








 Информатика
ИнформатикаПохожие презентации:
")

")
")

")




Типы данных в памяти
1.
Типы данных в памяти1. M – Модифицированная строка (Modified). Данные в строке M были
модифицированы, но измененная информация еще не переписана в
ОП. Следовательно, данные в рассматриваемой строке достоверны
только в данном кэше, а в основной памяти и кэшах других
процессоров недостоверны.
2.
E – Эксклюзивная строка (Exclusive). Данная строка в кэш-памяти не
менялась путем записи и совпадает с аналогичной строкой в ОП, но
отсутствует в любой другой локальной кэш-памяти. Данные в строке
достоверны.
3.
S – Разделяемая строка (Shared). Строка в кэш-памяти совпадет с
аналогичной строкой в ОП и может присутствовать в других кэшпамятях. Данные достоверны.
4.
I – Недействительная строка (Invalid). Строка в кэш-памяти,
помеченная как I, не содержит достоверных данных и становится
логически недоступной.
2.
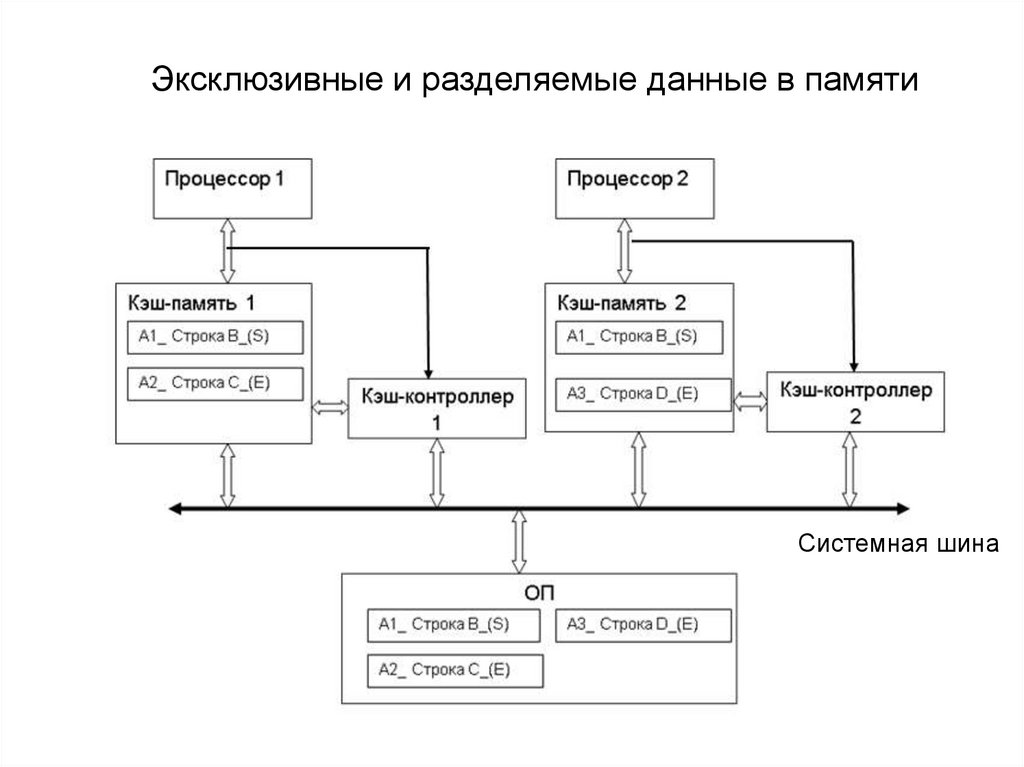
Эксклюзивные и разделяемые данные в памятиСистемная шина
3.
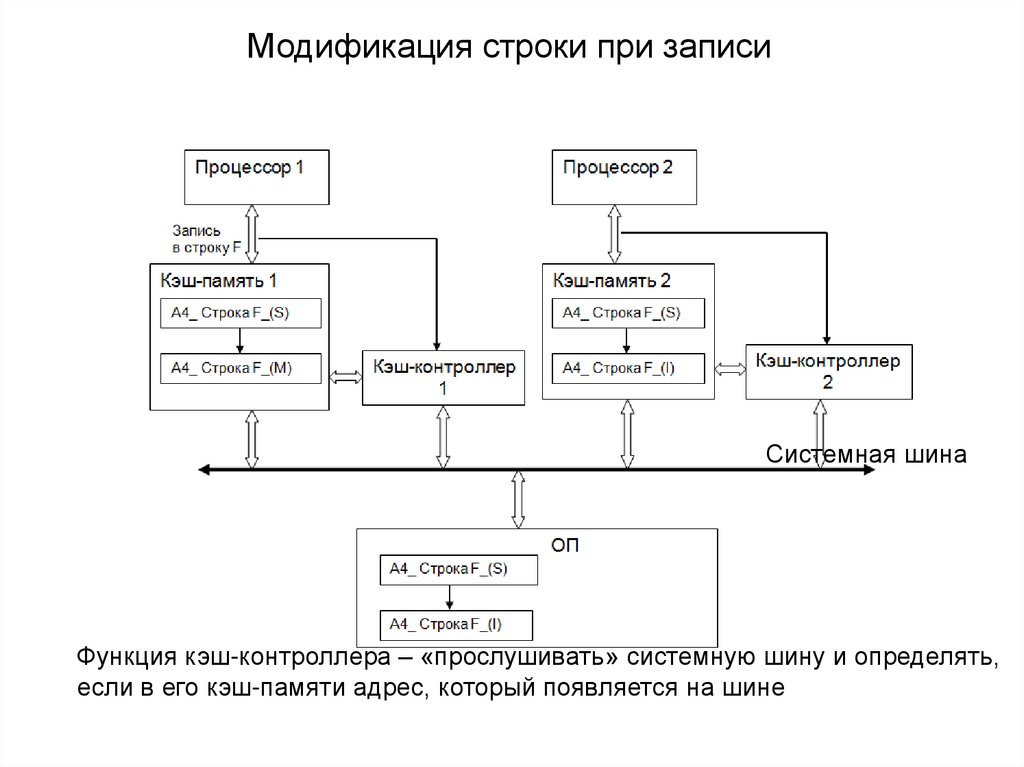
Модификация строки при записиСистемная шина
Функция кэш-контроллера – «прослушивать» системную шину и определять,
если в его кэш-памяти адрес, который появляется на шине
4.
Методы обеспечения когерентности данных1. Запись с аннулированием
В
любых
системах
основные
проблемы
возникают
при
записи
в разделяемую строку. Эта операция может выполняться одним из двух
методов (протоколов):
– записью с аннулированием;
– записью с обновлением.
Запись
с
аннулированием.
Если
какой-либо
процессор
производит
изменения в одной из строк своей локальной кэш-памяти, все имеющиеся
копии
этой
строки
в
других
локальных
кэшах
помечаются
как
недостоверные или аннулируются (бит достоверности обнуляется).
Если другой процессор обращается к такой строке, то происходит кэш-
промах и затем замещение корректным значением из той локальной памяти,
где произошла модификация данных.
5.
Методы обеспечения когерентности данных2. Запись с обновлением
Любая запись в одну локальную кэш-память дублируется в остальные
локальные кэши, содержащие копии изменяемой строки. При этом
дублирование в основную память может быть отложено.
Такой метод требует широковещательной передачи данных по шине
передачи данных для того, чтобы кэш-контроллеры определяли адреса
обновляемых строк.
Рассмотренные методы имеют следующие достоинства и недостатки.
Первый из них приостанавливает работу процессоров из-за конфликтов, а
второй требует увеличения полосы пропускания памяти. В последнем
случае можно снизить интенсивность обмена за счет использования
соответствующего признака строки («разделяемая» или нет). Наличие
такого признака при записи с аннулированием также ускоряет работу
системы (если строка неразделяемая, то аннулирование не нужно).
6.
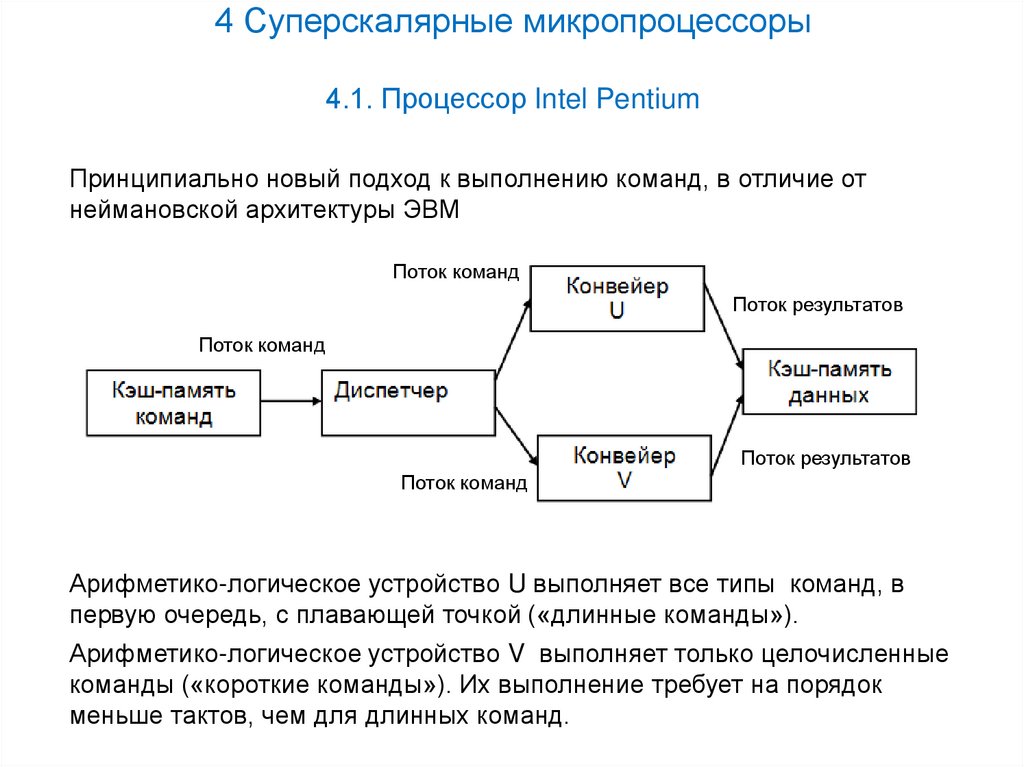
4 Суперскалярные микропроцессоры4.1. Процессор Intel Pentium
Принципиально новый подход к выполнению команд, в отличие от
неймановской архитектуры ЭВМ
Поток команд
Поток результатов
Поток команд
Поток результатов
Поток команд
Арифметико-логическое устройство U выполняет все типы команд, в
первую очередь, с плавающей точкой («длинные команды»).
Арифметико-логическое устройство V выполняет только целочисленные
команды («короткие команды»). Их выполнение требует на порядок
меньше тактов, чем для длинных команд.
7.
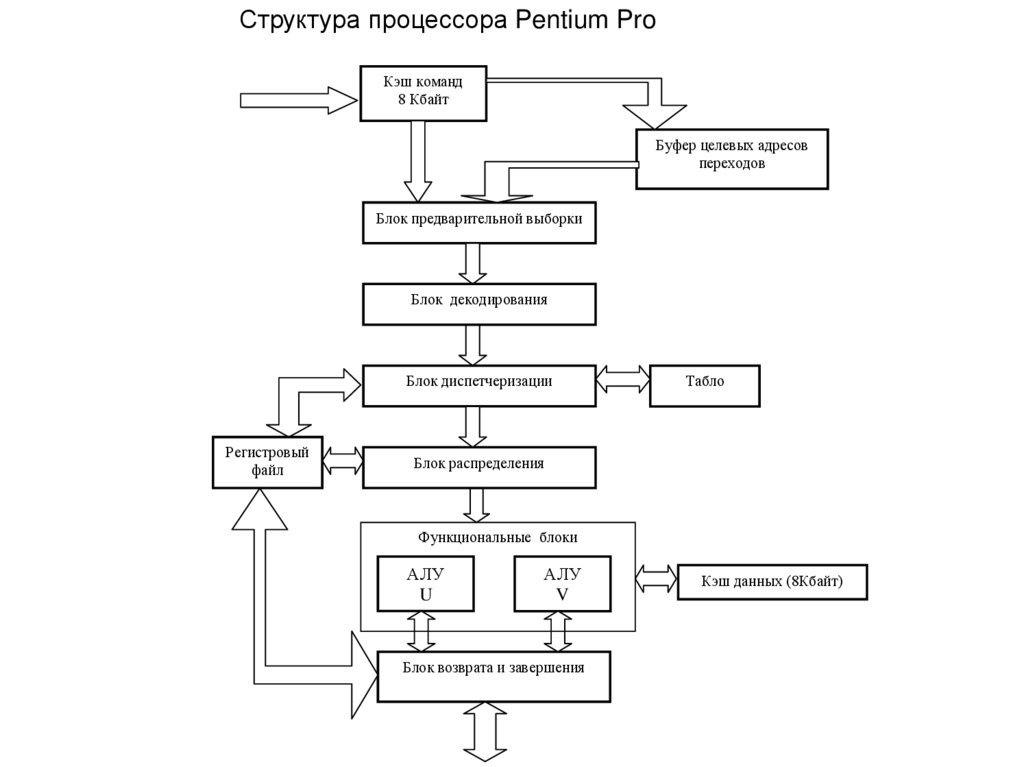
Структура процессора Pentium ProКэш команд
8 Кбайт
Буфер целевых адресов
переходов
Блок предварительной выборки
Блок декодирования
Блок диспетчеризации
Регистровый
файл
Табло
Блок распределения
Функциональные блоки
АЛУ
U
АЛУ
V
Блок возврата и завершения
Кэш данных (8Кбайт)
8.
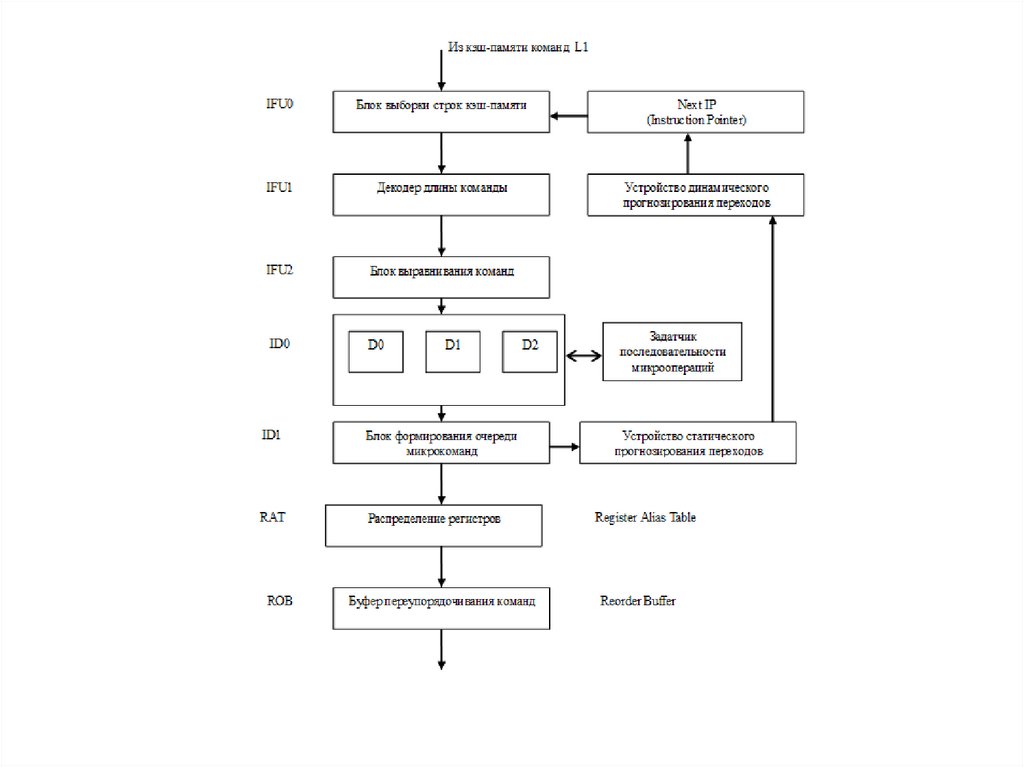
4 Суперскалярные микропроцессоры4.2. Выборка и декодирование команд
Выборка команд производится из кэш-памяти и затем поток команд
поступает на 7-ми ступенчатый конвейер.
В ступень IFU0 из кэш-памяти L1 команд загружаются целиком 32-байтовые
строки. Регистр Next IP содержит адрес следующей команды. При этом
выбирается либо следующая команда, либо команда по целевому адресу
перехода.
В ступени IFU1 анализируется поток команд и определяется начало каждой
из них. Архитектура IA-32 относится к типу CISC, поэтому команды имеют
разную длину. В этой ступени может анализироваться до 30 команд.
В ступени IFU2 команды выравниваются для облегчения декодирования. В
процессе декодирования команда превращается в последовательность
микрокоманд.
9.
В ступени ID0 имеются три внутренних декодера. Два их них – D0 и D1 –предназначены для простых команд, а третий декодер D2 – для любых
команд.
Очередь микрокоманд выстраивается в ступени ID1. Здесь же
происходит первичное статическое прогнозирование переходов. Для
уточнения прогноза затем используется динамическое прогнозирование
по схеме Смита с 4 битами предыстории.
Ступень RAT (Register Alias Table) – распределитель регистров,
производит переименование логических регистров для исключения
конфликтов по данным.
Регистры, использованные в команде, могут быть заменены любыми из
40 временных, организованных в буфере переупорядочивания ROB
(ReOrder Buffer). Здесь же собираются операнды для команд.
Микрокоманда становится доступной для выполнения в функциональных
блоках, когда готовы все ее операнды.
10.
11.
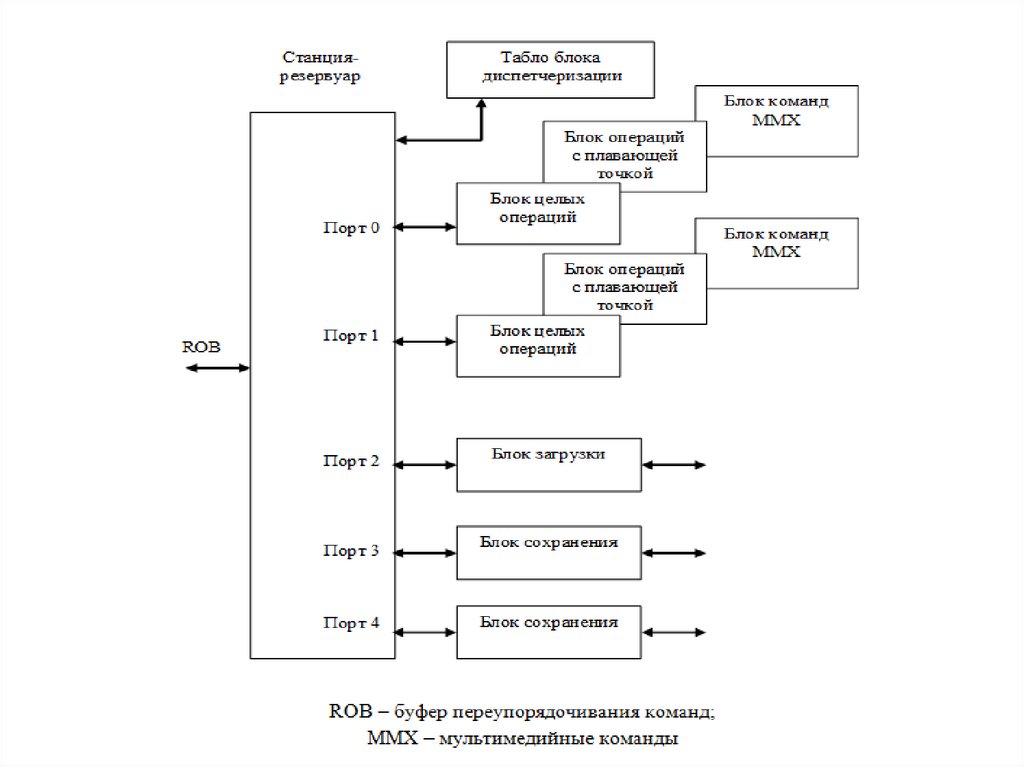
4.3. Диспетчеризация и выполнение командБлок диспетчеризации хранит список свободных функциональных блоков
(ФБ), который называется Табло. В каждом цикле этот блок извлекает
команды из своей очереди, считывает из памяти или из регистров операнды
этих команд, а затем по данным Табло помещает готовые команды в очередь
распределения к функциональному блоку по соответствующему порту.
В резервуаре образуется очередь до 20 микроопераций, ожидающих доступа
к ФБ. Из резервуара за один цикл можно выпустить 5 микроопераций. Если в
очереди к одному ФБ находятся несколько операций, то запускается
важнейшая из них. Например, операция условного перехода имеет
приоритет перед арифметическими операциями.
Блок загрузки обеспечивает считывание данных из кэш-памяти.
Блок сохранения выдает результаты операций в кэш-память.
12.
13.
4.4 . Блок возврата к естественнойпоследовательности команд
Когда операция выполнена, она переходит обратно в резервуар, а оттуда –
в буфер ROB, где ожидает возврата, т. е. завершения команды. Из-за
неупорядоченной выдачи и неупорядоченного исполнения команд могут
возникнуть конфликты. Для возврата к естественной последовательности
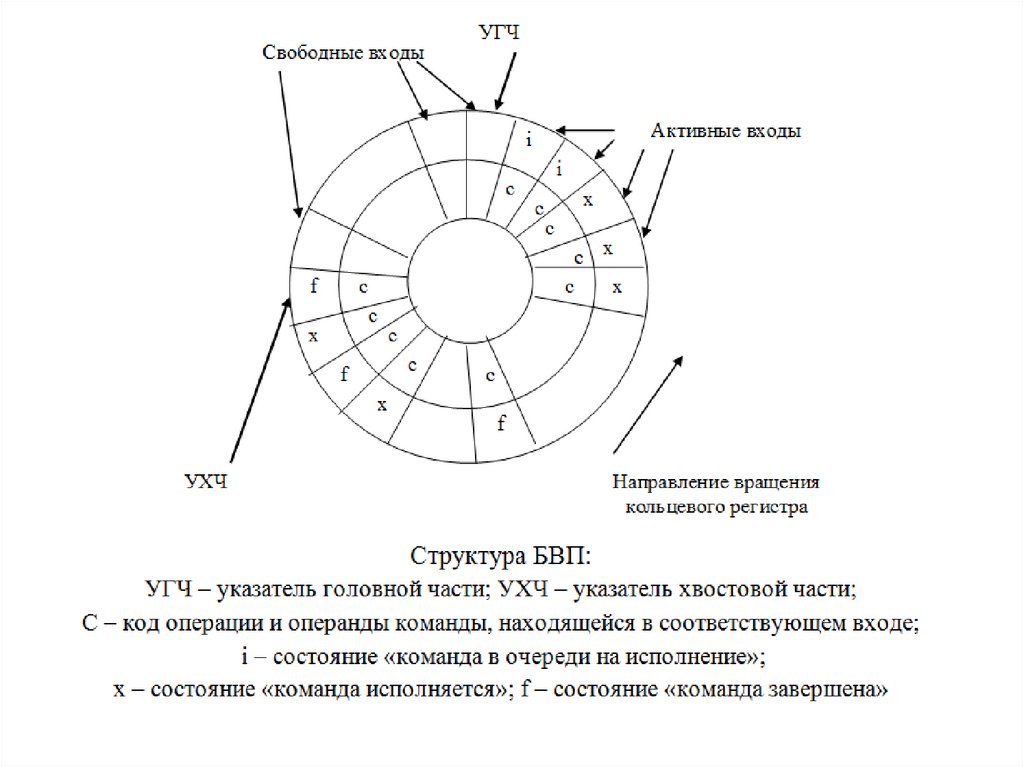
команд служит блок возврата, построенный по схеме Смита и Плескуна.
Эта схема называется буфером восстановления последовательности
(БВП).
БВП представляет собой кольцевой регистр с указателями головной и
хвостовой части (следующий слайд).
14.
15.
Указатель головной части (УГЧ) содержит адрес первого по направлениювращения свободного входа регистра. В свободный вход (сектор) заносится
код команды С, следующей в естественном порядке, определяемом
программой. После этого вход становится занятым. Каждый занятый
(активный) вход кроме самой команды содержит также информацию о ее
состоянии:
i – команда только что выдана и стоит в очереди на исполнение;
x – команда в стадии исполнения;
f – команда завершена.
Указатель хвостовой части (УХЧ) показывает на команду, уже завершенную и
подлежащую удалению из БВП прежде других.
Удаление команды разрешено, только если она завершена и все
предыдущие команды уже удалены из БВП. Это гарантирует удаление
команд в естественной последовательности программы.
А следующих слайдах показаны различные ситуации с заполнением блока
восстановления последовательности команд
16.
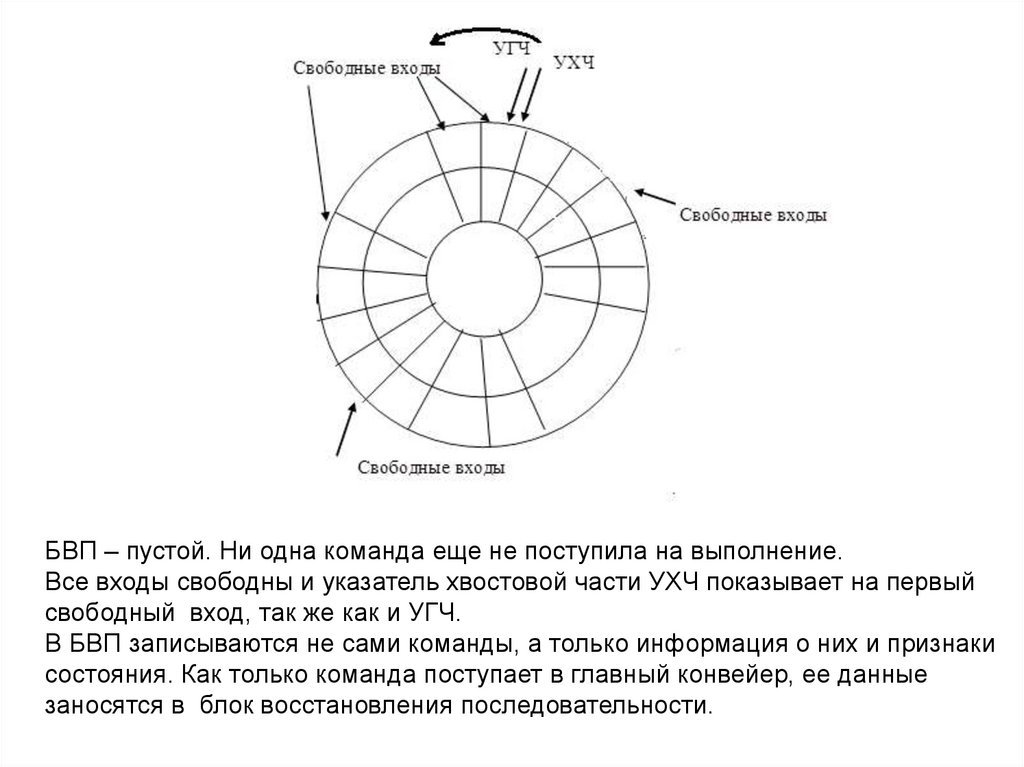
БВП – пустой. Ни одна команда еще не поступила на выполнение.Все входы свободны и указатель хвостовой части УХЧ показывает на первый
свободный вход, так же как и УГЧ.
В БВП записываются не сами команды, а только информация о них и признаки
состояния. Как только команда поступает в главный конвейер, ее данные
заносятся в блок восстановления последовательности.
17.
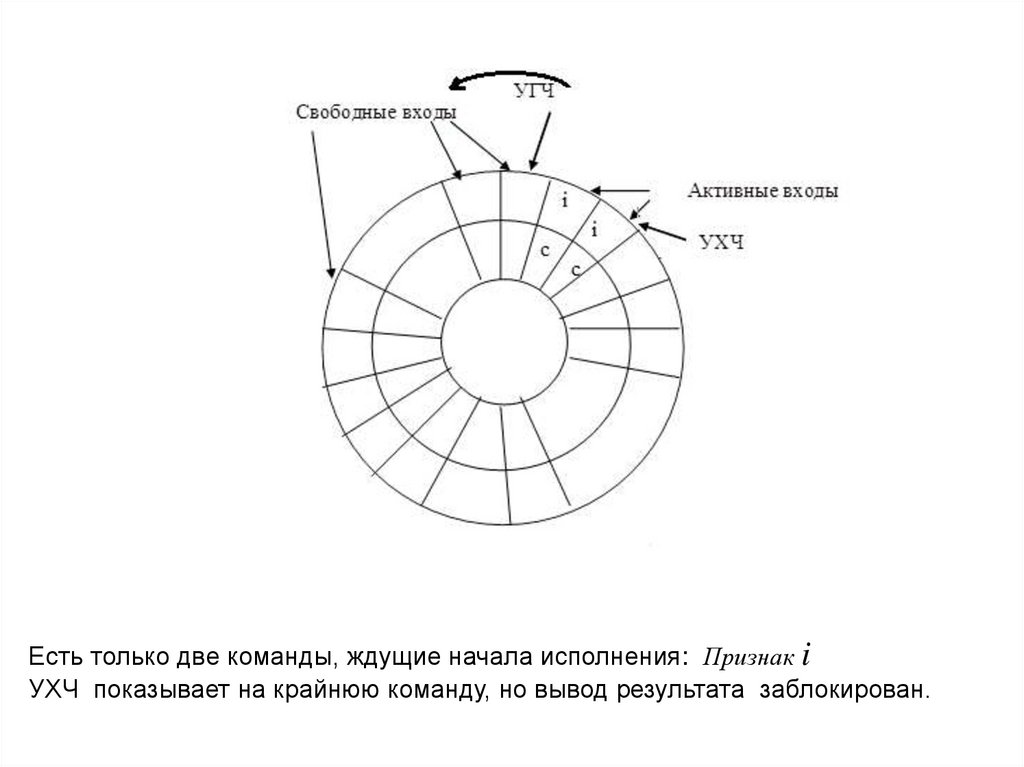
Есть только две команды, ждущие начала исполнения: Признак iУХЧ показывает на крайнюю команду, но вывод результата заблокирован.
18.
Три команды в состоянии ожидания (i). Первые две команды (см.предыдущий слайд) начали исполняться (x), но еще не завершились.
Это значит, что результаты еще не вычислены и вывод заблокирован.
19.
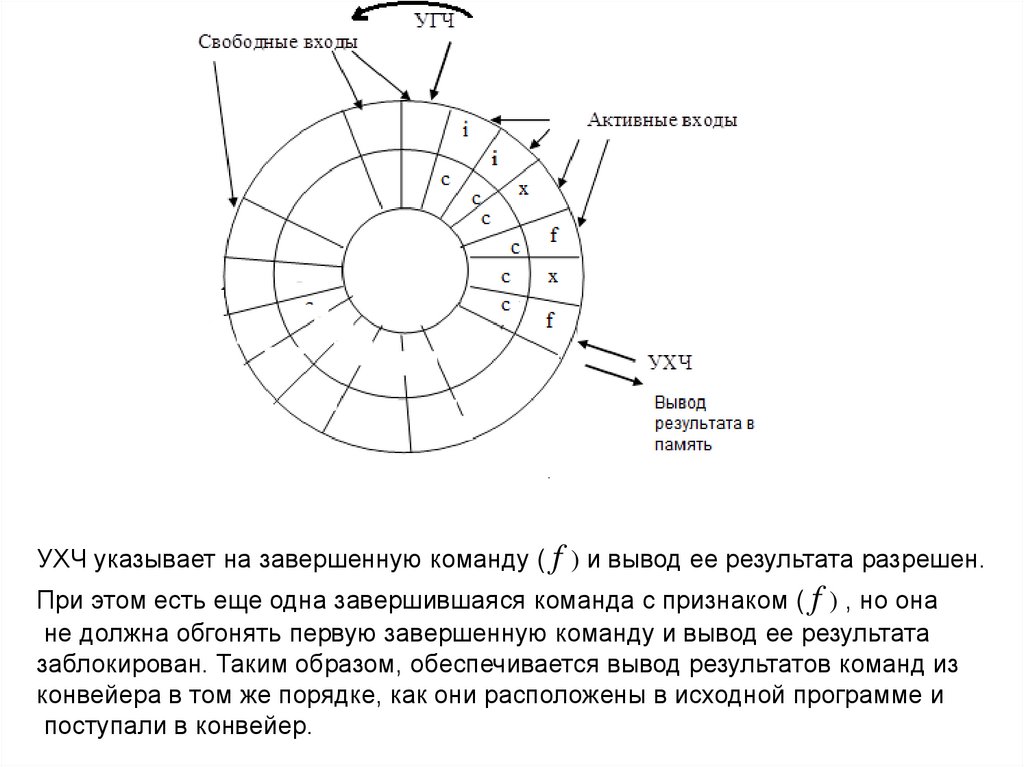
УХЧ указывает на завершенную команду ( f ) и вывод ее результата разрешен.При этом есть еще одна завершившаяся команда с признаком ( f ) , но она
не должна обгонять первую завершенную команду и вывод ее результата
заблокирован. Таким образом, обеспечивается вывод результатов команд из
конвейера в том же порядке, как они расположены в исходной программе и
поступали в конвейер.