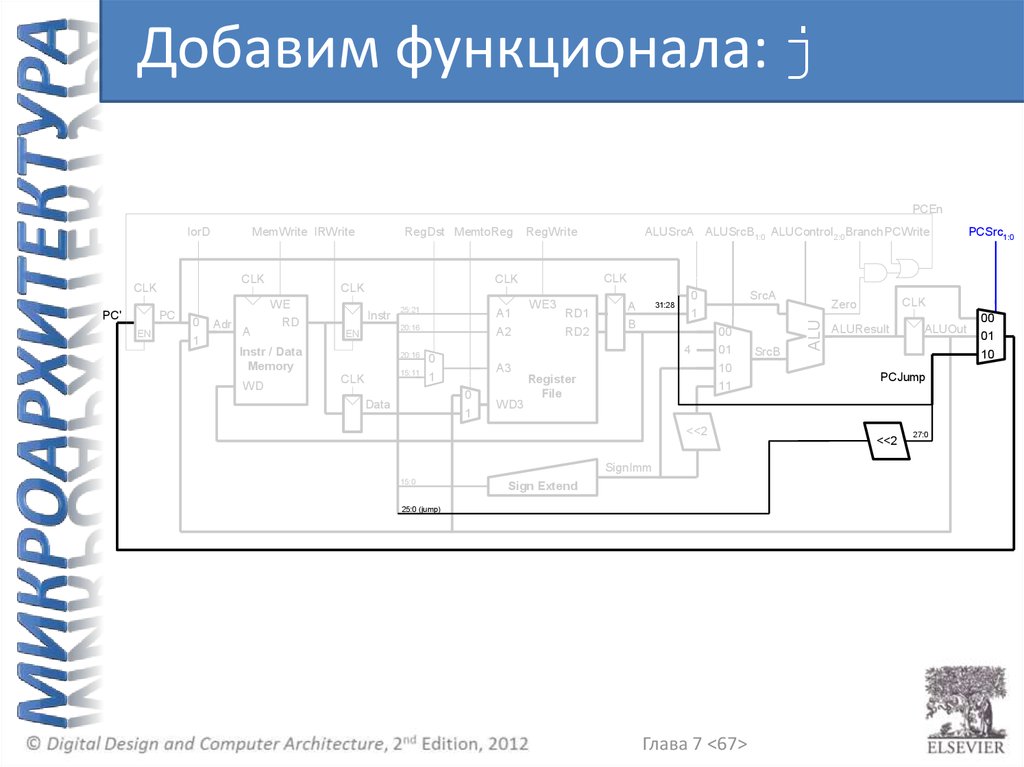
Добавим функционала: jPCEn
MemWrite IRWrite
CLK
CLK
RegDst MemtoReg
PC
EN
0
1
Adr
A
Instr
RD
EN
Instr / Data
Memory
WD
25:21
A1
20:16
A2
20:16
15:11
CLK
WE3
RD1
RD2
0
A
31:28
A3
1
0
1
WD3
SrcA
1
B
00
4
0
Data
ALUSrcA ALUSrcB1:0 ALUControl2:0 Branch PCWrite
01
10
Register
File
11
<<2
SignImm
15:0
PCSrc1:0
CLK
CLK
CLK
WE
PC'
RegWrite
Sign Extend
25:0 (jump)
Глава 7 <67>
SrcB
CLK
Zero
ALU
IorD
00
ALUResult
ALUOut
01
10
PCJump
<<2
27:0
68.
Основной управляющий автомат : jS0: Fetch
IorD = 0
AluSrcA = 0
ALUSrcB = 01
ALUOp = 00
PCSrc = 00
IRWrite
PCWrite
Reset
S2: MemAdr
S1: Decode
S11: Jump
ALUSrcA = 0
ALUSrcB = 11
ALUOp = 00
Op = J
Op = BEQ
Op = LW
or
Op = SW
Op = ADDI
Op = R-type
S6: Execute
ALUSrcA = 1
ALUSrcB = 10
ALUOp = 00
ALUSrcA = 1
ALUSrcB = 00
ALUOp = 10
S8: Branch
ALUSrcA = 1
ALUSrcB = 00
ALUOp = 01
PCSrc = 01
Branch
S9: ADDI
Execute
ALUSrcA = 1
ALUSrcB = 10
ALUOp = 00
Op = SW
Op = LW
S5: MemWrite
S3: MemRead
IorD = 1
IorD = 1
MemWrite
S7: ALU
Writeback
S10: ADDI
Writeback
RegDst = 1
MemtoReg = 0
RegWrite
RegDst = 0
MemtoReg = 0
RegWrite
S4: Mem
Writeback
RegDst = 0
MemtoReg = 1
RegWrite
Глава 7 <68>
69.
Основной управляющий автомат : jS0: Fetch
IorD = 0
AluSrcA = 0
ALUSrcB = 01
ALUOp = 00
PCSrc = 00
IRWrite
PCWrite
Reset
S2: MemAdr
S1: Decode
S11: Jump
ALUSrcA = 0
ALUSrcB = 11
ALUOp = 00
Op = J
PCSrc = 10
PCWrite
Op = BEQ
Op = LW
or
Op = SW
Op = ADDI
Op = R-type
S6: Execute
ALUSrcA = 1
ALUSrcB = 10
ALUOp = 00
ALUSrcA = 1
ALUSrcB = 00
ALUOp = 10
S8: Branch
ALUSrcA = 1
ALUSrcB = 00
ALUOp = 01
PCSrc = 01
Branch
S9: ADDI
Execute
ALUSrcA = 1
ALUSrcB = 10
ALUOp = 00
Op = SW
Op = LW
S5: MemWrite
S3: MemRead
IorD = 1
IorD = 1
MemWrite
S7: ALU
Writeback
S10: ADDI
Writeback
RegDst = 1
MemtoReg = 0
RegWrite
RegDst = 0
MemtoReg = 0
RegWrite
S4: Mem
Writeback
RegDst = 0
MemtoReg = 1
RegWrite
Глава 7 <69>
70.
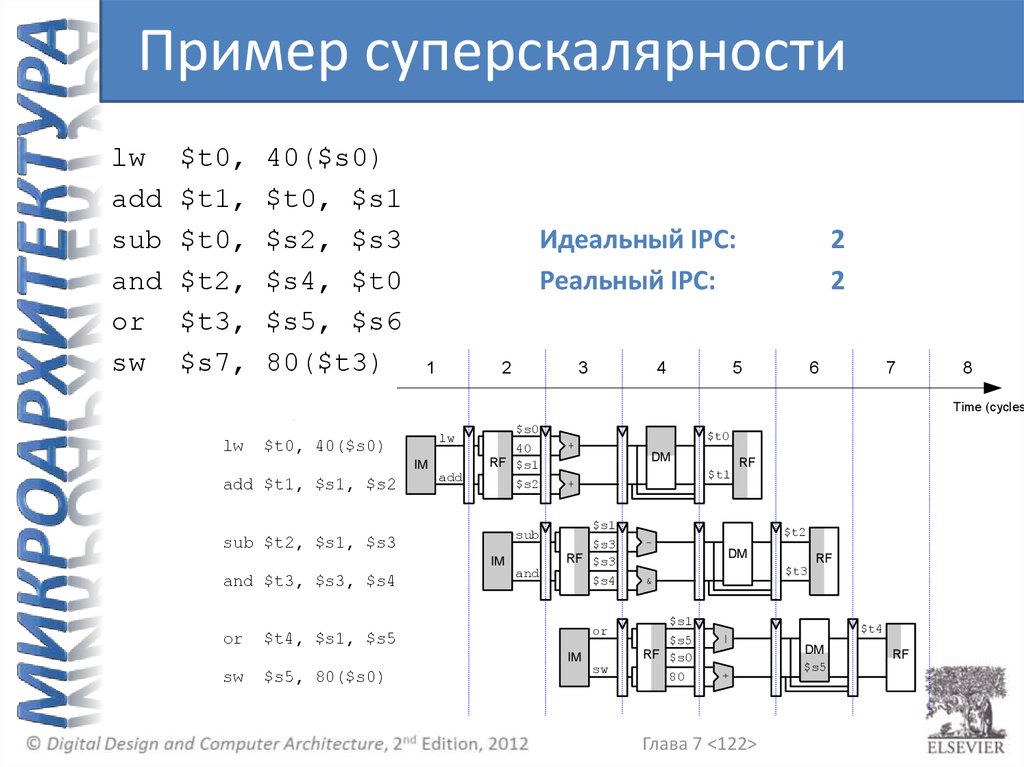
Производительность многотактного процессора• Инструкции выполняются за разное количество
тактов:
– 3 такта: beq, j
– 4 такта: R-тип, sw, addi
– 5 тактов: lw
• CPI будет средним значением
• Тестовый набор SPECINT2000 содержит:
–
–
–
–
–
25% инструкций lw
10% инструкций sw
11% условных переходов
2% безусловных переходов
52% инструкций R-типа
Средний CPI = (0.11 + 0.2)(3) + (0.52 + 0.10)(4) + (0.25)(5) = 4.12
Глава 7 <70>
71.
Производительность многотактного процессораЗадержка самой длинной цепи комбинационной логики
многотактного процессора:
Tc = tpcq + tmux + max(tALU + tmux, tmem) + tsetup
CLK
PCWrite
PCEn
Branch
IorD Control PCSrc
ALUControl2:0
Unit
MemWrite
ALUSrcB1:0
IRWrite
5:0
PC
EN
0
1
Adr
A
Instr
RD
25:21
20:16
EN
Instr / Data
Memory
WD
MemtoReg
CLK
WE
PC'
RegWrite
Funct
RegDst
CLK
CLK
ALUSrcA
Op
CLK
0
15:11
1
WE3
0
RD1
RD2
A
A3
1
WD3
SrcA
1
B
00
4
0
Data
A1
A2
20:16
CLK
CLK
01
SrcB
10
Register
File
11
<<2
SignImm
15:0
Sign Extend
Глава 7 <71>
Zero
ALU
31:26
CLK
0
ALUResult
ALUOut
1
72.
Посчитаем производительность многотактногопроцессора
Параметр
Обозначение Задержка (пс)
Время записи в регистр tpcq_PC
30
Время предустановки
регистра
tsetup
20
Задержка
мультиплексора
tmux
25
Задержка АЛУ
tALU
200
Задержка считывания
из памяти
tmem
250
Задержка считывания
из регистрового файла
tRFread
150
Время предустановки
регистрового файла
tRFsetup
20
Tc = ?
Глава 7 <72>
73.
Посчитаем производительность многотактногопроцессора
Tc = tpcq_PC + tmux + max(tALU + tmux, tmem) + tsetup
= tpcq_PC + tmux + tmem + tsetup
= [30 + 25 + 250 + 20] пс
= 325 пс
Глава 7 <73>
74.
Посчитаем производительность многотактногопроцессора
Предположим, в программе 100 миллиардов
инструкций:
– CPI = 4.12
– Tc = 325 пс
Время выполнения = (# инструкции) × CPI × Tc
= (100 × 109)(4.12)(325 × 10-12)
= 133.9 секунд
Это больше, чем для однотактного процессора
(92.5 секунд). Почему?
– У разных команд разная длительность выполнения
– Дополнительные задержки на каждом шаге (tpcq + tsetup= 50 пс)
Глава 7 <74>
75.
Повторение: однотактный процессорJump
31:26
5:0
MemtoReg
Control
MemWrite
Unit
Branch
ALUControl2:0
Op
ALUSrc
Funct
RegDst
PCSrc
RegWrite
CLK
0
1
0
PC'
PC
1
A
RD
Instr
Instruction
Memory
25:21
20:16
A1
A2
A3
WD3
CLK
WE3
RD2
0 SrcB
1
Register
File
20:16
PCJump
+
WriteReg4:0
PCPlus4
WriteData
1
SignImm
Sign Extend
<<2
+
15:0
ALUResult
0
15:11
4
Zero
SrcA
RD1
ALU
CLK
27:0
PCBranch
31:28
25:0
<<2
Глава 7 <75>
WE
A
RD
Data
Memory
WD
ReadData
0 Result
1
76.
Повторение: многотактный процессорCLK
PCWrite
PCEn
Branch
IorD Control PCSrc
ALUControl2:0
Unit
MemWrite
ALUSrcB1:0
IRWrite
5:0
ALUSrcA
Op
RegWrite
Funct
MemtoReg
RegDst
CLK
CLK
WE
PC'
PC
EN
0
1
Adr
A
Instr
RD
EN
Instr / Data
Memory
WD
CLK
CLK
CLK
25:21
A1
20:16
A2
20:16
15:11
CLK
RD1
RD2
A
0
31:28
A3
1
0
1
WD3
SrcA
1
B
00
4
0
Data
WE3
01
SrcB
10
Register
File
11
<<2
ImmExt
15:0
Sign Extend
25:0 (Addr)
Глава 7 <76>
CLK
Zero
ALU
31:26
00
ALUResult
ALUOut
01
10
PCJump
<<2
27:0
77.
Конвейерный MIPS процессор• Временной параллелизм
• Разделим однотактный процессор на 5
стадий:
–
–
–
–
–
Выборка
Декодирование
Выполнение
Доступ к памяти
Запись результатов
• Добавим регистры между стадиями
конвейера
Глава 7 <77>
78.
Однотактный / КонвейерныйSingle-Cycle
0
100
200
300
400
500
600
700
800
900
1000 1100 1200 1300 1400 1500 1600 1700 1800 1900
Instr
1
Fetch
Instruction
Decode
Read Reg
Execute
ALU
Memory
Read / Write
Time (ps)
Write
Reg
Fetch
Instruction
2
Decode
Read Reg
Execute
ALU
Memory
Read / Write
Pipelined
Instr
1
2
3
Fetch
Instruction
Decode
Read Reg
Fetch
Instruction
Execute
ALU
Decode
Read Reg
Fetch
Instruction
Memory
Read/Write
Execute
ALU
Decode
Read Reg
Write
Reg
Memory
Read/Write
Execute
ALU
Write
Reg
Memory
Read/Write
Глава 7 <78>
Write
Reg
Write
Reg
79.
Абстрактное представление конвейера1
2
3
4
5
6
7
8
9
10
Time (cycles)
lw
$s2, 40($0)
add $s3, $t1, $t2
sub $s4, $s1, $s5
and $s5, $t5, $t6
sw
$s6, 20($s1)
or
$s7, $t3, $t4
IM
lw
$0
RF 40
IM
add
DM
+
$t1
RF $t2
IM
sub
RF
DM
+
$s1
RF $s5
IM
$s2
and
RF
DM
-
$t5
RF $t6
IM
$s3
sw
RF
DM
&
$s1
RF 20
IM
$s4
or
+
$t3
RF $t4
Глава 7 <79>
$s5
RF
DM
|
$s6
RF
DM
$s7
RF
80.
Однотактный и конвейерный тракт данныхCLK
0
PC'
PC
1
A
Instr
RD
Instruction
Memory
25:21
20:16
A1
WE3
A2
A3
WD3
+
CLK
Zero
SrcA
RD1
RD2
0 SrcB
1
Register
File
20:16
0
15:11
1
ALU
CLK
WE
ALUResult
WriteData
ReadData
A
RD
Data
Memory
WD
0
1
WriteReg4:0
PCPlus4
SignImm
4
Sign Extend
<<2
+
15:0
PCBranch
Result
CLK
CLK
CLK
0
PC'
PCF
1
A
RD
Instruction
Memory
CLK
InstrD
25:21
20:16
A1
WE3
A2
A3
WD3
ALUOutW
CLK
CLK
RD2
0 SrcBE
1
Register
File
RdE
0
A
RD
Data
Memory
WD
ReadDataW
0
1
WriteRegE4:0
1
+
15:11
ALUOutM
WriteDataM
WriteDataE
RtE
20:16
WE
ZeroM
SrcAE
RD1
ALU
CLK
SignImmE
15:0
<<2
Sign Extend
PCBranchM
+
4
PCPlus4F
PCPlus4D
PCPlus4E
ResultW
Fetch
Decode
Execute
Memory
Глава 7 <80>
Writeback
81.
Исправленный конвейерный тракт данныхCLK
CLK
CLK
PC'
PCF
A
RD
Instruction
Memory
InstrD
25:21
20:16
A1
WE3
PCPlus4F
0 SrcBE
1
RtE
RdE
0
ALUOutM
WriteDataE
WriteDataM
WriteRegE4:0
WriteRegM4:0
A
RD
Data
Memory
WD
ReadDataW
0
1
WriteRegW 4:0
1
SignImmE
<<2
+
Sign Extend
PCPlus4D
WE
ZeroM
SrcAE
A2
RD2
A3
Register
WD3
File
15:11
4
CLK
RD1
20:16
15:0
ALUOutW
CLK
+
0
1
CLK
ALU
CLK
PCBranchM
PCPlus4E
ResultW
Fetch
Decode
Execute
Memory
Writeback
Теперь WriteRegW и ResultW подаются на входы
регистрового файла в стадии Writeback
одновременно.
Глава 7 <81>
82.
Управление конвейерным процессоромCLK
5:0
RegWriteM
RegWriteW
MemtoRegE
MemtoRegM
MemtoRegW
MemWriteD
MemWriteE
MemWriteM
BranchD
BranchE
BranchM
Op
ALUControlD
ALUControlE2:0
Funct
ALUSrcD
ALUSrcE
RegDstD
RegDstE
CLK
0
PC'
PCF
1
A
RD
Instruction
Memory
ALUOutW
CLK
InstrD
25:21
20:16
A1
A2
A3
WD3
CLK
WE3
RD2
0 SrcBE
1
Register
File
RtE
RdE
0
PCPlus4F
Sign Extend
WriteDataE
WriteDataM
WriteRegE4:0
WriteRegM4:0
SignImmE
PCPlus4D
A
RD
Data
Memory
WD
ReadDataW
0
1
WriteRegW 4:0
<<2
+
15:0
ALUOutM
1
+
15:11
WE
ZeroM
SrcAE
RD1
20:16
4
PCSrcM
ALU
CLK
CLK
RegWriteE
RegWriteD
Control
MemtoRegD
Unit
31:26
CLK
PCBranchM
PCPlus4E
ResultW
То же устройство управления, что и в однотактном процессоре
Сигналы управления доходят до соответствующей стадии с
задержкой (сигналы управления тоже конвейеризируются)
Глава 7 <82>
83.
Конфликты конвейера• В конвейере выполняется несколько
инструкций одновременно
• Конфликты случаются когда одна инструкция
зависит от результата другой, еще не
завершенной инструкции
• Типы конфликтов:
– Конфликты данных: результат инструкции еще не
записан в регистр, а следующая инструкция уже
пытается считать этот регистр
– Конфликты управления: процессор выбирает из
памяти следующую инструкцию до того, как стало
ясно, какую именно инструкцию надо
выбрать(возникают из-за условных переходов)
Глава 7 <83>
84.
Конфликты данных1
2
3
4
5
6
7
8
Time (cycles)
add $s0, $s2, $s3
and $t0, $s0, $s1
or
$t1, $s4, $s0
sub $t2, $s0, $s5
IM
add
$s2
RF $s3
IM
and
DM
+
$s0
RF $s1
IM
or
RF
DM
&
$s4
RF $s0
IM
$s0
sub
$t0
DM
|
$s0
RF $s5
RF
-
Глава 7 <84>
$t1
RF
DM
$t2
RF
85.
Разрешение конфликтов данных• Можно вставлять пустые инструкции (nop) в код
программы перед компиляцией или во время
компиляции
• Во время выполнения программы реализовать
аппаратную передачу данных с одного этапа
конвейера на другой не дожидаясь завершения
инструкции
• Во время выполнения программы останавливать
(stall) некоторые этапы конвейера до тех пор, пока
проблемная инструкция не запишет в
регистровый файл результат, от которого зависят
инструкции на остановленных этапах
Глава 7 <85>
86.
Устранение конфликтов на уровне компилятора• Вставить в код достаточно пустых инструкций (nop),
которые будут заполнять стадии конвейера, пока
необходимый результат не будет записан в регистр
1
2
3
4
5
6
7
8
9
10
Time (cycles)
add $s0, $s2, $s3
nop
add
$s2
RF $s3
IM
nop
nop
$t1, $s4, $s0
sub $t2, $s0, $s5
DM
+
$s0
RF
DM
RF
IM
and $t0, $s0, $s1
or
IM
nop
DM
RF
IM
RF
and
$s0
RF $s1
IM
or
DM
&
$s4
RF $s0
IM
RF
sub
|
$s0
RF $s5
Глава 7 <86>
$t0
RF
DM
-
$t1
RF
DM
$t2
RF
87.
Передача данных между стадиями(Forwarding, Bypass)
1
2
3
4
5
6
7
8
Time (cycles)
add $s0, $s2, $s3
and $t0, $s0, $s1
or
$t1, $s4, $s0
sub $t2, $s0, $s5
IM
add
$s2
RF $s3
IM
and
DM
+
$s0
RF $s1
IM
or
RF
DM
&
$s4
RF $s0
IM
$s0
sub
$t0
RF
DM
|
$t1
RF
$s0
RF $s5
Глава 7 <87>
-
DM
$t2
RF
88.
Передача данных между стадиями(Forwarding, Bypass)
CLK
Control
Unit
31:26
5:0
A
RD
Instruction
Memory
RegWriteM
RegWriteW
MemtoRegE
MemtoRegM
MemtoRegW
MemWriteD
MemWriteE
MemWriteM
ALUControlD2:0
ALUControlE2:0
Op
ALUSrcD
ALUSrcE
Funct
RegDstD
RegDstE
BranchD
BranchE
InstrD
CLK
WE3
25:21
A1
20:16
A2
RD2
A3
Register
WD3
File
RD1
25:21
20:16
15:11
15:0
4
PCSrcM
BranchM
Sign
Extend
SrcAE
00
01
10
00
01
10
0 SrcBE
1
RsE
RtD
RtE
RdD
RdE
ALUOutM
WriteDataM
WriteDataE
RsD
WE
ZeroM
A
RD
Data
Memory
WD
ReadDataW
ALUOutW
0
1
WriteRegE4:0
SignImmD
WriteRegM4:0
1
0
WriteRegW 4:0
SignImmE
+
<<2
PCPlus4D
PCPlus4E
PCBranchM
Hazard Unit
Глава 7 <88>
RegWriteW
ResultW
RegWriteM
PCPlus4F
ForwardBE
PCF
RegWriteE
MemtoRegD
ForwardAE
PC'
RegWriteD
CLK
+
0
1
CLK
ALU
CLK
CLK
CLK
89.
Передача данных между стадиями(Forwarding, Bypass)
• Можно передавать необходимые данные на
этап Выполнения с этапов:
– Доступа к памяти или
– Записи результатов в регистровый файл
• Управляющая логика для ForwardAE:
if
((rsE != 0) AND (rsE == WriteRegM) AND RegWriteM)
then
ForwardAE = 10
else if ((rsE != 0) AND (rsE == WriteRegW) AND RegWriteW)
then
ForwardAE = 01
else
ForwardAE = 00
Управляющая логика для ForwardBE похожа, но нужно
заменить rsE на rtE
Глава 7 <89>
90.
Останов конвейера1
2
3
4
5
6
7
8
Time (cycles)
lw $s0, 40($0)
IM
lw
$0
RF 40
DM
+
$s0
RF
Trouble!
and $t0, $s0, $s1
or
$t1, $s4, $s0
sub $t2, $s0, $s5
IM
and
$s0
RF $s1
IM
or
DM
&
$s4
RF $s0
IM
sub
$t0
RF
DM
|
$t1
RF
$s0
RF $s5
Глава 7 <90>
-
DM
$t2
RF
91.
Останов конвейера1
2
3
4
5
6
7
8
9
Time (cycles)
lw $s0, 40($0)
and $t0, $s0, $s1
or
$t1, $s4, $s0
IM
lw
$0
RF 40
IM
and
DM
+
$s0
RF $s1
IM
or
$s0
RF $s1
IM
or
$s0
RF
DM
&
$s4
RF $s0
Stall
sub $t2, $s0, $s5
IM
sub
|
$s0
RF $s5
Глава 7 <91>
$t0
RF
DM
-
$t1
RF
DM
$t2
RF
92.
Останов конвейераCLK
Control
Unit
31:26
5:0
PC'
PCF
EN
1
A
Instruction
Memory
RegWriteE
RegWriteM
RegWriteW
MemtoRegD
MemtoRegE
MemtoRegM
MemtoRegW
MemWriteD
MemWriteE
MemWriteM
ALUControlD2:0
ALUControlE2:0
Op
ALUSrcD
ALUSrcE
Funct
RegDstD
RegDstE
BranchD
BranchE
25:21
20:16
A1
CLK
WE3
A2
A3
WD3
RD1
15:11
+
00
01
10
Register
File
20:16
15:0
SrcAE
00
01
10
RD2
25:21
4
PCSrcM
BranchM
CLK
InstrD
RD
Sign
Extend
0 SrcBE
1
RsE
RtD
RtE
RdD
RdE
ALUOutM
WriteDataM
WriteDataE
RsD
WE
ZeroM
A
RD
Data
Memory
WD
ReadDataW
ALUOutW
0
WriteRegE4:0
WriteRegM4:0
1
0
WriteRegW 4:0
1
SignImmD
SignImmE
EN
PCPlus4F
PCPlus4D
CLR
+
<<2
PCPlus4E
PCBranchM
Hazard Unit
Глава 7 <92>
RegWriteW
RegWriteM
MemtoRegE
ForwardBE
ForwardAE
FlushE
StallF
ResultW
StallD
0
CLK
RegWriteD
ALU
CLK
CLK
CLK
93.
Логика управления остановом (дляинструкции lw)
lwstall =
((rsD==rtE) OR (rtD==rtE)) AND MemtoRegE
StallF = StallD = FlushE = lwstall
Глава 7 <93>
94.
Конфликты управления• beq:
– Будет выполнен условный переход или нет
становится известно только на 4-й стадии конвейера
– Пока это не станет известно, инструкции следующие
за инструкцией условного перехода продолжают
попадать в конвейер
– В случае необходимости условного перехода эти
инструкции (идущие после beq) не должны быть
выполнены и их необходимо удалить из конвейера
• Цена неправильного предсказания результата
условного перехода
– Количество инструкций, которые необходимо удалить
из конвейера, если переход все таки произойдет
– Это количество можно уменьшить, проверяя условие
перехода на более ранних стадиях конвейера
Глава 7 <94>
95.
Конвейер до разрешения конфликтовуправления
CLK
Control
Unit
31:26
5:0
PC'
PCF
EN
A
Instruction
Memory
RegWriteE
RegWriteM
RegWriteW
MemtoRegD
MemtoRegE
MemtoRegM
MemtoRegW
MemWriteD
MemWriteE
MemWriteM
ALUControlD2:0
ALUControlE2:0
Op
ALUSrcD
ALUSrcE
Funct
RegDstD
RegDstE
BranchD
BranchE
25:21
20:16
A1
CLK
WE3
RD1
+
15:11
15:0
Sign
Extend
SrcAE
00
01
10
A2
RD2
A3
Register
WD3
File
20:16
4
PCSrcM
BranchM
CLK
InstrD
RD
RegWriteD
25:21
00
01
10
0 SrcBE
1
RsE
RtD
RtE
RdD
RdE
ALUOutM
WriteDataM
WriteDataE
RsD
WE
ZeroM
A
RD
Data
Memory
WD
ReadDataW
ALUOutW
0
1
WriteRegE4:0
SignImmD
WriteRegM4:0
1
0
WriteRegW 4:0
SignImmE
+
<<2
PCPlus4D
PCPlus4E
CLR
EN
PCPlus4F
PCBranchM
Hazard Unit
Глава 7 <95>
RegWriteW
RegWriteM
MemtoRegE
ForwardBE
ForwardAE
FlushE
StallD
ResultW
StallF
0
1
CLK
ALU
CLK
CLK
CLK
96.
Конфликты управления1
2
3
4
5
6
7
8
9
Time (cycles)
20
beq $t1, $t2, 40
24
and $t0, $s0, $s1
28
or
$t1, $s4, $s0
2C
sub $t2, $s0, $s5
30
...
IM
lw
$t1
RF $t2
IM
and
DM
-
$s0
RF $s1
IM
or
RF
DM
&
RF $s0
IM
sub
DM
|
$s0
RF $s5
IM
slt
-
$s2
RF $s3
Глава 7 <96>
RF
DM
slt
slt $t3, $s2, $s3
Flush
these
instructions
$s4
...
64
RF
RF
DM
$t3
RF
97.
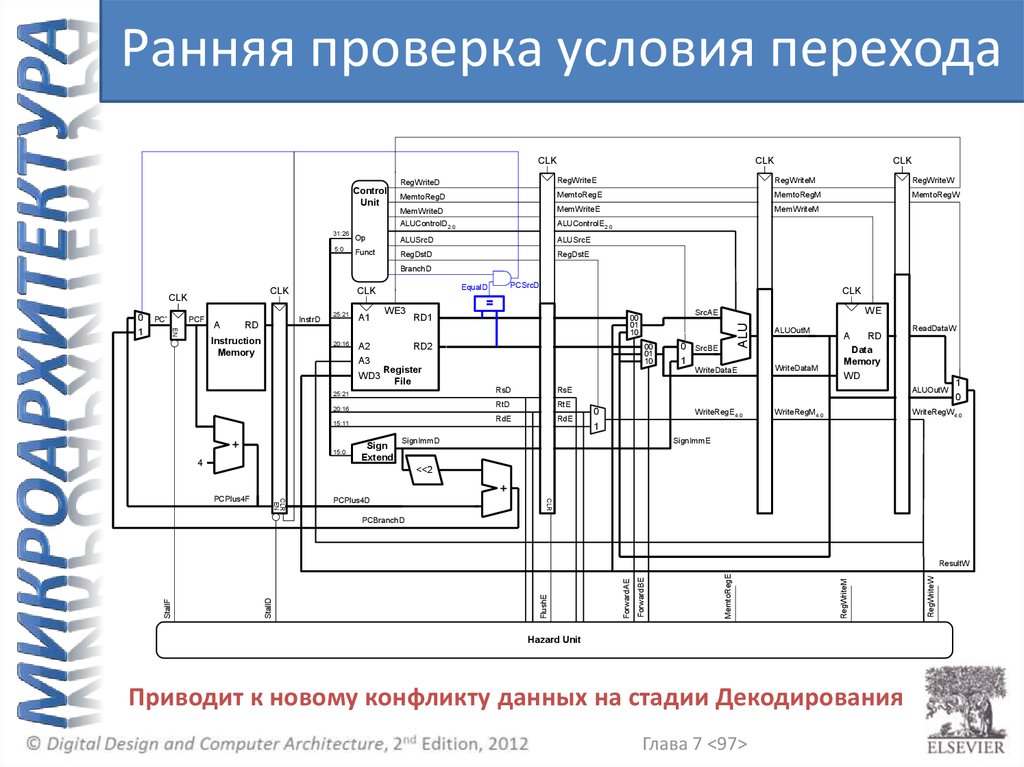
Ранняя проверка условия переходаCLK
Control
Unit
31:26
5:0
CLK
CLK
RegWriteD
RegWriteE
RegWriteM
RegWriteW
MemtoRegD
MemtoRegE
MemtoRegM
MemtoRegW
MemWriteD
MemWriteE
MemWriteM
ALUControlD2:0
ALUControlE2:0
Op
ALUSrcD
ALUSrcE
Funct
RegDstD
RegDstE
BranchD
PC'
PCF
EN
0
1
A
InstrD
RD
Instruction
Memory
25:21
20:16
A1
WE3
RD1
+
15:11
Sign
Extend
WE
SrcAE
00
01
10
A2
RD2
A3
Register
WD3
File
20:16
15:0
CLK
=
25:21
4
PCSrcD
EqualD
CLK
00
01
10
ALU
CLK
CLK
0 SrcBE
1
WriteDataE
RsD
RsE
RtD
RtE
RdE
RdE
ALUOutM
WriteDataM
A
RD
Data
Memory
WD
ReadDataW
ALUOutW
0
WriteRegE4:0
WriteRegM4:0
1
0
WriteRegW 4:0
1
SignImmD
SignImmE
+
<<2
PCPlus4D
CLR
CLR
EN
PCPlus4F
PCBranchD
Hazard Unit
Приводит к новому конфликту данных на стадии Декодирования
Глава 7 <97>
RegWriteW
RegWriteM
MemtoRegE
ForwardBE
ForwardAE
FlushE
StallD
StallF
ResultW
98.
Ранняя проверка условия перехода1
2
3
4
5
6
7
8
9
Time (cycles)
20
beq $t1, $t2, 40
24
and $t0, $s0, $s1
28
or
2C
sub $t2, $s0, $s5
30
...
IM
lw
$t1
RF $t2
IM
and
DM
-
$s0
RF $s1
DM
Flush
this
instruction
RF
$t1, $s4, $s0
...
slt $t3, $s2, $s3
IM
slt
$s2
RF $s3
slt
64
&
RF
DM
$t3
RF
Инструкцию загруженную в конвейер после beq не обязательно
удалять в случае выполнения перехода. Можно ввести условие,
что инструкция следующая за переходом (условным или
безусловным) выполняется всегда. Такое допущение называется
branch delay slot.
Глава 7 <98>
99.
Устранение конфликтов управления иданных
CLK
Control
Unit
31:26
5:0
CLK
CLK
RegWriteD
RegWriteE
RegWriteM
RegWriteW
MemtoRegD
MemtoRegE
MemtoRegM
MemtoRegW
MemWriteD
MemWriteE
MemWriteM
ALUControlD2:0
ALUControlE2:0
Op
ALUSrcD
ALUSrcE
Funct
RegDstD
RegDstE
BranchD
PCF
EN
A
InstrD
RD
25:21
A1
WE3
CLK
=
RD1
0
20:16
A2
A3
WD3
RD2
0
20:16
15:11
15:0
4
0 SrcBE
1
RsD
RsE
RtD
RtE
RdD
RdE
ALUOutM
WriteDataM
WriteDataE
25:21
Sign
Extend
00
01
10
1
Register
File
WE
SrcAE
00
01
10
1
Instruction
Memory
+
A
RD
Data
Memory
WD
ReadDataW
ALUOutW
0
WriteRegE4:0
WriteRegM4:0
1
0
WriteRegW 4:0
1
SignImmD
SignImmE
+
<<2
PCPlus4D
CLR
CLR
EN
PCPlus4F
PCBranchD
Глава 7 <99>
RegWriteW
RegWriteM
MemtoRegE
Hazard Unit
RegWriteE
ForwardBE
ForwardAE
FlushE
ForwardBD
ForwardAD
BranchD
ResultW
StallD
1
PC'
StallF
0
PCSrcD
EqualD
CLK
ALU
CLK
CLK
100.
Логика устранения конфликтов• Логика управления передачей данных между
стадиями конвейера (Forwarding logic):
ForwardAD = (rsD !=0) AND (rsD == WriteRegM) AND RegWriteM
ForwardBD = (rtD !=0) AND (rtD == WriteRegM) AND RegWriteM
• Логика останова конвейера (Stalling logic):
branchstall = BranchD AND RegWriteE AND
(WriteRegE == rsD OR WriteRegE == rtD)
OR
BranchD AND MemtoRegM AND
(WriteRegM == rsD OR WriteRegM == rtD)
StallF = StallD = FlushE = lwstall OR branchstall
Глава 7 <100>
101.
Предсказание переходов• Мы можем попробовать оценить на сколько
вероятно выполнение условного перехода и
использовать наиболее вероятный результат
– Например, в циклах наиболее вероятно выполнение
условных переходов назад (переходы на начало
итерации цикла скорее выполняются, чем нет)
– Для улучшения предсказания переходов можно
использовать результаты предыдущих предсказаний
(например, если три прошлых раза мы переходили
назад, то скорее всего это цикл и в следующий раз
условный переход назад тоже состоится)
• Хорошее предсказание уменьшает количество
сбросов стадий конвейера
Глава 7 <101>
102.
Оценим производительность конвейерногопроцессора
• Тестовый набор SPECINT2000 содержит :
–
–
–
–
–
25%
10%
11%
2%
52%
инструкций lw
инструкций sw
условных переходов
безусловных переходов
инструкций R-типа
• Предположим:
– 40% считываний из памяти используются следующей инструкцией
– 25% переходов предсказываются неверно
– Все переходы удаляют следующую инструкцию из конвейера
• Каков средний CPI?
Глава 7 <102>
103.
Оценим производительность конвейерногопроцессора
• Тестовый набор SPECINT2000 содержит :
–
–
–
–
–
25%
10%
11%
2%
52%
инструкций lw
инструкций sw
условных переходов
безусловных переходов
инструкций R-типа
• Предположим:
– 40% считываний из памяти используются следующей инструкцией
– 25% переходов предсказываются неверно
– Все переходы удаляют следующую инструкцию из конвейера
• Каков средний CPI?
– Для lw/beq CPI = 1 если нет останова, 2 в случае останова
– CPIlw = 1(0.6) + 2(0.4) = 1.4
– CPIbeq = 1(0.75) + 2(0.25) = 1.25
Средний CPI = (0.25)(1.4) + (0.1)(1) + (0.11)(1.25) + (0.02)(2) + (0.52)(1)
= 1.15
Глава 7 <103>
104.
Оценим производительность конвейерногопроцессора
• Задержка самой длинной цепи комбинационной
логики конвейерного процессора:
Tc = max {
tpcq + tmem + tsetup
2(tRFread + tmux + teq + tAND + tmux + tsetup )
tpcq + tmux + tmux + tALU + tsetup
tpcq + tmemwrite + tsetup
2(tpcq + tmux + tRFwrite) }
Глава 7 <104>
105.
Оценим производительность конвейерногопроцессора
Параметр
Обозначение
Задержка (пс)
Время записи в регистр
tpcq_PC
30
Время предустановки регистра
tsetup
20
Задержка мультиплексора
tmux
25
Задержка АЛУ
tALU
200
Задержка считывания из памяти
tmem
250
Задержка считывания из рег. файла
tRFread
150
Время предустановки рег. файла
tRFsetup
20
Задержка компаратора
teq
40
Задержка элемента И
tAND
15
Задержка записи в память
Tmemwrite
220
Задержка записи в рег. файл
tRFwrite
100 ps
Tc = 2(tRFread + tmux + teq + tAND + tmux + tsetup )
= 2[150 + 25 + 40 + 15 + 25 + 20] ps = 550 пс
Глава 7 <105>
106.
Оценим производительность конвейерногопроцессора
Предположим, в программе 100 миллиардов
инструкций
Время выполнения = (# инструкции) × CPI × Tc
= (100 × 109)(1.15)(550 × 10-12)
= 63 секунды
Глава 7 <106>
107.
Сравнение производительностиМикроархитектура
Время
выполнения
(секунды)
Прирост
производительности
Однотактная
92.5
1
Многотактная
133
0.70
Конвейерная
63
1.47
Глава 7 <107>
108.
Повторение: Исключения• Исключение (англ.: exception) – незапланированный вызов функцииобработчика исключения (exception handler)
• Исключения бывают:
– Аппаратные (например, нажатие клавиши на клавиатуре). Такие
исключения называют прерываниями (англ.: interrupt).
– Программные (например, неизвестная инструкция, деление на
ноль). Такие исключения называют ловушками (англ.: trap).
• При возникновении исключения процессор:
– Записывает в специальный регистр код причины исключения
– Сохраняет значение счетчика команд (PC) на момент
возникновения исключения (адрес инструкции вызвавшей искл.)
– Делает переход в функцию-обработчик исключения по адресу
0x80000180
– После выполнения обработчика исключения возвращает
управление прерванной программе, делая переход по ранее
сохраненному адресу
Глава 7 <108>
109.
Пример исключенияГлава 7 <109>
110.
Регистры обработки исключений• Отдельные регистры. Не входят в регистровый файл
– Cause
• Содержит код причины исключения
• Регистр 13 Сопроцессора 0
– EPC (Exception PC)
• Содержит значение счетчика команд (PC) на момент
возникновения исключения
• Регистр 14 Сопроцессора 0
• Инструкция считывания регистра Сопроцессора 0 в регистр
общего назначения
– mfc0 $t0, Cause
– Копирует содержимое Cause в регистр $t0
mfc0
010000
00000
$t0 (8) Cause (13)
31:26
25:21
20:16
15:11
00000000000
10:0
Глава 7 <110>
111.
Коды причин исключенийИсключение
Код причины
Аппаратное прерывание
0x00000000
Системный вызов
0x00000020
Точка останова / Деление на 0
0x00000024
Неизвестная инструкция
0x00000028
Арифметическое переполнение 0x00000030
Добавим в многотактный MIPS процессор
возможность обработки последних двух типов
исключений
Глава 7 <111>
112.
Аппаратура исключений: EPC & CauseEPCWrite
IntCause CauseWrite
CLK
CLK 0x30
0
0x28
1
Cause
EN
EPC
EN
PCEn
MemWrite IRWrite
CLK
CLK
RegDst MemtoReg
PC
EN
0
1
Adr
A
Instr
RD
EN
Instr / Data
Memory
WD
25:21
A1
20:16
A2
20:16
15:11
CLK
WE3
0
RD1
RD2
A
31:28
A3
1
0
1
WD3
SrcA
1
B
00
4
0
Data
ALUSrcA ALUSrcB1:0 ALUControl2:0 Branch PCWrite
01
SrcB
10
Register
File
11
<<2
SignImm
15:0
PCSrc1:0
CLK
CLK
CLK
WE
PC'
RegWrite
Sign Extend
25:0 (jump)
Глава 7 <112>
CLK
Zero
ALU
IorD
00
ALUResult
ALUOut
Overflow
01
10
PCJump
11
0x8000 0180
<<2
27:0
113.
Исключения в управляющем автоматеS12: Undefined
S14: MFC0
PCSrc = 11
PCWrite
IntCause = 1
CauseWrite
EPCWrite
RegDst = 0
Memtoreg = 10
RegWrite
Op = others
S0: Fetch
IorD = 0
AluSrcA = 0
ALUSrcB = 01
ALUOp = 00
PCSrc = 00
IRWrite
PCWrite
Reset
S2: MemAdr
S1: Decode
Op = mfc0
S11: Jump
ALUSrcA = 0
ALUSrcB = 11
ALUOp = 00
Op = J
PCSrc = 10
PCWrite
Op = BEQ
Op = LW
or
Op = SW
Op = ADDI
Op = R-type
S6: Execute
ALUSrcA = 1
ALUSrcB = 10
ALUOp = 00
ALUSrcA = 1
ALUSrcB = 00
ALUOp = 10
S8: Branch
ALUSrcA = 1
ALUSrcB = 00
ALUOp = 01
PCSrc = 01
Branch
S9: ADDI
Execute
ALUSrcA = 1
ALUSrcB = 10
ALUOp = 00
Op = SW
Op = LW
S5: MemWrite
S3: MemRead
IorD = 1
IorD = 1
MemWrite
Overflow
Overflow
S13:
Overflow
PCSrc = 11
RegDst = 1
PCWrite
MemtoReg = 00
IntCause = 0
RegWrite
CauseWrite
EPCWrite
S7: ALU
Writeback
S10: ADDI
Writeback
RegDst = 0
MemtoReg = 00
RegWrite
S4: Mem
Writeback
RegDst = 0
MemtoReg = 01
RegWrite
Глава 7 <113>
114.
Аппаратура исключений: mfc0EPCWrite
IntCause CauseWrite
CLK
CLK 0x30
0
0x28
1
Cause
EN
EPC
...
01101
C0
01110
...
EN
15:11
MemWrite IRWrite
CLK
CLK
RegDst MemtoReg1:0 RegWrite
WE
PC'
PC
EN
0
1
Adr
A
Instr
RD
EN
Instr / Data
Memory
WD
25:21
A1
20:16
A2
20:16
15:11
CLK
1
Data
WE3
0
RD1
RD2
A
31:28
A3
10
00
01
WD3
SrcA
1
B
00
4
0
01
SrcB
10
Register
File
11
<<2
SignImm
15:0
PCSrc1:0
CLK
CLK
CLK
ALUSrcA ALUSrcB1:0 ALUControl2:0 Branch PCWrite
Sign Extend
25:0 (jump)
Глава 7 <114>
CLK
Zero
ALU
IorD
PCEn
00
ALUResult
ALUOut
Overflow
01
10
PCJump
11
0x8000 0180
<<2
27:0
115.
Улучшения микроархитектурыДлинные конвейеры
Динамическое предсказание переходов
Суперскалярные процессоры
Процессоры с внеочередным выполнением
инструкций
Переименование регистров
SIMD
Многопоточность
Многопроцессорность
Глава 7 <115>
116.
Длинные конвейеры• Содержат 10-20 стадий
• Количество стадий ограничивается:
– Конфликтами конвейера
– Энергопотреблением
– Стоимостью
– Увеличением задержки тактового сигнала
Глава 7 <116>
117.
Предсказание переходов• У идеального конвейерного процессора: CPI = 1
• Неверное предсказание переходов увеличивает CPI
• Статическое предсказание переходов:
– Проверяем направление перехода (вперед или назад)
– Если переход назад, считаем, что он будет выполнен
– Иначе, считаем, что переход не будет выполнен
• Динамическое предсказание переходов:
– Процессор содержит таблицу с последними
несколькими сотнями (или тысячами) инструкций
условного перехода. Эту таблица иногда называют
буфером целевых адресов ветвлений (branch target
buffer). Она содержит адреса переходов и информацию
о том, был ли переход выполнен.
Глава 7 <117>
118.
Пример предсказания переходовadd
add
addi
for:
beq
add
addi
j
done:
$s1, $0, $0
$s0, $0, $0
$t0, $0, 10
# sum = 0
# i
= 0
# $t0 = 10
$s0, $t0, done
$s1, $s1, $s0
$s0, $s0, 1
for
# if i == 10, branch
# sum = sum + i
# increment i
Глава 7 <118>
119.
Однобитный динамический предсказательпереходов
• Запоминает, был ли переход выполнен в
прошлый раз, и предсказывает, что в
следующий раз произойдет то же самое
• Ошибается дважды: для первого и последнего
условных переходов цикла (на первой и
последней итерации)
Глава 7 <119>
120.
Двухбитный динамический предсказательпереходов
strongly
taken
predict
taken
taken
weakly
taken
taken
taken
weakly
not taken
predict
taken
taken
taken
predict
not taken
taken
taken
strongly
not taken
taken
predict
not taken
Дает неверное предсказание только для последнего
условного перехода цикла (на последней итерации)
Глава 7 <120>
121.
Суперскалярный процессор• Позволяет одновременно считывать и выполнять
несколько инструкций за счет дублирования
функциональных блоков
• Как будто в процессоре одновременно функционирует
несколько конвейеров
• Зависимости между инструкциями значительно
усложняют их одновременное выполнение
CLK
CLK
CLK
CLK
PC
A
RD
Instruction
Memory
A1
A2
A3
A4
A5
A6
WD3
WD6
RD1
RD4
Register
RD2
File
RD5
ALUs
CLK
Глава 7 <121>
A1
A2
RD1
RD2
Data
Memory
WD1
WD2
122.
Пример суперскалярностиlw
add
sub
and
or
sw
$t0,
$t1,
$t0,
$t2,
$t3,
$s7,
40($s0)
$t0, $s1
$s2, $s3
$s4, $t0
$s5, $s6
80($t3)
Идеальный IPC:
Реальный IPC:
1
2
3
4
2
2
5
6
7
8
Time (cycles)
lw
lw
$t0, 40($s0)
IM
add $t1, $s1, $s2
add
$s0
40
RF $s1
+
$s2
+
sub
sub $t2, $s1, $s3
IM
and $t3, $s3, $s4
or
and
DM
$s3
RF $s3
-
$s4
&
or
$t4, $s1, $s5
RF
sw
$t2
DM
$t3
RF
$s1
$s5
RF $s0
80
$t4
|
+
$s5, 80($s0)
$t1
$s1
IM
sw
$t0
Глава 7 <122>
DM
$s5
RF
123.
Суперскалярность с зависимостямиlw
add
sub
and
or
sw
$t0,
$t1,
$t0,
$t2,
$t3,
$s7,
40($s0)
$t0, $s1
$s2, $s3
$s4, $t0
$s5, $s6
80($t3)
Идеальный IPC:
Реальный IPC:
1
2
3
4
5
2
6/5 = 1.17
6
7
8
9
Time (cycles)
lw
$s0
lw
$t0, 40($s0)
IM
40
+
DM
RF
$t0
$t0
$s1
$s1
RF $s2
RF $s2
$s3
$s3
add
add $t1, $t0, $s1
IM
sub $t0, $s2, $s3
$t0
sub
RF
DM
and
IM
or
$t3, $s5, $s6
sw
$s7, 80($t3)
or
and
IM
or
$t0
-
Stall
and $t2, $s4, $t0
$t1
+
RF
$s4
$t0
RF $s5
&
$s6
|
$t3
$t3
sw
IM
$t2
DM
80
RF
Глава 7 <123>
+
RF
$s7
DM
RF
124.
Внеочередное выполнение инструкций• Процессор заранее просматривает наперед большое количество
инструкций, находит независимые друг от друга инструкции и
запускает их на одновременное выполнение
• Инструкции могут выполняться не в том порядке, в котором они
расположены в программе
• Процессор следит за тем, чтобы внеочередное выполнение не
нарушало алгоритм работы программы
• Зависимости:
– RAW (read after write, чтение после записи): предыдущая
инструкция записывает, следующая считывает регистр
– WAR (write after read, запись после чтения): предыдущая
инструкция считывает регистр, следующая инструкция
записывает этот регистр
– WAW (write after write, запись после записи): инструкция
пытается писать в регистр после того, как в него уже записала
следующая по ходу программы инструкция
Глава 7 <124>
125.
Внеочередное выполнение инструкций• Параллелизм на уровне инструкций (Instruction
level parallelism, ILP): число инструкций, которые
могут выполнятся одновременно (обычно < 3)
• Таблица готовности (Scoreboard): таблица,
хранящая информацию про:
– Инструкции ожидающие выполнения
– Доступные функциональные блоки (АЛУ,
порты памяти и т.д.)
– Зависимости между инструкциями
Глава 7 <125>
126.
Пример внеочередного выполненияlw
add
sub
and
or
sw
$t0,
$t1,
$t0,
$t2,
$t3,
$s7,
40($s0)
$t0, $s1
$s2, $s3
$s4, $t0
$s5, $s6
80($t3)
Идеальный IPC: 2
Реальный IPC: 6/4 = 1.5
1
2
3
4
5
6
7
8
Time (cycles)
lw
$t0, 40($s0)
or
$t3, $s5, $s6
$s0
lw
IM
or
40
DM
RF $s5
$s6
add $t1, $t0, $s1
WAR
sub $t0, $s2, $s3
$t3
sw
IM
RF
$t3
|
RAW
sw $s7, 80($t3)
two cycle latency
between load and RAW
use of $t0
$t0
+
80
$s7
+
DM
RF
$t0
add
IM
sub
RF
$s1
$t1
+
DM
RF $s2
$s3
RAW
$s4
and
and $t2, $s4, $t0
IM
RF
$t0
-
$t0
$t2
&
RF
Глава 7 <126>
DM
RF
127.
Переименование регистровlw
add
sub
and
or
sw
$t0,
$t1,
$t0,
$t2,
$t3,
$s7,
40($s0)
$t0, $s1
$s2, $s3
$s4, $t0
$s5, $s6
80($t3)
Идеальный IPC: 2
Реальный IPC: 6/3 = 2
1
2
3
4
5
6
7
Time (cycles)
lw
IM
sub $r0, $s2, $s3
$s0
lw
$t0, 40($s0)
sub
40
$s3
or
$s4
$r0
$s6
add
IM
$s7, 80($t3)
$t2
&
DM
RF $s5
RAW
add $t1, $t0, $s1
sw
RF
$r0
-
and
IM
$t3, $s5, $s6
DM
RF $s2
RAW
2-cycle RAW
and $t2, $s4, $r0
or
$t0
+
sw
$t3
|
RF
$t0
$s1
RF $t3
80
$t1
+
+
Глава 7 <127>
DM
$s7
RF
128.
SIMD• Одиночный поток команд, множественный поток данных
(Single Instruction Multiple Data, SIMD)
– Одна инструкция обрабатывает множество блоков данных
одновременно (например, параллельно суммирует
несколько пар чисел)
– Часто используется в компьютерной графике
– Выполняется арифметическая операция над несколькими
небольшими независимыми блоками данных (пакованная
арифметика)
• Например, в 32-разрядном сумматоре можно одновременно
суммировать 4-ре пары 8-битных операндов
padd8 $s2, $s0, $s1
32
+
24 23
16 15
8 7
0
Bit position
a3
a2
a1
a0
$s0
b3
b2
b1
b0
$s1
a3 + b3
a2 + b2
a1 + b1
a0 + b0
$s2
Глава 7 <128>
129.
Многопоточность и мультипроцессорность• Многопоточность
– Например, в текстовом редакторе один поток
может отвечать за обработку вводимых с
клавиатуры символов и набор текста, другой
поток “одновременно” выполнять проверку
правописания, третий поток может при этом
выводить текст на печать
• Мультипроцессорность
– Несколько отдельных процессоров внутри
одного чипа
Глава 7 <129>
130.
Потоки: Определения• Процесс: программа, которая выполняется
на компьютере
– Несколько процессов могут выполняться
одновременно, например: веб серфинг,
прослушивание музыки, написание статьи в
текстовом редакторе
• Поток: часть процесса (программы)
– Процесс может содержать несколько потоков,
например текстовый редактор может
содержать потоки для набора текста,
проверки орфографии, печати
Глава 7 <130>
131.
Потоки в обычном процессоре• В каждый момент времени выполняется один поток
• Когда выполнение потока блокируется (например, поток
ожидает данные из медленной внешней памяти):
– Архитектурное состояние потока сохраняется
– Архитектурное состояние следующего потока
загружается в процессор и поток запускается на
выполнение
– Такая процедура называется переключением
контекста
• До тех пор, пока процессор переключается между
потоками достаточно быстро, пользователю кажется, что
все потоки выполняются одновременно.
Глава 7 <131>
132.
Многопоточность• У многопоточного процессора есть несколько копий
архитектурного состояния
• Несколько потоков могут быть активны одновременно:
– Когда выполнение одного потока блокируется, сразу же
запускается выполнение другого потока на имеющихся
функциональных блоках
– Если один поток не использует все функциональные
блоки процессора, их использует другой поток
• Многопоточность не влияет на параллелизм на уровне
инструкций (ILP) отдельного потока, но увеличивает
общую производительность вычислений
Intel называет такую технологию “hyperthreading”
Глава 7 <132>
133.
Многопроцессорность• Многопроцессорная система (multiprocessor system), или
просто мультипроцессор, состоит из нескольких процессоров
и аппаратуры для соединения их между собой
• Типы:
– Гомогенная (симметричная) многопроцессорность:
несколько одинаковых процессоров подключены к общей
памяти
– Гетерогенная (асимметричная) многопроцессорность:
разные типы процессорных ядер используются для задач
разных типов (например, в мобильном телефоне для
вычислений используется обычный процессор, а для
обработки аудио/видео – специализированное DSP ядро)
– Кластеры: каждое ядро имеет свою собственную память
Глава 7 <133>
134.
Дополнительные ресурсы• Patterson & Hennessy’s: Computer
Architecture: A Quantitative Approach
• Conferences:
– www.cs.wisc.edu/~arch/www/
– ISCA (International Symposium on Computer
Architecture)
– HPCA (International Symposium on High Performance
Computer Architecture)
Глава 7 <134>