












































")

")
")


")
")
")
")







































 Информатика
Информатика Базы данных
Базы данныхПохожие презентации:
")


")






Организация данных. Данные, информация, информационные системы
1. Организация данных
Лектор: к.т.н., старший преподаватель кафедры 105Каратанов Александр Владимирович
2. Зачем Вам нужен этот курс?
У каждой мало-мальски серьезной организации естьсобственная база данных.
Да-да, все данные с
Вашей
странички
Вконтакте и на
Фейсбуке
также
хранятся в базе
данных.
Каждый Ваш запрос
в Google или Яндексе
– это, прежде всего
обращение к базе
данных.
Это все лежит в базе данных
3. Зачем Вам нужен этот курс?
Базы данных находят применение повсеместно:—в организациях для учёта персонала, ведения бухгалтерии, учёта
товаров на складе, поставщиков, партнёров, клиентов, ведения
электронного документооборота.
—в биллинговых системах для учёта трафика у интернет провайдеров,
потреблённых услуг у телефонных операторов, в банковском деле.
—в интернет-технологиях для организации хранения учётных записей
зарегистрированных пользователей, текстов сообщений на форумах, в
гостевых книгах, социальных сетях, интернет-дневниках и в новостных
лентах.
—без всякого сомнения, базы данных используются поисковыми
системами для хранения индексов отсканированных веб-страниц.
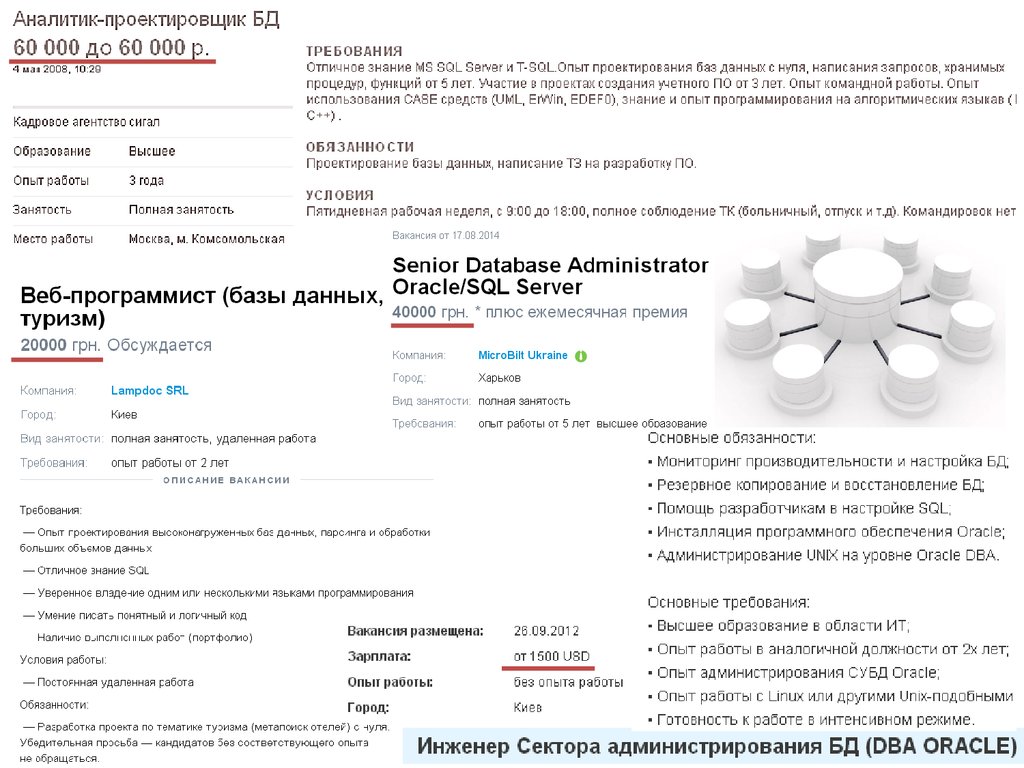
4. Кем я буду после изучения курса?
— аналитиком баз данных;— разработчиком баз данных;
— системным администратором БД;
— кем-то другим;
— никем.
5.
6. Как получить зачет?
1. Знать, как зовут преподавателя.2. Знать, как называется предмет.
3. Сдать все лабораторные.
4. Написать модуль (так, чтобы
преподавателю не было стыдно).
5. Сдать ДЗ.
Откуда берутся баллы?
Наименование
Max кол-во баллов
Модуль (1 шт.)
50
ДЗ
20
Лабораторные работы
5 × 4 = 20
Посещение лекций
10
7. Лекция 1. Данные, информация, информационные системы
• Данные – это представление фактов и идей в формализованном виде,пригодном для передачи и переработки в некотором процессе
[ГОСТ Р ИСО/МЭК 12119-2000].
IQ
Уровень
Сколько
их?
>130
Одаренность
2.2%
120-129
Высокий
6.7%
110-119
Хорошая
норма
16.1%
90-109
Средний
50%
80-89
Плохая норма
16.1%
70-79
Пограничная
зона
6.7%
50-69
Дебильность
20-49
Имбецильность
20
Идиотия
2.2%
8.
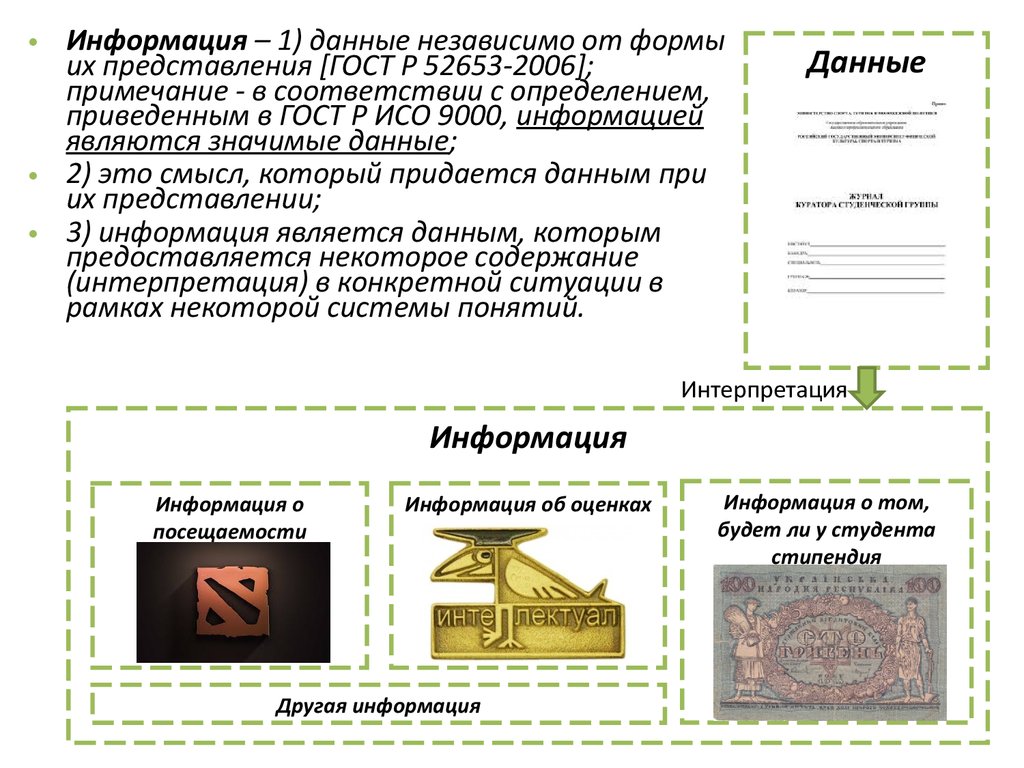
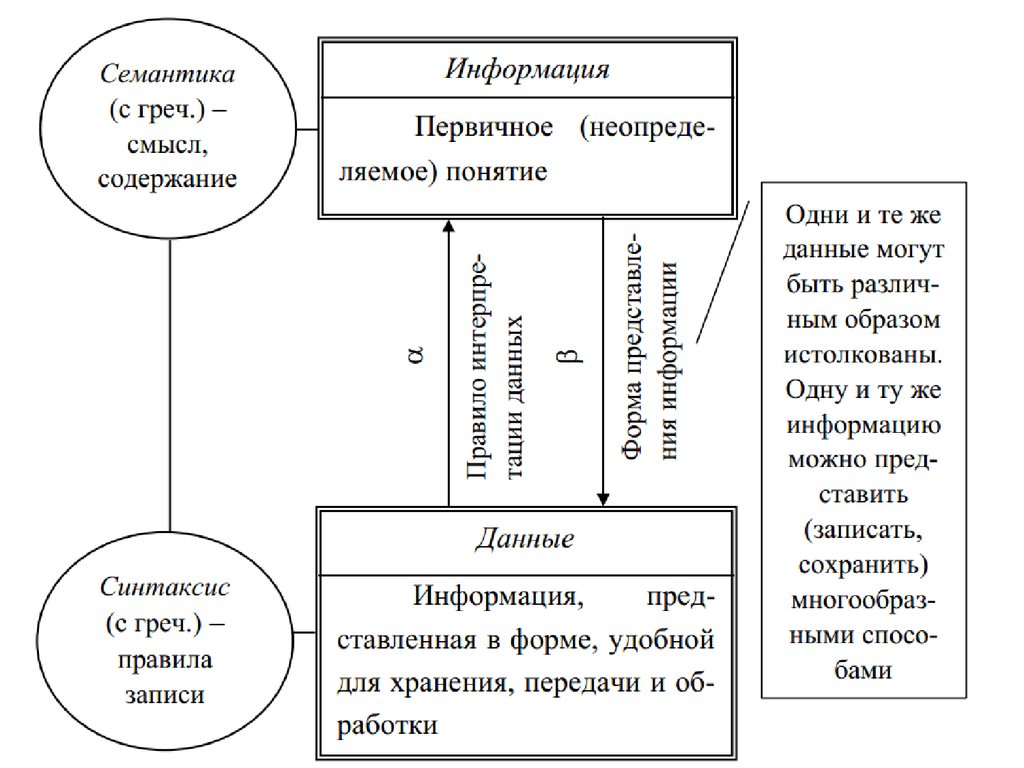
• Информация – 1) данные независимо от формыих представления [ГОСТ Р 52653-2006];
примечание - в соответствии с определением,
приведенным в ГОСТ Р ИСО 9000, информацией
являются значимые данные;
• 2) это смысл, который придается данным при
их представлении;
• 3) информация является данным, которым
предоставляется некоторое содержание
(интерпретация) в конкретной ситуации в
рамках некоторой системы понятий.
Данные
Интерпретация
Информация
Информация о
посещаемости
Информация об оценках
Другая информация
Информация о том,
будет ли у студента
стипендия
9.
10.
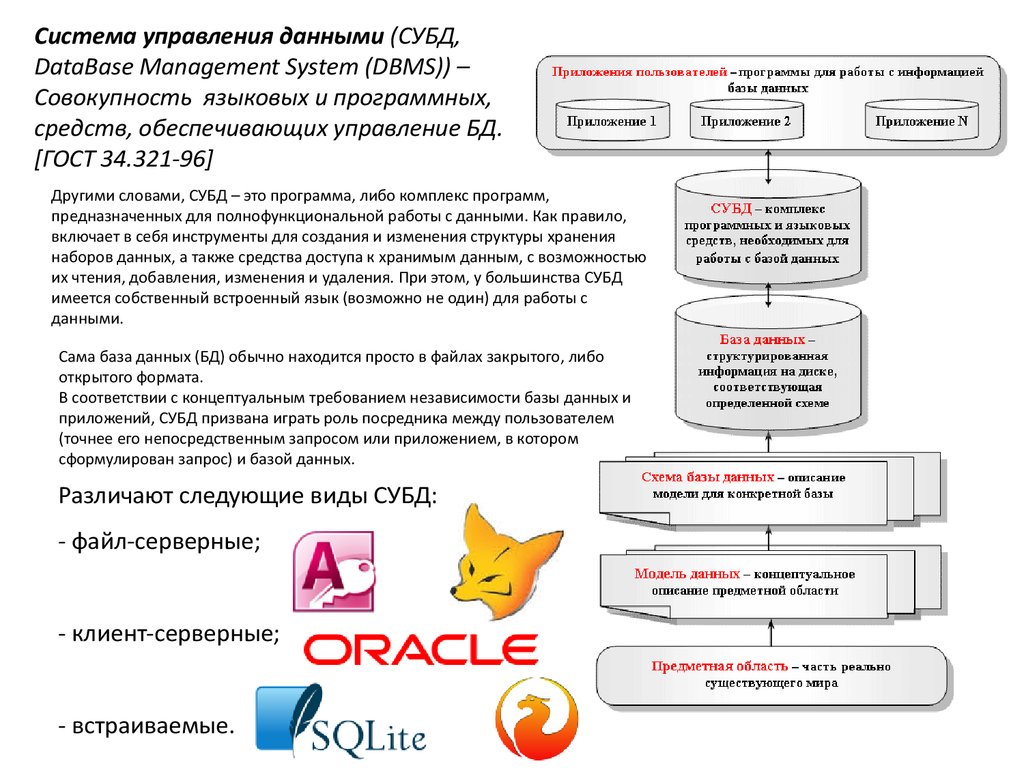
Информационная системаИсточник
информации
Прием
информации
Хранение и
преобразование
информации
Обратная связь
Информационная система (ИС,
Information system) – система,
которая организует хранение
и манипулирование информацией
о предметной области
[ГОСТ 34.321-96].
ИС предназначена для
своевременного обеспечения
надлежащих людей надлежащей
информацией.
Результатом функционирования
информационных систем является
информационная продукция —
документы, информационные
массивы, базы данных и
информационные услуги.
Вывод
информации
Потребитель
информации
11.
СтруктурноИнформационная
система
включают в себя:
-аппаратное обеспечение (hardware),
-программное обеспечение (software),
-коммуникационное обеспечение (netware),
-обеспечение
промежуточного
слоя
(middleware),
-лингвистическое обеспечение
-организационно-технологическое
обеспечение.
12.
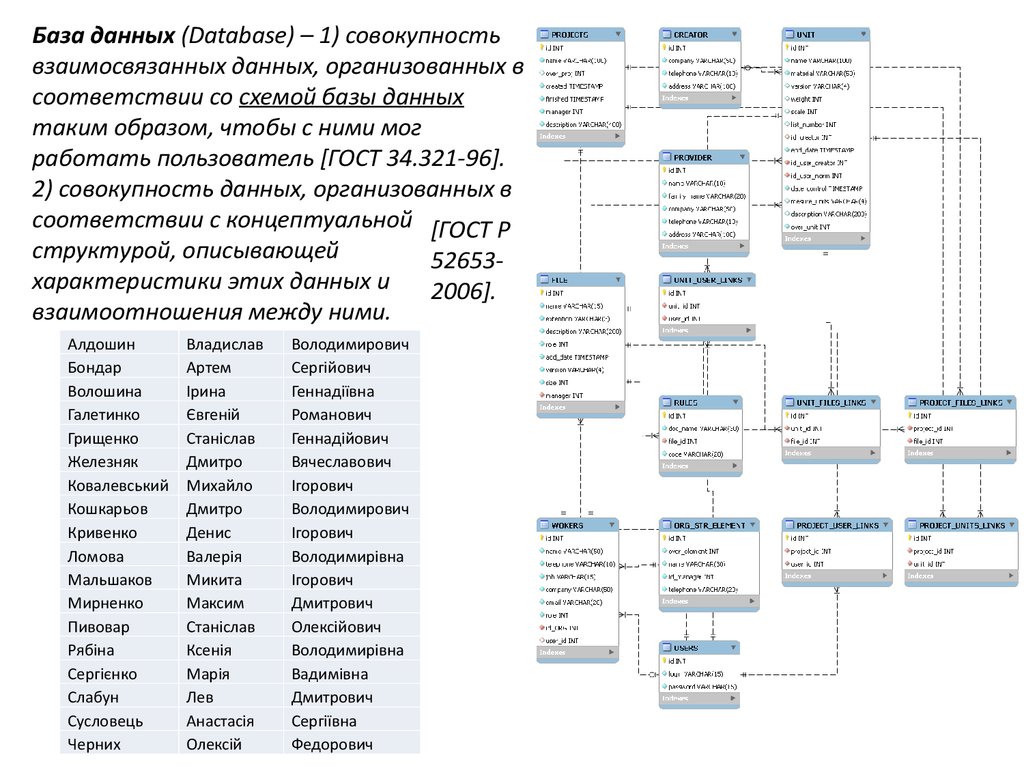
База данных (Database) – 1) совокупностьвзаимосвязанных данных, организованных в
соответствии со схемой базы данных
таким образом, чтобы с ними мог
работать пользователь [ГОСТ 34.321-96].
2) совокупность данных, организованных в
соответствии с концептуальной [ГОСТ Р
структурой, описывающей
52653характеристики этих данных и
2006].
взаимоотношения между ними.
Алдошин
Бондар
Волошина
Галетинко
Грищенко
Железняк
Ковалевський
Кошкарьов
Кривенко
Ломова
Мальшаков
Мирненко
Пивовар
Рябіна
Сергієнко
Слабун
Сусловець
Черних
Владислав
Артем
Ірина
Євгеній
Станіслав
Дмитро
Михайло
Дмитро
Денис
Валерія
Микита
Максим
Станіслав
Ксенія
Марія
Лев
Анастасія
Олексій
Володимирович
Сергійович
Геннадіївна
Романович
Геннадійович
Вячеславович
Ігорович
Володимирович
Ігорович
Володимирівна
Ігорович
Дмитрович
Олексійович
Володимирівна
Вадимівна
Дмитрович
Сергіївна
Федорович
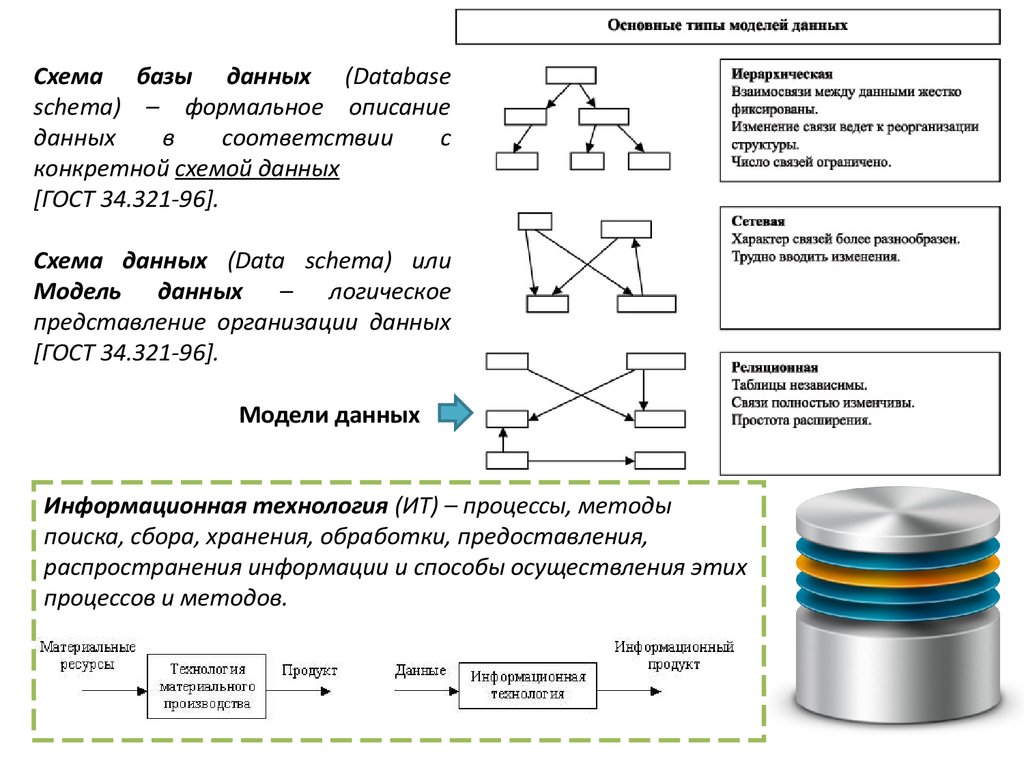
13.
Схема базы данных (Databaseschema) – формальное описание
данных
в
соответствии
с
конкретной схемой данных
[ГОСТ 34.321-96].
Схема данных (Data schema) или
Модель данных – логическое
представление организации данных
[ГОСТ 34.321-96].
Модели данных
Информационная технология (ИТ) – процессы, методы
поиска, сбора, хранения, обработки, предоставления,
распространения информации и способы осуществления этих
процессов и методов.
14. История БД
• Понятие истории баз данных обобщаетсядо истории любых средств, с помощью
которых
человечество
хранило
и
обрабатывало данные.
• Недостатком этого подхода является
размывание понятия «база данных» и
фактическое его слияние с понятиями
«архив» и даже «письменность».
15. Древняя история БД
• Средства учета царской казны и налогов в древнемШумере (4000 г. до н. э.);
• узелковая письменность инков — кипу,
• клинописи, содержащие документы Ассирийского царства
и т. п.
16. БД на перфокартах
На самых ранних стадиях развития информационных технологий
использовались списки — набитые на перфокарте и написанные на
магнитной ленте.
17. Первая БД
Североамериканская
компания
Rockwell заключила контракт с
правительством США на участие в
проекте
Apollo.
Построение
космического корабля включает в
себя
сборку
нескольких
миллионов деталей, поэтому
была создана система управления
файлами,
отслеживавшая
информацию о каждой детали.
Однако в ходе последующей
проверки обнаружилась огромная
избыточность. Выяснилось, что
почти все данные повторяются в
двух и более файлах.
18. Первая БД
• Столкнувшись с задачей координации заказов намиллионы деталей, компания Rockwell в
сотрудничестве с IBM в 1968 г. разработала
автоматизированную систему заказов.
• Названная IMS (Information Management System —
система управления информацией), она заложила
основу концепции СУБД.
19. Лекция 2. Модели данных, проектирование БД
20. Проектирование БД
Процесс проектирования базы данных представляет собойпоследовательность переходов от неформального словесного описания
информационной структуры предметной области к формализованному
описанию в терминах некоторой модели и в свою очередь включает
несколько стадий.
1.
2.
3.
4.
Анализ предметной области.
Проектирование информационной модели.
Разработка даталогической модели.
Физическое проектирование БД.
21. Анализ предметной области
Первая стадия проектирования БД предполагает определение диапазона действий и границприложения БД, состава его пользователей и областей применения (если это еще не было
определено в ТЗ на БД), сбор требований пользователей из всех возможных областей
применения, их системный анализ и словесное описание информационных объектов
предметной области.
Основной задачей этой стадии является сбор требований, предъявляемых всеми
пользователями к содержимому БД и процессу обработки информации, который
осуществляется для последующего создания основных пользовательских представлений.
22. Предметная область
• В основе любой БД лежит понятие предметнойобласти.
• Предметная область – это часть реального мира,
информация о которой должна содержаться в БД.
• Предметная
область
представляется
совокупностью реальных и абстрактных объектов,
которые характеризуется свойствами. Кроме того,
объекты предметной области связаны между
собой
смысловыми
(семантическими)
зависимостями.
23.
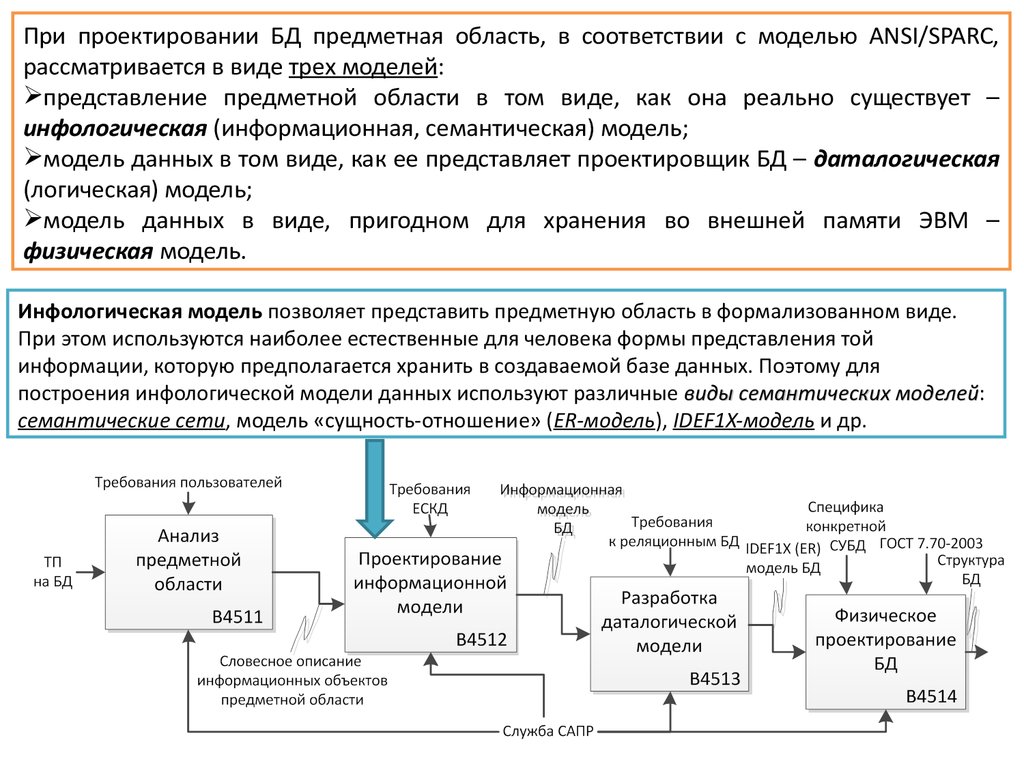
При проектировании БД предметная область, в соответствии с моделью ANSI/SPARC,рассматривается в виде трех моделей:
представление предметной области в том виде, как она реально существует –
инфологическая (информационная, семантическая) модель;
модель данных в том виде, как ее представляет проектировщик БД – даталогическая
(логическая) модель;
модель данных в виде, пригодном для хранения во внешней памяти ЭВМ –
физическая модель.
Инфологическая модель позволяет представить предметную область в формализованном виде.
При этом используются наиболее естественные для человека формы представления той
информации, которую предполагается хранить в создаваемой базе данных. Поэтому для
построения инфологической модели данных используют различные виды семантических моделей:
моделей
семантические сети, модель «сущность-отношение» (ER-модель), IDEF1X-модель и др.
24. Семантическая сеть
• Семантическая сеть — информационная модельпредметной
области,
имеющая
вид
ориентированного графа, вершины которого
соответствуют объектам предметной области, а
дуги (ребра) задают отношения между ними.
25.
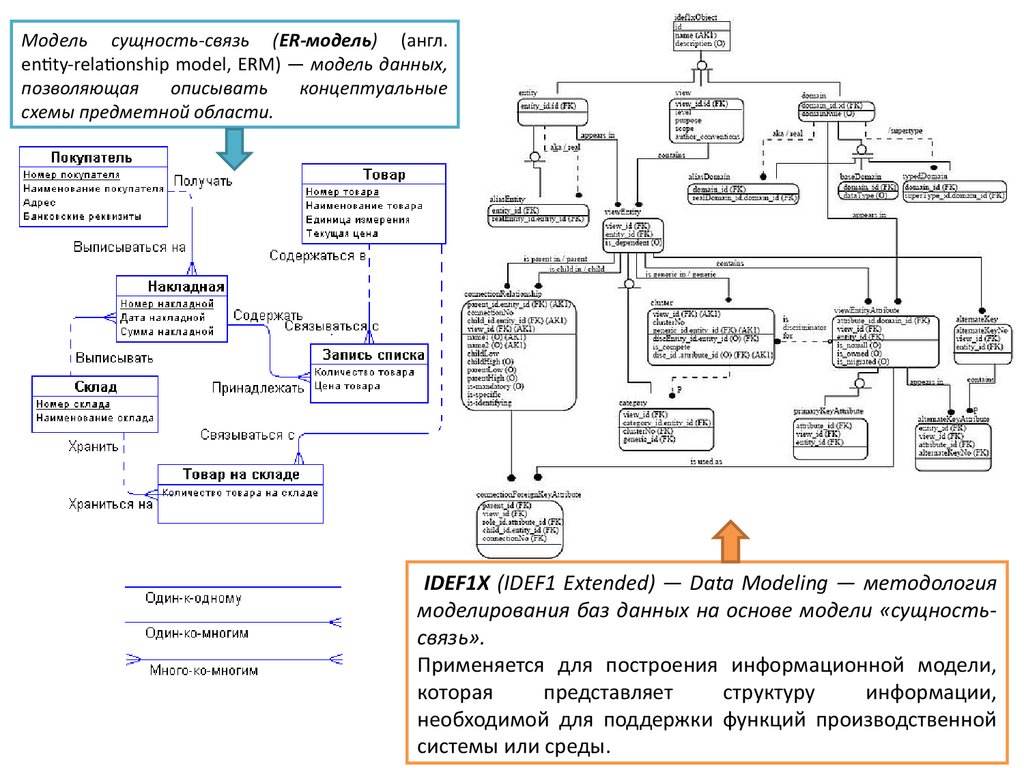
Модель сущность-связь (ER-модель) (англ.entity-relationship model, ERM) — модель данных,
позволяющая
описывать
концептуальные
схемы предметной области.
IDEF1X (IDEF1 Extended) — Data Modeling — методология
моделирования баз данных на основе модели «сущностьсвязь».
Применяется для построения информационной модели,
которая
представляет
структуру
информации,
необходимой для поддержки функций производственной
системы или среды.
26. Основные понятия ER-диаграмм
Сущность - это класс однотипных объектов, информация о которых должна быть учтена в модели.Каждая сущность должна иметь наименование, выраженное существительным в единственном
числе. Примерами сущностей могут быть такие классы объектов как "Поставщик", "Сотрудник",
"Накладная". Каждая сущность в модели изображается в виде прямоугольника с наименованием.
Экземпляр сущности - это конкретный представитель данной сущности.
Например, представителем сущности "Сотрудник" может быть "Сотрудник Фартушный".
Экземпляры сущностей должны быть различимы, т.е. сущности должны иметь некоторые свойства, уникальные
для каждого экземпляра этой сущности.
Атрибут сущности - это именованная характеристика, являющаяся некоторым
свойством сущности.
Наименование атрибута должно быть выражено существительным в единственном
числе (возможно, с характеризующими прилагательными).
Примерами атрибутов сущности "Сотрудник" могут быть такие атрибуты как "Табельный
номер", "Фамилия", "Имя", "Отчество", "Должность", "Зарплата" и т.п.
Атрибуты изображаются в пределах прямоугольника, определяющего сущность.
Ключ сущности - это неизбыточный набор атрибутов, значения которых в совокупности
являются уникальными для каждого экземпляра сущности.
Это минимальный набор атрибутов, по значениям которых можно однозначно найти
требуемый экземпляр сущности.
Ключевые атрибуты изображаются на диаграмме подчеркиванием.
Связь - это некоторая ассоциация между двумя сущностями.
Одна сущность может быть связана с другой сущностью или сама с собою.
Например, связи между сущностями могут выражаться следующими фразами –
"СОТРУДНИК может иметь несколько ДЕТЕЙ", "каждый СОТРУДНИК обязан числиться ровно
в одном ОТДЕЛЕ".
Графически связь изображается линией, соединяющей две сущности.
27.
Иерархическая модельданных — это модель данных,
где используется
представление базы данных
в виде древовидной
(иерархической) структуры,
состоящей из объектов
(данных) различных уровней.
Порядок обхода
Корень
Предок
Потомок
Между объектами существуют связи, каждый
объект может включать в себя несколько
объектов более низкого уровня. Такие объекты
находятся в отношении предка (объект более
близкий к корню) к потомку (объект более
низкого уровня), при этом возможна ситуация,
когда объект-предок не имеет потомков или
имеет их несколько, тогда как у объекта-потомка
обязательно только один предок. Объекты,
имеющие общего предка, называются
близнецами (в программировании
применительно к структуре данных «дерево»
устоялось название братья).
28.
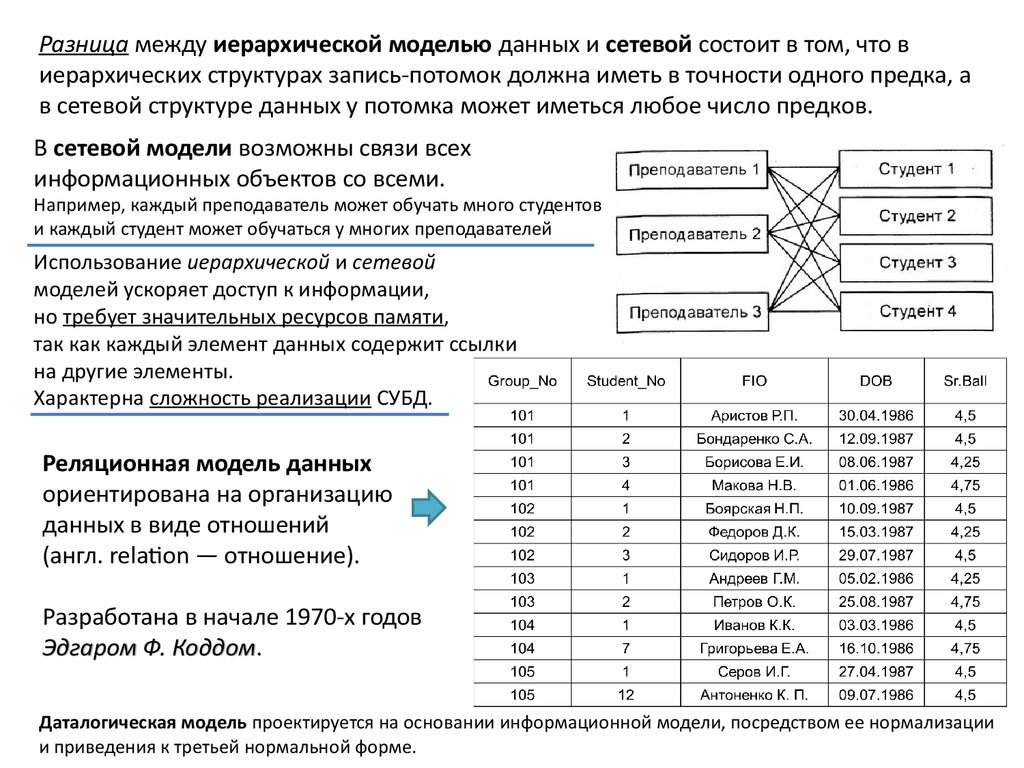
Разница между иерархической моделью данных и сетевой состоит в том, что виерархических структурах запись-потомок должна иметь в точности одного предка, а
в сетевой структуре данных у потомка может иметься любое число предков.
В сетевой модели возможны связи всех
информационных объектов со всеми.
Например, каждый преподаватель может обучать много студентов
и каждый студент может обучаться у многих преподавателей
Использование иерархической и сетевой
моделей ускоряет доступ к информации,
но требует значительных ресурсов памяти,
так как каждый элемент данных содержит ссылки
на другие элементы.
Характерна сложность реализации СУБД.
Реляционная модель данных
ориентирована на организацию
данных в виде отношений
(англ. relation — отношение).
Разработана в начале 1970-х годов
Эдгаром Ф. Коддом.
Коддом
Даталогическая модель проектируется на основании информационной модели, посредством ее нормализации
и приведения к третьей нормальной форме.
29. Лекция 3. Нормализация отношений
Нормализация – это последовательный процессразбиения и преобразования некоторого небольшого
исходного набора таблиц для построения набора
взаимосвязанных таблиц в нормальных формах.
• Процесс нормализации был впервые предложен Эдгаром
Франком Коддом в 1972 году.
Определение для альтернативно одаренных
Нормализация – это когда у нас было много таблиц, а мы сделаем
еще больше, чтобы они соответствовали каким-то там правилам.
30. Нормальная форма
Нормальная форма (НФ) – требование, предъявляемое кструктуре таблиц в теории реляционных баз данных для
устранения из базы избыточных функциональных
зависимостей между атрибутами (полями таблиц).
Всего существует восемь НФ:
– 1–6 НФ;
– доменно-ключевая НФ;
– НФ Бойса-Кодда.
31. Функциональная зависимость
Каждый из уровней нормализации ограничивает типы допустимыхфункциональных зависимостей отношения.
Функциональная зависимость имеет место, если значение кортежа на
одном множестве атрибутов единственным образом определяет их
на другом.
Другими словами, множество атрибутов Y функционально зависит
от X тогда и только тогда, когда в любой момент времени для
каждого из различных значений Y существует только одно из
различных значений X.
Встречается и эквивалентный термин: множество X определяет Y.
Обозначение –
X Y. зависимая часть
детерминанта
32. Функциональная зависимость
ПримерРассмотрим отношение, заданное следующей схемой:
график (Пилот, Рейс, Дата, Время).
Ясно, что допустимо не любое сочетание значений атрибутов. Их
зависимость задается следующими ограничениями:
для каждого рейса определено лишь одно время вылета;
для атрибутов (Пилот, Дата, Время) определен лишь один рейс;
для атрибутов (Рейс, Дата) определен единственный пилот.
Таким образом, задано множество функциональных зависимостей:
Рейс Время
(Пилот, Дата, Время) Рейс
(Рейс, Дата) Пилот
33. 1 нормальная форма
Условия первой нормальной формы:1)каждой сущности соответствует отдельная таблица;
2)каждый набор связанных данных идентифицирован
с помощью первичного ключа;
3)поля не имеют дубликатов в каждой записи;
4)каждое поле содержит только одно значение (атомарно).
Атомарность
(неделимость)
поля
означает,
что
содержащиеся в нем значения не должны делиться на
более мелкие.
34. 1 нормальная форма
Пример. Пусть для отношения со схемой Рейс (Номер, Пунктназначения, Вылет) атрибут Вылет определен как пара (День,
Время).
В этом случае легко реализовать запросы типа «Выдать все рейсы до
Уфы», в отличие от запроса «Выдать все рейсы, вылетающие по
понедельникам». С точки зрения второй задачи отношение не
находится в 1НФ.
Дублирование информации
Отсутствие атомарности
35. 1 нормальная форма
Преобразование очевидно: отношение заменяется другим со схемой:
Рейс (Номер, Пункт назначения, День вылета, Время вылета).
Это позволит достичь атомарности.
Выделение
для
пунктов назначения
отдельной таблицы
устранит
дублирование
информации.
36. 1 нормальная форма
•Пример 2. Если в поле «Подразделение» содержитсяназвание факультета и кафедры, требование неделимости
не соблюдается и необходимо выделить название
факультета или кафедры в отдельное поле.
37. 1 нормальная форма. Избыточность
Избыточность данных – повторение данных в базе данных.Таблица 1.1 – «Работник»
№ работ. Фамилия
Специальность № менеджера
1235
1412
1311
Электрик
Штукатур
Электрик
Железняк
Мирненко
Кривенко
1311
№
здания
{312, 515}
{312, 460, 435, 515}
435
Приведение к первой нормальной
форме провоцирует избыточность
Таблица 1.2 – «Работник»
№ работника
1235
1235
1412
1412
1412
1412
1311
Фамилия
Железняк
Железняк
Мирненко
Мирненко
Мирненко
Мирненко
Кривенко
Специальность
Электрик
Электрик
Штукатур
Штукатур
Штукатур
Штукатур
Электрик
№ менеджера
1311
1311
№ здания
312
515
312
460
435
515
435
38. 1 нормальная форма. Целостность
• Избыточность данных или повторение приводит нетолько к потере лишнего места; она может вызвать
нарушение целостности данных (противоречивость) в
базе данных.
Целостность данных – согласованность данных в базе
данных.
• Чтобы добиться целостности следует устранить аномалии.
Аномалия обновления – противоречивость
избыточностью и частичным обновлением.
Аномалия удаления – непреднамеренная
удалением других данных.
данных,
потеря
вызванная
данных,
их
вызванная
Аномалия ввода – невозможность ввести данные в таблицу, вызванная
отсутствием других данных.
39. 1 нормальная форма
Проблема возникает из-за того, что один и тот же работник может работать более,чем на одном здании. Предположим, что специальность Мирненко была указана
неправильно, а исправление было внесено только в первый кортеж. Тогда между
кортежами, содержащими информацию о Мирненко, возникает несоответствие, которое
называется аномалией обновления.
№ работника
1235
1235
1412
1412
1412
1412
1311
Фамилия
Железняк
Железняк
Мирненко
Мирненко
Мирненко
Мирненко
Кривенко
Специальность № менеджера
Электрик
1311
Электрик
1311
Штукатур
Штукатур
Штукатур
Штукатур
Электрик
№ здания
312
515
312
460
435
515
435
Теперь предположим, что Мирненко в течение трех месяцев был на больничном и все
здания, на которых он был назначен работать, уже закончены. Если принимается
решение удалить все строки о законченных зданиях из таблицы, то информация о
Мирненко, его специальности будет потеряна. Это называется аномалией удаления.
Обратный случай: мы могли нанять нового работника по фамилии Алдошин, которого
еще не успели назначить ни на какое здание. Если мы не допускаем пустых значений,
то не можем ввести информацию о Алдошине в базу данных. Это называется
аномалией ввода.
40. 1 нормальная форма
41. 1 нормальная форма
Предположим, что в ходе логического моделирования на первом шаге предложено хранить данные в одном отношении,имеющем следующие атрибуты:
СОТРУДНИКИ_ОТДЕЛЫ_ПРОЕКТЫ (Н_СОТР, ФАМ, Н_ОТД, ТЕЛ, Н_ПРО, ПРОЕКТ, Н_ЗАДАН)
Где Н_СОТР - табельный номер сотрудника,
ФАМ - фамилия сотрудника,
Н_ОТД - номер отдела, в котором числится сотрудник,
ТЕЛ - телефон сотрудника,
Н_ПРО - номер проекта, над которым работает сотрудник,
ПРОЕКТ - наименование проекта, над которым работает сотрудник,
Н_ЗАДАН - номер задания, над которым работает сотрудник.
Т.к. каждый сотрудник в каждом проекте выполняет ровно одно задание, то в качестве потенциального ключа отношения
необходимо взять пару атрибутов (Н_СОТР, Н_ПРО).
В текущий момент состояние предметной области отражается следующими фактами:
•Сотрудник Сусловец, работающий в 1 отделе, выполняет в первом проекте "Космос" задание 1 и во втором проекте
"Климат" задание 1.
•Сотрудник Сусловец, работающий в 1 отделе, выполняет в первом проекте "Космос" задание 2.
•Сотрудник Волошина, работающий во 2 отделе, выполняет в первом проекте "Космос" задание 3 и во втором проекте
"Климат" задание 2.
Это состояние отражается в таблице (курсивом выделены ключевые атрибуты):
Из таблицы
СОТРУДНИКИ_ОТДЕЛЫ_
ПРОЕКТЫ
видно, что данные
отношения хранятся
в ней с большой
избыточностью.
Во многих строках повторяются фамилии сотрудников, номера телефонов, наименования проектов. Кроме
того, в данном отношении хранятся вместе независимые друг от друга данные - и данные о сотрудниках, и
об отделах, и о проектах, и о работах по проектам.
42. 1 нормальная форма
Отношение СОТРУДНИКИ_ОТДЕЛЫ_ПРОЕКТЫ декомпозируем на три
отношения - СОТРУДНИКИ_ОТДЕЛЫ, ПРОЕКТЫ, ЗАДАНИЯ.
Таблица 2. Отношение СОТРУДНИКИ_ОТДЕЛЫ
Таблица 3. Отношение ПРОЕКТЫ
Таблица 4. Отношения ЗАДАНИЯ
Н_СОТР
ФАМ
Н_ОТД
ТЕЛ
Н_ПРО
ПРОЕКТ
Н_СОТР
Н_ПРО
Н_ЗАДАН
1
Сусловец
1
11-22-33
1
Космос
1
1
1
2
Сергиенко
1
11-22-33
2
Климат
1
2
1
3
Волошина
2
33-22-11
2
1
2
3
1
3
3
2
2
Функциональные зависимости:
Зависимость
атрибутов,
характеризующих
сотрудника
от
табельного номера сотрудника:
Н_СОТР → ФАМ
Н_СОТР → Н_ОТД
Н_СОТР → ТЕЛ
Зависимость номера телефона от номера
отдела:
Н_ОТД → ТЕЛ
Функциональные
зависимости:
Н_ПРО → ПРОЕКТ
Функциональные
зависимости:
(Н_СОТР, Н_ПРО) →
Н_ЗАДАН
43. 2 нормальная форма
Условия второй нормальной формы:1)модель удовлетворяет условиям 1 НФ;
2)все поля каждой таблицы, не входящие в
первичный
ключ,
связаны
полной
функциональной зависимостью с первичным
ключом.
•Замечание. Если ключ отношения является
простым,
то
отношение
автоматически
находится в 2НФ.
44. 2 нормальная форма
•Отношение СОТРУДНИКИ_ОТДЕЛЫ не находится в 2НФ, т.к. естьатрибуты, зависящие от части сложного ключа.
•(фамилия сотрудника не зависит от номера отдела)
•Для того, чтобы устранить зависимость атрибутов от части
сложного ключа, нужно произвести декомпозицию отношения на
несколько отношений. При этом те атрибуты, которые зависят от
части сложного ключа, выносятся в отдельное отношение.
Таблица 2. Отношение
СОТРУДНИКИ_ОТДЕЛЫ
Н_СОТР
ФАМ
Н_ОТД
1
Сусловец
1
2
Сергиенко
1
3
Волошина
2
Н_СОТР
ФАМ
Н_ОТД
ТЕЛ
1
Сусловец
1
11-22-33
2
Сергиенко
1
11-22-33
Н_ОТД
ТЕЛ
3
Волошина
2
33-22-11
1
11-22-33
2
33-22-11
45. 3 нормальная форма
Условия третьей нормальной формы:1)модель удовлетворяет условиям 2 НФ;
2)все не ключевые поля полностью зависят
от первичного ключа таблицы и не зависят
друг от друга.
• Неключевой атрибут — это атрибут, который не входит в состав первичного ключа
рассматриваемой переменной-отношения.
• Два или более атрибутов называются взаимно независимыми, если ни один из них
функционально не зависит от какой-либо комбинации остальных атрибутов. Подобная
независимость подразумевает, что каждый такой атрибут может обновляться
независимо от значений остальных атрибутов.
46. 3 нормальная форма. Альтернативное определение
Условия третьей нормальной формы:1)модель удовлетворяет условиям 2 НФ;
2)отсутствует транзитивная функциональная
зависимость
не
ключевых
полей
от первичного ключа.
• Неключевой атрибут — это атрибут, который не входит в состав первичного ключа
рассматриваемой переменной-отношения.
• Два или более атрибутов называются взаимно независимыми, если ни один из них
функционально не зависит от какой-либо комбинации остальных атрибутов. Подобная
независимость подразумевает, что каждый такой атрибут может обновляться
независимо от значений остальных атрибутов.
47. 3 нормальная форма
При приведении к первой нормальной формемы получили вот такую таблицу:
Н_СОТР
ФАМ
Н_ОТД
ТЕЛ
1
Сусловец
1
11-22-33
2
Сергиенко
1
11-22-33
3
Волошина
2
33-22-11
Таблица 5. Отношение СОТРУДНИКИ
Н_СОТР
ФАМ
Н_ОТД
Для приведения ко второй нормальной
форме мы разбили эту таблицу:
Однако могли поступить и проще – убрать
составной первичный ключ:
Н_СОТР
ФАМ
Н_ОТД
ТЕЛ
1
Сусловец
1
11-22-33
2
Сергиенко
1
11-22-33
3
Волошина
2
33-22-11
1
Сусловец
1
2
Сергиенко
1
3
Волошина
2
Таблица 6. Отношение ОТДЕЛЫ
Н_ОТД
ТЕЛ
1
11-22-33
2
33-22-11
Вот эта модель данных также
соответствует второй нормальной
форме.
48. 3 нормальная форма
Но таким образом вы всего лишь отодвинете своистрадания по нормализации до 3 НФ, вам все
равно придется разбить эту таблицу на две.
Н_СОТР
ФАМ
Н_ОТД
ТЕЛ
1
Сусловец
1
11-22-33
2
Сергиенко
1
11-22-33
3
Волошина
2
33-22-11
Отношение СОТРУДНИКИ_ОТДЕЛЫ не находится в
3НФ, т.к. имеется функциональная зависимость
неключевых атрибутов (зависимость номера
телефона от номера отдела): Н_ОТД → ТЕЛ
Таблица 5. Отношение СОТРУДНИКИ
Н_СОТР
ФАМ
Н_ОТД
1
Сусловец
1
2
Сергиенко
1
3
Волошина
2
Таблица 6. Отношение ОТДЕЛЫ
Н_ОТД
ТЕЛ
1
11-22-33
2
33-22-11
49. + и - нормализации
Как видно из таблицы, более сильно нормализованные отношения
оказываются лучше спроектированы (три плюса, один минус). Они
больше соответствуют предметной области, легче в разработке, для
них быстрее выполняются операции модификации базы данных.
Правда, это достигается ценой некоторого замедления выполнения
операций выборки данных.
Критерий
Отношения слабо
нормализованы
(1НФ, 2НФ)
Отношения сильно
нормализованы
(3НФ)
Адекватность базы данных
предметной области
ХУЖЕ (-)
ЛУЧШЕ (+)
Легкость разработки и
сопровождения базы данных
СЛОЖНЕЕ (-)
ЛЕГЧЕ (+)
Скорость выполнения вставки,
обновления, удаления
МЕДЛЕННЕЕ (-)
БЫСТРЕЕ (+)
Скорость выполнения выборки
данных
БЫСТРЕЕ (+)
МЕДЛЕННЕЕ (-)
50. Лекция 4. Нормализация отношений. Нормальные формы более высоких порядков
Критерии оценки качества логической модели данныхДля того чтобы оценить качество принимаемых решений на уровне логической модели данных, необходимо
сформулировать некоторые критерии качества и посмотреть, как различные решения, принятые в
процессе логического моделирования, влияют на скорость и качество работы базы данных.
Рассмотрим некоторые из таких критериев, которые являются безусловно важными с точки зрения
получения качественной базы данных:
- адекватность базы данных предметной области;
- легкость разработки и сопровождения базы данных;
- скорость выполнения операций обновления данных (вставка, обновление, удаление кортежей);
- скорость выполнения операций выборки данных.
Адекватность базы данных предметной области
База данных должна адекватно отражать предметную область. Это
означает, что должны выполняться следующие условия:
- состояние базы данных в каждый момент времени должно
соответствовать состоянию предметной области;
- изменение состояния предметной области должно приводить к
соответствующему изменению состояния базы данных;
- ограничения предметной области, отраженные в модели предметной
области, должны некоторым образом отражаться и учитываться базе
данных.
51. Критерии оценки качества логической модели данных
Легкость разработки и сопровождения базы данныхПрактически любая база данных, за исключением
совершенно элементарных, содержит некоторое
количество программного кода в виде триггеров и
хранимых процедур.
процедур
Очевидно, что чем больше программного кода в виде
триггеров и хранимых процедур содержит база
данных, тем сложнее ее разработка и дальнейшее
сопровождение.
Хранимые процедуры - это процедуры и функции, хранящиеся
непосредственно в БД в откомпилированном виде и которые могут
запускаться пользователями или приложениями, работающими с БД.
Хранимые процедуры обычно пишутся либо на специальном
процедурном расширении языка SQL (например, PL/SQL для ORACLE или
Transact-SQL для MS SQL Server), или на некотором универсальном языке
программирования, например, C++, с включением в код операторов SQL в
соответствии со специальными правилами такого включения.
Основное назначение хранимых процедур - реализация бизнес-процессов
предметной области.
Триггеры - это хранимые процедуры,
процедуры связанные с некоторыми
событиями, происходящими во время работы БД. В качестве таких
событий выступают операции вставки, обновления и удаления строк
таблиц. Если в базе данных определен некоторый триггер, то он
запускается автоматически всегда при возникновении события, с
которым этот триггер связан. Очень важным является то, что пользователь
не может обойти триггер. Триггер срабатывает независимо от того, кто из
пользователей и каким способом инициировал событие, вызвавшее
запуск триггера. Таким образом, основное назначение триггеров автоматическая поддержка целостности базы данных. Триггеры могут
быть как достаточно простыми, например, поддерживающими ссылочную
целостность, так и довольно сложными, реализующими какие-либо
сложные ограничения предметной области или сложные действия,
которые должны произойти при наступлении некоторых событий.
Например, с операцией вставки нового товара в накладную может быть связан триггер, который выполняет следующие действия проверяет, есть ли необходимое количество товара, при наличии товара добавляет его в накладную и уменьшает данные о наличии
товара на складе, при отсутствии товара формирует заказ на поставку недостающего товара и тут же посылает заказ по электронной
почте поставщику.
52. Критерии оценки качества логической модели данных
Скорость операций обновления данных (вставка,обновление, удаление)
В базах данных, требующих постоянных изменений
(складской учет, системы продаж билетов и т.п.)
производительность
определяется
скоростью
выполнения большого количества небольших
операций вставки, обновления и удаления.
Скорость выполнения операций вставки, обновления и
удаления уменьшается при увеличении количества индексов у
таблицы.
Чем больше атрибутов имеют отношения, разработанные в
ходе логического моделирования, тем медленнее будут
выполняться операции обновления данных, за счет затраты
времени на перестройку большего количества индексов.
индексов
Скорость операций выборки данных
Увеличение количества взаимосвязанных отношений
(для которых необходима операция соединения
таблиц ) приводит к замедлению выполнения
операций выборки данных.
Индексы - это специальные структуры в базах
данных, которые позволяют ускорить поиск и
сортировку по определенному полю или набору
полей в таблице.
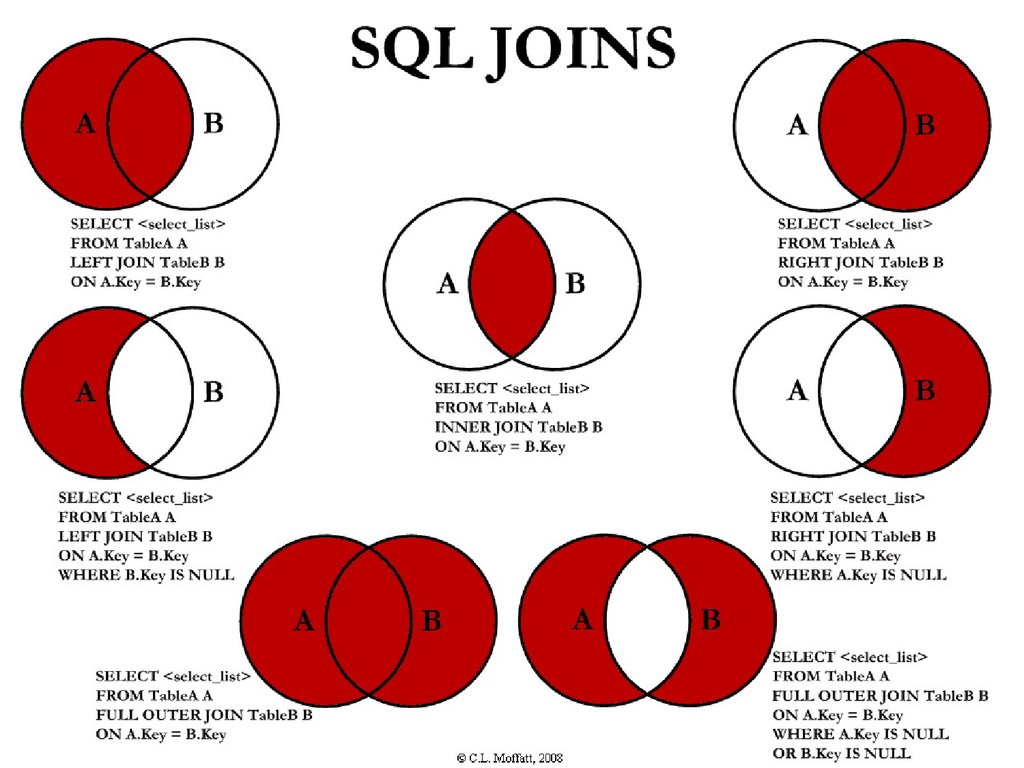
Информация извлекается из реляционной базы
данных при помощи оператора SQL - SELECT. Одной из
наиболее дорогостоящих операций при выполнении
оператора SELECT является операция соединение
таблиц. Таким образом, чем больше взаимосвязанных
отношений было создано в ходе логического
моделирования, тем больше вероятность того, что
при выполнении запросов эти отношения будут
соединяться, и, следовательно, тем медленнее будут
выполняться запросы. Таким образом, увеличение
количества отношений приводит к замедлению
выполнения операций выборки данных, особенно,
если запросы заранее неизвестны.
Например мы хотим найти запись, удовлетворяющую условию:
SELECT * FROM Customers
WHERE CustomerID = ‘ROMEY’
SQL Server прочитает все записи начиная с первой и заканчивая
последней и выберет те, которые будут удовлетворять
указанному условию.
SQL Server не знает что в таблице существует только одна
запись, удовлетворяющая условию, пока в таблице не
существует индекса.
Индексы отличаются от первичных ключей тем, что не
требуют непременной уникальности значений входящих
в их состав полей.
53. OLTP и OLAP-системы
OLTP (On-Line Transaction Processing–
оперативная
обработка
транзакций)
–
это
способ
организации БД, при котором
система работает с небольшими по
размерам
транзакциями,
но
идущими большим потоком, и при
этом клиенту требуется от системы
минимальное время отклика.
Сильно нормализованные модели данных
хорошо подходят для так называемых OLTPприложения.
Типичными примерами OLTP-приложений
являются:
-системы складского учета,
-системы заказов билетов,
-банковские
системы,
выполняющие
операции по переводу денег…
Основная
функция
подобных
систем
заключается
в
выполнении
большого
количества коротких транзакций.
OLAP (On-Line Analitical Processing - оперативная
аналитическая обработка данных) – это способ
организации БД, заключающаяся в подготовке
суммарной (агрегированной) информации на основе
больших массивов данных, структурированных по
многомерному принципу.
Другим типом приложений являются так называемые OLAPприложения. Это обобщенный термин, характеризующий принципы
построения:
-систем поддержки принятия решений (Decision Support System - DSS),
-хранилищ данных (Data Warehouse),
-систем интеллектуального анализа данных (Data Mining).
Такие системы предназначены для нахождения зависимостей между
данными (например, можно попытаться определить, как связан объем
продаж товаров с характеристиками потенциальных покупателей), для
проведения анализа "что если…".
Данные в таких системах целесообразно хранить в виде слабо
нормализованных отношений, содержащих заранее вычисленные
основные итоговые данные. Большая избыточность и связанные с ней
проблемы тут не страшны, т.к. обновление происходит только в момент
загрузки новой порции данных.
54. НФБК (Нормальная Форма Бойса-Кодда)
Условия нормальной формы Бойса-Кодда:1)модель удовлетворяет условиям 3 НФ;
2)детерминанты
всех
функциональных
зависимостей являются потенциальными
ключами.
55. Потенциальный ключ
Потенциальный ключ — в реляционной модели данных —подмножество
атрибутов
отношения,
удовлетворяющее
требованиям уникальности и минимальности (несократимости /
атомарности).
Уникальность означает, что не существует двух кортежей данного отношения, в которых
значения этого подмножества атрибутов совпадают (равны).
В отношении может быть одновременно несколько потенциальных ключей.
Один из них может быть выбран в качестве первичного ключа отношения,
тогда другие потенциальные ключи называют альтернативными ключами.
Теоретически, все потенциальные ключи равно пригодны в качестве
первичного ключа, на практике в качестве первичного обычно выбирается тот
из потенциальных ключей, который имеет меньший размер (физического
хранения) и/или включает меньшее количество атрибутов.
56. НФБК (Нормальная Форма Бойса-Кодда)
Ситуация, когда отношение будет находится в 3NF, но не в BCNF, возникает при условии, чтоотношение имеет два (или более) возможных ключа, которые являются составными и имеют
общий атрибут.
Заметим, что на практике такая ситуация встречается достаточно редко, для всех прочих
отношений 3NF и BCNF эквивалентны.
Существует функциональная зависимость Тариф → Номер корта, в
которой левая часть (детерминант) не является потенциальным
ключом отношения, то есть отношение не находится в нормальной
форме Бойса — Кодда.
Тариф
N
корта
Член клуба
«Бережливый»
1
Да
«Стандарт»
1
Нет
«Премиум-А»
2
Да
«Премиум-B»
2
Нет
N
корта
Время
начала
Время
окончания
Тариф
1
09:30
10:30
«Бережливый»
1
11:00
12:00
«Бережливый»
Тариф
Время начала
Время окончания
1
14:00
15:30
«Стандарт»
«Бережливый»
09:30
10:30
2
10:00
11:30
«Премиум-B»
«Бережливый»
11:00
12:00
2
11:30
13:30
«Премиум-B»
«Стандарт»
14:00
15:30
2
15:00
16:30
«Премиум-А»
«Премиум-B»
10:00
11:30
«Премиум-B»
11:30
13:00
«Премиум-А»
15:00
16:30
Недостатком данной структуры является то, что, например, по ошибке
можно приписать тариф «Бережливый» к бронированию 2 корта, хотя он
может относиться только к 1корту.
57. Четвертая нормальная форма (4NF)
Условия четвертой нормальной формы:1)модель удовлетворяет условиям НФБК;
2)все
нетривиальные
многозначные
зависимости
фактически
являются
функциональными зависимостями от её
потенциальных ключей.
58. Четвертая нормальная форма
• Другими словами все строки таблицы должны бытьнезависимыми друг от друга.
• В том смысле, что наличие какой-то строки X, не должно
означать, что строка Y тоже где-то есть в этой таблице.
Отношения с нетривиальными многозначными зависимостями возникают, как
правило, в результате естественного соединения двух отношений по общему
полю, которое не является ключевым ни в одном из отношений. Фактически это
приводит к попытке хранить в одном отношении информацию о двух
независимых сущностях.
В качестве примера можно привести ситуацию, когда сотрудник может иметь
много работ и много детей. Хранение информации о работах и детях в одном
отношении приводит к возникновению нетривиальной многозначной
зависимости Работник-Работа-Дети.
59. Четвертая нормальная форма
Декомпозиция отношения "Абитуриенты-Факультеты-Предметы" не может быть выполнена на основефункциональных зависимостей, т.к. это отношение не содержит никаких функциональных
зависимостей. Это отношение является полностью ключевым, т.е. ключом отношения является все
множество атрибутов. Но ясно, что какая-то взаимосвязь между атрибутами имеется. Эта взаимосвязь
описывается понятием многозначной зависимости.
Абитуриент
Факультет
Предмет
Факультет
Предмет
Руденкова
Самолетостроительный
Математика
Самолетостроительный
Математика
Руденкова
Самолетостроительный
Информатика
Самолетостроительный
Информатика
Руденкова
СУЛА
Математика
СУЛА
Математика
Руденкова
СУЛА
Физика
СУЛА
Физика
Шкода
Самолетостроительный
Математика
Шкода
Самолетостроительный
Информатика
В отношении "Абитуриенты-Факультеты-Предметы"
имеется именно нетривиальная многозначная
зависимость Факультет→→ Абитуриент | Предмет.
Абитуриент
Факультет
Руденкова
Самолетостроительный
Руденкова
СУЛА
Шкода
Самолетостроительный
60. Четвертая нормальная форма (4NF)
Кажется, что в отношении имеется аномалия обновления,обновления связанная с тем, что дублируются фамилии абитуриентов,
наименования факультетов и наименования предметов