

















 Математика
МатематикаПохожие презентации:
")









Обучение с подкреплением. Тема 2
1.
Обучение сподкреплением
Тема 2
2.
3.
V*(s) - полезность действий, Value, суммарное (максимальное) матожидание от выигрыша, которое мы можем получить всостоянии s
- политика, стратегия
Матожидание по политике заменим последовательностью действий (a0, a1, …)
4.
V*(s`) - предсказание вознаграждения в следующем состоянии (рекурсивное выражение для V)Уравнение Беллмана для функции полезности состояний V .
5.
Если мы знаем оценку полезностисостояний V, то мы понимаем
стратегию принимаемых действий.
Чтобы оценить V для нашей
игровой ситуации и принять
оптимальную
(лучшую
по
выигрышу) стратегию переходов. В
каждом состоянии есть выбор,
который
нужно
сделать
(терминальные и промежуточные
состояния).
Итерационный
процесс:
есть
проинициализированное V, далее
обновляем
V
в
следующем
состоянии, зависящее от V в
предыдущем, пока состояние не
стабилизируется.
Пример: среда, агент, ревард и
проигрыш,
переходы
в
0,
запрещенный переход.
6.
Начинаем оценивать состояния по формуле V итерационной (V*new):7.
Метод итерации Value8.
9.
10.
11.
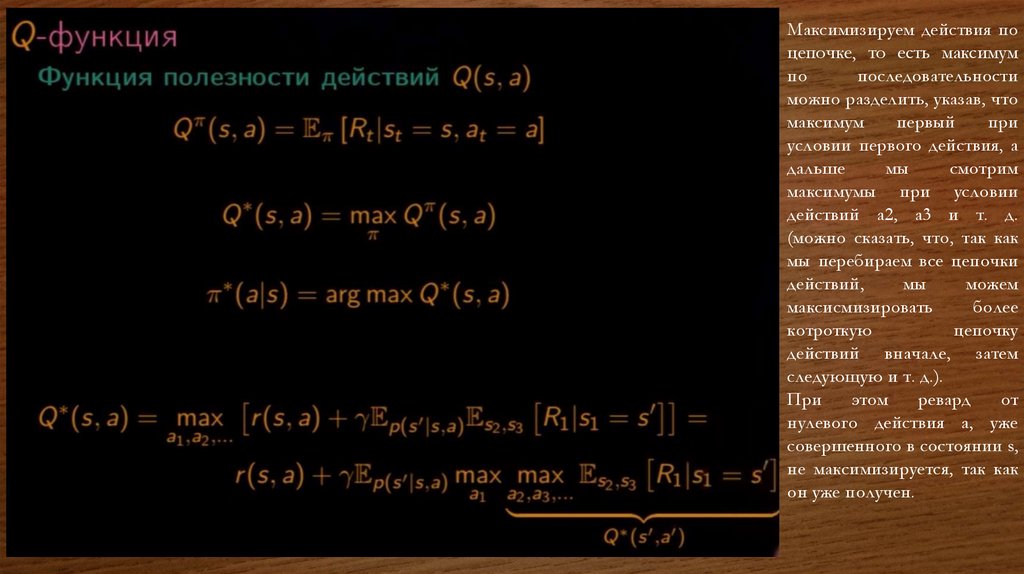
Максимизируем действия поцепочке, то есть максимум
по
последовательности
можно разделить, указав, что
максимум
первый
при
условии первого действия, а
дальше
мы
смотрим
максимумы при условии
действий a2, a3 и т. д.
(можно сказать, что, так как
мы перебираем все цепочки
действий,
мы
можем
максисмизировать
более
котроткую
цепочку
действий вначале, затем
следующую и т. д.).
При
этом
ревард
от
нулевого действия a, уже
совершенного в состоянии s,
не максимизируется, так как
он уже получен.
12.
Уравнение Беллмана для функции полезности действий Q . Равенство выполняется для всех состояний и всех действий.Q*(s, a) мы знаем приближенно. При переносе правой части влево мы переходим к задаче машинного обучения и должны
минимизировать Loss, так как Q только приближенное, в равнестве наблюдается несоответствие (ошибка), и мы должны
при вычитании минимизировать разницу.
Минимизацию выполняем методом наименьших квадратов. Возведем выражение (разницу) в квадрат и просуммируем по
всем действиям, для всех комбинаций s и a, то есть декартового произведения s и a, количество уравнений, которые должны
быть равны нулю, составит мощность множества S умноженную на мощность множества A (задача машинного обучения).
Минимизируем сумму квадратов по Q*, левый множитель не влияет на минимизацию и вставлен для нормирования
(показывает размерность).
13.
Исходя из методов оптимизации, когда мы минимизируем функцию F , мы движемся в сторону ее антиградиента.Обозначим функцию потерь L, продифференцируем ее по параметру Q (dL/dQ).
Функция обновления (Q*new) равна Q*old минус коэффициент , умноженный на градиент dL/dQ.
Посчитаем производную функции L.
Получаем метод Q-learning.
14.
15.
Введем множество As в состоянии s , то естьоптимальных действий в состоянии s может
быть несколько таких, в которых выигрыш
максимальный.
Вероятность принять это действие – 1/|As|.
Допустим, у нас 5 оптимальных действий, в
жадной стратегии вероятность принять каждое
оптимальное действие 1/5, все остальные из,
допустим, возможных 100 действий (95) – не
оптимальные для этой стратегии, шанс 0.
- шанс на каждое из действий, то есть
исследование. Тогда оптимальные действия из
множества As мы принимаем с вероятностью
(1- )/|As|, а все остальные действия – с
вероятностью /|A| (где A – 100 действий).
У неоптимального действия в правой части
равенства, при принятой =0.1 и A=100, будет
равен 0.001, то есть вероятность принять не
оптимальное действие 0.001. Оптимальные
действия – вероятность принять одно из 5 при
1-0.1 = 0.9 будет равна 0,9/5=0.18.
- сглаживает распределение до равномерного,
с течением времени уменьшается, влияем на
стратегию (политику).
16.
17.
Дляоптимального
по
затратам
обучения
нам
нужна
память.
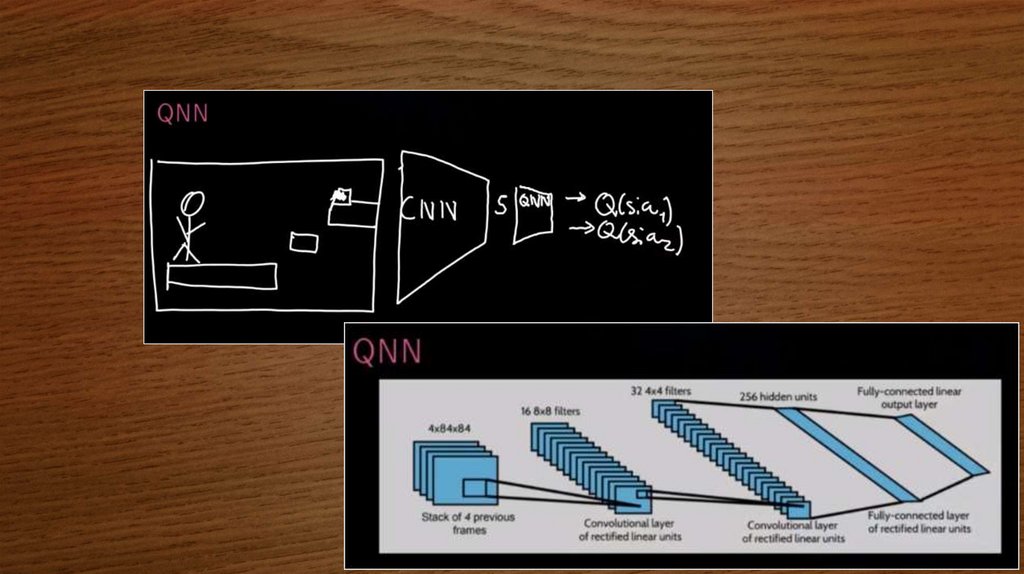
Инициализируем память и нейронную
сеть (обучаем QNN).
В цикле по эпизодам получаем код x0
(например,
кадр
изображения).
Прогоняем через CNN, получаем
состояние s0.
T шагов выполняем действия в соотв. с
ɛ-жадной стратегией:
получаем действие
получаем ревард, следующее состояние
заносим в память
получаем минибатч из памяти и
обновляем веса, ориентируясь на
значения из памяти (получаем y с
учетом Q).