






















 Информатика
ИнформатикаПохожие презентации:
")

")


")




Классификация параллельных процессоров. Архитектура и функционирование суперскалярних процессоров. (Тема 1.2)
1.
ТЕМА 1. АРХИТЕКТУРА И ФУНКЦИОНИРОВАНИЕСОВРЕМЕННЫХ ПАРАЛЛЕЛЬНЫХ ПРОЦЕССОРОВ.
Лекция 2. Классификация параллельных
процессоров.
Архитектура и функционирование суперскалярних
процессоров.
2.
3.
В узком смысле под архитектурой понимается архитектура наборакоманд.
В широком смысле архитектура охватывает понятие организации системы,
включающее такие высокоуровневые аспекты разработки компьютера как
систему памяти, структуру системной шины, организацию ввода/вывода и т.п.
Применительно
к
вычислительным
системам
-
"архитектура"
это
распределение функций, реализуемых системой, между ее уровнями, точнее
как определение границ между этими уровнями.
Архитектура первого уровня определяет, какие функции по обработке данных
выполняются системой в целом, а какие возлагаются на внешний мир.
Архитектура следующего уровня определяет разграничение функций между
процессорами ввода/вывода и контроллерами внешних устройств.
4.
АРХИТЕКТУРА СИСТЕМЫ - емкое понятие, включающее триважнейших вида взаимосвязанных структур: ФИЗИЧЕСКУЮ,
ЛОГИЧЕСКУЮ и ПРОГРАММНУЮ.
Элементами ФИЗИЧЕСКОЙ
ПРОГРАММНУЮ
СТРУКТУРЫ являются технические
СТРУКТУРУ образуют
объекты. В зависимости от того, какие
задачи решаются, этими объектами
Элементами ЛОГИЧЕСКОЙ
могут быть полупроводниковые
СТРУКТУРЫ являются
кристаллы, части вычислительных
функции, определяющие
машин, а также комплексы,
основные операции.
составленные из последних.
взаимосвязанные программы:
программы обработки
информации, и др.
5.
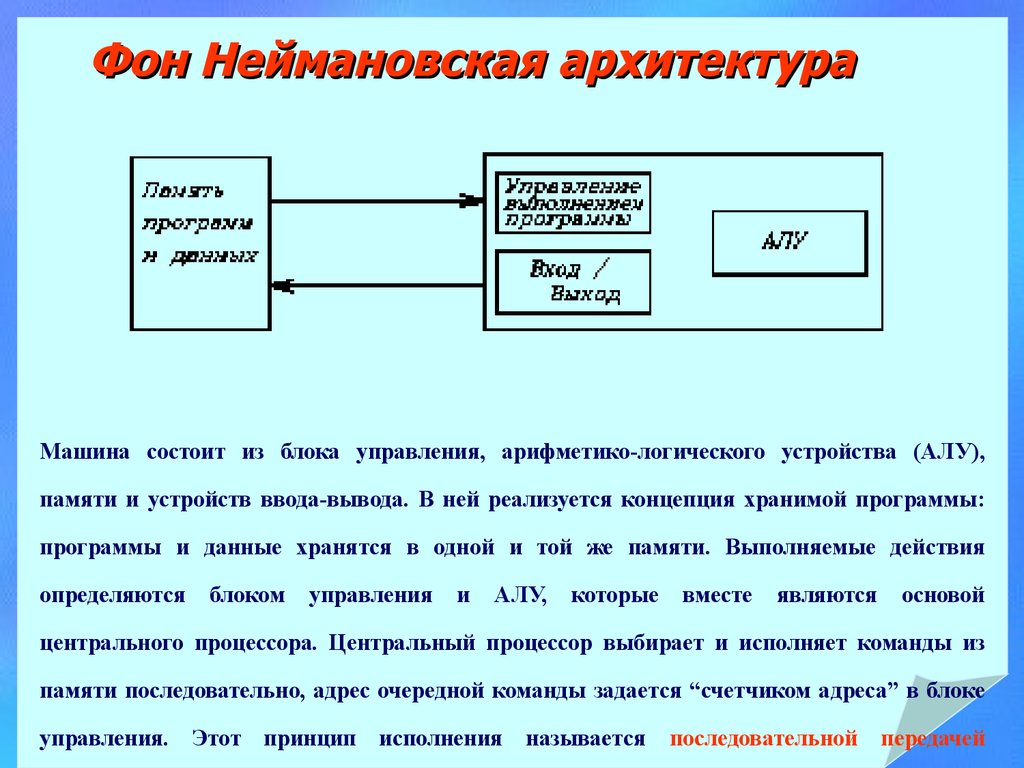
Фон Неймановская архитектураМашина состоит из блока управления, арифметико-логического устройства (АЛУ),
памяти и устройств ввода-вывода. В ней реализуется концепция хранимой программы:
программы и данные хранятся в одной и той же памяти. Выполняемые действия
определяются
блоком
управления
и
АЛУ,
которые
вместе
являются
основой
центрального процессора. Центральный процессор выбирает и исполняет команды из
памяти последовательно, адрес очередной команды задается “счетчиком адреса” в блоке
управления.
Этот принцип исполнения называется
последовательной передачей
6.
3 основных признака фон Неймановской архитектуры(Принстонская):
1. память состоит из последовательности ячеек памяти с
адресами;
2. хранение команд программы и обрабатываемых ими данных на одинаковых принципах (с точки зрения обработки
сообщений);
Почему ФН уже не удовлетворяет?
3. программа выполняется покомандно, в соответствии с их
УУ – централизовано.
Первое – это скорость,порядком.
сейчас в усредненной
задачи от скорости работы CPU
зависит не так уж много – важнее скорость работы памяти и других передач
данных. Узкое место – единый тракт.
7.
Гарвардская архитектураГарвардской архитектуре присущ один недостаток. Вследствие того, что память данных и
память программ разделены, на кристалле необходимо иметь в два раза больше выводов
адреса и данных. Кремниевая технология такова, что увеличение числа выводов на
кристалле приводит к росту цены. Выход состоит в том, чтобы для всех внешних данных,
включая команды, использовать одну шину, а другую – для адресации, внутри же процессора
иметь отдельную шину команд и шину данных и две соответствующих шины адреса.
Разделение информации о программе и данных на выводах процессора производится
благодаря их временному разделению (мультиплексированию). На это требуется два
командных цикла: в первом цикле на выводы поступает информация о программе, а во
8.
Архитектура системы команд. Классификация процессоров(CISC и RISC)
Для
CISC-процессоров
характерно:
сравнительно
небольшое
число
регистров общего назначения; большое количество машинных команд,
некоторые из которых нагружены семантически аналогично операторам
высокоуровневых языков программирования и выполняются за много
тактов; большое количество методов адресации; большое количество
форматов команд различной разрядности; двухадресный формат команд;
Основой
архитектуры
современных
рабочих станций и серверов является
наличие команд
обработки
типа регистр-память.
RISC-архитектура
компьютера
с
сокращенным
набором
команд.
Характерно: отделение медленной памяти от высокоскоростных регистров
и использование регистровых окон; отделение команды обработки от
команд работы с памятью; выполнение любой команды занимает
небольшое
количество
машинных
тактов
(предпочтительно
один
9.
Матричный процессорНаиболее распространенными из систем, класса: один поток команд множество - потоков данных, являются матричные системы, которые
лучше всего приспособлены для решения задач, характеризующихся
параллелизмом независимых объектов или данных. Организация систем
подобного типа на первый взгляд достаточно проста. Они имеют общее
управляющее устройство, генерирующее поток команд и большое число
процессорных элементов, работающих параллельно и обрабатывающих
каждая свой поток данных. Таким образом, производительность системы
оказывается равной сумме производительностей всех процессорных
элементов.
Однако
на
практике,
чтобы
обеспечить
достаточную
эффективность системы при решении широкого круга задач необходимо
организовать связи между процессорными элементами с тем, чтобы
10.
Структура матричной вычислительной системы "SOLOMON"Система SОLOМОN содержит 1024 процессорных
элемента, соединенных в виде матрицы: 32х32.
Каждый
процессорный
элемент
матрицы
включает в себя процессор, обеспечивающий
выполнение
последовательных
поразрядных
арифметических и логических операций, а также
оперативное ЗУ, емкостью 16 Кбайт. Длина слова переменная от 1 до 128 разрядов. Разрядность слов
устанавливается программно. По каналам связи от
устройства управления передаются команды и
общие
константы.
используется,
позволяет
В
процессорном
элементе
многомодальная логика, которая
каждому
процессорному
элементу
выполнять или не выполнять общую операцию в
зависимости от значений обрабатываемых данных.
В каждый момент все активные процессорные
11.
Идея многомодальности заключается в том, что в каждомпроцессорном элементе имеется специальный регистр на 4
состояния - регистр моды.
Мода (модальность) заносится в этот регистр от устройства
управления.
При выполнении последовательности команд модальность
передается в коде операции и сравнивается с содержимом
регистра моды. Если есть совпадения, то операция
выполняется.
В других случаях процессорный элемент не выполняет
операцию, но может, в зависимости от кода, пересылать свои
операнды соседнему процессорному элементу. Такой механизм
позволяет выделить строку или столбец процессорных
элементов, что очень полезно при операциях над матрицами.
Взаимодействуют процессорные элементы с периферийным
оборудованием через внешний процессор.
12.
ПРИМЕРЫ МАТРИЧНЫХ ПРОЦЕССОРОВДальнейшим
развитием
матричных
процессоров
стала
система
ILLIАC-4,
разработанная фирмой BARRОYS. Первоначально система должна была включать в
себя 256 процессорных элементов, разбитых на группы, каждый из которых должен
управляться специальным процессором. Однако была создана система, содержащая
одну группу процессорных элементов и управляющий процессор. Система работала с
быстродействием = 200 млн. операций в секунду. Эта система в течение ряда лет
считалась одной из самых высокопроизводительных в мире.
В начале 80-х годов в СССР была создана система: ПС-2000, которая также является
матричной. Основой этой системы является мультипроцессор - ПС-2000, состоящий из
решающего поля и устройства управления мультипроцессором. Решающее поле строится
из одного, двух, четырех или восьми устройств обработки, в каждом из которых - 8
процессорных элементов. Мультипроцессор из 64 процессорных элементов обеспечивает
быстродействие = 200 млн. операций в секунду на коротких операциях.
13.
ПРОЦЕССОР С КОНВЕЙЕРИЗАЦИЕЙ КОМАНДПРОЦЕССОР С КОНВЕЙЕРИЗАЦИЕЙ ОПЕРАЦИЙ
При параллелизме совмещение
операций достигается путем
Конвейеризация (или конвейерная
обработка) в общем случае основана на
воспроизведения в нескольких
разделении подлежащей исполнению
копиях аппаратной структуры.
функции на более мелкие части,
Высокая производительность
называемые ступенями, и выделении
достигается за счет
для каждой из них отдельного блока
одновременной работы всех
элементов структур,
аппаратуры. Производительность при
этом возрастает благодаря тому, что
осуществляющих решение
одновременно на различных ступенях
различных частей задачи.
конвейера выполняются несколько
команд.
14.
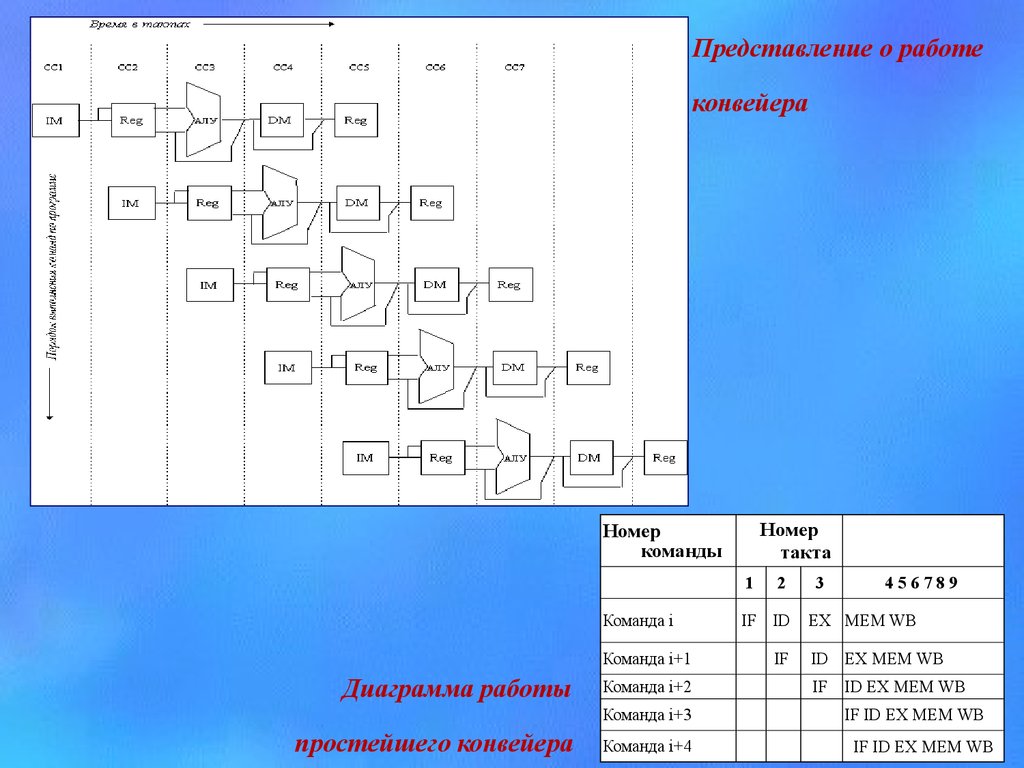
Представление о работеконвейера
Номер
такта
Номер
команды
1
Команда i
Команда i+1
Диаграмма работы
Команда i+2
Команда i+3
простейшего конвейера
Команда i+4
2
IF ID
IF
3
456789
EX MEM WB
ID EX MEM WB
IF
ID EX MEM WB
IF ID EX MEM WB
IF ID EX MEM WB
15.
Эффект конвейеризации при выполнении3-х команд - четырехкратное ускорение
16.
17.
Суперскалярным называется центральный процессор(ЦП), который одновременно выполняет более чем одну
скалярную команду.
Это достигается за счет включения в состав ЦП
нескольких
самостоятельных
функциональных
(исполнительных) блоков, каждый из которых отвечает за
свой класс операций и может присутствовать в процессоре в
нескольких экземплярах.
В микропроцессоре Pentium III блоки целочисленной
арифметики и операций с плавающей точкой дублированы, а
в микропроцессорах Pentium4 и Athlon – троированы.
18.
Архитектура суперскалярного процессораОбработка
ветвлений
Выборка команд
…
Кэш-память команд
выборка
Декодирование
…
декодирование
Диспетчеризация
…
Регистровый
файл
Табло
(scoreboard)
выдача
Распределение
…
запуск
Исполнение
функциональные блоки
…
…
завершение
Обновление состояния
…
покидание
Кэш-память
данных
19.
Блок выборки команд извлекает команды из основной памяти через кэшпамять команд. Этот блок хранит несколько значений счетчика команд иобрабатывает команды условного перехода.
Блок декодирования расшифровывает код операции, содержащейся в
извлеченных из кэш-памяти командах. В некоторых скалярных
процессорах, например в микропроцессорах фирмы Intel, блоки выборки
и декодирования совмещены.
Блоки диспетчеризации и распределения взаимодействуют между собой и
в совокупности играют в суперскалярном процессоре роль конроллера
трафика. Оба блока хранят очереди декодированных команд.
Очередь блока распределения часто рассредотачивается по нескольким
самостоятельным буферам – накопителям команд или схемам
резервирования,- предназначенным для хранения команд, которые уже
декодированы, но еще не выполнены. Каждый накопитель команд связан
со своим функциональным блоком (ФБ), поэтому число накопителей
обычно равно числу ФБ, но если в процессоре используется несколько
однотипных ФБ, то им придается общий накопитель.
20.
Очереди диспетчеризации и распределенияОчередь
диспетчера
Очередь
планировщика
…
Функциональный
блок 1
…
…
Функциональный
блок 2
…
…
…
Функциональный
блок N
В дополнение к очереди, блок диспетчеризации хранит также список свободных функциональных
блоков, называемых табло (scoreboard). Табло используется для отслеживания состояния очереди
распределения.
Один раз за цикл блок диспетчеризации извлекает команды из своей очереди, считывает из памяти или
регистров операнды этих команд, после чего, в зависимости от состояния табло, помещает команды и
значения операндов в очередь распределения. Эта операция называется выдачей команд. Блок
распределения в каждом цикле проверяет каждую команду в своих очередях на наличие всех
21.
Упрощенная блок схема процессора PentiumОсновные
команды
независимым
распределяются
исполнительным
по
двум
устройствам
(конвейерам U и V). Конвейер U может выполнять
любые
команды
семейства
x86,
включая
целочисленные команды и команды с плавающей
точкой. Конвейер V предназначен для выполнения
простых целочисленных команд и некоторых команд с
плавающей точкой. Команды могут направляться в
каждое из этих устройств одновременно, причем при
выдаче устройством управления в одном такте пары
•.
команд более сложная команда поступает в конвейер
U, а менее сложная - в конвейер V. Команды
арифметики
с
плавающей
точкой
не
могут
запускаться в паре с целочисленными командами.
Одновременная выдача двух команд возможна только
при отсутствии зависимостей по регистрам. При
22.
Суперскалярные процессорыорганизация вычислительного процесса в виде одной нити (в скалярных
процессорах) или нескольких одновременно (параллельно) выполняемых нитей (в
суперскалярных процессорах);
реализация нитей на основе метода конвейерной обработки данных.
«Нить» (thread) – неразветвляющаяся последовательность операций/машинных
Процессоры с длинным командным словом (Very Long Instruction Word, VLIW):
команд.
•разбиение
множества команд программы на фрагменты независимых команд,
реализация которых может начинаться в один и тот же момент времени;
•представление
каждого фрагмента
в виде длинной команды и оформление
параллельной программы в виде последовательности «длинных команд»;
•параллельное решение задачи путем одновременного (параллельного) выполнения в
23.
Особенности суперскалярных процессоров [ 1,2 ]:1. Суперскалярные процессоры обрабатывают несколько команд
одновременно в нескольких конвейерах (скалярные процессоры имеют один
конвейер), способны выполнять до четырех команд за такт и имеют от двух до
пяти конвейерных исполнительных устройств.
2. Используются жесткие (аппаратно реализованные) многоступенчатые
конвейеры обработки (без использования микропрограмм).
3. Большинство команд выполняются за один такт и лишь немногие – в
течение нескольких или нескольких десятков тактов.
4. Все команды обработки данных взаимодействуют только с содержимым
регистров, обращение к более медленной оперативной памяти осуществляется с
помощью отдельных инструкций (загрузить в регистр/записать в память).
24.
Преимущества суперскалярной машины по сравнению с VLIWмашиной:•во-первых, малое воздействие на плотность кода, поскольку машина
сама определяет, может ли быть выдана следующая команда, и нам не
надо следить за тем, чтобы команды соответствовали возможностям
выдачи;
•во-вторых, на таких машинах могут работать неоптимизированные
программы, или программы, откомпилированные в расчете на более
•.
старую реализацию.
Архитектура машин с очень длинным командным словом (VLIW Very Long Instruction Word) позволяет сократить объем оборудования,
25.
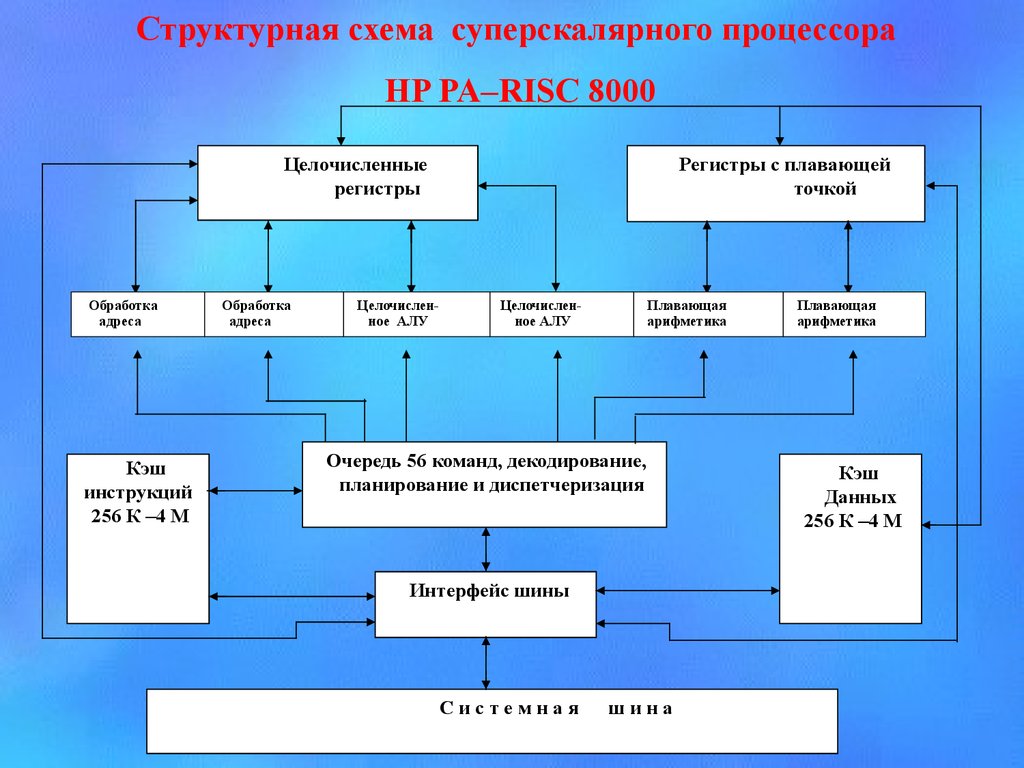
Структурная схема суперскалярного процесcораHP PA–RISC 8000
Целочисленные
регистры
Обработка
адреса
Кэш
инструкций
256 К –4 М
Обработка
адреса
Целочисленное АЛУ
Регистры с плавающей
точкой
Целочисленное АЛУ
Плавающая
арифметика
Очередь 56 команд, декодирование,
планирование и диспетчеризация
Интерфейс шины
Системная
шина
Плавающая
арифметика
Кэш
Данных
256 К –4 М
26. Литература:
1. Степанов А.Н. Архитектура вычислительныхсистем и компьютерных сетей. – СПб.: Питер, 2007.
– 509с.
2. Воеводин В.В., Воеводин Вл.В. Параллельные
вычисления. - СПб.: БХВ-Петербург, 2002.- 608 с.
3. Лацис А. Как построить и использовать
суперкомпьютер.- М.: Бестселлер, 2003.-240с.
4. www.parallel.rb.ru