











































 Информатика
ИнформатикаПохожие презентации:










Автоматический морфологический анализ (МорфАн)
1.
Для чего и как создаются моделикомпьютерной морфологии?
• Автоматический морфологический анализ
(МорфАн) – комплекс процедур, следующих за
графематическим анализом текста (отсечение
нетекстовых элементов, обработка таблиц,
рисунков, графиков, формул, ссылок,
библиографических описаний, иноязычных).
• Для разработки процедур МорфАн нужно
определить, какие грамматические категории
с какими граммемами и какими формальными
показателями должны попасть в модель.
2.
Для чего и как создаются моделикомпьютерной морфологии?
• Для разработки процедур МорфАн нужно
определить, какие грамматические категории
с какими граммемами и какими формальными
показателями должны попасть в модель.
• две букашки (Num f nom + N f nom pl) на
опушке (Prep + N f loc sg) шьют мышатам две
подушки (V tr pres imp + N m dat pl + Num f acc
+ N f acc pl)
3.
Для чего и как создаются моделикомпьютерной морфологии?
• Оптимальное число грамматических
категорий, грамматических значений,
граммем
• Как анализировать служебную лексику?
• Как решить проблему транспозиции?
• Как быть с грамматической омонимией?
4.
Основные процедурыавтоматической обработки текста
на морфологическом уровне
• Морфологический анализ – процедура установления
связей между вариантами лексической единицы и их
инвариантом (парадигматическая идентификация
словоформ ).
• Исследовать -> {исследовать} + Неопр.ф.
• Исследую -> {исследовать} + Наст., Буд. вр. + Ед.ч. + 1
л.
• Исследуешь -> {исследовать} + Наст., Буд. вр. + Ед.ч. +
2 л.
• Исследует -> {исследовать} + Наст., Буд. вр. + Ед.ч. + 3
л.
5.
Основные процедурыавтоматической обработки текста
на морфологическом уровне
• Обратная процедура – морфологический синтез
• {исследовать} + Неопр.ф. -> исследовать
• {исследовать} + Наст. вр. + Ед.ч. + 1 л. -> исследую
• {исследовать} + Наст. вр. + Ед.ч. + 2 л. -> исследуешь
• {исследовать} + Наст. вр. + Ед.ч. + 3 л. -> исследует
• …
6.
Основные процедурыавтоматической обработки текста
на морфологическом уровне
• Токенизация – идентификация словоформ в тексте.
Это синтагматическая идентификация словоформ
• Проблема – единица анализа:
• как анализировать обороты – аналитические формы
(буду писать), предлоги, сложные союзы (как бы,
потому что), сокращения (и т.п.),
терминологические словосочетания (железная
дорога), разрывные союзы (не только, но и)
7.
Основные процедурыавтоматической обработки текста
на морфологическом уровне
• Осложняющие факторы:
• сегменты текста между пробелами требуют
переразложения: буду (часто) писать; Марк
Твен; с разбегу;
• словоформы могут разделяться не только
пробелами:
• наконец-то (vs кто-то, во-первых, по-моему)
8.
Основные процедурыавтоматической обработки текста
на морфологическом уровне
• Лемматизация (нормализация) – сведение
различных словоформ к единому
представлению (исходной форме или лемме)
• Исследовать {исследовать}
• Исследую {исследовать}
• Исследуешь {исследовать}
• Исследует {исследовать}
9.
Основные процедурыавтоматической обработки текста
на морфологическом уровне
• Стемминг – вид нормализации, при
котором разные словоформы приводятся к
одной основе (псевдооснове).
• Есть задачи, где псевдоосновы будет
достаточно (например, информационный
поиск: фотографический, фотография – в
выдаче все документы)
10.
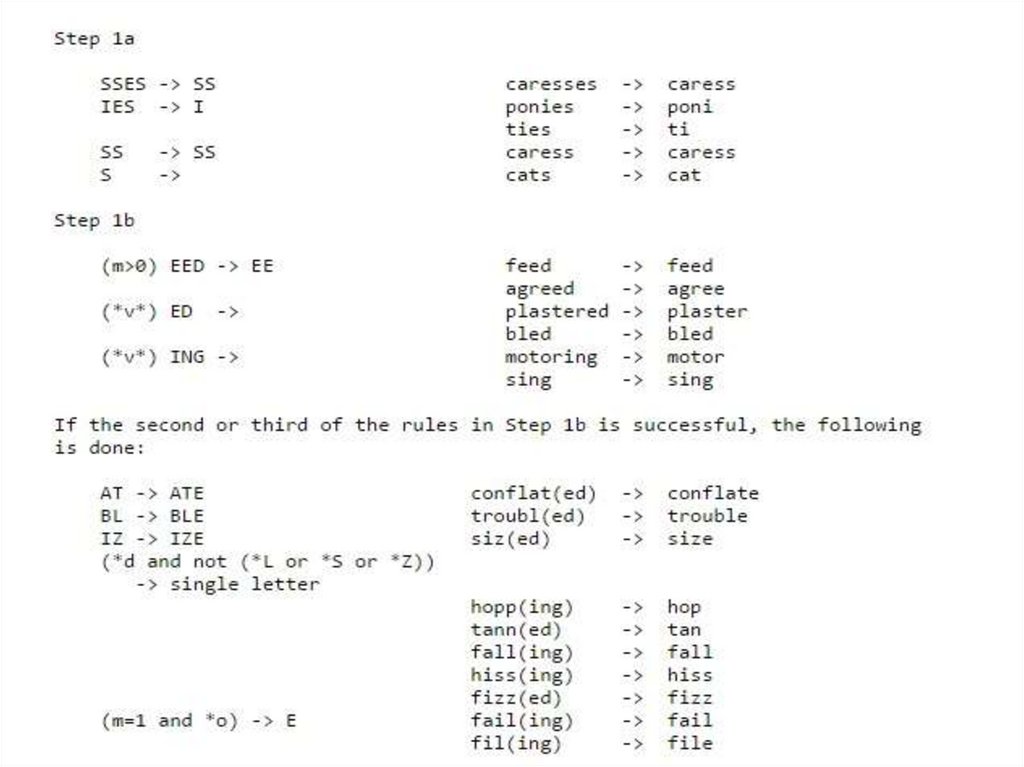
Стемминг• процесс нахождения основы слова для
заданного исходного слова.
• основа слова необязательно совпадает с
морфологическим корнем слова.
11.
Алгоритмы стемминга1. Алгоритм поиска флективной формы в имеющемся
словаре (полного перебора)
Простой стеммер ищет флективную форму в таблице
поиска.
2. Алгоритм усечения окончаний
используется список «правил», учитывающих форму
слова, чтобы найти его основу. Некоторые примеры
правил выглядят следующим образом:
если слово оканчивается на 'ed', удалить 'ed'
если слово оканчивается на 'ing', удалить 'ing'
если слово оканчивается на 'ly', удалить 'ly'
12.
13.
14.
Выделяют следующие виды ошибокнормализации:
• Under-stemming, когда морфологические
формы одного слова относят к разным
леммам;
• Over-stemming, когда разные слова
ошибочно относят к одной лемме.
15.
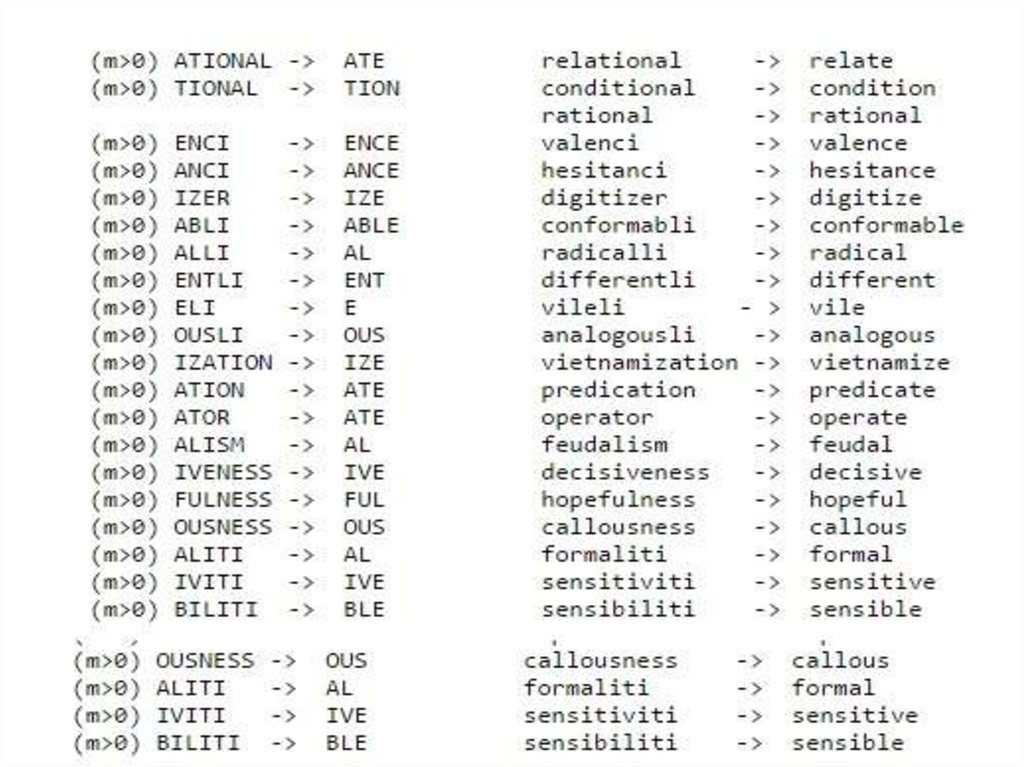
Стемминг для русского языка• Стеммер Портера
существует ограниченное количество
словообразующих суффиксов
стемминг слова происходит без использования
каких-либо баз основ: только множество
существующих суффиксов и вручную заданные
правила.
• Snowball
инструмент Портера для поддержки алгоритмов
стемминга и улучшения стеммеров английского
и некоторых других языков
16.
17.
Основные процедурыавтоматической обработки текста
на морфологическом уровне
• Частеречная разметка и полный
морфологический анализ (определение
части речи и/или грамматических
признаков словоформы)
18.
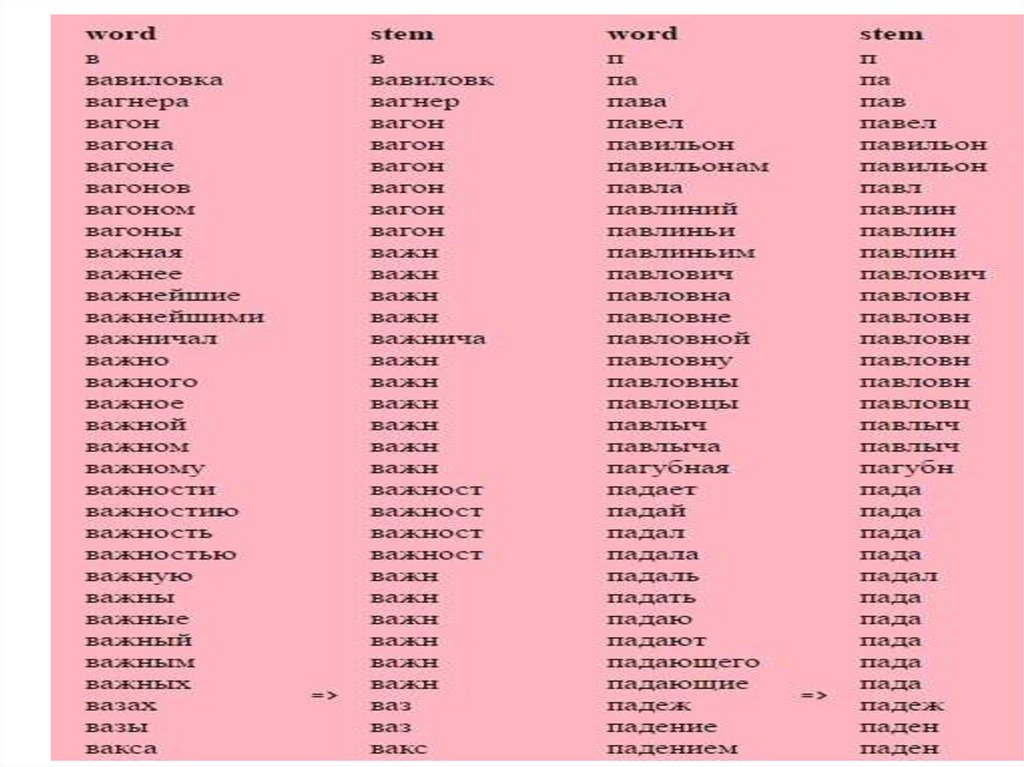
Методы морфологического анализа• Словарный метод морфологического
анализа
– со словарем словоформ (лучше, появился,
когда проблема ограничения памяти была
снята)
– со словарем основ (бег-беж воз-вож-вожд… )
был нужен, когда память машин была
ограничена, стек – стек, стечь, стекло,
стечь, стеклами, стеками – минус – много
шума)
19.
Методы морфологического анализаГрамматический словарь А.А.Зализняка
20.
Методы морфологического анализаГрамматический словарь А.А.Зализняка
Формат базы данных
Идентификатор лексемы Идентификатор парадигмы
Порогов
302
Пород
005
Породнени
002
Порожда
401
…
Идентификаторы парадигмы представляют собой
отсылки к таблицам с наборами правил для конкретных
парадигм.
21.
Методы морфологического анализаГрамматический словарь
А.А.Зализняка
• Идент. лексемы
• Пороговый
• Порода
• Породнение
• Порождать
• …
Основа
Идент.парадигмы
порогов
пород
породнени
порожда
302
005
002
401
22.
Методы морфологического анализа• Определение парадигмы слова
• если слово оканчивается на щийся, то ТП 5;
• если слово оканчивается на ин, ын, то ТП
20;
• если слово оканчивается на ов, ёв, ев, то ТП
21;
• если слово оканчивается на цый, то ТП 6;
• если слово оканчивается на ый, то ТП 1;
23.
Методы морфологического анализаРабота с парадигмами в словаре
• Парадигмы могут быть слишком дробными
для обработки письменного текста
• Например,
дол м 1е//1а
порт м 1е
клён м 1а
• имеют одинаковый набор окончаний
24.
Методы морфологического анализаРабота с парадигмами в словаре
• Парадигмы могут быть недостаточно точными
(для некоторых процедур компьютерной
морфологии)
• восстановление начальной формы:
• бугор м 1*b
бугра: (- ра), (+ ор)
• котёл м 1*b
котла: (- ла), (+ ёл)
• псалом м 1*b
псалма: (- ма), (+ ом)
• сон м 1*b
сна: (- на), (+ он)
• хребет м 1*b
хребта: (- та), (+
ет)
25.
Словарь OpenCorpora• ёж NOUN,anim,masc sing,nomn
• ежа NOUN,anim,masc sing,gent
• ежу NOUN,anim,masc sing,datv
• ежа NOUN,anim,masc sing,accs
• ежом NOUN,anim,masc sing,ablt
• еже NOUN,anim,masc sing,loct
• ежи NOUN,anim,masc plur,nomn
• ежей NOUN,anim,masc plur,gent
• ежам NOUN,anim,masc plur,datv
• ежей NOUN,anim,masc plur,accs
• ежами NOUN,anim,masc plur,ablt
• ежах NOUN,anim,masc plur,loct
26.
Словарь OpenCorpora• Лексема состоит из всех форм слова,
причем для каждой формы указана
грамматическая информация (тег). Первой
формой в списке идет нормальная форма
слова.
27.
Методы морфологического анализаБессловарные методы
• «Бессловарный анализ» или «анализ по
аналогии»?
• Термин «бессловарный анализ» применим в
ситуации полного отсутствия словаря
лексических единиц
• Термин «анализ по аналогии» описывает
анализ слов, которые не вошли в
существующий словарь.
• КРОВАТЬ – слово с парадигмой КРОВАТЬ,
КРУЙ, КРУЙТЕ, КРУЮ .. (как ПИРОВАТЬ)
28.
Методы морфологического анализаБессловарные методы
• Предсказание – анализ новых, редких слов, имен
собственных, окказионализмов (несловарных
словоформ), или анализ по аналогии
• Функциональное назначение предсказания –
морфологический анализ слов (словоформ),
отсутствующих в словаре
• Метод предсказания – выявление аналогий со
словоформами, распознаваемыми имеющимся
словарем
• предсказание префиксального образования
• предсказание по концовке, взятой из известных
словоформ
29.
Методы морфологического анализаБессловарные методы
• Предсказание префиксального образования:
попытка найти существующую словоформу
языка, которая максимально совпадала бы
справа со входным словом. Если левая часть
(потенциальный префикс) не длиннее M
символов (пяти), а правая часть (совпавшая с
известной словоформой) не короче N
символов (четырех), то слово разбирается по
образцу известной словоформы.
• [евро]технологию, [супер]коньками
30.
Методы морфологического анализаБессловарные методы
• Предсказание по концу: создается конечный автомат,
построенный на строках вида: ReverseSuffix(X)|Annot(X),
• где ReverseSuffix(Х) – инвертированная концовка
известной словоформы длины K (пять букв), Annot(X) –
аннотация словоформы X (анкод), например:
• меина|ед (анием) молчанием, мычанием, рычанием…
• где аннотация «ед» интерпретируется как «ср. род, ед. ч.,
тв. пад.»
• Такая строка заносится в исходный лексикон, если она
встречается:
• не менее L раз (трех) и чаще конкурентов (строк с таким
же ReverseSuffix(X), но другим Annot(X) ) в пределах одной
части речи
31.
32.
33.
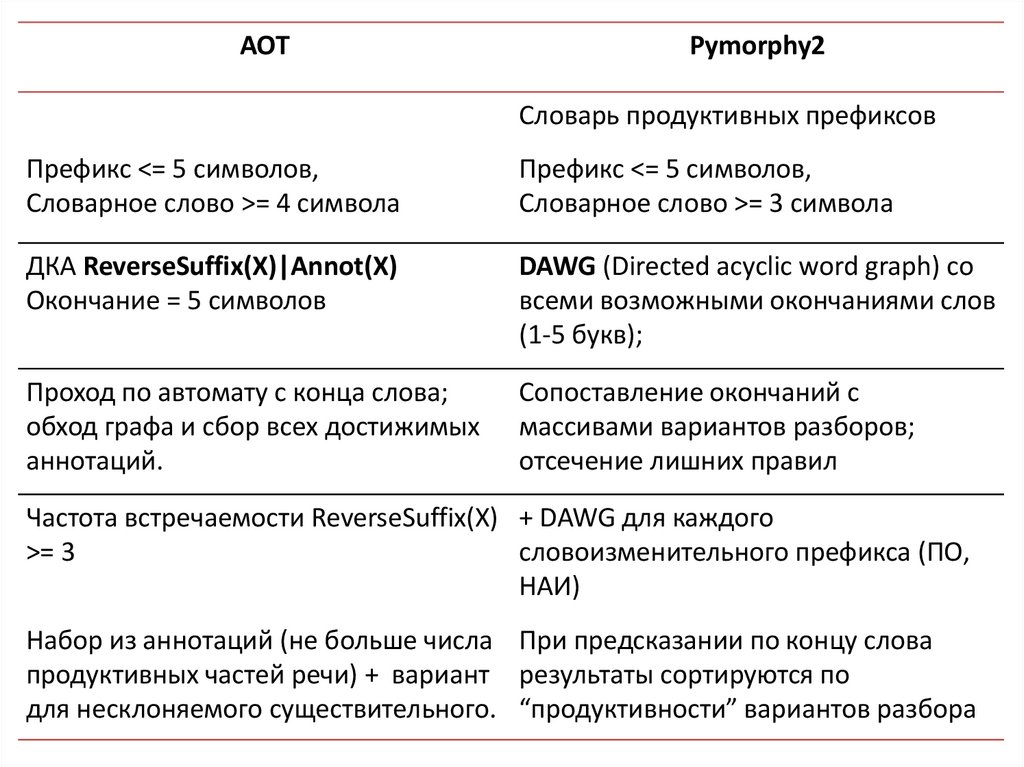
AOTPymorphy2
Словарь продуктивных префиксов
Префикс <= 5 символов,
Словарное слово >= 4 символа
Префикс <= 5 символов,
Словарное слово >= 3 символа
ДКА ReverseSuffix(X)|Annot(X)
Окончание = 5 символов
DAWG (Directed acyclic word graph) со
всеми возможными окончаниями слов
(1-5 букв);
Проход по автомату с конца слова;
обход графа и сбор всех достижимых
аннотаций.
Сопоставление окончаний с
массивами вариантов разборов;
отсечение лишних правил
Частота встречаемости ReverseSuffix(X) + DAWG для каждого
>= 3
словоизменительного префикса (ПО,
НАИ)
Набор из аннотаций (не больше числа При предсказании по концу слова
продуктивных частей речи) + вариант результаты сортируются по
для несклоняемого существительного. “продуктивности” вариантов разбора
34.
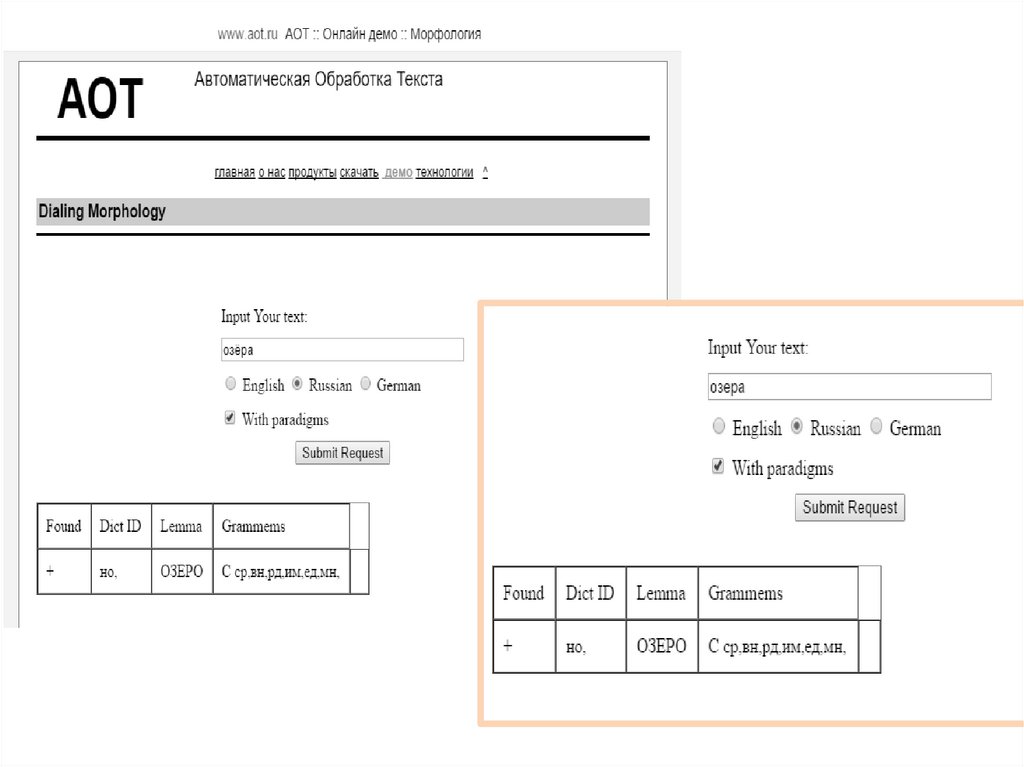
Морфоанализаторыдля русского языка
• АОТ
• Mystem
• Pymorphy
• Treetagger
• TnT
• …
• Stemka
• Snowball
35.
Морфоанализаторы для РЯ• Разметка с неснятой омонимией с помощью Mystem
• В{в:30948.70=PR=|в:0.00=S,сокр=им,ед|=S,сокр=им,мн|=S,сокр=ро
д,ед|=S,сокр=род,мн|=S,сокр=дат,ед|=S,сокр=дат,мн|=S,сокр=вин,
ед|=S,сокр=вин,мн|=S,сокр=твор,ед|=S,сокр=твор,мн|=S,сокр=пр,е
д|=S,сокр=пр,мн}
• этой{эта:0.00=S,жен,неод=твор,ед|этот:5357.80=APRO=род,ед,жен|
=APRO=дат,ед,жен|=APRO=твор,ед,жен|=APRO=пр,ед,жен}
• поучительной{поучительный:5.60=A=род,ед,полн,жен|=A=дат,ед,п
олн,жен|=A=твор,ед,полн,жен|=A=пр,ед,полн,жен}
• и{и:0.30=INTJ=|и:0.00=PART=|и:0.00=S,сокр=им,ед|=S,сокр=им,мн|
=S,сокр=род,ед|=S,сокр=род,мн|=S,сокр=дат,ед|=S,сокр=дат,мн|=S
,сокр=вин,ед|=S,сокр=вин,мн|=S,сокр=твор,ед|=S,сокр=твор,мн|=S
,сокр=пр,ед|=S,сокр=пр,мн|и:35302.69=CONJ=}
• развлекательной{развлекательный:5.80=A=род,ед,полн,жен|=A=да
т,ед,полн,жен|=A=твор,ед,полн,жен|=A=пр,ед,полн,жен}
• книге{книга:406.60=S,жен,неод=дат,ед|=S,жен,неод=пр,ед}
36.
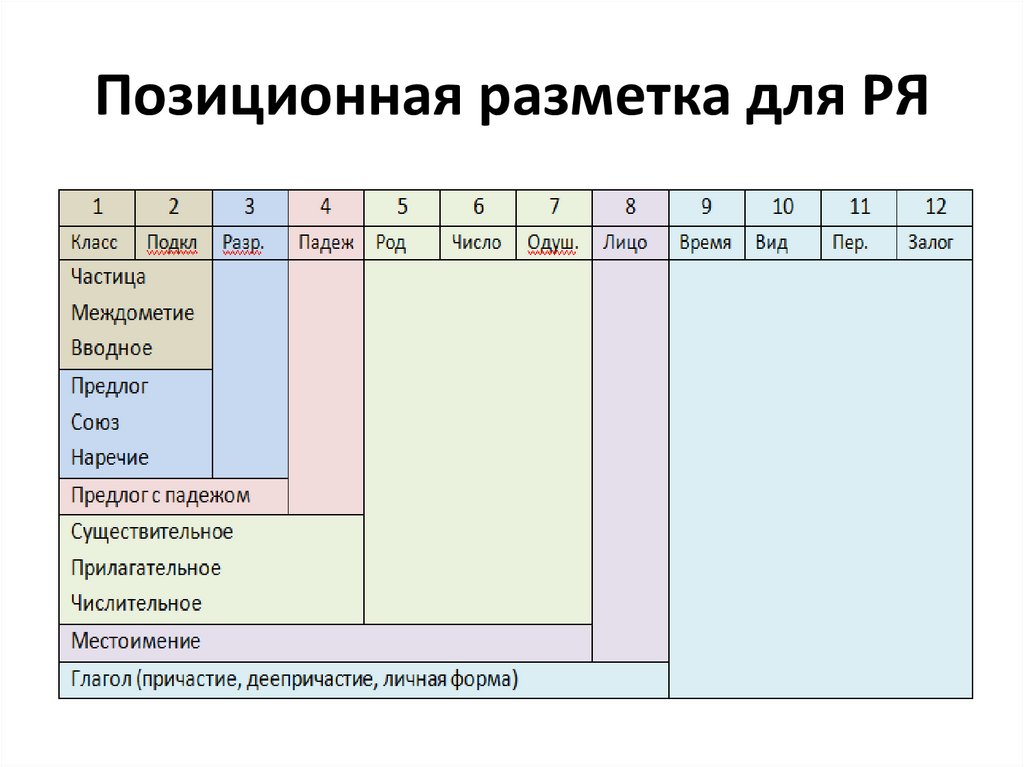
Позиционная разметка для РЯ37.
Автоматическое разрешениеморфологической неоднозначности
• Методы, основанные на контекстных
правилах, составляемых экспертамилингвистами
• Методы, основанные на контекстных
правилах, выводимых из текстов (с
управляемым и с неуправляемым обучением)
• Методы, основанные на вероятностных
моделях (с управляемым и с неуправляемым
обучением)
• Методы, основанные на нейронных сетях
• Гибридные методы
38.
Методы, основанные на контекстныхправилах, составляемых экспертамилингвистами
• Для английского языка - грамматика ограничений
(constraint grammar) Ф.Карлссона и А.Воутилайнена,
включает правила типа «выполни действие X над
объектом Y в контексте Z».
• В первой версии - 1200 правил, основанных на
грамматике, и 200 эвристических правил, потом
расширение до 3600 правил (для английского
языка).
• Контекстные правила могут быть закодированы в
виде конечных преобразователей (Э. Рош и
И.Шабес, амер. филиал Mitsubishi)
39.
• Правила применяются в определеннойпоследовательности, поочередно к каждому
слову текста, в несколько проходов (циклов), пока проход не даст нулевой результат
(исправлять более нечего).
Пример правила для английского языка:
tag:red ‘VB’ <- tag: ‘DT’@[-1] ○
«исключить тег VB, если сосед на расстоянии ‘-1’
(т.е. непосредств. сосед слева) имеет тег DT»
the / {DT} light / {JJ, NN, VB}
превращается в
the / {DT} light / {JJ, NN}
40.
Алгоритм Брилла с неуправляемымобучением
• Возможные варианты разметки
предложения «The can will rust»
The
can
will
rust
DT
MD
NN
VB
MD
NN
VB
NN
VB
41.
Алгоритм Брилла с неуправляемымобучением
• Анализируя корпус текстов при помощи словаря, мы
можем обнаружить, что среди всех слов, которые
встречаются после слова "the" (и для которых в словаре
указан только один возможный тэг), чаще всего
встречаются слова с тэгом NN. Исходя из этого, мы
можем сформулировать следующее правило:
• Заменять тег MD_NN_VB (т.е. сохраняющий три
варианта разметки) на NN после слова «the»
• Таким образом, первичная разметка дает неоднозначно
пазмеченный текст.
• Затем выводятся правила вида: «Заменить тег Х на тег Y
в контексте C, где Х является последовательностью из
двух или более тегов, а Y – один тег, такой что Y Х».
42.
Алгоритм Брилла с неуправляемымобучением
Шаблоны выводимых правил:
«Заменить тэг Х на тэг Y, если ...
• предшествующая словоформа
маркирована тэгом Z
• предшествующая словоформа есть W
• последующая словоформа маркирована
тэгом Z
• последующая словоформа есть W…»
43.
Вероятностные методы снятияморфологической омонимии
• Скрытые марковские модели
• Алгоритм Витерби
• Нейросетевые модели
44.
Разрешение морфологическойнеоднозначности на СММ
• Простейший (малопригодный) вариант –
присваивать каждой словоформе наиболее
вероятную морфологическую
интерпретацию
• За вероятности принимаются
относительные частоты присвоения той или
иной интерпретации определенной форме
в размеченном корпусе
45.
Разрешение морфологическойнеоднозначности на СММ
• Предположения о марковском характере
зависимости (модель первого порядка):
o встречаемость каждого тега в
определенном месте цепочки зависит
только от предыдущего тега;
o то, какое слово находится в том или ином
месте цепочки, полностью определяется
тегом (а не, допустим, соседними словами).
46.
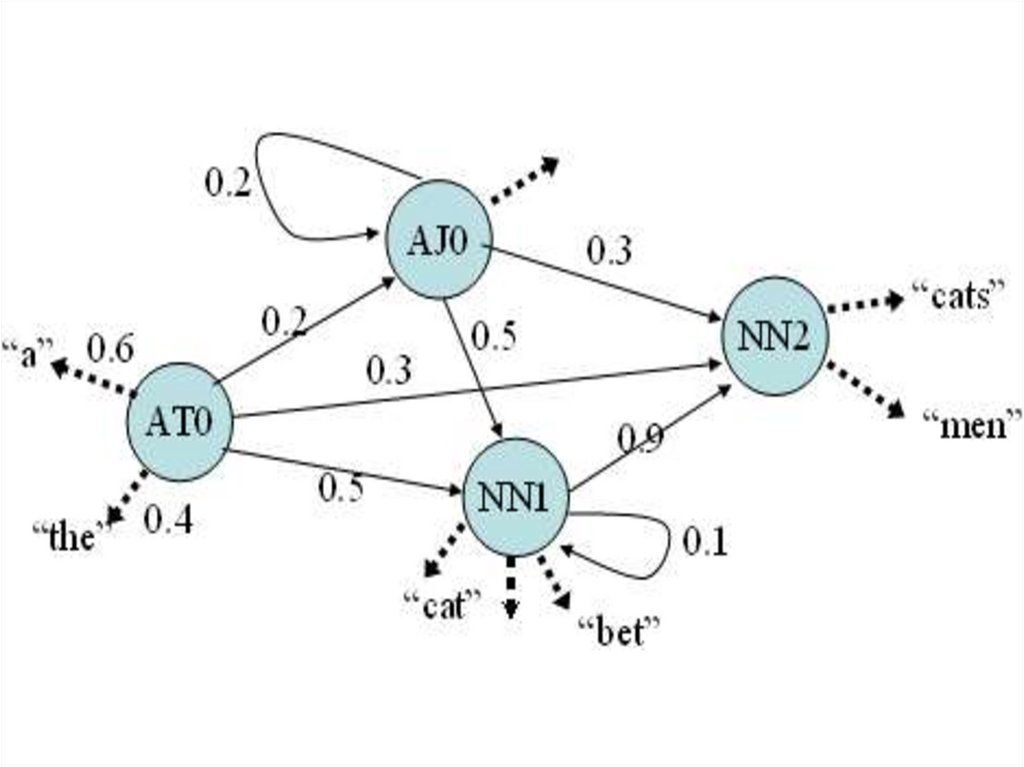
Разрешение морфологическойнеоднозначности на СММ
• Порождение правильно построенной
цепочки тегов уподобляется действию
конечного автомата
• Дуги помечены тегами с приписанными им
вероятностями
• Слова – это наблюдаемые реализации тегов
• Состояния определяются парой «текущий
тег + предыдущий тег»
47.
48.
Разрешение морфологическойнеоднозначности на СММ
• Если известна наблюдаемая реализация
цепочки тегов (т.е. предложение как
цепочка слов), то предстоит найти наиболее
вероятную цепочку тегов, лежащую в ее
основе, т.е.
o максимизировать вероятность того, что
данной цепочке слов <w> приписывается
именно такая цепочка тегов <t>:
49.
Разрешение морфологическойнеоднозначности на СММ
По теореме Байеса:
вводятся
вероятности соответствия именно такой цепочки
слов <w> заданной цепочке тегов <t> и
вероятность существования именно такой
цепочки тегов <t>.
50.
Разрешение морфологическойнеоднозначности на СММ
•находится максимум вероятности
•нужно посчитать произведение вероятностей
встречаемости каждого слова и тега в зависимости
от, соответственно, текущего и предыдущего тега.
• так для каждого тега, пользуясь заранее
достоверно (чаще всего вручную) размеченным
корпусом.
•требуется NL шагов вычислений, где L – длина цепочки
слов, N – количество тегов в наборе.
51.
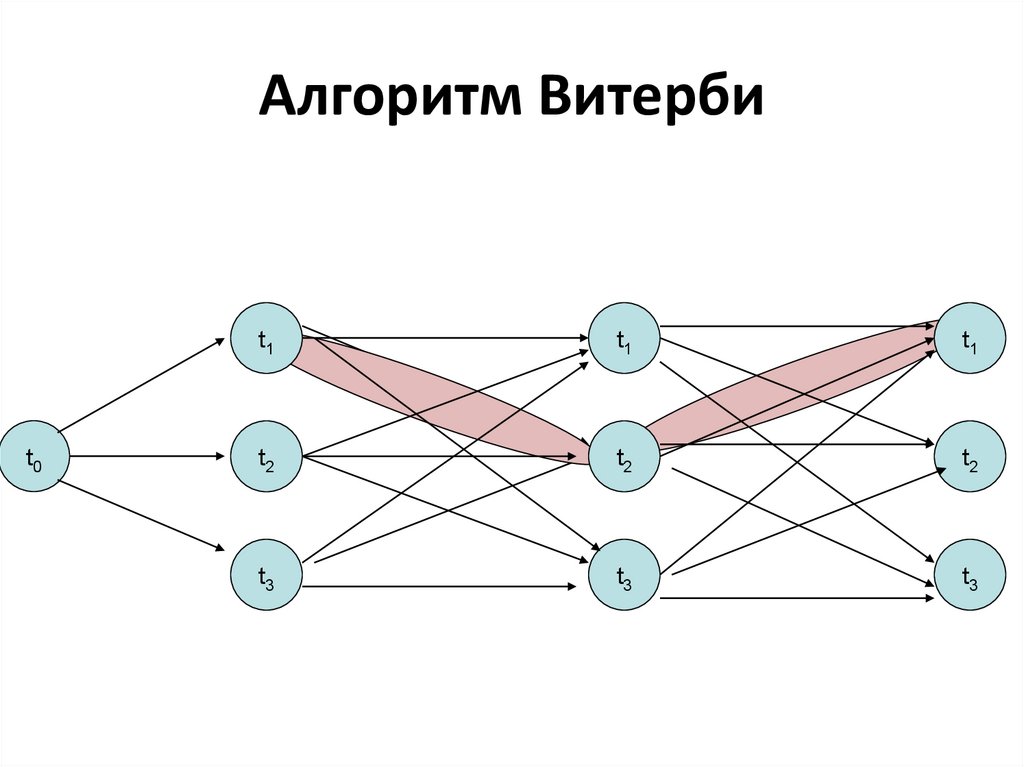
Алгоритм Витерби• позволяет сократить количество
вычислений, выбирая для каждого
очередного слова в предложении наиболее
вероятные варианты для левого
(пройденного) фрагмента цепочки с
заданным тегом на его краю
• этот прием позволяет сделать число шагов
вычислений кратным L*N
52.
Алгоритм Витербиt0
t1
t1
t1
t2
t2
t2
t3
t3
t3